
1. Einführung
Dieses Codelab bietet eine Anleitung für den Einstieg in QueryData für AlloyDB und die Verwendung der Funktion zum Generieren präziser und vorhersagbarer SQL-Anweisungen aus Eingaben in natürlicher Sprache in Agent-basierten Anwendungen.
Voraussetzungen
- Grundlegende Kenntnisse der Google Cloud Console
- Grundkenntnisse in der Befehlszeile und Cloud Shell
Lerninhalte
- AlloyDB-Cluster erstellen und Beispieldaten importieren
- AlloyDB Data Access API aktivieren
- QueryData für AlloyDB aktivieren
- Vorlagen generieren
- Attributsuche verwenden
- QueryData mit KI-Agenten verwenden
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
- Ein Webbrowser wie Chrome, der die Google Cloud Console und die Cloud Shell unterstützt
2. Einrichtung und Anforderungen
Projekteinrichtung
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:
Alternativ können Sie auch G und dann S drücken. Mit dieser Sequenz wird Cloud Shell aktiviert, wenn Sie sich in der Google Cloud Console befinden oder diesen Link verwenden.
Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
3. Hinweis
API aktivieren
Wenn Sie AlloyDB, Compute Engine, Netzwerkdienste und Vertex AI verwenden möchten, müssen Sie die entsprechenden APIs in Ihrem Google Cloud-Projekt aktivieren.
Prüfen Sie im Cloud Shell-Terminal, ob Ihre Projekt-ID eingerichtet ist:
gcloud config get-value project
In der Ausgabe sollte Ihre Projekt-ID angezeigt werden:
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
Legen Sie die Umgebungsvariable PROJECT_ID fest:
PROJECT_ID=$(gcloud config get-value project)
Aktivieren Sie alle erforderlichen Dienste:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Erwartete Ausgabe
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB bereitstellen
AlloyDB-Cluster und primäre Instanz erstellen Sie können die Lösung entweder mit einem vorbereiteten Skript bereitstellen, mit dem alle erforderlichen Ressourcen bereitgestellt werden, oder sie Schritt für Schritt selbst bereitstellen. Eine Anleitung dazu finden Sie in der Dokumentation.
AlloyDB mit automatisiertem Script bereitstellen
Bei diesem Ansatz wird ein automatisiertes Script verwendet, um den AlloyDB-Cluster bereitzustellen und die erforderlichen Informationen für die Arbeit mit den bereitgestellten Ressourcen bereitzustellen.
Führen Sie im Cloud Shell-Terminal den Befehl aus, um das Bereitstellungsscript aus dem Repository zu klonen.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
Führen Sie das Bereitstellungsskript aus.
./deploy_alloydb.sh --public-ip
Die Ausführung des Skripts dauert einige Zeit, in der Regel etwa 5 bis 7 Minuten. Dabei werden ein AlloyDB-Cluster und eine primäre Instanz mit öffentlicher und privater IP-Adresse bereitgestellt. Die öffentliche IP-Adresse ist nur für autorisierte Netzwerke oder über den AlloyDB Auth-Proxy verfügbar. Weitere Informationen zu öffentlichen IP-Adressen finden Sie in der Dokumentation. Das Skript sollte Informationen zu Ihrem bereitgestellten AlloyDB-Cluster ausgeben. Bitte beachten Sie, dass Ihr Passwort anders sein wird. Notieren Sie es sich für die spätere Verwendung.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
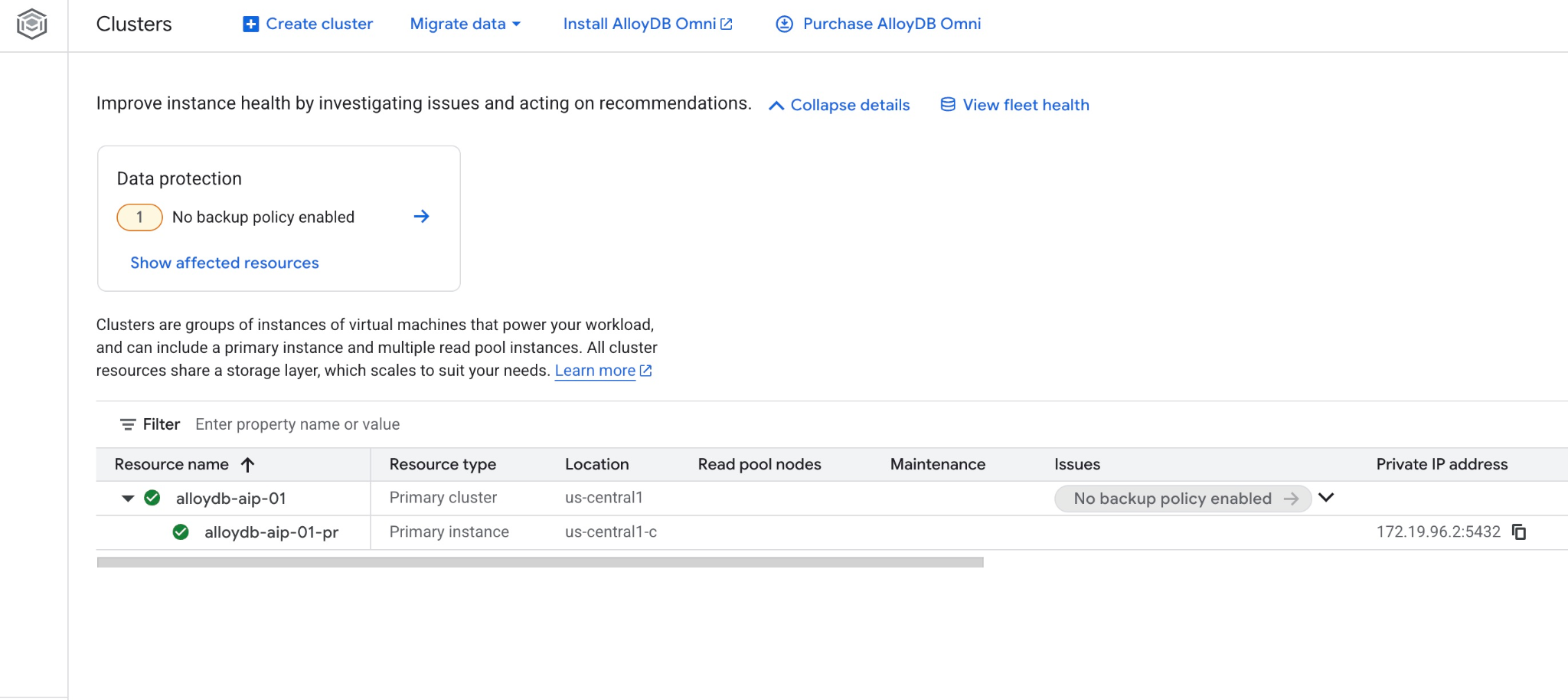
Den neuen Cluster und die primäre Instanz können Sie auch in der Webkonsole sehen.
5. Datenbank vorbereiten
Sie müssen die Vertex AI-Integration aktivieren, um KI-Funktionen und ‑Operatoren zu verwenden, die Data Access API aktivieren und eine Datenbank für das Beispieldataset erstellen.
Erforderliche Berechtigungen für AlloyDB erteilen
Fügen Sie dem AlloyDB-Dienst-Agent Vertex AI-Berechtigungen hinzu.
Öffnen Sie oben einen weiteren Cloud Shell-Tab, indem Sie auf das Pluszeichen (+) klicken.
Führen Sie im neuen Cloud Shell-Tab Folgendes aus:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Data Access API aktivieren
Sie müssen die Data Access API für den AlloyDB-Cluster aktivieren, um MCP-Tools wie execute_sql verwenden zu können.
Führen Sie den Befehl im selben Terminaltab aus.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
IAM-Authentifizierung aktivieren
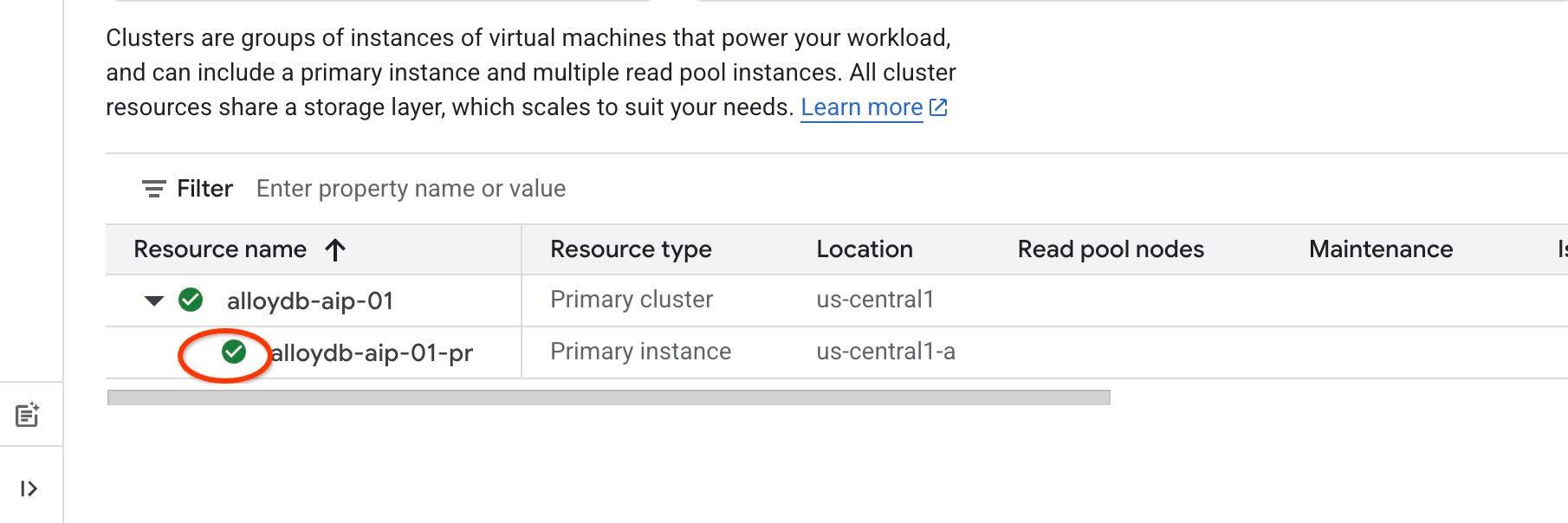
Wir verwenden die IAM-Authentifizierung für unsere Agent-Tools. Dazu müssen Sie die IAM-Authentifizierung für die Instanz aktivieren und sich selbst als Datenbanknutzer hinzufügen. Bevor Sie die IAM-Authentifizierung auf Instanzebene aktivieren, warten Sie, bis der vorherige Schritt zum Aktivieren der Datenzugriffs-API abgeschlossen ist. Der Status Ihrer Instanz sollte grün sein.
Wir beginnen mit der Aktivierung von IAM auf Instanzebene. Führen Sie den Befehl im selben Terminaltab aus.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Fügen Sie sich selbst als AlloyDB-Nutzer hinzu:
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
Schließen Sie den Tab, indem Sie entweder den Befehl „exit“ auf dem Tab ausführen:
exit
Verbindung zu AlloyDB Studio herstellen
In den folgenden Kapiteln können alle SQL-Befehle, für die eine Verbindung zur Datenbank erforderlich ist, in AlloyDB Studio ausgeführt werden. T
Rufen Sie die Seite „Cluster“ in AlloyDB for Postgres auf.
Öffnen Sie die Webkonsolenoberfläche für Ihren AlloyDB-Cluster, indem Sie auf die primäre Instanz klicken.
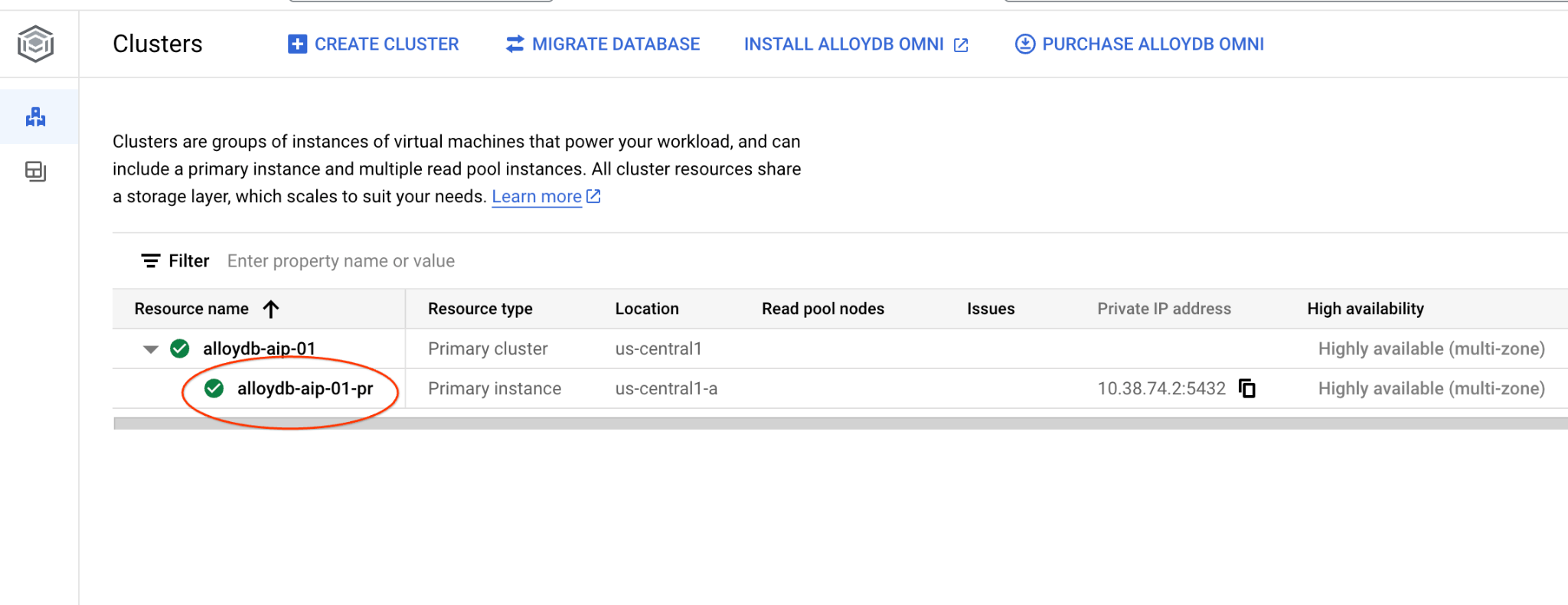
Klicken Sie dann links auf „AlloyDB Studio“:
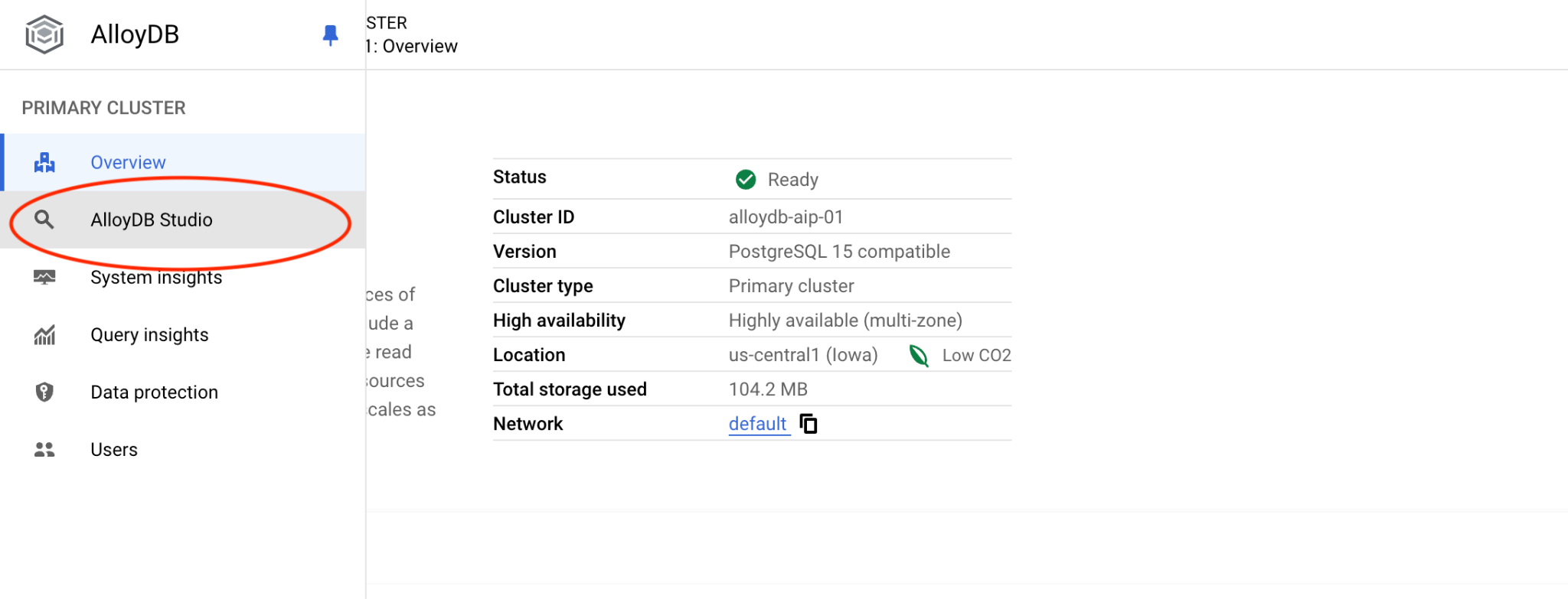
Wählen Sie die PostgreSQL-Datenbank und die IAM-Authentifizierung aus. Klicken Sie dann auf die Schaltfläche „Authentifizieren“.
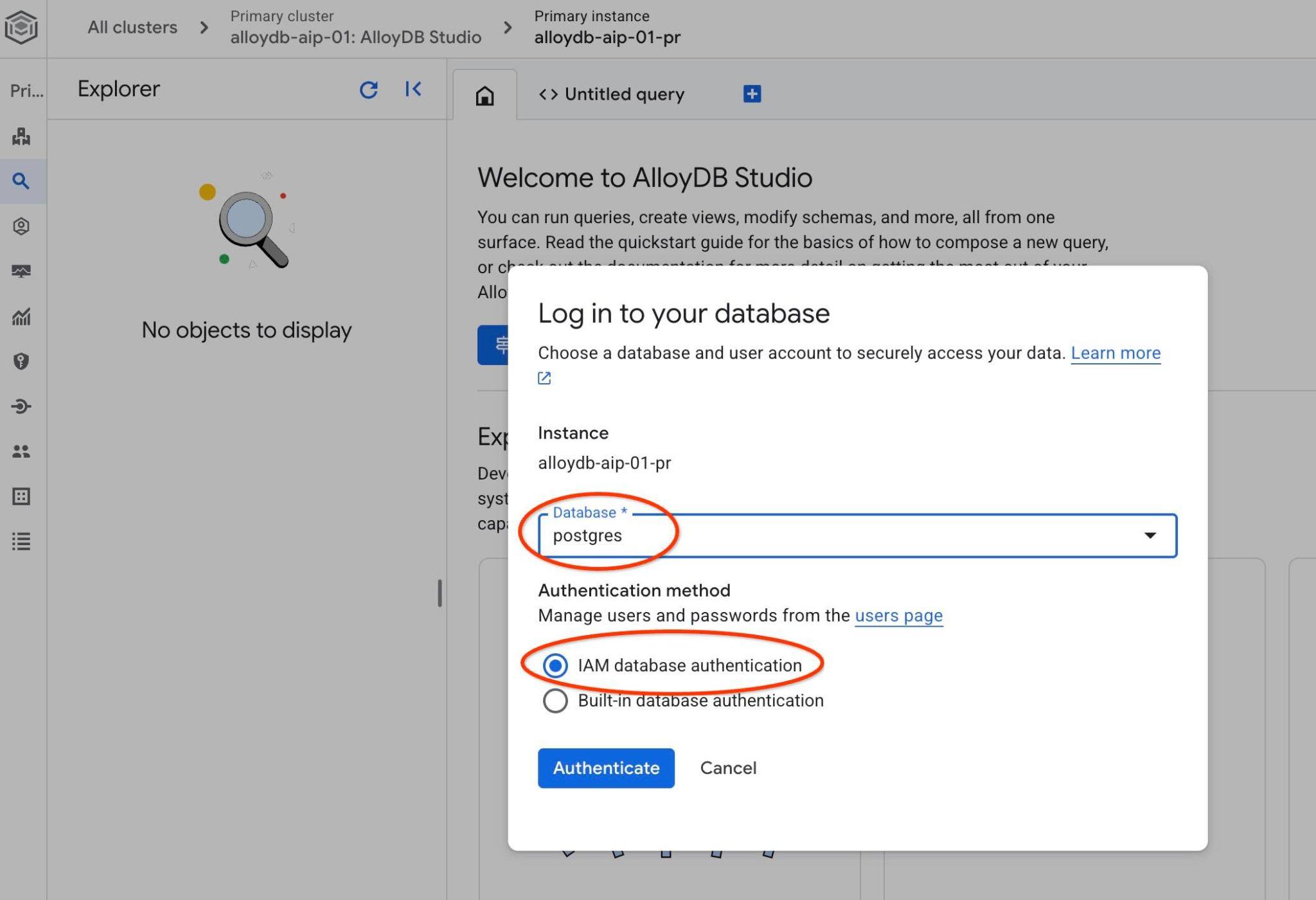
Die AlloyDB Studio-Benutzeroberfläche wird geöffnet. Wenn Sie die Befehle in der Datenbank ausführen möchten, klicken Sie rechts auf den Tab „Unbenannte Abfrage“.
Dadurch wird eine Schnittstelle geöffnet, in der Sie SQL-Befehle ausführen können.
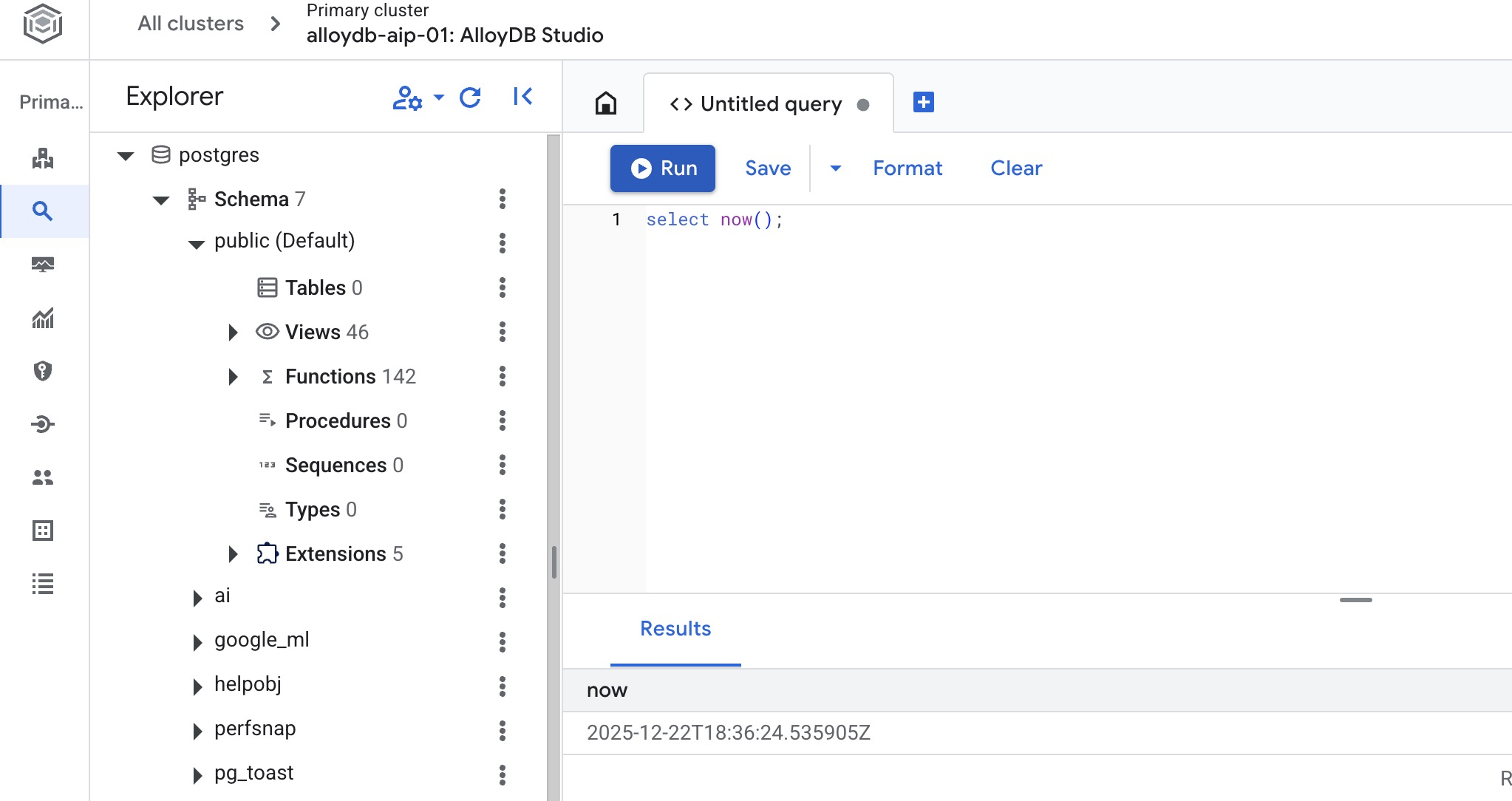
Datenbank erstellen
Schnellstart zum Erstellen von Datenbanken
Führen Sie im AlloyDB Studio-Editor den folgenden Befehl aus.
Datenbank erstellen:
CREATE DATABASE quickstart_db
Erwartete Ausgabe:
Statement executed successfully
Mit quickstart_db verbinden
Prüfen Sie, ob Ihre Datenbank erstellt wurde, indem Sie eine Verbindung zu ihr herstellen. Stellen Sie über die Schaltfläche zum Wechseln des Nutzers/der Datenbank eine neue Verbindung zum Studio her.
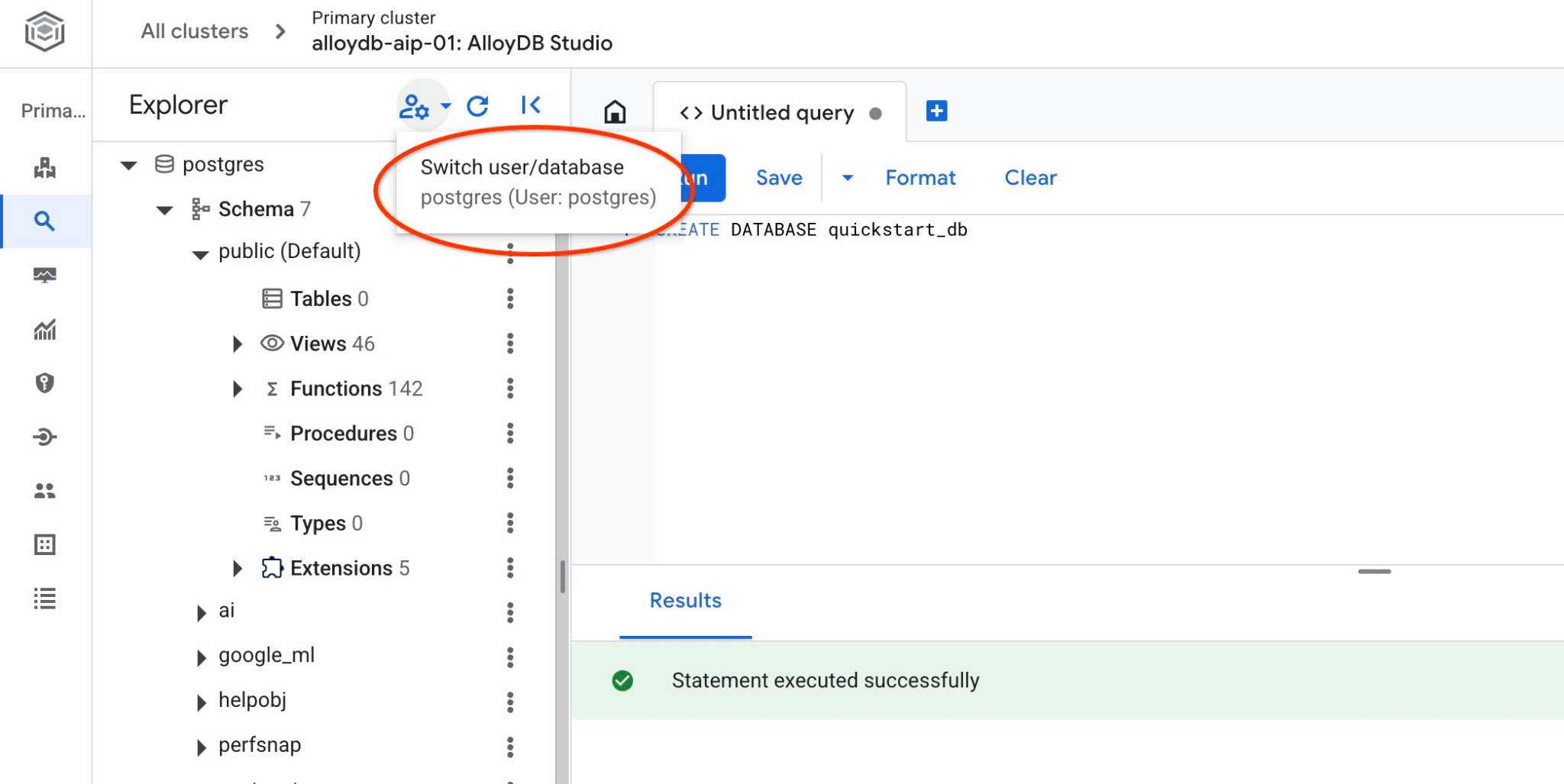
Wählen Sie in der Drop-down-Liste die neue Datenbank „quickstart_db“ aus und verwenden Sie dieselbe IAM-Authentifizierung.
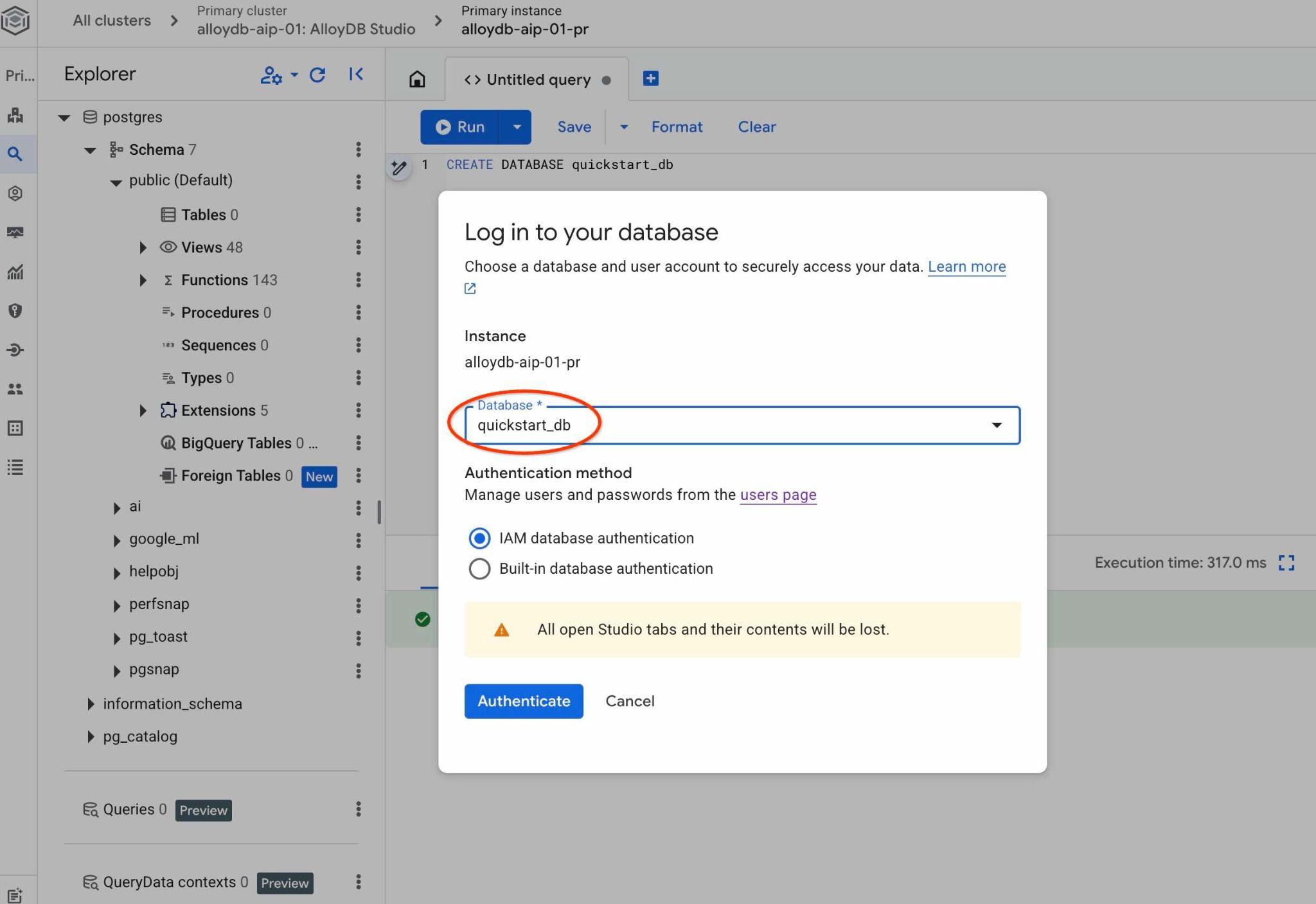
Dadurch wird eine neue Verbindung geöffnet, über die Sie mit Objekten aus der Datenbank quickstart_db arbeiten können. Dort können Sie Ihr importiertes Schema und Ihre Daten untersuchen und mit QueryData-Kontextsets arbeiten.
6. Beispieldaten
Jetzt müssen Sie Objekte in der Datenbank erstellen und Daten laden. Sie verwenden einen fiktiven Datensatz des Unternehmens Cymbal Shipping. Sie enthält fiktive Daten zu Waren, Lkw, Anfragen und Lkw-Fahrten sowie fiktive Fahrer.
Storage-Bucket erstellen
Sie verwenden das Google SDK (gcloud), um Daten aus Ihrem geklonten Repository in die AlloyDB-Datenbank zu importieren. Dazu müssen Sie einen Cloud Storage-Bucket erstellen und dem AlloyDB-Dienstkonto Zugriff gewähren. Alternativ können Sie es jederzeit über die Webkonsole versuchen, wie in der Dokumentation beschrieben.
Führen Sie im Google Cloud Shell-Terminal folgenden Befehl aus:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
Daten laden
Als Nächstes laden Sie die Daten. Unser komprimierter SQL-Dump befindet sich im Ordner des geklonten Repositorys. Beim folgenden Befehl wird davon ausgegangen, dass Sie Ihr Basisverzeichnis als Ausgangspunkt verwendet haben, als Sie das Repository im vorherigen Schritt beim Erstellen des AlloyDB-Clusters geklont haben.
Kopieren Sie den komprimierten SQL-Dump in den neuen Speicher-Bucket:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
Laden Sie die Daten dann in die quickstart_db-Datenbank:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
Mit dem Befehl wird das Beispieldataset in die Datenbank „quickstart_db“ geladen. Sie können die Tabellen und Datensätze mit AlloyDB Studio überprüfen.
7. Mit Data Agent arbeiten
Wir beginnen mit einem Beispiel-KI-Agenten, der mit dem Google ADK für Python erstellt wurde und über die MCP Toolbox for Databases eine Verbindung zu unserer AlloyDB-Instanz herstellt.
MCP Toolbox for Databases installieren
Die MCP Toolbox for Databases ist ein Open-Source-Projekt, das MCP-Unterstützung für mehrere Datenbankmodule bietet, darunter AlloyDB for PostgreSQL. Weitere Informationen zur MCP Toolbox finden Sie in der Dokumentation.
Sie müssen die aktuelle Version der Software für Ihre Plattform herunterladen. Die aktuelle Version finden Sie auf der Seite „Releases“. Im folgenden Beispiel wird gezeigt, wie Sie Version 31 der MCP Toolbox in Cloud Shell herunterladen.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Sie müssen eine Konfigurationsdatei für die Toolbox vorbereiten. Wir haben eine Beispieldatei tools.yaml.example im aktuellen Verzeichnis und bereiten die Datei „tools.yaml“ vor, indem wir zwei Platzhalter durch die Projekt-ID und die Region ersetzen.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
MCP Toolbox for Databases starten
Jetzt können Sie die MCP-Toolbox mit der vorbereiteten Konfigurationsdatei starten.
Öffnen Sie einen neuen Tab in Ihrer Google Cloud Shell, indem Sie oben in der Google Cloud Shell-Oberfläche auf die Schaltfläche „+“ klicken.
Wechseln Sie auf dem neuen Tab in das Verzeichnis mit der Binärdatei für die Toolbox und der Konfigurationsdatei „tools.yaml“ und starten Sie den MCP-Server.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
In der Ausgabe sollte „Server ready to serve!“ (Server bereit für die Bereitstellung) angezeigt werden, wie im Folgenden zu sehen ist.
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
Quellcode des Agents prüfen
Sehen Sie sich auf dem ersten Tab im geklonten Repository-Ordner den Agent-Code mit dem Google Cloud Shell-Editor an.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
Im Agent sehen Sie einen Abschnitt für den Google Cloud MCP-Server für AlloyDB. Wir stellen einen Endpunkt als MCP_SERVER_URL, Authentifizierung und Projekt-ID bereit und fügen ihn dem MCP-Toolset hinzu.
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
Im KI-Agentencode ist das MCP-Toolset als tools-Parameter für den KI-Agenten enthalten. Außerdem gibt es Cluster- und Instanznamen, die Region und die Datenbank als Variablen für den Agent-Prompt.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
Nachdem Sie den Code geprüft haben, wechseln Sie zurück zum Terminal, indem Sie rechts oben im Editorfenster auf die Schaltfläche „Terminal öffnen“ klicken.
Agent starten
Jetzt können Sie den Agenten im interaktiven Modus über die Google ADK-Weboberfläche starten. Die ADK-Weboberfläche bietet eine praktische Möglichkeit, die Workflows von Agenten zu testen und Fehler zu beheben.
Installieren wir zuerst alle erforderlichen Pakete für Python mit dem Paketmanager „uv“.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
Wenn alle Pakete installiert sind, müssen Sie dem Agent-Verzeichnis eine .env-Datei hinzufügen, damit der Agent Vertex AI für die gesamte Kommunikation mit den KI-Modellen verwendet.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
Dann können Sie den Agenten starten.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Die Ausgabe sollte in etwa so aussehen, wobei der Endpunkt http://127.0.0.1:8000 lautet .
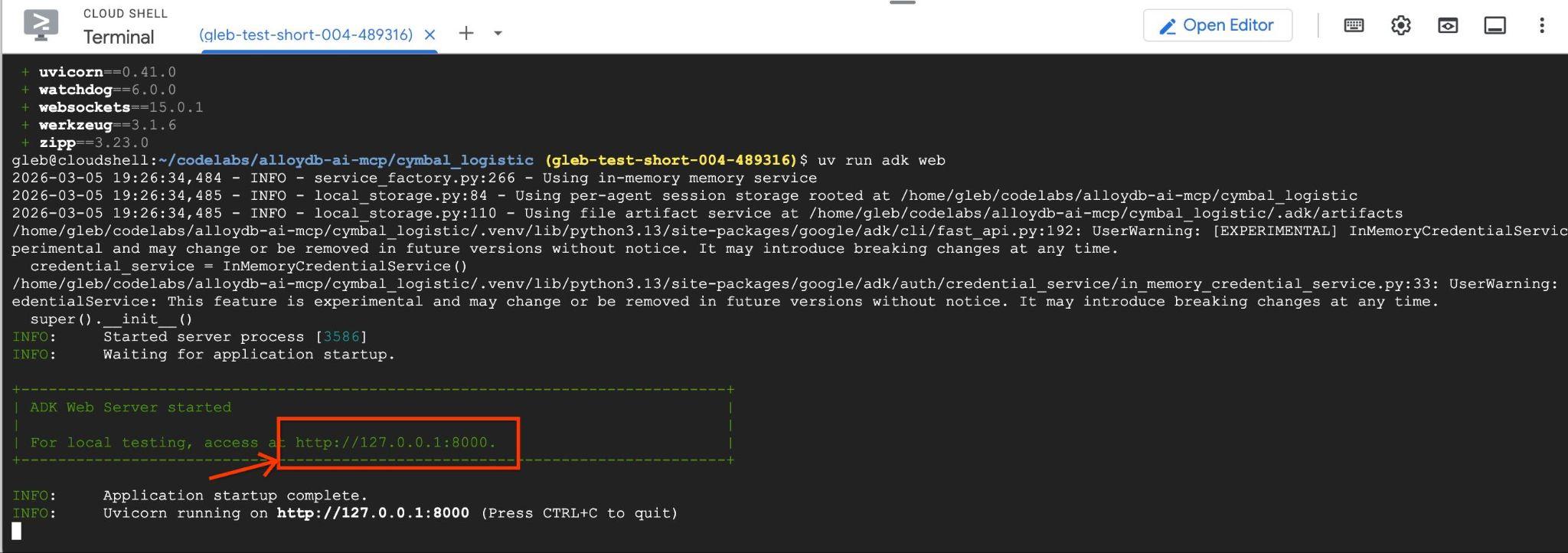
Sie können in der Cloud Shell auf diese URL klicken. Dadurch wird in einem separaten Browsertab ein Vorschaufenster geöffnet, in dem Sie data_agent aus der Drop-down-Liste auf der linken Seite auswählen.
Im ADK-Webinterface können Sie Ihre Fragen unten rechts eingeben und den vollständigen Ausführungsablauf mit den Traces für jeden Schritt auf der rechten Seite sehen.
8. NL2SQL ohne QueryData für AlloyDB testen
Mit dem Agenten können Sie Fragen in freiem Format in natürlicher Sprache stellen. Der Agent verwendet die MCP Toolbox for Databases als Tool, um die Fragen zu beantworten. Die Fragen werden unten rechts und die Antwort mit allen Aufrufen der Tools oben angezeigt.
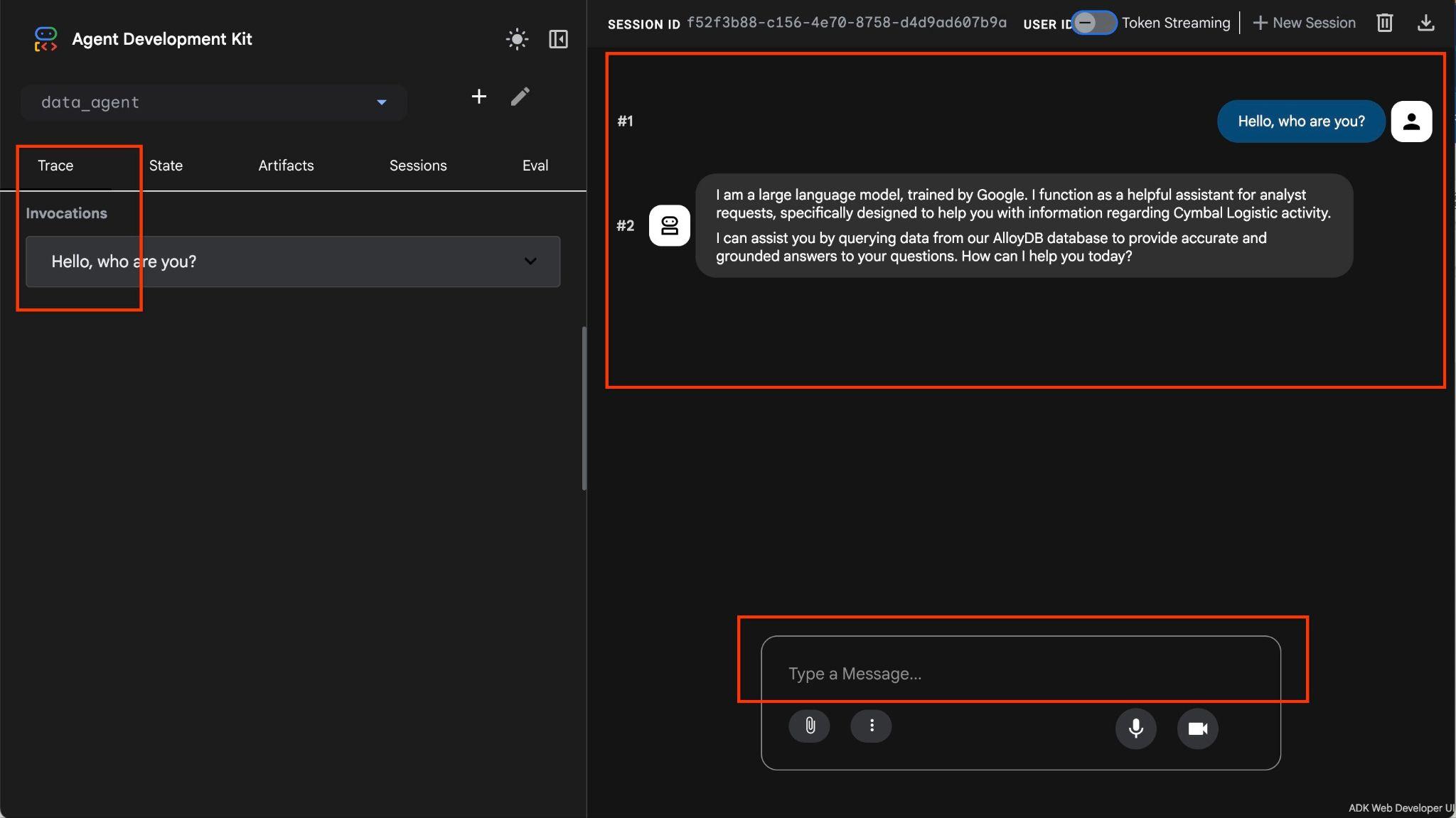
Sie arbeiten mit Betriebsdaten für ein Versandunternehmen, die Informationen zu Versandanträgen, Lkw, Fahrern und Fahrten enthalten. Die erste Frage bezieht sich auf die Anzahl der Fahrten, die im Februar 2026 durchgeführt wurden.
Geben Sie im Eingabefeld unten rechts Folgendes ein und drücken Sie die Eingabetaste.
Hello, can you tell me how many trips we've done in February?
Der Agent führt mehrere Tool-Aufrufe aus, um die richtigen Tabellen im Schema mithilfe von list_cymbal_logistics_schemas_tool und execute_sql_tool zu identifizieren. Außerdem führt er mehrere SQL-Anweisungen aus, um die richtigen Daten abzurufen.
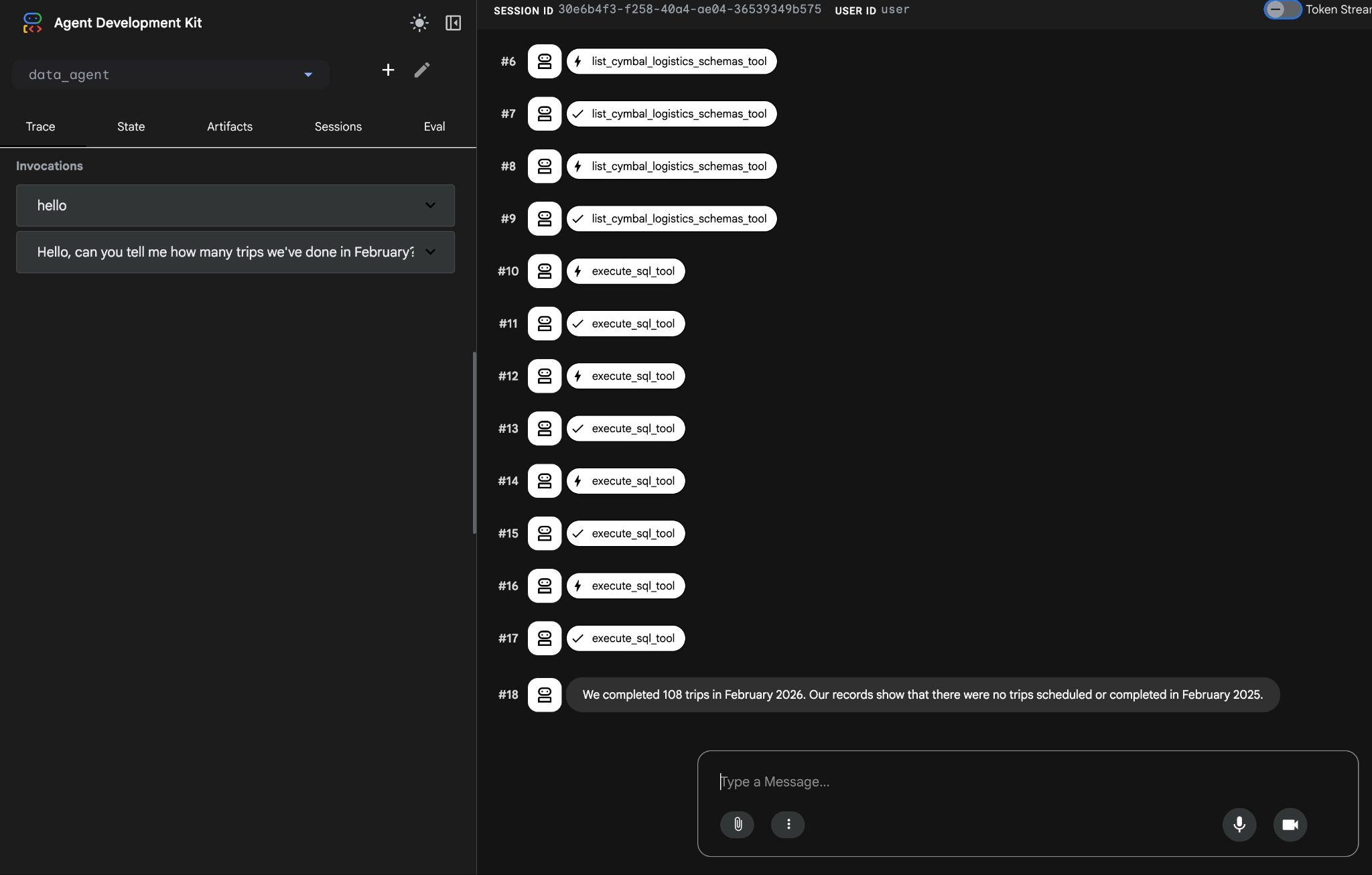
Schließlich wird das richtige Ergebnis ausgegeben, nachdem die richtige Abfrage erstellt und in der Datenbank ausgeführt wurde.
Im Februar 2026 haben wir 108 Fahrten abgeschlossen. Unseren Aufzeichnungen zufolge wurden im Februar 2025 keine Fahrten geplant oder abgeschlossen.
Sie können sehen, was jeder Tool-Aufruf bewirkt, indem Sie auf die Tool-Ausführung klicken. Hier ist beispielsweise die Abfrage, die ausgeführt wurde, um unsere Ergebnisse zu erhalten.
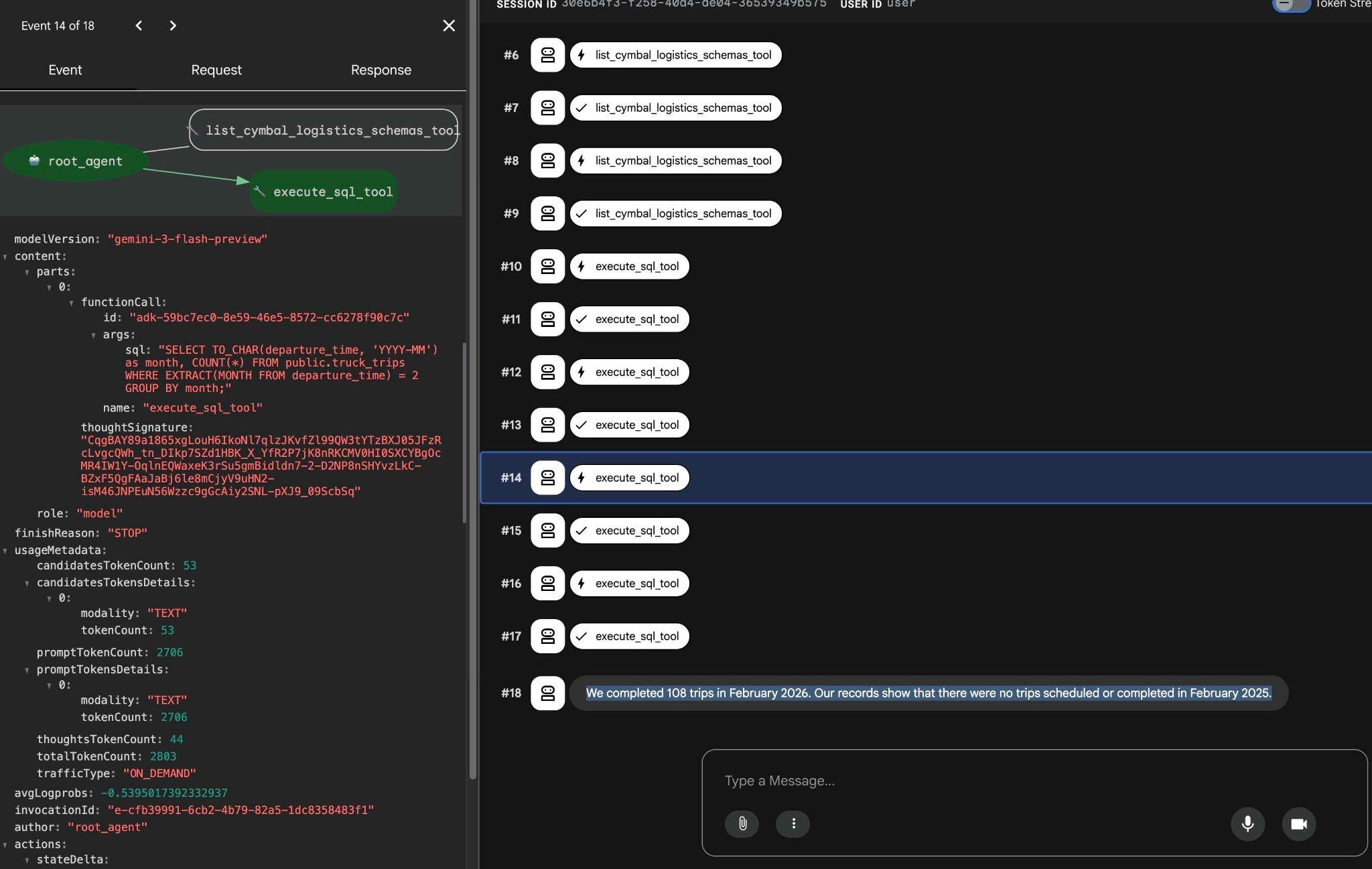
Probieren Sie andere einfache Anfragen über die ADK-Weboberfläche aus und sehen Sie sich an, wie verschiedene Anfragen ausgeführt werden, um die Ergebnisse zu erzielen.
Beenden Sie den Agent, indem Sie im Terminal ctrl+c drücken. Sie können den Browsertab mit der ADK-Weboberfläche schließen.
Sie können die MCP Toolbox auch auf dem zweiten Tab beenden, indem Sie dieselbe Tastenkombination ctrl+c drücken und den zweiten Tab schließen.
Im nächsten Schritt erstellen wir den Kontext „QueryData“, um die NL2SQL-Antwort und -Leistung zu verbessern.
9. QueryData-ContextSet erstellen
Im vorherigen Schritt haben Sie gesehen, dass das KI-Modell mehrere Aufrufe an das Informationsschema der Datenbank ausgeführt hat, um herauszufinden, welche Tabelle und Spalten zum Erstellen der SQL-Abfrage verwendet werden sollen. Um die Leistung und Genauigkeit zu verbessern und das Ergebnis vorhersehbarer zu machen, fügen wir Ihren QueryData-Kontext hinzu, der definiert, welche Abfrage als Reaktion auf eine bestimmte Anfrage ausgeführt werden soll.
Zielgerichtete Vorlagen erstellen
Der QueryData-ContextSet ist eine JSON-Datei mit Abfragevorlagen und ‑facetten, die dem KI-Modell die erforderlichen Daten und Anweisungen zur Verfügung stellen, um anhand von Abfragemustern und der Datenstruktur die richtige SQL-Abfrage oder die richtigen SQL-Abfrageteile zu verwenden, um die gewünschten Ziele zu erreichen.
Sie beginnen mit einer zielgerichteten Vorlage. Erstellen Sie eine Datei mit einem Cloud Shell-Editor. Führen Sie im Cloud Shell-Terminal folgenden Befehl aus:
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
Fügen Sie die Vorlage für die Natural Language-Abfrage ein, die wir im vorherigen Kapitel verwendet haben: „Wie viele Fahrten haben wir im Februar gemacht?“
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
Laden Sie die Vorlage dann über die Schaltfläche „Herunterladen“ aus Cloud Shell auf Ihren Computer herunter.
QueryData-Kontextsets laden
Um unsere QueryData-Kontextsets zu verwenden, müssen wir sie in unsere Datenbank hochladen.
Öffnen Sie AlloyDB Studio. Im linken Bereich unten sehen Sie QueryData Context und das Dreipunkt-Menü.
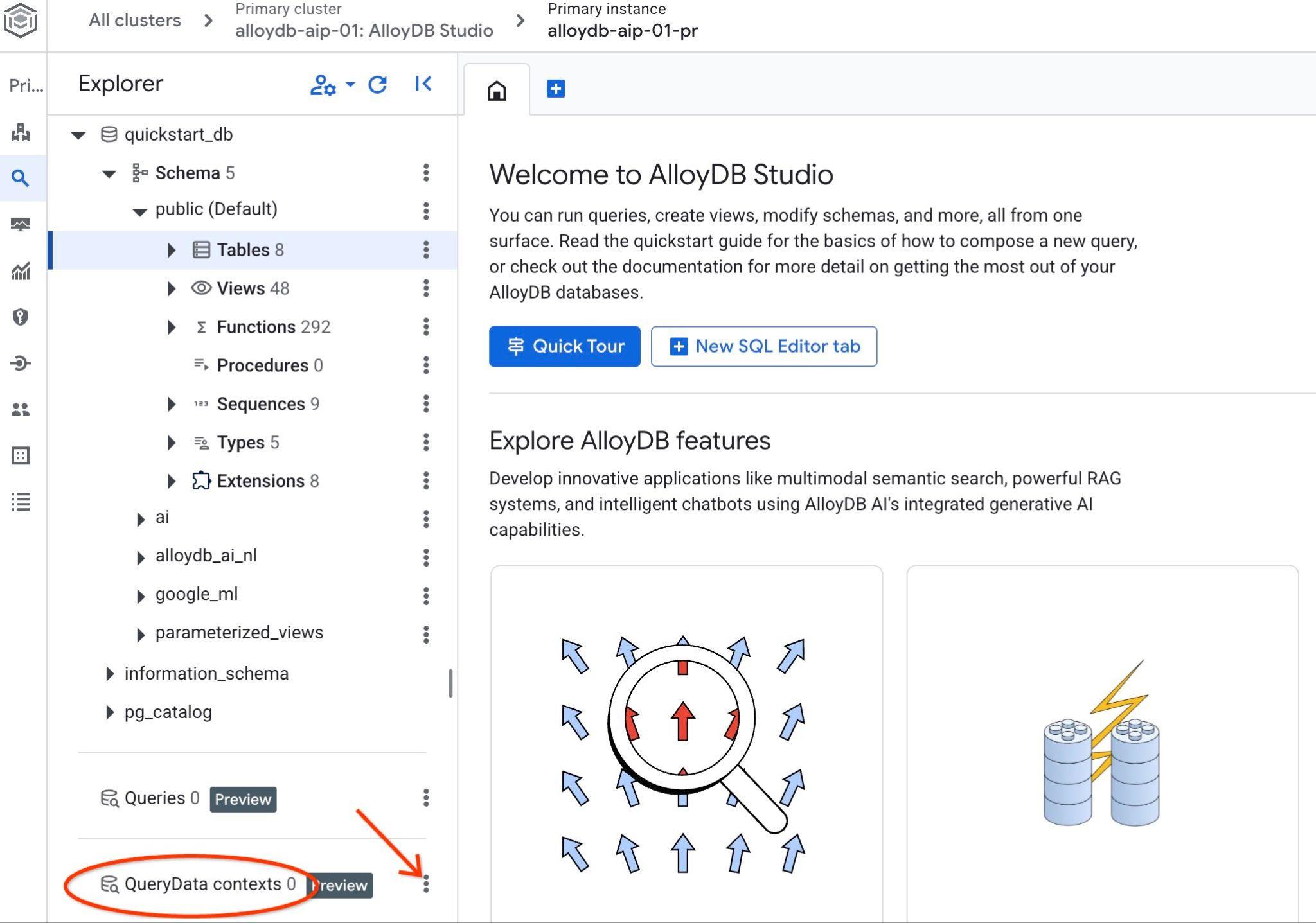
Klicken Sie auf die drei Punkte und wählen Sie „Kontext erstellen“ aus. Daraufhin wird ein Dialogfeld geöffnet, in dem Sie
- Name:
cymbal_context_set - Beschreibung:
Cymbal Logistic Query Data - Kontextdatei hochladen: Klicken Sie auf die Schaltfläche „
Browse“ und wählen Sie die JSON-Datei mit dem QueryData-ContextSet aus.
Wenn Sie auf die Schaltfläche „Speichern“ tippen, kann es einige Zeit dauern, bis der Kontextspeicher initialisiert ist, wenn Sie dies zum ersten Mal tun.
Sie sollten den heruntergeladenen Kontext sehen können. Wenn Sie rechts auf die drei vertikalen Schaltflächen klicken, werden die verfügbaren Aktionen angezeigt. Im nächsten Kapitel beginnen wir mit der Aktion „Testkontext“.
10. QueryData-Kontextset testen
Testvorlage
Verwenden Sie die Aktion „Test context“, um den Kontext in AlloyDB Studio zu testen. Wenn Sie auf „Kontext testen“ klicken, wird ein neues AlloyDB Studio-Editorfenster mit dem Titel „cymbal_context_set“ und der Einladung zur Gemini-SQL-Generierung mit dem Titel „Generate SQL using QueryData context: cymbal_context_set“ geöffnet. Klicken Sie auf die SQL-Generierung und geben Sie Folgendes ein:
Hello, can you tell me how many trips we've done in February?
Wenn die SQL-Abfrage generiert wurde, klicken Sie auf den Button „Insert“.
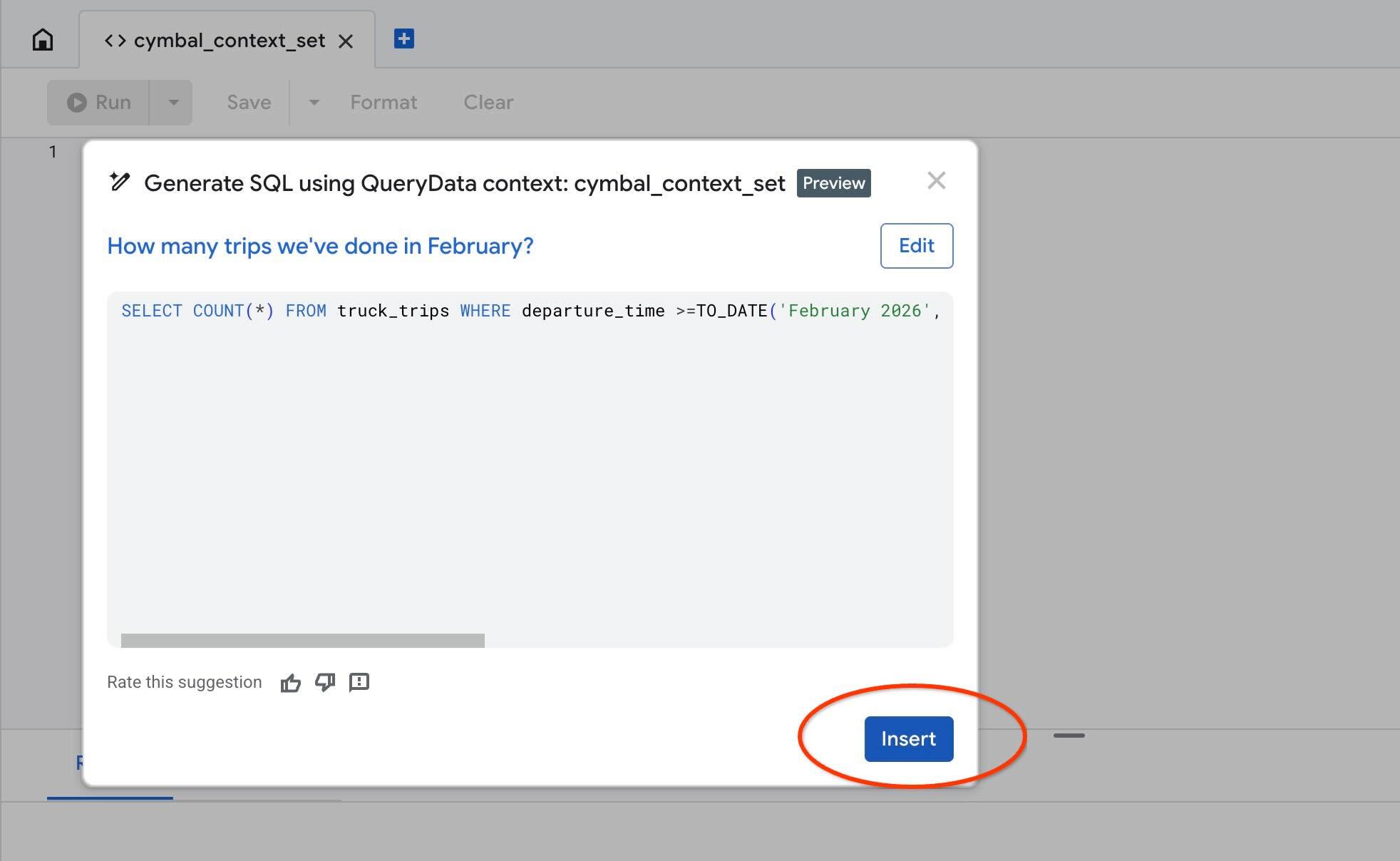
Sie sehen genau dieselbe Anfrage, die wir zuvor an unsere Kontextvorlage gestellt haben.
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
Ersetzen Sie den Monat durch „Januar“ und prüfen Sie die generierte SQL-Anweisung. Dabei wird der Monat als Parameter für die parametrisierte Intention verwendet und die SQL-Anweisung wird automatisch angepasst.
QueryData-Faceted erstellen
Wir haben eine Vorlage für eine Anfrage ausprobiert. Sie funktioniert, wenn wir wissen, welche Art von Nutzeranfrage wir erwarten. Manchmal ist es jedoch hilfreich, nur einen Teil einer Anfrage zu steuern, z. B. eine Bedingung oder einen Filter, wenn wir eine bestimmte Reihenfolge oder Klausel für eine neu definierte Intention bevorzugen.
Wenn wir beispielsweise Daten für „Letzter Monat“ anfordern, möchten wir den Bericht für den letzten Kalendermonat vom 1. bis zum letzten Tag dieses Monats, aber nicht für die letzten 30 Tage erhalten.
Wir können solche Facetten als SQL-Snippet zur ContextSet-Konfiguration hinzufügen, zusammen mit der Vorlage, die wir zuvor hinzugefügt haben. Öffnen Sie die Datei „querydata_cymbal_contextset.json“.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
Fügen Sie die Facetten nach unseren bereits vorhandenen Vorlagen hinzu. Der resultierende Inhalt in der Datei sollte folgender sein:
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
Speichern Sie die Datei und laden Sie sie auf Ihren Computer hoch.
Verwenden Sie dann die Kontextaktion „Kontext bearbeiten“ und laden Sie die geänderte Datei hoch, um den alten Kontext durch den neuen zu ersetzen.
Versuchen Sie nun noch einmal, den Testkontext zu verwenden und eine SQL-Anweisung mit der Intention „letzter Monat“ zu generieren. Wenn Sie beispielsweise SQL für den Begriff „show trucks trips for the last month"“ generieren, wird die von uns als Facette in der Datei „cymbal_context.json“ angegebene Bedingung verwendet.
Die Ausgabe sollte in etwa so aussehen:
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
Wie können Sie das mit KI‑Agents nutzen? Im nächsten Kapitel stellen wir den Kontext „Daten abfragen“ für KI-Agents zur Verfügung.
11. QueryData mit KI-Agents
Sie verwenden denselben Data Agent, aber die MCP Toolbox wird jetzt für die Verwendung des QueryData-ContextSet konfiguriert.
MCP Toolbox for Databases vorbereiten und starten
Wir benötigen eine neue Konfigurationsdatei für die MCP Toolbox, in der die Gemini Data Analytics API und AlloyDB als Datenbankquelle verwendet werden.
Führen Sie im Terminal folgenden Befehl aus:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
Wechseln Sie zum Editor und suchen Sie nach der Datei querydata.yaml. Die Konfigurationsdatei querydata.yaml würde so aussehen, mit Ausnahme der Projekt-ID und Region, die Ihre Umgebung widerspiegeln. Sie müssen jedoch weiterhin den Wert contextSetId aktualisieren und den Platzhalter "<add-context-set-id>" durch den Wert aus der Konsole ersetzen.
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
Klicken Sie auf die Schaltfläche „Bearbeiten“ für Ihr ContextSet, um die ContextSet-ID zu finden.
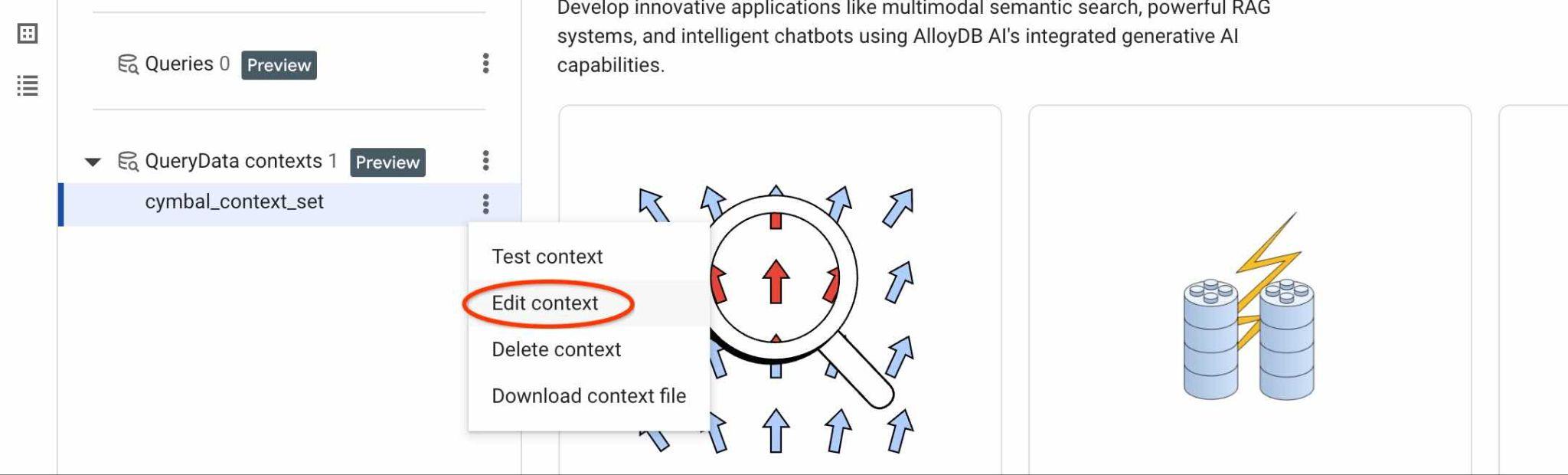
Die ID des Kontextsets wird oben auf dem neuen Tab rechts angezeigt.
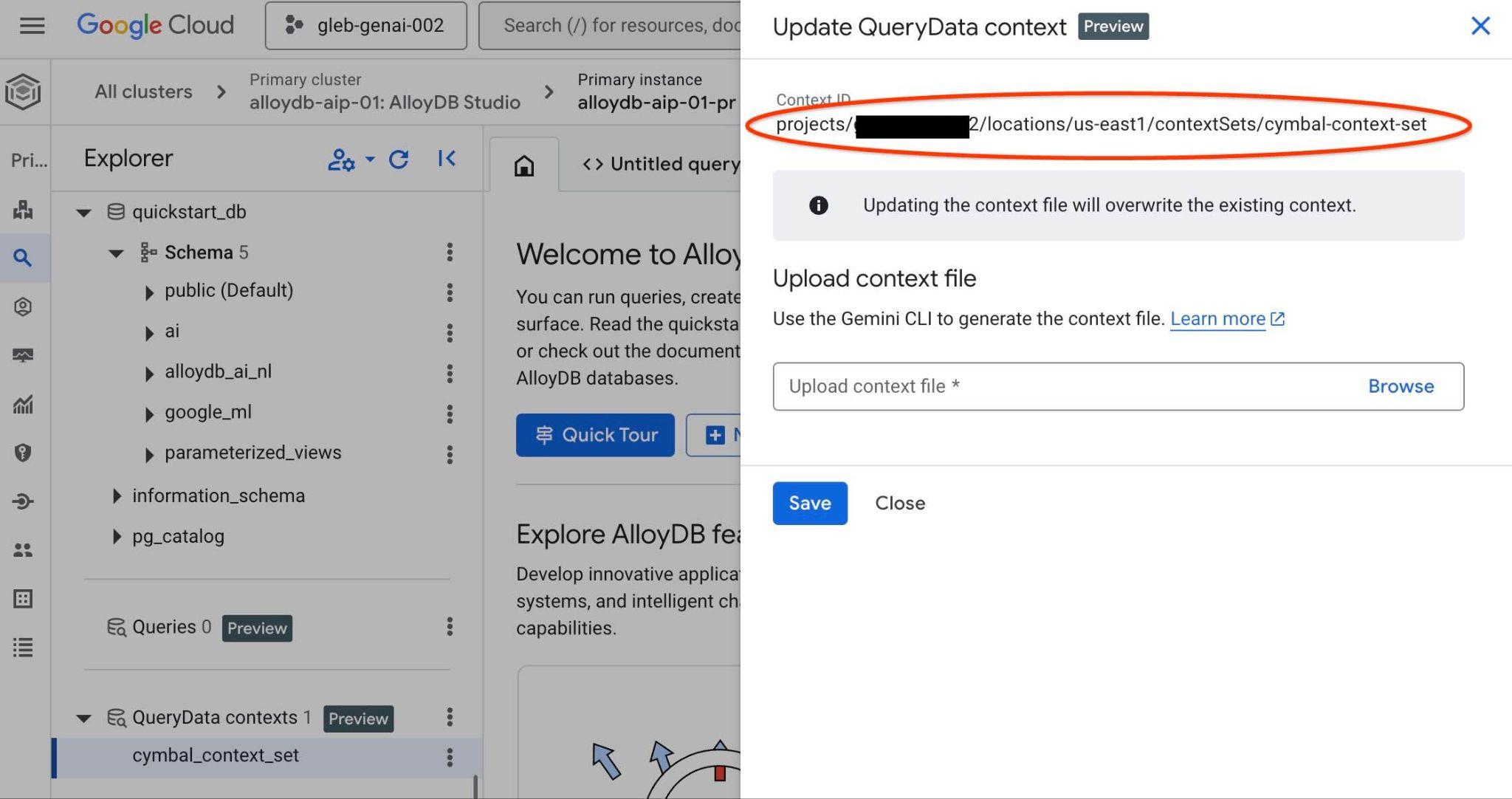
Dieser vollständige Pfad sollte anstelle des Platzhalters "<add-context-set-id>" in der Datei querydata.yaml eingefügt werden.
Wechseln Sie zum Terminal.
Öffnen Sie einen neuen Tab in Ihrer Google Cloud Shell, indem Sie oben in der Google Cloud Shell-Oberfläche auf die Schaltfläche „+“ klicken.
Wechseln Sie auf dem neuen Tab in das Verzeichnis mit der Binärdatei für die Toolbox und der Konfigurationsdatei „tools.yaml“ und starten Sie den MCP-Server.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
ADK-Agent ausführen
Starten Sie den KI-Agenten auf dem ersten Cloud Shell-Tab.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Wenn der Server gestartet wurde, klicken Sie noch einmal auf den Link http://127.0.0.1:8000 .
Sie sehen die bereits bekannte ADK-Webvorschau-Agent-Oberfläche. Stellen Sie genau dieselbe Frage wie beim letzten Mal.
Hello, can you tell me how many trips we've done in February?
Sehen Sie sich den Agentenworkflow an. Wenn alles richtig konfiguriert ist, sollte Folgendes angezeigt werden.
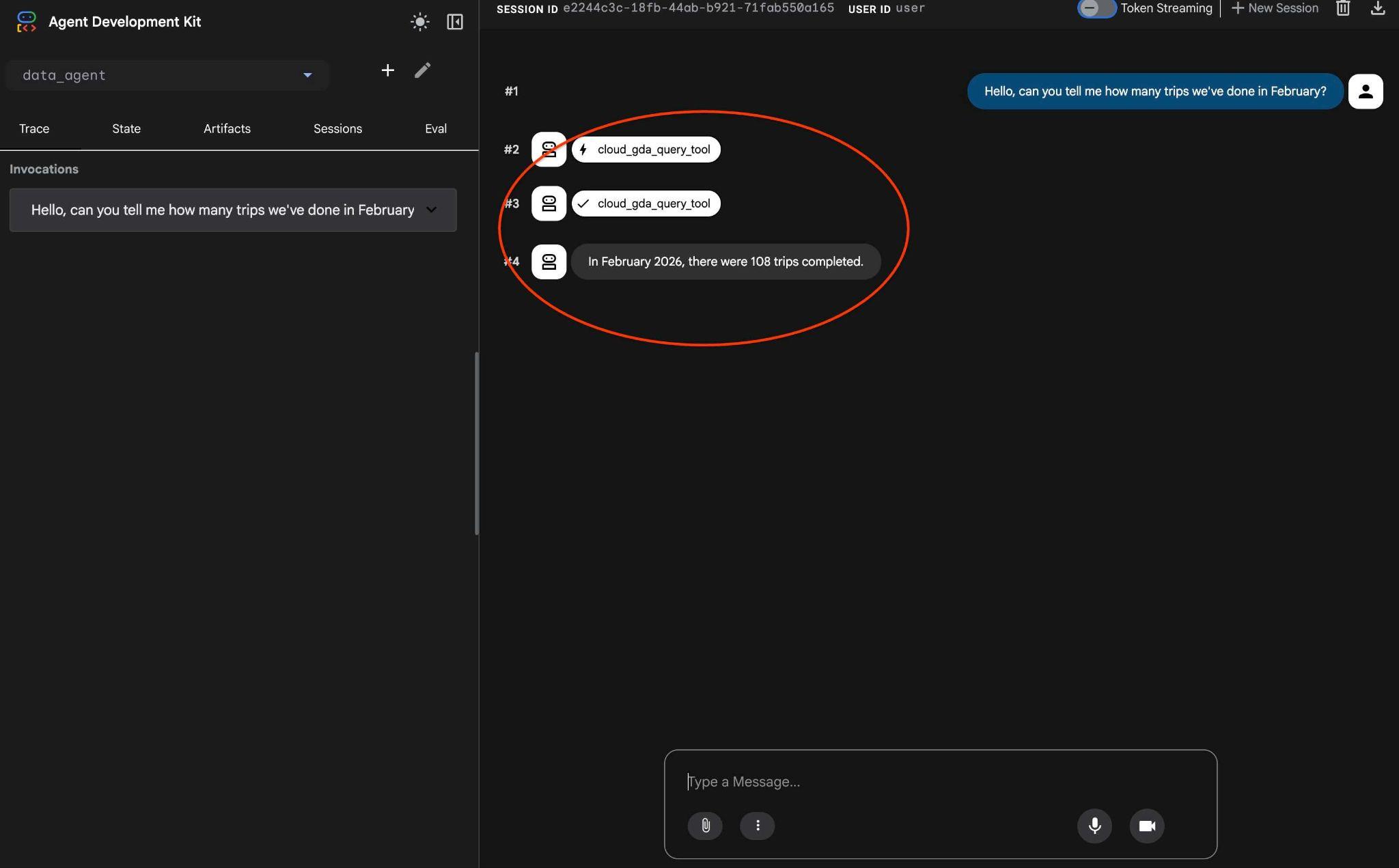
Die Anfrage, die beim letzten Mal mehrere Schritte erforderte, wurde in einen Aufruf des MCP-Tools umgewandelt und mit vorhersehbaren SQL-Anweisungen ausgeführt.
Sie können die konfigurierten Facetten mit der folgenden Anfrage testen:
how trucks trips for the last month
Wenn Sie in der Ausgabe auf die Tool-Aktion klicken, sehen Sie, dass dasselbe Tool verwendet und Facetten angewendet wurden, um das Ergebnis zu erhalten.
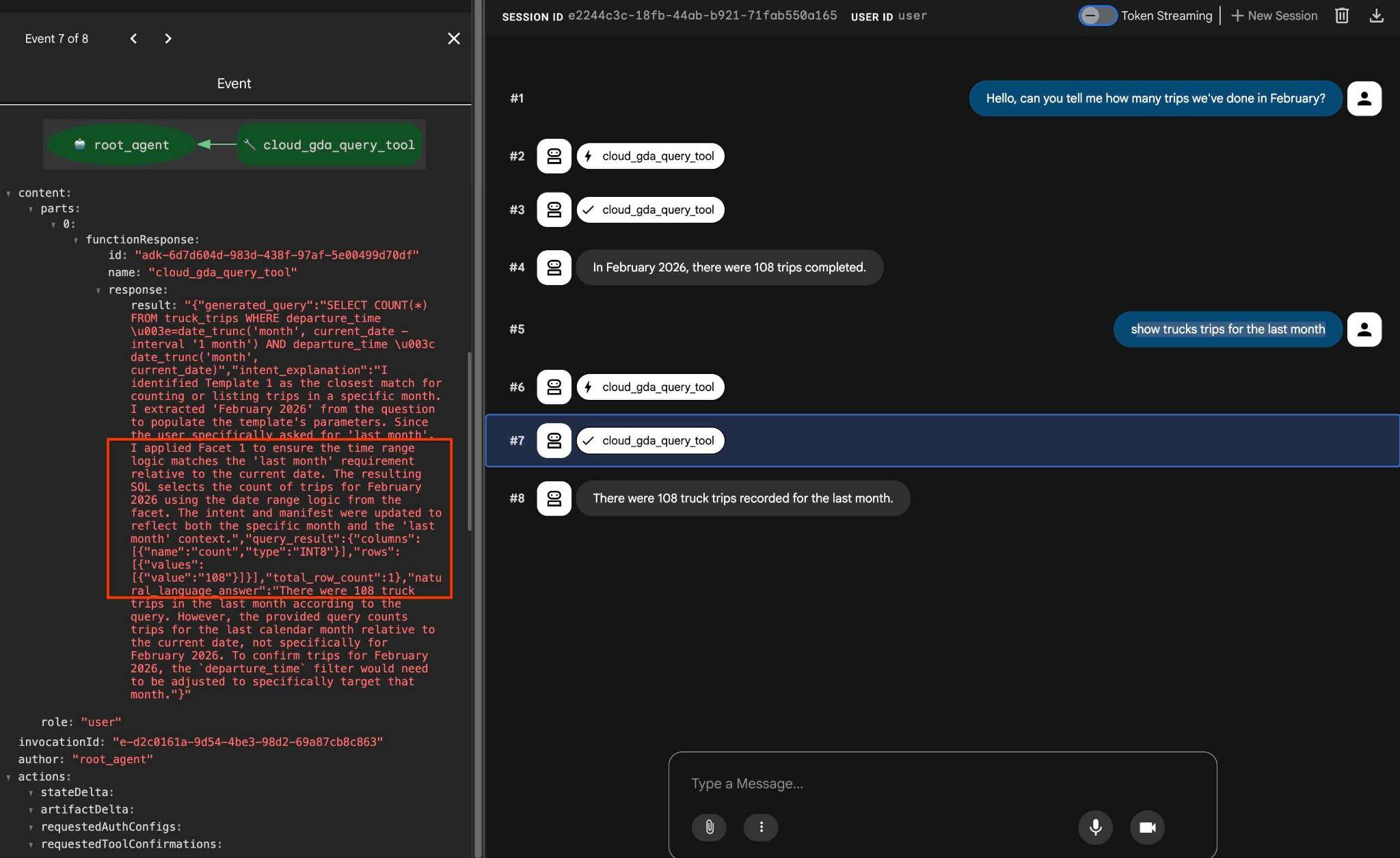
Damit ist das Lab abgeschlossen. Ich hoffe, Sie konnten sich alle Beispiele ansehen und erfahren, wie Sie QueryData für AlloyDB verwenden. Die bereitgestellte Technologie trägt dazu bei, dass Ihre agentenbasierte Arbeitslast und die SQL-Generierung vorhersehbar und zuverlässig sind.
12. Umgebung bereinigen
Um unerwartete Kosten zu vermeiden, sollten Sie die temporären Ressourcen bereinigen. Am zuverlässigsten ist es, das Projekt zu löschen, in dem Sie den Workflow getestet haben. Optional können Sie sich jedoch einschränken, indem Sie einzelne Ressourcen wie AlloyDB löschen.
Löschen Sie die AlloyDB-Instanzen und den Cluster, wenn Sie mit dem Lab fertig sind.
AlloyDB-Cluster und alle Instanzen löschen
Wenn Sie die Testversion von AlloyDB verwendet haben. Löschen Sie den Testcluster nicht, wenn Sie planen, andere Labs und Ressourcen damit zu testen. Sie können keinen weiteren Testcluster im selben Projekt erstellen.
Der Cluster wird mit der Option „force“ zerstört, wodurch auch alle zum Cluster gehörenden Instanzen gelöscht werden.
Definieren Sie in Cloud Shell die Projekt- und Umgebungsvariablen, wenn die Verbindung getrennt wurde und alle vorherigen Einstellungen verloren gegangen sind:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Löschen Sie den Cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB-Sicherungen löschen
Löschen Sie alle AlloyDB-Sicherungen für den Cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
13. Glückwunsch
Herzlichen Glückwunsch zum Abschluss des Codelabs.
Behandelte Themen
- AlloyDB-Cluster erstellen und Beispieldaten importieren
- AlloyDB Data Access API aktivieren
- QueryData für AlloyDB aktivieren
- Vorlagen generieren
- Attributsuche verwenden
- QueryData mit KI-Agenten verwenden
14. Umfrage
Ausgabe: