
1. 概览
在此 Codelab 中,您将构建一个数据科学智能体,该智能体可查询 BigQuery 公共数据集中的真实数据,并跨会话记住您的偏好设置。然后,您将智能体部署到 Agent Engine,这是一项全托管式 Google Cloud 服务,可处理基础架构、扩缩和会话管理。
该智能体使用三种核心功能,这些功能会逐步激活:
- BigQuery 工具集:智能体探索架构并针对真实的 BigQuery 数据集运行 SQL 查询,这在本地和部署时都有效。
- 记忆库:部署后,智能体会在断开连接的会话中记住用户偏好设置和上下文。
- 可观测性:Cloud Trace 通过 OpenTelemetry 插桩捕获智能体的推理步骤、工具调用和延迟时间。
学习内容
- 如何使用
BigQueryToolset创建 ADK 智能体以访问真实数据 - 如何配置记忆库以实现跨会话持久性
- 如何使用
adk deploy将智能体部署到 Agent Engine - 如何为已部署智能体的服务账号授予 IAM 权限
- 如何测试内存持久性和可观测性
所需条件
- 启用了结算功能的 Google Cloud 项目
- Google Cloud SDK (
gcloudCLI) - 网络浏览器,例如 Chrome
- uv(Python 软件包管理器)
- Python 3.12+(如果需要,由
uv自动安装)
ADK(智能体开发套件)是 Google 用于构建 AI 智能体的框架。此 Codelab 使用 ADK 创建智能体并将其部署到 Agent Engine。
此 Codelab 适用于对 Python 和 Google Cloud 有一定了解的中级开发者。
完成此 Codelab 大约需要 30 分钟(包括 5-10 分钟的部署时间)。
在此 Codelab 中创建的资源费用应低于 5 美元。
2. 设置您的环境
创建 Google Cloud 项目
- 在 Google Cloud 控制台 的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的云项目已启用结算功能。了解如何检查项目是否已启用结算功能。
设置环境变量
在您创建的 GCP 项目中打开 Cloud Shell 编辑器。
然后,依次选择“终端”>“新建终端”,并运行以下命令。
export GOOGLE_CLOUD_PROJECT=<INSERT_YOUR_GCP_PROJECT_HERE>
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
启用 API
在终端中,运行以下命令。
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
telemetry.googleapis.com \
--project=$GOOGLE_CLOUD_PROJECT
- AI Platform API (
aiplatform.googleapis.com) - Agent Engine 托管 - BigQuery API (
bigquery.googleapis.com) - 针对公共和私有数据集的 SQL 查询 - Telemetry API (
telemetry.googleapis.com) - 用于智能体可观测性的 OpenTelemetry 跟踪记录
创建虚拟环境并安装 ADK
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install google-adk google-auth
google-adk 软件包包含 adk CLI 工具,您将使用该工具测试和部署智能体。
3. 创建智能体
创建一个新的智能体项目目录。所有后续命令都应从此工作目录(data_science_agent/ 的父级)运行:
mkdir data_science_agent
最终目录结构将如下所示:
./
data_science_agent/
__init__.py
agent.py
requirements.txt # created in the Deploy step
.env # created in the Deploy step
您现在将创建 __init__.py 和 agent.py,然后在部署步骤中添加 requirements.txt 和 .env。
创建 data_science_agent/__init__.py - 需要此文件,以便 ADK 可以发现并加载您的智能体:
from . import agent # noqa: F401 — required by `adk eval` and `adk web`
创建 data_science_agent/agent.py:
此智能体连接到 BigQuery 以进行数据提取,并将会话保留到记忆库。
部署后,记忆会自动激活 - GOOGLE_CLOUD_AGENT_ENGINE_ID 环境变量由 Agent Engine 运行时设置,在本地运行时不存在。
from __future__ import annotations
import os
from google.adk.agents import LlmAgent
from google.adk.agents.callback_context import CallbackContext
from google.adk.apps import App
from google.adk.tools.bigquery import BigQueryCredentialsConfig
from google.adk.tools.bigquery import BigQueryToolset
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
import google.auth
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
if not PROJECT_ID:
raise ValueError(
"GOOGLE_CLOUD_PROJECT environment variable is required. "
"Set it with: export GOOGLE_CLOUD_PROJECT=<your-project-id>"
)
credentials, _ = google.auth.default()
bq_toolset = BigQueryToolset(credentials_config=BigQueryCredentialsConfig(credentials=credentials))
# GOOGLE_CLOUD_AGENT_ENGINE_ID is set automatically by the Agent Engine runtime.
agent_engine_id = os.getenv("GOOGLE_CLOUD_AGENT_ENGINE_ID")
async def _save_memory(callback_context: CallbackContext) -> None:
"""Persist the session to Memory Bank after each agent run.
Only activates on Agent Engine where Memory Bank is available.
"""
if agent_engine_id:
await callback_context.add_session_to_memory()
root_agent = LlmAgent(
name="data_science_agent",
model="gemini-2.5-pro",
instruction=(
"You are an expert Data Science Agent. "
"Your goal is to query enterprise BigQuery datasets, analyze the data, "
"and summarize your findings. "
f"When executing SQL queries, use project_id `{PROJECT_ID}` as the "
"billing project unless the user specifies a different one. "
"Present results clearly with formatted numbers. "
"Remember user preferences like preferred regions, date ranges, "
"or analysis formats across conversations."
),
tools=[bq_toolset, PreloadMemoryTool()],
after_agent_callback=_save_memory,
)
app = App(
name="data_science_agent",
root_agent=root_agent,
)
我们来了解一下此代码的作用:
- BigQueryToolset 为智能体提供
execute_sql、list_table_ids和get_table_info等工具 - 它可以探索架构并查询调用方有权访问的任何数据集。 - PreloadMemoryTool 会在每次 LLM 调用之前自动检索相关记忆,方法是在记忆库中搜索与用户消息相关的内容。
_save_memory回调会在每次智能体运行后将会话保留到记忆库,以便智能体可以在以后的会话中回忆起上下文。 - App 将根智能体封装到 Agent Engine 可以提供服务的可部署应用中。
name必须与目录名称 (data_science_agent) 匹配 -adk web使用此名称来查找和加载智能体。 - 指令 会告知智能体使用结算项目进行 SQL 查询,并记住用户偏好设置。
4. 部署到 Agent Engine
在 data_science_agent 目录中创建一个 requirements.txt 文件:
google-adk>=1.26.0
google-genai>=1.27.0
google-auth>=2.0.0
python-dotenv>=1.1.0
opentelemetry-instrumentation-fastapi
opentelemetry-instrumentation-google-genai
opentelemetry-instrumentation-httpx
opentelemetry-instrumentation-grpc
google-adk和google-genai- ADK 框架和 Gemini 客户端google-auth- Google Cloud 身份验证python-dotenv- 在启动时加载.env文件- 这四个
opentelemetry-instrumentation-*软件包启用了您稍后将探索的可观测性功能。它们对 FastAPI HTTP 请求、Gemini 模型调用和内部 gRPC/HTTP 通信进行插桩,以便跟踪记录显示在 Agent Engine 的“跟踪记录”标签页中。
在 data_science_agent 目录中创建一个 .env 文件,以在已部署的智能体上启用遥测:
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY=true
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY- 在 Agent Engine 运行时中激活 OpenTelemetry 流水线。OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT- 记录完整的提示输入和智能体回答,有助于调试。
部署智能体。最后一个实参 data_science_agent 是包含智能体代码的目录:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Data Science Agent" \
--trace_to_cloud \
--otel_to_cloud \
data_science_agent
标志 | 用途 |
| 目标 Google Cloud 项目和区域 |
| 在 Cloud 控制台中显示的人类可读名称 |
| 为智能体 span 启用 Cloud Trace 导出器 |
| 启用 OpenTelemetry 插桩流水线 |
部署到 Agent Engine 后,系统会自动激活两项功能:
- 记忆库:
PreloadMemoryTool连接到 Agent Engine 记忆库,_save_memory会自动保留会话。 - 可观测性:Cloud Trace 捕获智能体的推理步骤、工具调用和延迟时间。
5. 授予 BigQuery 权限
您需要授予 BigQuery 对 Agent Engine 服务账号的访问权限。部署后,智能体将作为 Google 管理的服务账号(而不是您的个人凭据)运行,因此需要明确的权限才能执行 SQL 查询。
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format='value(projectNumber)')
SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Required to execute SQL queries
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.jobUser"
# Required to read table metadata and data
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SA}" \
--role="roles/bigquery.dataViewer"
每个命令成功后都会打印 Updated IAM policy for project [...]。
6. 测试已部署的智能体
在 Google Cloud 控制台中打开 Agent Engine 页面。点击已部署的智能体以打开 Agent Engine Playground 。
测试 BigQuery 功能:
- “列出 bigquery-public-data.hacker_news 中的表”
- 预期:智能体调用
list_table_ids并返回表名称,包括full。
- 预期:智能体调用
- “查找 bigquery-public-data.hacker_news.full 中每年的帖子数”
- 预期:智能体使用 SQL 查询调用
execute_sql,并返回一个包含年份和帖子数的表。
- 预期:智能体使用 SQL 查询调用
- “帖子数量的同比百分比变化是多少?”
- 预期:智能体使用计算百分比变化的 SQL 查询调用
execute_sql,并返回结果。
- 预期:智能体使用计算百分比变化的 SQL 查询调用
7. 测试内存持久性
仍在 Playground 中,向智能体传授偏好设置:
- “记住我最喜欢的数据集是 bigquery-public-data.hacker_news”
- “它有哪些表?”
等待几秒钟,让记忆持久保留(_save_memory 回调在智能体响应后运行)。
现在,点击 Playground 边栏中的 "+ 新会话" 按钮开始新会话 ,然后询问:
- “我最喜欢的数据集是什么?”
智能体应回忆起 bigquery-public-data.hacker_news,即使这是一个全新的会话,没有任何对话历史记录。这是因为:
_save_memory通过callback_context.add_session_to_memory()将每个会话保留到记忆库PreloadMemoryTool会在每次 LLM 调用之前检索相关记忆- 记忆库按语义匹配内容,而不仅仅是按关键字匹配
8. 探索可观测性
在 Cloud 控制台中,前往已部署的智能体,然后点击跟踪记录 标签页。
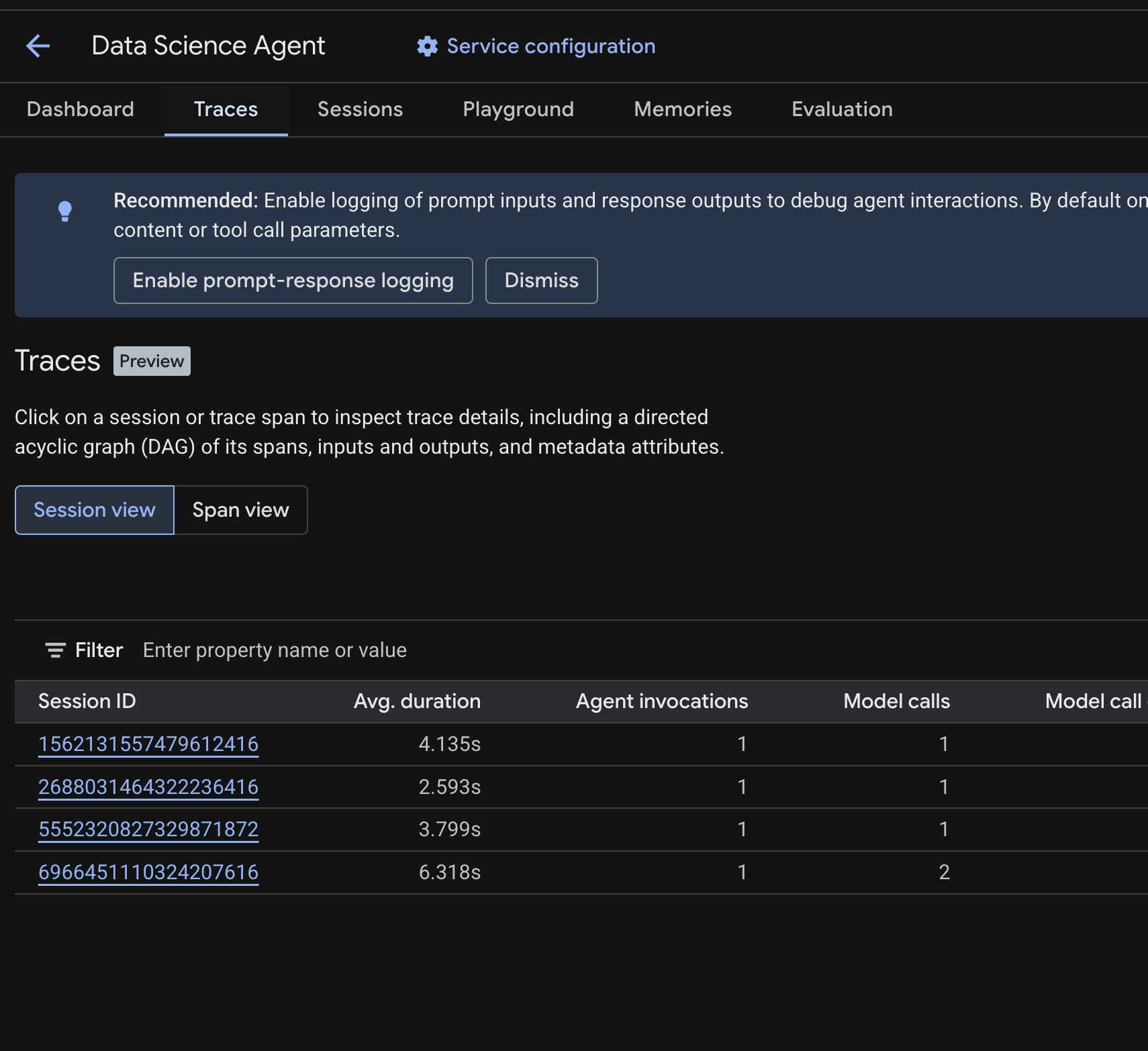
您应该会看到一个会话表 ,其中列出了您在之前的步骤中运行的测试查询的会话。该表显示了每个会话的摘要指标 - 平均时长、模型调用、工具调用、token 使用情况以及任何错误。
点击会话 以检查其跟踪记录详细信息,包括:
- 其 span 的有向无环图 (DAG) - 显示智能体推理、工具调用(BigQuery 查询)和延迟时间的逐步细分
- 每个 span 的输入和输出 (通过
.env中的OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT环境变量启用) - 元数据属性 ,例如 span ID、跟踪记录 ID 和时间
您还可以切换到span 视图 (顶部切换开关),以查看所有会话中的各个 span。
跟踪的工作原理
当您使用 --trace_to_cloud 和 --otel_to_cloud 进行部署时,Agent Engine 运行时会初始化 OpenTelemetry 流水线,该流水线会:
- 使用 OTLP 导出器创建 TracerProvider,该导出器会将 span 发送到
telemetry.googleapis.com - 使用
requirements.txt中的四个插桩软件包 从关键库(FastAPI、Gemini、httpx、gRPC)捕获 span -google-genai由运行时显式插桩,而其他库则通过 OpenTelemetry 自动发现贡献 span - 将 span 批量处理并导出到 Telemetry API,其中“跟踪记录”标签页会读取这些 span
Agent Engine 基础映像提供 OpenTelemetry SDK 和导出器,但不包含插桩软件包 。这就是为什么您的 requirements.txt 必须列出所有四个软件包 - 如果没有这些软件包,则不会创建任何 span,也不会显示任何跟踪记录。
问题排查
如果几分钟后未显示任何跟踪记录,请执行以下操作:
- 检查 Telemetry API 是否已启用 - 您在设置步骤中启用了该 API。使用以下命令进行验证:
gcloud services list --enabled --project=$GOOGLE_CLOUD_PROJECT | grep telemetry - 检查 Cloud Logging 中是否有警告 - 前往日志 > Logs Explorer ,然后搜索
"telemetry enabled but proceeding without"。如果您看到有关 GenAI 插桩的警告,则说明opentelemetry-instrumentation-google-genai在您的requirements.txt中缺失。 - 请勿将
google-cloud-aiplatform[agent-engines]添加到requirements.txt。ADK 部署 CLI 会自动添加它;使用不同版本重新声明它可能会导致 OpenTelemetry 软件包冲突,并以静默方式中断插桩。
9. 清理
为避免持续产生费用,请删除在此 Codelab 期间创建的资源。
在 Cloud 控制台的 Agent Engine 页面中**删除已部署的智能体**。选择您的智能体,然后点击删除 。
如果您专门为此 Codelab 创建了一个项目,则可以改为删除整个项目:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
(可选)清理本地环境:
deactivate
rm -rf .venv data_science_agent
10. 恭喜
您已构建一个有状态的数据科学智能体,并将其部署到 Agent Engine!
您学到的内容
- 如何使用
BigQueryToolset创建 ADK 智能体以访问真实数据 - 如何使用
PreloadMemoryTool和after_agent_callback通过记忆库启用持久性记忆 - 如何为已部署智能体的服务账号授予 IAM 权限
- 如何部署到 Agent Engine 并使用 Cloud Trace 启用可观测性
后续步骤
- 通过授予 Agent Engine 服务账号对您的数据的访问权限,查询您自己的私有 BigQuery 数据集
- 添加 代码执行 功能,以便在安全沙盒中运行 Python 分析
- 设置 Cloud Trace 可观测性 信息中心,以在生产环境中监控您的智能体
- 使用 MCP 工具 将结果发布到 Google Workspace