
1. Introducción
En este codelab, se proporciona una guía para comenzar a usar QueryData para AlloyDB y utilizarlo para generar instrucciones SQL precisas y predecibles a partir de entradas de lenguaje natural en aplicaciones basadas en agentes.
Requisitos previos
- Conocimientos básicos sobre la consola de Google Cloud
- Habilidades básicas de la interfaz de línea de comandos y de Cloud Shell
Qué aprenderás
- Cómo crear un clúster de AlloyDB y, luego, importar datos de muestra
- Cómo habilitar la API de acceso a los datos de AlloyDB
- Cómo habilitar QueryData para AlloyDB
- Cómo generar plantillas
- Cómo usar la búsqueda por facetas
- Cómo usar QueryData con agentes de IA
Requisitos
- Una cuenta de Google Cloud y un proyecto de Google Cloud
- Un navegador web, como Chrome, que admita la consola de Google Cloud y Cloud Shell
2. Configuración y requisitos
Configuración del proyecto
Crea un proyecto de Google Cloud
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
Inicia Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
También puedes presionar G y, luego, S. Esta secuencia activará Cloud Shell si estás en la consola de Google Cloud o usas este vínculo.
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
3. Antes de comenzar
Habilitar API
Para usar AlloyDB, Compute Engine, servicios de redes y Vertex AI, debes habilitar sus APIs respectivas en tu proyecto de Google Cloud.
En la terminal de Cloud Shell, asegúrate de que tu ID del proyecto esté configurado:
gcloud config get-value project
Deberías ver el ID de tu proyecto (tID) en el resultado:
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
Configura la variable de entorno PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Habilita todos los servicios necesarios con el siguiente comando:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Resultado esperado
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Implementa AlloyDB
Crea un clúster de AlloyDB y una instancia principal. Puedes implementarlo con una secuencia de comandos preparada que implementará todos los recursos necesarios o puedes hacerlo paso a paso por tu cuenta siguiendo la documentación.
Implementa AlloyDB con una secuencia de comandos automatizada
Este enfoque usa una secuencia de comandos automatizada para implementar el clúster de AlloyDB y proporcionar la información necesaria para comenzar a trabajar con los recursos implementados.
En la terminal de Cloud Shell, ejecuta el comando para clonar la secuencia de comandos de implementación desde el repositorio.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
Ejecuta la secuencia de comandos de implementación.
./deploy_alloydb.sh --public-ip
La secuencia de comandos tardará un tiempo en ejecutarse, por lo general, entre 5 y 7 minutos, y se implementará un clúster de AlloyDB y una instancia principal con IP pública y privada. La IP pública solo está disponible para las redes autorizadas o con el proxy de autenticación de AlloyDB. Puedes obtener más información sobre las IPs públicas en la documentación. Como resultado, la secuencia de comandos debe proporcionar información sobre tu clúster de AlloyDB implementado. Ten en cuenta que tu contraseña será diferente. Regístrala en algún lugar para usarla más adelante.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
También puedes ver el clúster nuevo y la instancia principal en la consola web.
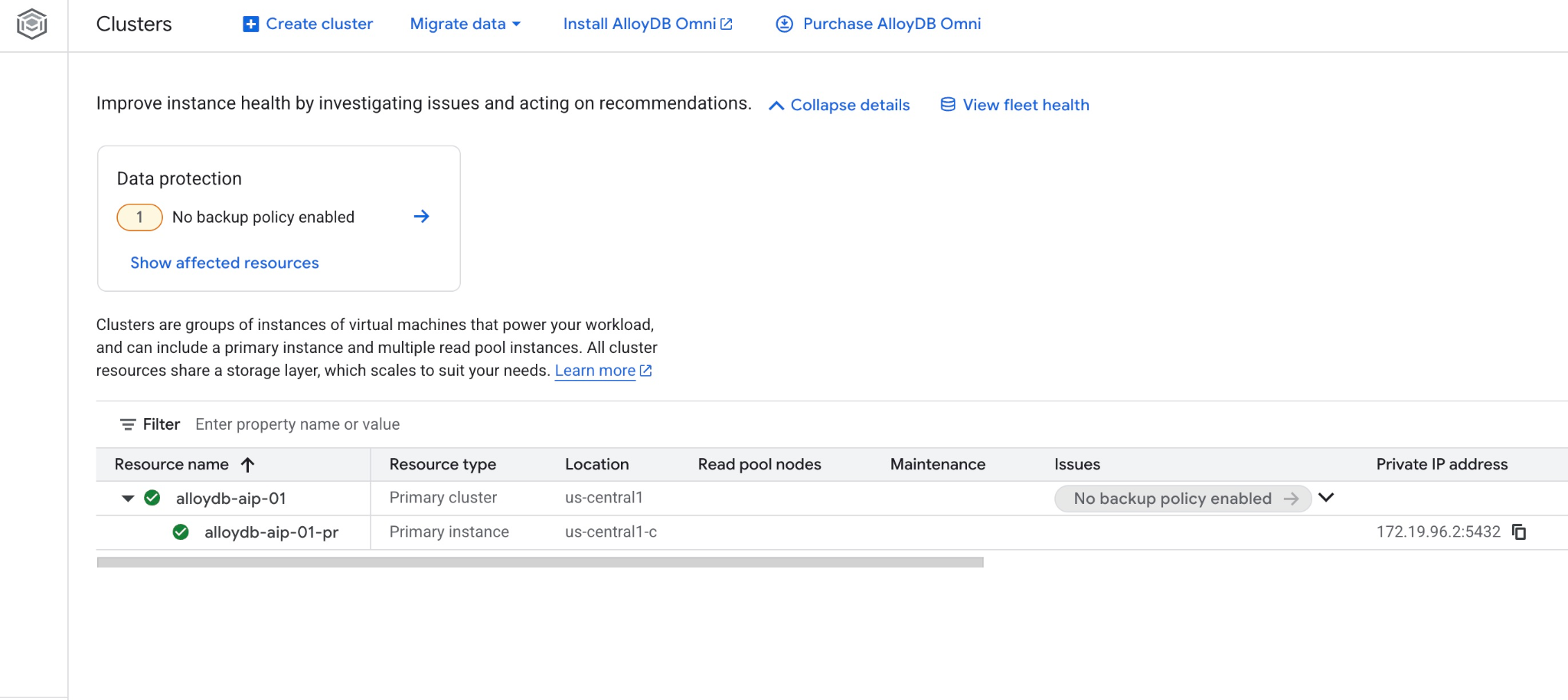
5. Prepara la base de datos
Debes habilitar la integración de Vertex AI para usar funciones y operadores de IA, habilitar la API de acceso a los datos y crear una base de datos para el conjunto de datos de muestra.
Otorga los permisos necesarios a AlloyDB
Agrega permisos de Vertex AI al agente de servicio de AlloyDB.
Abre otra pestaña de Cloud Shell con el signo "+" en la parte superior.
En la nueva pestaña de Cloud Shell, ejecuta lo siguiente:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Resultado esperado en la consola:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Habilita la API de Data Access
Debes habilitar la API de Data Access en el clúster de AlloyDB para poder usar herramientas de MCP como execute_sql.
En la misma pestaña de la terminal, ejecuta lo siguiente.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
Habilita la autenticación de IAM
Usaremos la autenticación de IAM para nuestras herramientas basadas en agentes, por lo que es necesario habilitar la autenticación de IAM en la instancia y agregarte como usuario de la base de datos. Antes de habilitar la autenticación con IAM a nivel de la instancia, espera a que finalice el paso anterior para habilitar la API de acceso a los datos. El estado de tu instancia debería ser verde.
Comenzaremos por habilitar IAM a nivel de la instancia. En la misma pestaña de la terminal, ejecuta lo siguiente.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Agrega tu cuenta como usuario de AlloyDB:
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
Cierra la pestaña con el comando de ejecución “exit” en la pestaña:
exit
Conéctate a AlloyDB Studio
En los siguientes capítulos, todos los comandos de SQL que requieren conexión a la base de datos se pueden ejecutar en AlloyDB Studio. T
Navega a la página Clústeres en AlloyDB para PostgreSQL.
Haz clic en la instancia principal para abrir la interfaz de la consola web de tu clúster de AlloyDB.
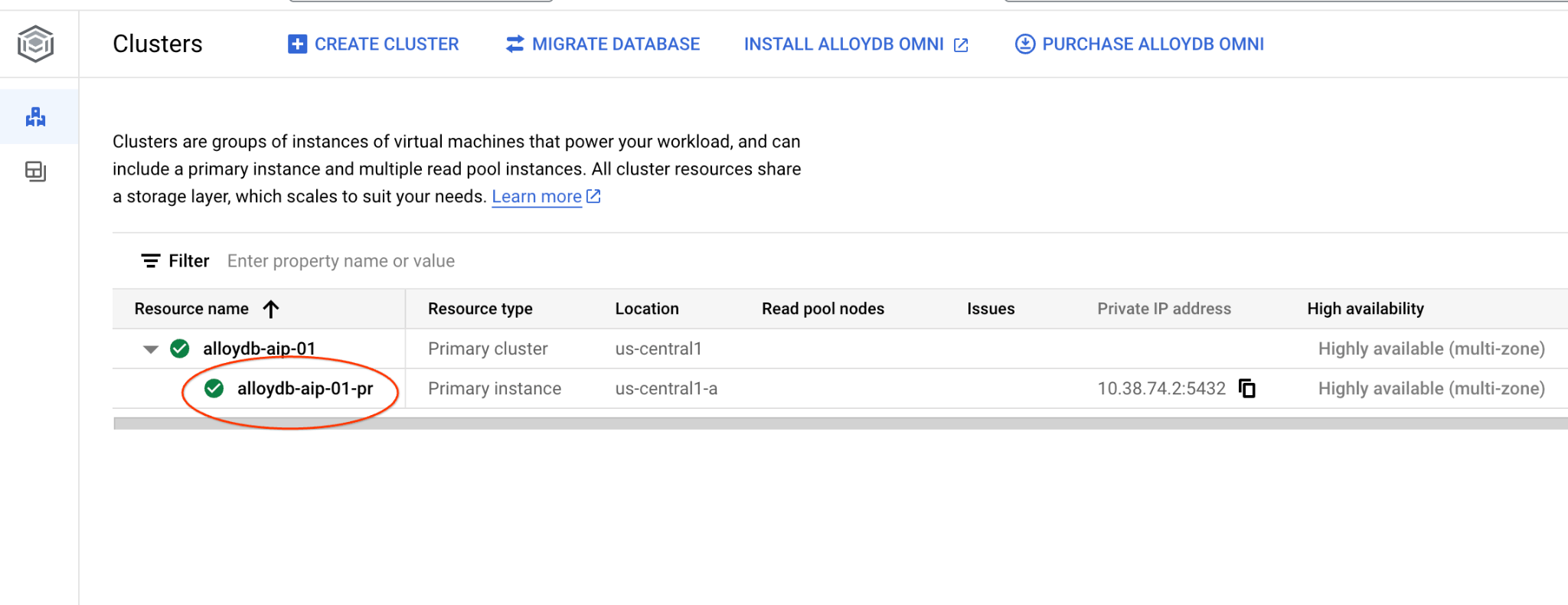
Luego, haz clic en AlloyDB Studio a la izquierda:
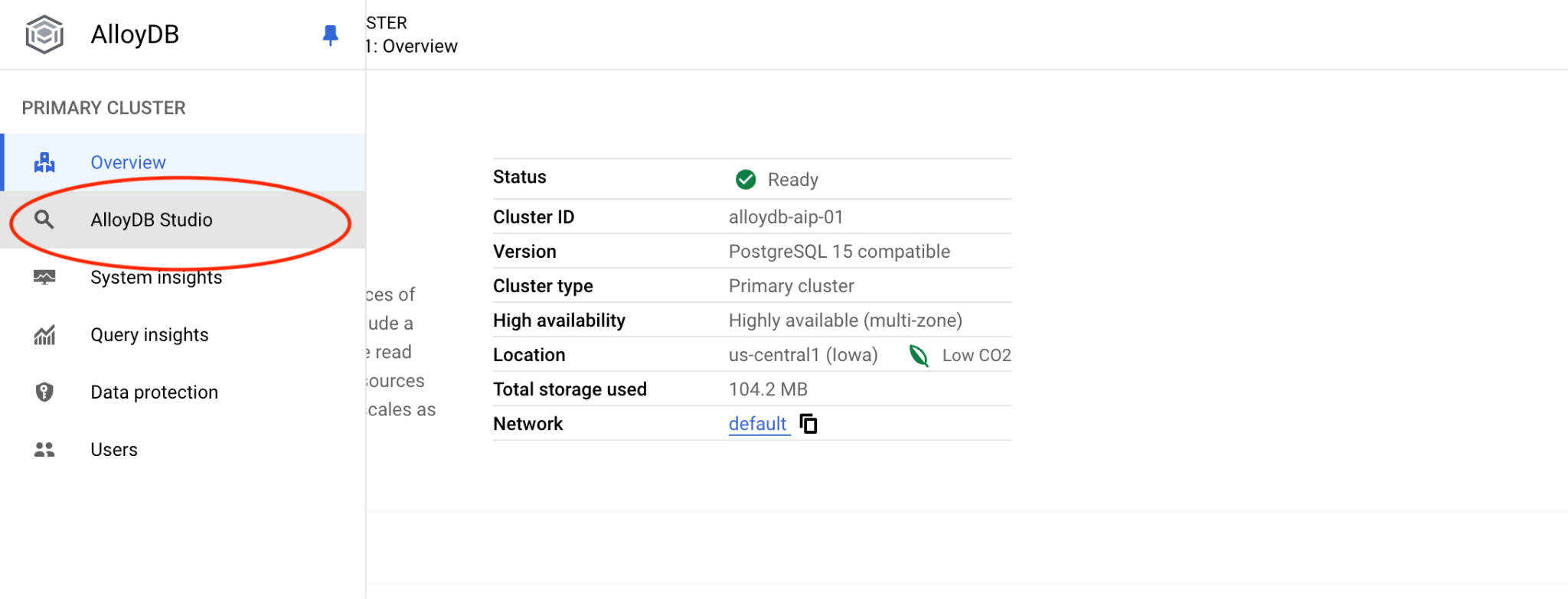
Elige la base de datos de Postgres y la autenticación de IAM. Luego, haz clic en el botón "Autenticar".
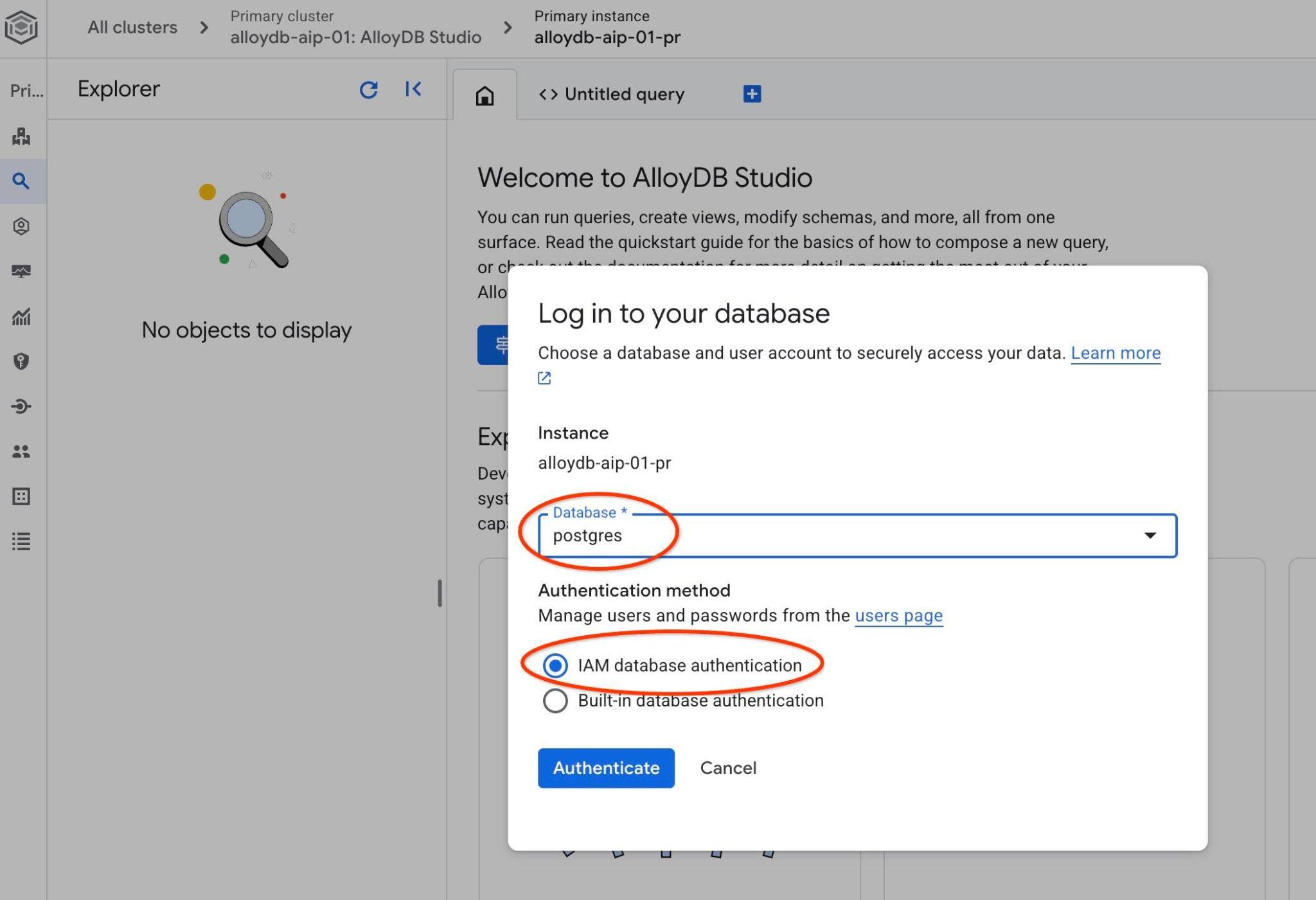
Se abrirá la interfaz de AlloyDB Studio. Para ejecutar los comandos en la base de datos, haz clic en la pestaña "Untitled Query" (Consulta sin título) que se encuentra a la derecha.
Se abre una interfaz en la que puedes ejecutar comandos de SQL.
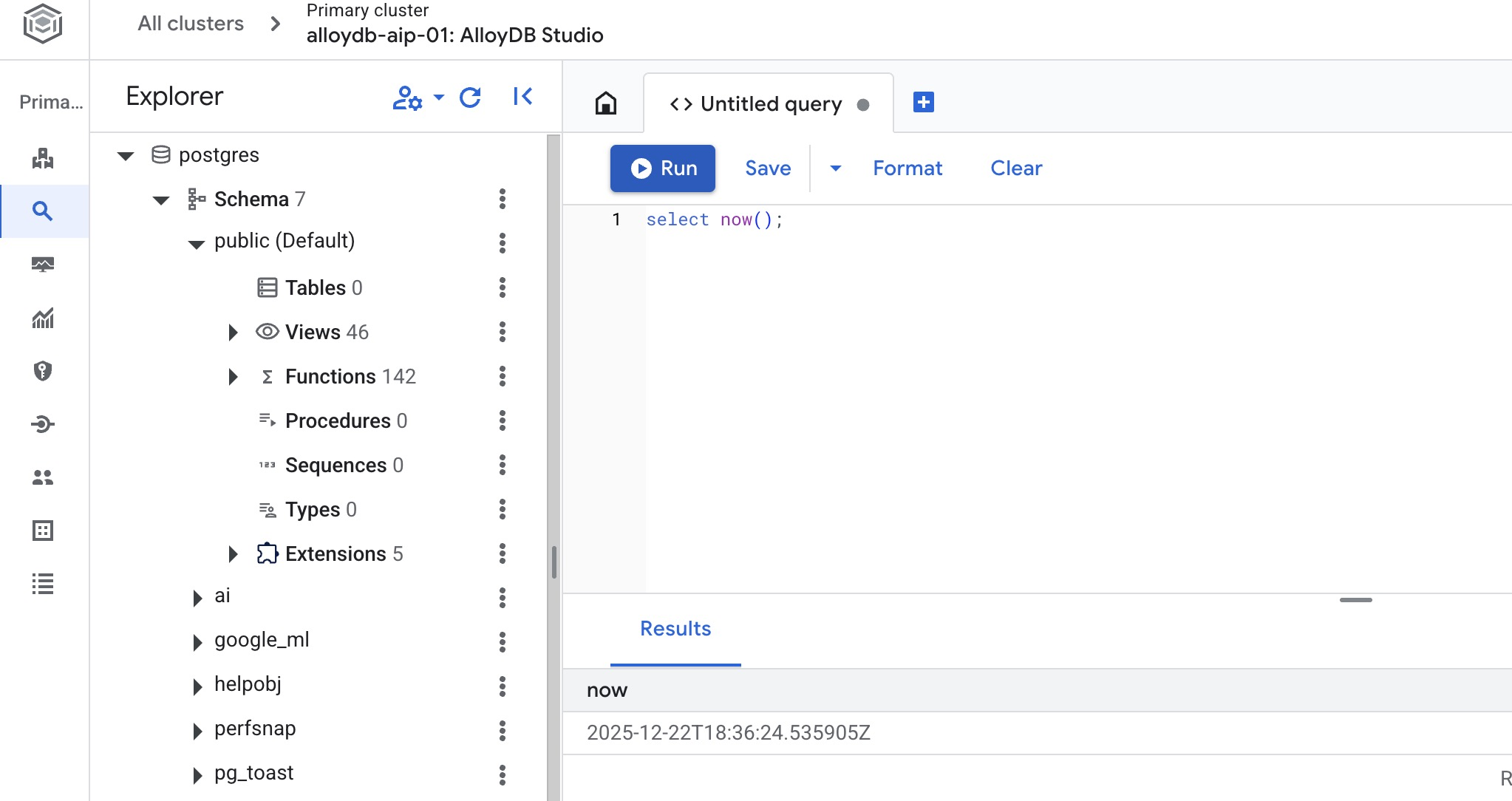
Crea la base de datos
Guía de inicio rápido para crear una base de datos
En el editor de AlloyDB Studio, ejecuta el siguiente comando.
Crea la base de datos:
CREATE DATABASE quickstart_db
Resultado esperado:
Statement executed successfully
Conéctate a quickstart_db
Comprueba si se creó tu base de datos conectándote a ella. Vuelve a conectarte al estudio con el botón para cambiar de usuario o base de datos.
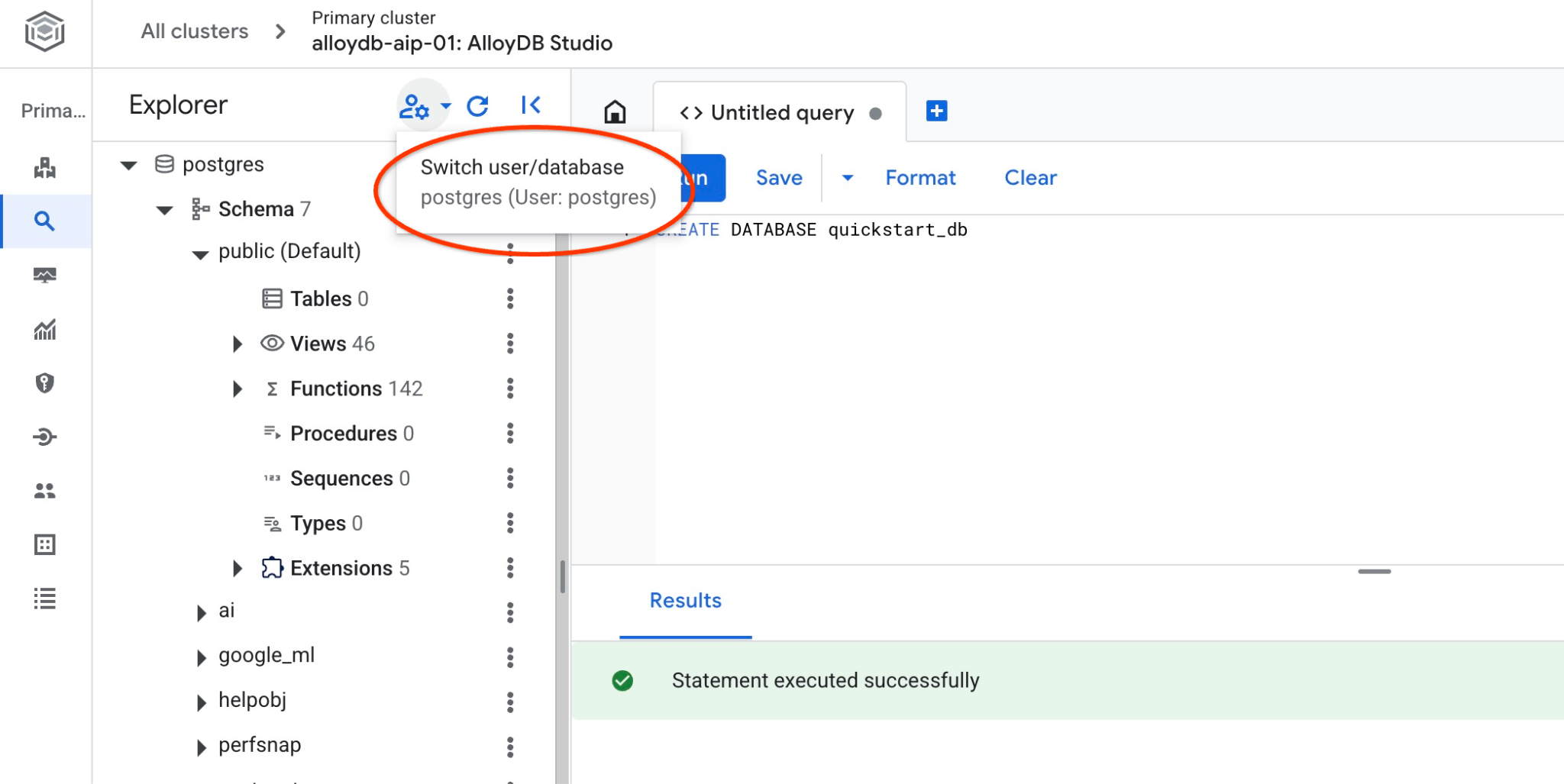
Selecciona la nueva base de datos quickstart_db en la lista desplegable y usa la misma autenticación de IAM.
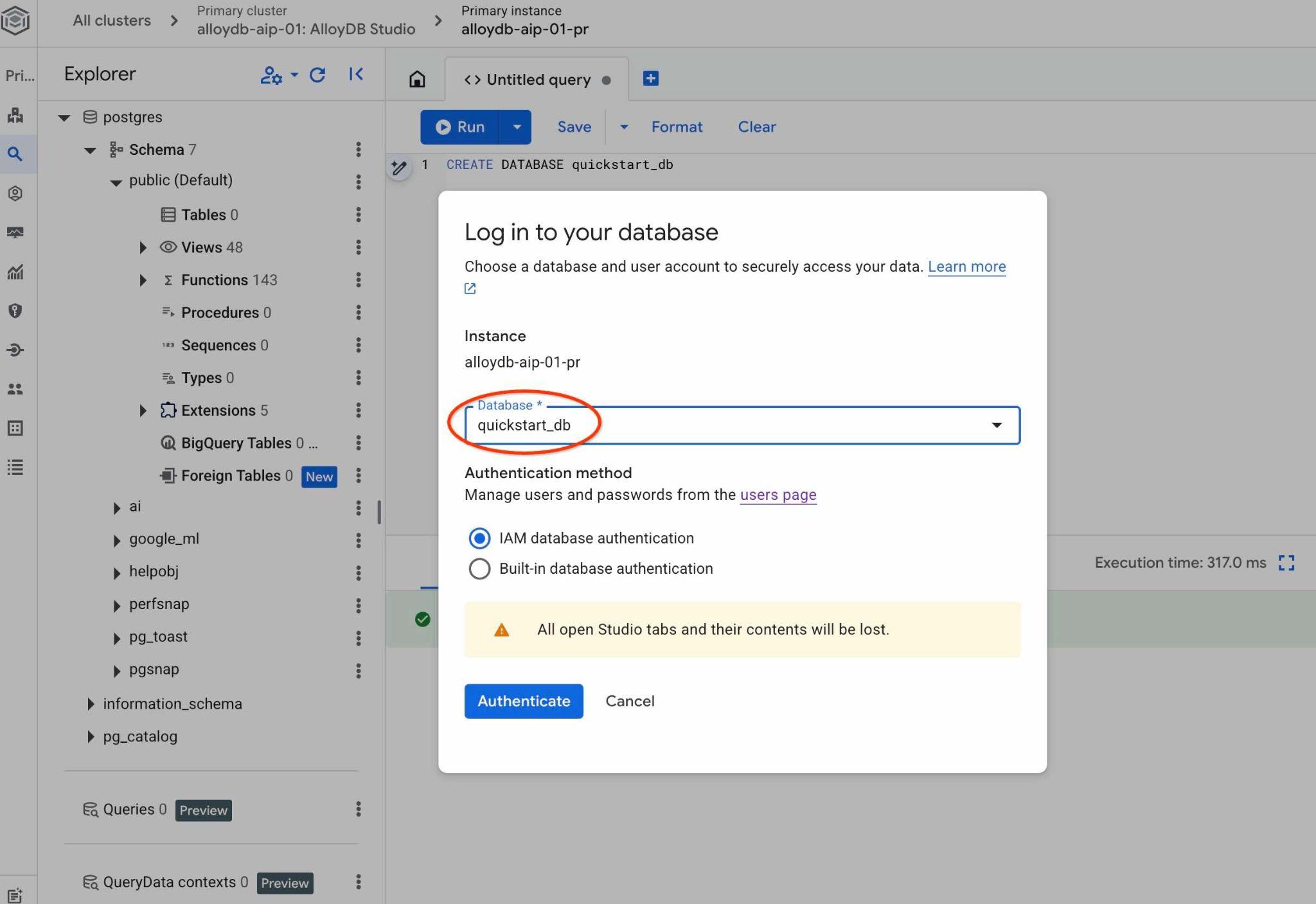
Se abrirá una conexión nueva en la que podrás trabajar con objetos de la base de datos quickstart_db. Allí podrás examinar el esquema y los datos importados, y trabajar con conjuntos de contexto de QueryData.
6. Datos de muestra
Ahora debes crear objetos en la base de datos y cargar datos. Usarás un conjunto de datos ficticio de la empresa Cymbal Shipping. Contiene datos ficticios sobre bienes, camiones, solicitudes y viajes de camiones, además de conductores ficticios.
Crear un bucket de Storage
Usarás el SDK de Google (gcloud) para importar datos desde tu repositorio clonado a la base de datos de AlloyDB. Para ello, deberás crear un bucket de Cloud Storage y otorgar acceso a la cuenta de servicio de AlloyDB. Como alternativa, siempre puedes intentar hacerlo con la consola web, como se describe en la documentación.
En la terminal de Google Cloud Shell, ejecuta el siguiente comando:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
Carga de datos
El siguiente paso es cargar los datos. Nuestro volcado de SQL comprimido se encuentra en la carpeta del repositorio clonado. En el siguiente comando, se supone que usaste tu directorio principal como punto de partida cuando clonaste el repositorio en el paso anterior mientras creabas el clúster de AlloyDB.
Copia el volcado de SQL comprimido en el nuevo bucket de almacenamiento:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
Luego, carga los datos en la base de datos quickstart_db:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
El comando cargará el conjunto de datos de muestra en la base de datos quickstart_db. Puedes verificar las tablas y los registros con AlloyDB Studio.
7. Trabaja con el agente de datos
Comencemos con un agente de IA de muestra creado con el ADK de Google para Python y conectándonos a nuestra instancia de AlloyDB con el kit de herramientas de MCP para bases de datos.
Instala MCP Toolbox para bases de datos
MCP Toolbox for Databases es un proyecto de código abierto que proporciona compatibilidad con MCP para varios motores de bases de datos, incluido AlloyDB para PostgreSQL. Puedes obtener más información sobre MCP Toolbox en la documentación.
Debes descargar la versión más reciente del software para tu plataforma. Para obtener la versión más reciente, consulta la página de versiones. En el siguiente ejemplo, se muestra cómo descargar la versión 31 de la caja de herramientas de MCP en Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Debes preparar un archivo de configuración para Toolbox. Tenemos un archivo tools.yaml.example de muestra en el directorio actual y prepararemos el archivo tools.yaml reemplazando dos marcadores de posición por el ID del proyecto y la región.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
Inicia MCP Toolbox para bases de datos
Ahora puedes iniciar la caja de herramientas de MCP con el archivo de configuración preparado.
Presiona el botón "+" en la parte superior de la interfaz de Google Cloud Shell para abrir una pestaña nueva.
En la nueva pestaña, cambia al directorio con el archivo binario de la caja de herramientas y el archivo de configuración tools.yaml, y, luego, inicia el servidor de MCP.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
En el resultado, deberías ver el mensaje "Server ready to serve!" similar al siguiente.
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
Verifica el código fuente del agente
En la primera pestaña de la carpeta del repositorio clonado, revisa el código del agente con el editor de Google Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
En el agente, puedes ver que tenemos una sección para el servidor de MCP de Google Cloud para AlloyDB. Proporcionamos un extremo como MCP_SERVER_URL, autenticación, ID del proyecto y lo agregamos al conjunto de herramientas de MCP.
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
En el código del agente, el conjunto de herramientas de MCP se incluye como parámetro tools para el agente. También hay nombres de clústeres y de instancias, la región y la base de datos como variables para la instrucción del agente.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
Después de examinar el código, vuelve a la terminal presionando el botón "Abrir terminal" en la parte superior derecha de la ventana del editor.
Inicia el agente
Ahora puedes iniciar el agente en modo interactivo con la interfaz web del ADK de Google. La interfaz web del ADK proporciona una forma conveniente de probar y solucionar problemas de los flujos de trabajo de los agentes.
Primero, instalemos todos los paquetes necesarios para Python con el administrador de paquetes uv.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
Cuando se instalen todos los paquetes, deberás agregar un archivo .env al directorio del agente para indicarle que use Vertex AI en todas las comunicaciones con los modelos de IA.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
Luego, puedes iniciar el agente
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Deberías ver un resultado como el siguiente con el extremo como http://127.0.0.1:8000 .
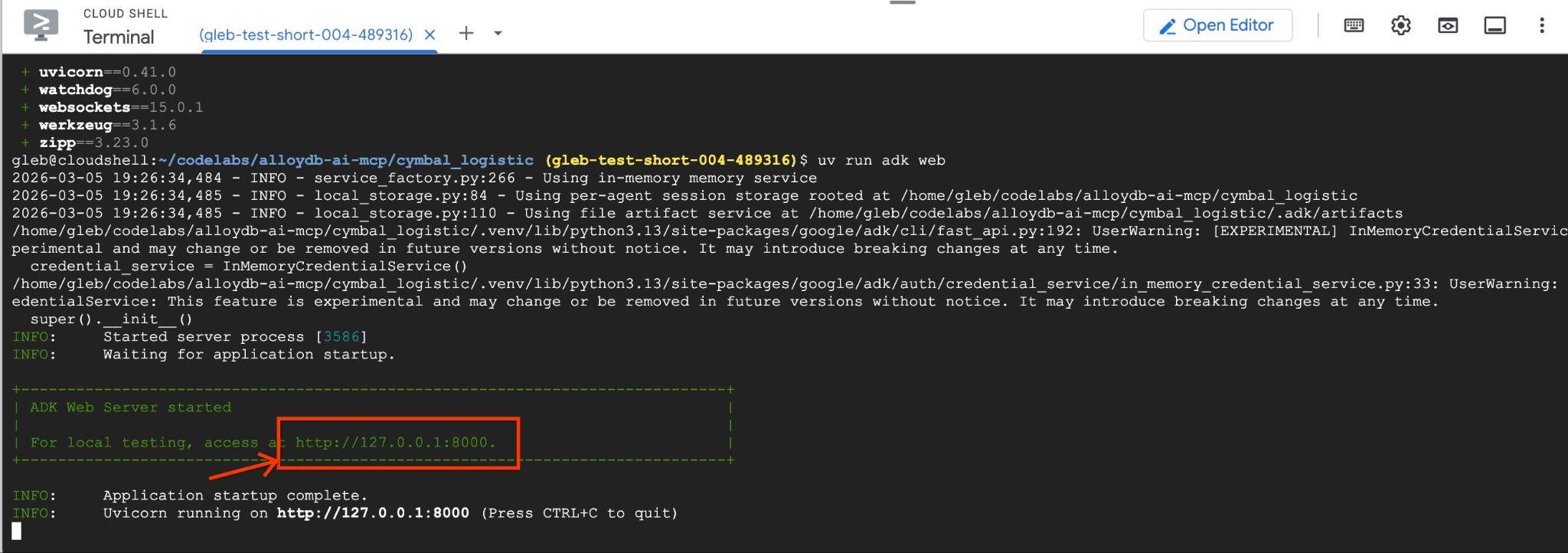
Puedes hacer clic en esa URL en Cloud Shell y se abrirá una ventana de vista previa en una pestaña separada del navegador en la que podrás elegir el data_agent en la lista desplegable de la izquierda.
En la interfaz web del ADK, puedes publicar tus preguntas en la parte inferior derecha y ver el flujo de ejecución completo, incluidos los registros de cada paso en el lado derecho.
8. Prueba NL2SQL sin QueryData para AlloyDB
El agente te permite hacer preguntas en formato libre con lenguaje natural, y el agente usará el kit de herramientas de MCP para bases de datos como herramienta para responder las preguntas. Las preguntas se publican en la parte inferior derecha y la respuesta con todas las llamadas a las herramientas aparecerá en la parte superior.
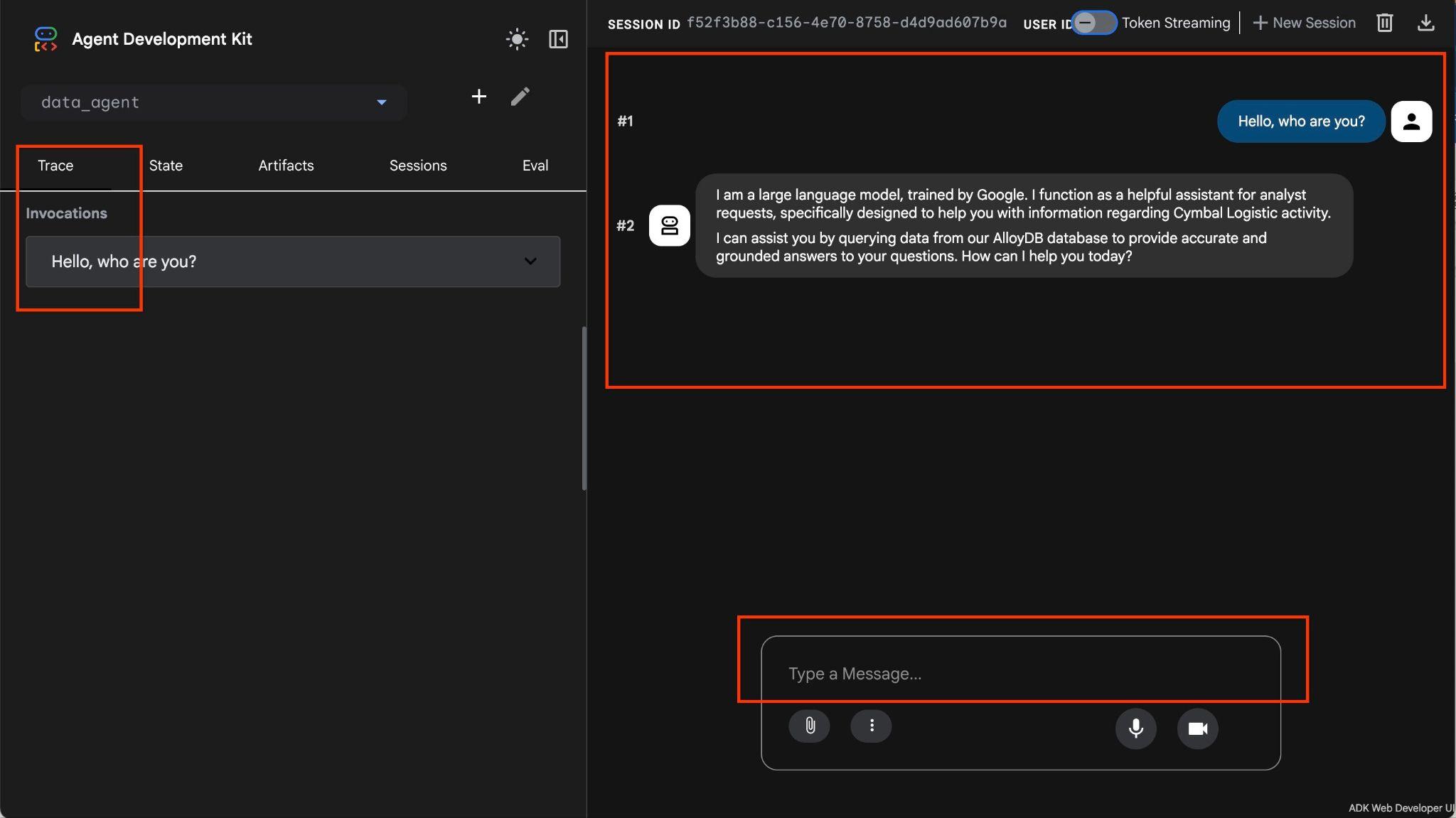
Trabajas con datos operativos de una empresa de envíos que tiene información sobre solicitudes de envío, camiones, conductores y viajes realizados por los conductores. La primera pregunta se refiere a la cantidad de viajes realizados en febrero de 2026.
En el campo de entrada de la parte inferior derecha, escribe lo siguiente y presiona Intro.
Hello, can you tell me how many trips we've done in February?
El agente ejecutará varias llamadas a herramientas para identificar las tablas correctas en el esquema con list_cymbal_logistics_schemas_tool y execute_sql_tool, y ejecutará varias instrucciones de SQL para obtener los datos correctos.
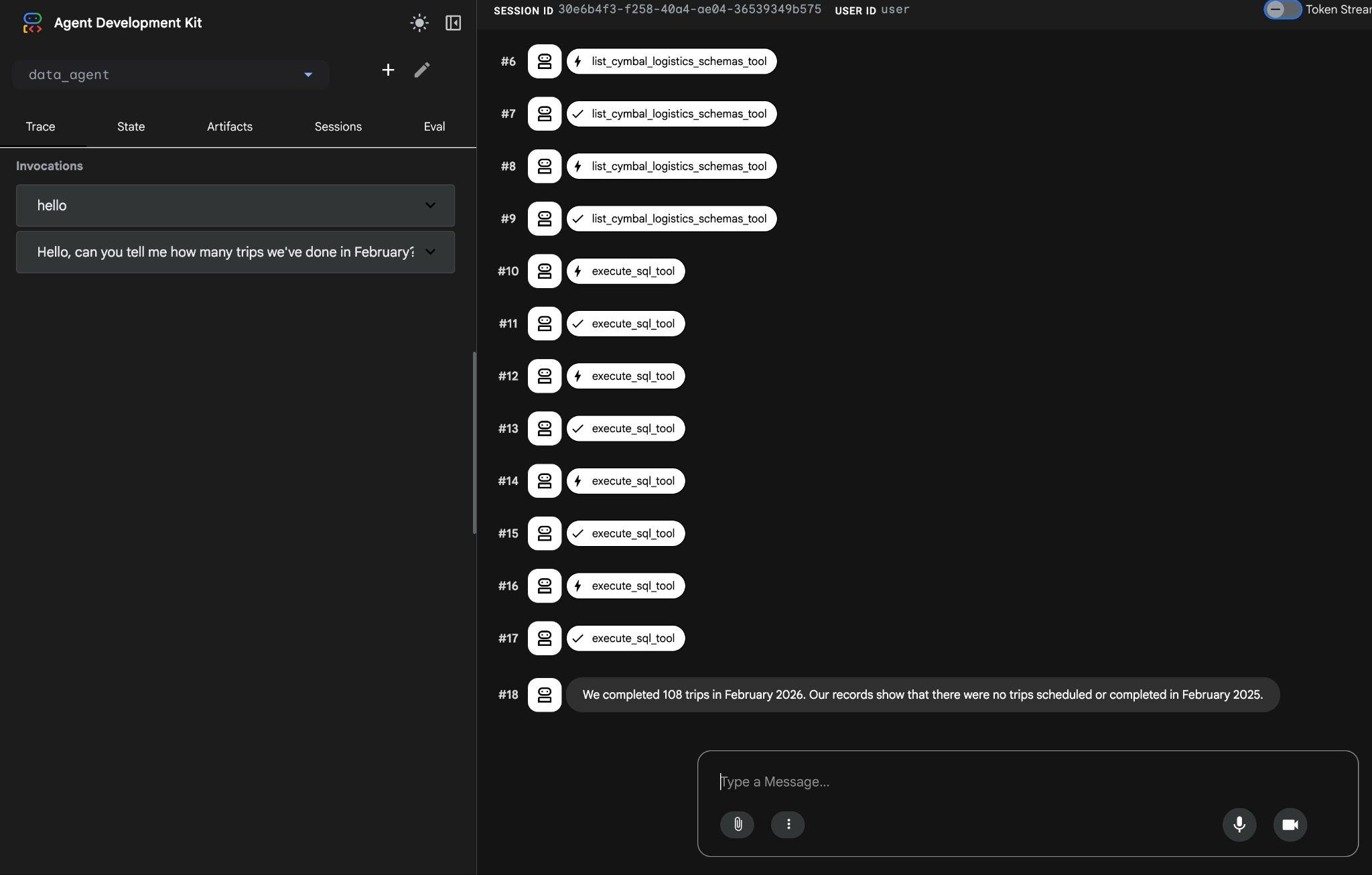
Finalmente, producirá el resultado correcto después de crear la consulta adecuada y ejecutarla en la base de datos.
Completamos 108 viajes en febrero de 2026. Según nuestros registros, no se programaron ni completaron viajes en febrero de 2025.
Puedes ver lo que hace cada llamada a la herramienta haciendo clic en la ejecución de la herramienta. Por ejemplo, esta es la consulta que se ejecutó para obtener nuestros resultados.
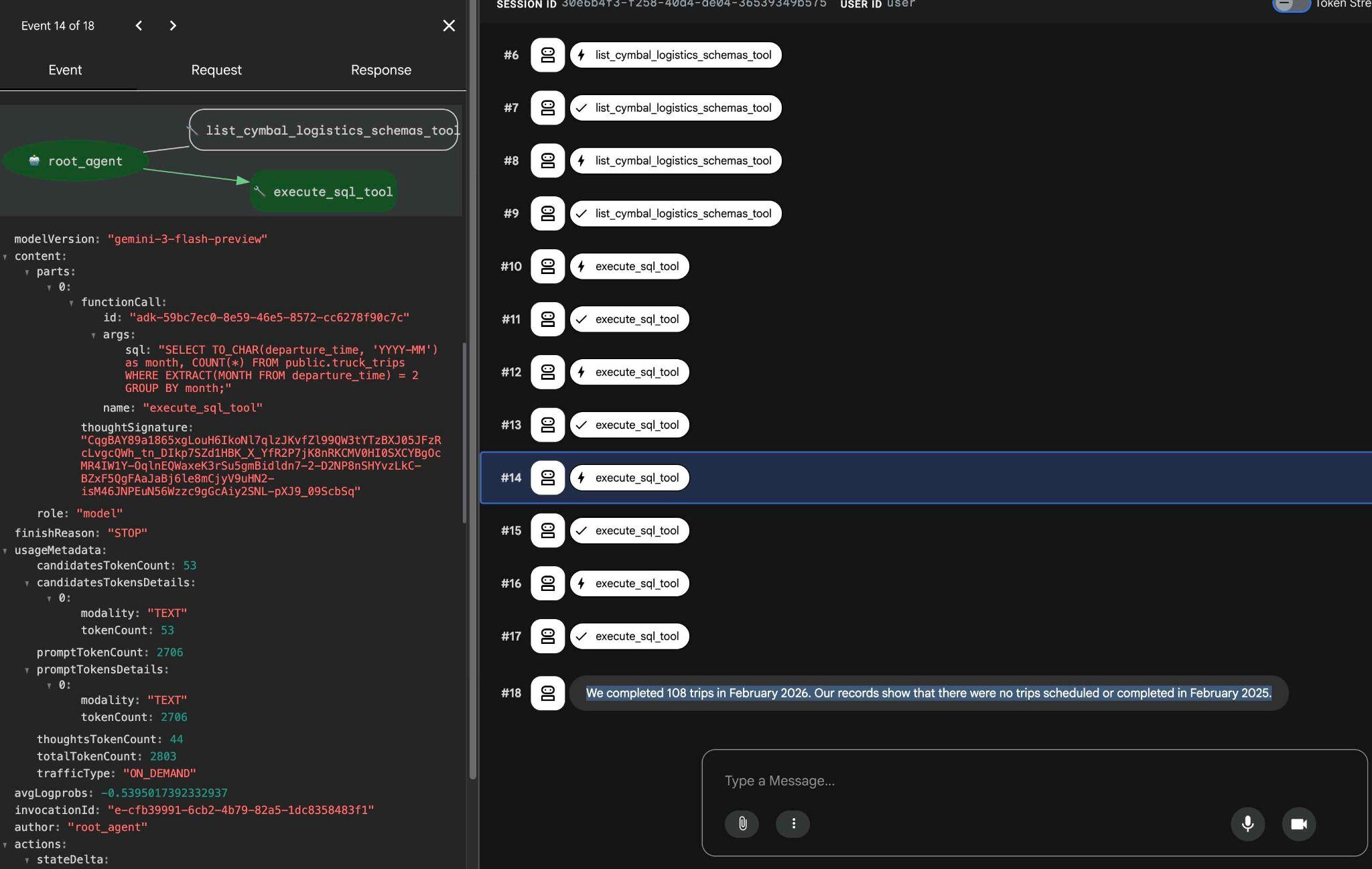
Prueba otras solicitudes simples con la interfaz web del ADK y observa cómo ejecuta diferentes búsquedas para obtener los resultados.
Para detener el agente, presiona ctrl+c en la terminal. Puedes cerrar la pestaña del navegador con la interfaz web del ADK.
También puedes detener la caja de herramientas de MCP en la segunda pestaña presionando la misma combinación de teclas ctrl+c y cerrar la segunda pestaña.
En el siguiente paso, compilaremos el contexto de QueryData para mejorar nuestra respuesta y rendimiento de NL2SQL.
9. Compila ContextSet de QueryData
En el paso anterior, pudiste ver que el modelo de IA realizó varias llamadas al esquema de información de la base de datos para determinar qué tabla y columnas debería usar para compilar la consulta en SQL. Para mejorar el rendimiento y la precisión, y hacer que el resultado sea más predecible, agregaremos tu contexto de QueryData, que define qué consulta se debe ejecutar en respuesta a una solicitud determinada.
Crea plantillas segmentadas
El ContextSet de QueryData es un archivo JSON con plantillas de búsqueda y facetas que proporcionan los datos y las instrucciones necesarios para que el modelo de IA use la consulta en SQL o las partes de la consulta en SQL correctas para lograr los objetivos solicitados en función de los patrones de búsqueda y la estructura de datos.
Comienzas con una plantilla segmentada. Crea un archivo con un editor de Cloud Shell. En la terminal de Cloud Shell, ejecuta el siguiente comando.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
Inserta la plantilla para la búsqueda en lenguaje natural que usamos en el capítulo anterior: "¿Cuántos viajes hicimos en febrero?".
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
Luego, descarga la plantilla a tu computadora desde Cloud Shell con el botón de descarga.
Carga conjuntos de contexto de QueryData
Para usar nuestros conjuntos de contextos de QueryData, debemos subirlos a nuestra base de datos.
Abre AlloyDB Studio. En el panel izquierdo, en la parte inferior, verás QueryData Context y tres puntos.
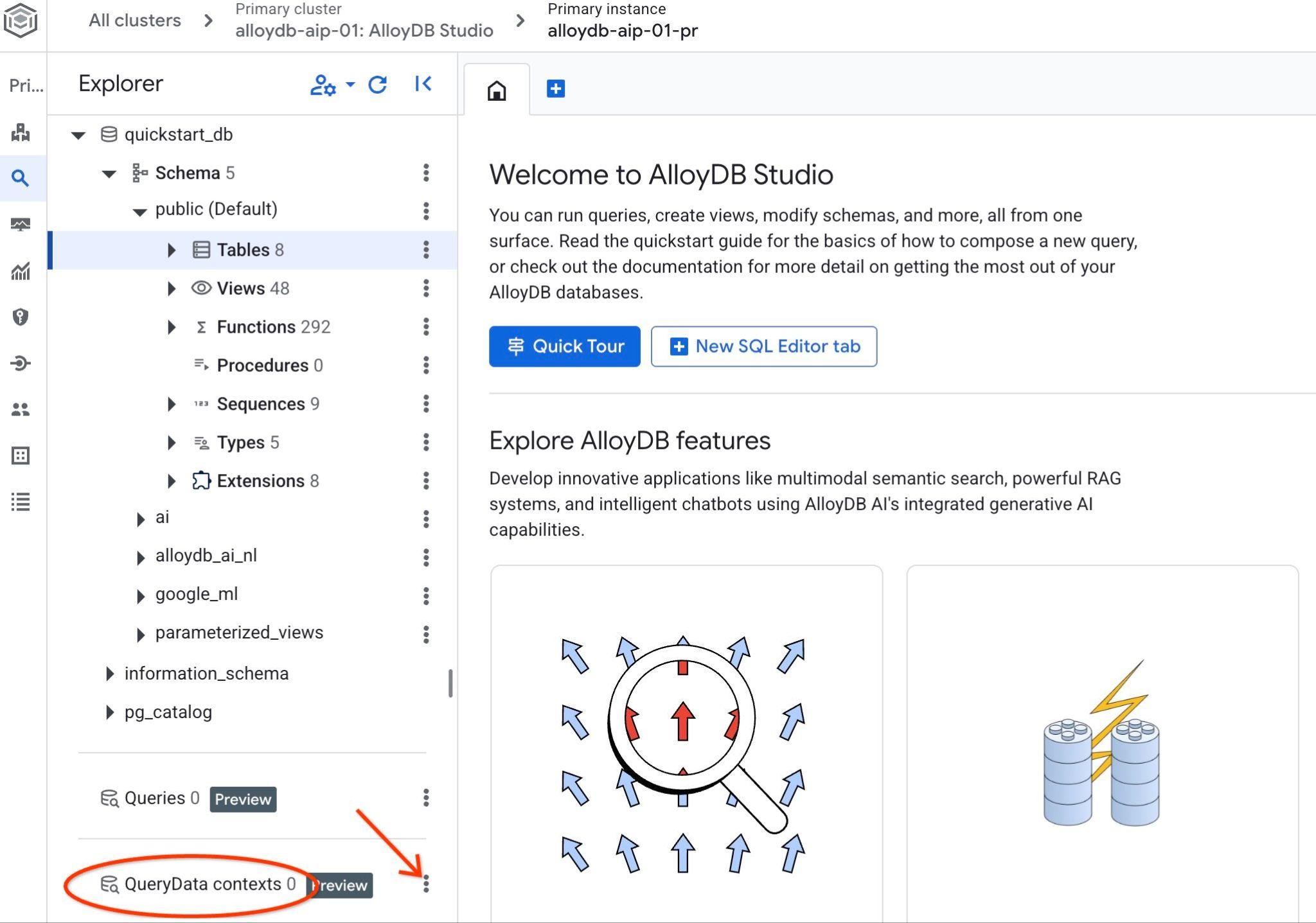
Haz clic en esos tres puntos y elige Crear contexto. Se abrirá un diálogo en el que deberás ingresar
- Nombre:
cymbal_context_set - Descripción:
Cymbal Logistic Query Data - Sube el archivo de contexto: Haz clic en el botón "
Browse" y elige tu archivo JSON con el ContextSet de QueryData.
Cuando presionas el botón de guardar, es posible que la inicialización del almacenamiento del contexto tarde un tiempo si lo haces por primera vez.
Deberías poder ver el contexto descargado y, si haces clic en los tres botones verticales de la derecha, verás las acciones disponibles. En el siguiente capítulo, comenzaremos con la acción "Contexto de prueba".
10. Probar el conjunto de contextos de QueryData
Plantilla de prueba
Usa la acción "Test context" para probar nuestro contexto en AlloyDB Studio. Cuando hagas clic en "Contexto de prueba", se abrirá una nueva ventana del editor de AlloyDB Studio con el título "cymbal_context_set" y la invitación a la generación de SQL de Gemini con el título "Generate SQL using QueryData context: cymbal_context_set ". Haz clic en la generación de SQL y escribe
Hello, can you tell me how many trips we've done in February?
Cuando se genere el código SQL, presiona el botón "Insert".
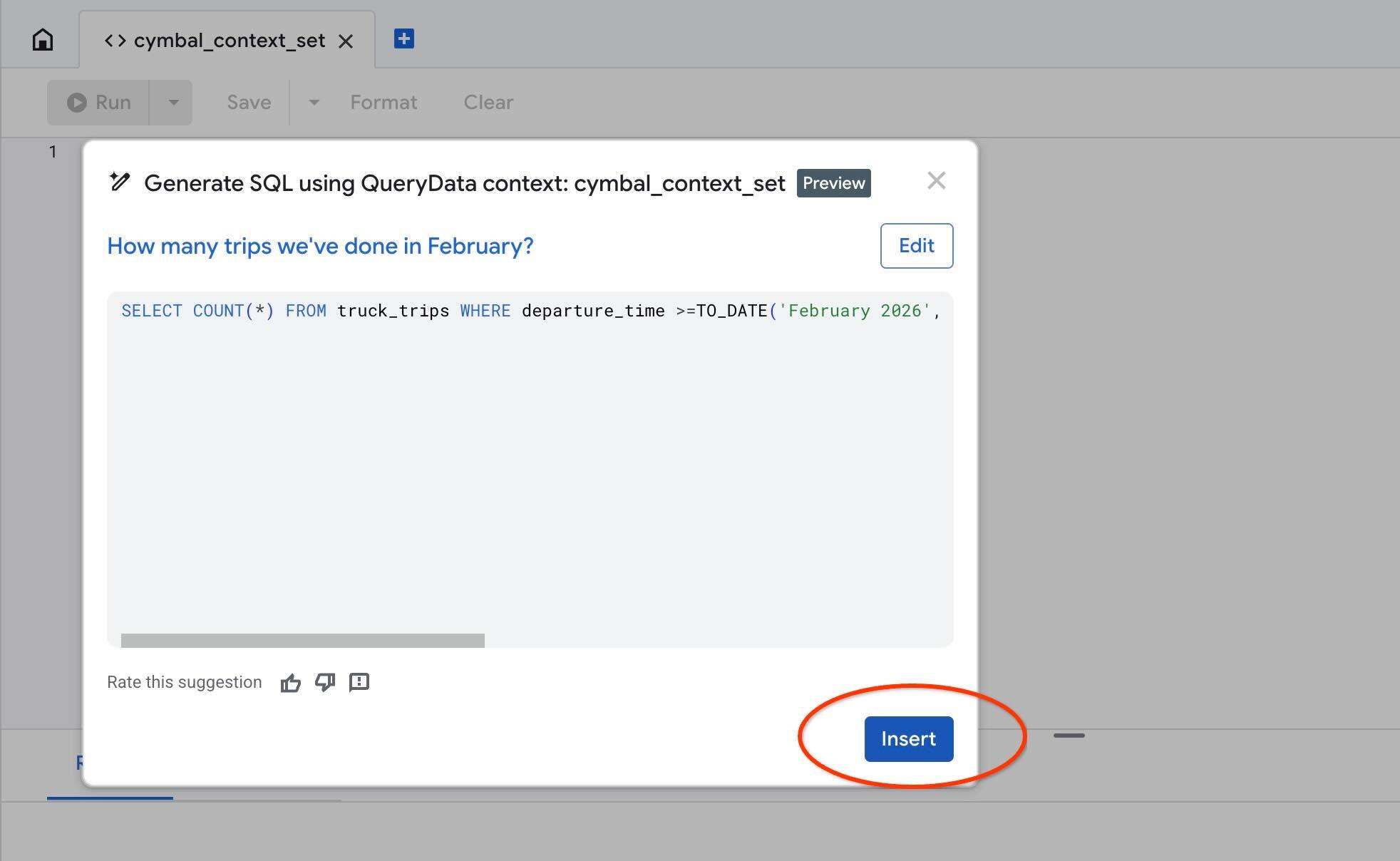
Verás exactamente la misma búsqueda que le hicimos a nuestra plantilla de contexto anteriormente.
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
Intenta reemplazar el mes por "enero" y verifica la sentencia de SQL generada. Usará el mes como parámetro para la intención parametrizada y ajustará automáticamente la sentencia de SQL.
Crea facetas de QueryData
Probamos una plantilla para una búsqueda y funciona cuando sabemos qué tipo de solicitud del usuario esperamos. Sin embargo, a veces es útil guiar solo una parte de una búsqueda, como la condición o el filtro, cuando preferimos que se use un orden determinado o una cláusula en particular para una intención redefinida.
Por ejemplo, si solicitamos que se muestren los datos del "mes pasado", queremos obtener el informe del último mes calendario, desde el día 1 hasta el último día de ese mes, pero no de los últimos 30 días.
Podemos agregar esas facetas como un fragmento de SQL a la configuración de ContextSet junto con la plantilla que agregamos anteriormente. Abre el archivo querydata_cymbal_contextset.json.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
Además, agrega los facets después de las plantillas existentes. El contenido resultante en el archivo debería ser el siguiente
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
Guarda el archivo y súbelo a tu computadora.
Luego, usa la acción de contexto de la búsqueda "Editar contexto" y sube el archivo modificado para reemplazar el conjunto de contexto anterior por el nuevo.
Ahora intenta usar el contexto de prueba nuevamente y genera una sentencia de SQL con la intención "el mes pasado". Por ejemplo, si generas una instrucción SQL para la frase "show trucks trips for the last month"", se usará la condición que proporcionamos como faceta en nuestro archivo cymbal_context.json.
Deberías obtener un resultado similar al siguiente:
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
Ahora, ¿cómo puedes usarlo con los agentes de IA? En el próximo capítulo, haremos que el contexto de datos de consultas esté disponible para los agentes de IA.
11. QueryData con agentes de IA
Usarás el mismo agente de datos, pero ahora el kit de herramientas de MCP se configurará para usar el ContextSet de QueryData.
Prepara y ejecuta MCP Toolbox para bases de datos
Necesitamos un nuevo archivo de configuración para MCP Toolbox que usará la API de Gemini Data Analytics y AlloyDB como fuente de la base de datos.
Ejecuta el siguiente comando en la terminal:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
Cambia al editor y busca el archivo querydata.yaml. El archivo de configuración querydata.yaml se vería de la siguiente manera, excepto el ID del proyecto y la región, que reflejarán tu entorno. Sin embargo, aún debes actualizar el valor de contextSetId y reemplazar el marcador de posición "<add-context-set-id>" por el valor de la consola.
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
Para encontrar el ID de tu ContextSet, haz clic en el botón de edición de tu conjunto de contextos, como se muestra en la imagen.
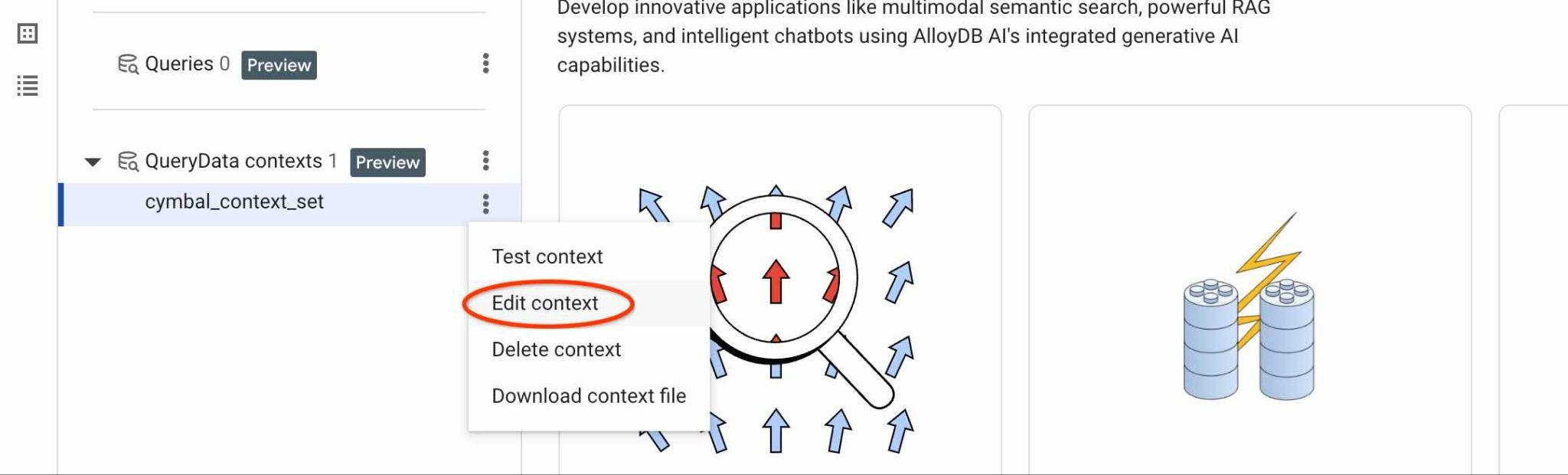
Verás el ID del conjunto de contexto en la parte superior de la nueva pestaña a la derecha.
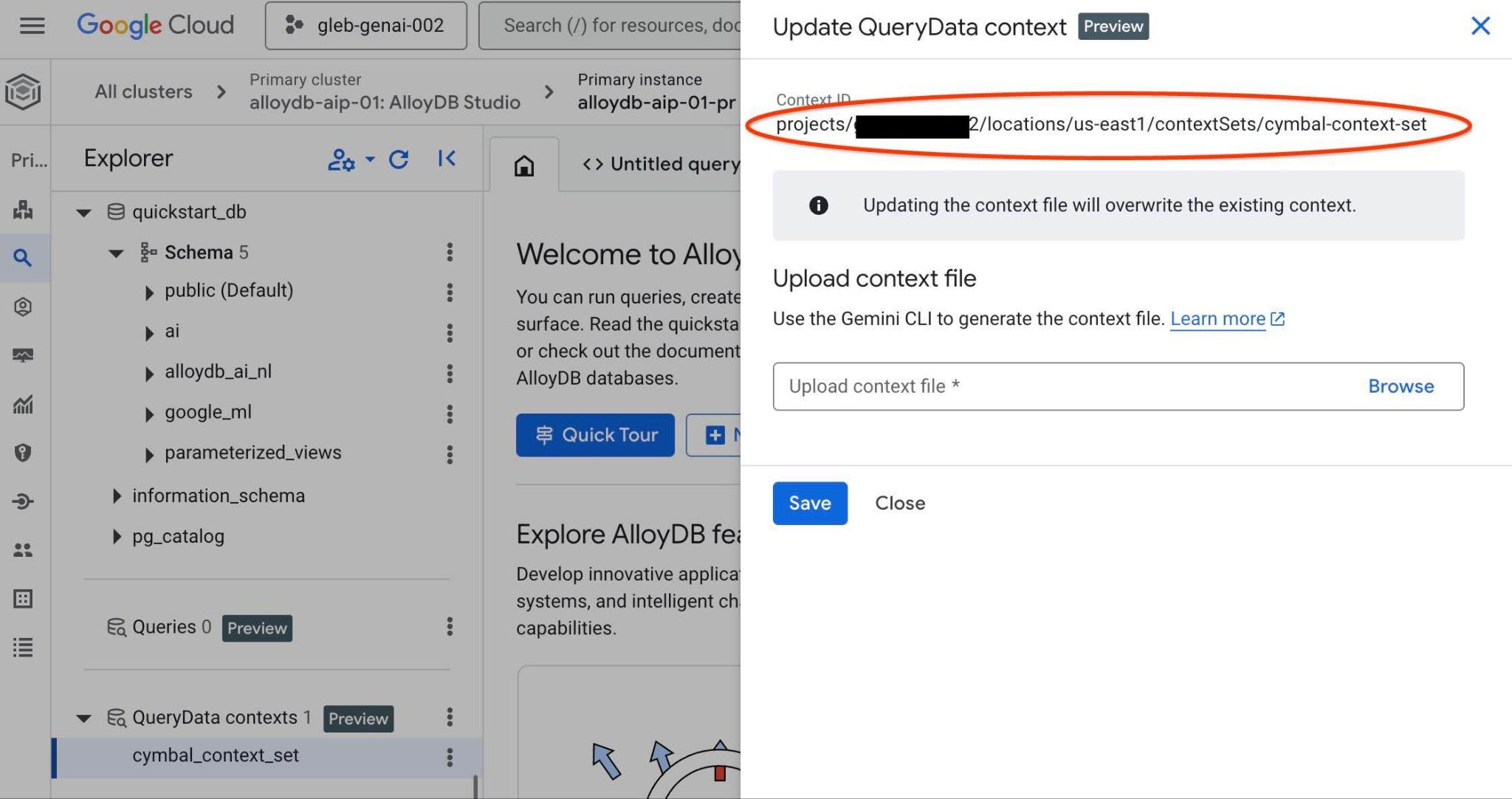
Esa ruta de acceso completa debe reemplazar el marcador de posición "<add-context-set-id>" en el archivo querydata.yaml.
Vuelve a la terminal.
Presiona el botón "+" en la parte superior de la interfaz de Google Cloud Shell para abrir una pestaña nueva.
En la nueva pestaña, cambia al directorio con el archivo binario de la caja de herramientas y el archivo de configuración tools.yaml, y, luego, inicia el servidor de MCP.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
Ejecuta el agente del ADK
En la primera pestaña de Cloud Shell, inicia el agente.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Cuando se inicie, vuelve a hacer clic en el vínculo a http://127.0.0.1:8000 .
Verás la interfaz del agente de vista previa web del ADK, que ya conoces. Publica exactamente la misma búsqueda que la última vez.
Hello, can you tell me how many trips we've done in February?
Y ver el flujo de trabajo del agente Si todo está configurado correctamente, deberías ver algo como lo siguiente.
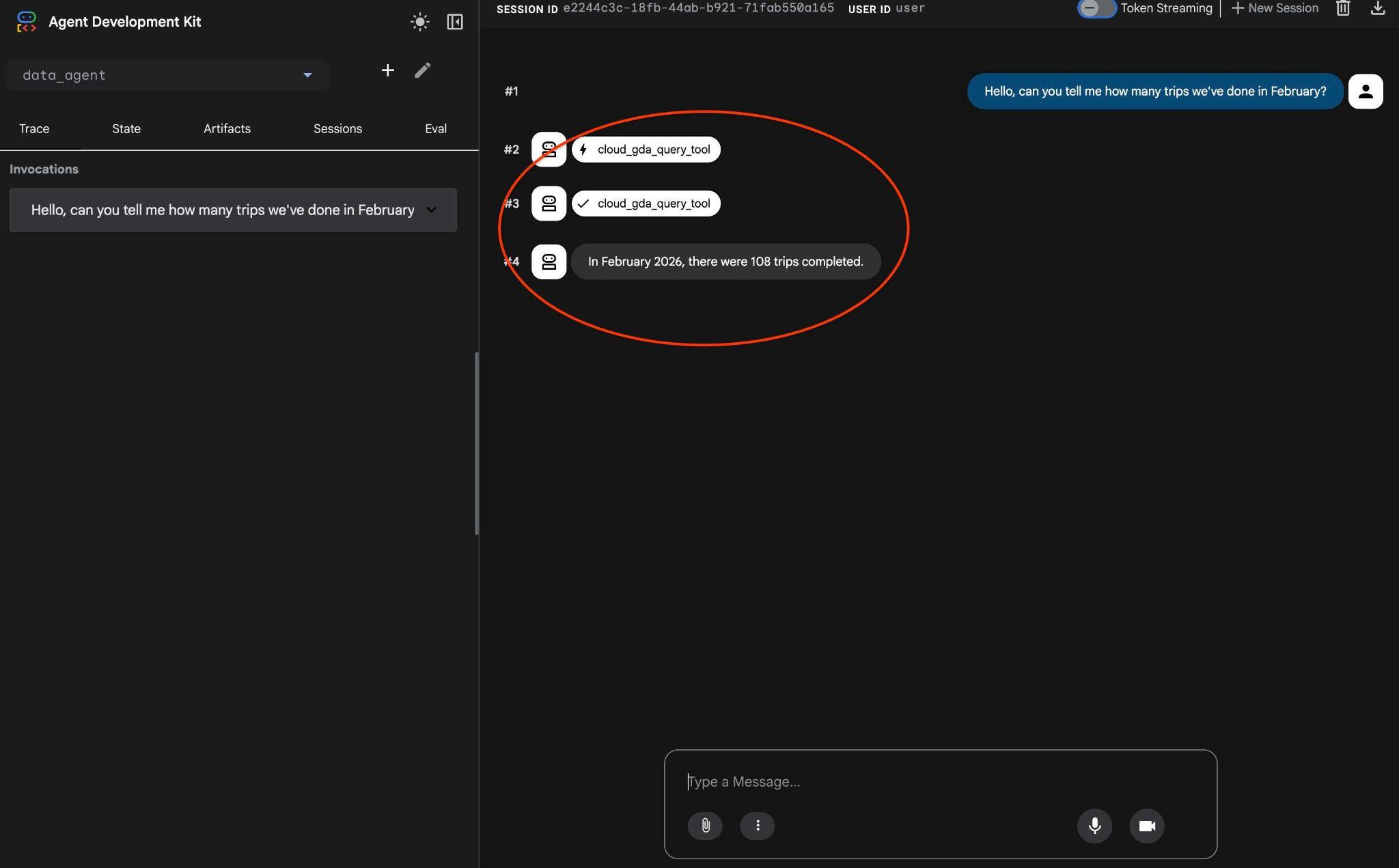
La solicitud que requirió varios turnos la última vez se transformó en una llamada a la herramienta de MCP y se ejecutó con instrucciones SQL predecibles.
Puedes probar las facetas configuradas con una solicitud como la siguiente:
how trucks trips for the last month
En el resultado, si haces clic en la acción de la herramienta, verás que se usó la misma herramienta y se aplicaron facetas para obtener el resultado.
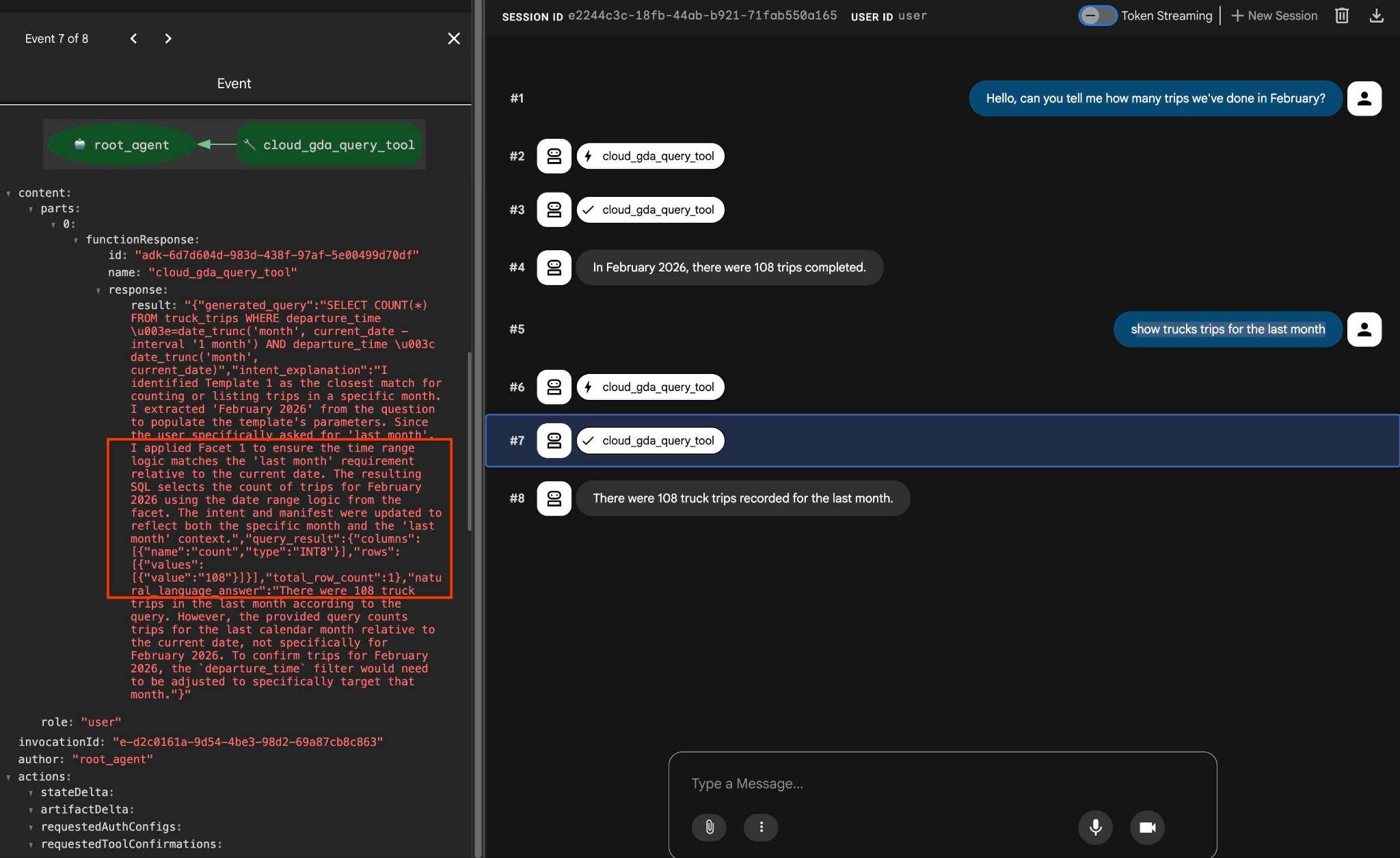
Con esto, finaliza el lab. Espero que hayas podido revisar todos los ejemplos y aprender a usar QueryData para AlloyDB. La tecnología proporcionada ayuda a que tu carga de trabajo de agente y la generación de SQL sean predecibles y confiables.
12. Limpia el entorno
Para evitar cargos inesperados, es una práctica recomendada liberar espacio de los recursos temporales. La forma más confiable es borrar el proyecto en el que probaste el flujo de trabajo. Sin embargo, de manera opcional, puedes limitar tu uso borrando recursos individuales, como AlloyDB.
Cuando termines el lab, destruye las instancias y el clúster de AlloyDB.
Borra el clúster de AlloyDB y todas las instancias
Si usaste la versión de prueba de AlloyDB No borres el clúster de prueba si planeas probar otros labs y recursos con él. No podrás crear otro clúster de prueba en el mismo proyecto.
El clúster se destruye con la opción force que también borra todas las instancias que pertenecen al clúster.
En Cloud Shell, define el proyecto y las variables de entorno si te desconectaste y se perdieron todos los parámetros de configuración anteriores:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Borra el clúster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Resultado esperado en la consola:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Borra las copias de seguridad de AlloyDB
Borra todas las copias de seguridad de AlloyDB del clúster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Resultado esperado en la consola:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
13. Felicitaciones
Felicitaciones por completar el codelab.
Temas abordados
- Cómo crear un clúster de AlloyDB y, luego, importar datos de muestra
- Cómo habilitar la API de acceso a los datos de AlloyDB
- Cómo habilitar QueryData para AlloyDB
- Cómo generar plantillas
- Cómo usar la búsqueda por facetas
- Cómo usar QueryData con agentes de IA
14. Encuesta
Resultado: