
۱. مقدمه
این آزمایشگاه کد، راهنمایی در مورد نحوه شروع کار با QueryData برای AlloyDB و استفاده از آن برای تولید دستورات SQL دقیق و قابل پیشبینی از ورودی زبان طبیعی در برنامههای عاملگرا ارائه میدهد.
پیشنیازها
- درک اولیه از کنسول گوگل کلود
- مهارتهای پایه در رابط خط فرمان و Cloud Shell
آنچه یاد خواهید گرفت
- نحوه ایجاد یک کلاستر AlloyDB و وارد کردن دادههای نمونه
- نحوه فعال کردن API دسترسی به داده AlloyDB
- نحوه فعال کردن QueryData برای AlloyDB
- نحوه تولید قالبها
- نحوه استفاده از جستجوی چندوجهی
- نحوه استفاده از QueryData با عاملهای هوش مصنوعی
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- یک مرورگر وب مانند کروم که از کنسول گوگل کلود و کلود شل پشتیبانی میکند
۲. تنظیمات و الزامات
راهاندازی پروژه
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید .
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
همچنین میتوانید دکمههای G و سپس S را فشار دهید. اگر در کنسول ابری گوگل باشید یا از این لینک استفاده کنید، این توالی، Cloud Shell را فعال میکند.
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
۳. قبل از شروع
فعال کردن API
برای استفاده از AlloyDB ، Compute Engine ، Networking services و Vertex AI ، باید API های مربوط به آنها را در پروژه Google Cloud خود فعال کنید.
در داخل ترمینال Cloud Shell، مطمئن شوید که شناسه پروژه شما تنظیم شده است:
gcloud config get-value project
شما باید tID پروژه خود را در خروجی مشاهده کنید:
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
متغیر محیطی PROJECT_ID را تنظیم کنید:
PROJECT_ID=$(gcloud config get-value project)
فعال کردن تمام سرویسهای لازم:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
خروجی مورد انتظار
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
۴. استقرار AlloyDB
کلاستر AlloyDB و نمونه اولیه آن را ایجاد کنید. میتوانید آن را با استفاده از یک اسکریپت آماده که تمام منابع لازم را مستقر میکند، مستقر کنید یا میتوانید این کار را گام به گام خودتان با دنبال کردن مستندات انجام دهید.
استقرار AlloyDB با استفاده از اسکریپت خودکار
این رویکرد با استفاده از یک اسکریپت خودکار، کلاستر AlloyDB را مستقر میکند و اطلاعات لازم را برای شروع کار با منابع مستقر شده فراهم میکند.
در ترمینال Cloud Shell، دستور را اجرا کنید تا اسکریپت استقرار از مخزن کلون شود.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
اسکریپت استقرار را اجرا کنید.
./deploy_alloydb.sh --public-ip
اجرای اسکریپت مدتی طول میکشد - معمولاً حدود ۵ تا ۷ دقیقه - و کلاستر AlloyDB و یک نمونه اولیه را با IP عمومی و خصوصی مستقر میکند. IP عمومی فقط برای شبکههای مجاز یا با استفاده از پروکسی AlloyDB Auth در دسترس است. میتوانید اطلاعات بیشتر در مورد IP عمومی را در مستندات بخوانید. به عنوان خروجی، اسکریپت باید اطلاعاتی در مورد کلاستر AlloyDB مستقر شده شما ارائه دهد. لطفاً توجه داشته باشید که رمز عبور شما متفاوت خواهد بود - رمز عبور را برای استفادههای بعدی در جایی ثبت کنید .
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
و همچنین میتوانید کلاستر جدید و نمونه اصلی را در کنسول وب مشاهده کنید.
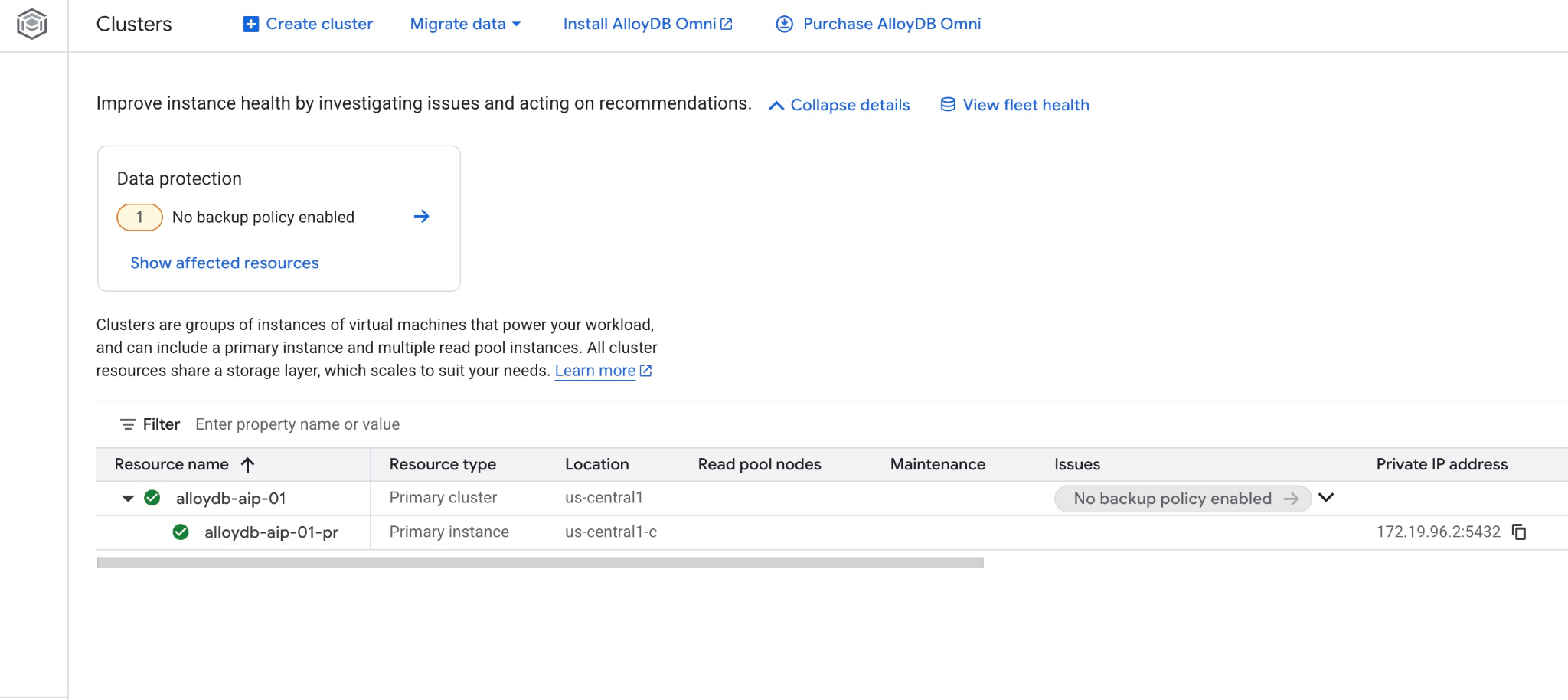
۵. آمادهسازی پایگاه داده
برای استفاده از توابع و عملگرهای هوش مصنوعی، باید ادغام هوش مصنوعی Vertex را فعال کنید، API دسترسی به داده را فعال کنید و یک پایگاه داده برای مجموعه دادههای نمونه ایجاد کنید.
مجوزهای لازم را به AlloyDB اعطا کنید
مجوزهای Vertex AI را به عامل سرویس AlloyDB اضافه کنید.
با استفاده از علامت "+" در بالا، یک تب Cloud Shell دیگر باز کنید.
در تب جدید cloud shell دستور زیر را اجرا کنید:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
فعال کردن API دسترسی به داده
برای اینکه بتوانید از ابزارهای MCP مانند execute_sql استفاده کنید، باید API دسترسی به داده (Data Access API) را در کلاستر AlloyDB فعال کنید.
در همان تب ترمینال، دستور زیر را اجرا کنید.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
فعال کردن احراز هویت IAM
ما قصد داریم از احراز هویت IAM برای ابزارهای عامل خود استفاده کنیم و این امر مستلزم فعال کردن احراز هویت IAM در نمونه و اضافه کردن خود به عنوان کاربر پایگاه داده است. قبل از فعال کردن احراز هویت IAM در سطح نمونه، لطفاً صبر کنید تا مرحله قبلی فعال کردن API دسترسی به داده به پایان برسد. وضعیت نمونه شما باید سبز باشد.
ما از فعال کردن IAM در سطح نمونه شروع میکنیم. در همان تب ترمینال، دستور را اجرا کنید.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
خودتان را به عنوان کاربر AlloyDB اضافه کنید:
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
با اجرای هر یک از دستورهای "exit" در تب، تب را ببندید:
exit
اتصال به استودیوی AlloyDB
در فصلهای بعدی، تمام دستورات SQL که نیاز به اتصال به پایگاه داده دارند، میتوانند در AlloyDB Studio اجرا شوند.
به صفحه خوشهها در AlloyDB برای Postgres بروید.
با کلیک روی نمونه اصلی، رابط کنسول وب را برای خوشه AlloyDB خود باز کنید.
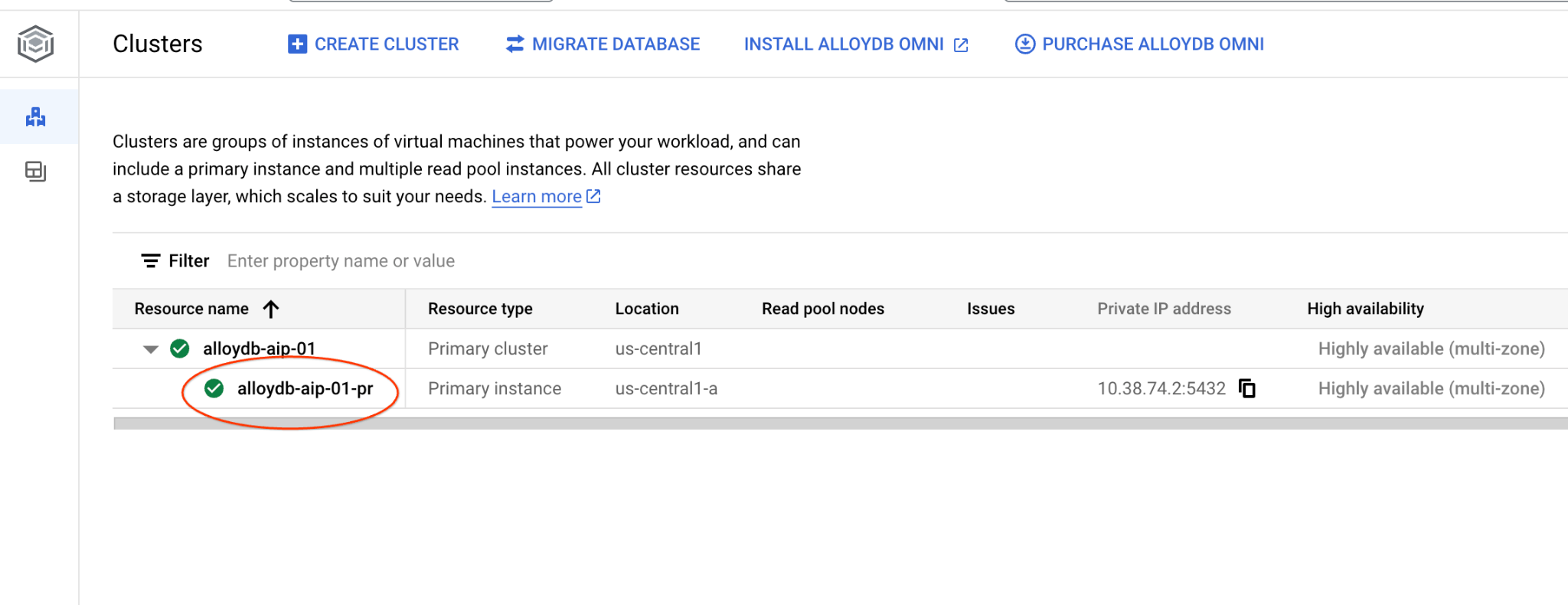
سپس در سمت چپ روی AlloyDB Studio کلیک کنید:
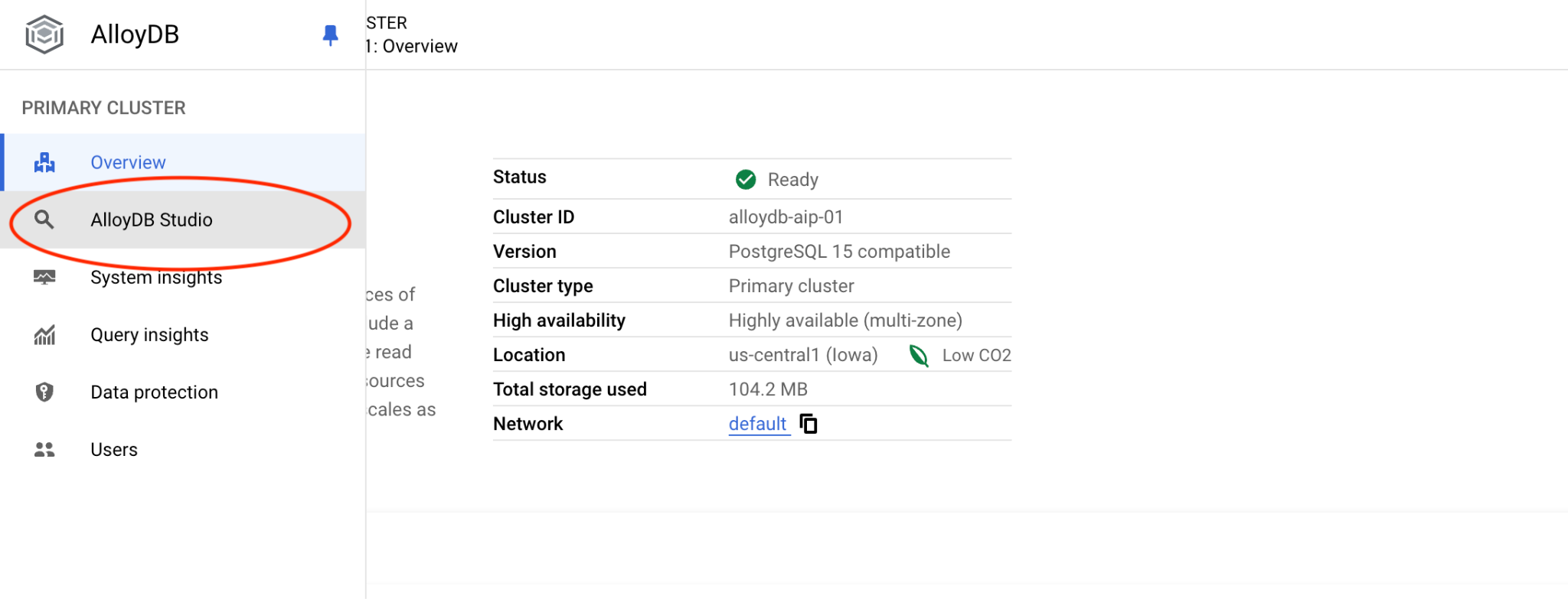
پایگاه داده postgres و احراز هویت IAM را انتخاب کنید. سپس روی دکمه "Authenticate" کلیک کنید.
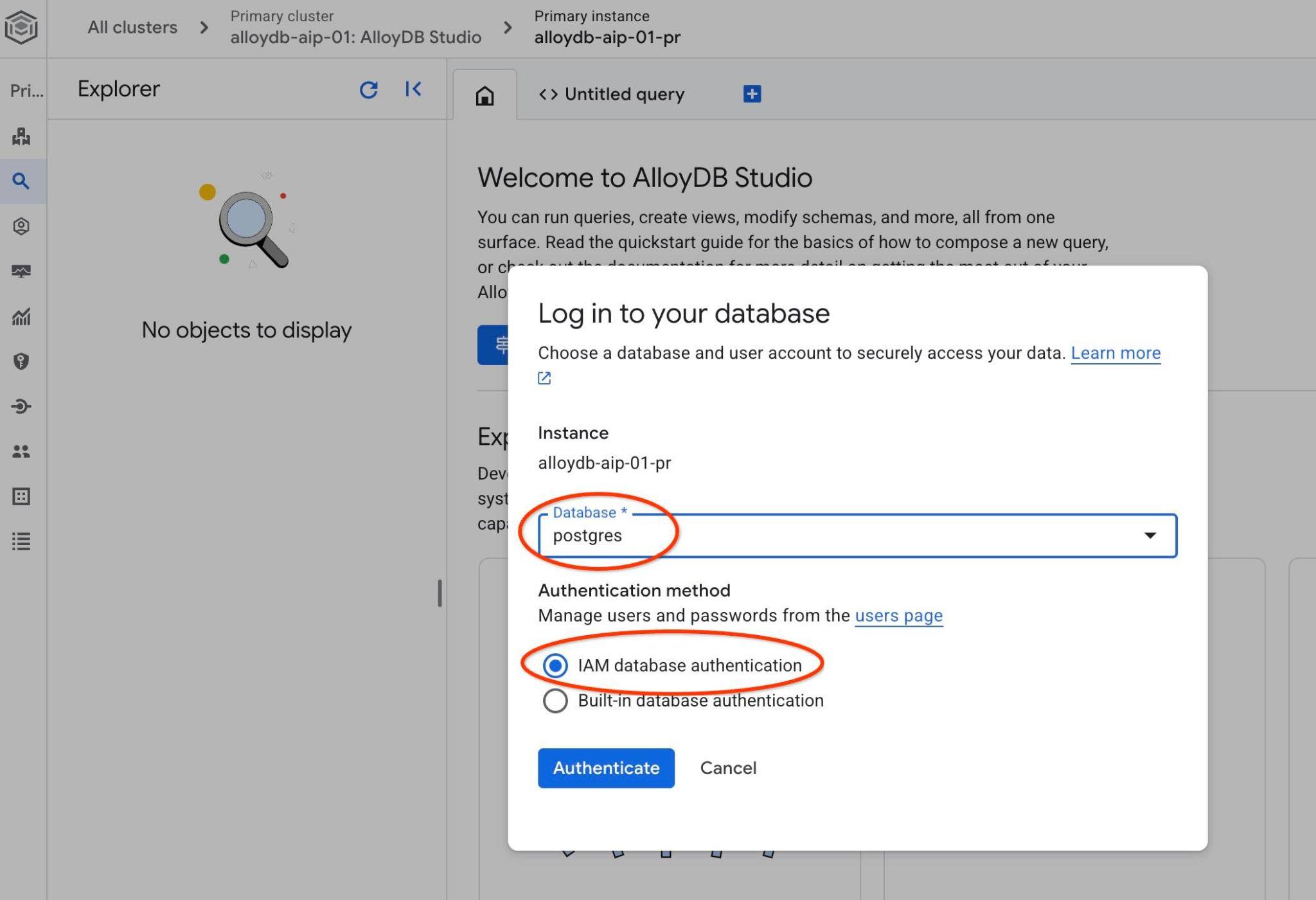
رابط کاربری AlloyDB Studio باز خواهد شد. برای اجرای دستورات در پایگاه داده، روی تب "Untitled Query" در سمت راست کلیک کنید.
رابطی را باز میکند که میتوانید دستورات SQL را در آن اجرا کنید
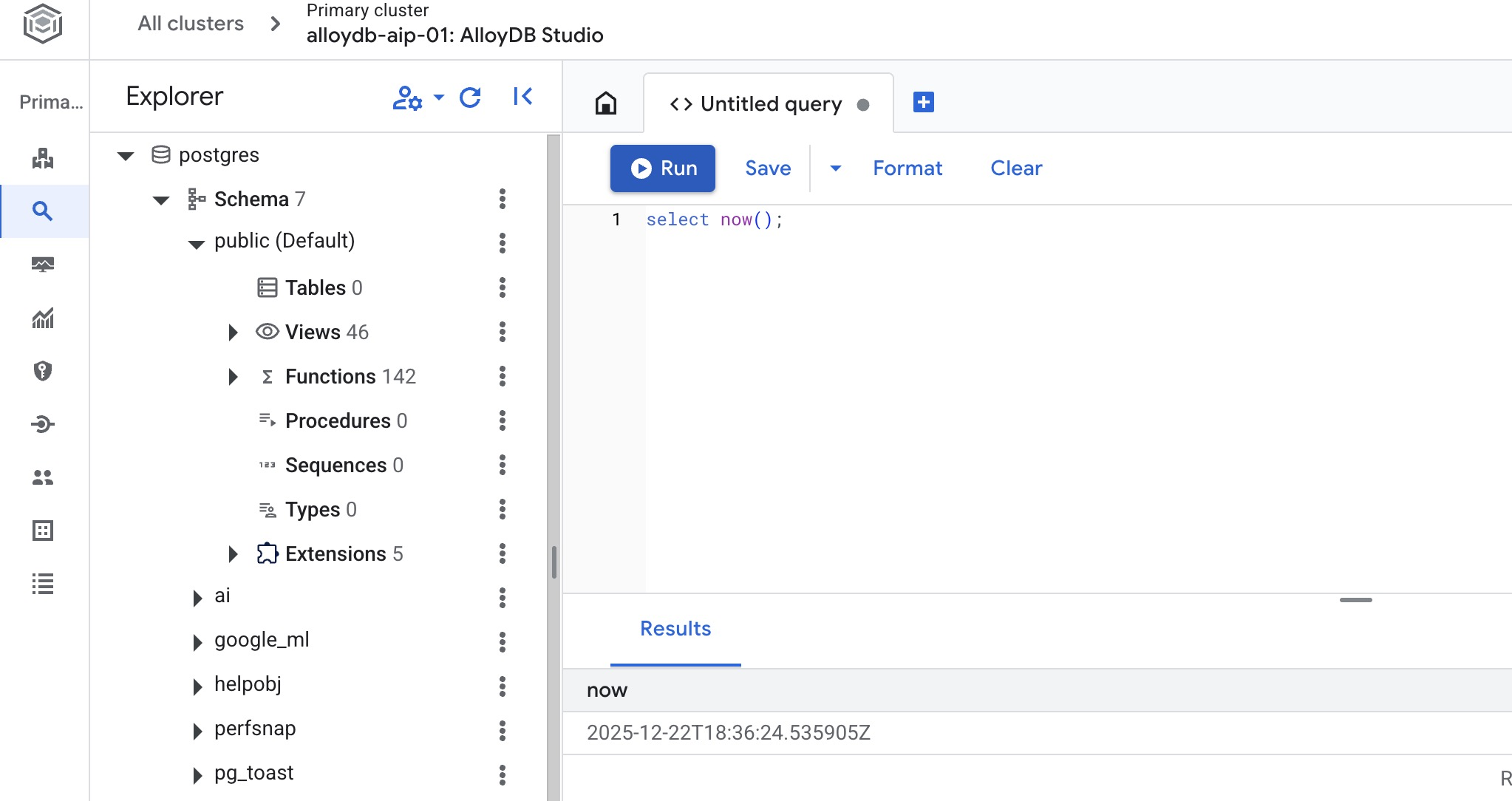
ایجاد پایگاه داده
ایجاد پایگاه داده با شروع سریع
در ویرایشگر استودیوی AlloyDB، دستور زیر را اجرا کنید.
ایجاد پایگاه داده:
CREATE DATABASE quickstart_db
خروجی مورد انتظار:
Statement executed successfully
اتصال به پایگاه دادهی quickstart_db
با اتصال به پایگاه داده، بررسی کنید که آیا پایگاه داده شما ایجاد شده است یا خیر. با استفاده از دکمه تغییر کاربر/پایگاه داده، دوباره به استودیو متصل شوید.
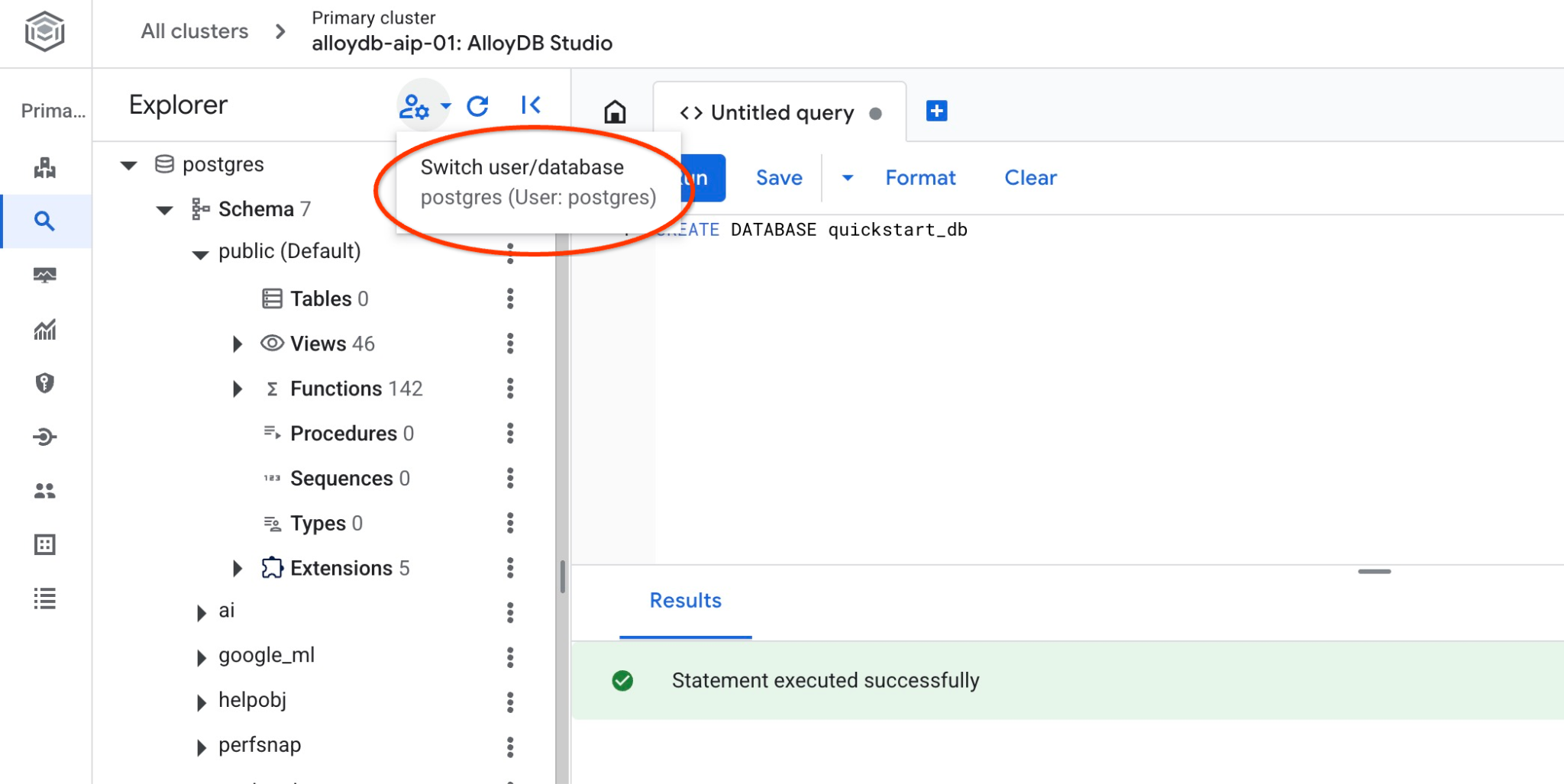
از لیست کشویی، پایگاه داده جدید quickstart_db را انتخاب کنید و از همان احراز هویت IAM استفاده کنید.
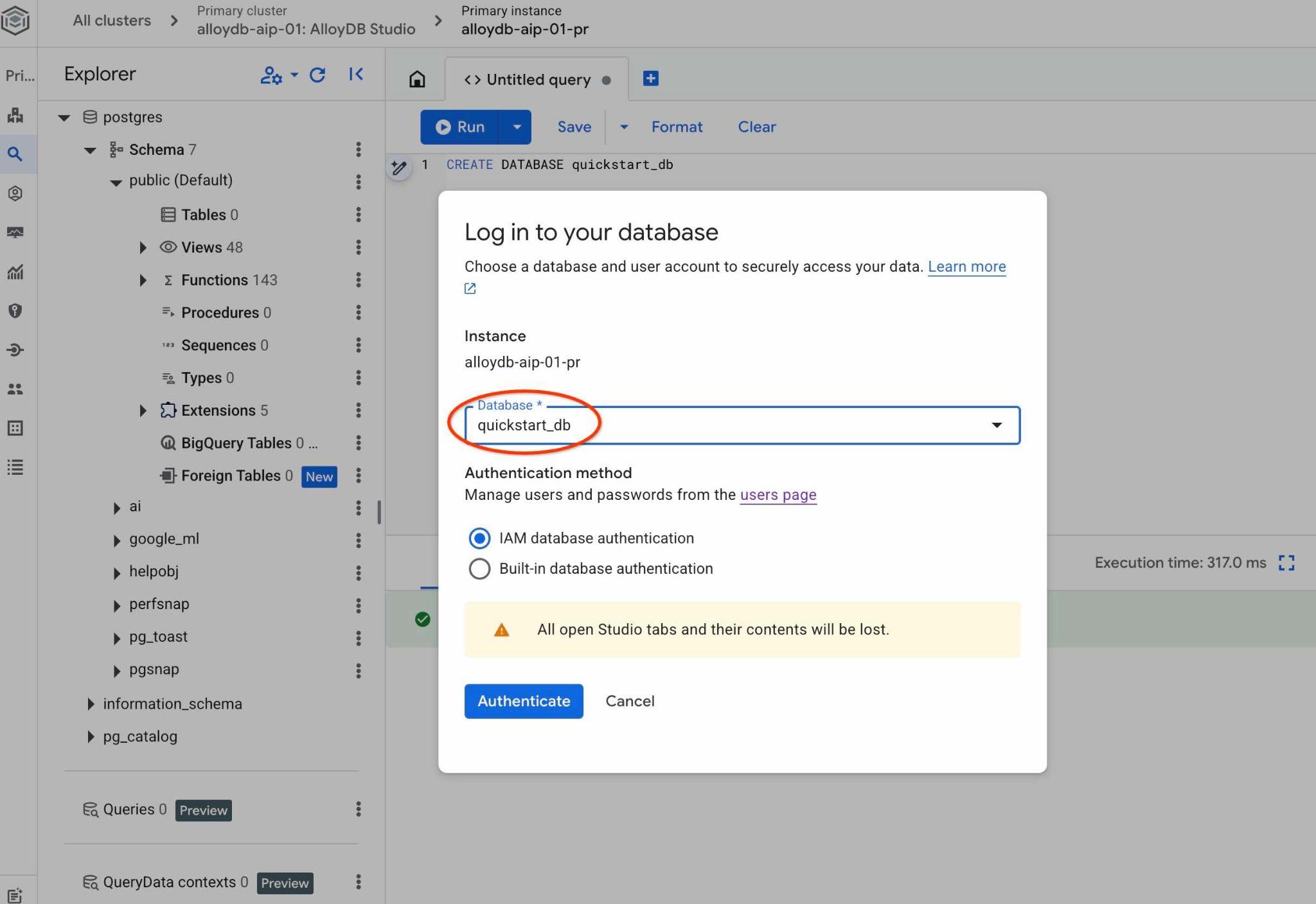
این یک اتصال جدید باز میکند که در آن میتوانید با اشیاء پایگاه داده quickstart_db کار کنید. در آنجا میتوانید طرحواره و دادههای وارد شده خود را بررسی کرده و با مجموعههای زمینه QueryData کار کنید.
۶. دادههای نمونه
حالا باید اشیاء را در پایگاه داده ایجاد کرده و دادهها را بارگذاری کنید. شما قصد دارید از یک مجموعه داده فرضی شرکت حمل و نقل Cymbal استفاده کنید. این مجموعه داده شامل دادههای فرضی در مورد کالاها، کامیونها، درخواستها و سفرهای کامیون به همراه رانندگان فرضی است.
ایجاد سطل ذخیرهسازی
شما قرار است از Google SDK (gcloud) برای وارد کردن دادهها از مخزن کلونشده خود به پایگاه داده AlloyDB استفاده کنید. برای این کار باید یک مخزن ذخیرهسازی ابری ایجاد کنید و به حساب سرویس AlloyDB دسترسی بدهید. همچنین، همانطور که در مستندات توضیح داده شده است، میتوانید این کار را با استفاده از کنسول وب انجام دهید.
در ترمینال Google Cloud Shell دستور زیر را اجرا کنید:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
بارگذاری داده
مرحله بعدی بارگذاری دادهها است. فایل فشرده SQL ما در پوشه مخزن کلون شده قرار دارد. دستور زیر فرض میکند که شما هنگام کلون کردن مخزن در مرحله قبل هنگام ایجاد خوشه AlloyDB، از دایرکتوری خانگی خود به عنوان نقطه شروع استفاده کردهاید.
فایل فشرده SQL dump را در حافظه جدید کپی کنید:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
سپس دادهها را در پایگاه داده quickstart_db بارگذاری کنید:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
این دستور، مجموعه دادههای نمونه را در پایگاه داده quickstart_db بارگذاری میکند. میتوانید جداول و رکوردها را با استفاده از AlloyDB Studio تأیید کنید.
۷. کار با عامل داده
بیایید از یک عامل هوش مصنوعی نمونه که با استفاده از Google ADK برای پایتون ایجاد شده و با استفاده از MCP Toolbox برای پایگاههای داده به نمونه AlloyDB ما متصل میشود، شروع کنیم.
نصب جعبه ابزار MCP برای پایگاههای داده
جعبه ابزار MCP برای پایگاههای داده، یک پروژه متنباز است که پشتیبانی MCP را برای چندین موتور پایگاه داده از جمله AlloyDB برای PostgreSQL ارائه میدهد. میتوانید اطلاعات بیشتر در مورد جعبه ابزار MCP را در مستندات مطالعه کنید.
شما باید آخرین نسخه نرمافزار را برای پلتفرم خود دانلود کنید. برای دریافت آخرین نسخه، صفحه انتشارها را بررسی کنید. مثال زیر نحوه دانلود نسخه ۳۱ از جعبه ابزار MCP را در Cloud Shell نشان میدهد.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
شما باید یک فایل پیکربندی برای جعبه ابزار آماده کنید. ما یک فایل نمونه tools.yaml.example در دایرکتوری فعلی داریم و قصد داریم فایل tools.yaml را با جایگزینی دو متغیر با شناسه پروژه و منطقه آماده کنیم.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
جعبه ابزار MCP را برای پایگاههای داده اجرا کنید
اکنون میتوانید جعبه ابزار MCP را با فایل پیکربندی آمادهشده اجرا کنید.
با فشار دادن دکمه "+" در بالای رابط کاربری Google Cloud Shell خود، یک تب جدید در Google Cloud Shell خود باز کنید.
در تب جدید، به دایرکتوری حاوی فایل باینری جعبه ابزار و فایل پیکربندی tools.yaml بروید و سرور MCP را اجرا کنید.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
شما باید در خروجی عبارت "Server ready to service!" مشابه زیر را ببینید.
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
کد منبع عامل را بررسی کنید
در اولین تب در پوشه مخزن کلون شده، کد عامل را با استفاده از ویرایشگر پوسته ابری گوگل (Google Cloud Shell) مرور کنید.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
میتوانید در agent ببینید که ما بخشی برای سرور Google Cloud MCP برای AlloyDB داریم. ما یک نقطه پایانی به عنوان MCP_SERVER_URL، احراز هویت، شناسه پروژه و اضافه کردن آن به مجموعه ابزار MCP ارائه میدهیم.
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
و در کد عامل، مجموعه ابزار MCP به عنوان پارامتر tools برای عامل گنجانده شده است. همچنین نامهای خوشه و نمونه، منطقه و پایگاه داده به عنوان متغیرهایی برای اعلان عامل وجود دارد.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
پس از بررسی کد، با فشار دادن دکمه «باز کردن ترمینال» در سمت راست بالای پنجره ویرایشگر، به ترمینال برگردید.
عامل را شروع کنید
اکنون میتوانید با استفاده از رابط وب Google ADK، عامل را در حالت تعاملی راهاندازی کنید. رابط وب ADK روشی مناسب برای آزمایش و عیبیابی گردش کار عاملها فراهم میکند.
ابتدا اجازه دهید تمام بستههای مورد نیاز برای پایتون را با استفاده از مدیر بسته uv نصب کنیم.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
وقتی همه بستهها نصب شدند، باید یک فایل .env را به دایرکتوری agent اضافه کنید تا آن را طوری هدایت کنید که برای همه ارتباطات با مدلهای هوش مصنوعی از Vertex AI استفاده کند.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
سپس میتوانید عامل را شروع کنید
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
شما باید خروجی مانند زیر را با نقطه پایانی مانند http://127.0.0.1:8000 ببینید.
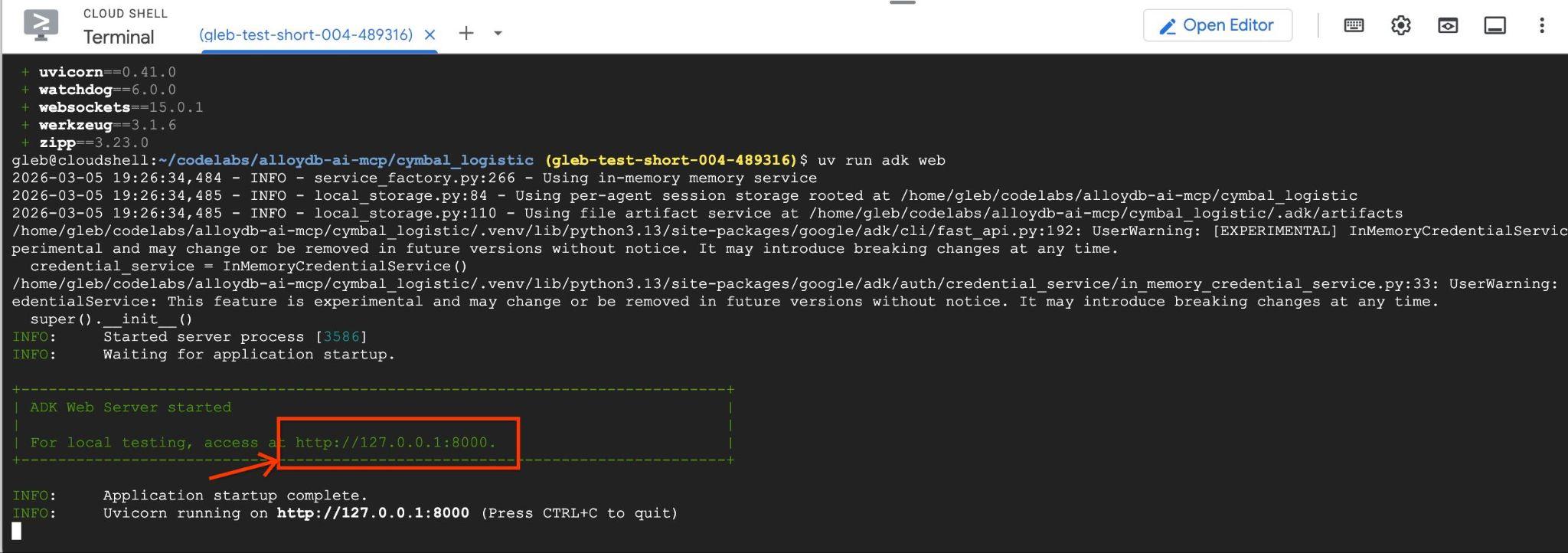
میتوانید روی آن URL در پوسته ابری کلیک کنید و یک پنجره پیشنمایش در یک برگه مرورگر جداگانه باز میشود که در آن میتوانید data_agent از لیست کشویی سمت چپ انتخاب کنید.
در رابط وب ADK میتوانید سوالات خود را در پایین سمت راست پست کنید و جریان کامل اجرا، شامل ردپاهای هر مرحله را در سمت راست مشاهده کنید.
۸. تست NL2SQL بدون QueryData برای AlloyDB
نماینده به شما اجازه میدهد تا با استفاده از زبان طبیعی، سوالات خود را به صورت رایگان بپرسید و نماینده از جعبه ابزار MCP برای پایگاههای داده به عنوان ابزاری برای پاسخ به سوالات استفاده خواهد کرد. سوالات در پایین سمت راست قرار میگیرند و پاسخ به همراه تمام فراخوانیهای ابزارها در بالا ظاهر میشود.
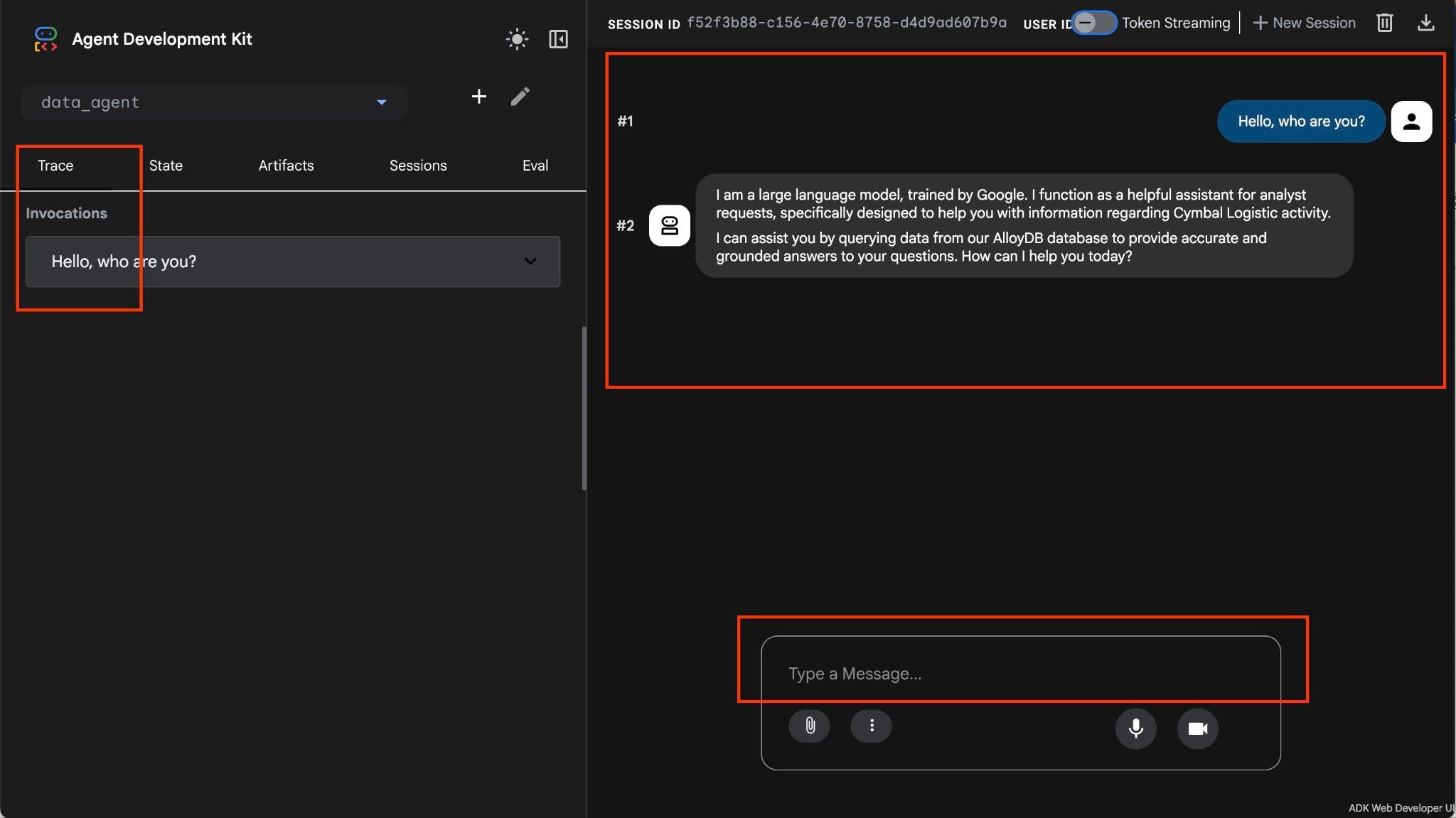
شما با دادههای عملیاتی یک شرکت حمل و نقل کار میکنید که اطلاعاتی در مورد درخواستهای حمل و نقل، کامیونها، رانندگان و سفرهای انجام شده توسط رانندگان دارد. اولین سوال در مورد تعداد سفرهای انجام شده در فوریه 2026 است.
در قسمت ورودی در پایین سمت راست، عبارت زیر را تایپ کنید و اینتر را بزنید.
Hello, can you tell me how many trips we've done in February?
عامل با اجرای فراخوانیهای متعدد ابزار برای شناسایی جداول مناسب در طرحواره با استفاده از list_cymbal_logistics_schemas_tool و execute_sql_tool ، چندین دستور SQL را برای دریافت دادههای مناسب اجرا میکند.
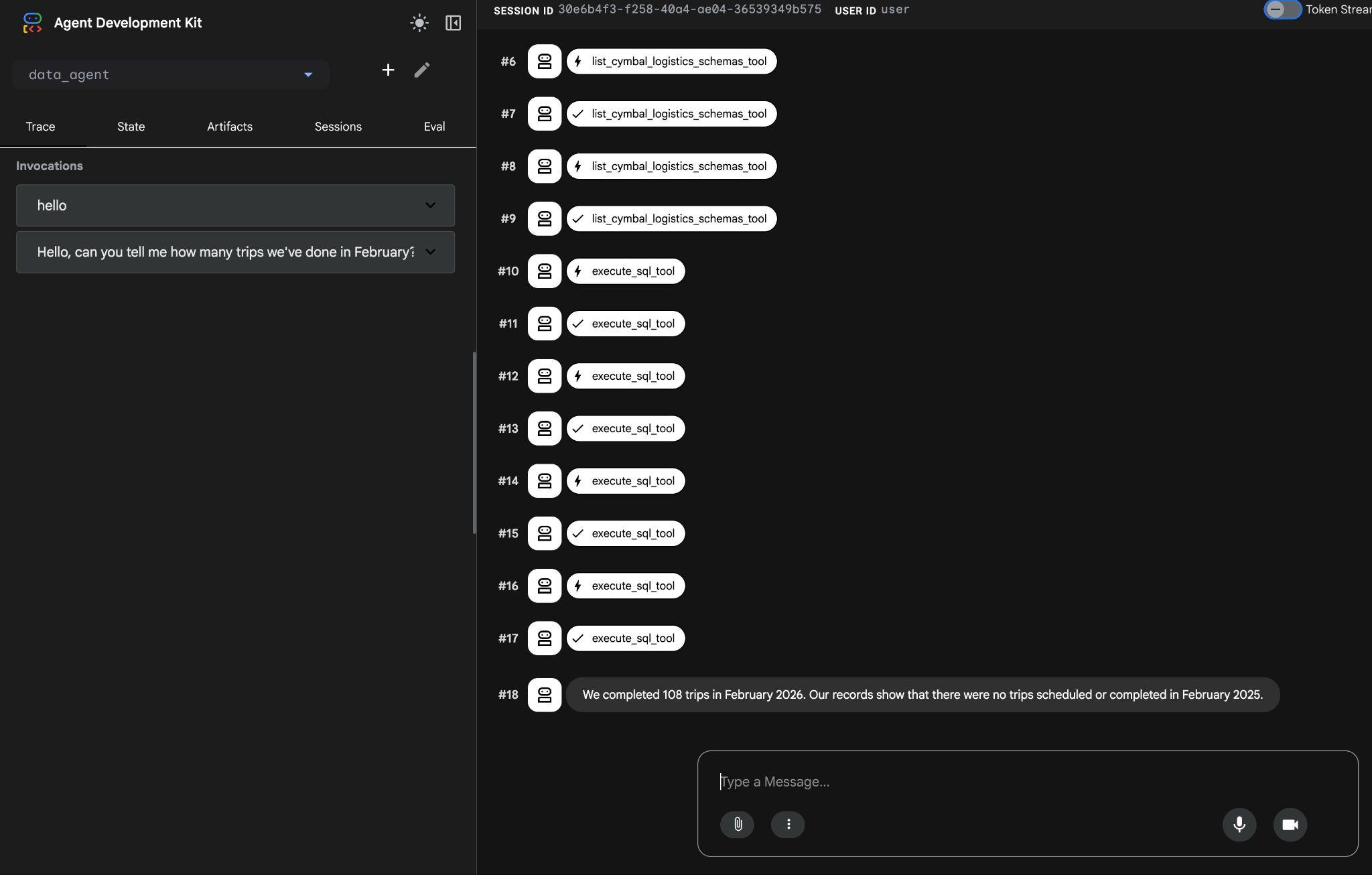
در نهایت، پس از ساخت کوئری مناسب و اجرای آن روی پایگاه داده، نتیجه صحیح را تولید خواهد کرد.
ما در فوریه ۲۰۲۶، ۱۰۸ سفر را به پایان رساندیم. سوابق ما نشان میدهد که در فوریه ۲۰۲۵ هیچ سفری برنامهریزی یا تکمیل نشده است.
شما میتوانید با کلیک روی اجرای ابزار، ببینید که هر فراخوانی ابزار چه کاری انجام میدهد. برای مثال، در اینجا کوئری اجرا شده برای دریافت نتایج ما آمده است.
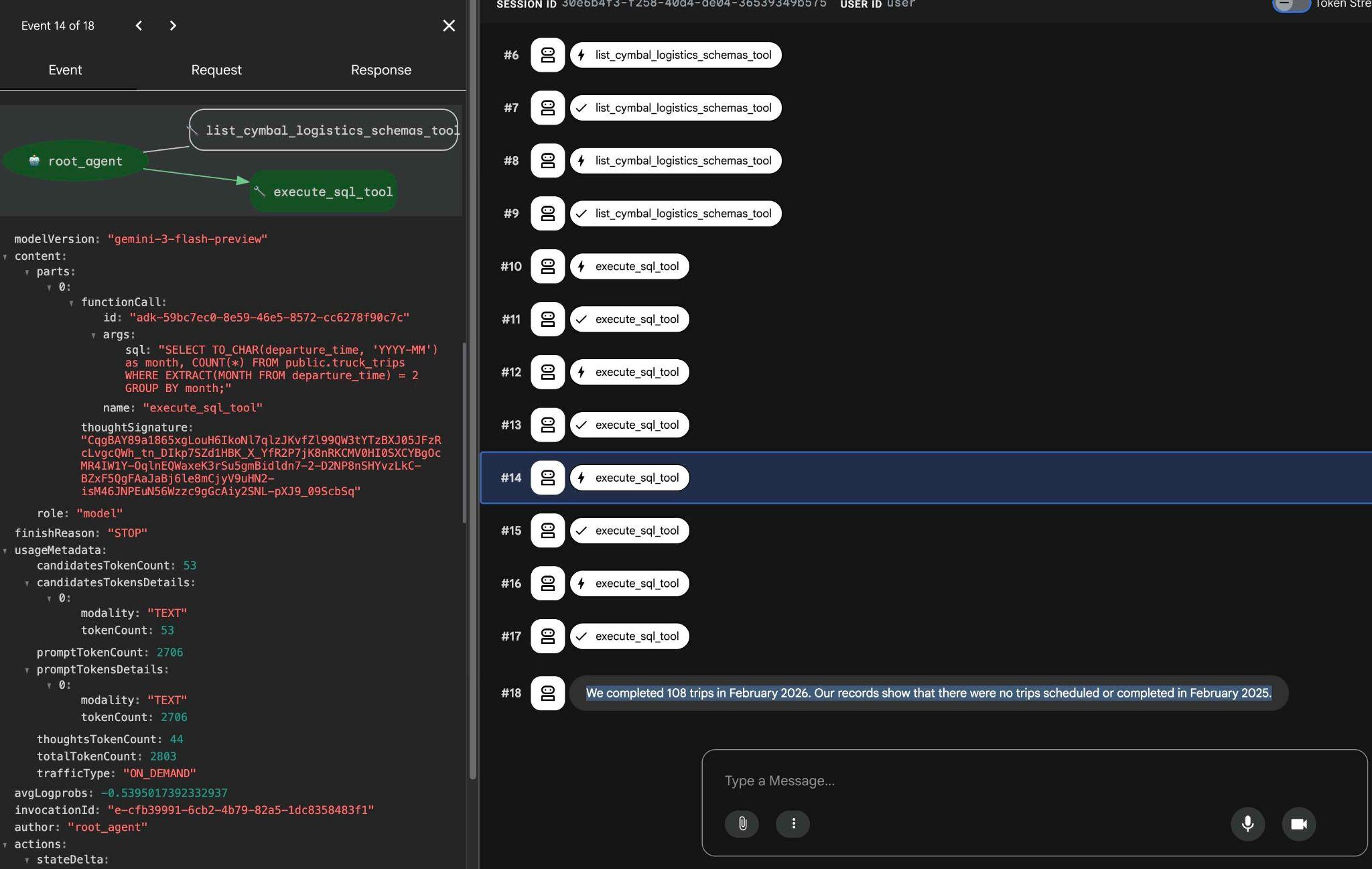
درخواستهای سادهی دیگری را با استفاده از رابط وب ADK امتحان کنید و ببینید که چگونه کوئریهای مختلف را برای دستیابی به نتایج اجرا میکند.
با فشردن ctrl+c در ترمینال، عامل را متوقف کنید. میتوانید با رابط وب ADK، تب مرورگر را ببندید.
همچنین میتوانید با فشردن همان کلیدهای میانبر ctrl+c جعبه ابزار MCP را در تب دوم متوقف کرده و تب دوم را ببندید.
در مرحله بعدی، ما زمینه QueryData را برای بهبود پاسخ و عملکرد NL2SQL خود ایجاد خواهیم کرد.
۹. ساخت ContextSet مربوط به QueryData
در مرحله قبل مشاهده کردید که مدل هوش مصنوعی چندین فراخوانی به طرح اطلاعاتی پایگاه داده انجام میداد تا بفهمد از چه جدول و ستونهایی باید برای ساخت کوئری SQL استفاده کند. برای بهبود عملکرد، دقت و قابل پیشبینیتر کردن نتیجه، زمینه QueryData شما را اضافه خواهیم کرد که مشخص میکند چه کوئری باید در پاسخ به یک درخواست خاص اجرا شود.
ایجاد قالبهای هدفمند
QueryData ContextSet یک فایل JSON با قالبها و جنبههای پرسوجو است که دادهها و دستورالعملهای لازم را برای مدل هوش مصنوعی فراهم میکند تا از پرسوجوی SQL یا بخشهای پرسوجوی SQL صحیح برای دستیابی به اهداف درخواستی بر اساس الگوهای پرسوجو و ساختار داده استفاده کند.
شما از یک الگوی هدفمند شروع میکنید. با استفاده از ویرایشگر Cloud Shell یک فایل ایجاد میکنید. در ترمینال Cloud Shell آن را اجرا میکنید.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
و الگوی مربوط به پرسش زبان طبیعی که در فصل قبل استفاده کردیم را وارد کنید - "در ماه فوریه چند سفر انجام دادهایم؟"
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
سپس با استفاده از دکمه دانلود، قالب را از Cloud Shell روی رایانه خود دانلود کنید.
بارگذاری مجموعههای زمینهی QueryData
برای استفاده از مجموعههای زمینهی QueryData، باید آنها را در پایگاه داده آپلود کنیم.
AlloyDB Studio را باز کنید. در پنل سمت چپ در پایین، QueryData Context و سه نقطه را خواهید دید.
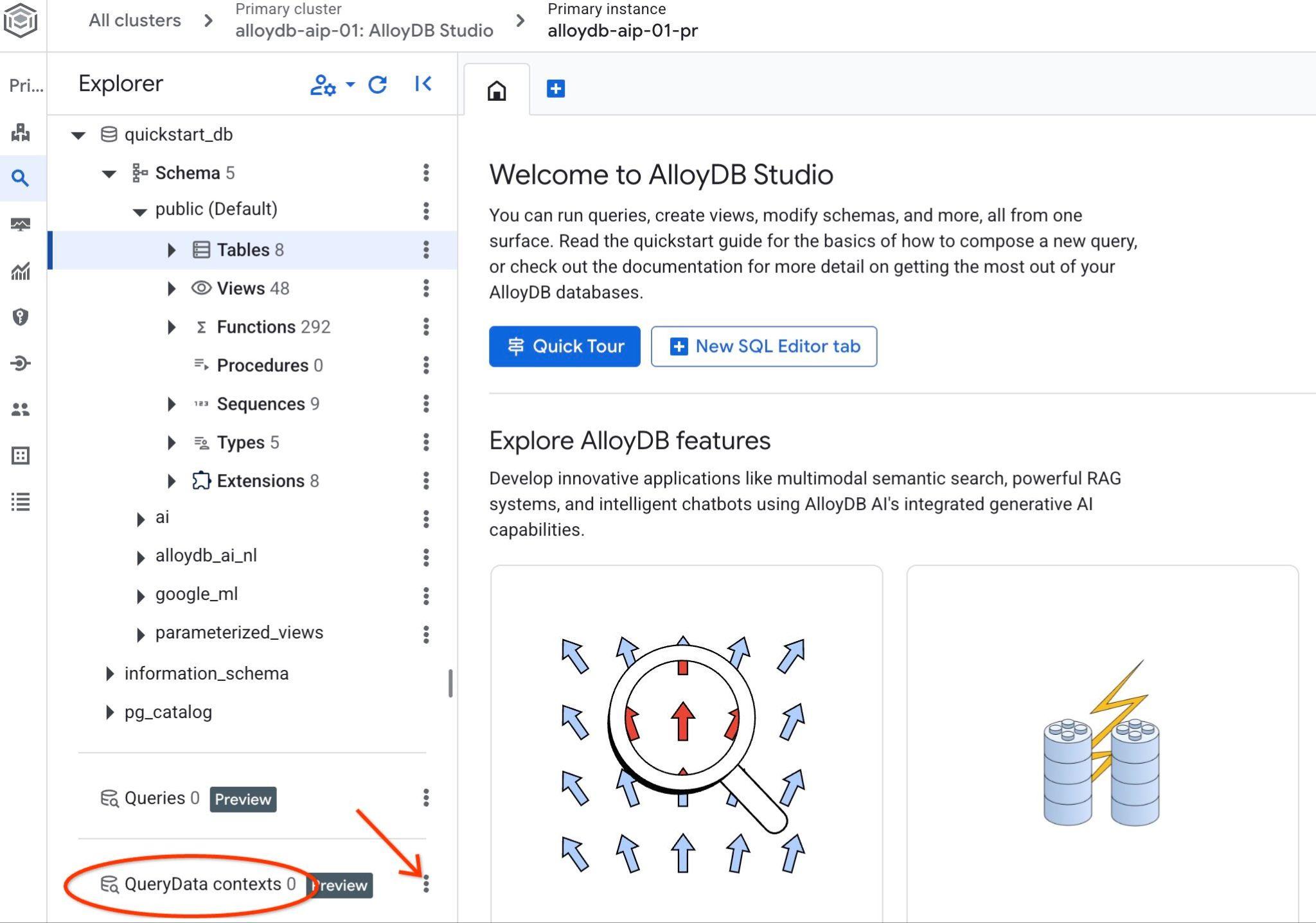
روی آن سه نقطه کلیک کنید و Create Context را انتخاب کنید. این کار یک کادر محاورهای باز میکند که در آن میتوانید متن مورد نظر را وارد کنید.
- نام:
cymbal_context_set - شرح:
Cymbal Logistic Query Data - آپلود فایل زمینه: روی دکمهی «
Browse» کلیک کنید و فایل JSON خود را به همراه QueryData ContextSet انتخاب کنید.
وقتی دکمه ذخیره را فشار میدهید، اگر برای اولین بار این کار را انجام دهید، ممکن است مقداری طول بکشد تا فضای ذخیرهسازی زمینه راهاندازی شود.
شما باید بتوانید context دانلود شده را ببینید و اگر روی سه دکمه عمودی در سمت راست کلیک کنید، اکشنهای موجود را خواهید دید. در فصل بعد از اکشن "Test context" شروع خواهیم کرد.
۱۰. مجموعه زمینه QueryData تست
الگوی آزمون
از اکشن « Test context » برای آزمایش context در AlloyDB Studio استفاده کنید. وقتی روی «Test context» کلیک میکنید، یک پنجره ویرایشگر AlloyDB Studio جدید با عنوان « cymbal_context_set » و دعوتنامه تولید SQL در Gemini با عنوان « Generate SQL using QueryData context: cymbal_context_set » باز میشود. روی تولید SQL کلیک کنید و تایپ کنید
Hello, can you tell me how many trips we've done in February?
و وقتی SQL تولید شد، دکمهی « Insert » را فشار دهید.
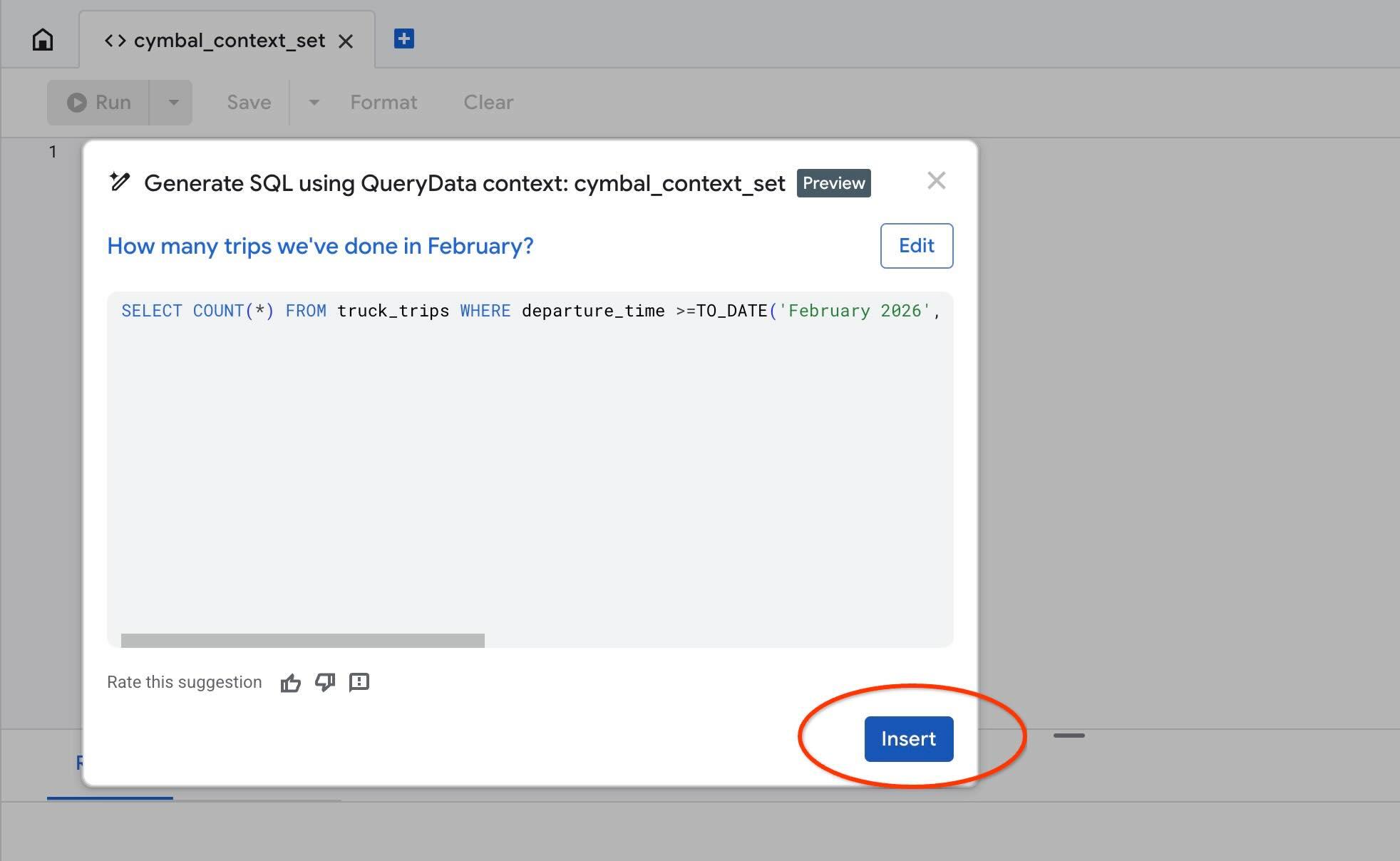
دقیقاً همان کوئری را که قبلاً در الگوی context خود قرار دادیم، مشاهده خواهید کرد.
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
سعی کنید ماه را با "ژانویه" جایگزین کنید و دستور SQL تولید شده را بررسی کنید. از ماه به عنوان پارامتری برای intent پارامتری استفاده میکند و به طور خودکار دستور SQL را تنظیم میکند.
ساخت وجههای QueryData
ما یک الگو برای یک پرسوجو امتحان کردیم و وقتی میدانیم چه نوع درخواستی از کاربر انتظار داریم، کار میکند. اما گاهی اوقات، وقتی ترجیح میدهیم ترتیب یا بند خاصی برای یک هدف تعریفشدهی جدید استفاده شود، مفید است که فقط بخشی از پرسوجو مانند شرط یا فیلتر را هدایت کنیم.
برای مثال، اگر بخواهیم دادههای مربوط به «ماه گذشته» را برگردانیم، میخواهیم گزارش مربوط به آخرین ماه تقویمی را از اول تا آخرین روز آن ماه دریافت کنیم، اما نه برای ۳۰ روز گذشته.
میتوانیم چنین جنبههایی را به عنوان یک قطعه کد SQL به پیکربندی ContextSet همراه با الگوی قبلی اضافه شده خود اضافه کنیم. فایل querydata_cymbal_contextset.json را باز کنید.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
و سطوح را بعد از قالبهای موجود اضافه کنید. محتوای حاصل در فایل باید به صورت زیر باشد.
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
فایل را ذخیره کرده و آن را در رایانه خود بارگذاری کنید.
سپس از اکشن «ویرایش متن» برای جستجوی متن استفاده کنید و فایل اصلاحشده را آپلود کنید تا متن جدید جایگزین متن قدیمی شود.
حالا دوباره سعی کنید از زمینه تست استفاده کنید و یک دستور SQL با استفاده از intent "ماه گذشته" تولید کنید. برای مثال، اگر یک SQL برای عبارت " show trucks trips for the last month" تولید کنید، از شرطی که ما به عنوان یک facet در فایل cymbal_context.json ارائه کردهایم، استفاده خواهد کرد.
شما باید چیزی شبیه به شکل زیر دریافت کنید:
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
حالا، چگونه میتوانید از آن با عاملهای هوش مصنوعی استفاده کنید؟ در فصل بعدی، زمینهی دادههای پرسوجو را برای عاملهای هوش مصنوعی در دسترس قرار میدهیم.
۱۱. کوئری دیتا با عاملهای هوش مصنوعی
شما از همان Data Agent استفاده خواهید کرد، اما اکنون جعبه ابزار MCP برای استفاده از QueryData ContextSet پیکربندی شده است.
آمادهسازی و اجرای جعبه ابزار MCP برای پایگاههای داده
ما به یک فایل پیکربندی جدید برای جعبه ابزار MCP نیاز داریم که قرار است از API تجزیه و تحلیل دادههای Gemini و AlloyDB به عنوان منبع پایگاه داده استفاده کند.
در ترمینال اجرا کنید:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
به ویرایشگر بروید و فایل querydata.yaml را پیدا کنید. فایل پیکربندی querydata.yaml به شکل زیر خواهد بود، به جز شناسه پروژه و منطقه که منعکس کننده محیط شما خواهد بود. اما شما هنوز باید مقدار contextSetId خود را بهروزرسانی کنید و مقدار "<add-context-set-id>" را از کنسول جایگزین کنید.
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
برای یافتن شناسه ContextSet خود، همانطور که در تصویر نشان داده شده است، روی دکمه ویرایش مجموعه زمینه خود کلیک کنید.
شناسه مجموعه زمینه را در بالای برگه جدید سمت راست مشاهده خواهید کرد.
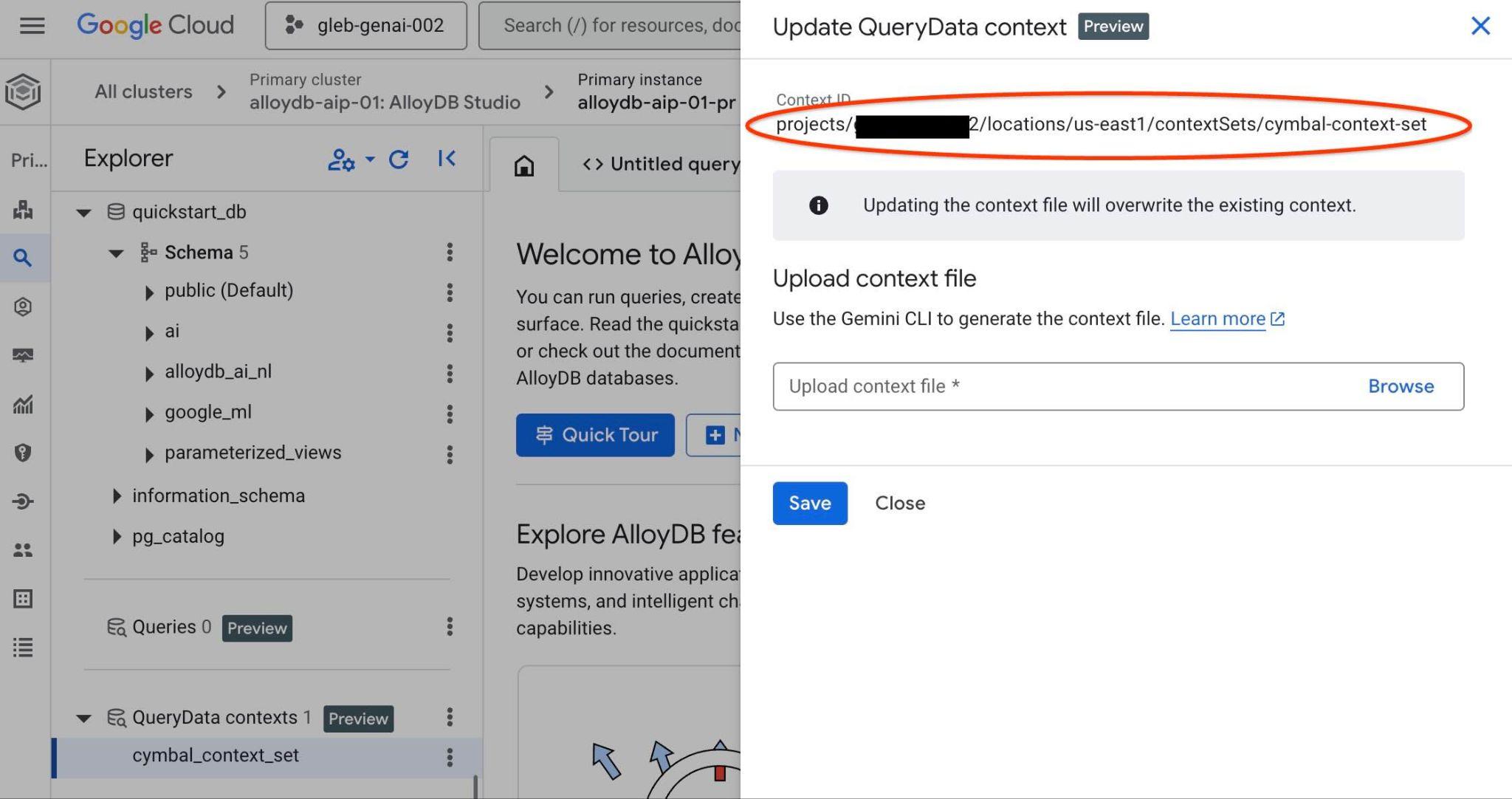
آن مسیر کامل باید جایگزین عبارت "<add-context-set-id>" در فایل querydata.yaml شود.
دوباره به ترمینال برگردید.
با فشار دادن دکمه "+" در بالای رابط کاربری Google Cloud Shell خود، یک تب جدید در Google Cloud Shell خود باز کنید.
در تب جدید، به دایرکتوری حاوی فایل باینری جعبه ابزار و فایل پیکربندی tools.yaml بروید و سرور MCP را اجرا کنید.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
عامل ADK را اجرا کنید
در اولین تب Cloud Shell، عامل را اجرا کنید.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
و وقتی شروع شد، دوباره روی لینک http://127.0.0.1:8000 کلیک کنید.
رابط کاربری پیش نمایش وب ADK که از قبل برای شما آشناست را مشاهده خواهید کرد. دقیقاً همان کوئری دفعه قبل را ارسال کنید.
Hello, can you tell me how many trips we've done in February?
و گردش کار عامل را ببینید. اگر همه چیز به درستی پیکربندی شده باشد، باید چیزی شبیه به موارد زیر را ببینید.
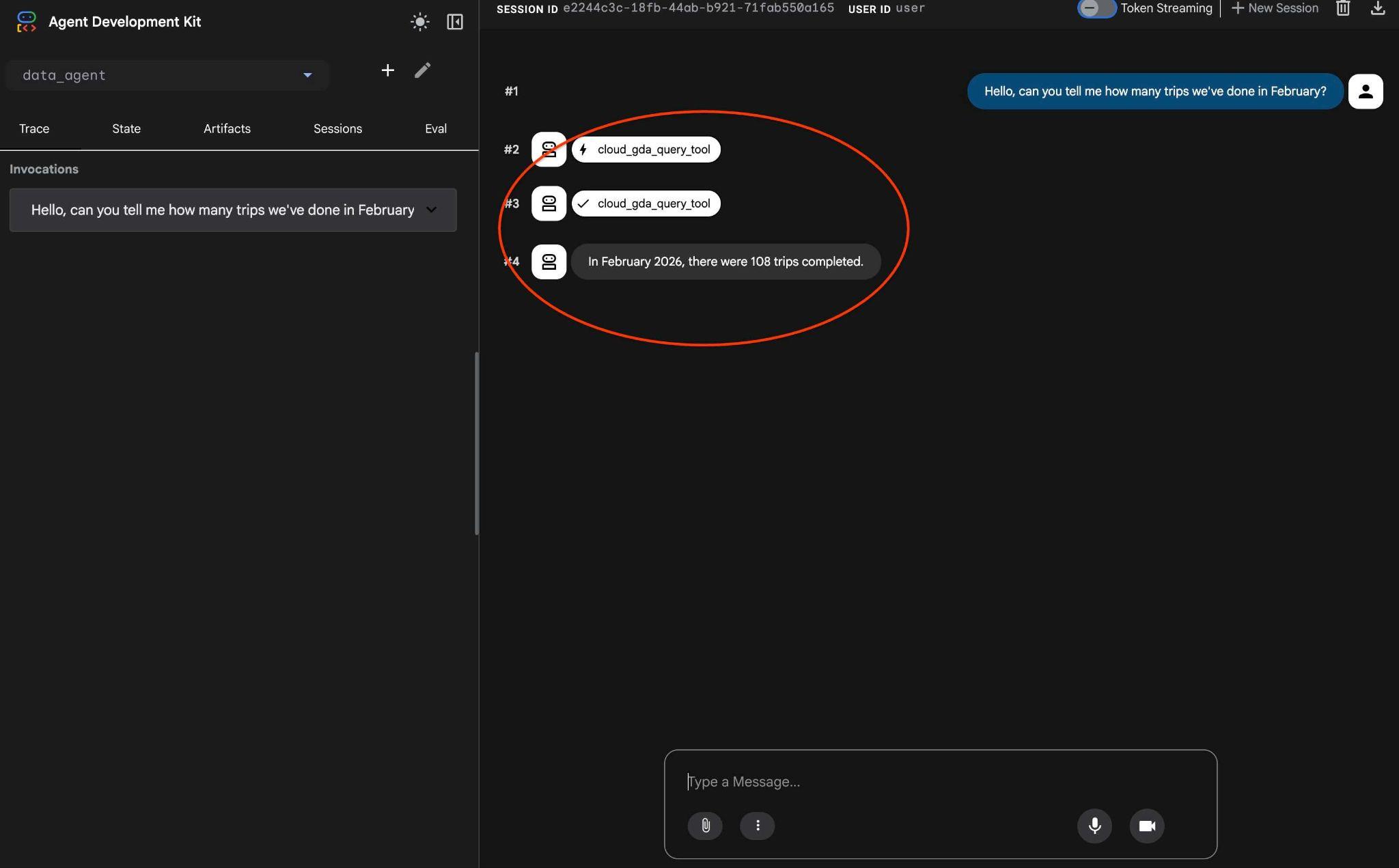
درخواستی که دفعهی قبل چندین بار تکرار شد، به یک فراخوانی به ابزار MCP تبدیل شده و با استفاده از دستورات SQL قابل پیشبینی اجرا شده است.
شما میتوانید با استفاده از درخواستی مانند زیر، جنبههای پیکربندیشده را آزمایش کنید.
how trucks trips for the last month
و در خروجی، اگر روی عملکرد ابزار کلیک کنید، میتوانید ببینید که از همان ابزار استفاده شده و سطوحی برای رسیدن به نتیجه اعمال شده است.
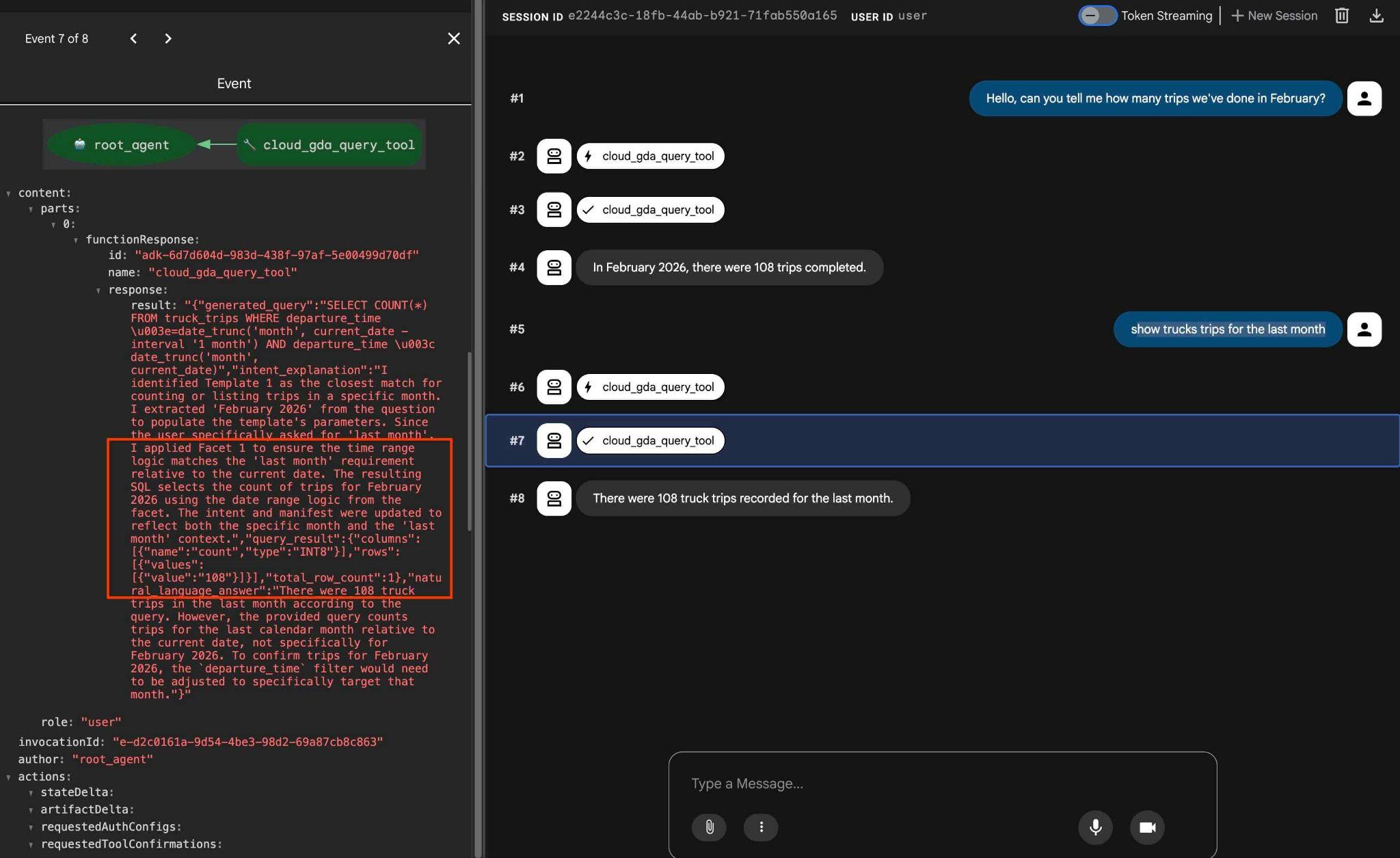
این پایان آزمایش ماست. امیدوارم توانسته باشید تمام مثالها را مرور کنید و نحوه استفاده از QueryData برای AlloyDB را یاد بگیرید. فناوری ارائه شده به شما کمک میکند تا حجم کار عاملمحور و تولید SQL خود را قابل پیشبینی و قابل اعتماد کنید.
۱۲. محیط را تمیز کنید
برای جلوگیری از هزینههای غیرمنتظره، پاکسازی منابع موقت روش خوبی است. مطمئنترین راه، حذف پروژهای است که در آن گردش کار را آزمایش میکردید. اما به صورت اختیاری میتوانید با حذف منابع منفرد، مانند AlloyDB، خود را محدود کنید.
وقتی کار آزمایشگاهیتان تمام شد، نمونهها و کلاستر AlloyDB را از بین ببرید.
کلاستر AlloyDB و تمام نمونههای آن را حذف کنید.
اگر از نسخه آزمایشی AlloyDB استفاده کردهاید. اگر قصد دارید آزمایشگاهها و منابع دیگری را با استفاده از خوشه آزمایشی آزمایش کنید، خوشه آزمایشی را حذف نکنید. شما قادر به ایجاد خوشه آزمایشی دیگری در همان پروژه نخواهید بود.
خوشه با استفاده از گزینهی Force از بین میرود که تمام نمونههای متعلق به خوشه را نیز حذف میکند.
در پوسته ابری، اگر اتصال شما قطع شده و تمام تنظیمات قبلی از بین رفته است، متغیرهای پروژه و محیط را تعریف کنید:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
حذف خوشه:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
حذف پشتیبانهای AlloyDB
تمام پشتیبانهای AlloyDB را برای کلاستر حذف کنید:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
۱۳. تبریک
تبریک میگویم که آزمایشگاه کد را تمام کردی.
آنچه ما پوشش دادهایم
- نحوه ایجاد یک کلاستر AlloyDB و وارد کردن دادههای نمونه
- نحوه فعال کردن API دسترسی به داده AlloyDB
- نحوه فعال کردن QueryData برای AlloyDB
- نحوه تولید قالبها
- نحوه استفاده از جستجوی چندوجهی
- نحوه استفاده از QueryData با عاملهای هوش مصنوعی
۱۴. نظرسنجی
خروجی: