
1. מבוא
ב-Codelab הזה נסביר איך להתחיל להשתמש ב-QueryData ל-AlloyDB כדי ליצור הצהרות SQL מדויקות וצפויות מקלט של שפה טבעית באפליקציות אקטיביות
דרישות מוקדמות
- הבנה בסיסית של מסוף Google Cloud
- מיומנויות בסיסיות בממשק שורת הפקודה וב-Cloud Shell
מה תלמדו
- איך יוצרים אשכול AlloyDB ומייבאים נתונים לדוגמה
- איך מפעילים את AlloyDB Data access API
- איך מפעילים את QueryData ל-AlloyDB
- איך יוצרים תבניות
- איך משתמשים בחיפוש עם היבטים
- איך משתמשים ב-QueryData עם סוכני AI
מה תצטרכו
- חשבון Google Cloud ופרויקט Google Cloud
- דפדפן אינטרנט כמו Chrome שתומך במסוף Google Cloud וב-Cloud Shell
2. הגדרה ודרישות
הגדרת פרויקט
יצירת פרויקט ב-Google Cloud
- במסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים פרויקט ב-Google Cloud או יוצרים פרויקט.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
מפעילים את Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-Codelab הזה נשתמש ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
ב-מסוף Google Cloud, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה:
אפשר גם ללחוץ על G ואז על S. אם אתם נמצאים במסוף Google Cloud, או אם אתם משתמשים בקישור הזה, רצף הפעולות הזה יפעיל את Cloud Shell.
יחלפו כמה רגעים עד שההקצאה והחיבור לסביבת העבודה יושלמו. בסיום התהליך, אמור להופיע משהו כזה:

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את כל העבודה ב-codelab הזה בדפדפן. לא צריך להתקין שום דבר.
3. לפני שמתחילים
הפעלת ה-API
כדי להשתמש ב-AlloyDB, ב-Compute Engine, ב-Networking services וב-Vertex AI, צריך להפעיל את ממשקי ה-API שלהם בפרויקט בענן של Google Cloud.
במסוף Cloud Shell, מוודאים שמזהה הפרויקט מוגדר:
gcloud config get-value project
המזהה של הפרויקט אמור להופיע בפלט:
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
מגדירים את משתנה הסביבה PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
מפעילים את כל השירותים הנדרשים:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
הפלט הצפוי
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. פריסת AlloyDB
יצירת אשכול AlloyDB ומכונה ראשית. אפשר לפרוס אותו באמצעות סקריפט מוכן שיפרוס את כל המשאבים הנדרשים, או לבצע את הפריסה שלב אחר שלב בעצמכם לפי התיעוד.
פריסת AlloyDB באמצעות סקריפט אוטומטי
בגישה הזו נעשה שימוש בסקריפט אוטומטי לפריסת אשכול AlloyDB, והסקריפט מספק את המידע הנדרש כדי להתחיל לעבוד עם המשאבים שנפרסו.
בטרמינל של Cloud Shell, מריצים את הפקודה כדי לשכפל את סקריפט הפריסה מהמאגר.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
מריצים את סקריפט הפריסה.
./deploy_alloydb.sh --public-ip
הסקריפט יפעל במשך זמן מה – בדרך כלל כ-5 עד 7 דקות – ויפרוס את אשכול AlloyDB ואת המכונה הראשית עם כתובת IP ציבורית ופרטית. כתובת ה-IP הציבורית זמינה רק לרשתות מורשות או באמצעות שרת proxy לאימות של AlloyDB. מידע נוסף על כתובות IP ציבוריות זמין במסמכי התיעוד. הסקריפט צריך לספק כפלט מידע על אשכול AlloyDB שנפרס. חשוב לדעת שהסיסמה תהיה שונה – כדאי לרשום את הסיסמה איפשהו לשימוש עתידי.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
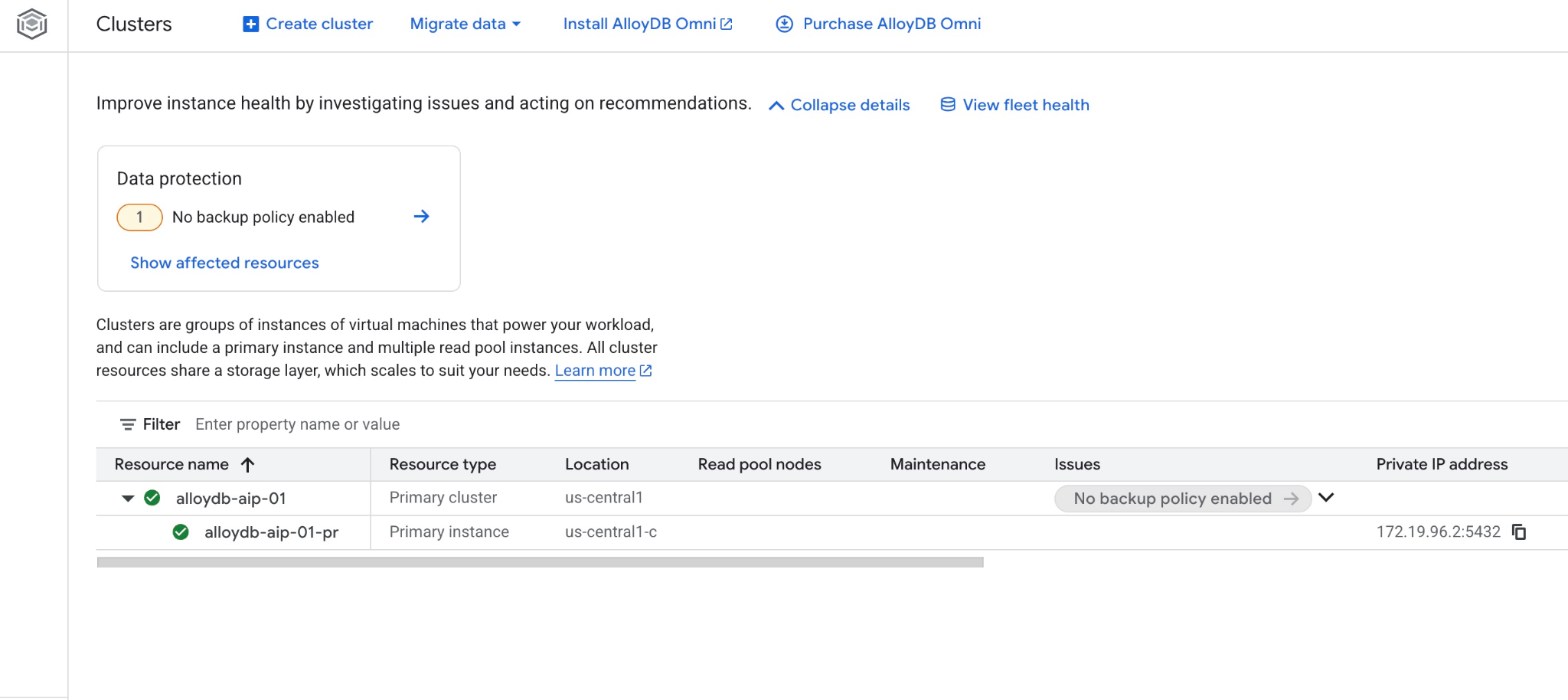
אפשר גם לראות את האשכול החדש ואת המופע הראשי במסוף האינטרנט.
5. הכנת מסד הנתונים
כדי להשתמש בפונקציות ובאופרטורים של AI, צריך להפעיל את השילוב עם Vertex AI, להפעיל את Data access API וליצור מסד נתונים למערך נתונים לדוגמה.
מתן ההרשאות הנדרשות ל-AlloyDB
מוסיפים הרשאות ל-Vertex AI לסוכן השירות של AlloyDB.
פותחים כרטיסייה נוספת ב-Cloud Shell באמצעות הסימן '+' בחלק העליון.
בכרטיסייה החדשה של Cloud Shell, מריצים את הפקודה:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
הפלט הצפוי במסוף:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
הפעלת Data Access API
כדי להשתמש בכלי MCP כמו execute_sql, צריך להפעיל את Data Access API באשכול AlloyDB.
בכרטיסיית המסוף, מריצים את הפקודה.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
הפעלת אימות IAM
אנחנו הולכים להשתמש באימות IAM עבור כלי ה-Agent שלנו, ולכן צריך להפעיל את אימות IAM במופע ולהוסיף את עצמכם כמשתמש במסד הנתונים. לפני שמפעילים את אימות IAM ברמת המופע, צריך להמתין עד לסיום השלב הקודם של הפעלת ה-API לגישה לנתונים. סטטוס המכונה צריך להיות ירוק.
אנחנו מתחילים בהפעלת IAM ברמת המופע. בכרטיסיית המסוף, מריצים את הפקודה.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
מוסיפים את עצמכם כמשתמש AlloyDB:
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
סוגרים את הכרטיסייה באמצעות הפקודה 'exit' בכרטיסייה:
exit
התחברות ל-AlloyDB Studio
בפרקים הבאים אפשר להריץ את כל פקודות ה-SQL שדורשות חיבור למסד הנתונים ב-AlloyDB Studio. T
עוברים אל הדף Clusters (אשכולות) ב-AlloyDB ל-Postgres.
כדי לפתוח את ממשק מסוף האינטרנט של אשכול AlloyDB, לוחצים על המופע הראשי.
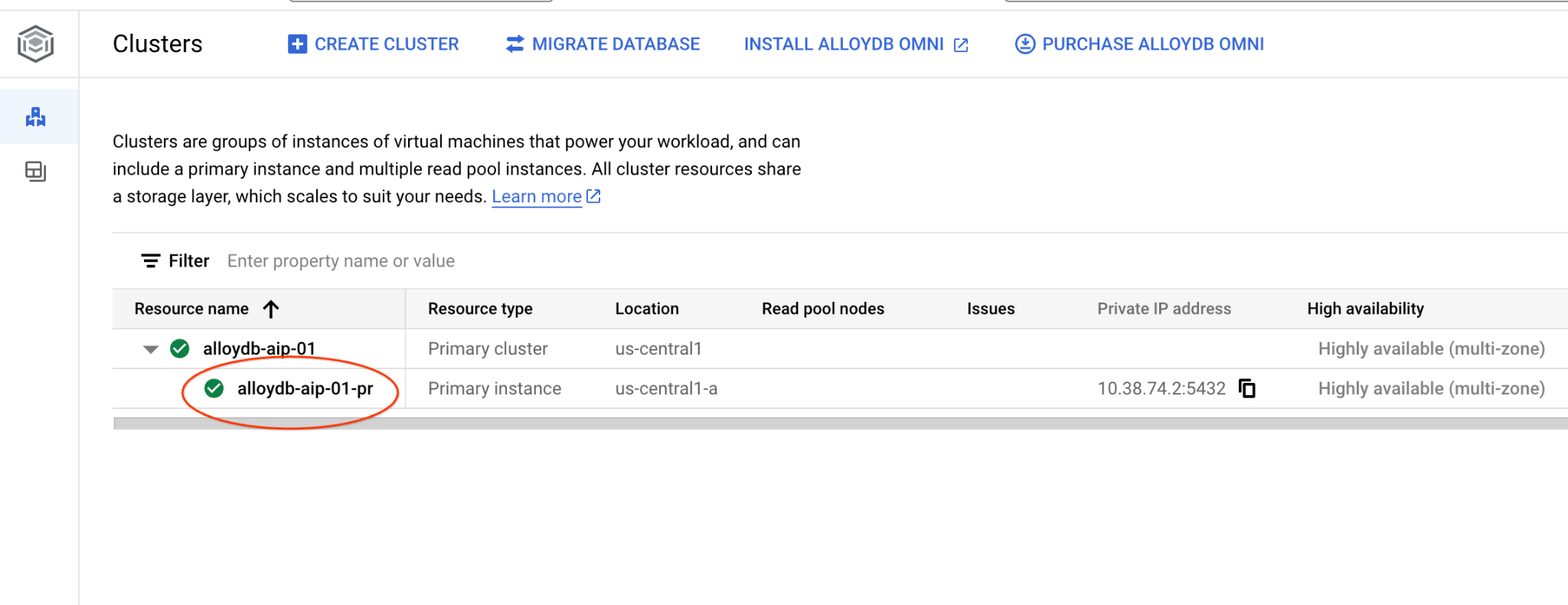
אחר כך לוחצים על AlloyDB Studio בצד ימין:
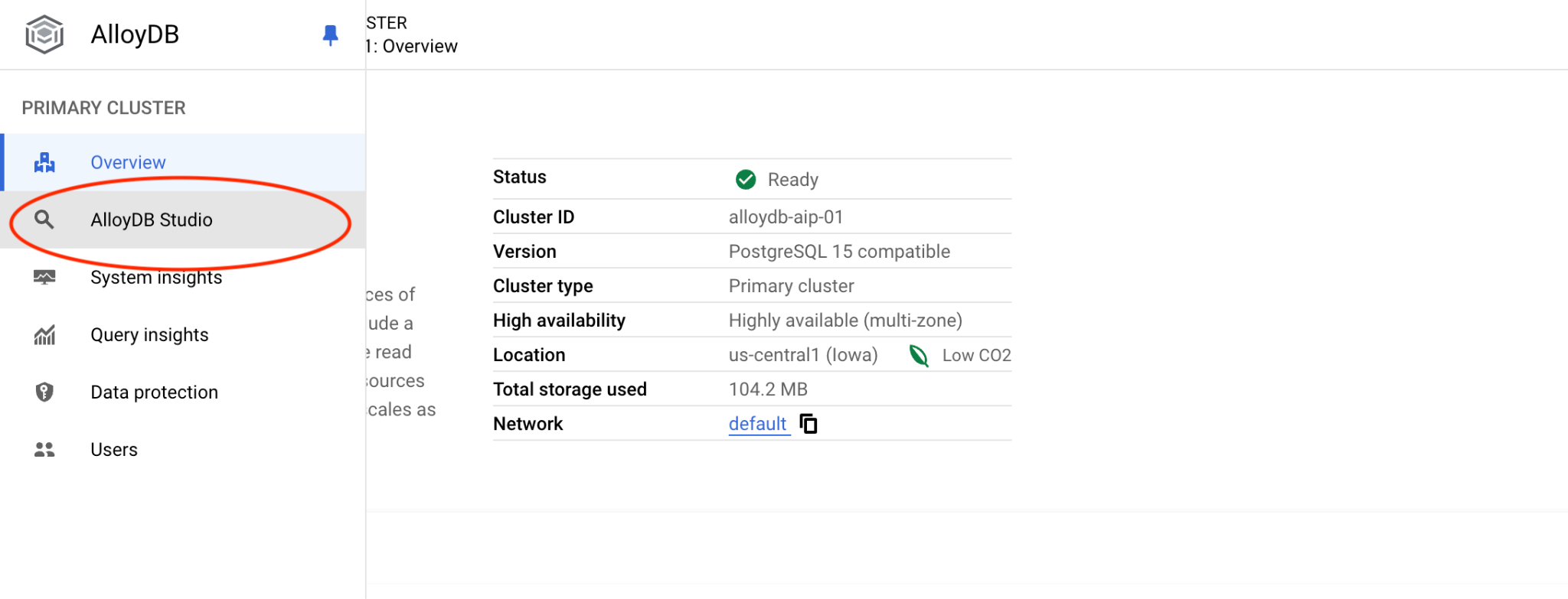
בוחרים את מסד הנתונים של postgres ואת אימות IAM. לאחר מכן לוחצים על הלחצן 'אימות'.
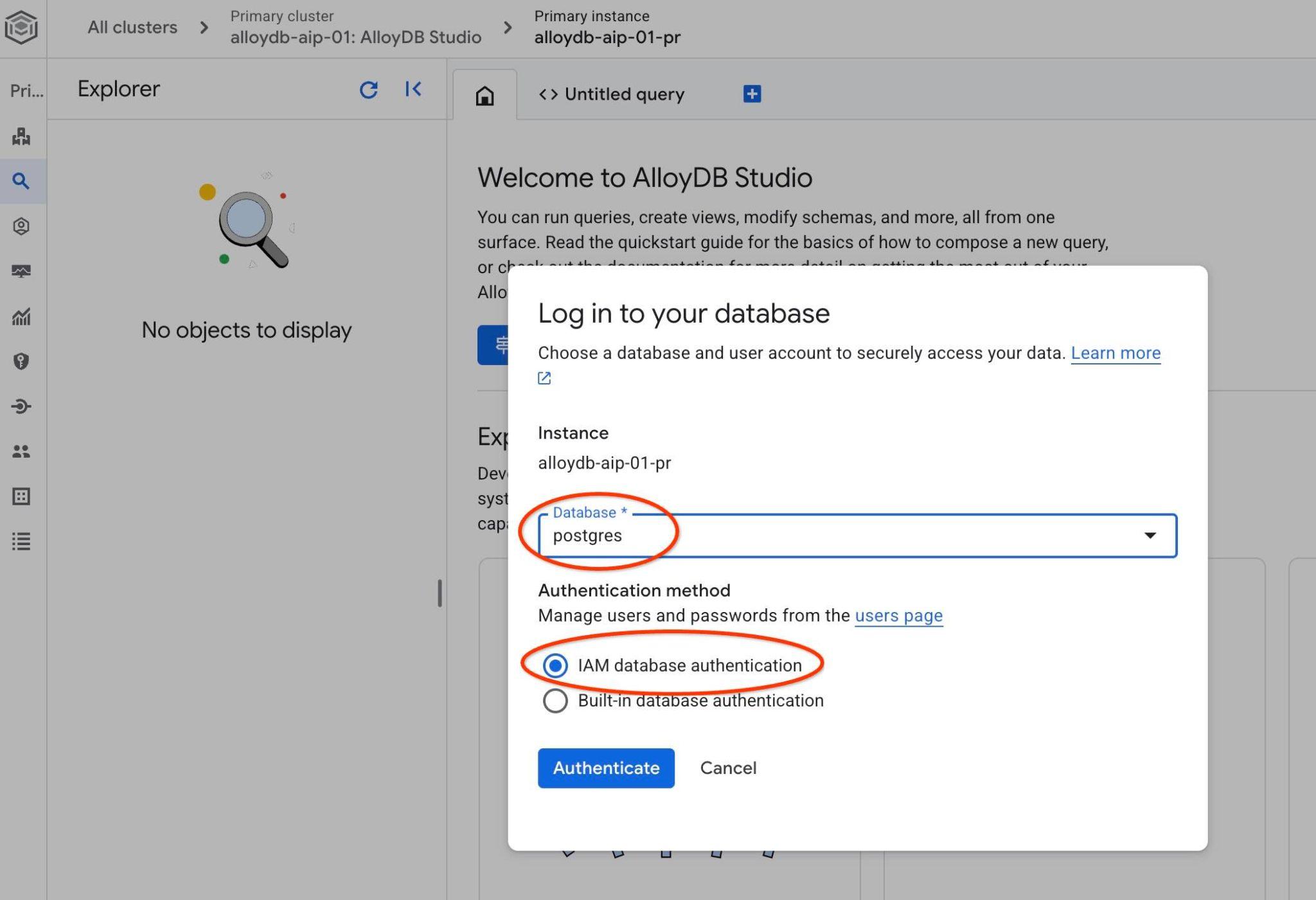
ממשק AlloyDB Studio ייפתח. כדי להריץ את הפקודות במסד הנתונים, לוחצים על הכרטיסייה 'שאילתה ללא שם' בצד ימין.
ייפתח ממשק שבו אפשר להריץ פקודות SQL
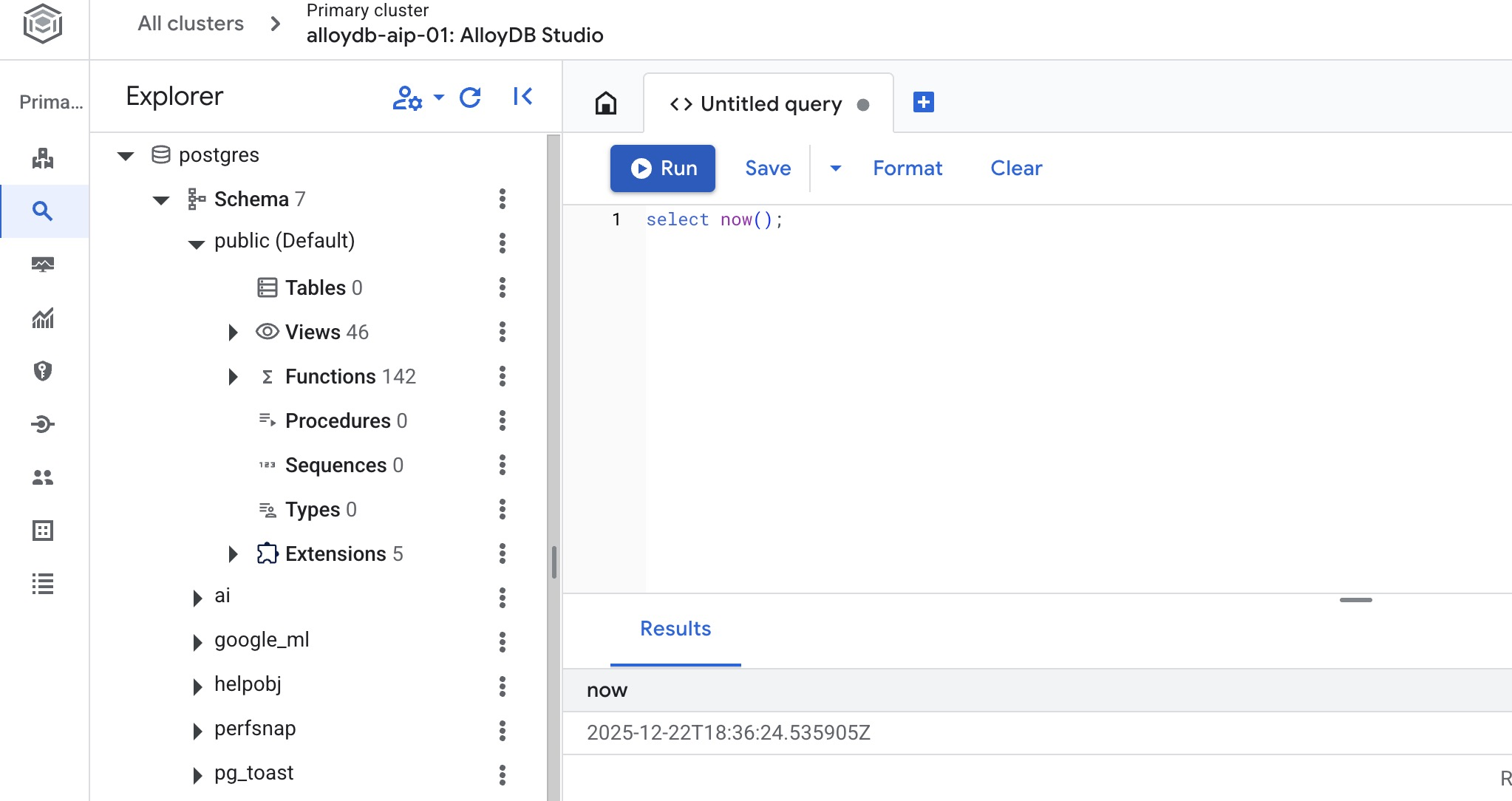
יצירת מסד נתונים
יצירת מסד נתונים – מדריך למתחילים
בעורך של AlloyDB Studio, מריצים את הפקודה הבאה.
יצירת מסד נתונים:
CREATE DATABASE quickstart_db
הפלט אמור להיראות כך:
Statement executed successfully
התחברות ל-quickstart_db
כדי לבדוק אם מסד הנתונים נוצר, מתחברים אליו. מתחברים מחדש לסטודיו באמצעות הלחצן להחלפת משתמש/מסד נתונים.
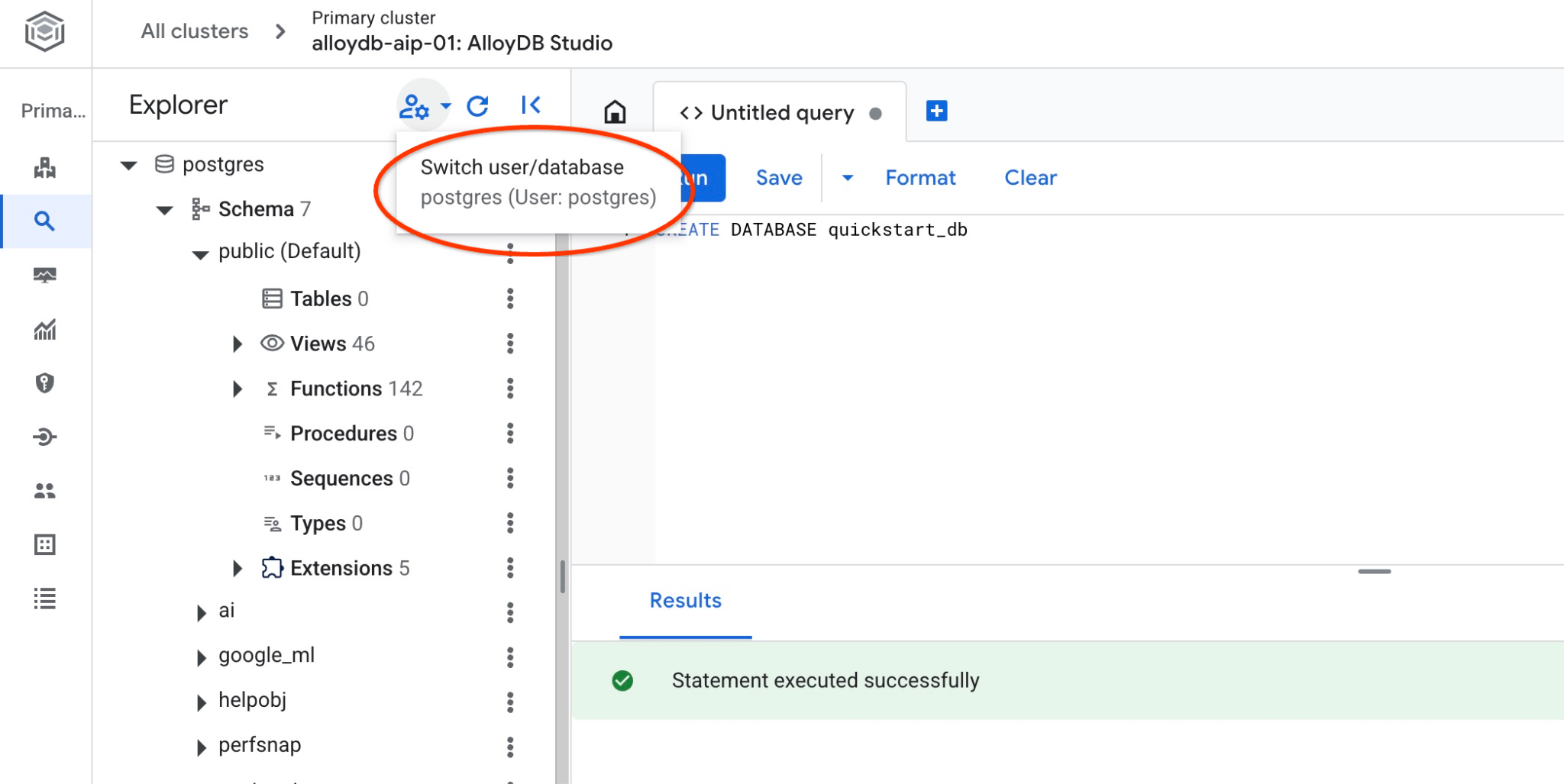
בוחרים את מסד הנתונים החדש quickstart_db מהרשימה הנפתחת ומשתמשים באותו אימות IAM.
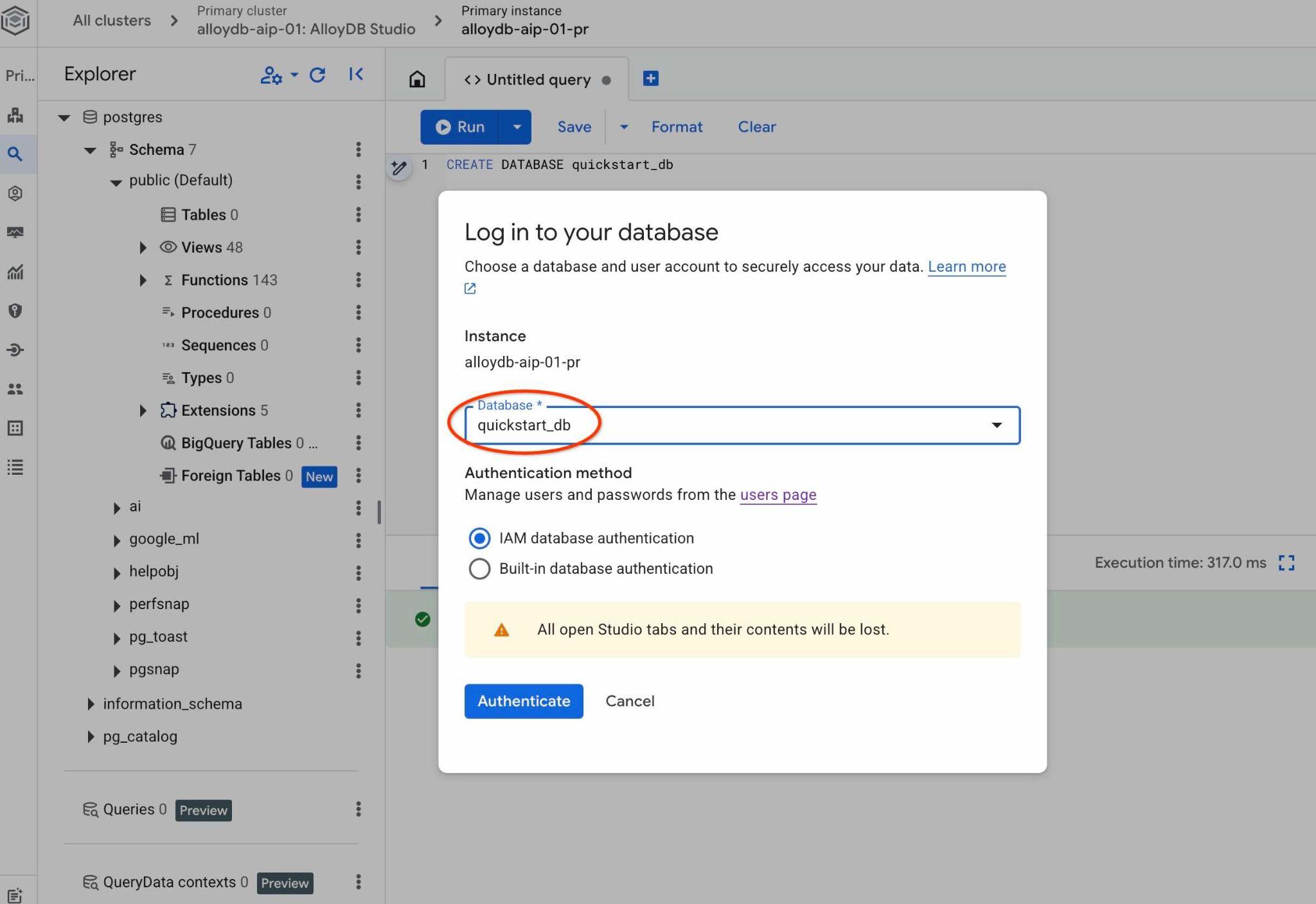
תיפתח לכם כרטיסייה חדשה שבה תוכלו לעבוד עם אובייקטים ממסד הנתונים quickstart_db. שם תוכלו לבדוק את הסכימה והנתונים שיובאו ולעבוד עם קבוצות הקשר של QueryData.
6. נתונים לדוגמה
עכשיו צריך ליצור אובייקטים במסד הנתונים ולטעון נתונים. תשתמשו במערך נתונים פיקטיבי של חברת Cymbal Shipping. היא כוללת נתונים פיקטיביים על מוצרים, משאיות, בקשות ונסיעות משאיות, וגם על נהגים פיקטיביים.
יצירת קטגוריית אחסון
תשתמשו ב-Google SDK (gcloud) כדי לייבא נתונים מהמאגר המשוכפל למסד הנתונים של AlloyDB. לשם כך, תצטרכו ליצור קטגוריה של Cloud Storage ולהעניק גישה לחשבון השירות של AlloyDB. אפשר גם לנסות לעשות את זה באמצעות מסוף האינטרנט, כמו שמתואר במסמכי התיעוד.
בטרמינל של Google Cloud Shell, מריצים את הפקודה:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
טעינת נתונים
השלב הבא הוא טעינת הנתונים. קובץ ה-SQL dump הדחוס שלנו נמצא בתיקיית המאגר המשוכפל. הפקודה הבאה מניחה שהשתמשתם בספריית הבית כנקודת התחלה כששיכפלתם את המאגר בשלב הקודם במהלך יצירת אשכול AlloyDB.
מעתיקים את קובץ ה-SQL הדחוס לקטגוריית האחסון החדשה:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
לאחר מכן טוענים את הנתונים למסד הנתונים quickstart_db:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
הפקודה תטען את מערך הנתונים לדוגמה למסד הנתונים quickstart_db. אפשר לאמת את הטבלאות והרשומות באמצעות AlloyDB Studio.
7. עבודה עם סוכן הנתונים
נתחיל מסוכן AI לדוגמה שנוצר באמצעות Google ADK ל-Python ומתחבר למופע AlloyDB באמצעות MCP Toolbox for Databases.
התקנה של MCP Toolbox for Databases
MCP Toolbox for databases הוא פרויקט קוד פתוח שמספק תמיכה ב-MCP למנועי מסדי נתונים רבים, כולל AlloyDB ל-PostgreSQL. מידע על MCP Toolbox זמין במסמכי התיעוד.
צריך להוריד את הגרסה העדכנית של התוכנה לפלטפורמה שלכם. כדי לראות את הגרסה העדכנית, אפשר לעיין בדף הגרסאות. בדוגמה הבאה אפשר לראות איך להוריד את גרסה 31 של MCP Toolbox ל-Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
צריך להכין קובץ תצורה לערכת הכלים. יש לנו קובץ tools.yaml.example לדוגמה בספרייה הנוכחית, ואנחנו הולכים להכין קובץ tools.yaml על ידי החלפה של שני placeholders במזהה הפרויקט ובאזור.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
הפעלת MCP Toolbox for Databases
עכשיו אפשר להפעיל את ערכת הכלים של MCP עם קובץ התצורה המוכן.
פותחים כרטיסייה חדשה ב-Google Cloud Shell על ידי לחיצה על הלחצן '+' בחלק העליון של ממשק Google Cloud Shell.
בכרטיסייה החדשה, עוברים לספרייה עם קובץ בינארי של ערכת הכלים וקובץ ההגדרות tools.yaml ומפעילים את שרת ה-MCP.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
הפלט אמור להיראות כך: "Server ready to serve!"
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
בדיקת קוד המקור של הסוכן
בכרטיסייה הראשונה בתיקיית המאגר המשוכפל, בודקים את קוד הסוכן באמצעות Google Cloud Shell Editor.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
אפשר לראות באגנט שיש לנו קטע לשרת Google Cloud MCP ל-AlloyDB. אנחנו מספקים נקודת קצה בתור MCP_SERVER_URL, אימות, מזהה פרויקט ומוסיפים אותה לערכת הכלים של MCP.
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
ובקוד הסוכן, ערכת הכלים של MCP נכללת כפרמטר tools של הסוכן. בנוסף, יש שמות של אשכולות ומופעים, האזור ומסד הנתונים כמשתנים בהנחיה של הסוכן.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
אחרי שבודקים את הקוד, חוזרים למסוף על ידי לחיצה על הלחצן 'פתיחת מסוף' בפינה השמאלית העליונה של חלון העריכה.
הפעלת הנציג
עכשיו אפשר להפעיל את הסוכן במצב אינטראקטיבי באמצעות ממשק האינטרנט של Google ADK. ממשק האינטרנט של ADK מאפשר לבדוק את תהליכי העבודה של הסוכנים ולפתור בעיות שקשורות אליהם.
קודם נתקין את כל החבילות הנדרשות ל-Python באמצעות מנהל החבילות uv.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
אחרי שמתקינים את כל החבילות, צריך להוסיף קובץ .env לספריית הסוכן כדי להנחות אותו להשתמש ב-Vertex AI לכל התקשורת עם מודלים של AI.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
אחר כך אפשר להפעיל את הסוכן.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
אמור להופיע פלט כמו זה שבהמשך, עם נקודת הקצה כמו http://127.0.0.1:8000 .
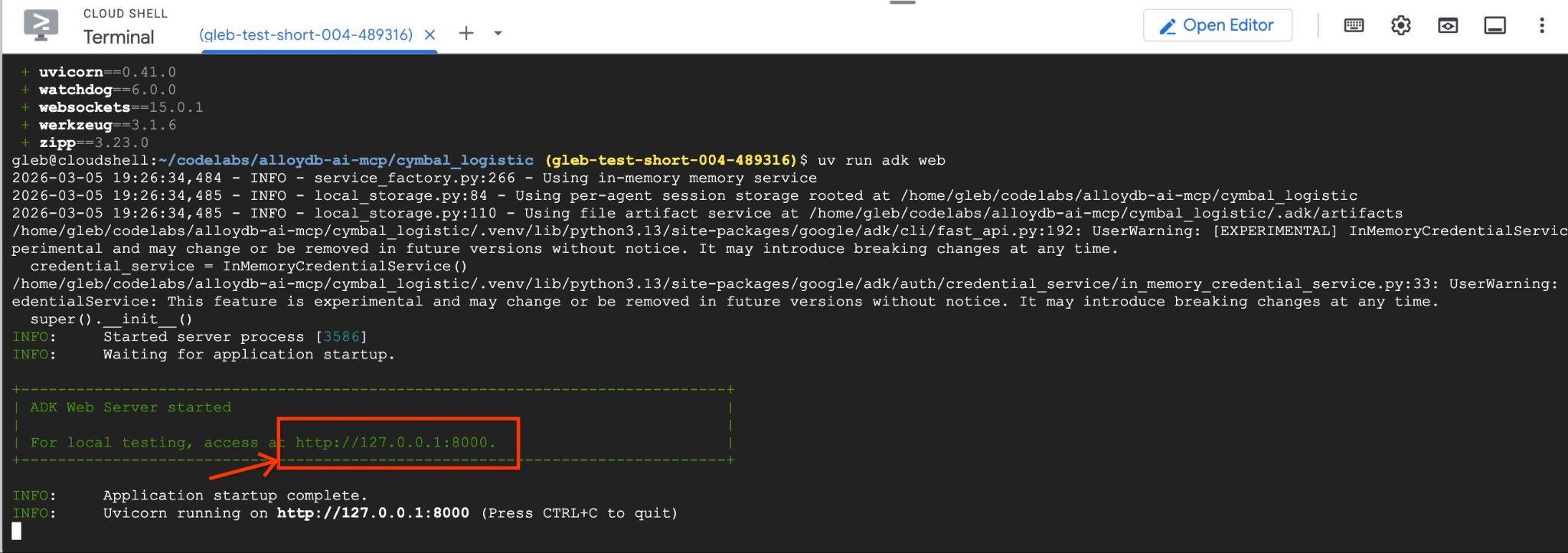
אפשר ללחוץ על כתובת ה-URL הזו ב-Cloud Shell, והיא תיפתח בחלון תצוגה מקדימה בכרטיסייה נפרדת בדפדפן. שם תוכלו לבחור את data_agent מתוך הרשימה הנפתחת בצד ימין.
בממשק האינטרנט של ADK אפשר לפרסם את השאלות בפינה הימנית התחתונה ולראות את כל תהליך ההפעלה, כולל העקבות של כל שלב בצד שמאל.
8. בדיקת NL2SQL ללא QueryData ל-AlloyDB
הסוכן מאפשר לכם לשאול שאלות בפריסה גמישה באמצעות שפה טבעית, והוא ישתמש ב-MCP toolbox for databases ככלי למענה על השאלות. השאלות מוצגות בפינה השמאלית התחתונה, והתשובה עם כל הקריאות לכלים תופיע בחלק העליון.
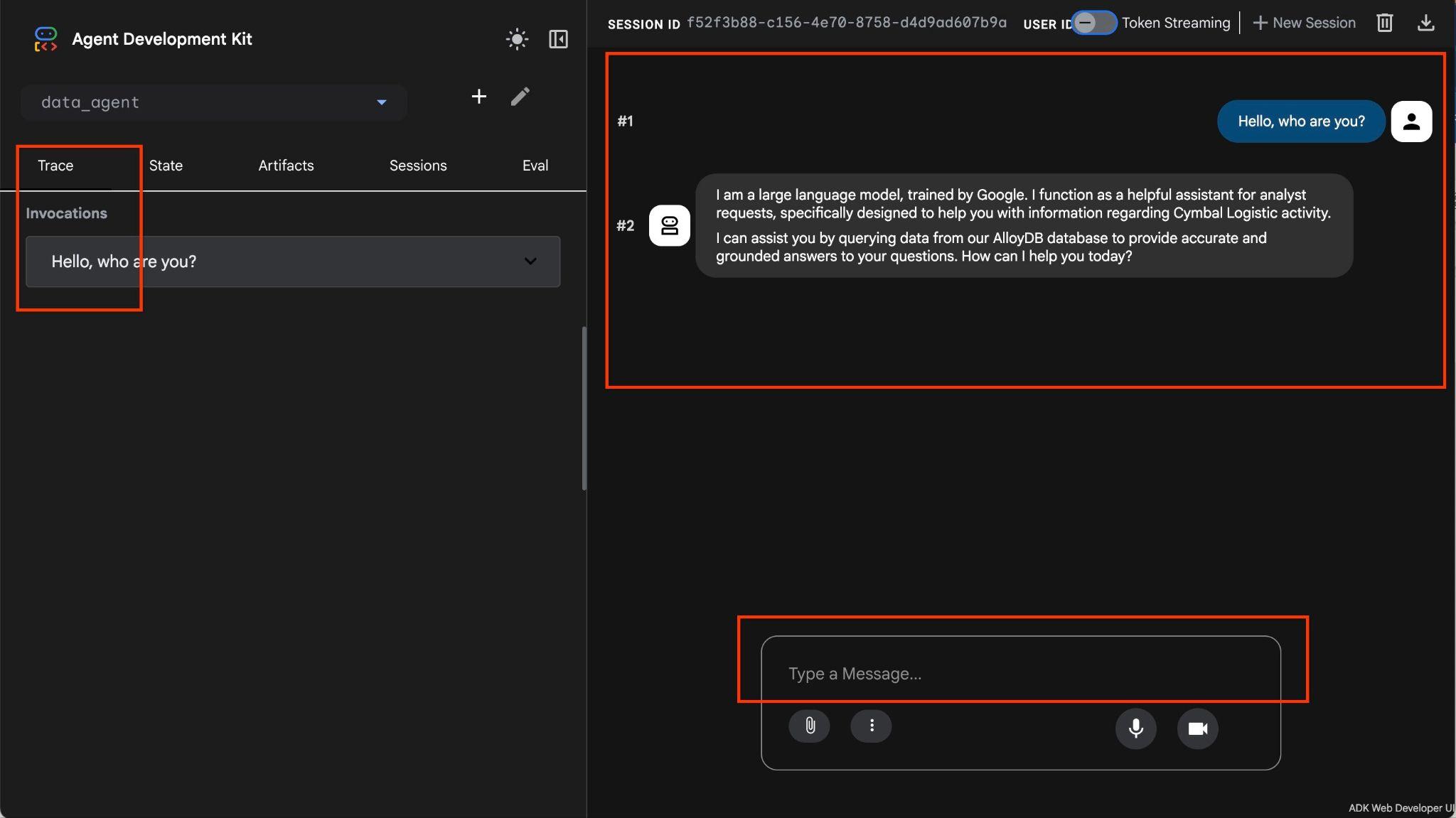
אתם עובדים עם נתונים תפעוליים של חברת משלוחים, שכוללים מידע על בקשות משלוח, משאיות, נהגים ונסיעות שבוצעו על ידי הנהגים. השאלה הראשונה היא לגבי מספר הנסיעות שבוצעו בפברואר 2026.
בשדה להזנת קלט בצד שמאל למטה, מקלידים את הפקודה הבאה ומקישים על Enter.
Hello, can you tell me how many trips we've done in February?
הסוכן יבצע כמה קריאות לכלים כדי לזהות את הטבלאות הנכונות בסכימה באמצעות list_cymbal_logistics_schemas_tool ו-execute_sql_tool, ויבצע כמה הצהרות SQL כדי לקבל את הנתונים הנכונים.
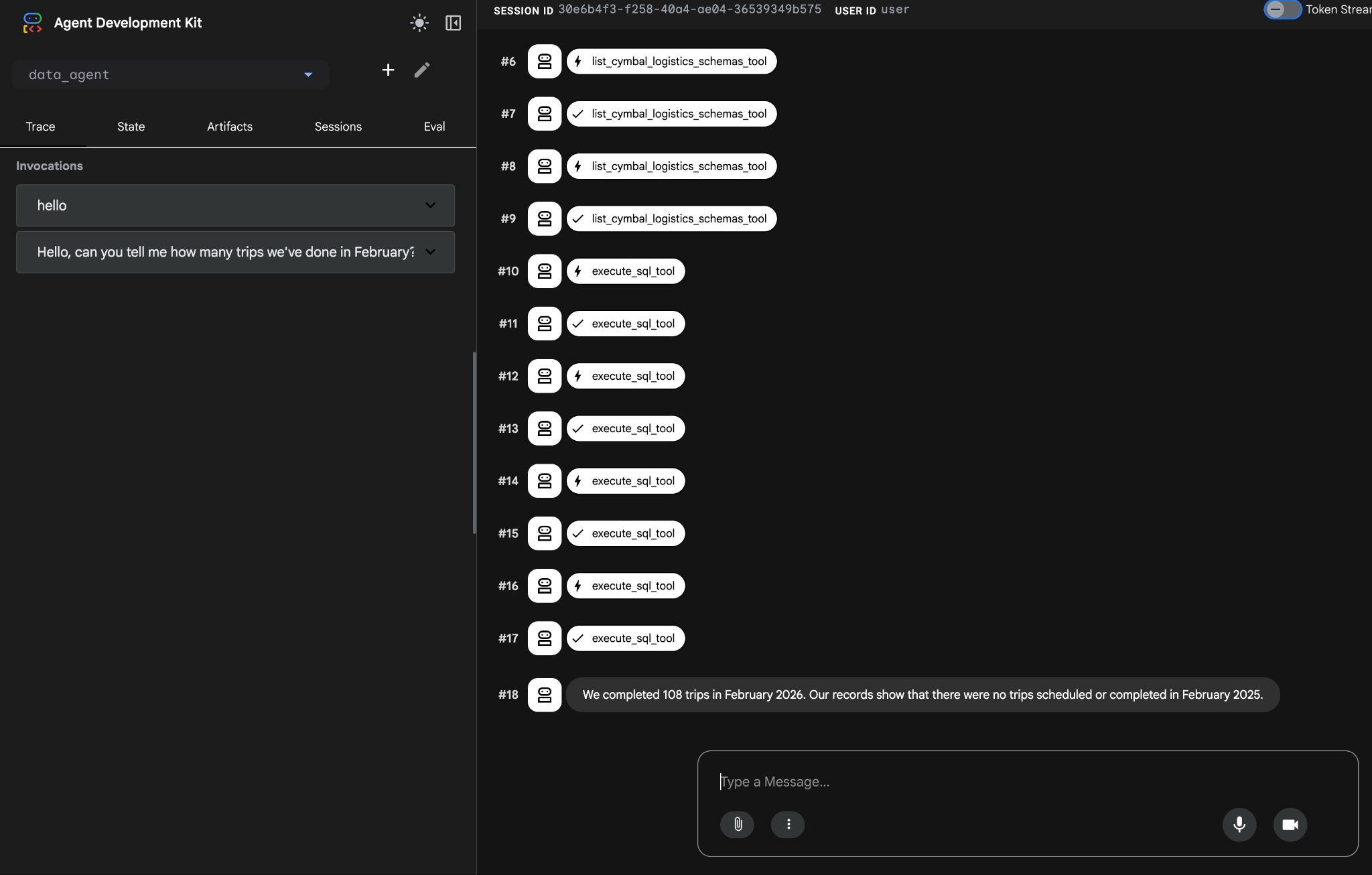
בסופו של דבר, הוא יפיק את התוצאה הנכונה אחרי שיבנה את השאילתה המתאימה ויריץ אותה במסד הנתונים.
השלמנו 108 נסיעות בפברואר 2026. לפי הרישומים שלנו, לא היו נסיעות מתוזמנות או נסיעות שהושלמו בפברואר 2025.
כדי לראות מה כל קריאה לכלי עושה, לוחצים על הפעלת הכלי. לדוגמה, הנה השאילתה שהופעלה כדי לקבל את התוצאות שלנו.
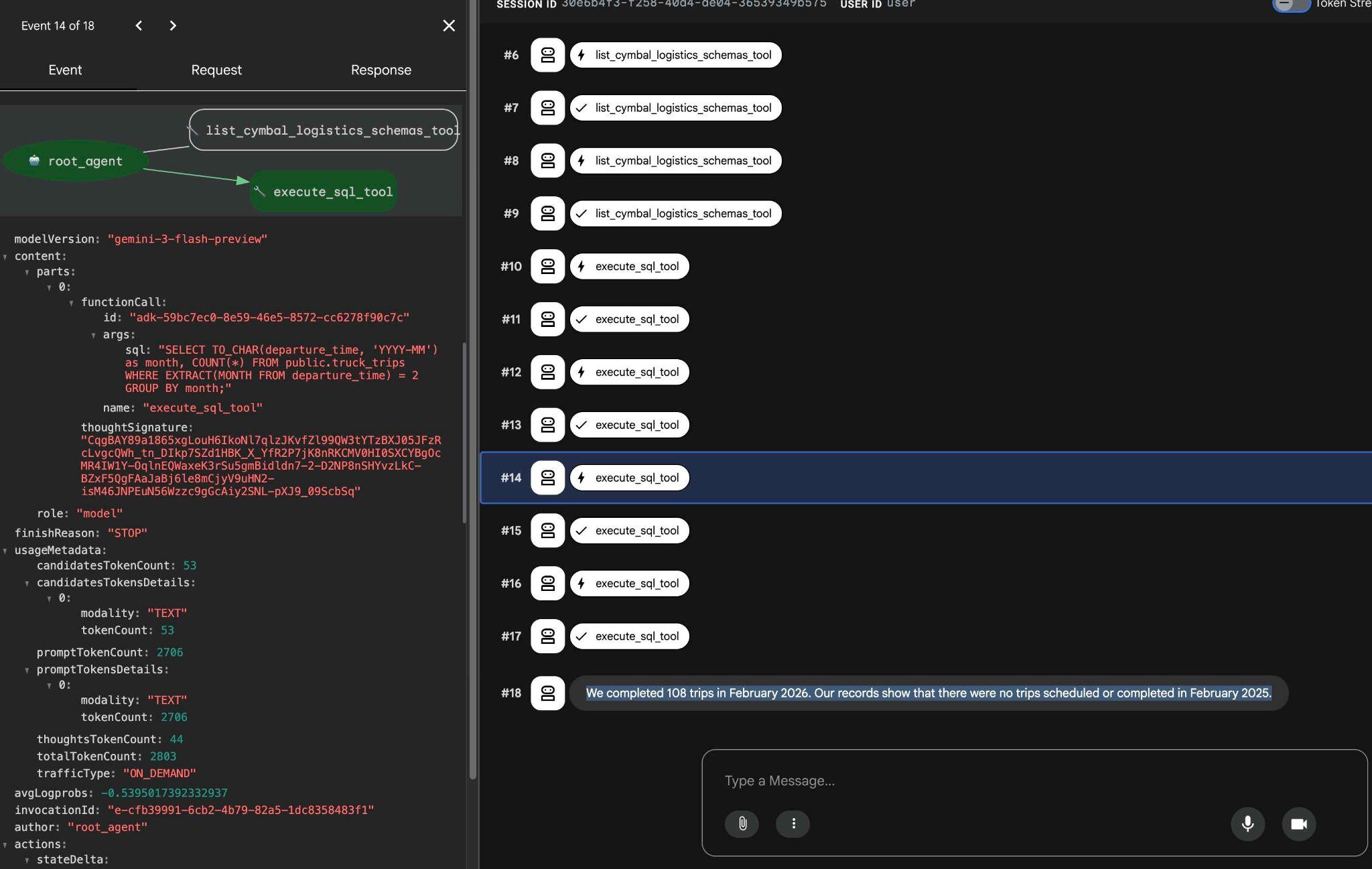
נסו להשתמש בממשק האינטרנט של ADK כדי להגיש בקשות פשוטות אחרות ולראות איך הוא מבצע שאילתות שונות כדי להשיג את התוצאות.
כדי לעצור את הסוכן, לוחצים על ctrl+c בטרמינל. אפשר לסגור את הכרטיסייה בדפדפן עם ממשק האינטרנט של ADK.
אפשר גם להפסיק את MCP Toolbox בכרטיסייה השנייה על ידי לחיצה על אותם מקשי קיצור ctrl+c וסגירת הכרטיסייה השנייה.
בשלב הבא ניצור הקשר QueryData כדי לשפר את התשובה והביצועים של NL2SQL.
9. יצירת QueryData ContextSet
בשלב הקודם ראינו שמודל ה-AI ביצע כמה קריאות לסכימת המידע של מסד הנתונים כדי להבין באילו טבלאות ועמודות עליו להשתמש כדי לבנות את שאילתת ה-SQL. כדי לשפר את הביצועים והדיוק ולהפוך את התוצאה לצפויה יותר, נוסיף את ההקשר של QueryData שמגדיר איזו שאילתה צריך להריץ בתגובה לבקשה מסוימת.
יצירת תבניות ממוקדות
ה-ContextSet QueryData הוא קובץ JSON עם תבניות של שאילתות ופנים שנותנים למודל ה-AI את הנתונים וההנחיות הדרושים כדי להשתמש בשאילתת SQL נכונה או בחלקים נכונים של שאילתת SQL, כדי להשיג את המטרות המבוקשות על סמך דפוסי שאילתות ומבנה נתונים.
מתחילים מתבנית מטורגטת. יוצרים קובץ באמצעות עורך Cloud Shell. בטרמינל של Cloud Shell, מריצים את הפקודה.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
מוסיפים את התבנית לשאילתת השפה הטבעית שבה השתמשנו בפרק הקודם – "כמה נסיעות ביצענו בפברואר?"
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
לאחר מכן מורידים את התבנית למחשב מ-Cloud Shell באמצעות לחצן ההורדה.
טעינת קבוצות של הקשר QueryData
כדי להשתמש במערכי ההקשר QueryData שלנו, צריך להעלות אותם למסד הנתונים.
פותחים את AlloyDB Studio. בחלונית הימנית, בחלק התחתון, יופיעו הסמל QueryData Context ושלוש נקודות.
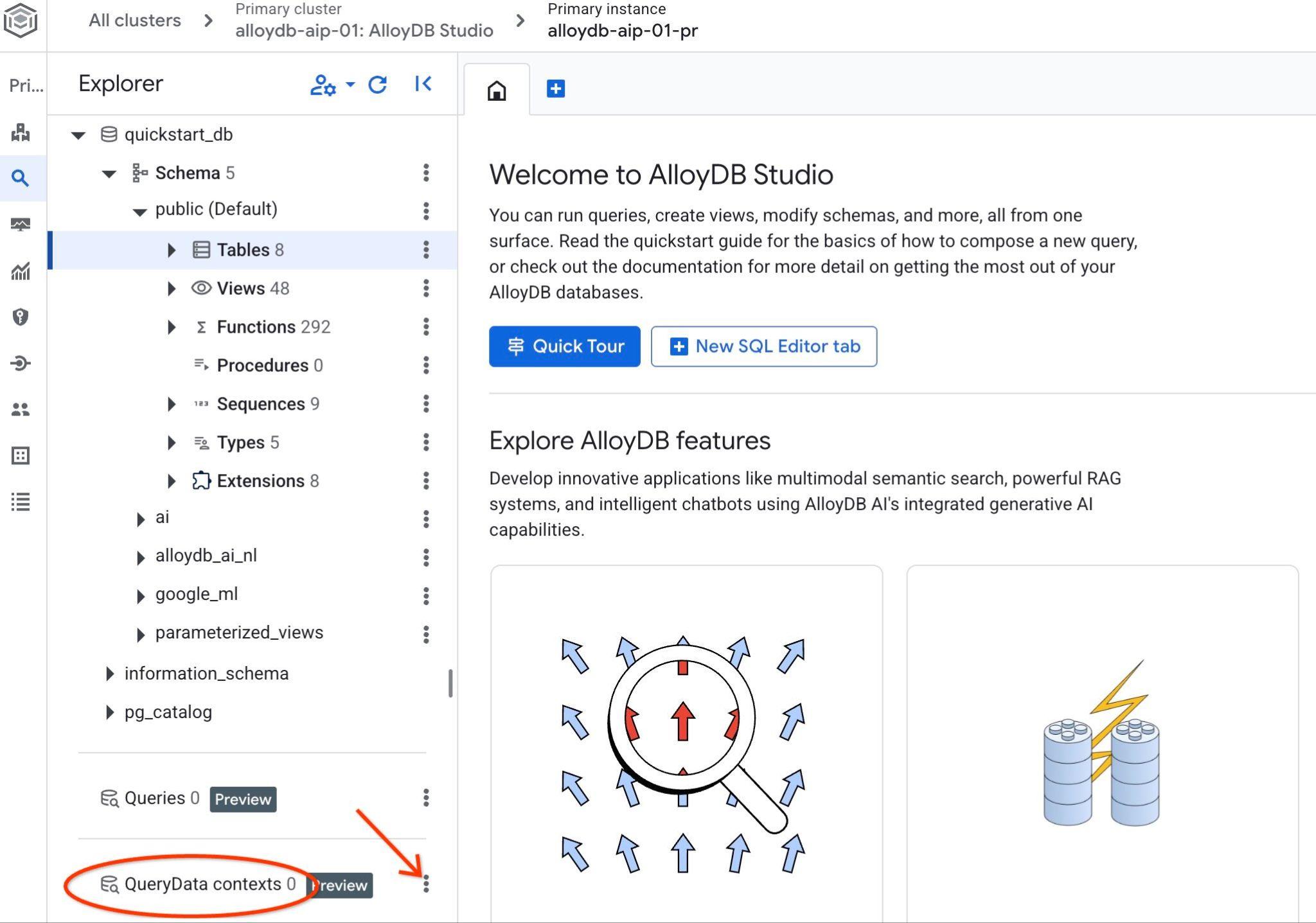
לוחצים על שלוש הנקודות ובוחרים באפשרות 'יצירת הקשר'. תיפתח תיבת דו-שיח שבה צריך להזין
- שם:
cymbal_context_set - תיאור:
Cymbal Logistic Query Data - העלאת קובץ הקשר: לוחצים על הלחצן
Browseובוחרים את קובץ ה-JSON עם QueryData ContextSet
כשלוחצים על לחצן השמירה, יכול להיות שיעבור זמן עד שהאחסון של ההקשר יופעל, אם עושים את זה בפעם הראשונה.
אפשר לראות את ההקשר שהורד, ואם לוחצים על שלושת הלחצנים האנכיים בצד ימין, מוצגות הפעולות הזמינות. בפרק הבא נתחיל מהפעולה Test context (בדיקת ההקשר).
10. בדיקה של קבוצת ההקשרים של QueryData
תבנית בדיקה
משתמשים בפעולה Test context כדי לבדוק את ההקשר שלנו ב-AlloyDB Studio. כשלוחצים על 'בדיקת ההקשר', נפתח חלון חדש של עורך AlloyDB Studio עם הכותרת cymbal_context_set וההזמנה ליצירת SQL עם Gemini שכותרתה Generate SQL using QueryData context: cymbal_context_set. לוחצים על יצירת SQL ומקלידים
Hello, can you tell me how many trips we've done in February?
אחרי שנוצר ה-SQL, לוחצים על הלחצן Insert.
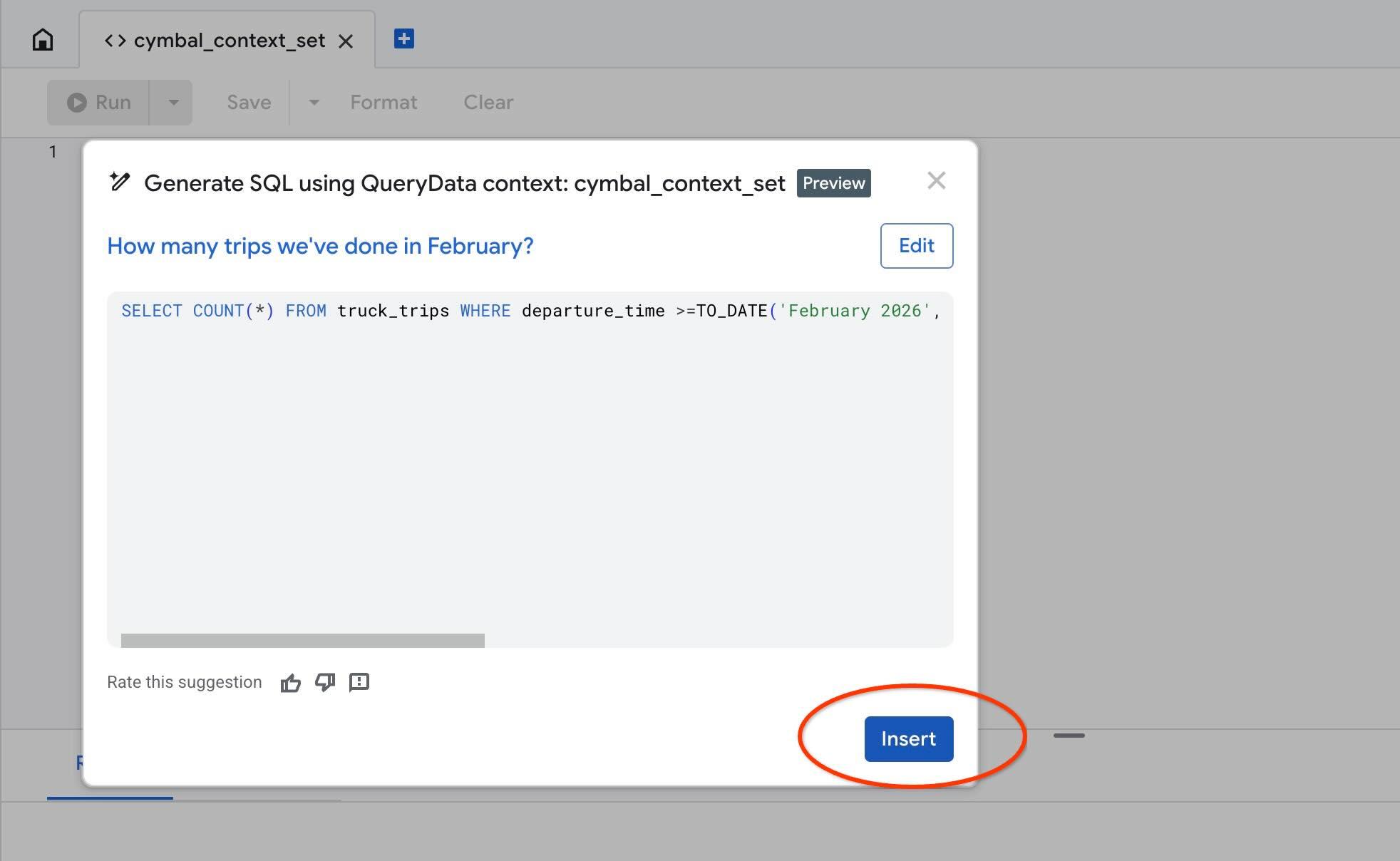
תראו בדיוק את אותה שאילתה שהזנו לתבנית ההקשר שלנו קודם.
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
מנסים להחליף את החודש ב-"January" ובודקים את הצהרת ה-SQL שנוצרה. הוא ישתמש בחודש כפרמטר לכוונת המשתמש עם הפרמטרים, ויבצע התאמה אוטומטית של הצהרת ה-SQL.
Build QueryData Facets
ניסינו תבנית לשאילתה והיא עובדת כשאנחנו יודעים איזה סוג של בקשת משתמש צפויה. אבל לפעמים כדאי להנחות רק חלק מהשאילתה, כמו תנאי או מסנן, אם אנחנו מעדיפים להשתמש בסדר מסוים או בסעיף מסוים כדי להגדיר מחדש את הכוונה.
לדוגמה, אם נבקש להחזיר נתונים עבור 'החודש שעבר', נרצה לקבל את הדוח עבור החודש הקלנדרי האחרון מהיום הראשון עד היום האחרון של אותו חודש, ולא עבור 30 הימים האחרונים.
אנחנו יכולים להוסיף היבטים כאלה כמו קטע SQL להגדרת ContextSet יחד עם התבנית שהוספנו קודם. פותחים את הקובץ querydata_cymbal_contextset.json.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
ואז מוסיפים את ההיבטים אחרי התבניות הקיימות. התוכן שיתקבל בקובץ צריך להיות כזה
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
שומרים את הקובץ ומעלים אותו למחשב.
לאחר מכן משתמשים בפעולה 'עריכת ההקשר' של השאילתה ומעלים את הקובץ ששונה כדי להחליף את ההקשר הישן בהקשר החדש.
עכשיו מנסים שוב להשתמש בהקשר של הבדיקה וליצור הצהרת SQL באמצעות כוונת המשתמש 'חודש שעבר'. לדוגמה, אם יוצרים SQL לביטוי show trucks trips for the last month", התנאי שסיפקנו ישמש כהיבט בקובץ cymbal_context.json.
אמורה להתקבל תוצאה שדומה לזו:
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
עכשיו נראה איך אפשר להשתמש בו עם סוכני AI. בפרק הבא נסביר איך להפוך את ההקשר Query Data לזמין לסוכני AI.
11. QueryData with AI Agents
תשתמשו באותו סוכן נתונים, אבל עכשיו ערכת הכלים של MCP תוגדר לשימוש ב-QueryData ContextSet.
הכנה והפעלה של MCP Toolbox for Databases
אנחנו צריכים קובץ הגדרה חדש ל-MCP Toolbox, שישתמש ב-Gemini Data Analytics API וב-AlloyDB כמקור הנתונים.
מריצים בטרמינל:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
עוברים לעורך ומחפשים את הקובץ querydata.yaml. קובץ התצורה querydata.yaml ייראה כמו הדוגמה הבאה, למעט מזהה הפרויקט והאזור שיהיו בהתאם לסביבה שלכם. אבל עדיין צריך לעדכן את הערך contextSetId ולהחליף את ה-placeholder "<add-context-set-id>" בערך מהמסוף.
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
כדי למצוא את מזהה ContextSet, לוחצים על לחצן העריכה של קבוצת ההקשר, כמו שמוצג בתמונה.
מזהה הגדרת ההקשר יופיע בחלק העליון של הכרטיסייה החדשה בצד שמאל.
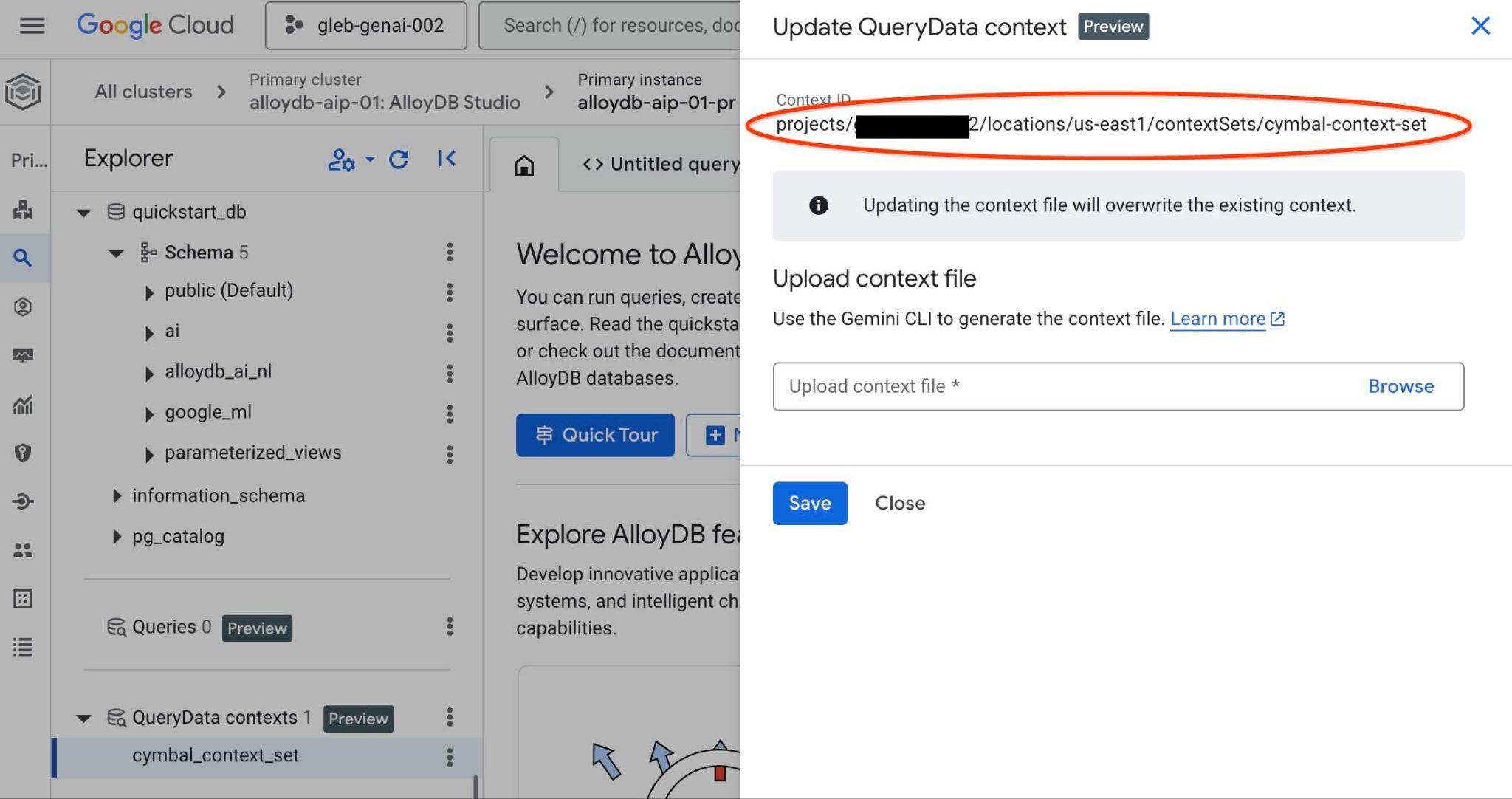
צריך להזין את הנתיב המלא במקום הפלייסהולדר "<add-context-set-id>" בקובץ querydata.yaml.
חוזרים לטרמינל.
פותחים כרטיסייה חדשה ב-Google Cloud Shell על ידי לחיצה על הלחצן '+' בחלק העליון של ממשק Google Cloud Shell.
בכרטיסייה החדשה, עוברים לספרייה עם קובץ בינארי של ערכת הכלים וקובץ ההגדרות tools.yaml ומפעילים את שרת ה-MCP.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
הרצת סוכן ADK
בכרטיסייה הראשונה של Cloud Shell, מפעילים את הסוכן.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
אחרי שמפעילים אותו, לוחצים שוב על הקישור http://127.0.0.1:8000 .
יוצג לכם הממשק המוכר של סוכן התצוגה המקדימה באינטרנט של ADK. מפרסמים בדיוק את אותה שאילתה כמו בפעם האחרונה.
Hello, can you tell me how many trips we've done in February?
ולראות את תהליך העבודה של הנציג. אם הכל מוגדר בצורה נכונה, אמור להופיע משהו כמו הדוגמה הבאה.
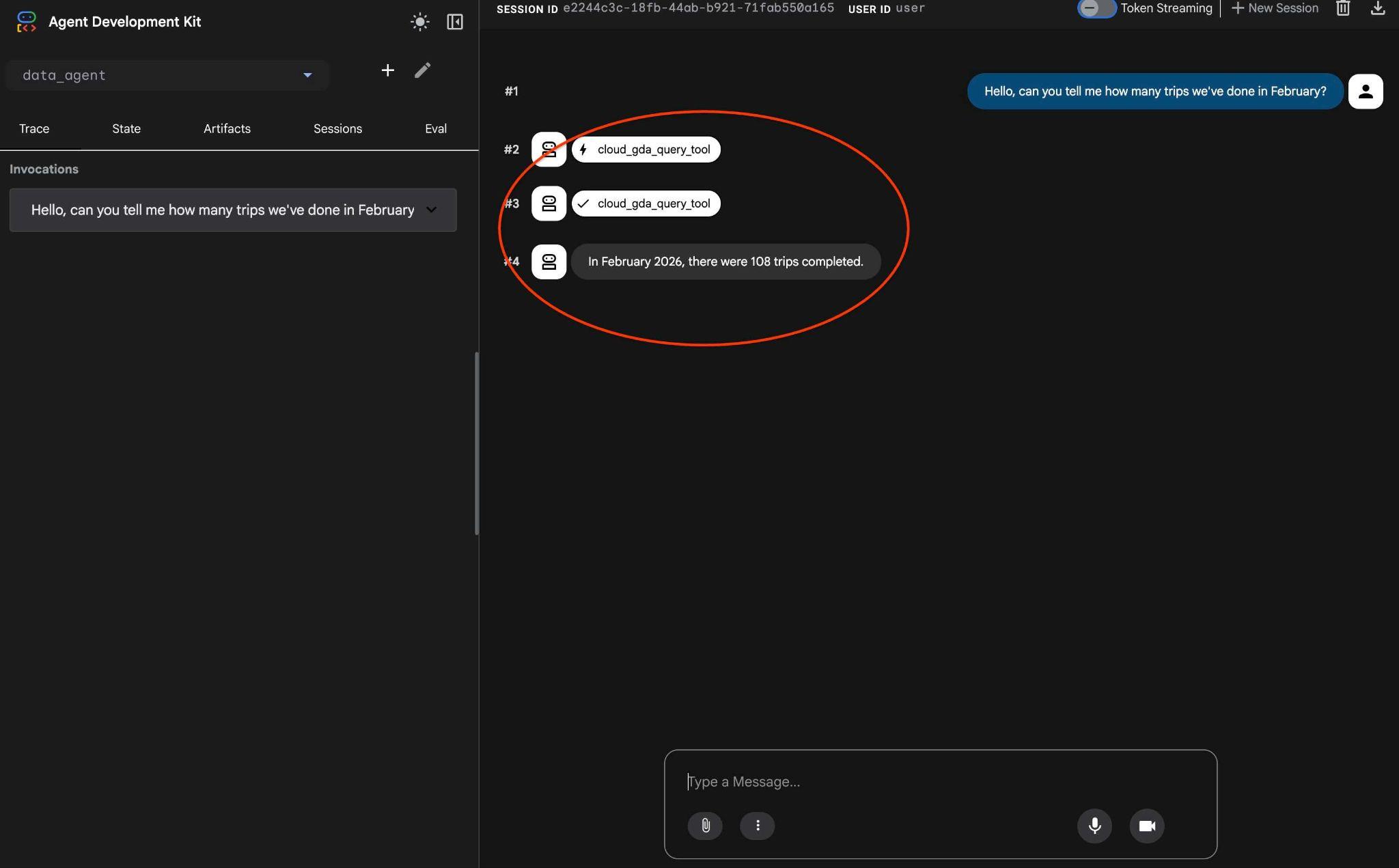
הבקשה שדרשה כמה תהליכים בפעם האחרונה הומרה לקריאה אחת לכלי MCP והופעלה באמצעות הצהרות SQL צפויות.
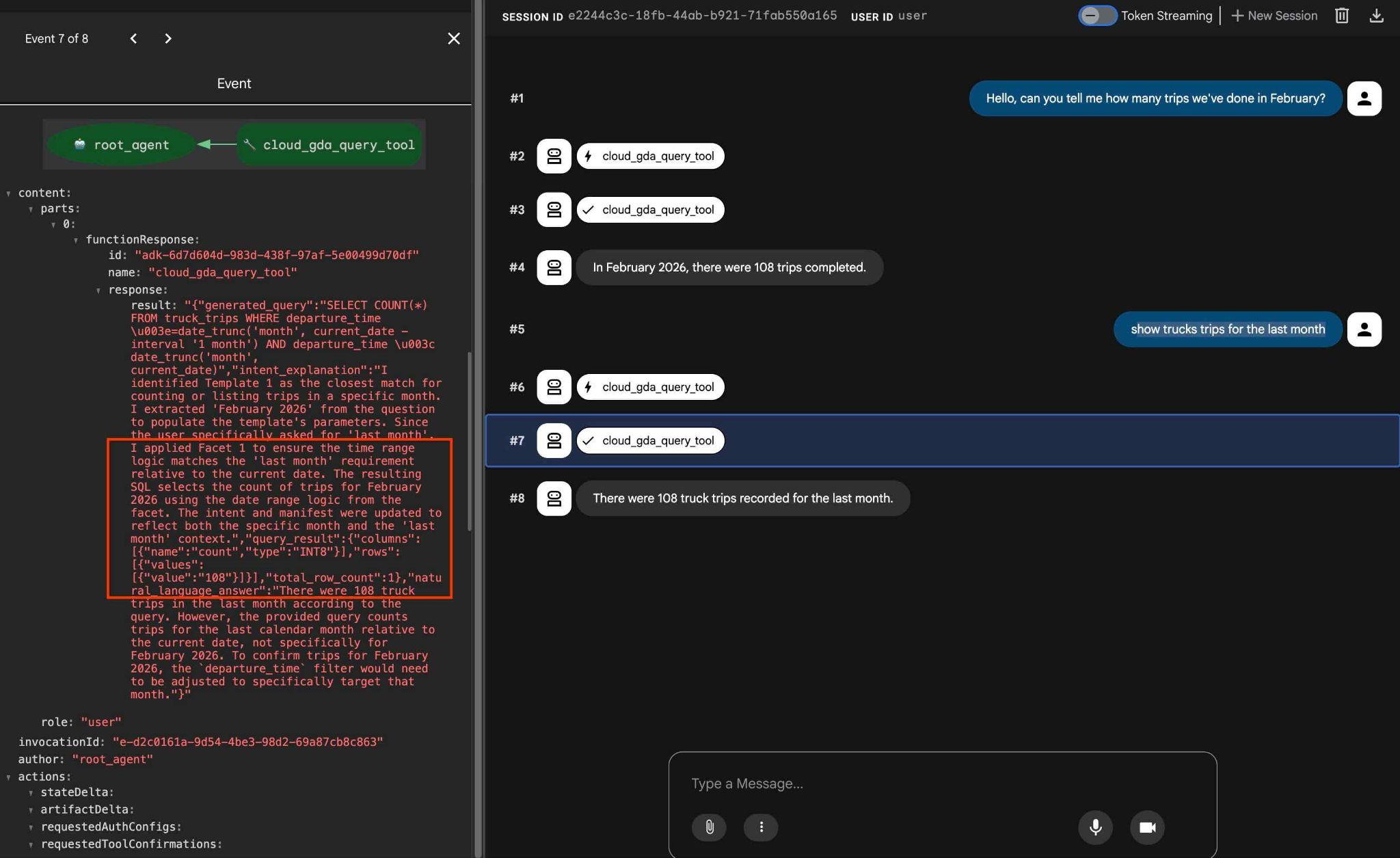
אפשר לבדוק את ההיבטים שהוגדרו באמצעות בקשה כמו
how trucks trips for the last month
בפלט, אם לוחצים על פעולת הכלי, אפשר לראות שהכלי הזה שימש להפקת התוצאה, ושהופעלו בו היבטים.
כאן מסתיים שיעור ה-Lab. אני מקווה שהצלחת לעבור על כל הדוגמאות וללמוד איך להשתמש ב-QueryData ל-AlloyDB. הטכנולוגיה הזו עוזרת להפוך את עומס העבודה של הסוכן ואת יצירת ה-SQL לצפויים ואמינים.
12. ניקוי הסביבה
כדי למנוע חיובים לא צפויים, מומלץ למחוק את המשאבים הזמניים. הדרך הכי אמינה היא למחוק את הפרויקט שבו בדקתם את תהליך העבודה. אבל אם רוצים, אפשר להגביל את עצמכם על ידי מחיקת משאבים ספציפיים, כמו AlloyDB.
בסיום שיעור ה-Lab, משמידים את המופעים ואת האשכול של AlloyDB.
מחיקת אשכול AlloyDB וכל המכונות
אם השתמשתם בגרסת הניסיון של AlloyDB. אל תמחקו את אשכול הניסיון אם אתם מתכננים לבדוק מעבדות ומשאבים אחרים באמצעות אשכול הניסיון. לא תוכלו ליצור אשכול ניסיון נוסף באותו פרויקט.
האשכול נהרס עם האפשרות force, שמוחקת גם את כל המופעים ששייכים לאשכול.
אם התנתקתם וכל ההגדרות הקודמות אבדו, מגדירים את משתני הפרויקט והסביבה ב-Cloud Shell:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
מחיקת האשכול:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
הפלט הצפוי במסוף:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
מחיקת גיבויים של AlloyDB
מחיקת כל הגיבויים של AlloyDB באשכול:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
הפלט הצפוי במסוף:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
13. מזל טוב
כל הכבוד, סיימתם את ה-Codelab.
מה נכלל
- איך יוצרים אשכול AlloyDB ומייבאים נתונים לדוגמה
- איך מפעילים את ממשק ה-API לגישה לנתונים ב-AlloyDB
- איך מפעילים את QueryData ל-AlloyDB
- איך יוצרים תבניות
- איך משתמשים בחיפוש עם היבטים
- איך משתמשים ב-QueryData עם סוכני AI
14. סקר
פלט: