
1. Übersicht
In diesem Codelab erstellen Sie einen Data Science-Agent, der echte Daten aus öffentlichen BigQuery-Datasets abfragt und sich Ihre Einstellungen sitzungsübergreifend merkt. Anschließend stellen Sie ihn in Agent Engine bereit, einem vollständig verwalteten Google Cloud-Dienst, der sich um Infrastruktur, Skalierung und Sitzungsverwaltung kümmert.
Der KI-Agent verwendet drei Kernfunktionen, die nach und nach aktiviert werden:
- BigQuery-Toolset: Der Agent untersucht Schemas und führt SQL-Abfragen für echte BigQuery-Datasets aus – das funktioniert sowohl lokal als auch bei der Bereitstellung.
- Memory Bank: Wenn der Agent bereitgestellt wird, merkt er sich die Nutzereinstellungen und den Kontext über getrennte Sitzungen hinweg.
- Observability: Cloud Trace erfasst die Reasoning-Schritte, Toolaufrufe und Latenzen des Agents über die OpenTelemetry-Instrumentierung.
Lerninhalte
- ADK-Agent mit
BigQueryToolsetfür den Zugriff auf echte Daten erstellen - Memory Bank für sitzungsübergreifende Persistenz konfigurieren
- KI-Agent mit
adk deployin der Agent Engine bereitstellen - IAM-Berechtigungen für das Dienstkonto des bereitgestellten Agents gewähren
- Persistenz und Beobachtbarkeit des Arbeitsspeichers testen
Voraussetzungen
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
- Google Cloud SDK (
gcloudCLI) - Ein Webbrowser wie Chrome
- uv (Python-Paketmanager)
- Python 3.12+ (wird bei Bedarf automatisch von
uvinstalliert)
Das ADK (Agent Development Kit) ist das Framework von Google zum Erstellen von KI-Agenten. In diesem Codelab wird das ADK verwendet, um einen Agenten zu erstellen und in Agent Engine bereitzustellen.
Dieses Codelab richtet sich an fortgeschrittene Entwickler, die mit Python und Google Cloud vertraut sind.
Dieses Codelab dauert etwa 30 Minuten (einschließlich 5–10 Minuten für das Deployment).
Die in diesem Codelab erstellten Ressourcen sollten weniger als 5 $kosten.
2. Umgebung einrichten
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Umgebungsvariablen festlegen
Öffnen Sie den Cloud Shell-Editor in Ihrem erstellten GCP-Projekt.
Erstellen Sie dann ein Terminal > Neues Terminal und führen Sie die folgenden Befehle aus.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
APIs aktivieren
Führen Sie im Terminal den folgenden Befehl aus.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- AI Platform API (
aiplatform.googleapis.com) – Agent Engine-Hosting - BigQuery API (
bigquery.googleapis.com): SQL-Abfragen für öffentliche und private Datasets - Telemetry API (
telemetry.googleapis.com): OpenTelemetry-Traces für die Agent-Beobachtbarkeit
Virtuelle Umgebung erstellen und ADK installieren
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
Das Paket google-adk enthält das adk-CLI-Tool, mit dem Sie den Agent testen und bereitstellen.
3. Agent erstellen
Erstellen Sie ein neues Agent-Projektverzeichnis. Alle nachfolgenden Befehle sollten in diesem Arbeitsverzeichnis (dem übergeordneten Verzeichnis von data_science_agent/) ausgeführt werden:
mkdir data_science_agent
Die endgültige Verzeichnisstruktur sieht so aus:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
Sie erstellen jetzt __init__.py und agent.py und fügen dann im Bereitstellungsschritt requirements.txt und .env hinzu.
Erstellen Sie data_science_agent/__init__.py. Diese Datei ist erforderlich, damit das ADK Ihren KI-Agenten erkennen und laden kann:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
data_science_agent/agent.py erstellen:
Dieser Agent stellt eine Verbindung zu BigQuery her, um Daten zu extrahieren, und speichert Sitzungen in Memory Bank.
Der Speicher wird automatisch aktiviert, wenn er bereitgestellt wird. Die Umgebungsvariable GOOGLE_CLOUD_AGENT_ENGINE_ID wird von der Agent Engine-Laufzeit festgelegt und ist bei der lokalen Ausführung nicht vorhanden.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
So funktioniert dieser Code:
- BigQueryToolset bietet dem Agent Tools wie
execute_sql,list_table_idsundget_table_info. Damit kann er Schemas untersuchen und beliebige Datasets abfragen, auf die der Anrufer Zugriff hat. - PreloadMemoryTool ruft automatisch relevante Erinnerungen vor jedem LLM-Aufruf ab, indem es in der Memory Bank nach Inhalten sucht, die sich auf die Nachricht des Nutzers beziehen. Mit dem
_save_memory-Callback wird die Sitzung nach jeder Ausführung des Agents im Memory Bank gespeichert, sodass der Agent den Kontext in zukünftigen Sitzungen abrufen kann. - App umschließt den Stamm-Agenten in einer bereitstellbaren Anwendung, die von Agent Engine bereitgestellt werden kann.
namemuss dem Verzeichnisnamen (data_science_agent) entsprechen.adk webverwendet diesen Namen, um den Agent zu finden und zu laden. - Die Anweisung weist den Agent an, das Abrechnungsprojekt für SQL-Abfragen zu verwenden und sich Nutzerpräferenzen zu merken.
4. In der Agent Engine bereitstellen
Erstellen Sie im Verzeichnis data_science_agent eine Datei requirements.txt:
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
google-adkundgoogle-genai: ADK-Framework und Gemini-Clientgoogle-auth– Google Cloud-Authentifizierungpython-dotenv– lädt die Datei.envbeim Start- Die vier
opentelemetry-instrumentation-*-Pakete ermöglichen die Funktionen zur Beobachtbarkeit, die Sie später kennenlernen werden. Sie instrumentieren FastAPI-HTTP-Anfragen, Gemini-Modellaufrufe und die interne gRPC-/HTTP-Kommunikation, sodass Traces auf dem Tab „Agent Engine Traces“ angezeigt werden.
Erstellen Sie im Verzeichnis data_science_agent eine .env-Datei, um die Telemetrie für den bereitgestellten Agent zu aktivieren:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY: Aktiviert die OpenTelemetry-Pipeline in der Agent Engine-Laufzeit.OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT: Protokolliert vollständige Prompt-Eingaben und Antworten des KI-Agenten, was für das Debugging nützlich ist.
Agent bereitstellen. Das letzte Argument data_science_agent ist das Verzeichnis mit Ihrem Agentencode:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
Flag | Zweck |
| Google Cloud-Projekt und ‑Region festlegen |
| Für Menschen lesbarer Name, der in der Cloud Console angezeigt wird |
| Aktiviert den Cloud Trace-Exporter für Agent-Spans. |
| Aktiviert die OpenTelemetry-Instrumentierungspipeline. |
Wenn Sie in Agent Engine bereitgestellt werden, werden zwei Funktionen automatisch aktiviert:
- Memory Bank:
PreloadMemoryToolstellt eine Verbindung zur Memory Bank der Agent Engine her und_save_memoryspeichert Sitzungen automatisch. - Beobachtbarkeit: Cloud Trace erfasst die Reasoning-Schritte, Tool-Aufrufe und Latenzen des Agents.
5. BigQuery-Berechtigungen erteilen
Sie müssen dem Agent Engine-Dienstkonto Zugriff auf BigQuery gewähren. Wenn der Agent bereitgestellt wird, wird er als von Google verwaltetes Dienstkonto ausgeführt (nicht mit Ihren persönlichen Anmeldedaten). Daher sind explizite Berechtigungen zum Ausführen von SQL-Abfragen erforderlich.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
Bei erfolgreicher Ausführung wird für jeden Befehl Updated IAM policy for project [...] ausgegeben.
6. Bereitgestellten KI-Agenten testen
Öffnen Sie in der Google Cloud Console die Seite „Agent Engine“. Klicken Sie auf den bereitgestellten Agent, um den Agent Engine Playground zu öffnen.
BigQuery-Funktionen testen:
- „List the tables in bigquery-public-data.hacker_news“
- Erwartet: Der Agent ruft
list_table_idsauf und gibt Tabellennamen zurück, darunterfull.
- Erwartet: Der Agent ruft
- „Find the number of posts per year in bigquery-public-data.hacker_news.full“
- Erwartet: Der Agent ruft
execute_sqlmit einer SQL-Abfrage auf und gibt eine Tabelle mit Jahren und der Anzahl der Beiträge zurück.
- Erwartet: Der Agent ruft
- „Wie hoch war die prozentuale Veränderung der Beiträge im Jahresvergleich?“
- Erwartet: Der Agent ruft
execute_sqlmit einer SQL-Abfrage auf, die die prozentuale Änderung berechnet und die Ergebnisse zurückgibt.
- Erwartet: Der Agent ruft
7. Speicherpersistenz testen
Weisen Sie dem KI-Agenten im Playground eine Präferenz zu:
- „Merk dir, dass mein Lieblingsdataset bigquery-public-data.hacker_news ist.“
- „Welche Tabellen sind enthalten?“
Warten Sie einige Sekunden, bis der Speicher beibehalten wird. Der _save_memory-Callback wird ausgeführt, nachdem der Agent geantwortet hat.
Starten Sie jetzt eine neue Sitzung, indem Sie in der Playground-Seitenleiste auf die Schaltfläche + Neue Sitzung klicken, und stellen Sie dann folgende Frage:
- „What is my favorite dataset?“ (Was ist mein bevorzugter Datensatz?)
Der Agent sollte sich an bigquery-public-data.hacker_news erinnern, obwohl dies eine brandneue Sitzung ohne Unterhaltungsverlauf ist. Das funktioniert, weil:
_save_memorywird in jeder Sitzung übercallback_context.add_session_to_memory()in der Memory Bank gespeichert.PreloadMemoryToolruft vor jedem LLM-Aufruf relevante Erinnerungen ab.- Memory Bank gleicht Inhalte semantisch ab, nicht nur anhand von Suchbegriffen.
8. Beobachtbarkeit kennenlernen
Rufen Sie in der Cloud Console Ihren bereitgestellten Agent auf und klicken Sie auf den Tab Traces.
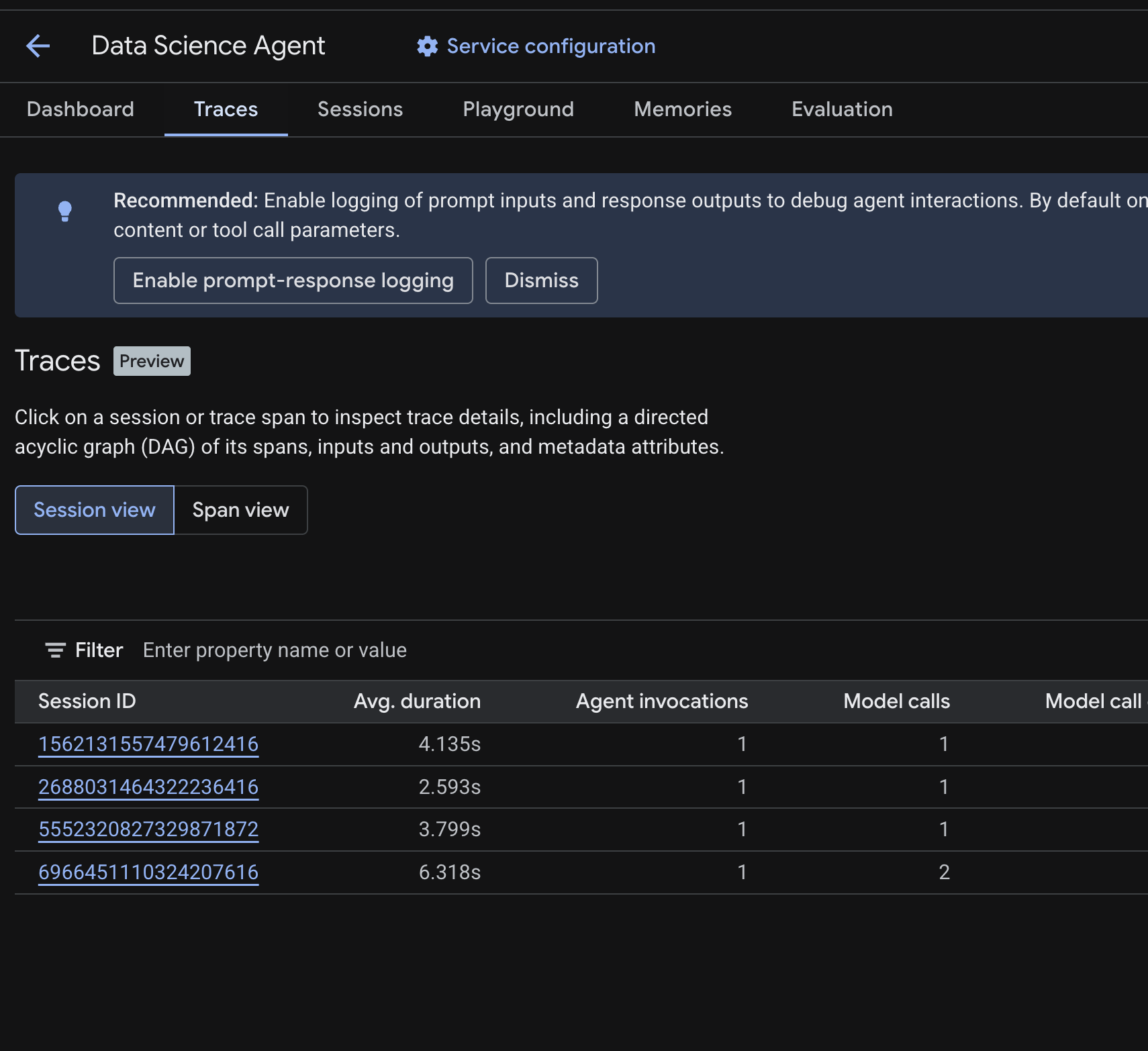
Sie sollten eine Sitzungstabelle sehen, in der die Sitzungen aus den Testabfragen aufgeführt sind, die Sie in den vorherigen Schritten ausgeführt haben. Die Tabelle enthält Zusammenfassungsmesswerte für jede Sitzung: durchschnittliche Dauer, Modellaufrufe, Tool-Aufrufe, Token-Nutzung und Fehler.
Klicken Sie auf eine Sitzung, um die zugehörigen Tracedetails zu prüfen, darunter:
- Ein gerichteter azyklischer Graph (DAG) der Spannen, der die schrittweise Aufschlüsselung der Agentenlogik, der Tool-Aufrufe (BigQuery-Abfragen) und der Latenzen zeigt
- Ein- und Ausgaben für jeden Zeitraum (aktiviert über die Umgebungsvariable
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTin.env) - Metadatenattribute wie Spannen-IDs, Trace-IDs und Zeitangaben
Sie können auch zur Span-Ansicht wechseln (oben umschalten), um einzelne Spans für alle Sitzungen zu sehen.
So funktioniert die Routenaufzeichnung
Wenn Sie mit --trace_to_cloud und --otel_to_cloud bereitstellen, initialisiert die Agent Engine-Laufzeit eine OpenTelemetry-Pipeline, die:
- Erstellt einen TracerProvider mit einem OTLP-Exporter, der Spans an
telemetry.googleapis.comsendet. - Verwendet die vier Instrumentierungspakete aus Ihrem
requirements.txt, um Spans aus wichtigen Bibliotheken (FastAPI, Gemini, httpx, gRPC) zu erfassen.google-genaiwird explizit von der Laufzeit instrumentiert, während die anderen über die automatische OpenTelemetry-Erkennung beitragen. - Batches und Exportspans an die Telemetry API, wo sie auf dem Tab „Traces“ gelesen werden
Das Agent Engine-Basis-Image enthält das OpenTelemetry SDK und den Exporter, aber nicht die Instrumentierungspakete. Deshalb müssen in Ihrem requirements.txt alle vier aufgeführt sein. Andernfalls werden keine Spans erstellt und keine Traces angezeigt.
Fehlerbehebung
Wenn nach einigen Minuten keine Spuren angezeigt werden:
- Prüfen Sie, ob die Telemetry API aktiviert ist. Sie haben sie im Einrichtungsschritt aktiviert. Bestätigen mit:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - Cloud Logging auf Warnungen prüfen: Rufen Sie Logging > Log-Explorer auf und suchen Sie nach
"telemetry enabled but proceeding without". Wenn Sie eine Warnung zur Instrumentierung von generativer KI sehen, fehltopentelemetry-instrumentation-google-genaiin Ihremrequirements.txt. - Fügen Sie Ihrem
requirements.txtgoogle-cloud-aiplatform[agent-engines]nicht hinzu. Die ADK Deploy CLI fügt sie automatisch hinzu. Wenn Sie sie mit einer anderen Version neu deklarieren, kann dies zu Konflikten mit OpenTelemetry-Paketen führen und die Instrumentierung wird möglicherweise nicht mehr ausgeführt.
9. Bereinigen
Löschen Sie die in diesem Codelab erstellten Ressourcen, um laufende Gebühren zu vermeiden.
Löschen Sie den bereitgestellten Agenten auf der Seite Agent Engine in der Cloud Console. Wählen Sie den Agent aus und klicken Sie auf Löschen.
Wenn Sie ein Projekt speziell für dieses Codelab erstellt haben, können Sie stattdessen das gesamte Projekt löschen:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
Optional: Lokale Umgebung bereinigen:
deactivate
rm -rf .venv data_science_agent
10. Glückwunsch
Sie haben einen zustandsorientierten Data-Scientist-Agent erstellt und in Agent Engine bereitgestellt.
Das haben Sie gelernt
- ADK-Agent mit
BigQueryToolsetfür den Zugriff auf echte Daten erstellen - Nichtflüchtigen Speicher mit Memory Bank über
PreloadMemoryToolundafter_agent_callbackaktivieren - IAM-Berechtigungen für das Dienstkonto des bereitgestellten Agents gewähren
- In Agent Engine bereitstellen und Beobachtbarkeit mit Cloud Trace aktivieren
Nächste Schritte
- Eigene private BigQuery-Datasets abfragen, indem Sie dem Agent Engine-Dienstkonto Zugriff auf Ihre Daten gewähren
- Codeausführung hinzufügen, um Python-Analysen in einer sicheren Sandbox auszuführen
- Cloud Trace-Dashboards für die Beobachtbarkeit einrichten, um Ihren Agent in der Produktion zu überwachen
- Ergebnisse mit MCP-Tools in Google Workspace veröffentlichen