
১. ভূমিকা
এই কোডল্যাবটি AlloyDB-এর জন্য QueryData দিয়ে কীভাবে কাজ শুরু করতে হয় এবং এজেন্টিক অ্যাপ্লিকেশনগুলিতে স্বাভাবিক ভাষার ইনপুট থেকে নির্ভুল ও অনুমানযোগ্য SQL স্টেটমেন্ট তৈরি করতে এটি কীভাবে ব্যবহার করতে হয়, তার একটি নির্দেশিকা প্রদান করে।
পূর্বশর্ত
- গুগল ক্লাউড কনসোল সম্পর্কে প্রাথমিক ধারণা
- কমান্ড লাইন ইন্টারফেস এবং ক্লাউড শেলে প্রাথমিক দক্ষতা
আপনি যা শিখবেন
- কীভাবে একটি AlloyDB ক্লাস্টার তৈরি করবেন এবং নমুনা ডেটা ইম্পোর্ট করবেন
- AlloyDB ডেটা অ্যাক্সেস API কীভাবে সক্রিয় করবেন
- AlloyDB-এর জন্য QueryData কীভাবে সক্রিয় করবেন
- টেমপ্লেট তৈরি করার পদ্ধতি
- ফেসেটেড সার্চ কীভাবে ব্যবহার করবেন
- এআই এজেন্টের সাথে QueryData কীভাবে ব্যবহার করবেন
আপনার যা যা লাগবে
- একটি গুগল ক্লাউড অ্যাকাউন্ট এবং গুগল ক্লাউড প্রজেক্ট
- ক্রোমের মতো একটি ওয়েব ব্রাউজার যা গুগল ক্লাউড কনসোল এবং ক্লাউড শেল সমর্থন করে।
২. সেটআপ এবং প্রয়োজনীয়তা
প্রজেক্ট সেটআপ
একটি গুগল ক্লাউড প্রজেক্ট তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন ।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন।
ক্লাউড শেল শুরু করুন
যদিও গুগল ক্লাউড আপনার ল্যাপটপ থেকে দূরবর্তীভাবে পরিচালনা করা যায়, এই কোডল্যাবে আপনি গুগল ক্লাউড শেল ব্যবহার করবেন, যা ক্লাউডে চালিত একটি কমান্ড লাইন পরিবেশ।
গুগল ক্লাউড কনসোল থেকে, উপরের ডানদিকের টুলবারে থাকা ক্লাউড শেল আইকনটিতে ক্লিক করুন:
বিকল্পভাবে আপনি প্রথমে G এবং তারপর S চাপতে পারেন। আপনি যদি গুগল ক্লাউড কনসোলের মধ্যে থাকেন, তাহলে এই ক্রমটি ক্লাউড শেল সক্রিয় করবে অথবা এই লিঙ্কটি ব্যবহার করুন।
পরিবেশটি প্রস্তুত করতে এবং এর সাথে সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগবে। এটি শেষ হলে, আপনি এইরকম কিছু দেখতে পাবেন:

এই ভার্চুয়াল মেশিনটিতে আপনার প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলস লোড করা আছে। এটি একটি স্থায়ী ৫ জিবি হোম ডিরেক্টরি প্রদান করে এবং গুগল ক্লাউডে চলে, যা নেটওয়ার্ক পারফরম্যান্স ও অথেনটিকেশনকে ব্যাপকভাবে উন্নত করে। এই কোডল্যাবে আপনার সমস্ত কাজ একটি ব্রাউজারের মধ্যেই করা যাবে। আপনাকে কিছুই ইনস্টল করতে হবে না।
৩. শুরু করার আগে
এপিআই সক্ষম করুন
AlloyDB , Compute Engine , Networking services , এবং Vertex AI ব্যবহার করার জন্য, আপনাকে আপনার Google Cloud প্রজেক্টে এগুলোর নিজ নিজ API সক্রিয় করতে হবে।
ক্লাউড শেল টার্মিনালের ভিতরে, নিশ্চিত করুন যে আপনার প্রজেক্ট আইডি সেটআপ করা আছে:
gcloud config get-value project
আউটপুটে আপনি আপনার প্রজেক্ট tID দেখতে পাবেন:
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
PROJECT_ID এনভায়রনমেন্ট ভেরিয়েবল সেট করুন:
PROJECT_ID=$(gcloud config get-value project)
সকল প্রয়োজনীয় পরিষেবা সক্রিয় করুন:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
প্রত্যাশিত আউটপুট
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
৪. AlloyDB স্থাপন করুন
AlloyDB ক্লাস্টার এবং প্রাইমারি ইনস্ট্যান্স তৈরি করুন। আপনি হয় একটি প্রস্তুত স্ক্রিপ্ট ব্যবহার করে এটি স্থাপন করতে পারেন, যা সমস্ত প্রয়োজনীয় রিসোর্স স্থাপন করবে, অথবা ডকুমেন্টেশন অনুসরণ করে ধাপে ধাপে নিজেই এটি করতে পারেন।
স্বয়ংক্রিয় স্ক্রিপ্ট ব্যবহার করে AlloyDB স্থাপন করুন
এই পদ্ধতিতে একটি স্বয়ংক্রিয় স্ক্রিপ্ট ব্যবহার করে AlloyDB ক্লাস্টার স্থাপন করা হয় এবং স্থাপিত রিসোর্সগুলোর সাথে কাজ শুরু করার জন্য প্রয়োজনীয় তথ্য সরবরাহ করা হয়।
ক্লাউড শেল টার্মিনালে রিপোজিটরি থেকে ডিপ্লয়মেন্ট স্ক্রিপ্টটি ক্লোন করার জন্য কমান্ডটি চালান।
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
ডিপ্লয়মেন্ট স্ক্রিপ্টটি চালান।
./deploy_alloydb.sh --public-ip
স্ক্রিপ্টটি চলতে কিছুটা সময় নেবে - সাধারণত প্রায় ৫-৭ মিনিট এবং এটি একটি AlloyDB ক্লাস্টার ও পাবলিক এবং প্রাইভেট আইপি সহ একটি প্রাইমারি ইনস্ট্যান্স স্থাপন করবে। পাবলিক আইপি শুধুমাত্র অনুমোদিত নেটওয়ার্কের জন্য অথবা AlloyDB Auth প্রক্সি ব্যবহার করে পাওয়া যাবে। আপনি ডকুমেন্টেশনে পাবলিক আইপি সম্পর্কে আরও পড়তে পারেন। আউটপুট হিসাবে, স্ক্রিপ্টটি আপনার স্থাপন করা AlloyDB ক্লাস্টার সম্পর্কে তথ্য প্রদান করবে। অনুগ্রহ করে মনে রাখবেন, আপনার পাসওয়ার্ডটি ভিন্ন হবে - ভবিষ্যতের ব্যবহারের জন্য পাসওয়ার্ডটি কোথাও লিখে রাখুন ।
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
এবং আপনি ওয়েব কনসোলে নতুন ক্লাস্টার এবং প্রাইমারি ইনস্ট্যান্সটিও দেখতে পারেন।
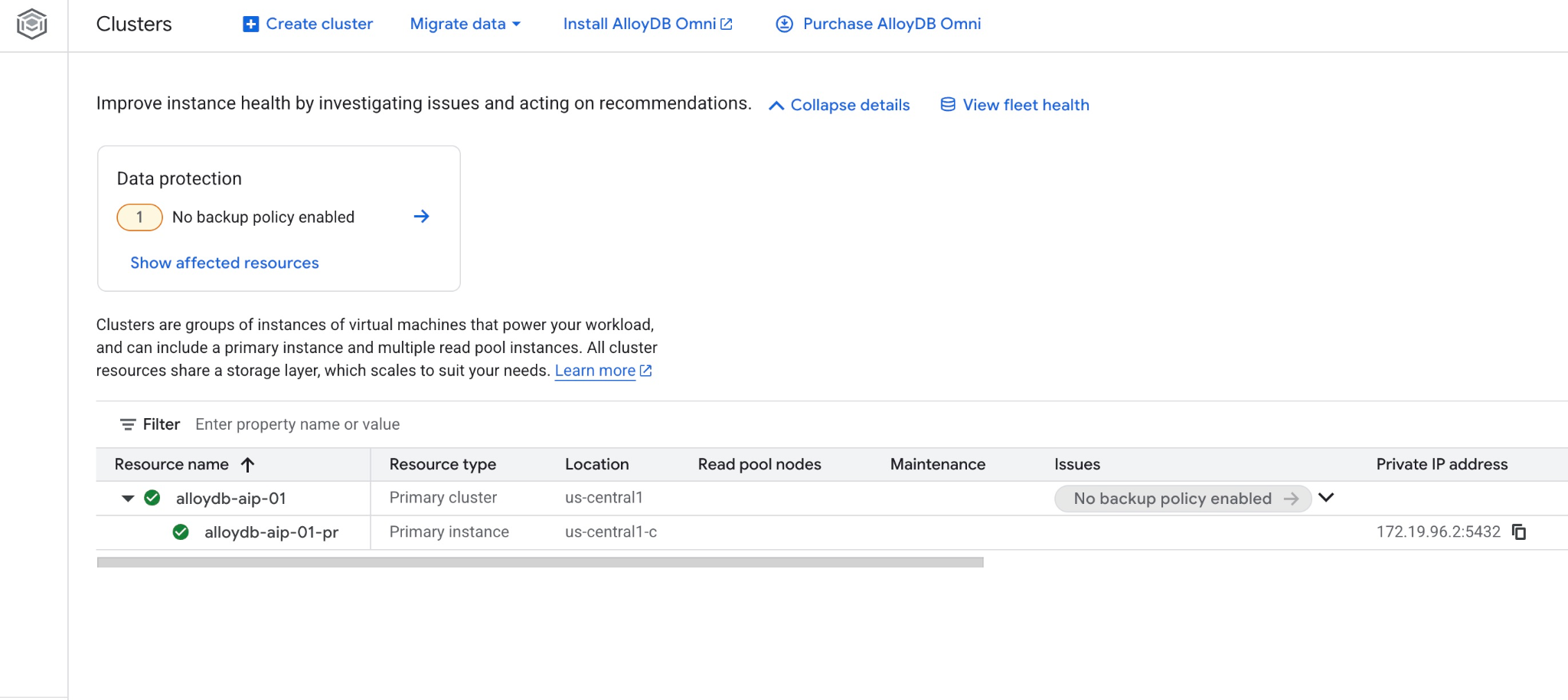
৫. ডাটাবেস প্রস্তুত করুন
এআই ফাংশন ও অপারেটর ব্যবহার করার জন্য আপনাকে ভার্টেক্স এআই ইন্টিগ্রেশন চালু করতে হবে, ডেটা অ্যাক্সেস এপিআই সক্রিয় করতে হবে এবং নমুনা ডেটাসেটের জন্য একটি ডেটাবেস তৈরি করতে হবে।
AlloyDB-কে প্রয়োজনীয় অনুমতি প্রদান করুন
AlloyDB সার্ভিস এজেন্টে Vertex AI-এর অনুমতি যোগ করুন।
উপরে থাকা "+" চিহ্নটি ব্যবহার করে আরেকটি ক্লাউড শেল ট্যাব খুলুন।
নতুন ক্লাউড শেল ট্যাবে নিম্নলিখিতটি চালান:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
ডেটা অ্যাক্সেস এপিআই সক্ষম করুন
execute_sql মতো MCP টুলগুলো ব্যবহার করতে হলে আপনাকে AlloyDB ক্লাস্টারে ডেটা অ্যাক্সেস API সক্রিয় করতে হবে।
একই টার্মিনাল ট্যাবে চালান।
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
IAM প্রমাণীকরণ সক্রিয় করুন
আমরা আমাদের এজেন্টিক টুলগুলির জন্য IAM অথেন্টিকেশন ব্যবহার করতে যাচ্ছি এবং এর জন্য ইনস্ট্যান্সে IAM অথেন্টিকেশন সক্রিয় করতে হবে ও নিজেকে একজন ডাটাবেস ব্যবহারকারী হিসেবে যুক্ত করতে হবে। ইনস্ট্যান্স লেভেলে IAM অথেন্টিকেশন সক্রিয় করার আগে, অনুগ্রহ করে পূর্ববর্তী ধাপ অর্থাৎ ডেটা অ্যাক্সেস API সক্রিয় করার কাজটি শেষ হওয়া পর্যন্ত অপেক্ষা করুন। আপনার ইনস্ট্যান্সের স্ট্যাটাস সবুজ হওয়া উচিত।
আমরা ইনস্ট্যান্স লেভেলে IAM সক্রিয় করার মাধ্যমে শুরু করব। একই টার্মিনাল ট্যাবে এটি চালান।
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
নিজেকে AlloyDB ব্যবহারকারী হিসেবে যুক্ত করুন:
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
ট্যাবের মধ্যে থাকা 'exit' কমান্ডটি চালিয়ে ট্যাবটি বন্ধ করুন:
exit
AlloyDB Studio-এর সাথে সংযোগ করুন
পরবর্তী অধ্যায়গুলোতে ডাটাবেসের সাথে সংযোগের প্রয়োজন হয় এমন সমস্ত SQL কমান্ড AlloyDB Studio-তে চালানো যাবে।
AlloyDB for Postgres-এর ক্লাস্টার পৃষ্ঠায় যান।
প্রাইমারি ইনস্ট্যান্সটিতে ক্লিক করে আপনার AlloyDB ক্লাস্টারের ওয়েব কনসোল ইন্টারফেসটি খুলুন।
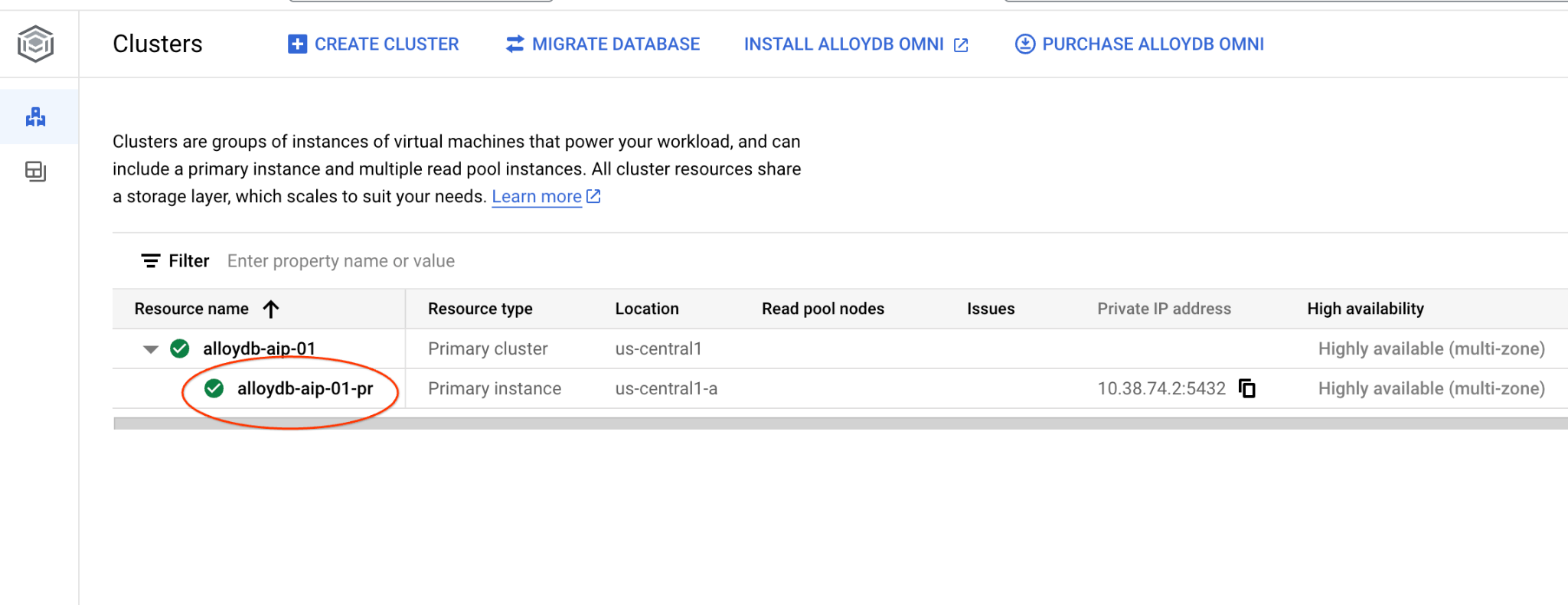
তারপর বাম দিকে AlloyDB Studio-তে ক্লিক করুন:
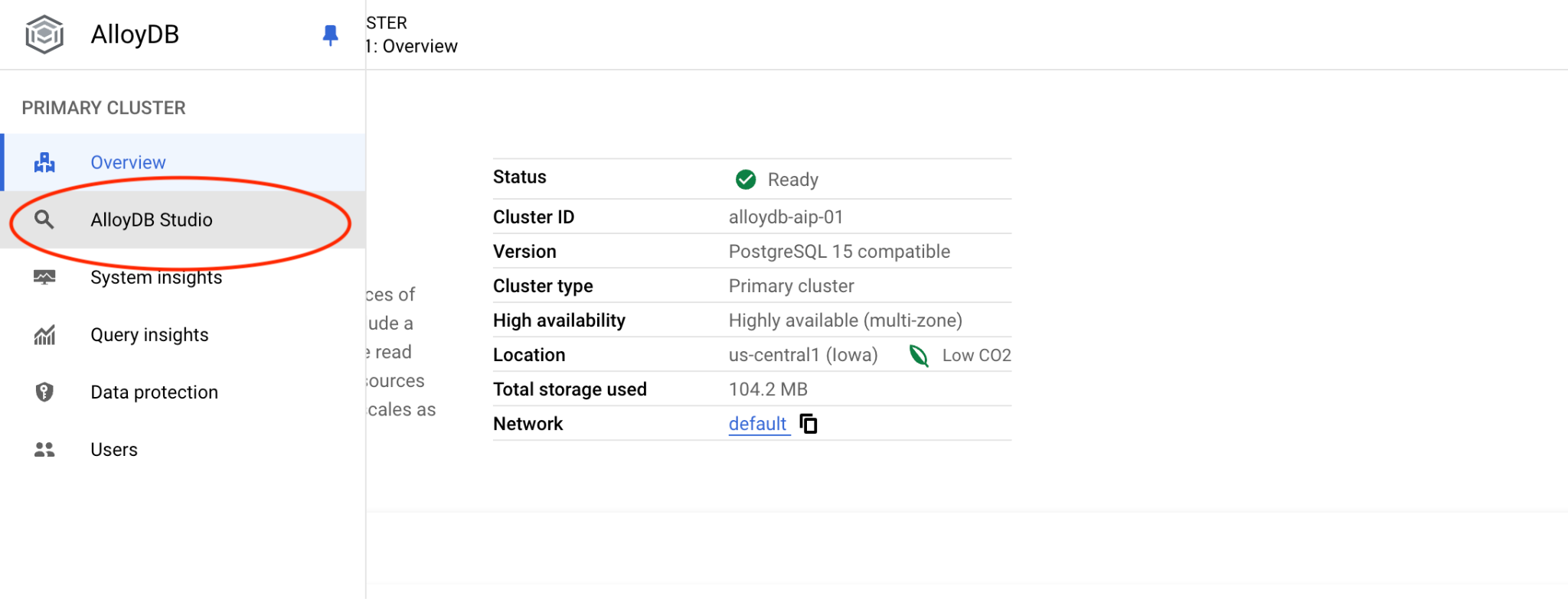
postgres ডাটাবেস এবং IAM অথেন্টিকেশন বেছে নিন। তারপর "Authenticate" বোতামে ক্লিক করুন।
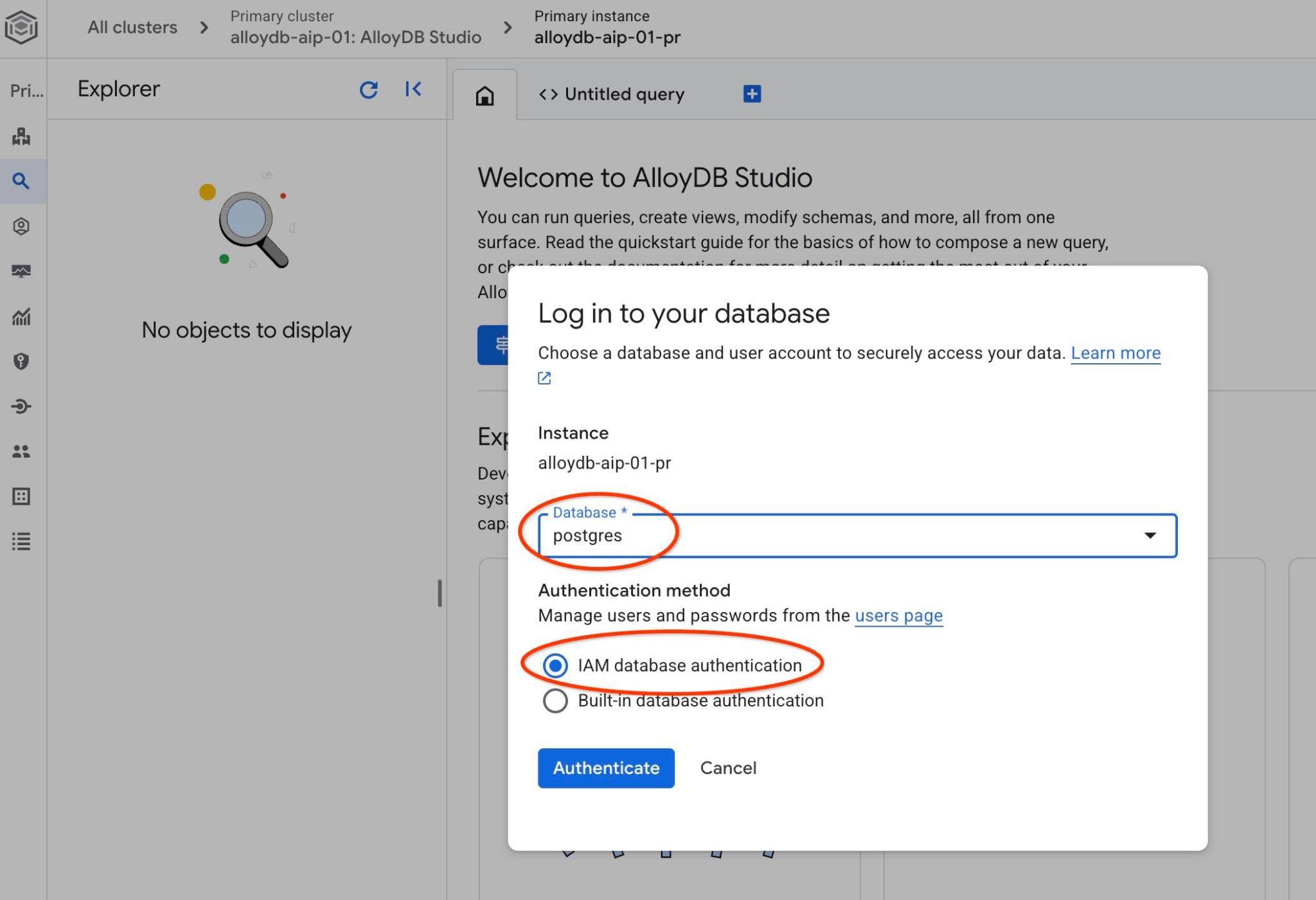
এটি AlloyDB Studio ইন্টারফেসটি খুলবে। ডাটাবেসে কমান্ডগুলো চালানোর জন্য ডানদিকে থাকা 'Untitled Query' ট্যাবে ক্লিক করুন।
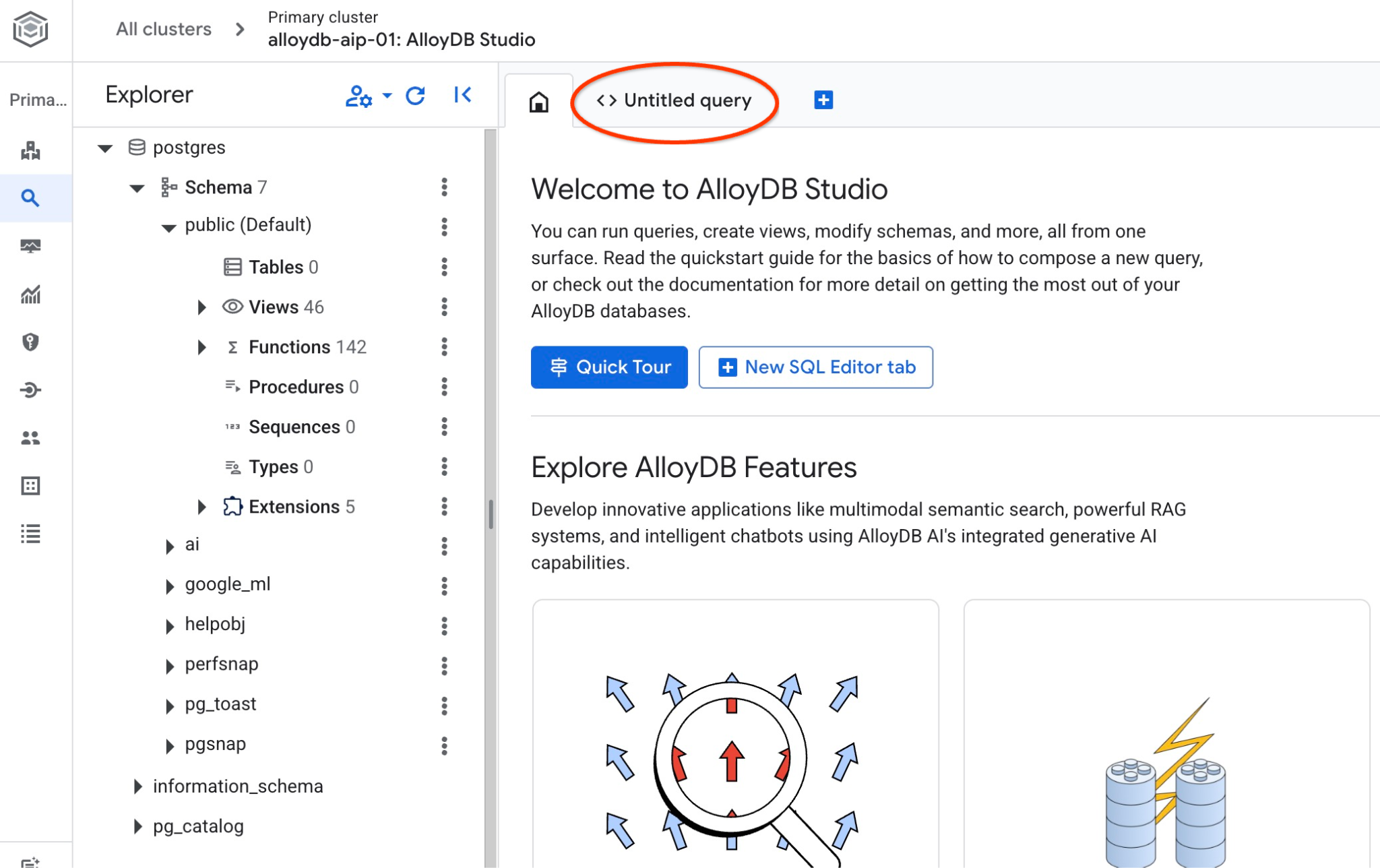
এটি এমন একটি ইন্টারফেস খোলে যেখানে আপনি SQL কমান্ড চালাতে পারেন।
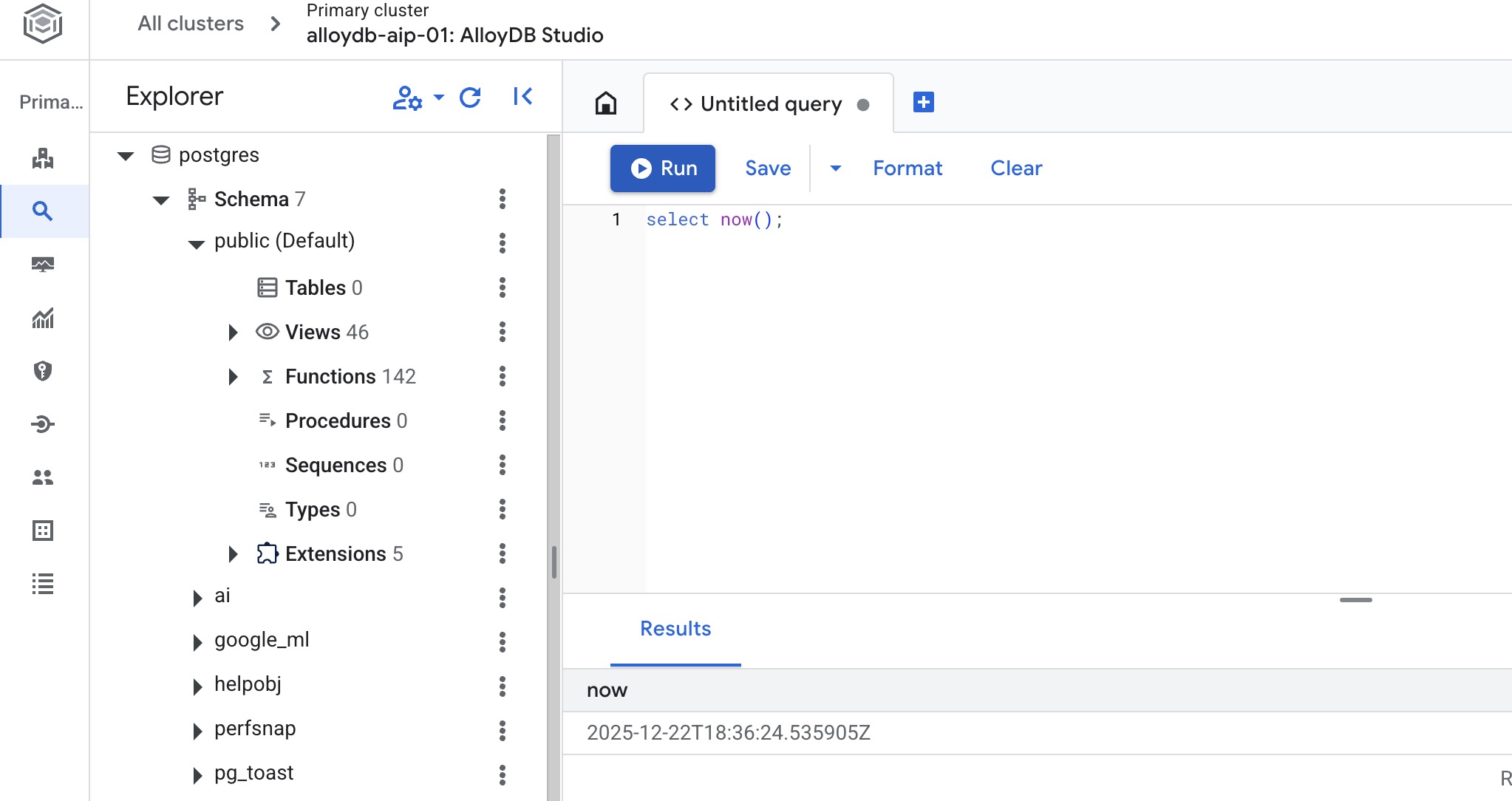
ডাটাবেস তৈরি করুন
ডাটাবেস কুইকস্টার্ট তৈরি করুন।
AlloyDB Studio Editor-এ নিম্নলিখিত কমান্ডটি চালান।
ডাটাবেস তৈরি করুন:
CREATE DATABASE quickstart_db
প্রত্যাশিত আউটপুট:
Statement executed successfully
quickstart_db-এর সাথে সংযোগ করুন
আপনার ডাটাবেসটি তৈরি হয়েছে কিনা তা পরীক্ষা করতে এতে সংযোগ করুন। ব্যবহারকারী/ডাটাবেস পরিবর্তন করার বোতামটি ব্যবহার করে স্টুডিওতে পুনরায় সংযোগ করুন।
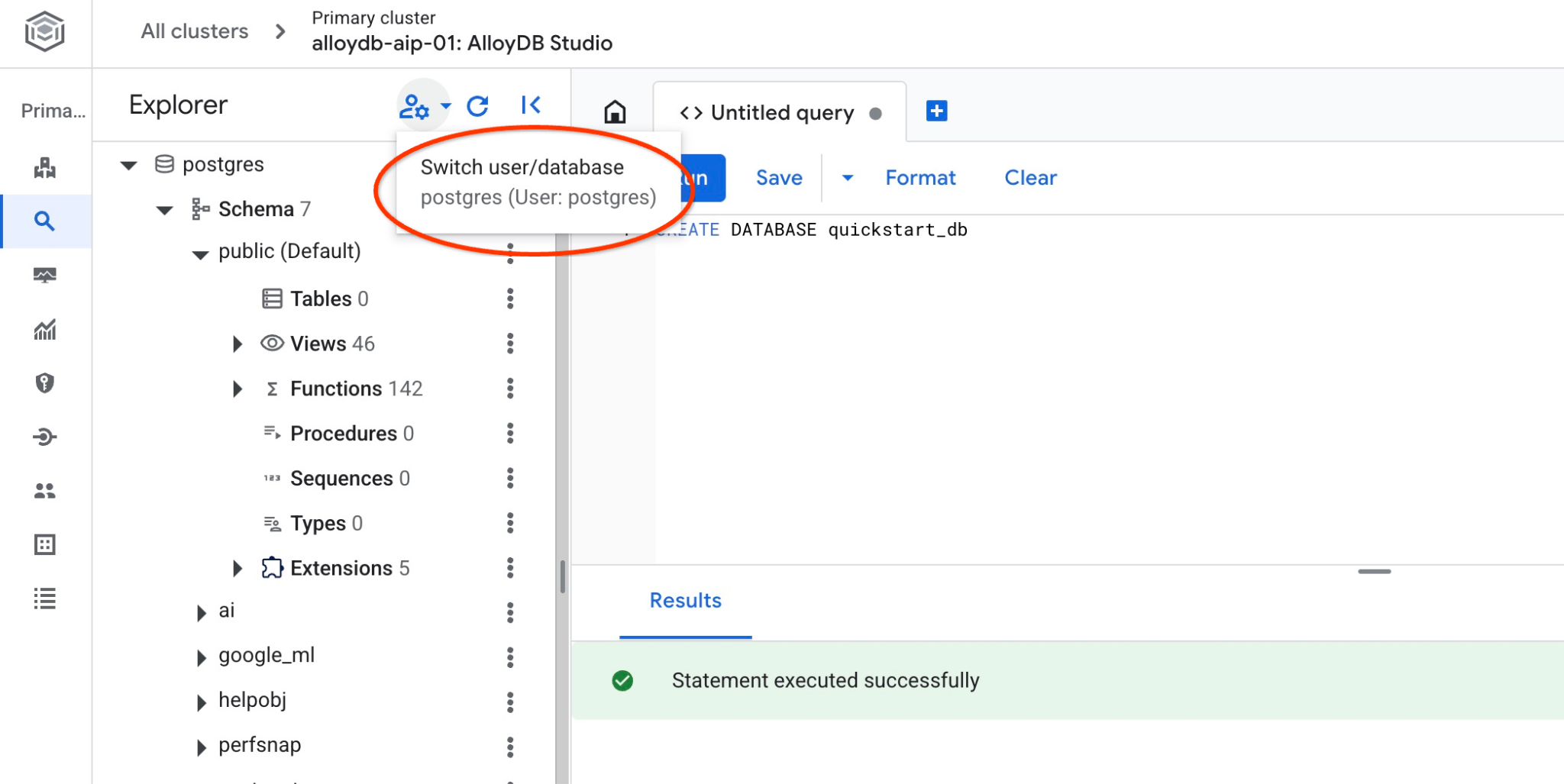
ড্রপডাউন তালিকা থেকে নতুন quickstart_db ডাটাবেসটি বেছে নিন এবং একই IAM প্রমাণীকরণ ব্যবহার করুন।
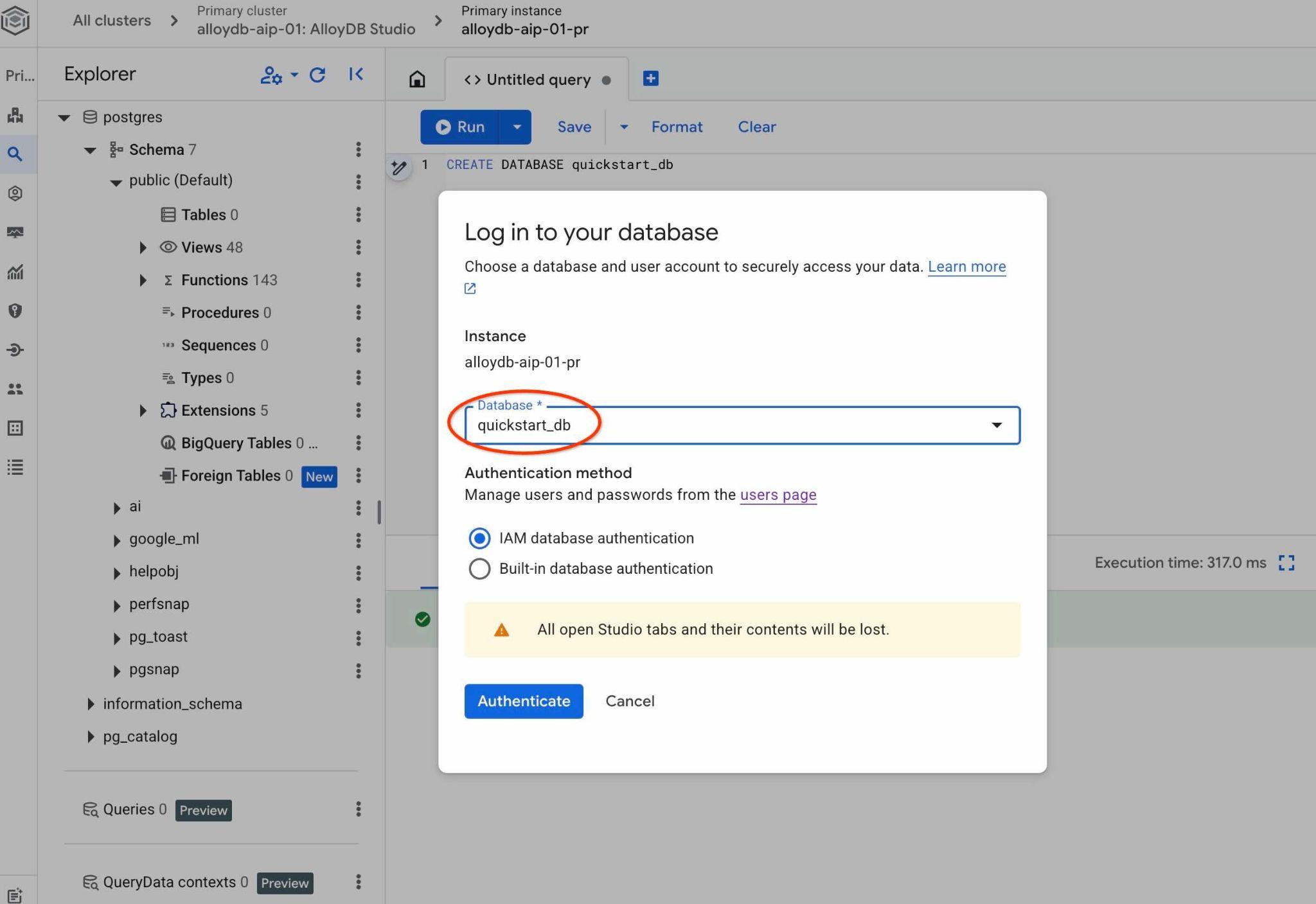
এটি একটি নতুন সংযোগ খুলবে যেখানে আপনি quickstart_db ডাটাবেসের অবজেক্টগুলো নিয়ে কাজ করতে পারবেন। সেখানে আপনি আপনার ইম্পোর্ট করা স্কিমা ও ডেটা পরীক্ষা করতে এবং QueryData কনটেক্সট সেটগুলো নিয়ে কাজ করতে পারবেন।
৬. নমুনা তথ্য
এখন আপনাকে ডাটাবেসে অবজেক্ট তৈরি করতে হবে এবং ডেটা লোড করতে হবে। আপনি একটি কাল্পনিক সিম্বল শিপিং কোম্পানির ডেটাসেট ব্যবহার করতে যাচ্ছেন। এতে পণ্য, ট্রাক, অনুরোধ এবং ট্রাক ট্রিপ সম্পর্কিত কাল্পনিক ডেটার পাশাপাশি কাল্পনিক ড্রাইভারও রয়েছে।
স্টোরেজ বাকেট তৈরি করুন
আপনি আপনার ক্লোন করা রিপোজিটরি থেকে AlloyDB ডেটাবেসে ডেটা ইম্পোর্ট করার জন্য Google SDK (gcloud) ব্যবহার করবেন। এর জন্য আপনাকে একটি ক্লাউড স্টোরেজ বাকেট তৈরি করতে হবে এবং AlloyDB সার্ভিস অ্যাকাউন্টকে অ্যাক্সেস দিতে হবে। বিকল্পভাবে, আপনি ডকুমেন্টেশনে বর্ণিত পদ্ধতি অনুযায়ী ওয়েব কনসোল ব্যবহার করেও এটি করার চেষ্টা করতে পারেন।
গুগল ক্লাউড শেল টার্মিনালে নিম্নলিখিত কমান্ডটি চালান:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
ডেটা লোড করুন
পরবর্তী ধাপ হলো ডেটা লোড করা। আমাদের কম্প্রেসড SQL ডাম্পটি ক্লোন করা রিপোজিটরি ফোল্ডারে অবস্থিত। নিম্নলিখিত কমান্ডটি ধরে নেয় যে, আপনি পূর্ববর্তী ধাপে AlloyDB ক্লাস্টার তৈরি করার সময় রিপোজিটরিটি ক্লোন করতে আপনার হোম ডিরেক্টরিকে প্রারম্ভিক বিন্দু হিসেবে ব্যবহার করেছিলেন।
সংকুচিত SQL ডাম্পটি নতুন স্টোরেজ বাকেটে কপি করুন:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
তারপর quickstart_db ডেটাবেসে ডেটা লোড করুন:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
এই কমান্ডটি স্যাম্পল ডেটাসেটটি quickstart_db ডেটাবেসে লোড করবে। আপনি AlloyDB Studio ব্যবহার করে টেবিল এবং রেকর্ডগুলো যাচাই করতে পারেন।
৭. ডেটা এজেন্টের সাথে কাজ করুন
চলুন, পাইথনের জন্য গুগল এডিকে (Google ADK for python) ব্যবহার করে তৈরি একটি নমুনা এআই এজেন্ট এবং ডেটাবেসের জন্য এমসিপি টুলবক্স (MCP Toolbox for databases) ব্যবহার করে আমাদের অ্যালয়ডিবি (AlloyDB) ইনস্ট্যান্সের সাথে সংযোগ স্থাপন দিয়ে শুরু করা যাক।
ডাটাবেসের জন্য এমসিপি টুলবক্স ইনস্টল করুন
ডেটাবেসের জন্য এমসিপি টুলবক্স একটি ওপেন সোর্স প্রজেক্ট যা পোস্টগ্রেসকিউএল-এর জন্য অ্যালয়ডিবি সহ একাধিক ডেটাবেস ইঞ্জিনের জন্য এমসিপি সাপোর্ট প্রদান করে। আপনি ডকুমেন্টেশনে এমসিপি টুলবক্স সম্পর্কে পড়তে পারেন।
আপনার প্ল্যাটফর্মের জন্য সফটওয়্যারটির সর্বশেষ সংস্করণ ডাউনলোড করতে হবে। সর্বশেষ সংস্করণের জন্য, রিলিজ পৃষ্ঠাটি দেখুন। নিচের উদাহরণটিতে দেখানো হয়েছে কীভাবে ক্লাউড শেলে এমসিপি টুলবক্সের ৩১তম সংস্করণটি ডাউনলোড করতে হয়।
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
টুলবক্সের জন্য আপনাকে একটি কনফিগারেশন ফাইল প্রস্তুত করতে হবে। বর্তমান ডিরেক্টরিতে আমাদের একটি নমুনা tools.yaml.example ফাইল আছে এবং আমরা প্রজেক্ট আইডি ও রিজিয়ন দিয়ে দুটি প্লেসহোল্ডার প্রতিস্থাপন করে tools.yaml ফাইলটি প্রস্তুত করতে যাচ্ছি।
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
ডাটাবেসের জন্য এমসিপি টুলবক্স শুরু করুন
এখন আপনি প্রস্তুত করা কনফিগারেশন ফাইলটি দিয়ে এমসিপি টুলবক্সটি চালু করতে পারেন।
আপনার Google Cloud Shell ইন্টারফেসের উপরের দিকে থাকা "+" বোতামটি চেপে একটি নতুন ট্যাব খুলুন।
নতুন ট্যাবে টুলবক্স বাইনারি ফাইল এবং কনফিগারেশন ফাইল tools.yaml থাকা ডিরেক্টরিতে যান এবং MCP সার্ভারটি চালু করুন।
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
আউটপুটে আপনি "Server ready to serve!"-এর মতো নিম্নলিখিত লেখাটি দেখতে পাবেন।
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
এজেন্ট সোর্স কোড পরীক্ষা করুন
ক্লোন করা রিপোজিটরি ফোল্ডারের প্রথম ট্যাবে গুগল ক্লাউড শেল এডিটর ব্যবহার করে এজেন্ট কোডটি পর্যালোচনা করুন।
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
আপনি এজেন্টে দেখতে পাবেন, AlloyDB-এর জন্য আমাদের একটি Google Cloud MCP সার্ভারের সেকশন রয়েছে। আমরা MCP_SERVER_URL হিসেবে একটি এন্ডপয়েন্ট, অথেনটিকেশন, প্রজেক্ট আইডি প্রদান করি এবং এটিকে MCP টুলসেটে যুক্ত করি।
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
এবং এজেন্ট কোডে MCP টুলসেটটি এজেন্টের জন্য tools প্যারামিটার হিসেবে অন্তর্ভুক্ত করা হয়েছে। এছাড়াও, এজেন্ট প্রম্পটের জন্য ভেরিয়েবল হিসেবে ক্লাস্টার ও ইনস্ট্যান্সের নাম, রিজিয়ন এবং ডেটাবেস রয়েছে।
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
কোডটি পরীক্ষা করার পর, এডিটর উইন্ডোর উপরের ডানদিকে থাকা 'ওপেন টার্মিনাল' বোতামটি চেপে টার্মিনালে ফিরে যান।
এজেন্ট শুরু করুন
এখন আপনি গুগল এডিকে ওয়েব ইন্টারফেস ব্যবহার করে এজেন্টটিকে ইন্টারেক্টিভ মোডে চালু করতে পারেন। এডিকে ওয়েব ইন্টারফেসটি এজেন্টের ওয়ার্কফ্লো পরীক্ষা এবং সমস্যা সমাধানের একটি সুবিধাজনক উপায় প্রদান করে।
প্রথমে আমরা uv প্যাকেজ ম্যানেজার ব্যবহার করে পাইথনের জন্য প্রয়োজনীয় সমস্ত প্যাকেজ ইনস্টল করে নেব।
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
সমস্ত প্যাকেজ ইনস্টল হয়ে গেলে, এআই মডেলগুলির সাথে সমস্ত যোগাযোগের জন্য ভার্টেক্স এআই (Vertex AI) ব্যবহার করার নির্দেশ দিতে আপনাকে এজেন্ট ডিরেক্টরিতে একটি .env ফাইল যোগ করতে হবে।
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
তারপর আপনি এজেন্টটি চালু করতে পারেন।
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
http://127.0.0.1:8000- এর মতো এন্ডপয়েন্ট ব্যবহার করলে আপনি নিম্নলিখিত আউটপুটের মতো কিছু দেখতে পাবেন।
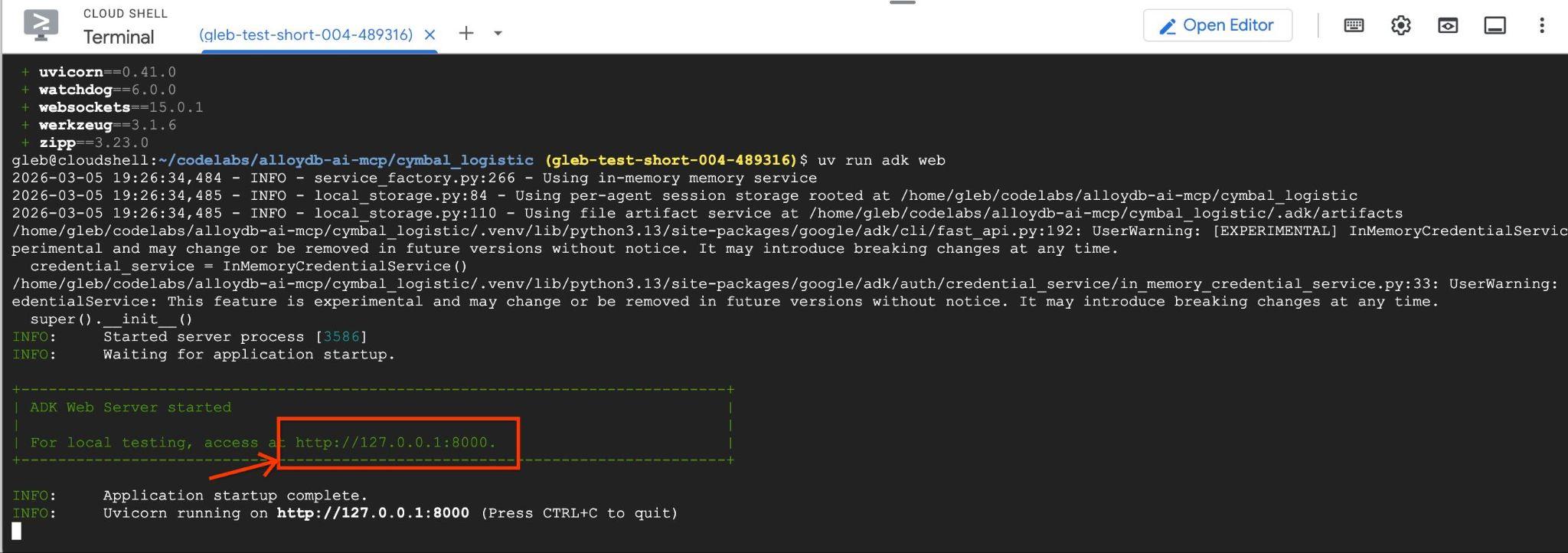
আপনি ক্লাউড শেলে সেই URL-টিতে ক্লিক করতে পারেন এবং এটি একটি আলাদা ব্রাউজার ট্যাবে একটি প্রিভিউ উইন্ডো খুলবে, যেখানে আপনি বাম দিকের ড্রপ-ডাউন তালিকা থেকে data_agent বেছে নিতে পারবেন।
ADK ওয়েব ইন্টারফেসে আপনি নীচের ডানদিকে আপনার প্রশ্ন পোস্ট করতে পারেন এবং ডানদিকে প্রতিটি ধাপের ট্রেস সহ সম্পূর্ণ এক্সিকিউশন ফ্লো দেখতে পারেন।
৮. AlloyDB-এর জন্য QueryData ছাড়া NL2SQL পরীক্ষা করুন
এজেন্টটি আপনাকে স্বাভাবিক ভাষায় স্বাধীনভাবে প্রশ্ন করার সুযোগ দেয় এবং প্রশ্নগুলোর উত্তর দেওয়ার জন্য এজেন্টটি ডাটাবেসের জন্য এমসিপি টুলবক্স ব্যবহার করবে। প্রশ্নগুলো ডানদিকের নিচে পোস্ট করা হয় এবং টুলগুলোতে করা সমস্ত কলের উত্তর উপরে প্রদর্শিত হবে।
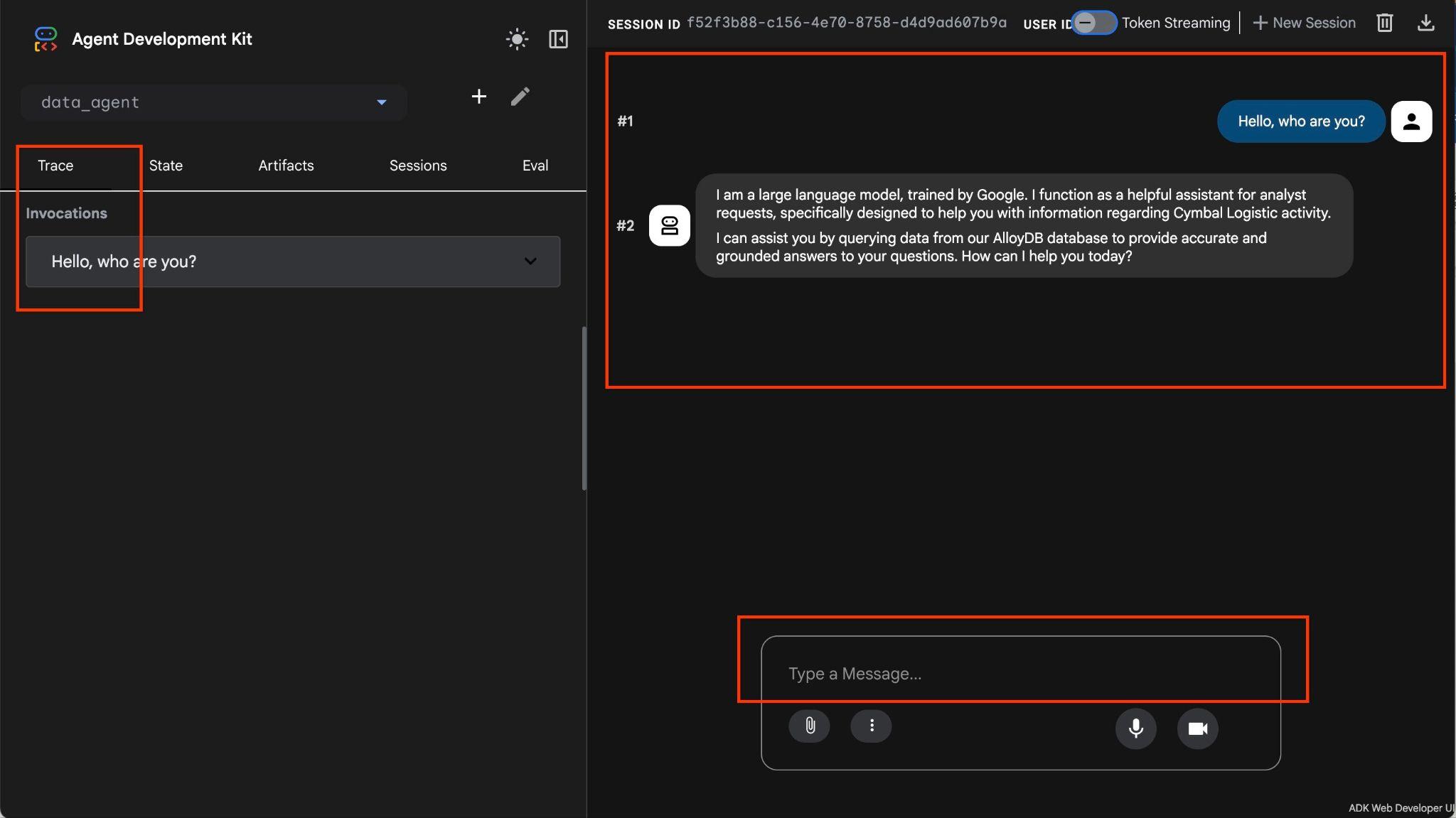
আপনি একটি শিপিং কোম্পানির পরিচালন সংক্রান্ত ডেটা নিয়ে কাজ করছেন, যেখানে শিপিং অনুরোধ, ট্রাক, ড্রাইভার এবং ড্রাইভারদের দ্বারা সম্পন্ন ট্রিপ সম্পর্কিত তথ্য রয়েছে। প্রথম প্রশ্নটি হলো ২০২৬ সালের ফেব্রুয়ারী মাসে সম্পাদিত ট্রিপের সংখ্যা সম্পর্কে।
ডানদিকের নিচের ইনপুট ফিল্ডে নিম্নলিখিতটি টাইপ করুন এবং এন্টার চাপুন।
Hello, can you tell me how many trips we've done in February?
এজেন্টটি list_cymbal_logistics_schemas_tool এবং execute_sql_tool ব্যবহার করে স্কিমার মধ্যে সঠিক টেবিলগুলো শনাক্ত করার জন্য একাধিক টুল কল সম্পাদন করবে, যা সঠিক ডেটা পাওয়ার জন্য একাধিক SQL স্টেটমেন্ট কার্যকর করবে।
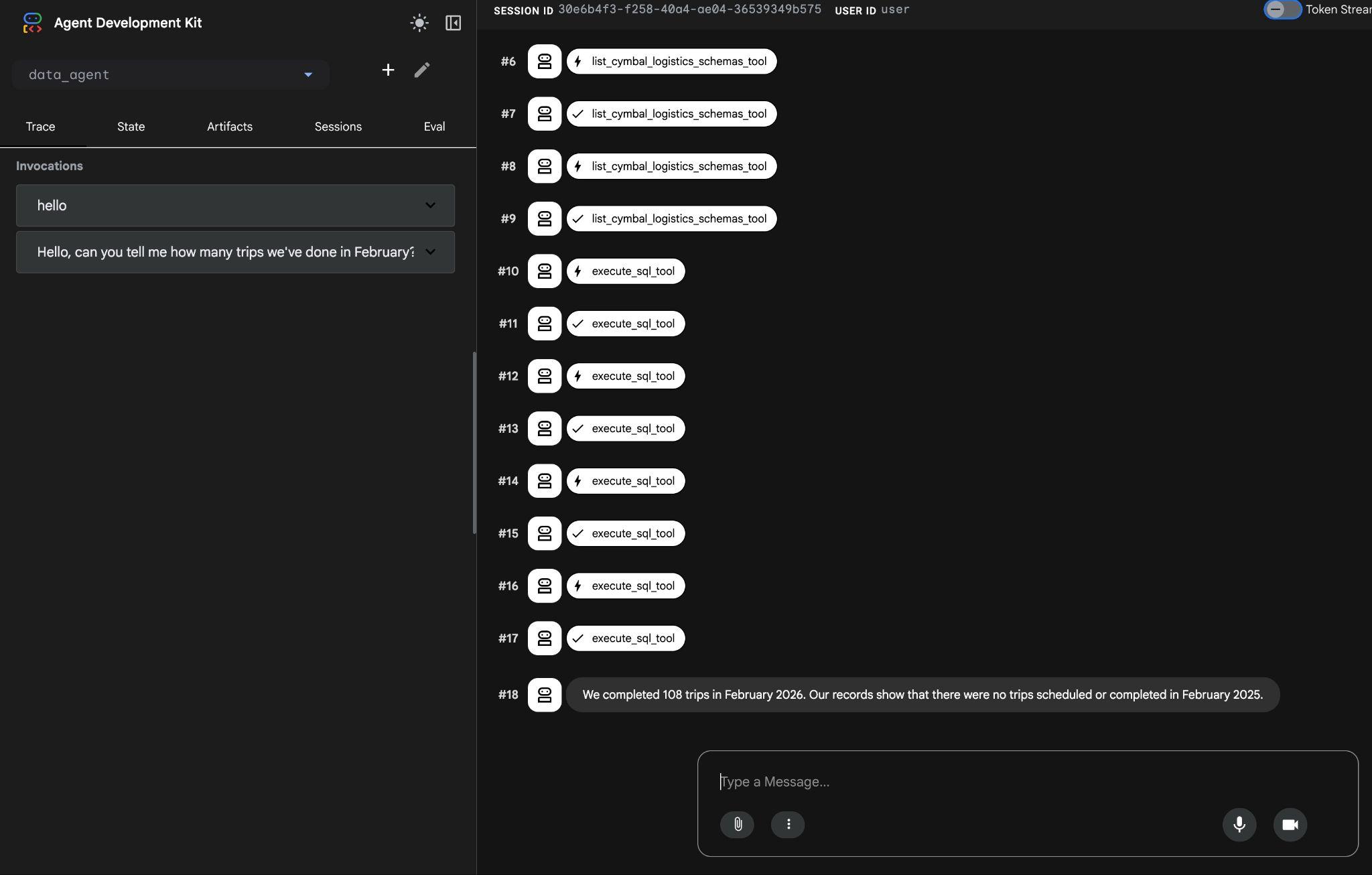
অবশেষে, সঠিক কোয়েরি তৈরি করে ডেটাবেসে তা কার্যকর করার পর এটি সঠিক ফলাফল দেবে।
আমরা ২০২৬ সালের ফেব্রুয়ারী মাসে ১০৮টি ট্রিপ সম্পন্ন করেছি। আমাদের রেকর্ড অনুযায়ী, ২০২৫ সালের ফেব্রুয়ারী মাসে কোনো ট্রিপ নির্ধারিত বা সম্পন্ন হয়নি।
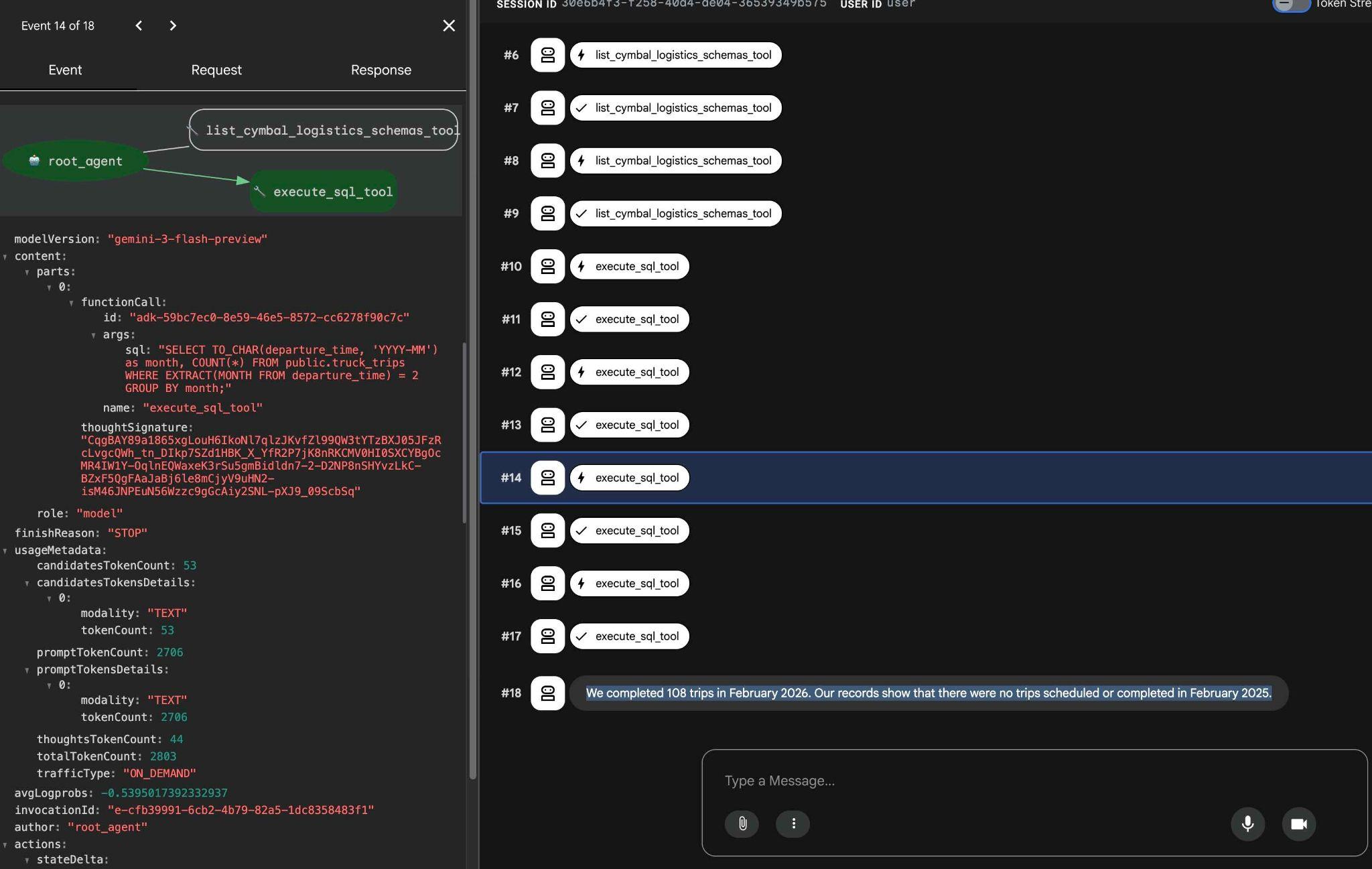
টুল এক্সিকিউশন-এর উপর ক্লিক করে আপনি দেখতে পারেন প্রতিটি টুল কল কী কাজ করে। উদাহরণস্বরূপ, আমাদের ফলাফল পাওয়ার জন্য যে কোয়েরিটি চালানো হয়েছিল তা এখানে দেওয়া হলো।
ADK ওয়েব ইন্টারফেস ব্যবহার করে অন্যান্য সাধারণ অনুরোধগুলো চেষ্টা করে দেখুন এবং লক্ষ্য করুন যে কাঙ্ক্ষিত ফলাফল অর্জনের জন্য এটি কীভাবে বিভিন্ন কোয়েরি সম্পাদন করে।
টার্মিনালে ctrl+c চেপে এজেন্টটি বন্ধ করুন। আপনি ADK ওয়েব ইন্টারফেস দিয়ে ব্রাউজার ট্যাবটি বন্ধ করতে পারেন।
এছাড়াও আপনি একই ctrl+c কী শর্টকাট চেপে দ্বিতীয় ট্যাবে থাকা MCP টুলবক্সটি বন্ধ করতে পারেন।
পরবর্তী ধাপে আমরা আমাদের NL2SQL রেসপন্স ও পারফরম্যান্স উন্নত করার জন্য QueryData কনটেক্সট তৈরি করব।
৯. কোয়েরি ডেটা কনটেক্সট সেট তৈরি করুন
আপনি আগের ধাপে দেখতে পেয়েছেন যে, SQL কোয়েরি তৈরি করার জন্য কোন টেবিল এবং কলাম ব্যবহার করা উচিত তা নির্ধারণ করতে AI মডেলটি ডাটাবেসের ইনফরমেশন স্কিমাতে একাধিকবার কল করছিল। পারফরম্যান্স ও নির্ভুলতা উন্নত করতে এবং ফলাফলকে আরও অনুমানযোগ্য করে তুলতে, আমরা আপনার QueryData কনটেক্সট যোগ করব, যা নির্ধারণ করবে একটি নির্দিষ্ট অনুরোধের জবাবে কোন কোয়েরিটি কার্যকর করা উচিত।
নির্দিষ্ট টেমপ্লেট তৈরি করুন
QueryData ContextSet হলো কোয়েরি টেমপ্লেট এবং ফ্যাসেট সম্বলিত একটি JSON ফাইল, যা কোয়েরি প্যাটার্ন এবং ডেটা স্ট্রাকচারের উপর ভিত্তি করে অনুরোধকৃত লক্ষ্য অর্জনের জন্য সঠিক SQL কোয়েরি বা এর অংশবিশেষ ব্যবহার করতে AI মডেলকে প্রয়োজনীয় ডেটা ও নির্দেশনা প্রদান করে।
আপনি একটি নির্দিষ্ট টেমপ্লেট থেকে শুরু করুন। ক্লাউড শেল এডিটর ব্যবহার করে একটি ফাইল তৈরি করুন। ক্লাউড শেল টার্মিনালে এক্সিকিউট করুন।
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
এবং আগের অধ্যায়ে ব্যবহৃত স্বাভাবিক ভাষার কোয়েরির টেমপ্লেটটি যোগ করুন - "ফেব্রুয়ারিতে আমরা কয়টি ট্রিপ করেছি?"
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
এরপর ক্লাউড শেল থেকে ডাউনলোড বাটনটি ব্যবহার করে টেমপ্লেটটি আপনার কম্পিউটারে ডাউনলোড করুন।
কোয়েরি ডেটা কনটেক্সট সেট লোড করুন
আমাদের QueryData কনটেক্সট সেটগুলো ব্যবহার করার জন্য সেগুলোকে ডাটাবেসে আপলোড করতে হবে।
AlloyDB Studio খুলুন। বাম প্যানেলের নীচে আপনি QueryData Context এবং তিনটি ডট দেখতে পাবেন।
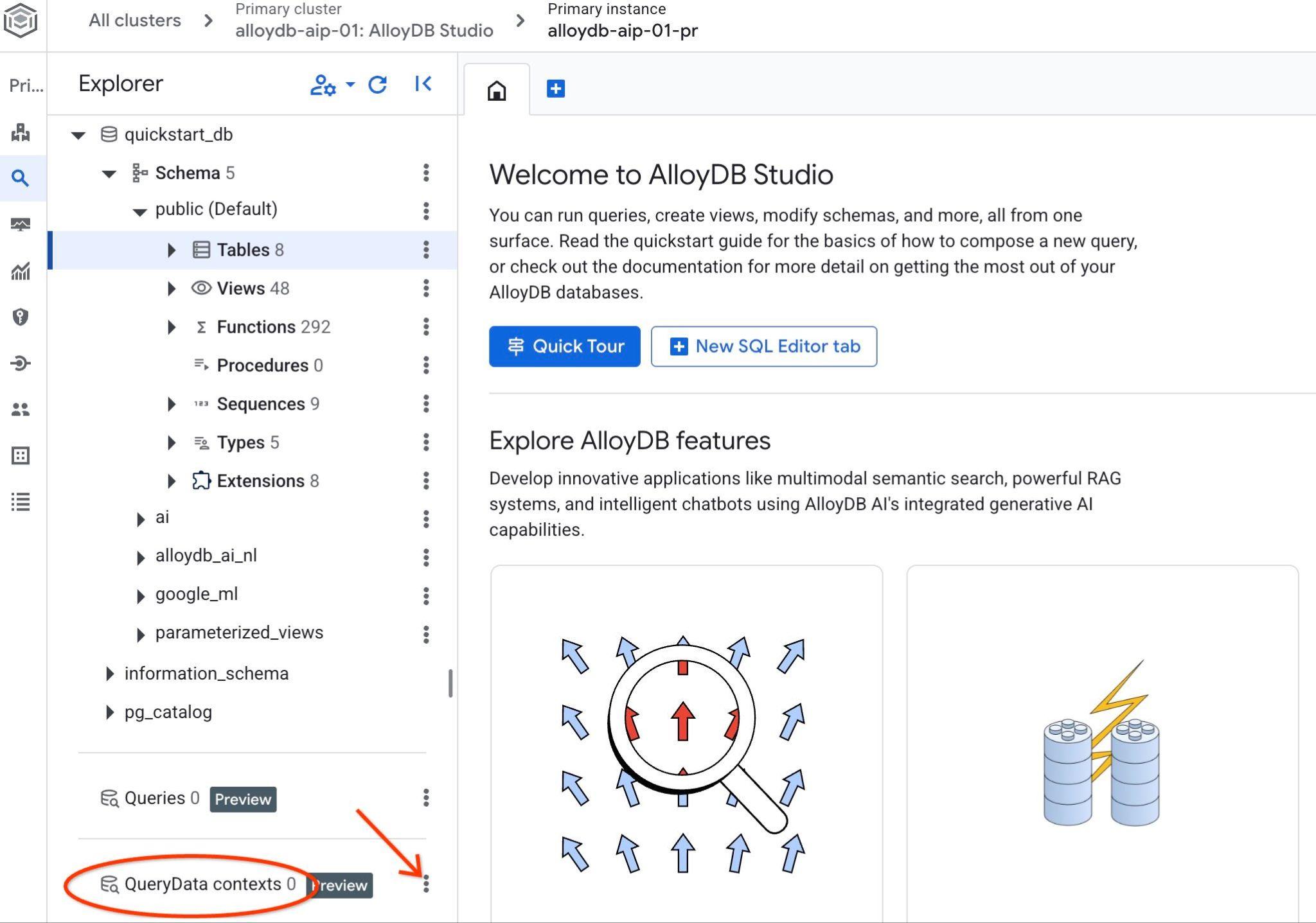
ওই তিনটি ডটে ক্লিক করুন এবং 'Create Context' বেছে নিন। এটি একটি ডায়ালগ বক্স খুলবে যেখানে আপনি তথ্য দেবেন।
- নাম:
cymbal_context_set - বিবরণ:
Cymbal Logistic Query Data - কনটেক্সট ফাইল আপলোড করুন: "
Browse" বোতামে ক্লিক করুন এবং QueryData ContextSet ব্যবহার করে আপনার JSON ফাইলটি বেছে নিন।
আপনি যদি প্রথমবারের মতো সেভ বাটনটি চাপেন, তাহলে কনটেক্সট স্টোরেজ ইনিশিয়ালাইজ হতে কিছুটা সময় লাগতে পারে।
আপনি ডাউনলোড করা কনটেক্সটটি দেখতে পাবেন এবং ডানদিকে থাকা তিনটি উল্লম্ব বোতামে ক্লিক করলে উপলব্ধ অ্যাকশনগুলো দেখতে পাবেন। পরবর্তী অধ্যায়ে আমরা "টেস্ট কনটেক্সট" অ্যাকশনটি থেকে শুরু করব।
১০. কোয়েরি ডেটা কনটেক্সট সেট পরীক্ষা করুন
পরীক্ষার টেমপ্লেট
AlloyDB Studio-তে আমাদের কনটেক্সট পরীক্ষা করার জন্য " Test context " অ্যাকশনটি ব্যবহার করুন। আপনি যখন "Test context"-এ ক্লিক করবেন, তখন " cymbal_context_set " শিরোনামে একটি নতুন AlloyDB Studio এডিটর উইন্ডো খুলবে এবং " Generate SQL using QueryData context: cymbal_context_set " শিরোনামে Gemini SQL জেনারেশন ইনভাইটটি আসবে। SQL জেনারেশনে ক্লিক করুন এবং টাইপ করুন
Hello, can you tell me how many trips we've done in February?
এবং যখন SQL তৈরি হবে, তখন " Insert " বোতামটি চাপুন।
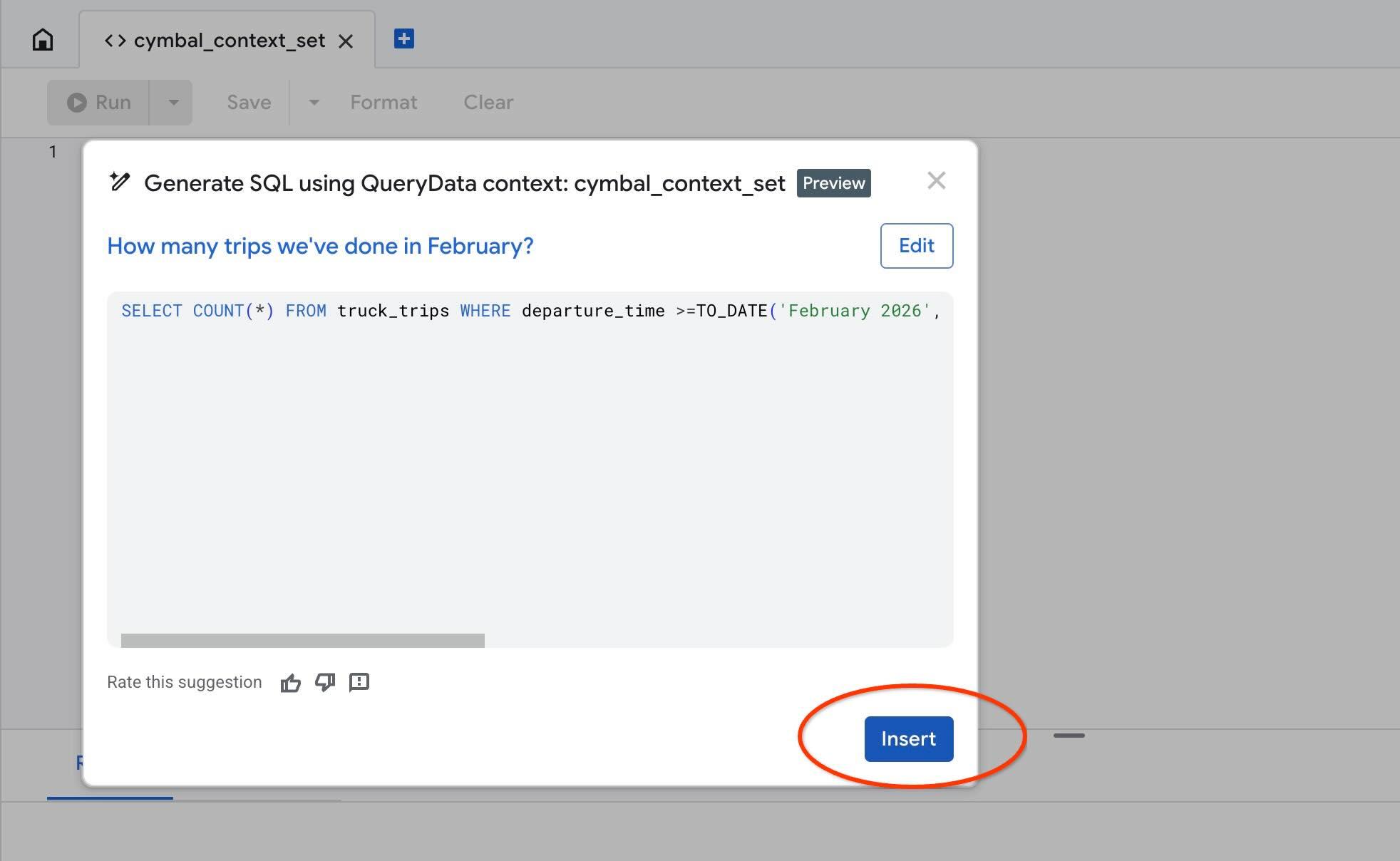
আপনি ঠিক সেই একই কোয়েরিটি দেখতে পাবেন যা আমরা আগে আমাদের কনটেক্সট টেমপ্লেটে দিয়েছিলাম।
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
মাসটিকে 'জানুয়ারি' দিয়ে প্রতিস্থাপন করে তৈরি হওয়া SQL স্টেটমেন্টটি পরীক্ষা করুন। এটি প্যারামিটারাইজড ইন্টেন্টের জন্য মাসটিকে একটি প্যারামিটার হিসেবে ব্যবহার করবে এবং স্বয়ংক্রিয়ভাবে SQL স্টেটমেন্টটি সামঞ্জস্য করে নেবে।
কোয়েরি ডেটা ফেসেট তৈরি করুন
আমরা কোয়েরির জন্য একটি টেমপ্লেট ব্যবহার করে দেখেছি এবং যখন আমরা জানি যে ব্যবহারকারীর কাছ থেকে কী ধরনের অনুরোধ আশা করছি, তখন এটি কাজ করে। কিন্তু কখনও কখনও কোয়েরির শুধুমাত্র একটি অংশ, যেমন কন্ডিশন বা ফিল্টার, নিয়ন্ত্রণ করা সহায়ক হয়, যখন আমরা একটি পুনঃসংজ্ঞায়িত ইন্টেন্টের জন্য একটি নির্দিষ্ট ক্রম বা বিশেষ ক্লজ ব্যবহার করতে চাই।
উদাহরণস্বরূপ, যদি আমরা 'গত মাসের' ডেটা ফেরত চাই, তাহলে আমরা গত ক্যালেন্ডার মাসের ১ তারিখ থেকে শেষ দিন পর্যন্ত রিপোর্টটি পেতে চাই, কিন্তু শেষ ৩০ দিনের ডেটা নয়।
আমরা আমাদের পূর্বে যোগ করা টেমপ্লেটের সাথে ContextSet কনফিগারেশনে একটি SQL স্নিপেট হিসেবে এই ধরনের ফেসেটগুলো যোগ করতে পারি। querydata_cymbal_contextset.json ফাইলটি খুলুন।
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
এবং আমাদের আগে থেকে বিদ্যমান টেমপ্লেটগুলোর পরে ফেসেটগুলো যোগ করুন। ফাইলটির চূড়ান্ত বিষয়বস্তু নিম্নলিখিতের মতো হবে।
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
ফাইলটি সংরক্ষণ করে আপনার কম্পিউটারে আপলোড করুন।
এরপর, 'Edit context' নামক Query context অ্যাকশনটি ব্যবহার করুন এবং পুরোনো কনটেক্সটটিকে নতুনটি দিয়ে প্রতিস্থাপন করতে পরিবর্তিত ফাইলটি আপলোড করুন।
এখন আবার টেস্ট কনটেক্সটটি ব্যবহার করার চেষ্টা করুন এবং 'last month' ইন্টেন্টটি ব্যবহার করে একটি SQL স্টেটমেন্ট তৈরি করুন। উদাহরণস্বরূপ, আপনি যদি " show trucks trips for the last month" এই বাক্যাংশটির জন্য একটি SQL তৈরি করেন, তাহলে এটি আমাদের cymbal_context.json ফাইলে ফেসেট হিসেবে দেওয়া কন্ডিশনটি ব্যবহার করবে।
আপনার নিচের মতো কিছু পাওয়া উচিত:
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
এখন, আপনি এটি এআই এজেন্টদের সাথে কীভাবে ব্যবহার করতে পারেন? পরবর্তী অধ্যায়ে আমরা এআই এজেন্টদের জন্য কোয়েরি ডেটা কনটেক্সট উপলব্ধ করব।
১১. এআই এজেন্টের সাহায্যে ডেটা অনুসন্ধান করুন
আপনি একই ডেটা এজেন্ট ব্যবহার করবেন, কিন্তু এখন এমসিপি টুলবক্সটি কোয়েরিডেটা কনটেক্সটসেট (QueryData ContextSet) ব্যবহার করার জন্য কনফিগার করা হবে।
ডাটাবেসের জন্য এমসিপি টুলবক্স প্রস্তুত করুন এবং চালু করুন।
আমাদের MCP টুলবক্সের জন্য একটি নতুন কনফিগারেশন ফাইল প্রয়োজন, যেটি ডেটাবেস উৎস হিসেবে Gemini Data Analytics API এবং AlloyDB ব্যবহার করবে।
টার্মিনালে চালান:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
এডিটর-এ যান এবং querydata.yaml ফাইলটি খুঁজুন। প্রজেক্ট আইডি এবং রিজিয়ন ছাড়া querydata.yaml কনফিগারেশন ফাইলটি দেখতে নিচের মতো হবে, কারণ প্রজেক্ট আইডি ও রিজিয়ন আপনার এনভায়রনমেন্টকে প্রতিফলিত করবে। কিন্তু আপনাকে আপনার contextSetId ভ্যালুটি আপডেট করতে হবে এবং কনসোল থেকে পাওয়া ভ্যালু দিয়ে "<add-context-set-id>" প্লেসহোল্ডারটি প্রতিস্থাপন করতে হবে।
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
আপনার ContextSet ID খুঁজে পেতে, ছবিতে দেখানো অনুযায়ী আপনার কনটেক্সট সেটের এডিট বাটনে ক্লিক করুন।
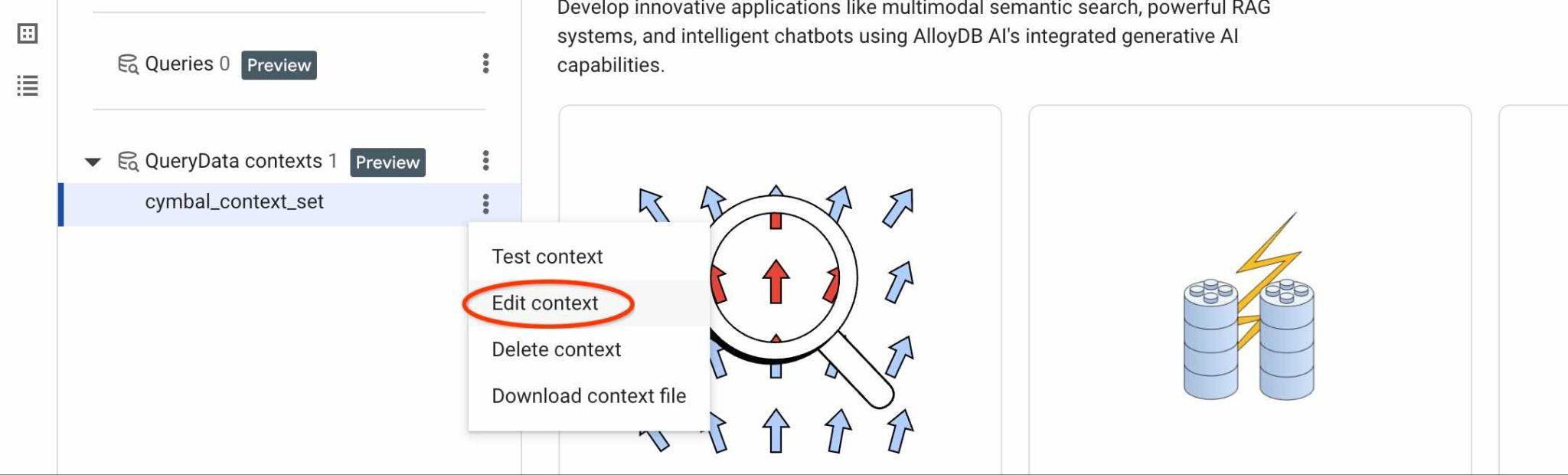
আপনি ডানদিকের নতুন ট্যাবের উপরে কন্টেক্সট সেট আইডিটি দেখতে পাবেন।
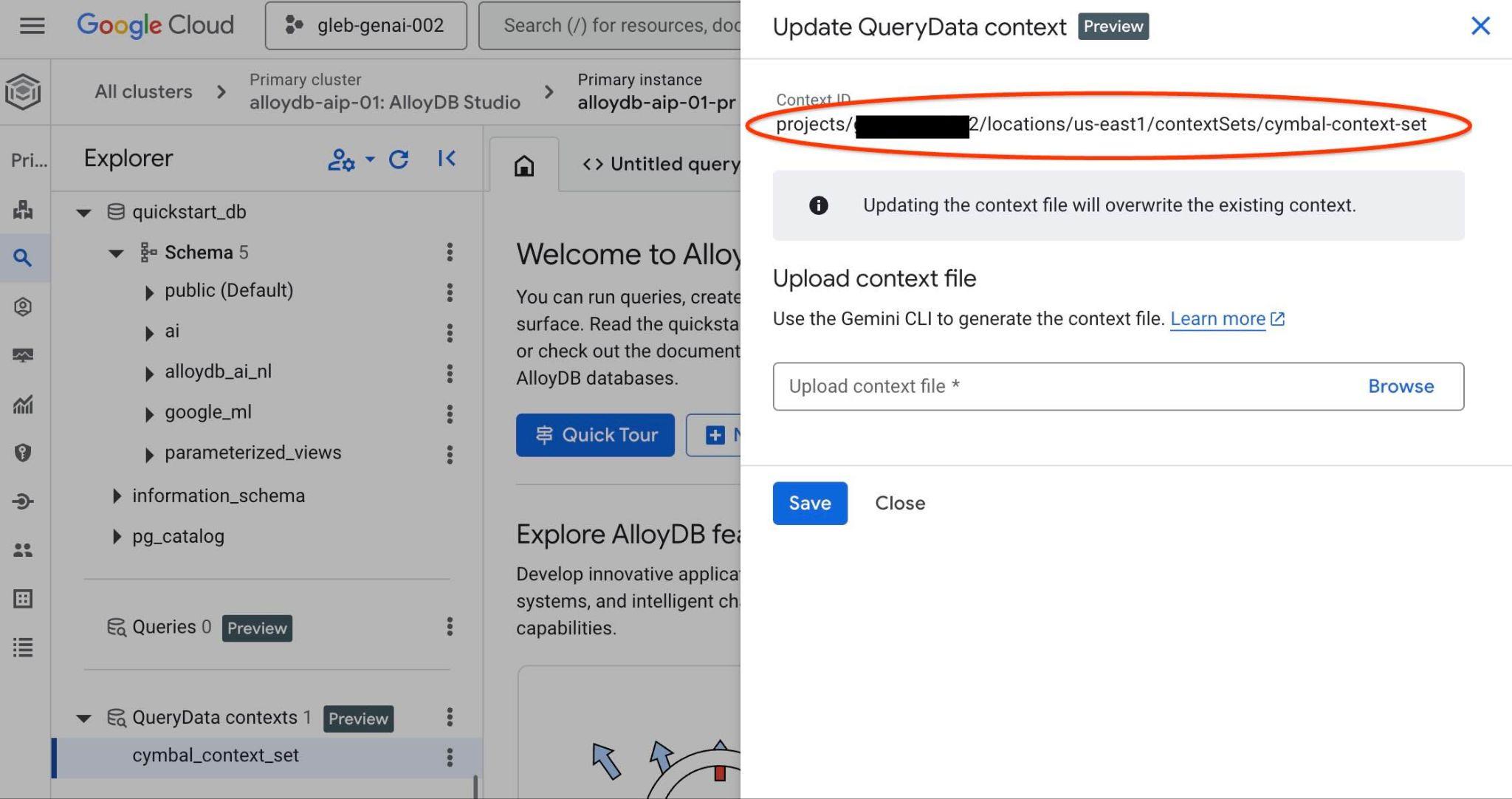
querydata.yaml ফাইলে থাকা "<add-context-set-id>" প্লেসহোল্ডারটির পরিবর্তে সম্পূর্ণ পাথটি বসাতে হবে।
টার্মিনালে ফিরে যান।
আপনার Google Cloud Shell ইন্টারফেসের উপরের দিকে থাকা "+" বোতামটি চেপে একটি নতুন ট্যাব খুলুন।
নতুন ট্যাবে টুলবক্স বাইনারি ফাইল এবং কনফিগারেশন ফাইল tools.yaml থাকা ডিরেক্টরিতে যান এবং MCP সার্ভারটি চালু করুন।
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
ADK এজেন্ট চালান
প্রথম ক্লাউড শেল ট্যাবে এজেন্টটি চালু করুন।
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
এবং এটি চালু হয়ে গেলে http://127.0.0.1:8000 লিঙ্কে আবার ক্লিক করুন।
আপনি আগে থেকেই পরিচিত ADK ওয়েব প্রিভিউ এজেন্ট ইন্টারফেসটি দেখতে পাবেন। আগের বারের মতো হুবহু একই কোয়েরি পোস্ট করুন।
Hello, can you tell me how many trips we've done in February?
এবং এজেন্ট ওয়ার্কফ্লোটি দেখুন। সবকিছু সঠিকভাবে কনফিগার করা থাকলে আপনি নিচের মতো কিছু দেখতে পাবেন।
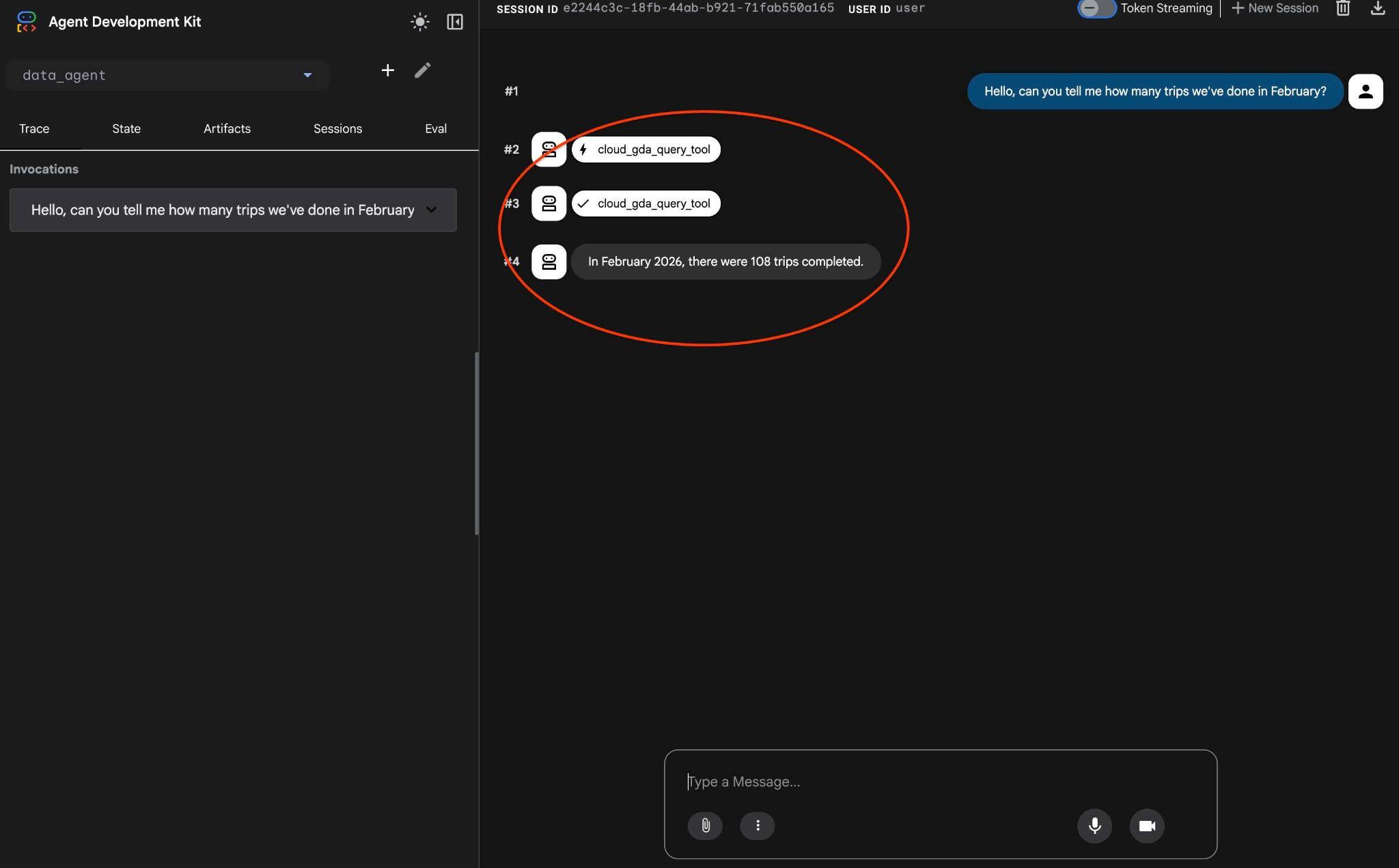
গতবার যে অনুরোধটি একাধিক ধাপে এগোচ্ছিল, সেটিকে এখন এমসিপি টুলে একটিমাত্র কলে রূপান্তরিত করা হয়েছে এবং অনুমানযোগ্য এসকিউএল স্টেটমেন্ট ব্যবহার করে তা কার্যকর করা হচ্ছে।
আপনি অনুরোধটি ব্যবহার করে কনফিগার করা দিকগুলো পরীক্ষা করতে পারেন, যেমন:
how trucks trips for the last month
এবং আউটপুটে আপনি যদি টুল অ্যাকশনে ক্লিক করেন, তাহলে দেখতে পাবেন যে ফলাফলটি পাওয়ার জন্য এটি একই টুল ব্যবহার করেছে এবং ফেসেট প্রয়োগ করেছে।
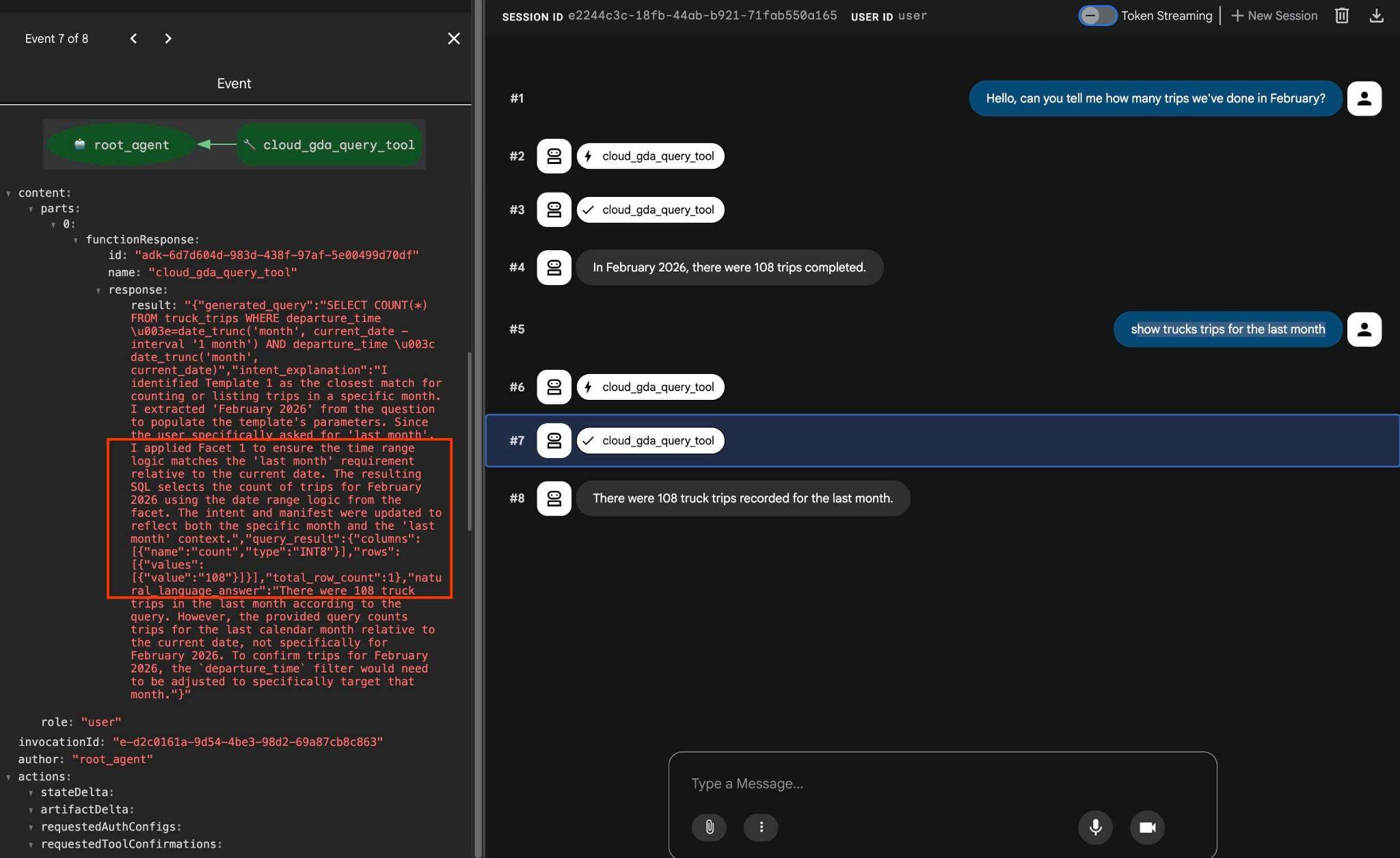
এর মাধ্যমেই আমাদের ল্যাব শেষ হলো। আমি আশা করি আপনারা সমস্ত উদাহরণগুলো ভালোভাবে দেখে নিতে পেরেছেন এবং AlloyDB-এর জন্য QueryData কীভাবে ব্যবহার করতে হয় তা শিখেছেন। এই প্রযুক্তি আপনার এজেন্টিক ওয়ার্কলোড এবং SQL জেনারেশনকে অনুমানযোগ্য ও নির্ভরযোগ্য করে তুলতে সাহায্য করে।
১২. পরিবেশ পরিষ্কার করা
অপ্রত্যাশিত চার্জ এড়ানোর জন্য অস্থায়ী রিসোর্সগুলো পরিষ্কার করে রাখা একটি ভালো অভ্যাস। এর সবচেয়ে নির্ভরযোগ্য উপায় হলো সেই প্রজেক্টটি ডিলিট করে দেওয়া, যেখানে আপনি ওয়ার্কফ্লোটি পরীক্ষা করছিলেন। তবে ঐচ্ছিকভাবে, আপনি অ্যালয়ডিবি (AlloyDB)-এর মতো স্বতন্ত্র রিসোর্স ডিলিট করে নিজেকে সীমাবদ্ধ রাখতে পারেন।
ল্যাবের কাজ শেষ হলে AlloyDB ইনস্ট্যান্স এবং ক্লাস্টারটি ধ্বংস করে দিন।
AlloyDB ক্লাস্টার এবং এর সমস্ত ইনস্ট্যান্স মুছে ফেলুন
আপনি যদি AlloyDB-এর ট্রায়াল সংস্করণ ব্যবহার করে থাকেন এবং সেই ট্রায়াল ক্লাস্টার ব্যবহার করে অন্যান্য ল্যাব ও রিসোর্স পরীক্ষা করার পরিকল্পনা থাকে, তাহলে সেটি ডিলিট করবেন না। আপনি একই প্রজেক্টে আরেকটি ট্রায়াল ক্লাস্টার তৈরি করতে পারবেন না।
`force` অপশনটির মাধ্যমে ক্লাস্টারটি ধ্বংস করা হয়, যা ক্লাস্টারের অন্তর্গত সমস্ত ইনস্ট্যান্সকেও মুছে দেয়।
যদি আপনার সংযোগ বিচ্ছিন্ন হয়ে যায় এবং পূর্বের সমস্ত সেটিংস হারিয়ে যায়, তাহলে ক্লাউড শেলে প্রজেক্ট এবং এনভায়রনমেন্ট ভেরিয়েবলগুলো নির্ধারণ করুন:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
ক্লাস্টারটি মুছে ফেলুন:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB ব্যাকআপগুলি মুছুন
ক্লাস্টারের সমস্ত AlloyDB ব্যাকআপ মুছে ফেলুন:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
১৩. অভিনন্দন
কোডল্যাবটি সম্পন্ন করার জন্য অভিনন্দন।
আমরা যা আলোচনা করেছি
- কীভাবে একটি AlloyDB ক্লাস্টার তৈরি করবেন এবং নমুনা ডেটা ইম্পোর্ট করবেন
- AlloyDB ডেটা অ্যাক্সেস API কীভাবে সক্রিয় করবেন
- AlloyDB-এর জন্য QueryData কীভাবে সক্রিয় করবেন
- টেমপ্লেট তৈরি করার পদ্ধতি
- ফেসেটেড সার্চ কীভাবে ব্যবহার করবেন
- এআই এজেন্টের সাথে QueryData কীভাবে ব্যবহার করবেন
১৪. জরিপ
আউটপুট: