
۱. مقدمه
در این آزمایشگاه کد، شما یاد خواهید گرفت که چگونه سرویسهای استنتاج تفکیکشده و با عملکرد بالا را روی موتور کوبرنتیز گوگل (GKE) با استفاده از TPUهای ابری گوگل مستقر کنید. شما از llm-d ، یک چارچوب متنباز برای سرویسدهی LLM توزیعشده، برای جداسازی مراحل پیشپرسازی و رمزگشایی در چندین میزبان TPU، راهاندازی ذخیرهسازی KV مشترک و دروازه استنتاج GKE استفاده خواهید کرد.
این تنظیمات، یک محیط عملیاتی را برای ارائه مدلهای بزرگی مانند Qwen3-32B با توان عملیاتی بالا و تأخیر کم شبیهسازی میکند.
کاری که انجام خواهید داد
- یک شبکه VPC سفارشی با MTU بهینه شده برای ترافیک شتاب دهنده ایجاد کنید.
- یک کلاستر GKE به همراه درایور GCS Fuse CSI و افزونههای Ray Operator تهیه کنید.
- ۸ مجموعه گره اختصاصی برای برشهای TPU v6e ایجاد کنید (در مجموع ۳۲ تراشه).
- پیکربندی هویت بار کاری و مجوزهای دسترسی به GCS.
-
llm-dبرای مدیریت ارائه تفکیکشده مدل Qwen3-32B مستقر کنید. - استقرار را با یک آزمون معیار تأیید کنید.
معماری
![معماری سرویسدهی تفکیکشدهی llm-d که مدل را به ۴ کپی ۲x۲ از پیشپرسازی و رمزگشایی تقسیم میکند] 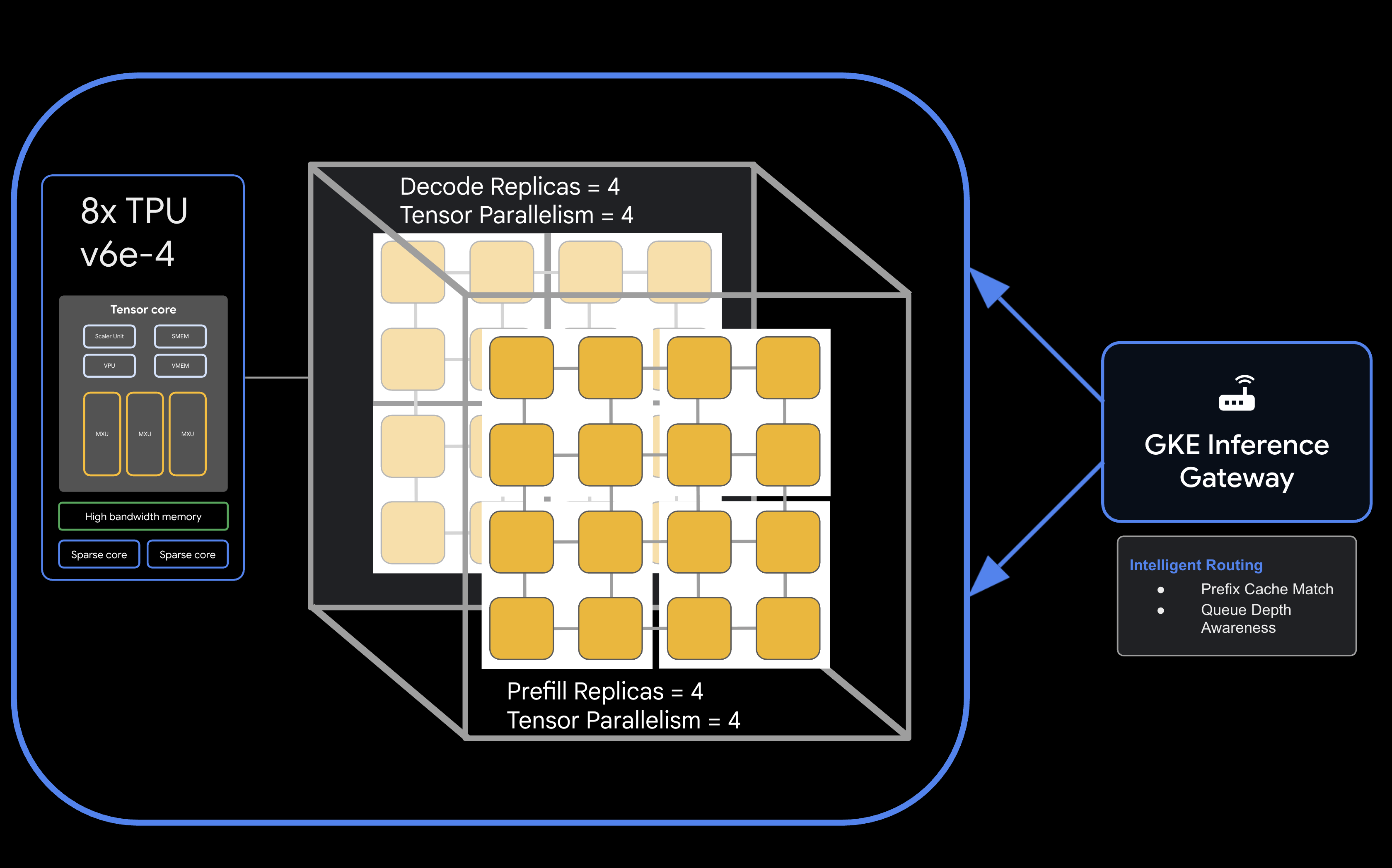
آنچه نیاز دارید
- یک پروژه گوگل کلود با قابلیت پرداخت.
- رزرو فضای ابری گوگل برای منابع TPU v6e (32 تراشه،
ct6e-standard-4t). - یک توکن دسترسی کاربر با قابلیت Hugging Face برای دانلود وزنهای مدل.
- Cloud Shell یا یک ترمینال محلی با
gcloud،kubectlوhelmنصب شده.
- مدت زمان تخمینی: ۶۰ دقیقه
- هزینه تخمینی: این آزمایشگاه شامل منابع قابل توجهی از TPU است و حداقل 60 دلار برای اتمام پروژه هزینه خواهد داشت. اطمینان حاصل کنید که بلافاصله پس از اتمام تمرینات، مراحل تمیزکاری را دنبال میکنید.
۲. قبل از شروع
یک پروژه Google Cloud ایجاد یا انتخاب کنید
- در کنسول گوگل کلود ، یک پروژه گوگل کلود انتخاب یا ایجاد کنید.
- مطمئن شوید که پرداخت برای پروژه ابری شما فعال است.
شروع پوسته ابری
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید.
- تأیید اعتبار:
gcloud auth list
- پروژه خود را تایید کنید:
gcloud config get project
- در صورت نیاز آن را تنظیم کنید:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
فعال کردن APIها
سرویسهای مورد نیاز Google Cloud را فعال کنید:
gcloud services enable \
container.googleapis.com \
compute.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com
تنظیم متغیرهای محیطی
متغیرهای زیر را در پوسته خود تعریف کنید. <YOUR_ZONE> را با منطقه TPU اختصاص داده شده خود، <YOUR_RESERVATION_NAME> را با شناسه رزرو خود و <YOUR_HUGGING_FACE_TOKEN> را با توکن خود جایگزین کنید.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE="<YOUR_ZONE>" # e.g., us-east5-a
export REGION=${ZONE%-*}
export NAMESPACE=default
export CLUSTER_NAME="qwen-serving-cluster"
export GVNIC_NETWORK_PREFIX="qwen-serving"
export RESERVATION_NAME="<YOUR_RESERVATION_NAME>"
export HF_TOKEN="<YOUR_HUGGING_FACE_TOKEN>"
۳. ایجاد شبکهسازی سفارشی
سرویسدهی تفکیکشده نیازمند پیکربندیهای شبکه خاصی است تا بتواند ترافیک پهنای باند بالا را بین گرههای پیشپرسازی و رمزگشایی مدیریت کند.
- برای ارتباط کارآمد شتابدهنده، شبکه VPC را با MTU بزرگ (8896) ایجاد کنید :
gcloud compute --project=${PROJECT_ID} \ networks create ${GVNIC_NETWORK_PREFIX}-main \ --subnet-mode=auto \ --bgp-routing-mode=regional \ --mtu=8896 - زیرشبکه را برای کلاستر ایجاد کنید :
gcloud compute --project=${PROJECT_ID} \ networks subnets create ${GVNIC_NETWORK_PREFIX}-tpu \ --network=${GVNIC_NETWORK_PREFIX}-main \ --region=${REGION} \ --range=10.10.0.0/18 - یک زیرشبکه فقط پروکسی مورد نیاز برای GKE Gateway API ایجاد کنید :
gcloud compute networks subnets create ${GVNIC_NETWORK_PREFIX}-proxy \ --purpose=REGIONAL_MANAGED_PROXY \ --role=ACTIVE \ --region=${REGION} \ --network=${GVNIC_NETWORK_PREFIX}-main \ --range=172.16.0.0/26 - ایجاد قوانین فایروال برای اجازه دادن به ارتباطات داخلی:
gcloud compute --project=${PROJECT_ID} firewall-rules create ${GVNIC_NETWORK_PREFIX}-allow-internal \ --network=${GVNIC_NETWORK_PREFIX}-main \ --allow=all \ --source-ranges=172.16.0.0/12,10.0.0.0/8 \ --description="Allow all internal traffic within the network."
۴. خوشه GKE تأمین
یک کلاستر استاندارد GKE ایجاد کنید که برای پشتیبانی از GCS Fuse mounts و بارهای کاری Ray Operator پیکربندی شده باشد.
- خوشه را ایجاد کنید :
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${REGION} \ --release-channel=rapid \ --machine-type=e2-standard-4 \ --network=${GVNIC_NETWORK_PREFIX}-main \ --subnetwork=${GVNIC_NETWORK_PREFIX}-tpu \ --num-nodes=1 \ --gateway-api=standard \ --enable-managed-prometheus \ --enable-dataplane-v2 \ --enable-dataplane-v2-metrics \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=HttpLoadBalancing,GcsFuseCsiDriver,RayOperator,HorizontalPodAutoscaling,NodeLocalDNS \ --enable-ip-alias - بازیابی اعتبارنامههای کلاستر :
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${REGION} - راز چهره در آغوش گرفته را بسازید :
kubectl create secret generic llm-d-hf-token \ --from-literal=hf_api_token=${HF_TOKEN} \ --dry-run=client -o yaml | kubectl apply -f -
۵. ایجاد استخرهای گره TPU رزرو شده
با استفاده از رزرو خود، 8 استخر گره اختصاصی را برای برشهای TPU v6e فراهم کنید.
حلقه زیر را برای ایجاد ۸ گره pool اجرا کنید:
for i in {1..8}
do
gcloud beta container node-pools create "tpu-v6e-single-$i" \
--project=${PROJECT_ID} \
--cluster=${CLUSTER_NAME} \
--region=${REGION} \
--node-locations=${ZONE} \
--machine-type=ct6e-standard-4t \
--tpu-topology=2x2 \
--num-nodes=1 \
--reservation-affinity=specific \
--reservation=${RESERVATION_NAME} \
--workload-metadata=GKE_METADATA &
done
صبر کنید تا همه گرهها ایجاد شوند و به خوشه بپیوندند. میتوانید وضعیت را با kubectl get nodes بررسی کنید.
۶. سرویس llm-d را مستقر کنید
اکنون چارچوب llm-d را برای مدیریت سرویسدهی تفکیکشده مستقر خواهید کرد.
- برای استقرار نمودارهای llm-d، Helm را نصب کنید :
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-4 chmod 700 get_helm.sh ./get_helm.sh - llm-d را کلون کنید و وابستگیهای مورد نیاز را نصب کنید:
git clone https://github.com/llm-d/llm-d.git # When using yq alongside Helm, you almost always want the version by Mike Farah (mikefarah/yq). We remove the most common yq installation before reinstalling sudo rm -rf /usr/local/bin/yq cd llm-d ./helpers/client-setup/install-deps.sh - فایل values_tpu.yaml سفارشی را برای پیکربندی سرویس تفکیکشده برای کلاستر خود آماده کنید :
cat <<EOF > llm-d/guides/pd-disaggregation/ms-pd/values_tpu.yaml multinode: false # Configure accelerator type for Google TPU accelerator: type: google modelArtifacts: uri: "hf://Qwen/Qwen3-32B" size: 200Gi authSecretName: "llm-d-hf-token" name: "Qwen/Qwen3-32B" labels: llm-d.ai/inference-serving: "true" llm-d.ai/guide: "pd-disaggregation" llm-d.ai/hardware-variant: "tpu" llm-d.ai/hardware-vendor: "google" llm-d.ai/model: "Qwen3-32B" tracing: enabled: true otlpEndpoint: "localhost:4317" serviceNames: routingProxy: "routing-proxy" sampling: sampler: "always_off" samplerArg: "0" routing: servicePort: 8000 proxy: image: ghcr.io/llm-d/llm-d-routing-sidecar:v0.5.0 connector: nixlv2 secure: false decode: parallelism: tensor: 4 create: true replicas: 4 modelCommand: custom extraConfig: nodeSelector: cloud.google.com/gke-tpu-accelerator: "tpu-v6e-slice" cloud.google.com/gke-tpu-topology: "2x2" monitoring: podmonitor: enabled: true portName: "vllm" path: "/metrics" interval: "30s" containers: - name: "vllm" image: "vllm/vllm-tpu:nightly" command: - "/bin/bash" - "-c" - | # ROLE: kv_consumer (Receives KV cache from prefill) KV_CONFIG="{\"kv_connector\":\"TPUConnector\", \"kv_connector_module_path\" : \"tpu_inference.distributed.tpu_connector\", \"kv_role\":\"kv_consumer\", \"kv_ip\" : \"$POD_IP\"}" echo "KV_CONFIG=$KV_CONFIG" python3 -m vllm.entrypoints.openai.api_server \ --model "Qwen/Qwen3-32B" \ --port 8200 \ --tensor-parallel-size 4 \ --kv-transfer-config "${KV_CONFIG}" \ --disable-uvicorn-access-log \ --max-num-seqs 256 \ --block-size 128 \ --gpu-memory-utilization 0.90 \ --max-model-len 8192 env: - name: POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: TPU_SIDE_CHANNEL_PORT value: "9600" - name: TPU_KV_TRANSFER_PORT value: "9100" ports: - containerPort: 8200 name: vllm protocol: TCP - containerPort: 9100 name: tpu-kv-transfer protocol: TCP - containerPort: 9600 name: tpu-coord protocol: TCP resources: limits: memory: 64Gi cpu: "16" google.com/tpu: 4 requests: memory: 64Gi cpu: "16" google.com/tpu: 4 mountModelVolume: true volumeMounts: - name: metrics-volume mountPath: /.config - name: shm mountPath: /dev/shm - name: torch-compile-cache mountPath: /.cache startupProbe: httpGet: path: /health port: vllm initialDelaySeconds: 15 periodSeconds: 30 timeoutSeconds: 5 failureThreshold: 120 livenessProbe: httpGet: path: /health port: vllm periodSeconds: 10 timeoutSeconds: 5 failureThreshold: 3 readinessProbe: httpGet: path: /v1/models port: vllm periodSeconds: 5 timeoutSeconds: 2 failureThreshold: 3 volumes: - name: metrics-volume emptyDir: {} - name: shm emptyDir: medium: Memory sizeLimit: "16Gi" - name: torch-compile-cache emptyDir: {} prefill: parallelism: tensor: 4 create: true replicas: 4 modelCommand: custom extraConfig: nodeSelector: cloud.google.com/gke-tpu-accelerator: "tpu-v6e-slice" cloud.google.com/gke-tpu-topology: "2x2" monitoring: podmonitor: enabled: true portName: "vllm" path: "/metrics" interval: "30s" containers: - name: "vllm" image: "vllm/vllm-tpu:nightly" command: - "/bin/bash" - "-c" - | # ROLE: kv_producer (Sends KV cache to decode) KV_CONFIG="{\"kv_connector\":\"TPUConnector\", \"kv_connector_module_path\" : \"tpu_inference.distributed.tpu_connector\", \"kv_role\":\"kv_producer\", \"kv_ip\" : \"$POD_IP\"}" echo "KV_CONFIG=$KV_CONFIG" python3 -m vllm.entrypoints.openai.api_server \ --model "Qwen/Qwen3-32B" \ --port 8200 \ --tensor-parallel-size 4 \ --kv-transfer-config "${KV_CONFIG}" \ --disable-uvicorn-access-log \ --enable-chunked-prefill \ --block-size 128 \ --gpu-memory-utilization 0.90 \ --max-model-len 8192 env: - name: POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: TPU_SIDE_CHANNEL_PORT value: "9600" - name: TPU_KV_TRANSFER_PORT value: "9100" ports: - containerPort: 8200 name: vllm protocol: TCP - containerPort: 9100 name: tpu-kv-transfer protocol: TCP - containerPort: 9600 name: tpu-coord protocol: TCP resources: limits: memory: 64Gi cpu: "16" google.com/tpu: 4 requests: memory: 64Gi cpu: "16" google.com/tpu: 4 mountModelVolume: true volumeMounts: - name: metrics-volume mountPath: /.config - name: shm mountPath: /dev/shm - name: torch-compile-cache mountPath: /.cache startupProbe: httpGet: path: /health port: vllm initialDelaySeconds: 15 periodSeconds: 30 timeoutSeconds: 5 failureThreshold: 120 livenessProbe: httpGet: path: /health port: vllm periodSeconds: 10 timeoutSeconds: 5 failureThreshold: 3 readinessProbe: httpGet: path: /v1/models port: vllm periodSeconds: 5 timeoutSeconds: 2 failureThreshold: 3 volumes: - name: metrics-volume emptyDir: {} - name: shm emptyDir: medium: Memory sizeLimit: "16Gi" - name: torch-compile-cache emptyDir: {} EOF - سرویس و دروازه را با استفاده از نمودار Helm مربوط به llm-d مستقر کنید :
cd llm-d/guides/pd-disaggregation/ helmfile apply -e gke_tpu -n $NAMESPACE kubectl apply -f ./httproute.gke.yaml - منتظر بمانید تا سرویسهای vLLM شروع به کار کنند. به گزارشهای رمزگشایی و پیشپر کردن POD توجه کنید تا عبارت «INFO: Application startup complete» را ببینید.
DECODE_POD=$(kubectl get pods -l llm-d.ai/modelservice-role=decode -o jsonpath='{.items[0].metadata.name}') # Get the first Prefill pod name PREFILL_POD=$(kubectl get pods -l llm-d.ai/modelservice-role=prefill -o jsonpath='{.items[0].metadata.name}') echo "Run each of these until vLLM starts successfully and then ctrl-C out" echo "kubectl logs -f $DECODE_POD -c vllm" echo "kubectl logs -f $PREFILL_POD -c vllm"
۷. پاسخ استقرار آزمایشی
اسکریپت زیر اتصال به خوشهی سرویسدهنده را از طریق GKE Inference Gateway آزمایش میکند و سپس یک تست بنچمارک اجرا میکند.
- تست اتصال و اجرای بنچمارک :
cat <<EOBF > ./run_benchmark.sh #!/bin/bash # Configuration NAMESPACE="default" JOB_NAME="qwen3-pd-benchmark" MODEL_NAME="Qwen/Qwen3-32B" echo "🔍 Discovering Gateway IP..." GATEWAY_IP=$(kubectl get gateway -n ${NAMESPACE} -o jsonpath='{.items[0].status.addresses[0].value}') if [ -z "$GATEWAY_IP" ]; then echo "❌ Error: Could not find Gateway IP. Check 'kubectl get gateway'." exit 1 fi TARGET_URL="http://${GATEWAY_IP}" echo "✅ Found Gateway at: $TARGET_URL" echo "🗑️ Cleaning up old benchmark jobs..." kubectl delete job $JOB_NAME --ignore-not-found=true echo "🚀 Generating and applying Benchmark Job..." cat <<EOF | kubectl apply -f - apiVersion: batch/v1 kind: Job metadata: name: $JOB_NAME namespace: $NAMESPACE spec: template: spec: containers: - name: llm-benchmark image: vllm/vllm-openai:latest command: ["/bin/bash", "-c"] args: - | # 1. Download dataset if [ ! -f /data/sharegpt.json ]; then echo "Downloading ShareGPT dataset..." curl -L "https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json" -o /data/sharegpt.json fi # 2. Wait for Gateway readiness echo "Checking connectivity to $MODEL_NAME..." until curl -s "$TARGET_URL/v1/models" | grep -q "$MODEL_NAME"; do echo "Waiting for Gateway backends to sync..." sleep 10 done # 3. Run Benchmark vllm bench serve \\ --base-url "$TARGET_URL" \\ --model "$MODEL_NAME" \\ --dataset-name "sharegpt" \\ --dataset-path "/data/sharegpt.json" \\ --request-rate 80.0 \\ --num-prompts 2000 \\ --tokenizer "$MODEL_NAME" volumeMounts: - name: dataset-volume mountPath: /data restartPolicy: Never volumes: - name: dataset-volume emptyDir: {} EOF echo "⏳ Job submitted. Follow logs with:" echo "kubectl logs -f job/$JOB_NAME" EOBF chmod a+x ./run_benchmark.sh ./run_benchmark.sh
۸. تمیز کردن
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود، منابع ایجاد شده در طول این codelab را حذف کنید.
برای پاکسازی داراییهایتان مراحل زیر را اجرا کنید:
# 1. Delete LeaderWorkerSet and Helm release
kubectl delete leaderworkerset qwen-simple-anywhere-cache --ignore-not-found
helm uninstall lws --namespace lws-system 2>/dev/null
kubectl delete namespace lws-system --ignore-not-found
# 2. Delete GKE Node Pools
# Note: Usually deleting the cluster deletes the node pools,
# but explicit deletion ensures it's gone before the cluster teardown begins.
for i in {1..8}
do
gcloud container node-pools delete "tpu-v6e-single-$i" \
--cluster="${CLUSTER_NAME}" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
done
# 3. Delete GKE Cluster
gcloud container clusters delete "${CLUSTER_NAME}" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
echo "--- Starting IAM and Service Account Cleanup ---"
# 1. Define the full Service Account email for clarity
SA_EMAIL="tpu-reader-sa@${PROJECT_ID}.iam.gserviceaccount.com"
# 2. Remove Storage Bucket IAM Binding
# This removes the 'objectViewer' role from the specific bucket
gcloud storage buckets remove-iam-policy-binding gs://inf-demo-model-storage \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectViewer" --quiet
# 3. Remove Workload Identity Binding
# This severs the link between the GKE KSA and the GCP SA
gcloud iam service-accounts remove-iam-policy-binding "${SA_EMAIL}" \
--role="roles/iam.workloadIdentityUser" \
--member="serviceAccount:${PROJECT_ID}.svc.id.goog[default/default]" --quiet
# 4. Delete the Service Account
gcloud iam service-accounts delete "${SA_EMAIL}" --project="${PROJECT_ID}" --quiet
echo "IAM cleanup complete!"
echo "--- Starting Network and Firewall Cleanup ---"
# 4. Delete Firewall Rules (Must go before the Network)
gcloud compute firewall-rules delete \
"${GVNIC_NETWORK_PREFIX}-allow-ssh" \
"${GVNIC_NETWORK_PREFIX}-allow-icmp" \
"${GVNIC_NETWORK_PREFIX}-allow-internal" \
"ray-allow-internal" \
--project="${PROJECT_ID}" --quiet
# 5. Delete Subnets (Must go before the Network)
gcloud compute networks subnets delete "${GVNIC_NETWORK_PREFIX}-tpu" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
gcloud compute networks subnets delete "${GVNIC_NETWORK_PREFIX}-proxy-sub" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
gcloud compute networks subnets delete "proxy-only-subnet" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
# 6. Finally, delete the VPC Network
gcloud compute networks delete "${GVNIC_NETWORK_PREFIX}-main" \
--project="${PROJECT_ID}" --quiet
echo "Cleanup complete!"
۹. تبریک
تبریک! شما با موفقیت Qwen3-32B را با استفاده llm-d و GKE روی TPUهای v6e تفکیکشده مستقر کردید.
آنچه آموختهاید
- نحوه پیکربندی شبکه سفارشی برای ترافیک پرسرعت TPU.
- نحوهی فراهم کردن استخرهای نود TPU رزرو شده در GKE.
- نحوهی پیادهسازی
llm-dبرای جداسازی حجم کار پیشپرسازی و رمزگشایی.