
1. บทนำ
ใน Codelab นี้ คุณจะได้เรียนรู้วิธีติดตั้งใช้งานบริการอนุมาน vLLM (โมเดลภาษาขนาดใหญ่เสมือน) แบบหลายโฮสต์ที่มีประสิทธิภาพสูงใน Google Kubernetes Engine (GKE) โดยใช้ Google Cloud TPU คุณจะกำหนดค่าการอนุมานแบบกระจายโดยใช้ Ray และจัดการภาระงานใน GKE โดยใช้ LeaderWorkerSets
คำแนะนำแบบทีละขั้นนี้จำลองการตั้งค่าการใช้งานจริงสำหรับการแสดงโมเดลขนาดใหญ่ เช่น Qwen 30B
สิ่งที่คุณต้องดำเนินการ
- สร้างเครือข่าย VPC ที่กำหนดเองสำหรับการรับส่งข้อมูลของตัวเร่ง
- จัดสรรคลัสเตอร์ GKE ด้วย Ray Operator และไดรเวอร์ GCS Fuse CSI
- เริ่มต้นแคชด่วนของ GCS เพื่อให้โหลดโมเดลได้เร็วขึ้น
- จัดสรร Node Pool TPU v6e แบบหลายโฮสต์ที่มีความจุที่สงวนไว้
- กำหนดค่า Workload Identity เพื่อให้เข้าถึงน้ำหนักของโมเดลได้อย่างปลอดภัย
- ติดตั้งใช้งานและทดสอบเครื่องมือ vLLM ที่ให้บริการโมเดลพารามิเตอร์ 30B
สิ่งที่คุณต้องมี
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- การจอง Google Cloud สำหรับทรัพยากร TPU v6e (ชิป 32 ตัว
ct6e-standard-4t) - สิทธิ์เข้าถึงเพื่อคัดลอกน้ำหนักของโมเดลจาก Bucket ต้นทาง
- Cloud Shell หรือเทอร์มินัลในเครื่องที่ติดตั้ง
gcloud,kubectlและhelm
- ระยะเวลาโดยประมาณ: 60 นาที
- ค่าใช้จ่ายโดยประมาณ: ต่ำกว่า $60 (สมมติว่ามีการแยกชิ้นส่วนทันที)
2. ก่อนเริ่มต้น
สร้างหรือเลือกโปรเจ็กต์ Google Cloud
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าโปรเจ็กต์ที่อยู่ในระบบคลาวด์เปิดใช้การเรียกเก็บเงินแล้ว
เริ่มต้น Cloud Shell
- คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud
- ยืนยันการตรวจสอบสิทธิ์
gcloud auth list
- ยืนยันโปรเจ็กต์
gcloud config get project
- ตั้งค่าหากจำเป็น
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
ตั้งค่าตัวแปรสภาพแวดล้อม
กำหนดตัวแปรต่อไปนี้ในเชลล์เพื่อให้เรียกใช้คำสั่งได้ง่ายขึ้น แทนที่ <YOUR_ZONE> ด้วยโซน TPU ที่จัดสรร และ <YOUR_RESERVATION_NAME> ด้วยรหัสการจอง คุณจะต้องสร้างโทเค็นเพื่อการเข้าถึงของผู้ใช้ Hugging Face เพื่อดาวน์โหลดน้ำหนักของโมเดลที่มีการควบคุมการเข้าถึง เมื่อสร้างแล้ว ให้แทนที่ <YOUR_HUGGING_FACE_TOKEN> ด้วยโทเค็นที่สร้างขึ้นใหม่
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export ZONE="<YOUR_ZONE>" # e.g., us-east5-a
export REGION=${ZONE%-*}
export CLUSTER_NAME="qwen-serving-cluster"
export GVNIC_NETWORK_PREFIX="qwen-serving"
export BUCKET_NAME="inf-demo-model-storage-${PROJECT_NUMBER}"
export RESERVATION_NAME="<YOUR_RESERVATION_NAME>"
export NODE_POOL_NAME="tpu-v6e-32-resvd-pool"
export MULTIHOST_COLLECTION_NAME="tpu-6-collection"
export HF_TOKEN="<YOUR_HUGGING_FACE_TOKEN>" # Token with access to Qwen model if restricted
เปิดใช้ API
เปิดใช้บริการ Google Cloud ที่จำเป็น
gcloud services enable \
container.googleapis.com \
compute.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com
3. สร้างเครือข่ายที่กำหนดเอง
ปริมาณงาน TPU แบบหลายโฮสต์ต้องมีการกำหนดค่าเครือข่ายที่เฉพาะเจาะจง ซึ่งรวมถึงขนาด MTU ที่สูงขึ้นเพื่อการสื่อสารของตัวเร่งที่มีประสิทธิภาพ สร้างเครือข่าย VPC ที่กำหนดเองสำหรับคลัสเตอร์
- สร้างเครือข่าย VPC ที่มี MTU ขนาดใหญ่ (8896)
gcloud compute --project=${PROJECT_ID} \ networks create ${GVNIC_NETWORK_PREFIX}-main \ --subnet-mode=custom \ --mtu=8896 - สร้างซับเน็ตสำหรับคลัสเตอร์
gcloud compute --project=${PROJECT_ID} \ networks subnets create ${GVNIC_NETWORK_PREFIX}-tpu \ --network=${GVNIC_NETWORK_PREFIX}-main \ --region=${REGION} \ --range=192.168.100.0/24 - สร้างกฎไฟร์วอลล์ที่อนุญาตให้มีการเข้าชมภายในเพื่อเปิดให้ Worker สื่อสารกันได้
gcloud compute --project=${PROJECT_ID} firewall-rules create ${GVNIC_NETWORK_PREFIX}-allow-internal \ --network=${GVNIC_NETWORK_PREFIX}-main \ --allow=all \ --source-ranges=172.16.0.0/12,192.168.0.0/16,10.0.0.0/8 \ --description="Allow all internal traffic within the network."
4. จัดสรรคลัสเตอร์ GKE
สร้างการตั้งค่าคลัสเตอร์ GKE มาตรฐานที่กำหนดค่าให้รองรับการติดตั้ง GCS Fuse และปริมาณงาน Ray Operator
- สร้างคลัสเตอร์
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${REGION} \ --release-channel=rapid \ --machine-type=e2-standard-4 \ --network=${GVNIC_NETWORK_PREFIX}-main \ --subnetwork=${GVNIC_NETWORK_PREFIX}-tpu \ --num-nodes=1 \ --gateway-api=standard \ --enable-managed-prometheus \ --enable-dataplane-v2 \ --enable-dataplane-v2-metrics \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,RayOperator \ --enable-ip-alias - เรียกข้อมูลเข้าสู่ระบบของคลัสเตอร์:
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${REGION} - สร้างข้อมูลลับของ Hugging Face: บันทึกโทเค็นอย่างปลอดภัยเพื่อดาวน์โหลดการเข้าถึงคอนเทนเนอร์
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --dry-run=client -o yaml | kubectl apply -f - - ติดตั้ง LeaderWorkerSet (LWS) ผ่าน Helm LWS จัดการกลุ่มพ็อดที่ต้องกำหนดเวลาด้วยกันดังนี้
helm install lws oci://registry.k8s.io/lws/charts/lws \ --version=0.7.0 \ --namespace lws-system \ --create-namespace \ --wait
5. เปิดใช้แคชด่วนของ GCS
หากต้องการเร่งการอ่านน้ำหนักหลายสิบ GB จาก Cloud Storage ในระหว่างการแสดงผล ให้สร้างที่เก็บข้อมูล GCS และเปิดใช้แคชด่วนของ GCS ในโซน
- สร้างที่เก็บข้อมูล
gcloud storage buckets create gs://$BUCKET_NAME \ --location=$REGION \ --uniform-bucket-level-access - เริ่มต้น Rapid Cache ในโซน TPU
gcloud storage buckets anywhere-caches create gs://$BUCKET_NAME $ZONE \ --ttl=1d \ --admission-policy=ADMIT_ON_FIRST_MISS
6. ตั้งค่า Workload Identity และสิทธิ์ในการจัดเก็บข้อมูล
กำหนดค่าลิงก์ข้อมูลประจำตัวเพื่อติดตั้งที่เก็บข้อมูลน้ำหนักในพ็อด GKE อย่างปลอดภัยโดยไม่ต้องฝังคีย์ที่มีอายุการใช้งานยาวนาน
- สร้างบัญชีบริการ IAM เฉพาะ
gcloud iam service-accounts create tpu-reader-sa - ให้สิทธิ์อ่าน Bucket:
gcloud storage buckets add-iam-policy-binding gs://${BUCKET_NAME} \ --member="serviceAccount:tpu-reader-sa@${PROJECT_ID}.iam.gserviceaccount.com" \ --role="roles/storage.objectAdmin" - สร้างการเชื่อมโยง Workload Identity สำหรับบัญชีบริการ Kubernetes ของเนมสเปซ
defaultgcloud iam service-accounts add-iam-policy-binding tpu-reader-sa@${PROJECT_ID}.iam.gserviceaccount.com \ --role="roles/iam.workloadIdentityUser" \ --member="serviceAccount:${PROJECT_ID}.svc.id.goog[default/default]" - ใส่คำอธิบายประกอบ SA ของ Kubernetes:
kubectl annotate serviceaccount default iam.gke.io/gcp-service-account=tpu-reader-sa@${PROJECT_ID}.iam.gserviceaccount.com
7. การตั้งค่าน้ำหนักของโมเดล
หากต้องการแสดงโมเดลพารามิเตอร์ 30B คุณต้องดาวน์โหลดน้ำหนักจาก Hugging Face ลงใน Bucket ของ GCS หากต้องการข้ามขีดจำกัดโควต้าดิสก์ของ Cloud Shell (5 GB) ให้ใช้ Job Kubernetes มาตรฐานเพื่อดาวน์โหลดภายในคลัสเตอร์โดยตรงและเขียนลงในวอลุ่ม GCS Fuse ที่ติดตั้งอย่างปลอดภัย
- ทำให้งานดาวน์โหลดโมเดลใช้งานได้: สร้างและใช้ไฟล์ Manifest ต่อไปนี้เพื่อเริ่มการดาวน์โหลด
cat <<EOF | kubectl apply -f - apiVersion: batch/v1 kind: Job metadata: name: model-downloader spec: ttlSecondsAfterFinished: 60 template: metadata: annotations: gke-gcsfuse/volumes: "true" gke-gcsfuse/memory-limit: "0" spec: serviceAccountName: default restartPolicy: OnFailure containers: - name: downloader image: python:3.10-slim command: ["/bin/sh", "-c"] args: - | pip install -U "huggingface_hub[hf_transfer]" filelock export HF_HUB_ENABLE_HF_TRANSFER=1 python -c ' import filelock class DummyLock: def __init__(self, *args, **kwargs): pass def __enter__(self): return self def __exit__(self, *args): pass def acquire(self, *args, **kwargs): pass def release(self, *args, **kwargs): pass filelock.FileLock = DummyLock from huggingface_hub import snapshot_download snapshot_download( repo_id="Qwen/Qwen3-30B-A3B", local_dir="/models/qwen3-30b-weights", local_dir_use_symlinks=False ) ' env: - name: HF_TOKEN valueFrom: secretKeyRef: name: hf-secret key: hf_api_token volumeMounts: - name: model-weights mountPath: /models volumes: - name: model-weights csi: driver: gcsfuse.csi.storage.gke.io volumeAttributes: bucketName: ${BUCKET_NAME} mountOptions: "implicit-dirs" EOF - ตรวจสอบการดาวน์โหลด: ตรวจสอบบันทึกของพ็อดดาวน์โหลดเพื่อติดตามความคืบหน้า
kubectl logs -f job/model-downloader
8. สร้าง Node Pool ของ TPU ที่จองไว้
จัดสรร Slice ของ TPU แบบหลายโฮสต์จริงโดยใช้การจองความจุที่มีอยู่
- เรียกใช้คำสั่งสร้าง
gcloud beta container node-pools create ${NODE_POOL_NAME} \ --project=${PROJECT_ID} \ --cluster=${CLUSTER_NAME} \ --region=${REGION} \ --node-locations=${ZONE} \ --machine-type=ct6e-standard-4t \ --tpu-topology=4x8 \ --num-nodes=8 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --reservation-affinity=specific \ --reservation=${RESERVATION_NAME} \ --accelerator-network-profile=auto \ --node-labels=cloud.google.com/gke-nodepool-group-name=${MULTIHOST_COLLECTION_NAME} \ --node-labels=cloud.google.com/gke-workload-type=HIGH_AVAILABILITY \ --node-labels=cloud.google.com/gke-networking-dra-driver=true - รอให้โหนดเข้าร่วม: คุณจะสังเกตการปรับขนาดการรวมโหนดได้โดยตรง รอจนกว่าโหนด 8 โหนดที่มี
ct6eจะเข้าร่วมkubectl get nodes
9. ติดตั้งใช้งานบริการ vLLM
- สร้างการอ้างสิทธิ์ในเครือข่าย: คุณต้องขอสภาพแวดล้อมของเครือข่ายโดยทำดังนี้
cat <<EOF | kubectl apply -f - apiVersion: resource.k8s.io/v1 kind: ResourceClaimTemplate metadata: name: all-netdev spec: spec: devices: requests: - name: req-netdev exactly: deviceClassName: netdev.google.com allocationMode: All EOF - ทำให้ใช้งานได้ปลายทาง API ของตัวจัดสรรภาระงาน:
cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Service metadata: name: vllm-tpu-service spec: type: LoadBalancer selector: leaderworkerset.sigs.k8s.io/name: vllm-tpu-qwen leaderworkerset.sigs.k8s.io/worker-index: "0" ports: - protocol: TCP port: 8000 targetPort: 8000 EOF - ติดตั้งใช้งานเวิร์กโหลด LeaderWorkerSet: Manifest นี้จะเริ่มการรวมหัว/Worker ของ Ray แบบไดนามิกในโฮสต์ 8 Slice
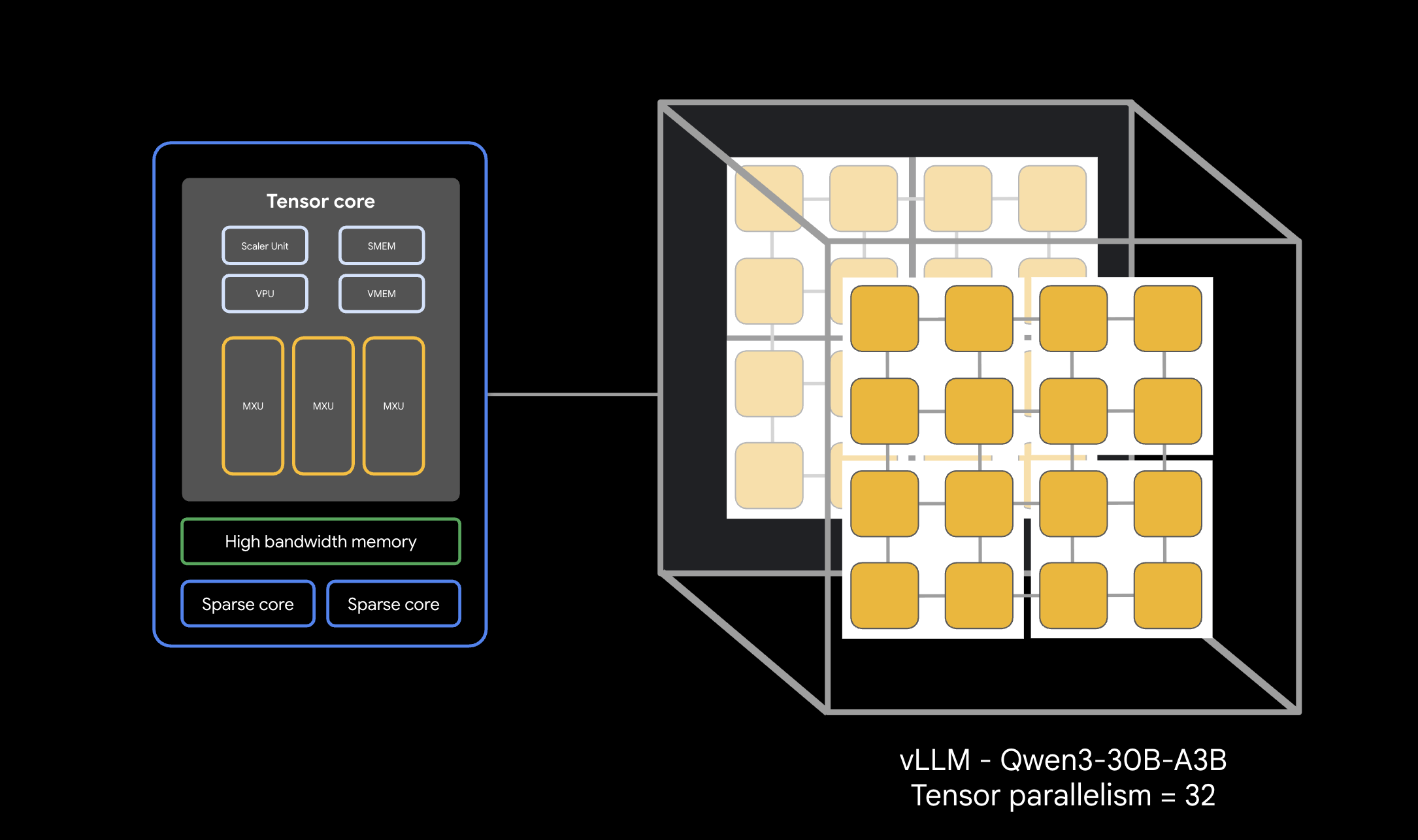
cat <<EOF | kubectl apply -f - apiVersion: leaderworkerset.x-k8s.io/v1 kind: LeaderWorkerSet metadata: name: vllm-tpu-qwen spec: replicas: 1 leaderWorkerTemplate: size: 8 restartPolicy: RecreateGroupOnPodRestart workerTemplate: metadata: annotations: gke-gcsfuse/volumes: "true" gke-gcsfuse/memory-limit: "0" labels: leaderworkerset.sigs.k8s.io/name: vllm-tpu-qwen gke-gcsfuse/volumes: "true" spec: hostname: vllm-tpu-qwen serviceAccountName: default containers: - name: vllm-tpu image: vllm/vllm-tpu:nightly command: ["sh", "-c"] args: - | MY_TPU_IP=\$(hostname -I | awk '{print \$1}') echo "My TPU Network IP is: \$MY_TPU_IP" LEADER_DNS="vllm-tpu-qwen-0.vllm-tpu-qwen" until getent hosts \$LEADER_DNS; do echo "DNS not ready. Sleeping 5s..." sleep 5 done LEADER_IP=\$(getent hosts \$LEADER_DNS | awk '{print \$1}') export JAX_PLATFORMS='' export SCAN_TPU_CHIPS=True export TPU_MULTIHOST_BACKEND=ray export JAX_DISTRIBUTED_INITIALIZATION_TIMEOUT=300 export LD_LIBRARY_PATH=\$LD_LIBRARY_PATH:/usr/local/lib export VLLM_HOST_IP=\$MY_TPU_IP if [ "\$LWS_WORKER_INDEX" = "0" ]; then echo "Starting Ray Head..." ray start --head --port=6379 --node-ip-address=\$MY_TPU_IP --resources='{"TPU": 4}' --block & sleep 20 until ray status; do sleep 5; done echo "Starting vLLM API Server..." python3 -m vllm.entrypoints.openai.api_server \ --model=/models/qwen3-30b-weights \ --tensor-parallel-size=32 \ --pipeline-parallel-size=1 \ --distributed-executor-backend=ray \ --host=0.0.0.0 --port=8000 \ --enforce-eager \ --gpu-memory-utilization=0.90 else ray start --address=\${LEADER_IP}:6379 --node-ip-address=\$MY_TPU_IP --resources='{"TPU": 4}' --block fi ports: - containerPort: 8000 - containerPort: 6379 volumeMounts: - name: model-weights mountPath: /models readOnly: true - name: dshm mountPath: /dev/shm resources: claims: - name: net-resources limits: google.com/tpu: 4 memory: "100Gi" requests: google.com/tpu: 4 memory: "100Gi" nodeSelector: cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice cloud.google.com/gke-tpu-topology: 4x8 gke.networks.io/accelerator-network-profile: auto resourceClaims: - name: net-resources resourceClaimTemplateName: all-netdev volumes: - name: model-weights csi: driver: gcsfuse.csi.storage.gke.io volumeAttributes: bucketName: ${BUCKET_NAME} mountOptions: "implicit-dirs" - name: dshm emptyDir: medium: Memory EOF
10. การตอบกลับการทดสอบการทำให้ใช้งานได้
พ็อดทั้งหมดใน LeaderWorkerSet อาจใช้เวลา 5-10 นาทีในการดึงอิมเมจคอนเทนเนอร์ เริ่มต้น Ray และกลายเป็น Ready อย่างเต็มรูปแบบ คุณติดตามสถานะได้โดยดูการเริ่มต้นพ็อด
kubectl get pods -l leaderworkerset.sigs.k8s.io/name=vllm-tpu-qwen -w
รอจนกว่าพ็อดทั้ง 8 vllm-tpu-qwen- จะแสดง STATUS เป็น Running และ READY เป็น 2/2 และตรวจสอบว่าตัวจัดสรรภาระงานได้รับ IP ภายนอกแล้วก่อนดำเนินการต่อ การดำเนินการนี้อาจใช้เวลา 7-10 นาที
- ดึงข้อมูล IP ภายนอก:
export EXTERNAL_IP=$(kubectl get svc vllm-tpu-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}') echo $EXTERNAL_IP
ข้อควรระวัง: ในบริการที่ใช้งานจริง ควรรักษาความปลอดภัยให้กับปลายทางนี้ด้วยเครื่องมืออย่าง Identity Aware Proxy (IAP)
- ส่งคำขออนุมานโดยใช้
curlcurl -N -s http://$EXTERNAL_IP:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/models/qwen3-30b-weights", "messages": [{"role": "user", "content": "Write a haiku about high-performance computing on TPUs."}], "temperature": 0.7, "max_tokens": 100, "stream": true }' | sed 's/^data: //' | grep -v '\[DONE\]' | grep -v '^$' | jq -rj '.choices[0].delta.content // empty' ; echo ""
11. ล้างข้อมูล
โปรดลบทรัพยากรที่สร้างขึ้นระหว่างการทำ Codelab นี้เพื่อหลีกเลี่ยงการเรียกเก็บเงินอย่างต่อเนื่องในบัญชี Google Cloud
- ลบ Node Pool:
gcloud container node-pools delete "${NODE_POOL_NAME}" \ --cluster="${CLUSTER_NAME}" \ --region="${REGION}" \ --project="${PROJECT_ID}" --quiet - ลบคลัสเตอร์:
gcloud container clusters delete "${CLUSTER_NAME}" \ --region="${REGION}" \ --project="${PROJECT_ID}" --quiet - ลบการตั้งค่าเครือข่ายและไฟร์วอลล์:
gcloud compute firewall-rules delete \ "${GVNIC_NETWORK_PREFIX}-allow-internal" \ --project="${PROJECT_ID}" --quiet gcloud compute networks subnets delete "${GVNIC_NETWORK_PREFIX}-tpu" \ --region="${REGION}" --quiet gcloud compute networks delete "${GVNIC_NETWORK_PREFIX}-main" --quiet - ยกเลิกการเชื่อมโยงและลบบัญชีบริการ
# 1. Create the cleanup script cat << 'EOF' > clean_up_sa.sh #!/bin/bash # Validate that PROJECT_ID is available if [ -z "$PROJECT_ID" ]; then echo "Error: PROJECT_ID environment variable is not set." exit 1 fi SA_EMAIL="tpu-reader-sa@${PROJECT_ID}.iam.gserviceaccount.com" SA_MEMBER="serviceAccount:${SA_EMAIL}" echo "Gathering IAM policy for ${SA_EMAIL}..." # Fetch roles assigned to this specific SA ROLES=$(gcloud projects get-iam-policy ${PROJECT_ID} \ --flatten="bindings[].members" \ --filter="bindings.members:${SA_MEMBER}" \ --format="value(bindings.role)") if [ -z "$ROLES" ]; then echo "No IAM bindings found for this service account." else for ROLE in $ROLES; do echo "Removing binding for: ${ROLE}..." gcloud projects remove-iam-policy-binding ${PROJECT_ID} \ --member="${SA_MEMBER}" \ --role="${ROLE}" --quiet > /dev/null done echo "Successfully unbound all roles." fi # 2. Delete the service account itself echo "Deleting service account..." gcloud iam service-accounts delete ${SA_EMAIL} --project=${PROJECT_ID} --quiet echo "Cleanup complete." EOF # 2. Make the script executable and run it chmod +x clean_up_sa.sh ./clean_up_sa.sh - ลบ Bucket ของ GCS ไปที่คอนโซลระบบคลาวด์ เลือก Cloud Storage -> Buckets เลือก inf-demo-model-storage แล้วเลือก "ลบ"
12. ขอแสดงความยินดี
ยินดีด้วย คุณได้ติดตั้งใช้งานสแต็ก vLLM ที่มีอัตราการอนุมานสูงแบบ TPU หลายโฮสต์โดยใช้ Ray แบบเนทีฟผ่าน Google Kubernetes Engine เรียบร้อยแล้ว
สิ่งที่คุณได้เรียนรู้
- การจัดสรรเส้นทางที่กำหนดเองซึ่งปรับให้เหมาะกับการรับส่งข้อมูล TPU ความเร็วสูง
- การปรับน้ำหนักโดยใช้ GCS Fuse และแคชด่วนระดับภูมิภาค
- การจัดระเบียบ Slice ของภาระงานแบบหลายโฮสต์ที่ซิงค์โดยตรงผ่าน LeaderWorkerSets
- ดูข้อมูลเพิ่มเติมได้ที่คู่มือผู้ใช้ vLLM และคู่มือการติดตั้งใช้งาน llm-d