
১. সংক্ষিপ্ত বিবরণ
এই কোডল্যাবে, আপনি এমন একটি ডেটা সায়েন্স এজেন্ট তৈরি করবেন যা BigQuery পাবলিক ডেটাসেট থেকে আসল ডেটা কোয়েরি করে এবং বিভিন্ন সেশনে আপনার পছন্দগুলো মনে রাখে। এরপর আপনি এটিকে এজেন্ট ইঞ্জিনে ডেপ্লয় করবেন, যা একটি সম্পূর্ণ পরিচালিত গুগল ক্লাউড পরিষেবা এবং এটি ইনফ্রাস্ট্রাকচার, স্কেলিং ও সেশন ম্যানেজমেন্টের কাজ সামলায়।
এজেন্টটি তিনটি মূল ক্ষমতা ব্যবহার করে যা ক্রমান্বয়ে সক্রিয় হয়:
- BigQuery টুলসেট : এজেন্টটি স্কিমা অন্বেষণ করে এবং আসল BigQuery ডেটাসেটের উপর SQL কোয়েরি চালায় — এটি স্থানীয়ভাবে এবং ডেপ্লয় করা অবস্থায় উভয় ক্ষেত্রেই কাজ করে।
- মেমরি ব্যাংক : স্থাপন করা হলে, এজেন্ট সংযোগ বিচ্ছিন্ন সেশনগুলোতেও ব্যবহারকারীর পছন্দ এবং প্রাসঙ্গিক তথ্য মনে রাখে।
- পর্যবেক্ষণযোগ্যতা : ক্লাউড ট্রেস ওপেনটেলিমেট্রি ইনস্ট্রুমেন্টেশনের মাধ্যমে এজেন্টের যুক্তির ধাপসমূহ, টুল কল এবং লেটেন্সি ক্যাপচার করে।
আপনি যা শিখবেন
- বাস্তব ডেটা অ্যাক্সেসের জন্য
BigQueryToolsetব্যবহার করে কীভাবে একটি ADK এজেন্ট তৈরি করবেন - ক্রস-সেশন পারসিস্টেন্সের জন্য মেমরি ব্যাংক কীভাবে কনফিগার করবেন
-
adk deployব্যবহার করে কীভাবে আপনার এজেন্টকে এজেন্ট ইঞ্জিনে স্থাপন করবেন - ডেপ্লয় করা এজেন্টের সার্ভিস অ্যাকাউন্টের জন্য কীভাবে IAM পারমিশন প্রদান করবেন
- স্মৃতির স্থায়িত্ব এবং পর্যবেক্ষণযোগ্যতা কীভাবে পরীক্ষা করবেন
আপনার যা যা লাগবে
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট
- গুগল ক্লাউড এসডিকে (
gcloudCLI) - ক্রোমের মতো একটি ওয়েব ব্রাউজার
- uv (পাইথন প্যাকেজ ম্যানেজার)
- পাইথন ৩.১২+ (প্রয়োজনে
uvদ্বারা স্বয়ংক্রিয়ভাবে ইনস্টল করা হয়)
ADK (এজেন্ট ডেভেলপমেন্ট কিট) হলো এআই এজেন্ট তৈরির জন্য গুগলের একটি ফ্রেমওয়ার্ক। এই কোডল্যাবটিতে ADK ব্যবহার করে একটি এজেন্ট তৈরি করা হয়েছে এবং সেটিকে এজেন্ট ইঞ্জিনে ডেপ্লয় করা হয়েছে।
এই কোডল্যাবটি সেইসব মধ্যম স্তরের ডেভেলপারদের জন্য, যাদের পাইথন এবং গুগল ক্লাউড সম্পর্কে কিছুটা ধারণা আছে।
এই কোডল্যাবটি সম্পূর্ণ করতে প্রায় ৩০ মিনিট সময় লাগে (এর মধ্যে ডেপ্লয়মেন্টের জন্য ৫-১০ মিনিট অন্তর্ভুক্ত)।
এই কোডল্যাবে তৈরি রিসোর্সগুলোর খরচ ৫ ডলারের কম হওয়া উচিত।
২. আপনার পরিবেশ প্রস্তুত করুন
একটি গুগল ক্লাউড প্রজেক্ট তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন ।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন।
পরিবেশ ভেরিয়েবল সেট করুন
আপনার তৈরি করা GCP প্রজেক্টে ক্লাউড শেল এডিটরটি খুলুন।
এরপর একটি টার্মিনাল তৈরি করুন > নতুন টার্মিনাল, এবং নিম্নলিখিত কমান্ডগুলো চালান।
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
এপিআই সক্ষম করুন
টার্মিনালে নিম্নলিখিত কমান্ডটি চালান।
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- এআই প্ল্যাটফর্ম এপিআই (
aiplatform.googleapis.com) — এজেন্ট ইঞ্জিন হোস্টিং - BigQuery API (
bigquery.googleapis.com) — পাবলিক এবং প্রাইভেট ডেটাসেটের বিরুদ্ধে SQL কোয়েরি - টেলিমেট্রি এপিআই (
telemetry.googleapis.com) — এজেন্ট পর্যবেক্ষণযোগ্যতার জন্য ওপেনটেলিমেট্রি ট্রেস
একটি ভার্চুয়াল পরিবেশ তৈরি করুন এবং ADK ইনস্টল করুন
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
google-adk প্যাকেজটিতে adk CLI টুলটি অন্তর্ভুক্ত রয়েছে, যা আপনি এজেন্টটি পরীক্ষা ও স্থাপন করতে ব্যবহার করবেন।
৩. এজেন্ট তৈরি করুন
একটি নতুন এজেন্ট প্রজেক্ট ডিরেক্টরি তৈরি করুন। পরবর্তী সমস্ত কমান্ড এই ওয়ার্কিং ডিরেক্টরি ( data_science_agent/ এর প্যারেন্ট) থেকে চালাতে হবে:
mkdir data_science_agent
আপনার চূড়ান্ত ডিরেক্টরি কাঠামোটি দেখতে এইরকম হবে:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
এখন আপনি __init__.py এবং agent.py তৈরি করবেন, তারপর Deploy ধাপে requirements.txt এবং .env যোগ করবেন।
data_science_agent/__init__.py ফাইলটি তৈরি করুন — এই ফাইলটি প্রয়োজন যাতে ADK আপনার এজেন্টকে খুঁজে বের করতে এবং লোড করতে পারে:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
data_science_agent/agent.py তৈরি করুন :
এই এজেন্ট ডেটা নিষ্কাশনের জন্য BigQuery-এর সাথে সংযোগ স্থাপন করে এবং সেশনগুলিকে মেমরি ব্যাংকে সংরক্ষণ করে।
ডেপ্লয় করার সময় মেমরি স্বয়ংক্রিয়ভাবে সক্রিয় হয় — GOOGLE_CLOUD_AGENT_ENGINE_ID এনভায়রনমেন্ট ভেরিয়েবলটি এজেন্ট ইঞ্জিন রানটাইম দ্বারা সেট করা হয় এবং স্থানীয়ভাবে চালানোর সময় এটি অনুপস্থিত থাকে।
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
চলুন দেখে নেওয়া যাক এই কোডটি কী করে:
- BigQueryToolset এজেন্টকে
execute_sql,list_table_ids, এবংget_table_infoমতো টুলগুলো দেয় — এর মাধ্যমে এটি স্কিমা অন্বেষণ করতে পারে এবং কলারের অ্যাক্সেস আছে এমন যেকোনো ডেটাসেট কোয়েরি করতে পারে। - PreloadMemoryTool প্রতিটি LLM কলের আগে ব্যবহারকারীর বার্তার সাথে সম্পর্কিত বিষয়বস্তু খুঁজে বের করার জন্য মেমোরি ব্যাংকে অনুসন্ধান করে স্বয়ংক্রিয়ভাবে প্রাসঙ্গিক মেমোরি পুনরুদ্ধার করে।
_save_memoryকলব্যাকটি প্রতিটি এজেন্ট রানের পরে সেশনটিকে মেমোরি ব্যাংকে সংরক্ষণ করে, যাতে এজেন্ট ভবিষ্যতের সেশনগুলিতে প্রাসঙ্গিক তথ্য স্মরণ করতে পারে। - অ্যাপটি রুট এজেন্টকে একটি ডেপ্লয়েবল অ্যাপ্লিকেশনে মোড়কজাত করে, যা এজেন্ট ইঞ্জিন পরিবেশন করতে পারে।
nameঅবশ্যই ডিরেক্টরির নামের (data_science_agent) সাথে মিলতে হবে —adk webএজেন্টকে সনাক্ত ও লোড করার জন্য এটি ব্যবহার করে। - নির্দেশনাটিতে এজেন্টকে SQL কোয়েরির জন্য বিলিং প্রজেক্ট ব্যবহার করতে এবং ব্যবহারকারীর পছন্দসমূহ মনে রাখতে বলা হয়েছে।
৪. এজেন্ট ইঞ্জিনে স্থাপন করুন
data_science_agent ডিরেক্টরিতে requirements.txt একটি ফাইল তৈরি করুন:
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
-
google-adkএবংgoogle-genai— ADK ফ্রেমওয়ার্ক এবং জেমিনি ক্লায়েন্ট -
google-auth— গুগল ক্লাউড প্রমাণীকরণ -
python-dotenv— স্টার্টআপের সময়.envফাইলটি লোড করে। - চারটি
opentelemetry-instrumentation-*প্যাকেজ সেইসব পর্যবেক্ষণযোগ্যতার বৈশিষ্ট্যগুলো সক্ষম করে যা আপনি পরবর্তীতে অন্বেষণ করবেন। এগুলো FastAPI HTTP অনুরোধ, Gemini মডেল কল এবং অভ্যন্তরীণ gRPC/HTTP যোগাযোগকে ইনস্ট্রুমেন্ট করে, যাতে এজেন্ট ইঞ্জিন ট্রেস ট্যাবে ট্রেসগুলো প্রদর্শিত হয়।
ডেপ্লয় করা এজেন্টে টেলিমেট্রি চালু করতে data_science_agent ডিরেক্টরিতে একটি .env ফাইল তৈরি করুন:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
-
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY— এজেন্ট ইঞ্জিন রানটাইমে ওপেনটেলিমেট্রি পাইপলাইন সক্রিয় করে। -
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT— সম্পূর্ণ প্রম্পট ইনপুট এবং এজেন্ট প্রতিক্রিয়া লগ করে, যা ডিবাগিংয়ের জন্য উপযোগী।
এজেন্টটি স্থাপন করুন। শেষ আর্গুমেন্ট data_science_agent হলো সেই ডিরেক্টরি যেখানে আপনার এজেন্ট কোড রয়েছে:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
পতাকা | উদ্দেশ্য |
| গুগল ক্লাউড প্রকল্প এবং অঞ্চলকে লক্ষ্য করুন |
| ক্লাউড কনসোলে প্রদর্শিত মানুষের পাঠযোগ্য নাম |
| এজেন্ট স্প্যানগুলির জন্য ক্লাউড ট্রেস এক্সপোর্টার সক্ষম করে |
| ওপেনটেলিমেট্রি ইন্সট্রুমেন্টেশন পাইপলাইন সক্ষম করে |
এজেন্ট ইঞ্জিনে স্থাপন করা হলে, দুটি ক্ষমতা স্বয়ংক্রিয়ভাবে সক্রিয় হয়:
- মেমোরি ব্যাংক :
PreloadMemoryToolএজেন্ট ইঞ্জিন মেমোরি ব্যাংকের সাথে সংযোগ স্থাপন করে এবং_save_memoryস্বয়ংক্রিয়ভাবে সেশনগুলো সংরক্ষণ করে। - পর্যবেক্ষণযোগ্যতা : ক্লাউড ট্রেস এজেন্টের যুক্তির ধাপসমূহ, টুল কল এবং লেটেন্সি ক্যাপচার করে।
৫. BigQuery-কে অনুমতি প্রদান করুন
আপনাকে এজেন্ট ইঞ্জিন সার্ভিস অ্যাকাউন্টে BigQuery-কে অ্যাক্সেস দিতে হবে। ডেপ্লয় করার পর, এজেন্টটি একটি গুগল-পরিচালিত সার্ভিস অ্যাকাউন্ট হিসেবে চলে (আপনার ব্যক্তিগত ক্রেডেনশিয়াল হিসেবে নয়), তাই SQL কোয়েরি চালানোর জন্য এটির সুস্পষ্ট অনুমতির প্রয়োজন হয়।
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
প্রতিটি কমান্ড সফল হলে Updated IAM policy for project [...] প্রিন্ট করে।
৬. ডেপ্লয় করা এজেন্টটি পরীক্ষা করুন
গুগল ক্লাউড কনসোলে এজেন্ট ইঞ্জিন পৃষ্ঠাটি খুলুন। এজেন্ট ইঞ্জিন প্লেগ্রাউন্ড খুলতে আপনার ডেপ্লয় করা এজেন্টের উপর ক্লিক করুন।
BigQuery-এর সক্ষমতা পরীক্ষা করুন:
- bigquery-public-data.hacker_news-এর টেবিলগুলো তালিকাভুক্ত করুন।
- প্রত্যাশিত : এজেন্ট
list_table_idsকল করবে এবংfullনামসহ টেবিলের নামগুলো ফেরত দেবে।
- প্রত্যাশিত : এজেন্ট
- bigquery-public-data.hacker_news.full-এ প্রতি বছর পোস্টের সংখ্যা খুঁজুন।
- প্রত্যাশিত : এজেন্ট একটি SQL কোয়েরি দিয়ে
execute_sqlকল করবে এবং এটি বছর ও পোস্টের সংখ্যা সম্বলিত একটি টেবিল ফেরত দেবে।
- প্রত্যাশিত : এজেন্ট একটি SQL কোয়েরি দিয়ে
- গত বছরের তুলনায় পোস্টের সংখ্যায় শতকরা পরিবর্তন কত ছিল?
- প্রত্যাশিত : এজেন্ট একটি SQL কোয়েরি দিয়ে
execute_sqlকল করবে, যা শতাংশ পরিবর্তন গণনা করে এবং ফলাফল ফেরত দেবে।
- প্রত্যাশিত : এজেন্ট একটি SQL কোয়েরি দিয়ে
৭. স্মৃতির স্থায়িত্ব পরীক্ষা করুন
প্লেগ্রাউন্ডে থাকাকালীন, এজেন্টকে একটি পছন্দ শিখিয়ে দিন:
- মনে রাখবেন যে আমার প্রিয় ডেটাসেট হলো bigquery-public-data.hacker_news
- এতে কী কী টেবিল আছে?
মেমোরি স্থায়ী হওয়ার জন্য কয়েক সেকেন্ড অপেক্ষা করুন (এজেন্টের সাড়া দেওয়ার পর _save_memory কলব্যাকটি চলে)।
এখন প্লেগ্রাউন্ড সাইডবারে থাকা "+ নতুন সেশন" বোতামে ক্লিক করে একটি নতুন সেশন শুরু করুন , তারপর জিজ্ঞাসা করুন:
- আমার প্রিয় ডেটাসেট কোনটি?
এজেন্টটির bigquery-public-data.hacker_news রিকল করা উচিত, যদিও এটি একটি একদম নতুন সেশন এবং এর কোনো কনভারসেশন হিস্ট্রি নেই। এটি কাজ করে কারণ:
-
_save_memorycallback_context.add_session_to_memory()এর মাধ্যমে প্রতিটি সেশনকে মেমোরি ব্যাংকে সংরক্ষণ করে। -
PreloadMemoryToolপ্রতিটি LLM কলের আগে প্রাসঙ্গিক মেমরি পুনরুদ্ধার করে। - মেমোরি ব্যাংক শুধু কীওয়ার্ডের মাধ্যমেই নয়, বরং শব্দার্থগতভাবেও বিষয়বস্তু মেলায়।
৮. পর্যবেক্ষণযোগ্যতা অন্বেষণ করুন
ক্লাউড কনসোলে, আপনার ডেপ্লয় করা এজেন্টে যান এবং ট্রেসেস ট্যাবে ক্লিক করুন।
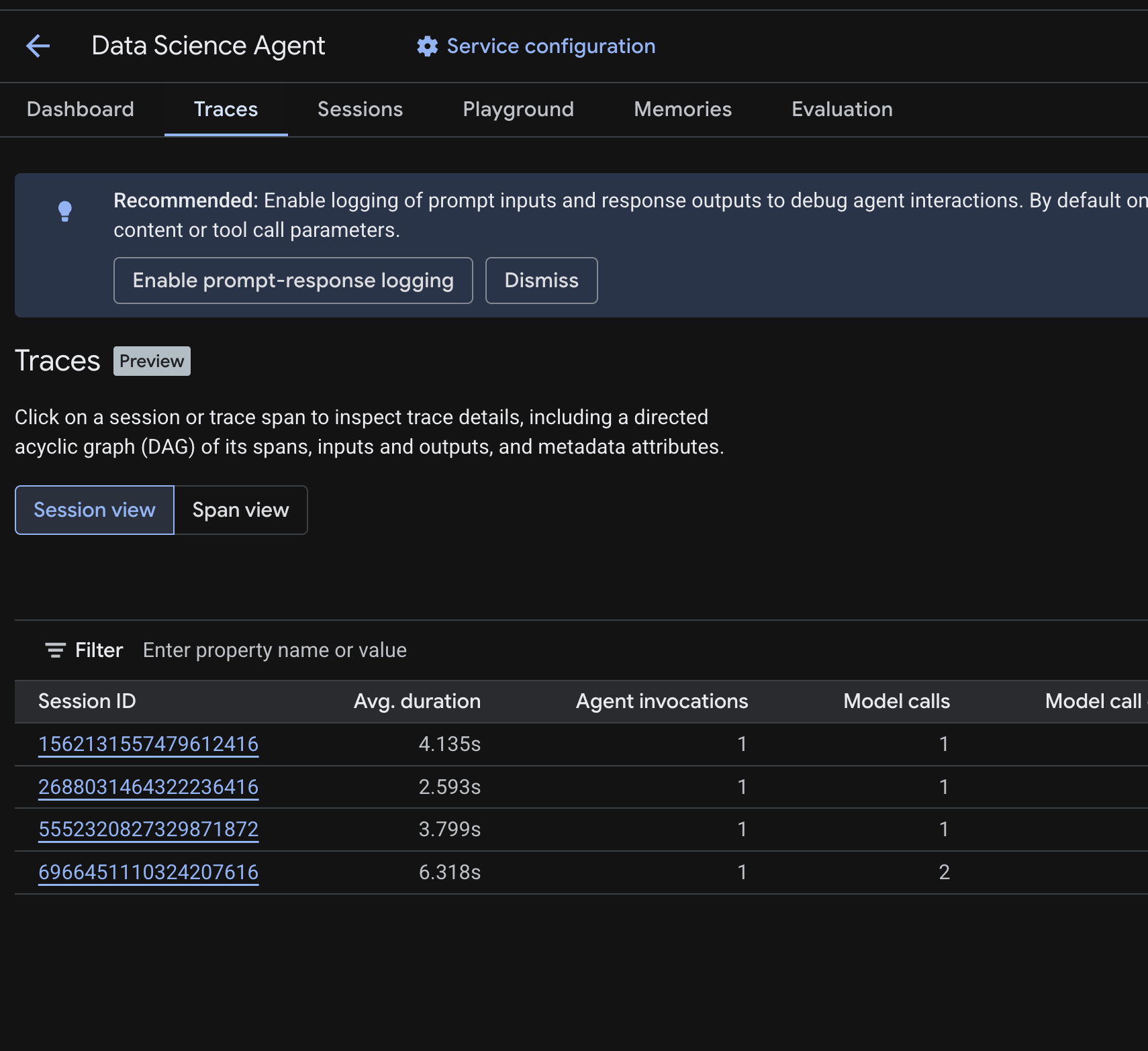
আপনি একটি সেশন টেবিল দেখতে পাবেন, যেখানে পূর্ববর্তী ধাপে চালানো টেস্ট কোয়েরিগুলোর সেশনগুলোর তালিকা থাকবে। টেবিলটিতে প্রতিটি সেশনের সারসংক্ষেপ মেট্রিকগুলো দেখানো হয় — যেমন গড় সময়কাল, মডেল কল, টুল কল, টোকেন ব্যবহার এবং যেকোনো ত্রুটি।
একটি সেশনের ট্রেস বিবরণ খতিয়ে দেখতে সেটির উপর ক্লিক করুন, যার মধ্যে অন্তর্ভুক্ত রয়েছে:
- এর স্প্যানগুলোর একটি ডিরেক্টেড অ্যাসাইক্লিক গ্রাফ (DAG) — যা এজেন্টের যুক্তিপ্রক্রিয়া, টুল কল (বিগকোয়েরি কোয়েরি), এবং ল্যাটেন্সির ধাপে ধাপে বিভাজন দেখায়।
- প্রতিটি স্প্যানের জন্য ইনপুট এবং আউটপুট (যা
.envফাইলে থাকাOTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTএনভ ভ্যারিয়েবলের মাধ্যমে সক্রিয় করা হয়)। - স্প্যান আইডি, ট্রেস আইডি এবং টাইমিং-এর মতো মেটাডেটা অ্যাট্রিবিউট
এছাড়াও, সমস্ত সেশন জুড়ে স্বতন্ত্র স্প্যানগুলি দেখতে আপনি স্প্যান ভিউতে (উপরের টগলটি) যেতে পারেন।
ট্রেসিং কীভাবে কাজ করে
যখন আপনি --trace_to_cloud এবং --otel_to_cloud সহ ডিপ্লয় করেন, তখন এজেন্ট ইঞ্জিন রানটাইম একটি ওপেনটেলিমেট্রি পাইপলাইন চালু করে যা:
- একটি OTLP এক্সপোর্টার সহ একটি TracerProvider তৈরি করে যা
telemetry.googleapis.comএ স্প্যান পাঠায়। - আপনার
requirements.txtএ থাকা চারটি ইন্সট্রুমেন্টেশন প্যাকেজ ব্যবহার করে এটি মূল লাইব্রেরিগুলো (FastAPI, Gemini, httpx, gRPC) থেকে স্প্যান ক্যাপচার করে —google-genaiরানটাইম দ্বারা সরাসরি ইন্সট্রুমেন্টেড হয়, আর বাকিগুলো OpenTelemetry অটো-ডিসকভারির মাধ্যমে অবদান রাখে। - ব্যাচ এবং এক্সপোর্টগুলি টেলিমেট্রি এপিআই-তে পাঠানো হয়, যেখানে ট্রেসেস ট্যাব সেগুলি পড়ে।
এজেন্ট ইঞ্জিন বেস ইমেজটি ওপেনটেলিমেট্রি এসডিকে এবং এক্সপোর্টার প্রদান করে, কিন্তু ইন্সট্রুমেন্টেশন প্যাকেজগুলো অন্তর্ভুক্ত করে না । এই কারণেই আপনার requirements.txt অবশ্যই এই চারটিই তালিকাভুক্ত করতে হবে — এগুলো ছাড়া কোনো স্প্যান তৈরি হয় না এবং কোনো ট্রেসও প্রদর্শিত হয় না।
সমস্যা সমাধান
কয়েক মিনিট পরেও যদি কোনো চিহ্ন না দেখা যায়:
- টেলিমেট্রি এপিআই (Telemetry API) চালু আছে কিনা তা পরীক্ষা করুন — আপনি সেটআপ ধাপে এটি চালু করেছিলেন। নিম্নলিখিত কমান্ড দিয়ে যাচাই করুন:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - সতর্কবার্তার জন্য ক্লাউড লগিং পরীক্ষা করুন — লগিং > লগস এক্সপ্লোরার- এ যান এবং
"telemetry enabled but proceeding without"লিখে অনুসন্ধান করুন। যদি আপনি GenAI ইন্সট্রুমেন্টেশন সম্পর্কে কোনো সতর্কবার্তা দেখতে পান, তাহলে আপনারrequirements.txtফাইলেopentelemetry-instrumentation-google-genaiঅনুপস্থিত রয়েছে। - আপনার
requirements.txtফাইলেgoogle-cloud-aiplatform[agent-engines]যোগ করবেন না । ADK deploy CLI এটি স্বয়ংক্রিয়ভাবে যোগ করে; ভিন্ন সংস্করণ দিয়ে এটি পুনরায় ঘোষণা করলে OpenTelemetry প্যাকেজের মধ্যে দ্বন্দ্ব সৃষ্টি হতে পারে এবং নীরবে ইন্সট্রুমেন্টেশন ভেঙে যেতে পারে।
৯. পরিষ্কার করা
চলমান চার্জ এড়াতে, এই কোডল্যাব চলাকালীন তৈরি করা রিসোর্সগুলো মুছে ফেলুন।
ক্লাউড কনসোলের এজেন্ট ইঞ্জিন পৃষ্ঠা থেকে স্থাপন করা এজেন্টটি মুছে ফেলুন । আপনার এজেন্টটি নির্বাচন করুন এবং ডিলিট-এ ক্লিক করুন।
আপনি যদি বিশেষভাবে এই কোডল্যাবের জন্য একটি প্রজেক্ট তৈরি করে থাকেন, তাহলে আপনি পুরো প্রজেক্টটি মুছে ফেলতে পারেন:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
ঐচ্ছিকভাবে, আপনার স্থানীয় পরিবেশ পরিষ্কার করুন:
deactivate
rm -rf .venv data_science_agent
১০. অভিনন্দন
আপনি একটি স্টেটফুল ডেটা সায়েন্স এজেন্ট তৈরি করে এজেন্ট ইঞ্জিনে স্থাপন করেছেন!
আপনি যা শিখেছেন
- বাস্তব ডেটা অ্যাক্সেসের জন্য
BigQueryToolsetব্যবহার করে কীভাবে একটি ADK এজেন্ট তৈরি করবেন -
PreloadMemoryToolএবংafter_agent_callbackব্যবহার করে মেমরি ব্যাংকের সাথে পারসিস্টেন্ট মেমরি কীভাবে সক্রিয় করবেন - ডেপ্লয় করা এজেন্টের সার্ভিস অ্যাকাউন্টের জন্য কীভাবে IAM পারমিশন প্রদান করবেন
- এজেন্ট ইঞ্জিনে কীভাবে ডিপ্লয় করবেন এবং ক্লাউড ট্রেসের মাধ্যমে অবজার্ভেবিলিটি চালু করবেন
পরবর্তী পদক্ষেপ
- এজেন্ট ইঞ্জিন সার্ভিস অ্যাকাউন্টকে আপনার ডেটাতে অ্যাক্সেস দিয়ে আপনার নিজস্ব ব্যক্তিগত BigQuery ডেটাসেটগুলো কোয়েরি করুন।
- একটি সুরক্ষিত স্যান্ডবক্সে পাইথন বিশ্লেষণ চালানোর জন্য কোড এক্সিকিউশন যোগ করুন।
- প্রোডাকশনে আপনার এজেন্ট নিরীক্ষণ করতে ক্লাউড ট্রেস অবজার্ভেবিলিটি ড্যাশবোর্ড সেট আপ করুন।
- MCP টুল ব্যবহার করে Google Workspace-এ ফলাফল প্রকাশ করুন