
1. Wprowadzenie
To ćwiczenie zawiera przewodnik po rozpoczęciu korzystania z QueryData w przypadku AlloyDB i używaniu go do generowania dokładnych i przewidywalnych instrukcji SQL na podstawie danych wejściowych w języku naturalnym w aplikacjach agentowych.
Wymagania wstępne
- Podstawowa znajomość konsoli Google Cloud
- Podstawowe umiejętności w zakresie interfejsu wiersza poleceń i Cloud Shell
Czego się nauczysz
- Jak utworzyć klaster AlloyDB i zaimportować przykładowe dane
- Jak włączyć interfejs API dostępu do danych AlloyDB
- Jak włączyć QueryData w AlloyDB
- Jak generować szablony
- Jak korzystać z wyszukiwania wieloaspektowego
- Jak używać QueryData z agentami AI
Czego potrzebujesz
- Konto Google Cloud i projekt Google Cloud
- przeglądarka internetowa, np. Chrome, obsługująca konsolę Google Cloud i Cloud Shell;
2. Konfiguracja i wymagania
Konfiguracja projektu
Tworzenie projektu Google Cloud
- W konsoli Google Cloud na stronie selektora projektu wybierz lub utwórz projekt w chmurze Google.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Uruchom Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym ćwiczeniu użyjesz Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Możesz też nacisnąć G, a potem S. Ta sekwencja aktywuje Cloud Shell, jeśli korzystasz z konsoli Google Cloud. Możesz też użyć tego linku.
Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
3. Zanim zaczniesz
Włącz API
Aby korzystać z usług AlloyDB, Compute Engine, usług sieciowych i Vertex AI, musisz włączyć odpowiednie interfejsy API w projekcie Google Cloud.
W terminalu Cloud Shell sprawdź, czy identyfikator projektu jest skonfigurowany:
gcloud config get-value project
W danych wyjściowych powinien pojawić się identyfikator projektu:
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
Ustaw zmienną środowiskową PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Włącz wszystkie niezbędne usługi:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Oczekiwane dane wyjściowe
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Wdrażanie AlloyDB
Utwórz klaster AlloyDB i instancję główną. Możesz wdrożyć go za pomocą gotowego skryptu, który wdroży wszystkie niezbędne zasoby, lub samodzielnie, wykonując czynności opisane w dokumentacji.
Wdrażanie AlloyDB za pomocą automatycznego skryptu
W tym podejściu używamy automatycznego skryptu do wdrożenia klastra AlloyDB i podajemy niezbędne informacje, aby rozpocząć pracę z wdrożonymi zasobami.
W terminalu Cloud Shell wykonaj polecenie, aby sklonować skrypt wdrożenia z repozytorium.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
Uruchom skrypt wdrażania.
./deploy_alloydb.sh --public-ip
Uruchomienie skryptu zajmie trochę czasu – zwykle około 5–7 minut. Wdroży on klaster AlloyDB i instancję główną z publicznym i prywatnym adresem IP. Publiczny adres IP jest dostępny tylko w przypadku autoryzowanych sieci lub przy użyciu serwera proxy uwierzytelniania AlloyDB. Więcej informacji o publicznym adresie IP znajdziesz w dokumentacji. W wyniku działania skryptu powinny zostać wyświetlone informacje o wdrożonym klastrze AlloyDB. Pamiętaj, że hasło będzie inne. Zapisz je w bezpiecznym miejscu, aby móc z niego korzystać w przyszłości.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
Nowy klaster i instancję podstawową możesz też zobaczyć w konsoli internetowej.
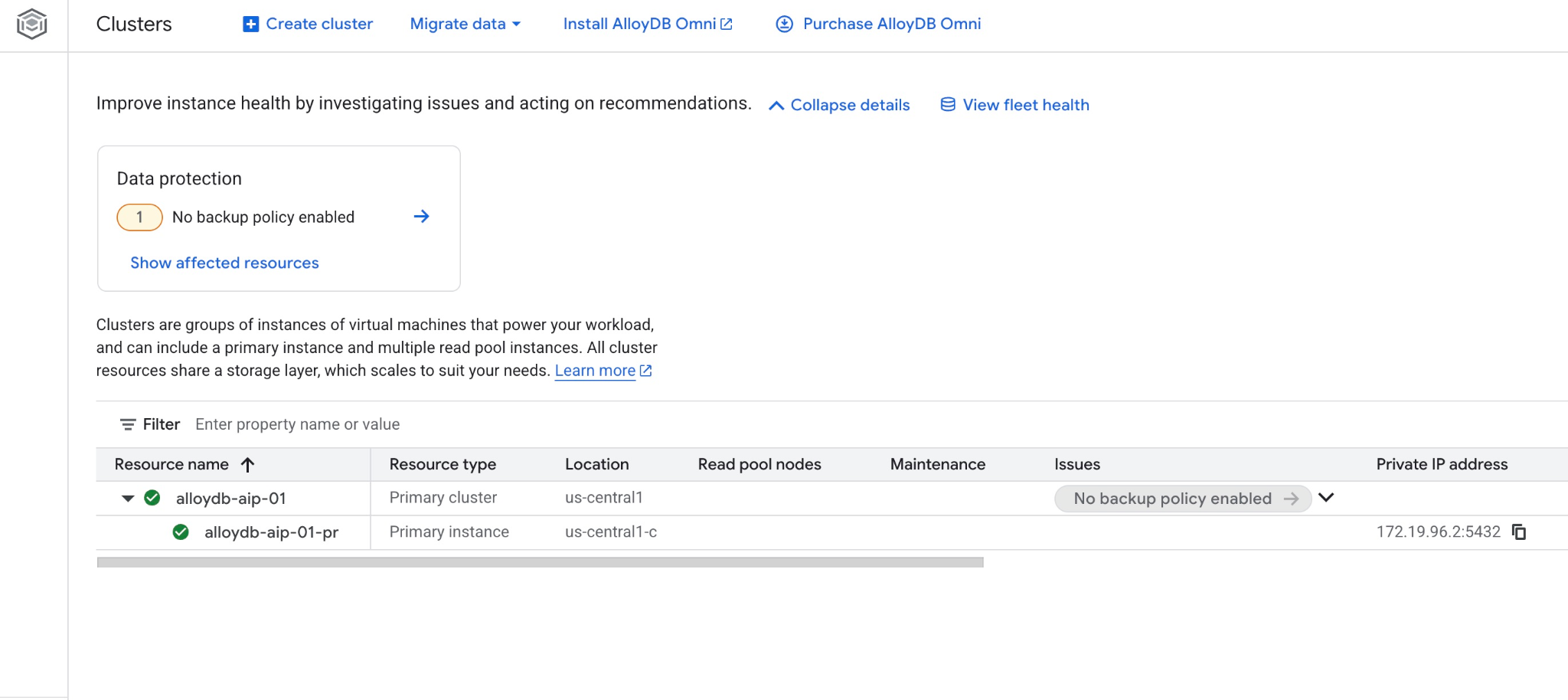
5. Przygotowywanie bazy danych
Aby korzystać z funkcji i operatorów AI, musisz włączyć integrację z Vertex AI, włączyć interfejs API dostępu do danych i utworzyć bazę danych dla przykładowego zbioru danych.
Przyznawanie AlloyDB niezbędnych uprawnień
Dodaj uprawnienia Vertex AI do agenta usługi AlloyDB.
Otwórz kolejną kartę Cloud Shell, klikając znak „+” u góry.
Na nowej karcie Cloud Shell wykonaj to polecenie:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Włączanie interfejsu Data Access API
Aby korzystać z narzędzi MCP, takich jak execute_sql, musisz włączyć interfejs Data Access API w klastrze AlloyDB.
W tej samej karcie terminala wykonaj to polecenie.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
Włączanie uwierzytelniania za pomocą uprawnień
W przypadku naszych narzędzi opartych na agentach będziemy używać uwierzytelniania z użyciem uprawnień. Wymaga to włączenia uwierzytelniania z użyciem uprawnień w instancji i dodania siebie jako użytkownika bazy danych. Zanim włączysz uwierzytelnianie IAM na poziomie instancji, zaczekaj na zakończenie poprzedniego kroku, w którym włączasz interfejs Data Access API. Stan instancji powinien być zielony.
Zaczynamy od włączenia IAM na poziomie instancji. W tej samej karcie terminala wykonaj to polecenie.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Dodaj siebie jako użytkownika AlloyDB:
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
Zamknij kartę, wpisując na niej polecenie „exit”:
exit
Łączenie się z AlloyDB Studio
W kolejnych rozdziałach wszystkie polecenia SQL wymagające połączenia z bazą danych można wykonywać w AlloyDB Studio. T
Otwórz stronę Klastry w AlloyDB for Postgres.
Otwórz interfejs konsoli internetowej klastra AlloyDB, klikając instancję główną.
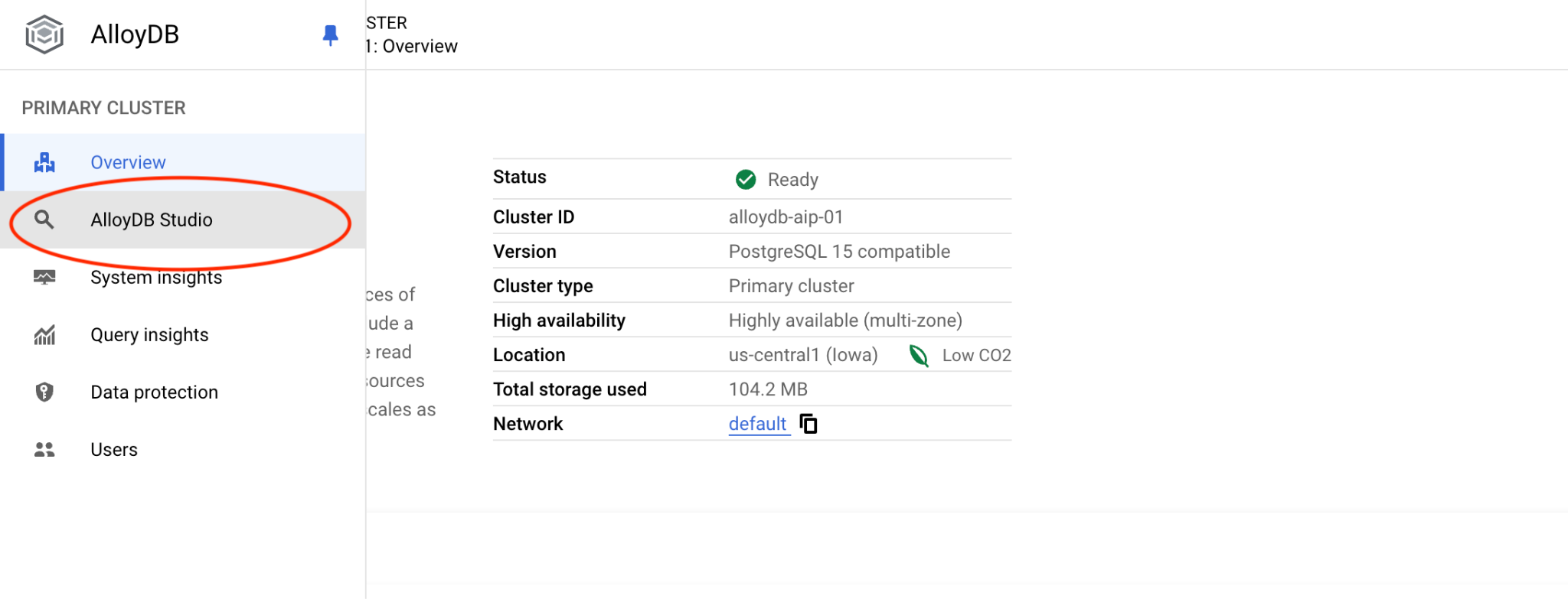
Następnie po lewej stronie kliknij AlloyDB Studio:
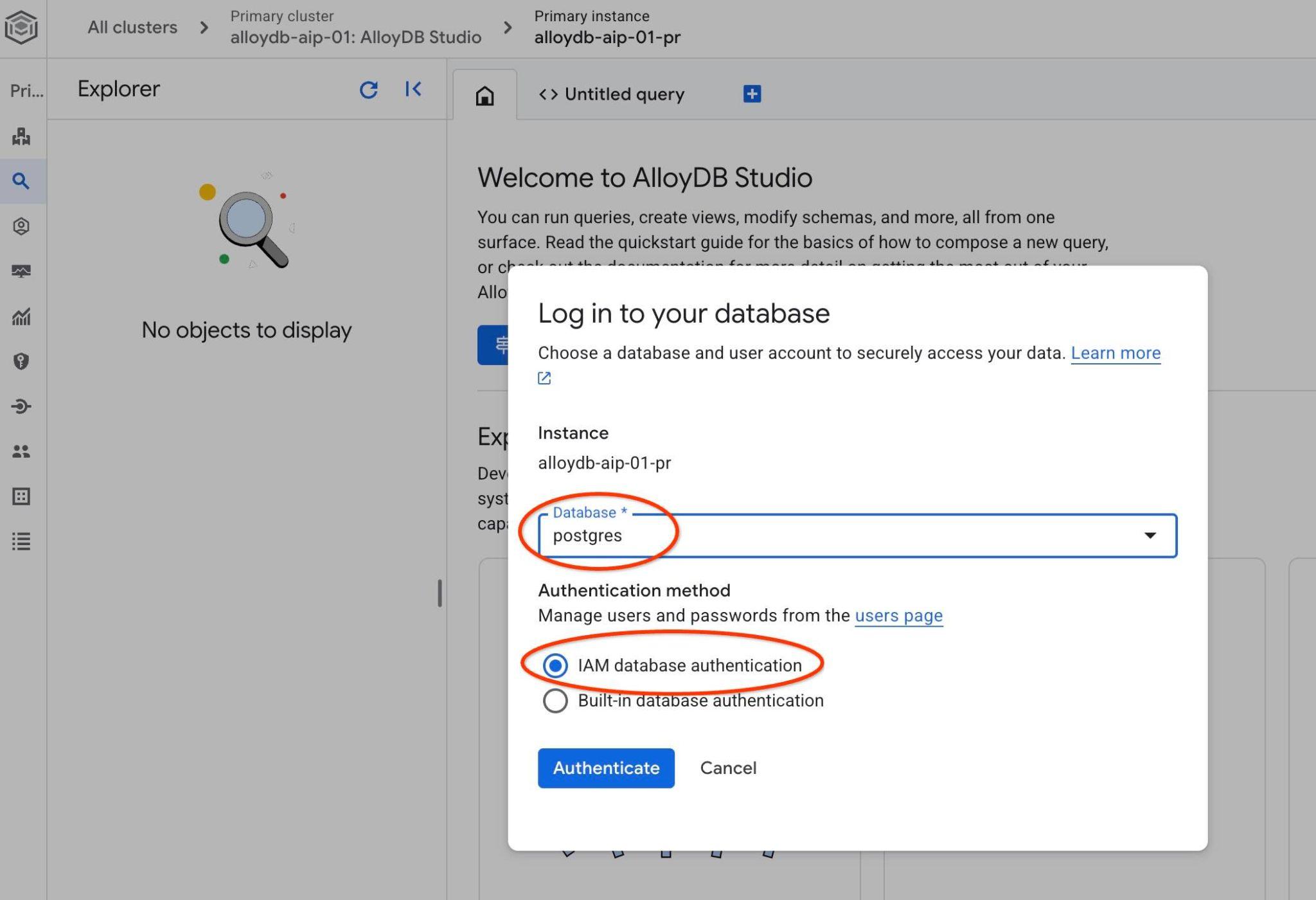
Wybierz bazę danych PostgreSQL i uwierzytelnianie z użyciem uprawnień. Następnie kliknij przycisk „Uwierzytelnij”.
Otworzy się interfejs AlloyDB Studio. Aby uruchomić polecenia w bazie danych, kliknij kartę „Untitled Query” (Nienazwane zapytanie) po prawej stronie.
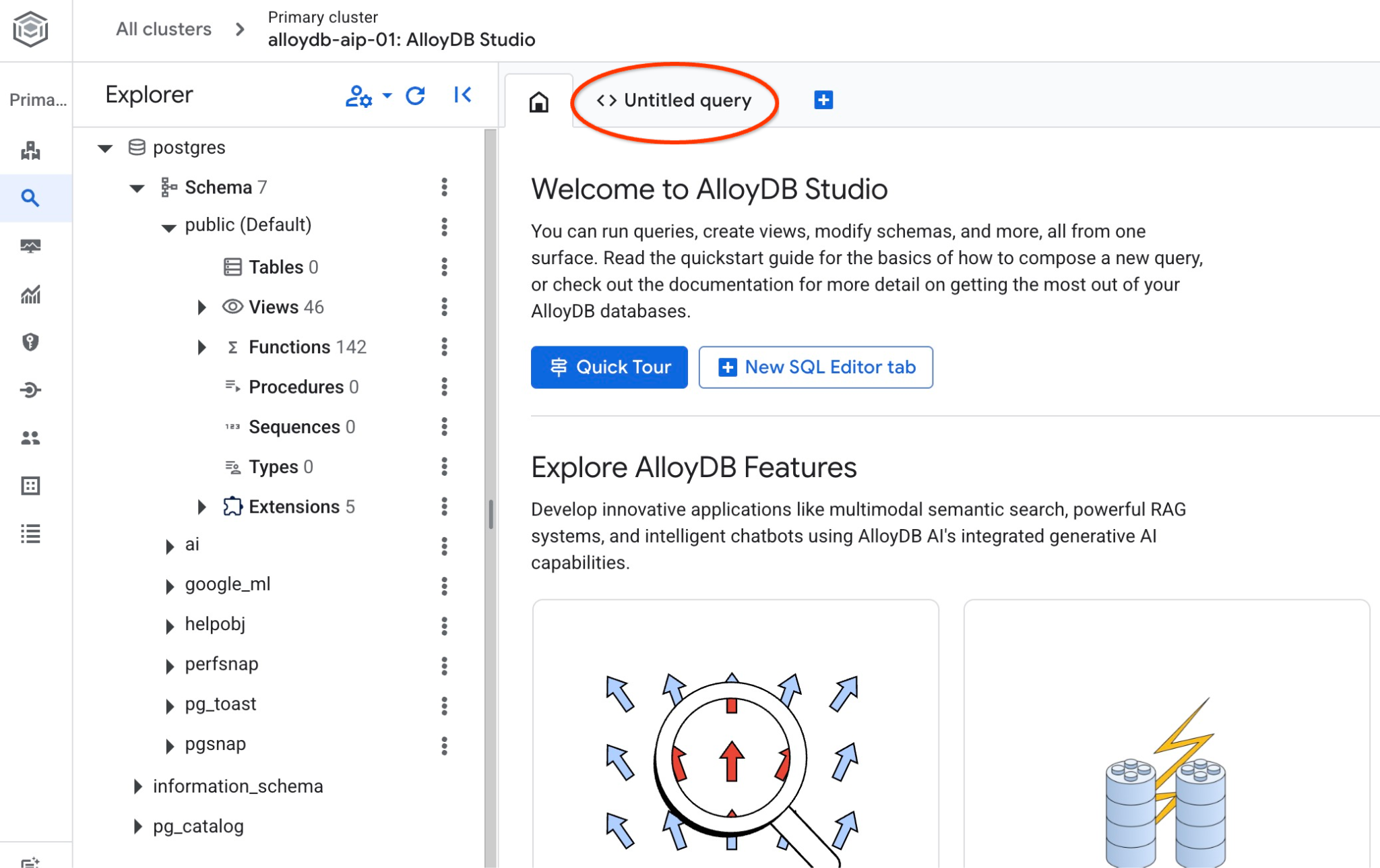
Otworzy się interfejs, w którym możesz uruchamiać polecenia SQL.
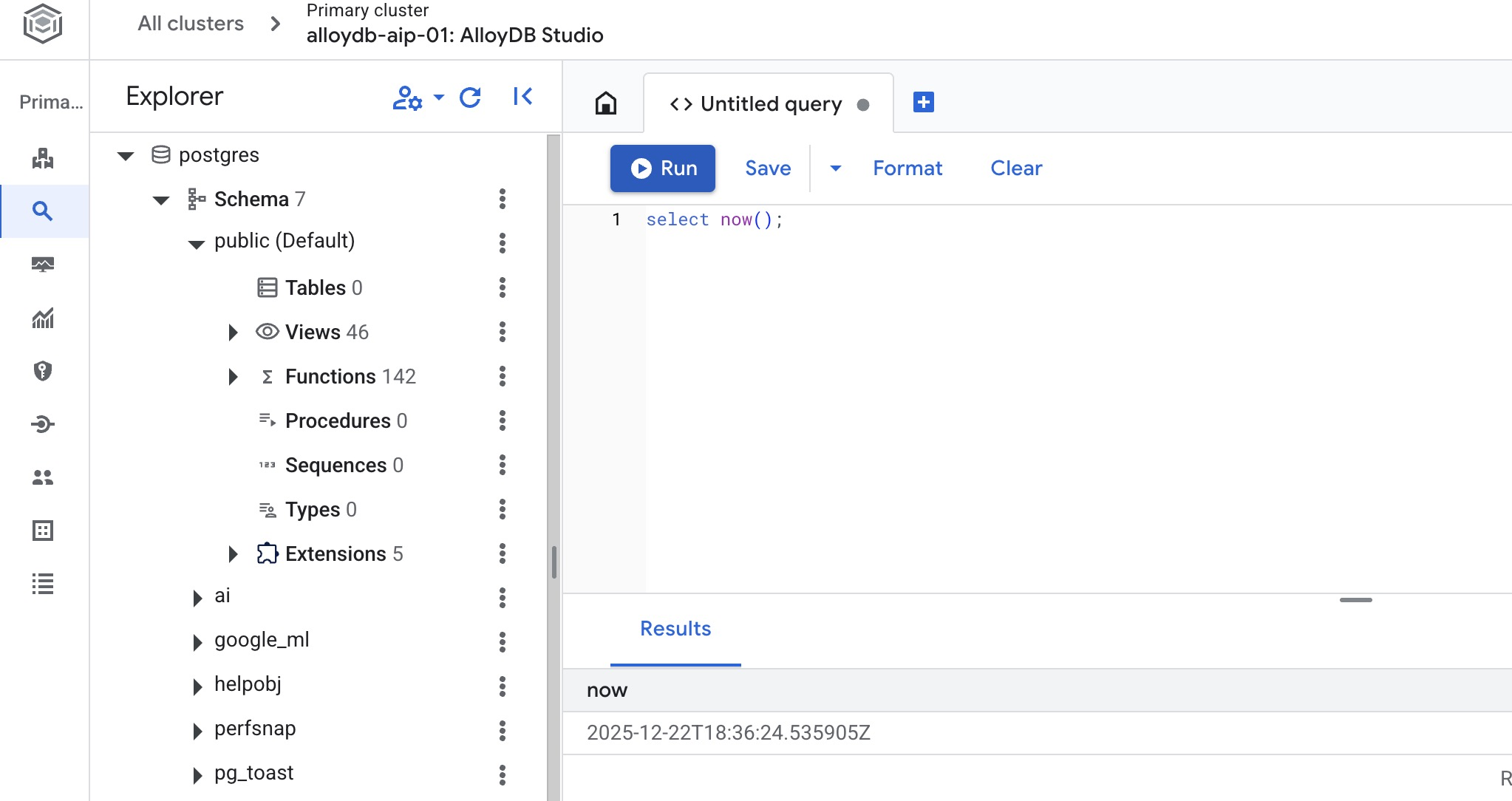
Utwórz bazę danych
Szybki start dotyczący tworzenia bazy danych.
W edytorze AlloyDB Studio wykonaj to polecenie.
Utwórz bazę danych:
CREATE DATABASE quickstart_db
Oczekiwane dane wyjściowe:
Statement executed successfully
Połącz się z bazą danych quickstart_db
Sprawdź, czy baza danych została utworzona, łącząc się z nią. Połącz się ponownie ze studiem, używając przycisku przełączania użytkownika lub bazy danych.
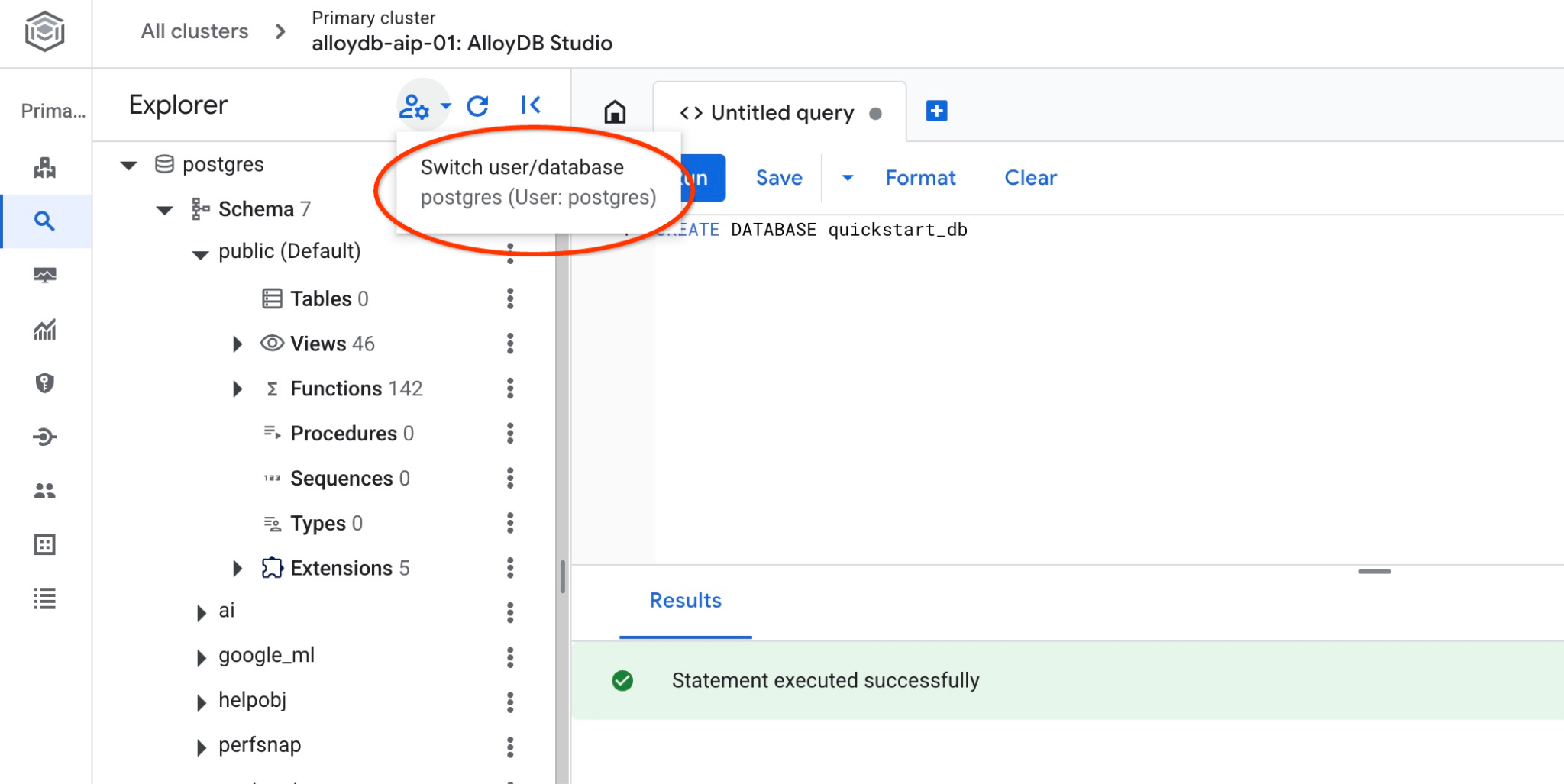
Na liście wybierz nową bazę danych quickstart_db i użyj tego samego uwierzytelniania uprawnień.
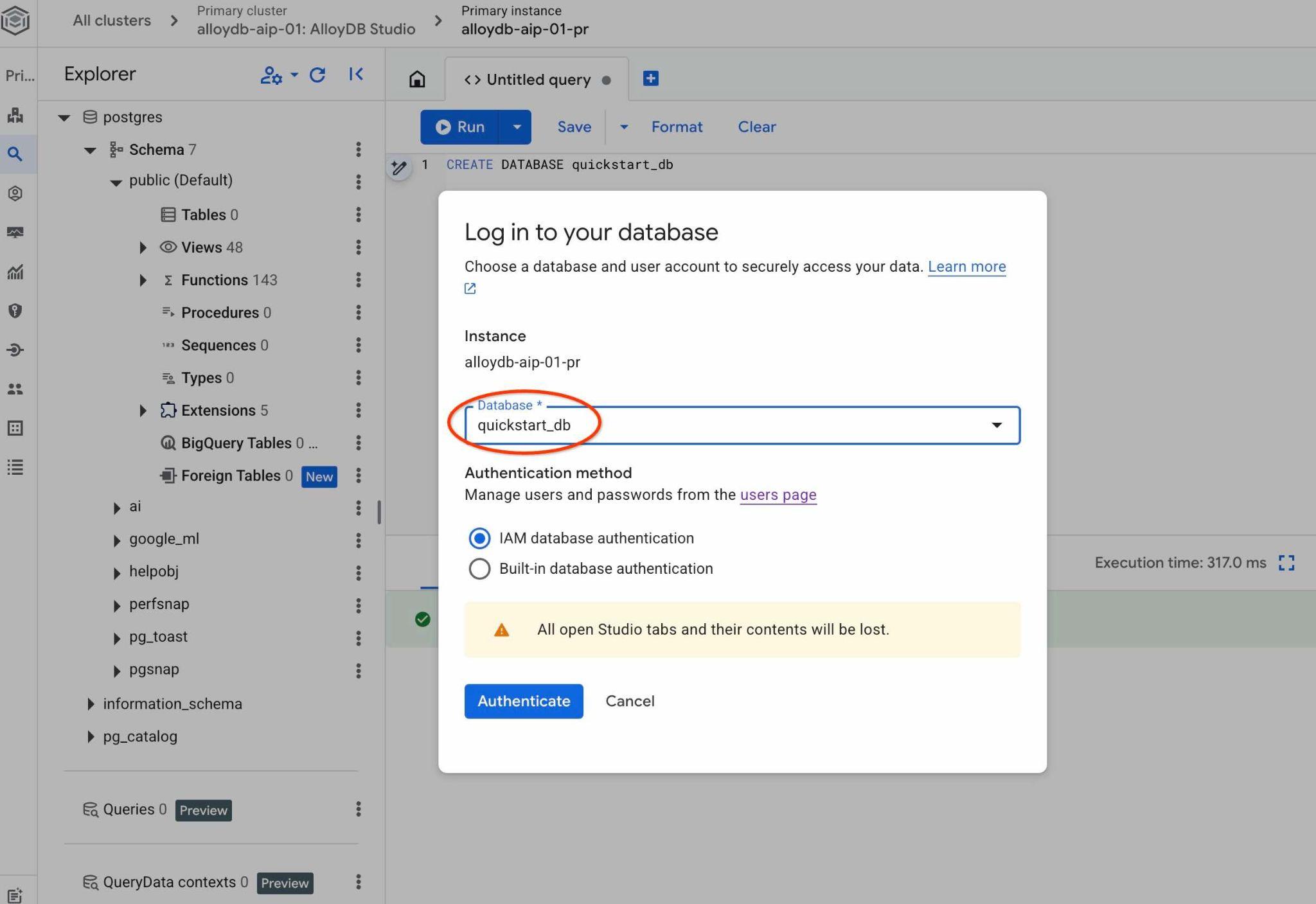
Otworzy się nowe połączenie, w którym możesz pracować z obiektami z bazy danych quickstart_db. Możesz tam sprawdzić zaimportowany schemat i dane oraz pracować z zestawami kontekstowymi QueryData.
6. Przykładowe dane
Teraz musisz utworzyć obiekty w bazie danych i załadować dane. Użyjesz fikcyjnego zbioru danych firmy Cymbal Shipping. Zawiera fikcyjne dane o towarach, ciężarówkach, żądaniach i przejazdach ciężarówek, a także fikcyjnych kierowców.
Tworzenie zasobnika na dane
Do zaimportowania danych ze sklonowanego repozytorium do bazy danych AlloyDB użyjesz pakietu Google SDK (gcloud). W tym celu musisz utworzyć zasobnik Cloud Storage i przyznać dostęp do konta usługi AlloyDB. Możesz też spróbować zrobić to za pomocą konsoli internetowej, zgodnie z opisem w dokumentacji.
W terminalu Google Cloud Shell wykonaj to polecenie:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
Wczytywanie danych
Następnym krokiem jest wczytanie danych. Skompresowany zrzut SQL znajduje się w sklonowanym folderze repozytorium. Poniższe polecenie zakłada, że podczas klonowania repozytorium w poprzednim kroku przy tworzeniu klastra AlloyDB jako punktu początkowego użyto katalogu domowego.
Skopiuj skompresowany zrzut SQL do nowego zasobnika pamięci:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
Następnie wczytaj dane do bazy danych quickstart_db:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
Polecenie wczyta przykładowy zbiór danych do bazy danych quickstart_db. Tabele i rekordy możesz sprawdzić za pomocą AlloyDB Studio.
7. Praca z agentem danych
Zacznijmy od przykładowego agenta AI utworzonego za pomocą pakietu Google ADK dla Pythona i połączonego z instancją AlloyDB za pomocą zestawu narzędzi MCP dla baz danych.
Instalowanie zestawu narzędzi MCP dla baz danych
Narzędzia MCP dla baz danych to projekt open source, który zapewnia obsługę MCP w przypadku wielu mechanizmów baz danych, w tym AlloyDB for PostgreSQL. Więcej informacji o narzędziach MCP znajdziesz w dokumentacji.
Musisz pobrać najnowszą wersję oprogramowania na swoją platformę. Najnowszą wersję znajdziesz na stronie wersji. Poniższy przykład pokazuje, jak pobrać wersję 31 pakietu MCP Toolbox do Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Musisz przygotować plik konfiguracji dla zestawu narzędzi. W bieżącym katalogu mamy przykładowy plik tools.yaml.example. Przygotujemy plik tools.yaml, zastępując 2 symbole zastępcze identyfikatorem projektu i regionem.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
Uruchamianie zestawu narzędzi MCP dla baz danych
Teraz możesz uruchomić zestaw narzędzi MCP za pomocą przygotowanego pliku konfiguracji.
Otwórz nową kartę w Google Cloud Shell, klikając przycisk „+” u góry interfejsu Google Cloud Shell.
Na nowej karcie przejdź do katalogu z binarnym plikiem narzędziowym i plikiem konfiguracji tools.yaml, a następnie uruchom serwer MCP.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
W danych wyjściowych powinien pojawić się komunikat „Server ready to serve!” (Serwer gotowy do obsługi) podobny do tego:
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
Sprawdzanie kodu źródłowego agenta
Na pierwszej karcie w sklonowanym folderze repozytorium sprawdź kod agenta za pomocą edytora Google Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
W agencie znajduje się sekcja serwera MCP Google Cloud dla AlloyDB. Podajemy punkt końcowy jako MCP_SERVER_URL, uwierzytelnianie, identyfikator projektu i dodajemy go do zestawu narzędzi MCP.
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
W kodzie agenta zestaw narzędzi MCP jest uwzględniony jako parametr tools agenta. W prompcie agenta znajdują się też nazwy klastra i instancji, region oraz baza danych jako zmienne.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
Po sprawdzeniu kodu wróć do terminala, klikając przycisk „Otwórz terminal” w prawym górnym rogu okna edytora.
Uruchamianie agenta
Teraz możesz uruchomić agenta w trybie interaktywnym za pomocą interfejsu internetowego Google ADK. Interfejs internetowy ADK zapewnia wygodny sposób testowania i rozwiązywania problemów z przepływami pracy agentów.
Najpierw zainstaluj wszystkie wymagane pakiety dla Pythona za pomocą menedżera pakietów uv.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
Po zainstalowaniu wszystkich pakietów musisz dodać do katalogu agenta plik .env, aby nakierować go na korzystanie z Vertex AI we wszystkich komunikatach z modelami AI.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
Następnie możesz uruchomić agenta.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Powinny się wyświetlić dane wyjściowe podobne do tych z punktem końcowym, np. http://127.0.0.1:8000.
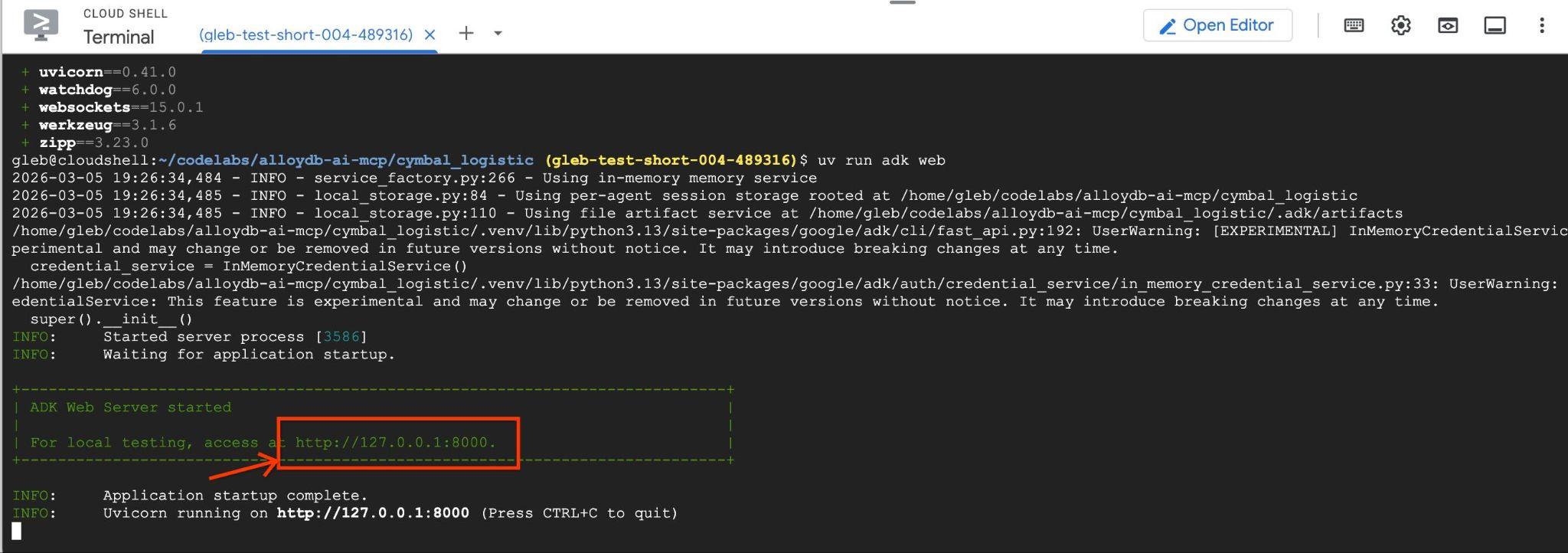
Możesz kliknąć ten adres URL w powłoce w chmurze. Spowoduje to otwarcie okna podglądu na osobnej karcie przeglądarki, w którym możesz wybrać data_agent z listy rozwijanej po lewej stronie.
W interfejsie ADK możesz zadawać pytania w prawym dolnym rogu i wyświetlać pełny przepływ wykonania, w tym ślady każdego kroku po prawej stronie.
8. Testowanie NL2SQL bez QueryData w AlloyDB
Agent umożliwia zadawanie pytań w formie eksploracji swobodnej z użyciem języka naturalnego. Agent będzie używać zestawu narzędzi MCP dla baz danych jako narzędzia do odpowiadania na pytania. Pytania są publikowane w prawym dolnym rogu, a odpowiedź ze wszystkimi wywołaniami narzędzi pojawia się u góry.
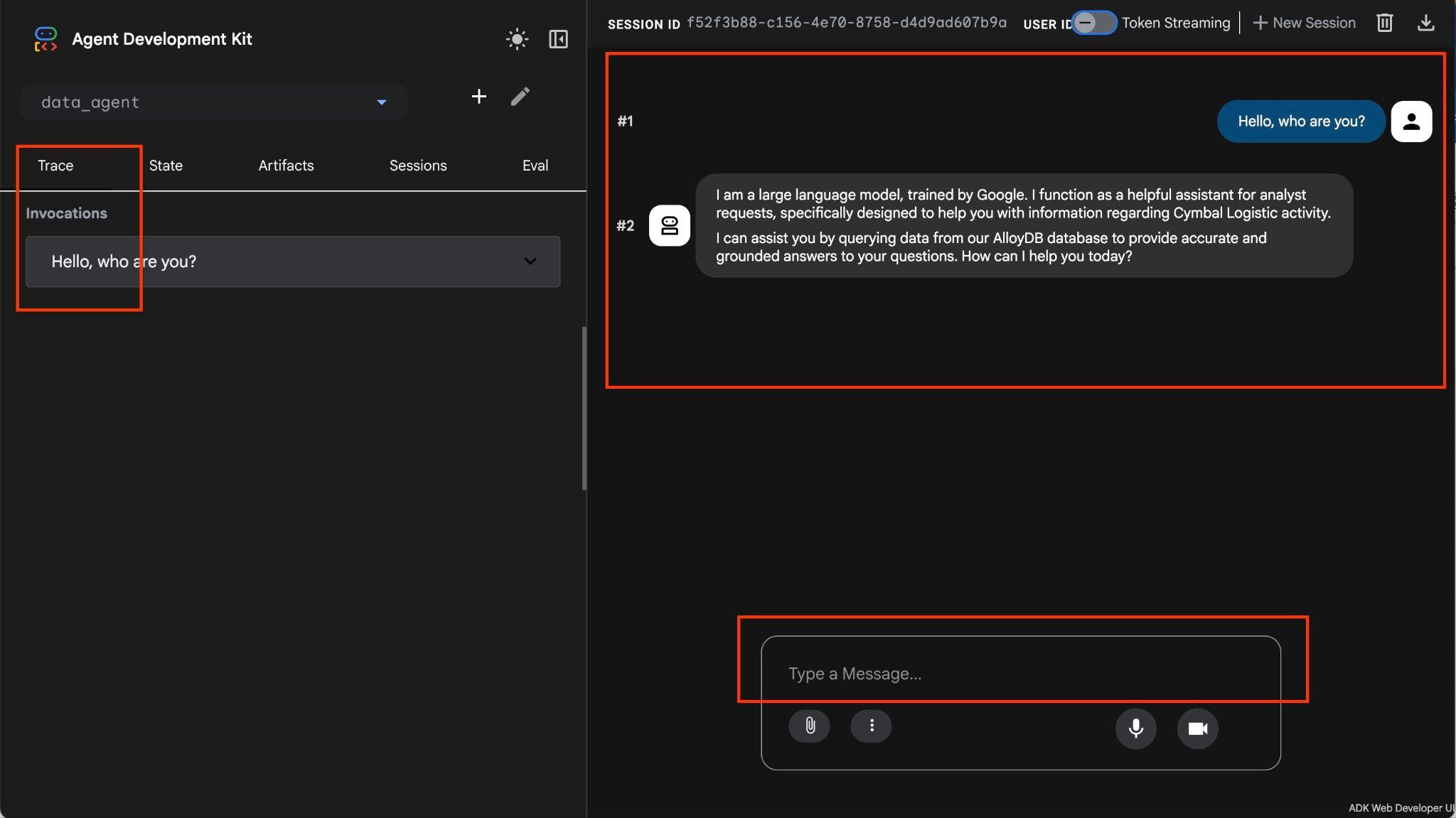
Pracujesz z danymi operacyjnymi firmy kurierskiej, które zawierają informacje o prośbach o dostawę, ciężarówkach, kierowcach i trasach pokonywanych przez kierowców. Pierwsze pytanie dotyczy liczby przejazdów zrealizowanych w lutym 2026 r.
W polu do wprowadzania danych w prawym dolnym rogu wpisz poniższy tekst i naciśnij Enter.
Hello, can you tell me how many trips we've done in February?
Agent będzie wykonywać wiele wywołań narzędzi, aby zidentyfikować odpowiednie tabele w schemacie za pomocą funkcji list_cymbal_logistics_schemas_tool i execute_sql_tool, wykonując wiele instrukcji SQL w celu uzyskania odpowiednich danych.
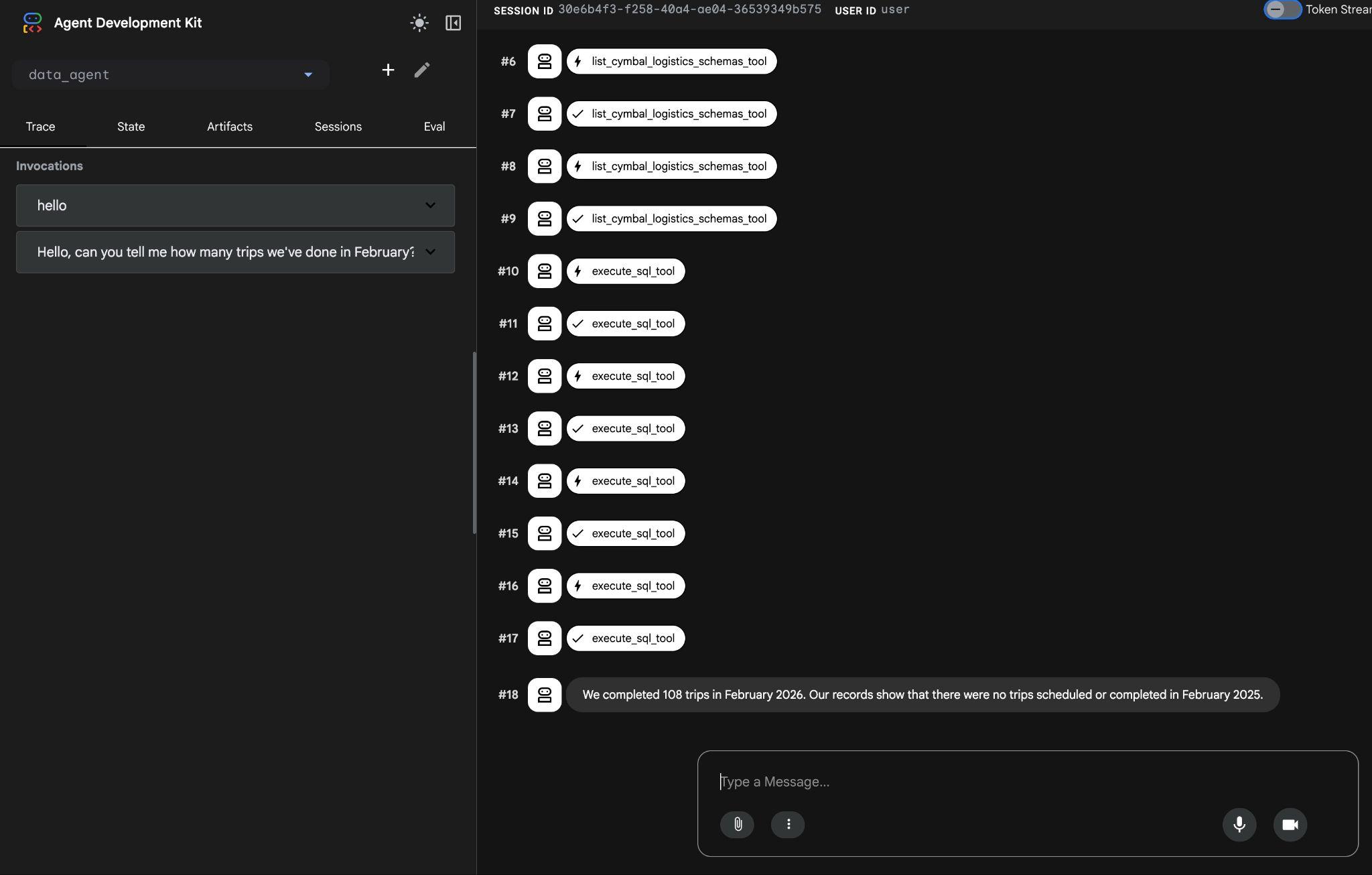
Po utworzeniu odpowiedniego zapytania i wykonaniu go w bazie danych ostatecznie zwróci prawidłowy wynik.
W lutym 2026 r. odbyliśmy 108 podróży. Z naszych danych wynika, że w lutym 2025 roku nie były zaplanowane ani zrealizowane żadne przejazdy.
Aby sprawdzić, co robi każde wywołanie narzędzia, kliknij jego wykonanie. Na przykład oto zapytanie, które zostało wykonane, aby uzyskać nasze wyniki.
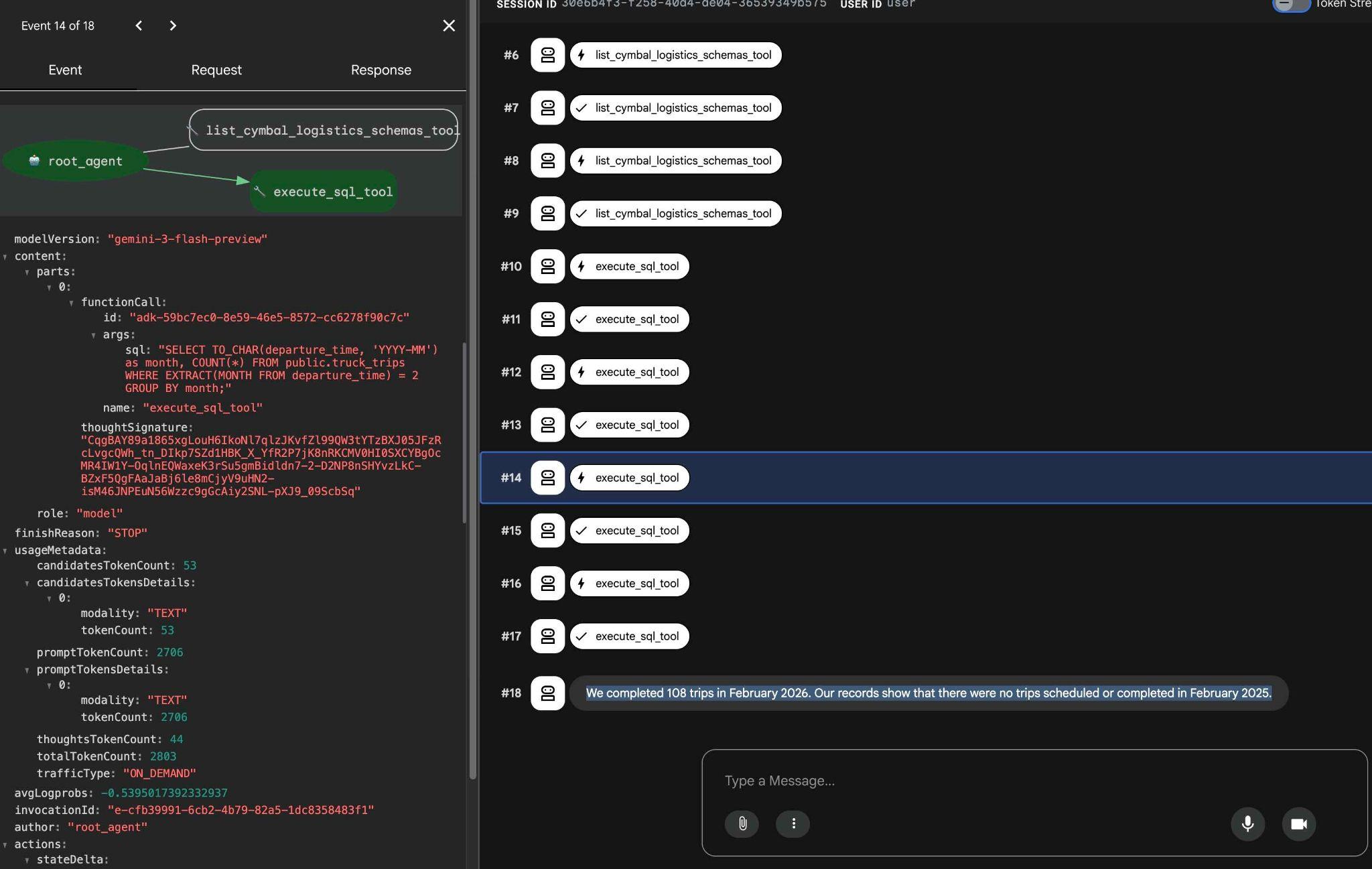
Wypróbuj inne proste żądania za pomocą interfejsu internetowego ADK i zobacz, jak wykonuje on różne zapytania, aby uzyskać wyniki.
Zatrzymaj agenta, naciskając ctrl+c w terminalu. Możesz zamknąć kartę przeglądarki z interfejsem internetowym ADK.
Możesz też zatrzymać MCP Toolbox na drugiej karcie, naciskając ten sam skrót klawiszowy ctrl+c i zamknąć drugą kartę.
W następnym kroku utworzymy kontekst QueryData, aby ulepszyć odpowiedź i wydajność NL2SQL.
9. Tworzenie kontekstu QueryData
W poprzednim kroku można było zauważyć, że model AI wielokrotnie wywoływał schemat informacji bazy danych, aby określić, których tabel i kolumn powinien użyć do utworzenia zapytania SQL. Aby zwiększyć wydajność i dokładność oraz sprawić, że wyniki będą bardziej przewidywalne, dodamy kontekst QueryData określający, jakie zapytanie powinno zostać wykonane w odpowiedzi na daną prośbę.
Tworzenie spersonalizowanych szablonów
QueryData ContextSet to plik JSON z szablonami zapytań i aspektami, które dostarczają modelowi AI niezbędne dane i wskazówki dotyczące używania prawidłowych zapytań SQL lub ich części w celu osiągnięcia żądanych rezultatów na podstawie wzorców zapytań i struktury danych.
Zaczynasz od szablonu docelowego. Utwórz plik za pomocą edytora Cloud Shell. W terminalu Cloud Shell wykonaj to polecenie.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
Wstaw szablon zapytania w języku naturalnym, którego użyliśmy w poprzednim rozdziale – „Ile podróży odbyliśmy w lutym?”.
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
Następnie pobierz szablon na komputer z Cloud Shell za pomocą przycisku pobierania.
Wczytywanie zestawów kontekstów QueryData
Aby używać naszych zbiorów kontekstów QueryData, musimy przesłać je do naszej bazy danych.
Otwórz AlloyDB Studio. W panelu po lewej stronie u dołu zobaczysz ikonę QueryData Context i 3 kropki.
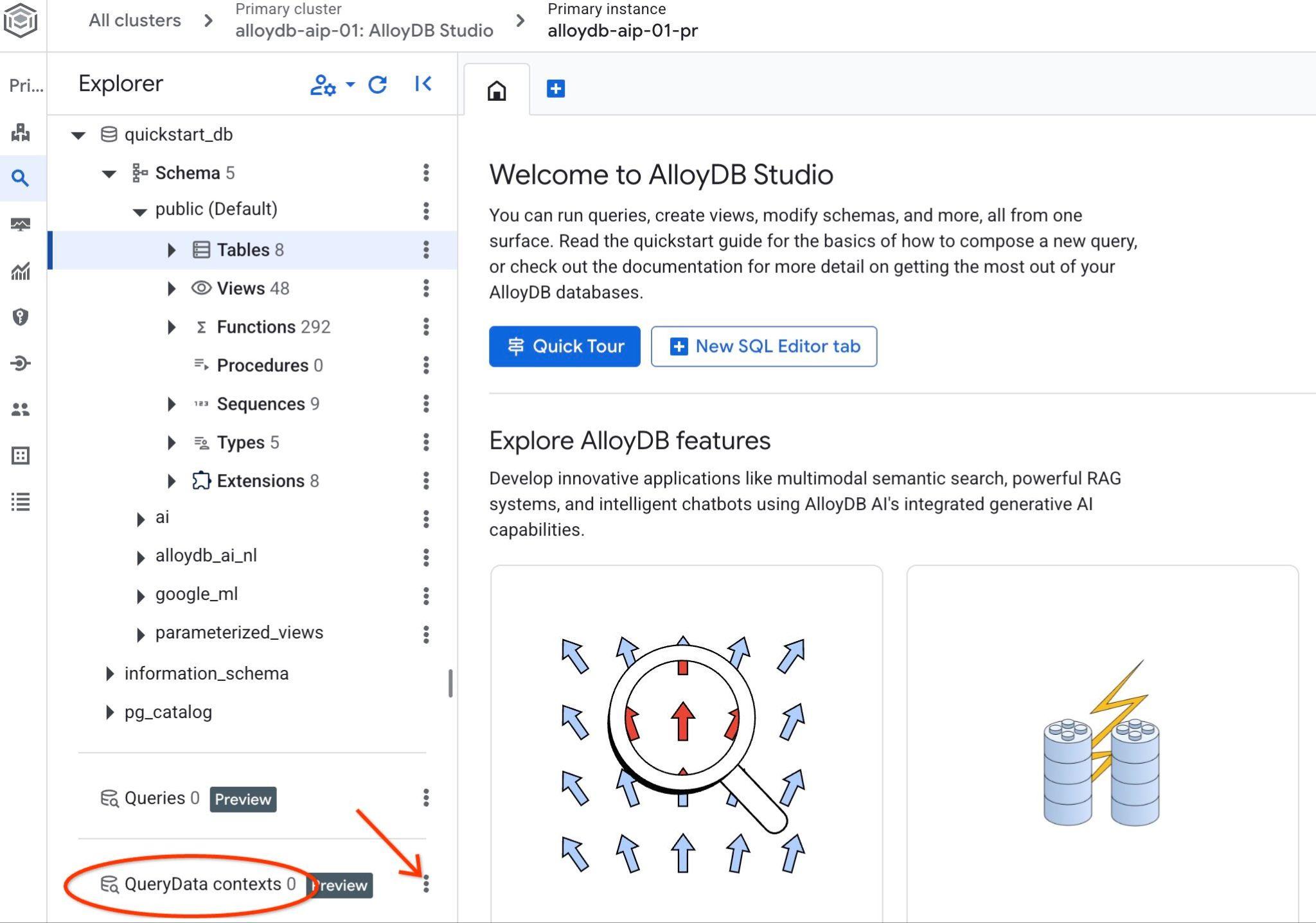
Kliknij te 3 kropki i wybierz Utwórz kontekst. Otworzy się okno, w którym możesz wpisać
- Nazwa:
cymbal_context_set - Opis:
Cymbal Logistic Query Data - Prześlij plik kontekstu: kliknij przycisk „
Browse” i wybierz plik JSON z elementem QueryData ContextSet.
Jeśli robisz to po raz pierwszy, zainicjowanie pamięci kontekstu po naciśnięciu przycisku Zapisz może zająć trochę czasu.
Powinien być widoczny pobrany kontekst. Jeśli klikniesz 3 pionowe przyciski po prawej stronie, zobaczysz dostępne działania. W następnym rozdziale zaczniemy od działania „Test context” (Kontekst testu).
10. Testowanie ustawionego kontekstu QueryData
Szablon testu
Aby przetestować kontekst w AlloyDB Studio, użyj działania „Test context”. Gdy klikniesz „Test context” (Testuj kontekst), otworzy się nowe okno edytora AlloyDB Studio z tytułem „cymbal_context_set” i zaproszeniem do generowania kodu SQL w Gemini o nazwie „Generate SQL using QueryData context: cymbal_context_set”. Kliknij generowanie kodu SQL i wpisz
Hello, can you tell me how many trips we've done in February?
Gdy wygenerowane zostanie zapytanie SQL, naciśnij przycisk „Insert”.
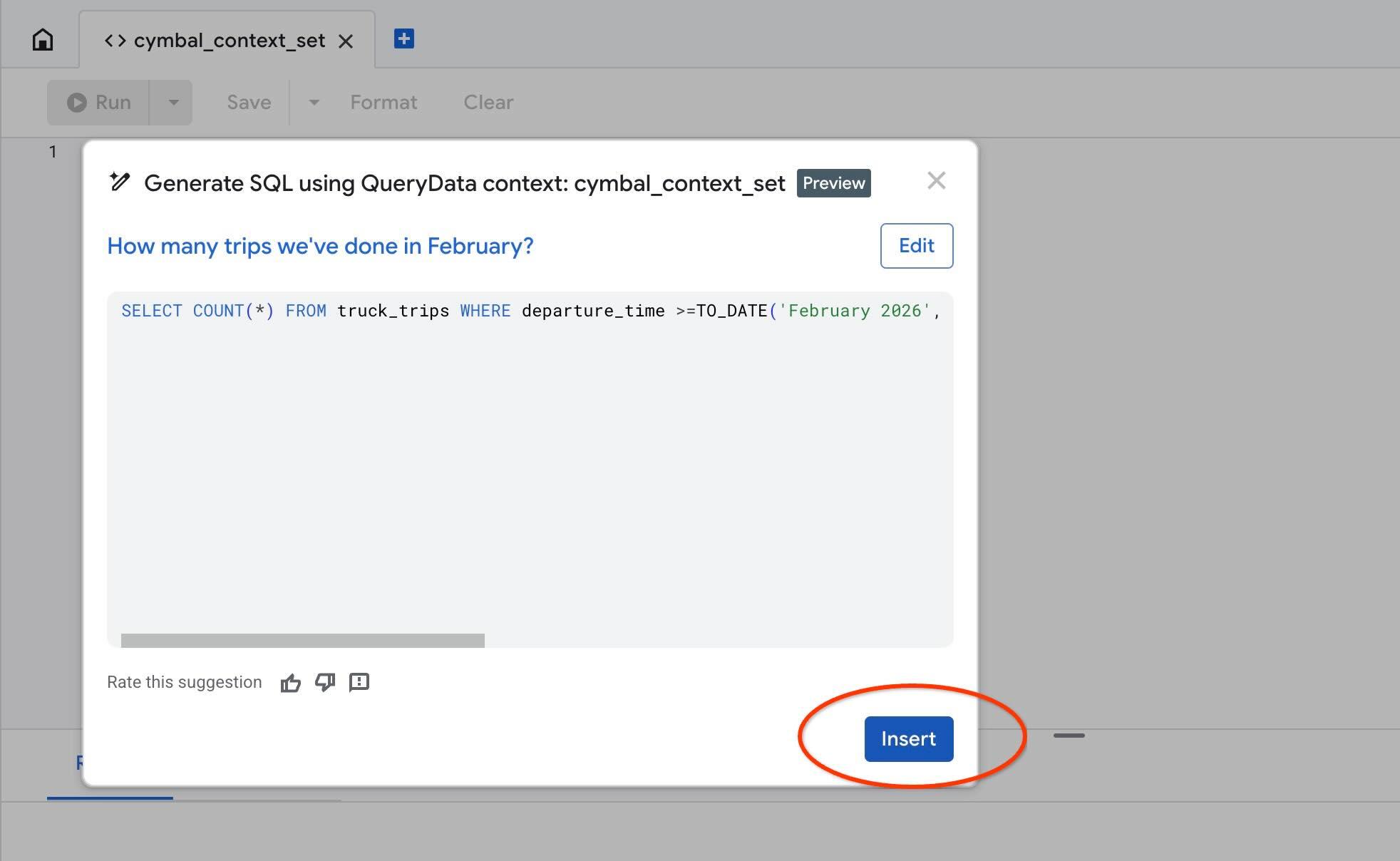
Zobaczysz dokładnie to samo zapytanie, które wcześniej wpisaliśmy w szablonie kontekstu.
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
Spróbuj zastąpić miesiąc ciągiem „January” i sprawdź wygenerowaną instrukcję SQL. Będzie używać miesiąca jako parametru w przypadku intencji sparametryzowanej i automatycznie dostosowywać instrukcję SQL.
Tworzenie aspektów QueryData
Wypróbowaliśmy szablon zapytania i działa on, gdy wiemy, jakiego rodzaju prośby użytkowników się spodziewamy. Czasami jednak warto kierować tylko częścią zapytania, np. warunkiem lub filtrem, gdy preferujemy określoną kolejność lub konkretną klauzulę, która ma być używana w przypadku przedefiniowanego zamiaru.
Jeśli na przykład poprosimy o zwrócenie danych za „ostatni miesiąc”, chcemy otrzymać raport za ostatni miesiąc kalendarzowy, czyli od 1 dnia do ostatniego dnia tego miesiąca, a nie za ostatnie 30 dni.
Możemy dodać takie aspekty jak fragment kodu SQL do konfiguracji ContextSet wraz z wcześniej dodanym szablonem. Otwórz plik querydata_cymbal_contextset.json.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
i dodaj aspekty po istniejących już szablonach. Zawartość pliku powinna wyglądać tak:
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
Zapisz plik i prześlij go na komputer.
Następnie użyj działania „Edytuj kontekst” i prześlij zmodyfikowany plik, aby zastąpić stary zestaw kontekstów nowym.
Spróbuj ponownie użyć kontekstu testowego i wygenerować instrukcję SQL za pomocą intencji „w zeszłym miesiącu”. Jeśli na przykład wygenerujesz zapytanie SQL dla frazy „show trucks trips for the last month"”, będzie ono używać warunku podanego jako aspekt w pliku cymbal_context.json.
Powinien pojawić się wynik podobny do tego:
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
Jak możesz go używać z agentami AI? W następnym rozdziale udostępnimy kontekst „Zapytanie o dane” agentom AI.
11. QueryData z agentami AI
Będziesz używać tego samego agenta danych, ale zestaw narzędzi MCP będzie teraz skonfigurowany do korzystania z zestawu kontekstów QueryData.
Przygotowywanie i uruchamianie zestawu narzędzi MCP dla baz danych
Potrzebujemy nowego pliku konfiguracyjnego dla zestawu narzędzi MCP, który będzie korzystać z interfejsu Gemini Data Analytics API i AlloyDB jako źródła bazy danych.
Uruchom w terminalu:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
Przełącz się na edytor i znajdź plik querydata.yaml. Plik konfiguracyjny querydata.yaml będzie wyglądać tak jak poniżej, z wyjątkiem identyfikatora projektu i regionu, które będą odzwierciedlać Twoje środowisko. Musisz jednak zaktualizować wartość contextSetId i zastąpić symbol zastępczy "<add-context-set-id>" wartością z konsoli.
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
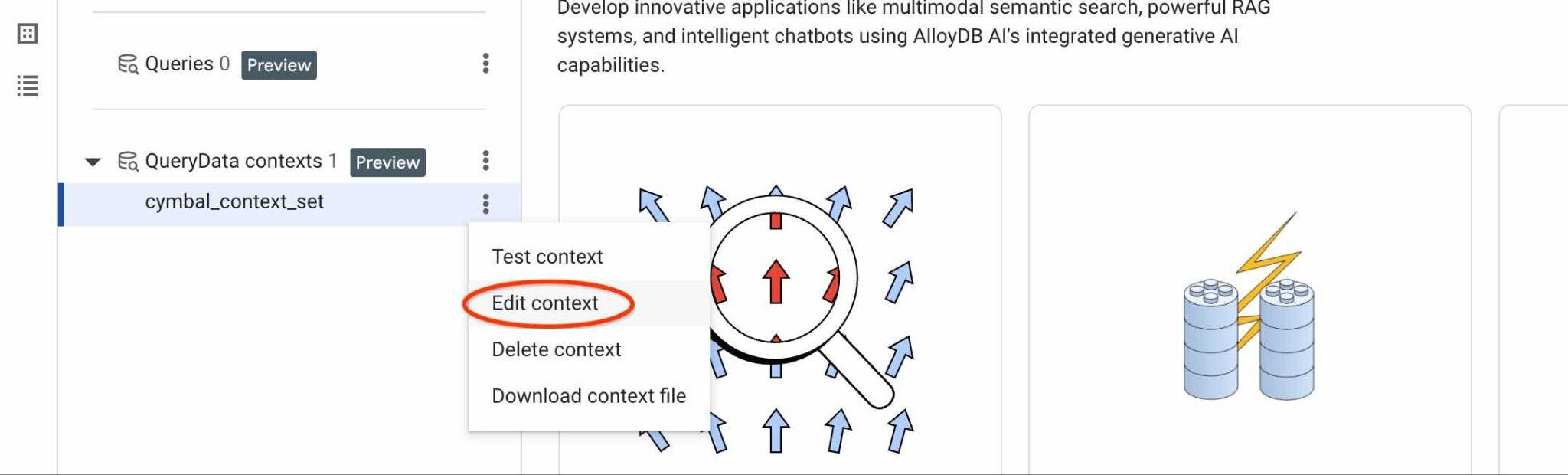
Aby znaleźć identyfikator ContextSet, kliknij przycisk edycji zestawu kontekstowego, jak pokazano na obrazku.
Identyfikator zestawu kontekstowego zobaczysz u góry nowej karty po prawej stronie.
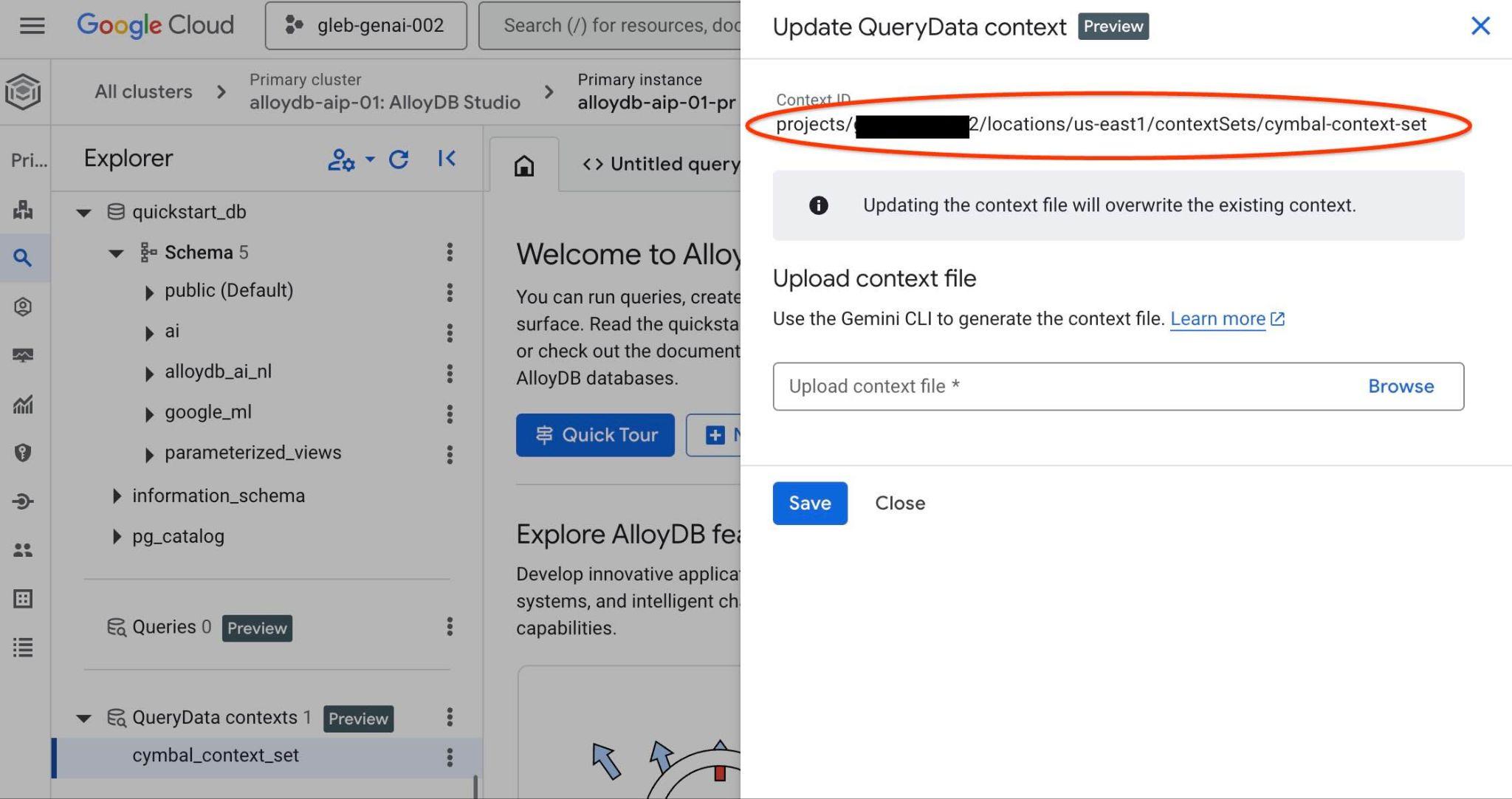
Pełną ścieżkę należy wstawić w miejsce obiektu zastępczego "<add-context-set-id>" w pliku querydata.yaml.
Wróć do terminala.
Otwórz nową kartę w Google Cloud Shell, klikając przycisk „+” u góry interfejsu Google Cloud Shell.
Na nowej karcie przejdź do katalogu z binarnym plikiem narzędziowym i plikiem konfiguracji tools.yaml, a następnie uruchom serwer MCP.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
Uruchom agenta ADK
Na pierwszej karcie Cloud Shell uruchom agenta.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Po uruchomieniu kliknij ponownie link http://127.0.0.1:8000 .
Zobaczysz znany już interfejs agenta podglądu internetowego ADK. Opublikuj dokładnie to samo zapytanie co ostatnio.
Hello, can you tell me how many trips we've done in February?
i zobacz przepływ pracy agenta. Jeśli wszystko jest poprawnie skonfigurowane, powinno wyświetlić się coś takiego:
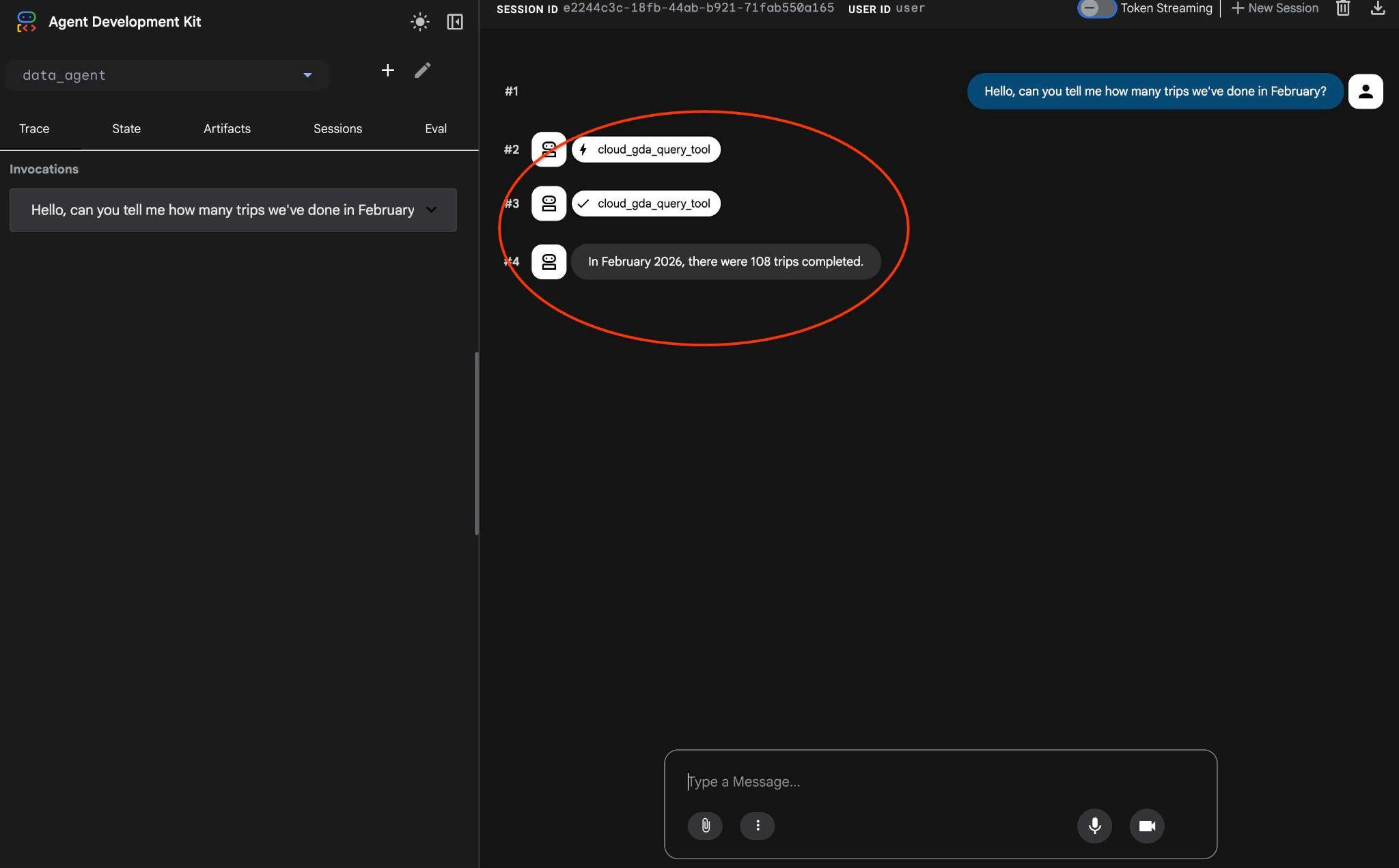
Żądanie, które ostatnio wymagało wielu interakcji, zostało przekształcone w jedno wywołanie narzędzia MCP i wykonane przy użyciu przewidywalnych instrukcji SQL.
Skonfigurowane aspekty możesz przetestować za pomocą takiego żądania:
how trucks trips for the last month
Jeśli w wyniku klikniesz działanie narzędzia, zobaczysz, że użyto tego samego narzędzia i zastosowano aspekty, aby uzyskać wynik.
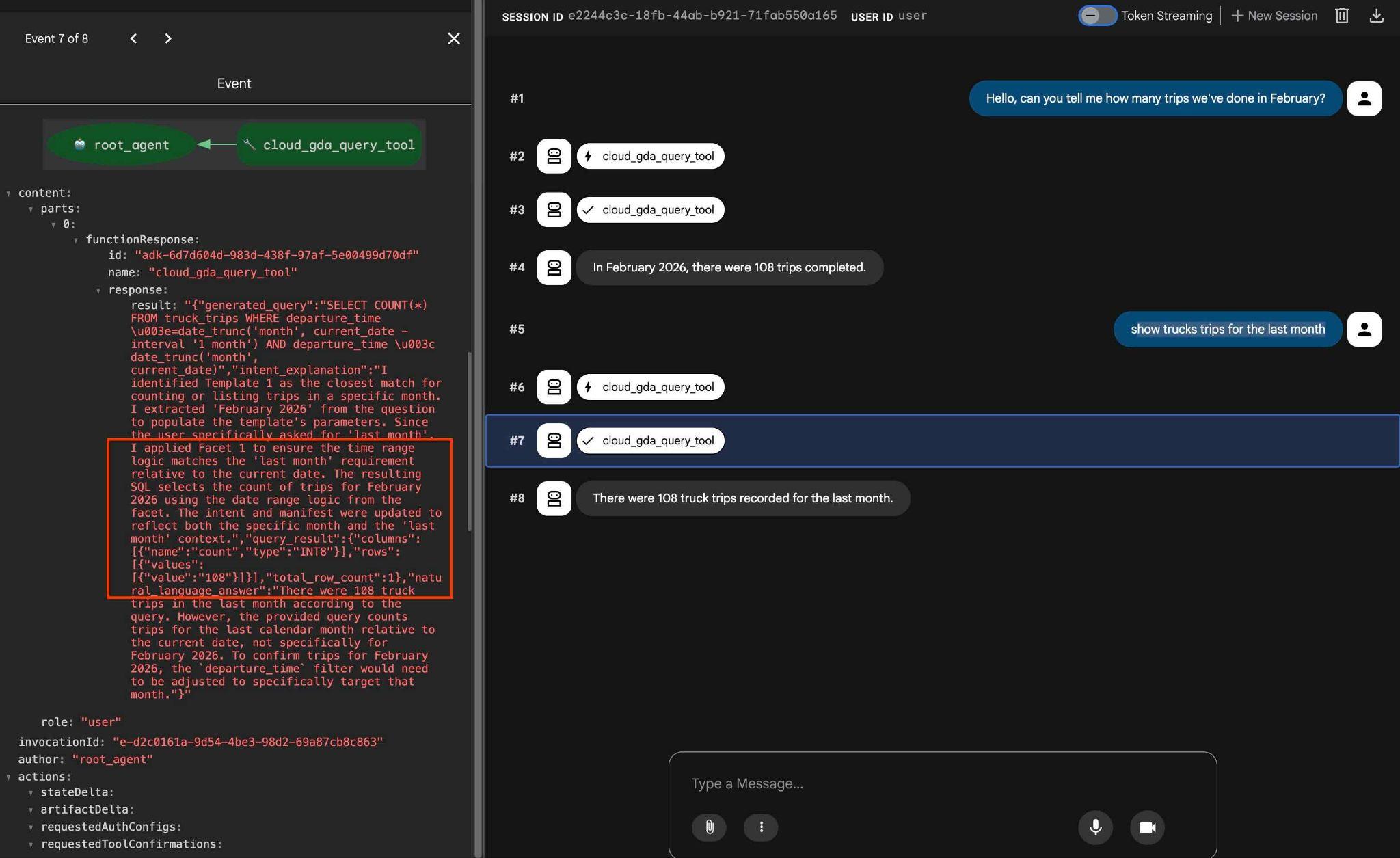
To koniec modułu. Mam nadzieję, że udało Ci się zapoznać ze wszystkimi przykładami i nauczyć się korzystać z QueryData w przypadku AlloyDB. Dostarczona technologia pomaga zapewnić przewidywalność i niezawodność zadań agenta i generowania kodu SQL.
12. Zwalnianie miejsca w środowisku
Aby uniknąć nieoczekiwanych opłat, warto usunąć zasoby tymczasowe. Najbardziej niezawodnym sposobem jest usunięcie projektu, w którym testowano przepływ pracy. Możesz jednak ograniczyć się, usuwając poszczególne zasoby, np. AlloyDB.
Po zakończeniu modułu zniszcz instancje i klaster AlloyDB.
Usuwanie klastra AlloyDB i wszystkich instancji
Jeśli korzystasz z wersji próbnej AlloyDB. Nie usuwaj klastra próbnego, jeśli planujesz testować inne laboratoria i zasoby przy użyciu tego klastra. Nie będzie można utworzyć kolejnego klastra próbnego w tym samym projekcie.
Klaster zostanie zniszczony z opcją force, która powoduje też usunięcie wszystkich instancji należących do klastra.
W Cloud Shell zdefiniuj projekt i zmienne środowiskowe, jeśli połączenie zostało przerwane i wszystkie poprzednie ustawienia zostały utracone:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Usuń klaster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Usuwanie kopii zapasowych AlloyDB
Usuń wszystkie kopie zapasowe AlloyDB dla klastra:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
13. Gratulacje
Gratulujemy ukończenia ćwiczenia.
Omówione zagadnienia
- Jak utworzyć klaster AlloyDB i zaimportować przykładowe dane
- Jak włączyć interfejs API dostępu do danych AlloyDB
- Jak włączyć QueryData w AlloyDB
- Jak generować szablony
- Jak korzystać z wyszukiwania wieloaspektowego
- Jak używać QueryData z agentami AI
14. Ankieta
Dane wyjściowe: