
1. Обзор
В этом практическом занятии вы создадите агента для анализа данных, который будет запрашивать реальные данные из общедоступных наборов данных BigQuery и запоминать ваши предпочтения между сессиями. Затем вы развернете его в Agent Engine, полностью управляемом сервисе Google Cloud, который занимается инфраструктурой, масштабированием и управлением сессиями.
Агент использует три основные возможности, которые активируются постепенно:
- Инструментарий BigQuery : Агент исследует схемы и выполняет SQL-запросы к реальным наборам данных BigQuery — это работает как локально, так и при развертывании.
- Банк памяти : После развертывания агент запоминает пользовательские предпочтения и контекст в условиях разъединенных сессий.
- Наблюдаемость : Cloud Trace фиксирует этапы обработки информации агентом, вызовы инструментов и задержки с помощью инструментов OpenTelemetry.
Что вы узнаете
- Как создать агент ADK с помощью
BigQueryToolsetдля доступа к реальным данным - Как настроить банк памяти для обеспечения сохранения данных между сессиями
- Как развернуть агент в Agent Engine с помощью
adk deploy - Как предоставить разрешения IAM для служебной учетной записи развернутого агента
- Как проверить устойчивость и наблюдаемость памяти
Что вам понадобится
- Проект Google Cloud с включенной функцией выставления счетов.
- Google Cloud SDK (
gcloudCLI) - Веб-браузер, например Chrome.
- uv (менеджер пакетов Python)
- Python 3.12+ (устанавливается автоматически программой
uvпри необходимости)
ADK (Agent Development Kit) — это фреймворк от Google для создания агентов искусственного интеллекта. В этом практическом занятии используется ADK для создания агента и его развертывания в Agent Engine.
Этот практический урок предназначен для разработчиков среднего уровня, имеющих некоторое представление о Python и Google Cloud.
Выполнение этого практического задания займет приблизительно 30 минут (включая 5–10 минут на развертывание).
Стоимость ресурсов, созданных в рамках этого практического занятия, должна составлять менее 5 долларов.
2. Настройте свою среду.
Создайте проект в Google Cloud.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud .
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
Установка переменных среды
Откройте редактор Cloud Shell в созданном вами проекте GCP.
Затем создайте терминал > Новый терминал и выполните следующие команды.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
Включить API
В терминале выполните следующую команду.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- API платформы ИИ (
aiplatform.googleapis.com) — хостинг Agent Engine - API BigQuery (
bigquery.googleapis.com) — SQL-запросы к общедоступным и закрытым наборам данных. - API телеметрии (
telemetry.googleapis.com) — трассировка OpenTelemetry для мониторинга агентов.
Создайте виртуальную среду и установите ADK.
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
В пакет google-adk входит инструмент командной строки adk , который вы будете использовать для тестирования и развертывания агента.
3. Создайте агента.
Создайте новый каталог проекта агента. Все последующие команды следует запускать из этого рабочего каталога (родительского каталога data_science_agent/ ):
mkdir data_science_agent
Итоговая структура ваших каталогов будет выглядеть следующим образом:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
Теперь создайте __init__.py и agent.py , а затем добавьте requirements.txt и .env на этапе развертывания.
Создайте файл data_science_agent/__init__.py — он необходим для того, чтобы ADK мог обнаружить и загрузить вашего агента:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
Создайте файл data_science_agent/agent.py :
Этот агент подключается к BigQuery для извлечения данных и сохраняет сессии в Memory Bank.
Память активируется автоматически при развертывании — переменная среды GOOGLE_CLOUD_AGENT_ENGINE_ID устанавливается средой выполнения Agent Engine и отсутствует при локальном запуске.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
Давайте разберем, что делает этот код:
- BigQueryToolset предоставляет агенту такие инструменты, как
execute_sql,list_table_idsиget_table_info— он может исследовать схемы и запрашивать любой набор данных, к которому имеет доступ вызывающая сторона. - PreloadMemoryTool автоматически извлекает соответствующие данные из памяти перед каждым вызовом LLM, выполняя поиск в банке памяти контента, связанного с сообщением пользователя. Функция обратного вызова
_save_memoryсохраняет сессию в банке памяти после каждого запуска агента, чтобы агент мог восстанавливать контекст в будущих сессиях. - Приложение инкапсулирует корневой агент в развертываемое приложение, которое может обслуживать Agent Engine.
nameдолжно совпадать с именем каталога (data_science_agent) —adk webиспользует это для поиска и загрузки агента. - Инструкция предписывает агенту использовать проект выставления счетов для SQL-запросов и запоминать пользовательские настройки.
4. Развертывание в Agent Engine
Создайте файл requirements.txt в каталоге data_science_agent :
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
-
google-adkиgoogle-genai— фреймворк ADK и клиент Gemini -
google-auth— аутентификация Google Cloud -
python-dotenv— загружает файл.envпри запуске. - Четыре пакета
opentelemetry-instrumentation-*обеспечивают функции мониторинга, которые вы изучите позже. Они инструментируют HTTP-запросы FastAPI, вызовы модели Gemini и внутреннюю связь gRPC/HTTP, так что трассировки отображаются на вкладке «Трассировки Agent Engine».
Создайте файл .env в каталоге data_science_agent , чтобы включить телеметрию на развернутом агенте:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
-
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY— активирует конвейер OpenTelemetry в среде выполнения Agent Engine. -
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT— регистрирует полные входные сигналы командной строки и ответы агентов, что полезно для отладки.
Разверните агента. Последний аргумент data_science_agent — это каталог, содержащий код вашего агента:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
Флаг | Цель |
| Целевой проект и регион Google Cloud |
| Удобочитаемое имя, отображаемое в консоли Cloud Console. |
| Включает экспорт трассировки Cloud Trace для трассировок агентов. |
| Включает конвейер обработки данных OpenTelemetry. |
При развертывании в Agent Engine автоматически активируются две возможности:
- Банк памяти :
PreloadMemoryToolподключается к банку памяти Agent Engine, а_save_memoryавтоматически сохраняет сессии. - Наблюдаемость : Cloud Trace фиксирует этапы обработки информации агентом, вызовы инструментов и задержки.
5. Предоставьте BigQuery разрешения.
Необходимо предоставить BigQuery доступ к учетной записи службы Agent Engine. После развертывания агент работает от имени учетной записи службы, управляемой Google (а не от вашего личного имени), поэтому ему требуются явные разрешения для выполнения SQL-запросов.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
Каждая команда при успешном выполнении выводит на экран Updated IAM policy for project [...] .
6. Проверьте развернутого агента.
Откройте страницу Agent Engine в консоли Google Cloud. Щелкните по развернутому агенту, чтобы открыть среду разработки Agent Engine Playground .
Проверьте возможности BigQuery:
- "Перечислите таблицы в bigquery-public-data.hacker_news"
- Ожидается : Агент вызывает
list_table_idsи возвращает имена таблиц, включаяfull.
- Ожидается : Агент вызывает
- "Найдите количество сообщений в год в bigquery-public-data.hacker_news.full"
- Ожидаемый результат : Агент вызывает
execute_sqlс SQL-запросом и возвращает таблицу с годами и количеством публикаций.
- Ожидаемый результат : Агент вызывает
- «Каково процентное изменение количества публикаций по сравнению с прошлым годом?»
- Ожидаемый результат : Агент вызывает
execute_sqlс SQL-запросом, который вычисляет процентное изменение и возвращает результаты.
- Ожидаемый результат : Агент вызывает
7. Проверка устойчивости памяти
Оставаясь на игровой площадке, научите агента одному из предпочтений:
- «Помните, что мой любимый набор данных — это bigquery-public-data.hacker_news»
- Какие столы в нём есть?
Подождите несколько секунд, пока память сохранится (функция обратного вызова _save_memory выполняется после того, как агент ответит).
Теперь начните новую сессию , нажав кнопку «+ Новая сессия» на боковой панели игровой площадки, а затем задайте следующий вопрос:
- «Какой мой любимый набор данных?»
Агент должен вспомнить ссылку bigquery-public-data.hacker_news , даже если это совершенно новая сессия без истории переписки. Это работает, потому что:
-
_save_memoryсохраняет данные каждой сессии в банк памяти черезcallback_context.add_session_to_memory() -
PreloadMemoryToolизвлекает соответствующие данные из памяти перед каждым вызовом LLM. - Memory Bank сопоставляет контент семантически, а не только по ключевым словам.
8. Изучите возможности наблюдения.
В консоли Cloud перейдите к развернутому агенту и нажмите вкладку «Трассировки» .
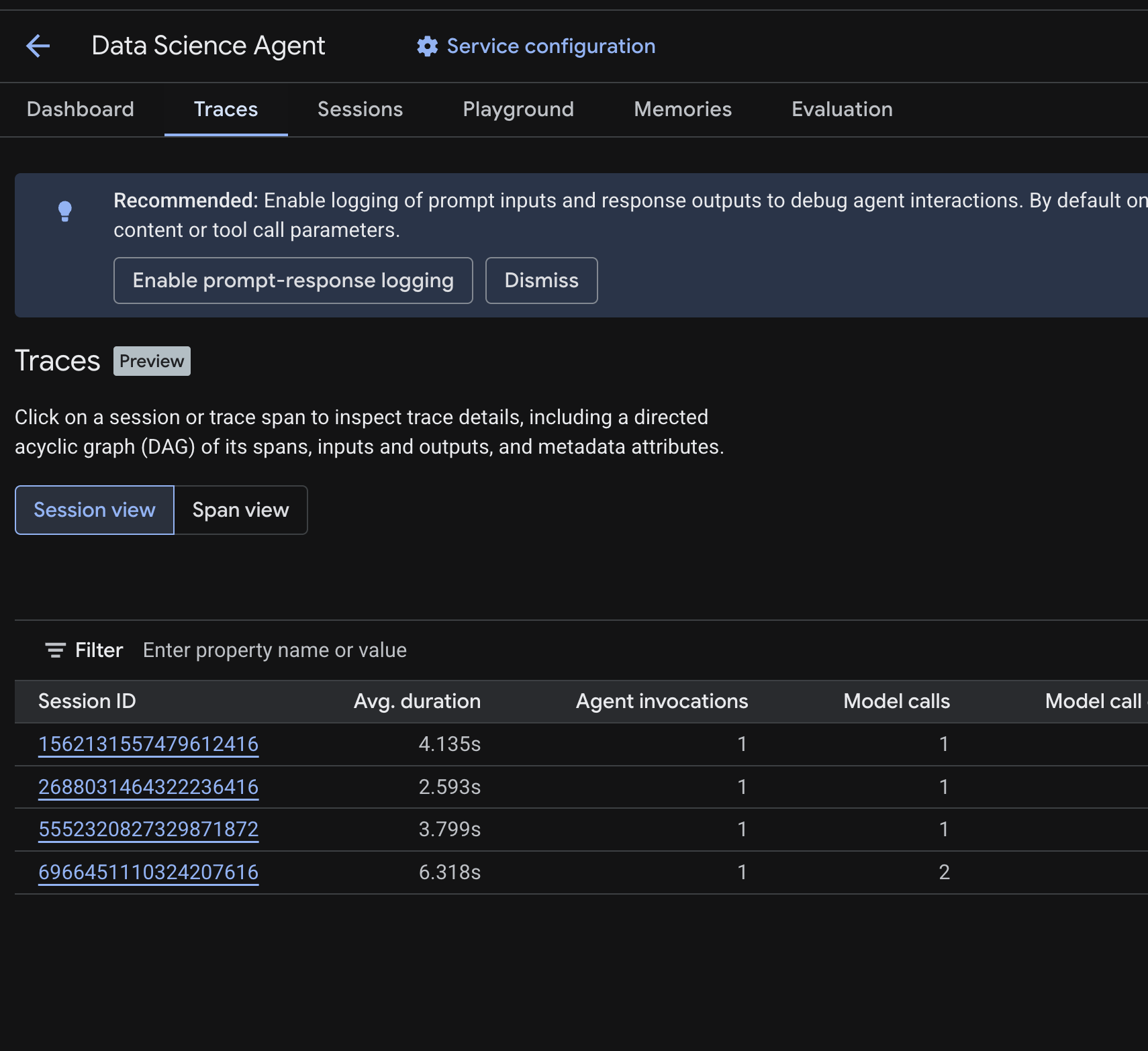
Вы должны увидеть таблицу «Сессии» , содержащую список сессий из тестовых запросов, выполненных на предыдущих шагах. В таблице отображаются сводные метрики для каждой сессии — средняя продолжительность, вызовы модели, вызовы инструментов, использование токенов и любые ошибки.
Щёлкните по сессии , чтобы просмотреть подробные сведения о её трассировке, включая:
- Направленный ациклический граф (DAG) его сегментов — показывающий пошаговое описание рассуждений агента, вызовов инструментов (запросов BigQuery) и задержек.
- Входы и выходы для каждого участка (включаются с помощью переменной окружения
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTв файле.env) - Метаданные, такие как идентификаторы сегментов, идентификаторы трассировки и временные параметры.
Вы также можете переключиться в режим просмотра отдельных фрагментов (переключатель вверху), чтобы увидеть отдельные фрагменты по всем сессиям.
Как работает отслеживание
При развертывании с --trace_to_cloud и --otel_to_cloud среда выполнения Agent Engine инициализирует конвейер OpenTelemetry, который:
- Создает объект TracerProvider с экспортером OTLP, который отправляет данные трассировки на
telemetry.googleapis.com - Использует четыре пакета инструментирования из вашего
requirements.txtдля захвата данных из ключевых библиотек (FastAPI, Gemini, httpx, gRPC) —google-genaiявно инструментируется средой выполнения, в то время как остальные вносят свой вклад через автоматическое обнаружение OpenTelemetry. - Пакетная обработка и экспорт данных осуществляется через API телеметрии, где вкладка «Трассировки» считывает их.
Базовый образ Agent Engine предоставляет SDK и экспортер OpenTelemetry, но не включает пакеты инструментов . Именно поэтому в вашем requirements.txt должны быть указаны все четыре пакета — без них не будут созданы трассировки и не будут отображаться данные трассировки.
Поиск неисправностей
Если через несколько минут следы не появятся:
- Убедитесь, что API телеметрии включен — вы включили его на этапе настройки. Проверьте это с помощью команды:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - Проверьте Cloud Logging на наличие предупреждений — перейдите в Logging > Logs Explorer и найдите
"telemetry enabled but proceeding without". Если вы видите предупреждение об инструментировании GenAI, значит,opentelemetry-instrumentation-google-genaiотсутствует в вашемrequirements.txt. - Не добавляйте
google-cloud-aiplatform[agent-engines]в вашrequirements.txt. CLI развертывания ADK добавляет его автоматически; повторное объявление с другой версией может вызвать конфликты пакетов OpenTelemetry и незаметно нарушить работу инструментария.
9. Уборка
Во избежание дальнейших списаний средств удалите ресурсы, созданные в ходе этого практического занятия.
Удалите развернутый агент со страницы Agent Engine в Cloud Console. Выберите свой агент и нажмите «Удалить» .
Если вы создали проект специально для этого практического занятия, вы можете удалить весь проект целиком:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
При желании, вы можете очистить окружающую среду в вашем регионе:
deactivate
rm -rf .venv data_science_agent
10. Поздравляем!
Вы создали агент для анализа данных с сохранением состояния и развернули его в Agent Engine!
Что вы узнали
- Как создать агент ADK с помощью
BigQueryToolsetдля доступа к реальным данным - Как включить постоянную память с помощью Memory Bank, используя
PreloadMemoryToolиafter_agent_callback - Как предоставить разрешения IAM для служебной учетной записи развернутого агента
- Как развернуть приложение в Agent Engine и включить мониторинг с помощью Cloud Trace
Следующие шаги
- Выполняйте запросы к собственным частным наборам данных BigQuery, предоставив учетной записи службы Agent Engine доступ к вашим данным.
- Добавьте функцию выполнения кода для запуска анализа на Python в защищенной песочнице.
- Настройте панели мониторинга Cloud Trace для отслеживания работы вашего агента в производственной среде.
- Опубликуйте результаты в Google Workspace с помощью инструментов MCP.