
1. ภาพรวม
ใน Codelab นี้ คุณจะได้สร้างเอเจนต์ด้านวิทยาศาสตร์ข้อมูลที่ค้นหาข้อมูลจริงจากชุดข้อมูลสาธารณะของ BigQuery และจดจำค่ากำหนดของคุณในเซสชันต่างๆ จากนั้นคุณจะนำไปใช้งานใน Agent Engine ซึ่งเป็นบริการ Google Cloud ที่มีการจัดการครบวงจรที่ดูแลโครงสร้างพื้นฐาน การปรับขนาด และการจัดการเซสชัน
เอเจนต์ใช้ความสามารถหลัก 3 อย่างที่เปิดใช้งานแบบค่อยเป็นค่อยไป ดังนี้
- ชุดเครื่องมือ BigQuery: เอเจนต์จะสำรวจสคีมาและเรียกใช้การค้นหา SQL กับชุดข้อมูล BigQuery จริง ซึ่งจะทำงานทั้งในเครื่องและเมื่อมีการติดตั้งใช้งาน
- Memory Bank: เมื่อใช้งานแล้ว เอเจนต์จะจดจำค่ากำหนดและบริบทของผู้ใช้ในเซสชันที่ไม่ได้เชื่อมต่อ
- ความสามารถในการสังเกต: Cloud Trace จะบันทึกขั้นตอนการให้เหตุผล การเรียกใช้เครื่องมือ และเวลาในการตอบสนองของ Agent ผ่านการวัดคุม OpenTelemetry
สิ่งที่คุณจะได้เรียนรู้
- วิธีสร้างเอเจนต์ ADK ด้วย
BigQueryToolsetเพื่อเข้าถึงข้อมูลจริง - วิธีกำหนดค่า Memory Bank เพื่อให้ข้อมูลคงอยู่ข้ามเซสชัน
- วิธีทําให้ Agent ใช้งานได้กับ Agent Engine ด้วย
adk deploy - วิธีให้สิทธิ์ IAM สำหรับบัญชีบริการของเอเจนต์ที่ติดตั้งใช้งาน
- วิธีทดสอบการคงอยู่ของหน่วยความจำและความสามารถในการสังเกต
สิ่งที่คุณต้องมี
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- Google Cloud SDK (
gcloudCLI) - เว็บเบราว์เซอร์ เช่น Chrome
- uv (เครื่องมือจัดการแพ็กเกจ Python)
- Python 3.12 ขึ้นไป (
uvจะติดตั้งให้โดยอัตโนมัติหากจำเป็น)
ADK (Agent Development Kit) คือเฟรมเวิร์กของ Google สำหรับการสร้าง AI Agent Codelab นี้ใช้ ADK เพื่อสร้าง Agent และติดตั้งใช้งานใน Agent Engine
Codelab นี้เหมาะสำหรับนักพัฒนาแอปที่มีความรู้ระดับกลางซึ่งคุ้นเคยกับ Python และ Google Cloud บ้าง
Codelab นี้ใช้เวลาประมาณ 30 นาทีจึงจะเสร็จสมบูรณ์ (รวมถึงเวลา 5-10 นาทีสำหรับการติดตั้งใช้งาน)
ทรัพยากรที่สร้างในโค้ดแล็บนี้ควรมีค่าใช้จ่ายน้อยกว่า $5
2. ตั้งค่าสภาพแวดล้อม
สร้างโปรเจ็กต์ Google Cloud
- ในคอนโซล Google Cloud ในหน้าตัวเลือกโปรเจ็กต์ ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
ตั้งค่าตัวแปรสภาพแวดล้อม
เปิด Cloud Shell Editor ในโปรเจ็กต์ GCP ที่คุณสร้างขึ้น
จากนั้นสร้างเทอร์มินัล > เทอร์มินัลใหม่ แล้วเรียกใช้คำสั่งต่อไปนี้
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
เปิดใช้ API
เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- AI Platform API (
aiplatform.googleapis.com) — การโฮสต์ Agent Engine - BigQuery API (
bigquery.googleapis.com) - ข้อความค้นหา SQL กับชุดข้อมูลสาธารณะและส่วนตัว - Telemetry API (
telemetry.googleapis.com) - การติดตาม OpenTelemetry สำหรับการสังเกตการณ์ Agent
สร้างสภาพแวดล้อมเสมือนและติดตั้ง ADK
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
google-adk แพ็กเกจมีเครื่องมือ adk CLI ที่คุณจะใช้เพื่อทดสอบและติดตั้งใช้งานเอเจนต์
3. สร้าง Agent
สร้างไดเรกทอรีโปรเจ็กต์ของ Agent ใหม่ คำสั่งต่อๆ ไปทั้งหมดควรเรียกใช้จากไดเรกทอรีที่ทำงานนี้ (ไดเรกทอรีหลักของ data_science_agent/)
mkdir data_science_agent
โครงสร้างไดเรกทอรีสุดท้ายจะมีลักษณะดังนี้
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
ตอนนี้คุณจะสร้าง __init__.py และ agent.py จากนั้นเพิ่ม requirements.txt และ .env ในขั้นตอนการติดตั้งใช้งาน
สร้าง data_science_agent/__init__.py ซึ่งเป็นไฟล์ที่จำเป็นเพื่อให้ ADK ค้นพบและโหลด Agent ของคุณได้
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
สร้าง data_science_agent/agent.py:
เอเจนต์นี้เชื่อมต่อกับ BigQuery เพื่อการดึงข้อมูลและคงเซสชันไว้ใน Memory Bank
หน่วยความจำจะเปิดใช้งานโดยอัตโนมัติเมื่อมีการติดตั้งใช้งาน โดยรันไทม์ของ Agent Engine จะตั้งค่าตัวแปรสภาพแวดล้อม GOOGLE_CLOUD_AGENT_ENGINE_ID และจะไม่มีเมื่อเรียกใช้ในเครื่อง
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
มาดูกันว่าโค้ดนี้ทำอะไร
- BigQueryToolset ให้เครื่องมือแก่ตัวแทน เช่น
execute_sql,list_table_idsและget_table_infoซึ่งสามารถสำรวจสคีมาและค้นหาชุดข้อมูลใดก็ได้ที่ผู้โทรมีสิทธิ์เข้าถึง - PreloadMemoryTool จะดึงความทรงจำที่เกี่ยวข้องโดยอัตโนมัติก่อนการเรียกใช้ LLM แต่ละครั้งโดยการค้นหาเนื้อหาที่เกี่ยวข้องกับข้อความของผู้ใช้ใน Memory Bank การเรียกกลับ
_save_memoryจะคงเซสชันไว้ใน Memory Bank หลังจากที่ตัวแทนทำงานแต่ละครั้ง เพื่อให้ตัวแทนเรียกคืนบริบทในเซสชันในอนาคตได้ - แอปจะรวมเอเจนต์รูทไว้ในแอปพลิเคชันที่ทำให้ใช้งานได้ซึ่ง Agent Engine สามารถให้บริการได้
nameต้องตรงกับชื่อไดเรกทอรี (data_science_agent) โดยadk webจะใช้ชื่อนี้เพื่อค้นหาและโหลดเอเจนต์ - คำสั่งจะบอกให้ Agent ใช้โปรเจ็กต์การเรียกเก็บเงินสำหรับการค้นหา SQL และจดจำค่ากำหนดของผู้ใช้
4. ทำให้ใช้งานได้กับ Agent Engine
สร้างไฟล์ requirements.txt ในไดเรกทอรี data_science_agent
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
google-adkและgoogle-genaiซึ่งเป็นเฟรมเวิร์ก ADK และไคลเอ็นต์ Geminigoogle-auth— การตรวจสอบสิทธิ์ Google Cloudpython-dotenv— โหลดไฟล์.envเมื่อเริ่มต้นopentelemetry-instrumentation-*แพ็กเกจทั้ง 4 รายการจะเปิดใช้ฟีเจอร์ความสามารถในการสังเกตที่คุณจะสำรวจในภายหลัง โดยจะตรวจสอบคำขอ HTTP ของ FastAPI, การเรียกโมเดล Gemini และการสื่อสาร gRPC/HTTP ภายในเพื่อให้ร่องรอยปรากฏในแท็บร่องรอยของ Agent Engine
สร้างไฟล์ .env ในไดเรกทอรี data_science_agent เพื่อเปิดใช้การวัดและส่งข้อมูลในเอเจนต์ที่ติดตั้งใช้งาน
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY— เปิดใช้งานไปป์ไลน์ OpenTelemetry ในรันไทม์ของ Agent EngineOTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT— บันทึกอินพุตพรอมต์และคำตอบของเอเจนต์ทั้งหมด ซึ่งมีประโยชน์สำหรับการแก้ไขข้อบกพร่อง
ติดตั้งใช้งาน Agent อาร์กิวเมนต์สุดท้าย data_science_agent คือไดเรกทอรีที่มีโค้ดของเอเจนต์
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
ธง | วัตถุประสงค์ |
| โปรเจ็กต์ที่อยู่ในระบบคลาวด์และภูมิภาค Google Cloud เป้าหมาย |
| ชื่อที่ผู้ใช้อ่านได้ซึ่งแสดงใน Cloud Console |
| เปิดใช้เครื่องมือส่งออก Cloud Trace สำหรับช่วงของ Agent |
| เปิดใช้ไปป์ไลน์การวัดและส่งข้อมูลของ OpenTelemetry |
เมื่อติดตั้งใช้งานใน Agent Engine ความสามารถ 2 อย่างจะเปิดใช้งานโดยอัตโนมัติ ได้แก่
- Memory Bank:
PreloadMemoryToolเชื่อมต่อกับ Agent Engine Memory Bank และ_save_memoryคงเซสชันโดยอัตโนมัติ - ความสามารถในการสังเกต: Cloud Trace จะบันทึกขั้นตอนการให้เหตุผล การเรียกใช้เครื่องมือ และเวลาในการตอบสนองของ Agent
5. ให้สิทธิ์เข้าถึง BigQuery
คุณต้องให้สิทธิ์เข้าถึง BigQuery แก่บัญชีบริการของ Agent Engine เมื่อติดตั้งใช้งานแล้ว เอเจนต์จะทำงานเป็นบัญชีบริการที่จัดการโดย Google (ไม่ใช่ข้อมูลเข้าสู่ระบบส่วนตัวของคุณ) จึงต้องมีสิทธิ์ที่ชัดเจนในการเรียกใช้คำค้นหา SQL
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
แต่ละคำสั่งจะพิมพ์ Updated IAM policy for project [...] เมื่อสำเร็จ
6. ทดสอบ Agent ที่ติดตั้งใช้งาน
เปิดหน้า Agent Engine ในคอนโซล Google Cloud คลิกเอเจนต์ที่ติดตั้งใช้งานเพื่อเปิด Agent Engine Playground
ทดสอบความสามารถของ BigQuery โดยทำดังนี้
- "แสดงรายการตารางใน bigquery-public-data.hacker_news"
- คาดการณ์: ตัวแทนเรียกใช้
list_table_idsและแสดงชื่อตาราง รวมถึงfull
- คาดการณ์: ตัวแทนเรียกใช้
- "ค้นหาจำนวนโพสต์ต่อปีใน bigquery-public-data.hacker_news.full"
- คาดการณ์: เอเจนต์เรียกใช้
execute_sqlด้วยการค้นหา SQL และแสดงผลตารางปีและจำนวนโพสต์
- คาดการณ์: เอเจนต์เรียกใช้
- "การเปลี่ยนแปลงของเปอร์เซ็นต์โพสต์เมื่อเทียบกับปีก่อนเป็นเท่าใด"
- คาดการณ์: เอเจนต์เรียกใช้
execute_sqlด้วยการค้นหา SQL ที่คำนวณการเปลี่ยนแปลงเปอร์เซ็นต์และแสดงผลลัพธ์
- คาดการณ์: เอเจนต์เรียกใช้
7. ทดสอบการคงอยู่ของหน่วยความจำ
ขณะที่ยังอยู่ใน Playground ให้สอนความชอบแก่เอเจนต์
- "จำไว้ว่าชุดข้อมูลที่ฉันชอบคือ bigquery-public-data.hacker_news"
- "มีตารางอะไรบ้าง"
รอสักครู่เพื่อให้หน่วยความจำคงอยู่ (_save_memory การเรียกกลับจะทำงานหลังจากที่ตัวแทนตอบกลับ)
ตอนนี้เริ่มเซสชันใหม่โดยคลิกปุ่ม "+ เซสชันใหม่" ในแถบด้านข้างของ Playground แล้วถามว่า
- "ชุดข้อมูลที่ฉันชื่นชอบคืออะไร"
ตัวแทนควรจดจำ bigquery-public-data.hacker_news แม้ว่านี่จะเป็นเซสชันใหม่ที่ไม่มีประวัติการสนทนาก็ตาม ซึ่งได้ผลเนื่องจากเหตุผลต่อไปนี้
_save_memoryจะบันทึกแต่ละเซสชันลงใน Memory Bank ผ่านcallback_context.add_session_to_memory()PreloadMemoryToolจะดึงความทรงจำที่เกี่ยวข้องก่อนการเรียกใช้ LLM แต่ละครั้ง- Memory Bank จะจับคู่เนื้อหาตามความหมาย ไม่ใช่แค่ตามคีย์เวิร์ด
8. สำรวจ Observability
ใน Cloud Console ให้ไปที่เอเจนต์ที่ติดตั้งใช้งาน แล้วคลิกแท็บการติดตาม
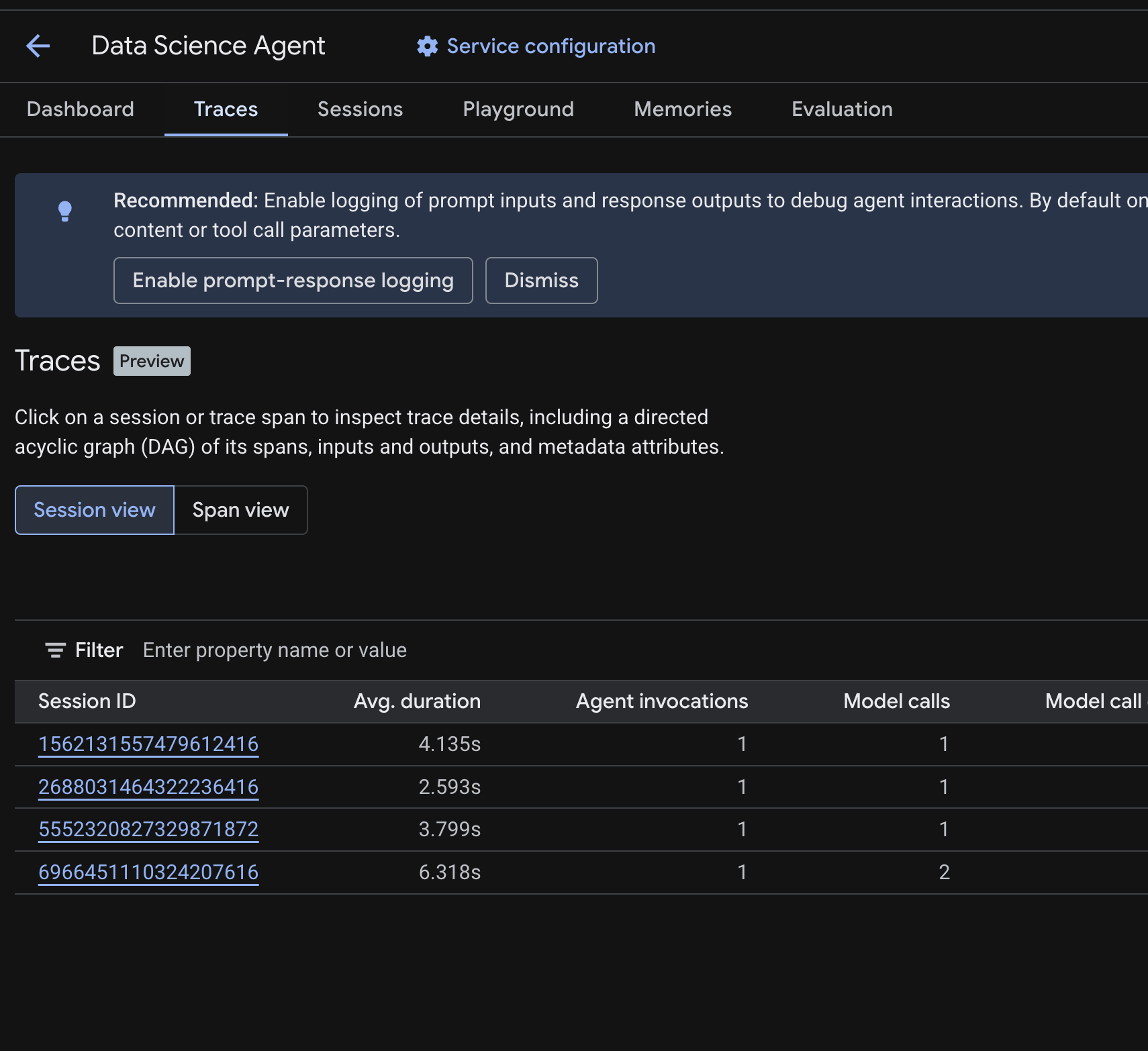
คุณควรเห็นตารางเซสชันที่แสดงเซสชันจากคำค้นหาทดสอบที่คุณเรียกใช้ในขั้นตอนก่อนหน้า ตารางจะแสดงเมตริกสรุปสําหรับแต่ละเซสชัน ได้แก่ ระยะเวลาเฉลี่ย การเรียกโมเดล การเรียกเครื่องมือ การใช้โทเค็น และข้อผิดพลาด
คลิกเซสชันเพื่อตรวจสอบรายละเอียดการติดตาม ซึ่งรวมถึงข้อมูลต่อไปนี้
- กราฟแบบมีทิศทางและไม่มีวงจร (DAG) ของช่วง ซึ่งแสดงรายละเอียดแบบทีละขั้นตอนของการให้เหตุผลของ Agent, การเรียกใช้เครื่องมือ (การค้นหา BigQuery) และเวลาในการตอบสนอง
- อินพุตและเอาต์พุตสำหรับแต่ละช่วง (เปิดใช้ผ่านตัวแปรสภาพแวดล้อม
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTใน.env) - แอตทริบิวต์ข้อมูลเมตา เช่น รหัสช่วง รหัสการติดตาม และเวลา
นอกจากนี้ คุณยังเปลี่ยนไปใช้มุมมองช่วง (สลับที่ด้านบน) เพื่อดูช่วงแต่ละช่วงในทุกเซสชันได้ด้วย
วิธีการทำงานของการติดตาม
เมื่อคุณติดตั้งใช้งานด้วย --trace_to_cloud และ --otel_to_cloud รันไทม์ของ Agent Engine จะเริ่มต้นไปป์ไลน์ OpenTelemetry ซึ่งมีลักษณะดังนี้
- สร้าง TracerProvider ด้วยเครื่องมือส่งออก OTLP ที่ส่งช่วงไปยัง
telemetry.googleapis.com - ใช้แพ็กเกจการวัดคุมทั้ง 4 รายการจาก
requirements.txtเพื่อบันทึก Span จากไลบรารีหลัก (FastAPI, Gemini, httpx, gRPC) โดยgoogle-genaiจะได้รับการวัดคุมอย่างชัดเจนโดยรันไทม์ ส่วนรายการอื่นๆ จะมีส่วนร่วมผ่านการค้นหาอัตโนมัติของ OpenTelemetry - ส่งชุดข้อมูลและช่วงไปยัง Telemetry API ซึ่งแท็บการติดตามจะอ่านข้อมูลเหล่านั้น
อิมเมจพื้นฐานของ Agent Engine มี SDK และเครื่องมือส่งออก OpenTelemetry แต่ไม่มีแพ็กเกจการตรวจสอบ ด้วยเหตุนี้ requirements.txt จึงต้องแสดงทั้ง 4 รายการนี้ หากไม่มีรายการใดรายการหนึ่ง ระบบจะไม่สร้างช่วงและไม่แสดงร่องรอย
การแก้ปัญหา
หากไม่พบร่องรอยใดๆ หลังจากผ่านไป 2-3 นาที ให้ทำดังนี้
- ตรวจสอบว่าได้เปิดใช้ Telemetry API แล้ว - คุณเปิดใช้ในขั้นตอนการตั้งค่า ยืนยันด้วย
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - ตรวจสอบคำเตือนใน Cloud Logging — ไปที่ Logging > Logs Explorer แล้วค้นหา
"telemetry enabled but proceeding without"หากเห็นคำเตือนเกี่ยวกับการวัดคุม GenAI แสดงว่าไม่มีopentelemetry-instrumentation-google-genaiในrequirements.txt - อย่าเพิ่ม
google-cloud-aiplatform[agent-engines]ลงในrequirements.txtCLI การติดตั้งใช้งาน ADK จะเพิ่มโดยอัตโนมัติ การประกาศอีกครั้งด้วยเวอร์ชันอื่นอาจทำให้เกิดความขัดแย้งของแพ็กเกจ OpenTelemetry และทำให้การวัดคุมหยุดทำงานโดยไม่มีการแจ้งเตือน
9. ล้าง
โปรดลบทรัพยากรที่สร้างขึ้นระหว่างการทำ Codelab นี้เพื่อไม่ให้มีการเรียกเก็บเงินอย่างต่อเนื่อง
ลบเอเจนต์ที่ติดตั้งใช้งานจากหน้าเครื่องมือเอเจนต์ใน Cloud Console เลือกเอเจนต์แล้วคลิกลบ
หากสร้างโปรเจ็กต์สำหรับ Codelab นี้โดยเฉพาะ คุณสามารถลบทั้งโปรเจ็กต์แทนได้โดยทำดังนี้
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
(ไม่บังคับ) ล้างข้อมูลในสภาพแวดล้อมภายในด้วยวิธีการต่อไปนี้
deactivate
rm -rf .venv data_science_agent
10. ขอแสดงความยินดี
คุณสร้าง Data Science Agent แบบเก็บสถานะและทำให้ใช้งานได้กับ Agent Engine แล้ว
สิ่งที่คุณได้เรียนรู้
- วิธีสร้างเอเจนต์ ADK ด้วย
BigQueryToolsetเพื่อเข้าถึงข้อมูลจริง - วิธีเปิดใช้หน่วยความจำถาวรด้วย Memory Bank โดยใช้
PreloadMemoryToolและafter_agent_callback - วิธีให้สิทธิ์ IAM สำหรับบัญชีบริการของเอเจนต์ที่ติดตั้งใช้งาน
- วิธีติดตั้งใช้งานใน Agent Engine และเปิดใช้ความสามารถในการสังเกตด้วย Cloud Trace
ขั้นตอนถัดไป
- ค้นหาชุดข้อมูล BigQuery ส่วนตัวของคุณเองโดยให้สิทธิ์เข้าถึงข้อมูลแก่บัญชีบริการ Agent Engine
- เพิ่มการดำเนินการโค้ดเพื่อเรียกใช้การวิเคราะห์ Python ในแซนด์บ็อกซ์ที่ปลอดภัย
- ตั้งค่าแดชบอร์ดการสังเกตการณ์ Cloud Trace เพื่อตรวจสอบเอเจนต์ในเวอร์ชันที่ใช้งานจริง
- เผยแพร่ผลลัพธ์ไปยัง Google Workspace โดยใช้เครื่องมือ MCP