
1. परिचय
इस कोडलैब में, AlloyDB के लिए QueryData का इस्तेमाल शुरू करने के बारे में जानकारी दी गई है. साथ ही, इसमें यह भी बताया गया है कि इसका इस्तेमाल, एजेंटिक ऐप्लिकेशन में नैचुरल लैंग्वेज के इनपुट से सटीक और अनुमानित एसक्यूएल स्टेटमेंट जनरेट करने के लिए कैसे किया जाए
ज़रूरी शर्तें
- Google Cloud Console की बुनियादी जानकारी
- कमांड लाइन इंटरफ़ेस और Cloud Shell में बुनियादी कौशल
आपको क्या सीखने को मिलेगा
- AlloyDB क्लस्टर बनाने और सैंपल डेटा इंपोर्ट करने का तरीका
- AlloyDB Data access API को चालू करने का तरीका
- AlloyDB के लिए QueryData को चालू करने का तरीका
- टेंप्लेट जनरेट करने का तरीका
- फ़ैसेट वाली खोज की सुविधा इस्तेमाल करने का तरीका
- एआई एजेंट के साथ QueryData का इस्तेमाल करने का तरीका
आपको इन चीज़ों की ज़रूरत होगी
- Google Cloud खाता और Google Cloud प्रोजेक्ट
- Google Cloud Console और Cloud Shell के साथ काम करने वाला वेब ब्राउज़र, जैसे कि Chrome
2. सेटअप और ज़रूरी शर्तें
प्रोजेक्ट सेटअप करना
Google Cloud प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
Cloud Shell शुरू करें
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:
इसके अलावा, G और फिर S दबाकर भी यह सुविधा ऐक्सेस की जा सकती है. इस क्रम से, Cloud Shell चालू हो जाएगा. इसके लिए, आपको Google Cloud Console में होना चाहिए या इस लिंक का इस्तेमाल करना होगा.
इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद होते हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
3. शुरू करने से पहले
एपीआई चालू करना
AlloyDB, Compute Engine, नेटवर्किंग सेवाएं, और Vertex AI का इस्तेमाल करने के लिए, आपको अपने Google Cloud प्रोजेक्ट में इनसे जुड़े एपीआई चालू करने होंगे.
Cloud Shell टर्मिनल में, पक्का करें कि आपका प्रोजेक्ट आईडी सेट अप हो:
gcloud config get-value project
आपको आउटपुट में अपना प्रोजेक्ट tID दिखेगा:
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
PROJECT_ID एनवायरमेंट वैरिएबल सेट करें:
PROJECT_ID=$(gcloud config get-value project)
सभी ज़रूरी सेवाएं चालू करें:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
अनुमानित आउटपुट
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB डिप्लॉय करना
AlloyDB क्लस्टर और प्राइमरी इंस्टेंस बनाएं. इसे डिप्लॉय करने के लिए, तैयार की गई स्क्रिप्ट का इस्तेमाल किया जा सकता है. इससे सभी ज़रूरी संसाधन डिप्लॉय हो जाएंगे. इसके अलावा, दस्तावेज़ में दिए गए तरीके का इस्तेमाल करके, इसे चरण-दर-चरण डिप्लॉय किया जा सकता है.
ऑटोमेटेड स्क्रिप्ट का इस्तेमाल करके AlloyDB डिप्लॉय करना
इस तरीके में, AlloyDB क्लस्टर को डिप्लॉय करने के लिए, अपने-आप काम करने वाली स्क्रिप्ट का इस्तेमाल किया जा रहा है. साथ ही, डिप्लॉय किए गए संसाधनों का इस्तेमाल शुरू करने के लिए ज़रूरी जानकारी दी जा रही है.
डिपार्टमेंट स्क्रिप्ट को रिपॉज़िटरी से क्लोन करने के लिए, Cloud Shell टर्मिनल में कमांड चलाएं.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
डिप्लॉयमेंट स्क्रिप्ट चलाएं.
./deploy_alloydb.sh --public-ip
स्क्रिप्ट को चलने में कुछ समय लगेगा. आम तौर पर, इसमें करीब 5 से 7 मिनट लगते हैं. साथ ही, यह सार्वजनिक और निजी आईपी पते के साथ AlloyDB क्लस्टर और प्राइमरी इंस्टेंस को डिप्लॉय करती है. सार्वजनिक आईपी सिर्फ़ उन नेटवर्क के लिए उपलब्ध होता है जिन्हें अनुमति मिली है. इसके अलावा, इसे AlloyDB Auth proxy का इस्तेमाल करके भी ऐक्सेस किया जा सकता है. दस्तावेज़ में जाकर, सार्वजनिक आईपी के बारे में ज़्यादा जानें. स्क्रिप्ट को आउटपुट के तौर पर, डिप्लॉय किए गए AlloyDB क्लस्टर के बारे में जानकारी देनी चाहिए. कृपया ध्यान दें कि आपका पासवर्ड अलग होगा. इसे कहीं लिख लें, ताकि आने वाले समय में इसका इस्तेमाल किया जा सके.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
साथ ही, वेब कंसोल में नया क्लस्टर और प्राइमरी इंस्टेंस भी देखा जा सकता है
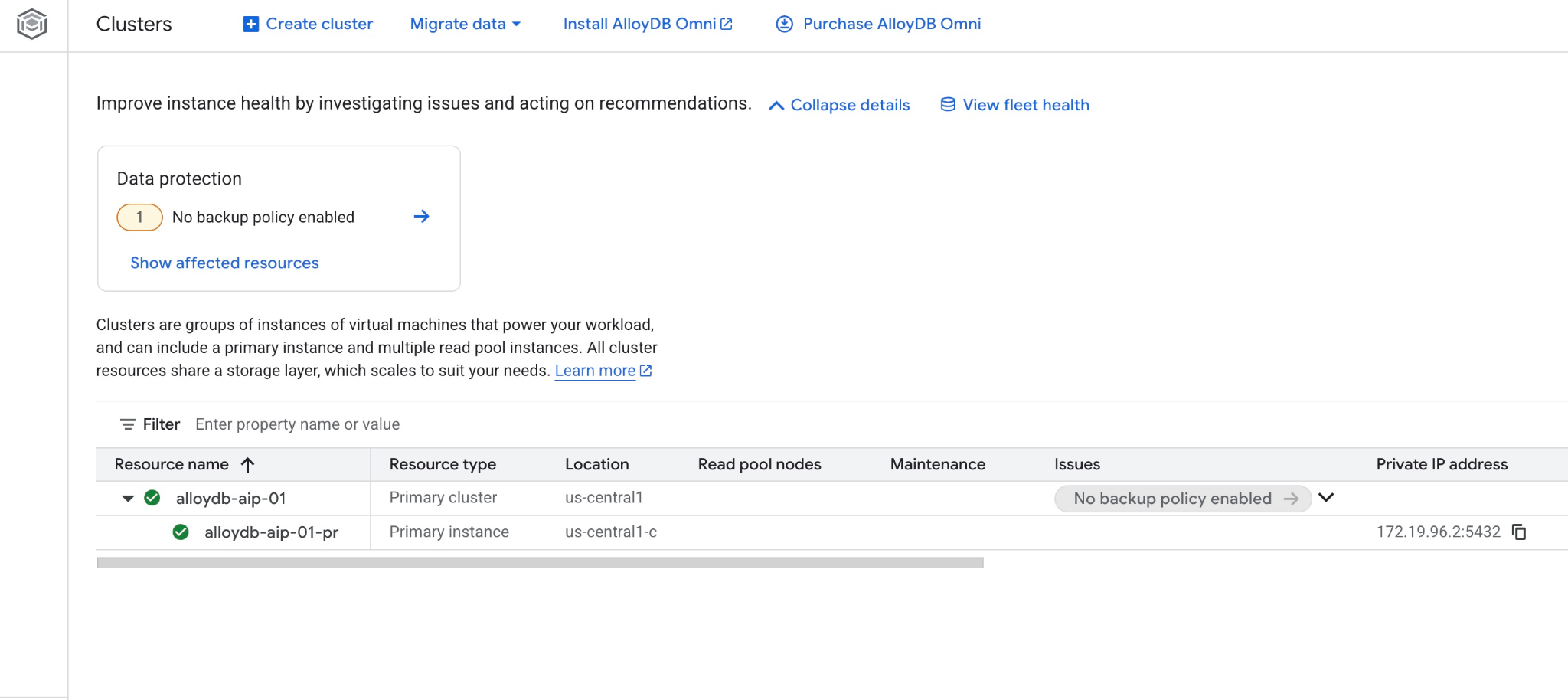
5. डेटाबेस तैयार करना
एआई फ़ंक्शन और ऑपरेटर इस्तेमाल करने के लिए, आपको Vertex AI इंटिग्रेशन चालू करना होगा. साथ ही, डेटा ऐक्सेस एपीआई चालू करना होगा और सैंपल डेटासेट के लिए डेटाबेस बनाना होगा.
AlloyDB को ज़रूरी अनुमतियां देना
AlloyDB के सेवा एजेंट को Vertex AI की अनुमतियां दें.
सबसे ऊपर मौजूद "+" साइन का इस्तेमाल करके, Cloud Shell का कोई दूसरा टैब खोलें.
नए क्लाउड शेल टैब में यह कमांड चलाएं:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Data Access API चालू करना
execute_sql जैसे एमसीपी टूल का इस्तेमाल करने के लिए, आपको AlloyDB क्लस्टर पर Data Access API चालू करना होगा.
उसी टर्मिनल टैब में एक्ज़ीक्यूट करें.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
आईएएम की मदद से पुष्टि करने की सुविधा चालू करना
हम अपने एजेंटिक टूल के लिए, IAM की मदद से पुष्टि करने की सुविधा का इस्तेमाल करने जा रहे हैं. इसके लिए, आपको इंस्टेंस पर IAM की मदद से पुष्टि करने की सुविधा चालू करनी होगी. साथ ही, खुद को डेटाबेस उपयोगकर्ता के तौर पर जोड़ना होगा. इंस्टेंस लेवल पर IAM की पुष्टि करने की सुविधा चालू करने से पहले, कृपया डेटा ऐक्सेस करने की सुविधा देने वाले एपीआई को चालू करने का पिछला चरण पूरा होने तक इंतज़ार करें. आपके इंस्टेंस की स्थिति हरे रंग में दिखनी चाहिए.
हम इंस्टेंस लेवल पर IAM को चालू करने से शुरुआत करते हैं. उसी टर्मिनल टैब में एक्ज़ीक्यूट करें.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
खुद को AlloyDB उपयोगकर्ता के तौर पर जोड़ें:
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
टैब में "exit" कमांड डालकर टैब बंद करें:
exit
AlloyDB Studio से कनेक्ट करना
यहां दिए गए अध्यायों में, डेटाबेस से कनेक्ट करने के लिए ज़रूरी सभी SQL कमांड, AlloyDB Studio में एक्ज़ीक्यूट की जा सकती हैं. T
AlloyDB for Postgres में क्लस्टर पेज पर जाएं.
प्राइमरी इंस्टेंस पर क्लिक करके, अपने AlloyDB क्लस्टर के लिए वेब कंसोल इंटरफ़ेस खोलें.
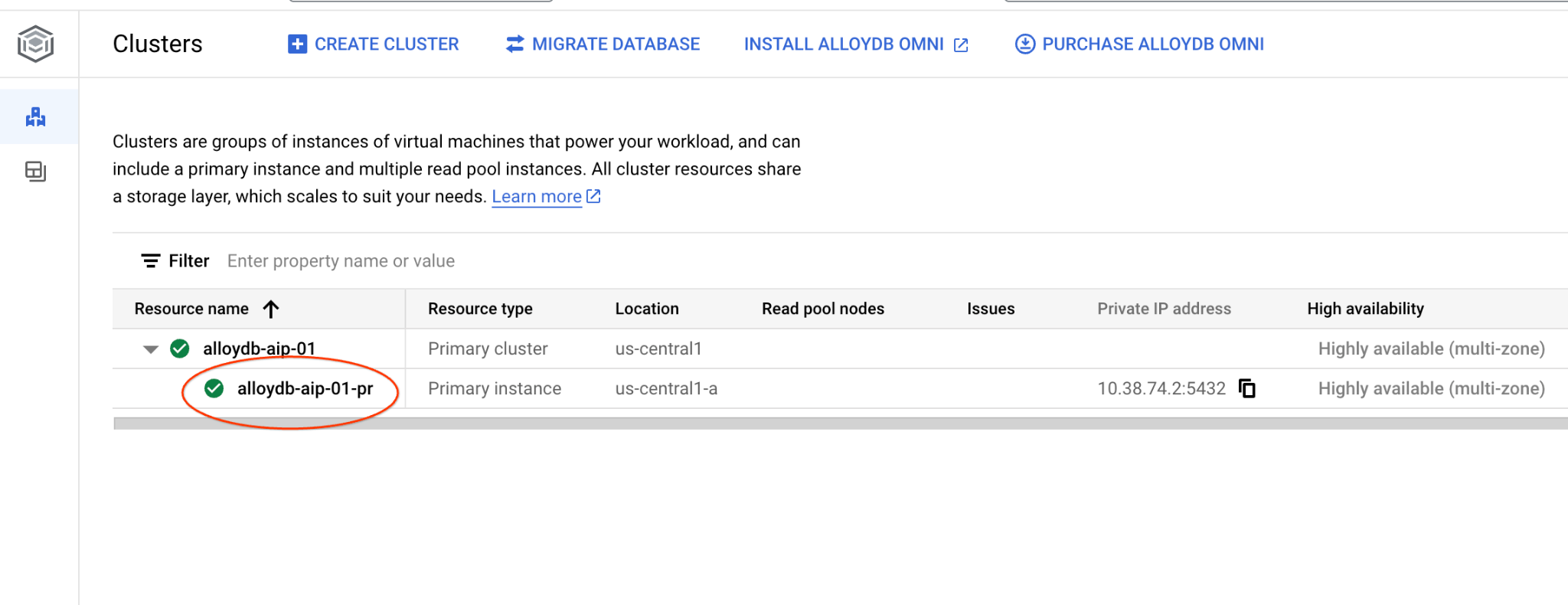
इसके बाद, बाईं ओर मौजूद AlloyDB Studio पर क्लिक करें:
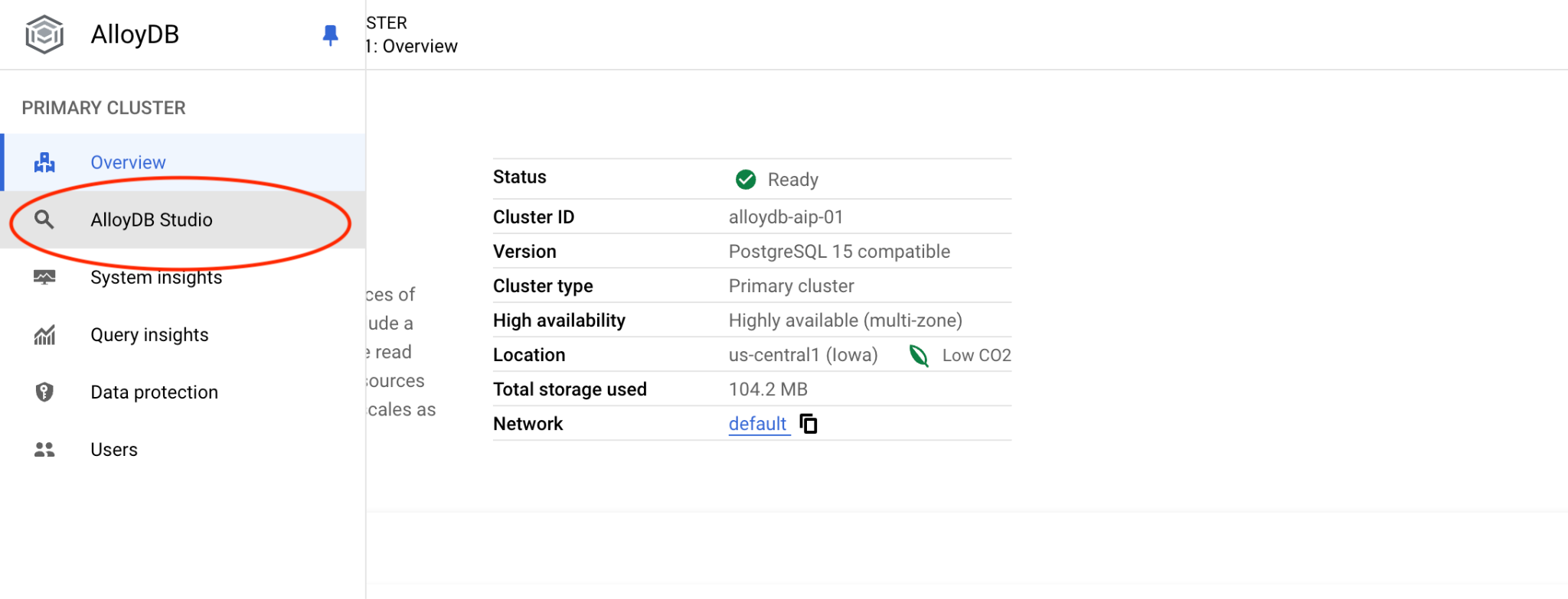
Postgres डेटाबेस और IAM की मदद से पुष्टि करने की सुविधा चुनें. इसके बाद, "Authenticate" बटन पर क्लिक करें.
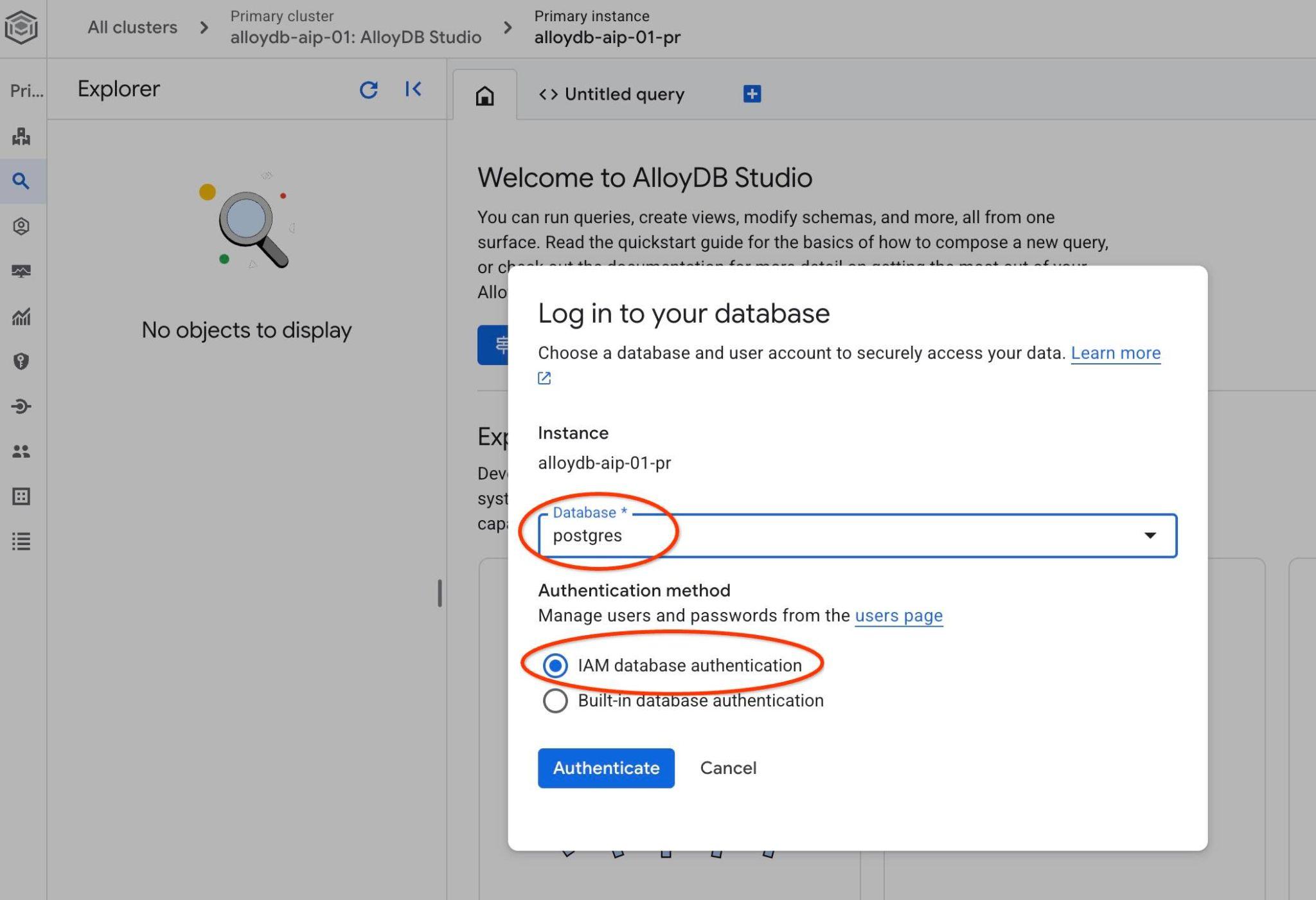
इससे AlloyDB Studio का इंटरफ़ेस खुल जाएगा. डेटाबेस में कमांड चलाने के लिए, दाईं ओर मौजूद "बिना टाइटल वाली क्वेरी" टैब पर क्लिक करें.
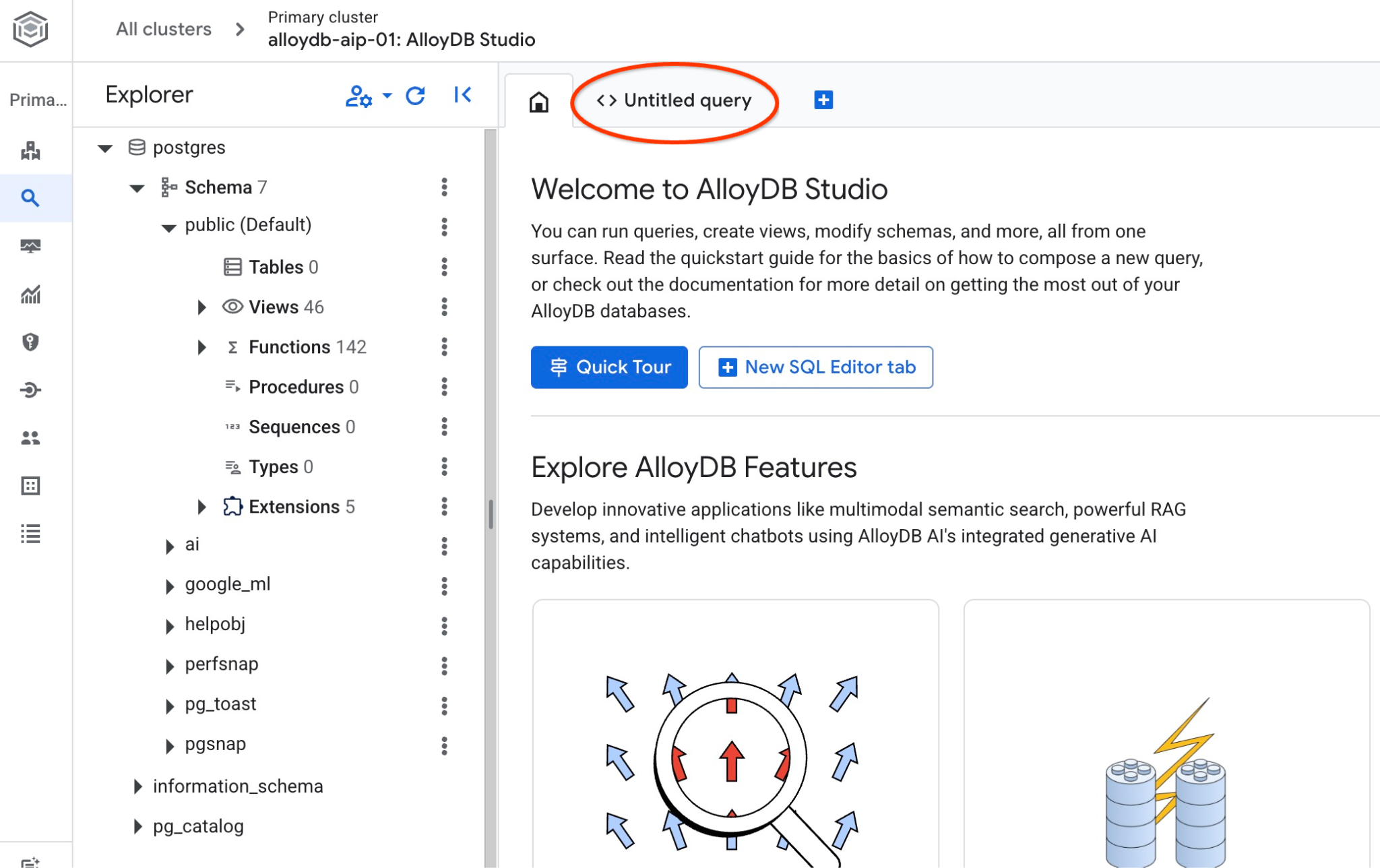
इससे एक इंटरफ़ेस खुलता है, जहां एसक्यूएल कमांड चलाई जा सकती हैं
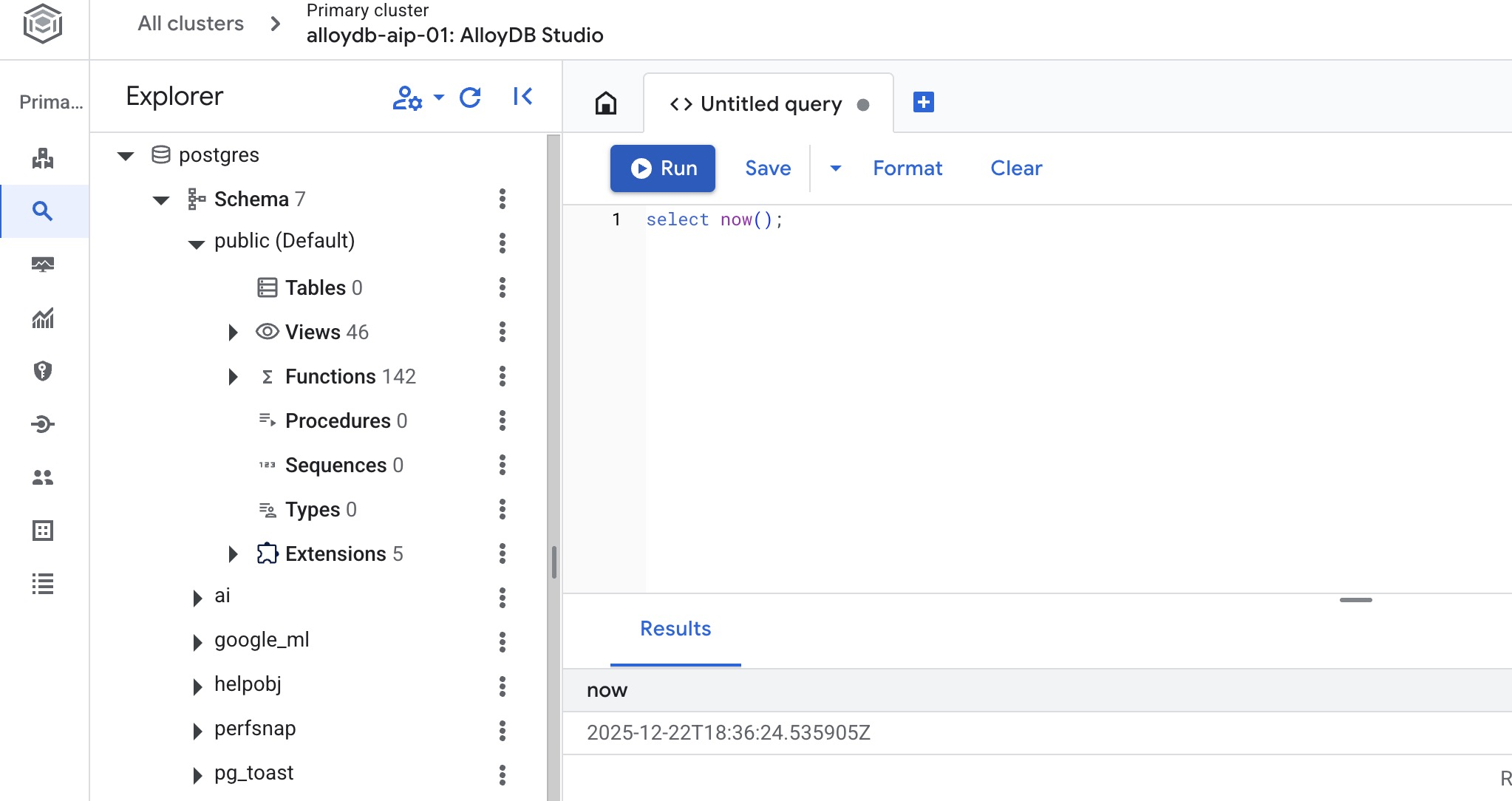
डेटाबेस बनाएं
डेटाबेस बनाने के बारे में क्विकस्टार्ट गाइड.
AlloyDB Studio Editor में, यह कमांड चलाएं.
डेटाबेस बनाएं:
CREATE DATABASE quickstart_db
अनुमानित आउटपुट:
Statement executed successfully
quickstart_db से कनेक्ट करें
देखें कि डेटाबेस, उससे कनेक्ट करके बनाया गया हो. उपयोगकर्ता/डेटाबेस बदलने के बटन का इस्तेमाल करके, स्टूडियो से फिर से कनेक्ट करें.
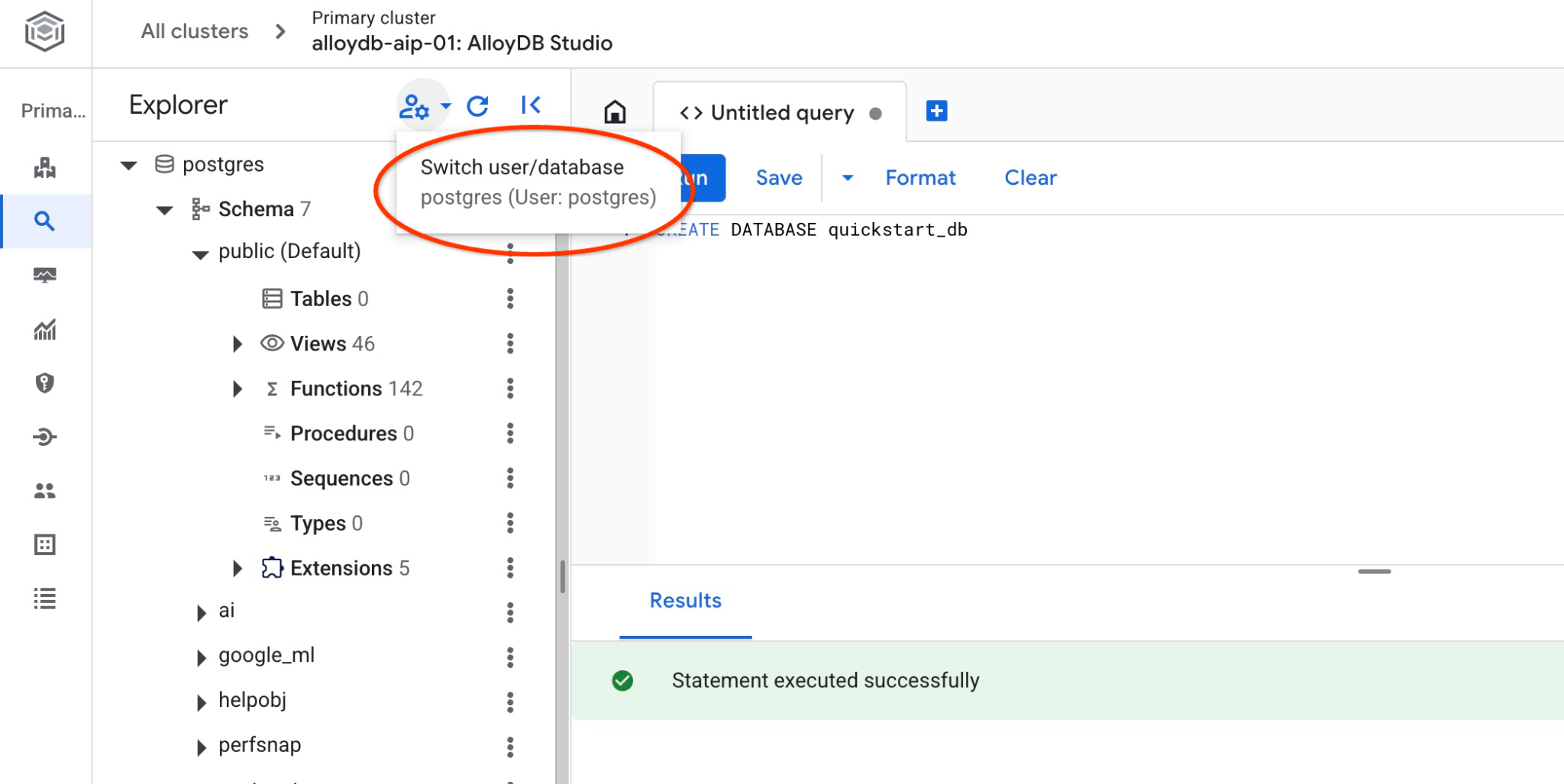
ड्रॉपडाउन सूची से नया quickstart_db डेटाबेस चुनें और उसी IAM पुष्टि का इस्तेमाल करें.
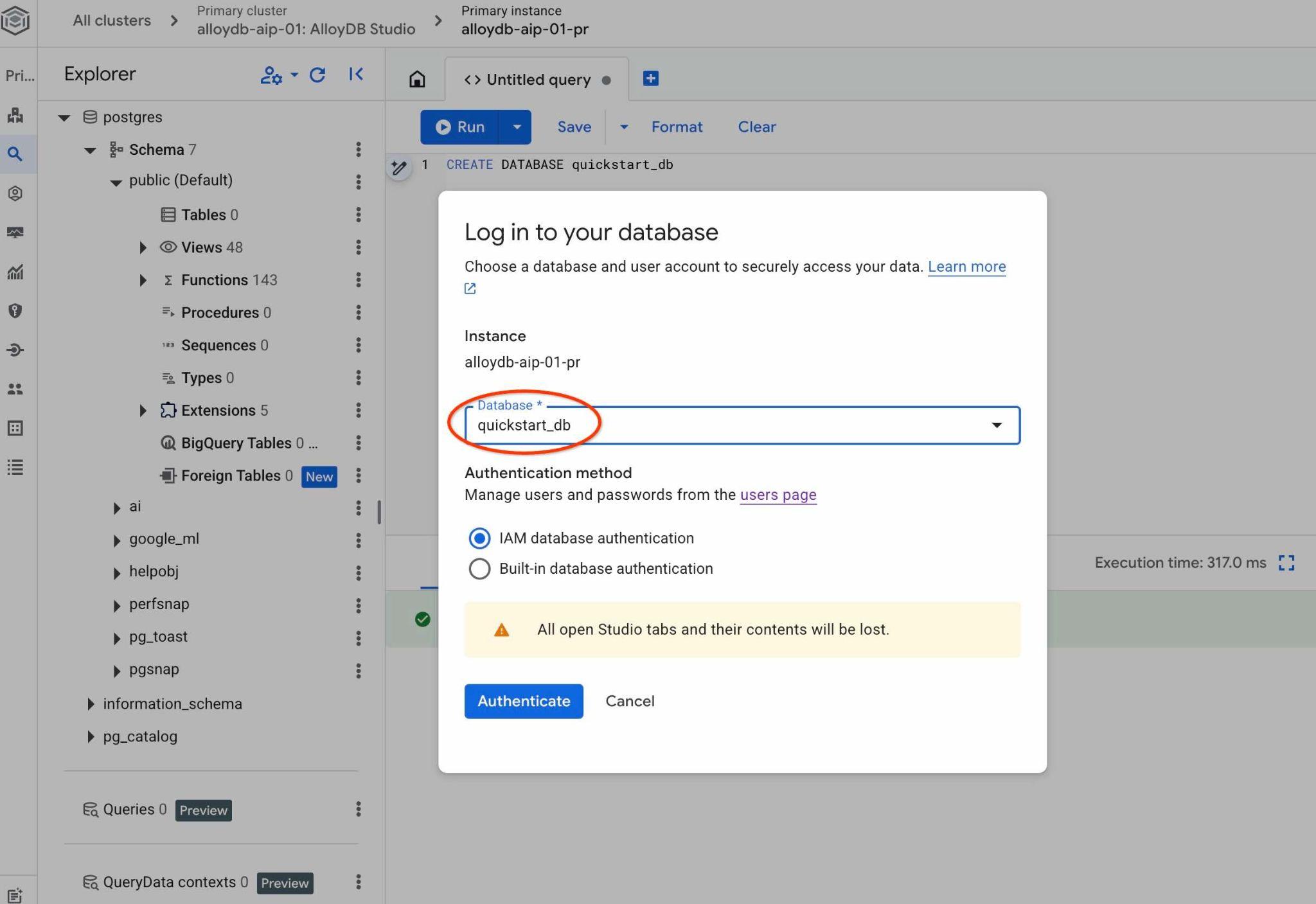
इससे एक नया कनेक्शन खुलेगा. यहां quickstart_db डेटाबेस के ऑब्जेक्ट इस्तेमाल किए जा सकते हैं. यहां इंपोर्ट किए गए स्कीमा और डेटा की जांच की जा सकती है. साथ ही, QueryData कॉन्टेक्स्ट सेट के साथ काम किया जा सकता है.
6. सैंपल डेटा
अब आपको डेटाबेस में ऑब्जेक्ट बनाने और डेटा लोड करने की ज़रूरत है. आपको काल्पनिक Cymbal Shipping कंपनी के डेटासेट का इस्तेमाल करना है. इसमें सामान, ट्रक, अनुरोधों, और ट्रक की यात्राओं के बारे में काल्पनिक डेटा होता है. साथ ही, इसमें काल्पनिक ड्राइवर भी शामिल होते हैं.
स्टोरेज बकेट बनाना
आपको क्लोन की गई अपनी रिपॉज़िटरी से AlloyDB डेटाबेस में डेटा इंपोर्ट करने के लिए, Google SDK (gcloud) का इस्तेमाल करना होगा. इसके लिए, आपको एक Cloud Storage बकेट बनानी होगी. साथ ही, AlloyDB सेवा खाते को ऐक्सेस देना होगा. इसके अलावा, वेब कंसोल का इस्तेमाल करके भी ऐसा किया जा सकता है. इसके बारे में दस्तावेज़ में बताया गया है.
Google Cloud Shell टर्मिनल में यह कमांड चलाएं:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
डेटा लोड करें
अगला चरण, डेटा लोड करना है. हमारा कंप्रेस किया गया SQL डंप, क्लोन किए गए रिपॉज़िटरी फ़ोल्डर में मौजूद है. नीचे दिए गए कमांड में यह माना गया है कि आपने AlloyDB क्लस्टर बनाते समय, पिछले चरण में रिपॉज़िटरी को क्लोन करते समय अपनी होम डायरेक्ट्री का इस्तेमाल शुरुआती पॉइंट के तौर पर किया था.
कंप्रेस किए गए SQL डंप को नए स्टोरेज बकेट में कॉपी करें:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
इसके बाद, डेटा को quickstart_db डेटाबेस में लोड करें:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
इस कमांड से, सैंपल डेटासेट को quickstart_db डेटाबेस में लोड किया जाएगा. AlloyDB Studio का इस्तेमाल करके, टेबल और रिकॉर्ड की पुष्टि की जा सकती है.
7. डेटा एजेंट का इस्तेमाल करना
हम Python के लिए Google ADK का इस्तेमाल करके बनाए गए एक सैंपल एआई एजेंट से शुरुआत करते हैं. साथ ही, डेटाबेस के लिए एमसीपी टूलबॉक्स का इस्तेमाल करके, इसे अपने AlloyDB इंस्टेंस से कनेक्ट करते हैं.
डेटाबेस के लिए MCP Toolbox इंस्टॉल करना
डेटाबेस के लिए एमसीपी टूलबॉक्स एक ओपन सोर्स प्रोजेक्ट है. यह AlloyDB for PostgreSQL के साथ-साथ कई डेटाबेस इंजन के लिए एमसीपी की सुविधा देता है. दस्तावेज़ में जाकर, एमसीपी टूलबॉक्स के बारे में पढ़ा जा सकता है.
आपको अपने प्लैटफ़ॉर्म के लिए, सॉफ़्टवेयर का नया वर्शन डाउनलोड करना होगा. सबसे नए वर्शन के लिए, रिलीज़ पेज देखें. यहां दिए गए उदाहरण में, Cloud Shell पर MCP Toolbox का वर्शन 31 डाउनलोड करने का तरीका बताया गया है.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
आपको टूलबॉक्स के लिए एक कॉन्फ़िगरेशन फ़ाइल तैयार करनी होगी. हमारे पास मौजूदा डायरेक्ट्री में एक सैंपल tools.yaml.example फ़ाइल है. अब हम project ID और region की जानकारी देने वाले दो प्लेसहोल्डर को बदलकर, tools.yaml फ़ाइल तैयार करेंगे.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
डेटाबेस के लिए MCP Toolbox शुरू करना
अब तैयार की गई कॉन्फ़िगरेशन फ़ाइल की मदद से, एमसीपी टूलबॉक्स का इस्तेमाल शुरू किया जा सकता है.
Google Cloud Shell इंटरफ़ेस में सबसे ऊपर मौजूद "+" बटन दबाकर, Google Cloud Shell में नया टैब खोलें.
नए टैब में, टूलबॉक्स की बाइनरी फ़ाइल और कॉन्फ़िगरेशन फ़ाइल tools.yaml वाली डायरेक्ट्री पर जाएं. इसके बाद, एमसीपी सर्वर शुरू करें.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
आपको आउटपुट में "Server ready to serve!" दिखेगा. यह कुछ इस तरह का होगा.
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
एजेंट के सोर्स कोड की जांच करना
क्लोन की गई रिपॉज़िटरी फ़ोल्डर के पहले टैब में, Google Cloud Shell एडिटर का इस्तेमाल करके एजेंट कोड की समीक्षा करें.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
एजेंट में, AlloyDB के लिए Google Cloud MCP सर्वर का सेक्शन मौजूद है. हम एमसीपी_SERVER_URL, पुष्टि करने की सुविधा, प्रोजेक्ट आईडी के तौर पर एक एंडपॉइंट उपलब्ध कराते हैं. साथ ही, इसे एमसीपी टूलसेट में जोड़ने की सुविधा भी देते हैं.
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
साथ ही, एजेंट कोड में एमसीपी टूलसेट को एजेंट के लिए tools पैरामीटर के तौर पर शामिल किया जाता है. इसके अलावा, एजेंट प्रॉम्प्ट के लिए क्लस्टर और इंस्टेंस के नाम, क्षेत्र, और डेटाबेस को वैरिएबल के तौर पर इस्तेमाल किया जाता है.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
कोड की जांच करने के बाद, एडिटर विंडो में सबसे ऊपर दाईं ओर मौजूद "टर्मिनल खोलें" बटन दबाकर, वापस टर्मिनल पर जाएं.
एजेंट शुरू करना
अब Google ADK के वेब इंटरफ़ेस का इस्तेमाल करके, एजेंट को इंटरैक्टिव मोड में शुरू किया जा सकता है. ADK का वेब इंटरफ़ेस, एजेंट के वर्कफ़्लो की जांच करने और समस्याओं को हल करने का आसान तरीका उपलब्ध कराता है.
सबसे पहले, uv पैकेज मैनेजर का इस्तेमाल करके Python के लिए ज़रूरी सभी पैकेज इंस्टॉल करें.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
सभी पैकेज इंस्टॉल हो जाने के बाद, आपको एजेंट डायरेक्ट्री में .env फ़ाइल जोड़नी होगी. इससे एजेंट को यह निर्देश मिलेगा कि वह एआई मॉडल के साथ सभी कम्यूनिकेशन के लिए Vertex AI का इस्तेमाल करे.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
इसके बाद, एजेंट को शुरू किया जा सकता है
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
आपको http://127.0.0.1:8000 जैसे एंडपॉइंट के साथ, इस तरह का आउटपुट दिखेगा .
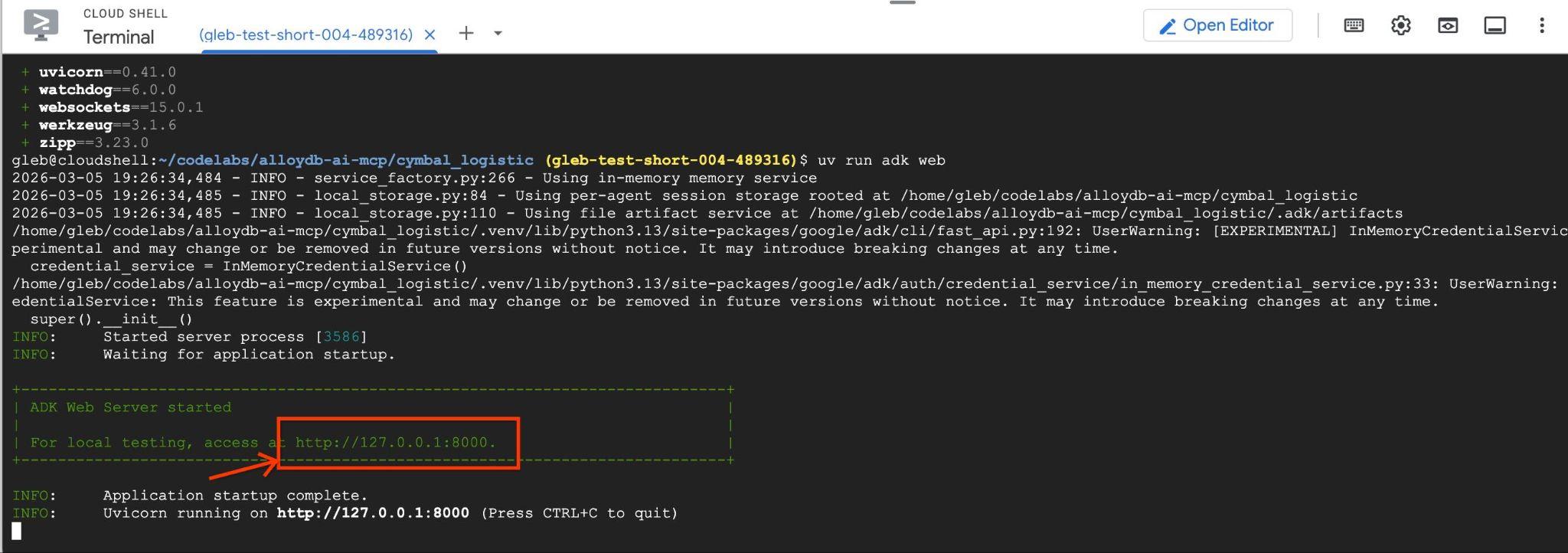
क्लाउड शेल में मौजूद उस यूआरएल पर क्लिक करें. इससे, एक अलग ब्राउज़र टैब में झलक वाली विंडो खुलेगी. इसमें, बाईं ओर मौजूद ड्रॉप-डाउन सूची से data_agent चुनें.
ADK के वेब इंटरफ़ेस में, सबसे नीचे दाईं ओर अपने सवाल पोस्ट किए जा सकते हैं. साथ ही, पूरे एक्ज़ीक्यूशन फ़्लो को देखा जा सकता है. इसमें हर चरण के लिए ट्रेस शामिल होते हैं, जो दाईं ओर दिखते हैं.
8. AlloyDB के लिए QueryData के बिना NL2SQL की जांच करना
इस एजेंट की मदद से, आम भाषा में फ़्री फ़ॉर्म में सवाल पूछे जा सकते हैं. एजेंट, सवालों के जवाब देने के लिए, डेटाबेस के लिए MCP टूलबॉक्स का इस्तेमाल करेगा. सवाल, सबसे नीचे दाईं ओर पोस्ट किए जाते हैं. साथ ही, टूल के सभी कॉल के साथ जवाब सबसे ऊपर दिखेगा.
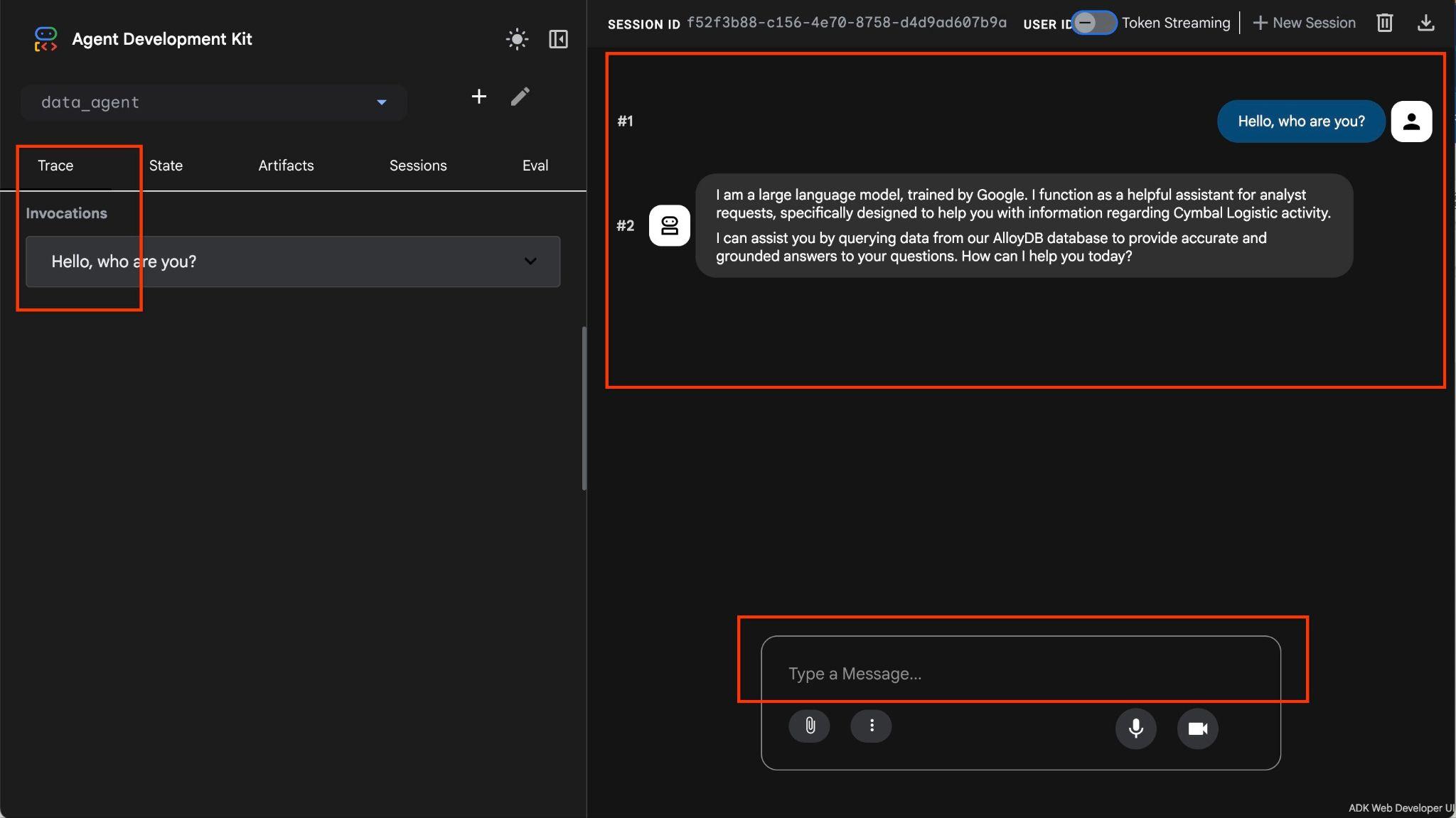
आपको शिपिंग कंपनी के ऑपरेशनल डेटा पर काम करना है. इसमें शिपिंग के अनुरोधों, ट्रकों, ड्राइवर, और ड्राइवर की यात्राओं के बारे में जानकारी होती है. पहला सवाल, फ़रवरी 2026 में की गई यात्राओं की संख्या के बारे में है.
सबसे नीचे दाईं ओर मौजूद इनपुट फ़ील्ड में, यह टाइप करें और Enter दबाएं.
Hello, can you tell me how many trips we've done in February?
एजेंट, कई टूल कॉल को लागू करके काम करेगा. इससे वह list_cymbal_logistics_schemas_tool का इस्तेमाल करके स्कीमा में सही टेबल की पहचान कर पाएगा. साथ ही, execute_sql_tool का इस्तेमाल करके कई एसक्यूएल स्टेटमेंट लागू कर पाएगा, ताकि सही डेटा मिल सके.
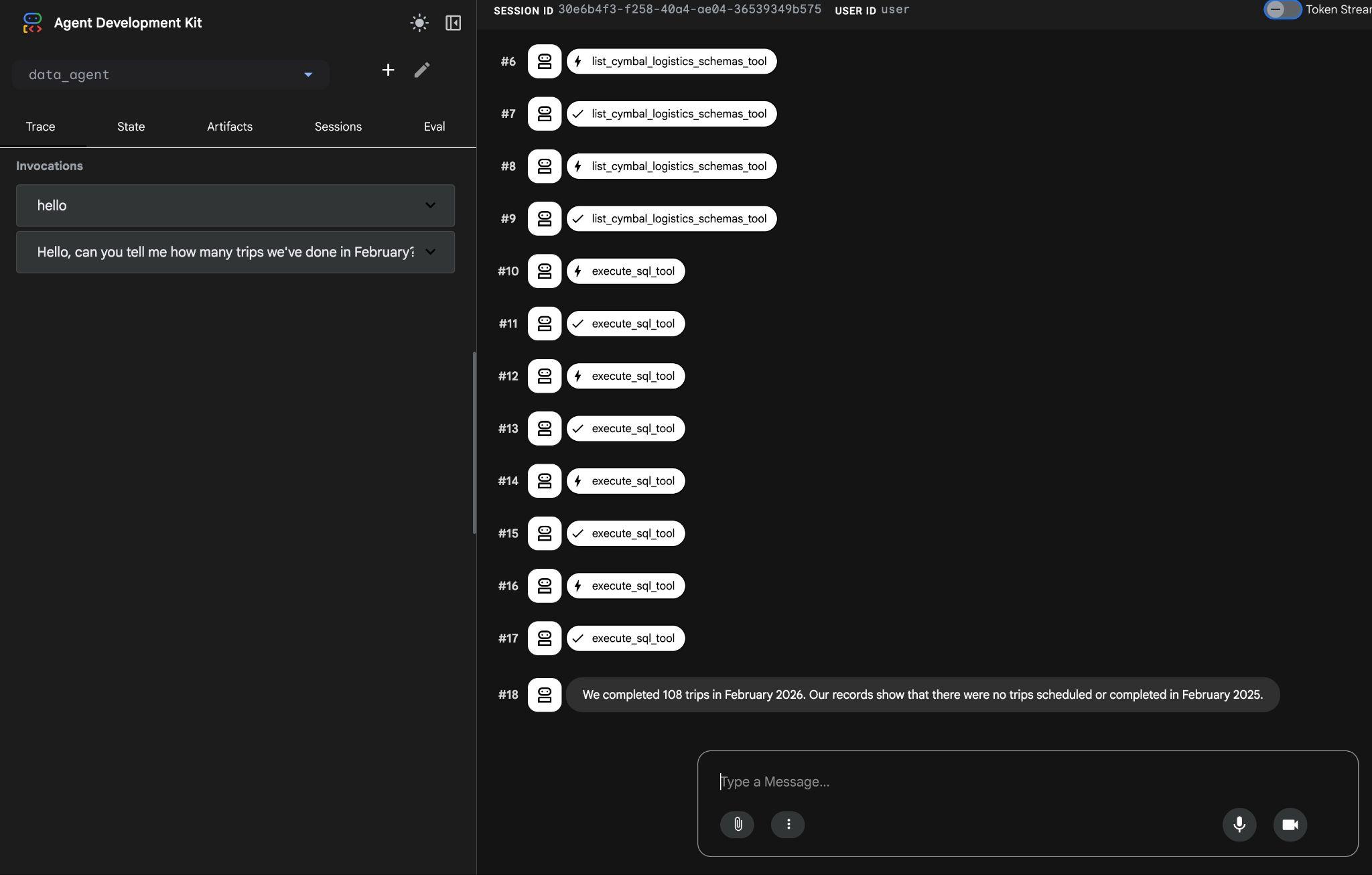
सही क्वेरी बनाने और उसे डेटाबेस पर लागू करने के बाद, यह सही नतीजा देगा.
हमने फ़रवरी 2026 में 108 यात्राएं पूरी कीं. हमारे रिकॉर्ड के मुताबिक, फ़रवरी 2025 में कोई भी यात्रा शेड्यूल नहीं की गई थी और न ही कोई यात्रा पूरी की गई थी.
टूल के इस्तेमाल पर क्लिक करके, यह देखा जा सकता है कि हर टूल कॉल क्या करता है. उदाहरण के लिए, हमारे नतीजे पाने के लिए यहां क्वेरी दी गई है.
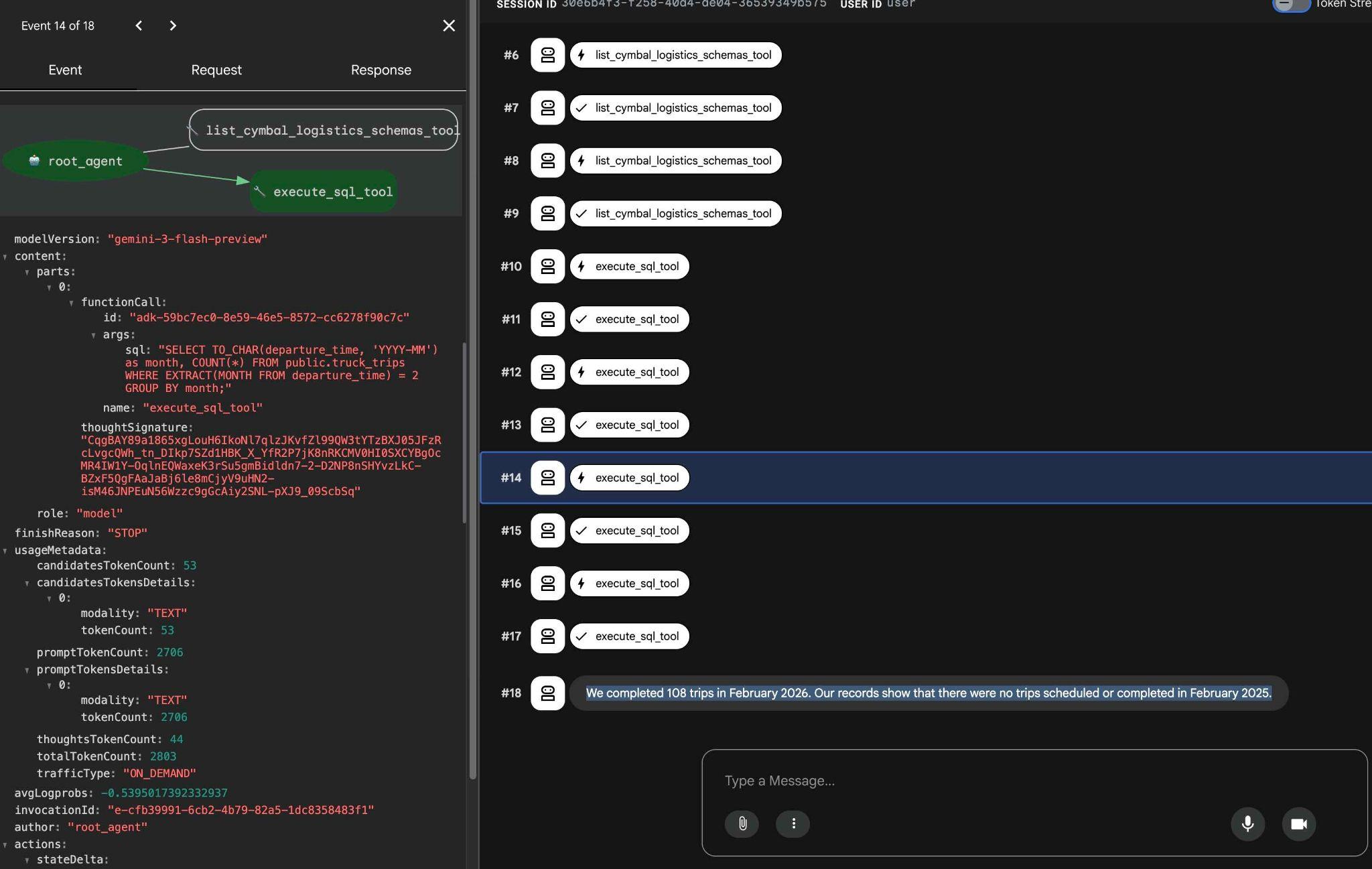
ADK के वेब इंटरफ़ेस का इस्तेमाल करके, अन्य सामान्य अनुरोध आज़माएं. साथ ही, देखें कि नतीजे पाने के लिए, यह अलग-अलग क्वेरी कैसे पूरी करता है.
टर्मिनल में ctrl+c दबाकर, एजेंट को रोकें. ADK के वेब इंटरफ़ेस वाले ब्राउज़र टैब को बंद किया जा सकता है.
दूसरे टैब में MCP टूलबॉक्स को बंद करने के लिए, ctrl+c कीबोर्ड शॉर्टकट को फिर से दबाएं. इसके बाद, दूसरे टैब को बंद करें.
अगले चरण में, हम QueryData कॉन्टेक्स्ट बनाएंगे, ताकि NL2SQL के जवाब और परफ़ॉर्मेंस को बेहतर बनाया जा सके.
9. QueryData ContextSet बनाना
पिछले चरण में, आपने देखा कि एआई मॉडल, डेटाबेस के सूचना स्कीमा को कई बार कॉल कर रहा था. ऐसा इसलिए, ताकि वह यह पता लगा सके कि SQL क्वेरी बनाने के लिए, उसे किस टेबल और कॉलम का इस्तेमाल करना चाहिए. हम आपकी क्वेरी के डेटा का कॉन्टेक्स्ट जोड़ेंगे. इससे परफ़ॉर्मेंस और सटीक नतीजे पाने में मदद मिलेगी. साथ ही, यह भी तय किया जा सकेगा कि किसी अनुरोध के जवाब में कौनसी क्वेरी को एक्ज़ीक्यूट किया जाना चाहिए.
टारगेट किए गए टेंप्लेट बनाना
QueryData ContextSet एक JSON फ़ाइल होती है. इसमें क्वेरी टेंप्लेट और फ़ैसेट होते हैं. ये क्वेरी पैटर्न और डेटा स्ट्रक्चर के आधार पर, एआई मॉडल को ज़रूरी डेटा और निर्देश देते हैं. इससे एआई मॉडल, अनुरोध किए गए लक्ष्यों को पूरा करने के लिए सही एसक्यूएल क्वेरी या एसक्यूएल क्वेरी के हिस्सों का इस्तेमाल कर पाता है.
आपको टारगेट किए गए टेंप्लेट से शुरुआत करनी होगी. Cloud Shell एडिटर का इस्तेमाल करके कोई फ़ाइल बनाएं. Cloud Shell टर्मिनल में यह कमांड चलाएं.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
इसके बाद, पिछले चैप्टर में इस्तेमाल की गई नैचुरल लैंग्वेज क्वेरी के लिए टेंप्लेट डालें - "हमने फ़रवरी में कितनी यात्राएं कीं?"
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
इसके बाद, डाउनलोड बटन का इस्तेमाल करके, Cloud Shell से टेंप्लेट को अपने कंप्यूटर पर डाउनलोड करें.
Load QueryData Context Sets
QueryData कॉन्टेक्स्ट सेट का इस्तेमाल करने के लिए, हमें उन्हें अपने डेटाबेस में अपलोड करना होगा.
AlloyDB Studio खोलें. सबसे नीचे मौजूद बाएं पैनल में, आपको QueryData Context और तीन बिंदु दिखेंगे.
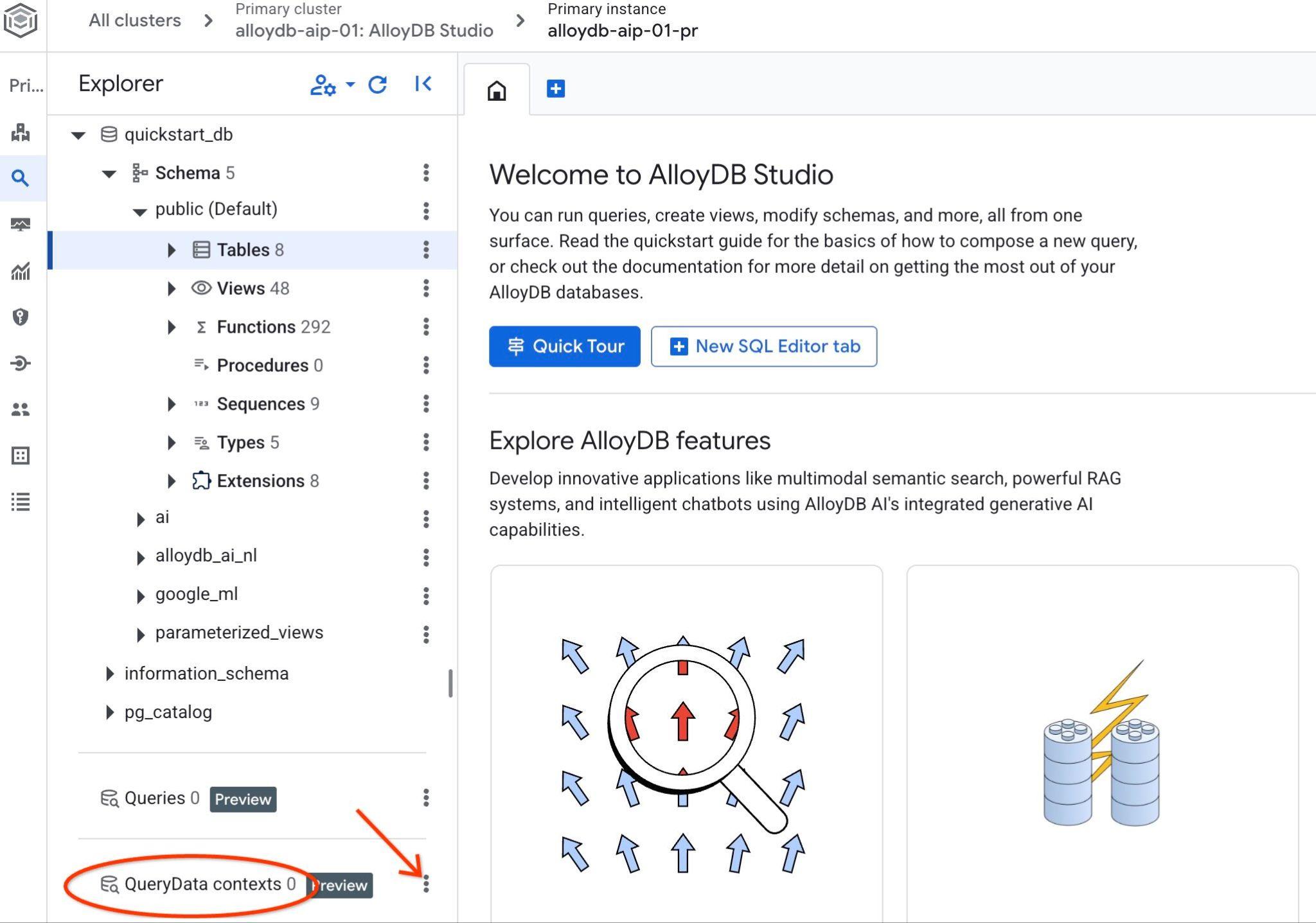
उन तीन बिंदुओं पर क्लिक करें और कॉन्टेक्स्ट बनाएं चुनें. इससे एक डायलॉग बॉक्स खुलेगा. इसमें आपको
- नाम:
cymbal_context_set - विवरण:
Cymbal Logistic Query Data - कॉन्टेक्स्ट फ़ाइल अपलोड करें: "
Browse" बटन पर क्लिक करें और QueryData ContextSet वाली JSON फ़ाइल चुनें
सेव करें बटन दबाने पर, अगर आपने पहली बार कॉन्टेक्स्ट स्टोरेज को चालू किया है, तो इसे शुरू होने में कुछ समय लग सकता है.
आपको डाउनलोड किया गया कॉन्टेक्स्ट दिखेगा. साथ ही, दाईं ओर मौजूद तीन वर्टिकल बटन पर क्लिक करने से, आपको उपलब्ध कार्रवाइयां दिखेंगी. अगले चैप्टर में, हम "टेस्ट कॉन्टेक्स्ट" ऐक्शन से शुरुआत करेंगे.
10. QueryData टूल के कॉन्टेक्स्ट सेट की जांच करना
टेस्ट टेंप्लेट
AlloyDB Studio में हमारे कॉन्टेक्स्ट को टेस्ट करने के लिए, "Test context" ऐक्शन का इस्तेमाल करें. "कॉन्टेक्स्ट की जांच करें" पर क्लिक करने से, AlloyDB Studio का नया एडिटर विंडो खुलेगा. इसका टाइटल "cymbal_context_set" होगा. साथ ही, Gemini की एसक्यूएल जनरेशन सुविधा का न्योता "Generate SQL using QueryData context: cymbal_context_set " टाइटल के साथ दिखेगा. एसक्यूएल जनरेशन पर क्लिक करें और टाइप करें
Hello, can you tell me how many trips we've done in February?
एसक्यूएल जनरेट होने के बाद, "Insert" बटन दबाएं.
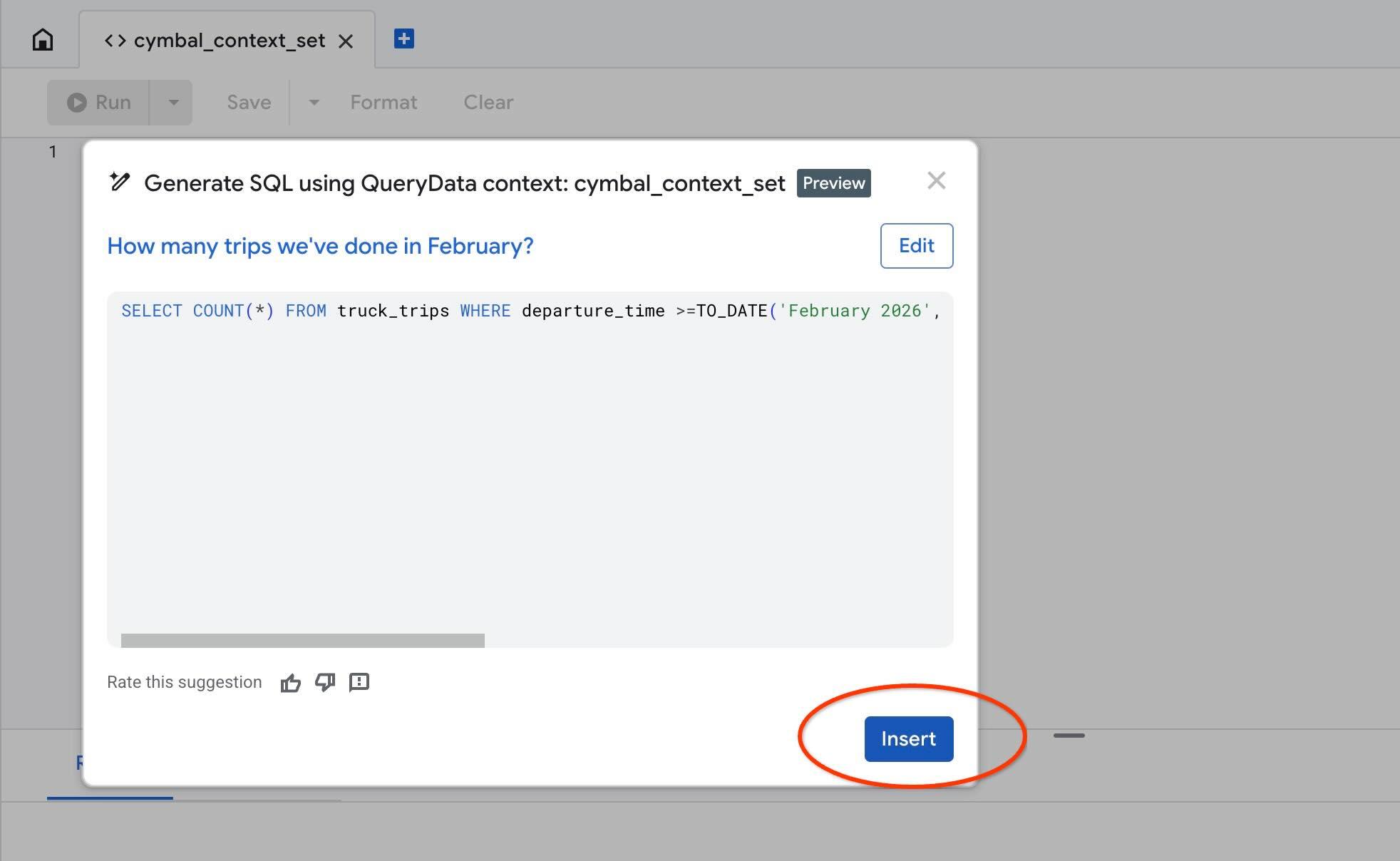
आपको वही क्वेरी दिखेगी जो हमने कॉन्टेक्स्ट टेंप्लेट में पहले डाली थी.
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
महीने की जगह "जनवरी" डालकर देखें और जनरेट किया गया SQL स्टेटमेंट देखें. यह पैरामीटर वाले इंटेंट के लिए, महीने को पैरामीटर के तौर पर इस्तेमाल करेगा और SQL स्टेटमेंट को अपने-आप अडजस्ट करेगा.
Build QueryData Facets
हमने एक क्वेरी के लिए टेंप्लेट का इस्तेमाल किया. यह तब काम करता है, जब हमें पता हो कि उपयोगकर्ता किस तरह का अनुरोध कर सकता है. हालांकि, कभी-कभी क्वेरी के सिर्फ़ एक हिस्से को गाइड करना मददगार होता है. जैसे, जब हमें फिर से तय किए गए इंटेंट के लिए किसी खास क्रम या क्लॉज़ का इस्तेमाल करना हो, तो हम शर्त या फ़िल्टर को गाइड करते हैं.
उदाहरण के लिए, अगर हम "पिछले महीने" का डेटा दिखाने के लिए कहते हैं, तो हमें पिछले कैलेंडर महीने की रिपोर्ट चाहिए. यह रिपोर्ट, महीने के पहले दिन से लेकर आखिरी दिन तक की होनी चाहिए, न कि पिछले 30 दिनों की.
हम ऐसे फ़ैसेट को, ContextSet कॉन्फ़िगरेशन में एसक्यूएल स्निपेट के तौर पर जोड़ सकते हैं. साथ ही, पहले से जोड़े गए टेंप्लेट का इस्तेमाल भी कर सकते हैं. querydata_cymbal_contextset.json खोलें.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
साथ ही, हमारे पहले से मौजूद टेंप्लेट के बाद फ़ेसट जोड़ें. फ़ाइल में मौजूद कॉन्टेंट इस तरह का होना चाहिए
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
फ़ाइल को सेव करें और उसे अपने कंप्यूटर पर अपलोड करें.
इसके बाद, क्वेरी के कॉन्टेक्स्ट ऐक्शन "कॉन्टेक्स्ट में बदलाव करें" का इस्तेमाल करें. साथ ही, बदली गई फ़ाइल को अपलोड करके, नए कॉन्टेक्स्ट से पुराने कॉन्टेक्स्ट को बदलें.
अब टेस्ट कॉन्टेक्स्ट का फिर से इस्तेमाल करें और "पिछले महीने" इंटेंट का इस्तेमाल करके एसक्यूएल स्टेटमेंट जनरेट करें. उदाहरण के लिए, अगर आपने "show trucks trips for the last month"" वाक्यांश के लिए एसक्यूएल जनरेट किया है, तो यह cymbal_context.json फ़ाइल में फ़ेसट के तौर पर दी गई शर्त का इस्तेमाल करेगा.
आपको कुछ ऐसा दिखेगा:
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
अब, एआई एजेंट के साथ इसका इस्तेमाल कैसे किया जा सकता है? अगले चैप्टर में, हम एआई एजेंट के लिए क्वेरी डेटा कॉन्टेक्स्ट उपलब्ध कराते हैं.
11. एआई एजेंट की मदद से QueryData
आपके पास एक ही डेटा एजेंट का इस्तेमाल करने का विकल्प होगा. हालांकि, अब MCP टूलबॉक्स को QueryData ContextSet का इस्तेमाल करने के लिए कॉन्फ़िगर किया जाएगा.
डेटाबेस के लिए एमसीपी टूलबॉक्स तैयार करना और उसे शुरू करना
हमें MCP टूलबॉक्स के लिए एक नई कॉन्फ़िगरेशन फ़ाइल की ज़रूरत है. यह Gemini Data Analytics API और AlloyDB को डेटाबेस सोर्स के तौर पर इस्तेमाल करेगी.
टर्मिनल में यह कमांड चलाएं:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
एडिटर पर जाएं और फ़ाइल querydata.yaml ढूंढें. कॉन्फ़िगरेशन फ़ाइल querydata.yaml ऐसी दिखेगी. हालांकि, प्रोजेक्ट आईडी और क्षेत्र आपके एनवायरमेंट के हिसाब से दिखेंगे. हालांकि, आपको अब भी contextSetId वैल्यू को अपडेट करना होगा. साथ ही, "<add-context-set-id>" प्लेसहोल्डर को कंसोल से मिली वैल्यू से बदलना होगा.
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
ContextSet आईडी ढूंढने के लिए, अपनी इमेज में दिखाए गए कॉन्टेक्स्ट सेट के लिए, 'बदलाव करें' बटन पर क्लिक करें.
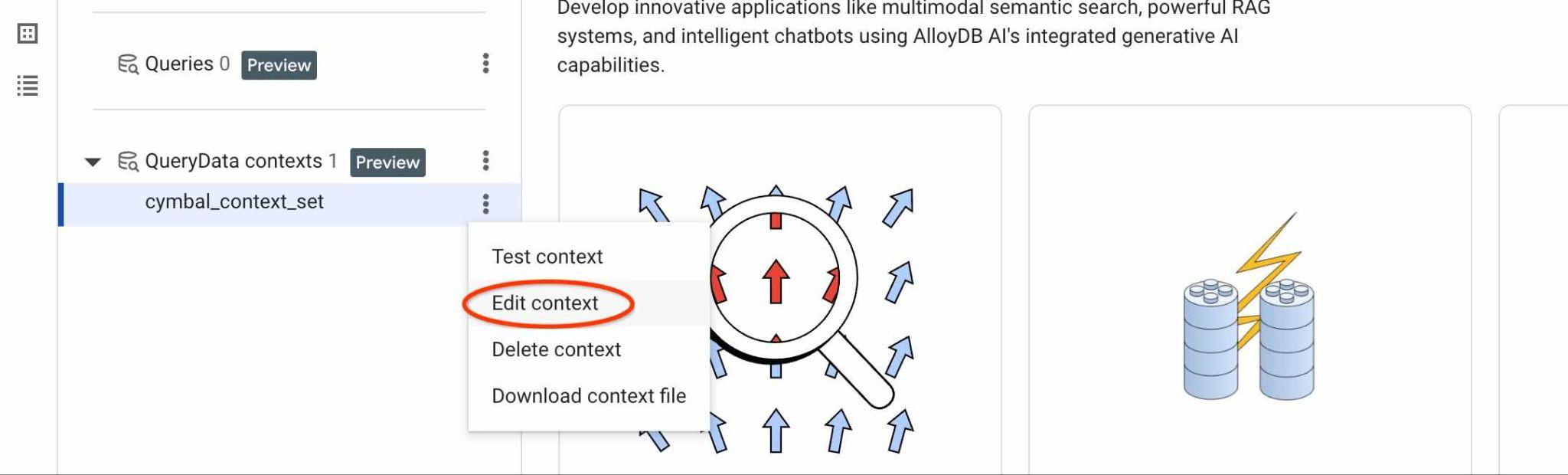
आपको दाईं ओर मौजूद नए टैब में सबसे ऊपर कॉन्टेक्स्ट सेट आईडी दिखेगा.
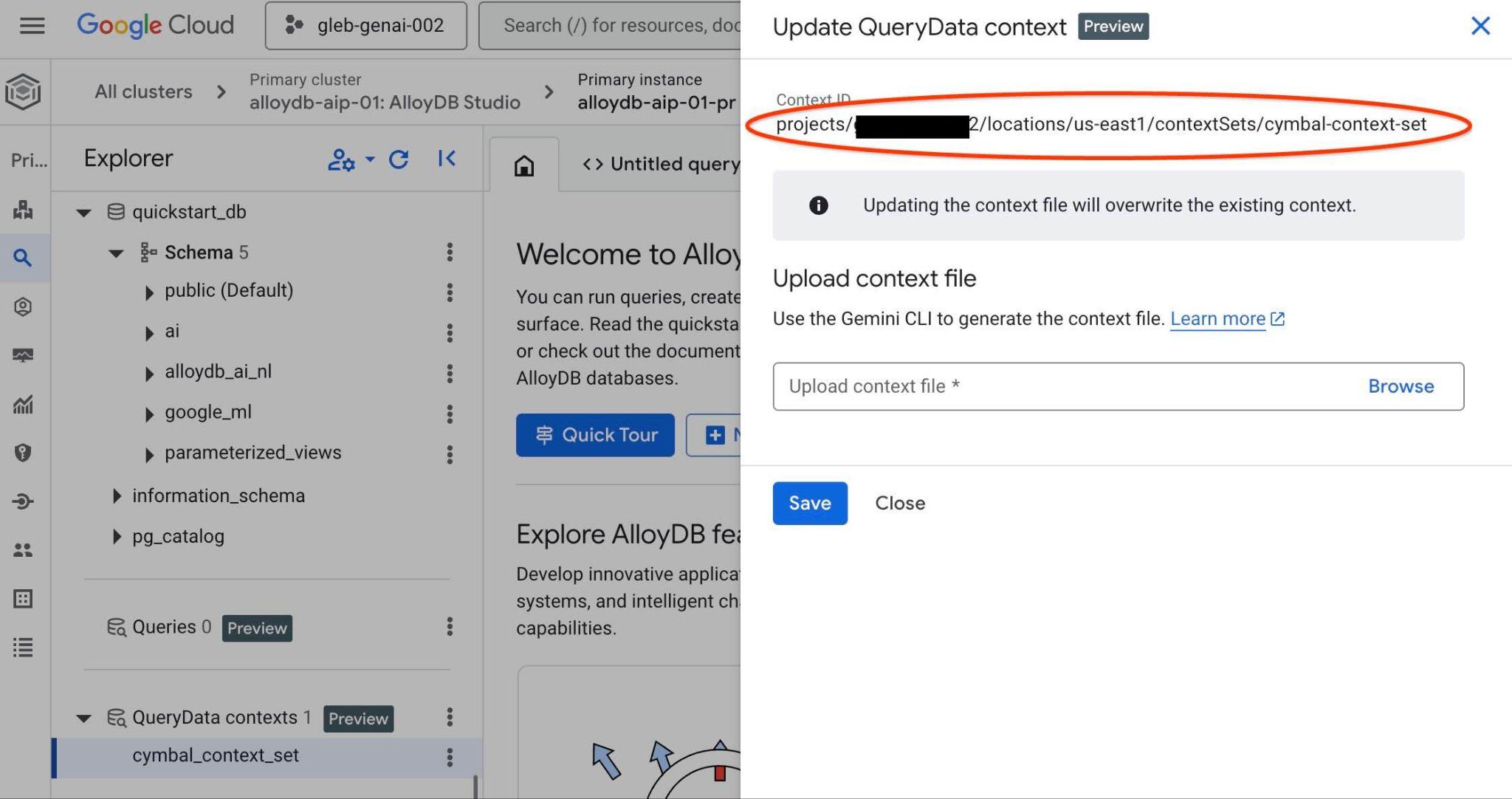
पूरे पाथ को querydata.yaml फ़ाइल में "<add-context-set-id>" प्लेसहोल्डर की जगह पर रखना चाहिए.
टर्मिनल पर वापस जाएं.
Google Cloud Shell इंटरफ़ेस में सबसे ऊपर मौजूद "+" बटन दबाकर, Google Cloud Shell में नया टैब खोलें.
नए टैब में, टूलबॉक्स की बाइनरी फ़ाइल और कॉन्फ़िगरेशन फ़ाइल tools.yaml वाली डायरेक्ट्री पर जाएं. इसके बाद, एमसीपी सर्वर शुरू करें.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
ADK एजेंट को चलाना
पहले Cloud Shell टैब में एजेंट शुरू करें.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
इसके बाद, जब यह शुरू हो जाए, तो http://127.0.0.1:8000 लिंक पर फिर से क्लिक करें .
आपको ADK वेब प्रीव्यू एजेंट का जाना-पहचाना इंटरफ़ेस दिखेगा. ठीक वही क्वेरी पोस्ट करें जो आपने पिछली बार की थी.
Hello, can you tell me how many trips we've done in February?
साथ ही, एजेंट का वर्कफ़्लो देखें. अगर सब कुछ सही तरीके से कॉन्फ़िगर किया गया है, तो आपको कुछ ऐसा दिखेगा.
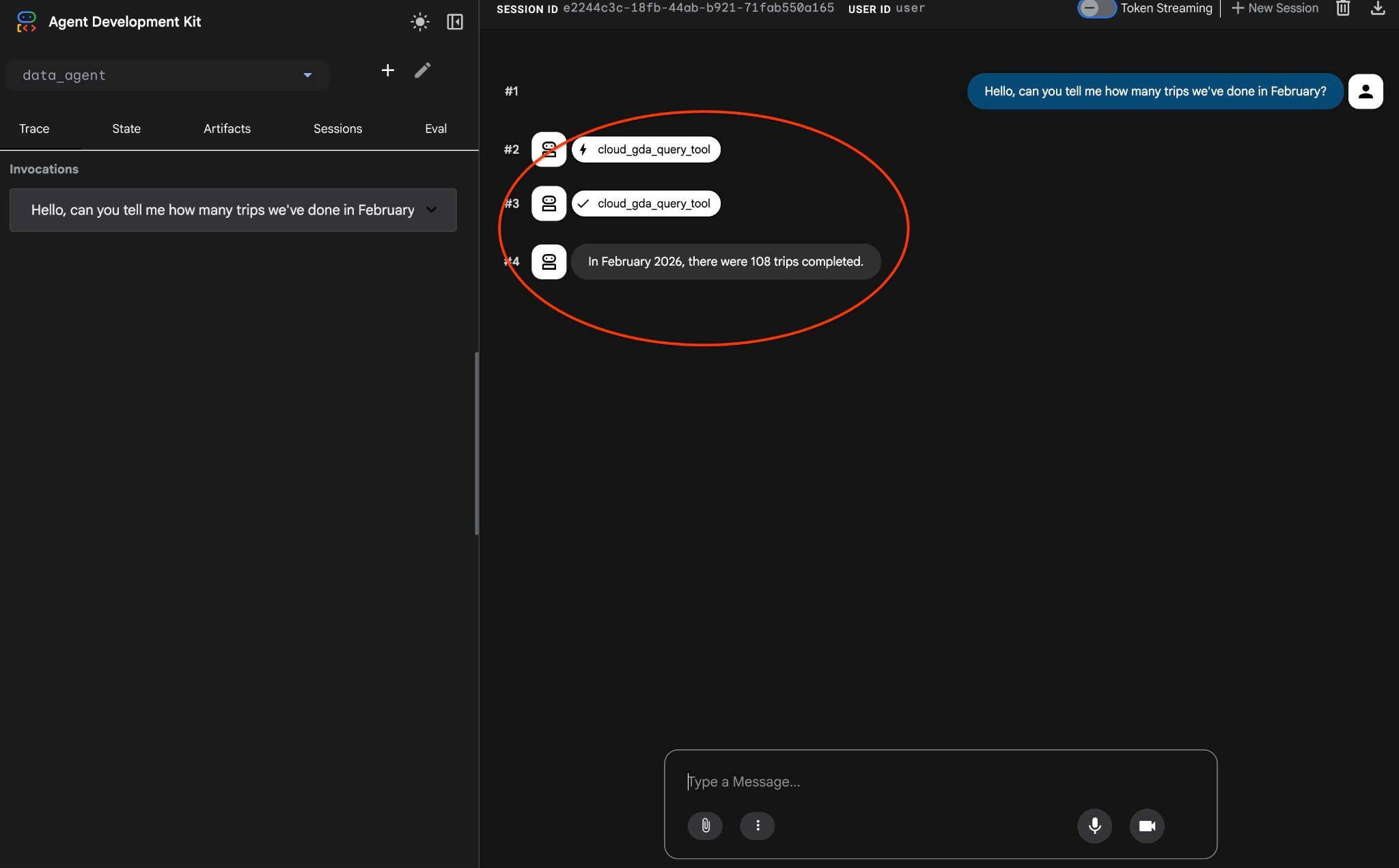
पिछली बार, अनुरोध को कई बार घुमाया गया था. अब इसे एमसीपी टूल को एक कॉल में बदल दिया गया है और अनुमानित एसक्यूएल स्टेटमेंट का इस्तेमाल करके इसे पूरा किया गया है.
कॉन्फ़िगर किए गए फ़ैसेट की जांच करने के लिए, इस तरह के अनुरोध का इस्तेमाल किया जा सकता है
how trucks trips for the last month
साथ ही, आउटपुट में टूल ऐक्शन पर क्लिक करने से पता चलता है कि नतीजे पाने के लिए, उसी टूल का इस्तेमाल किया गया था और फ़ैसेट लागू किए गए थे.
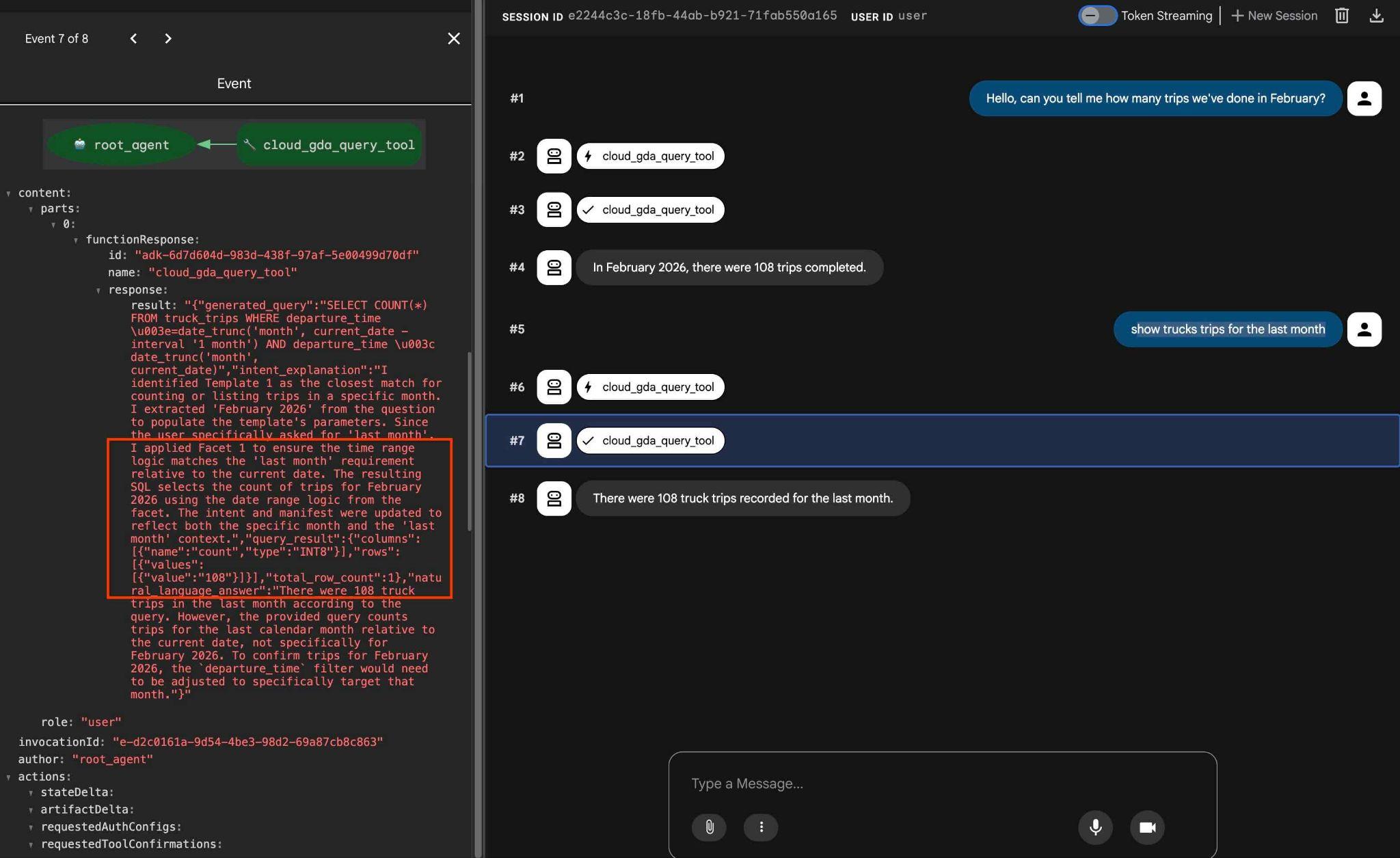
हमारी लैब यहीं खत्म होती है. हमें उम्मीद है कि आपने सभी उदाहरण देख लिए होंगे और आपको यह पता चल गया होगा कि AlloyDB के लिए QueryData का इस्तेमाल कैसे किया जाता है. इस टेक्नोलॉजी की मदद से, एजेंट के काम और एसक्यूएल जनरेशन को भरोसेमंद बनाया जा सकता है.
12. पर्यावरण को साफ़-सुथरा रखना
अचानक लगने वाले शुल्क से बचने के लिए, अस्थायी संसाधनों को हटा देना चाहिए. सबसे भरोसेमंद तरीका यह है कि उस प्रोजेक्ट को मिटा दें जहां वर्कफ़्लो की टेस्टिंग की जा रही थी. हालांकि, आपके पास अलग-अलग संसाधनों को मिटाकर, खुद को सीमित करने का विकल्प होता है. जैसे, AlloyDB.
लैब का काम पूरा हो जाने के बाद, AlloyDB इंस्टेंस और क्लस्टर को मिटा दें.
AlloyDB क्लस्टर और सभी इंस्टेंस मिटाना
अगर आपने AlloyDB का मुफ़्त में आज़माने की सुविधा वाला वर्शन इस्तेमाल किया है. अगर आपको ट्रायल क्लस्टर का इस्तेमाल करके अन्य लैब और संसाधनों की जांच करनी है, तो ट्रायल क्लस्टर को न मिटाएं. आपके पास एक ही प्रोजेक्ट में दूसरा ट्रायल क्लस्टर बनाने का विकल्प नहीं होगा.
फ़ोर्स विकल्प का इस्तेमाल करके क्लस्टर को डिस्ट्रॉय किया जाता है. इससे क्लस्टर से जुड़े सभी इंस्टेंस भी मिट जाते हैं.
अगर आपका कनेक्शन बंद हो गया है और पिछली सभी सेटिंग मिट गई हैं, तो क्लाउड शेल में प्रोजेक्ट और एनवायरमेंट वैरिएबल तय करें:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
क्लस्टर मिटाने के लिए:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB के बैकअप मिटाना
क्लस्टर के सभी AlloyDB बैकअप मिटाने के लिए:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
13. बधाई हो
कोडलैब पूरा करने के लिए बधाई.
हमने क्या-क्या बताया
- AlloyDB क्लस्टर बनाने और सैंपल डेटा इंपोर्ट करने का तरीका
- AlloyDB डेटा ऐक्सेस एपीआई को चालू करने का तरीका
- AlloyDB के लिए QueryData को चालू करने का तरीका
- टेंप्लेट जनरेट करने का तरीका
- फ़ैसेट वाली खोज की सुविधा इस्तेमाल करने का तरीका
- एआई एजेंट के साथ QueryData का इस्तेमाल करने का तरीका
14. सर्वे
आउटपुट: