
1. Visão geral
Neste codelab, você vai criar um agente de ciência de dados que consulta dados reais de conjuntos de dados públicos do BigQuery e lembra suas preferências entre as sessões. Em seguida, você vai implantá-lo no Agent Engine, um serviço totalmente gerenciado do Google Cloud que processa infraestrutura, escalonamento e gerenciamento de sessões.
O agente usa três recursos principais que são ativados progressivamente:
- BigQuery Toolset: o agente explora esquemas e executa consultas SQL em conjuntos de dados reais do BigQuery. Isso funciona localmente e quando implantado.
- Memory Bank: quando implantado, o agente lembra as preferências e o contexto do usuário em sessões desconectadas.
- Observabilidade: o Cloud Trace captura as etapas de raciocínio, as chamadas de ferramentas e as latências do agente pela instrumentação do OpenTelemetry.
O que você vai aprender
- Como criar um agente do ADK com
BigQueryToolsetpara acesso aos dados reais - Como configurar o Memory Bank para persistência entre sessões
- Como implantar o agente no Agent Engine com
adk deploy - Como conceder permissões do IAM para a conta de serviço do agente implantado
- Como testar a persistência e a observabilidade da memória
O que é necessário
- Tenha um projeto na nuvem do Google Cloud com o faturamento ativado.
- SDK Google Cloud (
gcloudCLI) - Um navegador da web, como o Chrome
- uv (gerenciador de pacotes do Python)
- Python 3.12 ou mais recente (instalado automaticamente pelo
uvse necessário)
O ADK (Kit de Desenvolvimento de Agente) é o framework do Google para criar agentes de IA. Este codelab usa o ADK para criar um agente e implantá-lo no Agent Engine.
Este codelab é destinado a desenvolvedores intermediários que têm alguma familiaridade com o Python e o Google Cloud.
Este codelab leva aproximadamente 30 minutos para ser concluído (incluindo 5 a 10 minutos para implantação).
Os recursos criados neste codelab custam menos de US $5.
2. Configurar o ambiente
Criar um projeto do Google Cloud
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto na nuvem. Saiba como verificar se o faturamento está ativado em um projeto.
Definir variáveis de ambiente
Abra o editor do Cloud Shell no projeto do GCP criado.
Em seguida, crie um terminal > novo terminal e execute os seguintes comandos.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
Ativar APIs
No terminal, execute o seguinte comando.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- API AI Platform (
aiplatform.googleapis.com) — hospedagem do Agent Engine - API BigQuery (
bigquery.googleapis.com) — consultas SQL em conjuntos de dados públicos e privados - API Telemetry (
telemetry.googleapis.com) — traces do OpenTelemetry para observabilidade do agente
Criar um ambiente virtual e instalar o ADK
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
O pacote google-adk inclui a ferramenta de CLI adk que você vai usar para testar e implantar o agente.
3. Criar o agente
Crie um novo diretório de projeto do agente. Todos os comandos subsequentes precisam ser executados nesse diretório de trabalho (o pai de data_science_agent/):
mkdir data_science_agent
Sua estrutura de diretórios final será assim:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
Você vai criar __init__.py e agent.py agora e, em seguida, adicionar requirements.txt e .env na etapa de implantação.
Crie data_science_agent/__init__.py. Esse arquivo é necessário para que o ADK possa descobrir e carregar o agente:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
Crie data_science_agent/agent.py:
Esse agente se conecta ao BigQuery para extração de dados e mantém as sessões no Memory Bank.
A memória é ativada automaticamente quando implantada. A variável de ambiente GOOGLE_CLOUD_AGENT_ENGINE_ID é definida pelo ambiente de execução do Agent Engine e está ausente ao executar localmente.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
Vamos analisar o que esse código faz:
- BigQueryToolset oferece ao agente ferramentas como
execute_sql,list_table_idseget_table_info. Ele pode explorar esquemas e consultar qualquer conjunto de dados a que o autor da chamada tenha acesso. - PreloadMemoryTool recupera automaticamente memórias relevantes antes de cada chamada de LLM, pesquisando o Memory Bank por conteúdo relacionado à mensagem do usuário. O callback
_save_memorymantém a sessão no Memory Bank após cada execução do agente, para que ele possa recuperar o contexto em sessões futuras. - App envolve o agente raiz em um aplicativo implantável que o Agent Engine pode veicular. O
nameprecisa corresponder ao nome do diretório (data_science_agent). Oadk webusa isso para localizar e carregar o agente. - A instrução informa ao agente para usar o projeto de faturamento para consultas SQL e lembrar as preferências do usuário.
4. Implantar no Agent Engine
Crie um arquivo requirements.txt no diretório data_science_agent:
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
google-adkegoogle-genai: o framework do ADK e o cliente do Geminigoogle-auth: autenticação do Google Cloudpython-dotenv: carrega o arquivo.envna inicialização- Os quatro pacotes
opentelemetry-instrumentation-*ativam os recursos de observabilidade que você vai explorar mais tarde. Eles instrumentam solicitações HTTP do FastAPI, chamadas de modelo do Gemini e comunicação gRPC/HTTP interna para que os traces apareçam na guia "Traces" do Agent Engine.
Crie um arquivo .env no diretório data_science_agent para ativar a telemetria no agente implantado:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY: ativa o pipeline do OpenTelemetry no ambiente de execução do Agent Engine.OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT: registra entradas de comandos e respostas de agentes completas, úteis para depuração.
Implante o agente. O último argumento data_science_agent é o diretório que contém o código do agente:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
Sinalização | Finalidade |
| Projeto na nuvem e região do Google Cloud de destino |
| Nome legível mostrado no console do Cloud |
| Ativa o exportador do Cloud Trace para intervalos de agentes |
| Ativa o pipeline de instrumentação do OpenTelemetry |
Quando implantados no Agent Engine, dois recursos são ativados automaticamente:
- Memory Bank:
PreloadMemoryToolse conecta ao Memory Bank do Agent Engine e_save_memorymantém as sessões automaticamente. - Observabilidade: o Cloud Trace captura as etapas de raciocínio, as chamadas de ferramentas e as latências do agente.
5. Conceder permissões do BigQuery
Você precisa conceder acesso do BigQuery à conta de serviço do Agent Engine. Quando implantado, o agente é executado como uma conta de serviço gerenciada pelo Google (não suas credenciais pessoais). Portanto, ele precisa de permissões explícitas para executar consultas SQL.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
Cada comando imprime Updated IAM policy for project [...] quando bem-sucedido.
6. Testar o agente implantado
Abra a página do Agent Engine no console do Google Cloud. Clique no agente implantado para abrir o playground do Agent Engine.
Teste os recursos do BigQuery:
- "List the tables in bigquery-public-data.hacker_news"
- Esperado: o agente chama
list_table_idse retorna nomes de tabelas, incluindofull.
- Esperado: o agente chama
- "Find the number of posts per year in bigquery-public-data.hacker_news.full"
- Esperado: o agente chama
execute_sqlcom uma consulta SQL e retorna uma tabela de anos e contagens de postagens.
- Esperado: o agente chama
- "What was the year-over-year percentage change in posts?"
- Esperado: o agente chama
execute_sqlcom uma consulta SQL que calcula a mudança percentual e retorna os resultados.
- Esperado: o agente chama
7. Testar a persistência da memória
Ainda no playground, ensine uma preferência ao agente:
- "Remember that my favorite dataset is bigquery-public-data.hacker_news"
- "What tables does it have?"
Aguarde alguns segundos para que a memória persista (o callback _save_memory é executado depois que o agente responde).
Agora, inicie uma nova sessão clicando no botão "+ New Session" na barra lateral do playground e pergunte:
- "What is my favorite dataset?"
O agente precisa lembrar bigquery-public-data.hacker_news, mesmo que seja uma sessão totalmente nova sem histórico de conversas. Isso funciona porque:
_save_memorymantém cada sessão no Memory Bank viacallback_context.add_session_to_memory()PreloadMemoryToolrecupera memórias relevantes antes de cada chamada de LLM- O Memory Bank corresponde ao conteúdo semanticamente, não apenas por palavra-chave
8. Conheça a observabilidade
No console do Cloud, navegue até o agente implantado e clique na guia Traces.
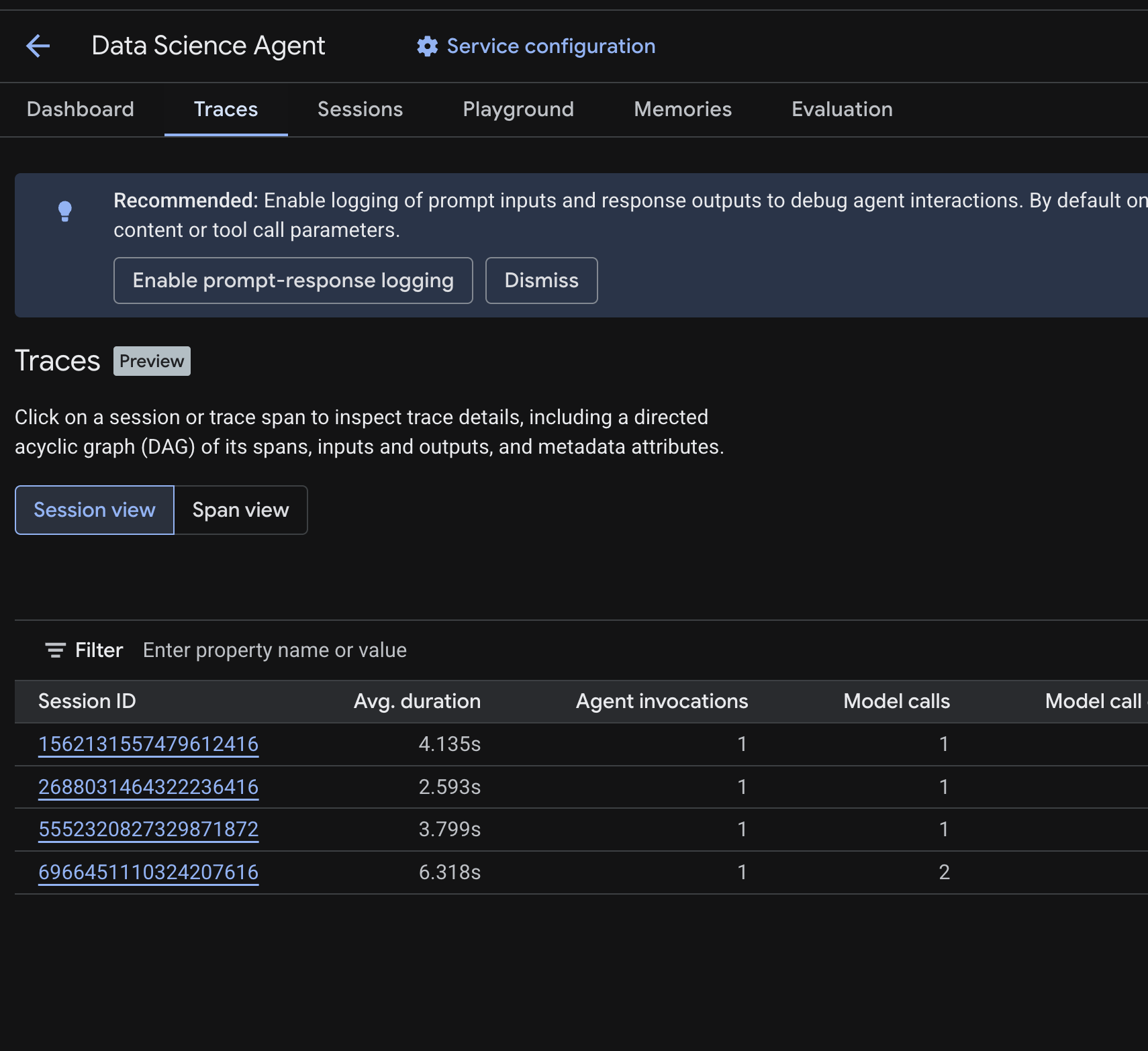
Você vai encontrar uma tabela de sessões listando as sessões das consultas de teste executadas nas etapas anteriores. A tabela mostra métricas de resumo para cada sessão: duração média, chamadas de modelo, chamadas de ferramentas, uso de token e erros.
Clique em uma sessão para inspecionar os detalhes do trace, incluindo:
- Um gráfico acíclico dirigido (DAG) dos intervalos, mostrando a detalhamento das etapas do raciocínio do agente, chamadas de ferramentas (consultas do BigQuery) e latências
- Entradas e saídas para cada intervalo (ativado pela variável de ambiente
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTem.env) - Atributos de metadados, como IDs de período, IDs de trace e tempo
Você também pode alternar para a visualização de intervalo (alternar na parte de cima) para conferir intervalos individuais em todas as sessões.
Como o rastreamento funciona
Ao implantar com --trace_to_cloud e --otel_to_cloud, o ambiente de execução do Agent Engine inicializa um pipeline do OpenTelemetry que:
- Cria um TracerProvider com um exportador OTLP que envia intervalos para
telemetry.googleapis.com - Usa os quatro pacotes de instrumentação do seu
requirements.txtpara capturar intervalos de bibliotecas importantes (FastAPI, Gemini, httpx, gRPC).google-genaié instrumentado explicitamente pelo ambiente de execução, enquanto os outros contribuem pela descoberta automática do OpenTelemetry - Agrupa e exporta intervalos para a API Telemetry, em que a guia "Traces" os lê
A imagem base do Agent Engine fornece o SDK e o exportador do OpenTelemetry, mas não inclui os pacotes de instrumentação. É por isso que seu requirements.txt precisa listar todos os quatro. Sem eles, nenhum intervalo é criado e nenhum trace aparece.
Solução de problemas
Se nenhum trace aparecer após alguns minutos:
- Verifique se a API Telemetry está ativada : você a ativou na etapa de configuração. Verifique com:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - Verifique o Cloud Logging em busca de avisos : acesse Logging > Análise de registros e pesquise
"telemetry enabled but proceeding without". Se você encontrar um aviso sobre a instrumentação do GenAI,opentelemetry-instrumentation-google-genaiestará ausente do seurequirements.txt. - Não adicione
google-cloud-aiplatform[agent-engines]ao seurequirements.txt. A CLI de implantação do ADK a adiciona automaticamente. Declará-la novamente com uma versão diferente pode causar conflitos de pacote do OpenTelemetry e interromper a instrumentação silenciosamente.
9. Limpeza
Para evitar cobranças contínuas, exclua os recursos criados durante este codelab.
Exclua o agente implantado da página do Agent Engine no console do Cloud. Selecione o agente e clique em Excluir.
Se você criou um projeto especificamente para este codelab, poderá excluir o projeto inteiro:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
Opcionalmente, limpe seu ambiente local:
deactivate
rm -rf .venv data_science_agent
10. Parabéns
Você criou um agente de ciência de dados com estado e o implantou no Agent Engine.
O que você aprendeu
- Como criar um agente do ADK com
BigQueryToolsetpara acesso aos dados reais - Como ativar a memória persistente com o Memory Bank usando
PreloadMemoryTooleafter_agent_callback - Como conceder permissões do IAM para a conta de serviço do agente implantado
- Como implantar no Agent Engine e ativar a observabilidade com o Cloud Trace
Próximas etapas
- Consulte seus próprios conjuntos de dados privados do BigQuery concedendo à conta de serviço do Agent Engine acesso aos seus dados
- Adicione a execução de código para executar a análise do Python em um sandbox seguro
- Configure painéis de observabilidade do Cloud Trace para monitorar seu agente em produção
- Publique resultados no Google Workspace usando ferramentas do MCP