
1. Introdução
Este codelab ensina como começar a usar o QueryData para AlloyDB e gerar instruções SQL precisas e previsíveis com base em entradas de linguagem natural em aplicativos de agentes.
Pré-requisitos
- Conhecimentos básicos sobre o console do Google Cloud
- Habilidades básicas na interface de linha de comando e no Cloud Shell
O que você vai aprender
- Como criar um cluster do AlloyDB e importar dados de amostra
- Como ativar a API de acesso aos dados do AlloyDB
- Como ativar o QueryData para o AlloyDB
- Como gerar modelos
- Como usar a pesquisa refinada
- Como usar o QueryData com agentes de IA
O que é necessário
- Uma conta e um projeto do Google Cloud
- Um navegador da Web, como o Chrome, que seja compatível com o console do Google Cloud e o Cloud Shell
2. Configuração e requisitos
Configuração do projeto
Criar um projeto do Google Cloud
- No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto na nuvem do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
Inicie o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
Ou pressione G e S. Essa sequência vai ativar o Cloud Shell se você estiver no console do Google Cloud ou usar este link.
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
3. Antes de começar
Ativar API
Para usar o AlloyDB, o Compute Engine, os serviços de rede e a Vertex AI, é necessário ativar as APIs respectivas no seu projeto do Google Cloud.
No terminal do Cloud Shell, verifique se o ID do projeto está configurado:
gcloud config get-value project
Você vai ver o tID do seu projeto na saída:
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
Defina a variável de ambiente PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Ative todos os serviços necessários:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Resultado esperado
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Implantar o AlloyDB
Crie um cluster do AlloyDB e uma instância principal. Você pode implantar usando um script preparado que vai implantar todos os recursos necessários ou fazer isso etapa por etapa seguindo a documentação.
Implantar o AlloyDB usando um script automatizado
Essa abordagem usa um script automatizado para implantar o cluster do AlloyDB e fornece as informações necessárias para começar a trabalhar com os recursos implantados.
No terminal do Cloud Shell, execute o comando para clonar o script de implantação do repositório.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
Execute o script de implantação.
./deploy_alloydb.sh --public-ip
O script leva algum tempo para ser executado, geralmente de 5 a 7 minutos, e implanta o cluster do AlloyDB e uma instância principal com IP público e privado. O IP público só está disponível para redes autorizadas ou usando o proxy de autenticação do AlloyDB. Leia mais sobre o IP público na documentação. Como saída, o script precisa fornecer informações sobre o cluster do AlloyDB implantado. A senha será diferente. Anote-a em algum lugar para uso futuro.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
Também é possível conferir o novo cluster e a instância principal no console da Web.
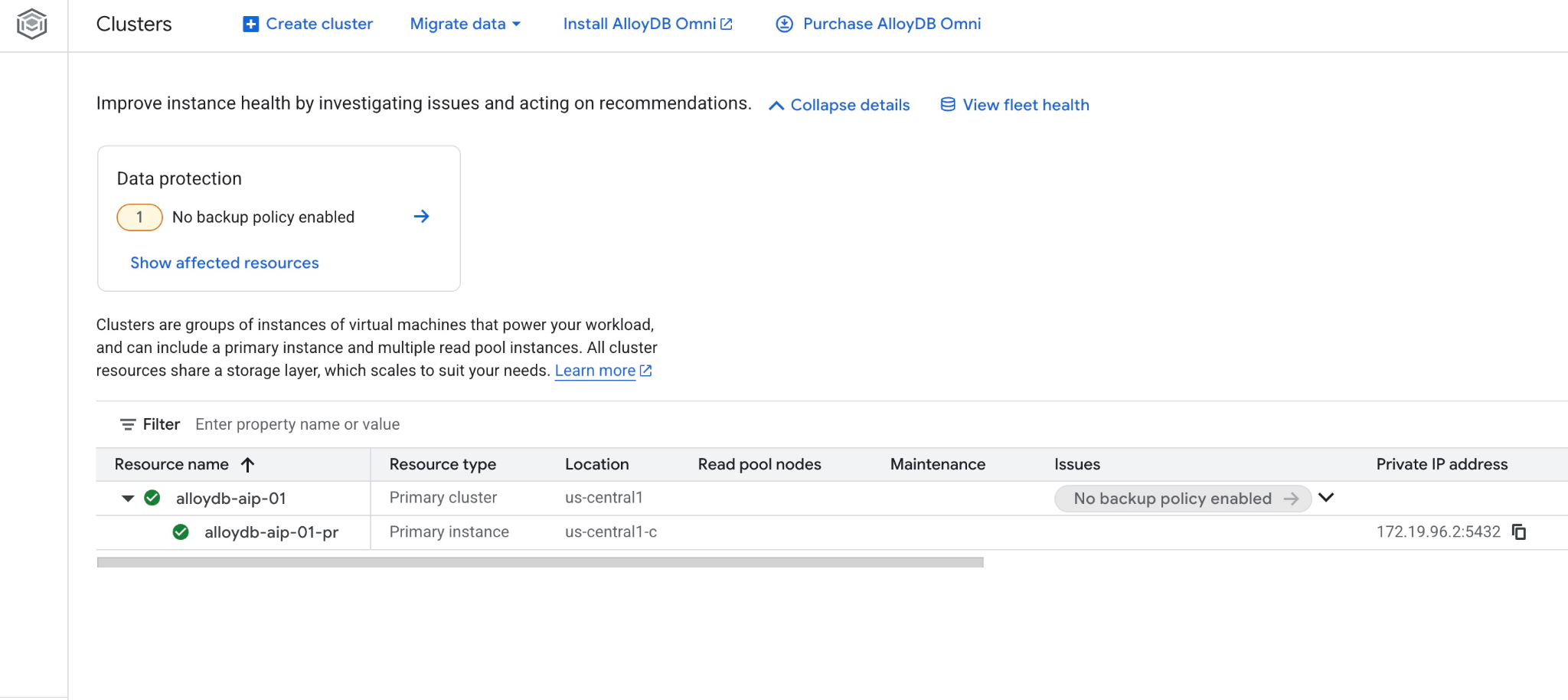
5. Preparar banco de dados
Você precisa ativar a integração da Vertex AI para usar funções e operadores de IA, ativar a API de acesso aos dados e criar um banco de dados para o conjunto de dados de exemplo.
Conceder as permissões necessárias ao AlloyDB
Adicione permissões da Vertex AI ao agente de serviço do AlloyDB.
Abra outra guia do Cloud Shell pelo sinal "+" na parte superior.
Na nova guia do Cloud Shell, execute:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Ativar a API Data Access
É necessário ativar a API Data Access no cluster do AlloyDB para usar ferramentas do MCP, como o execute_sql.
Na mesma guia do terminal, execute.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
Ativar a autenticação do IAM
Vamos usar a autenticação do IAM nas nossas ferramentas de agente. Para isso, é necessário ativar a autenticação do IAM na instância e se adicionar como um usuário do banco de dados. Antes de ativar a autenticação do IAM no nível da instância, aguarde a conclusão da etapa anterior, que ativa a API de acesso aos dados. O status da instância deve estar verde.
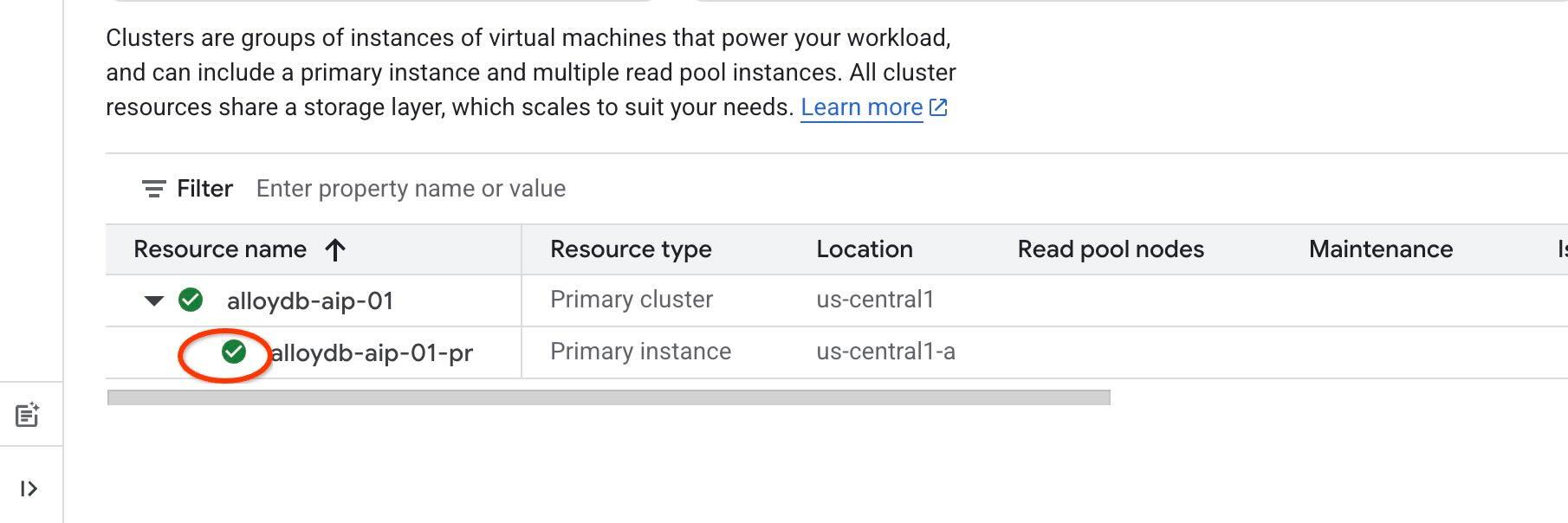
Começamos ativando o IAM no nível da instância. Na mesma guia do terminal, execute.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Adicione você mesmo como usuário do AlloyDB:
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
Feche a guia pelo comando de execução "sair" na guia:
exit
Conectar-se ao AlloyDB Studio
Nos capítulos a seguir, todos os comandos SQL que exigem conexão com o banco de dados podem ser executados no AlloyDB Studio. T
Navegue até a página "Clusters" no AlloyDB para Postgres.
Abra a interface do console da Web do cluster do AlloyDB clicando na instância principal.
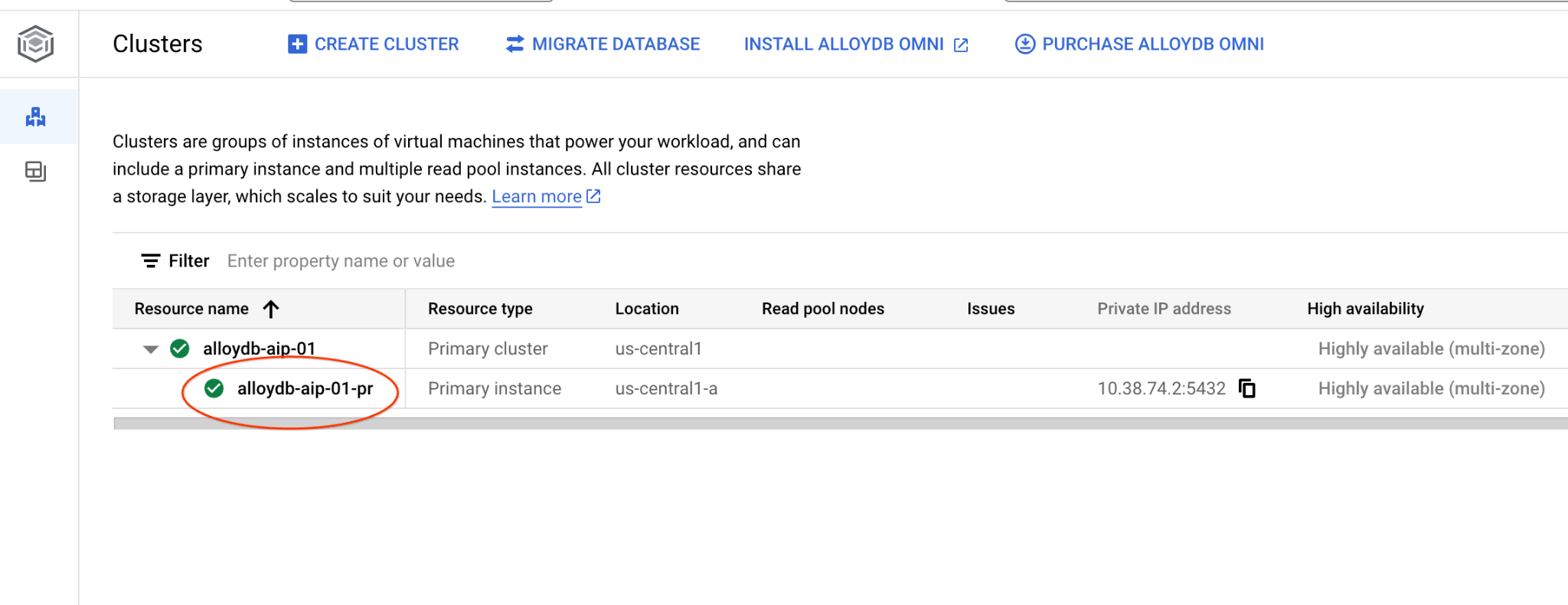
Em seguida, clique em "AlloyDB Studio" à esquerda:
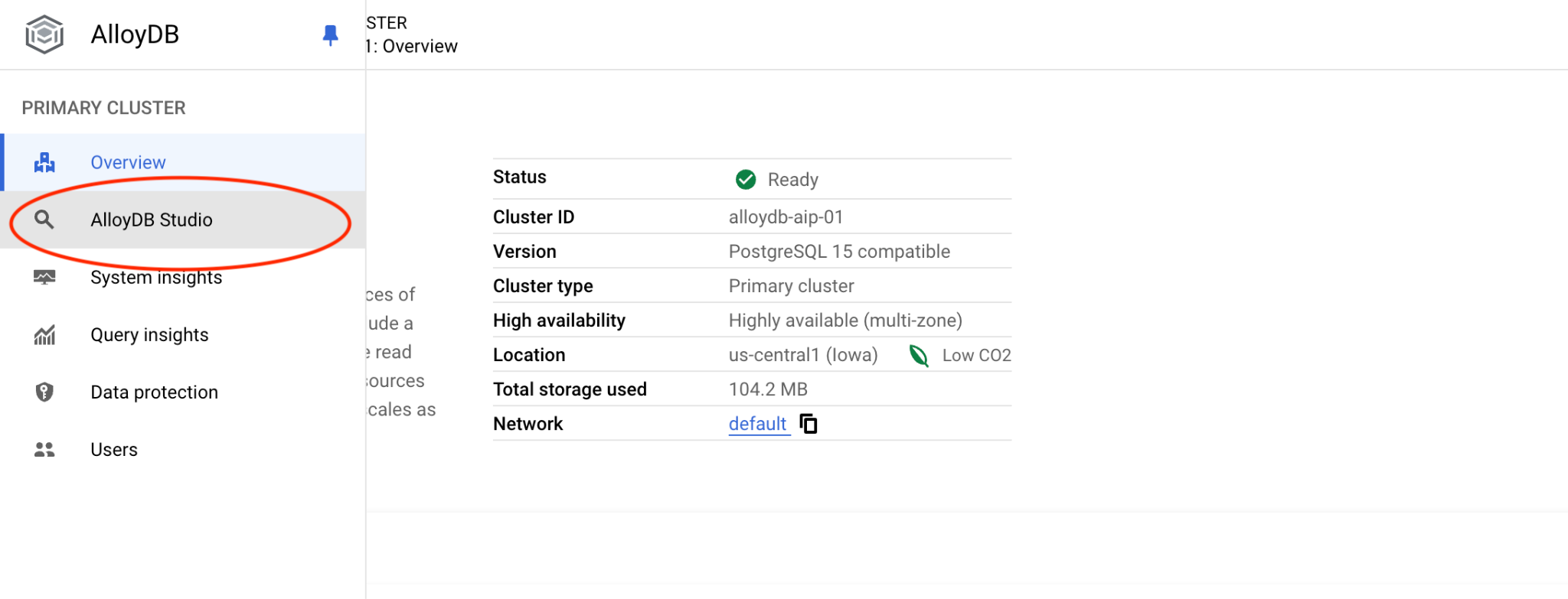
Escolha o banco de dados postgres e a autenticação do IAM. Em seguida, clique no botão "Autenticar".
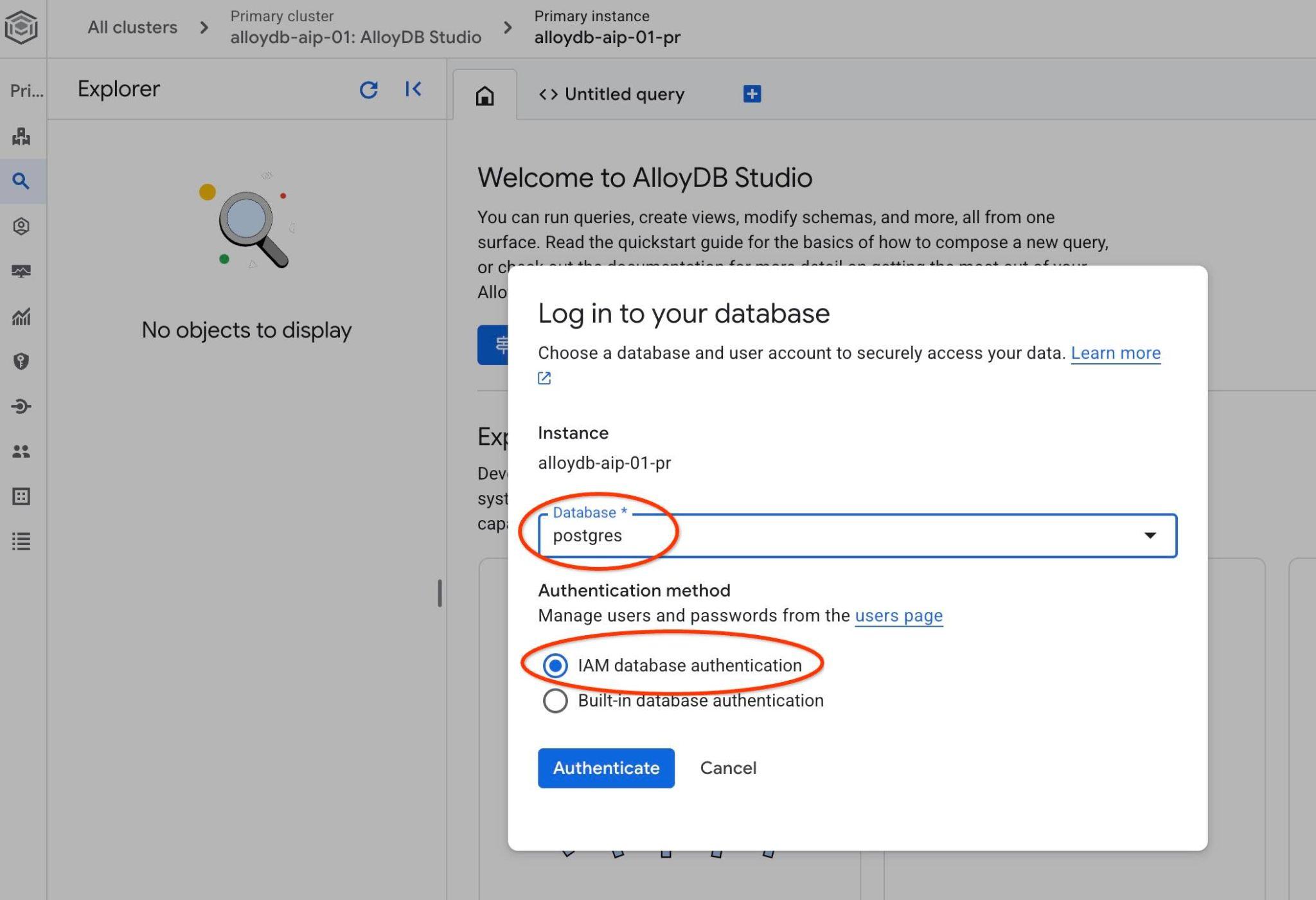
A interface do AlloyDB Studio será aberta. Para executar os comandos no banco de dados, clique na guia "Consulta sem título" à direita.
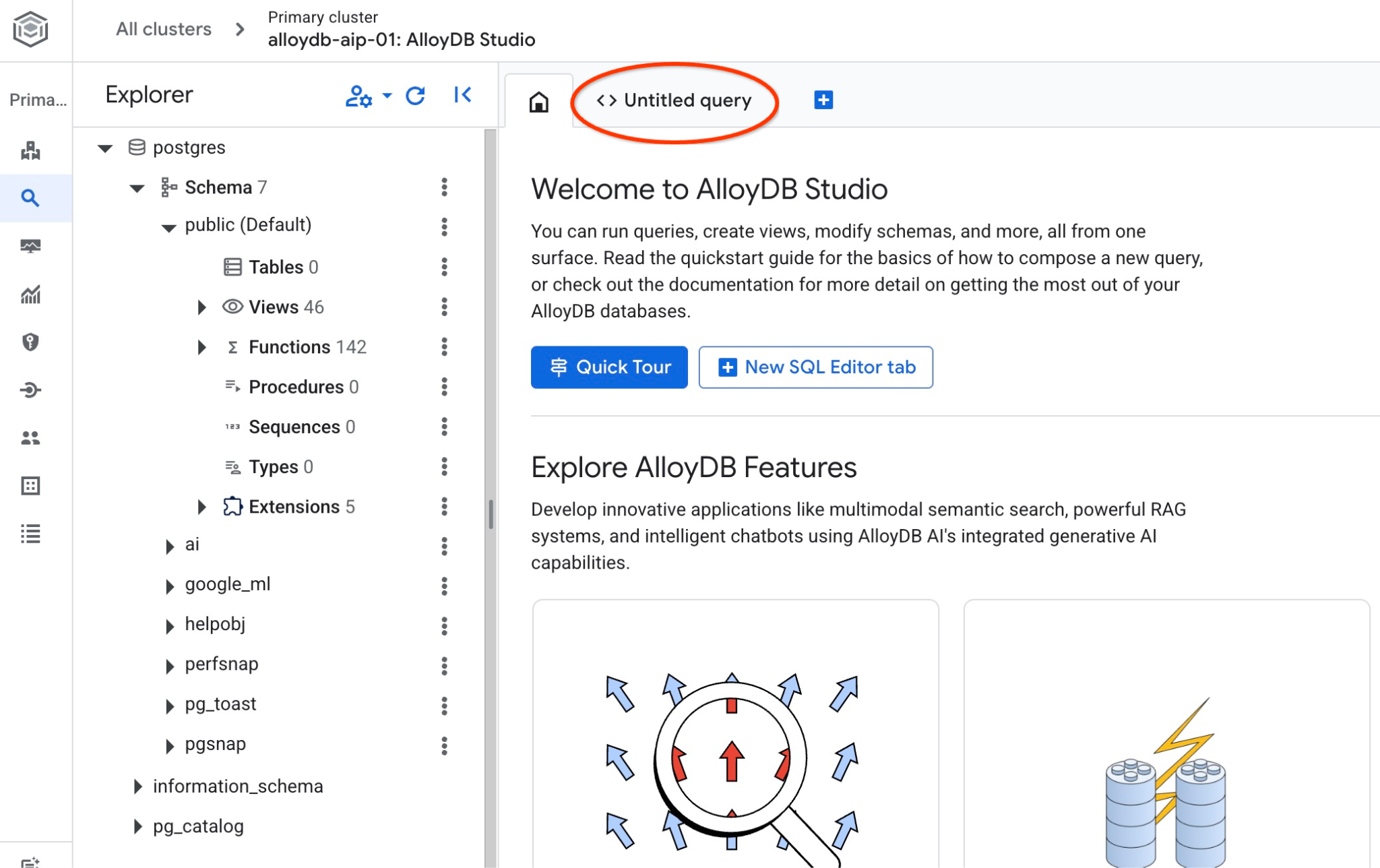
Ela abre uma interface em que é possível executar comandos SQL.
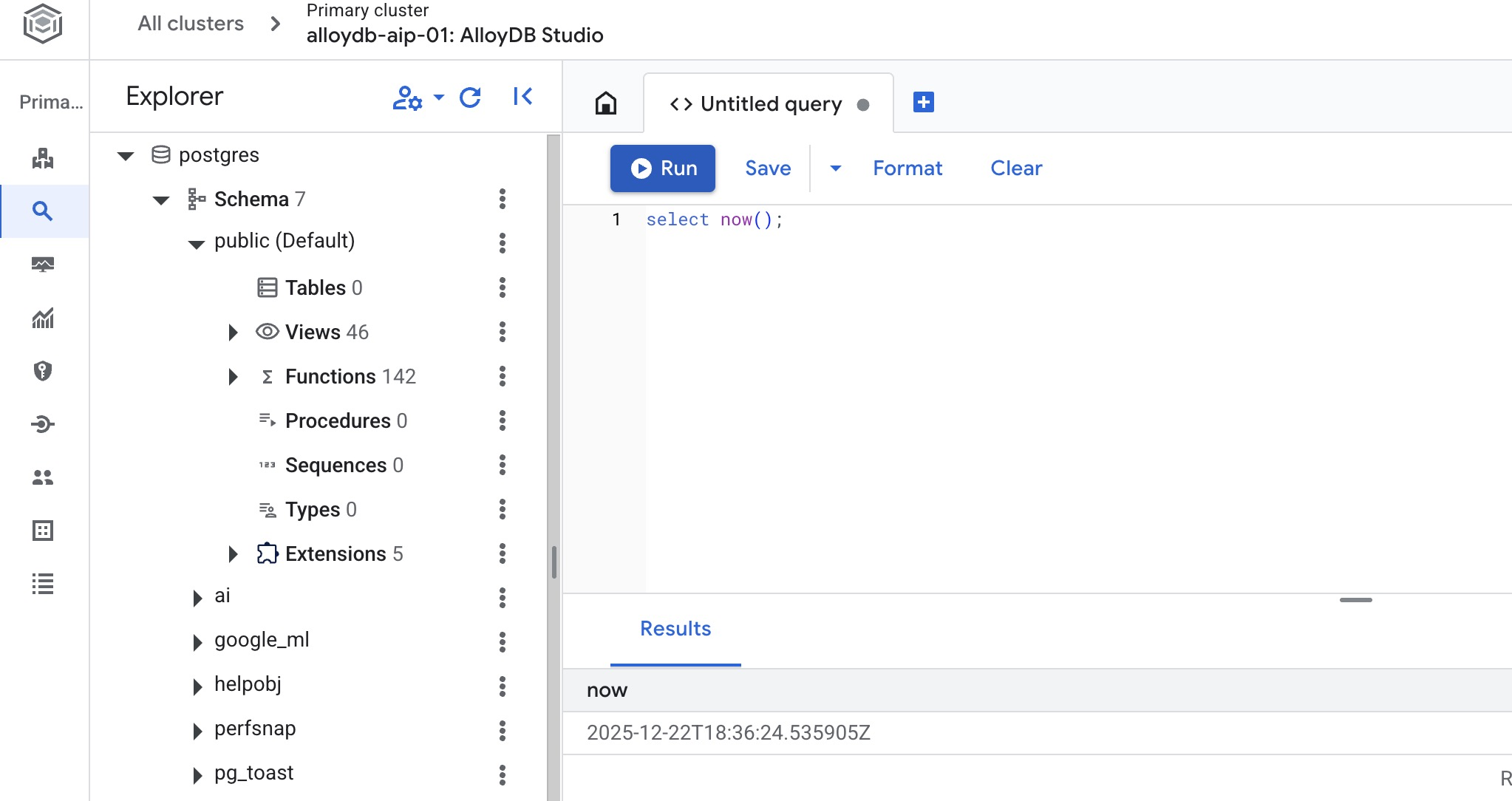
Criar banco de dados
Início rápido para criar um banco de dados.
No editor do AlloyDB Studio, execute o comando a seguir.
Crie o banco de dados:
CREATE DATABASE quickstart_db
Saída esperada:
Statement executed successfully
Conectar-se a quickstart_db
Confira se o banco de dados foi criado conectando-se a ele. Reconecte-se ao estúdio usando o botão para mudar de usuário/banco de dados.
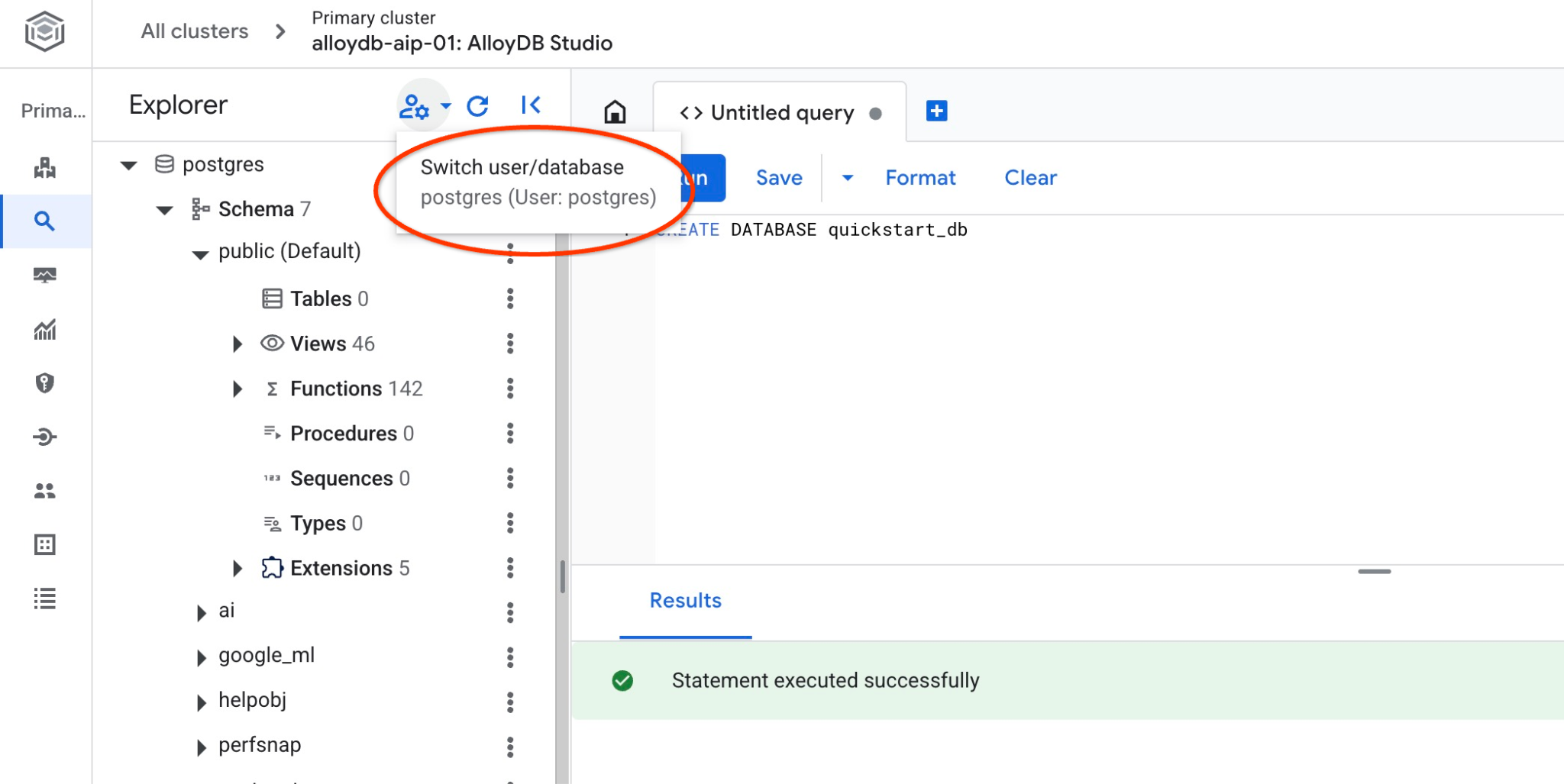
Escolha o novo banco de dados quickstart_db na lista suspensa e use a mesma autenticação do IAM.
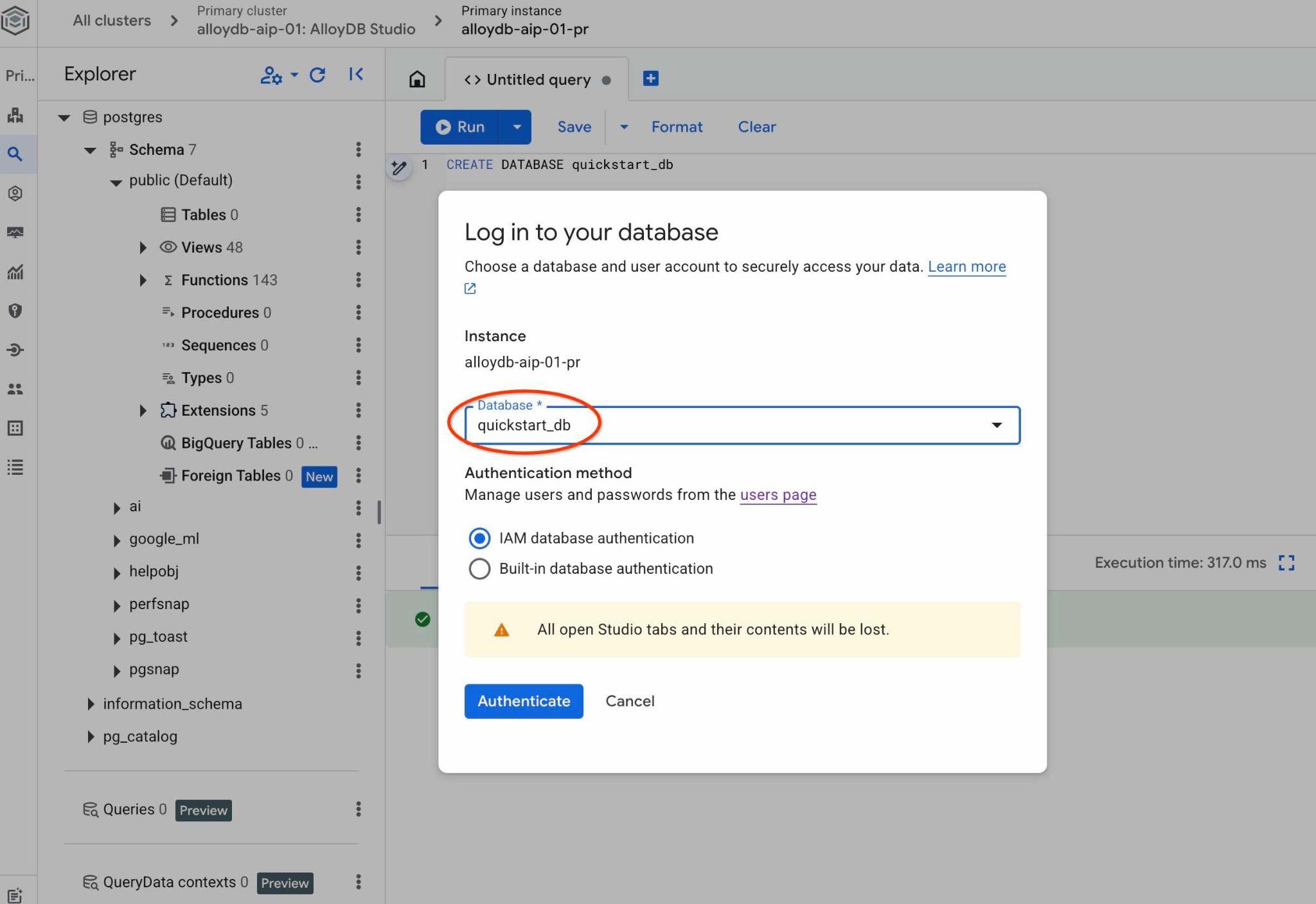
Isso vai abrir uma nova conexão em que você pode trabalhar com objetos do banco de dados quickstart_db. Lá, você poderá examinar o esquema e os dados importados e trabalhar com conjuntos de contexto QueryData.
6. Dados de amostra
Agora você precisa criar objetos no banco de dados e carregar dados. Você vai usar um conjunto de dados fictício da empresa Cymbal Shipping. Ele tem dados fictícios sobre mercadorias, caminhões, solicitações e viagens de caminhão, além de motoristas fictícios.
Criar bucket de armazenamento
Você vai usar o SDK do Google (gcloud) para importar dados do repositório clonado para o banco de dados do AlloyDB. Para isso, crie um bucket do Cloud Storage e conceda acesso à conta de serviço do AlloyDB. Como alternativa, você sempre pode tentar fazer isso usando o console da Web, conforme descrito na documentação.
No terminal do Google Cloud Shell, execute:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
Carregar dados
A próxima etapa é carregar os dados. O dump SQL compactado está localizado na pasta do repositório clonado. O comando a seguir pressupõe que você usou seu diretório principal como ponto de partida ao clonar o repositório na etapa anterior durante a criação do cluster do AlloyDB.
Copie o dump SQL compactado para o novo bucket de armazenamento:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
Em seguida, carregue os dados no banco de dados quickstart_db:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
O comando vai carregar o conjunto de dados de amostra no banco de dados quickstart_db. É possível verificar as tabelas e os registros usando o AlloyDB Studio.
7. Trabalhar com o agente de dados
Vamos começar com um exemplo de agente de IA criado usando o ADK do Google para Python e conectado à nossa instância do AlloyDB usando o MCP Toolbox for Databases.
Instalar a MCP Toolbox para bancos de dados
A MCP Toolbox for Databases é um projeto de código aberto que oferece suporte da MCP para vários mecanismos de banco de dados, incluindo o AlloyDB para PostgreSQL. Leia sobre a MCP Toolbox na documentação.
Faça o download da versão mais recente do software para sua plataforma. Para conferir a versão mais recente, acesse a página de versões. O exemplo a seguir mostra como fazer o download da versão 31 da caixa de ferramentas do MCP para o Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
É necessário preparar um arquivo de configuração para a caixa de ferramentas. Temos um arquivo tools.yaml.example de exemplo no diretório atual e vamos preparar o arquivo tools.yaml substituindo dois marcadores de posição pelo ID do projeto e pela região.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
Iniciar a MCP Toolbox para bancos de dados
Agora você pode iniciar a caixa de ferramentas do MCP com o arquivo de configuração preparado.
Abra uma nova guia no Google Cloud Shell pressionando o botão "+" na parte de cima da interface do Google Cloud Shell.
Na nova guia, mude para o diretório com o arquivo binário da caixa de ferramentas e o arquivo de configuração tools.yaml e inicie o servidor MCP.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
A saída vai mostrar "Server ready to serve!" (Servidor pronto para atender!), semelhante a isto.
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
Verificar o código-fonte do agente
Na primeira guia da pasta do repositório clonado, analise o código do agente usando o editor do Google Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
No agente, há uma seção para o servidor MCP do Google Cloud para o AlloyDB. Fornecemos um endpoint como MCP_SERVER_URL, autenticação, ID do projeto e adicionamos ao conjunto de ferramentas do MCP.
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
No código do agente, o conjunto de ferramentas do MCP é incluído como parâmetro tools. Também há nomes de cluster e instância, a região e o banco de dados como variáveis para o comando do agente.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
Depois de examinar o código, volte ao terminal pressionando o botão "Abrir terminal" no canto superior direito da janela do editor.
Iniciar o agente
Agora você pode iniciar o agente no modo interativo usando a interface da web do ADK do Google. A interface da Web do ADK oferece uma maneira conveniente de testar e resolver problemas nos fluxos de trabalho dos agentes.
Primeiro, vamos instalar todos os pacotes necessários para Python usando o gerenciador de pacotes uv.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
Quando todos os pacotes estiverem instalados, adicione um arquivo .env ao diretório do agente para direcioná-lo a usar a Vertex AI em todas as comunicações com os modelos de IA.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
Em seguida, você pode iniciar o agente
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Você vai ver uma saída como esta, com o endpoint http://127.0.0.1:8000 .
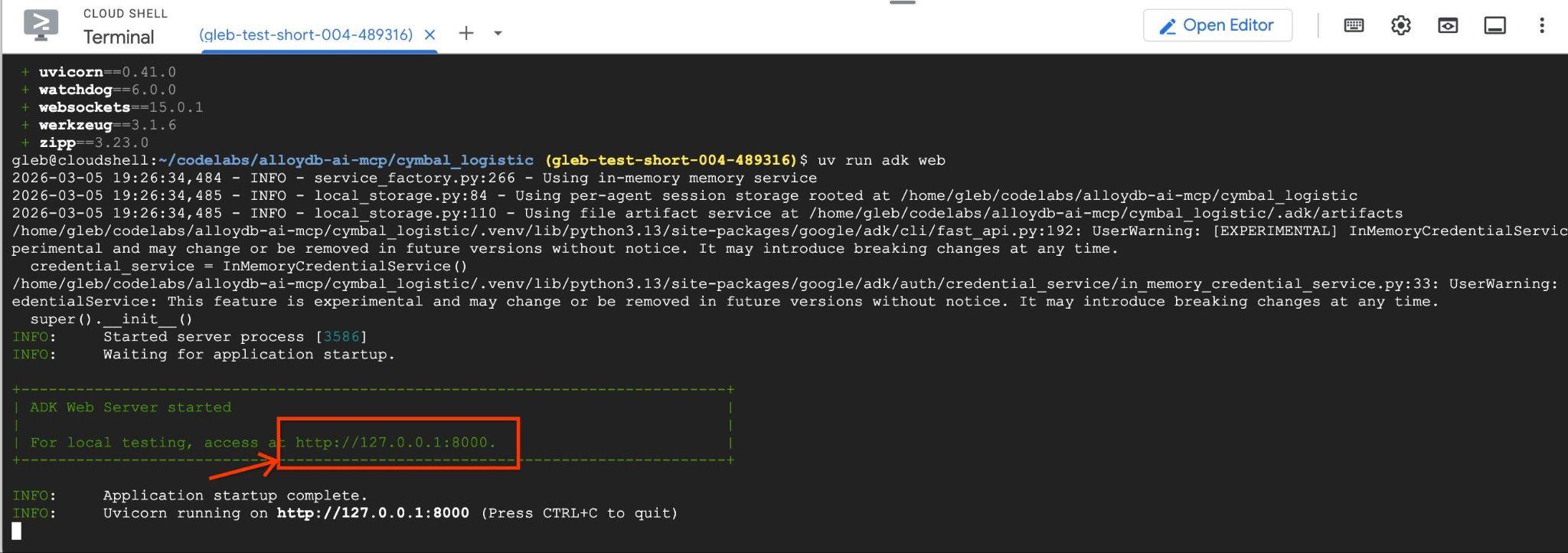
Clique no URL no Cloud Shell para abrir uma janela de visualização em outra guia do navegador. Nela, escolha o data_agent na lista suspensa à esquerda.
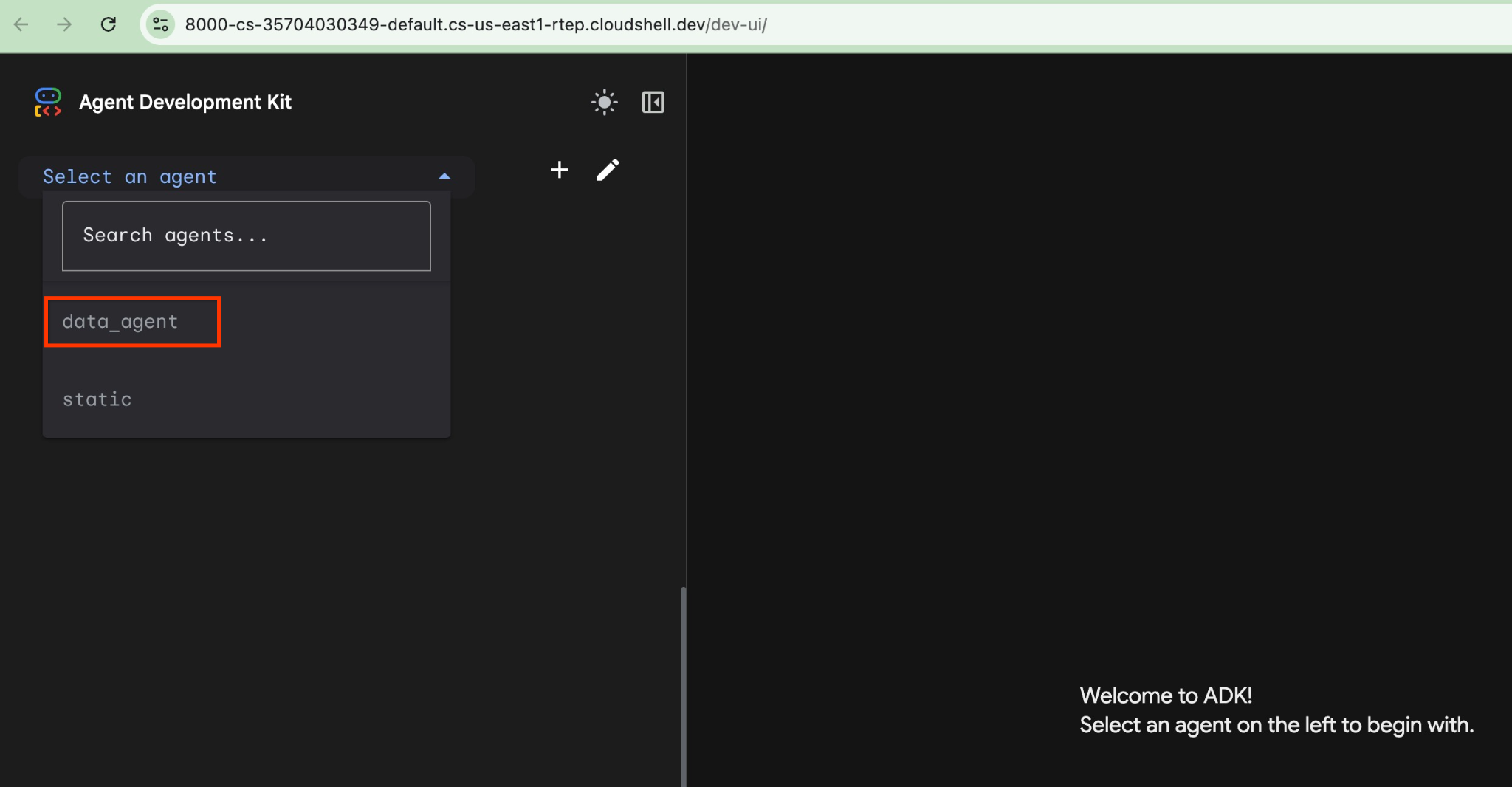
Na interface da Web do ADK, você pode postar suas perguntas no canto inferior direito e conferir o fluxo de execução completo, incluindo os rastreamentos de cada etapa no lado direito.
8. Testar o NL2SQL sem o QueryData para AlloyDB
Com ele, você pode fazer perguntas em formato livre usando linguagem natural, e o agente usa a caixa de ferramentas do MCP para bancos de dados como ferramenta para responder. As perguntas são postadas na parte de baixo à direita, e a resposta com todas as chamadas para as ferramentas aparece na parte de cima.
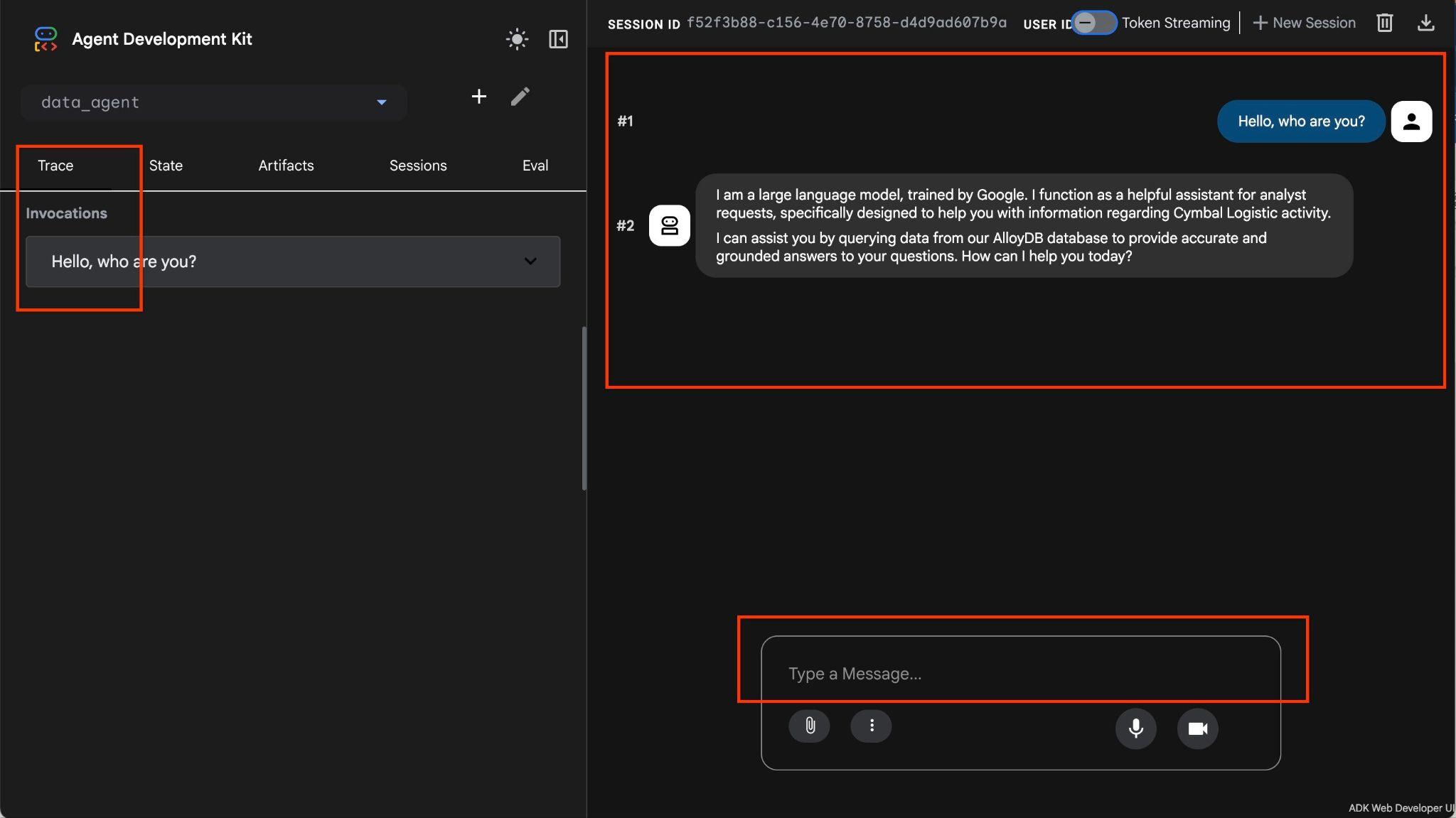
Você está trabalhando com dados operacionais de uma empresa de transporte que tem informações sobre solicitações de envio, caminhões, motoristas e viagens feitas por eles. A primeira pergunta é sobre o número de viagens realizadas em fevereiro de 2026.
No campo de entrada na parte inferior direita, digite o seguinte e pressione Enter.
Hello, can you tell me how many trips we've done in February?
O agente vai executar várias chamadas de ferramentas para identificar as tabelas certas no esquema usando list_cymbal_logistics_schemas_tool e execute_sql_tool, executando várias instruções SQL para receber os dados corretos.
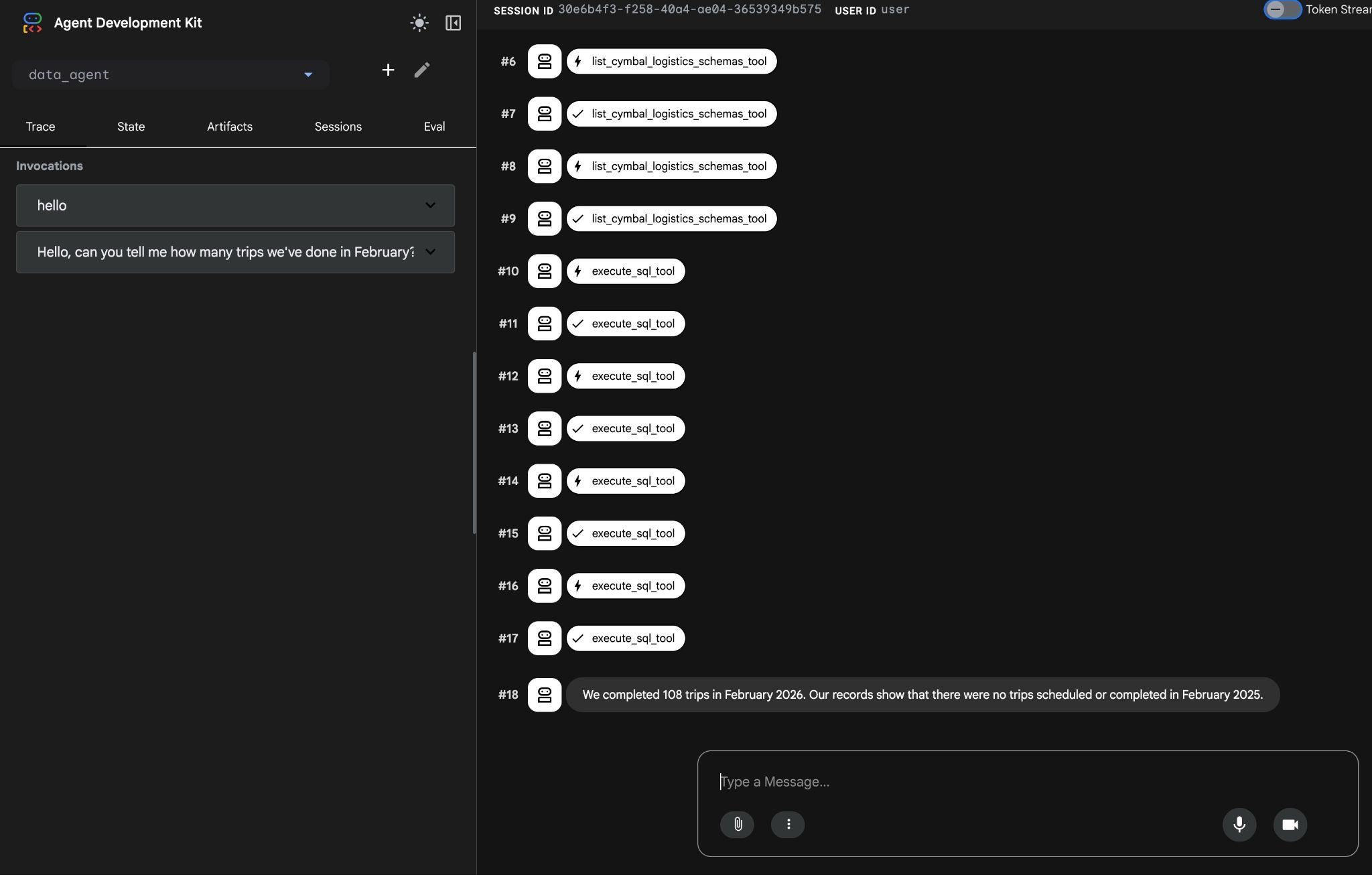
Eventualmente, ele vai produzir o resultado correto depois de criar e executar a consulta adequada no banco de dados.
Concluímos 108 viagens em fevereiro de 2026. Nossos registros mostram que não houve viagens programadas ou concluídas em fevereiro de 2025.
Para saber o que cada chamada de ferramenta faz, clique na execução dela. Por exemplo, esta é a consulta executada para receber nossos resultados.
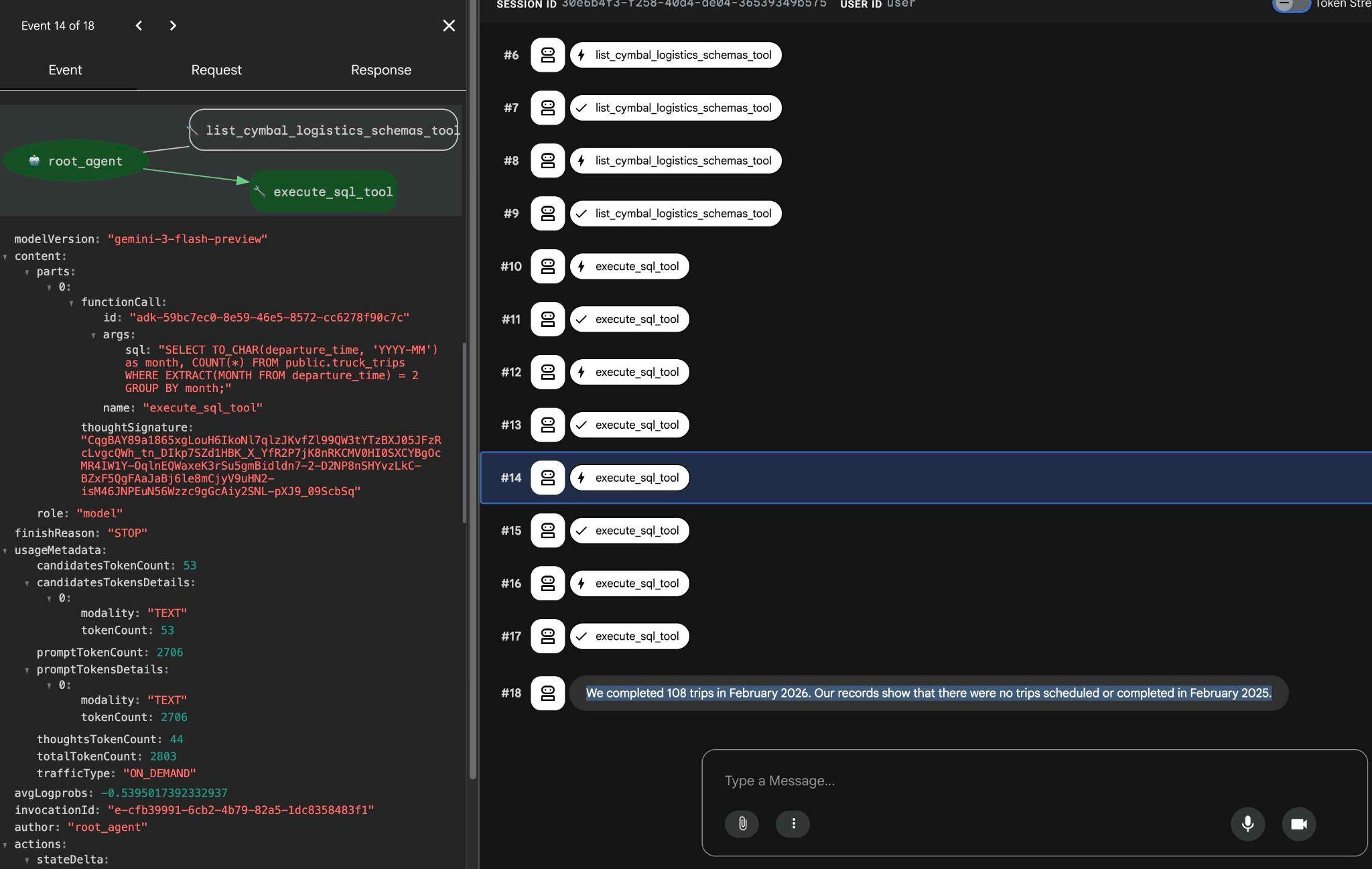
Tente outros comandos simples usando a interface da Web do ADK e veja como ele executa diferentes consultas para alcançar os resultados.
Interrompa o agente pressionando ctrl+c no terminal. Você pode fechar a guia do navegador com a interface da Web do ADK.
Você também pode interromper a caixa de ferramentas do MCP na segunda guia pressionando o mesmo atalho de teclas ctrl+c e fechar a segunda guia.
Na próxima etapa, vamos criar o contexto QueryData para melhorar a resposta e a performance do NL2SQL.
9. Criar um ContextSet do QueryData
Na etapa anterior, você viu que o modelo de IA estava fazendo várias chamadas ao esquema de informações do banco de dados para descobrir qual tabela e quais colunas usar para criar a consulta SQL. Para melhorar a performance, a acurácia e tornar o resultado mais previsível, vamos adicionar seu contexto QueryData, definindo qual consulta deve ser executada em resposta a uma determinada solicitação.
Criar modelos segmentados
O ContextSet QueryData é um arquivo JSON com modelos de consulta e facetas que fornecem os dados e as instruções necessários para que o modelo de IA use a consulta SQL ou partes dela corretas para alcançar as metas solicitadas com base em padrões de consulta e estrutura de dados.
Você começa com um modelo segmentado. Crie um arquivo usando um editor do Cloud Shell. No terminal do Cloud Shell, execute:
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
Insira o modelo da consulta em linguagem natural que usamos no capítulo anterior: "Quantas viagens fizemos em fevereiro?"
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
Em seguida, baixe o modelo para seu computador no Cloud Shell usando o botão de download.
Carregar conjuntos de contexto do QueryData
Para usar nossos conjuntos de contexto do QueryData, precisamos fazer upload deles para nosso banco de dados.
Abra o AlloyDB Studio. No painel esquerdo, na parte de baixo, você vai encontrar QueryData Context e três pontos.
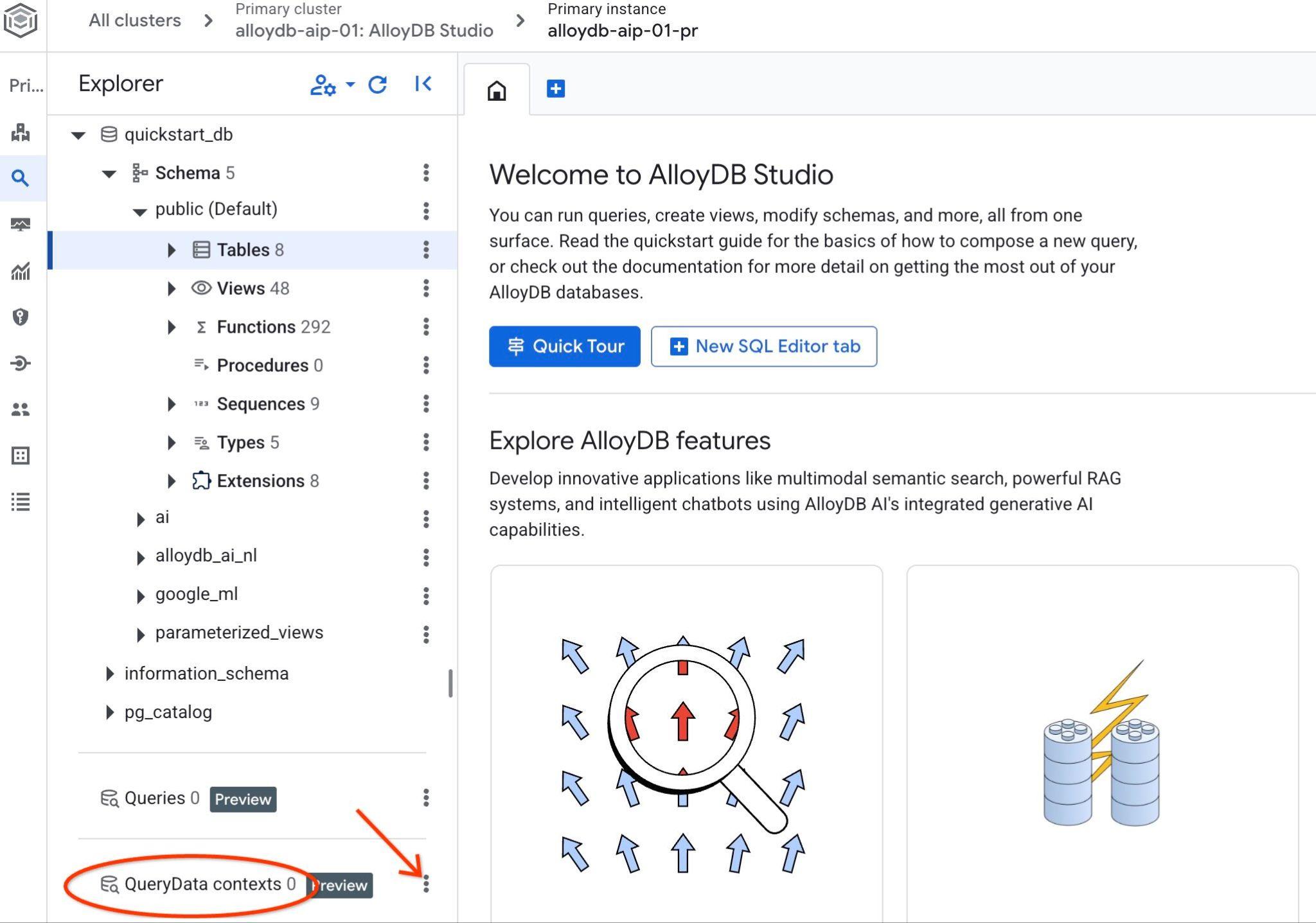
Clique nos três pontos e escolha "Criar contexto". Uma caixa de diálogo será aberta para você inserir
- Nome:
cymbal_context_set - Descrição:
Cymbal Logistic Query Data - Fazer upload do arquivo de contexto: clique no botão "
Browse" e escolha o arquivo JSON com o ContextSet QueryData.
Ao pressionar o botão de salvar, pode levar algum tempo para inicializar o armazenamento de contexto se você estiver fazendo isso pela primeira vez.
Você vai conseguir ver o contexto baixado. Clique nos três botões verticais à direita para conferir as ações disponíveis. No próximo capítulo, vamos começar com a ação "Contexto de teste".
10. Testar o conjunto de contextos do QueryData
Modelo de teste
Use a ação "Test context" para testar nosso contexto no AlloyDB Studio. Ao clicar em "Test context", uma nova janela do editor do AlloyDB Studio será aberta com o título "cymbal_context_set" e o convite para a geração de SQL do Gemini, intitulado "Generate SQL using QueryData context: cymbal_context_set ". Clique na geração de SQL e digite
Hello, can you tell me how many trips we've done in February?
Quando o SQL gerado aparecer, pressione o botão Insert.
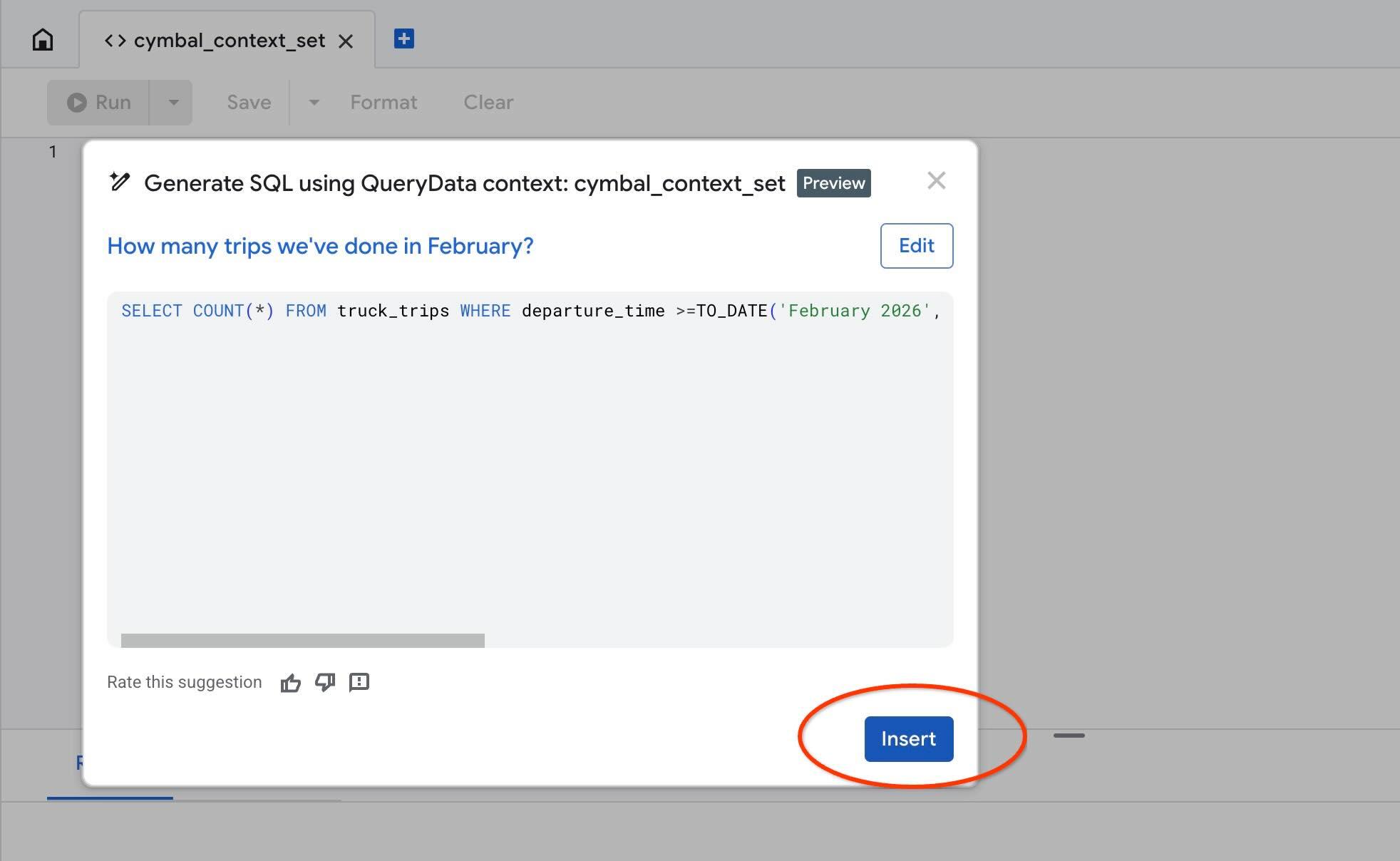
Você vai ver exatamente a mesma consulta que fizemos ao nosso modelo de contexto antes.
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
Tente substituir o mês por "janeiro" e confira a instrução SQL gerada. Ele vai usar o mês como parâmetro para a intent parametrizada e ajustar automaticamente a instrução SQL.
Criar facetas QueryData
Testamos um modelo para uma consulta, e ele funciona quando sabemos que tipo de solicitação do usuário esperamos. Mas às vezes é útil orientar apenas uma parte de uma consulta, como condição ou filtro, quando preferimos que uma determinada ordem ou cláusula seja usada para uma intenção redefinida.
Por exemplo, se pedirmos para retornar dados do "mês passado", queremos receber o relatório do último mês civil, do dia 1º ao último dia desse mês, e não dos últimos 30 dias.
Podemos adicionar essas facetas como um snippet SQL à configuração do ContextSet junto com o modelo adicionado anteriormente. Abra o arquivo querydata_cymbal_contextset.json.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
E adicione as facetas depois dos modelos já existentes. O conteúdo resultante no arquivo deve ser o seguinte
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
Salve o arquivo e faça upload dele no seu computador.
Em seguida, use a ação de contexto de consulta "Editar contexto" e faça upload do arquivo modificado para substituir o conjunto de contexto antigo pelo novo.
Agora tente usar o contexto de teste novamente e gere uma instrução SQL usando a intenção "mês passado". Por exemplo, se você gerar um SQL para a frase "show trucks trips for the last month"", ele usará a condição que fornecemos como um aspecto no arquivo cymbal_context.json.
Você vai receber algo parecido com isto:
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
Agora, como você pode usar com os agentes de IA? No próximo capítulo, vamos disponibilizar o contexto "Consultar dados" para os agentes de IA.
11. QueryData com agentes de IA
Você vai usar o mesmo agente de dados, mas agora a caixa de ferramentas do MCP será configurada para usar o QueryData ContextSet.
Preparar e iniciar a MCP Toolbox para bancos de dados
Precisamos de um novo arquivo de configuração para a MCP Toolbox, que vai usar a API Gemini Data Analytics e o AlloyDB como fonte de banco de dados.
Execute no terminal:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
Mude para o editor e encontre o arquivo querydata.yaml. O arquivo de configuração querydata.yaml seria semelhante ao seguinte, exceto pelo ID do projeto e pela região, que refletirão seu ambiente. No entanto, ainda é necessário atualizar o valor contextSetId e substituir o marcador de posição "<add-context-set-id>" pelo valor do console.
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
Para encontrar o ID do ContextSet, clique no botão de edição do conjunto de contexto, conforme mostrado na imagem.
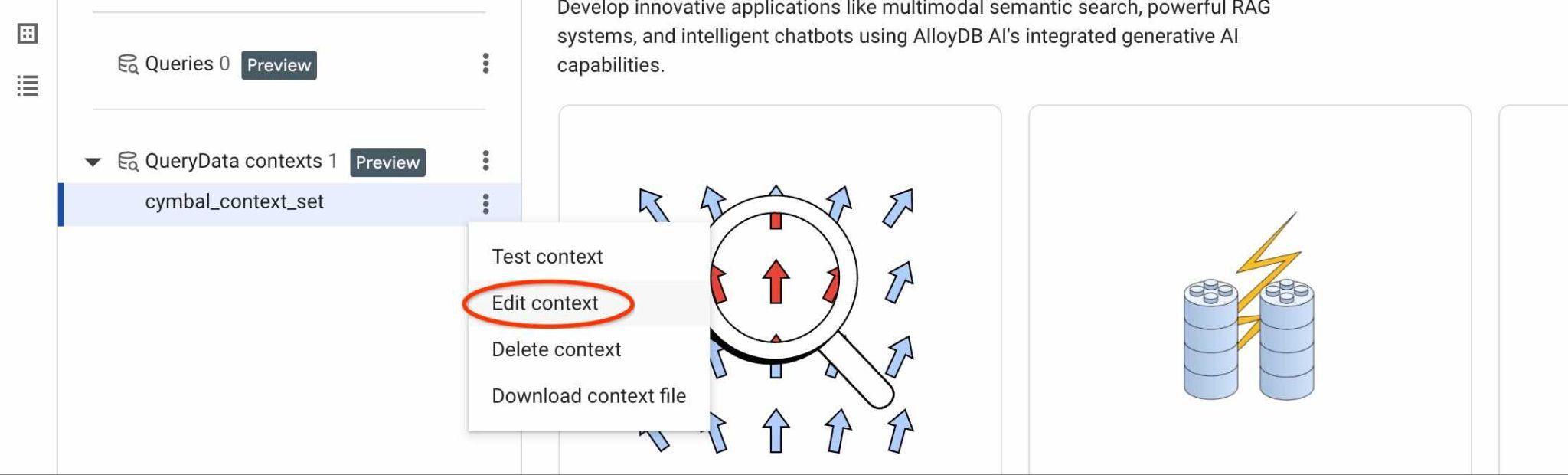
O ID do conjunto de contexto vai aparecer na parte de cima da nova guia à direita.
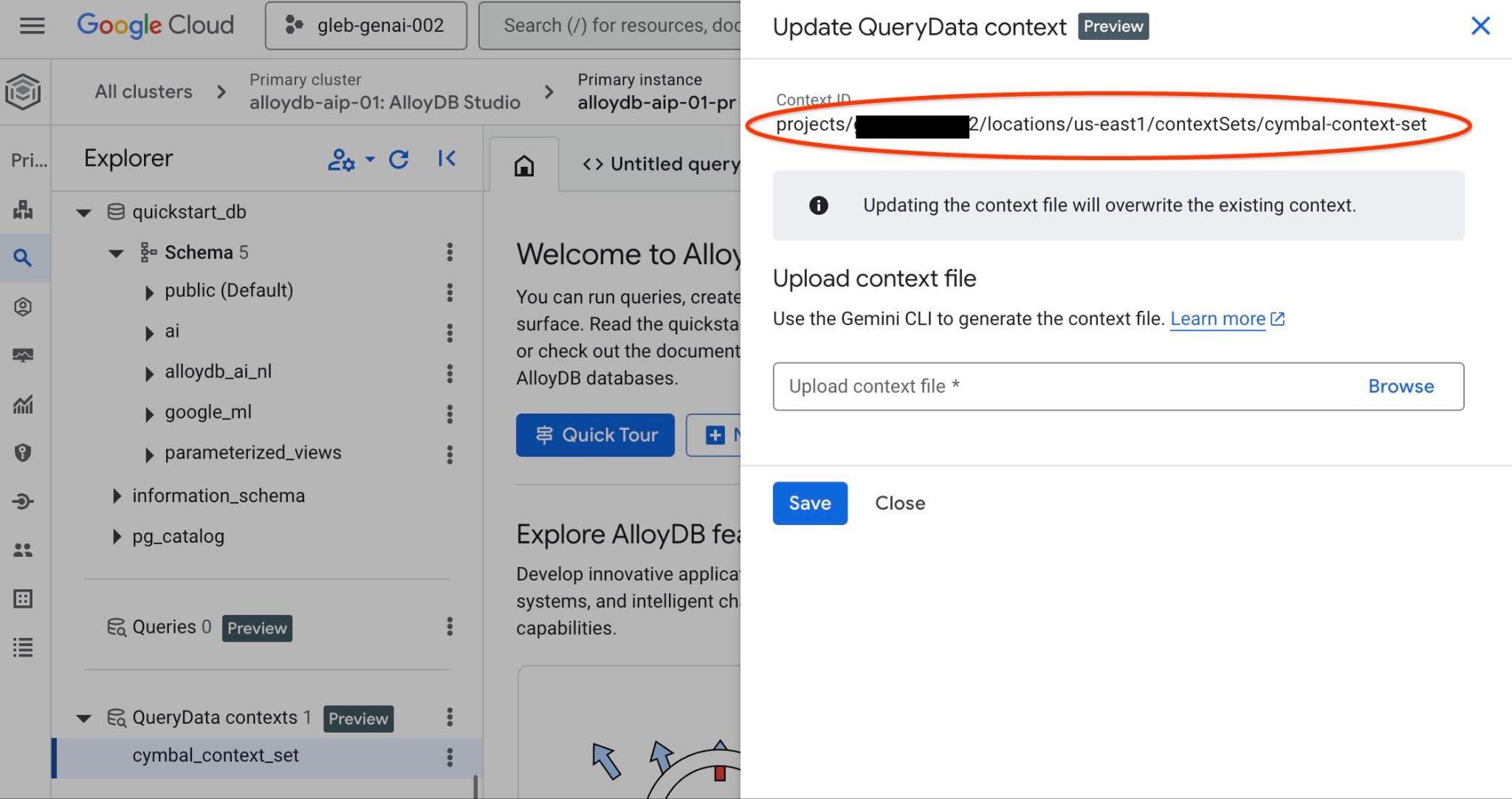
Esse caminho completo deve ser colocado para substituir o marcador de posição "<add-context-set-id>" no arquivo querydata.yaml.
Volte para o terminal.
Abra uma nova guia no Google Cloud Shell pressionando o botão "+" na parte de cima da interface do Google Cloud Shell.
Na nova guia, mude para o diretório com o arquivo binário da caixa de ferramentas e o arquivo de configuração tools.yaml e inicie o servidor MCP.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
Executar o agente do ADK
Na primeira guia do Cloud Shell, inicie o agente.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Quando ele for iniciado, clique novamente no link http://127.0.0.1:8000 .
Você vai ver a interface do agente de prévia da Web do ADK, que já é conhecida. Publique exatamente a mesma consulta da última vez.
Hello, can you tell me how many trips we've done in February?
e confira o fluxo de trabalho do agente. Se tudo estiver configurado corretamente, você verá algo como o seguinte.
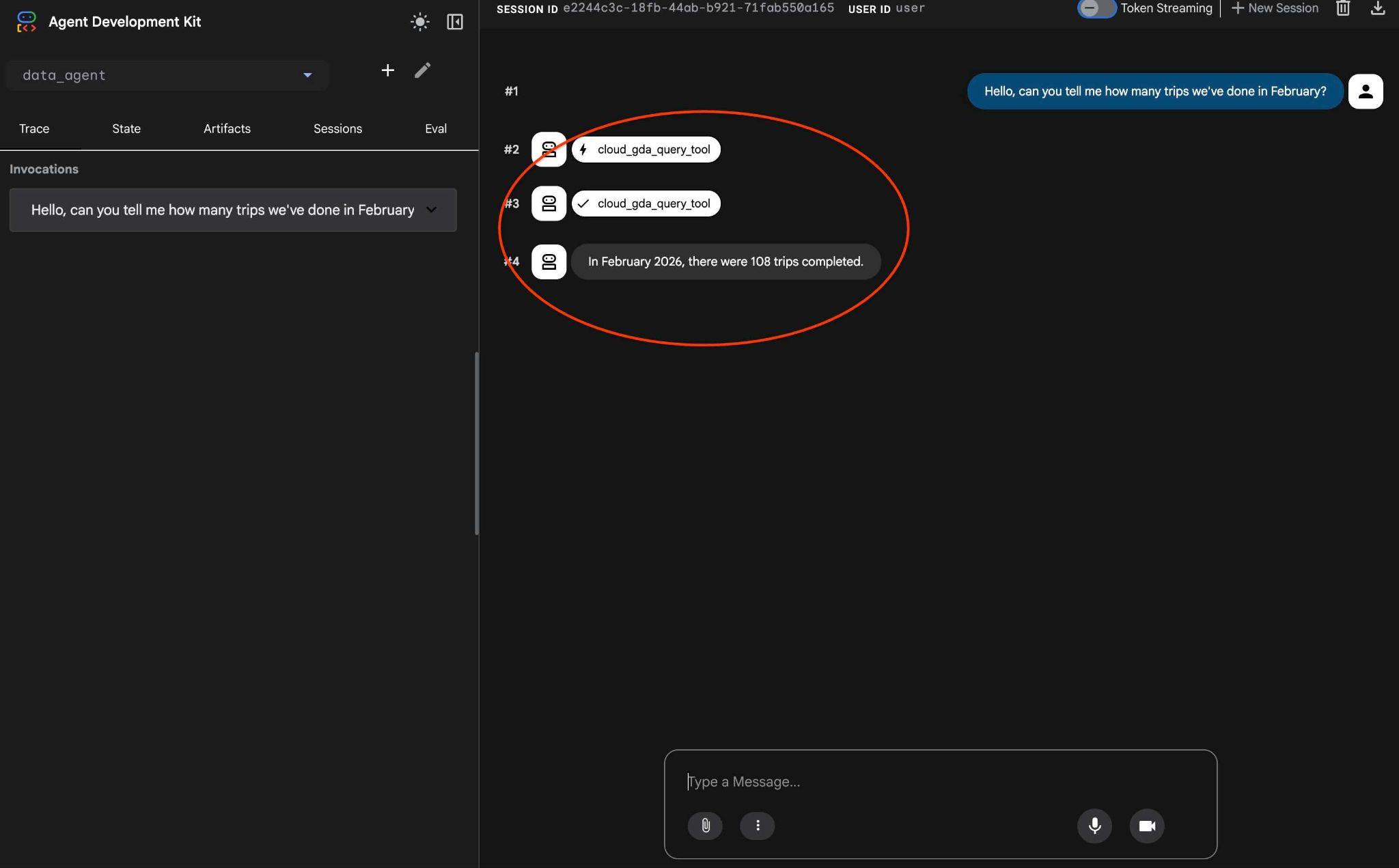
A solicitação que levou várias rodadas da última vez foi transformada em uma chamada para a ferramenta MCP e executada usando instruções SQL previsíveis.
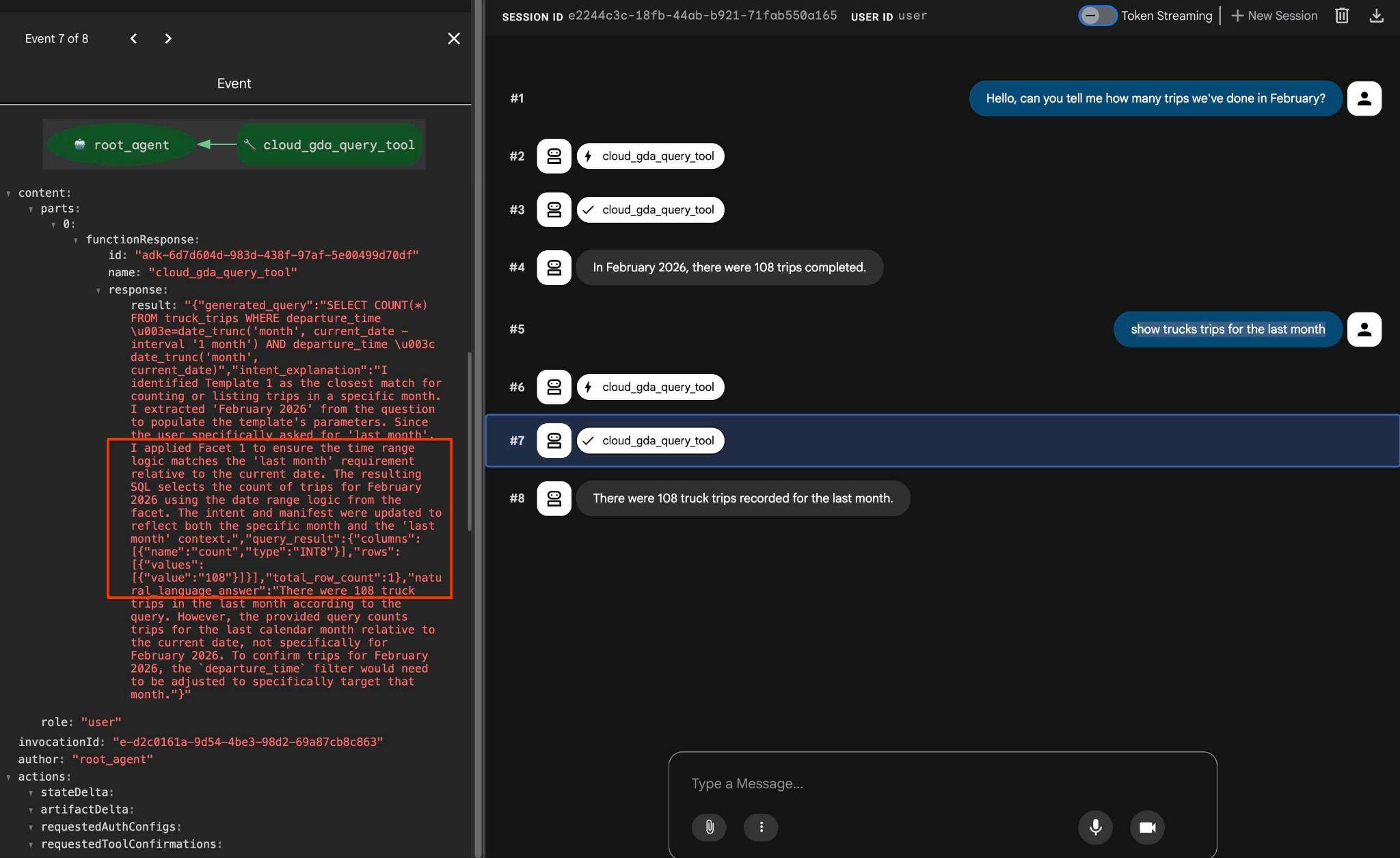
É possível testar as facetas configuradas usando a solicitação como
how trucks trips for the last month
E na saída, se você clicar na ação da ferramenta, vai ver que ela usou a mesma ferramenta e aplicou facetas para chegar ao resultado.
Isso conclui o laboratório. Espero que você tenha conseguido conferir todos os exemplos e aprender a usar o QueryData para AlloyDB. A tecnologia fornecida ajuda a tornar sua carga de trabalho de agente e a geração de SQL previsíveis e confiáveis.
12. Limpar o ambiente
Para evitar cobranças inesperadas, é recomendável limpar os recursos temporários. A maneira mais confiável é excluir o projeto em que você estava testando o fluxo de trabalho. Mas, se quiser, você pode se limitar excluindo recursos individuais, como o AlloyDB.
Destrua as instâncias e o cluster do AlloyDB quando terminar o laboratório.
Excluir o cluster do AlloyDB e todas as instâncias
Se você usou a versão de teste do AlloyDB. Não exclua o cluster de teste se você planeja testar outros laboratórios e recursos usando esse cluster. Não será possível criar outro cluster de teste no mesmo projeto.
O cluster é destruído com a opção "force" que também exclui todas as instâncias pertencentes.
No Cloud Shell, defina o projeto e as variáveis de ambiente se tiver ocorrido uma desconexão e todas as configurações anteriores forem perdidas:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Exclua o cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Excluir backups do AlloyDB
Exclua todos os backups do AlloyDB do cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
13. Parabéns
Parabéns por concluir o codelab.
O que vimos
- Como criar um cluster do AlloyDB e importar dados de amostra
- Como ativar a API de acesso aos dados do AlloyDB
- Como ativar o QueryData para o AlloyDB
- Como gerar modelos
- Como usar a pesquisa refinada
- Como usar o QueryData com agentes de IA
14. Pesquisa
Saída: