
1. Présentation
Dans cet atelier de programmation, vous allez créer un agent de science des données qui interroge des données réelles provenant d'ensembles de données publics BigQuery et mémorise vos préférences d'une session à l'autre. Vous le déploierez ensuite sur Agent Engine, un service Google Cloud entièrement géré qui gère l'infrastructure, le scaling et la gestion des sessions.
L'agent utilise trois fonctionnalités principales qui s'activent progressivement :
- Ensemble d'outils BigQuery : l'agent explore les schémas et exécute des requêtes SQL sur de vrais ensembles de données BigQuery. Cela fonctionne à la fois en local et lors du déploiement.
- Banque de mémoire : une fois déployé, l'agent mémorise les préférences et le contexte de l'utilisateur lors des sessions déconnectées.
- Observabilité : Cloud Trace capture les étapes de raisonnement, les appels d'outils et les latences de l'agent via l'instrumentation OpenTelemetry.
Points abordés
- Créer un agent ADK avec
BigQueryToolsetpour accéder à des données réelles - Configurer Memory Bank pour la persistance multisession
- Déployer votre agent sur Agent Engine avec
adk deploy - Accorder des autorisations IAM pour le compte de service de l'agent déployé
- Tester la persistance et l'observabilité de la mémoire
Prérequis
- Un projet Google Cloud avec facturation activée
- SDK Google Cloud (CLI
gcloud) - Un navigateur Web (par exemple, Chrome)
- uv (gestionnaire de packages Python)
- Python 3.12 ou version ultérieure (installé automatiquement par
uvsi nécessaire)
ADK (Agent Development Kit) est le framework de Google pour créer des agents d'IA. Cet atelier de programmation utilise l'ADK pour créer un agent et le déployer sur Agent Engine.
Cet atelier de programmation s'adresse aux développeurs intermédiaires qui connaissent déjà Python et Google Cloud.
Cet atelier de programmation prend environ 30 minutes (dont 5 à 10 minutes pour le déploiement).
Les ressources créées dans cet atelier de programmation devraient coûter moins de 5 $.
2. Configurer votre environnement
Créer un projet Google Cloud
- Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Définir des variables d'environnement
Ouvrez l'éditeur Cloud Shell dans le projet GCP que vous avez créé.
Créez ensuite un terminal en cliquant sur Terminal > Nouveau terminal, puis exécutez les commandes suivantes.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
Activer les API
Dans le terminal, exécutez la commande suivante.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- API AI Platform (
aiplatform.googleapis.com) : hébergement Agent Engine - API BigQuery (
bigquery.googleapis.com) : requêtes SQL sur des ensembles de données publics et privés - API Telemetry (
telemetry.googleapis.com) : traces OpenTelemetry pour l'observabilité des agents
Créer un environnement virtuel et installer ADK
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
Le package google-adk inclut l'outil CLI adk que vous utiliserez pour tester et déployer l'agent.
3. Créer l'agent
Créez un répertoire de projet d'agent. Toutes les commandes suivantes doivent être exécutées à partir de ce répertoire de travail (le parent de data_science_agent/) :
mkdir data_science_agent
La structure finale de votre répertoire doit ressembler à ceci :
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
Vous allez créer __init__.py et agent.py maintenant, puis ajouter requirements.txt et .env à l'étape de déploiement.
Créez data_science_agent/__init__.py. Ce fichier est nécessaire pour qu'ADK puisse découvrir et charger votre agent :
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
Créez data_science_agent/agent.py :
Cet agent se connecte à BigQuery pour l'extraction de données et conserve les sessions dans Memory Bank.
La mémoire s'active automatiquement lors du déploiement. La variable d'environnement GOOGLE_CLOUD_AGENT_ENGINE_ID est définie par le moteur d'exécution Agent Engine et est absente lors de l'exécution en local.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
Examinons ce que fait ce code :
- BigQueryToolset fournit à l'agent des outils tels que
execute_sql,list_table_idsetget_table_info. Il peut explorer les schémas et interroger n'importe quel ensemble de données auquel l'appelant a accès. - PreloadMemoryTool récupère automatiquement les souvenirs pertinents avant chaque appel LLM en recherchant dans la banque de mémoire du contenu lié au message de l'utilisateur. Le rappel
_save_memoryconserve la session dans la Memory Bank après chaque exécution de l'agent, ce qui lui permet de se souvenir du contexte lors des prochaines sessions. - App encapsule l'agent racine dans une application déployable qu'Agent Engine peut diffuser. Le champ
namedoit correspondre au nom du répertoire (data_science_agent).adk webl'utilise pour localiser et charger l'agent. - L'instruction indique à l'agent d'utiliser le projet de facturation pour les requêtes SQL et de mémoriser les préférences de l'utilisateur.
4. Déployer sur Agent Engine
Créez un fichier requirements.txt dans le répertoire data_science_agent :
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
google-adketgoogle-genai: framework ADK et client Geminigoogle-auth: authentification Google Cloudpython-dotenv: charge le fichier.envau démarrage.- Les quatre packages
opentelemetry-instrumentation-*activent les fonctionnalités d'observabilité que vous découvrirez plus tard. Ils instrumentent les requêtes HTTP FastAPI, les appels de modèle Gemini et la communication gRPC/HTTP interne afin que les traces apparaissent dans l'onglet "Traces Agent Engine".
Créez un fichier .env dans le répertoire data_science_agent pour activer la télémétrie sur l'agent déployé :
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY: active le pipeline OpenTelemetry dans l'environnement d'exécution Agent Engine.OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT: enregistre les entrées de prompt et les réponses de l'agent dans leur intégralité, ce qui est utile pour le débogage.
Déployez l'agent. Le dernier argument data_science_agent est le répertoire contenant le code de votre agent :
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
Option | Objectif |
| Projet et région Google Cloud cibles |
| Nom lisible affiché dans la console Cloud |
| Active l'exportateur Cloud Trace pour les spans d'agent |
| Active le pipeline d'instrumentation OpenTelemetry. |
Lorsque vous déployez l'Agent Engine, deux fonctionnalités s'activent automatiquement :
- Memory Bank :
PreloadMemoryToolse connecte à la mémoire Memory Bank d'Agent Engine et_save_memoryconserve automatiquement les sessions. - Observabilité : Cloud Trace capture les étapes de raisonnement, les appels d'outils et les latences de l'agent.
5. Accorder des autorisations BigQuery
Vous devez accorder à BigQuery l'accès au compte de service Agent Engine. Une fois déployé, l'agent s'exécute en tant que compte de service géré par Google (et non avec vos identifiants personnels). Il a donc besoin d'autorisations explicites pour exécuter des requêtes SQL.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
Chaque commande affiche Updated IAM policy for project [...] en cas de réussite.
6. Tester l'agent déployé
Ouvrez la page Agent Engine dans la console Google Cloud. Cliquez sur votre agent déployé pour ouvrir le bac à sable Agent Engine.
Testez les capacités de BigQuery :
- "Liste les tables dans bigquery-public-data.hacker_news"
- Résultat attendu : l'agent appelle
list_table_idset renvoie les noms de tables, y comprisfull.
- Résultat attendu : l'agent appelle
- "Trouve le nombre de posts par an dans bigquery-public-data.hacker_news.full"
- Attendu : l'agent appelle
execute_sqlavec une requête SQL et renvoie un tableau des années et du nombre de posts.
- Attendu : l'agent appelle
- "Quel a été le pourcentage de variation des posts d'une année sur l'autre ?"
- Résultat attendu : l'agent appelle
execute_sqlavec une requête SQL qui calcule la variation en pourcentage et renvoie les résultats.
- Résultat attendu : l'agent appelle
7. Tester la persistance de la mémoire
Toujours dans Playground, apprenez une préférence à l'agent :
- "Rappelle-toi que mon ensemble de données préféré est bigquery-public-data.hacker_news"
- "Quels sont les tableaux qu'il contient ?"
Patientez quelques secondes pour que la mémoire persiste (le rappel _save_memory s'exécute après la réponse de l'agent).
Démarrez une nouvelle session en cliquant sur le bouton + Nouvelle session dans la barre latérale de l'atelier de programmation, puis posez la question suivante :
- "Quel est mon ensemble de données préféré ?"
L'agent doit se souvenir de bigquery-public-data.hacker_news, même s'il s'agit d'une toute nouvelle session sans historique de conversation. Voici pourquoi :
_save_memoryest conservé dans la Memory Bank à chaque session viacallback_context.add_session_to_memory().PreloadMemoryToolrécupère les souvenirs pertinents avant chaque appel LLM.- La Banque de mémoire met en correspondance le contenu de manière sémantique, et pas seulement par mot clé.
8. Découvrir Observability
Dans la console Cloud, accédez à l'agent déployé, puis cliquez sur l'onglet Traces.
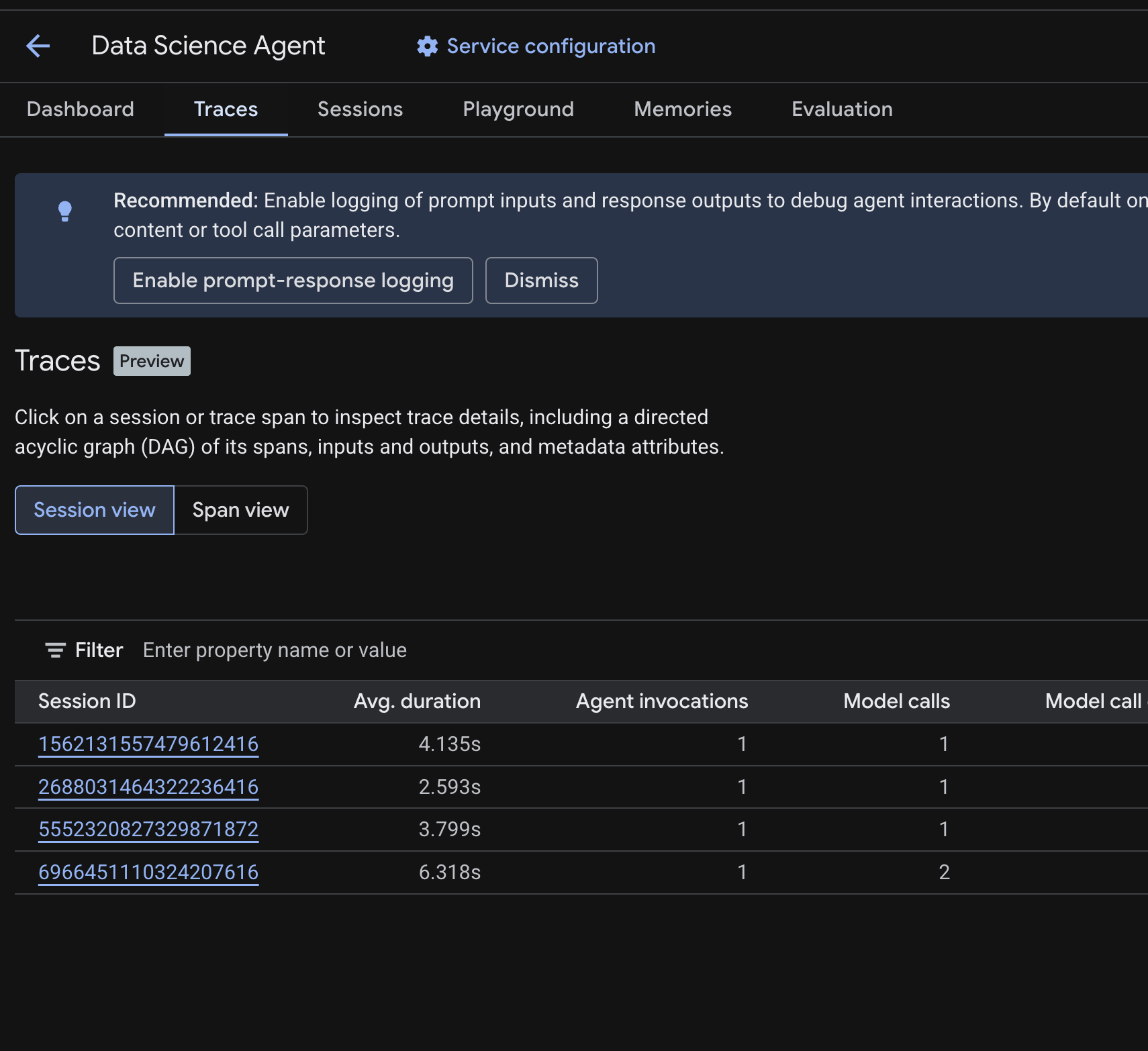
Une table des sessions doit s'afficher, listant les sessions des requêtes de test que vous avez exécutées lors des étapes précédentes. Le tableau affiche des métriques récapitulatives pour chaque session : durée moyenne, appels de modèle, appels d'outil, utilisation de jetons et éventuelles erreurs.
Cliquez sur une session pour inspecter les détails de la trace, y compris :
- Un graphe orienté acyclique (DAG) de ses portées, qui montre la répartition étape par étape du raisonnement de l'agent, des appels d'outils (requêtes BigQuery) et des latences
- Entrées et sorties pour chaque portée (activées via la variable d'environnement
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTdans.env) - Attributs de métadonnées tels que les ID de portée, les ID de trace et le timing
Vous pouvez également passer à la vue "Portée" (en haut de l'écran) pour afficher les portées individuelles de toutes les sessions.
Fonctionnement du traçage
Lorsque vous déployez avec --trace_to_cloud et --otel_to_cloud, le runtime Agent Engine initialise un pipeline OpenTelemetry qui :
- Crée un TracerProvider avec un exportateur OTLP qui envoie des spans à
telemetry.googleapis.com - Utilise les quatre packages d'instrumentation de votre
requirements.txtpour capturer les spans des bibliothèques clés (FastAPI, Gemini, httpx, gRPC).google-genaiest instrumenté de manière explicite par le runtime, tandis que les autres contribuent via la découverte automatique OpenTelemetry. - Les lots et les exportations couvrent l'API Telemetry, où l'onglet "Traces" les lit.
L'image de base Agent Engine fournit le SDK et l'exportateur OpenTelemetry, mais n'inclut pas les packages d'instrumentation. C'est pourquoi votre requirements.txt doit lister les quatre, sans quoi aucune étendue n'est créée et aucune trace n'apparaît.
Dépannage
Si aucune trace n'apparaît après quelques minutes :
- Vérifiez que l'API Telemetry est activée (vous l'avez activée lors de la configuration). Valider avec :
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - Recherchez les avertissements dans Cloud Logging : accédez à Logging > Explorateur de journaux et recherchez
"telemetry enabled but proceeding without". Si un avertissement concernant l'instrumentation de l'IA générative s'affiche, cela signifie queopentelemetry-instrumentation-google-genaiest manquant dans votrerequirements.txt. - N'ajoutez pas
google-cloud-aiplatform[agent-engines]à votrerequirements.txt. La CLI de déploiement ADK l'ajoute automatiquement. Si vous le déclarez à nouveau avec une version différente, cela peut entraîner des conflits de packages OpenTelemetry et interrompre l'instrumentation sans que vous le sachiez.
9. Effectuer un nettoyage
Pour éviter des frais récurrents, supprimez les ressources créées pendant cet atelier de programmation.
Supprimez l'agent déployé sur la page Agent Engine de la console Cloud. Sélectionnez votre agent, puis cliquez sur Supprimer.
Si vous avez créé un projet spécifiquement pour cet atelier de programmation, vous pouvez le supprimer entièrement :
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
Si vous le souhaitez, nettoyez votre environnement local :
deactivate
rm -rf .venv data_science_agent
10. Félicitations
Vous avez créé un agent data scientist avec état et l'avez déployé sur Agent Engine.
Connaissances acquises
- Créer un agent ADK avec
BigQueryToolsetpour accéder à des données réelles - Activer la mémoire persistante avec Memory Bank à l'aide de
PreloadMemoryTooletafter_agent_callback - Accorder des autorisations IAM pour le compte de service de l'agent déployé
- Déployer sur Agent Engine et activer l'observabilité avec Cloud Trace
Étapes suivantes
- Interrogez vos propres ensembles de données BigQuery privés en accordant au compte de service Agent Engine l'accès à vos données.
- Ajoutez Exécution de code pour exécuter l'analyse Python dans un bac à sable sécurisé.
- Configurer des tableaux de bord Cloud Trace pour surveiller votre agent en production
- Publier les résultats dans Google Workspace à l'aide des outils MCP