
1. نظرة عامة
في هذا الدرس التطبيقي حول الترميز، ستنشئ وكيل علوم بيانات يستعلم عن بيانات حقيقية من مجموعات البيانات العامة في BigQuery ويتذكّر إعداداتك المفضّلة بين الجلسات. بعد ذلك، ستنشره على Agent Engine، وهي خدمة مُدارة بالكامل من Google Cloud تتولى إدارة البنية التحتية والتوسيع وإدارة الجلسات.
يستخدم الوكيل ثلاث إمكانات أساسية يتم تفعيلها تدريجيًا:
- BigQuery Toolset: يستكشف الوكيل المخططات ويُجري طلبات SQL على مجموعات بيانات BigQuery الحقيقية، ويعمل ذلك محليًا وعند النشر.
- Memory Bank: عند التفعيل، يتذكّر الوكيل الإعدادات المفضّلة للمستخدم والسياق بين الجلسات غير المتصلة.
- إمكانية الملاحظة: تسجِّل خدمة Cloud Trace خطوات الاستدلال التي يتّخذها الوكيل وعمليات استدعاء الأدوات وحالات وقت الاستجابة من خلال قياس حالة التطبيق OpenTelemetry.
أهداف الدورة التعليمية
- كيفية إنشاء وكيل ADK باستخدام
BigQueryToolsetللوصول إلى البيانات الحقيقية - كيفية ضبط Memory Bank للاحتفاظ بالبيانات بين الجلسات
- كيفية نشر وكيلك على Agent Engine باستخدام
adk deploy - كيفية منح أذونات إدارة الهوية والوصول (IAM) لحساب خدمة الوكيل الذي تم نشره
- كيفية اختبار الاحتفاظ بالذاكرة وإمكانية تتبُّع البيانات
المتطلبات
- مشروع على Google Cloud تم تفعيل الفوترة فيه
- Google Cloud SDK (
gcloudCLI) - متصفح ويب مثل Chrome
- uv (مدير حِزم Python)
- Python 3.12 والإصدارات الأحدث (يتم تثبيته تلقائيًا بواسطة
uvإذا لزم الأمر)
ADK (حزمة تطوير الوكلاء) هي إطار عمل Google لإنشاء وكلاء الذكاء الاصطناعي. يستخدم هذا الدرس التطبيقي حول الترميز حزمة ADK لإنشاء وكيل ونشره على Agent Engine.
هذا الدرس التطبيقي حول الترميز مخصّص للمطوّرين ذوي الخبرة المتوسطة الذين لديهم بعض المعرفة بلغة Python وGoogle Cloud.
يستغرق إكمال هذا الدرس التطبيقي حول الترميز 30 دقيقة تقريبًا (بما في ذلك 5 إلى 10 دقائق للنشر).
يجب أن تكون تكلفة الموارد التي تم إنشاؤها في هذا الدرس التطبيقي حول الترميز أقل من 5 دولارات أمريكية.
2. إعداد البيئة
إنشاء مشروع على Google Cloud
- في Google Cloud Console، في صفحة اختيار المشروع، اختَر مشروعًا على Google Cloud أو أنشِئ مشروعًا.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. تعرّف على كيفية التحقّق مما إذا كانت الفوترة مفعّلة في مشروع.
ضبط المتغيرات البيئية
افتح Cloud Shell Editor في مشروع Google Cloud الذي أنشأته.
بعد ذلك، أنشئ وحدة طرفية > وحدة طرفية جديدة، وشغِّل الأوامر التالية.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
تفعيل واجهات برمجة التطبيقات
نفِّذ الأمر التالي في الوحدة الطرفية:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- AI Platform API (
aiplatform.googleapis.com): استضافة Agent Engine - BigQuery API (
bigquery.googleapis.com): طلبات SQL على مجموعات البيانات العامة والخاصة - Telemetry API (
telemetry.googleapis.com): عمليات تتبُّع OpenTelemetry لإمكانية تتبُّع الوكيل
إنشاء بيئة افتراضية وتثبيت حزمة ADK
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
تتضمّن حزمة google-adk أداة سطر الأوامر adk التي ستستخدمها لاختبار الوكيل ونشره.
3. إنشاء الوكيل
أنشئ دليل مشروع وكيل جديدًا. يجب تشغيل جميع الأوامر اللاحقة من دليل العمل هذا (الدليل الرئيسي لـ data_science_agent/):
mkdir data_science_agent
سيبدو هيكل الدليل النهائي على النحو التالي:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
ستنشئ الآن الملفَين __init__.py وagent.py، ثم ستضيف requirements.txt و.env في خطوة النشر.
أنشئ data_science_agent/__init__.py، هذا الملف مطلوب حتى يتمكّن ADK من اكتشاف وكيلك وتحميله:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
أنشئ data_science_agent/agent.py:
يتصل هذا الوكيل بـ BigQuery لاستخراج البيانات ويحفظ الجلسات في Memory Bank.
يتم تفعيل الذاكرة تلقائيًا عند النشر، ويتم ضبط متغيّر البيئة GOOGLE_CLOUD_AGENT_ENGINE_ID بواسطة بيئة تشغيل Agent Engine ولا يكون متاحًا عند التشغيل محليًا.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
لنستعرض ما يفعله هذا الرمز:
- تمنح BigQueryToolset الوكيل أدوات مثل
execute_sqlوlist_table_idsوget_table_info. ويمكنها استكشاف المخططات والاستعلام عن أي مجموعة بيانات يمكن للمتصل الوصول إليها. - تسترد PreloadMemoryTool تلقائيًا الذكريات ذات الصلة قبل كل عملية استدعاء لنموذج لغوي كبير من خلال البحث في Memory Bank عن محتوى ذي صلة برسالة المستخدم. تحفظ معاودة الاتصال
_save_memoryالجلسة في Memory Bank بعد كل عملية تشغيل للوكيل، ما يتيح للوكيل استرجاع السياق في الجلسات المستقبلية. - تغلّف App الوكيل الرئيسي في تطبيق قابل للنشر يمكن أن يعرضه Agent Engine. يجب أن يتطابق
nameمع اسم الدليل (data_science_agent)، ويستخدمadk webهذا الاسم للعثور على الوكيل وتحميله. - تطلب التعليمات من الوكيل استخدام مشروع الفوترة لطلبات SQL وتذكُّر الإعدادات المفضّلة للمستخدم.
4. النشر على Agent Engine
أنشئ ملف requirements.txt في الدليل data_science_agent:
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
google-adkوgoogle-genai: إطار عمل ADK وعميل Geminigoogle-auth: المصادقة على Google Cloudpython-dotenv: تحميل ملف.envعند بدء التشغيل- تفعِّل حِزم
opentelemetry-instrumentation-*الأربع ميزات إمكانية تتبُّع البيانات التي ستستكشفها لاحقًا. وهي تُعدِّل طلبات FastAPI HTTP وعمليات استدعاء نموذج Gemini وعمليات الاتصال الداخلية بتنسيق gRPC/HTTP بحيث تظهر عمليات التتبُّع في علامة التبويب "عمليات التتبُّع" في Agent Engine.
أنشئ ملف .env في الدليل data_science_agent لتفعيل بيانات القياس عن بُعد على الوكيل الذي تم نشره:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY: تفعيل خط أنابيب OpenTelemetry في بيئة تشغيل Agent EngineOTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT: تسجيل عمليات إدخال الطلبات الكاملة وردود الوكيل، ما يفيد في تحديد الأخطاء وحلّها
انشر الوكيل. الوسيطة الأخيرة data_science_agent هي الدليل الذي يحتوي على رمز الوكيل:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
علم | الغرض |
| مشروع Google Cloud والمنطقة المستهدفة |
| الاسم الذي يمكن للمستخدِم قراءته ويظهر في Cloud Console |
| تفعيل أداة التصدير إلى Cloud Trace للنطاقات الخاصة بالوكيل |
| تفعيل خط أنابيب أجهزة OpenTelemetry |
عند النشر على Agent Engine، يتم تفعيل إمكانتَين تلقائيًا:
- Memory Bank:
PreloadMemoryToolتتصل بـ Agent Engine Memory Bank وتحفظ_save_memoryالجلسات تلقائيًا. - إمكانية تتبُّع البيانات: تسجِّل Cloud Trace خطوات الاستدلال التي يتّخذها الوكيل وعمليات استدعاء الأدوات وحالات التأخير.
5. منح أذونات BigQuery
عليك منح Agent Engine إذن الوصول إلى حساب الخدمة. عند النشر، يتم تشغيل الوكيل كحساب خدمة تديره Google (وليس بيانات الاعتماد الشخصية)، لذا يحتاج إلى أذونات صريحة لتنفيذ طلبات SQL.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
يعرض كل أمر Updated IAM policy for project [...] عند نجاحه.
6. اختبار الوكيل الذي تم نشره
افتح صفحة Agent Engine في Google Cloud Console. انقر على الوكيل الذي تم نشره لفتح Agent Engine Playground.
اختبِر إمكانات BigQuery:
- "List the tables in bigquery-public-data.hacker_news"
- النتيجة المتوقّعة: يستدعي الوكيل
list_table_idsويعرض أسماء الجداول بما في ذلكfull.
- النتيجة المتوقّعة: يستدعي الوكيل
- "Find the number of posts per year in bigquery-public-data.hacker_news.full"
- النتيجة المتوقّعة: يستدعي الوكيل
execute_sqlباستخدام طلب SQL ويعرض جدولاً يتضمّن السنوات وعدد المشاركات.
- النتيجة المتوقّعة: يستدعي الوكيل
- "What was the year-over-year percentage change in posts?"
- النتيجة المتوقّعة: يستدعي الوكيل
execute_sqlباستخدام طلب SQL يحسب التغيير المئوي ويعرض النتائج.
- النتيجة المتوقّعة: يستدعي الوكيل
7. اختبار الاحتفاظ بالذاكرة
في Playground، علِّم الوكيل إعدادًا مفضّلاً:
- "Remember that my favorite dataset is bigquery-public-data.hacker_news"
- "What tables does it have?"
انتظِر بضع ثوانٍ حتى يتم حفظ الذاكرة (يتم تشغيل معاودة الاتصال _save_memory بعد أن يردّ الوكيل).
الآن ابدأ جلسة جديدة من خلال النقر على الزر "+ جلسة جديدة" في الشريط الجانبي لـ Playground، ثم اطرح السؤال التالي:
- "What is my favorite dataset?"
يجب أن يسترجع الوكيل bigquery-public-data.hacker_news على الرغم من أنّ هذه جلسة جديدة تمامًا بدون سجلّ محادثات. يعمل ذلك بسبب ما يلي:
- تحفظ
_save_memoryكل جلسة في Memory Bank من خلالcallback_context.add_session_to_memory() - تسترد
PreloadMemoryToolالذكريات ذات الصلة قبل كل عملية استدعاء لنموذج لغوي كبير - يطابق Memory Bank المحتوى دلاليًا، وليس بالكلمة الرئيسية فقط
8. استكشاف إمكانية تتبُّع البيانات
في Cloud Console، انتقِل إلى الوكيل الذي تم نشره وانقر على علامة التبويب عمليات التتبُّع.
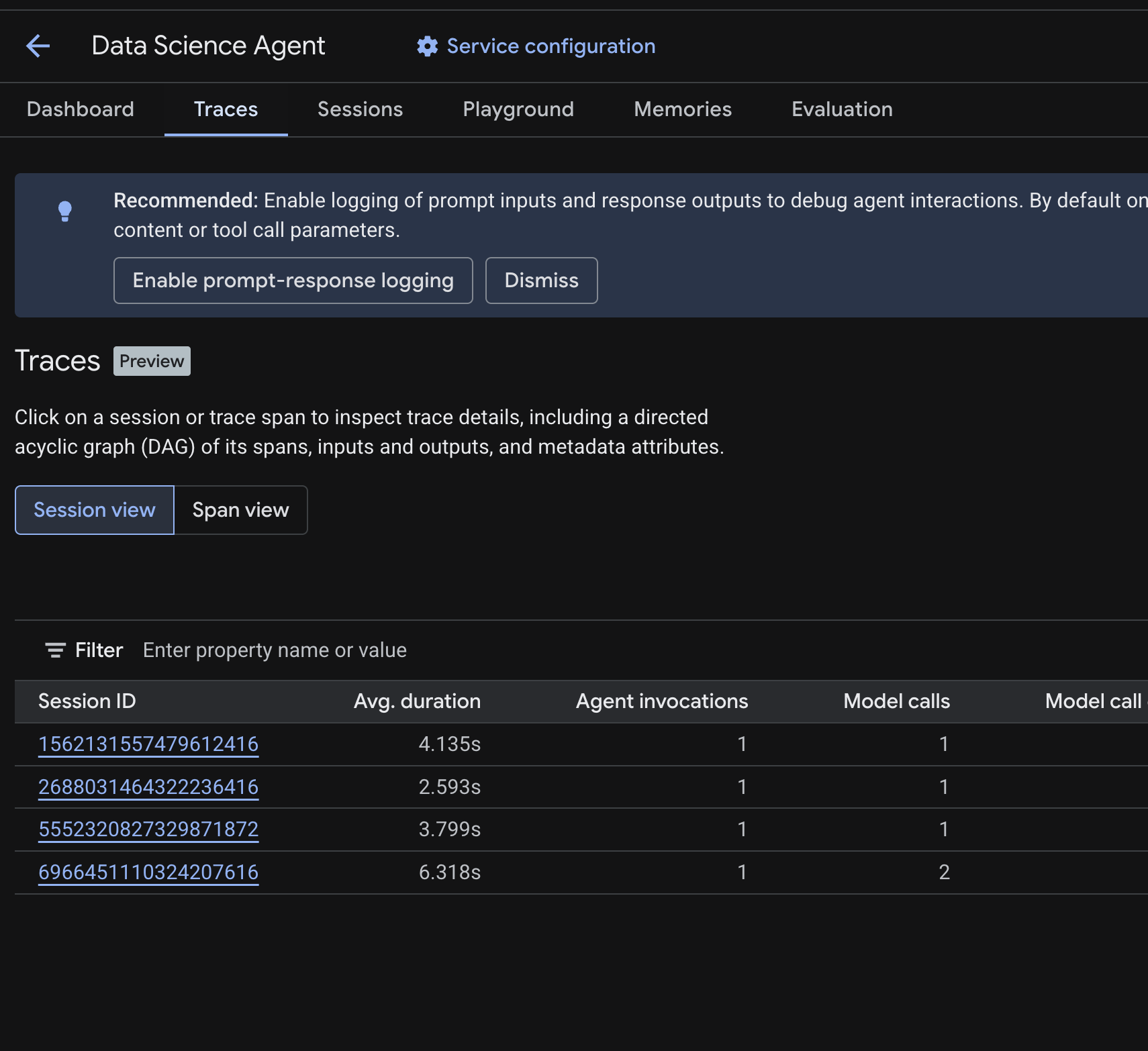
يجب أن يظهر جدول الجلسات الذي يسرد الجلسات من طلبات الاختبار التي أجريتها في الخطوات السابقة. يعرض الجدول مقاييس ملخّصة لكل جلسة، مثل متوسط المدة وعمليات استدعاء النموذج وعمليات استدعاء الأدوات واستخدام الرموز وأي أخطاء.
انقر على جلسة لفحص تفاصيل عملية التتبُّع، بما في ذلك:
- رسم بياني موجّه غير دوري (DAG) للنطاقات، يعرض تفاصيل خطوات استدلال الوكيل وعمليات استدعاء الأدوات (طلبات BigQuery) وحالات التأخير
- عمليات الإدخال والإخراج لكل نطاق (يتم تفعيلها من خلال متغيّر البيئة
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTفي.env) - سمات البيانات الوصفية مثل أرقام تعريف النطاقات وأرقام تعريف عمليات التتبُّع والتوقيت
يمكنك أيضًا التبديل إلى عرض النطاق (التبديل في أعلى الصفحة) للاطّلاع على النطاقات الفردية في جميع الجلسات.
كيفية عمل التتبُّع
عند النشر باستخدام --trace_to_cloud و--otel_to_cloud، تهيئ بيئة تشغيل Agent Engine خط أنابيب OpenTelemetry الذي:
- ينشئ TracerProvider باستخدام أداة تصدير OTLP التي تُرسِل النطاقات إلى
telemetry.googleapis.com - يستخدم حِزم قياس حالة التطبيق الأربع من
requirements.txtلتسجيل النطاقات من المكتبات الرئيسية (FastAPI وGemini وhttpx وgRPC)، ويتم تعديلgoogle-genaiبشكل صريح بواسطة وقت التشغيل، بينما تساهم الحِزم الأخرى من خلال الاكتشاف التلقائي لـ OpenTelemetry - يُجمِّع النطاقات ويصدِّرها إلى Telemetry API، حيث تقرأها علامة التبويب "عمليات التتبُّع"
توفّر الصورة الأساسية لـ Agent Engine حزمة OpenTelemetry SDK وأداة التصدير، ولكن لا تتضمّن حِزم الأدوات. لهذا السبب يجب أن يسرد requirements.txt جميع الحِزم الأربع، وبدونها لن يتم إنشاء أي نطاقات ولن تظهر أي عمليات تتبُّع.
تحديد المشاكل وحلّها
إذا لم تظهر أي عمليات تتبُّع بعد بضع دقائق:
- تأكَّد من تفعيل Telemetry API ، لقد فعّلتها في خطوة الإعداد. تحقَّق من ذلك باستخدام:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - تحقَّق من Cloud Logging بحثًا عن تحذيرات ، انتقِل إلى Logging > مستكشف السجلّات وابحث عن
"telemetry enabled but proceeding without". إذا ظهر لك تحذير بشأن أجهزة GenAI، يعني ذلك أنّopentelemetry-instrumentation-google-genaiغير متوفّر فيrequirements.txt. - لا تُضِف
google-cloud-aiplatform[agent-engines]إلىrequirements.txt. يضيف سطر الأوامر ADK deploy هذا الخيار تلقائيًا، ويمكن أن تؤدي إعادة التعريف بإصدار مختلف إلى حدوث تعارضات في حزمة OpenTelemetry وإيقاف قياس حالة التطبيق بدون إشعار.
9. تنظيف
لتجنُّب تحصيل رسوم مستمرة، احذف الموارد التي تم إنشاؤها خلال هذا الدرس التطبيقي حول الترميز.
احذف الوكيل الذي تم نش1ره من صفحة Agent Engine في Cloud Console. اختَر وكيلك وانقر على حذف.
إذا أنشأت مشروعًا خصيصًا لهذا الدرس التطبيقي حول الترميز، يمكنك حذف المشروع بأكمله بدلاً من ذلك:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
يمكنك اختياريًا تنظيف بيئتك المحلية:
deactivate
rm -rf .venv data_science_agent
10. تهانينا
لقد أنشأت وكيل علوم بيانات يحافظ على الحالة ونشرته على Agent Engine.
ما الذي ستتعلمه
- كيفية إنشاء وكيل ADK باستخدام
BigQueryToolsetللوصول إلى البيانات الحقيقية - كيفية تفعيل الذاكرة المستمرة باستخدام Memory Bank من خلال
PreloadMemoryToolوafter_agent_callback - كيفية منح أذونات إدارة الهوية والوصول (IAM) لحساب خدمة الوكيل الذي تم نشره
- كيفية النشر على Agent Engine وتفعيل إمكانية تتبُّع البيانات باستخدام Cloud Trace
الخطوات التالية
- الاستعلام عن مجموعات بيانات BigQuery الخاصة بك من خلال منح حساب خدمة Agent Engine إذن الوصول إلى بياناتك
- إضافة ميزة "تنفيذ الرمز" لتشغيل تحليل Python في بيئة آمنة
- إعداد لوحات بيانات إمكانية تتبُّع البيانات في Cloud Trace لمراقبة وكيلك في بيئة الإنتاج
- نشر النتائج على Google Workspace باستخدام أدوات MCP