
1. Tổng quan
Trong lớp học lập trình này, bạn sẽ tạo một tác nhân khoa học dữ liệu truy vấn dữ liệu thực từ các tập dữ liệu công khai của BigQuery và ghi nhớ các lựa chọn ưu tiên của bạn trong các phiên. Sau đó, bạn sẽ triển khai tác nhân này vào Agent Engine, một dịch vụ được quản lý toàn diện của Google Cloud xử lý cơ sở hạ tầng, khả năng mở rộng và quản lý phiên.
Tác nhân này sử dụng 3 chức năng cốt lõi được kích hoạt dần:
- Bộ công cụ BigQuery: Tác nhân khám phá các lược đồ và chạy truy vấn SQL đối với các tập dữ liệu BigQuery thực. Chức năng này hoạt động cả ở cục bộ và khi được triển khai.
- Ngân hàng bộ nhớ: Khi được triển khai, tác nhân sẽ ghi nhớ các lựa chọn ưu tiên và bối cảnh của người dùng trong các phiên bị ngắt kết nối.
- Khả năng quan sát: Cloud Trace ghi lại các bước suy luận, lệnh gọi công cụ và độ trễ của tác nhân thông qua tính năng ghi nhận OpenTelemetry.
Kiến thức bạn sẽ học được
- Cách tạo tác nhân ADK bằng
BigQueryToolsetđể truy cập dữ liệu thực - Cách định cấu hình Ngân hàng bộ nhớ để duy trì dữ liệu giữa các phiên
- Cách triển khai tác nhân vào Agent Engine bằng
adk deploy - Cách cấp quyền IAM cho tài khoản dịch vụ của tác nhân đã triển khai
- Cách kiểm thử khả năng duy trì bộ nhớ và khả năng quan sát
Bạn cần có
- Một dự án trên Google Cloud đã bật tính năng thanh toán
- Google Cloud SDK (
gcloudCLI) - Một trình duyệt web như Chrome
- uv (trình quản lý gói Python)
- Python 3.12 trở lên (tự động cài đặt bằng
uvnếu cần)
ADK (Bộ công cụ phát triển tác nhân) là khung của Google để tạo tác nhân AI. Lớp học lập trình này sử dụng ADK để tạo một tác nhân và triển khai tác nhân đó vào Agent Engine.
Lớp học lập trình này dành cho các nhà phát triển trung cấp đã quen thuộc với Python và Google Cloud.
Lớp học lập trình này mất khoảng 30 phút để hoàn tất (bao gồm 5–10 phút để triển khai).
Các tài nguyên được tạo trong lớp học lập trình này sẽ có chi phí dưới 5 USD.
2. Thiết lập môi trường
Tạo một dự án trên Google Cloud
- Trong Google Cloud Console, trên trang bộ chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo rằng bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không.
Đặt các biến môi trường
Mở Trình chỉnh sửa Cloud Shell trong dự án GCP mà bạn đã tạo.
Sau đó, hãy tạo một Cửa sổ dòng lệnh > Cửa sổ dòng lệnh mới rồi chạy các lệnh sau.
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
Bật API
Trong cửa sổ dòng lệnh, hãy chạy lệnh sau.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- AI Platform API (
aiplatform.googleapis.com) — Dịch vụ lưu trữ Agent Engine - BigQuery API (
bigquery.googleapis.com) — Truy vấn SQL đối với các tập dữ liệu công khai và riêng tư - Telemetry API (
telemetry.googleapis.com) — Dấu vết OpenTelemetry để quan sát tác nhân
Tạo môi trường ảo và cài đặt ADK
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
Gói google-adk bao gồm công cụ CLI adk mà bạn sẽ dùng để kiểm thử và triển khai tác nhân.
3. Tạo tác nhân
Tạo một thư mục dự án tác nhân mới. Tất cả các lệnh tiếp theo phải được chạy từ thư mục làm việc này (thư mục mẹ của data_science_agent/):
mkdir data_science_agent
Cấu trúc thư mục cuối cùng sẽ có dạng như sau:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
Bây giờ, bạn sẽ tạo __init__.py và agent.py, sau đó thêm requirements.txt và .env trong bước Triển khai.
Tạo data_science_agent/__init__.py — tệp này là bắt buộc để ADK có thể phát hiện và tải tác nhân của bạn:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
Tạo data_science_agent/agent.py:
Tác nhân này kết nối với BigQuery để trích xuất dữ liệu và duy trì các phiên vào Ngân hàng bộ nhớ.
Bộ nhớ tự động kích hoạt khi được triển khai — biến môi trường GOOGLE_CLOUD_AGENT_ENGINE_ID được đặt bởi thời gian chạy Agent Engine và không có khi chạy cục bộ.
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
Hãy cùng xem qua chức năng của mã này:
- BigQueryToolset cung cấp cho tác nhân các công cụ như
execute_sql,list_table_idsvàget_table_info. Công cụ này có thể khám phá các lược đồ và truy vấn bất kỳ tập dữ liệu nào mà trình gọi có quyền truy cập. - PreloadMemoryTool tự động truy xuất các bộ nhớ có liên quan trước mỗi lệnh gọi LLM bằng cách tìm kiếm trong Ngân hàng bộ nhớ nội dung liên quan đến thông báo của người dùng. Lệnh gọi lại
_save_memoryduy trì phiên vào Ngân hàng bộ nhớ sau mỗi lần tác nhân chạy, nhờ đó, tác nhân có thể nhớ lại bối cảnh trong các phiên sau này. - Ứng dụng bao bọc tác nhân gốc thành một ứng dụng có thể triển khai mà Agent Engine có thể phân phát.
namephải khớp với tên thư mục (data_science_agent) —adk websử dụng tên này để xác định vị trí và tải tác nhân. - Lệnh yêu cầu tác nhân sử dụng dự án thanh toán cho các truy vấn SQL và ghi nhớ các lựa chọn ưu tiên của người dùng.
4. Triển khai vào Agent Engine
Tạo một tệp requirements.txt trong thư mục data_science_agent:
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
google-adkvàgoogle-genai— khung ADK và ứng dụng Geminigoogle-auth— Xác thực Google Cloudpython-dotenv— tải tệp.envkhi khởi động- 4 gói
opentelemetry-instrumentation-*cho phép các tính năng quan sát mà bạn sẽ khám phá sau này. Các gói này ghi nhận các yêu cầu HTTP FastAPI, lệnh gọi mô hình Gemini và giao tiếp gRPC/HTTP nội bộ để dấu vết xuất hiện trong thẻ Dấu vết của Agent Engine.
Tạo một tệp .env trong thư mục data_science_agent để bật tính năng đo từ xa trên tác nhân đã triển khai:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY— kích hoạt quy trình OpenTelemetry trong thời gian chạy Agent Engine.OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT— ghi lại toàn bộ nội dung đầu vào của lời nhắc và phản hồi của tác nhân, hữu ích cho việc gỡ lỗi.
Triển khai tác nhân. Đối số cuối cùng data_science_agent là thư mục chứa mã tác nhân của bạn:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
Cờ | Mục đích |
| Dự án trên đám mây và khu vực mục tiêu của Google Cloud |
| Tên dễ đọc hiển thị trong Cloud Console |
| Bật trình xuất Cloud Trace cho các khoảng thời gian của tác nhân |
| Bật quy trình ghi nhận OpenTelemetry |
Khi được triển khai vào Agent Engine, 2 chức năng sẽ tự động kích hoạt:
- Ngân hàng bộ nhớ:
PreloadMemoryToolkết nối với Ngân hàng bộ nhớ của Agent Engine và_save_memorytự động duy trì các phiên. - Khả năng quan sát: Cloud Trace ghi lại các bước suy luận, lệnh gọi công cụ và độ trễ của tác nhân.
5. Cấp quyền BigQuery
Bạn cần cấp quyền truy cập BigQuery cho tài khoản dịch vụ Agent Engine. Khi được triển khai, tác nhân sẽ chạy dưới dạng tài khoản dịch vụ do Google quản lý (không phải thông tin đăng nhập cá nhân của bạn), vì vậy, tác nhân cần có quyền rõ ràng để thực thi các truy vấn SQL.
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
Mỗi lệnh sẽ in Updated IAM policy for project [...] khi thành công.
6. Kiểm thử tác nhân đã triển khai
Mở trang Agent Engine trong Google Cloud Console. Nhấp vào tác nhân đã triển khai để mở Sân chơi Agent Engine.
Kiểm thử các chức năng của BigQuery:
- "List the tables in bigquery-public-data.hacker_news"
- Dự kiến: Tác nhân gọi
list_table_idsvà trả về tên bảng, bao gồmfull.
- Dự kiến: Tác nhân gọi
- "Find the number of posts per year in bigquery-public-data.hacker_news.full"
- Dự kiến: Tác nhân gọi
execute_sqlbằng một truy vấn SQL và trả về một bảng gồm các năm và số lượng bài đăng.
- Dự kiến: Tác nhân gọi
- "What was the year-over-year percentage change in posts?"
- Dự kiến: Tác nhân gọi
execute_sqlbằng một truy vấn SQL tính toán tỷ lệ phần trăm thay đổi và trả về kết quả.
- Dự kiến: Tác nhân gọi
7. Kiểm thử khả năng duy trì bộ nhớ
Vẫn ở trong Sân chơi, hãy dạy tác nhân một lựa chọn ưu tiên:
- "Remember that my favorite dataset is bigquery-public-data.hacker_news"
- "What tables does it have?"
Đợi vài giây để bộ nhớ duy trì (lệnh gọi lại _save_memory chạy sau khi tác nhân phản hồi).
Bây giờ, hãy bắt đầu một phiên mới bằng cách nhấp vào nút "+ Phiên mới" trong thanh bên Sân chơi, sau đó hỏi:
- "What is my favorite dataset?"
Tác nhân sẽ nhớ lại bigquery-public-data.hacker_news mặc dù đây là một phiên hoàn toàn mới và không có nhật ký trò chuyện. Điều này hoạt động vì:
_save_memoryduy trì mỗi phiên vào Ngân hàng bộ nhớ thông quacallback_context.add_session_to_memory()PreloadMemoryTooltruy xuất các bộ nhớ có liên quan trước mỗi lệnh gọi LLM- Ngân hàng bộ nhớ so khớp nội dung theo ngữ nghĩa, không chỉ theo từ khoá
8. Khám phá khả năng quan sát
Trong Cloud Console, hãy chuyển đến tác nhân đã triển khai rồi nhấp vào thẻ Dấu vết.
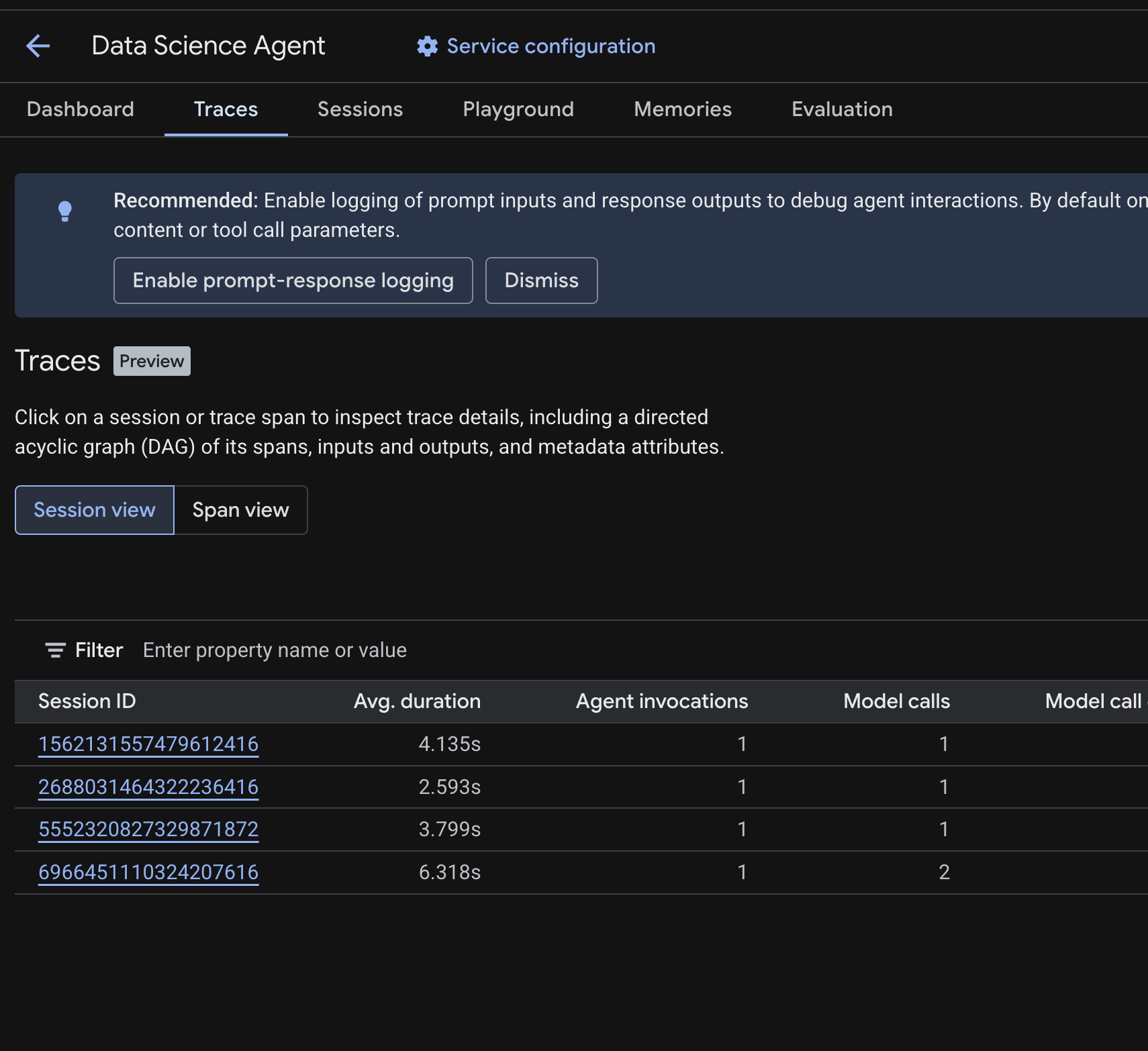
Bạn sẽ thấy một Bảng phiên liệt kê các phiên từ các truy vấn kiểm thử mà bạn đã chạy trong các bước trước. Bảng này hiển thị các chỉ số tóm tắt cho mỗi phiên — thời lượng trung bình, lệnh gọi mô hình, lệnh gọi công cụ, mức sử dụng mã thông báo và mọi lỗi.
Nhấp vào một phiên để kiểm tra thông tin chi tiết về dấu vết của phiên đó, bao gồm:
- Biểu đồ có hướng không có chu trình (DAG) của các khoảng thời gian — cho thấy sự phân tích từng bước về suy luận của tác nhân, lệnh gọi công cụ (truy vấn BigQuery) và độ trễ
- Nội dung đầu vào và đầu ra cho mỗi khoảng thời gian (được bật thông qua biến môi trường
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTtrong.env) - Thuộc tính siêu dữ liệu như mã khoảng thời gian, mã dấu vết và thời gian
Bạn cũng có thể chuyển sang Chế độ xem khoảng thời gian (chuyển đổi ở trên cùng) để xem các khoảng thời gian riêng lẻ trên tất cả các phiên.
Cách hoạt động của tính năng theo dõi
Khi bạn triển khai bằng --trace_to_cloud và --otel_to_cloud, thời gian chạy Agent Engine sẽ khởi chạy một quy trình OpenTelemetry:
- Tạo một TracerProvider bằng trình xuất OTLP gửi các khoảng thời gian đến
telemetry.googleapis.com - Sử dụng 4 gói ghi nhận từ
requirements.txtđể ghi lại các khoảng thời gian từ các thư viện chính (FastAPI, Gemini, httpx, gRPC) —google-genaiđược thời gian chạy ghi nhận một cách rõ ràng, trong khi các thư viện khác đóng góp thông qua tính năng tự động phát hiện OpenTelemetry - Gộp hàng loạt và xuất các khoảng thời gian sang Telemetry API, nơi thẻ Dấu vết đọc các khoảng thời gian đó
Hình ảnh cơ sở của Agent Engine cung cấp SDK và trình xuất OpenTelemetry, nhưng không bao gồm các gói khả năng đo lường. Đây là lý do requirements.txt phải liệt kê cả 4 gói — nếu không có các gói này, sẽ không có khoảng thời gian nào được tạo và không có dấu vết nào xuất hiện.
Khắc phục sự cố
Nếu không có dấu vết nào xuất hiện sau vài phút:
- Kiểm tra để đảm bảo Telemetry API đã được bật — bạn đã bật API này trong bước thiết lập. Xác minh bằng:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - Kiểm tra Cloud Logging để tìm cảnh báo — chuyển đến Logging > Logs Explorer (Ghi nhật ký > Trình khám phá nhật ký) rồi tìm kiếm
"telemetry enabled but proceeding without". Nếu bạn thấy cảnh báo về tính năng ghi nhận GenAI, thìopentelemetry-instrumentation-google-genaibị thiếu trongrequirements.txt. - Không thêm
google-cloud-aiplatform[agent-engines]vàorequirements.txt. CLI triển khai ADK sẽ tự động thêm phần phụ thuộc này; việc khai báo lại phần phụ thuộc này bằng một phiên bản khác có thể gây ra xung đột gói OpenTelemetry và khiến tính năng đo lường bị lỗi một cách âm thầm.
9. Dọn dẹp
Để tránh bị tính phí liên tục, hãy xoá các tài nguyên được tạo trong lớp học lập trình này.
Xoá tác nhân đã triển khai khỏi trang Agent Engine trong Cloud Console. Chọn tác nhân của bạn rồi nhấp vào Xoá.
Nếu bạn đã tạo một dự án dành riêng cho lớp học lập trình này, thì bạn có thể xoá toàn bộ dự án:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
Bạn có thể dọn dẹp môi trường cục bộ (không bắt buộc):
deactivate
rm -rf .venv data_science_agent
10. Xin chúc mừng
Bạn đã tạo một tác nhân khoa học dữ liệu có trạng thái và triển khai tác nhân đó vào Agent Engine!
Kiến thức bạn học được
- Cách tạo tác nhân ADK bằng
BigQueryToolsetđể truy cập dữ liệu thực - Cách bật bộ nhớ liên tục bằng Ngân hàng bộ nhớ bằng
PreloadMemoryToolvàafter_agent_callback - Cách cấp quyền IAM cho tài khoản dịch vụ của tác nhân đã triển khai
- Cách triển khai vào Agent Engine và bật khả năng quan sát bằng Cloud Trace
Các bước tiếp theo
- Truy vấn các tập dữ liệu BigQuery riêng tư của riêng bạn bằng cách cấp quyền truy cập cho tài khoản dịch vụ Agent Engine vào dữ liệu của bạn
- Thêm Thực thi mã để chạy phân tích Python trong một hộp cát an toàn
- Thiết lập trang tổng quan về khả năng ghi nhận Cloud Trace để giám sát tác nhân của bạn trong môi trường sản xuất
- Phát hành kết quả lên Google Workspace bằng các công cụ MCP