
1. Przegląd
W tym ćwiczeniu utworzysz agenta badania danych, który będzie wysyłać zapytania do rzeczywistych danych z publicznych zbiorów danych BigQuery i zapamiętywać Twoje preferencje w różnych sesjach. Następnie wdrożysz go w Agent Engine, czyli w pełni zarządzanej usłudze Google Cloud, która obsługuje infrastrukturę, skalowanie i zarządzanie sesjami.
Agent korzysta z 3 podstawowych funkcji, które są aktywowane stopniowo:
- BigQuery Toolset: agent przegląda schematy i uruchamia zapytania SQL w rzeczywistych zbiorach danych BigQuery. Działa to zarówno lokalnie, jak i po wdrożeniu.
- Bank zapamiętanych informacji: po wdrożeniu agent zapamiętuje preferencje użytkownika i kontekst w rozłączonych sesjach.
- Dostrzegalność: Cloud Trace rejestruje kroki rozumowania agenta, wywołania narzędzi i opóźnienia za pomocą instrumentacji OpenTelemetry.
Czego się nauczysz
- Jak utworzyć agenta ADK za pomocą
BigQueryToolset, aby uzyskać dostęp do rzeczywistych danych - Jak skonfigurować Bank zapamiętanych informacji na potrzeby utrwalania danych w różnych sesjach
- Jak wdrożyć agenta w Agent Engine za pomocą
adk deploy - Jak przyznać uprawnienia IAM kontu usługi wdrożonego agenta
- Jak przetestować utrwalanie pamięci i dostrzegalność
Czego potrzebujesz
- Projekt Google Cloud z włączonymi płatnościami
- Google Cloud SDK (
gcloudCLI) - Przeglądarka internetowa, np. Chrome
- uv (system zarządzania pakietami Pythona)
- Python 3.12+ (w razie potrzeby zainstalowany automatycznie przez
uv)
ADK (pakiet Agent Development Kit) to platforma Google do tworzenia agentów AI. W tym ćwiczeniu użyjesz ADK do utworzenia agenta i wdrożenia go w Agent Engine.
To ćwiczenie jest przeznaczone dla programistów na poziomie średniozaawansowanym, którzy znają Pythona i Google Cloud.
Wykonanie tego ćwiczenia zajmuje około 30 minut (w tym 5–10 minut na wdrożenie).
Zasoby utworzone w tym ćwiczeniu powinny kosztować mniej niż 5 USD.
2. Konfigurowanie środowiska
Utwórz projekt Google Cloud
- W konsoli Google Cloud na stronie selektora projektu wybierz lub utwórz projekt w chmurze Google.
- Sprawdź, czy w projekcie w chmurze włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Ustawianie zmiennych środowiskowych
W utworzonym projekcie GCP otwórz edytor Cloud Shell.
Następnie utwórz Terminal > Nowy terminal i uruchom te polecenia.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
Włącz interfejsy API
W terminalu uruchom to polecenie.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- AI Platform API (
aiplatform.googleapis.com) – hosting Agent Engine - BigQuery API (
bigquery.googleapis.com) – zapytania SQL dotyczące publicznych i prywatnych zbiorów danych - Telemetry API (
telemetry.googleapis.com) – logi czasu OpenTelemetry na potrzeby dostrzegalności agenta
Tworzenie środowiska wirtualnego i instalowanie ADK
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
Pakiet google-adk zawiera narzędzie CLI adk, którego użyjesz do testowania i wdrażania agenta.
3. Tworzenie agenta
Utwórz nowy katalog projektu agenta. Wszystkie kolejne polecenia należy uruchamiać z tego katalogu roboczego (nadrzędnego względem data_science_agent/):
mkdir data_science_agent
Ostateczna struktura katalogów będzie wyglądać tak:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
Teraz utworzysz pliki __init__.py i agent.py, a następnie w kroku wdrażania dodasz pliki requirements.txt i .env.
Utwórz plik data_science_agent/__init__.py. Jest on wymagany, aby ADK mógł wykryć i wczytać agenta:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
Utwórz plik data_science_agent/agent.py:
Ten agent łączy się z BigQuery w celu wyodrębnienia danych i utrwala sesje w Banku zapamiętanych informacji.
Pamięć aktywuje się automatycznie po wdrożeniu. Zmienna środowiskowa GOOGLE_CLOUD_AGENT_ENGINE_ID jest ustawiana przez środowisko wykonawcze Agent Engine i nie występuje podczas uruchamiania lokalnego.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
Omówmy, co robi ten kod:
- BigQueryToolset udostępnia agentowi narzędzia takie jak
execute_sql,list_table_idsiget_table_info. Może on przeglądać schematy i wysyłać zapytania do dowolnego zbioru danych, do którego ma dostęp wywołujący. - PreloadMemoryTool automatycznie pobiera odpowiednie informacje przed każdym wywołaniem LLM, wyszukując w Banku zapamiętanych informacji treści powiązane z wiadomością użytkownika. Wywołanie zwrotne
_save_memoryutrwala sesję w Banku zapamiętanych informacji po każdym uruchomieniu agenta, dzięki czemu agent może przywoływać kontekst w przyszłych sesjach. - App opakowuje agenta głównego w aplikację, którą można wdrożyć i która może być obsługiwana przez Agent Engine.
namemusi być zgodna z nazwą katalogu (data_science_agent).adk webużywa tej nazwy do lokalizowania i wczytywania agenta. - Instrukcja informuje agenta, aby używał projektu rozliczeniowego do zapytań SQL i zapamiętywał preferencje użytkownika.
4. Wdrażanie w Agent Engine
Utwórz plik requirements.txt w katalogu data_science_agent:
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
google-adkigoogle-genai– platforma ADK i klient Geminigoogle-auth– uwierzytelnianie Google Cloudpython-dotenv– wczytuje plik.envpodczas uruchamiania- 4 pakiety
opentelemetry-instrumentation-*umożliwiają korzystanie z funkcji dostrzegalności, które poznasz później. Instrumentują one żądania HTTP FastAPI, wywołania modelu Gemini i wewnętrzną komunikację gRPC/HTTP, dzięki czemu logi czasu pojawiają się na karcie Logi czasu Agent Engine.
Utwórz plik .env w katalogu data_science_agent, aby włączyć logi czasu w wdrożonym agencie:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY– aktywuje potok OpenTelemetry w środowisku wykonawczym Agent Engine.OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT– rejestruje pełne dane wejściowe promptów i odpowiedzi agenta, co jest przydatne do debugowania.
Wdróż agenta. Ostatni argument data_science_agent to katalog zawierający kod agenta:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
Flaga | Cel |
| Docelowy projekt w chmurze i region Google Cloud |
| Czytelna nazwa wyświetlana w konsoli Cloud |
| Włącza eksporter Cloud Trace dla spanów agenta |
| Włącza potok instrumentacji OpenTelemetry |
Po wdrożeniu w Agent Engine automatycznie aktywują się 2 funkcje:
- Bank zapamiętanych informacji:
PreloadMemoryToolłączy się z Memory Bank Agent Engine, a_save_memoryautomatycznie utrwala sesje. - Dostrzegalność: Cloud Trace rejestruje kroki rozumowania agenta, wywołania narzędzi i opóźnienia.
5. Przyznawanie uprawnień BigQuery
Musisz przyznać dostęp do BigQuery kontu usługi Agent Engine. Po wdrożeniu agent działa jako konto usługi zarządzane przez Google (a nie Twoje dane logowania), dlatego potrzebuje wyraźnych uprawnień do wykonywania zapytań SQL.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
Po pomyślnym wykonaniu każdego polecenia wyświetla się komunikat Updated IAM policy for project [...].
6. Testowanie wdrożonego agenta
W konsoli Google Cloud otwórz stronę Agent Engine. Kliknij wdrożonego agenta, aby otworzyć plac zabaw Agent Engine.
Przetestuj funkcje BigQuery:
- „List the tables in bigquery-public-data.hacker_news”
- Oczekiwane: agent wywołuje
list_table_idsi zwraca nazwy tabel, w tymfull.
- Oczekiwane: agent wywołuje
- „Find the number of posts per year in bigquery-public-data.hacker_news.full”
- Oczekiwane: agent wywołuje
execute_sqlz zapytaniem SQL i zwraca tabelę lat oraz liczby postów.
- Oczekiwane: agent wywołuje
- „What was the year-over-year percentage change in posts?”
- Oczekiwane: agent wywołuje
execute_sqlz zapytaniem SQL, które oblicza zmianę procentową, i zwraca wyniki.
- Oczekiwane: agent wywołuje
7. Testowanie utrwalania pamięci
Na placu zabaw naucz agenta preferencji:
- „Remember that my favorite dataset is bigquery-public-data.hacker_news”
- „What tables does it have?”
Poczekaj kilka sekund, aż pamięć się utrwali (wywołanie zwrotne _save_memory jest uruchamiane po odpowiedzi agenta).
Teraz rozpocznij nową sesję , klikając przycisk „+ Nowa sesja” na pasku bocznym placu zabaw, a następnie zadaj pytanie:
- „What is my favorite dataset?”
Agent powinien przywołać bigquery-public-data.hacker_news, mimo że jest to zupełnie nowa sesja bez historii rozmów. Dzieje się tak, ponieważ:
_save_memoryutrwala każdą sesję w Banku zapamiętanych informacji za pomocącallback_context.add_session_to_memory()PreloadMemoryToolpobiera odpowiednie informacje przed każdym wywołaniem LLM- Bank zapamiętanych informacji dopasowuje treści semantycznie, a nie tylko według słów kluczowych
8. Poznaj usługę dostrzegalności
W konsoli Cloud otwórz wdrożonego agenta i kliknij kartę Logi czasu.
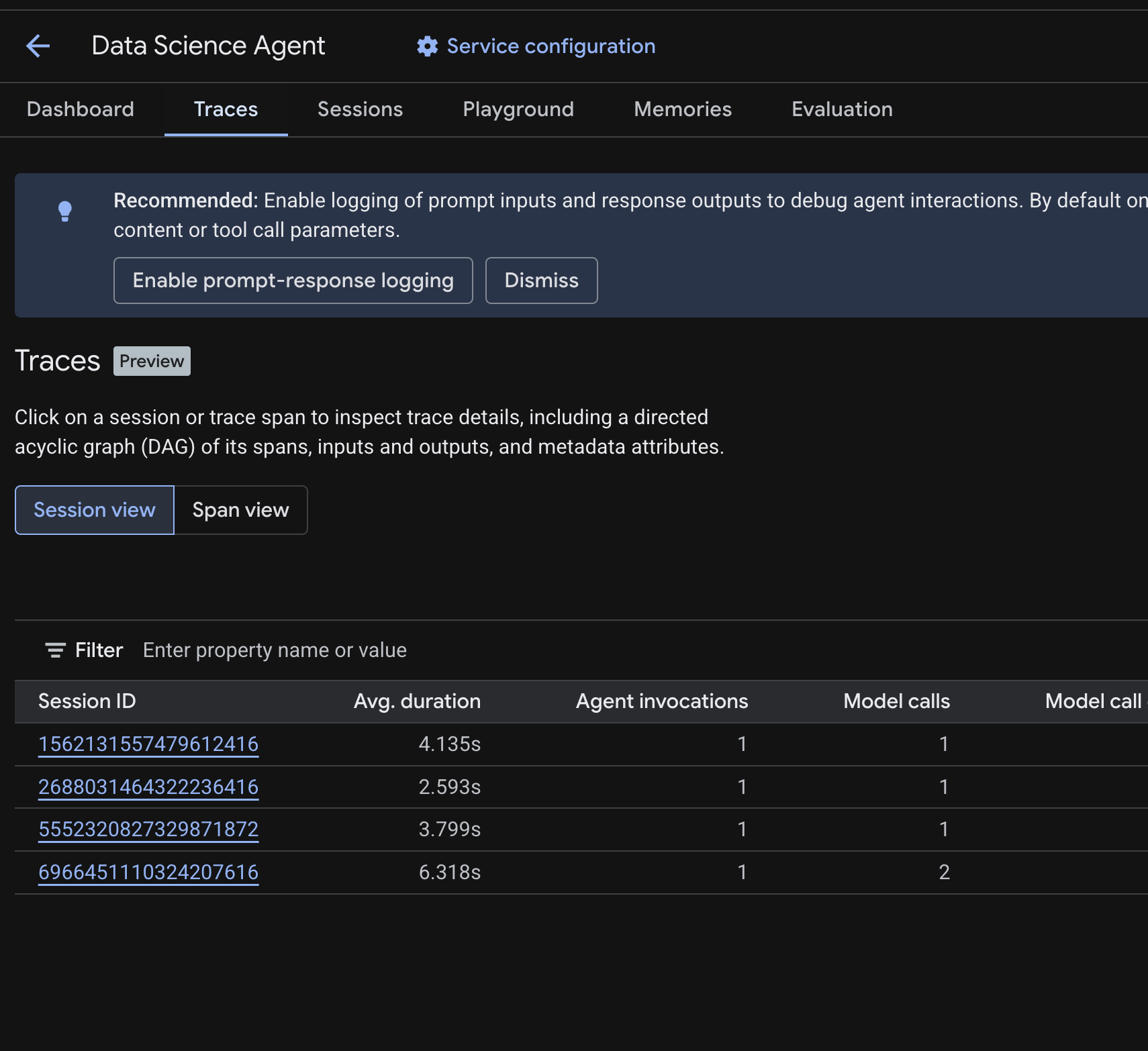
Powinna się wyświetlić tabela sesji zawierająca sesje z zapytań testowych uruchomionych w poprzednich krokach. Tabela zawiera podsumowanie danych każdej sesji – średni czas trwania, wywołania modelu, wywołania narzędzi, wykorzystanie tokenów i wszelkie błędy.
Kliknij sesję , aby sprawdzić jej szczegóły, w tym:
- Skierowany graf acykliczny (DAG) jego spanów – pokazuje szczegółowy podział rozumowania agenta, wywołań narzędzi (zapytań BigQuery) i opóźnień.
- Dane wejściowe i wyjściowe każdego spanu (włączone za pomocą zmiennej środowiskowej
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTw pliku.env). - Atrybuty metadanych, takie jak identyfikatory spanów, identyfikatory logów czasu i czas.
Możesz też przełączyć się na widok spanów (przełącznik u góry), aby zobaczyć poszczególne spany we wszystkich sesjach.
Jak działa śledzenie
Gdy wdrożysz agenta za pomocą flag --trace_to_cloud i --otel_to_cloud, środowisko wykonawcze Agent Engine zainicjuje potok OpenTelemetry, który:
- Tworzy TracerProvider z eksporterem OTLP, który wysyła spany do
telemetry.googleapis.com. - Używa 4 pakietów instrumentacji z pliku
requirements.txtdo rejestrowania spanów z kluczowych bibliotek (FastAPI, Gemini, httpx, gRPC).google-genaijest instrumentowany jawnie przez środowisko wykonawcze, a pozostałe pakiety działają dzięki automatycznemu wykrywaniu OpenTelemetry. - Gromadzi i eksportuje spany do Telemetry API, gdzie odczytuje je karta Logi czasu.
Obraz podstawowy Agent Engine zawiera pakiet SDK i eksporter OpenTelemetry, ale nie zawiera pakietów instrumentacji. Dlatego plik requirements.txt musi zawierać wszystkie 4 pakiety. Bez nich nie są tworzone żadne spany i nie pojawiają się żadne logi czasu.
Rozwiązywanie problemów
Jeśli po kilku minutach nie pojawią się żadne logi czasu:
- Sprawdź, czy Telemetry API jest włączony – został włączony w kroku konfiguracji. Sprawdź za pomocą polecenia:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - Sprawdź, czy w Cloud Logging nie ma ostrzeżeń – otwórz Logging > Eksplorator logów i wyszukaj frazę
"telemetry enabled but proceeding without". Jeśli zobaczysz ostrzeżenie dotyczące instrumentacji generatywnej AI, oznacza to, że w plikurequirements.txtbrakuje pakietuopentelemetry-instrumentation-google-genai. - Nie dodawaj
google-cloud-aiplatform[agent-engines]do plikurequirements.txt. Interfejs wiersza poleceń ADK deploy dodaje go automatycznie. Ponowne zadeklarowanie go w innej wersji może spowodować konflikty pakietów OpenTelemetry i cicho przerwać instrumentację.
9. Czyszczenie
Aby uniknąć naliczania opłat, usuń zasoby utworzone podczas tego ćwiczenia.
Usuń wdrożonego agenta ze strony Agent Engine w konsoli Cloud. Wybierz agenta i kliknij Usuń.
Jeśli masz projekt utworzony specjalnie na potrzeby tego ćwiczenia, możesz zamiast tego usunąć cały projekt:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
Opcjonalnie, zwalniaj miejsce w środowisku lokalnym:
deactivate
rm -rf .venv data_science_agent
10. Gratulacje
Udało Ci się utworzyć agenta badania danych z zachowaniem stanu i wdrożyć go w Agent Engine.
Czego się nauczysz
- Jak utworzyć agenta ADK za pomocą
BigQueryToolset, aby uzyskać dostęp do rzeczywistych danych - Jak włączyć utrwalanie pamięci za pomocą Banku zapamiętanych informacji przy użyciu
PreloadMemoryTooliafter_agent_callback - Jak przyznać uprawnienia IAM kontu usługi wdrożonego agenta
- Jak wdrożyć agenta w Agent Engine i włączyć dostrzegalność za pomocą Cloud Trace
Dalsze kroki
- Wysyłaj zapytania do własnych prywatnych zbiorów danych BigQuery, przyznając kontu usługi Agent Engine dostęp do swoich danych.
- Dodaj wykonywanie kodu, aby uruchamiać analizę w Pythonie w bezpiecznym piaskownicy.
- Skonfiguruj panele dostrzegalności Cloud Trace, aby monitorować agenta w środowisku produkcyjnym.
- Publikuj wyniki w Google Workspace za pomocą narzędzi MCP.