
1. סקירה כללית
ב-codelab הזה תבנו סוכן מדעי נתונים ששולח שאילתות לנתונים אמיתיים ממערכי נתונים ציבוריים של BigQuery וזוכר את ההעדפות שלכם בין סשנים. לאחר מכן פורסים אותו ב-Agent Engine, שירות מנוהל לחלוטין של Google Cloud שמטפל בתשתית, בהרחבת היקף ובניהול סשנים.
הסוכן משתמש בשלוש יכולות ליבה שמופעלות באופן הדרגתי:
- BigQuery Toolset: הסוכן בודק סכימות ומריץ שאילתות SQL מול מערכי נתונים אמיתיים של BigQuery – הפעולה הזו מתבצעת באופן מקומי וגם כשהסוכן נפרס.
- Memory Bank: כשהסוכן נפרס, הוא זוכר את העדפות המשתמש וההקשר בסשנים לא מחוברים.
- ניראות (observability): Cloud Trace מתעד את שלבי החשיבה הרציונלית של הסוכן, את הקריאות לכלים ואת זמני האחזור באמצעות אינסטרומנטציה של OpenTelemetry.
מה תלמדו
- איך יוצרים סוכן ADK באמצעות
BigQueryToolsetלגישה לנתונים אמיתיים - איך מגדירים את Memory Bank כך שהנתונים יישמרו בין סשנים
- איך פורסים את הסוכן ב-Agent Engine באמצעות
adk deploy - איך מעניקים הרשאות IAM לחשבון השירות של הסוכן שנפרס
- איך בודקים את התמדת הזיכרון ואת יכולת התצפית
הדרישות
- פרויקט ב-Google Cloud שהחיוב בו מופעל
- Google Cloud SDK (
gcloudCLI) - דפדפן אינטרנט כמו Chrome
- uv (כלי לניהול חבילות Python)
- Python 3.12 ואילך (מותקן אוטומטית על ידי
uvאם צריך)
הערכה לפיתוח סוכנים (ADK) היא ה-framework של Google ליצירת סוכני AI. בשיעור Codelab הזה נשתמש ב-ADK כדי ליצור סוכן ולפרוס אותו ב-Agent Engine.
שיעור ה-Codelab הזה מיועד למפתחים ברמת ביניים שיש להם היכרות מסוימת עם Python ו-Google Cloud.
השלמת ה-codelab הזה תיקח בערך 30 דקות (כולל 5-10 דקות לפריסה).
העלות של המשאבים שנוצרו ב-codelab הזה צריכה להיות פחות מ-5$.
2. הגדרת הסביבה
יצירת פרויקט ב-Google Cloud
- במסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים פרויקט ב-Google Cloud או יוצרים פרויקט.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
הגדרה של משתני סביבה
פותחים את Cloud Shell Editor בפרויקט GCP שיצרתם.
לאחר מכן יוצרים טרמינל חדש באמצעות Terminal > New Terminal ומריצים את הפקודות הבאות.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
הפעלת ממשקי ה-API
במסוף, מריצים את הפקודה הבאה.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- AI Platform API (
aiplatform.googleapis.com) – אירוח של Agent Engine - BigQuery API (
bigquery.googleapis.com) – שאילתות SQL במערכי נתונים ציבוריים ופרטיים - Telemetry API (
telemetry.googleapis.com) – עקבות OpenTelemetry לצורך יכולת צפייה בסוכן
יצירת סביבה וירטואלית והתקנת ADK
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
חבילת google-adk כוללת את כלי ה-CLI adk שבו תשתמשו כדי לבדוק ולפרוס את הסוכן.
3. יצירת הסוכן
יוצרים ספרייה חדשה של פרויקט סוכן. צריך להריץ את כל הפקודות הבאות מהספרייה הפעילה הזו (הספרייה הראשית של data_science_agent/):
mkdir data_science_agent
מבנה הספריות הסופי ייראה כך:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
תצטרכו ליצור את __init__.py ואת agent.py עכשיו, ואז להוסיף את requirements.txt ואת .env בשלב הפריסה.
יוצרים את הקובץ data_science_agent/__init__.py – הקובץ הזה נדרש כדי שה-ADK יוכל לגלות ולטעון את הסוכן:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
יצירת data_science_agent/agent.py:
הסוכן הזה מתחבר ל-BigQuery כדי לחלץ נתונים, ושומר את הסשנים ב-Memory Bank.
הזיכרון מופעל אוטומטית כשמבצעים פריסה – משתנה הסביבה GOOGLE_CLOUD_AGENT_ENGINE_ID מוגדר על ידי זמן הריצה של Agent Engine ולא קיים כשמריצים באופן מקומי.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
בואו נסביר מה הקוד הזה עושה:
- BigQueryToolset מספק לאמצעי התקשורת כלים כמו
execute_sql,list_table_idsו-get_table_info– הוא יכול לבדוק סכימות ולהריץ שאילתות על כל מערך נתונים שיש למשתמש גישה אליו. - PreloadMemoryTool מאחזר באופן אוטומטי זיכרונות רלוונטיים לפני כל קריאה ל-LLM, על ידי חיפוש ב-Memory Bank תוכן שקשור להודעה של המשתמש. הפונקציה
_save_memorycallback שומרת את הסשן ב-Memory Bank אחרי כל הפעלה של הסוכן, כדי שהסוכן יוכל לשחזר את ההקשר בסשנים עתידיים. - App עוטף את סוכן הבסיס באפליקציה שאפשר לפרוס וש-Agent Engine יכול להפעיל. הערך של
nameצריך להיות זהה לשם הספרייה (data_science_agent) – המערכת שלadk webמשתמשת בערך הזה כדי לאתר ולטעון את הסוכן. - ההוראה אומרת לסוכן להשתמש בפרויקט החיוב לשאילתות SQL ולזכור את העדפות המשתמש.
4. פריסה ל-Agent Engine
יוצרים קובץ requirements.txt בספרייה data_science_agent:
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
-
google-adkו-google-genai– מסגרת ADK ולקוח Gemini -
google-auth— אימות ב-Google Cloud -
python-dotenv— טעינת הקובץ.envבמהלך ההפעלה - ארבע חבילות
opentelemetry-instrumentation-*מאפשרות להשתמש בתכונות של יכולת התבוננות, שנסביר עליהן בהמשך. הם מבצעים אינסטרומנטציה של בקשות HTTP ב-FastAPI, קריאות למודל Gemini ותקשורת פנימית מסוג gRPC/HTTP, כך שהעקבות מופיעים בכרטיסייה 'עקבות' ב-Agent Engine.
כדי להפעיל טלמטריה בסוכן שנפרס, יוצרים קובץ .env בספרייה data_science_agent:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
-
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY— מפעיל את צינור OpenTelemetry בזמן הריצה של Agent Engine. -
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT– רישום של קלט ההנחיות המלא ותשובות הסוכן, שימושי לניפוי באגים.
פורסים את הסוכן. הארגומנט האחרון data_science_agent הוא הספרייה שמכילה את קוד הסוכן:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
דגל | מטרה |
| פרויקט בענן ומיקום יעד ב-Google Cloud |
| שם שקריא לאנשים ומוצג ב-Cloud Console |
| הפעלת כלי הייצוא של Cloud Trace לטווחים של סוכנים |
| הפעלה של צינור עיבוד הנתונים של OpenTelemetry |
כשפורסים את Agent Engine, שתי יכולות מופעלות באופן אוטומטי:
- Memory Bank:
PreloadMemoryToolמתחבר ל-Memory Bank של Agent Engine ו_save_memoryשומר את ההפעלות באופן אוטומטי. - ניראות (Observability): Cloud Trace מתעד את שלבי החשיבה הרציונלית של הסוכן, את הקריאות לכלים ואת זמני האחזור.
5. מתן הרשאות ב-BigQuery
צריך להעניק ל-BigQuery גישה לחשבון השירות של Agent Engine. בזמן הפריסה, הסוכן פועל כחשבון שירות בניהול Google (ולא כפרטי הכניסה האישיים שלכם), ולכן הוא צריך הרשאות מפורשות כדי להריץ שאילתות SQL.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
כל פקודה מדפיסה Updated IAM policy for project [...] אם היא מצליחה.
6. בדיקת הסוכן הפעיל
פותחים את הדף Agent Engine במסוף Google Cloud. לוחצים על הסוכן שפרסתם כדי לפתוח את מגרש המשחקים של Agent Engine.
בודקים את היכולות של BigQuery:
- "List the tables in bigquery-public-data.hacker_news"
- התנהגות צפויה: הסוכן מתקשר אל
list_table_idsומחזיר שמות של טבלאות, כוללfull.
- התנהגות צפויה: הסוכן מתקשר אל
- "Find the number of posts per year in bigquery-public-data.hacker_news.full"
- Expected: The agent calls
execute_sqlwith a SQL query and returns a table of years and post counts.
- Expected: The agent calls
- "מה היה אחוז השינוי במספר הפוסטים בהשוואה לשנה הקודמת?"
- מה צפוי: הסוכן קורא ל-
execute_sqlעם שאילתת SQL שמחשבת את השינוי באחוזים ומחזירה את התוצאות.
- מה צפוי: הסוכן קורא ל-
7. בדיקת שימור הזיכרון
עדיין בסביבת ההדמיה, מלמדים את הנציג העדפה:
- "Remember that my favorite dataset is bigquery-public-data.hacker_news" (תזכור שמערך הנתונים המועדף עליי הוא bigquery-public-data.hacker_news)
- "What tables does it have?" (אילו טבלאות יש בו?)
ממתינים כמה שניות עד שהזיכרון יישמר (הקריאה החוזרת _save_memory מופעלת אחרי שהסוכן מגיב).
עכשיו מתחילים סשן חדש בלחיצה על הכפתור + סשן חדש בסרגל הצד של Playground, ואז שואלים:
- "What is my favorite dataset?" (מה מערך הנתונים המועדף שלי?)
הנציג צריך לזכור את bigquery-public-data.hacker_news גם אם מדובר בסשן חדש לגמרי ללא היסטוריית שיחות. השיטה הזו פועלת כי:
-
_save_memoryשומר כל סשן ב-Memory Bank באמצעותcallback_context.add_session_to_memory() PreloadMemoryToolמאחזר זיכרונות רלוונטיים לפני כל שיחה עם מודל שפה גדול- התאמת התוכן ב-Memory Bank היא סמנטית, ולא רק לפי מילות מפתח
8. סקירת יכולות ה-Observability
ב-Cloud Console, עוברים לסוכן שפרסתם ולוחצים על הכרטיסייה Traces.
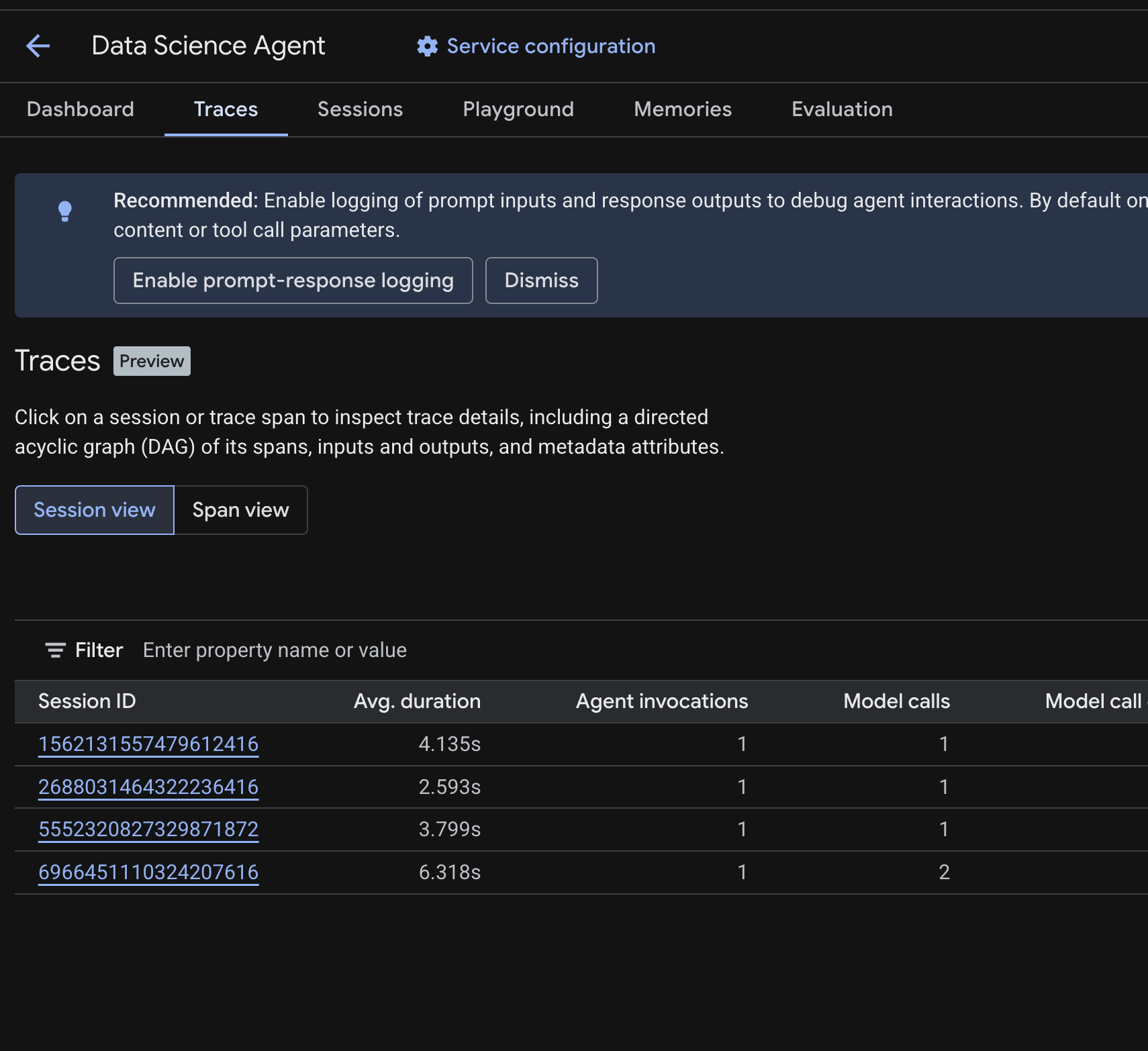
אמורה להופיע טבלת סשנים עם רשימה של הסשנים מהשאילתות שבדקתם בשלבים הקודמים. בטבלה מוצגים מדדי סיכום לכל סשן – משך ממוצע, קריאות למודל, קריאות לכלים, שימוש בטוקנים ושגיאות.
לוחצים על session כדי לבדוק את פרטי המעקב שלה, כולל:
- גרף אציקלי מכוון (DAG) של יחידות לוגיות למעקב – שבו מוצג פירוט של שלבי החשיבה הרציונלית של הסוכן, קריאות הכלים (שאילתות BigQuery) וזמן הטעינה
- קלט ופלט לכל טווח (מופעל באמצעות משתנה הסביבה
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTב-.env) - מאפייני מטא-נתונים כמו מזהי יחידה לוגית למעקב, מזהי מעקב ותזמון
אפשר גם לעבור לתצוגת טווח (המתג נמצא בחלק העליון) כדי לראות טווחים נפרדים בכל הפעילויות.
איך פועל מעקב
כשפורסים עם --trace_to_cloud ו---otel_to_cloud, זמן הריצה של Agent Engine מאתחל צינור OpenTelemetry ש:
- יוצר TracerProvider עם OTLP exporter ששולח span ל-
telemetry.googleapis.com - הוא משתמש בארבעת חבילות האינסטרומנטציה מ-
requirements.txtכדי לתעד יחידות לוגיות למעקב מספריות מפתח (FastAPI, Gemini, httpx, gRPC) –google-genaiמופעל באופן מפורש על ידי זמן הריצה, בעוד שהאחרות תורמות באמצעות גילוי אוטומטי של OpenTelemetry - מקבצים ומייצאים טווחים אל Telemetry API, שבו הכרטיסייה Traces קוראת אותם
תמונת הבסיס של Agent Engine מספקת את ה-SDK ואת כלי הייצוא של OpenTelemetry, אבל לא כוללת את חבילות האינסטרומנטציה. לכן, ב-requirements.txt צריך לציין את כל ארבעת המאפיינים האלה – בלעדיהם לא נוצרים טווחים ולא מופיעים עקבות.
פתרון בעיות
אם לא מופיעים עקבות אחרי כמה דקות:
- בודקים שממשק ה-API של הטלמטריה מופעל – הפעלתם אותו בשלב ההגדרה. אימות באמצעות:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - בודקים אם יש אזהרות ב-Cloud Logging – עוברים אל Logging > Logs Explorer ומחפשים את
"telemetry enabled but proceeding without". אם מוצגת אזהרה לגבי כלי מדידה של AI גנרטיבי, סימן שהתגopentelemetry-instrumentation-google-genaiחסר ב-requirements.txt. - אל תוסיפו את
google-cloud-aiplatform[agent-engines]אלrequirements.txt. ה-CLI של ADK deploy מוסיף אותו באופן אוטומטי. אם מצהירים עליו מחדש עם גרסה שונה, עלולים להתרחש עימותים בין חבילות OpenTelemetry, והאינסטרומנטציה עלולה להיפסק בלי שיוצג לכך סימן.
9. הסרת המשאבים
כדי להימנע מחיובים שוטפים, מוחקים את המשאבים שנוצרו במהלך ה-codelab הזה.
מוחקים את הסוכן שפרסתם מהדף Agent Engine במסוף Cloud. בוחרים את הנציג ולוחצים על מחיקה.
אם יצרתם פרויקט במיוחד בשביל ה-Codelab הזה, אתם יכולים למחוק את הפרויקט כולו במקום זאת:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
אפשר גם לנקות את הסביבה המקומית:
deactivate
rm -rf .venv data_science_agent
10. מזל טוב
יצרתם סוכן מדעי נתונים עם מצב ופרסתם אותו ב-Agent Engine.
מה למדתם
- איך יוצרים סוכן ADK באמצעות
BigQueryToolsetלגישה לנתונים אמיתיים - איך מפעילים זיכרון קבוע באמצעות Memory Bank באמצעות
PreloadMemoryToolו-after_agent_callback - איך מעניקים הרשאות IAM לחשבון השירות של הסוכן שנפרס
- איך פורסים ב-Agent Engine ומפעילים ניראות (observability) באמצעות Cloud Trace
השלבים הבאים
- הענקת גישה לנתונים שלכם לחשבון השירות של Agent Engine כדי להריץ שאילתות על מערכי נתונים פרטיים של BigQuery
- הוספת Code Execution כדי להריץ ניתוח Python בארגז חול מאובטח
- הגדרת לוחות בקרה של Cloud Trace observability כדי לעקוב אחרי הסוכן בסביבת הייצור
- פרסום תוצאות ב-Google Workspace באמצעות כלים של MCP