
1. مقدمة
في هذا الدرس التطبيقي حول الترميز، ستتعرّف على كيفية نشر خدمات استنتاجية عالية الأداء ومجزّأة على Google Kubernetes Engine (GKE) باستخدام وحدات TPU من Google Cloud. ستستخدم llm-d، وهو إطار عمل مفتوح المصدر لتقديم نماذج لغوية كبيرة موزّعة، لفصل مرحلتَي التعبئة المسبقة وفك الترميز على مستوى عدة مضيفات لوحدات معالجة الموتّرات، وإعداد التخزين المؤقت المشترَك لمفاتيح وقيم، وGKE Inference Gateway.
يحاكي هذا الإعداد بيئة إنتاج لعرض نماذج كبيرة مثل Qwen3-32B مع معدل نقل بيانات عالٍ وزمن استجابة منخفض.
الإجراءات التي ستنفذّها
- أنشئ شبكة VPC مخصّصة مع وحدة MTU محسّنة لحركة بيانات أداة التسريع.
- توفير مجموعة GKE مع إضافات برنامج تشغيل GCS Fuse CSI وRay Operator
- أنشئ 8 مجموعات عقد مخصّصة لشرائح TPU v6e (إجمالي 32 شريحة).
- ضبط Workload Identity والأذونات للوصول إلى GCS
- استخدِم
llm-dلإدارة العرض المجزّأ لنموذج Qwen3-32B. - تحقَّق من عملية النشر باستخدام اختبار قياسي.
الهندسة المعمارية
![llm-d disaggregated serving architecture showing model split into 4 2x2 replicas of prefill and the same for decode]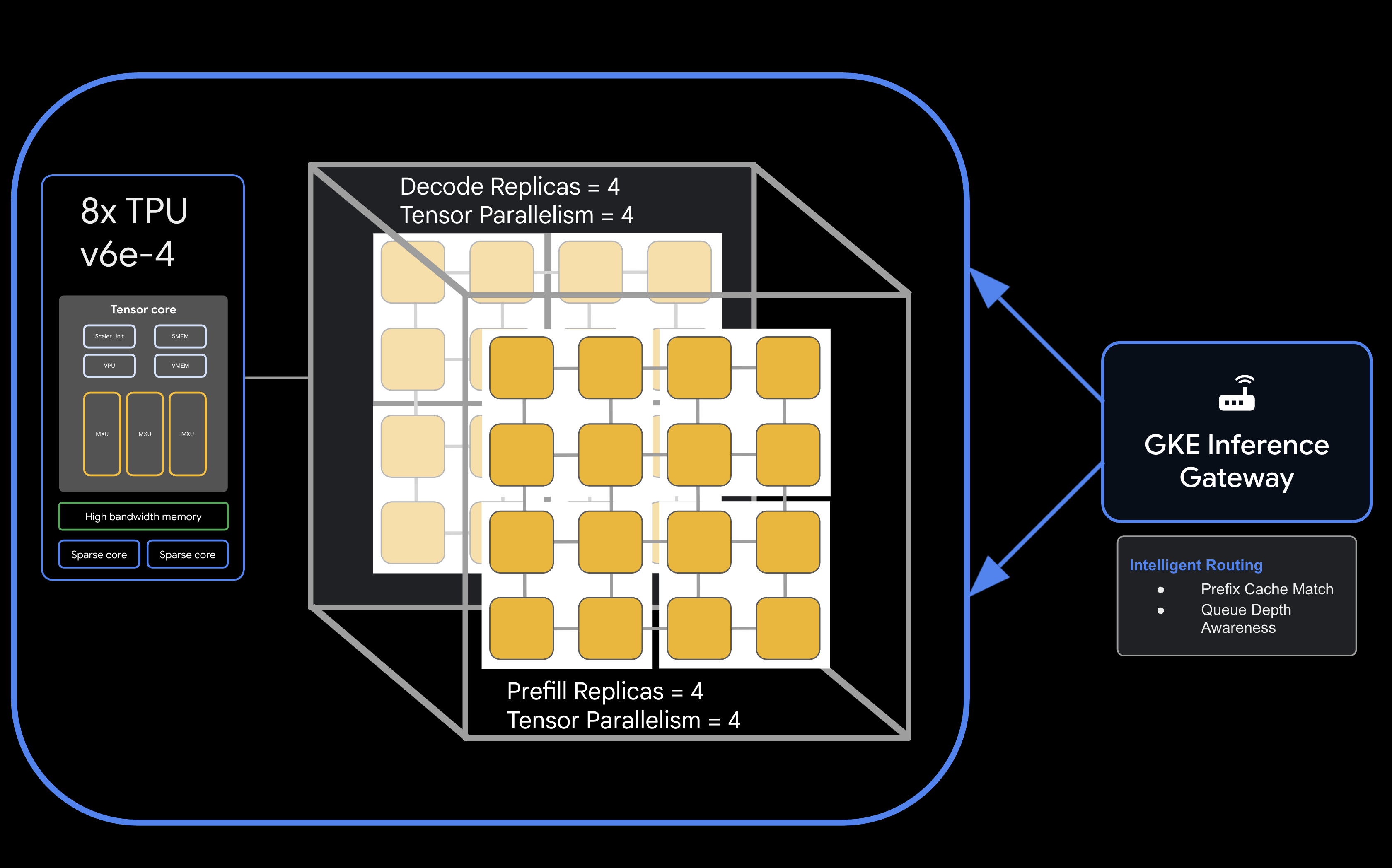
المتطلبات
- مشروع Google Cloud تم تفعيل الفوترة فيه
- حجز على Google Cloud لموارد TPU v6e (32 شريحة،
ct6e-standard-4t) - رمز دخول مستخدم Hugging Face لتنزيل أوزان النموذج
- Cloud Shell أو وحدة طرفية محلية مثبَّت عليها
gcloudوkubectlوhelm
- المدة المقدَّرة: 60 دقيقة
- التكلفة المقدّرة: تتضمّن هذه التجربة المختبرية استخدام موارد كبيرة من وحدات معالجة الموتّرات، وستكلّف 60 دولارًا أمريكيًا كحدّ أدنى لإكمال المشروع. احرص على اتّباع خطوات التنظيف فور الانتهاء من التمارين.
2. قبل البدء
إنشاء مشروع Google Cloud أو اختياره
- في Google Cloud Console، اختَر مشروعًا على Google Cloud أو أنشِئ مشروعًا.
- تأكَّد من تفعيل الفوترة لمشروعك على Cloud.
بدء Cloud Shell
- انقر على تفعيل Cloud Shell في أعلى "وحدة تحكّم Google Cloud".
- إثبات صحة المصادقة:
gcloud auth list
- أكِّد مشروعك:
gcloud config get project
- اضبطه إذا لزم الأمر:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
تفعيل واجهات برمجة التطبيقات
فعِّل خدمات Google Cloud المطلوبة:
gcloud services enable \
container.googleapis.com \
compute.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com
ضبط متغيرات البيئة
حدِّد المتغيّرات التالية في shell. استبدِل <YOUR_ZONE> بمنطقة TPU المخصّصة لك، و<YOUR_RESERVATION_NAME> بمعرّف الحجز، و <YOUR_HUGGING_FACE_TOKEN> بالرمز المميز.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE="<YOUR_ZONE>" # e.g., us-east5-a
export REGION=${ZONE%-*}
export NAMESPACE=default
export CLUSTER_NAME="qwen-serving-cluster"
export GVNIC_NETWORK_PREFIX="qwen-serving"
export RESERVATION_NAME="<YOUR_RESERVATION_NAME>"
export HF_TOKEN="<YOUR_HUGGING_FACE_TOKEN>"
3- إنشاء شبكة مخصّصة
يتطلّب العرض المجزّأ إعدادات شبكة معيّنة للتعامل مع حركة المرور ذات معدل نقل البيانات العالي بين عقدتي التعبئة المسبقة وفك الترميز.
- أنشئ شبكة السحابة الإلكترونية الافتراضية الخاصة (VPC) باستخدام وحدة نقل قصوى (MTU) كبيرة (8896) لضمان التواصل الفعّال بين أدوات التسريع:
gcloud compute --project=${PROJECT_ID} \ networks create ${GVNIC_NETWORK_PREFIX}-main \ --subnet-mode=auto \ --bgp-routing-mode=regional \ --mtu=8896 - أنشئ الشبكة الفرعية للمجموعة:
gcloud compute --project=${PROJECT_ID} \ networks subnets create ${GVNIC_NETWORK_PREFIX}-tpu \ --network=${GVNIC_NETWORK_PREFIX}-main \ --region=${REGION} \ --range=10.10.0.0/18 - أنشئ شبكة فرعية مخصّصة للوكيل فقط مطلوبة لواجهة برمجة التطبيقات GKE Gateway API:
gcloud compute networks subnets create ${GVNIC_NETWORK_PREFIX}-proxy \ --purpose=REGIONAL_MANAGED_PROXY \ --role=ACTIVE \ --region=${REGION} \ --network=${GVNIC_NETWORK_PREFIX}-main \ --range=172.16.0.0/26 - إنشاء قواعد جدار الحماية للسماح بالتواصل الداخلي:
gcloud compute --project=${PROJECT_ID} firewall-rules create ${GVNIC_NETWORK_PREFIX}-allow-internal \ --network=${GVNIC_NETWORK_PREFIX}-main \ --allow=all \ --source-ranges=172.16.0.0/12,10.0.0.0/8 \ --description="Allow all internal traffic within the network."
4. توفير مجموعة GKE
أنشئ مجموعة GKE عادية تم إعدادها لتوافق عمليات ربط GCS Fuse وأحمال عمل Ray Operator.
- إنشاء المجموعة:
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${REGION} \ --release-channel=rapid \ --machine-type=e2-standard-4 \ --network=${GVNIC_NETWORK_PREFIX}-main \ --subnetwork=${GVNIC_NETWORK_PREFIX}-tpu \ --num-nodes=1 \ --gateway-api=standard \ --enable-managed-prometheus \ --enable-dataplane-v2 \ --enable-dataplane-v2-metrics \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=HttpLoadBalancing,GcsFuseCsiDriver,RayOperator,HorizontalPodAutoscaling,NodeLocalDNS \ --enable-ip-alias - استرداد بيانات اعتماد المجموعة:
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${REGION} - إنشاء رمز Hugging Face السرّي:
kubectl create secret generic llm-d-hf-token \ --from-literal=hf_api_token=${HF_TOKEN} \ --dry-run=client -o yaml | kubectl apply -f -
5- إنشاء مجموعات عقد TPU محجوزة
وفِّر مجموعات العُقد المخصّصة الثماني لشرائح TPU v6e باستخدام حجزك.
نفِّذ الحلقة التالية لإنشاء مجموعات العُقد الثماني:
for i in {1..8}
do
gcloud beta container node-pools create "tpu-v6e-single-$i" \
--project=${PROJECT_ID} \
--cluster=${CLUSTER_NAME} \
--region=${REGION} \
--node-locations=${ZONE} \
--machine-type=ct6e-standard-4t \
--tpu-topology=2x2 \
--num-nodes=1 \
--reservation-affinity=specific \
--reservation=${RESERVATION_NAME} \
--workload-metadata=GKE_METADATA &
done
انتظِر إلى أن يتم إنشاء جميع العُقد والانضمام إلى المجموعة. يمكنك التحقّق من الحالة من خلال kubectl get nodes.
6. نشر خدمة llm-d
عليك الآن نشر إطار عمل llm-d لإدارة العرض المجزّأ.
- ثبِّت Helm لنشر مخططات llm-d:
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-4 chmod 700 get_helm.sh ./get_helm.sh - استنساخ llm-d وتثبيت التبعيات المطلوبة:
git clone https://github.com/llm-d/llm-d.git # When using yq alongside Helm, you almost always want the version by Mike Farah (mikefarah/yq). We remove the most common yq installation before reinstalling sudo rm -rf /usr/local/bin/yq cd llm-d ./helpers/client-setup/install-deps.sh - إعداد ملف custom_values_tpu.yaml لتحديد إعدادات العرض المجزّأ للمجموعة:
cat <<EOF > llm-d/guides/pd-disaggregation/ms-pd/values_tpu.yaml multinode: false # Configure accelerator type for Google TPU accelerator: type: google modelArtifacts: uri: "hf://Qwen/Qwen3-32B" size: 200Gi authSecretName: "llm-d-hf-token" name: "Qwen/Qwen3-32B" labels: llm-d.ai/inference-serving: "true" llm-d.ai/guide: "pd-disaggregation" llm-d.ai/hardware-variant: "tpu" llm-d.ai/hardware-vendor: "google" llm-d.ai/model: "Qwen3-32B" tracing: enabled: true otlpEndpoint: "localhost:4317" serviceNames: routingProxy: "routing-proxy" sampling: sampler: "always_off" samplerArg: "0" routing: servicePort: 8000 proxy: image: ghcr.io/llm-d/llm-d-routing-sidecar:v0.5.0 connector: nixlv2 secure: false decode: parallelism: tensor: 4 create: true replicas: 4 modelCommand: custom extraConfig: nodeSelector: cloud.google.com/gke-tpu-accelerator: "tpu-v6e-slice" cloud.google.com/gke-tpu-topology: "2x2" monitoring: podmonitor: enabled: true portName: "vllm" path: "/metrics" interval: "30s" containers: - name: "vllm" image: "vllm/vllm-tpu:nightly" command: - "/bin/bash" - "-c" - | # ROLE: kv_consumer (Receives KV cache from prefill) KV_CONFIG="{\"kv_connector\":\"TPUConnector\", \"kv_connector_module_path\" : \"tpu_inference.distributed.tpu_connector\", \"kv_role\":\"kv_consumer\", \"kv_ip\" : \"$POD_IP\"}" echo "KV_CONFIG=$KV_CONFIG" python3 -m vllm.entrypoints.openai.api_server \ --model "Qwen/Qwen3-32B" \ --port 8200 \ --tensor-parallel-size 4 \ --kv-transfer-config "${KV_CONFIG}" \ --disable-uvicorn-access-log \ --max-num-seqs 256 \ --block-size 128 \ --gpu-memory-utilization 0.90 \ --max-model-len 8192 env: - name: POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: TPU_SIDE_CHANNEL_PORT value: "9600" - name: TPU_KV_TRANSFER_PORT value: "9100" ports: - containerPort: 8200 name: vllm protocol: TCP - containerPort: 9100 name: tpu-kv-transfer protocol: TCP - containerPort: 9600 name: tpu-coord protocol: TCP resources: limits: memory: 64Gi cpu: "16" google.com/tpu: 4 requests: memory: 64Gi cpu: "16" google.com/tpu: 4 mountModelVolume: true volumeMounts: - name: metrics-volume mountPath: /.config - name: shm mountPath: /dev/shm - name: torch-compile-cache mountPath: /.cache startupProbe: httpGet: path: /health port: vllm initialDelaySeconds: 15 periodSeconds: 30 timeoutSeconds: 5 failureThreshold: 120 livenessProbe: httpGet: path: /health port: vllm periodSeconds: 10 timeoutSeconds: 5 failureThreshold: 3 readinessProbe: httpGet: path: /v1/models port: vllm periodSeconds: 5 timeoutSeconds: 2 failureThreshold: 3 volumes: - name: metrics-volume emptyDir: {} - name: shm emptyDir: medium: Memory sizeLimit: "16Gi" - name: torch-compile-cache emptyDir: {} prefill: parallelism: tensor: 4 create: true replicas: 4 modelCommand: custom extraConfig: nodeSelector: cloud.google.com/gke-tpu-accelerator: "tpu-v6e-slice" cloud.google.com/gke-tpu-topology: "2x2" monitoring: podmonitor: enabled: true portName: "vllm" path: "/metrics" interval: "30s" containers: - name: "vllm" image: "vllm/vllm-tpu:nightly" command: - "/bin/bash" - "-c" - | # ROLE: kv_producer (Sends KV cache to decode) KV_CONFIG="{\"kv_connector\":\"TPUConnector\", \"kv_connector_module_path\" : \"tpu_inference.distributed.tpu_connector\", \"kv_role\":\"kv_producer\", \"kv_ip\" : \"$POD_IP\"}" echo "KV_CONFIG=$KV_CONFIG" python3 -m vllm.entrypoints.openai.api_server \ --model "Qwen/Qwen3-32B" \ --port 8200 \ --tensor-parallel-size 4 \ --kv-transfer-config "${KV_CONFIG}" \ --disable-uvicorn-access-log \ --enable-chunked-prefill \ --block-size 128 \ --gpu-memory-utilization 0.90 \ --max-model-len 8192 env: - name: POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: TPU_SIDE_CHANNEL_PORT value: "9600" - name: TPU_KV_TRANSFER_PORT value: "9100" ports: - containerPort: 8200 name: vllm protocol: TCP - containerPort: 9100 name: tpu-kv-transfer protocol: TCP - containerPort: 9600 name: tpu-coord protocol: TCP resources: limits: memory: 64Gi cpu: "16" google.com/tpu: 4 requests: memory: 64Gi cpu: "16" google.com/tpu: 4 mountModelVolume: true volumeMounts: - name: metrics-volume mountPath: /.config - name: shm mountPath: /dev/shm - name: torch-compile-cache mountPath: /.cache startupProbe: httpGet: path: /health port: vllm initialDelaySeconds: 15 periodSeconds: 30 timeoutSeconds: 5 failureThreshold: 120 livenessProbe: httpGet: path: /health port: vllm periodSeconds: 10 timeoutSeconds: 5 failureThreshold: 3 readinessProbe: httpGet: path: /v1/models port: vllm periodSeconds: 5 timeoutSeconds: 2 failureThreshold: 3 volumes: - name: metrics-volume emptyDir: {} - name: shm emptyDir: medium: Memory sizeLimit: "16Gi" - name: torch-compile-cache emptyDir: {} EOF - نشر الخدمة والبوابة باستخدام مخطط Helm الخاص بـ llm-d:
cd llm-d/guides/pd-disaggregation/ helmfile apply -e gke_tpu -n $NAMESPACE kubectl apply -f ./httproute.gke.yaml - انتظِر حتى تبدأ خدمات vLLMشاهِد سجلّات حزمة تطوير البرامج الخاصة بفك الترميز والتعبئة المسبقة إلى أن يظهر لك "INFO: Application startup complete."
DECODE_POD=$(kubectl get pods -l llm-d.ai/modelservice-role=decode -o jsonpath='{.items[0].metadata.name}') # Get the first Prefill pod name PREFILL_POD=$(kubectl get pods -l llm-d.ai/modelservice-role=prefill -o jsonpath='{.items[0].metadata.name}') echo "Run each of these until vLLM starts successfully and then ctrl-C out" echo "kubectl logs -f $DECODE_POD -c vllm" echo "kubectl logs -f $PREFILL_POD -c vllm"
7. استجابة اختبار النشر
سيختبر النص البرمجي أدناه إمكانية الاتصال بمجموعة الخوادم من خلال GKE Inference Gateway، ثم سيُجري اختبارًا معياريًا.
- اختبار الاتصال وقياس الأداء:
cat <<EOBF > ./run_benchmark.sh #!/bin/bash # Configuration NAMESPACE="default" JOB_NAME="qwen3-pd-benchmark" MODEL_NAME="Qwen/Qwen3-32B" echo "🔍 Discovering Gateway IP..." GATEWAY_IP=$(kubectl get gateway -n ${NAMESPACE} -o jsonpath='{.items[0].status.addresses[0].value}') if [ -z "$GATEWAY_IP" ]; then echo "❌ Error: Could not find Gateway IP. Check 'kubectl get gateway'." exit 1 fi TARGET_URL="http://${GATEWAY_IP}" echo "✅ Found Gateway at: $TARGET_URL" echo "🗑️ Cleaning up old benchmark jobs..." kubectl delete job $JOB_NAME --ignore-not-found=true echo "🚀 Generating and applying Benchmark Job..." cat <<EOF | kubectl apply -f - apiVersion: batch/v1 kind: Job metadata: name: $JOB_NAME namespace: $NAMESPACE spec: template: spec: containers: - name: llm-benchmark image: vllm/vllm-openai:latest command: ["/bin/bash", "-c"] args: - | # 1. Download dataset if [ ! -f /data/sharegpt.json ]; then echo "Downloading ShareGPT dataset..." curl -L "https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json" -o /data/sharegpt.json fi # 2. Wait for Gateway readiness echo "Checking connectivity to $MODEL_NAME..." until curl -s "$TARGET_URL/v1/models" | grep -q "$MODEL_NAME"; do echo "Waiting for Gateway backends to sync..." sleep 10 done # 3. Run Benchmark vllm bench serve \\ --base-url "$TARGET_URL" \\ --model "$MODEL_NAME" \\ --dataset-name "sharegpt" \\ --dataset-path "/data/sharegpt.json" \\ --request-rate 80.0 \\ --num-prompts 2000 \\ --tokenizer "$MODEL_NAME" volumeMounts: - name: dataset-volume mountPath: /data restartPolicy: Never volumes: - name: dataset-volume emptyDir: {} EOF echo "⏳ Job submitted. Follow logs with:" echo "kubectl logs -f job/$JOB_NAME" EOBF chmod a+x ./run_benchmark.sh ./run_benchmark.sh
8. تَنظيم
لتجنُّب الرسوم المستمرة على حسابك على Google Cloud، احذف الموارد التي تم إنشاؤها أثناء هذا الدرس العملي.
اتّبِع الخطوات التالية لتنظيف مواد العرض:
# 1. Delete LeaderWorkerSet and Helm release
kubectl delete leaderworkerset qwen-simple-anywhere-cache --ignore-not-found
helm uninstall lws --namespace lws-system 2>/dev/null
kubectl delete namespace lws-system --ignore-not-found
# 2. Delete GKE Node Pools
# Note: Usually deleting the cluster deletes the node pools,
# but explicit deletion ensures it's gone before the cluster teardown begins.
for i in {1..8}
do
gcloud container node-pools delete "tpu-v6e-single-$i" \
--cluster="${CLUSTER_NAME}" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
done
# 3. Delete GKE Cluster
gcloud container clusters delete "${CLUSTER_NAME}" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
echo "--- Starting IAM and Service Account Cleanup ---"
# 1. Define the full Service Account email for clarity
SA_EMAIL="tpu-reader-sa@${PROJECT_ID}.iam.gserviceaccount.com"
# 2. Remove Storage Bucket IAM Binding
# This removes the 'objectViewer' role from the specific bucket
gcloud storage buckets remove-iam-policy-binding gs://inf-demo-model-storage \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectViewer" --quiet
# 3. Remove Workload Identity Binding
# This severs the link between the GKE KSA and the GCP SA
gcloud iam service-accounts remove-iam-policy-binding "${SA_EMAIL}" \
--role="roles/iam.workloadIdentityUser" \
--member="serviceAccount:${PROJECT_ID}.svc.id.goog[default/default]" --quiet
# 4. Delete the Service Account
gcloud iam service-accounts delete "${SA_EMAIL}" --project="${PROJECT_ID}" --quiet
echo "IAM cleanup complete!"
echo "--- Starting Network and Firewall Cleanup ---"
# 4. Delete Firewall Rules (Must go before the Network)
gcloud compute firewall-rules delete \
"${GVNIC_NETWORK_PREFIX}-allow-ssh" \
"${GVNIC_NETWORK_PREFIX}-allow-icmp" \
"${GVNIC_NETWORK_PREFIX}-allow-internal" \
"ray-allow-internal" \
--project="${PROJECT_ID}" --quiet
# 5. Delete Subnets (Must go before the Network)
gcloud compute networks subnets delete "${GVNIC_NETWORK_PREFIX}-tpu" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
gcloud compute networks subnets delete "${GVNIC_NETWORK_PREFIX}-proxy-sub" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
gcloud compute networks subnets delete "proxy-only-subnet" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
# 6. Finally, delete the VPC Network
gcloud compute networks delete "${GVNIC_NETWORK_PREFIX}-main" \
--project="${PROJECT_ID}" --quiet
echo "Cleanup complete!"
9- تهانينا
تهانينا! لقد تمكّنت من نشر Qwen3-32B بنجاح على وحدات TPU المنفصلة من الإصدار 6e باستخدام llm-d وGKE.
ما تعلّمته
- كيفية إعداد شبكة مخصّصة لنقل البيانات بسرعة عالية بين وحدات TPU
- كيفية توفير مجموعات عقد TPU المحجوزة على GKE
- كيفية نشر
llm-dلفصل أعباء العمل الخاصة بالتعبئة المُسبَقة وفك الترميز