
1. Introduction
This codelab provides a guide on how to get started with QueryData for AlloyDB and use it to generate accurate and predictable SQL statements from natural language input in agentic applications
Prerequisites
- A basic understanding of Google Cloud console
- Basic skills in command line interface and Cloud Shell
What you'll learn
- How to create an AlloyDB cluster and import sample data
- How to enable AlloyDB Data access API
- How to enable QueryData for AlloyDB
- How to generate templates
- How to use faceted search
- How to use QueryData with AI Agents
What you'll need
- A Google Cloud Account and Google Cloud Project
- A web browser such as Chrome supporting Google Cloud console and Cloud Shell
2. Setup and Requirements
Project setup
Create a Google Cloud Project
- In the Google Cloud Console, on the project selector page, select or create a Google Cloud project.
- Make sure that billing is enabled for your Cloud project. Learn how to check if billing is enabled on a project.
Start Cloud Shell
While Google Cloud can be operated remotely from your laptop, in this codelab you will be using Google Cloud Shell, a command line environment running in the Cloud.
From the Google Cloud Console, click the Cloud Shell icon on the top right toolbar:
Alternatively you can press G then S. This sequence will activate Cloud Shell if you are within the Google Cloud Console or use this link.
It should only take a few moments to provision and connect to the environment. When it is finished, you should see something like this:

This virtual machine is loaded with all the development tools you'll need. It offers a persistent 5GB home directory, and runs on Google Cloud, greatly enhancing network performance and authentication. All of your work in this codelab can be done within a browser. You do not need to install anything.
3. Before you begin
Enable API
To use AlloyDB, Compute Engine, Networking services, and Vertex AI, you need to enable their respective APIs in your Google Cloud project.
Inside Cloud Shell terminal, make sure that your project ID is setup:
gcloud config get-value project
You should see your project tID in the output:
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
Set environment variable PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Enable all necessary services:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Expected output
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Deploy AlloyDB
Create AlloyDB cluster and primary instance. You can either deploy it using a prepared script which will deploy all necessary resources or you can do it step-by-step by yourself following documentation.
Deploy AlloyDB Using Automated Script
This approach is using an automated script to deploy the AlloyDB cluster and providing necessary information to start working with the deployed resources.
In the Cloud Shell terminal execute command to clone the deployment script from the repository.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
Run the deployment script.
./deploy_alloydb.sh --public-ip
The script will take some time to run - usually about 5-7 minutes and deploy AlloyDB cluster and a primary instance with public and private IP. The public IP is available only for authorized networks or by using AlloyDB Auth proxy. You can read more about public IP in the documentation. As the output the script should provide information about your deployed AlloyDB cluster. Please be aware your password will be different - record the password somewhere for future use.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
And you can also see the new cluster and the primary instance in the web console
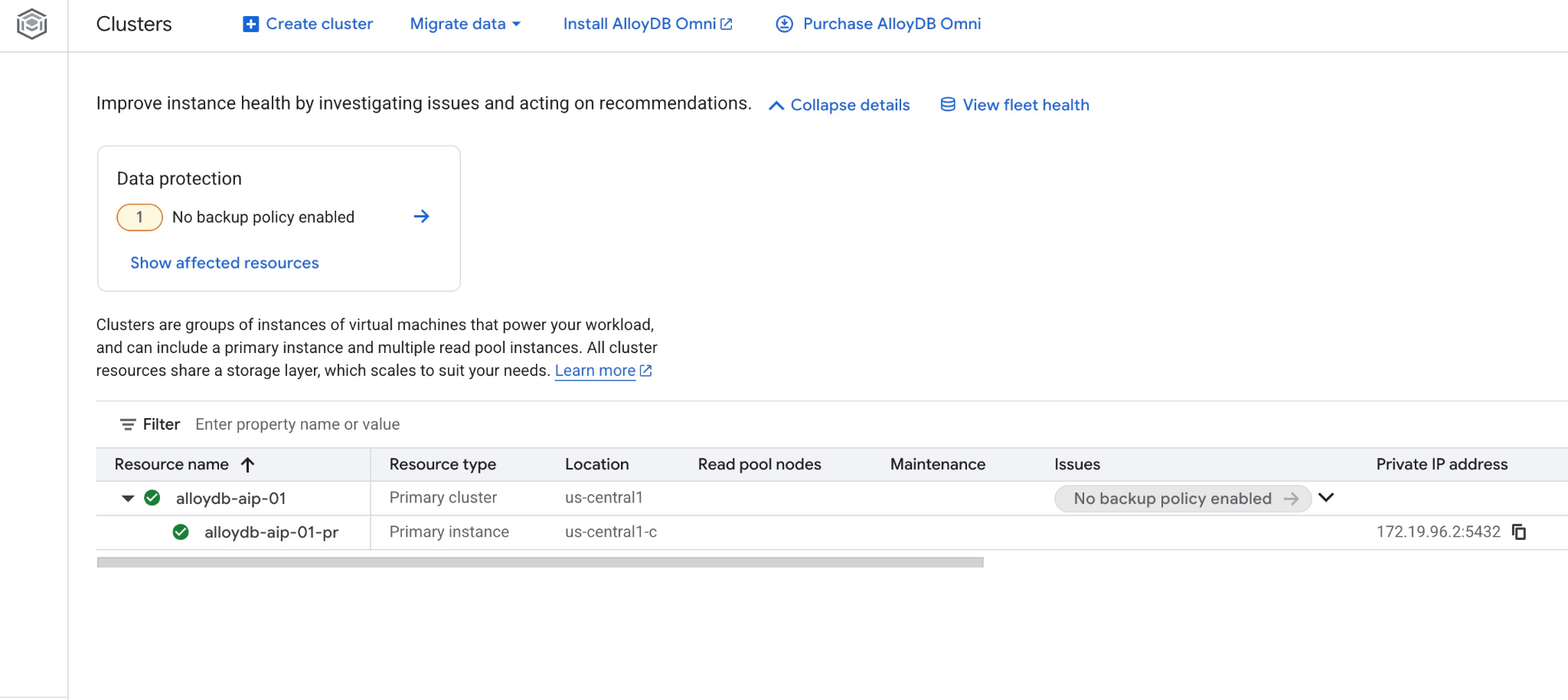
5. Prepare Database
You need to enable Vertex AI integration to use AI functions and operators, enable Data access API and create a database for sample dataset.
Grant Necessary Permissions to AlloyDB
Add Vertex AI permissions to the AlloyDB service agent.
Open another Cloud Shell tab using the sign "+" at the top.
In the new cloud shell tab execute:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Expected console output:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Enable Data Access API
You have to enable the Data Access API on the AlloyDB cluster to be able to use MCP tools like execute_sql.
In the same terminal tab execute.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
Enable IAM Authentication
We are going to use IAM authentication for our agentic tools and it requires to enable the IAM authentication on the instance and add yourself as a database user. Before enabling the IAM authentication on the instance level please wait until the previous step enabling data access API is finished. Your instance status should be green.
We start from enabling the IAM on the instance level. In the same terminal tab execute.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Add yourself as AlloyDB user:
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
Close the tab by either execution command "exit" in the tab:
exit
Connect to AlloyDB Studio
In the following chapters all the SQL commands requiring connection to the database can be executed in the AlloyDB Studio. T
Navigate to the Clusters page in AlloyDB for Postgres.
Open the web console interface for your AlloyDB cluster by clicking on the primary instance.
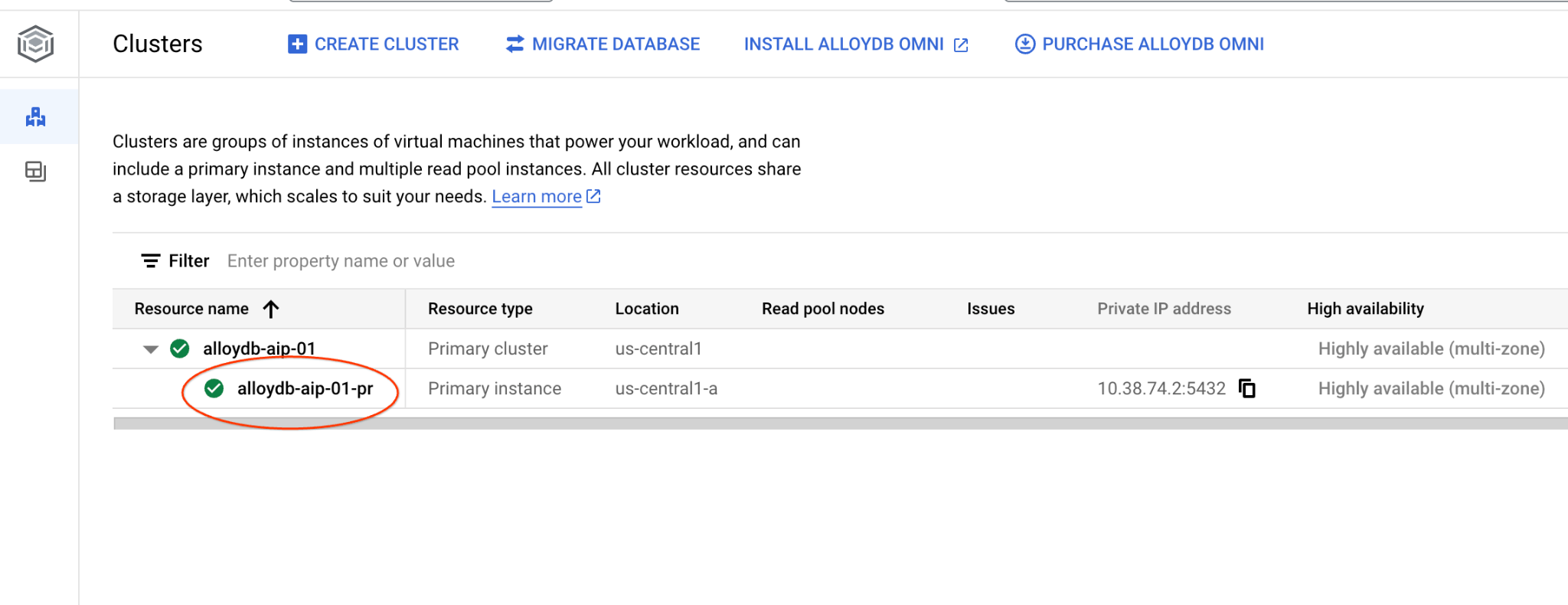
Then click on AlloyDB Studio on the left:
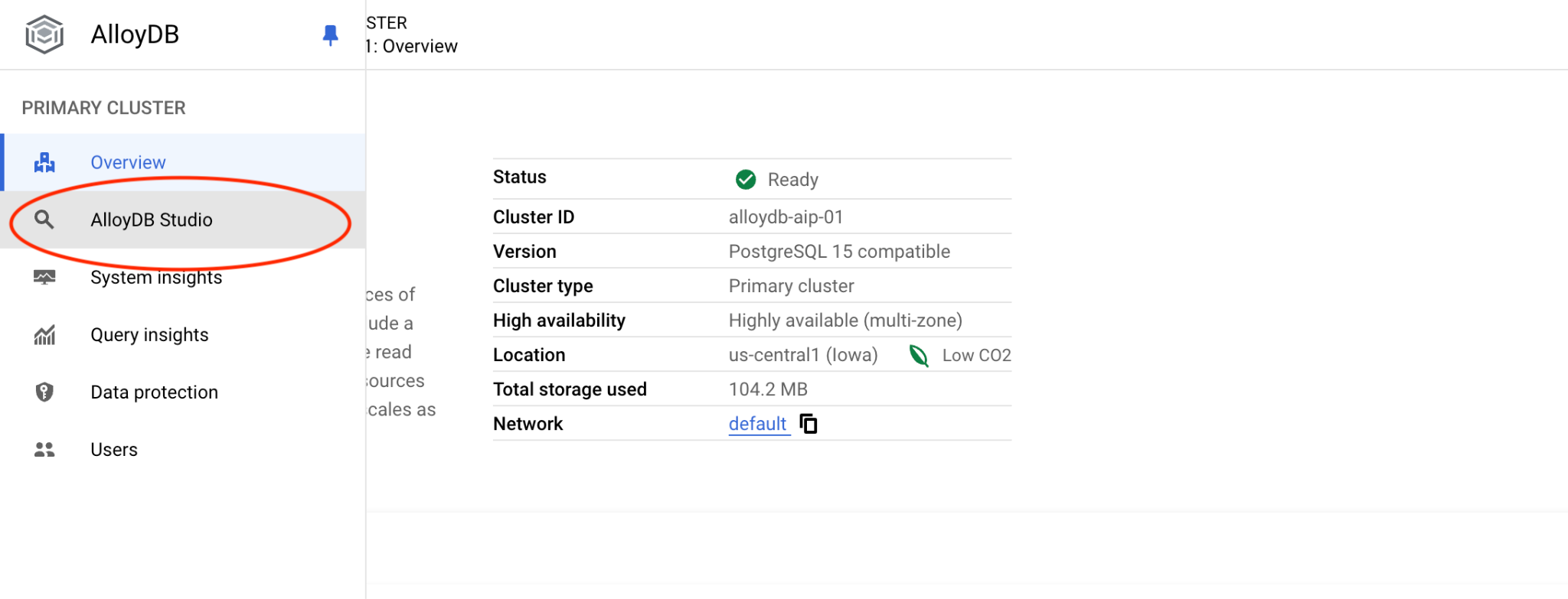
Choose the postgres database and IAM authentication. Then click on the "Authenticate" button.
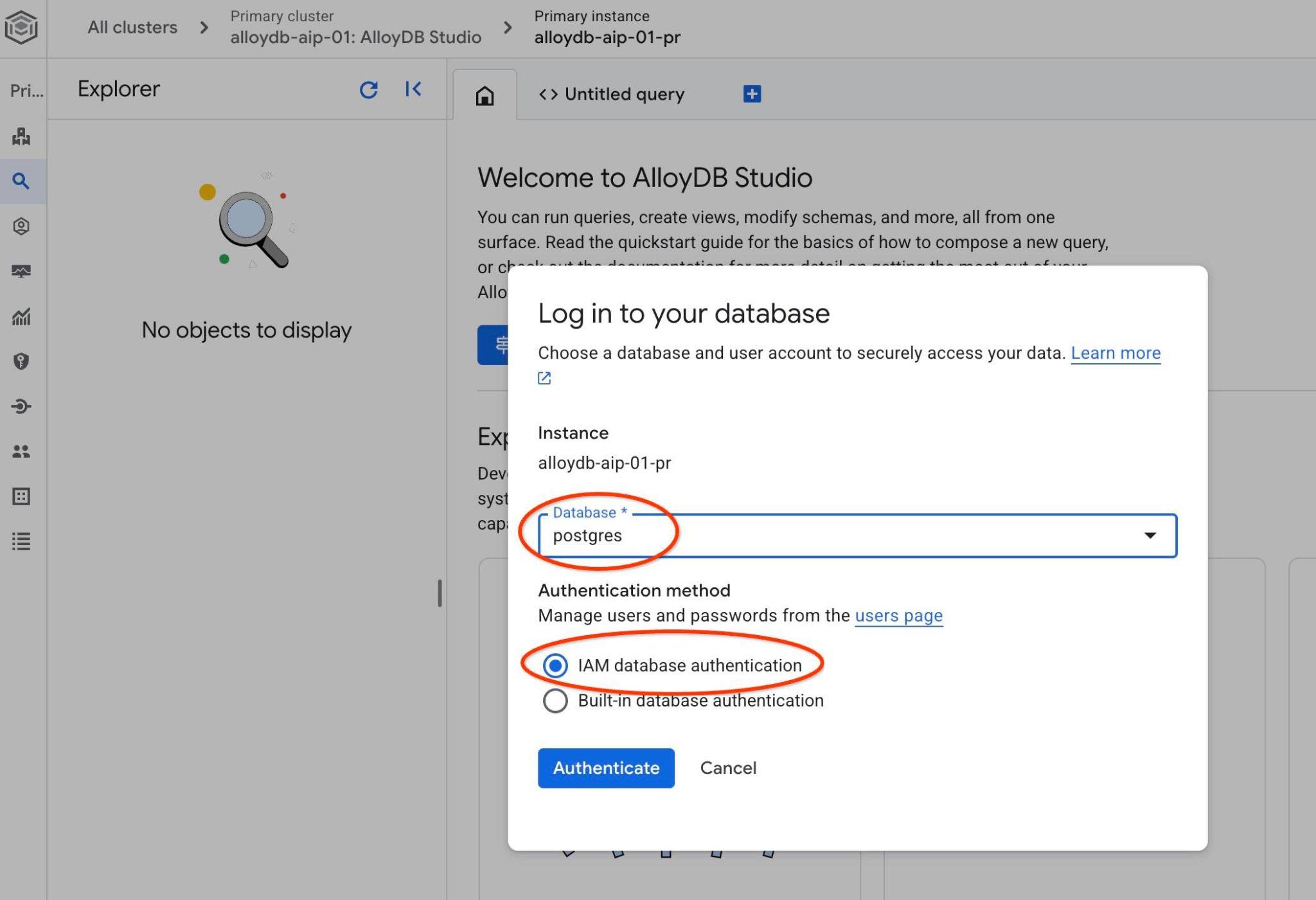
It will open the AlloyDB Studio interface. To run the commands in the database you click on the "Untitled Query" tab on the right.
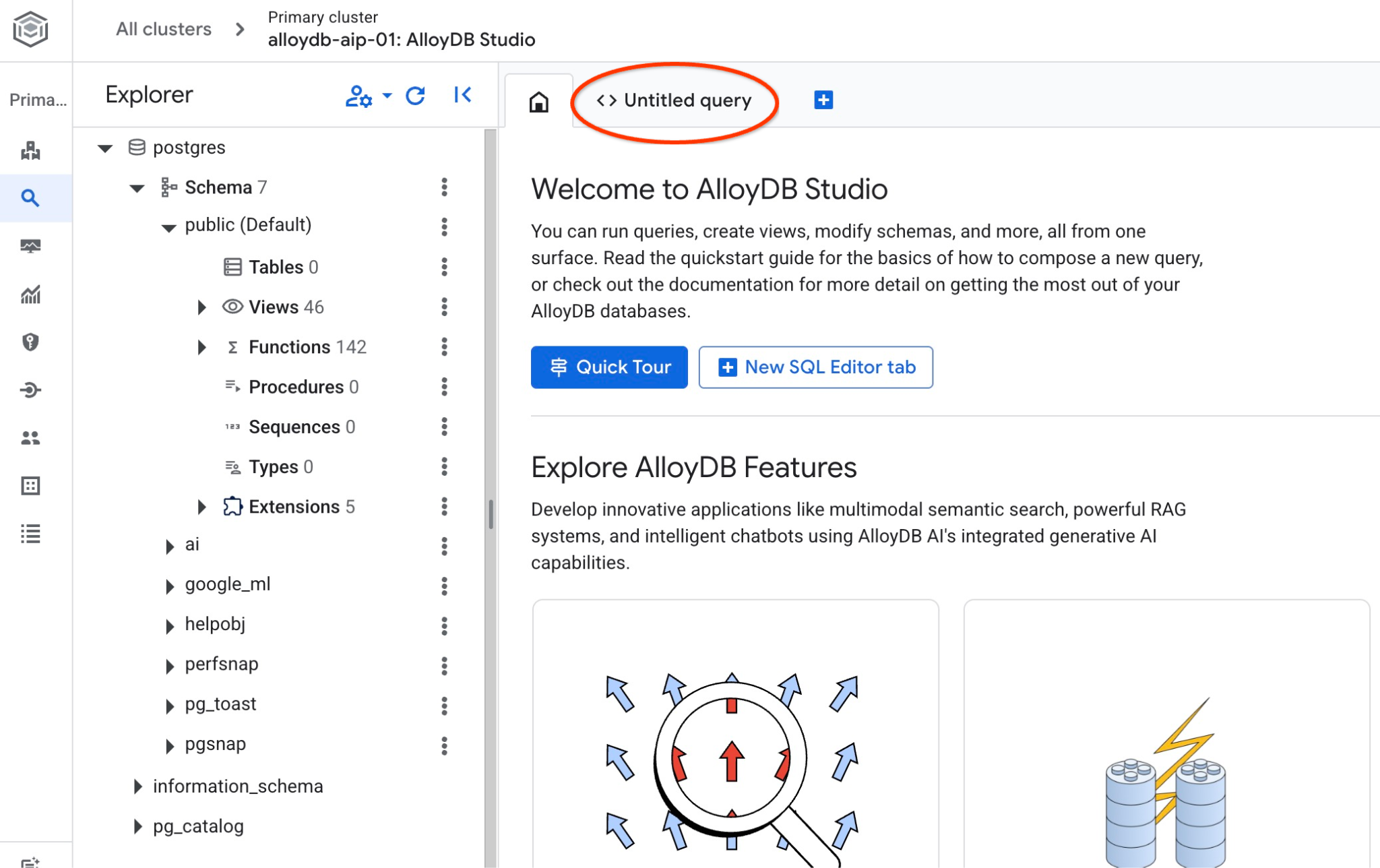
It opens interface where you can run SQL commands
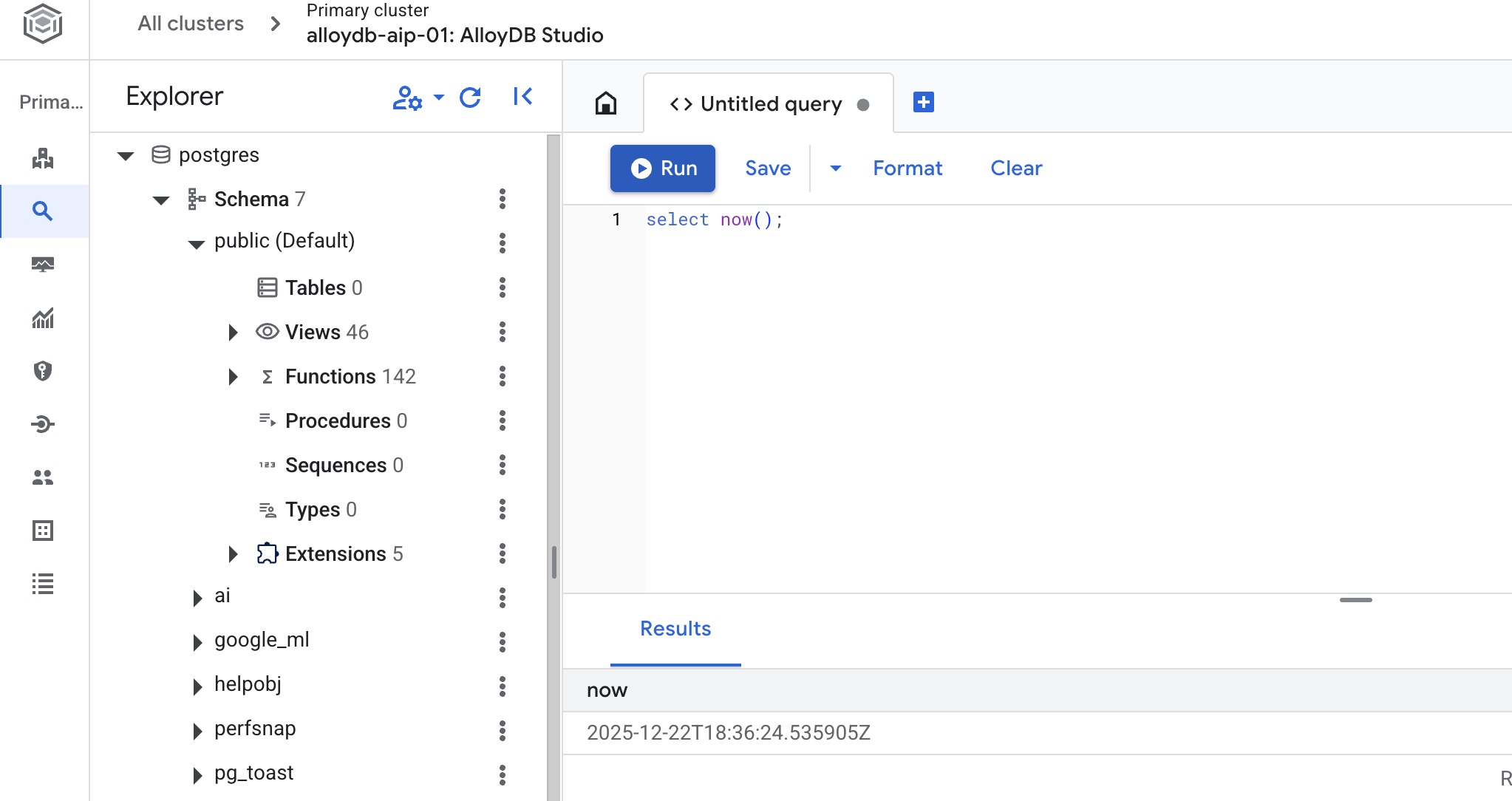
Create Database
Create database quickstart.
In the AlloyDB Studio Editor execute the following command.
Create database:
CREATE DATABASE quickstart_db
Expected output:
Statement executed successfully
Connect to quickstart_db
Check if your database is created by connecting to it. Reconnect to the studio using the button to switch user/database.
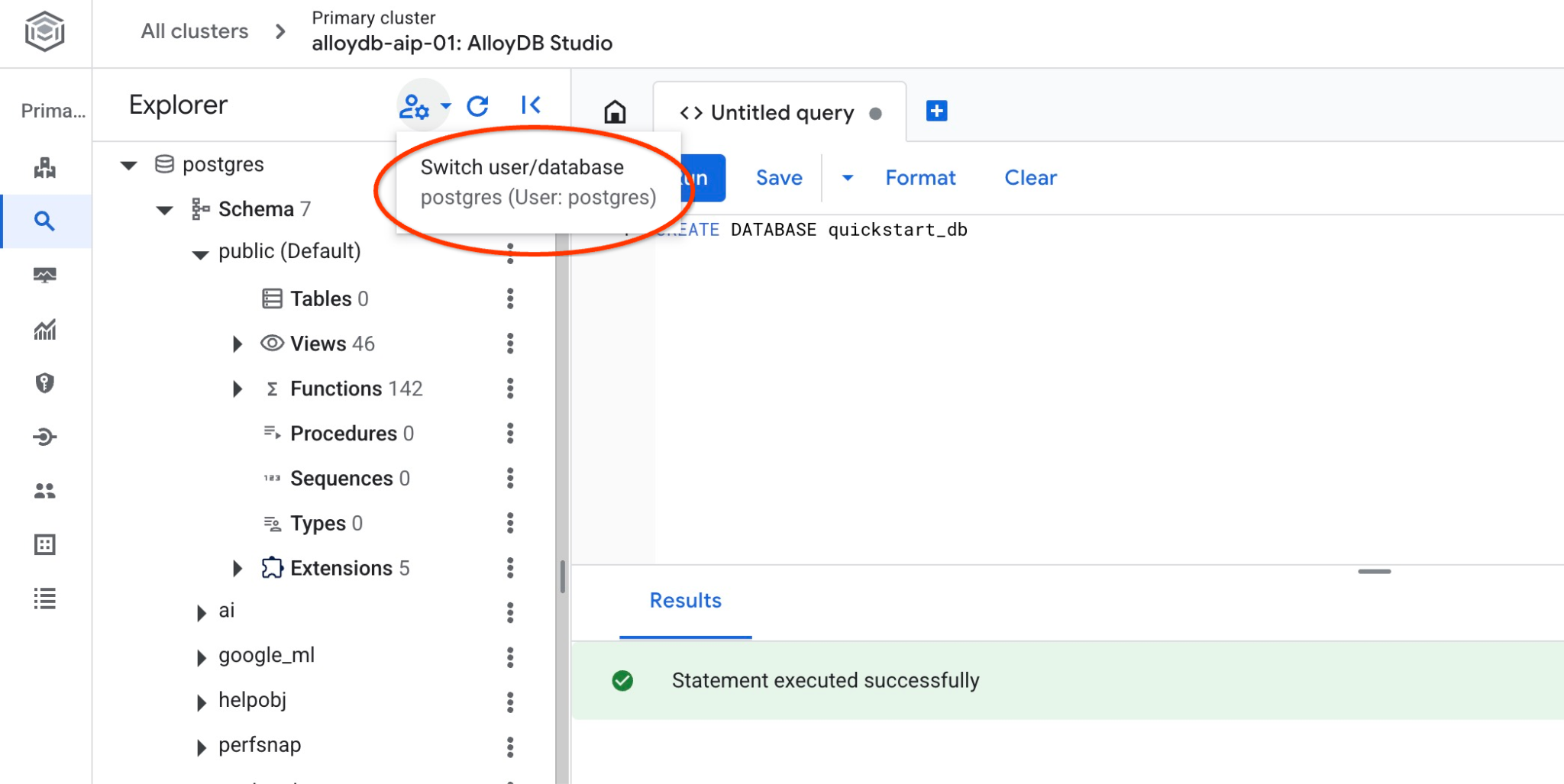
Pick up from the dropdown list the new quickstart_db database and use the same IAM authentication.
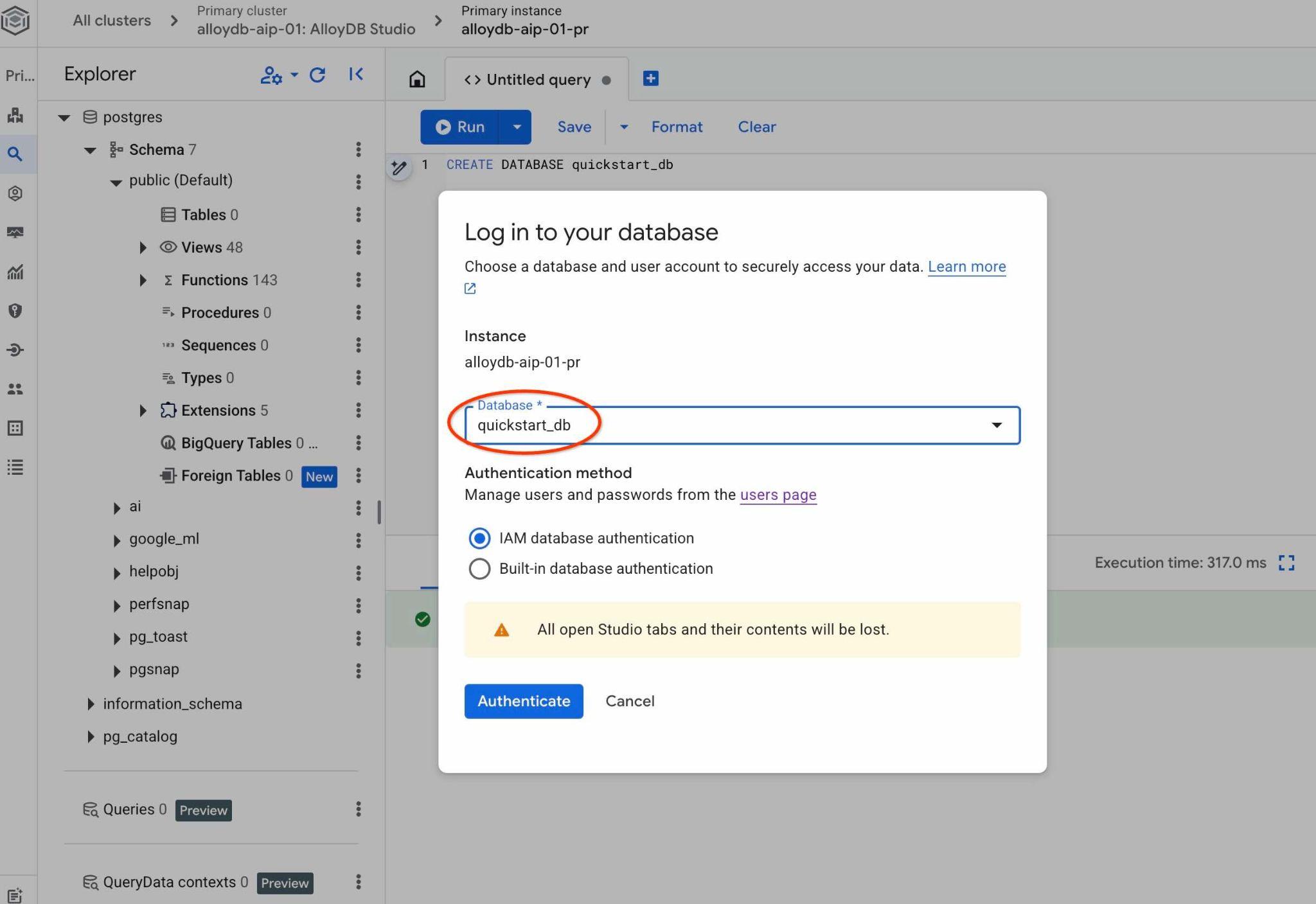
It will open a new connection where you can work with objects from the quickstart_db database. There you will be able to examine your imported schema and data and work with QueryData context sets.
6. Sample Data
Now you need to create objects in the database and load data. You are going to use a fictional Cymbal Shipping company dataset. It has fictional data about goods, trucks, requests, and truck trips, along with fictional drivers.
Create Storage Bucket
You are going to use the Google SDK (gcloud) to import data from your cloned repository to the AlloyDB database. You will need to create a Cloud Storage bucket for that and grant access to the AlloyDB service account. Alternatively, you can always try to do it using the web console, as described in the documentation.
In the Google Cloud Shell terminal execute:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
Load Data
The next step is to load the data. Our compressed SQL dump is located in the cloned repository folder. The following command assumes you used your home directory as the starting point when you cloned the repository in the previous step while creating the AlloyDB cluster.
Copy the compressed SQL dump to the new storage bucket:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
Then load the data to the quickstart_db database:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
The command will load the sample dataset to the quickstart_db database. You can verify the tables and records using AlloyDB Studio.
7. Work with Data Agent
Let us start from a sample AI agent created using Google ADK for python and connecting to our AlloyDB instance using MCP Toolbox for databases.
Install MCP Toolbox for databases
MCP Toolbox for databases is an open source project providing MCP support for multiple database engines including AlloyDB for PostgreSQL. You can read about MCP Toolbox in the documentation.
You need to download the latest version of the software for your platform. For the latest version, check the releases page. The following example shows how to download version 31 of the MCP Toolbox to Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
You need to prepare a configuration file for the toolbox. We have a sample tools.yaml.example file in the current directory and are going to prepare tools.yaml file by replacing two placeholders by the project ID and region.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
Start MCP Toolbox for databases
Now you can start the MCP toolbox with the prepared configuration file.
Open a new tab in your Google Cloud Shell by pressing the "+" button at the top of your Google Cloud Shell interface.
In the new tab switch to the directory with the toolbox binary file and the configuration file tools.yaml and start the MCP server.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
You should see in the output "Server ready to serve!" similar tothe following.
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
Check the Agent source code
In the first tab in the cloned repository folder review the agent code using Google Cloud Shell editor.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
You can see in the agent we have a section for the Google Cloud MCP server for AlloyDB. We provide an endpoint as MCP_SERVER_URL, authentication, project id and adding it to the MCP toolset.
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
And in the agent code the MCP toolset is included as tools parameter for the agent. Also there are cluster and instance names, the region and the database as variables for the agent prompt.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
After examining the code, switch back to the terminal pressing the button "Open terminal" on the top right of the editor window.
Start the Agent
Now you can start the agent in interactive mode using Google ADK web interface. The ADK web interface provides a convenient way to test and troubleshoot agents' workflows.
First let us install all required packages for Python using the uv package manager.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
When all the packages are installed you need to add a .env file to the agent directory to direct it to use Vertex AI for all communications with the AI models.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
Then you can start the agent
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
You should see output like the following with the endpoint like http://127.0.0.1:8000 .
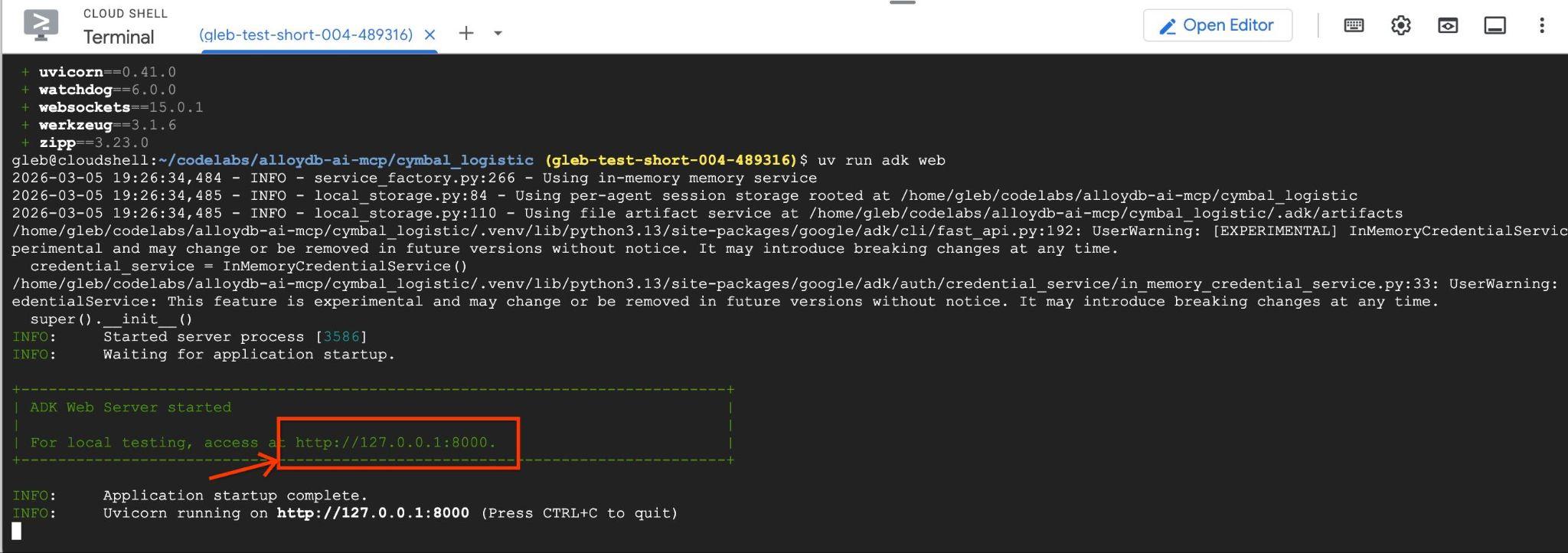
You can click on that URL in the cloud shell and it will open a preview window in a separate browser tab where you choose the data_agent from the drop down list on the left.
In the ADK web interface you can post your questions in the bottom right and see the full execution flow including the traces for each step on the right side.
8. Test NL2SQL without QueryData for AlloyDB
The Agent allows you to ask questions in free form using natural language and the agent will use the MCP toolbox for databases as a tool to answer the questions. The questions are posted in the right bottom and the answer with all calls to the tools will appear at the top.
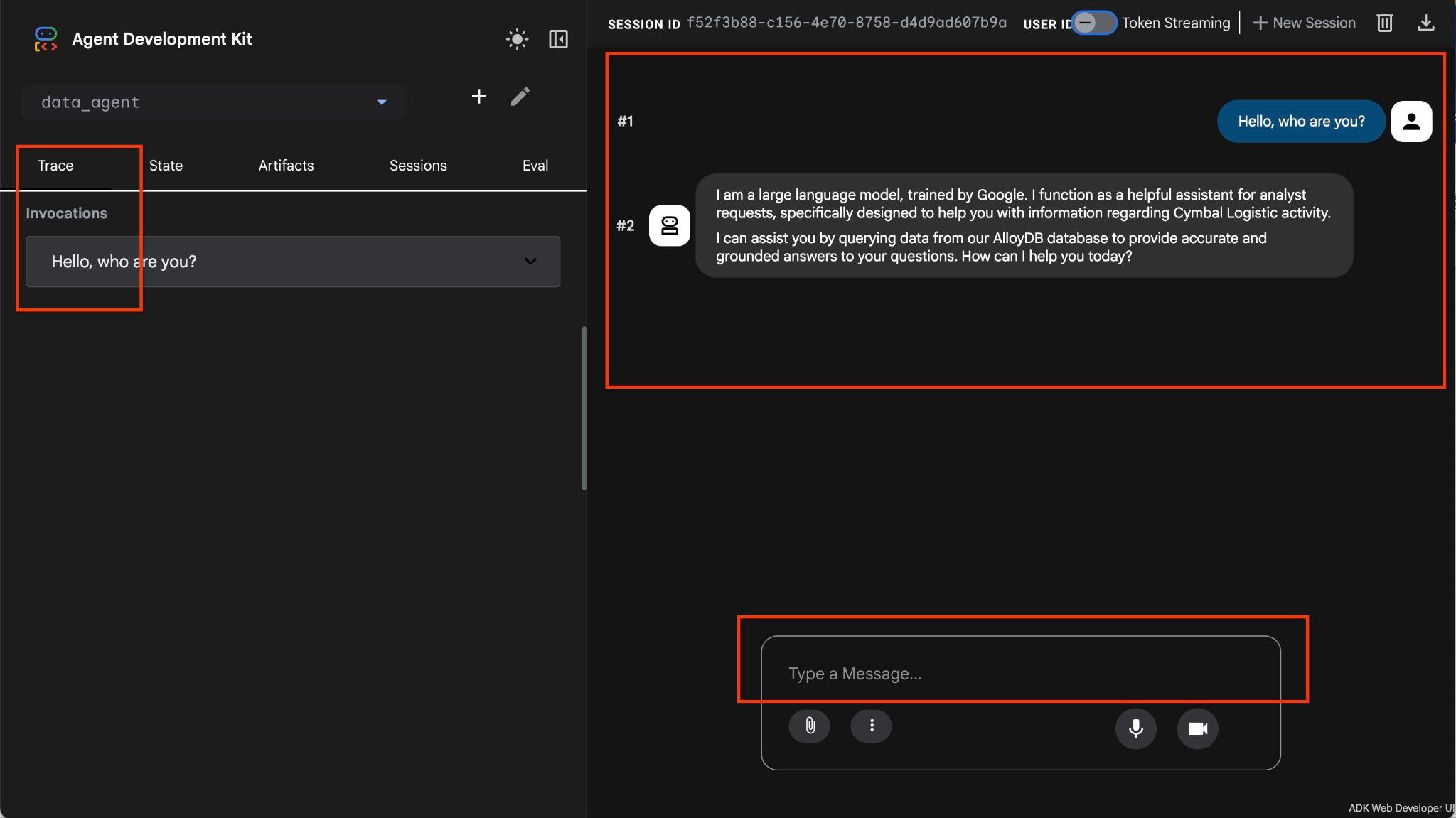
You are working with operational data for a shipping company which has information about shipping requests, trucks, drivers and trips done by drivers. The first question is about the number of trips executed in February 2026.
In the input field on the right bottom type the following and press enter.
Hello, can you tell me how many trips we've done in February?
The agent will work executing multiple tool calls to identify the right tables in the schema using the list_cymbal_logistics_schemas_tool and the execute_sql_tool executing the multiple SQL statements to get the right data.
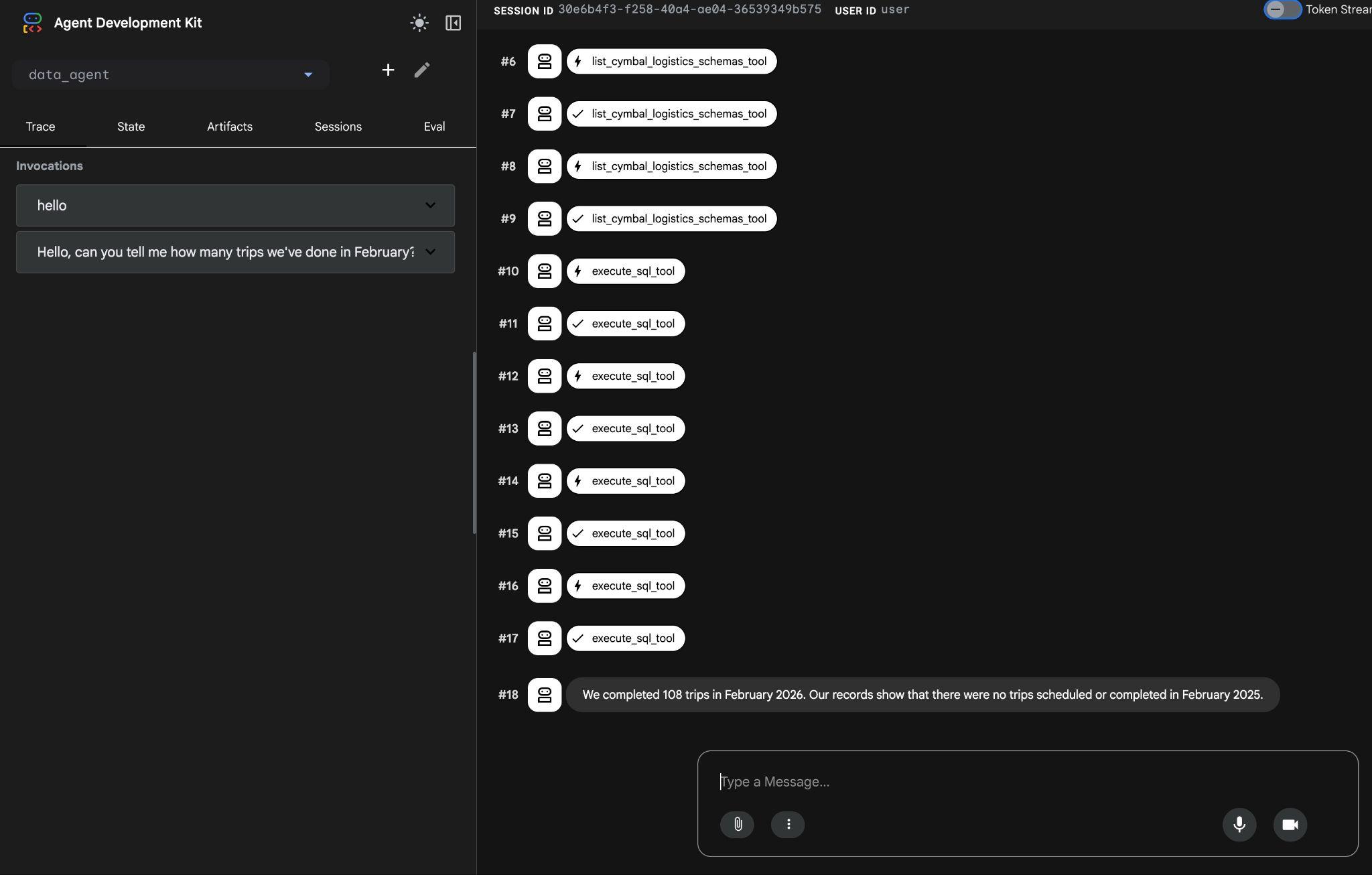
Eventually it will produce the correct result after building the proper query and executing it on the database.
We completed 108 trips in February 2026. Our records show that there were no trips scheduled or completed in February 2025.
You can see what each tool call does by clicking on the tool execution. For example, here is the query executed to get our results.
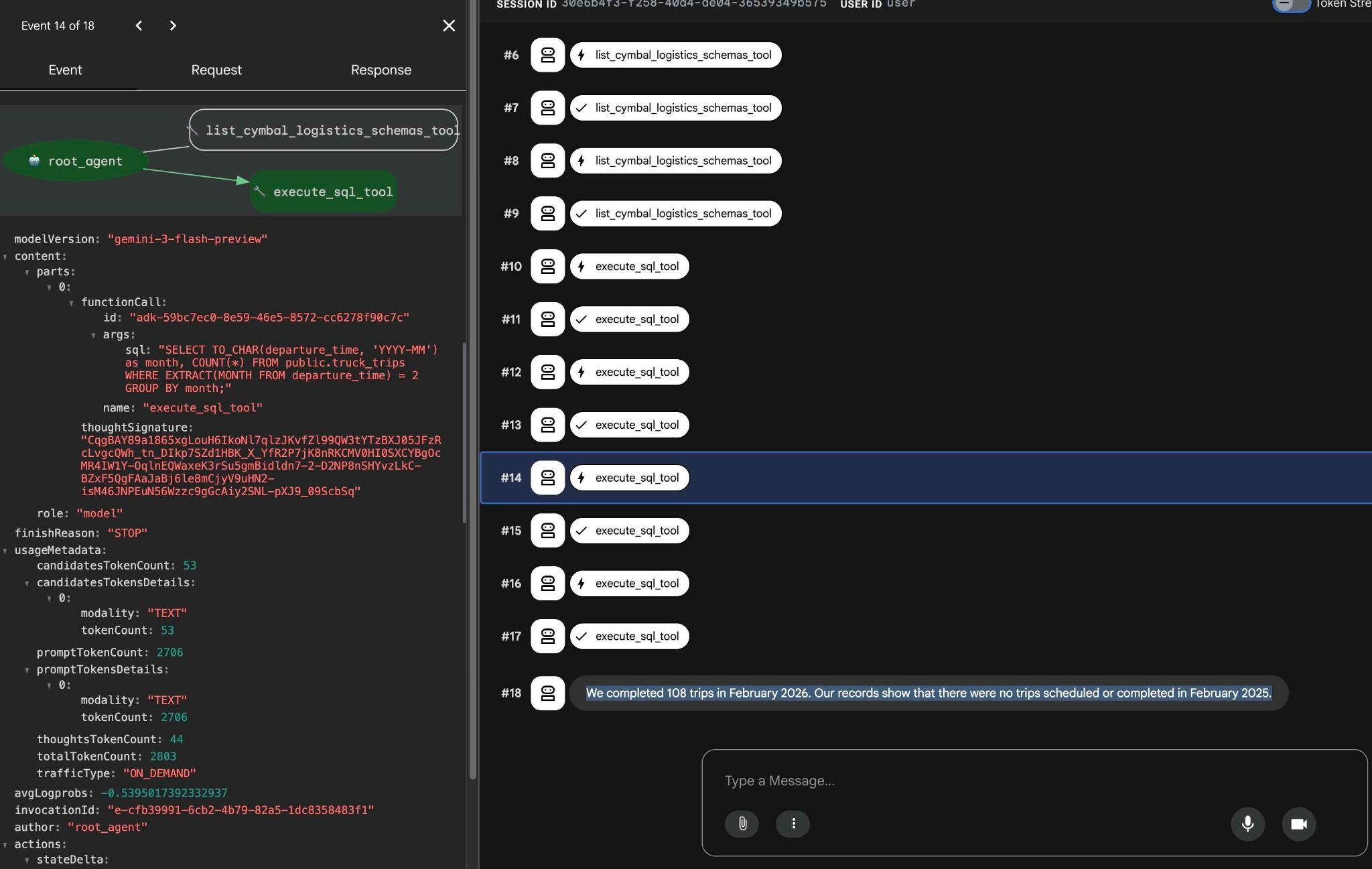
Try other simple requests using the ADK web interface and see how it executes different queries to achieve the results.
Stop the agent pressing ctrl+c in the terminal. You can close the browser tab with ADK web interface.
You also can stop the MCP Toolbox in the second tab by pressing the same ctrl+c keys shortcut and close the second tab.
In the next step we will build QueryData context to improve our NL2SQL response and performance.
9. Build QueryData ContextSet
You could see in the previous step the AI model was doing multiple calls to the information schema of the database to figure out what table and columns it should use to build the SQL query. To improve performance, accuracy and make the result more predictable we will add your QueryData context defining what query should be executed in response to a certain request.
Create Targeted Templates
The QueryData ContextSet is a JSON file with query templates and facets which provide necessary data and directions to the AI model to use correct SQL query or SQL query parts to achieve the requested goals based on query patterns and data structure.
You start from a targeted template. Create a file using a Cloud Shell editor. In the Cloud Shell terminal execute.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
And insert the template for the natural language query we've used in the previous chapter - "How many trips we've done in February?"
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
Then download the template to your computer from the Cloud Shell using the download button.
Load QueryData Context Sets
To use our QueryData context sets we need to upload them to our database.
Open AlloyDB Studio. In the left panel at the bottom you will see QueryData Context and three dots.
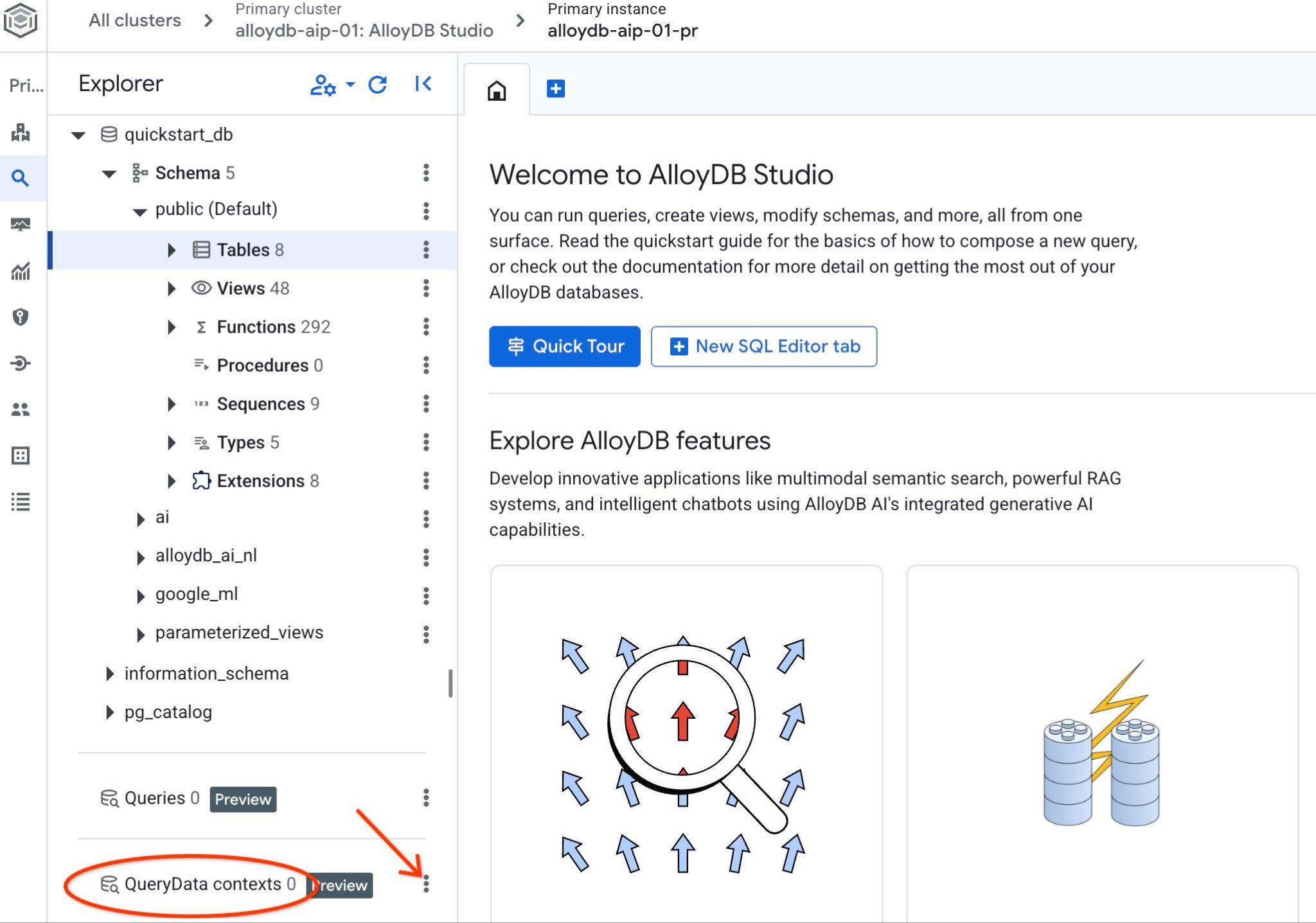
Click on those three dots and choose Create Context. It will open a dialog where you put
- Name:
cymbal_context_set - Description:
Cymbal Logistic Query Data - Upload context file: click on the "
Browse" button and choose you JSON file with the QueryData ContextSet
When you push the save button it might take some time to initialize the context storage if you do it for the first time.
You should be able to see the downloaded context and if you click on three vertical buttons on the right you will see the available actions. In the next chapter we will start from the "Test context" action.
10. Test QueryData Context Set
Test template
Use the "Test context" action to test our context in AlloyDB Studio. When you click on the "Test context" it will open a new AlloyDB Studio editor window with title "cymbal_context_set" and the Gemini SQL generation invite titled "Generate SQL using QueryData context: cymbal_context_set ". Click on the SQL generation and type
Hello, can you tell me how many trips we've done in February?
And when the SQL generated push the "Insert" button.
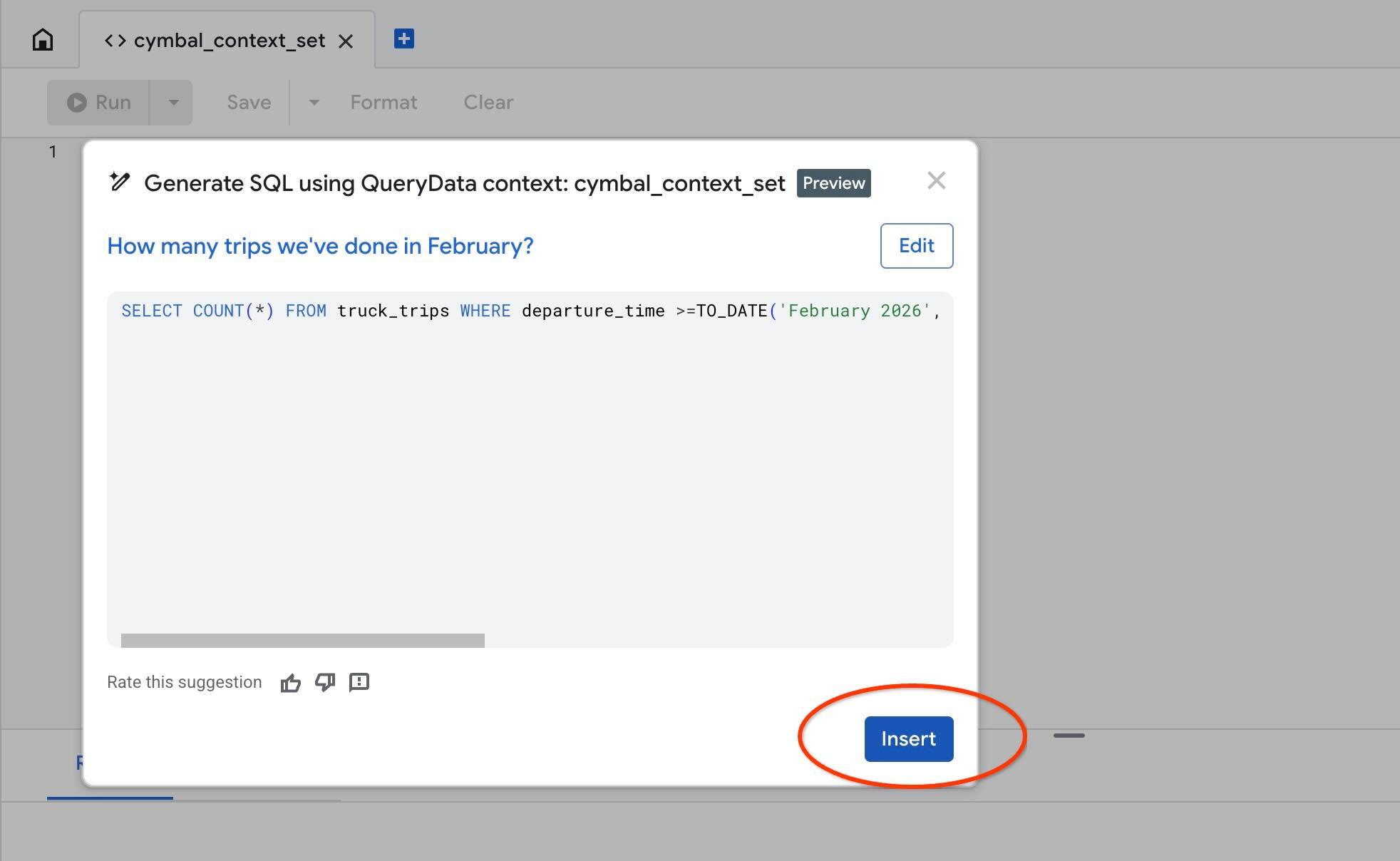
You are going to see exactly the same query we put to our context template earlier.
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
Try to replace the month with "January" and check the generated SQL statement. It will be using the month as a parameter for the parameterized intent and automatically adjust the SQL statement.
Build QueryData Facets
We tried a template for a query and it works when we know what kind of user's request we expect. But sometimes it is helpful to guide only a part of a query such as condition or filter when we prefer a certain order or particular clause to be used for a redefined intent.
For example, if we ask to return data for "last month" we want to get the report for the last calendar month from the 1st to the last day of that month but not for the last 30 days.
We can add such facets as an SQL snippet to the ContextSet configuration along with our previously added template. Open the querydata_cymbal_contextset.json.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
And add the facets after our already existing templates. The resulting content in the file should be the following
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
Save the file and upload it to your computer.
Then use the Query context action "Edit context" and upload the modified file to replace the old context set by the new one.
Now try to use the test context again and generate a SQL statement using the "last month" intent. For example if you generate a SQL for the phrase "show trucks trips for the last month" it will be using the condition we provided as a facet in our cymbal_context.json file.
You should get something like the following:
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
Now, how can you use it with AI Agents? In the next chapter we make the Query Data context available for AI Agents.
11. QueryData with AI Agents
You will be using the same Data Agent but now the MCP toolbox will be configured to use the QueryData ContextSet.
Prepare and start MCP Toolbox for databases
We need a new configuration file for the MCP Toolbox which is going to use the Gemini Data Analytics API and the AlloyDB as the database source.
Run in the terminal:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
Switch to the editor and find the file querydata.yaml. The configuration file querydata.yaml would look like the following except the project id and region which will reflect your environment. But you still need to update your contextSetId value and replace the "<add-context-set-id>" placeholder by value from the console.
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
To find your ContextSet ID click the edit button for your context set as shown on the picture.
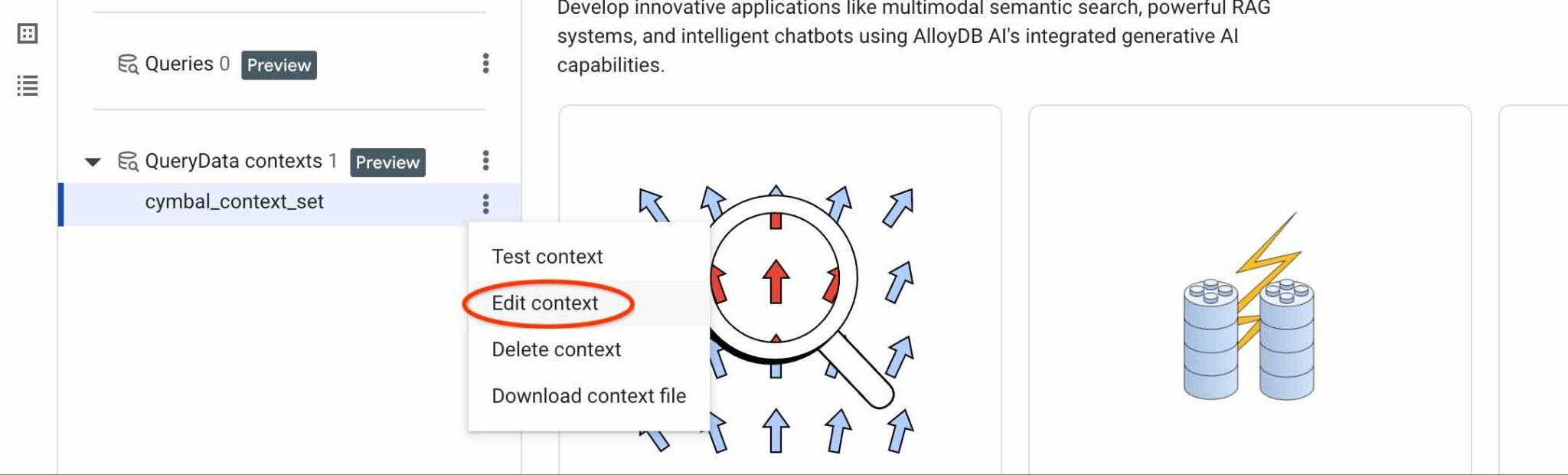
You will see the context set ID on the top in the new tab on the right.
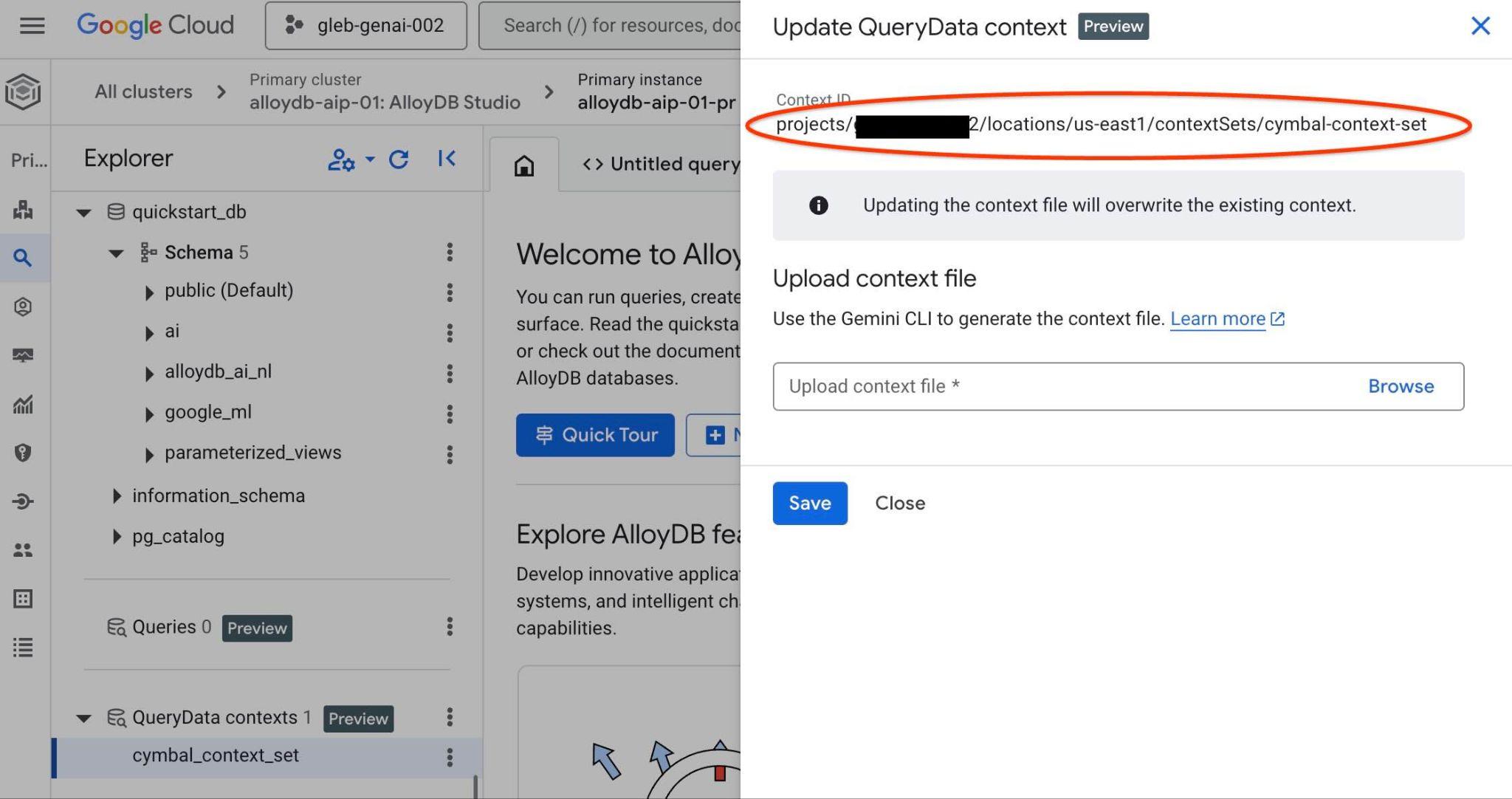
That full path should be put to replace the "<add-context-set-id>" placeholder in the querydata.yaml file.
Switch back to the terminal.
Open a new tab in your Google Cloud Shell by pressing the "+" button at the top of your Google Cloud Shell interface.
In the new tab switch to the directory with the toolbox binary file and the configuration file tools.yaml and start the MCP server.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
Run the ADK agent
In the first Cloud Shell tab start the agent.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
And when it is started click again on the link to http://127.0.0.1:8000 .
You will see the already familiar ADK web preview agent interface. Post exactly the same query as the last time.
Hello, can you tell me how many trips we've done in February?
And see the agent workflow. If everything is configured correctly you should see something like the following.
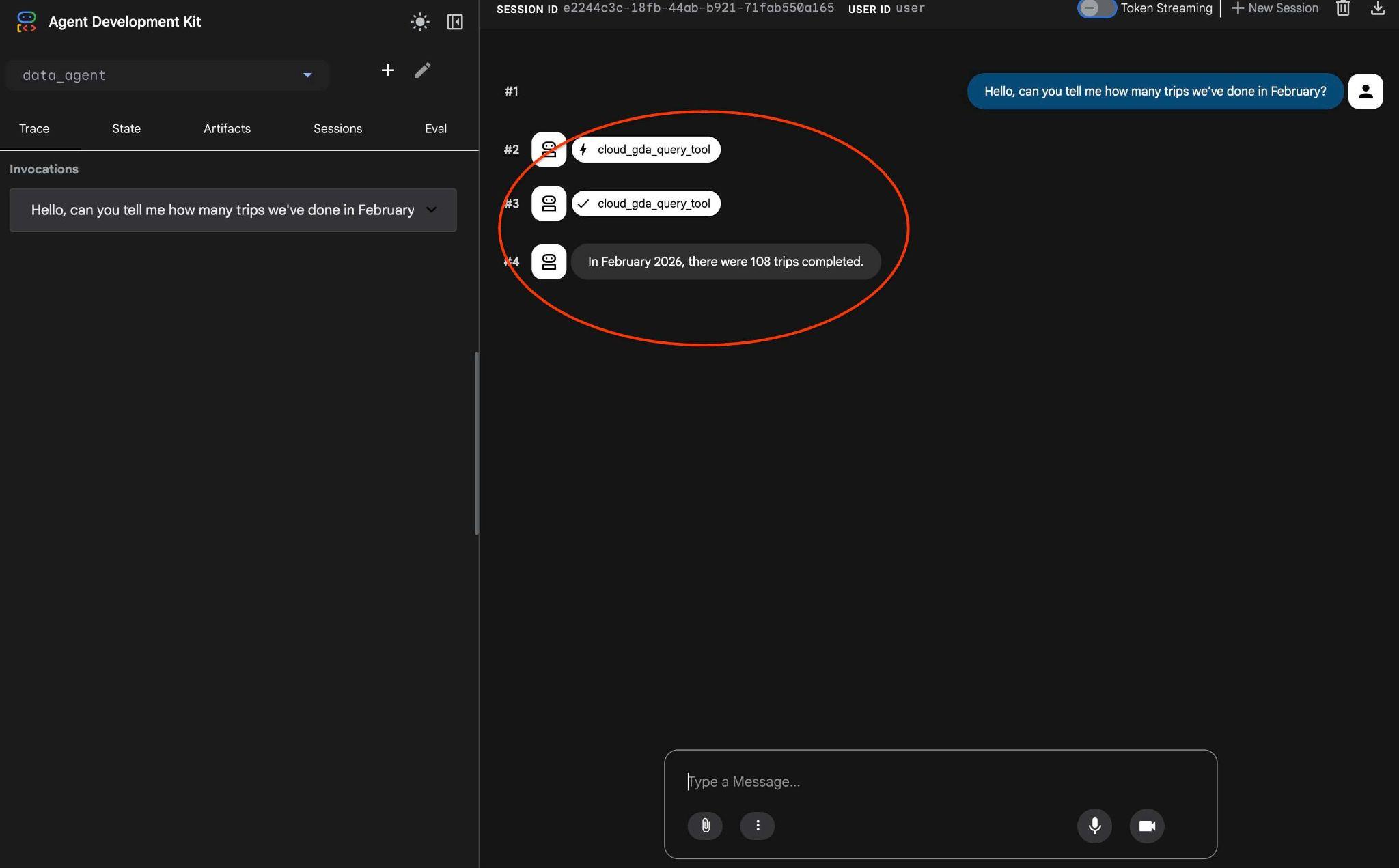
The request taking multiple turns last time has been transformed to one call to the MCP tool and executed using predictable SQL statements.
You can test the configured facets using the request like
how trucks trips for the last month
And in the output if you click on the tool action you can see it was using the same tool and applied facets to get the result.
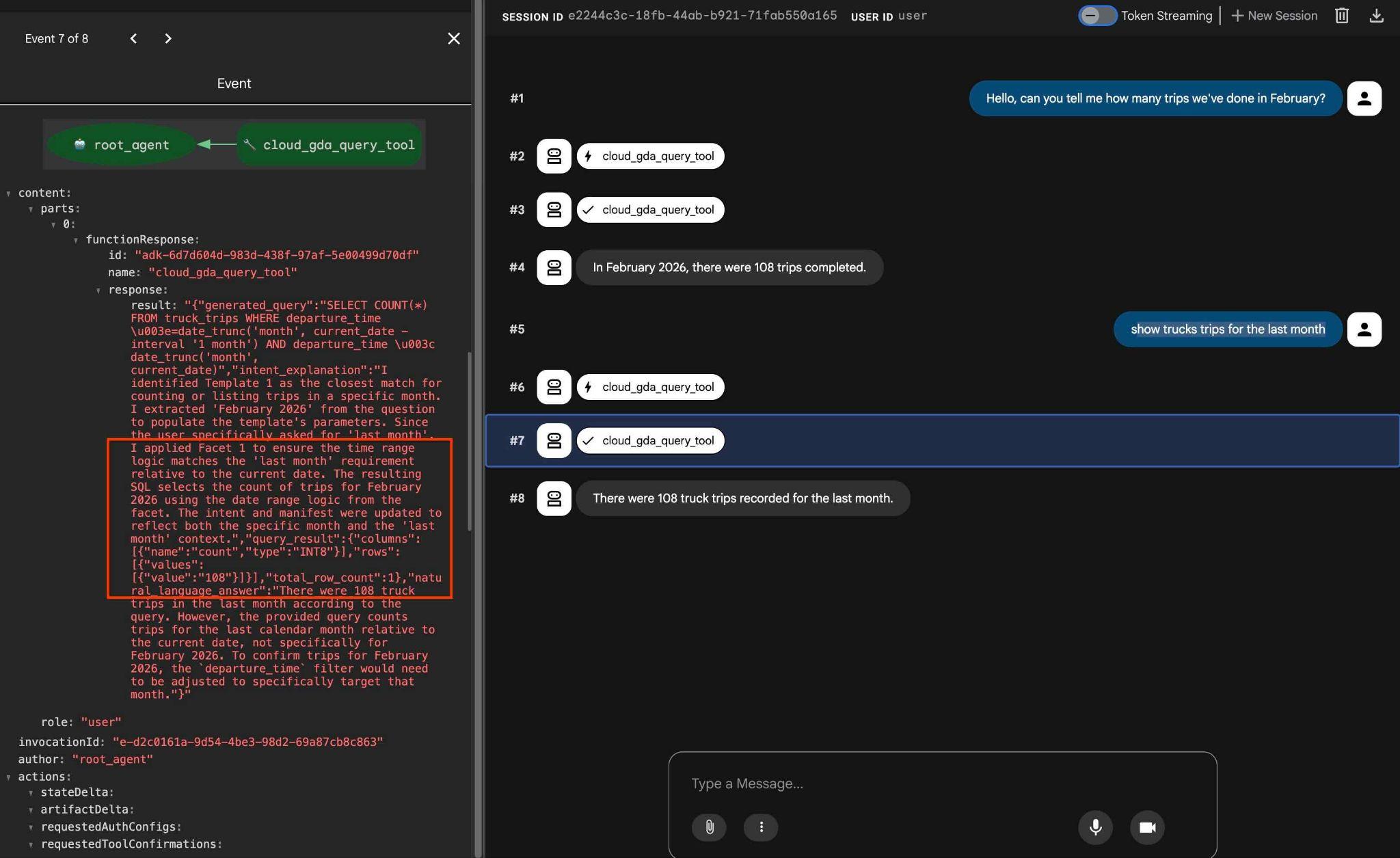
That concludes our lab. I hope you've been able to go through all the examples and learn how to use QueryData for AlloyDB. The provided technology helps to make your agentic workload and SQL generation predictable and reliable.
12. Clean up environment
To prevent unexpected charges it is good practice to clean up the temporary resources. The most reliable way is to delete the project where you were testing the workflow. But optionally you can limit yourself by deleting individual resources, such as AlloyDB.
Destroy the AlloyDB instances and cluster when you are done with the lab.
Delete AlloyDB cluster and all instances
If you've used the trial version of AlloyDB. Do not delete the trial cluster if you have plans to test other labs and resources using the trial cluster. You will not be able to create another trial cluster in the same project.
The cluster is destroyed with option force which also deletes all the instances belonging to the cluster.
In the cloud shell define the project and environment variables if you've been disconnected and all the previous settings are lost:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Delete the cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Expected console output:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Delete AlloyDB Backups
Delete all AlloyDB backups for the cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Expected console output:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
13. Congratulations
Congratulations for completing the codelab.
What we've covered
- How to create an AlloyDB cluster and import sample data
- How to enable AlloyDB Data access API
- How to enable QueryData for AlloyDB
- How to generate templates
- How to use faceted search
- How to use QueryData with AI Agents
14. Survey
Output: