
1. Panoramica
In questo codelab creerai un agente di data science che esegue query sui dati reali dei set di dati pubblici di BigQuery e ricorda le tue preferenze tra le sessioni. Poi ne eseguirai il deployment in Agent Engine, un servizio Google Cloud completamente gestito che gestisce l'infrastruttura, lo scaling e la gestione delle sessioni.
L'agente utilizza tre funzionalità principali che si attivano progressivamente:
- BigQuery Toolset: l'agente esplora gli schemi ed esegue query SQL sui set di dati BigQuery reali. Questa operazione funziona sia in locale sia quando viene eseguito il deployment.
- Memory Bank: quando viene eseguito il deployment, l'agente ricorda le preferenze e il contesto dell'utente tra le sessioni disconnesse.
- Osservabilità: Cloud Trace acquisisce i passaggi di ragionamento, le chiamate agli strumenti e le latenze dell'agente tramite l'instrumentazione OpenTelemetry.
Obiettivi didattici
- Come creare un agente ADK con
BigQueryToolsetper l'accesso ai dati reali - Come configurare Memory Bank per la persistenza tra le sessioni
- Come eseguire il deployment dell'agente in Agent Engine con
adk deploy - Come concedere le autorizzazioni IAM per il service account dell'agente di cui è stato eseguito il deployment
- Come testare la persistenza della memoria e l'osservabilità
Che cosa ti serve
- Un progetto cloud Google Cloud con la fatturazione abilitata
- Google Cloud SDK (
gcloudCLI) - Un browser web come Chrome
- uv (gestore di pacchetti Python)
- Python 3.12+ (installato automaticamente da
uvse necessario)
ADK (Agent Development Kit) è il framework di Google per la creazione di agenti AI. Questo codelab utilizza ADK per creare un agente ed eseguirne il deployment in Agent Engine.
Questo codelab è destinato a sviluppatori di livello intermedio che hanno una certa familiarità con Python e Google Cloud.
Il completamento di questo codelab richiede circa 30 minuti (inclusi 5-10 minuti per il deployment).
Le risorse create in questo codelab dovrebbero costare meno di 5 $.
2. Configura l'ambiente
Crea un progetto Google Cloud
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
Imposta le variabili di ambiente
Apri l'editor di Cloud Shell nel progetto GCP creato.
Poi crea un terminale > Nuovo terminale ed esegui i seguenti comandi.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
Abilita API
Nel terminale, esegui il seguente comando.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- API AI Platform (
aiplatform.googleapis.com) — hosting di Agent Engine - API BigQuery (
bigquery.googleapis.com) — query SQL su set di dati pubblici e privati - API Telemetry (
telemetry.googleapis.com) — tracce OpenTelemetry per l'osservabilità dell'agente
Crea un ambiente virtuale e installa ADK
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
Il pacchetto google-adk include lo strumento CLI adk che utilizzerai per testare ed eseguire il deployment dell'agente.
3. Crea l'agente
Crea una nuova directory del progetto dell'agente. Tutti i comandi successivi devono essere eseguiti da questa directory di lavoro (la directory principale di data_science_agent/):
mkdir data_science_agent
La struttura di directory finale sarà simile alla seguente:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
Ora creerai __init__.py e agent.py, poi aggiungerai requirements.txt e .env nel passaggio Esegui il deployment.
Crea data_science_agent/__init__.py. Questo file è necessario per consentire ad ADK di rilevare e caricare l'agente:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
Crea data_science_agent/agent.py:
Questo agente si connette a BigQuery per l'estrazione dei dati e rende persistenti le sessioni in Memory Bank.
La memoria si attiva automaticamente quando viene eseguito il deployment. La variabile di ambiente GOOGLE_CLOUD_AGENT_ENGINE_ID viene impostata dal runtime di Agent Engine ed è assente quando viene eseguita in locale.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
Vediamo cosa fa questo codice:
- BigQueryToolset fornisce all'agente strumenti come
execute_sql,list_table_idseget_table_info. Può esplorare gli schemi ed eseguire query su qualsiasi set di dati a cui il chiamante ha accesso. - PreloadMemoryTool recupera automaticamente le memorie pertinenti prima di ogni chiamata LLM cercando in Memory Bank i contenuti correlati al messaggio dell'utente. Il callback
_save_memoryrende persistente la sessione in Memory Bank dopo ogni esecuzione dell'agente, in modo che l'agente possa richiamare il contesto nelle sessioni future. - App racchiude l'agente root in un'applicazione di cui è possibile eseguire il deployment e che Agent Engine può pubblicare. Il
namedeve corrispondere al nome della directory (data_science_agent).adk weblo utilizza per individuare e caricare l'agente. - L'istruzione indica all'agente di utilizzare il progetto di fatturazione per le query SQL e di ricordare le preferenze dell'utente.
4. Esegui il deployment in Agent Engine
Crea un file requirements.txt nella directory data_science_agent:
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
google-adkegoogle-genai: il framework ADK e il client Geminigoogle-auth: autenticazione Google Cloudpython-dotenv: carica il file.envall'avvio- I quattro pacchetti
opentelemetry-instrumentation-*abilitano le funzionalità di osservabilità che esplorerai in un secondo momento. Strumentano le richieste HTTP FastAPI, le chiamate al modello Gemini e la comunicazione gRPC/HTTP interna in modo che le tracce vengano visualizzate nella scheda Tracce di Agent Engine.
Crea un file .env nella directory data_science_agent per abilitare la telemetria sull'agente di cui è stato eseguito il deployment:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY: attiva la pipeline OpenTelemetry nel runtime di Agent Engine.OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT: registra gli input dei prompt completi e le risposte dell'agente, utili per il debug.
Esegui il deployment dell'agente. L'ultimo argomento data_science_agent è la directory contenente il codice dell'agente:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
Flag | Finalità |
| Progetto cloud e regione Google Cloud di destinazione |
| Nome leggibile visualizzato nella console Cloud |
| Abilita l'esportatore Cloud Trace per gli span dell'agente |
| Abilita la pipeline di instrumentazione OpenTelemetry |
Quando viene eseguito il deployment in Agent Engine, due funzionalità si attivano automaticamente:
- Memory Bank:
PreloadMemoryToolsi connette a Memory Bank di Agent Engine e_save_memoryrende persistenti le sessioni automaticamente. - Osservabilità: Cloud Trace acquisisce i passaggi di ragionamento, le chiamate agli strumenti e le latenze dell'agente.
5. Concedi le autorizzazioni BigQuery
Devi concedere l'accesso a BigQuery al service account di Agent Engine. Quando viene eseguito il deployment, l'agente viene eseguito come service account gestito da Google (non le tue credenziali personali), quindi ha bisogno di autorizzazioni esplicite per eseguire query SQL.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
Ogni comando stampa Updated IAM policy for project [...] se l'operazione va a buon fine.
6. Testa l'agente di cui è stato eseguito il deployment
Apri la pagina Agent Engine nella console Google Cloud. Fai clic sull'agente di cui è stato eseguito il deployment per aprire Agent Engine Playground.
Testa le funzionalità di BigQuery:
- "List the tables in bigquery-public-data.hacker_news"
- Previsto: l'agente chiama
list_table_idse restituisce i nomi delle tabelle, inclusofull.
- Previsto: l'agente chiama
- "Find the number of posts per year in bigquery-public-data.hacker_news.full"
- Previsto: l'agente chiama
execute_sqlcon una query SQL e restituisce una tabella di anni e conteggi dei post.
- Previsto: l'agente chiama
- "What was the year-over-year percentage change in posts?"
- Previsto: l'agente chiama
execute_sqlcon una query SQL che calcola la variazione percentuale e restituisce i risultati.
- Previsto: l'agente chiama
7. Testa la persistenza della memoria
Sempre in Playground, insegna all'agente una preferenza:
- "Remember that my favorite dataset is bigquery-public-data.hacker_news"
- "What tables does it have?"
Attendi qualche secondo affinché la memoria diventi persistente (il callback _save_memory viene eseguito dopo che l'agente risponde).
Ora avvia una nuova sessione facendo clic sul pulsante "+ New Session" nella barra laterale di Playground, quindi chiedi:
- "What is my favorite dataset?"
L'agente dovrebbe richiamare bigquery-public-data.hacker_news, anche se si tratta di una sessione completamente nuova senza cronologia delle conversazioni. Questo funziona perché:
_save_memoryrende persistente ogni sessione in Memory Bank tramitecallback_context.add_session_to_memory()PreloadMemoryToolrecupera le memorie pertinenti prima di ogni chiamata LLM- Memory Bank abbina i contenuti semanticamente, non solo per parola chiave
8. Esplora l'osservabilità
Nella console Cloud, vai all'agente di cui è stato eseguito il deployment e fai clic sulla scheda Tracce.
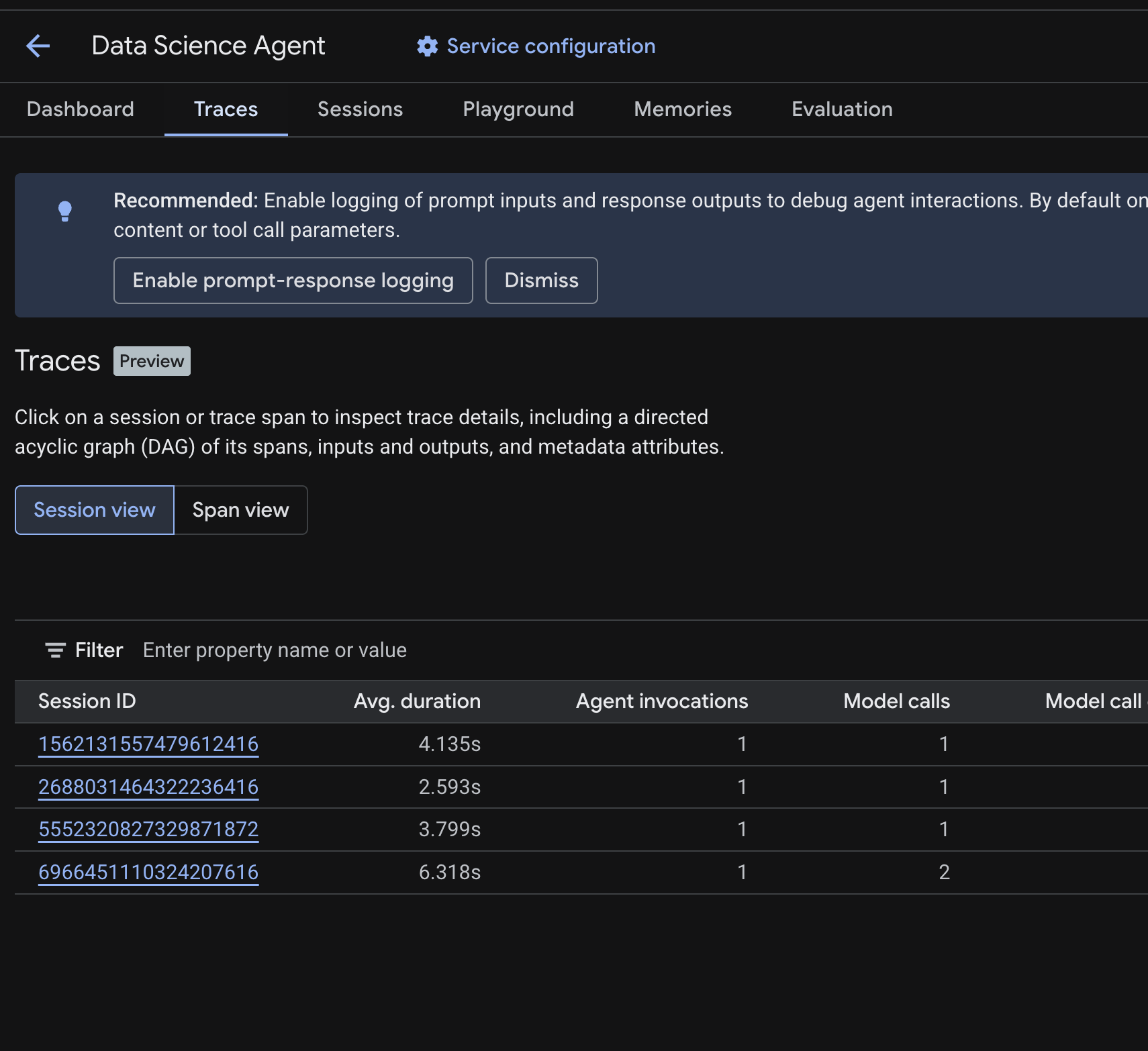
Dovresti vedere una tabella Sessioni che elenca le sessioni delle query di test eseguite nei passaggi precedenti. La tabella mostra le metriche di riepilogo per ogni sessione: durata media, chiamate al modello, chiamate agli strumenti, utilizzo dei token ed eventuali errori.
Fai clic su una sessione per ispezionarne i dettagli della traccia, tra cui:
- Un grafo diretto aciclico (DAG) dei relativi span, che mostra la suddivisione passo passo del ragionamento dell'agente, le chiamate agli strumenti (query BigQuery) e le latenze
- Input e output per ogni span (abilitati tramite la variabile di ambiente
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTin.env) - Attributi dei metadati come ID span, ID traccia e tempistiche
Puoi anche passare alla visualizzazione Span (attiva/disattiva in alto) per visualizzare i singoli span in tutte le sessioni.
Come funziona la traccia
Quando esegui il deployment con --trace_to_cloud e --otel_to_cloud, il runtime di Agent Engine inizializza una pipeline OpenTelemetry che:
- Crea un TracerProvider con un esportatore OTLP che invia gli span a
telemetry.googleapis.com - Utilizza i quattro pacchetti di instrumentazione di
requirements.txtper acquisire gli span dalle librerie chiave (FastAPI, Gemini, httpx, gRPC).google-genaiviene strumentato in modo esplicito dal runtime, mentre gli altri contribuiscono tramite il rilevamento automatico di OpenTelemetry - Raggruppa ed esporta gli span nell'API Telemetry, dove la scheda Tracce li legge
L'immagine di base di Agent Engine fornisce l'SDK e l'esportatore OpenTelemetry, ma non include i pacchetti di instrumentazione. Per questo motivo, requirements.txt deve elencare tutti e quattro i pacchetti. In caso contrario, non vengono creati span e non vengono visualizzate tracce.
Risoluzione dei problemi
Se dopo qualche minuto non vengono visualizzate tracce:
- Verifica che l'API Telemetry sia abilitata. L'hai abilitata nel passaggio di configurazione. Verifica con:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - Controlla Cloud Logging per gli avvisi. Vai a Logging > Esplora log e cerca
"telemetry enabled but proceeding without". Se vedi un avviso relativo all'instrumentazione GenAI, significa cheopentelemetry-instrumentation-google-genainon è presente inrequirements.txt. - Non aggiungere
google-cloud-aiplatform[agent-engines]arequirements.txt. La CLI di deployment ADK lo aggiunge automaticamente. Se lo dichiari di nuovo con una versione diversa, possono verificarsi conflitti di pacchetti OpenTelemetry e l'instrumentazione viene interrotta silenziosamente.
9. Elimina
Per evitare addebiti continui, elimina le risorse create durante questo codelab.
Elimina l'agente di cui è stato eseguito il deployment dalla pagina Agent Engine nella console Cloud. Seleziona l'agente e fai clic su Elimina.
Se hai creato un progetto specifico per questo codelab, puoi eliminare l'intero progetto:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
Facoltativamente, puoi liberare spazio nel tuo ambiente locale:
deactivate
rm -rf .venv data_science_agent
10. Complimenti
Hai creato un agente di data science con stato e ne hai eseguito il deployment in Agent Engine.
Che cosa hai imparato
- Come creare un agente ADK con
BigQueryToolsetper l'accesso ai dati reali - Come abilitare la memoria persistente con Memory Bank utilizzando
PreloadMemoryTooleafter_agent_callback - Come concedere le autorizzazioni IAM per il service account dell'agente di cui è stato eseguito il deployment
- Come eseguire il deployment in Agent Engine e abilitare l'osservabilità con Cloud Trace
Passaggi successivi
- Esegui query sui tuoi set di dati BigQuery privati concedendo al service account di Agent Engine l'accesso ai tuoi dati
- Aggiungi l'esecuzione del codice per eseguire l'analisi Python in una sandbox sicura
- Configura le dashboard di osservabilità di Cloud Trace per monitorare l'agente in produzione
- Pubblica i risultati in Google Workspace utilizzando gli strumenti MCP