
১. ভূমিকা
এই কোডল্যাবে, আপনি শিখবেন কিভাবে গুগল ক্লাউড টিপিইউ (TPU) ব্যবহার করে গুগল কুবারনেটিস ইঞ্জিন (GKE)-এ উচ্চ-পারফরম্যান্স সম্পন্ন, মাল্টি-হোস্ট ভিএলএলএম (ভার্চুয়াল লার্জ ল্যাঙ্গুয়েজ মডেল) ইনফারেন্সিং সার্ভিস ডেপ্লয় করতে হয়। আপনি রে (Ray) ব্যবহার করে ডিস্ট্রিবিউটেড ইনফারেন্স কনফিগার করবেন এবং লিডারওয়ার্কারসেট (LeaderWorkerSets) ব্যবহার করে জিকেই (GKE)-তে নেটিভভাবে ওয়ার্কলোড পরিচালনা করবেন।
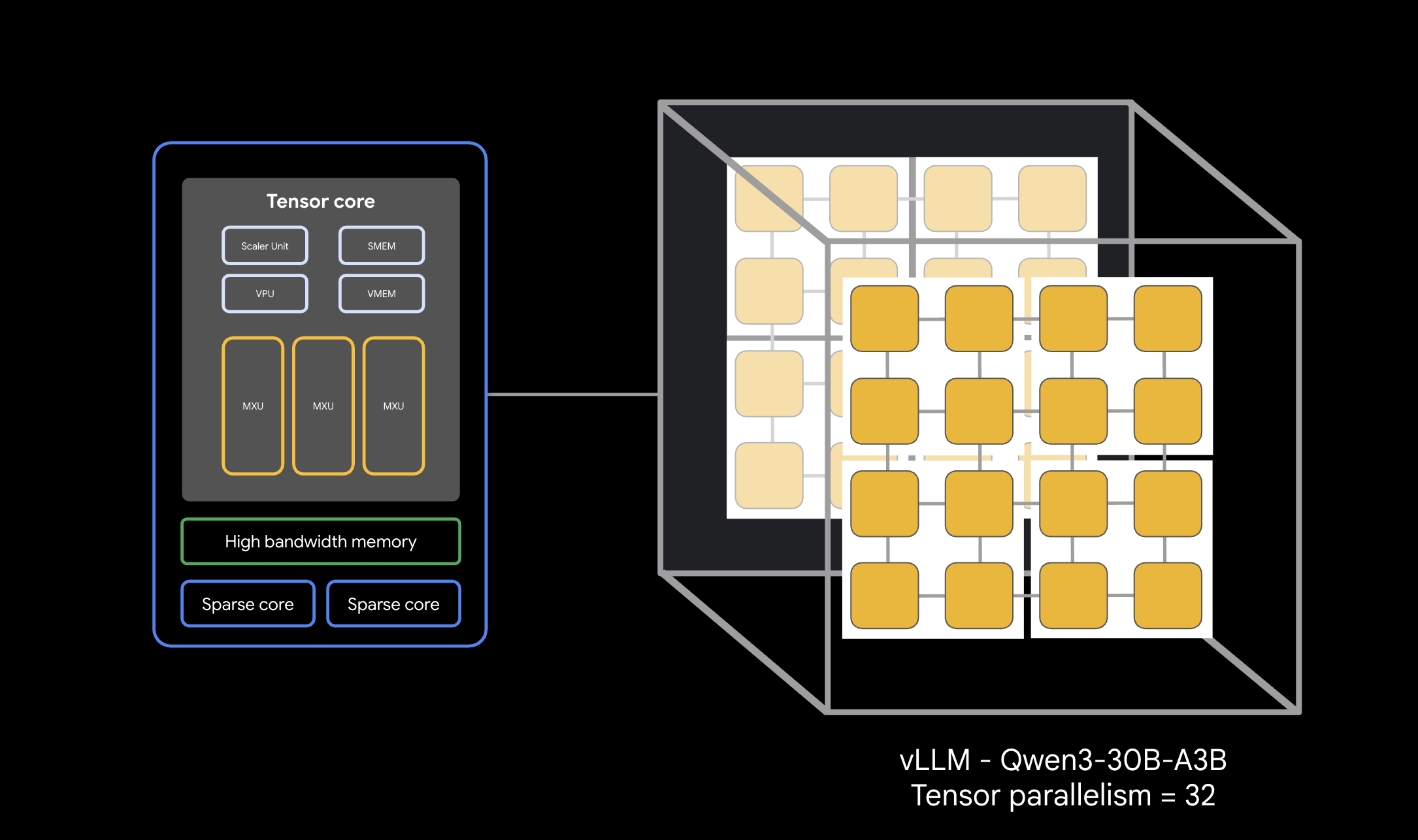
এই ওয়াকথ্রুটিতে Qwen 30B-এর মতো বড় মডেল পরিষেবা দেওয়ার জন্য একটি উৎপাদন ব্যবস্থার অনুকরণ করা হয়েছে।
আপনি যা করবেন
- অ্যাক্সিলারেটর ট্র্যাফিকের জন্য একটি কাস্টম ভিপিসি নেটওয়ার্ক তৈরি করুন।
- Ray Operator এবং GCS Fuse CSI ড্রাইভার দিয়ে একটি GKE ক্লাস্টার প্রস্তুত করুন।
- দ্রুত মডেল লোড করার জন্য একটি GCS র্যাপিড ক্যাশে চালু করুন।
- সংরক্ষিত ক্ষমতাসহ একটি মাল্টি-হোস্ট TPU v6e নোড পুল প্রস্তুত করুন।
- মডেল ওয়েট-এ নিরাপদ অ্যাক্সেসের জন্য ওয়ার্কলোড আইডেন্টিটি কনফিগার করুন।
- ৩০ বাইট প্যারামিটার মডেল পরিবেশনকারী vLLM ইঞ্জিনটি স্থাপন ও পরীক্ষা করুন।
আপনার যা যা লাগবে
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
- TPU v6e রিসোর্সের (৩২টি চিপ,
ct6e-standard-4t) জন্য একটি গুগল ক্লাউড রিজার্ভেশন । - সোর্স বাকেট থেকে মডেলের ওয়েট কপি করার অ্যাক্সেস।
- ক্লাউড শেল অথবা একটি লোকাল টার্মিনাল, যেখানে
gcloud,kubectlএবংhelmইনস্টল করা আছে।
- আনুমানিক সময়কাল: ৬০ মিনিট
- আনুমানিক খরচ: $60-এর কম (যদি দ্রুত ভাঙার কাজ শুরু করা হয়)।
২. শুরু করার আগে
একটি গুগল ক্লাউড প্রজেক্ট তৈরি করুন বা নির্বাচন করুন
- গুগল ক্লাউড কনসোলে , একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন।
ক্লাউড শেল শুরু করুন
- Google Cloud কনসোলের শীর্ষে থাকা Activate Cloud Shell-এ ক্লিক করুন।
- প্রমাণীকরণ যাচাই করুন:
gcloud auth list
- আপনার প্রকল্পটি নিশ্চিত করুন:
gcloud config get project
- প্রয়োজনে সেট করুন:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
পরিবেশ ভেরিয়েবল সেট করুন
কমান্ড চালানো সহজ করার জন্য, আপনার শেলে নিম্নলিখিত ভেরিয়েবলগুলো সংজ্ঞায়িত করুন। <YOUR_ZONE>-কে আপনার বরাদ্দকৃত TPU জোন এবং <YOUR_RESERVATION_NAME>-কে আপনার রিজার্ভেশন আইডি দিয়ে প্রতিস্থাপন করুন। গেটেড মডেলের ওজন ডাউনলোড করার জন্য আপনাকে একটি হাগিং ফেস ইউজার অ্যাক্সেস টোকেন তৈরি করতে হবে। এটি তৈরি হয়ে গেলে, <YOUR_HUGGING_FACE_TOKEN>-কে আপনার নতুন তৈরি করা টোকেন দিয়ে প্রতিস্থাপন করুন।
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export ZONE="<YOUR_ZONE>" # e.g., us-east5-a
export REGION=${ZONE%-*}
export CLUSTER_NAME="qwen-serving-cluster"
export GVNIC_NETWORK_PREFIX="qwen-serving"
export BUCKET_NAME="inf-demo-model-storage-${PROJECT_NUMBER}"
export RESERVATION_NAME="<YOUR_RESERVATION_NAME>"
export NODE_POOL_NAME="tpu-v6e-32-resvd-pool"
export MULTIHOST_COLLECTION_NAME="tpu-6-collection"
export HF_TOKEN="<YOUR_HUGGING_FACE_TOKEN>" # Token with access to Qwen model if restricted
এপিআই সক্ষম করুন
প্রয়োজনীয় গুগল ক্লাউড পরিষেবাগুলি সক্রিয় করুন:
gcloud services enable \
container.googleapis.com \
compute.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com
৩. কাস্টম নেটওয়ার্কিং তৈরি করুন
একাধিক হোস্টের TPU ওয়ার্কলোডের জন্য নির্দিষ্ট নেটওয়ার্ক কনফিগারেশন প্রয়োজন, যার মধ্যে অ্যাক্সিলারেটরের সাথে কার্যকর যোগাযোগের জন্য উচ্চতর MTU সাইজ অন্তর্ভুক্ত। আপনার ক্লাস্টারের জন্য একটি কাস্টম VPC নেটওয়ার্ক তৈরি করুন।
- একটি বৃহৎ MTU (8896) সহ VPC নেটওয়ার্ক তৈরি করুন :
gcloud compute --project=${PROJECT_ID} \ networks create ${GVNIC_NETWORK_PREFIX}-main \ --subnet-mode=custom \ --mtu=8896 - ক্লাস্টারের জন্য সাবনেট তৈরি করুন :
gcloud compute --project=${PROJECT_ID} \ networks subnets create ${GVNIC_NETWORK_PREFIX}-tpu \ --network=${GVNIC_NETWORK_PREFIX}-main \ --region=${REGION} \ --range=192.168.100.0/24 - কর্মীদের যোগাযোগের সুবিধার্থে অভ্যন্তরীণ ট্র্যাফিকের জন্য ফায়ারওয়াল নিয়ম তৈরি করুন :
gcloud compute --project=${PROJECT_ID} firewall-rules create ${GVNIC_NETWORK_PREFIX}-allow-internal \ --network=${GVNIC_NETWORK_PREFIX}-main \ --allow=all \ --source-ranges=172.16.0.0/12,192.168.0.0/16,10.0.0.0/8 \ --description="Allow all internal traffic within the network."
৪. GKE ক্লাস্টারের ব্যবস্থা করা
GCS ফিউজ মাউন্ট এবং রে অপারেটর ওয়ার্কলোড সমর্থন করার জন্য কনফিগার করা একটি স্ট্যান্ডার্ড GKE ক্লাস্টার সেটআপ তৈরি করুন।
- ক্লাস্টার তৈরি করুন :
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${REGION} \ --release-channel=rapid \ --machine-type=e2-standard-4 \ --network=${GVNIC_NETWORK_PREFIX}-main \ --subnetwork=${GVNIC_NETWORK_PREFIX}-tpu \ --num-nodes=1 \ --gateway-api=standard \ --enable-managed-prometheus \ --enable-dataplane-v2 \ --enable-dataplane-v2-metrics \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,RayOperator \ --enable-ip-alias - ক্লাস্টার ক্রেডেনশিয়াল পুনরুদ্ধার করুন :
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${REGION} - হাগিং ফেস সিক্রেট তৈরি করুন : কন্টেইনার অ্যাক্সেস ডাউনলোডের জন্য আপনার টোকেনটি নিরাপদে সংরক্ষণ করুন:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --dry-run=client -o yaml | kubectl apply -f - - Helm-এর মাধ্যমে LeaderWorkerSet (LWS) ইনস্টল করুন । LWS সেইসব পডের গ্রুপ পরিচালনা করে যাদেরকে একসাথে শিডিউল করতে হয়:
helm install lws oci://registry.k8s.io/lws/charts/lws \ --version=0.7.0 \ --namespace lws-system \ --create-namespace \ --wait
৫. GCS র্যাপিড ক্যাশে সক্রিয় করুন
সার্ভিংয়ের সময় ক্লাউড স্টোরেজ থেকে কয়েক ডজন জিবি ওয়েট দ্রুত পড়ার জন্য, একটি GCS বাকেট তৈরি করুন এবং আপনার জোনে GCS র্যাপিড ক্যাশে সক্রিয় করুন।
- বালতি তৈরি করুন :
gcloud storage buckets create gs://$BUCKET_NAME \ --location=$REGION \ --uniform-bucket-level-access - আপনার TPU জোনে র্যাপিড ক্যাশে চালু করুন :
gcloud storage buckets anywhere-caches create gs://$BUCKET_NAME $ZONE \ --ttl=1d \ --admission-policy=ADMIT_ON_FIRST_MISS
৬. ওয়ার্কলোড আইডেন্টিটি এবং স্টোরেজ পারমিশন সেটআপ করুন
দীর্ঘস্থায়ী কী এম্বেড না করেই আপনার GKE পডগুলিতে ওয়েট বাকেটকে নিরাপদে মাউন্ট করতে আইডেন্টিটি লিঙ্কগুলি কনফিগার করুন।
- একটি ডেডিকেটেড IAM সার্ভিস অ্যাকাউন্ট তৈরি করুন :
gcloud iam service-accounts create tpu-reader-sa - গ্রান্ট বাকেট পড়ার অনুমতি :
gcloud storage buckets add-iam-policy-binding gs://${BUCKET_NAME} \ --member="serviceAccount:tpu-reader-sa@${PROJECT_ID}.iam.gserviceaccount.com" \ --role="roles/storage.objectAdmin" -
defaultনেমস্পেস কুবারনেটিস সার্ভিস অ্যাকাউন্টের জন্য ওয়ার্কলোড আইডেন্টিটি বাইন্ডিং তৈরি করুন :gcloud iam service-accounts add-iam-policy-binding tpu-reader-sa@${PROJECT_ID}.iam.gserviceaccount.com \ --role="roles/iam.workloadIdentityUser" \ --member="serviceAccount:${PROJECT_ID}.svc.id.goog[default/default]" - Kubernetes SA-কে টীকাযুক্ত করুন :
kubectl annotate serviceaccount default iam.gke.io/gcp-service-account=tpu-reader-sa@${PROJECT_ID}.iam.gserviceaccount.com
৭. মডেলের ওজন সেটআপ
একটি ৩০ বাইট প্যারামিটার মডেল পরিবেশন করার জন্য, আপনাকে হাগিং ফেস (Hugging Face) থেকে আপনার জিসিএস (GCS) বাকেটে ওয়েটগুলো ডাউনলোড করতে হবে। ক্লাউড শেল (Cloud Shell)-এর ডিস্ক কোটার সীমাবদ্ধতা (৫ জিবি) এড়ানোর জন্য, একটি স্ট্যান্ডার্ড কুবারনেটিস জব (Standard Kubernetes Job) ব্যবহার করে সরাসরি ক্লাস্টারের ভেতরে ডাউনলোড করুন এবং মাউন্ট করা জিসিএস ফিউজ (GCS Fuse) ভলিউমে নিরাপদে লিখুন।
- মডেল ডাউনলোডার জবটি ডিপ্লয় করুন : ডাউনলোড শুরু করার জন্য নিম্নলিখিত ম্যানিফেস্টটি তৈরি ও প্রয়োগ করুন:
cat <<EOF | kubectl apply -f - apiVersion: batch/v1 kind: Job metadata: name: model-downloader spec: ttlSecondsAfterFinished: 60 template: metadata: annotations: gke-gcsfuse/volumes: "true" gke-gcsfuse/memory-limit: "0" spec: serviceAccountName: default restartPolicy: OnFailure containers: - name: downloader image: python:3.10-slim command: ["/bin/sh", "-c"] args: - | pip install -U "huggingface_hub[hf_transfer]" filelock export HF_HUB_ENABLE_HF_TRANSFER=1 python -c ' import filelock class DummyLock: def __init__(self, *args, **kwargs): pass def __enter__(self): return self def __exit__(self, *args): pass def acquire(self, *args, **kwargs): pass def release(self, *args, **kwargs): pass filelock.FileLock = DummyLock from huggingface_hub import snapshot_download snapshot_download( repo_id="Qwen/Qwen3-30B-A3B", local_dir="/models/qwen3-30b-weights", local_dir_use_symlinks=False ) ' env: - name: HF_TOKEN valueFrom: secretKeyRef: name: hf-secret key: hf_api_token volumeMounts: - name: model-weights mountPath: /models volumes: - name: model-weights csi: driver: gcsfuse.csi.storage.gke.io volumeAttributes: bucketName: ${BUCKET_NAME} mountOptions: "implicit-dirs" EOF - ডাউনলোড পর্যবেক্ষণ করুন : অগ্রগতি জানতে ডাউনলোডার পডের লগগুলো দেখুন:
kubectl logs -f job/model-downloader
৮. সংরক্ষিত টিপিইউ নোড পুল তৈরি করুন
আপনার বিদ্যমান ক্যাপাসিটি রিজার্ভেশন ব্যবহার করে প্রকৃত মাল্টি-হোস্ট টিপিইউ স্লাইসটি প্রোভিশন করুন।
- তৈরির কমান্ডটি চালান :
gcloud beta container node-pools create ${NODE_POOL_NAME} \ --project=${PROJECT_ID} \ --cluster=${CLUSTER_NAME} \ --region=${REGION} \ --node-locations=${ZONE} \ --machine-type=ct6e-standard-4t \ --tpu-topology=4x8 \ --num-nodes=8 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --reservation-affinity=specific \ --reservation=${RESERVATION_NAME} \ --accelerator-network-profile=auto \ --node-labels=cloud.google.com/gke-nodepool-group-name=${MULTIHOST_COLLECTION_NAME} \ --node-labels=cloud.google.com/gke-workload-type=HIGH_AVAILABILITY \ --node-labels=cloud.google.com/gke-networking-dra-driver=true - নোডগুলির যোগদানের জন্য অপেক্ষা করুন : আপনি সরাসরি নোড অ্যাগ্রিগেশন স্কেলিং পর্যবেক্ষণ করতে পারেন।
ct6eধারণকারী ৮টি নোডkubectl get nodesযোগদান না করা পর্যন্ত অপেক্ষা করুন।
৯. vLLM সার্ভিস ডিপ্লয় করুন
- নেটওয়ার্ক ক্লেইম তৈরি করুন : আপনাকে নেটওয়ার্ক পরিবেশের জন্য অনুরোধ করতে হবে:
cat <<EOF | kubectl apply -f - apiVersion: resource.k8s.io/v1 kind: ResourceClaimTemplate metadata: name: all-netdev spec: spec: devices: requests: - name: req-netdev exactly: deviceClassName: netdev.google.com allocationMode: All EOF - লোড ব্যালেন্সার এপিআই এন্ডপয়েন্ট স্থাপন করুন :
cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Service metadata: name: vllm-tpu-service spec: type: LoadBalancer selector: leaderworkerset.sigs.k8s.io/name: vllm-tpu-qwen leaderworkerset.sigs.k8s.io/worker-index: "0" ports: - protocol: TCP port: 8000 targetPort: 8000 EOF - LeaderWorkerSet ওয়ার্কলোড স্থাপন করুন : এই ম্যানিফেস্টটি ৮টি স্লাইস হোস্ট জুড়ে গতিশীলভাবে Ray হেড/ওয়ার্কার অ্যাগ্রিগেশন শুরু করে।
cat <<EOF | kubectl apply -f - apiVersion: leaderworkerset.x-k8s.io/v1 kind: LeaderWorkerSet metadata: name: vllm-tpu-qwen spec: replicas: 1 leaderWorkerTemplate: size: 8 restartPolicy: RecreateGroupOnPodRestart workerTemplate: metadata: annotations: gke-gcsfuse/volumes: "true" gke-gcsfuse/memory-limit: "0" labels: leaderworkerset.sigs.k8s.io/name: vllm-tpu-qwen gke-gcsfuse/volumes: "true" spec: hostname: vllm-tpu-qwen serviceAccountName: default containers: - name: vllm-tpu image: vllm/vllm-tpu:nightly command: ["sh", "-c"] args: - | MY_TPU_IP=\$(hostname -I | awk '{print \$1}') echo "My TPU Network IP is: \$MY_TPU_IP" LEADER_DNS="vllm-tpu-qwen-0.vllm-tpu-qwen" until getent hosts \$LEADER_DNS; do echo "DNS not ready. Sleeping 5s..." sleep 5 done LEADER_IP=\$(getent hosts \$LEADER_DNS | awk '{print \$1}') export JAX_PLATFORMS='' export SCAN_TPU_CHIPS=True export TPU_MULTIHOST_BACKEND=ray export JAX_DISTRIBUTED_INITIALIZATION_TIMEOUT=300 export LD_LIBRARY_PATH=\$LD_LIBRARY_PATH:/usr/local/lib export VLLM_HOST_IP=\$MY_TPU_IP if [ "\$LWS_WORKER_INDEX" = "0" ]; then echo "Starting Ray Head..." ray start --head --port=6379 --node-ip-address=\$MY_TPU_IP --resources='{"TPU": 4}' --block & sleep 20 until ray status; do sleep 5; done echo "Starting vLLM API Server..." python3 -m vllm.entrypoints.openai.api_server \ --model=/models/qwen3-30b-weights \ --tensor-parallel-size=32 \ --pipeline-parallel-size=1 \ --distributed-executor-backend=ray \ --host=0.0.0.0 --port=8000 \ --enforce-eager \ --gpu-memory-utilization=0.90 else ray start --address=\${LEADER_IP}:6379 --node-ip-address=\$MY_TPU_IP --resources='{"TPU": 4}' --block fi ports: - containerPort: 8000 - containerPort: 6379 volumeMounts: - name: model-weights mountPath: /models readOnly: true - name: dshm mountPath: /dev/shm resources: claims: - name: net-resources limits: google.com/tpu: 4 memory: "100Gi" requests: google.com/tpu: 4 memory: "100Gi" nodeSelector: cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice cloud.google.com/gke-tpu-topology: 4x8 gke.networks.io/accelerator-network-profile: auto resourceClaims: - name: net-resources resourceClaimTemplateName: all-netdev volumes: - name: model-weights csi: driver: gcsfuse.csi.storage.gke.io volumeAttributes: bucketName: ${BUCKET_NAME} mountOptions: "implicit-dirs" - name: dshm emptyDir: medium: Memory EOF
১০. পরীক্ষা স্থাপনের প্রতিক্রিয়া
LeaderWorkerSet-এর সমস্ত পডের কন্টেইনার ইমেজ পুল করতে, Ray ইনিশিয়ালাইজ করতে এবং সম্পূর্ণরূপে Ready হতে ৫-১০ মিনিট সময় লাগতে পারে। আপনি পড ইনিশিয়ালাইজেশন পর্যবেক্ষণ করে স্ট্যাটাস ট্র্যাক করতে পারেন:
kubectl get pods -l leaderworkerset.sigs.k8s.io/name=vllm-tpu-qwen -w
এগিয়ে যাওয়ার আগে, ৮টি vllm-tpu-qwen- পডের সবকটির STATUS Running এবং READY 2/2 না দেখানো পর্যন্ত অপেক্ষা করুন এবং লোড ব্যালেন্সার একটি External IP পেয়েছে কিনা তা নিশ্চিত করুন। এতে ৭-১০ মিনিট সময় লাগতে পারে।
- Retrieve External IP :
export EXTERNAL_IP=$(kubectl get svc vllm-tpu-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}') echo $EXTERNAL_IP
সতর্কতা: প্রোডাকশন সার্ভিসে, এই এন্ডপয়েন্টটিকে আইডেন্টিটি অ্যাওয়্যার প্রক্সি (IAP)- এর মতো কোনো কিছু দিয়ে সুরক্ষিত করা উচিত।
-
curlব্যবহার করে অনুমানের অনুরোধ জমা দিন :curl -N -s http://$EXTERNAL_IP:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/models/qwen3-30b-weights", "messages": [{"role": "user", "content": "Write a haiku about high-performance computing on TPUs."}], "temperature": 0.7, "max_tokens": 100, "stream": true }' | sed 's/^data: //' | grep -v '\[DONE\]' | grep -v '^$' | jq -rj '.choices[0].delta.content // empty' ; echo ""
১১. পরিষ্কার করুন
আপনার গুগল ক্লাউড অ্যাকাউন্টে চলমান চার্জ এড়াতে, এই কোডল্যাব চলাকালীন তৈরি করা রিসোর্সগুলো মুছে ফেলুন।
- নোড পুল মুছুন :
gcloud container node-pools delete "${NODE_POOL_NAME}" \ --cluster="${CLUSTER_NAME}" \ --region="${REGION}" \ --project="${PROJECT_ID}" --quiet - ক্লাস্টার মুছুন :
gcloud container clusters delete "${CLUSTER_NAME}" \ --region="${REGION}" \ --project="${PROJECT_ID}" --quiet - নেটওয়ার্ক এবং ফায়ারওয়াল সেটআপগুলি মুছুন :
gcloud compute firewall-rules delete \ "${GVNIC_NETWORK_PREFIX}-allow-internal" \ --project="${PROJECT_ID}" --quiet gcloud compute networks subnets delete "${GVNIC_NETWORK_PREFIX}-tpu" \ --region="${REGION}" --quiet gcloud compute networks delete "${GVNIC_NETWORK_PREFIX}-main" --quiet - সার্ভিস অ্যাকাউন্ট আনবাইন্ড এবং ডিলিট করুন :
# 1. Create the cleanup script cat << 'EOF' > clean_up_sa.sh #!/bin/bash # Validate that PROJECT_ID is available if [ -z "$PROJECT_ID" ]; then echo "Error: PROJECT_ID environment variable is not set." exit 1 fi SA_EMAIL="tpu-reader-sa@${PROJECT_ID}.iam.gserviceaccount.com" SA_MEMBER="serviceAccount:${SA_EMAIL}" echo "Gathering IAM policy for ${SA_EMAIL}..." # Fetch roles assigned to this specific SA ROLES=$(gcloud projects get-iam-policy ${PROJECT_ID} \ --flatten="bindings[].members" \ --filter="bindings.members:${SA_MEMBER}" \ --format="value(bindings.role)") if [ -z "$ROLES" ]; then echo "No IAM bindings found for this service account." else for ROLE in $ROLES; do echo "Removing binding for: ${ROLE}..." gcloud projects remove-iam-policy-binding ${PROJECT_ID} \ --member="${SA_MEMBER}" \ --role="${ROLE}" --quiet > /dev/null done echo "Successfully unbound all roles." fi # 2. Delete the service account itself echo "Deleting service account..." gcloud iam service-accounts delete ${SA_EMAIL} --project=${PROJECT_ID} --quiet echo "Cleanup complete." EOF # 2. Make the script executable and run it chmod +x clean_up_sa.sh ./clean_up_sa.sh - GCS বাকেট মুছতে আপনার ক্লাউড কনসোলে যান, Cloud Storage -> Buckets নির্বাচন করুন, inf-demo-model-storage নির্বাচন করুন এবং তারপর 'Delete' বেছে নিন।
১২. অভিনন্দন
অভিনন্দন! আপনি সফলভাবে গুগল কুবারনেটিস ইঞ্জিনে রে (Ray) ব্যবহার করে একটি মাল্টি-হোস্ট টিপিইউ হাই-ইনফারেন্স রেট ভিএলএলএম স্ট্যাক স্থাপন করেছেন।
আপনি যা শিখেছেন
- উচ্চ-গতির টিপিইউ ট্র্যাফিকের জন্য বিশেষভাবে তৈরি কাস্টম পাথওয়ের ব্যবস্থা করা হচ্ছে।
- GCS Fuse এবং আঞ্চলিক দ্রুত ক্যাশ ব্যবহার করে ওজন স্থাপন করা।
- লিডারওয়ার্কারসেট-এর মাধ্যমে স্বাভাবিকভাবে সিঙ্ক্রোনাইজ করা একাধিক হোস্টের ওয়ার্কলোড স্লাইসগুলোর সমন্বয় সাধন।
- আরও জানতে vLLM ব্যবহারকারী নির্দেশিকা এবং llm-d স্থাপন নির্দেশিকা দেখুন।