
1. Descripción general
En este codelab, crearás un agente de ciencia de datos que consulta datos reales de conjuntos de datos públicos de BigQuery y recuerda tus preferencias en diferentes sesiones. Luego, lo implementarás en Agent Engine, un servicio de Google Cloud completamente administrado que se encarga de la infraestructura, el escalamiento y la administración de sesiones.
El agente usa tres capacidades principales que se activan de forma progresiva:
- BigQuery Toolset: El agente explora esquemas y ejecuta consultas de SQL en conjuntos de datos reales de BigQuery, lo que funciona de forma local y cuando se implementa.
- Banco de memoria: Cuando se implementa, el agente recuerda las preferencias y el contexto del usuario en las sesiones desconectadas.
- Observabilidad: Cloud Trace captura los pasos de razonamiento, las llamadas a herramientas y las latencias del agente a través de la instrumentación de OpenTelemetry.
Qué aprenderás
- Cómo crear un agente de ADK con
BigQueryToolsetpara acceder a datos reales - Cómo configurar Memory Bank para la persistencia entre sesiones
- Cómo implementar tu agente en Agent Engine con
adk deploy - Cómo otorgar permisos de IAM a la cuenta de servicio del agente implementado
- Cómo probar la persistencia y la observabilidad de la memoria
Requisitos
- Un proyecto de Google Cloud con la facturación habilitada.
- SDK de Google Cloud (CLI de
gcloud) - Un navegador web, como Chrome
- uv (administrador de paquetes de Python)
- Python 3.12 o versiones posteriores (
uvlo instala automáticamente si es necesario)
El ADK (Kit de desarrollo de agentes) es el framework de Google para crear agentes de IA. En este codelab, se usa el ADK para crear un agente y, luego, implementarlo en Agent Engine.
Este codelab es para desarrolladores intermedios que tienen cierta familiaridad con Python y Google Cloud.
Este codelab toma aproximadamente 30 minutos en completarse (incluidos entre 5 y 10 minutos para la implementación).
Los recursos creados en este codelab deberían costar menos de USD 5.
2. Configura tu entorno
Crea un proyecto de Google Cloud
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
Configura variables de entorno
Abre el Editor de Cloud Shell en el proyecto de GCP que creaste.
Luego, crea una Terminal > Nueva terminal y ejecuta los siguientes comandos.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
Habilita las APIs
En la terminal, ejecuta el siguiente comando.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- API de AI Platform (
aiplatform.googleapis.com): Hosting de Agent Engine - API de BigQuery (
bigquery.googleapis.com): Consultas en SQL en conjuntos de datos públicos y privados - API de Telemetry (
telemetry.googleapis.com): Registros de OpenTelemetry para la observabilidad del agente
Crea un entorno virtual y, luego, instala el ADK
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
El paquete google-adk incluye la herramienta de CLI de adk que usarás para probar e implementar el agente.
3. Crea el agente
Crea un directorio de proyecto de agente nuevo. Todos los comandos posteriores se deben ejecutar desde este directorio de trabajo (el principal de data_science_agent/):
mkdir data_science_agent
La estructura de directorio final se verá así:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
Ahora crearás __init__.py y agent.py, y, luego, agregarás requirements.txt y .env en el paso de implementación.
Crea data_science_agent/__init__.py. Este archivo es necesario para que el ADK pueda descubrir y cargar tu agente:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
Crea data_science_agent/agent.py:
Este agente se conecta a BigQuery para la extracción de datos y persiste las sesiones en Memory Bank.
La memoria se activa automáticamente cuando se implementa. El tiempo de ejecución de Agent Engine establece la variable de entorno GOOGLE_CLOUD_AGENT_ENGINE_ID, que no está presente cuando se ejecuta de forma local.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
Veamos qué hace este código:
- BigQueryToolset proporciona al agente herramientas como
execute_sql,list_table_idsyget_table_info. Puede explorar esquemas y consultar cualquier conjunto de datos al que tenga acceso el llamador. - PreloadMemoryTool recupera automáticamente recuerdos relevantes antes de cada llamada al LLM buscando en Memory Bank contenido relacionado con el mensaje del usuario. La devolución de llamada
_save_memorypersiste la sesión en Memory Bank después de cada ejecución del agente, de modo que el agente pueda recordar el contexto en sesiones futuras. - App encapsula el agente raíz en una aplicación implementable que Agent Engine puede entregar. El
namedebe coincidir con el nombre del directorio (data_science_agent).adk weblo usa para ubicar y cargar el agente. - La instrucción le indica al agente que use el proyecto de facturación para las consultas de SQL y que recuerde las preferencias del usuario.
4. Implementa en Agent Engine
Crea un archivo requirements.txt en el directorio data_science_agent:
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
google-adkygoogle-genai: El framework de ADK y el cliente de Geminigoogle-auth: Autenticación de Google Cloudpython-dotenv: Carga el archivo.enval inicio.- Los cuatro paquetes
opentelemetry-instrumentation-*habilitan las funciones de observabilidad que explorarás más adelante. Instrumentan las solicitudes HTTP de FastAPI, las llamadas al modelo de Gemini y la comunicación interna de gRPC/HTTP para que los registros aparezcan en la pestaña Agent Engine Traces.
Crea un archivo .env en el directorio data_science_agent para habilitar la telemetría en el agente implementado:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY: Activa la canalización de OpenTelemetry en el tiempo de ejecución de Agent Engine.OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT: Registra las entradas de instrucciones completas y las respuestas del agente, lo que resulta útil para la depuración.
Implementa el agente. El último argumento data_science_agent es el directorio que contiene el código del agente:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
Marcar | Objetivo |
| Proyecto y región de Google Cloud de destino |
| Nombre legible que se muestra en Cloud Console |
| Habilita el exportador de Cloud Trace para los intervalos del agente |
| Habilita la canalización de instrumentación de OpenTelemetry |
Cuando se implementa en Agent Engine, se activan automáticamente dos capacidades:
- Memory Bank:
PreloadMemoryToolse conecta a Memory Bank de Agent Engine y_save_memorypersiste las sesiones automáticamente. - Observabilidad: Cloud Trace captura los pasos de razonamiento, las llamadas a herramientas y las latencias del agente.
5. Otorga permisos de BigQuery
Debes otorgar acceso a BigQuery a la cuenta de servicio de Agent Engine. Cuando se implementa, el agente se ejecuta como una cuenta de servicio administrada por Google (no con tus credenciales personales), por lo que necesita permisos explícitos para ejecutar consultas SQL.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
Cada comando imprime Updated IAM policy for project [...] cuando se ejecuta correctamente.
6. Prueba el agente implementado
Abre la página Agent Engine en la consola de Google Cloud. Haz clic en el agente implementado para abrir Agent Engine Playground.
Prueba las capacidades de BigQuery:
- "Enumera las tablas en bigquery-public-data.hacker_news"
- Resultado esperado: El agente llama a
list_table_idsy devuelve nombres de tablas, incluidofull.
- Resultado esperado: El agente llama a
- "Busca la cantidad de publicaciones por año en bigquery-public-data.hacker_news.full"
- Esperado: El agente llama a
execute_sqlcon una consulta en SQL y devuelve una tabla de años y recuentos de publicaciones.
- Esperado: El agente llama a
- "¿Cuál fue el cambio porcentual interanual en las publicaciones?"
- Resultado esperado: El agente llama a
execute_sqlcon una consulta en SQL que calcula el cambio porcentual y devuelve los resultados.
- Resultado esperado: El agente llama a
7. Prueba la persistencia de la memoria
En Playground, enséñale al agente una preferencia:
- "Recuerda que mi conjunto de datos favorito es bigquery-public-data.hacker_news".
- "¿Qué tablas tiene?"
Espera unos segundos para que persista la memoria (la devolución de llamada _save_memory se ejecuta después de que responde el agente).
Ahora, inicia una sesión nueva haciendo clic en el botón "+ New Session" en la barra lateral de Playground y, luego, haz la siguiente pregunta:
- "¿Cuál es mi conjunto de datos favorito?"
El agente debe recordar bigquery-public-data.hacker_news, aunque se trate de una sesión completamente nueva sin historial de conversaciones. Esto funciona por los siguientes motivos:
_save_memorypersiste cada sesión en Memory Bank a través decallback_context.add_session_to_memory()PreloadMemoryToolrecupera recuerdos pertinentes antes de cada llamada al LLM- Memory Bank relaciona el contenido de forma semántica, no solo por palabras clave.
8. Explora la observabilidad
En la consola de Cloud, navega al agente implementado y haz clic en la pestaña Registros.
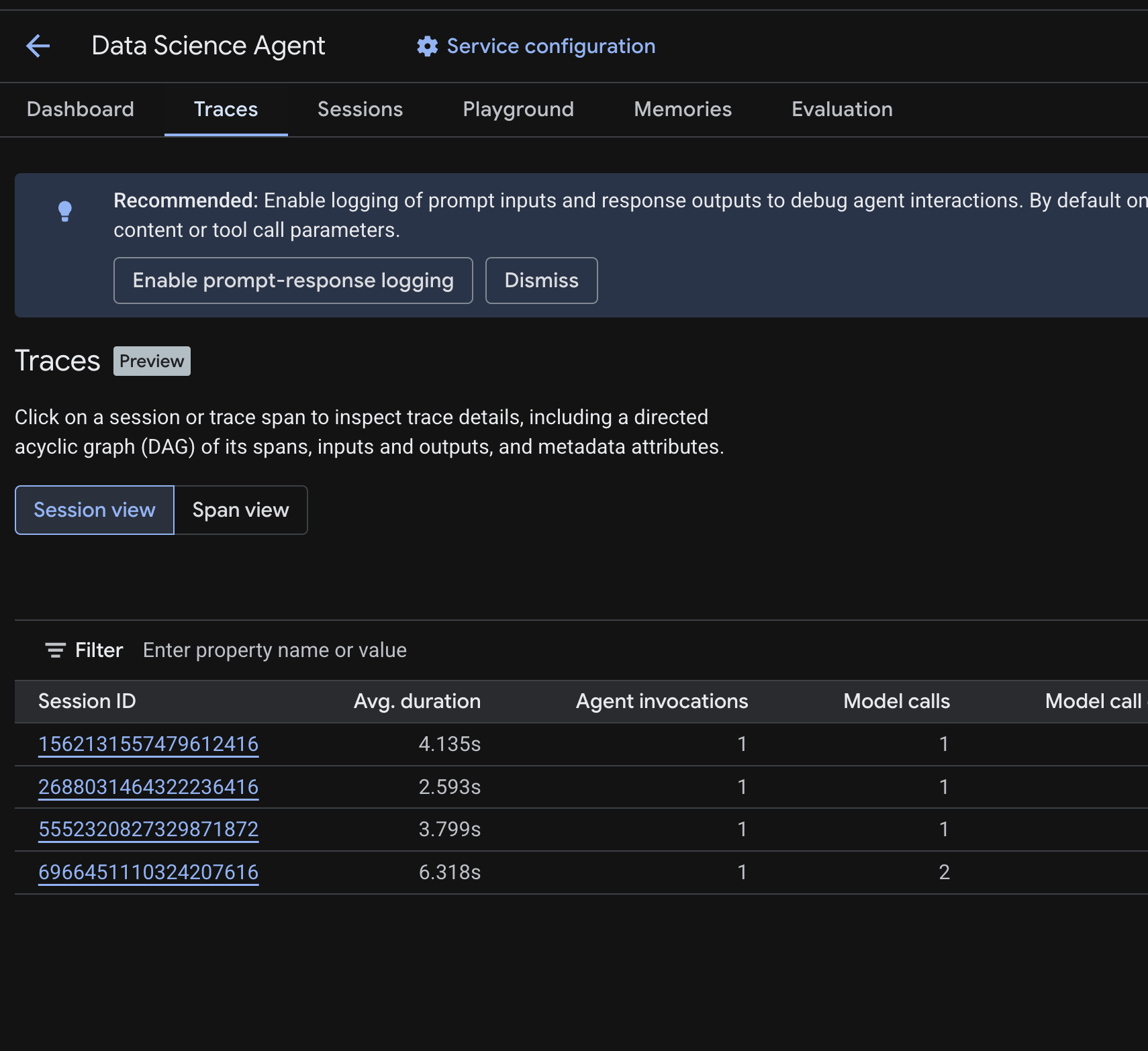
Deberías ver una tabla de sesiones que enumera las sesiones de las búsquedas de prueba que ejecutaste en los pasos anteriores. En la tabla, se muestran las métricas de resumen de cada sesión: duración promedio, llamadas al modelo, llamadas a herramientas, uso de tokens y errores.
Haz clic en una sesión para inspeccionar los detalles de su registro, incluidos los siguientes:
- Un grafo acíclico dirigido (DAG) de sus intervalos, que muestra el desglose paso a paso del razonamiento del agente, las llamadas a herramientas (consultas de BigQuery) y las latencias
- Entradas y salidas para cada intervalo (habilitado a través de la variable de entorno
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTen.env) - Atributos de metadatos, como IDs de tramo, IDs de seguimiento y sincronización
También puedes cambiar a la vista de intervalo (alternar en la parte superior) para ver los intervalos individuales en todas las sesiones.
Cómo funciona el registro
Cuando realizas la implementación con --trace_to_cloud y --otel_to_cloud, el entorno de ejecución de Agent Engine inicializa una canalización de OpenTelemetry que hace lo siguiente:
- Crea un TracerProvider con un exportador de OTLP que envía intervalos a
telemetry.googleapis.com. - Usa los cuatro paquetes de instrumentación de tu
requirements.txtpara capturar intervalos de bibliotecas clave (FastAPI, Gemini, httpx, gRPC).google-genaise instrumenta de forma explícita con el tiempo de ejecución, mientras que los demás contribuyen a través del descubrimiento automático de OpenTelemetry. - Envía por lotes y exporta intervalos a la API de Telemetry, donde la pestaña Traces los lee.
La imagen base de Agent Engine proporciona el SDK y el exportador de OpenTelemetry, pero no incluye los paquetes de instrumentación. Por eso, tu requirements.txt debe incluir los cuatro. Sin ellos, no se crearán intervalos ni aparecerán seguimientos.
Solución de problemas
Si no aparecen rastros después de unos minutos, haz lo siguiente:
- Verifica que la API de Telemetry esté habilitada, ya que la habilitaste en el paso de configuración. Verificar con:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - Verifica si hay advertencias en Cloud Logging: Ve a Logging > Explorador de registros y busca
"telemetry enabled but proceeding without". Si ves una advertencia sobre la instrumentación de la IA generativa, significa que faltaopentelemetry-instrumentation-google-genaien turequirements.txt. - No agregues
google-cloud-aiplatform[agent-engines]a turequirements.txt. La CLI de ADK Deploy la agrega automáticamente. Si la vuelves a declarar con una versión diferente, se pueden generar conflictos en el paquete de OpenTelemetry y se puede interrumpir la instrumentación de forma silenciosa.
9. Limpieza
Para evitar cargos continuos, borra los recursos que creaste durante este codelab.
Borra el agente implementado de la página Agent Engine en la consola de Cloud. Selecciona tu agente y haz clic en Borrar.
Si creaste un proyecto específicamente para este codelab, puedes borrar todo el proyecto:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
De manera opcional, limpia tu entorno local:
deactivate
rm -rf .venv data_science_agent
10. Felicitaciones
Creaste un agente de ciencia de datos con estado y lo implementaste en Agent Engine.
Qué aprendiste
- Cómo crear un agente de ADK con
BigQueryToolsetpara acceder a datos reales - Cómo habilitar la memoria persistente con Memory Bank usando
PreloadMemoryToolyafter_agent_callback - Cómo otorgar permisos de IAM a la cuenta de servicio del agente implementado
- Cómo realizar la implementación en Agent Engine y habilitar la observabilidad con Cloud Trace
Próximos pasos
- Consulta tus propios conjuntos de datos privados de BigQuery otorgando acceso a tus datos a la cuenta de servicio de Agent Engine
- Agrega Ejecución de código para ejecutar análisis de Python en una zona de pruebas segura
- Configura paneles de observabilidad de Cloud Trace para supervisar tu agente en producción
- Publicar los resultados en Google Workspace con las herramientas del MCP