
1. はじめに
この Codelab では、AlloyDB 用 QueryData を使用して、エージェント アプリケーションの自然言語入力から正確で予測可能な SQL ステートメントを生成する方法について説明します。
前提条件
- Google Cloud コンソールの基本的な知識
- コマンドライン インターフェースと Cloud Shell の基本的なスキル
学習内容
- AlloyDB クラスタを作成してサンプルデータをインポートする方法
- AlloyDB Data access API を有効にする方法
- AlloyDB で QueryData を有効にする方法
- テンプレートを生成する方法
- ファセット検索の使用方法
- AI エージェントで QueryData を使用する方法
必要なもの
- Google Cloud アカウントと Google Cloud プロジェクト
- Google Cloud コンソールと Cloud Shell をサポートするウェブブラウザ(Chrome など)
2. 設定と要件
プロジェクトのセットアップ
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト セレクタ ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud Console で、右上のツールバーにある Cloud Shell アイコンをクリックします。
または、G キーを押してから S キーを押します。このシーケンスは、Google Cloud コンソール内からアクセスした場合、またはこのリンクを使用した場合に Cloud Shell をアクティブにします。
プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
3. はじめに
API を有効にする
AlloyDB、Compute Engine、ネットワーキング サービス、Vertex AI を使用するには、Google Cloud プロジェクトでそれぞれの API を有効にする必要があります。
Cloud Shell ターミナルで、プロジェクト ID が設定されていることを確認します。
gcloud config get-value project
出力にプロジェクト tID が表示されます。
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
環境変数 PROJECT_ID を設定します。
PROJECT_ID=$(gcloud config get-value project)
必要なサービスをすべて有効にします。
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
想定される出力
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB をデプロイする
AlloyDB クラスタとプライマリ インスタンスを作成します。必要なリソースをすべてデプロイする準備済みのスクリプトを使用してデプロイすることも、ドキュメントに沿って手順ごとに自分でデプロイすることもできます。
自動化スクリプトを使用して AlloyDB をデプロイする
このアプローチでは、自動化されたスクリプトを使用して AlloyDB クラスタをデプロイし、デプロイされたリソースの操作を開始するために必要な情報を提供します。
Cloud Shell ターミナルでコマンドを実行して、リポジトリからデプロイ スクリプトのクローンを作成します。
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
デプロイ スクリプトを実行します。
./deploy_alloydb.sh --public-ip
スクリプトの実行にはしばらく時間がかかります(通常は約 5 ~ 7 分)。AlloyDB クラスタとパブリック IP とプライベート IP を持つプライマリ インスタンスがデプロイされます。パブリック IP は、承認済みネットワークでのみ使用できます。または、AlloyDB Auth Proxy を使用して使用できます。パブリック IP の詳細については、ドキュメントをご覧ください。スクリプトの出力として、デプロイされた AlloyDB クラスタに関する情報が提供されます。パスワードは異なります。後で使用できるように、パスワードをどこかに記録しておいてください。
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
新しいクラスタとプライマリ インスタンスは、ウェブ コンソールでも確認できます。
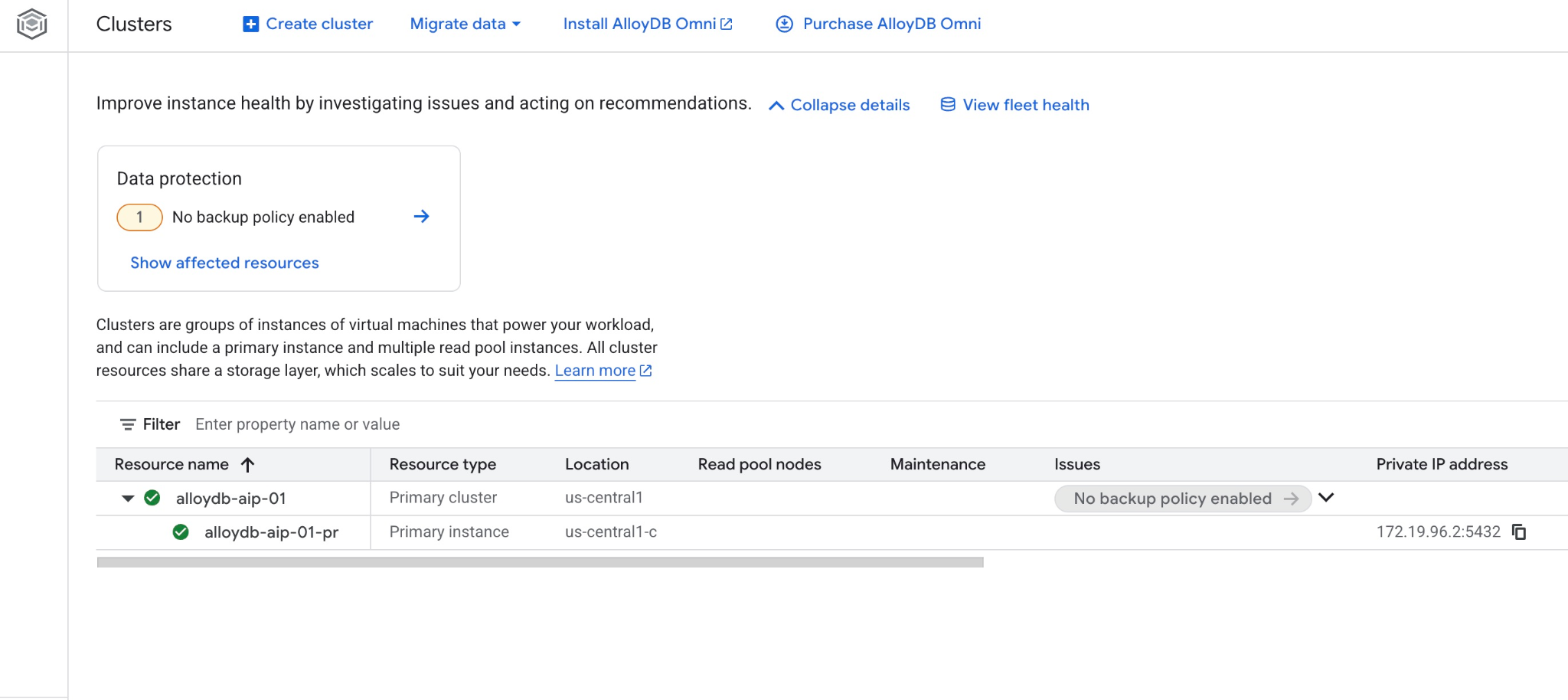
5. データベースを準備する
AI 関数と演算子を使用するには、Vertex AI インテグレーションを有効にし、データアクセス API を有効にして、サンプル データセットのデータベースを作成する必要があります。
AlloyDB に必要な権限を付与する
AlloyDB サービス エージェントに Vertex AI 権限を追加します。
上部の「+」記号を選択して、別の Cloud Shell タブを開きます。
新しい Cloud Shell タブで、次のコマンドを実行します。
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
想定されるコンソール出力:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
データアクセス API を有効にする
execute_sql などの MCP ツールを使用するには、AlloyDB クラスタで Data Access API を有効にする必要があります。
同じターミナル タブで実行します。
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
IAM 認証を有効にする
エージェント ツールに IAM 認証を使用するには、インスタンスで IAM 認証を有効にして、自分自身をデータベース ユーザーとして追加する必要があります。インスタンス レベルで IAM 認証を有効にする前に、データアクセス API を有効にする前のステップが完了するまでお待ちください。インスタンスのステータスが緑色になっているはずです。
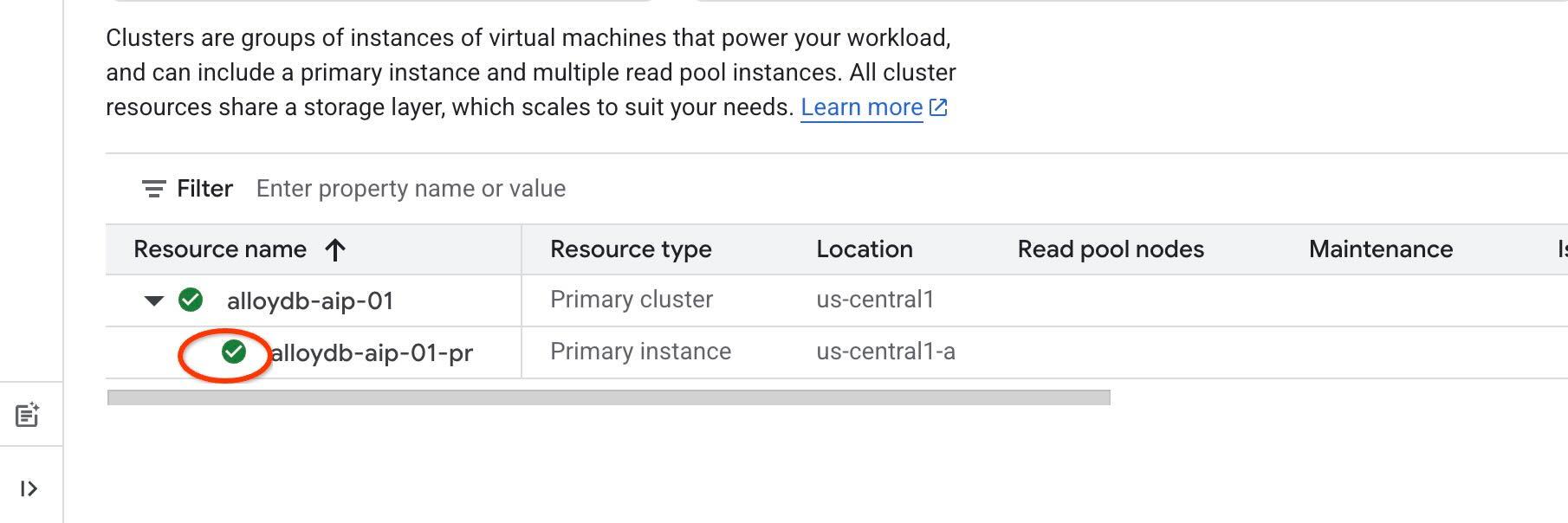
まず、インスタンス レベルで IAM を有効にします。同じターミナル タブで実行します。
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
AlloyDB ユーザーとして自分自身を追加します。
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
タブに実行コマンド「exit」を入力して、タブを閉じます。
exit
AlloyDB Studio に接続する
以降の章では、データベースへの接続を必要とするすべての SQL コマンドを AlloyDB Studio で実行できます。T
AlloyDB for Postgres の [クラスタ] ページに移動します。
プライマリ インスタンスをクリックして、AlloyDB クラスタのウェブ コンソール インターフェースを開きます。
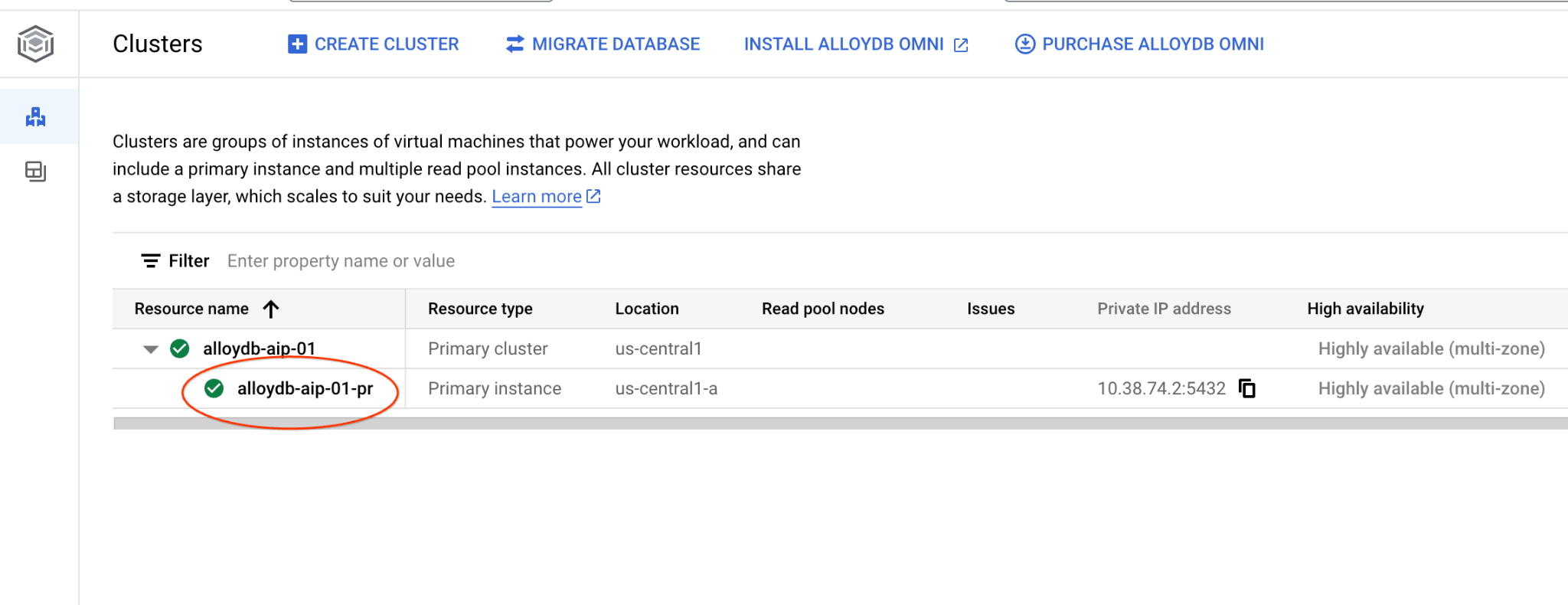
次に、左側の [AlloyDB Studio] をクリックします。
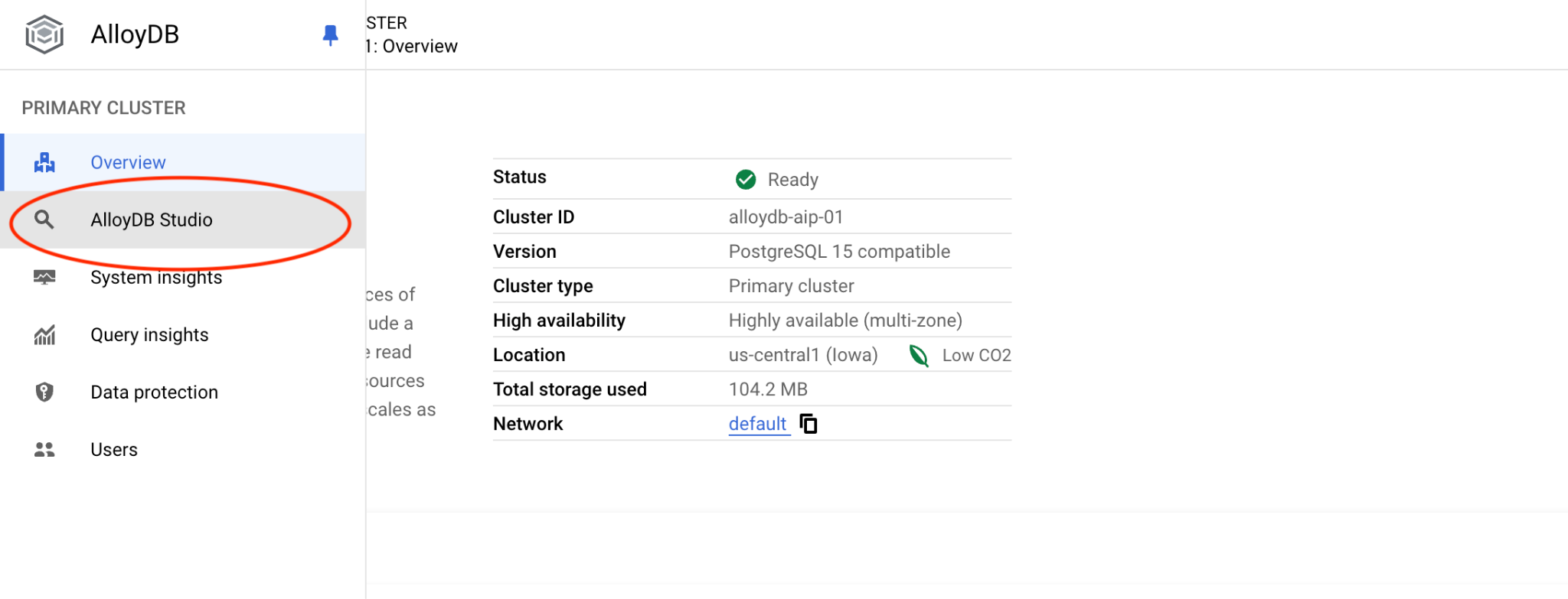
postgres データベースと IAM 認証を選択します。[認証] ボタンをクリックします。
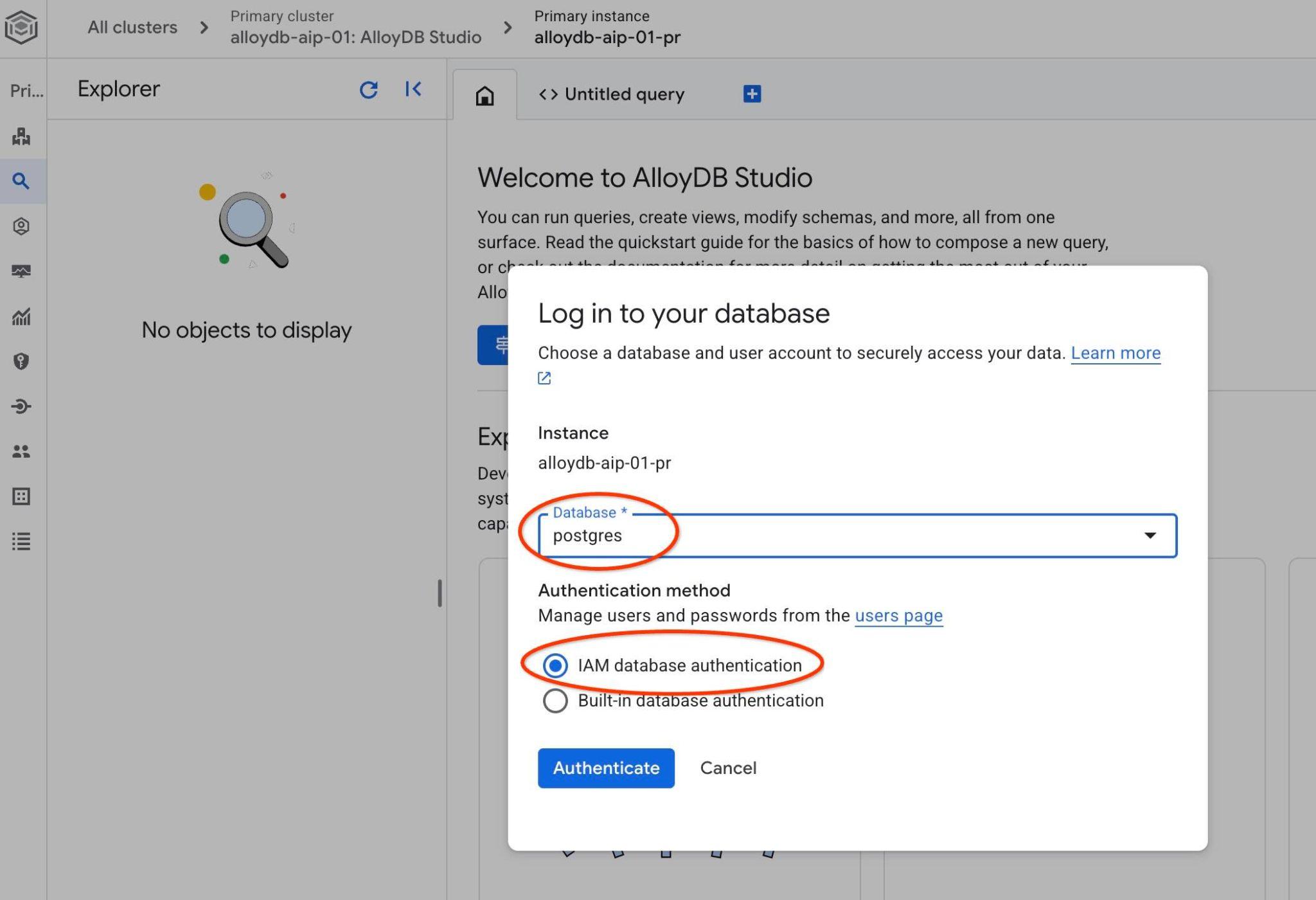
AlloyDB Studio インターフェースが開きます。データベースでコマンドを実行するには、右側の [無題のクエリ] タブをクリックします。
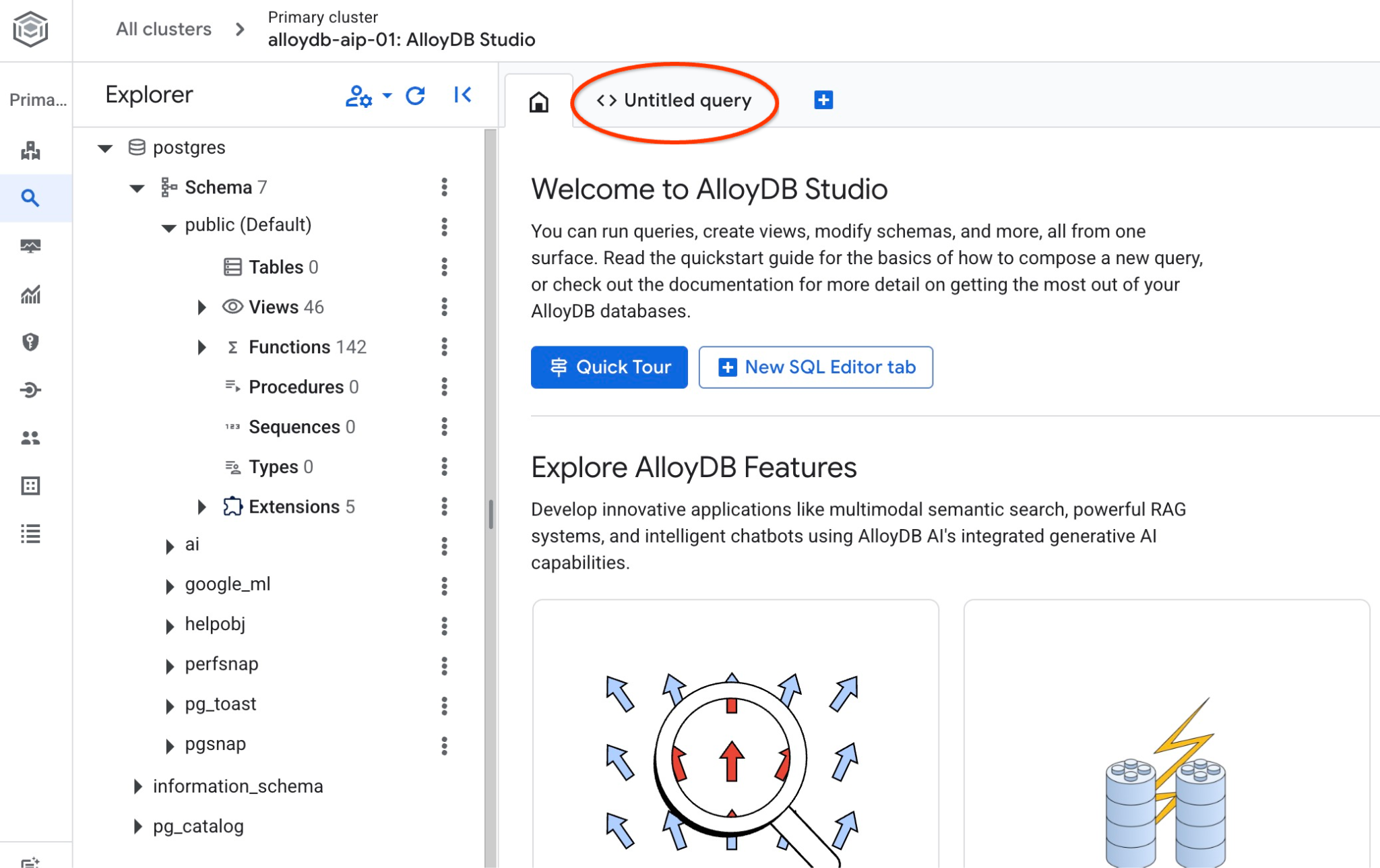
SQL コマンドを実行できるインターフェースが開きます。
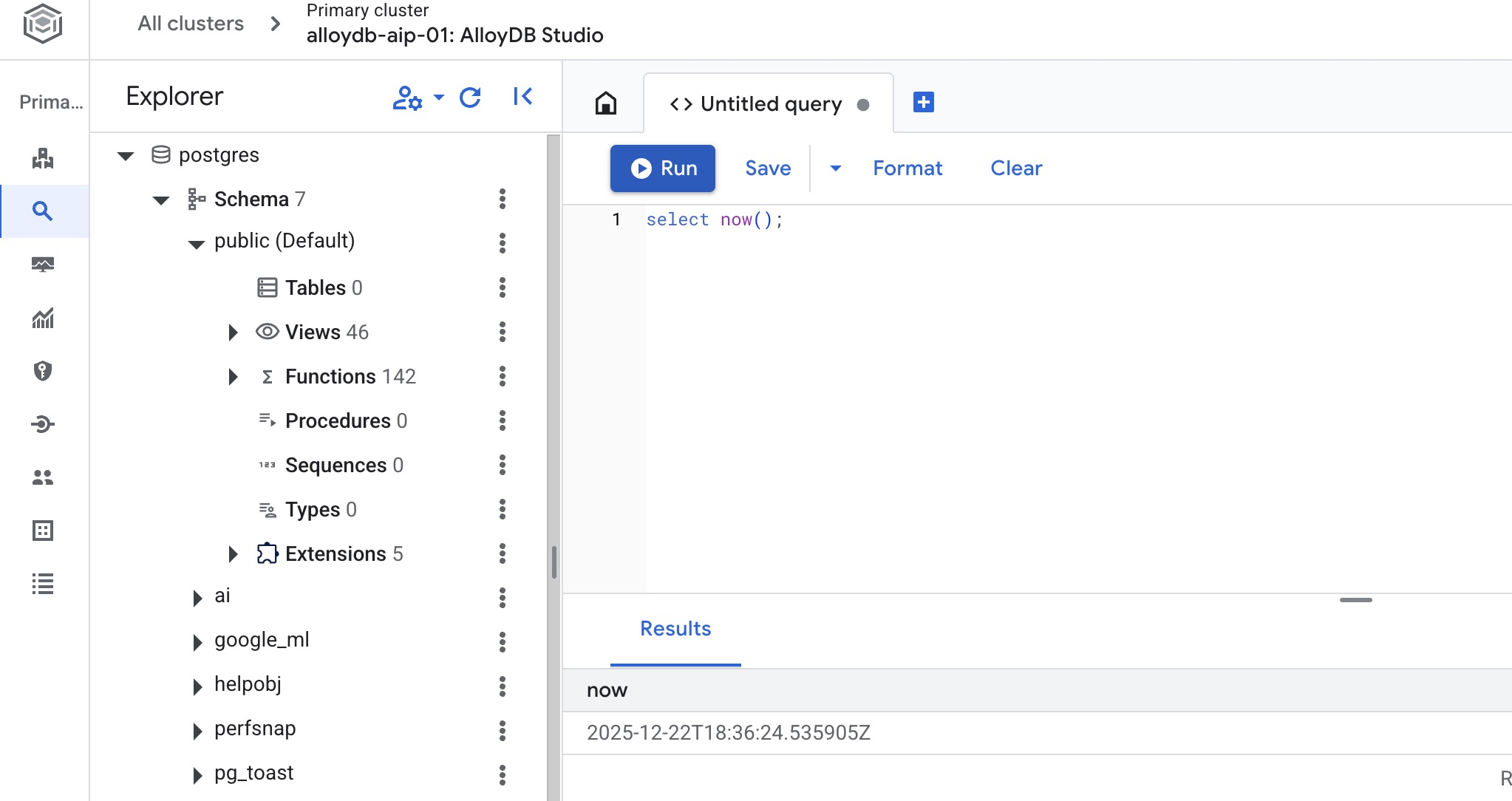
データベースを作成する
データベース作成のクイックスタート。
AlloyDB Studio エディタで、次のコマンドを実行します。
データベースを作成します。
CREATE DATABASE quickstart_db
予想される出力:
Statement executed successfully
quickstart_db に接続する
データベースに接続して、データベースが作成されているかどうかを確認します。ユーザー/データベースを切り替えるボタンを使用して、スタジオに再接続します。
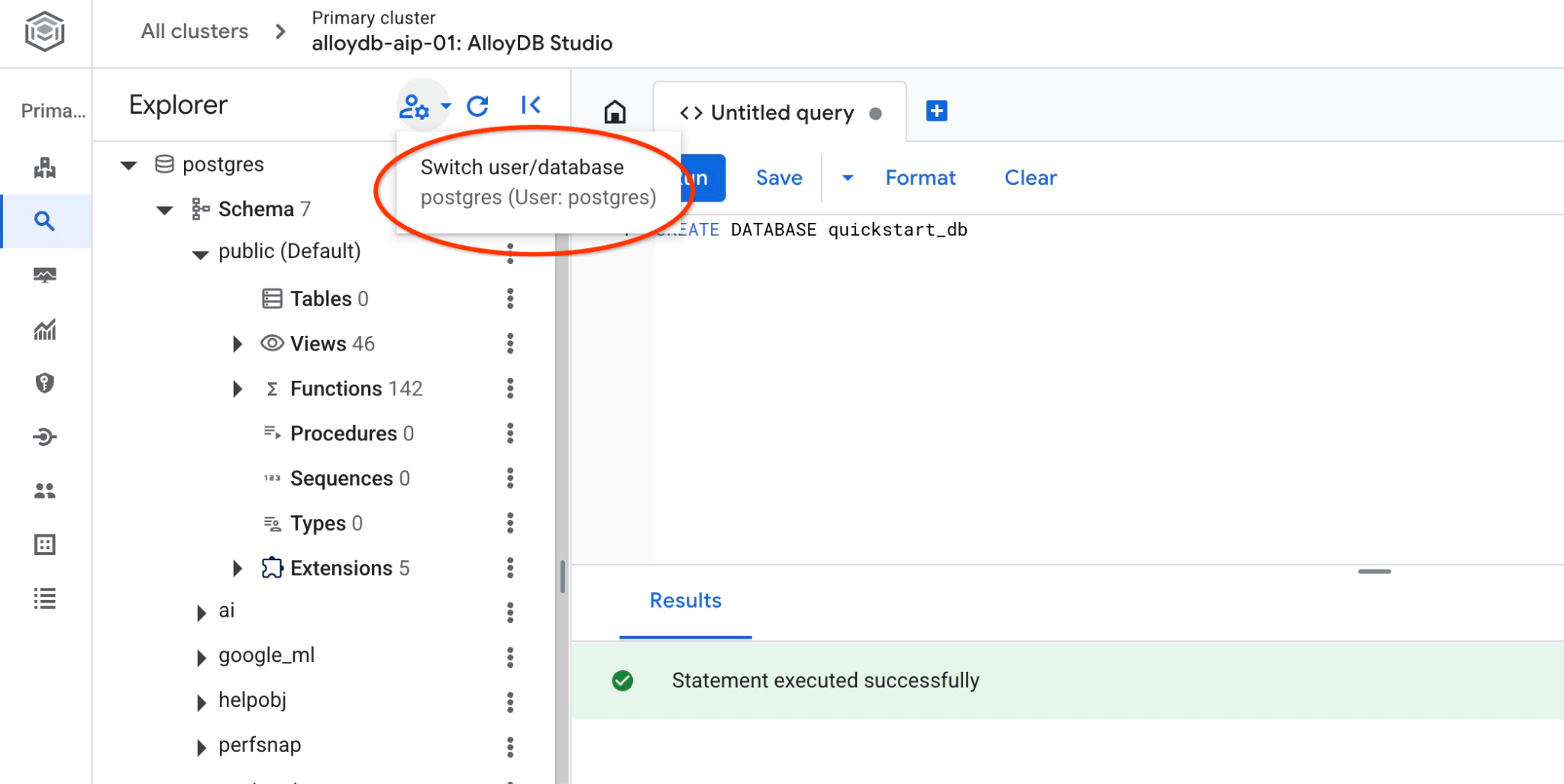
プルダウン リストから新しい quickstart_db データベースを選択し、同じ IAM 認証を使用します。
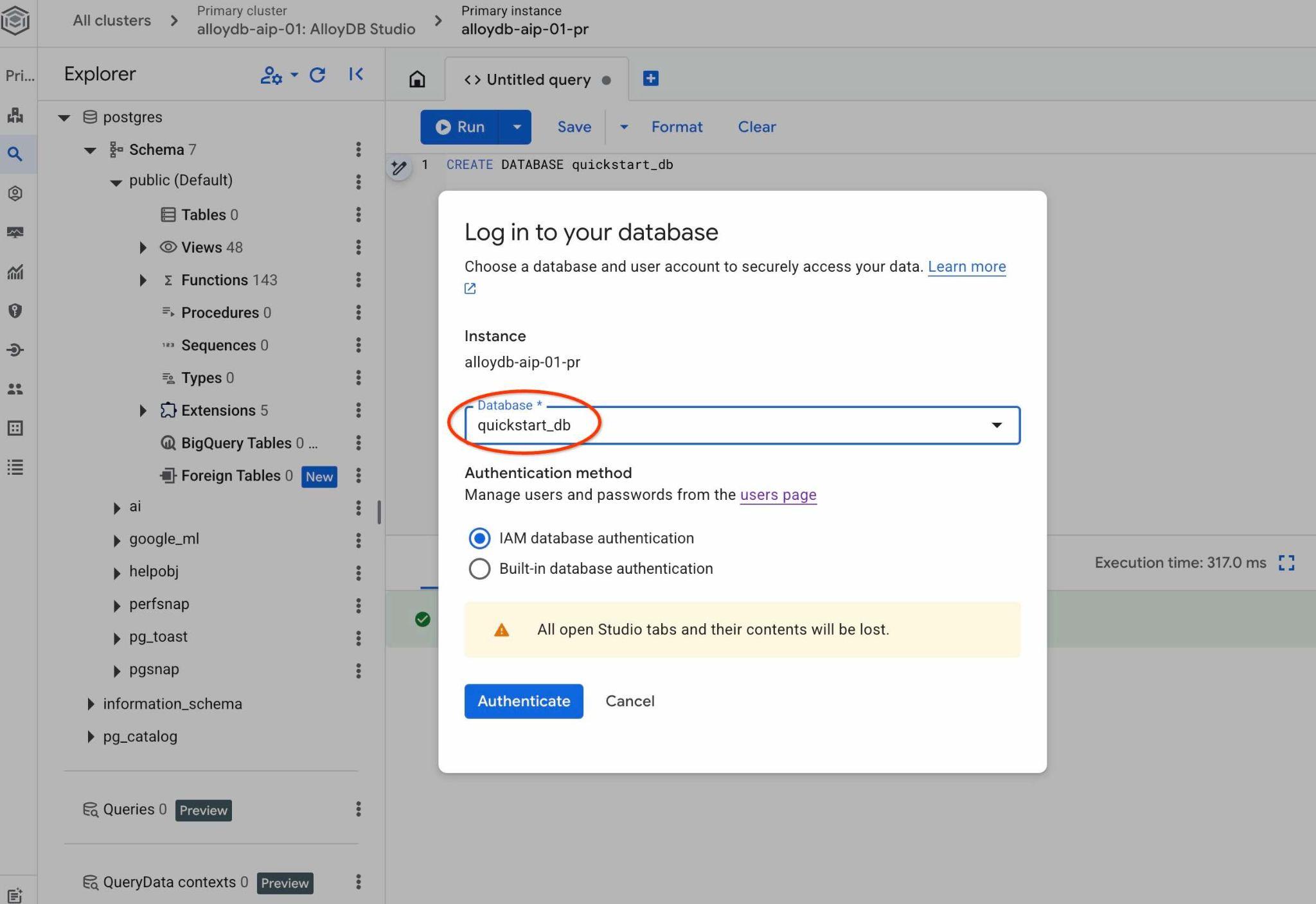
新しい接続が開き、quickstart_db データベースのオブジェクトを操作できます。インポートしたスキーマとデータを調べ、QueryData コンテキスト セットを操作できます。
6. サンプルデータ
次に、データベースにオブジェクトを作成してデータを読み込む必要があります。架空の Cymbal Shipping 社のデータセットを使用します。商品、トラック、リクエスト、トラックの走行に関する架空のデータと、架空のドライバーが含まれています。
ストレージ バケットを作成する
Google SDK(gcloud)を使用して、クローン作成したリポジトリから AlloyDB データベースにデータをインポートします。そのためには、Cloud Storage バケットを作成し、AlloyDB サービス アカウントにアクセス権を付与する必要があります。または、ドキュメントで説明されているように、ウェブ コンソールを使用していつでも実行できます。
Google Cloud Shell ターミナルで、次のコマンドを実行します。
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
データの読み込み
次のステップは、データを読み込むことです。圧縮された SQL ダンプは、クローン作成されたリポジトリ フォルダにあります。次のコマンドは、AlloyDB クラスタの作成時に前の手順でリポジトリをクローンしたときに、ホーム ディレクトリを開始点として使用したことを前提としています。
圧縮された SQL ダンプを新しいストレージ バケットにコピーします。
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
次に、データを quickstart_db データベースに読み込みます。
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
このコマンドは、サンプル データセットを quickstart_db データベースに読み込みます。AlloyDB Studio を使用して、テーブルとレコードを確認できます。
7. Data Agent を操作する
まず、Python 用 Google ADK を使用して作成されたサンプル AI エージェントから始め、データベース用 MCP ツールボックスを使用して AlloyDB インスタンスに接続します。
データベース向け MCP ツールボックスをインストールする
データベース向け MCP ツールボックスは、AlloyDB for PostgreSQL を含む複数のデータベース エンジンに対する MCP サポートを提供するオープンソース プロジェクトです。MCP ツールボックスについては、ドキュメントをご覧ください。
プラットフォーム用のソフトウェアの最新バージョンをダウンロードする必要があります。最新バージョンについては、リリースページをご覧ください。次の例は、MCP ツールボックスのバージョン 31 を Cloud Shell にダウンロードする方法を示しています。
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
ツールボックスの構成ファイルを準備する必要があります。現在のディレクトリに tools.yaml.example ファイルのサンプルがあります。2 つのプレースホルダをプロジェクト ID とリージョンに置き換えて、tools.yaml ファイルを準備します。
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
データベース向け MCP ツールボックスを起動する
これで、準備した構成ファイルを使用して MCP ツールボックスを起動できます。
Google Cloud Shell インターフェースの上部にある「+」ボタンを押して、Google Cloud Shell で新しいタブを開きます。
新しいタブで、ツールボックス バイナリ ファイルと構成ファイル tools.yaml があるディレクトリに切り替え、MCP サーバーを起動します。
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
出力には、次のように「Server ready to serve!」と表示されます。
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
エージェントのソースコードを確認する
クローンされたリポジトリ フォルダの最初のタブで、Google Cloud Shell エディタを使用してエージェント コードを確認します。
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
エージェントには、AlloyDB 用の Google Cloud MCP サーバーのセクションがあります。エンドポイントを MCP_SERVER_URL として提供し、認証、プロジェクト ID を MCP ツールセットに追加します。
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
エージェント コードでは、MCP ツールセットはエージェントの tools パラメータとして含まれています。また、エージェント プロンプトの変数として、クラスタ名、インスタンス名、リージョン、データベースもあります。
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
コードを確認したら、エディタ ウィンドウの右上にある [ターミナルを開く] ボタンを押して、ターミナルに戻ります。
エージェントを起動する
Google ADK ウェブ インターフェースを使用して、エージェントをインタラクティブ モードで起動できるようになりました。ADK ウェブ インターフェースを使用すると、エージェントのワークフローを簡単にテストしてトラブルシューティングできます。
まず、uv パッケージ マネージャーを使用して、Python に必要なパッケージをすべてインストールします。
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
すべてのパッケージがインストールされたら、エージェント ディレクトリに .env ファイルを追加して、AI モデルとのすべての通信に Vertex AI を使用するように指示する必要があります。
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
その後、エージェントを起動できます。
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
次のような出力が表示されます。エンドポイントは http://127.0.0.1:8000 のようになります。
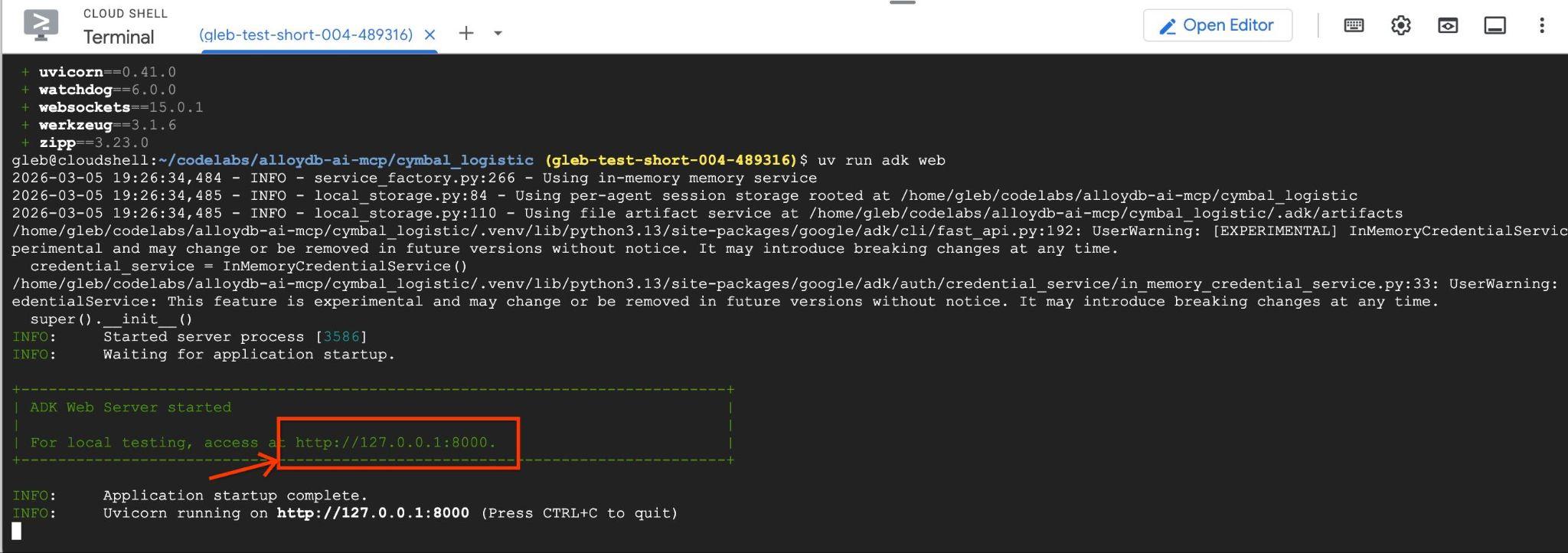
クラウド シェルでその URL をクリックすると、別のブラウザタブでプレビュー ウィンドウが開き、左側のプルダウン リストから data_agent を選択できます。
ADK ウェブ インターフェースでは、右下に質問を投稿できます。また、右側には各ステップのトレースを含む実行フロー全体が表示されます。
8. AlloyDB 用の QueryData を使用せずに NL2SQL をテストする
エージェントを使用すると、自然言語を使用して自由形式で質問できます。エージェントは、MCP Toolbox for Databases をツールとして使用して質問に回答します。質問は右下に投稿され、ツールへのすべての呼び出しを含む回答が上部に表示されます。
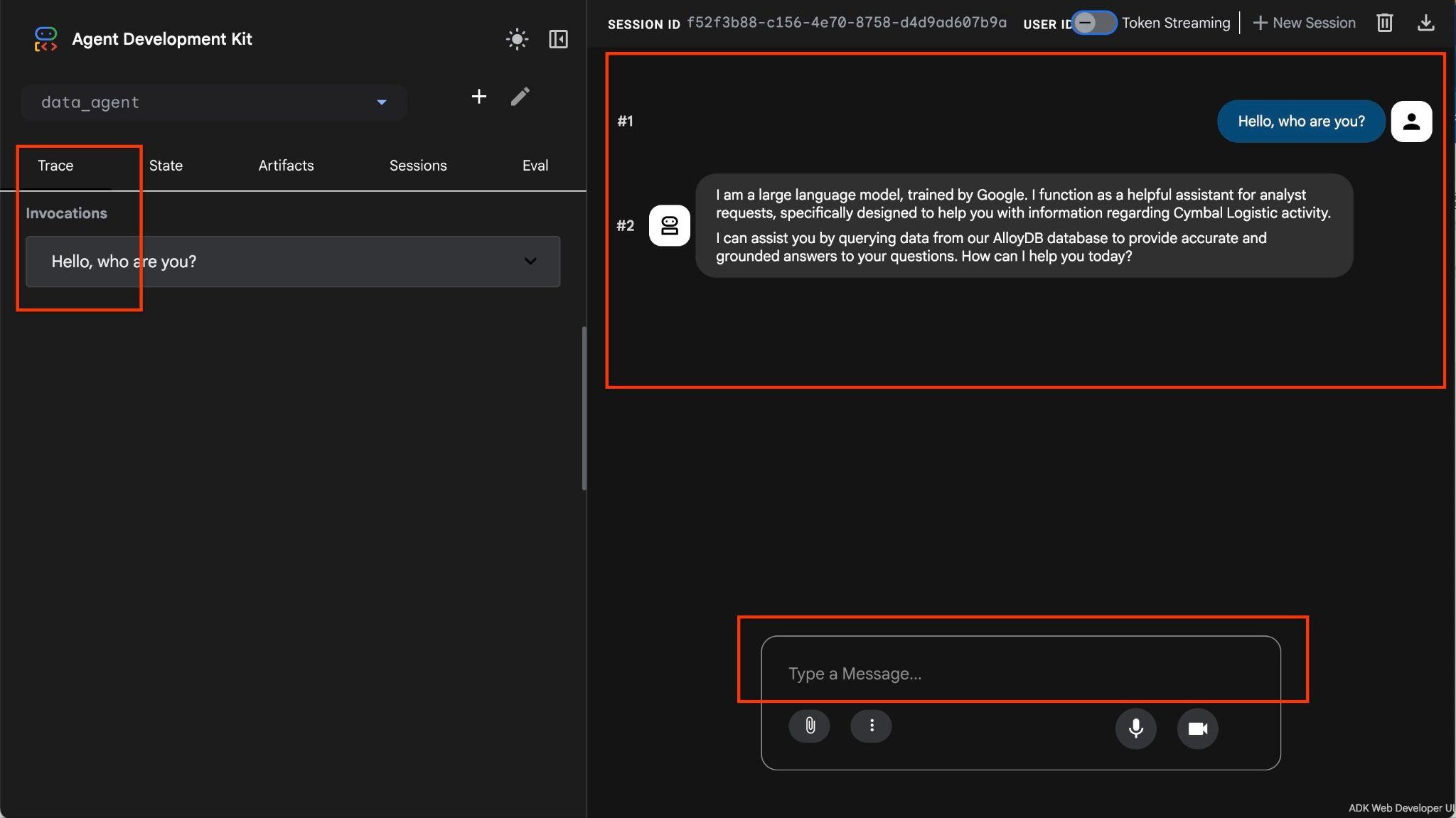
あなたは、配送リクエスト、トラック、ドライバー、ドライバーによる配送に関する情報を含む運送会社の運用データを扱っています。最初の質問は、2026 年 2 月に実行された乗車回数に関するものです。
右下の入力フィールドに次のように入力して、Enter キーを押します。
Hello, can you tell me how many trips we've done in February?
エージェントは、複数のツール呼び出しを実行して、list_cymbal_logistics_schemas_tool と execute_sql_tool を使用してスキーマ内の適切なテーブルを特定し、複数の SQL ステートメントを実行して適切なデータを取得します。
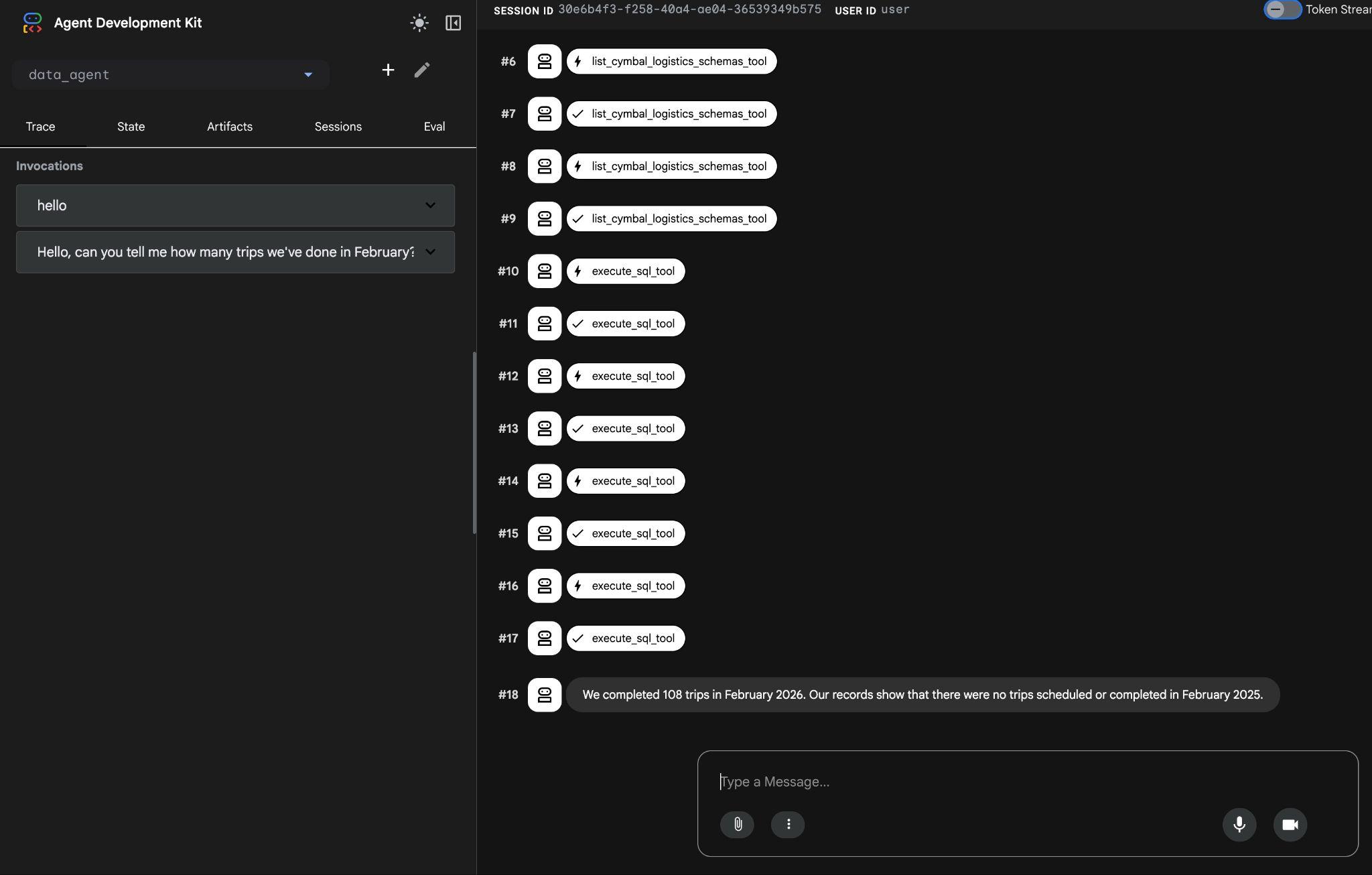
最終的には、適切なクエリを作成してデータベースで実行し、正しい結果を生成します。
2026 年 2 月に 108 回の旅行を完了しました。Google の記録によると、2025 年 2 月に予定されている旅行や完了した旅行はありません。
ツール実行をクリックすると、各ツール呼び出しの処理内容を確認できます。たとえば、結果を取得するために実行されたクエリは次のとおりです。
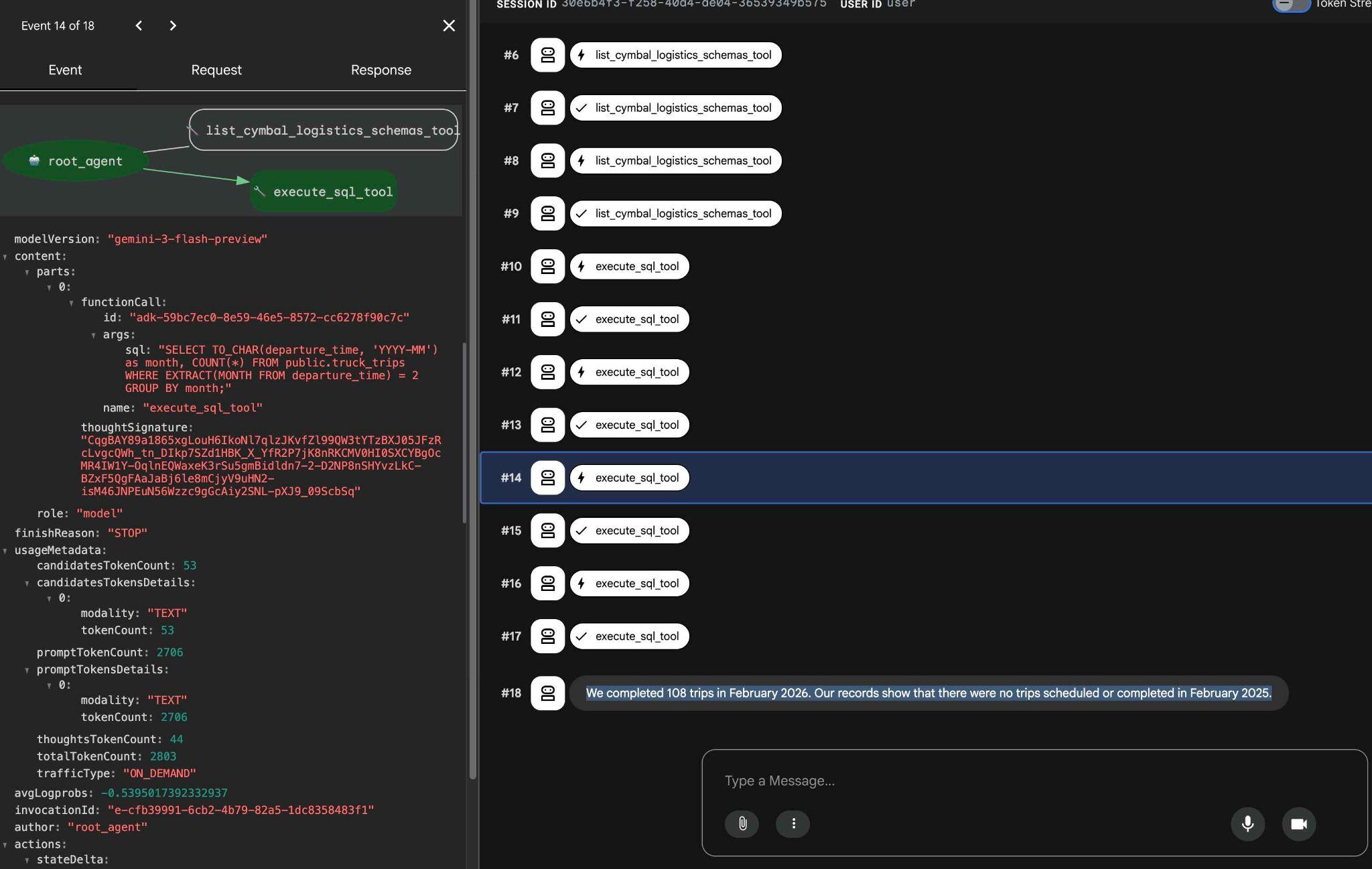
ADK ウェブ インターフェースを使用して他の簡単なリクエストを試し、さまざまなクエリを実行して結果を取得する方法を確認します。
ターミナルで ctrl+c を押してエージェントを停止します。ADK ウェブ インターフェースのブラウザタブを閉じます。
2 つ目のタブで同じ ctrl+c キーのショートカットを押して MCP Toolbox を停止し、2 つ目のタブを閉じることもできます。
次のステップでは、NL2SQL のレスポンスとパフォーマンスを改善するために QueryData コンテキストを構築します。
9. QueryData ContextSet をビルドする
前の手順で、AI モデルがデータベースの情報スキーマに複数回呼び出しを行い、SQL クエリの構築に使用するテーブルと列を特定していることがわかりました。パフォーマンスと精度を向上させ、結果をより予測可能にするために、特定のリクエストに応じて実行されるクエリを定義する QueryData コンテキストを追加します。
ターゲットを絞ったテンプレートを作成する
QueryData ContextSet は、クエリ テンプレートとファセットを含む JSON ファイルです。このファイルは、クエリ パターンとデータ構造に基づいて、リクエストされた目標を達成するために正しい SQL クエリまたは SQL クエリ部分を使用するよう AI モデルに必要なデータと指示を提供します。
ターゲット テンプレートから開始します。Cloud Shell エディタを使用してファイルを作成します。Cloud Shell ターミナルで実行します。
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
前の章で使用した自然言語クエリのテンプレート(「2 月に何回旅行しましたか?」)を挿入します。
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
次に、ダウンロード ボタンを使用して、Cloud Shell からパソコンにテンプレートをダウンロードします。
QueryData コンテキスト セットを読み込む
QueryData コンテキスト セットを使用するには、データベースにアップロードする必要があります。
AlloyDB Studio を開きます。左側のパネルの下部に QueryData Context と 3 つのドットが表示されます。
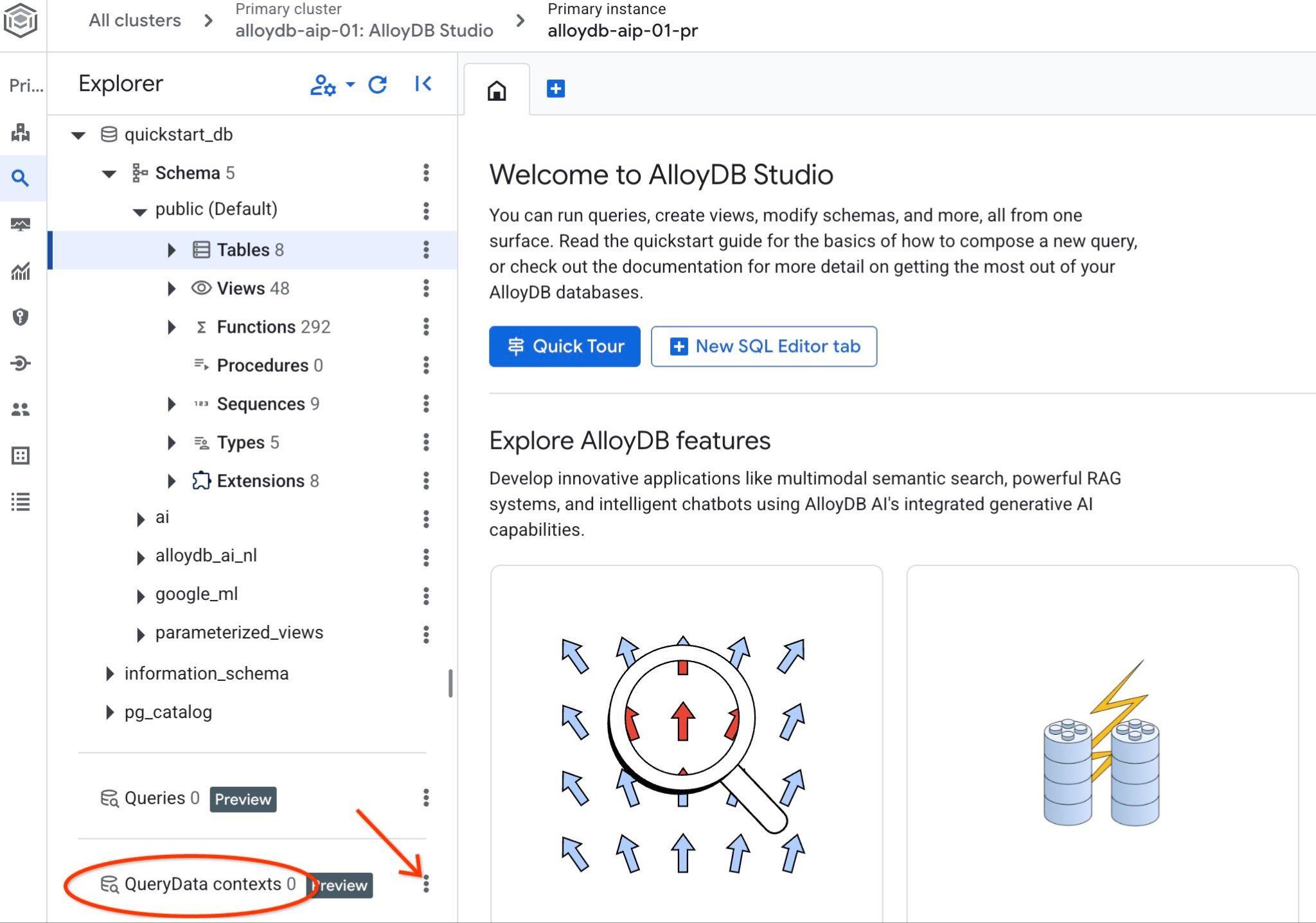
3 つの点をクリックして、[コンテキストを作成] を選択します。ダイアログが開き、
- 名前:
cymbal_context_set - 説明:
Cymbal Logistic Query Data - コンテキスト ファイルをアップロードする: [
Browse] ボタンをクリックし、QueryData ContextSet を含む JSON ファイルを選択します。
保存ボタンを押すと、初回の場合はコンテキスト ストレージの初期化に時間がかかることがあります。
ダウンロードしたコンテキストが表示されます。右側の縦に並んだ 3 つのボタンをクリックすると、利用可能なアクションが表示されます。次の章では、「テスト コンテキスト」アクションから始めます。
10. QueryData コンテキスト セットをテストする
テスト テンプレート
AlloyDB Studio でコンテキストをテストするには、Test context アクションを使用します。[テスト コンテキスト] をクリックすると、タイトルが「cymbal_context_set」の新しい AlloyDB Studio エディタ ウィンドウと、タイトルが「Generate SQL using QueryData context: cymbal_context_set」の Gemini SQL 生成の招待状が開きます。SQL 生成をクリックして、次のように入力します。
Hello, can you tell me how many trips we've done in February?
SQL が生成されたら、[Insert] ボタンを押します。
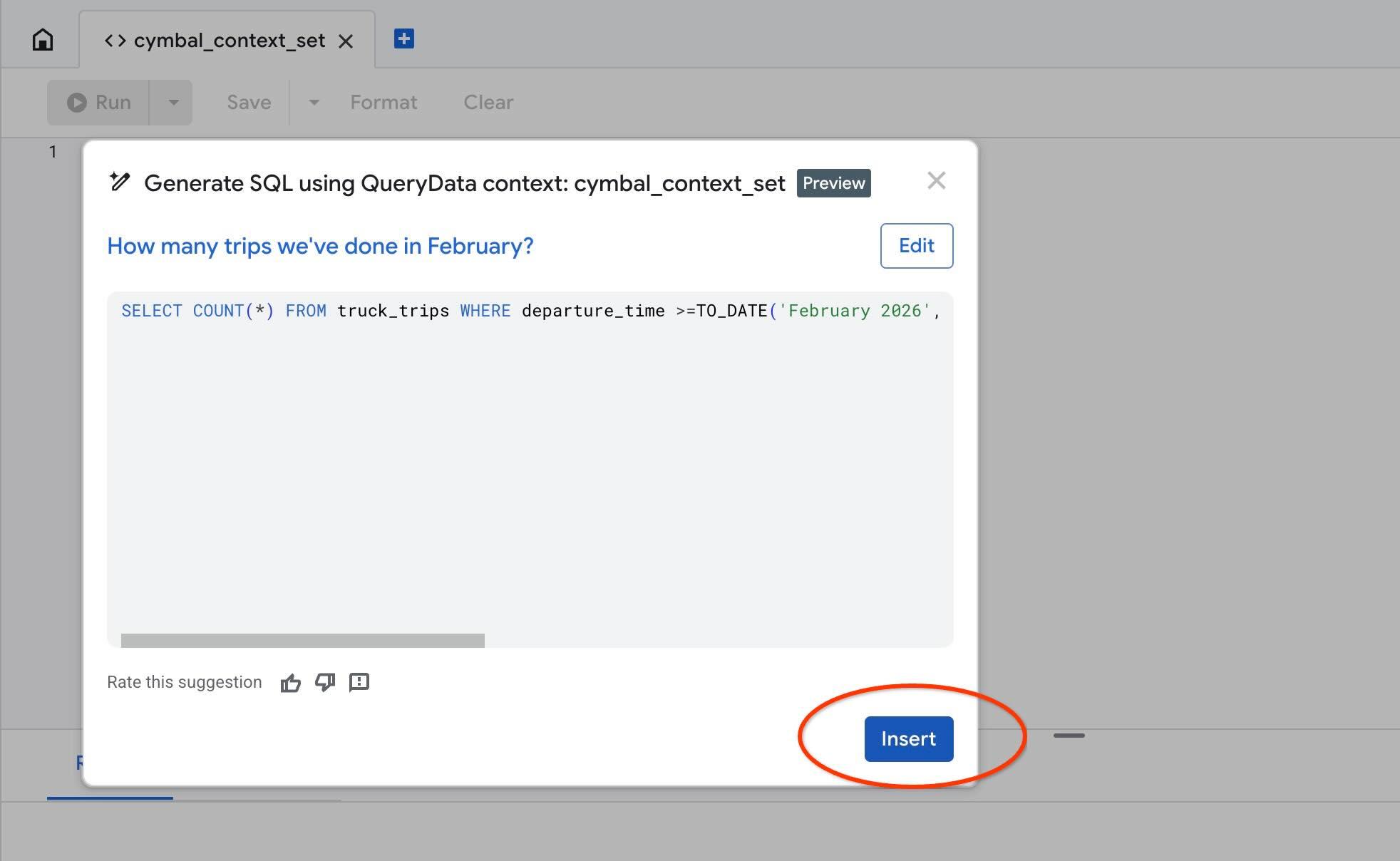
先ほどコンテキスト テンプレートに設定したクエリとまったく同じものが表示されます。
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
月を「1 月」に置き換えて、生成された SQL ステートメントを確認します。パラメータ化されたインテントのパラメータとして月が使用され、SQL ステートメントが自動的に調整されます。
QueryData ファセットをビルドする
クエリのテンプレートを試してみたところ、どのようなユーザーのリクエストが想定されるかがわかっている場合は機能しました。ただし、特定の順序や特定の句を再定義されたインテントに使用したい場合は、条件やフィルタなどのクエリの一部のみをガイドすると便利なことがあります。
たとえば、「先月」のデータを返すようリクエストした場合、過去 30 日間ではなく、先月の 1 日から最終日までのレポートを取得します。
このようなファセットは、以前に追加したテンプレートとともに、SQL スニペットとして ContextSet 構成に追加できます。querydata_cymbal_contextset.json を開きます。
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
既存のテンプレートの後にファセットを追加します。ファイル内の結果のコンテンツは次のようになります。
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
ファイルを保存してパソコンにアップロードします。
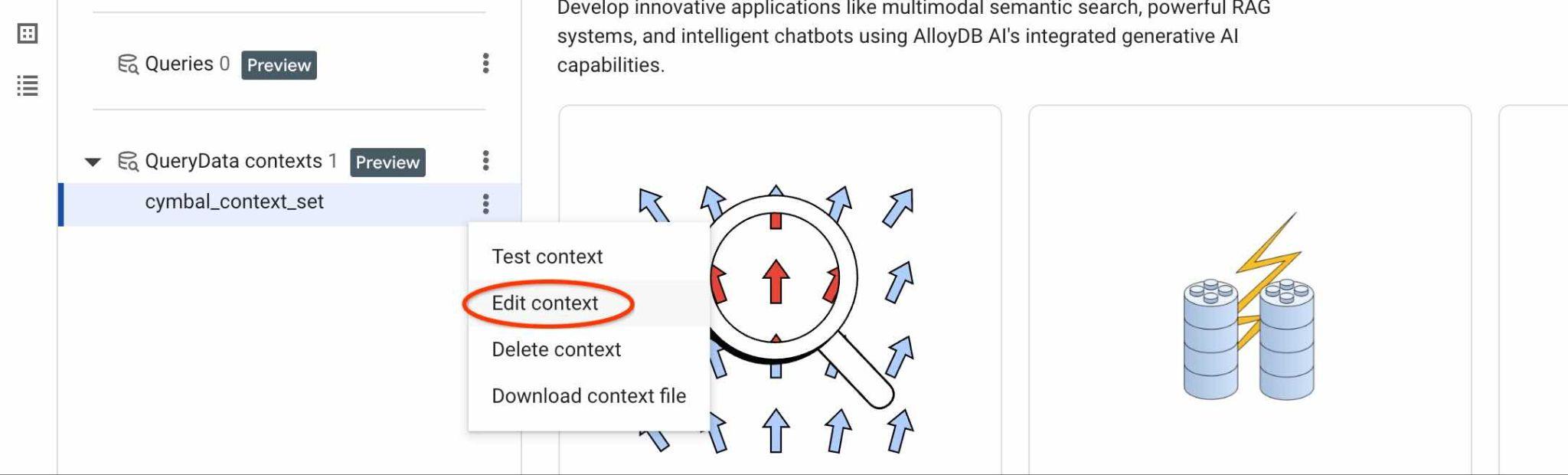
次に、クエリ コンテキスト アクションの [コンテキストを編集] を使用して、変更したファイルをアップロードし、古いコンテキストを新しいコンテキストに置き換えます。
もう一度テスト コンテキストを使用して、「先月」のインテントで SQL ステートメントを生成してみます。たとえば、「show trucks trips for the last month"」というフレーズの SQL を生成する場合、cymbal_context.json ファイルでファセットとして指定した条件が使用されます。
次のような出力が表示されます。
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
では、AI エージェントでどのように使用できるのでしょうか?次の章では、AI エージェントで Query Data コンテキストを使用できるようにします。
11. AI エージェントによる QueryData
同じデータ エージェントを使用しますが、MCP ツールボックスは QueryData ContextSet を使用するように構成されます。
データベース向け MCP ツールボックスを準備して起動する
Gemini Data Analytics API と AlloyDB をデータベース ソースとして使用する MCP ツールボックス用の新しい構成ファイルが必要です。
ターミナルで次のコマンドを実行します。
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
エディタに切り替えて、ファイル querydata.yaml を見つけます。構成ファイル querydata.yaml は、環境を反映するプロジェクト ID とリージョンを除き、次のようになります。ただし、contextSetId の値を更新し、"<add-context-set-id>" プレースホルダをコンソールの値に置き換える必要があります。
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
ContextSet ID を確認するには、図に示すように、コンテキスト セットの編集ボタンをクリックします。
右側の新しいタブの上部にコンテキスト セット ID が表示されます。
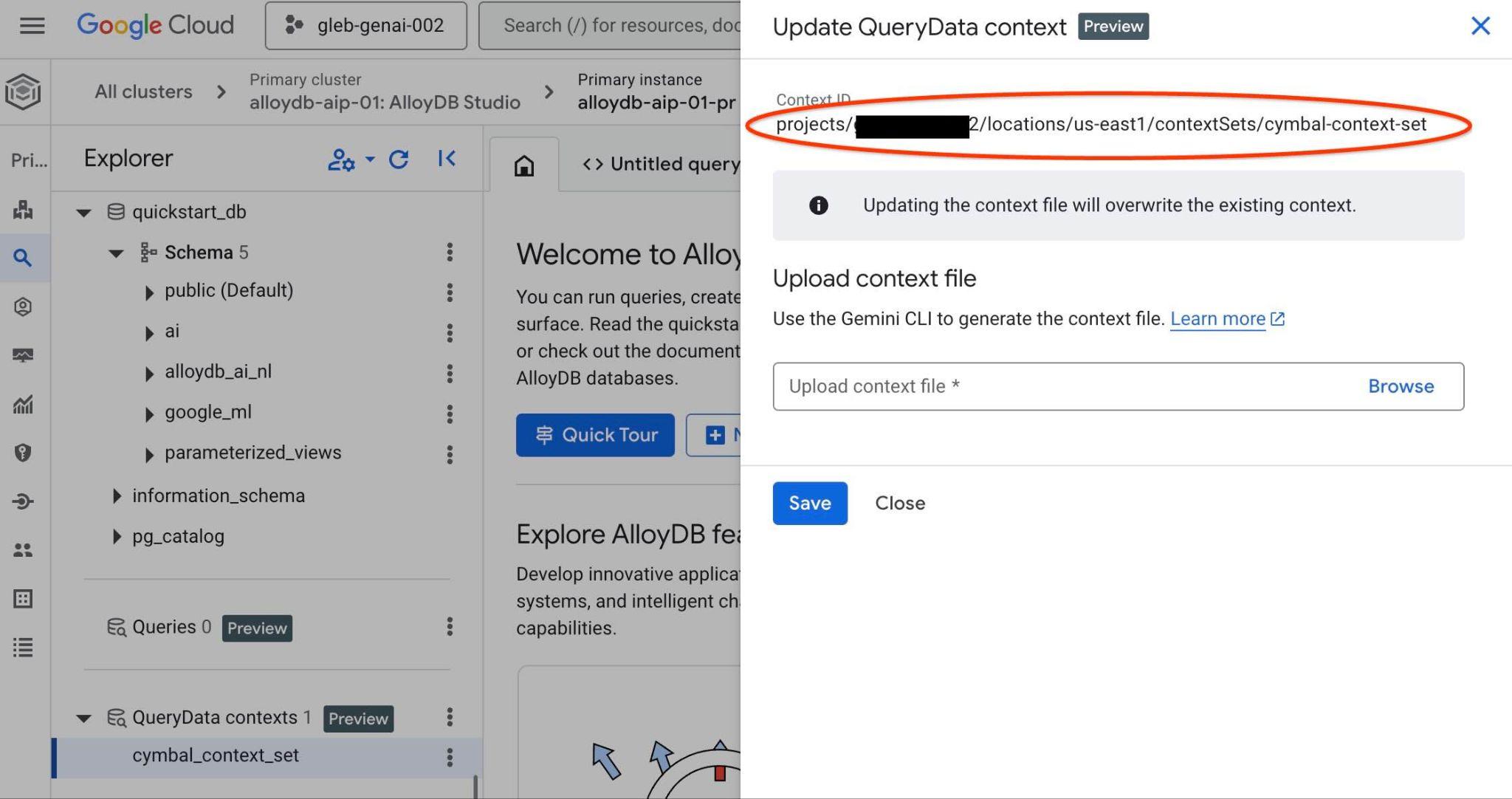
このフルパスは、querydata.yaml ファイルの "<add-context-set-id>" プレースホルダを置き換えるために使用します。
ターミナルに戻ります。
Google Cloud Shell インターフェースの上部にある「+」ボタンを押して、Google Cloud Shell で新しいタブを開きます。
新しいタブで、ツールボックス バイナリ ファイルと構成ファイル tools.yaml があるディレクトリに切り替え、MCP サーバーを起動します。
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
ADK エージェントを実行する
最初の Cloud Shell タブでエージェントを起動します。
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
起動したら、http://127.0.0.1:8000 へのリンクをもう一度クリックします。
おなじみの ADK ウェブ プレビュー エージェント インターフェースが表示されます。前回とまったく同じクエリを投稿します。
Hello, can you tell me how many trips we've done in February?
エージェントのワークフローを確認します。すべてが正しく構成されていれば、次のような画面が表示されます。
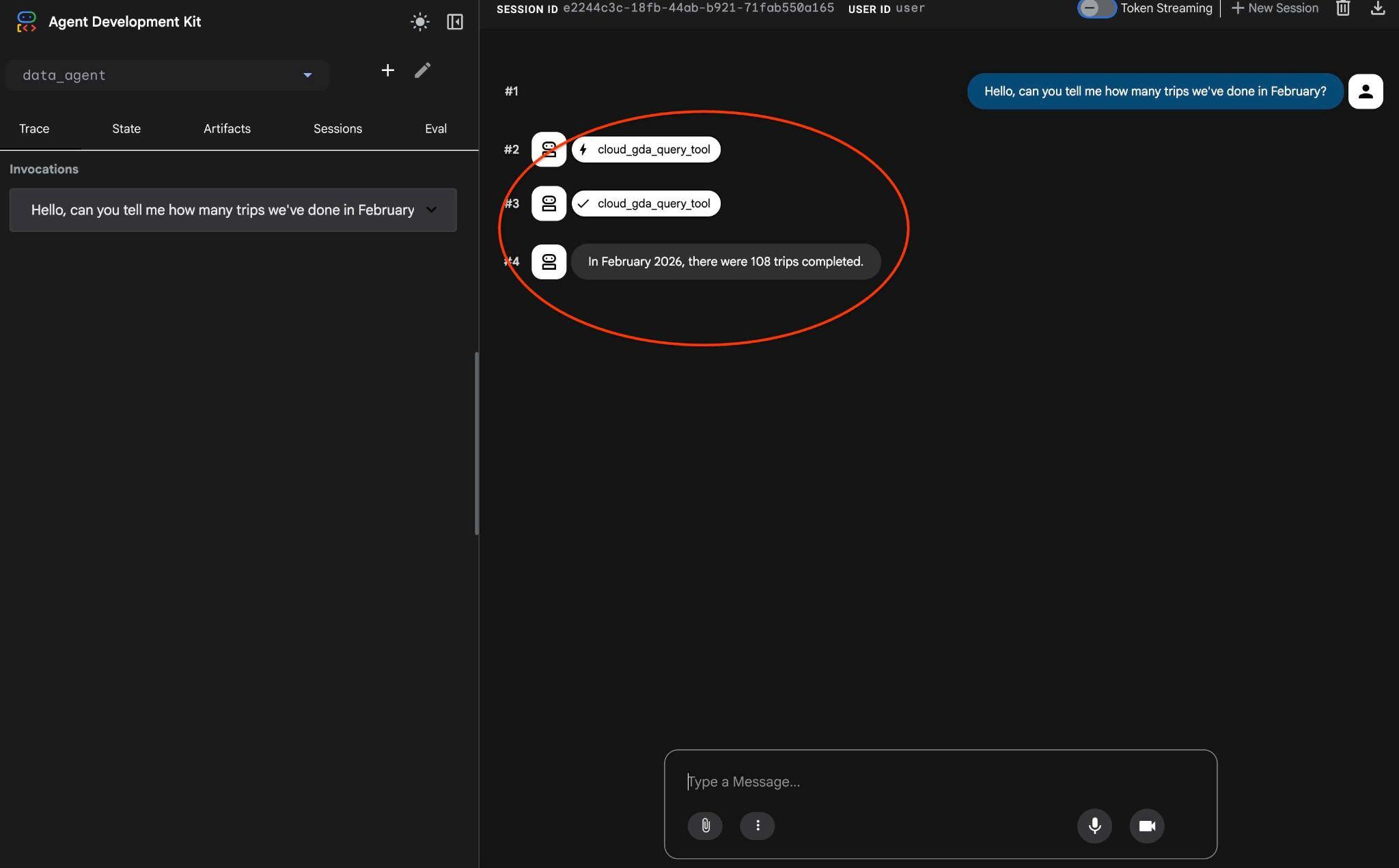
前回複数回実行されたリクエストは、MCP ツールへの 1 回の呼び出しに変換され、予測可能な SQL ステートメントを使用して実行されます。
構成したファセットは、次のようなリクエストを使用してテストできます。
how trucks trips for the last month
出力でツール アクションをクリックすると、同じツールを使用してファセットを適用し、結果を取得したことがわかります。
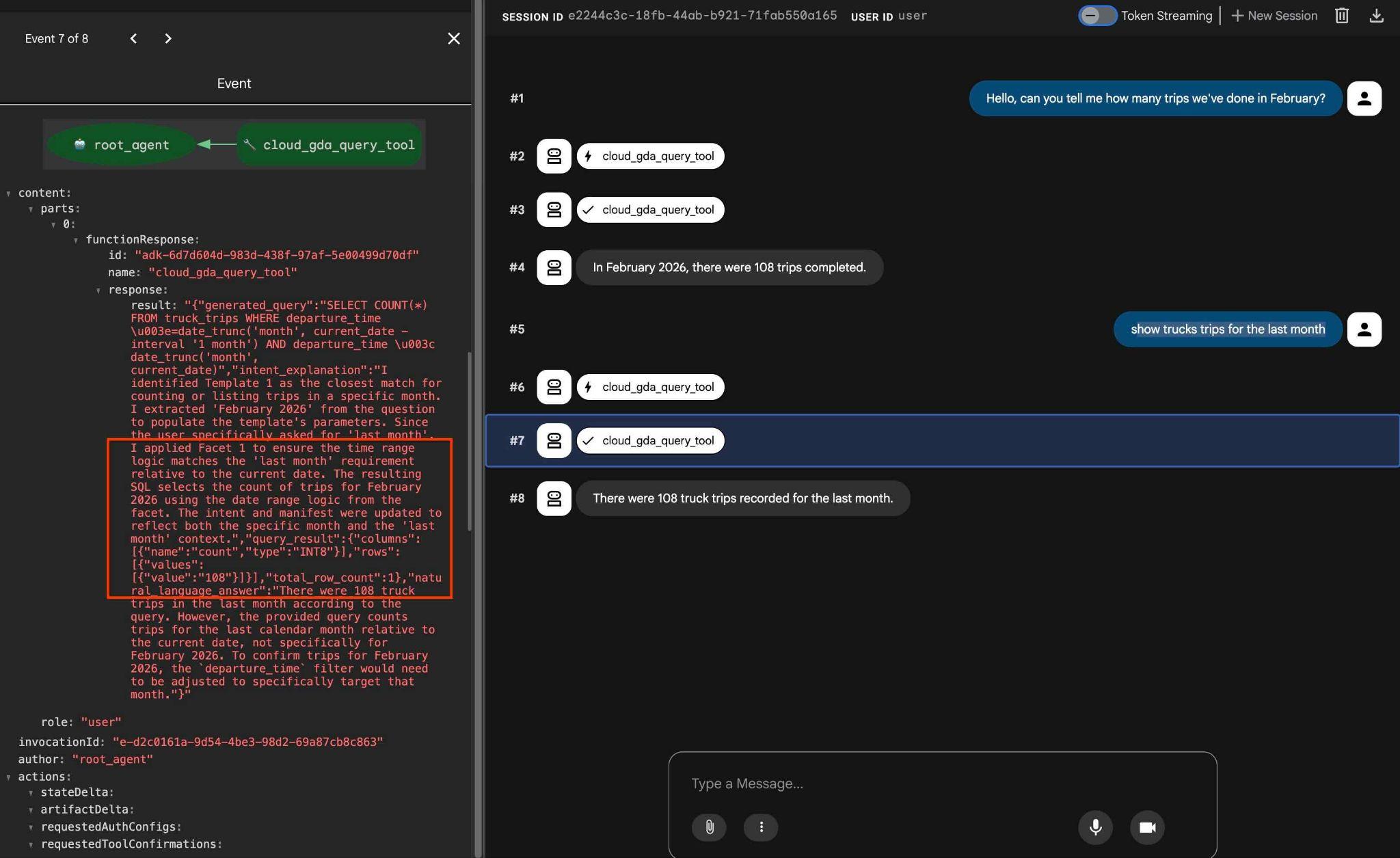
これでラボは終了です。すべての例を確認し、AlloyDB 用 QueryData の使用方法を理解できたことを願っています。提供されたテクノロジーにより、エージェント ワークロードと SQL 生成の予測可能性と信頼性が向上します。
12. 環境をクリーンアップする
予期しない請求が発生しないように、一時リソースをクリーンアップすることをおすすめします。最も確実な方法は、ワークフローをテストしていたプロジェクトを削除することです。ただし、AlloyDB などの個々のリソースを削除することで、必要に応じて制限できます。
ラボの終了時に AlloyDB インスタンスとクラスタを破棄します。
AlloyDB クラスタとすべてのインスタンスを削除する
AlloyDB の試用版を使用した場合。トライアル クラスタを使用して他のラボやリソースをテストする予定がある場合は、トライアル クラスタを削除しないでください。同じプロジェクトに別のトライアル クラスタを作成することはできません。
クラスタは force オプションで破棄され、クラスタに属するすべてのインスタンスも削除されます。
接続が切断され、以前の設定がすべて失われた場合は、Cloud Shell でプロジェクトと環境変数を定義します。
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
クラスタを削除します。
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
想定されるコンソール出力:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB バックアップを削除する
クラスタの AlloyDB バックアップをすべて削除します。
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
想定されるコンソール出力:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
13. 完了
以上で、この Codelab は完了です。
学習した内容
- AlloyDB クラスタを作成してサンプルデータをインポートする方法
- AlloyDB データアクセス API を有効にする方法
- AlloyDB で QueryData を有効にする方法
- テンプレートを生成する方法
- ファセット検索の使用方法
- AI エージェントで QueryData を使用する方法
14. アンケート
出力: