
۱. مرور کلی
در این آزمایشگاه کد، شما یک عامل علوم داده خواهید ساخت که دادههای واقعی را از مجموعه دادههای عمومی BigQuery پرسوجو میکند و تنظیمات برگزیده شما را در طول جلسات به خاطر میسپارد. سپس آن را در Agent Engine، یک سرویس Google Cloud کاملاً مدیریتشده که زیرساخت، مقیاسپذیری و مدیریت جلسه را مدیریت میکند، مستقر خواهید کرد.
این عامل از سه قابلیت اصلی استفاده میکند که به تدریج فعال میشوند:
- مجموعه ابزارهای BigQuery : این عامل، طرحوارهها را بررسی کرده و پرسوجوهای SQL را روی مجموعه دادههای واقعی BigQuery اجرا میکند - این قابلیت هم به صورت محلی و هم در زمان استقرار، کار میکند.
- بانک حافظه : هنگام استقرار، عامل تنظیمات و زمینه کاربر را در جلسات قطع شده به خاطر میسپارد.
- قابلیت مشاهده : Cloud Trace مراحل استدلال عامل، فراخوانی ابزارها و تأخیرها را از طریق ابزار OpenTelemetry ثبت میکند.
آنچه یاد خواهید گرفت
- نحوه ایجاد یک عامل ADK با
BigQueryToolsetبرای دسترسی به دادههای واقعی - نحوه پیکربندی بانک حافظه برای پایداری بین جلساتی
- چگونه عامل خود را با استفاده از
adk deployدر Agent Engine مستقر کنیم؟ - نحوه اعطای مجوزهای IAM برای حساب سرویس عامل مستقر شده
- چگونه پایداری حافظه و مشاهدهپذیری را آزمایش کنیم
آنچه نیاز دارید
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب
- کیت توسعه نرمافزار گوگل کلود (
gcloudCLI) - یک مرورگر وب مانند کروم
- uv (مدیر بسته پایتون)
- پایتون ۳.۱۲+ (در صورت نیاز به صورت خودکار توسط
uvنصب میشود)
ADK (کیت توسعه عامل) چارچوب گوگل برای ساخت عاملهای هوش مصنوعی است. این آزمایشگاه کد از ADK برای ایجاد یک عامل و استقرار آن در موتور عامل استفاده میکند.
این آزمایشگاه کد برای توسعهدهندگان سطح متوسط است که با پایتون و گوگل کلود آشنایی دارند.
این آزمایشگاه کد تقریباً 30 دقیقه طول میکشد (شامل 5 تا 10 دقیقه برای استقرار).
منابع ایجاد شده در این آزمایشگاه کد باید کمتر از ۵ دلار هزینه داشته باشند.
۲. محیط خود را آماده کنید
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید .
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
تنظیم متغیرهای محیطی
ویرایشگر Cloud Shell را در پروژه GCP ایجاد شده خود باز کنید.
سپس یک ترمینال > ترمینال جدید ایجاد کنید و دستورات زیر را اجرا کنید.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
فعال کردن APIها
در ترمینال، دستور زیر را اجرا کنید.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- رابط برنامهنویسی کاربردی پلتفرم هوش مصنوعی (
aiplatform.googleapis.com) — میزبانی موتور عامل - BigQuery API (
bigquery.googleapis.com) — کوئریهای SQL در برابر مجموعه دادههای عمومی و خصوصی - API تلهمتری (
telemetry.googleapis.com) — ردیابیهای OpenTelemetry برای مشاهدهپذیری عامل
ایجاد یک محیط مجازی و نصب ADK
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
بسته google-adk شامل ابزار adk CLI است که برای آزمایش و استقرار عامل از آن استفاده خواهید کرد.
۳. عامل را ایجاد کنید
یک دایرکتوری پروژه عامل جدید ایجاد کنید. تمام دستورات بعدی باید از این دایرکتوری کاری (والد data_science_agent/ ) اجرا شوند:
mkdir data_science_agent
ساختار دایرکتوری نهایی شما به این شکل خواهد بود:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
اکنون __init__.py و agent.py ایجاد خواهید کرد، سپس requirements.txt و .env را در مرحله Deploy اضافه خواهید کرد.
data_science_agent/__init__.py را ایجاد کنید - این فایل برای اینکه ADK بتواند عامل شما را کشف و بارگذاری کند، لازم است:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
data_science_agent/agent.py را ایجاد کنید:
این عامل برای استخراج دادهها به BigQuery متصل میشود و جلسات را در Memory Bank ذخیره میکند.
حافظه هنگام استقرار به طور خودکار فعال میشود - متغیر محیطی GOOGLE_CLOUD_AGENT_ENGINE_ID توسط زمان اجرای Agent Engine تنظیم میشود و هنگام اجرای محلی وجود ندارد.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
بیایید بررسی کنیم که این کد چه کاری انجام میدهد:
- BigQueryToolset ابزارهایی مانند
execute_sql،list_table_idsوget_table_infoرا در اختیار عامل قرار میدهد - این ابزار میتواند طرحوارهها را بررسی کرده و از هر مجموعه دادهای که فراخواننده به آن دسترسی دارد، پرسوجو کند. - PreloadMemoryTool به طور خودکار قبل از هر فراخوانی LLM، با جستجوی محتوای مرتبط با پیام کاربر در Memory Bank، خاطرات مرتبط را بازیابی میکند. تابع فراخوانی
_save_memoryپس از هر بار اجرای عامل، جلسه را در Memory Bank حفظ میکند، بنابراین عامل میتواند زمینه را در جلسات آینده فراخوانی کند. - App، عامل ریشه را در یک برنامه قابل استقرار که Agent Engine میتواند به آن سرویس دهد، قرار میدهد.
nameباید با نام دایرکتوری (data_science_agent) مطابقت داشته باشد -adk webاز این برای یافتن و بارگذاری عامل استفاده میکند. - این دستورالعمل به اپراتور میگوید که از پروژه صورتحساب برای پرسوجوهای SQL استفاده کند و تنظیمات کاربر را به خاطر بسپارد.
۴. استقرار در موتور عامل
یک فایل requirements.txt در پوشه data_science_agent ایجاد کنید:
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
-
google-adkوgoogle-genai— چارچوب ADK و کلاینت Gemini -
google-auth— احراز هویت در فضای ابری گوگل -
python-dotenv- فایل.envرا در هنگام راهاندازی بارگذاری میکند. - چهار بسته
opentelemetry-instrumentation-*ویژگیهای مشاهدهپذیری را که بعداً بررسی خواهید کرد، فعال میکنند. آنها درخواستهای HTTP مربوط به FastAPI، فراخوانیهای مدل Gemini و ارتباطات داخلی gRPC/HTTP را به گونهای ابزاربندی میکنند که ردپاها در تب Agent Engine Traces ظاهر شوند.
یک فایل .env در دایرکتوری data_science_agent ایجاد کنید تا تلهمتری را روی عامل مستقر شده فعال کنید:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
-
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY— خط لوله OpenTelemetry را در زمان اجرای Agent Engine فعال میکند. -
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT— ورودیهای کامل و پاسخهای عامل را ثبت میکند که برای اشکالزدایی مفید است.
عامل را مستقر کنید. آخرین آرگومان data_science_agent دایرکتوری حاوی کد عامل شماست:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
پرچم | هدف |
| هدف قرار دادن پروژه و منطقه گوگل کلود |
| نام قابل خواندن توسط انسان در کنسول ابری نشان داده شده است |
| فعالسازی صادرکننده Cloud Trace برای محدودههای عامل |
| خط لوله ابزار دقیق OpenTelemetry را فعال میکند |
هنگام استقرار در Agent Engine، دو قابلیت به طور خودکار فعال میشوند:
- بانک حافظه :
PreloadMemoryToolبه بانک حافظه موتور عامل متصل میشود و_save_memoryبه طور خودکار جلسات را حفظ میکند. - قابلیت مشاهده : Cloud Trace مراحل استدلال، فراخوانی ابزارها و تأخیرهای عامل را ثبت میکند.
۵. مجوزهای BigQuery را اعطا کنید
شما باید به BigQuery اجازه دسترسی به حساب سرویس Agent Engine را بدهید. پس از استقرار، این agent به عنوان یک حساب سرویس تحت مدیریت گوگل (نه اعتبارنامههای شخصی شما) اجرا میشود، بنابراین برای اجرای کوئریهای SQL به مجوزهای صریح نیاز دارد.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
هر دستور در صورت موفقیتآمیز بودن، Updated IAM policy for project [...] را چاپ میکند.
۶. تست عامل مستقر شده
صفحه Agent Engine را در کنسول Google Cloud باز کنید. روی Agent مستقر شده خود کلیک کنید تا Agent Engine Playground باز شود.
قابلیتهای BigQuery را آزمایش کنید:
- "جدولهای موجود در bigquery-public-data.hacker_news را فهرست کنید"
- مورد انتظار : عامل
list_table_idsرا فراخوانی میکند و نام جدولها از جملهfullرا برمیگرداند.
- مورد انتظار : عامل
- "تعداد پستهای سالانه را در bigquery-public-data.hacker_news.full پیدا کن"
- مورد انتظار : عامل
execute_sqlبا یک کوئری SQL فراخوانی میکند و جدولی از سالها و تعداد پستها را برمیگرداند.
- مورد انتظار : عامل
- «درصد تغییر پستها نسبت به سال گذشته چقدر بوده است؟»
- مورد انتظار : عامل
execute_sqlرا با یک پرسوجوی SQL فراخوانی میکند که درصد تغییر را محاسبه کرده و نتایج را برمیگرداند.
- مورد انتظار : عامل
۷. تست پایداری حافظه
هنوز در زمین بازی هستید، به نماینده یک اولویت را آموزش دهید:
- «به یاد داشته باشید که مجموعه داده مورد علاقه من bigquery-public-data.hacker_news است.»
- «چه میزهایی دارد؟»
چند ثانیه صبر کنید تا حافظه باقی بماند (فراخوان _save_memory پس از پاسخ عامل اجرا میشود).
اکنون با کلیک بر روی دکمه "+ جلسه جدید" در نوار کناری Playground، یک جلسه جدید را شروع کنید ، سپس بپرسید:
- «مجموعه داده مورد علاقه من چیست؟»
حتی اگر این یک جلسه کاملاً جدید و بدون سابقه مکالمه باشد، عامل باید bigquery-public-data.hacker_news را فراخوانی کند. این روش به دلایل زیر کار میکند:
- تابع
_save_memoryهر جلسه را از طریقcallback_context.add_session_to_memory()در Memory Bank ذخیره میکند. -
PreloadMemoryToolقبل از هر فراخوانی LLM، خاطرات مربوطه را بازیابی میکند. - بانک حافظه، محتوا را از نظر معنایی تطبیق میدهد، نه فقط با کلمه کلیدی
۸. مشاهدهپذیری را بررسی کنید
در کنسول ابری، به عامل مستقر شده خود بروید و روی برگه ردیابیها (Traces) کلیک کنید.
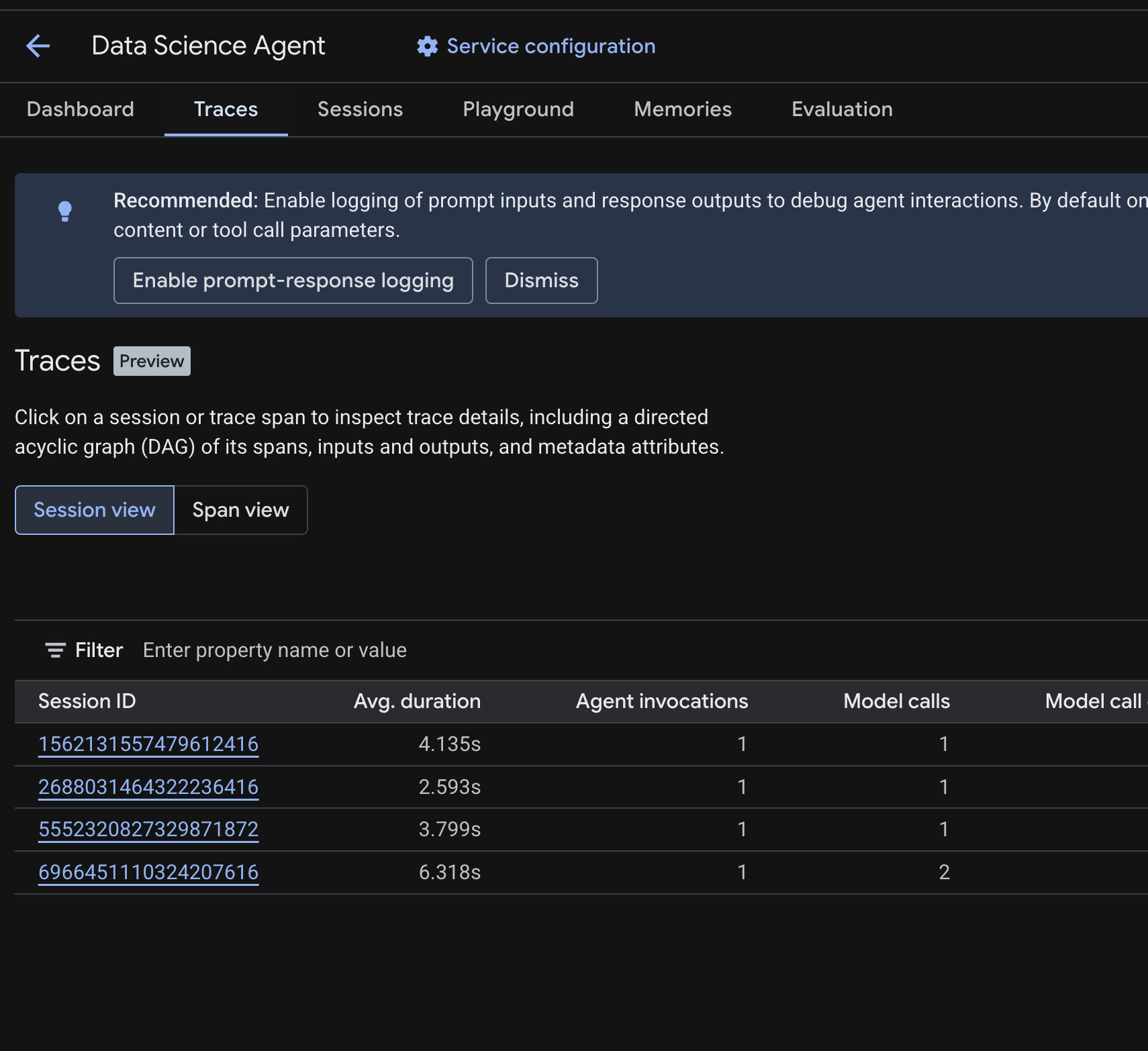
شما باید یک جدول Session را ببینید که Sessionهای حاصل از کوئریهای آزمایشی که در مراحل قبلی اجرا کردهاید را فهرست میکند. این جدول خلاصهای از معیارهای هر Session را نشان میدهد - میانگین مدت زمان، فراخوانیهای مدل، فراخوانیهای ابزار، استفاده از توکن و هرگونه خطا.
برای بررسی جزئیات ردیابی یک جلسه ، از جمله موارد زیر، روی آن کلیک کنید:
- یک گراف جهتدار غیرمدور (DAG) از محدودههای آن - که تجزیه گام به گام استدلال عامل، فراخوانیهای ابزار (پرسوجوهای BigQuery) و تأخیرها را نشان میدهد.
- ورودیها و خروجیها برای هر محدوده (فعال شده از طریق متغیر
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTenv در فایل.env) - ویژگیهای فرادادهای مانند شناسههای دهانه، شناسههای ردیابی و زمانبندی
همچنین میتوانید به نمای Span (در بالا تغییر وضعیت دهید) بروید تا spanهای جداگانه را در تمام جلسات مشاهده کنید.
نحوهی کار ردیابی
وقتی با --trace_to_cloud و --otel_to_cloud مستقر میشوید، زمان اجرای Agent Engine یک خط لوله OpenTelemetry را راهاندازی میکند که:
- یک TracerProvider با یک صادرکننده OTLP ایجاد میکند که spanها را به
telemetry.googleapis.comارسال میکند. - از چهار بسته ابزار دقیق موجود
requirements.txtشما برای ثبت spanها از کتابخانههای کلیدی (FastAPI، Gemini، httpx، gRPC) استفاده میکند -google-genaiبه صراحت توسط زمان اجرا ابزارسازی میشود، در حالی که بقیه از طریق کشف خودکار OpenTelemetry مشارکت میکنند. - دستهها و خروجیها به API تلهمتری (Telemetry API) متصل میشوند، جایی که تب Traces آنها را میخواند.
ایمیج پایه Agent Engine، SDK و export مربوط به OpenTelemetry را ارائه میدهد، اما شامل بستههای ابزار دقیق نمیشود . به همین دلیل است که requirements.txt شما باید هر چهار مورد را فهرست کند - بدون آنها، هیچ span ایجاد نمیشود و هیچ اثری ظاهر نمیشود.
عیبیابی
اگر بعد از چند دقیقه هیچ اثری ظاهر نشد:
- بررسی کنید که رابط برنامهنویسی کاربردی تلهمتری فعال باشد - شما آن را در مرحله راهاندازی فعال کردهاید. با این دستور تأیید کنید:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - هشدارهای مربوط به Cloud Logging را بررسی کنید - به Logging > Logs Explorer بروید و عبارت
"telemetry enabled but proceeding without"را جستجو کنید. اگر هشداری در مورد GenAI instrumentation مشاهده کردید،opentelemetry-instrumentation-google-genaiدرrequirements.txtشما وجود ندارد. -
google-cloud-aiplatform[agent-engines]را بهrequirements.txtخود اضافه نکنید . رابط خط فرمان (CLI) توسعه ADK آن را به طور خودکار اضافه میکند؛ اعلام مجدد آن با یک نسخه متفاوت میتواند باعث تداخل بسته OpenTelemetry و اختلال در عملکرد ابزار دقیق شود.
۹. تمیز کردن
برای جلوگیری از هزینههای جاری، منابع ایجاد شده در طول این آزمایش کد را حذف کنید.
عامل مستقر شده را از صفحه Agent Engine در Cloud Console حذف کنید. عامل خود را انتخاب کرده و روی Delete کلیک کنید.
اگر پروژهای را بهطور خاص برای این آزمایشگاه کد ایجاد کردهاید، میتوانید کل پروژه را حذف کنید:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
در صورت تمایل، محیط محلی خود را پاکسازی کنید:
deactivate
rm -rf .venv data_science_agent
۱۰. تبریک
شما یک عامل علم داده با وضعیت (stateful data science agent) ساخته و آن را در Agent Engine مستقر کردهاید!
آنچه آموختهاید
- نحوه ایجاد یک عامل ADK با
BigQueryToolsetبرای دسترسی به دادههای واقعی - نحوه فعال کردن حافظه پایدار با Memory Bank با استفاده از
PreloadMemoryToolوafter_agent_callback - نحوه اعطای مجوزهای IAM برای حساب سرویس عامل مستقر شده
- نحوه استقرار در Agent Engine و فعال کردن قابلیت مشاهده با Cloud Trace
مراحل بعدی
- با اعطای دسترسی حساب سرویس Agent Engine به دادههایتان، مجموعه دادههای خصوصی BigQuery خود را جستجو کنید.
- اضافه کردن اجرای کد برای اجرای تحلیل پایتون در یک محیط امن (sandbox)
- داشبوردهای رصدپذیری Cloud Trace را برای نظارت بر عامل خود در محیط عملیاتی تنظیم کنید
- انتشار نتایج در Google Workspace با استفاده از ابزارهای MCP