
1. 개요
이 Codelab에서는 BigQuery 공개 데이터 세트의 실제 데이터를 쿼리하고 세션 간에 환경설정을 기억하는 데이터 과학 에이전트를 빌드합니다. 그런 다음 인프라, 확장, 세션 관리를 처리하는 완전 관리형 Google Cloud 서비스인 Agent Engine에 배포합니다.
에이전트는 점진적으로 활성화되는 세 가지 핵심 기능을 사용합니다.
- BigQuery 도구 모음: 에이전트는 스키마를 탐색하고 실제 BigQuery 데이터 세트에 대해 SQL 쿼리를 실행합니다. 이는 로컬 및 배포 시 모두 작동합니다.
- 메모리 뱅크: 배포 시 에이전트는 연결이 끊긴 세션 간에 사용자 환경설정 및 컨텍스트를 기억합니다.
- 모니터링 가능성: Cloud Trace는 OpenTelemetry 계측을 통해 에이전트의 추론 단계, 도구 호출, 지연 시간을 캡처합니다.
학습할 내용
- 실제 데이터 액세스를 위해
BigQueryToolset으로 ADK 에이전트를 만드는 방법 - 세션 간 지속성을 위해 메모리 뱅크를 구성하는 방법
adk deploy로 에이전트를 Agent Engine에 배포하는 방법- 배포된 에이전트의 서비스 계정에 IAM 권한을 부여하는 방법
- 메모리 지속성 및 모니터링 가능성을 테스트하는 방법
필요한 항목
- 결제가 사용 설정된 Google Cloud 프로젝트
- Google Cloud SDK (
gcloudCLI) - 웹브라우저(예: Chrome)
- uv (Python 패키지 관리자)
- Python 3.12 이상 (
uv에서 필요한 경우 자동으로 설치)
ADK (에이전트 개발 키트)는 AI 에이전트를 빌드하기 위한 Google의 프레임워크입니다. 이 Codelab에서는 ADK를 사용하여 에이전트를 만들고 Agent Engine에 배포합니다.
이 Codelab은 Python 및 Google Cloud에 익숙한 중급 개발자를 위한 것입니다.
이 Codelab을 완료하는 데 약 30분이 소요됩니다 (배포에 5~10분 포함).
이 Codelab에서 만든 리소스의 비용은 $5 미만이어야 합니다.
2. 환경 설정
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
환경 변수 설정
만든 GCP 프로젝트에서 Cloud Shell 편집기를 엽니다.
그런 다음 터미널 > 새 터미널을 만들고 다음 명령어를 실행합니다.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
API 사용 설정
터미널에서 다음 명령어를 실행합니다.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- AI Platform API (
aiplatform.googleapis.com) — Agent Engine 호스팅 - BigQuery API (
bigquery.googleapis.com) — 공개 및 비공개 데이터 세트에 대한 SQL 쿼리 - Telemetry API (
telemetry.googleapis.com) — 에이전트 모니터링 가능성을 위한 OpenTelemetry trace
가상 환경 만들기 및 ADK 설치
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
google-adk 패키지에는 에이전트를 테스트하고 배포하는 데 사용할 adk CLI 도구가 포함되어 있습니다.
3. 에이전트 만들기
새 에이전트 프로젝트 디렉터리를 만듭니다. 이후의 모든 명령어는 이 작업 디렉터리 (data_science_agent/의 상위 디렉터리)에서 실행해야 합니다.
mkdir data_science_agent
최종 디렉터리 구조는 다음과 같습니다.
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
이제 __init__.py 및 agent.py를 만든 다음 배포 단계에서 requirements.txt 및 .env를 추가합니다.
data_science_agent/__init__.py를 만듭니다. 이 파일은 ADK가 에이전트를 검색하고 로드할 수 있도록 하는 데 필요합니다.
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
data_science_agent/agent.py를 만듭니다.
이 에이전트는 데이터 추출을 위해 BigQuery에 연결하고 세션을 메모리 뱅크에 유지합니다.
메모리는 배포 시 자동으로 활성화됩니다. GOOGLE_CLOUD_AGENT_ENGINE_ID 환경 변수는 Agent Engine 런타임에 의해 설정되며 로컬에서 실행할 때는 없습니다.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
이 코드의 역할을 살펴보겠습니다.
- BigQueryToolset 은 에이전트 도구(
execute_sql,list_table_ids,get_table_info등)를 제공합니다. 스키마를 탐색하고 호출자가 액세스할 수 있는 데이터 세트를 쿼리할 수 있습니다. - PreloadMemoryTool 은 각 LLM 호출 전에 메모리 뱅크에서 사용자 메시지와 관련된 콘텐츠를 검색하여 관련 메모리를 자동으로 가져옵니다.
_save_memory콜백은 각 에이전트 실행 후 세션을 메모리 뱅크에 유지하므로 에이전트는 향후 세션에서 컨텍스트를 불러올 수 있습니다. - App 은 루트 에이전트를 Agent Engine에서 제공할 수 있는 배포 가능한 애플리케이션으로 래핑합니다.
name은 디렉터리 이름 (data_science_agent)과 일치해야 합니다.adk web은 이를 사용하여 에이전트를 찾고 로드합니다. - instruction 은 에이전트가 SQL 쿼리에 결제 프로젝트를 사용하고 사용자 환경설정을 기억하도록 지시합니다.
4. Agent Engine에 배포
data_science_agent 디렉터리에 requirements.txt 파일을 만듭니다.
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
google-adk및google-genai— ADK 프레임워크 및 Gemini 클라이언트google-auth— Google Cloud 인증python-dotenv— 시작 시.env파일 로드- 4개의
opentelemetry-instrumentation-*패키지는 나중에 살펴볼 모니터링 가능성 기능을 사용 설정합니다. Agent Engine trace 탭에 trace가 표시되도록 FastAPI HTTP 요청, Gemini 모델 호출, 내부 gRPC/HTTP 통신을 계측합니다.
data_science_agent 디렉터리에 .env 파일을 만들어 배포된 에이전트에서 원격 분석을 사용 설정합니다.
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY— Agent Engine 런타임에서 OpenTelemetry 파이프라인을 활성화합니다.OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT— 디버깅에 유용한 전체 프롬프트 입력 및 에이전트 응답을 로깅합니다.
에이전트를 배포합니다. 마지막 인수 data_science_agent는 에이전트 코드가 포함된 디렉터리입니다.
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
플래그 | 목적 |
| Google Cloud 대상 프로젝트 및 리전 |
| Cloud 콘솔에 표시되는 사람이 읽을 수 있는 이름 |
| 에이전트 스팬에 Cloud Trace 내보내기 도구를 사용 설정합니다. |
| OpenTelemetry 계측 파이프라인을 사용 설정합니다. |
Agent Engine에 배포되면 두 가지 기능이 자동으로 활성화됩니다.
- 메모리 뱅크:
PreloadMemoryTool은 Agent Engine 메모리 뱅크에 연결하고_save_memory는 세션을 자동으로 유지합니다. - 모니터링 가능성: Cloud Trace는 에이전트의 추론 단계, 도구 호출, 지연 시간을 캡처합니다.
5. BigQuery 권한 부여
Agent Engine 서비스 계정에 BigQuery 액세스 권한을 부여해야 합니다. 배포 시 에이전트는 Google에서 관리하는 서비스 계정 (개인 사용자 인증 정보가 아님)으로 실행되므로 SQL 쿼리를 실행하려면 명시적인 권한이 필요합니다.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
각 명령어는 성공 시 Updated IAM policy for project [...]를 출력합니다.
6. 배포된 에이전트 테스트
Google Cloud 콘솔에서 Agent Engine 페이지를 엽니다. 배포된 에이전트를 클릭하여 Agent Engine Playground 를 엽니다.
BigQuery 기능을 테스트합니다.
- 'bigquery-public-data.hacker_news의 테이블 나열'
- 예상: 에이전트가
list_table_ids를 호출하고full을 포함한 테이블 이름을 반환합니다.
- 예상: 에이전트가
- 'bigquery-public-data.hacker_news.full의 연간 게시물 수 찾기'
- 예상: 에이전트가 SQL 쿼리로
execute_sql을 호출하고 연도 및 게시물 수 테이블을 반환합니다.
- 예상: 에이전트가 SQL 쿼리로
- '게시물의 전년 대비 변화율은 얼마였나요?'
- 예상: 에이전트가 변화율을 계산하는 SQL 쿼리로
execute_sql을 호출하고 결과를 반환합니다.
- 예상: 에이전트가 변화율을 계산하는 SQL 쿼리로
7. 메모리 지속성 테스트
Playground에서 에이전트에 환경설정을 알려줍니다.
- '내 즐겨찾기 데이터 세트는 bigquery-public-data.hacker_news임을 기억해'
- '테이블은 뭐가 있지?'
메모리가 유지될 때까지 몇 초 정도 기다립니다 (_save_memory 콜백은 에이전트가 응답한 후에 실행됨).
이제 Playground 사이드바에서 "+ 새 세션" 버튼을 클릭하여 새 세션을 시작 한 다음 다음을 요청합니다.
- '내 즐겨찾기 데이터 세트는 뭐야?'
에이전트는 대화 기록이 없는 완전히 새로운 세션임에도 불구하고 bigquery-public-data.hacker_news를 불러와야 합니다. 이는 다음과 같은 이유로 작동합니다.
_save_memory는callback_context.add_session_to_memory()를 통해 각 세션을 메모리 뱅크에 유지합니다.PreloadMemoryTool은 각 LLM 호출 전에 관련 메모리를 가져옵니다.- 메모리 뱅크는 키워드뿐만 아니라 시맨틱으로 콘텐츠를 일치시킵니다.
8. 모니터링 가능성 살펴보기
Cloud 콘솔에서 배포된 에이전트로 이동하여 trace 탭을 클릭합니다.
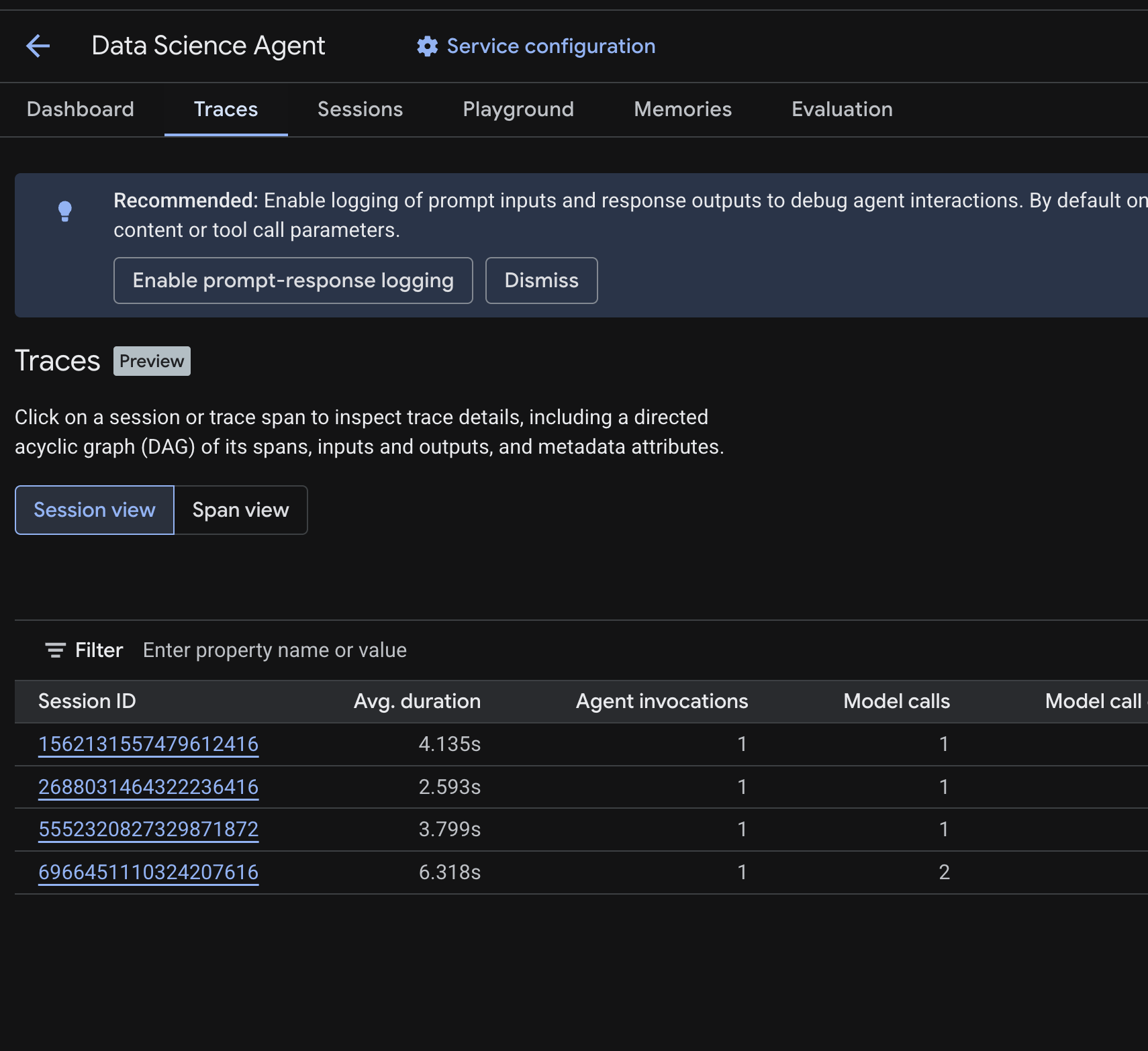
이전 단계에서 실행한 테스트 쿼리의 세션을 나열하는 세션 테이블 이 표시됩니다. 테이블에는 각 세션의 요약 측정항목(평균 기간, 모델 호출, 도구 호출, 토큰 사용량, 오류)이 표시됩니다.
세션 을 클릭하여 다음을 포함한 trace 세부정보를 검사합니다.
- 스팬의 방향성 비순환 그래프 (DAG) : 에이전트 추론, 도구 호출 (BigQuery 쿼리), 지연 시간의 단계별 분석을 보여줍니다.
- 각 스팬의 입력 및 출력 (
.env의OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTenv var를 통해 사용 설정) - 스팬 ID, trace ID, 타이밍과 같은 메타데이터 속성
스팬 뷰 (상단에서 전환)로 전환하여 모든 세션에서 개별 스팬을 볼 수도 있습니다.
trace 작동 방식
--trace_to_cloud 및 --otel_to_cloud로 배포하면 Agent Engine 런타임이 다음을 수행하는 OpenTelemetry 파이프라인을 초기화합니다.
telemetry.googleapis.com으로 스팬을 전송하는 OTLP 내보내기 도구로 TracerProvider 를 만듭니다.requirements.txt의 4개 계측 패키지 를 사용하여 주요 라이브러리 (FastAPI, Gemini, httpx, gRPC)에서 스팬을 캡처합니다.google-genai는 런타임에 의해 명시적으로 계측되는 반면 다른 패키지는 OpenTelemetry 자동 검색을 통해 기여합니다.- trace 탭에서 읽는 Telemetry API로 스팬을 일괄 처리하고 내보냅니다.
Agent Engine 기본 이미지는 OpenTelemetry SDK 및 내보내기 도구를 제공하지만 계측 패키지는 포함하지 않습니다. 따라서 requirements.txt에 4개를 모두 나열해야 합니다. 나열하지 않으면 스팬이 생성되지 않고 trace가 표시되지 않습니다.
문제 해결
몇 분 후에도 trace가 표시되지 않으면 다음을 수행하세요.
- Telemetry API가 사용 설정되어 있는지 확인 합니다. 설정 단계에서 사용 설정했습니다.
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry로 확인합니다. - Cloud Logging에서 경고를 확인 합니다. Logging > 로그 탐색기 로 이동하여
"telemetry enabled but proceeding without"을 검색합니다. GenAI 계측에 대한 경고가 표시되면requirements.txt에opentelemetry-instrumentation-google-genai가 누락된 것입니다. requirements.txt에google-cloud-aiplatform[agent-engines]를 추가하면 안 됩니다. ADK 배포 CLI는 이를 자동으로 추가합니다. 다른 버전으로 다시 선언하면 OpenTelemetry 패키지 충돌이 발생하여 계측이 자동으로 중단될 수 있습니다.
9. 삭제
지속적인 요금이 발생하지 않도록 하려면 이 Codelab 중에 만든 리소스를 삭제하세요.
Cloud 콘솔의 Agent Engine 페이지에서 배포된 에이전트를 삭제 합니다. 에이전트를 선택하고 삭제 를 클릭합니다.
이 Codelab을 위해 특별히 프로젝트를 만든 경우 전체 프로젝트를 삭제할 수 있습니다.
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
필요한 경우 로컬 환경을 정리합니다.
deactivate
rm -rf .venv data_science_agent
10. 축하합니다
상태 저장 데이터 과학 에이전트를 빌드하고 Agent Engine에 배포했습니다.
학습한 내용
- 실제 데이터 액세스를 위해
BigQueryToolset으로 ADK 에이전트를 만드는 방법 PreloadMemoryTool및after_agent_callback을 사용하여 메모리 뱅크로 영구 메모리를 사용 설정하는 방법- 배포된 에이전트의 서비스 계정에 IAM 권한을 부여하는 방법
- Agent Engine에 배포하고 Cloud Trace로 모니터링 가능성을 사용 설정하는 방법
다음 단계
- Agent Engine 서비스 계정에 데이터 액세스 권한을 부여하여 자체 비공개 BigQuery 데이터 세트를 쿼리합니다.
- 코드 실행을 추가하여 보안 샌드박스에서 Python 분석을 실행합니다.
- Cloud Trace 모니터링 가능성 대시보드를 설정하여 프로덕션에서 에이전트를 모니터링합니다.
- MCP 도구를 사용하여 Google Workspace에 결과를 게시합니다.