
১. ভূমিকা
এই কোডল্যাবে, আপনি শিখবেন কীভাবে গুগল ক্লাউড টিপিইউ ব্যবহার করে গুগল কুবারনেটিস ইঞ্জিন (GKE)-এ উচ্চ-পারফরম্যান্স সম্পন্ন, ডিসঅ্যাগ্রিগেটেড ইনফারেন্সিং সার্ভিস ডেপ্লয় করতে হয়। আপনি ডিস্ট্রিবিউটেড এলএলএম সার্ভিংয়ের জন্য একটি ওপেন-সোর্স ফ্রেমওয়ার্ক, llm-d ব্যবহার করে একাধিক টিপিইউ হোস্টের মধ্যে প্রিফিল এবং ডিকোড পর্যায়গুলোকে আলাদা করবেন, শেয়ার্ড কেভি ক্যাশিং এবং জিকেই ইনফারেন্স গেটওয়ে সেট আপ করবেন।
এই সেটআপটি Qwen3-32B-এর মতো বড় মডেলগুলোকে উচ্চ থ্রুপুট ও কম ল্যাটেন্সিতে পরিষেবা দেওয়ার জন্য একটি প্রোডাকশন পরিবেশের অনুকরণ করে।
আপনি যা করবেন
- অ্যাক্সিলারেটর ট্র্যাফিকের জন্য অপ্টিমাইজ করা MTU সহ একটি কাস্টম VPC নেটওয়ার্ক তৈরি করুন।
- GCS Fuse CSI ড্রাইভার এবং Ray Operator অ্যাডঅন সহ একটি GKE ক্লাস্টার প্রস্তুত করুন।
- TPU v6e স্লাইসগুলোর জন্য ৮টি ডেডিকেটেড নোড পুল তৈরি করুন (মোট ৩২টি চিপ)।
- GCS অ্যাক্সেসের জন্য ওয়ার্কলোড আইডেন্টিটি এবং অনুমতি কনফিগার করুন।
- Qwen3-32B মডেলের বিচ্ছিন্ন পরিবেশন পরিচালনা করতে
llm-dস্থাপন করুন। - বেঞ্চমার্ক পরীক্ষার মাধ্যমে ডেপ্লয়মেন্টটি যাচাই করুন।
স্থাপত্য
[llm-d বিচ্ছিন্ন পরিবেশন স্থাপত্য, যেখানে মডেলটিকে প্রিফিলের ৪টি ২x২ প্রতিরূপে এবং ডিকোডের জন্যও একই রকমভাবে বিভক্ত দেখানো হচ্ছে] 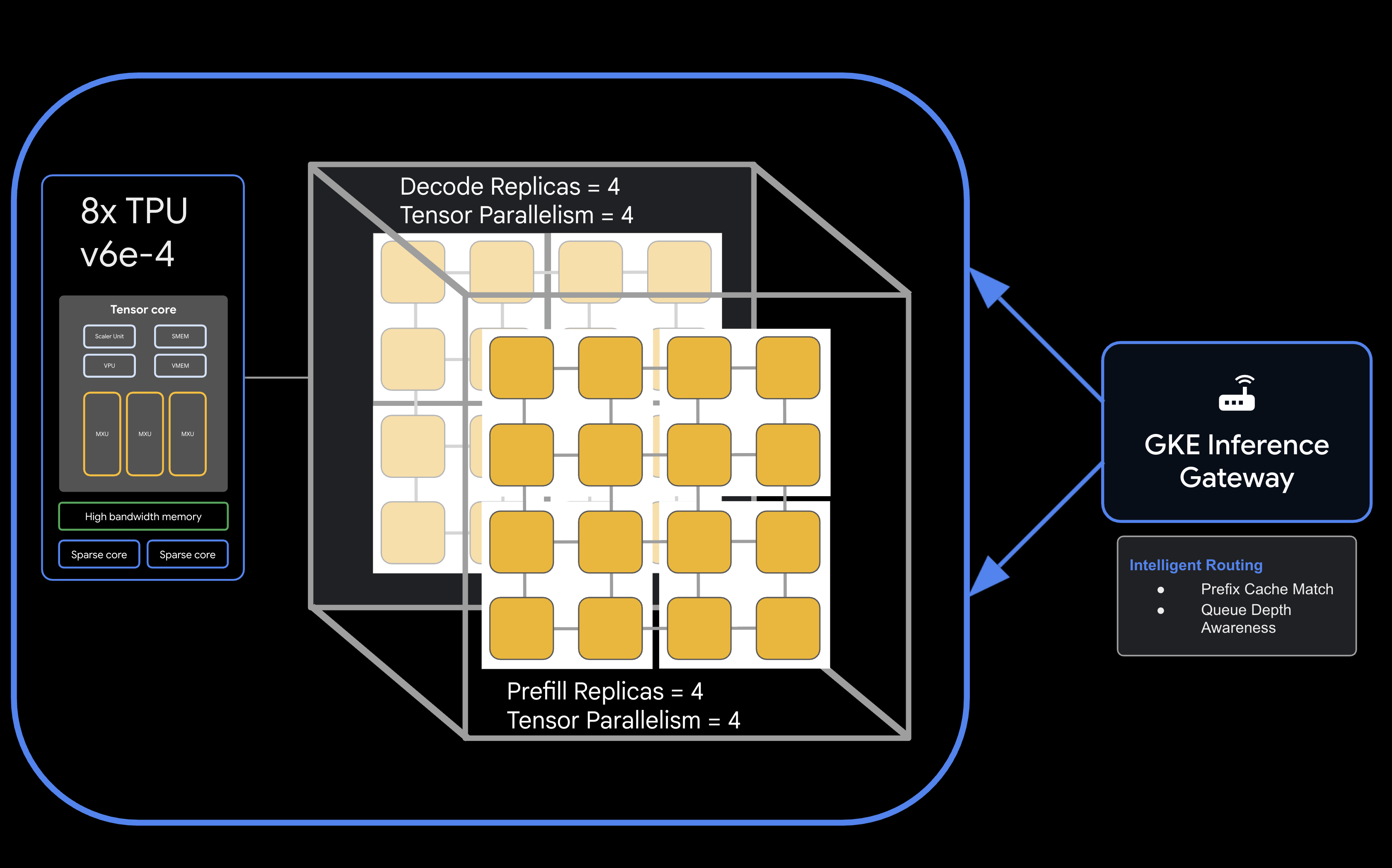
আপনার যা যা লাগবে
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
- TPU v6e রিসোর্সের (৩২টি চিপ,
ct6e-standard-4t) জন্য একটি গুগল ক্লাউড রিজার্ভেশন । - মডেলের ওজন ডাউনলোড করার জন্য একটি হাগিং ফেস ইউজার অ্যাক্সেস টোকেন প্রয়োজন ।
- ক্লাউড শেল অথবা একটি লোকাল টার্মিনাল, যেখানে
gcloud,kubectlএবংhelmইনস্টল করা আছে।
- আনুমানিক সময়কাল: ৬০ মিনিট
- আনুমানিক খরচ: এই ল্যাবটিতে টিপিইউ-এর উল্লেখযোগ্য পরিমাণ রিসোর্সের প্রয়োজন হবে এবং প্রকল্পটি শেষ করতে ন্যূনতম $60 খরচ হবে। অনুশীলনগুলো শেষ করার সাথে সাথেই পরিষ্কার-পরিচ্ছন্নতার ধাপগুলো অনুসরণ করা নিশ্চিত করুন।
২. শুরু করার আগে
একটি গুগল ক্লাউড প্রজেক্ট তৈরি করুন বা নির্বাচন করুন
- গুগল ক্লাউড কনসোলে , একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন।
ক্লাউড শেল শুরু করুন
- Google Cloud কনসোলের শীর্ষে থাকা Activate Cloud Shell-এ ক্লিক করুন।
- প্রমাণীকরণ যাচাই করুন:
gcloud auth list
- আপনার প্রকল্পটি নিশ্চিত করুন:
gcloud config get project
- প্রয়োজনে সেট করুন:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
এপিআই সক্ষম করুন
প্রয়োজনীয় গুগল ক্লাউড পরিষেবাগুলি সক্রিয় করুন:
gcloud services enable \
container.googleapis.com \
compute.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com
পরিবেশ ভেরিয়েবল সেট করুন
আপনার শেলে নিম্নলিখিত ভেরিয়েবলগুলো সংজ্ঞায়িত করুন। <YOUR_ZONE> এর জায়গায় আপনার বরাদ্দকৃত TPU জোন, <YOUR_RESERVATION_NAME> এর জায়গায় আপনার রিজার্ভেশন আইডি এবং <YOUR_HUGGING_FACE_TOKEN> এর জায়গায় আপনার টোকেন বসান।
export PROJECT_ID=$(gcloud config get-value project)
export ZONE="<YOUR_ZONE>" # e.g., us-east5-a
export REGION=${ZONE%-*}
export NAMESPACE=default
export CLUSTER_NAME="qwen-serving-cluster"
export GVNIC_NETWORK_PREFIX="qwen-serving"
export RESERVATION_NAME="<YOUR_RESERVATION_NAME>"
export HF_TOKEN="<YOUR_HUGGING_FACE_TOKEN>"
৩. কাস্টম নেটওয়ার্কিং তৈরি করুন
প্রিফিল এবং ডিকোড নোডগুলির মধ্যে উচ্চ-ব্যান্ডউইথ ট্র্যাফিক পরিচালনা করার জন্য ডিসঅ্যাগ্রিগেটেড সার্ভিংয়ের ক্ষেত্রে নির্দিষ্ট নেটওয়ার্ক কনফিগারেশনের প্রয়োজন হয়।
- দক্ষ অ্যাক্সিলারেটর যোগাযোগের জন্য একটি বড় MTU (8896) সহ VPC নেটওয়ার্ক তৈরি করুন :
gcloud compute --project=${PROJECT_ID} \ networks create ${GVNIC_NETWORK_PREFIX}-main \ --subnet-mode=auto \ --bgp-routing-mode=regional \ --mtu=8896 - ক্লাস্টারের জন্য সাবনেট তৈরি করুন :
gcloud compute --project=${PROJECT_ID} \ networks subnets create ${GVNIC_NETWORK_PREFIX}-tpu \ --network=${GVNIC_NETWORK_PREFIX}-main \ --region=${REGION} \ --range=10.10.0.0/18 - GKE গেটওয়ে API-এর জন্য প্রয়োজনীয় একটি প্রক্সি-অনলি সাবনেট তৈরি করুন :
gcloud compute networks subnets create ${GVNIC_NETWORK_PREFIX}-proxy \ --purpose=REGIONAL_MANAGED_PROXY \ --role=ACTIVE \ --region=${REGION} \ --network=${GVNIC_NETWORK_PREFIX}-main \ --range=172.16.0.0/26 - অভ্যন্তরীণ যোগাযোগের অনুমতি দেওয়ার জন্য ফায়ারওয়াল নিয়ম তৈরি করুন :
gcloud compute --project=${PROJECT_ID} firewall-rules create ${GVNIC_NETWORK_PREFIX}-allow-internal \ --network=${GVNIC_NETWORK_PREFIX}-main \ --allow=all \ --source-ranges=172.16.0.0/12,10.0.0.0/8 \ --description="Allow all internal traffic within the network."
৪. GKE ক্লাস্টারের ব্যবস্থা করা
GCS ফিউজ মাউন্ট এবং রে অপারেটর ওয়ার্কলোড সমর্থন করার জন্য কনফিগার করা একটি স্ট্যান্ডার্ড GKE ক্লাস্টার তৈরি করুন।
- ক্লাস্টার তৈরি করুন :
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${REGION} \ --release-channel=rapid \ --machine-type=e2-standard-4 \ --network=${GVNIC_NETWORK_PREFIX}-main \ --subnetwork=${GVNIC_NETWORK_PREFIX}-tpu \ --num-nodes=1 \ --gateway-api=standard \ --enable-managed-prometheus \ --enable-dataplane-v2 \ --enable-dataplane-v2-metrics \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=HttpLoadBalancing,GcsFuseCsiDriver,RayOperator,HorizontalPodAutoscaling,NodeLocalDNS \ --enable-ip-alias - ক্লাস্টার ক্রেডেনশিয়াল পুনরুদ্ধার করুন :
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${REGION} - আলিঙ্গন করার মতো মুখের গোপন রহস্য তৈরি করুন :
kubectl create secret generic llm-d-hf-token \ --from-literal=hf_api_token=${HF_TOKEN} \ --dry-run=client -o yaml | kubectl apply -f -
৫. সংরক্ষিত টিপিইউ নোড পুল তৈরি করুন
আপনার রিজার্ভেশন ব্যবহার করে TPU v6e স্লাইসগুলির জন্য ৮টি ডেডিকেটেড নোড পুল প্রোভিশন করুন।
৮টি নোড পুল তৈরি করতে নিম্নলিখিত লুপটি চালান:
for i in {1..8}
do
gcloud beta container node-pools create "tpu-v6e-single-$i" \
--project=${PROJECT_ID} \
--cluster=${CLUSTER_NAME} \
--region=${REGION} \
--node-locations=${ZONE} \
--machine-type=ct6e-standard-4t \
--tpu-topology=2x2 \
--num-nodes=1 \
--reservation-affinity=specific \
--reservation=${RESERVATION_NAME} \
--workload-metadata=GKE_METADATA &
done
সমস্ত নোড তৈরি হয়ে ক্লাস্টারে যোগ দেওয়া পর্যন্ত অপেক্ষা করুন। আপনি kubectl get nodes দিয়ে স্ট্যাটাস চেক করতে পারেন।
৬. llm-d সার্ভিস ডিপ্লয় করুন
এখন আপনি বিচ্ছিন্ন পরিবেশন ব্যবস্থাপনার জন্য llm-d ফ্রেমওয়ার্কটি স্থাপন করবেন।
- llm-d চার্ট ডিপ্লয় করতে Helm ইনস্টল করুন :
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-4 chmod 700 get_helm.sh ./get_helm.sh - llm-d ক্লোন করুন এবং প্রয়োজনীয় নির্ভরতাগুলো ইনস্টল করুন:
git clone https://github.com/llm-d/llm-d.git # When using yq alongside Helm, you almost always want the version by Mike Farah (mikefarah/yq). We remove the most common yq installation before reinstalling sudo rm -rf /usr/local/bin/yq cd llm-d ./helpers/client-setup/install-deps.sh - আপনার ক্লাস্টারের জন্য ডিসঅ্যাগ্রিগেটেড সার্ভিং কনফিগার করতে কাস্টম values_tpu.yaml প্রস্তুত করুন :
cat <<EOF > llm-d/guides/pd-disaggregation/ms-pd/values_tpu.yaml multinode: false # Configure accelerator type for Google TPU accelerator: type: google modelArtifacts: uri: "hf://Qwen/Qwen3-32B" size: 200Gi authSecretName: "llm-d-hf-token" name: "Qwen/Qwen3-32B" labels: llm-d.ai/inference-serving: "true" llm-d.ai/guide: "pd-disaggregation" llm-d.ai/hardware-variant: "tpu" llm-d.ai/hardware-vendor: "google" llm-d.ai/model: "Qwen3-32B" tracing: enabled: true otlpEndpoint: "localhost:4317" serviceNames: routingProxy: "routing-proxy" sampling: sampler: "always_off" samplerArg: "0" routing: servicePort: 8000 proxy: image: ghcr.io/llm-d/llm-d-routing-sidecar:v0.5.0 connector: nixlv2 secure: false decode: parallelism: tensor: 4 create: true replicas: 4 modelCommand: custom extraConfig: nodeSelector: cloud.google.com/gke-tpu-accelerator: "tpu-v6e-slice" cloud.google.com/gke-tpu-topology: "2x2" monitoring: podmonitor: enabled: true portName: "vllm" path: "/metrics" interval: "30s" containers: - name: "vllm" image: "vllm/vllm-tpu:nightly" command: - "/bin/bash" - "-c" - | # ROLE: kv_consumer (Receives KV cache from prefill) KV_CONFIG="{\"kv_connector\":\"TPUConnector\", \"kv_connector_module_path\" : \"tpu_inference.distributed.tpu_connector\", \"kv_role\":\"kv_consumer\", \"kv_ip\" : \"$POD_IP\"}" echo "KV_CONFIG=$KV_CONFIG" python3 -m vllm.entrypoints.openai.api_server \ --model "Qwen/Qwen3-32B" \ --port 8200 \ --tensor-parallel-size 4 \ --kv-transfer-config "${KV_CONFIG}" \ --disable-uvicorn-access-log \ --max-num-seqs 256 \ --block-size 128 \ --gpu-memory-utilization 0.90 \ --max-model-len 8192 env: - name: POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: TPU_SIDE_CHANNEL_PORT value: "9600" - name: TPU_KV_TRANSFER_PORT value: "9100" ports: - containerPort: 8200 name: vllm protocol: TCP - containerPort: 9100 name: tpu-kv-transfer protocol: TCP - containerPort: 9600 name: tpu-coord protocol: TCP resources: limits: memory: 64Gi cpu: "16" google.com/tpu: 4 requests: memory: 64Gi cpu: "16" google.com/tpu: 4 mountModelVolume: true volumeMounts: - name: metrics-volume mountPath: /.config - name: shm mountPath: /dev/shm - name: torch-compile-cache mountPath: /.cache startupProbe: httpGet: path: /health port: vllm initialDelaySeconds: 15 periodSeconds: 30 timeoutSeconds: 5 failureThreshold: 120 livenessProbe: httpGet: path: /health port: vllm periodSeconds: 10 timeoutSeconds: 5 failureThreshold: 3 readinessProbe: httpGet: path: /v1/models port: vllm periodSeconds: 5 timeoutSeconds: 2 failureThreshold: 3 volumes: - name: metrics-volume emptyDir: {} - name: shm emptyDir: medium: Memory sizeLimit: "16Gi" - name: torch-compile-cache emptyDir: {} prefill: parallelism: tensor: 4 create: true replicas: 4 modelCommand: custom extraConfig: nodeSelector: cloud.google.com/gke-tpu-accelerator: "tpu-v6e-slice" cloud.google.com/gke-tpu-topology: "2x2" monitoring: podmonitor: enabled: true portName: "vllm" path: "/metrics" interval: "30s" containers: - name: "vllm" image: "vllm/vllm-tpu:nightly" command: - "/bin/bash" - "-c" - | # ROLE: kv_producer (Sends KV cache to decode) KV_CONFIG="{\"kv_connector\":\"TPUConnector\", \"kv_connector_module_path\" : \"tpu_inference.distributed.tpu_connector\", \"kv_role\":\"kv_producer\", \"kv_ip\" : \"$POD_IP\"}" echo "KV_CONFIG=$KV_CONFIG" python3 -m vllm.entrypoints.openai.api_server \ --model "Qwen/Qwen3-32B" \ --port 8200 \ --tensor-parallel-size 4 \ --kv-transfer-config "${KV_CONFIG}" \ --disable-uvicorn-access-log \ --enable-chunked-prefill \ --block-size 128 \ --gpu-memory-utilization 0.90 \ --max-model-len 8192 env: - name: POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: TPU_SIDE_CHANNEL_PORT value: "9600" - name: TPU_KV_TRANSFER_PORT value: "9100" ports: - containerPort: 8200 name: vllm protocol: TCP - containerPort: 9100 name: tpu-kv-transfer protocol: TCP - containerPort: 9600 name: tpu-coord protocol: TCP resources: limits: memory: 64Gi cpu: "16" google.com/tpu: 4 requests: memory: 64Gi cpu: "16" google.com/tpu: 4 mountModelVolume: true volumeMounts: - name: metrics-volume mountPath: /.config - name: shm mountPath: /dev/shm - name: torch-compile-cache mountPath: /.cache startupProbe: httpGet: path: /health port: vllm initialDelaySeconds: 15 periodSeconds: 30 timeoutSeconds: 5 failureThreshold: 120 livenessProbe: httpGet: path: /health port: vllm periodSeconds: 10 timeoutSeconds: 5 failureThreshold: 3 readinessProbe: httpGet: path: /v1/models port: vllm periodSeconds: 5 timeoutSeconds: 2 failureThreshold: 3 volumes: - name: metrics-volume emptyDir: {} - name: shm emptyDir: medium: Memory sizeLimit: "16Gi" - name: torch-compile-cache emptyDir: {} EOF - llm-d-এর Helm চার্ট ব্যবহার করে সার্ভিস এবং গেটওয়ে ডিপ্লয় করুন :
cd llm-d/guides/pd-disaggregation/ helmfile apply -e gke_tpu -n $NAMESPACE kubectl apply -f ./httproute.gke.yaml - vLLM পরিষেবাগুলি চালু হওয়ার জন্য অপেক্ষা করুন। "INFO: Application startup complete" না দেখা পর্যন্ত ডিকোড এবং প্রিফিল POD লগগুলি পর্যবেক্ষণ করুন।
DECODE_POD=$(kubectl get pods -l llm-d.ai/modelservice-role=decode -o jsonpath='{.items[0].metadata.name}') # Get the first Prefill pod name PREFILL_POD=$(kubectl get pods -l llm-d.ai/modelservice-role=prefill -o jsonpath='{.items[0].metadata.name}') echo "Run each of these until vLLM starts successfully and then ctrl-C out" echo "kubectl logs -f $DECODE_POD -c vllm" echo "kubectl logs -f $PREFILL_POD -c vllm"
৭. পরীক্ষা স্থাপনের প্রতিক্রিয়া
নিচের স্ক্রিপ্টটি GKE ইনফারেন্স গেটওয়ের মাধ্যমে সার্ভিং ক্লাস্টারের সাথে সংযোগ পরীক্ষা করবে এবং তারপর একটি বেঞ্চমার্কিং পরীক্ষা চালাবে।
- সংযোগ পরীক্ষা করুন এবং বেঞ্চমার্ক চালান :
cat <<EOBF > ./run_benchmark.sh #!/bin/bash # Configuration NAMESPACE="default" JOB_NAME="qwen3-pd-benchmark" MODEL_NAME="Qwen/Qwen3-32B" echo "🔍 Discovering Gateway IP..." GATEWAY_IP=$(kubectl get gateway -n ${NAMESPACE} -o jsonpath='{.items[0].status.addresses[0].value}') if [ -z "$GATEWAY_IP" ]; then echo "❌ Error: Could not find Gateway IP. Check 'kubectl get gateway'." exit 1 fi TARGET_URL="http://${GATEWAY_IP}" echo "✅ Found Gateway at: $TARGET_URL" echo "🗑️ Cleaning up old benchmark jobs..." kubectl delete job $JOB_NAME --ignore-not-found=true echo "🚀 Generating and applying Benchmark Job..." cat <<EOF | kubectl apply -f - apiVersion: batch/v1 kind: Job metadata: name: $JOB_NAME namespace: $NAMESPACE spec: template: spec: containers: - name: llm-benchmark image: vllm/vllm-openai:latest command: ["/bin/bash", "-c"] args: - | # 1. Download dataset if [ ! -f /data/sharegpt.json ]; then echo "Downloading ShareGPT dataset..." curl -L "https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json" -o /data/sharegpt.json fi # 2. Wait for Gateway readiness echo "Checking connectivity to $MODEL_NAME..." until curl -s "$TARGET_URL/v1/models" | grep -q "$MODEL_NAME"; do echo "Waiting for Gateway backends to sync..." sleep 10 done # 3. Run Benchmark vllm bench serve \\ --base-url "$TARGET_URL" \\ --model "$MODEL_NAME" \\ --dataset-name "sharegpt" \\ --dataset-path "/data/sharegpt.json" \\ --request-rate 80.0 \\ --num-prompts 2000 \\ --tokenizer "$MODEL_NAME" volumeMounts: - name: dataset-volume mountPath: /data restartPolicy: Never volumes: - name: dataset-volume emptyDir: {} EOF echo "⏳ Job submitted. Follow logs with:" echo "kubectl logs -f job/$JOB_NAME" EOBF chmod a+x ./run_benchmark.sh ./run_benchmark.sh
৮. পরিষ্কার করুন
আপনার গুগল ক্লাউড অ্যাকাউন্টে চলমান চার্জ এড়াতে, এই কোডল্যাব চলাকালীন তৈরি করা রিসোর্সগুলো মুছে ফেলুন।
আপনার অ্যাসেটগুলো পরিষ্কার করতে নিম্নলিখিত ধাপগুলো অনুসরণ করুন:
# 1. Delete LeaderWorkerSet and Helm release
kubectl delete leaderworkerset qwen-simple-anywhere-cache --ignore-not-found
helm uninstall lws --namespace lws-system 2>/dev/null
kubectl delete namespace lws-system --ignore-not-found
# 2. Delete GKE Node Pools
# Note: Usually deleting the cluster deletes the node pools,
# but explicit deletion ensures it's gone before the cluster teardown begins.
for i in {1..8}
do
gcloud container node-pools delete "tpu-v6e-single-$i" \
--cluster="${CLUSTER_NAME}" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
done
# 3. Delete GKE Cluster
gcloud container clusters delete "${CLUSTER_NAME}" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
echo "--- Starting IAM and Service Account Cleanup ---"
# 1. Define the full Service Account email for clarity
SA_EMAIL="tpu-reader-sa@${PROJECT_ID}.iam.gserviceaccount.com"
# 2. Remove Storage Bucket IAM Binding
# This removes the 'objectViewer' role from the specific bucket
gcloud storage buckets remove-iam-policy-binding gs://inf-demo-model-storage \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectViewer" --quiet
# 3. Remove Workload Identity Binding
# This severs the link between the GKE KSA and the GCP SA
gcloud iam service-accounts remove-iam-policy-binding "${SA_EMAIL}" \
--role="roles/iam.workloadIdentityUser" \
--member="serviceAccount:${PROJECT_ID}.svc.id.goog[default/default]" --quiet
# 4. Delete the Service Account
gcloud iam service-accounts delete "${SA_EMAIL}" --project="${PROJECT_ID}" --quiet
echo "IAM cleanup complete!"
echo "--- Starting Network and Firewall Cleanup ---"
# 4. Delete Firewall Rules (Must go before the Network)
gcloud compute firewall-rules delete \
"${GVNIC_NETWORK_PREFIX}-allow-ssh" \
"${GVNIC_NETWORK_PREFIX}-allow-icmp" \
"${GVNIC_NETWORK_PREFIX}-allow-internal" \
"ray-allow-internal" \
--project="${PROJECT_ID}" --quiet
# 5. Delete Subnets (Must go before the Network)
gcloud compute networks subnets delete "${GVNIC_NETWORK_PREFIX}-tpu" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
gcloud compute networks subnets delete "${GVNIC_NETWORK_PREFIX}-proxy-sub" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
gcloud compute networks subnets delete "proxy-only-subnet" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
# 6. Finally, delete the VPC Network
gcloud compute networks delete "${GVNIC_NETWORK_PREFIX}-main" \
--project="${PROJECT_ID}" --quiet
echo "Cleanup complete!"
৯. অভিনন্দন
অভিনন্দন! আপনি llm-d এবং GKE ব্যবহার করে বিচ্ছিন্ন v6e TPU-গুলিতে Qwen3-32B সফলভাবে স্থাপন করেছেন।
আপনি যা শিখেছেন
- উচ্চ-গতির টিপিইউ ট্র্যাফিকের জন্য কাস্টম নেটওয়ার্কিং কীভাবে কনফিগার করবেন
- GKE-তে সংরক্ষিত TPU নোড পুল কীভাবে প্রোভিশন করতে হয়।
- প্রিফিল এবং ডিকোড ওয়ার্কলোড আলাদা করার জন্য কীভাবে
llm-dস্থাপন করবেন।