
1. Einführung
In diesem Codelab erfahren Sie, wie Sie leistungsstarke, disaggregierte Inferenzdienste in Google Kubernetes Engine (GKE) mit Google Cloud-TPUs bereitstellen. Sie verwenden llm-d, ein Open-Source-Framework für die verteilte Bereitstellung von LLMs, um die Prefill- und Decodierungsphasen auf mehrere TPU-Hosts aufzuteilen, ein gemeinsames KV-Caching und das GKE Inference Gateway einzurichten.
Diese Einrichtung simuliert eine Produktionsumgebung für die Bereitstellung großer Modelle wie Qwen3-32B mit hohem Durchsatz und niedriger Latenz.
Aufgaben
- Erstellen Sie ein benutzerdefiniertes VPC-Netzwerk mit optimierter MTU für Accelerator-Traffic.
- Stellen Sie einen GKE-Cluster mit dem GCS Fuse-CSI-Treiber und den Ray Operator-Add-ons bereit.
- Erstellen Sie 8 dedizierte Knotenpools für TPU v6e-Slices (insgesamt 32 Chips).
- Workload Identity und Berechtigungen für den GCS-Zugriff konfigurieren
- Stellen Sie
llm-dbereit, um die disaggregierte Bereitstellung des Qwen3-32B-Modells zu verwalten. - Prüfen Sie die Bereitstellung mit einem Benchmarktest.
Architektur
![llm-d disaggregated serving architecture showing model split into 4 2x2 replicas of prefill and the same for decode]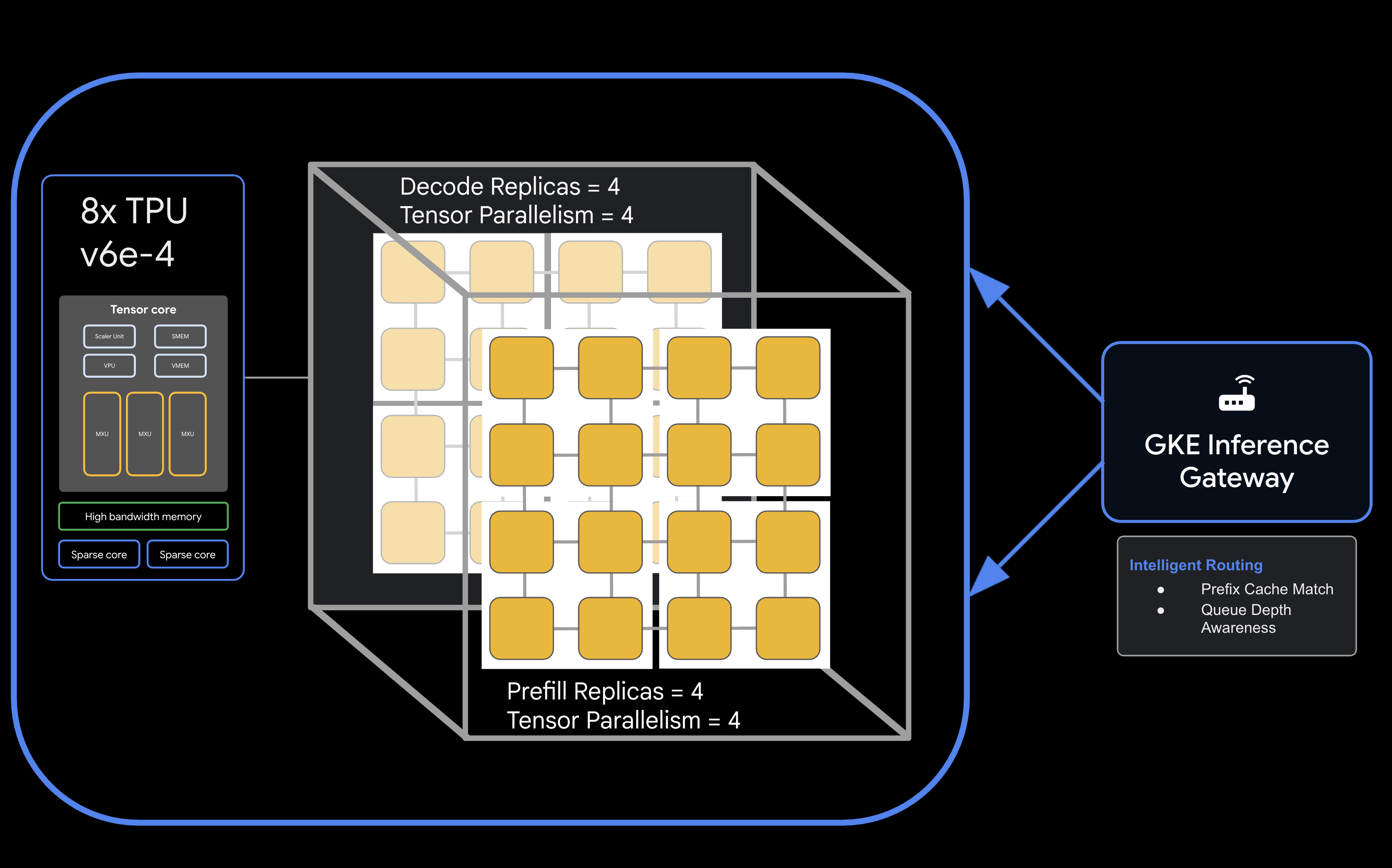
Voraussetzungen
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
- Eine Google Cloud-Reservierung für TPU v6e-Ressourcen (32 Chips,
ct6e-standard-4t). - Ein Hugging Face-Nutzerzugriffstoken zum Herunterladen von Modellgewichten.
- Cloud Shell oder ein lokales Terminal mit den installierten Tools
gcloud,kubectlundhelm.
- Geschätzte Dauer:60 Minuten
- Geschätzte Kosten:Für dieses Lab sind erhebliche TPU-Ressourcen erforderlich. Die Mindestkosten für die Fertigstellung des Projekts betragen 60 $. Führen Sie die Bereinigungsschritte unmittelbar nach Abschluss der Übungen aus.
2. Hinweis
Google Cloud-Projekt erstellen oder auswählen
- Wählen Sie in der Google Cloud Console ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Prüfen Sie, ob für Ihr Cloud-Projekt die Abrechnung aktiviert ist.
Cloud Shell starten
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.
- Authentifizierung überprüfen:
gcloud auth list
- Bestätigen Sie Ihr Projekt:
gcloud config get project
- Legen Sie sie bei Bedarf fest:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
APIs aktivieren
Aktivieren Sie die erforderlichen Google Cloud-Dienste:
gcloud services enable \
container.googleapis.com \
compute.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com
Umgebungsvariablen festlegen
Definieren Sie die folgenden Variablen in Ihrer Shell. Ersetzen Sie <YOUR_ZONE> durch Ihre zugewiesene TPU-Zone, <YOUR_RESERVATION_NAME> durch Ihre Reservierungs-ID und <YOUR_HUGGING_FACE_TOKEN> durch Ihr Token.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE="<YOUR_ZONE>" # e.g., us-east5-a
export REGION=${ZONE%-*}
export NAMESPACE=default
export CLUSTER_NAME="qwen-serving-cluster"
export GVNIC_NETWORK_PREFIX="qwen-serving"
export RESERVATION_NAME="<YOUR_RESERVATION_NAME>"
export HF_TOKEN="<YOUR_HUGGING_FACE_TOKEN>"
3. Benutzerdefiniertes Netzwerk erstellen
Für die disaggregierte Bereitstellung sind bestimmte Netzwerkkonfigurationen erforderlich, um Traffic mit hoher Bandbreite zwischen Prefill- und Decodierungsknoten zu verarbeiten.
- Erstellen Sie das VPC-Netzwerk mit einer großen MTU (8896) für eine effiziente Beschleunigerkommunikation:
gcloud compute --project=${PROJECT_ID} \ networks create ${GVNIC_NETWORK_PREFIX}-main \ --subnet-mode=auto \ --bgp-routing-mode=regional \ --mtu=8896 - Subnetz für den Cluster erstellen:
gcloud compute --project=${PROJECT_ID} \ networks subnets create ${GVNIC_NETWORK_PREFIX}-tpu \ --network=${GVNIC_NETWORK_PREFIX}-main \ --region=${REGION} \ --range=10.10.0.0/18 - Nur-Proxy-Subnetz erstellen, das für die GKE Gateway API erforderlich ist:
gcloud compute networks subnets create ${GVNIC_NETWORK_PREFIX}-proxy \ --purpose=REGIONAL_MANAGED_PROXY \ --role=ACTIVE \ --region=${REGION} \ --network=${GVNIC_NETWORK_PREFIX}-main \ --range=172.16.0.0/26 - Firewallregeln erstellen, um die interne Kommunikation zuzulassen:
gcloud compute --project=${PROJECT_ID} firewall-rules create ${GVNIC_NETWORK_PREFIX}-allow-internal \ --network=${GVNIC_NETWORK_PREFIX}-main \ --allow=all \ --source-ranges=172.16.0.0/12,10.0.0.0/8 \ --description="Allow all internal traffic within the network."
4. GKE-Cluster bereitstellen
Erstellen Sie einen Standard-GKE-Cluster, der für die Unterstützung von GCS Fuse-Bereitstellungen und Ray-Operator-Arbeitslasten konfiguriert ist.
- Cluster erstellen:
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${REGION} \ --release-channel=rapid \ --machine-type=e2-standard-4 \ --network=${GVNIC_NETWORK_PREFIX}-main \ --subnetwork=${GVNIC_NETWORK_PREFIX}-tpu \ --num-nodes=1 \ --gateway-api=standard \ --enable-managed-prometheus \ --enable-dataplane-v2 \ --enable-dataplane-v2-metrics \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=HttpLoadBalancing,GcsFuseCsiDriver,RayOperator,HorizontalPodAutoscaling,NodeLocalDNS \ --enable-ip-alias - Clusteranmeldedaten abrufen:
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${REGION} - Hugging Face-Secret erstellen:
kubectl create secret generic llm-d-hf-token \ --from-literal=hf_api_token=${HF_TOKEN} \ --dry-run=client -o yaml | kubectl apply -f -
5. Reservierte TPU-Knotenpools erstellen
Stellen Sie die acht dedizierten Knotenpools für die TPU v6e-Slices mit Ihrer Reservierung bereit.
Führen Sie die folgende Schleife aus, um die acht Knotenpools zu erstellen:
for i in {1..8}
do
gcloud beta container node-pools create "tpu-v6e-single-$i" \
--project=${PROJECT_ID} \
--cluster=${CLUSTER_NAME} \
--region=${REGION} \
--node-locations=${ZONE} \
--machine-type=ct6e-standard-4t \
--tpu-topology=2x2 \
--num-nodes=1 \
--reservation-affinity=specific \
--reservation=${RESERVATION_NAME} \
--workload-metadata=GKE_METADATA &
done
Warten Sie, bis alle Knoten erstellt wurden und dem Cluster beigetreten sind. Sie können den Status mit kubectl get nodes prüfen.
6. LLM-D-Dienst bereitstellen
Jetzt stellen Sie das llm-d-Framework bereit, um die disaggregierte Bereitstellung zu verwalten.
- Installieren Sie Helm, um llm-d-Diagramme bereitzustellen:
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-4 chmod 700 get_helm.sh ./get_helm.sh - llm-d klonen und erforderliche Abhängigkeiten installieren:
git clone https://github.com/llm-d/llm-d.git # When using yq alongside Helm, you almost always want the version by Mike Farah (mikefarah/yq). We remove the most common yq installation before reinstalling sudo rm -rf /usr/local/bin/yq cd llm-d ./helpers/client-setup/install-deps.sh - Bereiten Sie die Datei „custom_values_tpu.yaml“ vor, um die disaggregierte Bereitstellung für Ihren Cluster zu konfigurieren:
cat <<EOF > llm-d/guides/pd-disaggregation/ms-pd/values_tpu.yaml multinode: false # Configure accelerator type for Google TPU accelerator: type: google modelArtifacts: uri: "hf://Qwen/Qwen3-32B" size: 200Gi authSecretName: "llm-d-hf-token" name: "Qwen/Qwen3-32B" labels: llm-d.ai/inference-serving: "true" llm-d.ai/guide: "pd-disaggregation" llm-d.ai/hardware-variant: "tpu" llm-d.ai/hardware-vendor: "google" llm-d.ai/model: "Qwen3-32B" tracing: enabled: true otlpEndpoint: "localhost:4317" serviceNames: routingProxy: "routing-proxy" sampling: sampler: "always_off" samplerArg: "0" routing: servicePort: 8000 proxy: image: ghcr.io/llm-d/llm-d-routing-sidecar:v0.5.0 connector: nixlv2 secure: false decode: parallelism: tensor: 4 create: true replicas: 4 modelCommand: custom extraConfig: nodeSelector: cloud.google.com/gke-tpu-accelerator: "tpu-v6e-slice" cloud.google.com/gke-tpu-topology: "2x2" monitoring: podmonitor: enabled: true portName: "vllm" path: "/metrics" interval: "30s" containers: - name: "vllm" image: "vllm/vllm-tpu:nightly" command: - "/bin/bash" - "-c" - | # ROLE: kv_consumer (Receives KV cache from prefill) KV_CONFIG="{\"kv_connector\":\"TPUConnector\", \"kv_connector_module_path\" : \"tpu_inference.distributed.tpu_connector\", \"kv_role\":\"kv_consumer\", \"kv_ip\" : \"$POD_IP\"}" echo "KV_CONFIG=$KV_CONFIG" python3 -m vllm.entrypoints.openai.api_server \ --model "Qwen/Qwen3-32B" \ --port 8200 \ --tensor-parallel-size 4 \ --kv-transfer-config "${KV_CONFIG}" \ --disable-uvicorn-access-log \ --max-num-seqs 256 \ --block-size 128 \ --gpu-memory-utilization 0.90 \ --max-model-len 8192 env: - name: POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: TPU_SIDE_CHANNEL_PORT value: "9600" - name: TPU_KV_TRANSFER_PORT value: "9100" ports: - containerPort: 8200 name: vllm protocol: TCP - containerPort: 9100 name: tpu-kv-transfer protocol: TCP - containerPort: 9600 name: tpu-coord protocol: TCP resources: limits: memory: 64Gi cpu: "16" google.com/tpu: 4 requests: memory: 64Gi cpu: "16" google.com/tpu: 4 mountModelVolume: true volumeMounts: - name: metrics-volume mountPath: /.config - name: shm mountPath: /dev/shm - name: torch-compile-cache mountPath: /.cache startupProbe: httpGet: path: /health port: vllm initialDelaySeconds: 15 periodSeconds: 30 timeoutSeconds: 5 failureThreshold: 120 livenessProbe: httpGet: path: /health port: vllm periodSeconds: 10 timeoutSeconds: 5 failureThreshold: 3 readinessProbe: httpGet: path: /v1/models port: vllm periodSeconds: 5 timeoutSeconds: 2 failureThreshold: 3 volumes: - name: metrics-volume emptyDir: {} - name: shm emptyDir: medium: Memory sizeLimit: "16Gi" - name: torch-compile-cache emptyDir: {} prefill: parallelism: tensor: 4 create: true replicas: 4 modelCommand: custom extraConfig: nodeSelector: cloud.google.com/gke-tpu-accelerator: "tpu-v6e-slice" cloud.google.com/gke-tpu-topology: "2x2" monitoring: podmonitor: enabled: true portName: "vllm" path: "/metrics" interval: "30s" containers: - name: "vllm" image: "vllm/vllm-tpu:nightly" command: - "/bin/bash" - "-c" - | # ROLE: kv_producer (Sends KV cache to decode) KV_CONFIG="{\"kv_connector\":\"TPUConnector\", \"kv_connector_module_path\" : \"tpu_inference.distributed.tpu_connector\", \"kv_role\":\"kv_producer\", \"kv_ip\" : \"$POD_IP\"}" echo "KV_CONFIG=$KV_CONFIG" python3 -m vllm.entrypoints.openai.api_server \ --model "Qwen/Qwen3-32B" \ --port 8200 \ --tensor-parallel-size 4 \ --kv-transfer-config "${KV_CONFIG}" \ --disable-uvicorn-access-log \ --enable-chunked-prefill \ --block-size 128 \ --gpu-memory-utilization 0.90 \ --max-model-len 8192 env: - name: POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: TPU_SIDE_CHANNEL_PORT value: "9600" - name: TPU_KV_TRANSFER_PORT value: "9100" ports: - containerPort: 8200 name: vllm protocol: TCP - containerPort: 9100 name: tpu-kv-transfer protocol: TCP - containerPort: 9600 name: tpu-coord protocol: TCP resources: limits: memory: 64Gi cpu: "16" google.com/tpu: 4 requests: memory: 64Gi cpu: "16" google.com/tpu: 4 mountModelVolume: true volumeMounts: - name: metrics-volume mountPath: /.config - name: shm mountPath: /dev/shm - name: torch-compile-cache mountPath: /.cache startupProbe: httpGet: path: /health port: vllm initialDelaySeconds: 15 periodSeconds: 30 timeoutSeconds: 5 failureThreshold: 120 livenessProbe: httpGet: path: /health port: vllm periodSeconds: 10 timeoutSeconds: 5 failureThreshold: 3 readinessProbe: httpGet: path: /v1/models port: vllm periodSeconds: 5 timeoutSeconds: 2 failureThreshold: 3 volumes: - name: metrics-volume emptyDir: {} - name: shm emptyDir: medium: Memory sizeLimit: "16Gi" - name: torch-compile-cache emptyDir: {} EOF - Stellen Sie den Dienst und das Gateway mit dem Helm-Diagramm von llm-d bereit:
cd llm-d/guides/pd-disaggregation/ helmfile apply -e gke_tpu -n $NAMESPACE kubectl apply -f ./httproute.gke.yaml - Warten, bis die vLLM-Dienste gestartet sind: Beobachten Sie die Protokolle der Decode- und Prefill-Pods, bis INFO: Application startup complete. angezeigt wird.
DECODE_POD=$(kubectl get pods -l llm-d.ai/modelservice-role=decode -o jsonpath='{.items[0].metadata.name}') # Get the first Prefill pod name PREFILL_POD=$(kubectl get pods -l llm-d.ai/modelservice-role=prefill -o jsonpath='{.items[0].metadata.name}') echo "Run each of these until vLLM starts successfully and then ctrl-C out" echo "kubectl logs -f $DECODE_POD -c vllm" echo "kubectl logs -f $PREFILL_POD -c vllm"
7. Antwort auf Testbereitstellung
Mit dem folgenden Script wird die Verbindung zum Serving-Cluster über das GKE Inference Gateway getestet und dann ein Benchmark-Test ausgeführt.
- Konnektivität testen und Benchmark ausführen:
cat <<EOBF > ./run_benchmark.sh #!/bin/bash # Configuration NAMESPACE="default" JOB_NAME="qwen3-pd-benchmark" MODEL_NAME="Qwen/Qwen3-32B" echo "🔍 Discovering Gateway IP..." GATEWAY_IP=$(kubectl get gateway -n ${NAMESPACE} -o jsonpath='{.items[0].status.addresses[0].value}') if [ -z "$GATEWAY_IP" ]; then echo "❌ Error: Could not find Gateway IP. Check 'kubectl get gateway'." exit 1 fi TARGET_URL="http://${GATEWAY_IP}" echo "✅ Found Gateway at: $TARGET_URL" echo "🗑️ Cleaning up old benchmark jobs..." kubectl delete job $JOB_NAME --ignore-not-found=true echo "🚀 Generating and applying Benchmark Job..." cat <<EOF | kubectl apply -f - apiVersion: batch/v1 kind: Job metadata: name: $JOB_NAME namespace: $NAMESPACE spec: template: spec: containers: - name: llm-benchmark image: vllm/vllm-openai:latest command: ["/bin/bash", "-c"] args: - | # 1. Download dataset if [ ! -f /data/sharegpt.json ]; then echo "Downloading ShareGPT dataset..." curl -L "https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json" -o /data/sharegpt.json fi # 2. Wait for Gateway readiness echo "Checking connectivity to $MODEL_NAME..." until curl -s "$TARGET_URL/v1/models" | grep -q "$MODEL_NAME"; do echo "Waiting for Gateway backends to sync..." sleep 10 done # 3. Run Benchmark vllm bench serve \\ --base-url "$TARGET_URL" \\ --model "$MODEL_NAME" \\ --dataset-name "sharegpt" \\ --dataset-path "/data/sharegpt.json" \\ --request-rate 80.0 \\ --num-prompts 2000 \\ --tokenizer "$MODEL_NAME" volumeMounts: - name: dataset-volume mountPath: /data restartPolicy: Never volumes: - name: dataset-volume emptyDir: {} EOF echo "⏳ Job submitted. Follow logs with:" echo "kubectl logs -f job/$JOB_NAME" EOBF chmod a+x ./run_benchmark.sh ./run_benchmark.sh
8. Bereinigen
Löschen Sie die in diesem Codelab erstellten Ressourcen, um laufende Gebühren für Ihr Google Cloud-Konto zu vermeiden.
Führen Sie die folgenden Schritte aus, um Ihre Assets zu bereinigen:
# 1. Delete LeaderWorkerSet and Helm release
kubectl delete leaderworkerset qwen-simple-anywhere-cache --ignore-not-found
helm uninstall lws --namespace lws-system 2>/dev/null
kubectl delete namespace lws-system --ignore-not-found
# 2. Delete GKE Node Pools
# Note: Usually deleting the cluster deletes the node pools,
# but explicit deletion ensures it's gone before the cluster teardown begins.
for i in {1..8}
do
gcloud container node-pools delete "tpu-v6e-single-$i" \
--cluster="${CLUSTER_NAME}" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
done
# 3. Delete GKE Cluster
gcloud container clusters delete "${CLUSTER_NAME}" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
echo "--- Starting IAM and Service Account Cleanup ---"
# 1. Define the full Service Account email for clarity
SA_EMAIL="tpu-reader-sa@${PROJECT_ID}.iam.gserviceaccount.com"
# 2. Remove Storage Bucket IAM Binding
# This removes the 'objectViewer' role from the specific bucket
gcloud storage buckets remove-iam-policy-binding gs://inf-demo-model-storage \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectViewer" --quiet
# 3. Remove Workload Identity Binding
# This severs the link between the GKE KSA and the GCP SA
gcloud iam service-accounts remove-iam-policy-binding "${SA_EMAIL}" \
--role="roles/iam.workloadIdentityUser" \
--member="serviceAccount:${PROJECT_ID}.svc.id.goog[default/default]" --quiet
# 4. Delete the Service Account
gcloud iam service-accounts delete "${SA_EMAIL}" --project="${PROJECT_ID}" --quiet
echo "IAM cleanup complete!"
echo "--- Starting Network and Firewall Cleanup ---"
# 4. Delete Firewall Rules (Must go before the Network)
gcloud compute firewall-rules delete \
"${GVNIC_NETWORK_PREFIX}-allow-ssh" \
"${GVNIC_NETWORK_PREFIX}-allow-icmp" \
"${GVNIC_NETWORK_PREFIX}-allow-internal" \
"ray-allow-internal" \
--project="${PROJECT_ID}" --quiet
# 5. Delete Subnets (Must go before the Network)
gcloud compute networks subnets delete "${GVNIC_NETWORK_PREFIX}-tpu" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
gcloud compute networks subnets delete "${GVNIC_NETWORK_PREFIX}-proxy-sub" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
gcloud compute networks subnets delete "proxy-only-subnet" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
# 6. Finally, delete the VPC Network
gcloud compute networks delete "${GVNIC_NETWORK_PREFIX}-main" \
--project="${PROJECT_ID}" --quiet
echo "Cleanup complete!"
9. Glückwunsch
Glückwunsch! Sie haben Qwen3-32B erfolgreich auf disaggregierten v6e-TPUs mit llm-d und GKE bereitgestellt.
Das haben Sie gelernt
- Benutzerdefiniertes Netzwerk für TPU-Traffic mit hoher Geschwindigkeit konfigurieren
- So stellen Sie reservierte TPU-Knotenpools in GKE bereit.
llm-dzum Trennen von Prefill- und Decodierungs-Arbeitslasten bereitstellen