
1. 소개
이 Codelab에서는 AlloyDB용 QueryData를 시작하고 이를 사용하여 에이전트 애플리케이션의 자연어 입력에서 정확하고 예측 가능한 SQL 문을 생성하는 방법을 안내합니다.
기본 요건
- Google Cloud 콘솔에 관한 기본적인 이해
- 명령줄 인터페이스 및 Cloud Shell의 기본 기술
학습할 내용
- AlloyDB 클러스터를 만들고 샘플 데이터를 가져오는 방법
- AlloyDB 데이터 액세스 API를 사용 설정하는 방법
- AlloyDB에서 QueryData를 사용 설정하는 방법
- 템플릿을 생성하는 방법
- 상품 속성별 검색 사용 방법
- AI 에이전트와 함께 QueryData를 사용하는 방법
필요한 항목
- Google Cloud 계정 및 Google Cloud 프로젝트
- Google Cloud 콘솔 및 Cloud Shell을 지원하는 웹브라우저(예: Chrome)
2. 설정 및 요구사항
프로젝트 설정
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
Cloud Shell 시작
Google Cloud를 노트북에서 원격으로 실행할 수 있지만, 이 Codelab에서는 Cloud에서 실행되는 명령줄 환경인 Google Cloud Shell을 사용합니다.
Google Cloud Console의 오른쪽 상단 툴바에 있는 Cloud Shell 아이콘을 클릭합니다.
또는 G를 누른 다음 S를 누릅니다. Google Cloud 콘솔에 있거나 이 링크를 사용하는 경우 이 시퀀스를 통해 Cloud Shell이 활성화됩니다.
환경을 프로비저닝하고 연결하는 데 몇 분 정도 소요됩니다. 완료되면 다음과 같이 표시됩니다.

가상 머신에는 필요한 개발 도구가 모두 들어있습니다. 영구적인 5GB 홈 디렉터리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 이 Codelab의 모든 작업은 브라우저 내에서 수행할 수 있습니다. 아무것도 설치할 필요가 없습니다.
3. 시작하기 전에
API 사용 설정
AlloyDB, Compute Engine, 네트워킹 서비스, Vertex AI를 사용하려면 Google Cloud 프로젝트에서 각 API를 사용 설정해야 합니다.
Cloud Shell 터미널 내에 프로젝트 ID가 설정되어 있는지 확인합니다.
gcloud config get-value project
출력에 프로젝트 tID가 표시됩니다.
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
환경 변수 PROJECT_ID를 설정합니다.
PROJECT_ID=$(gcloud config get-value project)
필요한 모든 서비스를 사용 설정합니다.
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
예상 출력
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB 배포
AlloyDB 클러스터 및 기본 인스턴스를 만듭니다. 필요한 모든 리소스를 배포하는 준비된 스크립트를 사용하여 배포하거나 문서에 따라 단계별로 직접 배포할 수 있습니다.
자동 스크립트를 사용하여 AlloyDB 배포
이 접근 방식은 자동화된 스크립트를 사용하여 AlloyDB 클러스터를 배포하고 배포된 리소스를 사용하기 시작하는 데 필요한 정보를 제공합니다.
Cloud Shell 터미널에서 명령어를 실행하여 저장소에서 배포 스크립트를 클론합니다.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
배포 스크립트를 실행합니다.
./deploy_alloydb.sh --public-ip
스크립트를 실행하는 데 시간이 걸립니다. 일반적으로 5~7분 정도 걸리며 공개 및 비공개 IP가 있는 AlloyDB 클러스터와 기본 인스턴스를 배포합니다. 공개 IP는 승인된 네트워크에서만 또는 AlloyDB 인증 프록시를 사용하여 사용할 수 있습니다. 공개 IP에 대한 자세한 내용은 문서를 참고하세요. 스크립트는 배포된 AlloyDB 클러스터에 관한 정보를 출력해야 합니다. 비밀번호가 달라지므로 나중에 사용할 수 있도록 비밀번호를 어딘가에 기록해 두세요.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
웹 콘솔에서 새 클러스터와 기본 인스턴스를 확인할 수도 있습니다.
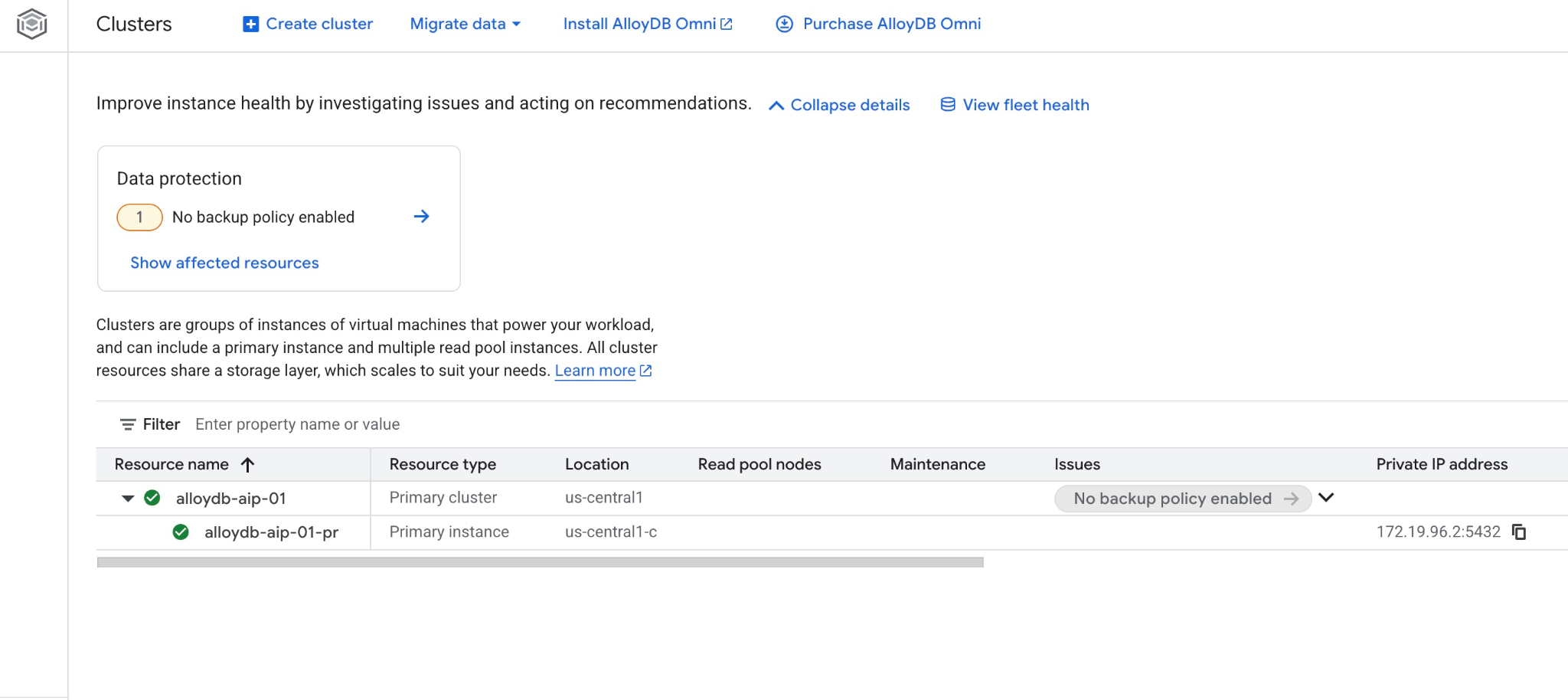
5. 데이터베이스 준비
AI 함수와 연산자를 사용하고, 데이터 액세스 API를 사용 설정하고, 샘플 데이터 세트용 데이터베이스를 만들려면 Vertex AI 통합을 사용 설정해야 합니다.
AlloyDB에 필요한 권한 부여
AlloyDB 서비스 에이전트에 Vertex AI 권한을 추가합니다.
맨 위에 있는 '+' 기호를 사용하여 다른 Cloud Shell 탭을 엽니다.
새 Cloud Shell 탭에서 다음을 실행합니다.
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
데이터 액세스 API 사용 설정
execute_sql와 같은 MCP 도구를 사용하려면 AlloyDB 클러스터에서 데이터 액세스 API를 사용 설정해야 합니다.
동일한 터미널 탭에서 다음을 실행합니다.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
IAM 인증 사용 설정
Google에서는 에이전트 도구에 IAM 인증을 사용할 예정이며, 이를 위해서는 인스턴스에서 IAM 인증을 사용 설정하고 자신을 데이터베이스 사용자로 추가해야 합니다. 인스턴스 수준에서 IAM 인증을 사용 설정하기 전에 데이터 액세스 API를 사용 설정하는 이전 단계가 완료될 때까지 기다리세요. 인스턴스 상태가 녹색이어야 합니다.
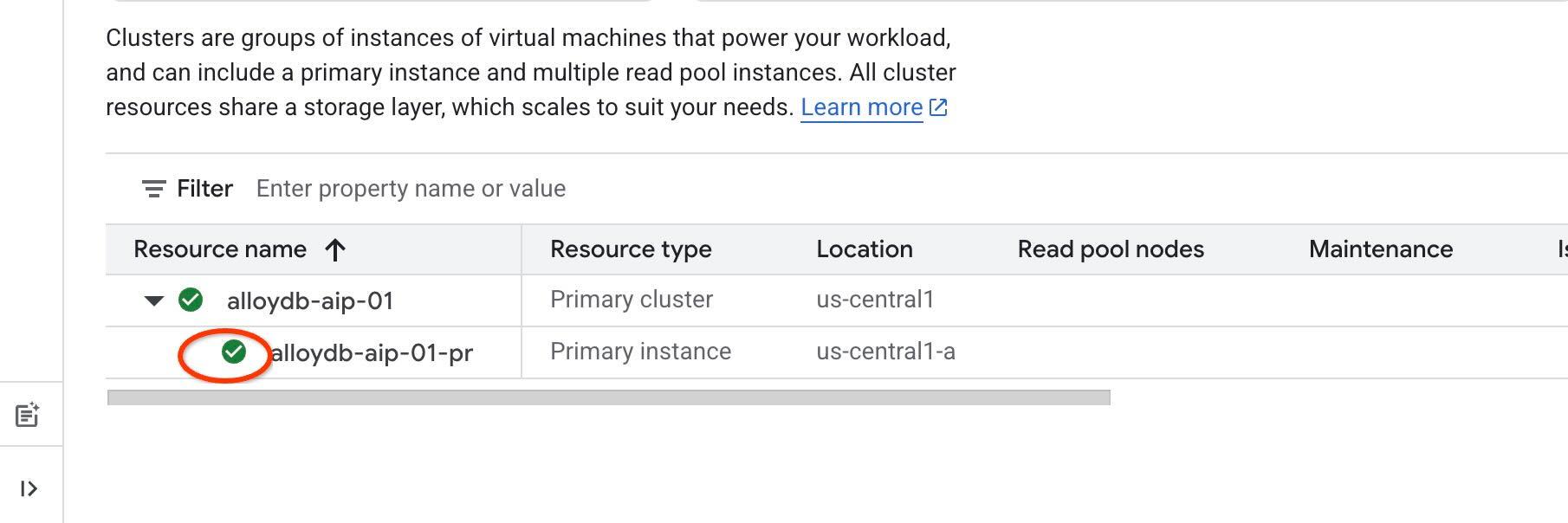
인스턴스 수준에서 IAM을 사용 설정하는 것부터 시작합니다. 동일한 터미널 탭에서 다음을 실행합니다.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
본인을 AlloyDB 사용자로 추가합니다.
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
탭에서 실행 명령어 'exit' 중 하나를 사용하여 탭을 닫습니다.
exit
AlloyDB Studio에 연결
다음 장에서는 데이터베이스에 연결해야 하는 모든 SQL 명령어를 AlloyDB Studio에서 실행할 수 있습니다. T
Postgres용 AlloyDB의 클러스터 페이지로 이동합니다.
기본 인스턴스를 클릭하여 AlloyDB 클러스터의 웹 콘솔 인터페이스를 엽니다.
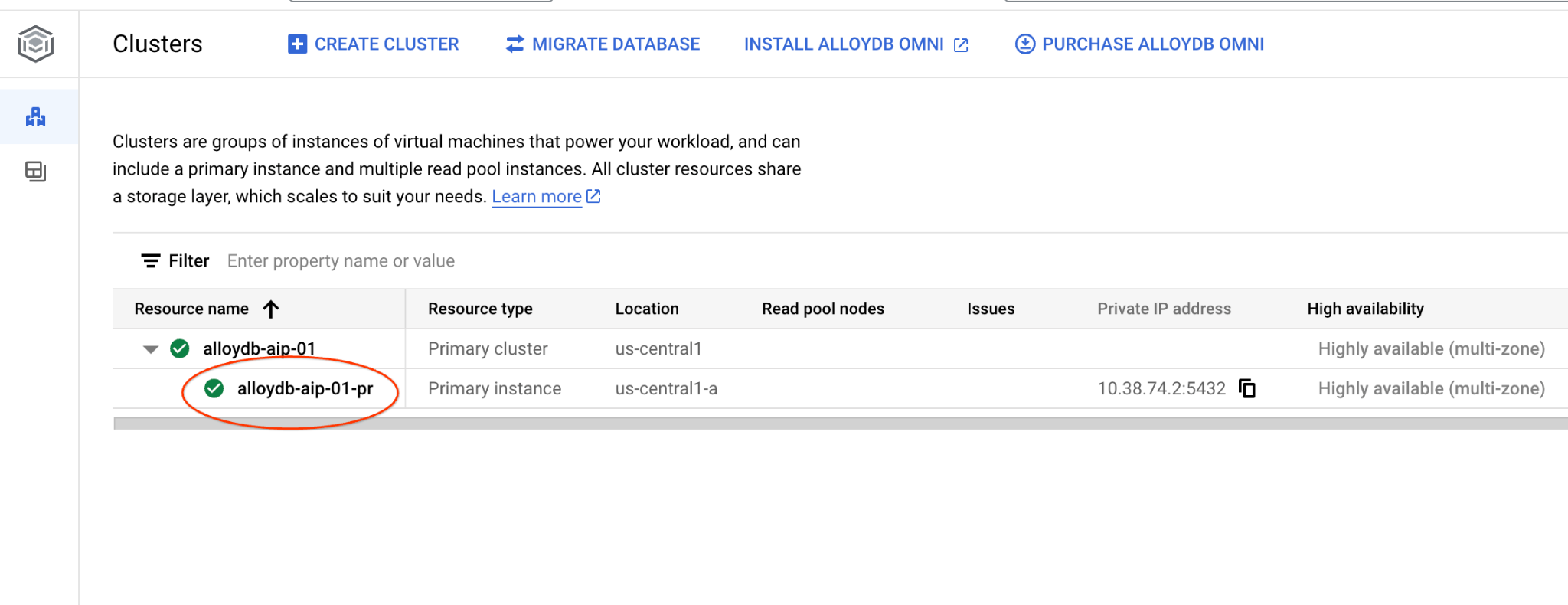
그런 다음 왼쪽에 있는 AlloyDB Studio를 클릭합니다.
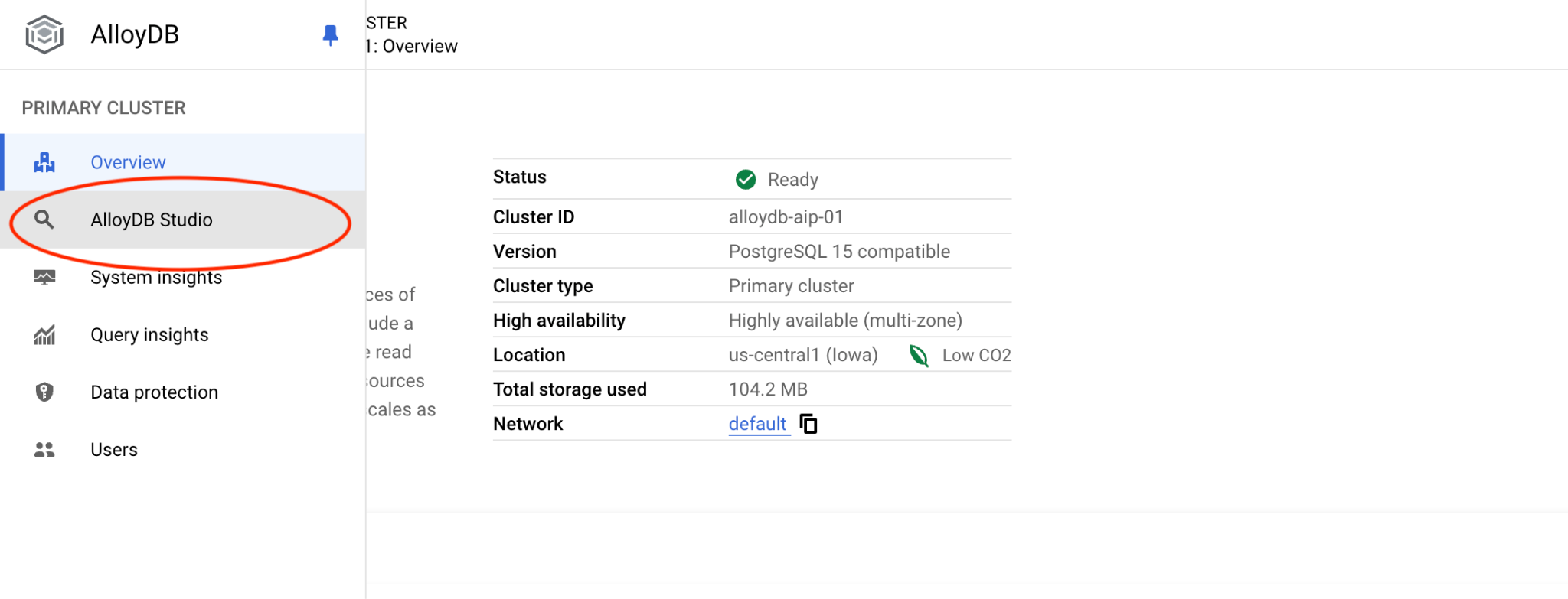
Postgres 데이터베이스와 IAM 인증을 선택합니다. 그런 다음 '인증' 버튼을 클릭합니다.
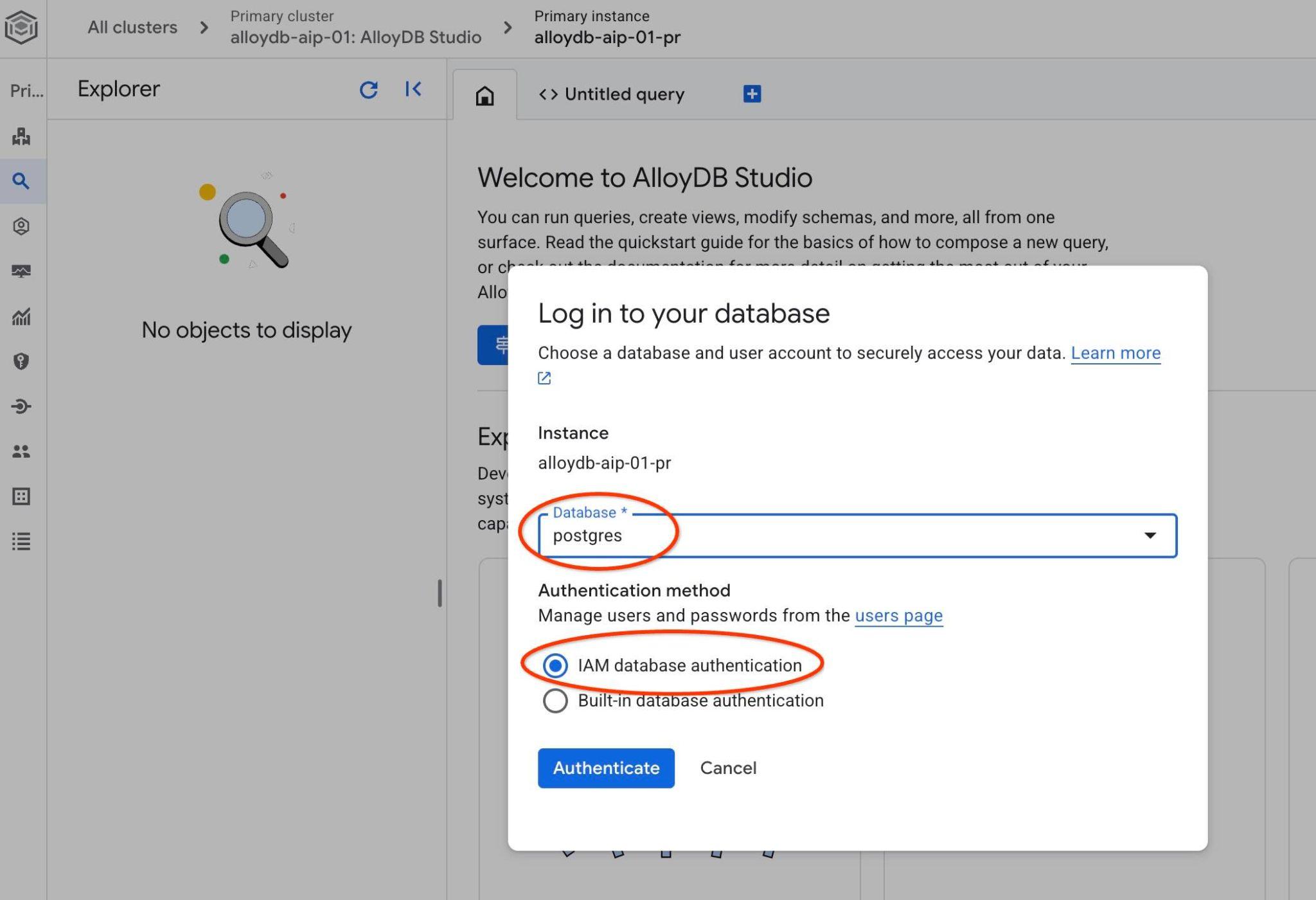
AlloyDB Studio 인터페이스가 열립니다. 데이터베이스에서 명령어를 실행하려면 오른쪽의 '제목이 없는 쿼리' 탭을 클릭합니다.
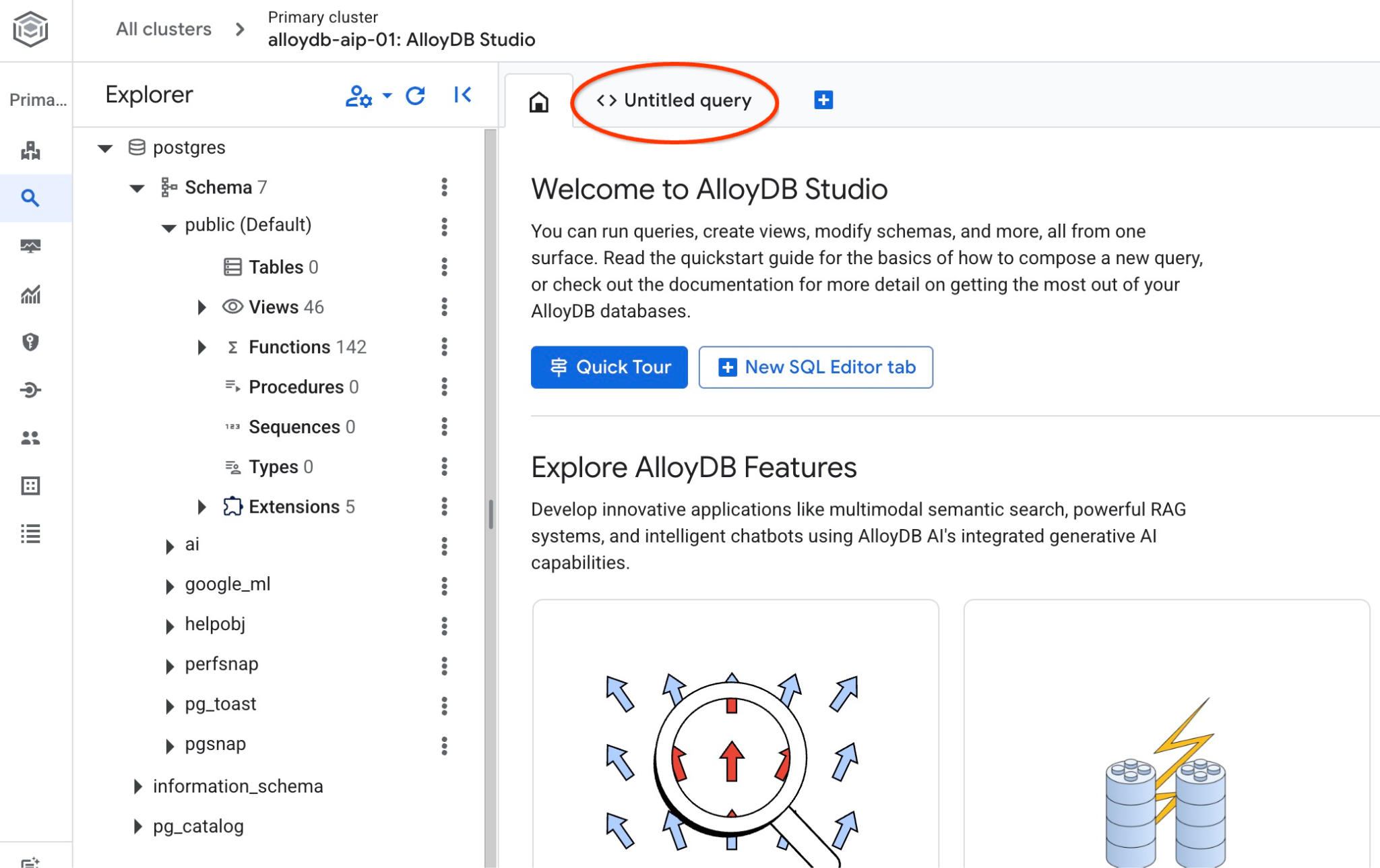
SQL 명령어를 실행할 수 있는 인터페이스가 열립니다.
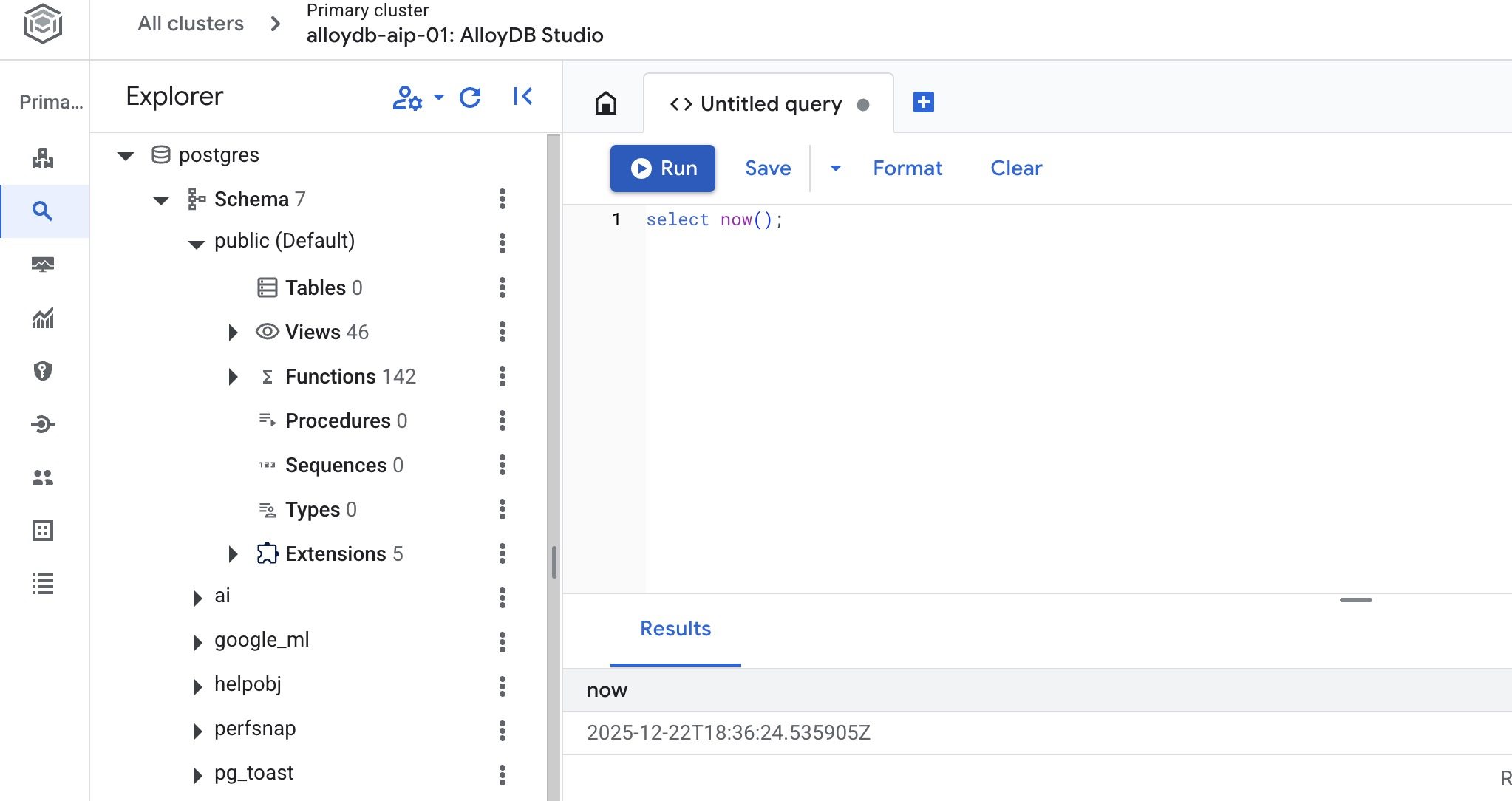
데이터베이스 만들기
데이터베이스 만들기 빠른 시작
AlloyDB Studio 편집기에서 다음 명령어를 실행합니다.
데이터베이스를 만듭니다.
CREATE DATABASE quickstart_db
예상 출력:
Statement executed successfully
quickstart_db에 연결
데이터베이스에 연결하여 데이터베이스가 생성되었는지 확인합니다. 사용자/데이터베이스 전환 버튼을 사용하여 스튜디오에 다시 연결합니다.
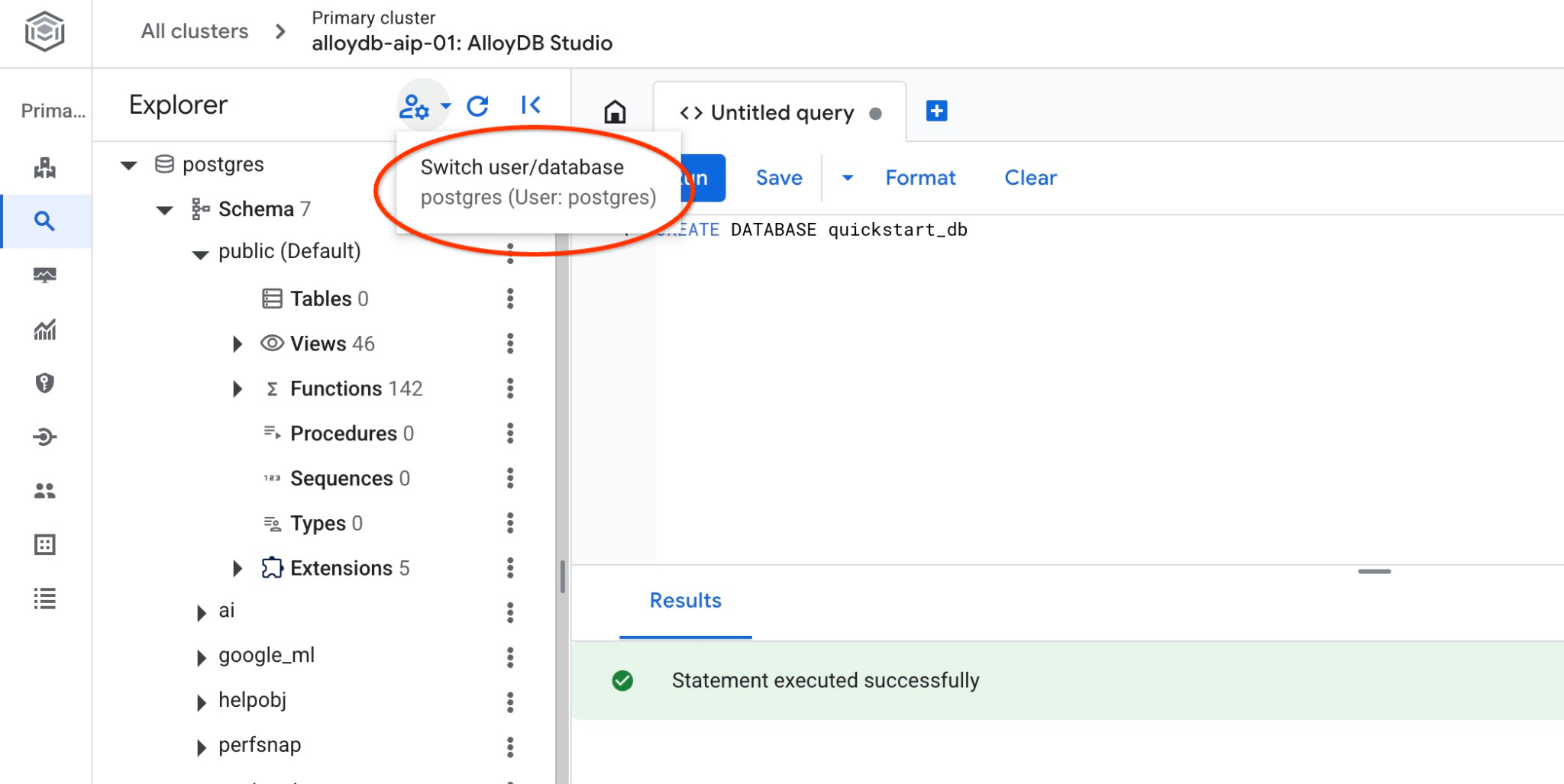
드롭다운 목록에서 새 quickstart_db 데이터베이스를 선택하고 동일한 IAM 인증을 사용합니다.
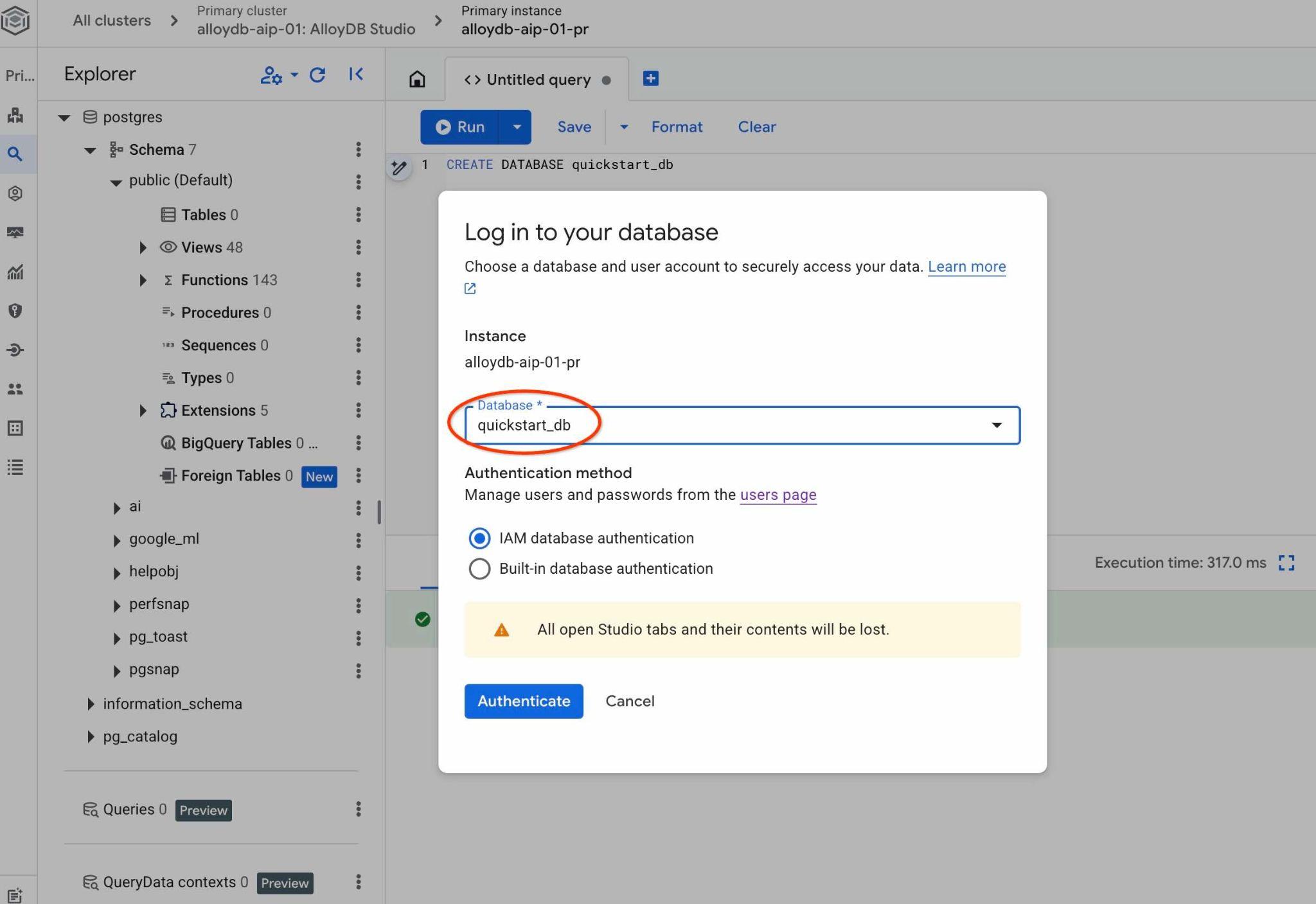
quickstart_db 데이터베이스의 객체를 사용할 수 있는 새 연결이 열립니다. 여기에서 가져온 스키마와 데이터를 검사하고 QueryData 컨텍스트 세트로 작업할 수 있습니다.
6. 샘플 데이터
이제 데이터베이스에서 객체를 만들고 데이터를 로드해야 합니다. 가상의 Cymbal Shipping 회사 데이터 세트를 사용합니다. 상품, 트럭, 요청, 트럭 운행에 관한 가상 데이터와 가상 운전자가 있습니다.
스토리지 버킷 만들기
Google SDK (gcloud)를 사용하여 클론된 저장소에서 AlloyDB 데이터베이스로 데이터를 가져옵니다. 이를 위해서는 Cloud Storage 버킷을 만들고 AlloyDB 서비스 계정에 액세스 권한을 부여해야 합니다. 또는 문서에 설명된 대로 웹 콘솔을 사용하여 항상 시도할 수 있습니다.
Google Cloud Shell 터미널에서 다음을 실행합니다.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
데이터 로드
다음 단계는 데이터를 로드하는 것입니다. 압축된 SQL 덤프는 클론된 저장소 폴더에 있습니다. 다음 명령어는 AlloyDB 클러스터를 만드는 동안 이전 단계에서 저장소를 클론할 때 홈 디렉터리를 시작점으로 사용했다고 가정합니다.
압축된 SQL 덤프를 새 스토리지 버킷에 복사합니다.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
그런 다음 quickstart_db 데이터베이스에 데이터를 로드합니다.
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
이 명령어를 실행하면 샘플 데이터 세트가 quickstart_db 데이터베이스에 로드됩니다. AlloyDB Studio를 사용하여 테이블과 레코드를 확인할 수 있습니다.
7. 데이터 에이전트 사용
Python용 Google ADK를 사용하여 생성되고 데이터베이스용 MCP 도구 상자를 사용하여 AlloyDB 인스턴스에 연결되는 샘플 AI 에이전트부터 시작해 보겠습니다.
데이터베이스용 MCP 도구 상자 설치
데이터베이스용 MCP 도구 상자는 PostgreSQL용 AlloyDB를 비롯한 여러 데이터베이스 엔진에 MCP 지원을 제공하는 오픈소스 프로젝트입니다. MCP 도구 상자에 관한 자세한 내용은 문서를 참고하세요.
플랫폼에 맞는 최신 버전의 소프트웨어를 다운로드해야 합니다. 최신 버전은 출시 페이지를 확인하세요. 다음 예시에서는 MCP 도구 상자 버전 31을 Cloud Shell에 다운로드하는 방법을 보여줍니다.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
도구 상자의 구성 파일을 준비해야 합니다. 현재 디렉터리에 샘플 tools.yaml.example 파일이 있으며 프로젝트 ID와 리전으로 두 자리표시자를 바꿔 tools.yaml 파일을 준비합니다.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
데이터베이스용 MCP 도구 상자 시작
이제 준비된 구성 파일로 MCP 툴박스를 시작할 수 있습니다.
Google Cloud Shell 인터페이스 상단의 '+' 버튼을 눌러 Google Cloud Shell에서 새 탭을 엽니다.
새 탭에서 툴박스 바이너리 파일과 구성 파일 tools.yaml이 있는 디렉터리로 전환하고 MCP 서버를 시작합니다.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
출력에 다음과 비슷한 'Server ready to serve!'가 표시됩니다.
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
에이전트 소스 코드 확인
클론된 저장소 폴더의 첫 번째 탭에서 Google Cloud Shell 편집기를 사용하여 에이전트 코드를 검토합니다.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
에이전트에는 AlloyDB용 Google Cloud MCP 서버 섹션이 있습니다. 엔드포인트를 MCP_SERVER_URL로 제공하고, 인증하고, 프로젝트 ID를 추가하고, MCP 도구 모음에 추가합니다.
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
에이전트 코드에서 MCP 툴셋은 에이전트의 tools 매개변수로 포함됩니다. 또한 클러스터 및 인스턴스 이름, 리전, 데이터베이스가 에이전트 프롬프트의 변수로 있습니다.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
코드를 검토한 후 편집기 창 오른쪽 상단의 '터미널 열기' 버튼을 눌러 터미널로 다시 전환합니다.
에이전트 시작
이제 Google ADK 웹 인터페이스를 사용하여 대화형 모드로 에이전트를 시작할 수 있습니다. ADK 웹 인터페이스는 에이전트의 워크플로를 테스트하고 문제를 해결하는 편리한 방법을 제공합니다.
먼저 uv 패키지 관리자를 사용하여 Python에 필요한 모든 패키지를 설치합니다.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
모든 패키지가 설치되면 에이전트 디렉터리에 .env 파일을 추가하여 AI 모델과의 모든 통신에 Vertex AI를 사용하도록 지시해야 합니다.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
그런 다음 에이전트를 시작할 수 있습니다.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
http://127.0.0.1:8000과 같은 엔드포인트가 포함된 다음과 같은 출력이 표시됩니다 .
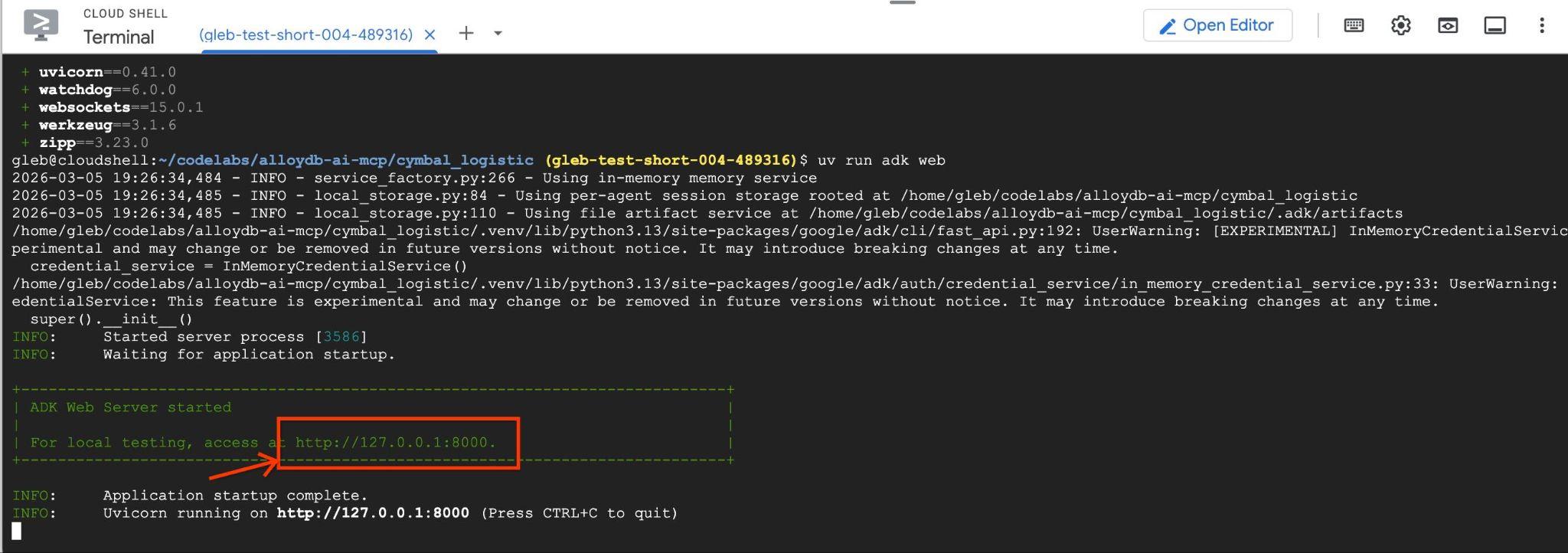
Cloud Shell에서 해당 URL을 클릭하면 별도의 브라우저 탭에서 미리보기 창이 열리고 왼쪽의 드롭다운 목록에서 data_agent을 선택할 수 있습니다.
ADK 웹 인터페이스에서 오른쪽 하단에 질문을 게시하고 오른쪽에서 각 단계의 트레이스를 포함한 전체 실행 흐름을 확인할 수 있습니다.
8. AlloyDB용 QueryData 없이 NL2SQL 테스트
상담사를 사용하면 자연어를 사용하여 자유 형식으로 질문할 수 있으며, 상담사는 데이터베이스용 MCP 도구 상자를 도구로 사용하여 질문에 답변합니다. 질문은 오른쪽 하단에 게시되고 도구에 대한 모든 호출이 포함된 답변은 상단에 표시됩니다.
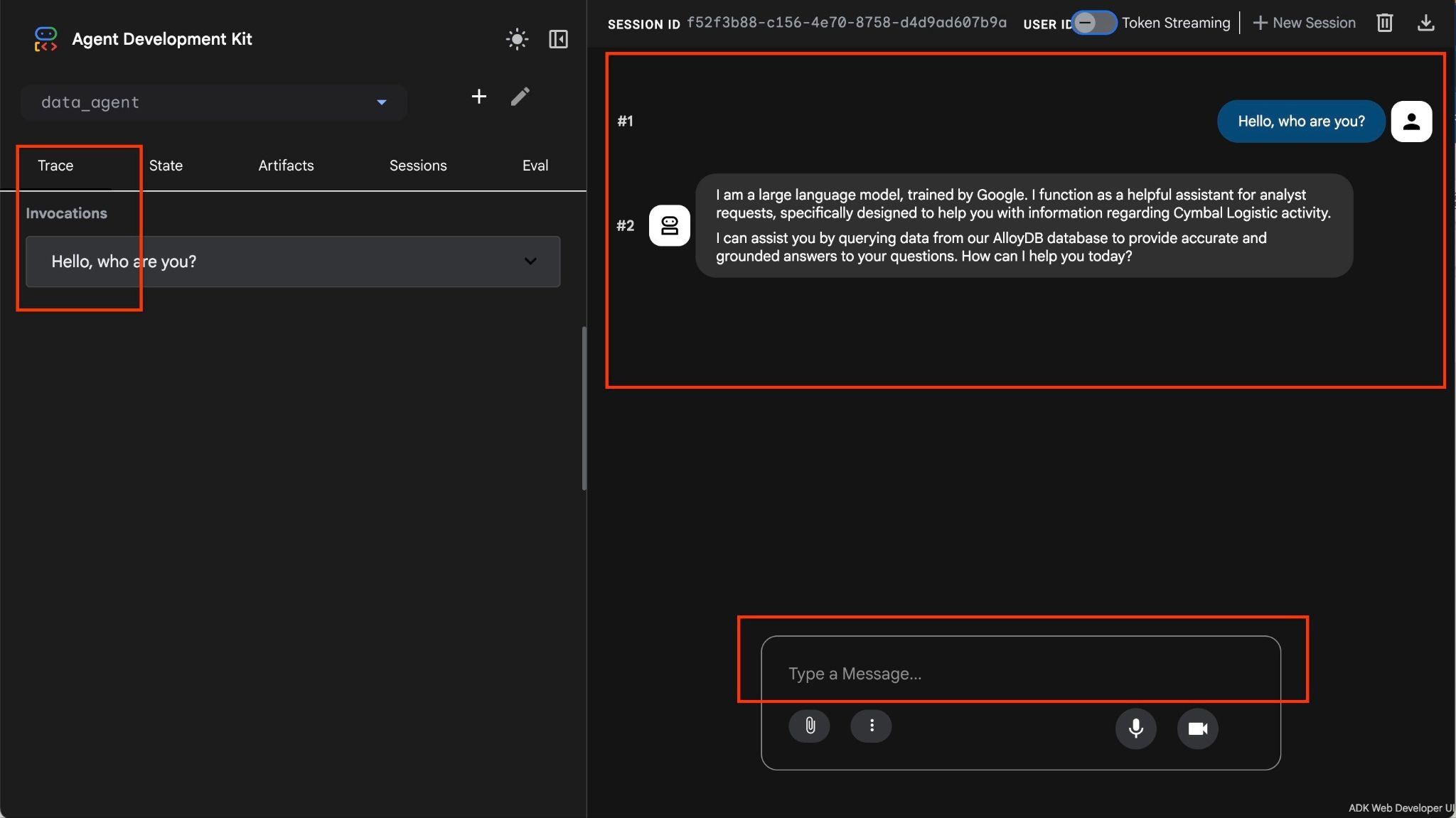
배송 요청, 트럭, 운전자, 운전자가 완료한 여정에 관한 정보가 있는 배송 회사의 운영 데이터를 사용하고 있습니다. 첫 번째 질문은 2026년 2월에 실행된 여정 수에 관한 것입니다.
오른쪽 하단의 입력란에 다음을 입력하고 Enter 키를 누릅니다.
Hello, can you tell me how many trips we've done in February?
에이전트는 여러 도구 호출을 실행하여 list_cymbal_logistics_schemas_tool를 사용하여 스키마에서 올바른 테이블을 식별하고 execute_sql_tool를 사용하여 올바른 데이터를 가져오기 위해 여러 SQL 문을 실행합니다.
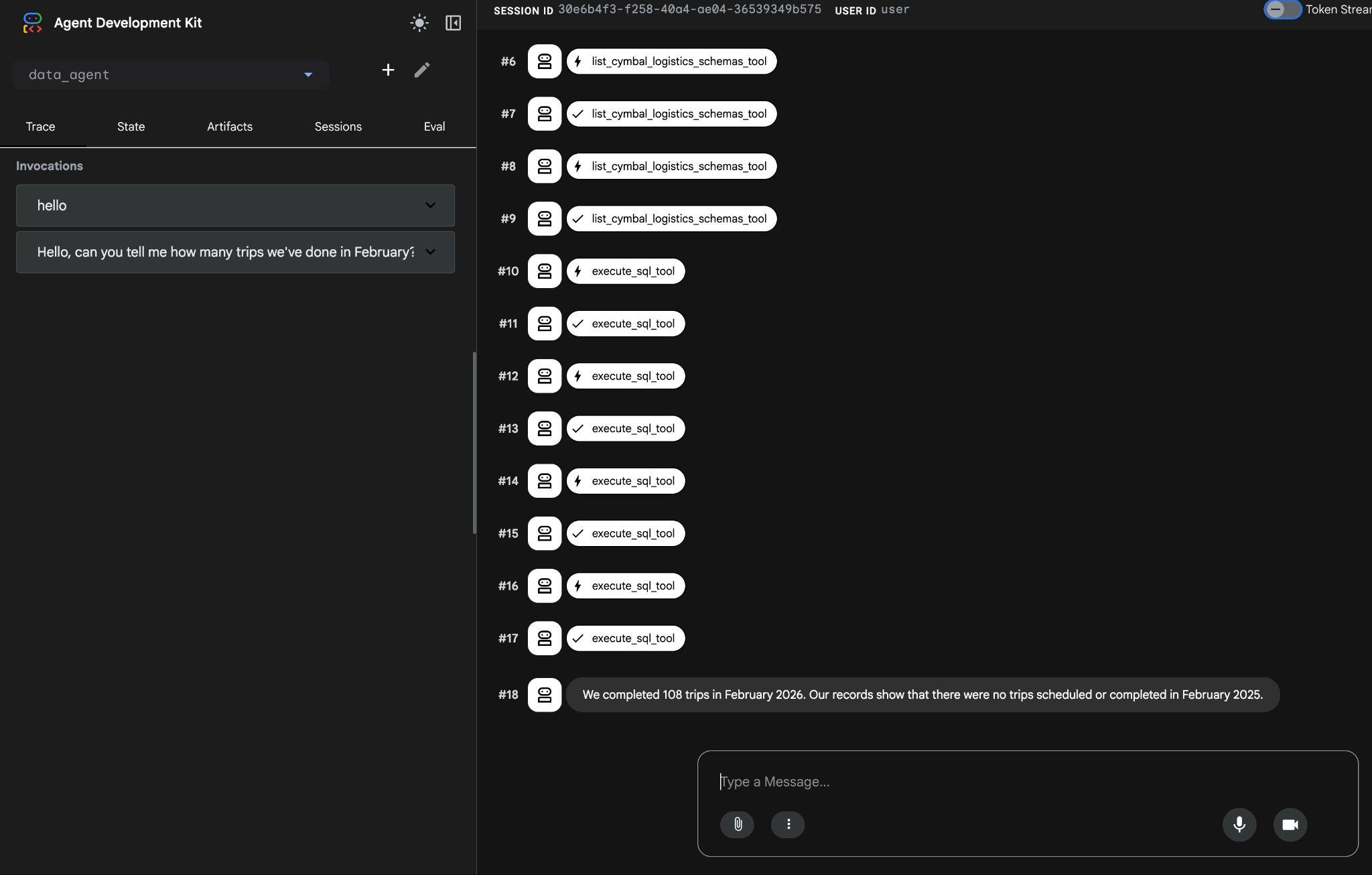
결국 적절한 쿼리를 작성하고 데이터베이스에서 실행하면 올바른 결과가 생성됩니다.
2026년 2월에 108건의 여행을 완료했습니다. Google 기록에 따르면 2025년 2월에 예약되거나 완료된 여정이 없습니다.
도구 실행을 클릭하면 각 도구 호출이 수행하는 작업을 확인할 수 있습니다. 예를 들어 결과를 얻기 위해 실행된 쿼리는 다음과 같습니다.
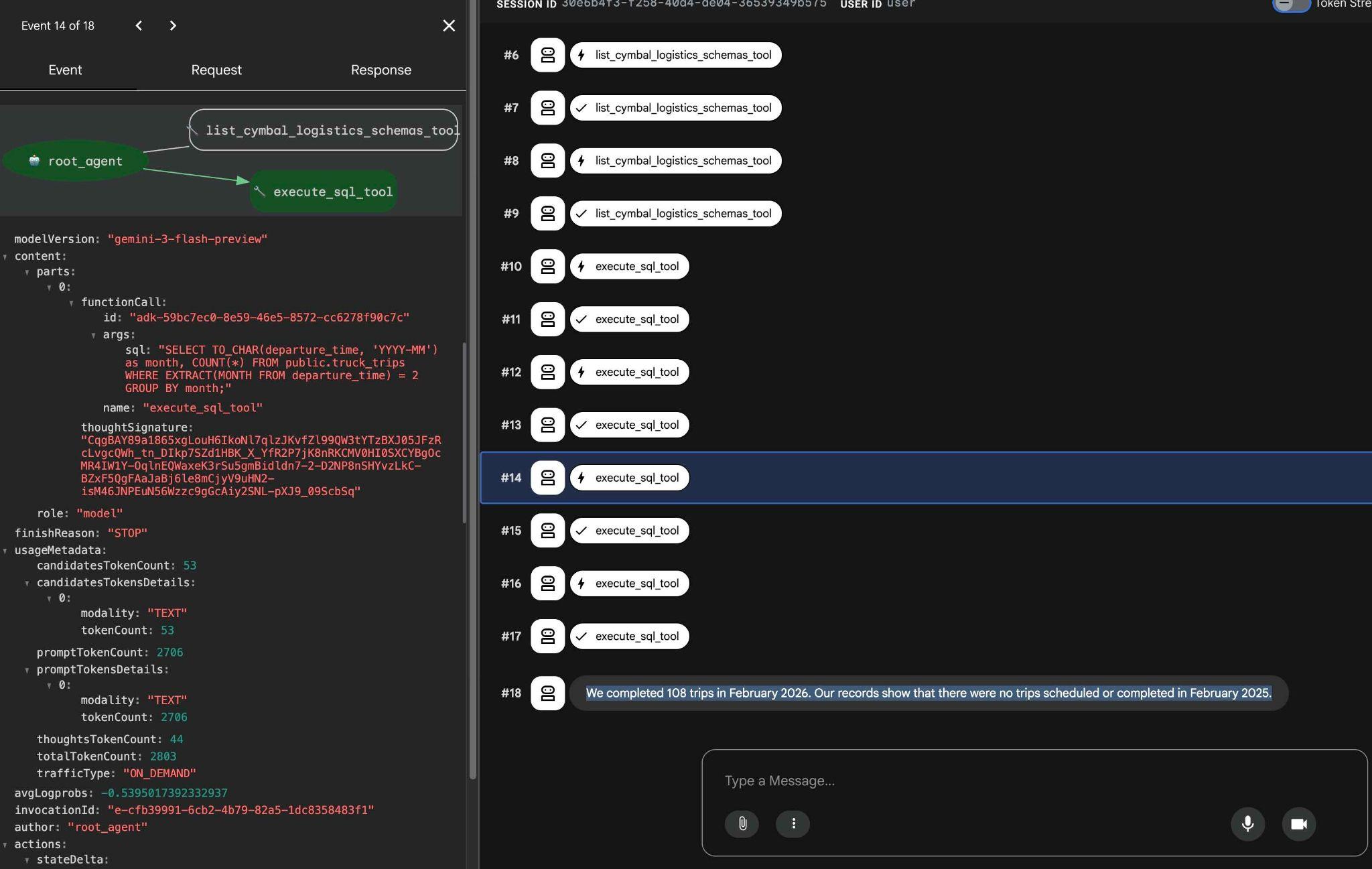
ADK 웹 인터페이스를 사용하여 다른 간단한 요청을 시도하고 결과를 얻기 위해 다양한 쿼리를 실행하는 방법을 확인합니다.
터미널에서 ctrl+c를 눌러 에이전트를 중지합니다. ADK 웹 인터페이스가 표시된 브라우저 탭을 닫아도 됩니다.
동일한 ctrl+c 키 단축키를 눌러 두 번째 탭에서 MCP 도구 상자를 중지하고 두 번째 탭을 닫을 수도 있습니다.
다음 단계에서는 NL2SQL 응답과 성능을 개선하기 위해 QueryData 컨텍스트를 빌드합니다.
9. QueryData ContextSet 빌드
이전 단계에서 AI 모델이 SQL 쿼리를 빌드하는 데 사용할 테이블과 열을 파악하기 위해 데이터베이스의 정보 스키마를 여러 번 호출하는 것을 확인할 수 있습니다. 성능과 정확도를 개선하고 결과를 더 예측 가능하게 만들기 위해 특정 요청에 대한 응답으로 실행해야 하는 쿼리를 정의하는 QueryData 컨텍스트가 추가됩니다.
타겟팅된 템플릿 만들기
QueryData ContextSet은 쿼리 패턴과 데이터 구조에 따라 요청된 목표를 달성하기 위해 AI 모델이 올바른 SQL 쿼리 또는 SQL 쿼리 부분을 사용하도록 필요한 데이터와 방향을 제공하는 쿼리 템플릿과 패싯이 포함된 JSON 파일입니다.
타겟팅된 템플릿에서 시작합니다. Cloud Shell 편집기를 사용하여 파일을 만듭니다. Cloud Shell 터미널에서 다음을 실행합니다.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
이전 챕터에서 사용한 자연어 질문 템플릿인 '2월에 몇 번의 여행을 했어?'를 삽입합니다.
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
그런 다음 다운로드 버튼을 사용하여 Cloud Shell에서 컴퓨터로 템플릿을 다운로드합니다.
QueryData 컨텍스트 세트 로드
QueryData 컨텍스트 세트를 사용하려면 데이터베이스에 업로드해야 합니다.
AlloyDB Studio를 엽니다. 왼쪽 패널 하단에 QueryData Context 및 점 3개가 표시됩니다.
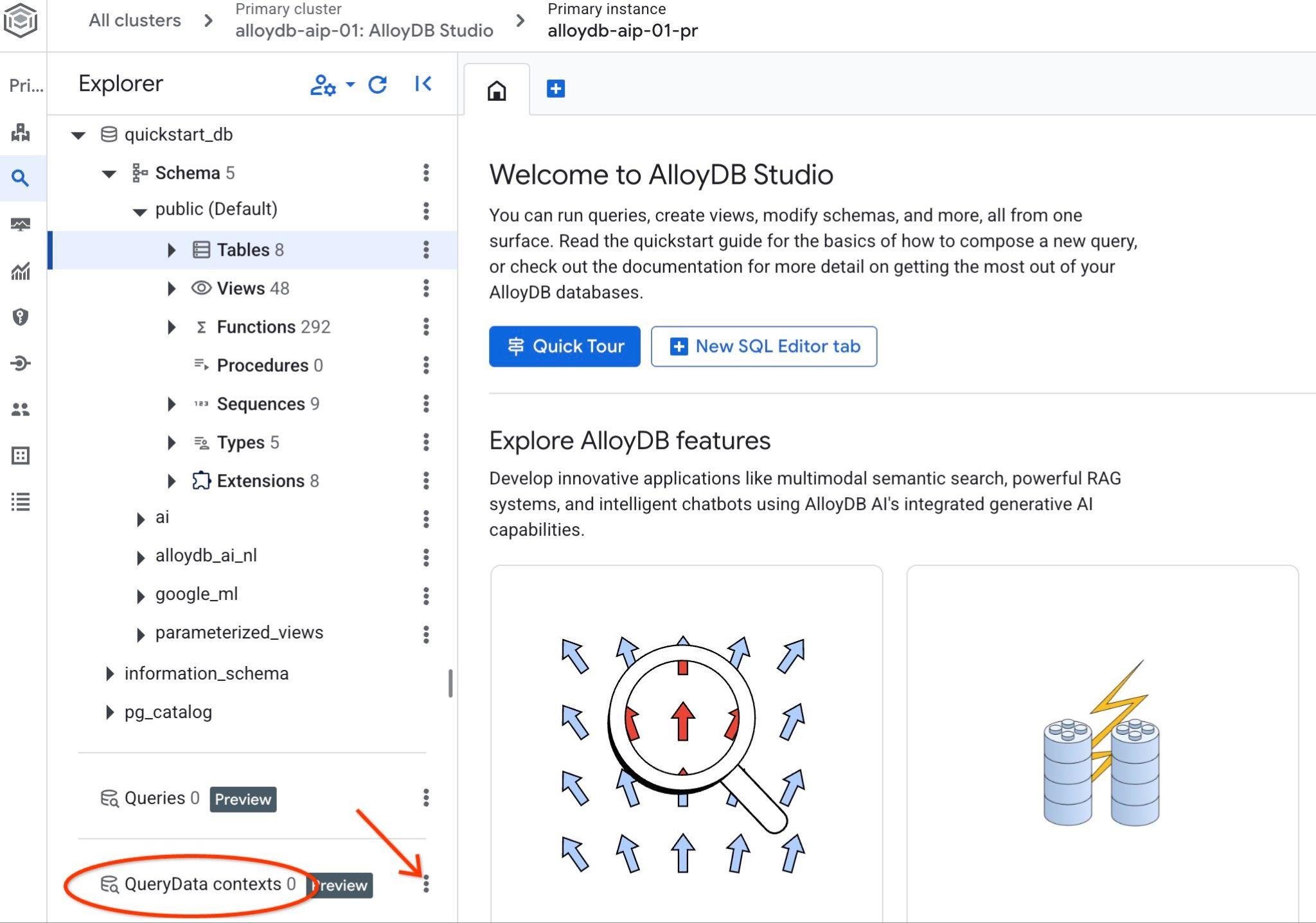
점 3개를 클릭하고 '컨텍스트 만들기'를 선택합니다. 그러면 다음을 입력할 수 있는 대화상자가 열립니다.
- 이름:
cymbal_context_set - 설명:
Cymbal Logistic Query Data - 환경설정 파일 업로드: '
Browse' 버튼을 클릭하고 QueryData ContextSet이 포함된 JSON 파일을 선택합니다.
처음으로 저장 버튼을 누르면 컨텍스트 스토리지를 초기화하는 데 시간이 걸릴 수 있습니다.
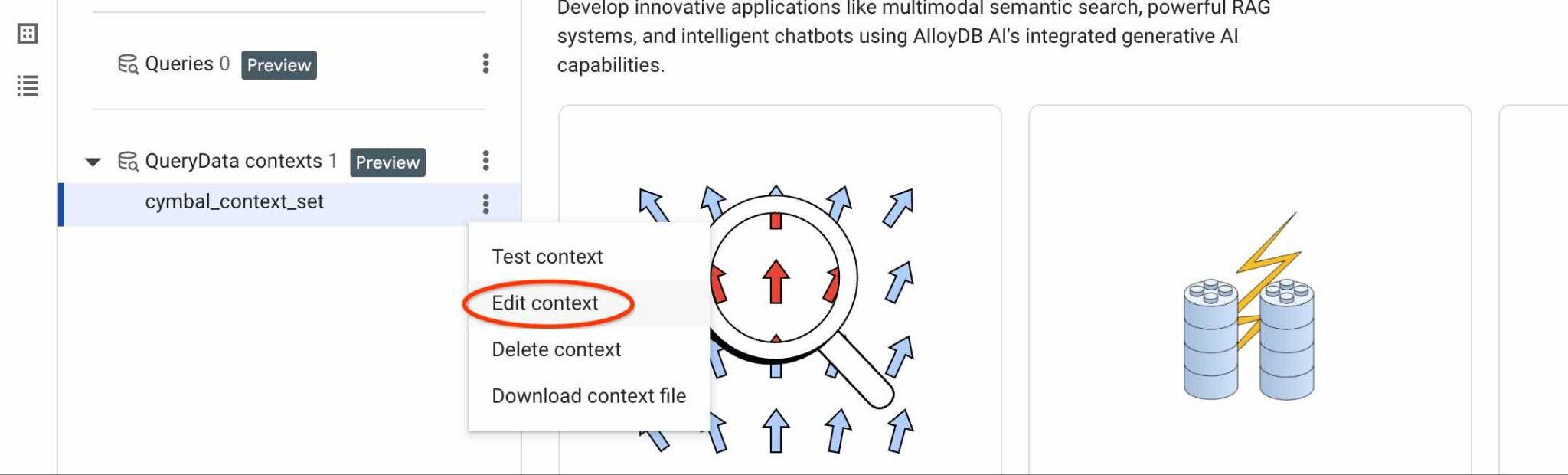
다운로드된 컨텍스트를 볼 수 있으며, 오른쪽에 있는 세로 버튼 3개를 클릭하면 사용 가능한 작업이 표시됩니다. 다음 장에서는 '테스트 컨텍스트' 작업부터 시작합니다.
10. QueryData 컨텍스트 세트 테스트
테스트 템플릿
'Test context' 작업을 사용하여 AlloyDB Studio에서 컨텍스트를 테스트합니다. '테스트 컨텍스트'를 클릭하면 제목이 'cymbal_context_set'인 새 AlloyDB Studio 편집기 창과 제목이 'Generate SQL using QueryData context: cymbal_context_set'인 Gemini SQL 생성 초대 창이 열립니다. SQL 생성을 클릭하고 다음을 입력합니다.
Hello, can you tell me how many trips we've done in February?
SQL이 생성되면 'Insert' 버튼을 누릅니다.
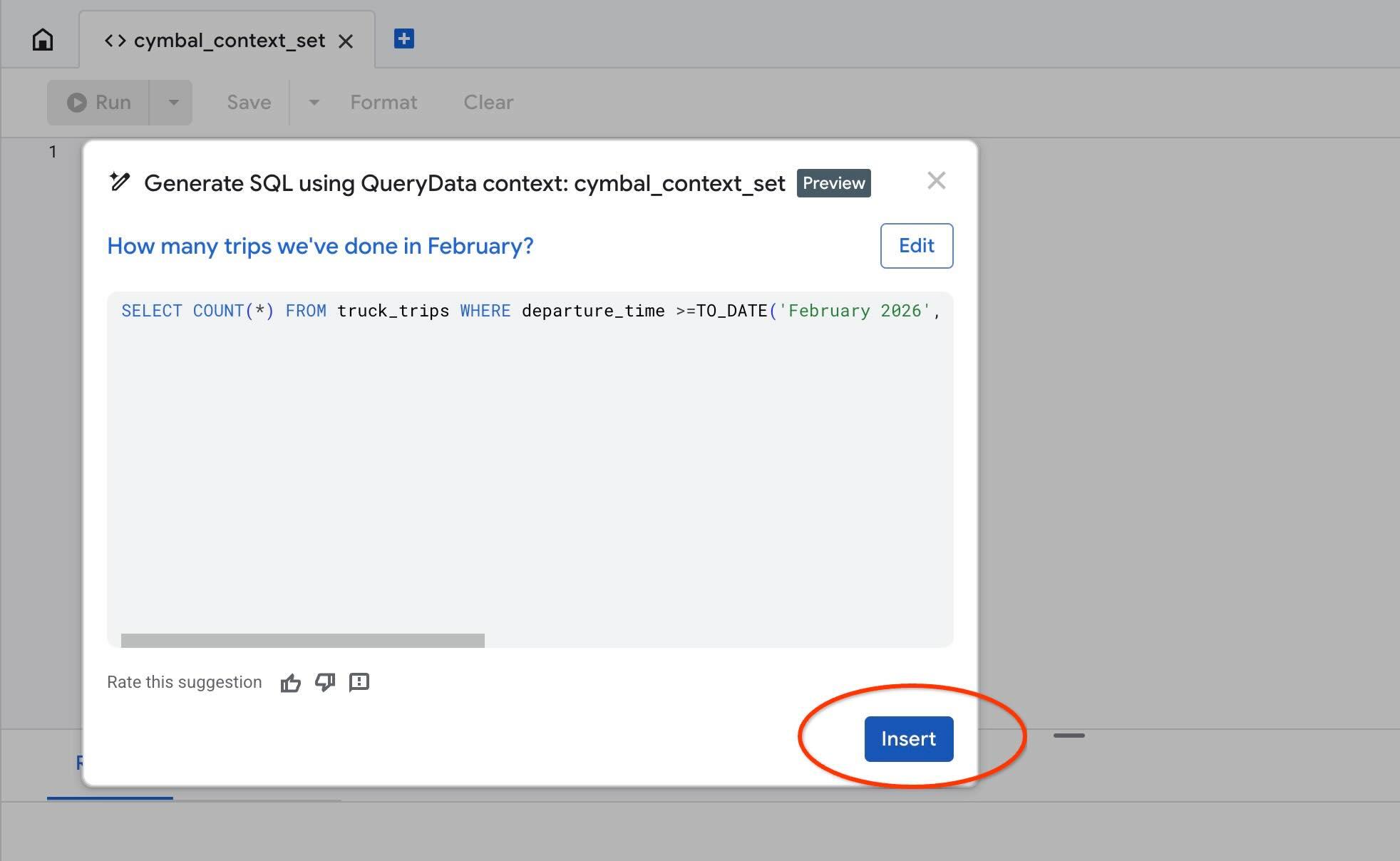
앞서 컨텍스트 템플릿에 입력한 것과 동일한 질문이 표시됩니다.
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
월을 'January'로 바꿔 보고 생성된 SQL 문을 확인합니다. 매개변수화된 인텐트의 매개변수로 월을 사용하고 SQL 문을 자동으로 조정합니다.
QueryData 패싯 빌드
질문에 대한 템플릿을 사용해 보았는데, 예상되는 사용자 요청의 종류를 알고 있을 때는 효과가 있었습니다. 하지만 재정의된 인텐트에 특정 순서나 특정 절을 사용하는 것이 바람직한 경우 조건이나 필터와 같은 쿼리의 일부만 안내하는 것이 유용할 수 있습니다.
예를 들어 '지난달'의 데이터를 반환해 달라고 요청하면 지난 30일이 아닌 지난 달의 1일부터 마지막 날까지의 보고서를 가져오고 싶습니다.
이러한 패싯을 이전에 추가한 템플릿과 함께 ContextSet 구성에 SQL 스니펫으로 추가할 수 있습니다. querydata_cymbal_contextset.json을 엽니다.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
기존 템플릿 뒤에 패싯을 추가합니다. 파일의 결과 콘텐츠는 다음과 같아야 합니다.
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
파일을 저장하고 컴퓨터에 업로드합니다.
그런 다음 쿼리 컨텍스트 작업 '컨텍스트 수정'을 사용하고 수정된 파일을 업로드하여 이전 컨텍스트를 새 컨텍스트로 바꿉니다.
이제 테스트 컨텍스트를 다시 사용하여 '지난달' 인텐트를 사용하여 SQL 문을 생성해 보세요. 예를 들어 'show trucks trips for the last month"'라는 문구에 대한 SQL을 생성하면 cymbal_context.json 파일에서 패싯으로 제공한 조건이 사용됩니다.
다음과 같은 결과가 표시됩니다.
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
이제 AI 에이전트와 함께 사용하는 방법을 알아보겠습니다. 다음 장에서는 AI 에이전트가 데이터 쿼리 컨텍스트를 사용할 수 있도록 합니다.
11. AI 에이전트로 QueryData
동일한 데이터 에이전트를 사용하지만 이제 MCP 도구 상자가 QueryData ContextSet을 사용하도록 구성됩니다.
데이터베이스용 MCP 도구 상자 준비 및 시작
Gemini 데이터 분석 API와 AlloyDB를 데이터베이스 소스로 사용하는 MCP 도구 상자를 위한 새 구성 파일이 필요합니다.
터미널에서 다음을 실행합니다.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
편집기로 전환하여 querydata.yaml 파일을 찾습니다. 구성 파일 querydata.yaml는 환경을 반영하는 프로젝트 ID와 리전을 제외하고 다음과 같이 표시됩니다. 하지만 contextSetId 값을 업데이트하고 "<add-context-set-id>" 자리표시자를 콘솔의 값으로 바꿔야 합니다.
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
ContextSet ID를 찾으려면 그림에 표시된 대로 컨텍스트 세트의 수정 버튼을 클릭합니다.
오른쪽의 새 탭 상단에 컨텍스트 세트 ID가 표시됩니다.
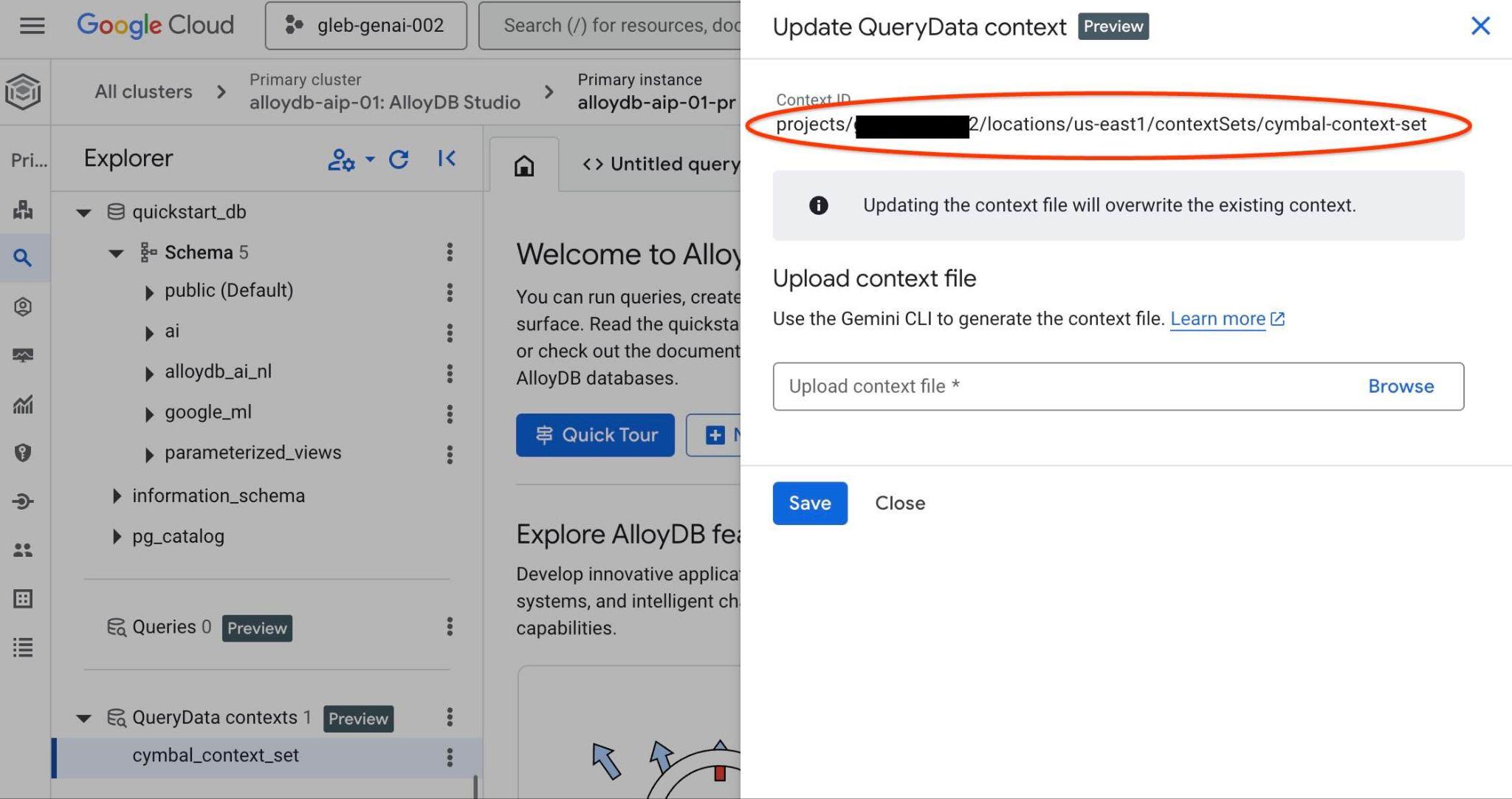
이 전체 경로를 querydata.yaml 파일의 "<add-context-set-id>" 자리표시자를 대체하는 데 사용해야 합니다.
터미널로 돌아갑니다.
Google Cloud Shell 인터페이스 상단의 '+' 버튼을 눌러 Google Cloud Shell에서 새 탭을 엽니다.
새 탭에서 툴박스 바이너리 파일과 구성 파일 tools.yaml이 있는 디렉터리로 전환하고 MCP 서버를 시작합니다.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
ADK 에이전트 실행
첫 번째 Cloud Shell 탭에서 에이전트를 시작합니다.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
시작되면 http://127.0.0.1:8000 링크를 다시 클릭합니다 .
이미 익숙한 ADK 웹 미리보기 에이전트 인터페이스가 표시됩니다. 이전과 정확히 동일한 질문을 게시합니다.
Hello, can you tell me how many trips we've done in February?
에이전트 워크플로를 확인합니다. 모든 항목이 올바르게 구성되면 다음과 같은 화면이 표시됩니다.
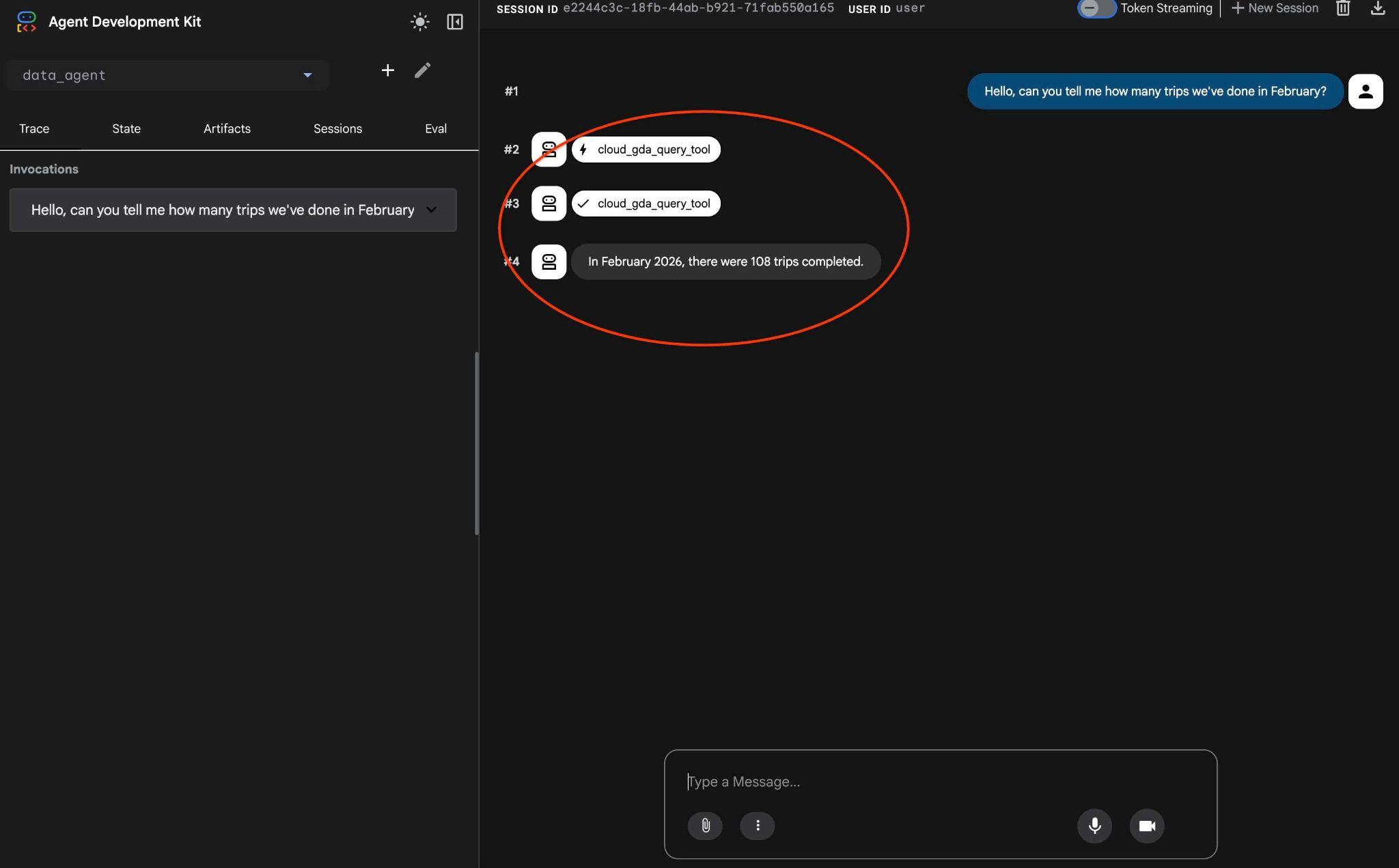
지난번에 여러 차례의 요청이 있었던 것이 MCP 도구에 대한 하나의 호출로 변환되어 예측 가능한 SQL 문을 사용하여 실행되었습니다.
다음과 같은 요청을 사용하여 구성된 패싯을 테스트할 수 있습니다.
how trucks trips for the last month
출력에서 도구 작업을 클릭하면 동일한 도구를 사용하고 패싯을 적용하여 결과를 얻은 것을 확인할 수 있습니다.
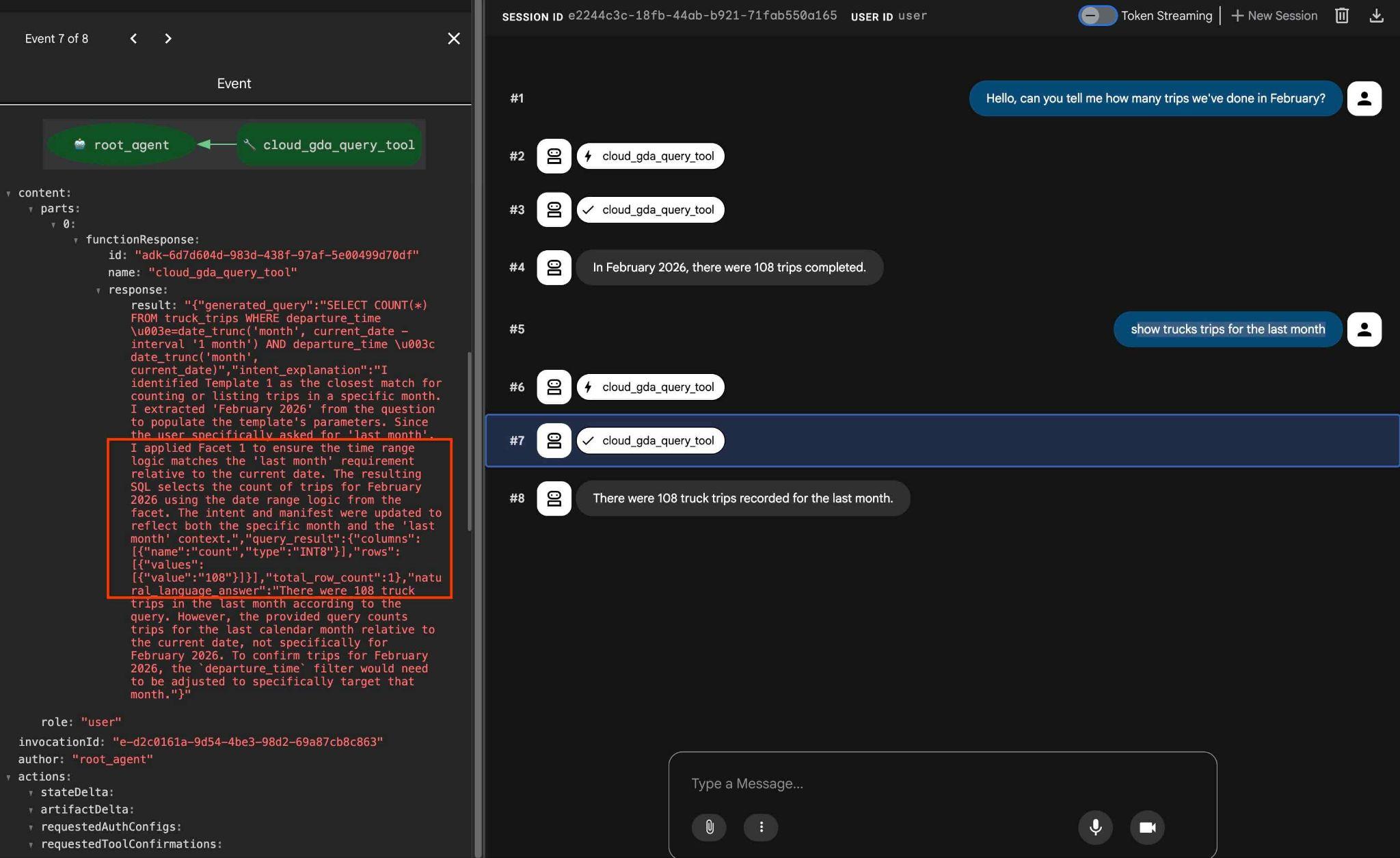
이것으로 실습을 마치겠습니다. 모든 예시를 살펴보고 AlloyDB용 QueryData를 사용하는 방법을 배우셨기를 바랍니다. 제공된 기술은 에이전트 워크로드와 SQL 생성을 예측 가능하고 안정적으로 만드는 데 도움이 됩니다.
12. 환경 정리
예기치 않은 요금이 청구되지 않도록 임시 리소스를 정리하는 것이 좋습니다. 가장 확실한 방법은 워크플로를 테스트한 프로젝트를 삭제하는 것입니다. 하지만 AlloyDB와 같은 개별 리소스를 삭제하여 직접 제한할 수도 있습니다.
실습을 마치면 AlloyDB 인스턴스와 클러스터를 폐기합니다.
AlloyDB 클러스터 및 모든 인스턴스 삭제
AlloyDB 무료 체험판을 사용한 경우 체험 클러스터를 사용하여 다른 실습과 리소스를 테스트할 계획이 있다면 체험 클러스터를 삭제하지 마세요. 동일한 프로젝트에서 다른 체험 클러스터를 만들 수 없습니다.
클러스터는 옵션 강제로 폐기되며, 클러스터에 속한 모든 인스턴스도 삭제됩니다.
연결이 끊어지고 이전 설정이 모두 손실된 경우 Cloud Shell에서 프로젝트와 환경 변수를 정의합니다.
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
다음과 같이 클러스터를 삭제합니다.
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB 백업 삭제
클러스터의 모든 AlloyDB 백업을 삭제합니다.
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
13. 축하합니다
축하합니다. Codelab을 완료했습니다.
학습한 내용
- AlloyDB 클러스터를 만들고 샘플 데이터를 가져오는 방법
- AlloyDB 데이터 액세스 API를 사용 설정하는 방법
- AlloyDB에서 QueryData를 사용 설정하는 방법
- 템플릿을 생성하는 방법
- 상품 속성별 검색 사용 방법
- AI 에이전트와 함께 QueryData를 사용하는 방법
14. 설문조사
결과: