
1. Genel Bakış
Bu codelab'de, BigQuery herkese açık veri kümelerindeki gerçek verileri sorgulayan ve oturumlar arasında tercihlerinizi hatırlayan bir veri bilimi aracısı oluşturacaksınız. Ardından, altyapı, ölçekleme ve oturum yönetimini ele alan, tümüyle yönetilen bir Google Cloud hizmeti olan Agent Engine'e dağıtırsınız.
Aracı, kademeli olarak etkinleştirilen üç temel özelliği kullanır:
- BigQuery Araç Seti: Aracı, şemaları keşfeder ve gerçek BigQuery veri kümelerine karşı SQL sorguları çalıştırır. Bu, hem yerel olarak hem de dağıtıldığında çalışır.
- Hafıza Bankası: Kullanıma sunulduğunda aracı, bağlantısı kesilmiş oturumlarda kullanıcı tercihlerini ve bağlamı hatırlar.
- Gözlemlenebilirlik: Cloud Trace, OpenTelemetry enstrümantasyonu aracılığıyla aracının muhakeme adımlarını, araç çağrılarını ve gecikmelerini yakalar.
Neler öğreneceksiniz?
- Gerçek verilere erişmek için
BigQueryToolsetile ADK ajanı oluşturma - Oturumlar arası kalıcılık için Memory Bank'ı yapılandırma
- Aracınızı
adk deployile Agent Engine'e dağıtma - Dağıtılan aracının hizmet hesabı için IAM izinleri verme
- Bellek kalıcılığı ve gözlemlenebilirliği nasıl test edilir?
İhtiyacınız olanlar
- Faturalandırmanın etkin olduğu bir Google Cloud projesi
- Google Cloud SDK (
gcloudKSA) - Chrome gibi bir web tarayıcısı
- uv (Python paket yöneticisi)
- Python 3.12+ (gerekirse
uvtarafından otomatik olarak yüklenir)
ADK (Agent Development Kit), Google'ın yapay zeka ajanları oluşturmaya yönelik çerçevesidir. Bu codelab, bir ajan oluşturmak ve bunu Agent Engine'e dağıtmak için ADK'yı kullanır.
Bu codelab, Python ve Google Cloud hakkında bilgi sahibi olan orta düzey geliştiriciler içindir.
Bu codelab'in tamamlanması yaklaşık 30 dakika sürer (dağıtım için 5-10 dakika dahil).
Bu kod laboratuvarında oluşturulan kaynakların maliyeti 5 ABD dolarından az olmalıdır.
2. Ortamınızı ayarlama
Google Cloud projesi oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin.
Ortam değişkenlerini ayarlama
Oluşturduğunuz GCP projesinde Cloud Shell Düzenleyici'yi açın.
Ardından Terminal > New Terminal'ı (Terminal > Yeni Terminal) oluşturun ve aşağıdaki komutları çalıştırın.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
API'leri etkinleştir
Terminalde aşağıdaki komutu çalıştırın.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- AI Platform API'si (
aiplatform.googleapis.com) — Agent Engine barındırma - BigQuery API (
bigquery.googleapis.com): Herkese açık ve özel veri kümelerine karşı SQL sorguları - Telemetry API (
telemetry.googleapis.com): Aracı gözlemlenebilirliği için OpenTelemetry izleri
Sanal ortam oluşturma ve ADK'yı yükleme
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
google-adk paketi, temsilciyi test etmek ve dağıtmak için kullanacağınız adk KSA aracını içerir.
3. Aracı oluşturma
Yeni bir aracı projesi dizini oluşturun. Sonraki tüm komutlar bu çalışma dizininden (data_science_agent/ öğesinin üst öğesi) çalıştırılmalıdır:
mkdir data_science_agent
Son dizin yapınız şu şekilde görünür:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
Şimdi __init__.py ve agent.py öğelerini oluşturacak, ardından dağıtım adımında requirements.txt ve .env öğelerini ekleyeceksiniz.
data_science_agent/__init__.py oluşturun. ADK'nın temsilcinizi bulup yükleyebilmesi için bu dosya gereklidir:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
Oluşturma data_science_agent/agent.py:
Bu aracı, veri ayıklama için BigQuery'ye bağlanır ve oturumları Memory Bank'te kalıcı hale getirir.
Bellek, dağıtıldığında otomatik olarak etkinleşir. GOOGLE_CLOUD_AGENT_ENGINE_ID ortam değişkeni, Agent Engine çalışma zamanı tarafından ayarlanır ve yerel olarak çalıştırıldığında mevcut değildir.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
Bu kodun ne yaptığını adım adım inceleyelim:
- BigQueryToolset, aracıya
execute_sql,list_table_idsveget_table_infogibi araçlar sunar. Bu araçlar, şemaları keşfedebilir ve arayanın erişebildiği tüm veri kümelerini sorgulayabilir. - PreloadMemoryTool, Memory Bank'te kullanıcının mesajıyla ilgili içerik arayarak her LLM çağrısından önce ilgili anıları otomatik olarak alır.
_save_memorygeri çağırma işlevi, her temsilci çalıştırmasından sonra oturumu Memory Bank'te kalıcı hale getirir. Böylece temsilci, gelecekteki oturumlarda bağlamı hatırlayabilir. - App, kök aracıyı Agent Engine'in sunabileceği dağıtılabilir bir uygulamaya sarmalar.
name, dizin adıyla (data_science_agent) eşleşmelidir.adk web, aracıyı bulup yüklemek için bunu kullanır. - Talimat, aracıya SQL sorguları için faturalandırma projesini kullanmasını ve kullanıcı tercihlerini hatırlamasını söyler.
4. Agent Engine'e dağıtma
data_science_agent dizininde requirements.txt dosyası oluşturma:
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
google-adkvegoogle-genai: ADK çerçevesi ve Gemini istemcisigoogle-auth— Google Cloud kimlik doğrulamasıpython-dotenv: Başlangıçta.envdosyasını yükler.- Dört
opentelemetry-instrumentation-*paketi, daha sonra keşfedeceğiniz gözlemlenebilirlik özelliklerini etkinleştirir. İzlerin Agent Engine Traces sekmesinde görünmesi için FastAPI HTTP isteklerini, Gemini modeli çağrılarını ve dahili gRPC/HTTP iletişimini izlerler.
Dağıtılan aracıda telemetriyi etkinleştirmek için data_science_agent dizininde bir .env dosyası oluşturun:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY: Temsilci motoru çalışma zamanında OpenTelemetry ardışık düzenini etkinleştirir.OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT: Hata ayıklama için yararlı olan tam istem girişlerini ve aracı yanıtlarını günlüğe kaydeder.
Aracıyı dağıtın. Son bağımsız değişken data_science_agent, aracı kodunuzu içeren dizindir:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
İşaret | Amaç |
| Hedef Google Cloud projesi ve bölgesi |
| Cloud Console'da gösterilen, kullanıcılar tarafından okunabilir ad |
| Aracı kapsamları için Cloud Trace dışa aktarıcısını etkinleştirir. |
| OpenTelemetry enstrümantasyon ardışık düzenini etkinleştirir. |
Agent Engine'e dağıtıldığında iki özellik otomatik olarak etkinleştirilir:
- Memory Bank:
PreloadMemoryTool, Agent Engine Memory Bank'e bağlanır ve_save_memoryoturumları otomatik olarak kalıcı hale getirir. - Gözlemlenebilirlik: Cloud Trace, aracının muhakeme adımlarını, araç çağrılarını ve gecikmelerini yakalar.
5. BigQuery İzinleri Verme
BigQuery'ye Agent Engine hizmet hesabına erişim izni vermeniz gerekir. Dağıtıldığında aracı, Google tarafından yönetilen bir hizmet hesabı olarak (kişisel kimlik bilgileriniz değil) çalışır. Bu nedenle, SQL sorgularını yürütmek için açık izinlere ihtiyacı vardır.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
Her komut başarılı olduğunda Updated IAM policy for project [...] yazdırır.
6. Dağıtılan Ajanı Test Etme
Google Cloud Console'da Agent Engine sayfasını açın. Agent Engine Playground'u açmak için dağıtılan temsilcinizi tıklayın.
BigQuery özelliklerini test edin:
- "bigquery-public-data.hacker_news içindeki tabloları listele"
- Beklenen: Temsilci,
list_table_idsişlevini çağırır vefulldahil olmak üzere tablo adlarını döndürür.
- Beklenen: Temsilci,
- "bigquery-public-data.hacker_news.full içinde yıllık yayın sayısını bul"
- Beklenen: Aracı,
execute_sqlile bir SQL sorgusu çağırır ve yıllar ile yayın sayılarını içeren bir tablo döndürür.
- Beklenen: Aracı,
- "Yayınlardaki yıldan yıla yüzde değişim neydi?"
- Beklenen: Aracı, yüzde değişimi hesaplayan ve sonuçları döndüren bir SQL sorgusuyla
execute_sql'ı çağırır.
- Beklenen: Aracı, yüzde değişimi hesaplayan ve sonuçları döndüren bir SQL sorgusuyla
7. Bellek Kalıcılığını Test Etme
Hâlâ Playground'dayken aracıya bir tercih öğretin:
- "En sevdiğim veri kümesinin bigquery-public-data.hacker_news olduğunu unutma"
- "Hangi tabloları içeriyor?"
Belleğin kalıcı olması için birkaç saniye bekleyin (_save_memory geri çağırma, temsilci yanıt verdikten sonra çalışır).
Şimdi Playground kenar çubuğunda "+ Yeni Oturum" düğmesini tıklayarak yeni bir oturum başlatın ve şu soruyu sorun:
- "En sevdiğim veri kümesi hangisi?"
Ajan, görüşme geçmişi olmayan yepyeni bir oturum olmasına rağmen bigquery-public-data.hacker_news bilgisini hatırlamalı. Bu yöntemin işe yaramasının nedeni:
_save_memory, her oturumucallback_context.add_session_to_memory()aracılığıyla Hafıza Bankası'nda saklar.PreloadMemoryTool, her büyük dil modeli çağrısından önce ilgili anıları alır.- Hafıza Bankası, içeriği yalnızca anahtar kelimeye göre değil, semantik olarak da eşleştirir.
8. Gözlemlenebilirliği keşfedin
Cloud Console'da dağıtılan aracınıza gidin ve İzlemeler sekmesini tıklayın.
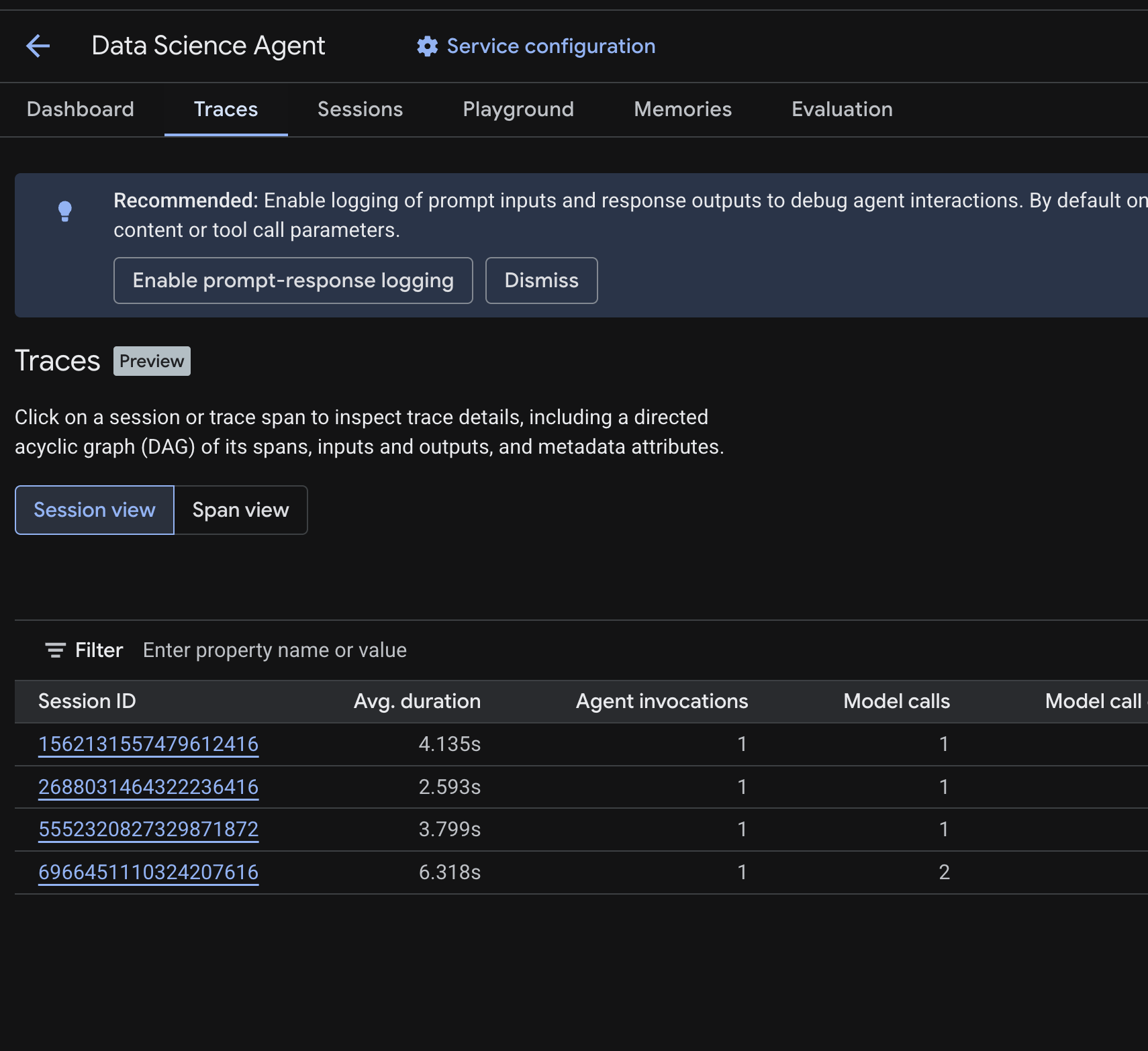
Önceki adımlarda çalıştırdığınız test sorgularından elde edilen oturumların listelendiği bir oturum tablosu görmeniz gerekir. Tabloda her oturumla ilgili özet metrikler (ortalama süre, model çağrıları, araç çağrıları, jeton kullanımı ve hatalar) gösterilir.
İzleme ayrıntılarını (ör. şunlar) incelemek için bir oturumu tıklayın:
- Kapsamlarının yönlendirilmiş döngüsüz grafiği (DAG): Ajanın muhakemesinin, araç çağrılarının (BigQuery sorguları) ve gecikmelerin adım adım dökümünü gösterir.
- Her bir kapsam için girişler ve çıkışlar (
.enviçindeOTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTortam değişkeni aracılığıyla etkinleştirilir) - Kapsam kimlikleri, izleme kimlikleri ve zamanlama gibi meta veri özellikleri
Tüm oturumlardaki tek tek aralıkları görmek için Aralık görünümüne de geçebilirsiniz (en üstteki açma/kapatma düğmesi).
İzleme özelliğinin işleyiş şekli
--trace_to_cloud ve --otel_to_cloud ile dağıtım yaptığınızda Agent Engine çalışma zamanı, aşağıdakileri yapan bir OpenTelemetry işlem hattı başlatır:
- Aralıkları
telemetry.googleapis.comadresine gönderen bir OTLP dışa aktarıcıyla TracerProvider oluşturur. - Önemli kitaplıklardaki (FastAPI, Gemini, httpx, gRPC) kapsamları yakalamak için
requirements.txt'nizdeki dört enstrümantasyon paketini kullanır.google-genai, çalışma zamanı tarafından açıkça enstrümante edilirken diğerleri OpenTelemetry otomatik keşfi aracılığıyla katkıda bulunur. - Span'leri gruplandırır ve Telemetry API'ye aktarır. İzler sekmesi, bu span'leri okur.
Agent Engine temel görüntüsü OpenTelemetry SDK'sını ve dışa aktarıcısını sağlar ancak enstrümantasyon paketlerini içermez. Bu nedenle, requirements.txt öğenizde bu dört öğenin de listelenmesi gerekir. Aksi takdirde, kapsam oluşturulmaz ve izler görünmez.
Sorun giderme
Birkaç dakika sonra iz görünmüyorsa:
- Telemetri API'sinin etkinleştirildiğini kontrol edin. Bu API'yi kurulum adımında etkinleştirmiştiniz. Şununla doğrulayın:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - Uyarılar için Cloud Logging'i kontrol edin: Logging > Logs Explorer'a (Günlük Kaydı > Günlük Gezgini) gidin ve
"telemetry enabled but proceeding without"simgesini arayın. Üretken yapay zeka enstrümantasyonu hakkında bir uyarı görürsenizopentelemetry-instrumentation-google-genai,requirements.txtöğenizde eksik demektir. requirements.txtöğenizegoogle-cloud-aiplatform[agent-engines]requirements.txteklemeyin. ADK deploy CLI, bunu otomatik olarak ekler. Farklı bir sürümle yeniden bildirmek OpenTelemetry paket çakışmalarına neden olabilir ve enstrümantasyonu sessizce bozabilir.
9. Temizleme
Devam eden ücretleri önlemek için bu codelab sırasında oluşturulan kaynakları silin.
Cloud Console'daki Agent Engine sayfasından dağıtılan aracı silin. Temsilcinizi seçin ve Sil'i tıklayın.
Bu codelab için özel olarak bir proje oluşturduysanız bunun yerine projenin tamamını silebilirsiniz:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
İsteğe bağlı olarak yerel ortamınızı temizleyin:
deactivate
rm -rf .venv data_science_agent
10. Tebrikler
Durumlu bir veri bilimi aracısı oluşturup Agent Engine'e dağıttınız.
Öğrendikleriniz
- Gerçek verilere erişmek için
BigQueryToolsetile ADK ajanı oluşturma PreloadMemoryToolveafter_agent_callbackkullanarak Memory Bank ile kalıcı belleği etkinleştirme- Dağıtılan aracının hizmet hesabı için IAM izinleri verme
- Agent Engine'e dağıtma ve Cloud Trace ile gözlemlenebilirliği etkinleştirme
Sonraki adımlar
- Agent Engine hizmet hesabına verilerinize erişim izni vererek kendi özel BigQuery veri kümelerinizi sorgulama
- Güvenli bir korumalı alanda Python analizi çalıştırmak için Code Execution'ı (Kod Yürütme) ekleyin.
- Üretimdeki aracınızı izlemek için Cloud Trace gözlemlenebilirlik kontrol panellerini ayarlama
- MCP araçlarını kullanarak sonuçları Google Workspace'te yayınlama