
1. Introduction
Cet atelier de programmation explique comment commencer à utiliser QueryData pour AlloyDB et l'utiliser pour générer des instructions SQL précises et prévisibles à partir d'entrées en langage naturel dans les applications agentiques.
Prérequis
- Connaissances de base concernant la console Google Cloud
- Compétences de base concernant l'interface de ligne de commande et Cloud Shell
Points abordés
- Créer un cluster AlloyDB et importer des exemples de données
- Activer l'API AlloyDB Data Access
- Activer QueryData pour AlloyDB
- Générer des modèles
- Utiliser la recherche par facettes
- Utiliser QueryData avec les agents d'IA
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Un navigateur Web tel que Chrome, compatible avec la console Google Cloud et Cloud Shell
2. Préparation
Configuration du projet
Créer un projet Google Cloud
- Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Vous pouvez également appuyer sur G, puis sur S. Cette séquence activera Cloud Shell si vous êtes dans la console Google Cloud ou si vous utilisez ce lien.
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
3. Avant de commencer
Activer l'API
Pour utiliser AlloyDB, Compute Engine, les services réseau et Vertex AI, vous devez activer leurs API respectives dans votre projet Google Cloud.
Dans le terminal Cloud Shell, assurez-vous que l'ID de votre projet est configuré :
gcloud config get-value project
L'ID de votre projet devrait s'afficher dans le résultat :
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
Définissez la variable d'environnement PROJECT_ID :
PROJECT_ID=$(gcloud config get-value project)
Activez tous les services nécessaires :
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Résultat attendu
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Déployer AlloyDB
Créez un cluster AlloyDB et une instance principale. Vous pouvez le déployer à l'aide d'un script préparé qui déploiera toutes les ressources nécessaires, ou le faire vous-même étape par étape en suivant la documentation.
Déployer AlloyDB à l'aide d'un script automatisé
Cette approche utilise un script automatisé pour déployer le cluster AlloyDB et fournit les informations nécessaires pour commencer à utiliser les ressources déployées.
Dans le terminal Cloud Shell, exécutez la commande permettant de cloner le script de déploiement à partir du dépôt.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
Exécutez le script de déploiement.
./deploy_alloydb.sh --public-ip
L'exécution du script prendra un certain temps (environ cinq à sept minutes) pour déployer le cluster AlloyDB et une instance principale avec des adresses IP publiques et privées. L'adresse IP publique n'est disponible que pour les réseaux autorisés ou en utilisant le proxy d'authentification AlloyDB. Pour en savoir plus sur les adresses IP publiques, consultez la documentation. Le script doit fournir des informations sur votre cluster AlloyDB déployé. Veuillez noter que votre mot de passe sera différent. Enregistrez-le quelque part pour une utilisation ultérieure.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
Vous pouvez également voir le nouveau cluster et l'instance principale dans la console Web.
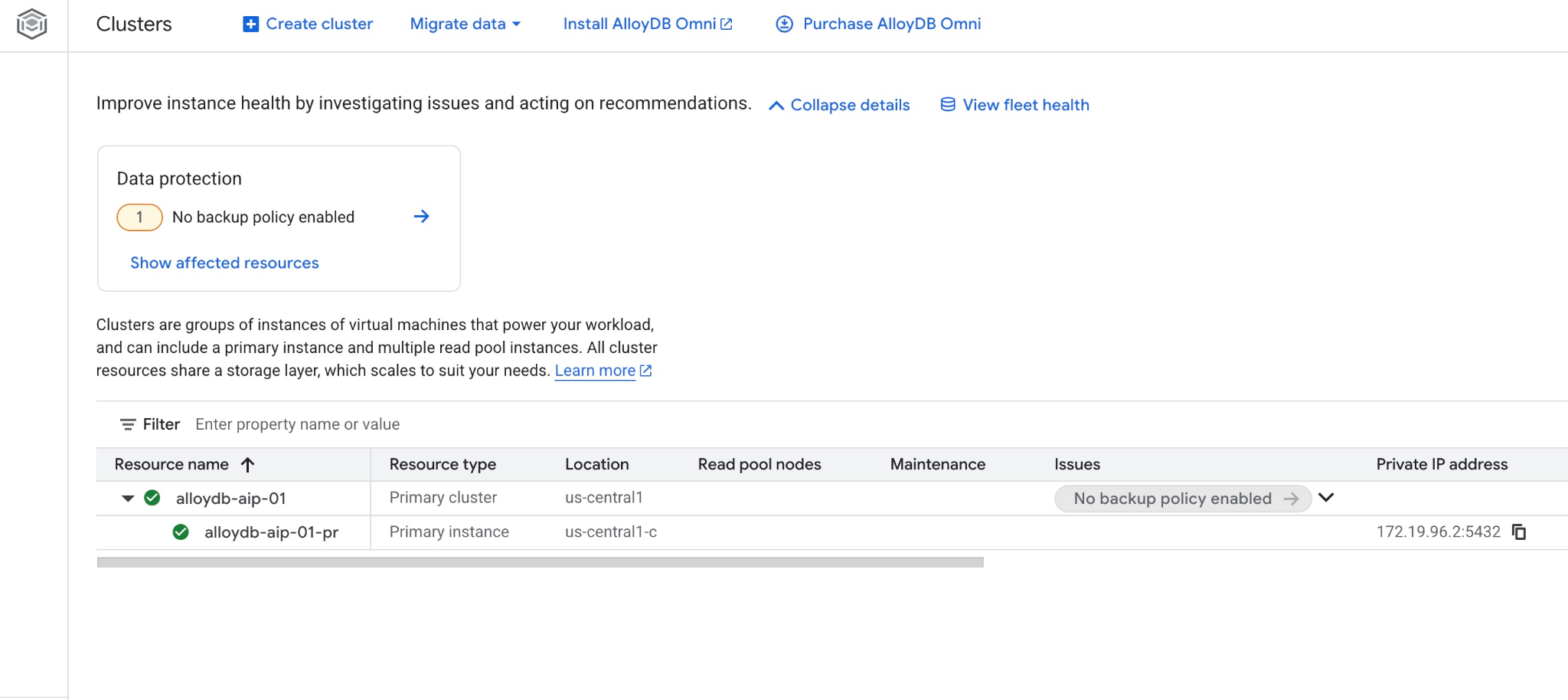
5. Préparer la base de données
Pour utiliser les fonctions et opérateurs d'IA, vous devez activer l'intégration de Vertex AI, activer l'API Data Access et créer une base de données pour l'ensemble de données exemple.
Accorder les autorisations nécessaires à AlloyDB
Ajoutez des autorisations Vertex AI à l'agent de service AlloyDB.
Ouvrez un autre onglet Cloud Shell à l'aide du signe "+" situé en haut.
Dans le nouvel onglet Cloud Shell, exécutez :
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Activer l'API Data Access
Vous devez activer l'API Data Access sur le cluster AlloyDB pour pouvoir utiliser les outils MCP tels que execute_sql.
Dans le même onglet de terminal, exécutez la commande suivante :
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
Activer l'authentification IAM
Nous allons utiliser l'authentification IAM pour nos outils agentiques. Pour cela, vous devez activer l'authentification IAM sur l'instance et vous ajouter en tant qu'utilisateur de base de données. Avant d'activer l'authentification IAM au niveau de l'instance, veuillez attendre la fin de l'étape précédente d'activation de l'API d'accès aux données. L'état de votre instance doit être vert.
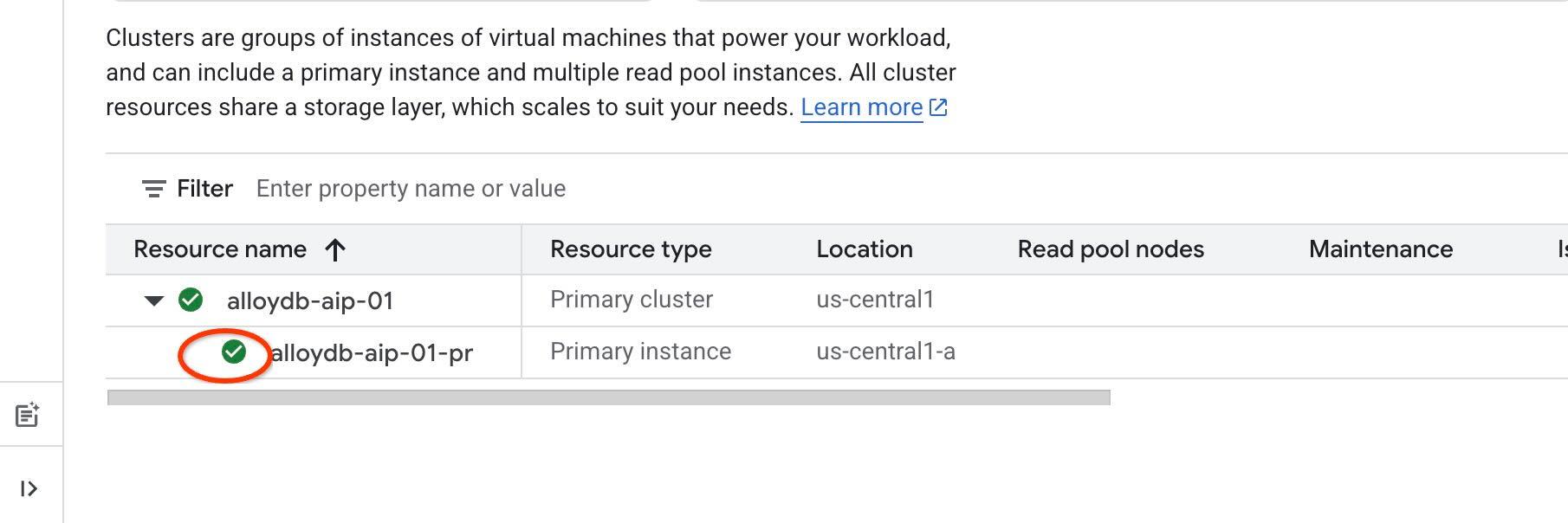
Nous allons commencer par activer IAM au niveau de l'instance. Dans le même onglet de terminal, exécutez la commande suivante :
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Ajoutez-vous en tant qu'utilisateur AlloyDB :
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
Fermez l'onglet en exécutant la commande "exit" dans l'onglet :
exit
Se connecter à AlloyDB Studio
Dans les chapitres suivants, toutes les commandes SQL nécessitant une connexion à la base de données peuvent être exécutées dans AlloyDB Studio. T
Accédez à la page "Clusters" dans AlloyDB pour PostgreSQL.
Ouvrez l'interface de la console Web pour votre cluster AlloyDB en cliquant sur l'instance principale.

Cliquez ensuite sur AlloyDB Studio à gauche :
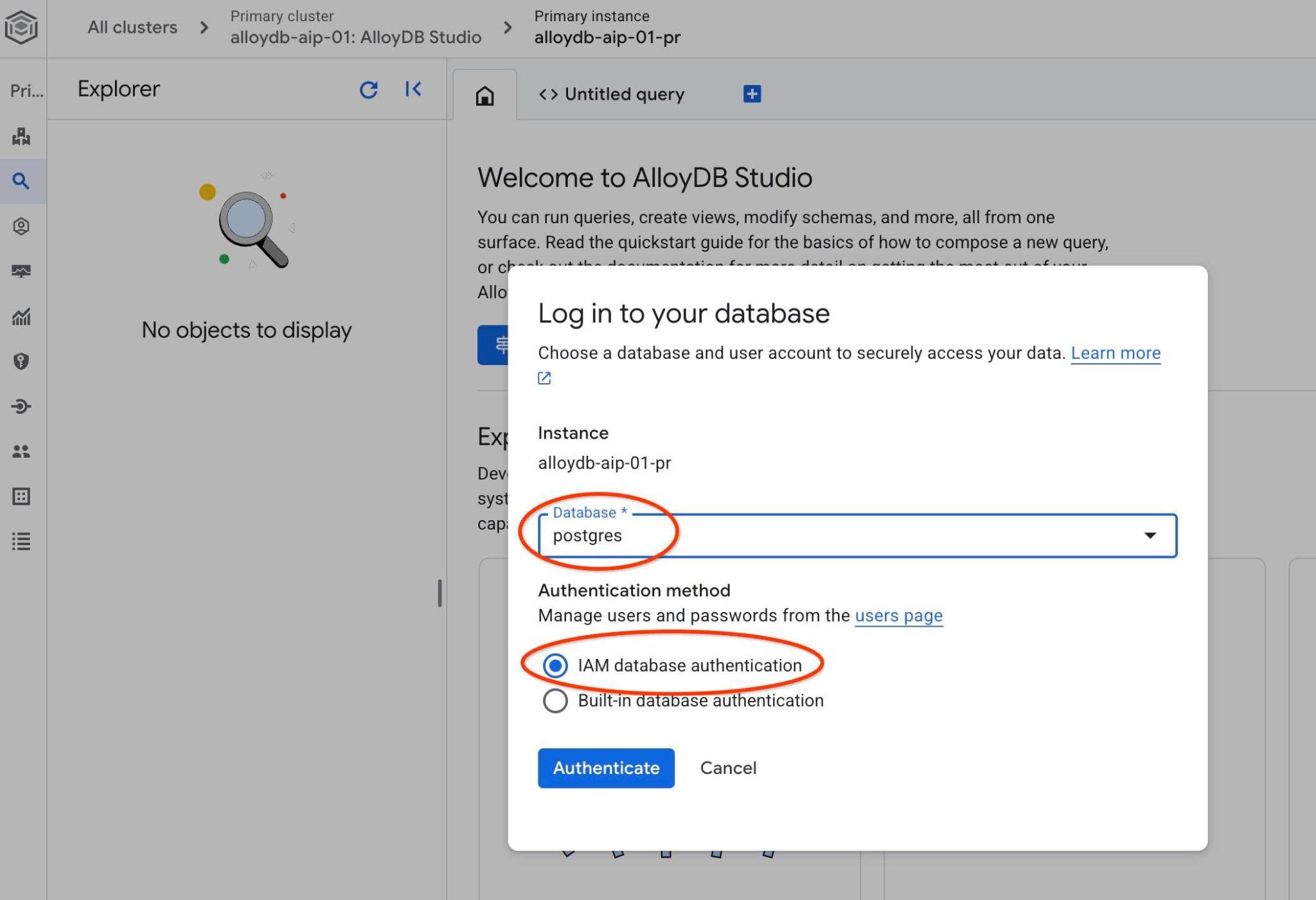
Choisissez la base de données PostgreSQL et l'authentification IAM. Cliquez ensuite sur le bouton "Authenticate" (S'authentifier).
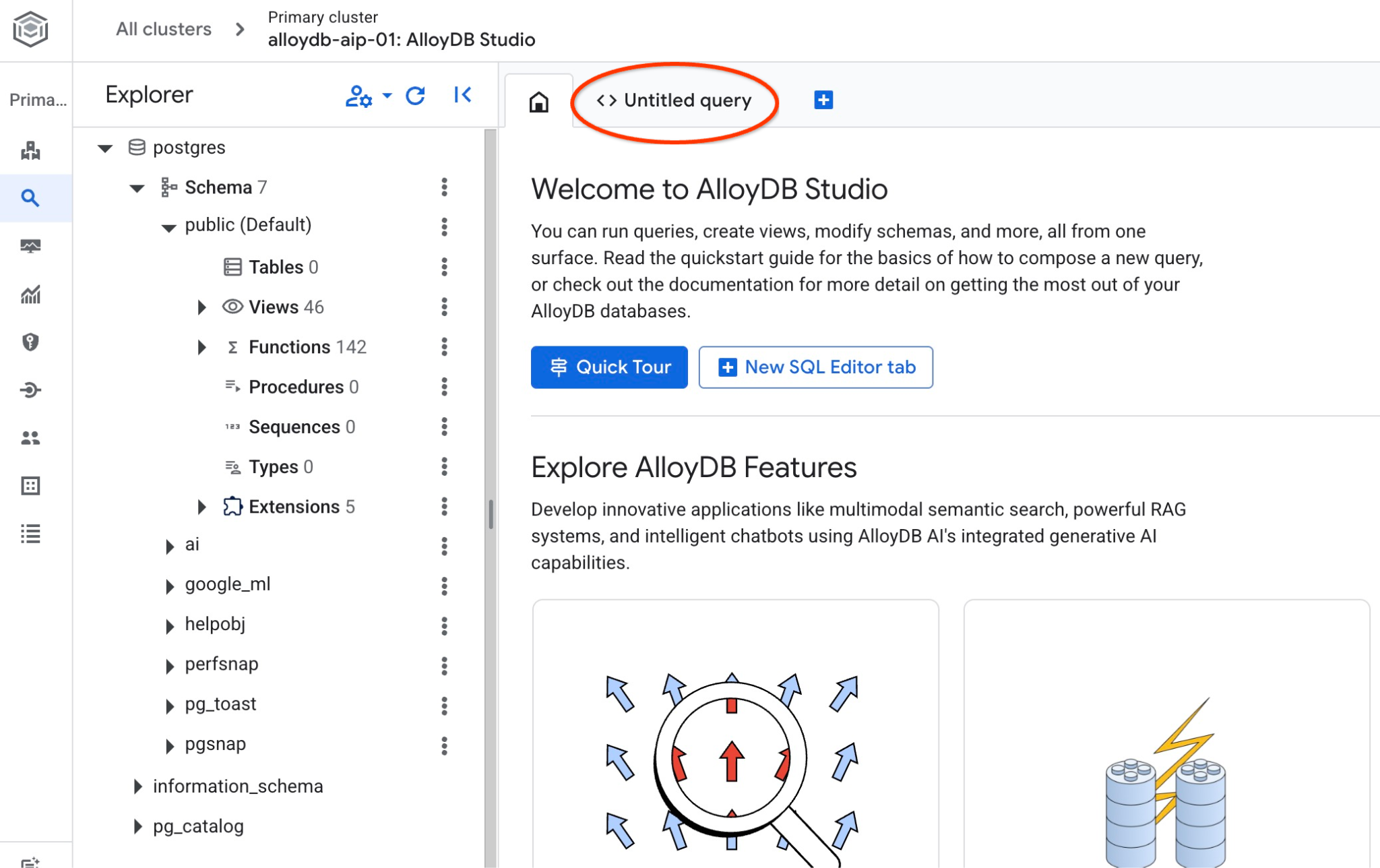
L'interface AlloyDB Studio s'ouvre. Pour exécuter les commandes dans la base de données, cliquez sur l'onglet "Requête sans titre" à droite.
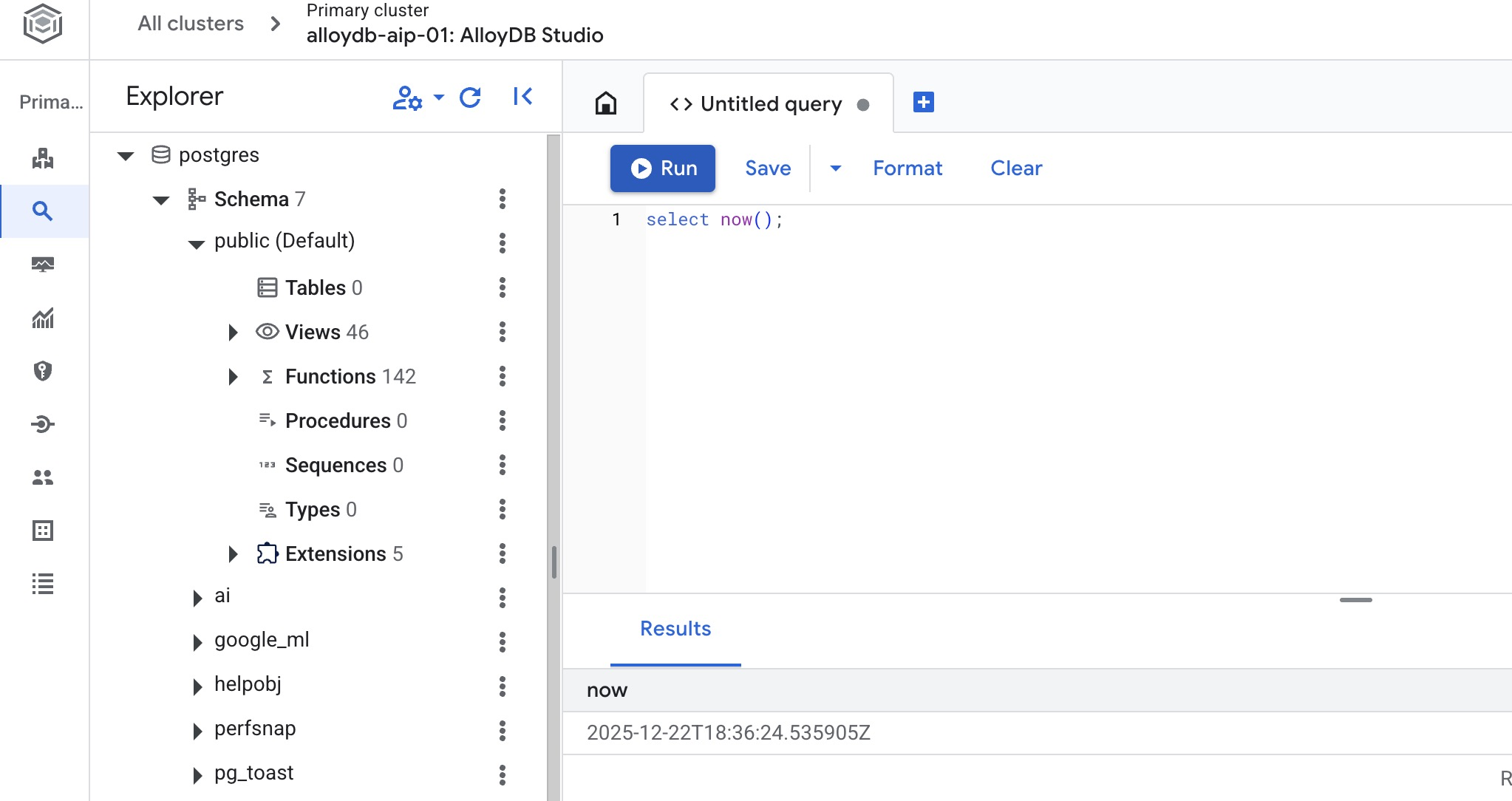
L'interface qui s'ouvre vous permet d'exécuter des commandes SQL.
Créer une base de données
Créez un démarrage rapide de base de données.
Dans l'éditeur AlloyDB Studio, exécutez la commande suivante.
Créez une base de données :
CREATE DATABASE quickstart_db
Résultat attendu :
Statement executed successfully
Se connecter à quickstart_db
Vérifiez si votre base de données a été créée en vous y connectant. Reconnectez-vous au studio à l'aide du bouton permettant de changer d'utilisateur ou de base de données.
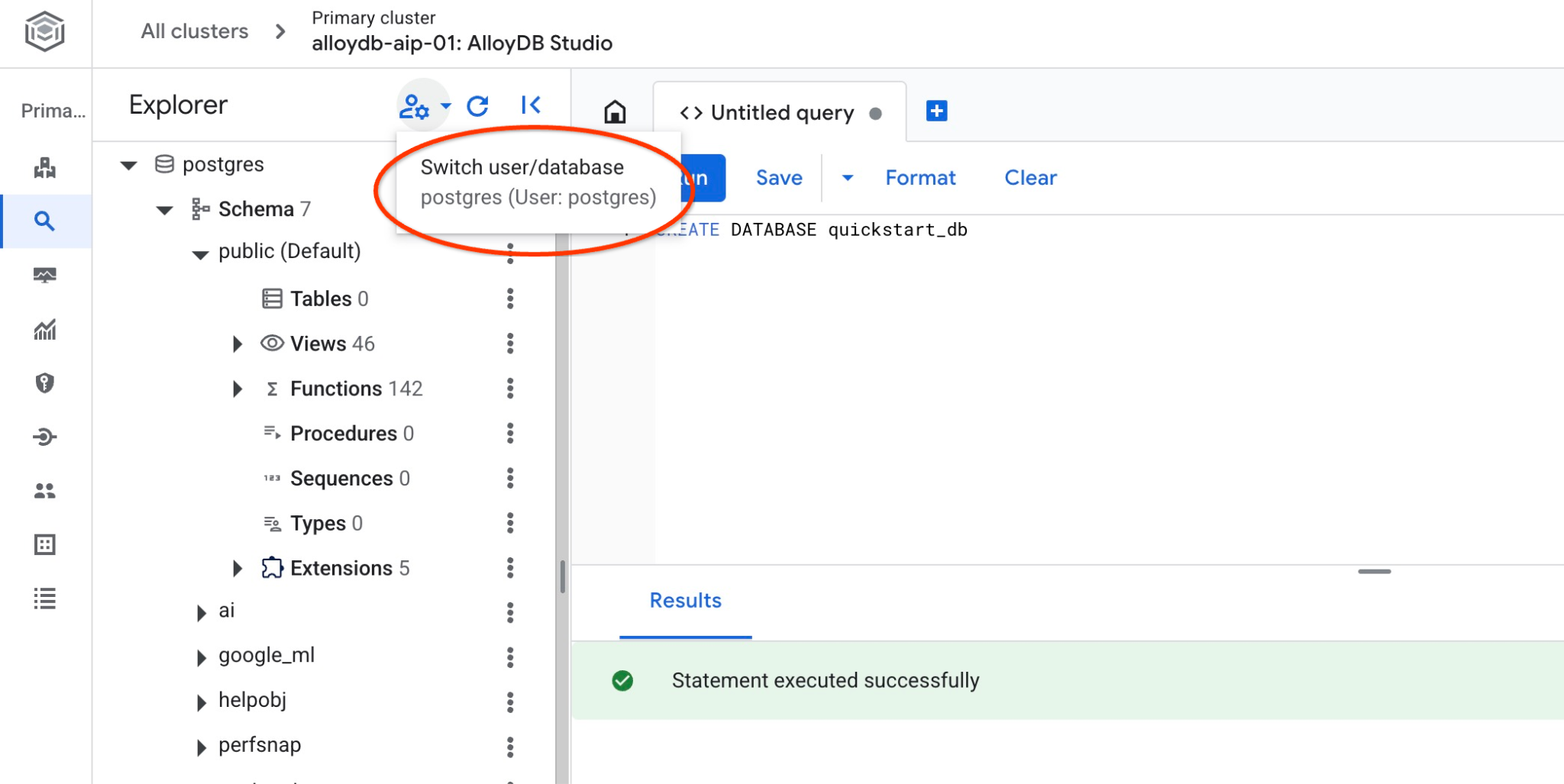
Dans la liste déroulante, sélectionnez la nouvelle base de données quickstart_db et utilisez la même authentification IAM.
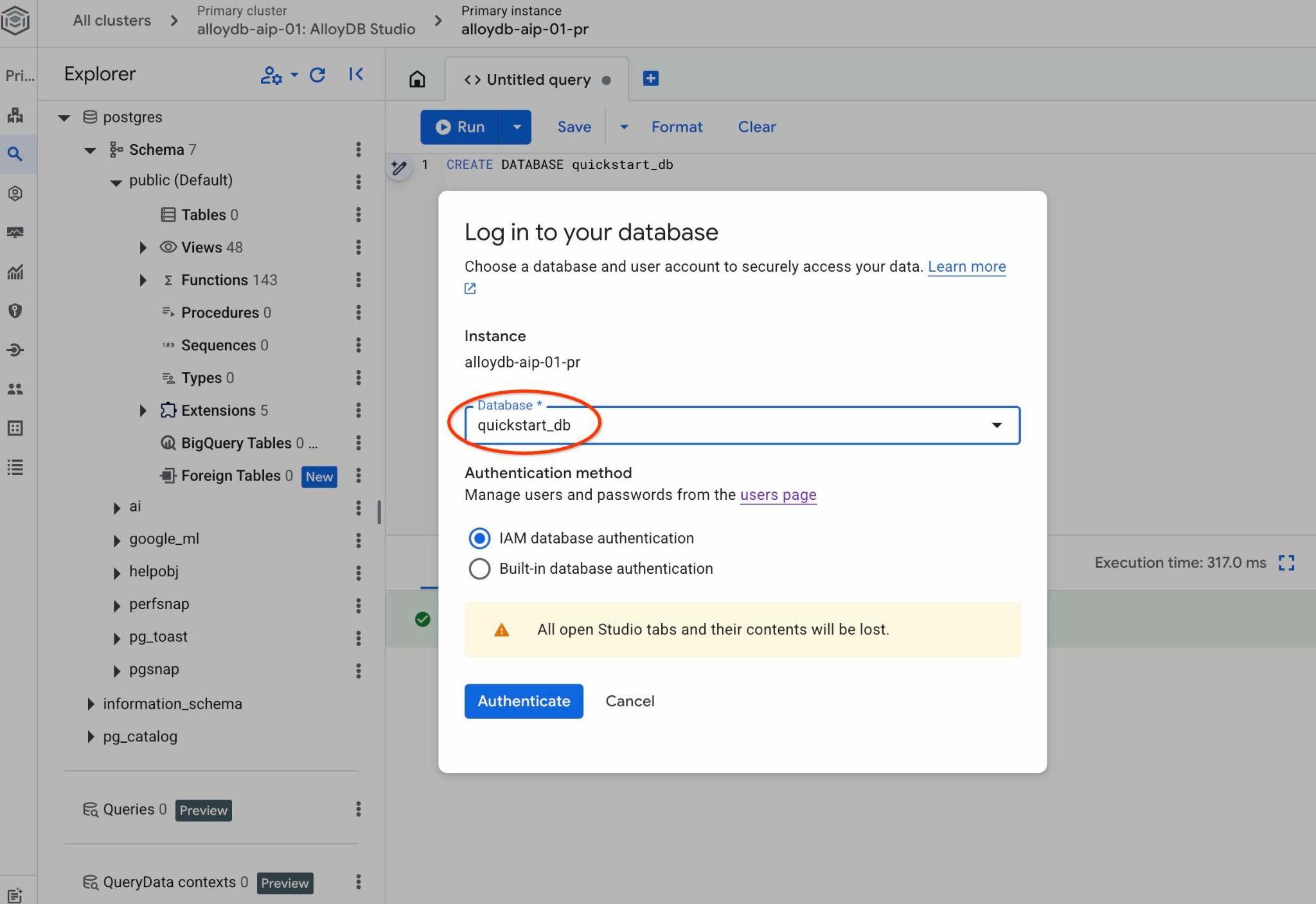
Une nouvelle connexion s'ouvre, vous permettant de travailler avec des objets de la base de données quickstart_db. Vous pourrez y examiner votre schéma et vos données importés, et travailler avec les ensembles de contexte QueryData.
6. Exemples de données
Vous devez maintenant créer des objets dans la base de données et charger des données. Vous allez utiliser un ensemble de données fictif de l'entreprise Cymbal Shipping. Il contient des données fictives sur les marchandises, les camions, les demandes et les trajets des camions, ainsi que sur les conducteurs fictifs.
Créer un bucket Storage
Vous allez utiliser le SDK Google (gcloud) pour importer des données de votre dépôt cloné vers la base de données AlloyDB. Pour ce faire, vous devrez créer un bucket Cloud Storage et accorder l'accès au compte de service AlloyDB. Vous pouvez également essayer de le faire à l'aide de la console Web, comme décrit dans la documentation.
Dans le terminal Google Cloud Shell, exécutez :
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
Charger des données
L'étape suivante consiste à charger les données. Notre vidage SQL compressé se trouve dans le dossier du dépôt cloné. La commande suivante suppose que vous avez utilisé votre répertoire d'accueil comme point de départ lorsque vous avez cloné le dépôt à l'étape précédente lors de la création du cluster AlloyDB.
Copiez le vidage SQL compressé dans le nouveau bucket de stockage :
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
Chargez ensuite les données dans la base de données quickstart_db :
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
La commande chargera l'ensemble de données exemple dans la base de données quickstart_db. Vous pouvez vérifier les tables et les enregistrements à l'aide d'AlloyDB Studio.
7. Utiliser l'agent de données
Commençons par un exemple d'agent d'IA créé à l'aide de Google ADK pour Python et connecté à notre instance AlloyDB à l'aide de MCP Toolbox for Databases.
Installer MCP Toolbox for Databases
MCP Toolbox for Databases est un projet Open Source qui fournit une assistance MCP pour plusieurs moteurs de base de données, y compris AlloyDB pour PostgreSQL. Pour en savoir plus sur MCP Toolbox, consultez la documentation.
Vous devez télécharger la dernière version du logiciel pour votre plate-forme. Pour obtenir la dernière version, consultez la page des versions. L'exemple suivant montre comment télécharger la version 31 de la boîte à outils MCP dans Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Vous devez préparer un fichier de configuration pour la boîte à outils. Nous disposons d'un exemple de fichier tools.yaml.example dans le répertoire actuel et nous allons préparer le fichier tools.yaml en remplaçant deux espaces réservés par l'ID du projet et la région.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
Démarrer MCP Toolbox for Databases
Vous pouvez maintenant démarrer la boîte à outils MCP avec le fichier de configuration préparé.
Ouvrez un nouvel onglet dans Google Cloud Shell en appuyant sur le bouton "+" en haut de l'interface Google Cloud Shell.
Dans le nouvel onglet, accédez au répertoire contenant le fichier binaire de la boîte à outils et le fichier de configuration tools.yaml, puis démarrez le serveur MCP.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
Le résultat obtenu doit ressembler à ceci : "Server ready to serve!" (Serveur prêt à servir !).
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
Vérifier le code source de l'agent
Dans le premier onglet du dossier du dépôt cloné, examinez le code de l'agent à l'aide de l'éditeur Google Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
Vous pouvez voir dans l'agent que nous avons une section pour le serveur MCP Google Cloud pour AlloyDB. Nous fournissons un point de terminaison en tant que MCP_SERVER_URL, une authentification, un ID de projet et l'ajoutons à l'ensemble d'outils MCP.
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
Dans le code de l'agent, l'ensemble d'outils MCP est inclus en tant que paramètre tools pour l'agent. Le nom du cluster et de l'instance, la région et la base de données sont également disponibles en tant que variables pour la requête de l'agent.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
Après avoir examiné le code, revenez au terminal en cliquant sur le bouton "Ouvrir le terminal" en haut à droite de la fenêtre de l'éditeur.
Démarrer l'agent
Vous pouvez maintenant démarrer l'agent en mode interactif à l'aide de l'interface Web Google ADK. L'interface Web de l'ADK permet de tester et de dépanner facilement les workflows des agents.
Commençons par installer tous les packages Python requis à l'aide du gestionnaire de packages uv.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
Une fois tous les packages installés, vous devez ajouter un fichier .env au répertoire de l'agent pour lui indiquer d'utiliser Vertex AI pour toutes les communications avec les modèles d'IA.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
Vous pouvez ensuite démarrer l'agent.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Un résultat semblable à celui-ci doit s'afficher, avec le point de terminaison http://127.0.0.1:8000 .
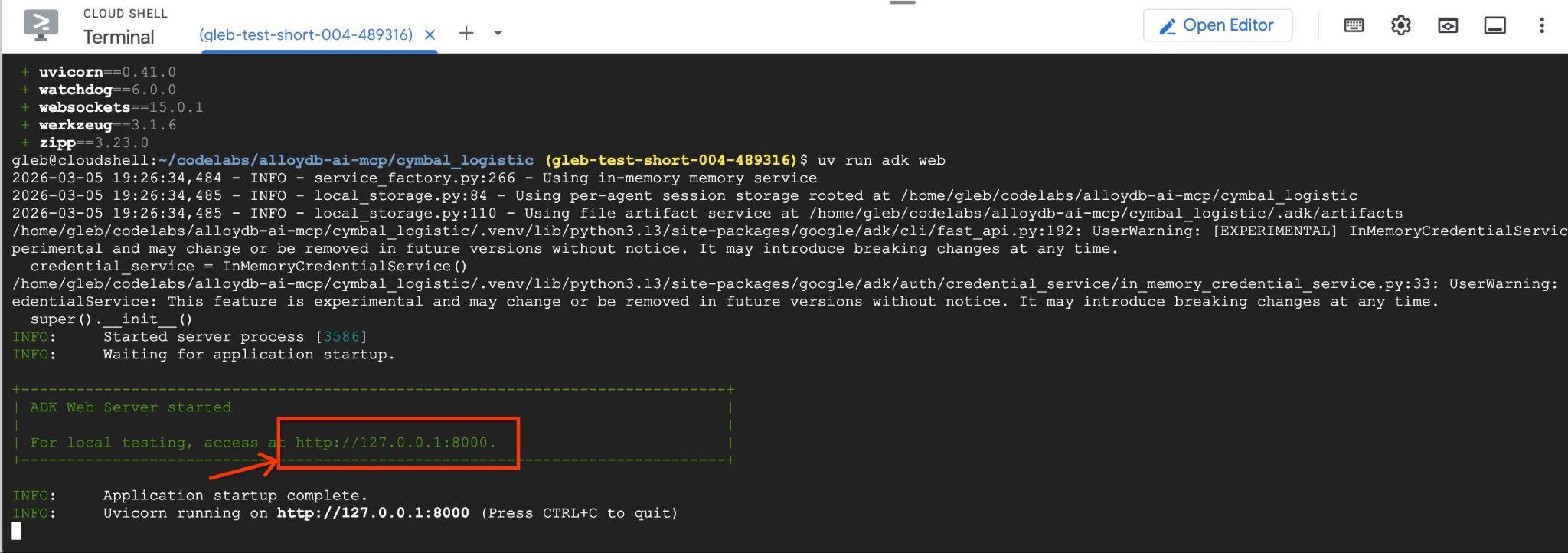
Vous pouvez cliquer sur cette URL dans Cloud Shell. Une fenêtre d'aperçu s'ouvre alors dans un onglet de navigateur distinct. Vous pouvez y sélectionner data_agent dans la liste déroulante de gauche.
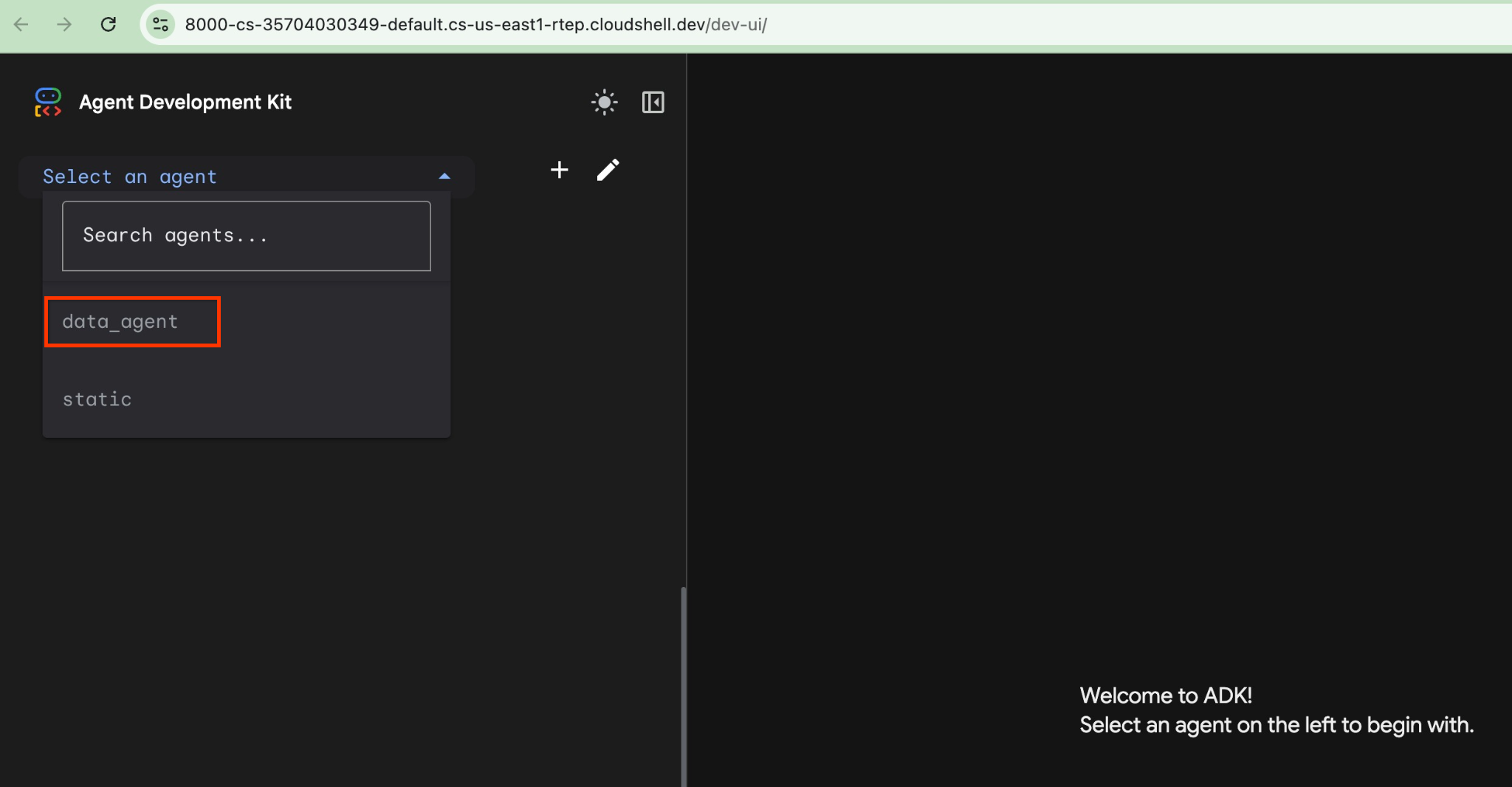
Dans l'interface Web de l'ADK, vous pouvez poser vos questions en bas à droite et voir le flux d'exécution complet, y compris les traces de chaque étape sur la droite.
8. Tester NL2SQL sans QueryData pour AlloyDB
L'agent vous permet de poser des questions en langage naturel et il utilise la boîte à outils MCP pour les bases de données comme outil pour y répondre. Les questions sont publiées en bas à droite et la réponse avec tous les appels aux outils s'affiche en haut.
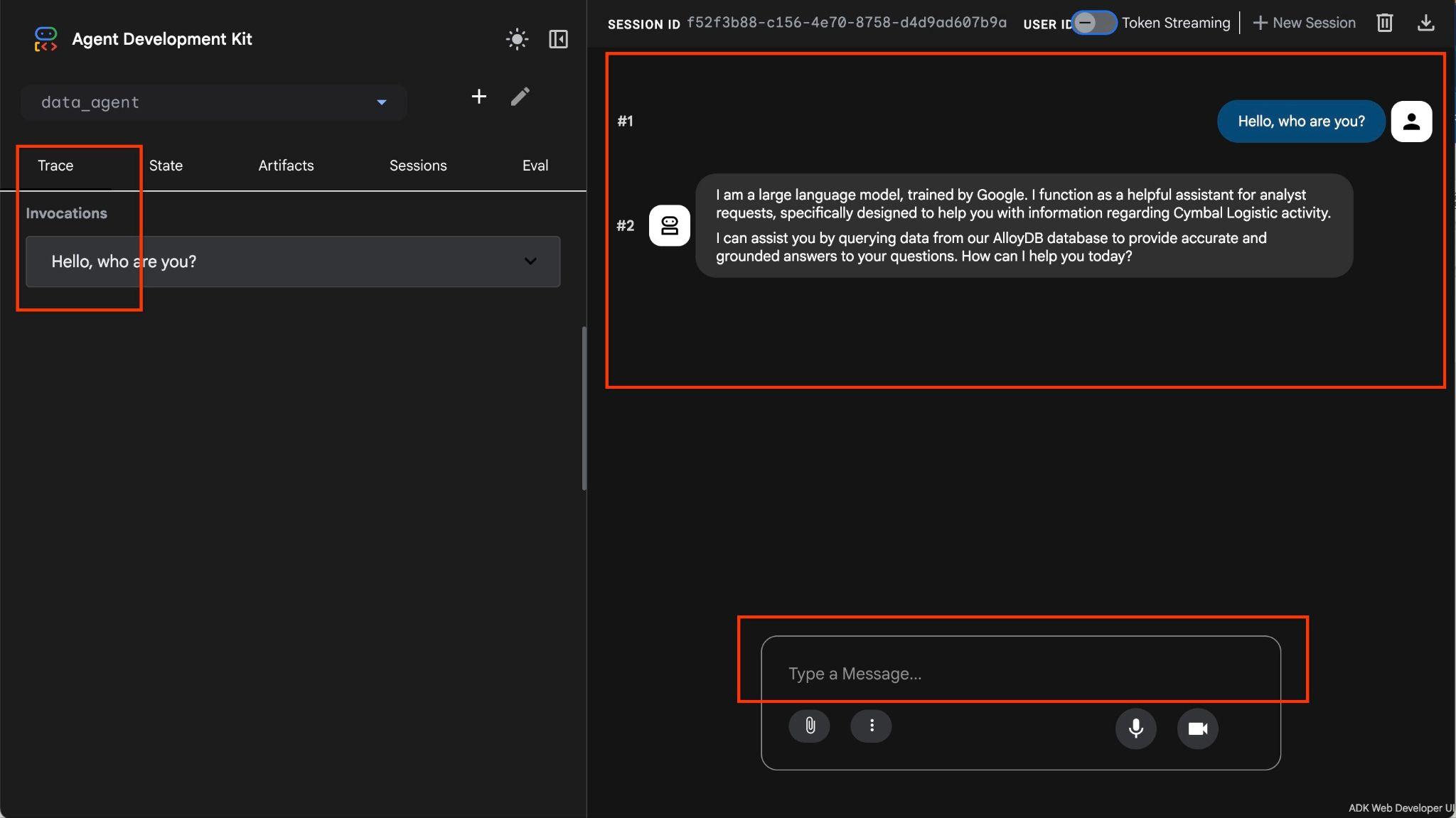
Vous travaillez avec des données opérationnelles pour une entreprise de transport maritime qui dispose d'informations sur les demandes d'expédition, les camions, les chauffeurs et les trajets effectués par les chauffeurs. La première question porte sur le nombre de trajets effectués en février 2026.
Dans le champ de saisie en bas à droite, saisissez ce qui suit, puis appuyez sur Entrée.
Hello, can you tell me how many trips we've done in February?
L'agent exécutera plusieurs appels d'outils pour identifier les bonnes tables dans le schéma à l'aide de list_cymbal_logistics_schemas_tool et execute_sql_tool, en exécutant plusieurs instructions SQL pour obtenir les bonnes données.
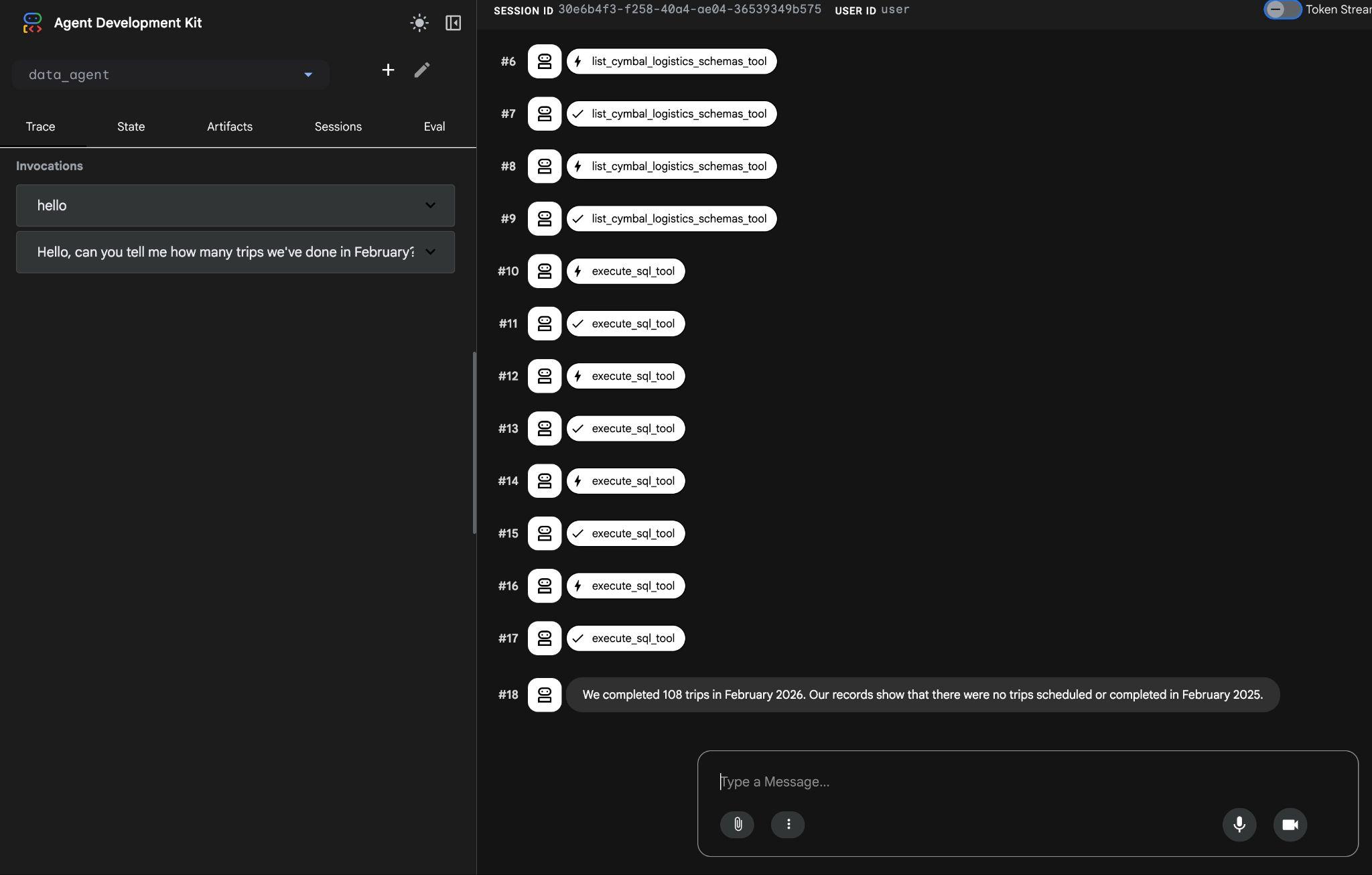
Il finira par produire le bon résultat après avoir créé la requête appropriée et l'avoir exécutée sur la base de données.
J'ai effectué 108 trajets en février 2026. D'après nos informations, aucun trajet n'a été programmé ni effectué en février 2025.
Vous pouvez voir ce que fait chaque appel d'outil en cliquant sur l'exécution de l'outil. Par exemple, voici la requête exécutée pour obtenir nos résultats.
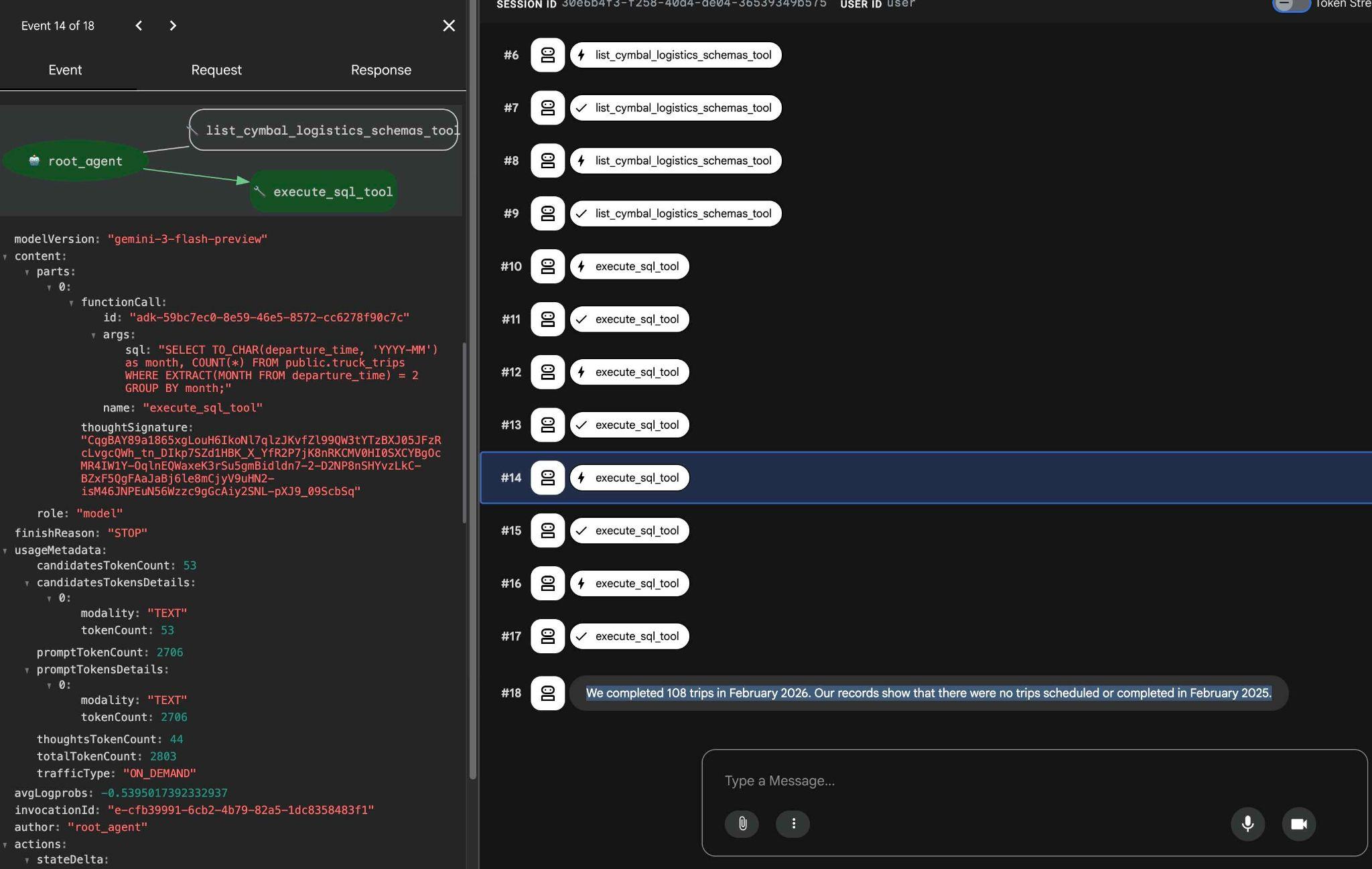
Essayez d'autres requêtes simples à l'aide de l'interface Web ADK et voyez comment il exécute différentes requêtes pour obtenir les résultats.
Arrêtez l'agent en appuyant sur ctrl+c dans le terminal. Vous pouvez fermer l'onglet du navigateur contenant l'interface Web ADK.
Vous pouvez également arrêter la boîte à outils MCP dans le deuxième onglet en appuyant sur le même raccourci clavier ctrl+c, puis fermer le deuxième onglet.
Dans l'étape suivante, nous allons créer un contexte QueryData pour améliorer notre réponse et nos performances NL2SQL.
9. Créer un ContextSet QueryData
Comme vous avez pu le voir à l'étape précédente, le modèle d'IA a effectué plusieurs appels au schéma d'informations de la base de données pour déterminer les tables et les colonnes à utiliser pour créer la requête SQL. Pour améliorer les performances et la précision, et rendre le résultat plus prévisible, nous ajouterons votre contexte QueryData qui définit la requête à exécuter en réponse à une demande spécifique.
Créer des modèles ciblés
Le ContextSet QueryData est un fichier JSON contenant des modèles de requête et des facettes qui fournissent les données et les instructions nécessaires au modèle d'IA pour utiliser la requête SQL ou les parties de requête SQL appropriées afin d'atteindre les objectifs demandés en fonction des modèles de requête et de la structure des données.
Vous commencez par un modèle ciblé. Créez un fichier à l'aide d'un éditeur Cloud Shell. Dans le terminal Cloud Shell, exécutez la commande suivante :
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
Insérez le modèle de requête en langage naturel que nous avons utilisé dans le chapitre précédent : "Combien de trajets avons-nous effectués en février ?"
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
Téléchargez ensuite le modèle sur votre ordinateur depuis Cloud Shell à l'aide du bouton de téléchargement.
Charger les ensembles de contextes QueryData
Pour utiliser nos ensembles de contexte QueryData, nous devons les importer dans notre base de données.
Ouvrez AlloyDB Studio. En bas du panneau de gauche, vous verrez QueryData Context et trois points.
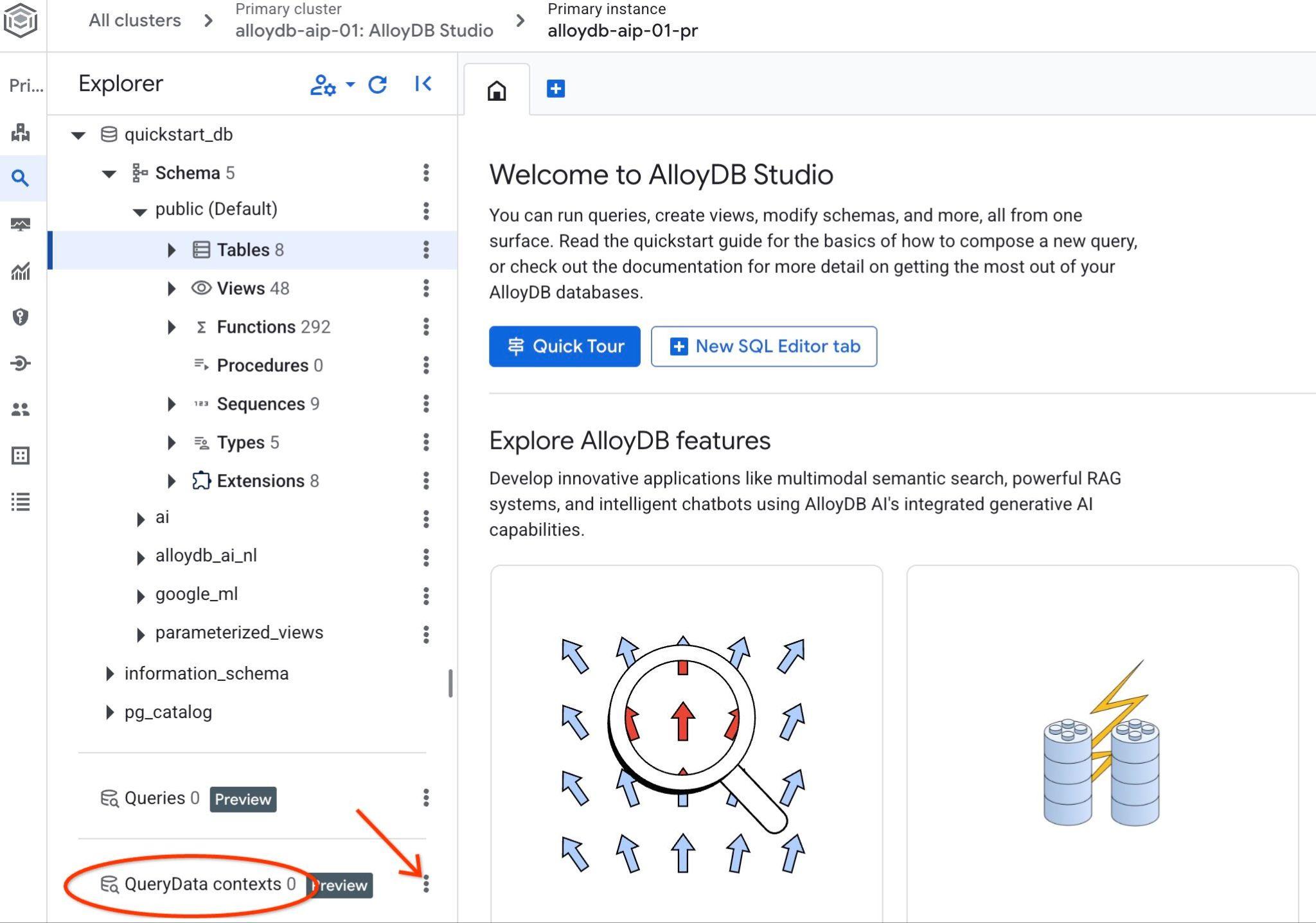
Cliquez sur ces trois points, puis sélectionnez "Créer un contexte". Une boîte de dialogue s'ouvre.
- Nom :
cymbal_context_set - Description :
Cymbal Logistic Query Data - Importez le fichier de contexte : cliquez sur le bouton
Browseet sélectionnez votre fichier JSON avec le QueryData ContextSet.
Lorsque vous appuyez sur le bouton "Enregistrer", l'initialisation du stockage du contexte peut prendre un certain temps si vous le faites pour la première fois.
Vous devriez pouvoir voir le contexte téléchargé. Si vous cliquez sur les trois boutons verticaux à droite, vous verrez les actions disponibles. Dans le chapitre suivant, nous commencerons par l'action "Test context" (Tester le contexte).
10. Tester l'ensemble de contexte QueryData
Modèle de test
Utilisez l'action "Test context" pour tester notre contexte dans AlloyDB Studio. Lorsque vous cliquez sur "Tester le contexte", une nouvelle fenêtre de l'éditeur AlloyDB Studio s'ouvre avec le titre "cymbal_context_set" et l'invitation à la génération de code SQL Gemini intitulée "Generate SQL using QueryData context: cymbal_context_set". Cliquez sur la génération de code SQL et saisissez
Hello, can you tell me how many trips we've done in February?
Lorsque le code SQL est généré, appuyez sur le bouton Insert.
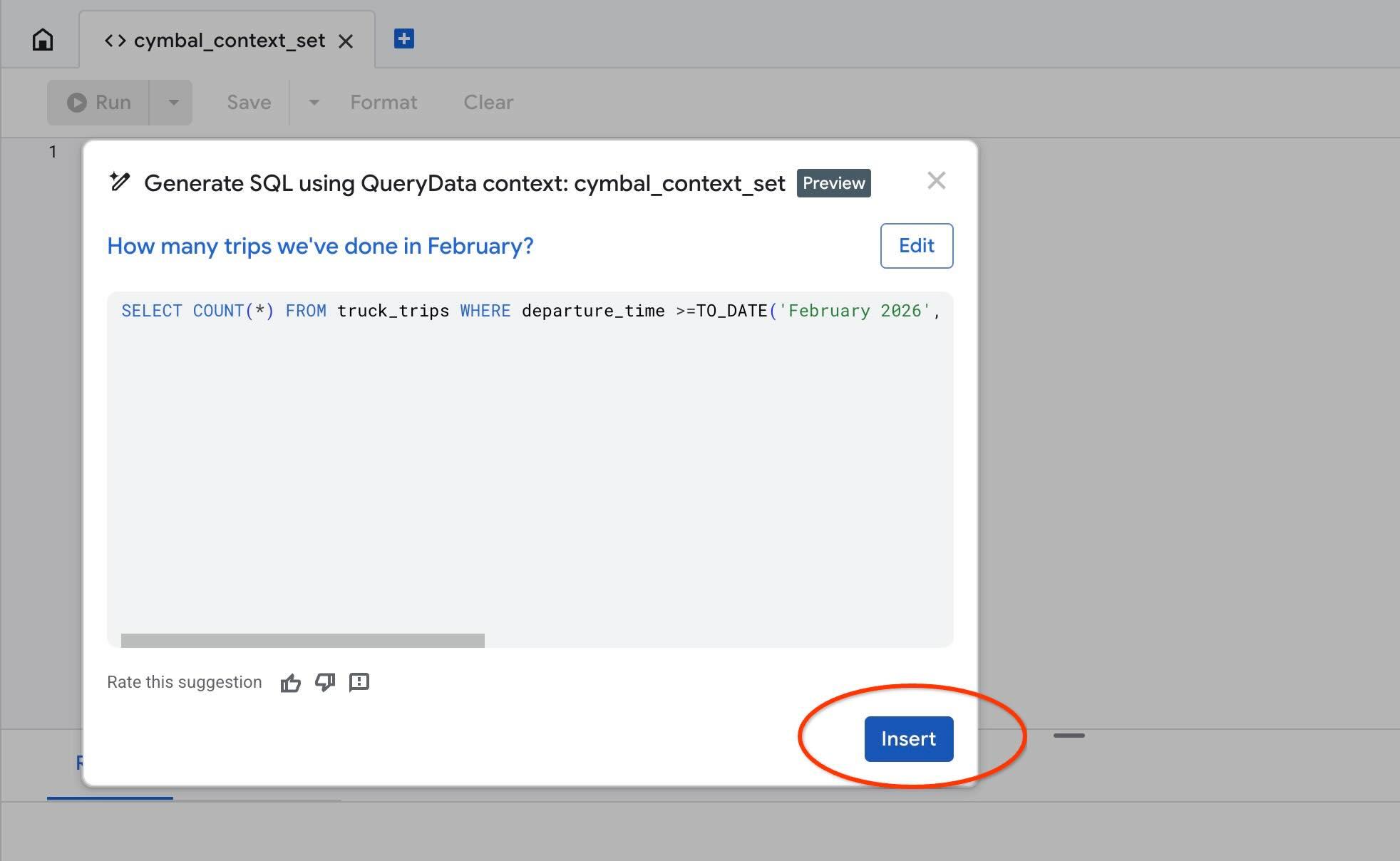
Vous allez voir exactement la même requête que celle que nous avons envoyée à notre modèle de contexte précédemment.
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
Essayez de remplacer le mois par "janvier" et vérifiez l'instruction SQL générée. Il utilisera le mois comme paramètre pour l'intention paramétrée et ajustera automatiquement l'instruction SQL.
Créer des facettes QueryData
Nous avons essayé un modèle pour une requête, et cela fonctionne lorsque nous savons quel type de demande d'utilisateur nous attendons. Toutefois, il est parfois utile de guider uniquement une partie d'une requête, comme une condition ou un filtre, lorsque nous préférons qu'un certain ordre ou une clause particulière soient utilisés pour une intention redéfinie.
Par exemple, si nous demandons de renvoyer les données du "mois dernier", nous souhaitons obtenir le rapport du dernier mois calendaire, du 1er jour au dernier jour de ce mois, et non celui des 30 derniers jours.
Nous pouvons ajouter ces facettes en tant qu'extrait SQL à la configuration ContextSet, en plus du modèle que nous avons ajouté précédemment. Ouvrez le fichier querydata_cymbal_contextset.json.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
Ajoutez les facettes après nos modèles existants. Le contenu du fichier obtenu doit être le suivant :
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
Enregistrez le fichier et importez-le sur votre ordinateur.
Utilisez ensuite l'action de contexte de requête "Modifier le contexte" et importez le fichier modifié pour remplacer l'ancien contexte par le nouveau.
Maintenant, essayez à nouveau d'utiliser le contexte de test et de générer une instruction SQL à l'aide de l'intention "le mois dernier". Par exemple, si vous générez un code SQL pour l'expression "show trucks trips for the last month"", la condition que nous avons fournie sera utilisée comme facette dans notre fichier cymbal_context.json.
Vous devriez obtenir un résultat semblable à celui-ci :
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
Comment l'utiliser avec les agents IA ? Dans le chapitre suivant, nous mettrons le contexte "Interroger les données" à la disposition des agents d'IA.
11. QueryData avec des agents d'IA
Vous utiliserez le même agent de données, mais la boîte à outils MCP sera désormais configurée pour utiliser le ContextSet QueryData.
Préparer et démarrer MCP Toolbox for Databases
Nous avons besoin d'un nouveau fichier de configuration pour MCP Toolbox, qui utilisera l'API Gemini Data Analytics et AlloyDB comme source de données.
Exécutez la commande suivante dans le terminal :
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
Accédez à l'éditeur et recherchez le fichier querydata.yaml. Le fichier de configuration querydata.yaml ressemblerait à ce qui suit, à l'exception de l'ID de projet et de la région, qui refléteront votre environnement. Toutefois, vous devez toujours mettre à jour votre valeur contextSetId et remplacer l'espace réservé "<add-context-set-id>" par la valeur de la console.
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
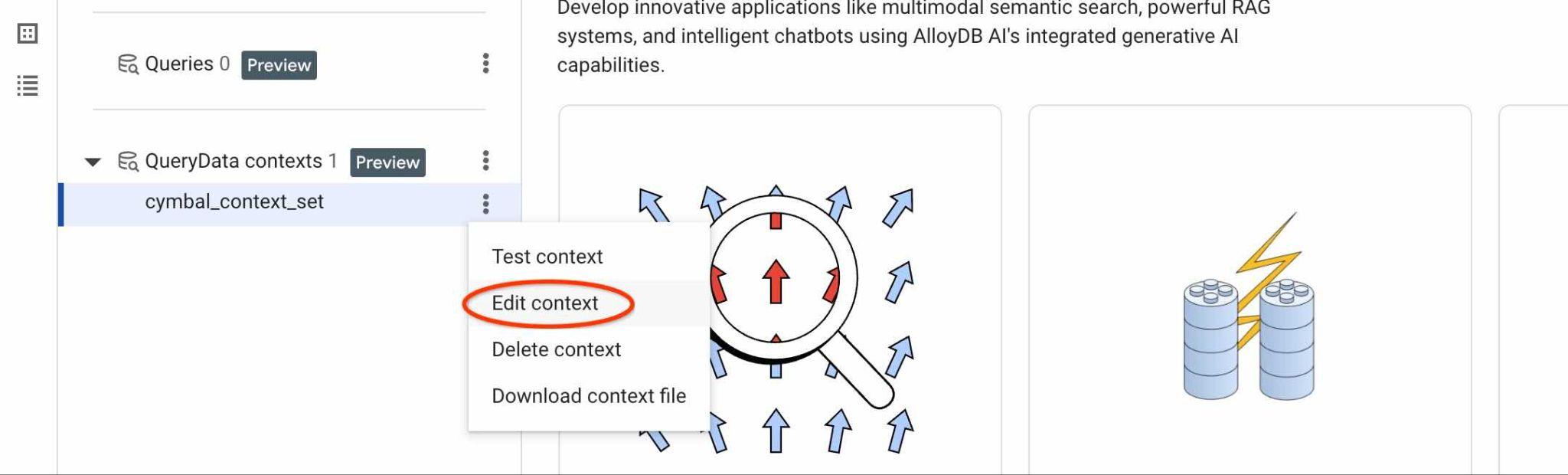
Pour trouver l'ID de votre ContextSet, cliquez sur le bouton "Modifier" de votre ensemble de contexte, comme indiqué sur l'image.
L'ID de l'ensemble de contexte s'affiche en haut du nouvel onglet à droite.
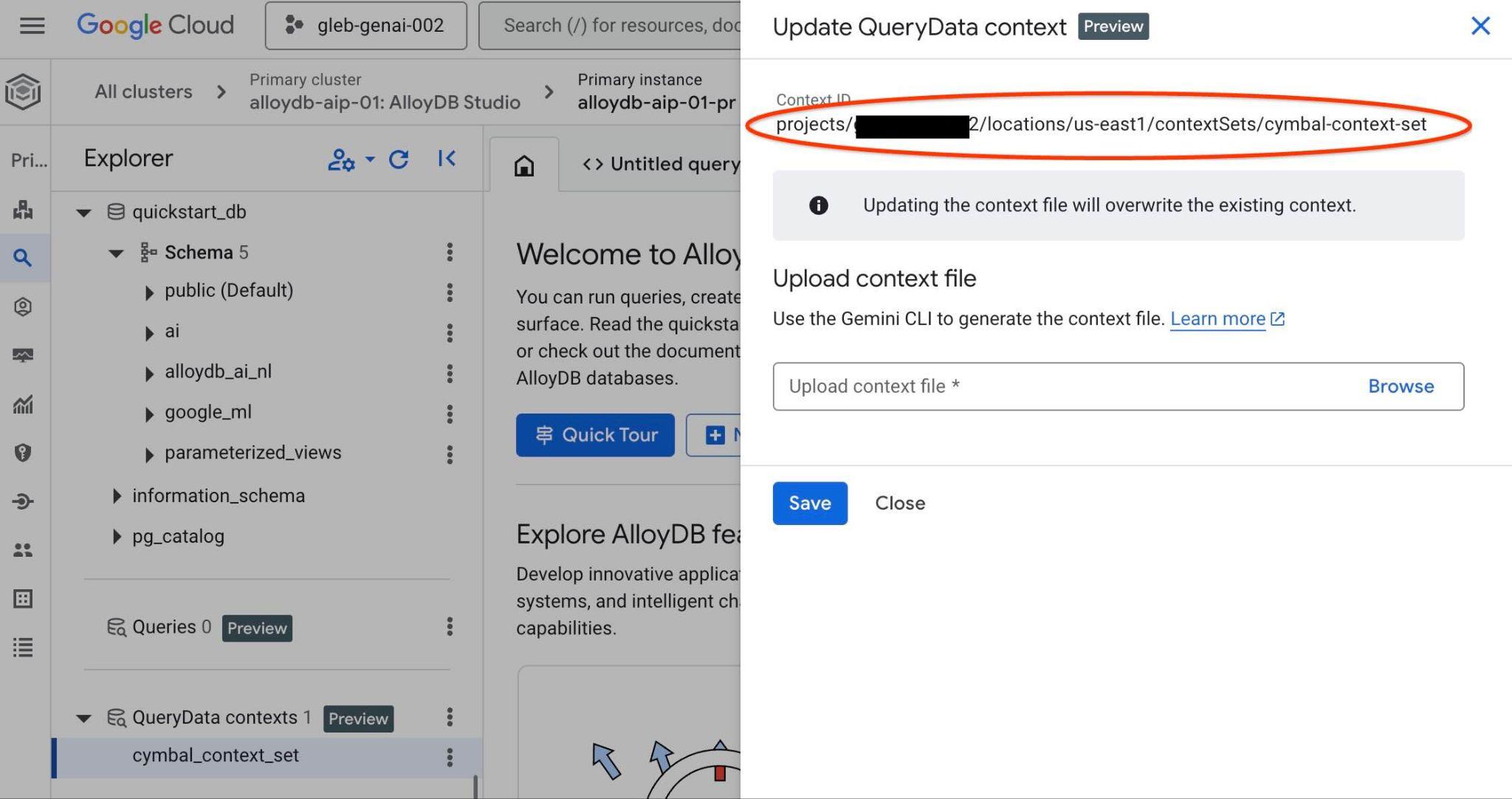
Ce chemin d'accès complet doit être utilisé pour remplacer l'espace réservé "<add-context-set-id>" dans le fichier querydata.yaml.
Revenez au terminal.
Ouvrez un nouvel onglet dans Google Cloud Shell en appuyant sur le bouton "+" en haut de l'interface Google Cloud Shell.
Dans le nouvel onglet, accédez au répertoire contenant le fichier binaire de la boîte à outils et le fichier de configuration tools.yaml, puis démarrez le serveur MCP.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
Exécuter l'agent ADK
Dans le premier onglet Cloud Shell, démarrez l'agent.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Une fois le serveur démarré, cliquez à nouveau sur le lien http://127.0.0.1:8000 .
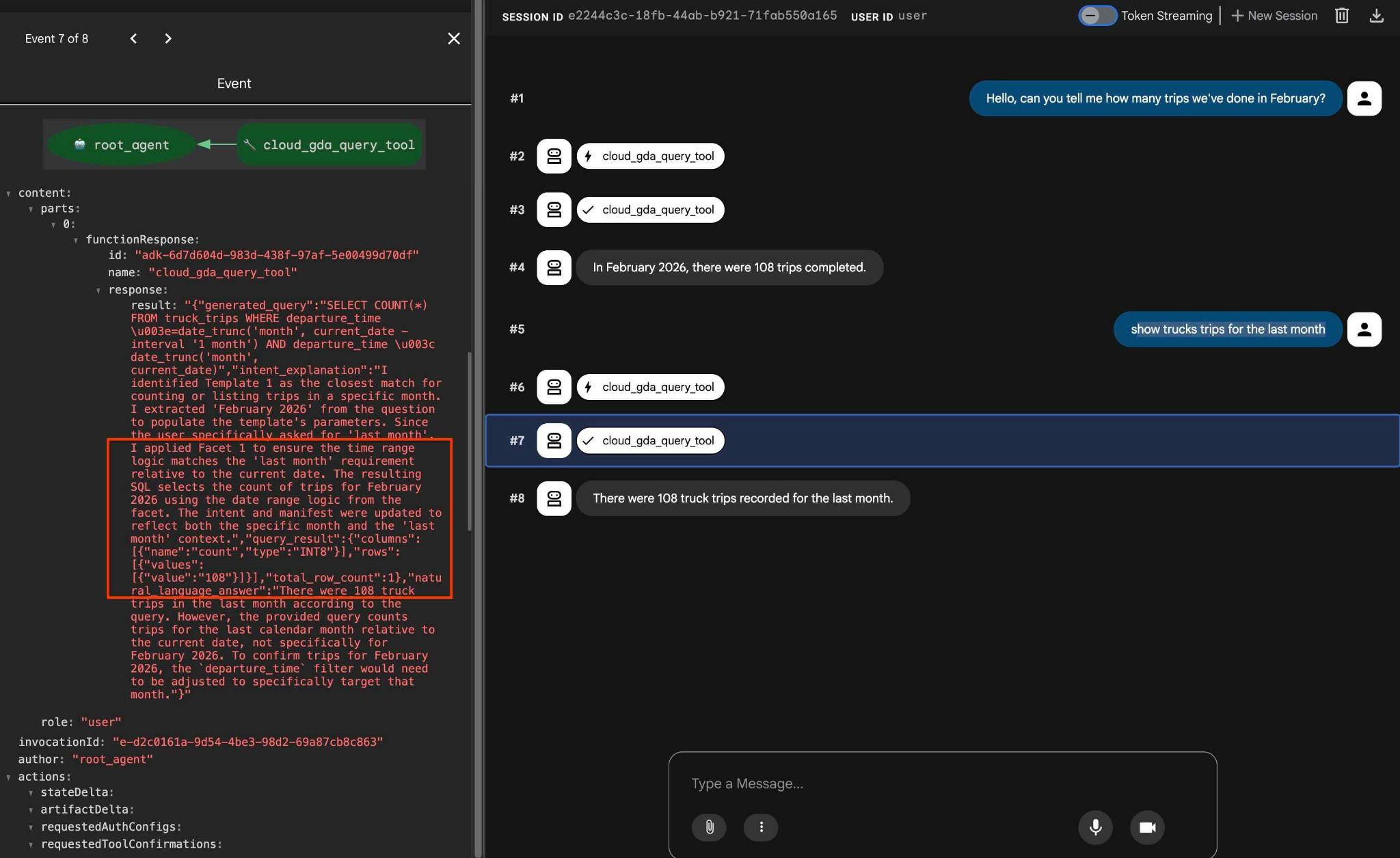
L'interface de l'agent d'aperçu Web ADK, que vous connaissez déjà, s'affiche. Envoyez exactement la même requête que la dernière fois.
Hello, can you tell me how many trips we've done in February?
Découvrez le workflow de l'agent. Si tout est correctement configuré, vous devriez obtenir un résultat semblable à celui-ci.
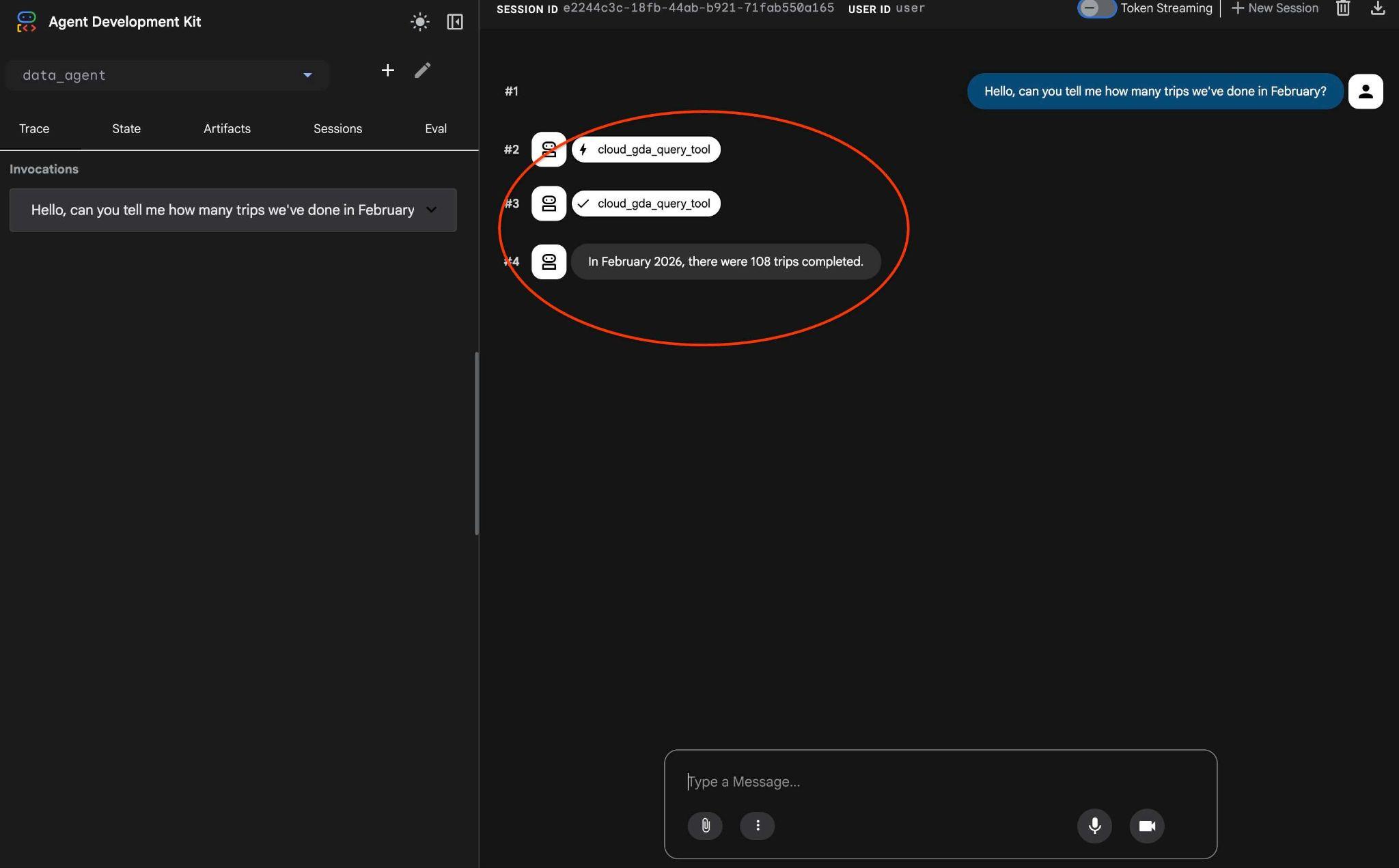
La requête qui a nécessité plusieurs tours la dernière fois a été transformée en un appel à l'outil MCP et exécutée à l'aide d'instructions SQL prévisibles.
Vous pouvez tester les facettes configurées à l'aide d'une requête semblable à celle-ci :
how trucks trips for the last month
Dans le résultat, si vous cliquez sur l'action de l'outil, vous pouvez voir qu'il utilisait le même outil et appliquait des facettes pour obtenir le résultat.
Cet atelier est maintenant terminé. J'espère que vous avez pu parcourir tous les exemples et apprendre à utiliser QueryData pour AlloyDB. La technologie fournie permet de rendre votre charge de travail agentique et la génération de code SQL prévisibles et fiables.
12. Nettoyer l'environnement
Pour éviter des frais inattendus, il est recommandé de nettoyer les ressources temporaires. Le moyen le plus fiable consiste à supprimer le projet dans lequel vous avez testé le workflow. Toutefois, vous pouvez également vous limiter en supprimant des ressources individuelles, telles qu'AlloyDB.
Détruisez les instances et le cluster AlloyDB une fois l'atelier terminé.
Supprimer le cluster AlloyDB et toutes les instances
Si vous avez utilisé la version d'essai d'AlloyDB. Ne supprimez pas le cluster d'essai si vous prévoyez de tester d'autres ateliers et ressources à l'aide de ce cluster. Vous ne pourrez pas créer d'autre cluster d'essai dans le même projet.
Le cluster est détruit avec l'option "force", qui supprime également toutes les instances appartenant au cluster.
Dans Cloud Shell, définissez le projet et les variables d'environnement si vous avez été déconnecté et que tous les paramètres précédents sont perdus :
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Supprimez le cluster :
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Supprimer les sauvegardes AlloyDB
Supprimez toutes les sauvegardes AlloyDB du cluster :
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
13. Félicitations
Bravo ! Vous avez terminé cet atelier de programmation.
Points abordés
- Créer un cluster AlloyDB et importer des exemples de données
- Activer l'API AlloyDB Data Access
- Activer QueryData pour AlloyDB
- Générer des modèles
- Utiliser la recherche par facettes
- Utiliser QueryData avec les agents d'IA
14. Enquête
Résultat :