
1. खास जानकारी
इस कोडलैब में, आपको एक डेटा साइंस एजेंट बनाना है. यह एजेंट, BigQuery के सार्वजनिक डेटासेट से असली डेटा को क्वेरी करता है. साथ ही, यह अलग-अलग सेशन में आपकी प्राथमिकताओं को याद रखता है. इसके बाद, इसे Agent Engine पर डिप्लॉय किया जाएगा. यह Google Cloud की पूरी तरह से मैनेज की जाने वाली सेवा है. यह सेवा, इन्फ़्रास्ट्रक्चर, स्केलिंग, और सेशन मैनेजमेंट को मैनेज करती है.
एजेंट तीन मुख्य क्षमताओं का इस्तेमाल करता है. ये क्षमताएं धीरे-धीरे चालू होती हैं:
- BigQuery टूलसेट: एजेंट, स्कीमा एक्सप्लोर करता है और BigQuery के असली डेटासेट के ख़िलाफ़ SQL क्वेरी चलाता है. यह सुविधा, स्थानीय तौर पर और डिप्लॉय किए जाने पर, दोनों स्थितियों में काम करती है.
- मेमोरी बैंक: इस सुविधा को चालू करने पर, एजेंट को उपयोगकर्ता की प्राथमिकताओं और संदर्भ के बारे में जानकारी मिलती है. भले ही, उपयोगकर्ता ने सेशन बंद कर दिया हो.
- निगरानी: Cloud Trace, OpenTelemetry इंस्ट्रुमेंटेशन के ज़रिए एजेंट के फ़ैसले लेने के चरणों, टूल कॉल, और लेटेंसी को कैप्चर करता है.
आपको क्या सीखने को मिलेगा
- रीयल डेटा ऐक्सेस करने के लिए,
BigQueryToolsetकी मदद से एडीके एजेंट बनाने का तरीका - क्रॉस-सेशन पर्सिस्टेंस के लिए मेमोरी बैंक को कॉन्फ़िगर करने का तरीका
adk deployकी मदद से, अपने एजेंट को एजेंट इंजन में डिप्लॉय करने का तरीका- डिप्लॉय किए गए एजेंट के सेवा खाते के लिए, IAM अनुमतियां देने का तरीका
- मेमोरी के बने रहने और उसकी निगरानी करने की सुविधा की जांच कैसे करें
आपको किन चीज़ों की ज़रूरत होगी
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट
- Google Cloud SDK (
gcloudसीएलआई) - कोई वेब ब्राउज़र, जैसे कि Chrome
- uv (Python पैकेज मैनेजर)
- Python 3.12+ (ज़रूरत पड़ने पर,
uvइसे अपने-आप इंस्टॉल कर देता है)
एडीके (एजेंट डेवलपमेंट किट), एआई एजेंट बनाने के लिए Google का फ़्रेमवर्क है. इस कोडलैब में, ADK का इस्तेमाल करके एजेंट बनाने और उसे Agent Engine पर डिप्लॉय करने का तरीका बताया गया है.
यह कोडलैब, उन डेवलपर के लिए है जिन्हें Python और Google Cloud के बारे में थोड़ी जानकारी है.
इस कोडलैब को पूरा करने में करीब 30 मिनट लगते हैं. इसमें डिप्लॉयमेंट के लिए 5 से 10 मिनट शामिल हैं.
इस कोडलैब में बनाए गए संसाधनों की लागत 5 डॉलर से कम होनी चाहिए.
2. अपना एनवायरमेंट सेट अप करने का तरीका
Google Cloud प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
एनवायरमेंट वैरिएबल सेट करना
बनाए गए GCP प्रोजेक्ट में, Cloud Shell Editor खोलें.
इसके बाद, टर्मिनल > नया टर्मिनल बनाएं और ये कमांड चलाएं.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
एपीआई चालू करें
टर्मिनल में, यह कमांड चलाएं.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- AI Platform API (
aiplatform.googleapis.com) — एजेंट इंजन होस्टिंग - BigQuery API (
bigquery.googleapis.com) — सार्वजनिक और निजी डेटासेट के ख़िलाफ़ SQL क्वेरी - Telemetry API (
telemetry.googleapis.com) — एजेंट की परफ़ॉर्मेंस को मॉनिटर करने के लिए OpenTelemetry ट्रेस
वर्चुअल एनवायरमेंट बनाना और ADK इंस्टॉल करना
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
google-adk पैकेज में adk सीएलआई टूल शामिल है. इसका इस्तेमाल एजेंट को टेस्ट और डिप्लॉय करने के लिए किया जाएगा.
3. एजेंट बनाना
नया एजेंट प्रोजेक्ट डायरेक्ट्री बनाएं. इसके बाद के सभी निर्देश, इस वर्किंग डायरेक्ट्री (data_science_agent/ की पैरंट डायरेक्ट्री) से चलाए जाने चाहिए:
mkdir data_science_agent
आपकी फ़ाइनल डायरेक्ट्री का स्ट्रक्चर ऐसा दिखेगा:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
अब __init__.py और agent.py बनाएं. इसके बाद, डिप्लॉय करने के चरण में requirements.txt और .env जोड़ें.
data_science_agent/__init__.py बनाएं — यह फ़ाइल ज़रूरी है, ताकि ADK आपके एजेंट का पता लगा सके और उसे लोड कर सके:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
data_science_agent/agent.py बनाएं:
यह एजेंट, डेटा निकालने के लिए BigQuery से कनेक्ट होता है. साथ ही, सेशन को Memory Bank में सेव करता है.
मेमोरी को डिप्लॉय करने पर, यह अपने-आप चालू हो जाती है. GOOGLE_CLOUD_AGENT_ENGINE_ID एनवायरमेंट वैरिएबल को एजेंट इंजन रनटाइम सेट करता है. यह लोकल तौर पर चलाने पर मौजूद नहीं होता.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
आइए, जानते हैं कि यह कोड क्या करता है:
- BigQueryToolset, एजेंट को
execute_sql,list_table_ids, औरget_table_infoजैसे टूल देता है. यह स्कीमा एक्सप्लोर कर सकता है और कॉलर के पास जिस डेटासेट का ऐक्सेस है उसे क्वेरी कर सकता है. - PreloadMemoryTool, हर एलएलएम कॉल से पहले, काम की यादें अपने-आप ढूंढ लेता है. इसके लिए, यह Memory Bank में उपयोगकर्ता के मैसेज से जुड़ा कॉन्टेंट खोजता है.
_save_memoryकॉलबैक, हर एजेंट रन के बाद सेशन को मेमोरी बैंक में सेव करता है, ताकि एजेंट आने वाले समय में होने वाले सेशन में कॉन्टेक्स्ट को याद रख सके. - ऐप्लिकेशन, रूट एजेंट को डिप्लॉय किए जा सकने वाले ऐप्लिकेशन में रैप करता है. इसे एजेंट इंजन इस्तेमाल कर सकता है.
name, डायरेक्ट्री के नाम (data_science_agent) से मेल खाना चाहिए.adk webइसका इस्तेमाल, एजेंट का पता लगाने और उसे लोड करने के लिए करता है. - निर्देश से एजेंट को SQL क्वेरी के लिए बिलिंग प्रोजेक्ट का इस्तेमाल करने और उपयोगकर्ता की प्राथमिकताओं को याद रखने के लिए कहा जाता है.
4. एजेंट इंजन में डिप्लॉय करना
data_science_agent डायरेक्ट्री में requirements.txt फ़ाइल बनाएं:
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
google-adkऔरgoogle-genai— ADK फ़्रेमवर्क और Gemini क्लाइंटgoogle-auth— Google Cloud की मदद से पुष्टि करनाpython-dotenv— इससे स्टार्टअप के समय.envफ़ाइल लोड होती हैopentelemetry-instrumentation-*के चार पैकेज, निगरानी से जुड़ी उन सुविधाओं को चालू करते हैं जिनके बारे में आपको बाद में पता चलेगा. ये FastAPI एचटीटीपी अनुरोधों, Gemini मॉडल कॉल, और इंटरनल gRPC/एचटीटीपी कम्यूनिकेशन को इंस्ट्रुमेंट करते हैं, ताकि एजेंट इंजन के ट्रेस टैब में ट्रेस दिखें.
डिप्लॉय किए गए एजेंट पर टेलीमेट्री की सुविधा चालू करने के लिए, data_science_agent डायरेक्ट्री में .env फ़ाइल बनाएं:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY— इससे एजेंट इंजन के रनटाइम में OpenTelemetry पाइपलाइन चालू हो जाती है.OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT— इसमें पूरे प्रॉम्प्ट इनपुट और एजेंट के जवाब लॉग किए जाते हैं. यह डीबग करने के लिए काम आता है.
एजेंट को डिप्लॉय करें. आखिरी आर्ग्युमेंट data_science_agent, वह डायरेक्ट्री है जिसमें आपका एजेंट कोड मौजूद है:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
झंडा | मकसद |
| Google Cloud प्रोजेक्ट और क्षेत्र को टारगेट करना |
| Cloud Console में दिखने वाला ऐसा नाम जिसे कोई व्यक्ति आसानी से पढ़ सके |
| यह एजेंट स्पैन के लिए Cloud Trace एक्सपोर्टर चालू करता है |
| इस कुकी से, OpenTelemetry इंस्ट्रूमेंटेशन पाइपलाइन चालू होती है |
Agent Engine में डिप्लॉय करने पर, दो सुविधाएं अपने-आप चालू हो जाती हैं:
- मेमोरी बैंक:
PreloadMemoryToolयह एजेंट इंजन के मेमोरी बैंक से कनेक्ट होता है और_save_memoryसेशन को अपने-आप सेव करता है. - ऑब्ज़र्वेबिलिटी: Cloud Trace, एजेंट के फ़ैसले लेने के चरणों, टूल कॉल, और इंतज़ार के समय को कैप्चर करता है.
5. BigQuery की अनुमतियां देना
आपको Agent Engine सेवा खाते को BigQuery का ऐक्सेस देना होगा. डिप्लॉय किए जाने पर, एजेंट Google की ओर से मैनेज किए जाने वाले सेवा खाते के तौर पर काम करता है. यह आपके निजी क्रेडेंशियल के तौर पर काम नहीं करता. इसलिए, इसे एसक्यूएल क्वेरी चलाने के लिए साफ़ तौर पर अनुमतियों की ज़रूरत होती है.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
हर निर्देश के पूरा होने पर, Updated IAM policy for project [...] प्रिंट होता है.
6. डिप्लॉय किए गए एजेंट को टेस्ट करना
Google Cloud Console में, Agent Engine पेज खोलें. डिप्लॉय किए गए एजेंट पर क्लिक करके, Agent Engine Playground खोलें.
BigQuery की सुविधाओं को आज़माएं:
- "bigquery-public-data.hacker_news में मौजूद टेबल की सूची बनाओ"
- अनुमानित: एजेंट
list_table_idsको कॉल करता है औरfullके साथ टेबल के नाम दिखाता है.
- अनुमानित: एजेंट
- "bigquery-public-data.hacker_news.full में हर साल की पोस्ट की संख्या पता करो"
- जवाब: एजेंट, एसक्यूएल क्वेरी के साथ
execute_sqlको कॉल करता है और सालों और पोस्ट की संख्या वाली टेबल दिखाता है.
- जवाब: एजेंट, एसक्यूएल क्वेरी के साथ
- "पिछले साल की तुलना में इस साल पोस्ट की संख्या में कितने प्रतिशत का बदलाव हुआ?"
- अनुमानित: एजेंट, एसक्यूएल क्वेरी के साथ
execute_sqlको कॉल करता है. यह क्वेरी, प्रतिशत में हुए बदलाव का हिसाब लगाती है और नतीजे दिखाती है.
- अनुमानित: एजेंट, एसक्यूएल क्वेरी के साथ
7. मेमोरी पर्सिस्टेंस की जांच करना
प्लेग्राउंड में ही, एजेंट को अपनी पसंद के बारे में बताएं:
- "याद रखना कि मेरा पसंदीदा डेटासेट bigquery-public-data.hacker_news है"
- "इसमें कौनसी टेबल मौजूद हैं?"
मेमोरी को सेव होने में कुछ सेकंड लगते हैं. _save_memory कॉलबैक, एजेंट के जवाब देने के बाद चलता है.
अब Playground की साइडबार में मौजूद, "+ नया सेशन" बटन पर क्लिक करके, नया सेशन शुरू करें. इसके बाद, यह सवाल पूछें:
- "मेरा पसंदीदा डेटासेट कौनसा है?"
एजेंट को bigquery-public-data.hacker_news को याद रखना चाहिए, भले ही यह बिलकुल नया सेशन हो और इसमें बातचीत का कोई इतिहास न हो. यह इसलिए काम करता है, क्योंकि:
_save_memory, हर सेशन के लिएcallback_context.add_session_to_memory()के ज़रिए Memory Bank में डेटा सेव करता हैPreloadMemoryTool, एलएलएम से किए जाने वाले हर कॉल से पहले, काम की यादें वापस लाता है- Memory Bank, कॉन्टेंट को सिर्फ़ कीवर्ड के हिसाब से नहीं, बल्कि सिमैंटिक के हिसाब से मैच करता है
8. जांचने की क्षमता के बारे में जानें
Cloud Console में, डिप्लॉय किए गए एजेंट पर जाएं और ट्रेस टैब पर क्लिक करें.
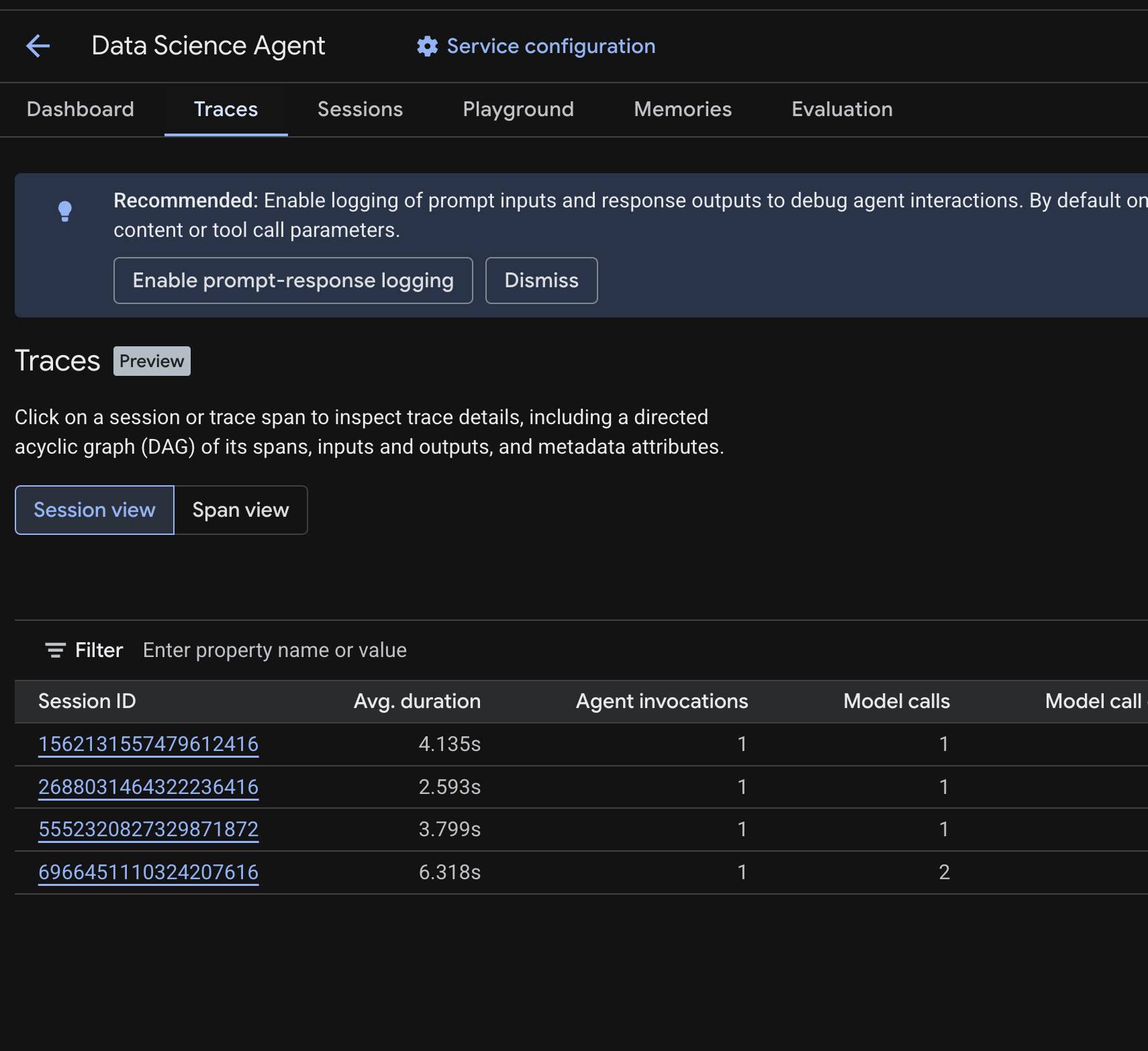
आपको सेशन टेबल दिखेगी. इसमें, पिछले चरणों में चलाई गई टेस्ट क्वेरी के सेशन की सूची होगी. इस टेबल में, हर सेशन के लिए खास जानकारी वाली मेट्रिक दिखती हैं. जैसे, औसत अवधि, मॉडल कॉल, टूल कॉल, टोकन का इस्तेमाल, और कोई भी गड़बड़ी.
सेशन पर क्लिक करके, उसके ट्रेस की जानकारी देखें. इसमें यह जानकारी शामिल होती है:
- इसके स्पैन का डायरेक्टेड एसाइक्लिक ग्राफ़ (डीएजी) — इसमें एजेंट के तर्क, टूल कॉल (BigQuery क्वेरी), और इंतज़ार के समय की जानकारी सिलसिलेवार तरीके से दी गई है
- हर स्पैन के लिए इनपुट और आउटपुट (
.envमेंOTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTenv var के ज़रिए चालू किया गया) - मेटाडेटा एट्रिब्यूट, जैसे कि स्पैन आईडी, ट्रेस आईडी, और टाइमिंग
सभी सेशन में अलग-अलग स्पैन देखने के लिए, स्पैन व्यू पर भी स्विच किया जा सकता है. इसके लिए, सबसे ऊपर मौजूद टॉगल का इस्तेमाल करें.
ट्रेसिंग की सुविधा कैसे काम करती है
--trace_to_cloud और --otel_to_cloud की मदद से डिप्लॉय करने पर, Agent Engine रनटाइम एक OpenTelemetry पाइपलाइन शुरू करता है. यह पाइपलाइन:
- यह फ़ंक्शन, OTLP एक्सपोर्टर के साथ TracerProvider बनाता है. यह एक्सपोर्टर, स्पैन को
telemetry.googleapis.comपर भेजता है - यह आपकी
requirements.txtसे चार इंस्ट्रुमेंटेशन पैकेज का इस्तेमाल करता है, ताकि मुख्य लाइब्रेरी (FastAPI, Gemini, httpx, gRPC) से स्पैन कैप्चर किए जा सकें.google-genaiको रनटाइम के ज़रिए साफ़ तौर पर इंस्ट्रुमेंट किया जाता है, जबकि अन्य OpenTelemetry की अपने-आप खोज करने की सुविधा के ज़रिए योगदान देते हैं - यह स्पैन को Telemetry API में बैच और एक्सपोर्ट करता है. Traces टैब, इन्हें पढ़ता है
Agent Engine की बेस इमेज में OpenTelemetry SDK और एक्सपोर्टर उपलब्ध होता है. हालांकि, इसमें इंस्ट्रुमेंटेशन पैकेज शामिल नहीं होते. इसलिए, आपके requirements.txt में ये चारों चीज़ें शामिल होनी चाहिए. इनके बिना, कोई स्पैन नहीं बनाया जाता और न ही कोई ट्रेस दिखता है.
समस्या का हल
अगर कुछ मिनट बाद भी कोई निशान नहीं दिखता है, तो:
- देखें कि Telemetry API चालू हो — आपने इसे सेटअप के दौरान चालू किया था. इनसे पुष्टि की गई:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - चेतावनी के लिए Cloud Logging की जांच करें — Logging > Logs Explorer पर जाएं और
"telemetry enabled but proceeding without"खोजें. अगर आपको जेन एआई इंस्ट्रूमेंटेशन के बारे में चेतावनी दिखती है, तो इसका मतलब है कि आपकेrequirements.txtमेंopentelemetry-instrumentation-google-genaiमौजूद नहीं है. - अपने
requirements.txtमेंgoogle-cloud-aiplatform[agent-engines]न जोड़ें. ADK डिप्लॉय सीएलआई इसे अपने-आप जोड़ देता है. इसे किसी दूसरे वर्शन के साथ फिर से घोषित करने से, OpenTelemetry पैकेज में टकराव हो सकता है और इंस्ट्रुमेंटेशन चुपचाप बंद हो सकता है.
9. क्लीन अप करें
शुल्क से बचने के लिए, इस कोडलैब के दौरान बनाए गए संसाधनों को मिटाएं.
Cloud Console में एजेंट इंजन पेज पर जाकर, डिप्लॉय किए गए एजेंट को मिटाएं. अपना एजेंट चुनें और मिटाएं पर क्लिक करें.
अगर आपने इस कोडलैब के लिए कोई प्रोजेक्ट बनाया है, तो आपके पास पूरे प्रोजेक्ट को मिटाने का विकल्प है:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
इसके अलावा, अपने लोकल एनवायरमेंट को साफ़ करें:
deactivate
rm -rf .venv data_science_agent
10. बधाई हो
आपने स्टेटफ़ुल डेटा साइंस एजेंट बनाया है और उसे एजेंट इंजन में डिप्लॉय किया है!
आपको क्या सीखने को मिला
- रीयल डेटा ऐक्सेस करने के लिए,
BigQueryToolsetकी मदद से एडीके एजेंट बनाने का तरीका PreloadMemoryToolऔरafter_agent_callbackका इस्तेमाल करके, मेमोरी बैंक की मदद से लगातार याद रखने की सुविधा को चालू करने का तरीका- डिप्लॉय किए गए एजेंट के सेवा खाते के लिए, IAM अनुमतियां देने का तरीका
- Agent Engine पर डिप्लॉय करने और Cloud Trace की मदद से ऑब्ज़र्वेबिलिटी चालू करने का तरीका
अगले चरण
- अपने निजी BigQuery डेटासेट की क्वेरी करें. इसके लिए, Agent Engine सेवा खाते को अपने डेटा का ऐक्सेस दें
- सुरक्षित सैंडबॉक्स में Python का विश्लेषण करने के लिए, कोड एक्ज़ीक्यूशन जोड़ें
- प्रोडक्शन में अपने एजेंट को मॉनिटर करने के लिए, Cloud Trace observability डैशबोर्ड सेट अप करें
- MCP टूल का इस्तेमाल करके, Google Workspace पर नतीजे पब्लिश करना