
1. परिचय
इस कोडलैब में, Google Cloud TPU का इस्तेमाल करके, Google Kubernetes Engine (GKE) पर ज़्यादा परफ़ॉर्मेंस वाली, डिसऐग्रिगेटेड इन्फ़्रेंसिंग सेवाओं को डिप्लॉय करने का तरीका बताया गया है. आपको llm-d का इस्तेमाल करना होगा. यह डिस्ट्रिब्यूटेड एलएलएम सर्विंग के लिए एक ओपन-सोर्स फ़्रेमवर्क है. इसकी मदद से, कई टीपीयू होस्ट पर प्रीफ़िल और डिकोड फ़ेज़ को अलग किया जा सकता है. साथ ही, शेयर की गई केवी कैश मेमोरी और GKE इन्फ़रेंस गेटवे को सेट अप किया जा सकता है.
यह सेटअप, प्रोडक्शन एनवायरमेंट की तरह काम करता है. इससे Qwen3-32B जैसे बड़े मॉडल को कम समय में ज़्यादा डेटा प्रोसेस करने और कम समय में जवाब देने में मदद मिलती है.
आपको क्या करना होगा
- ऐक्सलरेटर ट्रैफ़िक के लिए ऑप्टिमाइज़ किए गए MTU के साथ कस्टम वीपीसी नेटवर्क बनाएं.
- GCS Fuse CSI ड्राइवर और Ray Operator ऐडऑन के साथ GKE क्लस्टर को प्रोविज़न करें.
- टीपीयू v6e स्लाइस (कुल 32 चिप) के लिए, आठ नोड पूल बनाएं.
- GCS को ऐक्सेस करने के लिए, Workload Identity और अनुमतियां कॉन्फ़िगर करें.
- Qwen3-32B मॉडल की डिसऐग्रीगेटेड सर्विंग को मैनेज करने के लिए,
llm-dडिप्लॉय करें. - बेंचमार्क टेस्ट की मदद से, डिप्लॉयमेंट की पुष्टि करें.
आर्किटेक्चर
![llm-d disaggregated serving architecture showing model split into 4 2x2 replicas of prefill and the same for decode]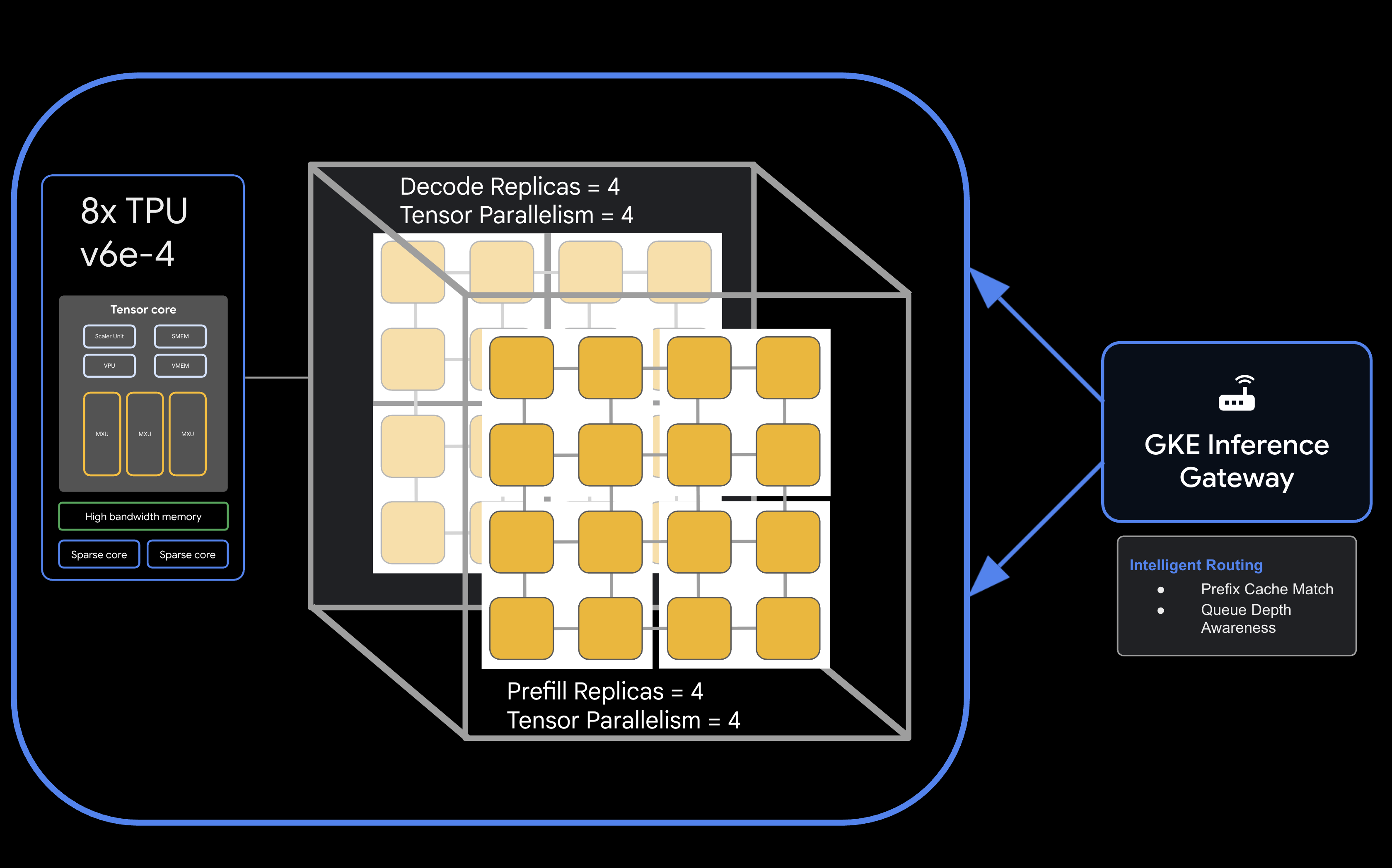
आपको किन चीज़ों की ज़रूरत होगी
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट.
- TPU v6e संसाधनों (32 चिप,
ct6e-standard-4t) के लिए Google Cloud Reservation. - मॉडल के वेट डाउनलोड करने के लिए, Hugging Face User Access Token.
- Cloud Shell या
gcloud,kubectl, औरhelmइंस्टॉल किया गया लोकल टर्मिनल.
- अनुमानित अवधि: 60 मिनट
- अनुमानित लागत: इस लैब में टीपीयू के काफ़ी संसाधनों का इस्तेमाल होता है. इस प्रोजेक्ट को पूरा करने के लिए, कम से कम 6,000 रुपये खर्च होंगे. पक्का करें कि आपने एक्सरसाइज़ पूरी करने के तुरंत बाद, साफ़-सफ़ाई से जुड़े निर्देशों का पालन किया हो.
2. शुरू करने से पहले
Google Cloud प्रोजेक्ट बनाना या चुनना
- Google Cloud Console में, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग की सुविधा चालू हो.
Cloud Shell शुरू करना
- Google Cloud कंसोल में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.
- पुष्टि करें:
gcloud auth list
- अपने प्रोजेक्ट की पुष्टि करें:
gcloud config get project
- अगर ज़रूरी हो, तो इसे सेट करें:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
एपीआई चालू करें
ज़रूरी Google Cloud सेवाएं चालू करें:
gcloud services enable \
container.googleapis.com \
compute.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com
एनवायरमेंट वैरिएबल सेट करना
अपनी शेल में इन वैरिएबल को तय करें. <YOUR_ZONE> की जगह, आपको असाइन किया गया टीपीयू ज़ोन, <YOUR_RESERVATION_NAME> की जगह, आपका रिज़र्वेशन आईडी, और <YOUR_HUGGING_FACE_TOKEN> की जगह, अपना टोकन डालें.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE="<YOUR_ZONE>" # e.g., us-east5-a
export REGION=${ZONE%-*}
export NAMESPACE=default
export CLUSTER_NAME="qwen-serving-cluster"
export GVNIC_NETWORK_PREFIX="qwen-serving"
export RESERVATION_NAME="<YOUR_RESERVATION_NAME>"
export HF_TOKEN="<YOUR_HUGGING_FACE_TOKEN>"
3. कस्टम नेटवर्किंग बनाना
डिसऐग्रिगेटेड सर्विंग के लिए, खास नेटवर्क कॉन्फ़िगरेशन की ज़रूरत होती है. इससे प्रीफ़िल और डिकोड नोड के बीच ज़्यादा बैंडविड्थ वाले ट्रैफ़िक को मैनेज किया जा सकता है.
- ऐक्सलरेटर के साथ बेहतर तरीके से कम्यूनिकेट करने के लिए, बड़े एमटीयू (8896) वाला वीपीसी नेटवर्क बनाएं:
gcloud compute --project=${PROJECT_ID} \ networks create ${GVNIC_NETWORK_PREFIX}-main \ --subnet-mode=auto \ --bgp-routing-mode=regional \ --mtu=8896 - क्लस्टर के लिए सबनेट बनाएं:
gcloud compute --project=${PROJECT_ID} \ networks subnets create ${GVNIC_NETWORK_PREFIX}-tpu \ --network=${GVNIC_NETWORK_PREFIX}-main \ --region=${REGION} \ --range=10.10.0.0/18 - GKE Gateway API के लिए ज़रूरी प्रॉक्सी-ओनली सबनेट बनाएं:
gcloud compute networks subnets create ${GVNIC_NETWORK_PREFIX}-proxy \ --purpose=REGIONAL_MANAGED_PROXY \ --role=ACTIVE \ --region=${REGION} \ --network=${GVNIC_NETWORK_PREFIX}-main \ --range=172.16.0.0/26 - इंटरनल कम्यूनिकेशन की अनुमति देने के लिए, फ़ायरवॉल के नियम बनाएं:
gcloud compute --project=${PROJECT_ID} firewall-rules create ${GVNIC_NETWORK_PREFIX}-allow-internal \ --network=${GVNIC_NETWORK_PREFIX}-main \ --allow=all \ --source-ranges=172.16.0.0/12,10.0.0.0/8 \ --description="Allow all internal traffic within the network."
4. GKE क्लस्टर सेटअप करना
एक स्टैंडर्ड GKE क्लस्टर बनाएं, जिसे GCS फ़्यूज़ माउंट और Ray Operator वर्कलोड के साथ काम करने के लिए कॉन्फ़िगर किया गया हो.
- क्लस्टर बनाएं:
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${REGION} \ --release-channel=rapid \ --machine-type=e2-standard-4 \ --network=${GVNIC_NETWORK_PREFIX}-main \ --subnetwork=${GVNIC_NETWORK_PREFIX}-tpu \ --num-nodes=1 \ --gateway-api=standard \ --enable-managed-prometheus \ --enable-dataplane-v2 \ --enable-dataplane-v2-metrics \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=HttpLoadBalancing,GcsFuseCsiDriver,RayOperator,HorizontalPodAutoscaling,NodeLocalDNS \ --enable-ip-alias - क्लस्टर क्रेडेंशियल वापस पाना:
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${REGION} - Hugging Face का सीक्रेट बनाएं:
kubectl create secret generic llm-d-hf-token \ --from-literal=hf_api_token=${HF_TOKEN} \ --dry-run=client -o yaml | kubectl apply -f -
5. आरक्षित किए गए टीपीयू नोड पूल बनाना
टीपीयू v6e स्लाइस के लिए, रिज़र्वेशन का इस्तेमाल करके आठ नोड पूल प्रोविज़न करें.
आठ नोड पूल बनाने के लिए, यह लूप चलाएं:
for i in {1..8}
do
gcloud beta container node-pools create "tpu-v6e-single-$i" \
--project=${PROJECT_ID} \
--cluster=${CLUSTER_NAME} \
--region=${REGION} \
--node-locations=${ZONE} \
--machine-type=ct6e-standard-4t \
--tpu-topology=2x2 \
--num-nodes=1 \
--reservation-affinity=specific \
--reservation=${RESERVATION_NAME} \
--workload-metadata=GKE_METADATA &
done
सभी नोड बनने और क्लस्टर में शामिल होने तक इंतज़ार करें. kubectl get nodes से स्थिति देखी जा सकती है.
6. llm-d सेवा डिप्लॉय करना
अब आपको डिसऐग्रिगेटेड सर्वरिंग को मैनेज करने के लिए, llm-d फ़्रेमवर्क को डिप्लॉय करना होगा.
- llm-d चार्ट डिप्लॉय करने के लिए, Helm इंस्टॉल करें:
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-4 chmod 700 get_helm.sh ./get_helm.sh - llm-d का क्लोन बनाएं और ज़रूरी डिपेंडेंसी इंस्टॉल करें:
git clone https://github.com/llm-d/llm-d.git # When using yq alongside Helm, you almost always want the version by Mike Farah (mikefarah/yq). We remove the most common yq installation before reinstalling sudo rm -rf /usr/local/bin/yq cd llm-d ./helpers/client-setup/install-deps.sh - अपने क्लस्टर के लिए डिसऐग्रिगेटेड सर्विंग को कॉन्फ़िगर करने के लिए, custom_values_tpu.yaml फ़ाइल तैयार करें:
cat <<EOF > llm-d/guides/pd-disaggregation/ms-pd/values_tpu.yaml multinode: false # Configure accelerator type for Google TPU accelerator: type: google modelArtifacts: uri: "hf://Qwen/Qwen3-32B" size: 200Gi authSecretName: "llm-d-hf-token" name: "Qwen/Qwen3-32B" labels: llm-d.ai/inference-serving: "true" llm-d.ai/guide: "pd-disaggregation" llm-d.ai/hardware-variant: "tpu" llm-d.ai/hardware-vendor: "google" llm-d.ai/model: "Qwen3-32B" tracing: enabled: true otlpEndpoint: "localhost:4317" serviceNames: routingProxy: "routing-proxy" sampling: sampler: "always_off" samplerArg: "0" routing: servicePort: 8000 proxy: image: ghcr.io/llm-d/llm-d-routing-sidecar:v0.5.0 connector: nixlv2 secure: false decode: parallelism: tensor: 4 create: true replicas: 4 modelCommand: custom extraConfig: nodeSelector: cloud.google.com/gke-tpu-accelerator: "tpu-v6e-slice" cloud.google.com/gke-tpu-topology: "2x2" monitoring: podmonitor: enabled: true portName: "vllm" path: "/metrics" interval: "30s" containers: - name: "vllm" image: "vllm/vllm-tpu:nightly" command: - "/bin/bash" - "-c" - | # ROLE: kv_consumer (Receives KV cache from prefill) KV_CONFIG="{\"kv_connector\":\"TPUConnector\", \"kv_connector_module_path\" : \"tpu_inference.distributed.tpu_connector\", \"kv_role\":\"kv_consumer\", \"kv_ip\" : \"$POD_IP\"}" echo "KV_CONFIG=$KV_CONFIG" python3 -m vllm.entrypoints.openai.api_server \ --model "Qwen/Qwen3-32B" \ --port 8200 \ --tensor-parallel-size 4 \ --kv-transfer-config "${KV_CONFIG}" \ --disable-uvicorn-access-log \ --max-num-seqs 256 \ --block-size 128 \ --gpu-memory-utilization 0.90 \ --max-model-len 8192 env: - name: POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: TPU_SIDE_CHANNEL_PORT value: "9600" - name: TPU_KV_TRANSFER_PORT value: "9100" ports: - containerPort: 8200 name: vllm protocol: TCP - containerPort: 9100 name: tpu-kv-transfer protocol: TCP - containerPort: 9600 name: tpu-coord protocol: TCP resources: limits: memory: 64Gi cpu: "16" google.com/tpu: 4 requests: memory: 64Gi cpu: "16" google.com/tpu: 4 mountModelVolume: true volumeMounts: - name: metrics-volume mountPath: /.config - name: shm mountPath: /dev/shm - name: torch-compile-cache mountPath: /.cache startupProbe: httpGet: path: /health port: vllm initialDelaySeconds: 15 periodSeconds: 30 timeoutSeconds: 5 failureThreshold: 120 livenessProbe: httpGet: path: /health port: vllm periodSeconds: 10 timeoutSeconds: 5 failureThreshold: 3 readinessProbe: httpGet: path: /v1/models port: vllm periodSeconds: 5 timeoutSeconds: 2 failureThreshold: 3 volumes: - name: metrics-volume emptyDir: {} - name: shm emptyDir: medium: Memory sizeLimit: "16Gi" - name: torch-compile-cache emptyDir: {} prefill: parallelism: tensor: 4 create: true replicas: 4 modelCommand: custom extraConfig: nodeSelector: cloud.google.com/gke-tpu-accelerator: "tpu-v6e-slice" cloud.google.com/gke-tpu-topology: "2x2" monitoring: podmonitor: enabled: true portName: "vllm" path: "/metrics" interval: "30s" containers: - name: "vllm" image: "vllm/vllm-tpu:nightly" command: - "/bin/bash" - "-c" - | # ROLE: kv_producer (Sends KV cache to decode) KV_CONFIG="{\"kv_connector\":\"TPUConnector\", \"kv_connector_module_path\" : \"tpu_inference.distributed.tpu_connector\", \"kv_role\":\"kv_producer\", \"kv_ip\" : \"$POD_IP\"}" echo "KV_CONFIG=$KV_CONFIG" python3 -m vllm.entrypoints.openai.api_server \ --model "Qwen/Qwen3-32B" \ --port 8200 \ --tensor-parallel-size 4 \ --kv-transfer-config "${KV_CONFIG}" \ --disable-uvicorn-access-log \ --enable-chunked-prefill \ --block-size 128 \ --gpu-memory-utilization 0.90 \ --max-model-len 8192 env: - name: POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: TPU_SIDE_CHANNEL_PORT value: "9600" - name: TPU_KV_TRANSFER_PORT value: "9100" ports: - containerPort: 8200 name: vllm protocol: TCP - containerPort: 9100 name: tpu-kv-transfer protocol: TCP - containerPort: 9600 name: tpu-coord protocol: TCP resources: limits: memory: 64Gi cpu: "16" google.com/tpu: 4 requests: memory: 64Gi cpu: "16" google.com/tpu: 4 mountModelVolume: true volumeMounts: - name: metrics-volume mountPath: /.config - name: shm mountPath: /dev/shm - name: torch-compile-cache mountPath: /.cache startupProbe: httpGet: path: /health port: vllm initialDelaySeconds: 15 periodSeconds: 30 timeoutSeconds: 5 failureThreshold: 120 livenessProbe: httpGet: path: /health port: vllm periodSeconds: 10 timeoutSeconds: 5 failureThreshold: 3 readinessProbe: httpGet: path: /v1/models port: vllm periodSeconds: 5 timeoutSeconds: 2 failureThreshold: 3 volumes: - name: metrics-volume emptyDir: {} - name: shm emptyDir: medium: Memory sizeLimit: "16Gi" - name: torch-compile-cache emptyDir: {} EOF - llm-d के हेल्म चार्ट का इस्तेमाल करके, सेवा और गेटवे को डिप्लॉय करें:
cd llm-d/guides/pd-disaggregation/ helmfile apply -e gke_tpu -n $NAMESPACE kubectl apply -f ./httproute.gke.yaml - vLLM सेवाओं के शुरू होने का इंतज़ार करेंजब तक आपको "INFO: Application startup complete." न दिखे, तब तक डिकोड और प्रीफ़िल POD लॉग देखें
DECODE_POD=$(kubectl get pods -l llm-d.ai/modelservice-role=decode -o jsonpath='{.items[0].metadata.name}') # Get the first Prefill pod name PREFILL_POD=$(kubectl get pods -l llm-d.ai/modelservice-role=prefill -o jsonpath='{.items[0].metadata.name}') echo "Run each of these until vLLM starts successfully and then ctrl-C out" echo "kubectl logs -f $DECODE_POD -c vllm" echo "kubectl logs -f $PREFILL_POD -c vllm"
7. टेस्ट डिप्लॉयमेंट का जवाब
नीचे दी गई स्क्रिप्ट, GKE Inference Gateway के ज़रिए सर्विंग क्लस्टर से कनेक्टिविटी की जांच करेगी. इसके बाद, बेंचमार्किंग टेस्ट चलाएगी.
- कनेक्टिविटी की जांच करें और मानदंड लागू करें:
cat <<EOBF > ./run_benchmark.sh #!/bin/bash # Configuration NAMESPACE="default" JOB_NAME="qwen3-pd-benchmark" MODEL_NAME="Qwen/Qwen3-32B" echo "🔍 Discovering Gateway IP..." GATEWAY_IP=$(kubectl get gateway -n ${NAMESPACE} -o jsonpath='{.items[0].status.addresses[0].value}') if [ -z "$GATEWAY_IP" ]; then echo "❌ Error: Could not find Gateway IP. Check 'kubectl get gateway'." exit 1 fi TARGET_URL="http://${GATEWAY_IP}" echo "✅ Found Gateway at: $TARGET_URL" echo "🗑️ Cleaning up old benchmark jobs..." kubectl delete job $JOB_NAME --ignore-not-found=true echo "🚀 Generating and applying Benchmark Job..." cat <<EOF | kubectl apply -f - apiVersion: batch/v1 kind: Job metadata: name: $JOB_NAME namespace: $NAMESPACE spec: template: spec: containers: - name: llm-benchmark image: vllm/vllm-openai:latest command: ["/bin/bash", "-c"] args: - | # 1. Download dataset if [ ! -f /data/sharegpt.json ]; then echo "Downloading ShareGPT dataset..." curl -L "https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json" -o /data/sharegpt.json fi # 2. Wait for Gateway readiness echo "Checking connectivity to $MODEL_NAME..." until curl -s "$TARGET_URL/v1/models" | grep -q "$MODEL_NAME"; do echo "Waiting for Gateway backends to sync..." sleep 10 done # 3. Run Benchmark vllm bench serve \\ --base-url "$TARGET_URL" \\ --model "$MODEL_NAME" \\ --dataset-name "sharegpt" \\ --dataset-path "/data/sharegpt.json" \\ --request-rate 80.0 \\ --num-prompts 2000 \\ --tokenizer "$MODEL_NAME" volumeMounts: - name: dataset-volume mountPath: /data restartPolicy: Never volumes: - name: dataset-volume emptyDir: {} EOF echo "⏳ Job submitted. Follow logs with:" echo "kubectl logs -f job/$JOB_NAME" EOBF chmod a+x ./run_benchmark.sh ./run_benchmark.sh
8. व्यवस्थित करें
अपने Google Cloud खाते से लगातार शुल्क लिए जाने से बचने के लिए, इस कोडलैब के दौरान बनाई गई संसाधन मिटाएं.
अपनी ऐसेट को हटाने के लिए, यह तरीका अपनाएं:
# 1. Delete LeaderWorkerSet and Helm release
kubectl delete leaderworkerset qwen-simple-anywhere-cache --ignore-not-found
helm uninstall lws --namespace lws-system 2>/dev/null
kubectl delete namespace lws-system --ignore-not-found
# 2. Delete GKE Node Pools
# Note: Usually deleting the cluster deletes the node pools,
# but explicit deletion ensures it's gone before the cluster teardown begins.
for i in {1..8}
do
gcloud container node-pools delete "tpu-v6e-single-$i" \
--cluster="${CLUSTER_NAME}" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
done
# 3. Delete GKE Cluster
gcloud container clusters delete "${CLUSTER_NAME}" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
echo "--- Starting IAM and Service Account Cleanup ---"
# 1. Define the full Service Account email for clarity
SA_EMAIL="tpu-reader-sa@${PROJECT_ID}.iam.gserviceaccount.com"
# 2. Remove Storage Bucket IAM Binding
# This removes the 'objectViewer' role from the specific bucket
gcloud storage buckets remove-iam-policy-binding gs://inf-demo-model-storage \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectViewer" --quiet
# 3. Remove Workload Identity Binding
# This severs the link between the GKE KSA and the GCP SA
gcloud iam service-accounts remove-iam-policy-binding "${SA_EMAIL}" \
--role="roles/iam.workloadIdentityUser" \
--member="serviceAccount:${PROJECT_ID}.svc.id.goog[default/default]" --quiet
# 4. Delete the Service Account
gcloud iam service-accounts delete "${SA_EMAIL}" --project="${PROJECT_ID}" --quiet
echo "IAM cleanup complete!"
echo "--- Starting Network and Firewall Cleanup ---"
# 4. Delete Firewall Rules (Must go before the Network)
gcloud compute firewall-rules delete \
"${GVNIC_NETWORK_PREFIX}-allow-ssh" \
"${GVNIC_NETWORK_PREFIX}-allow-icmp" \
"${GVNIC_NETWORK_PREFIX}-allow-internal" \
"ray-allow-internal" \
--project="${PROJECT_ID}" --quiet
# 5. Delete Subnets (Must go before the Network)
gcloud compute networks subnets delete "${GVNIC_NETWORK_PREFIX}-tpu" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
gcloud compute networks subnets delete "${GVNIC_NETWORK_PREFIX}-proxy-sub" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
gcloud compute networks subnets delete "proxy-only-subnet" \
--region="${REGION}" \
--project="${PROJECT_ID}" --quiet
# 6. Finally, delete the VPC Network
gcloud compute networks delete "${GVNIC_NETWORK_PREFIX}-main" \
--project="${PROJECT_ID}" --quiet
echo "Cleanup complete!"
9. बधाई हो
बधाई हो! आपने llm-d और GKE का इस्तेमाल करके, डिसऐग्रीगेट किए गए v6e टीपीयू पर Qwen3-32B को डिप्लॉय कर लिया है.
आपको क्या सीखने को मिला
- तेज़ टीपीयू ट्रैफ़िक के लिए कस्टम नेटवर्किंग को कॉन्फ़िगर करने का तरीका.
- GKE पर रिज़र्व की गई टीपीयू नोड पूल की सुविधा चालू करने का तरीका.
- प्रीफ़िल और डिकोड वर्कलोड को अलग करने के लिए,
llm-dको डिप्लॉय करने का तरीका.