
1. Введение
Этот практический пример покажет, как начать работу с QueryData для AlloyDB и использовать его для генерации точных и предсказуемых SQL-запросов на основе входных данных на естественном языке в агентных приложениях.
Предварительные требования
- Базовое понимание консоли Google Cloud.
- Базовые навыки работы с командной строкой и Cloud Shell.
Что вы узнаете
- Как создать кластер AlloyDB и импортировать тестовые данные
- Как включить API доступа к данным AlloyDB
- Как включить QueryData для AlloyDB
- Как создавать шаблоны
- Как использовать фасетный поиск
- Как использовать QueryData с агентами искусственного интеллекта
Что вам понадобится
- Аккаунт Google Cloud и проект Google Cloud
- Веб-браузер, такой как Chrome , поддерживающий консоль Google Cloud и Cloud Shell.
2. Настройка и требования
Настройка проекта
Создайте проект в Google Cloud.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud .
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:
В качестве альтернативы вы можете нажать G, а затем S. Эта последовательность активирует Cloud Shell, если вы находитесь в консоли Google Cloud, или воспользуйтесь этой ссылкой .
Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
3. Прежде чем начать
Включить API
Для использования AlloyDB , Compute Engine , сетевых сервисов и Vertex AI необходимо включить соответствующие API в вашем проекте Google Cloud.
В терминале Cloud Shell убедитесь, что идентификатор вашего проекта указан правильно:
gcloud config get-value project
В выходных данных вы должны увидеть идентификатор вашего проекта (tID):
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
Установите переменную среды PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Включите все необходимые службы:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Ожидаемый результат
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Развертывание AlloyDB
Создайте кластер AlloyDB и основной экземпляр. Вы можете развернуть его либо с помощью готового скрипта, который развернет все необходимые ресурсы, либо сделать это пошагово самостоятельно, следуя документации .
Развертывание AlloyDB с помощью автоматизированного скрипта
Данный подход использует автоматизированный скрипт для развертывания кластера AlloyDB и предоставления необходимой информации для начала работы с развернутыми ресурсами.
В терминале Cloud Shell выполните команду для клонирования скрипта развертывания из репозитория.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
Запустите скрипт развертывания.
./deploy_alloydb.sh --public-ip
Выполнение скрипта займет некоторое время — обычно около 5-7 минут — и развернет кластер AlloyDB и основной экземпляр с публичным и частным IP-адресами. Публичный IP-адрес доступен только для авторизованных сетей или через прокси-сервер аутентификации AlloyDB. Подробнее о публичном IP-адресе можно прочитать в документации . В качестве результата скрипт должен предоставить информацию о развернутом кластере AlloyDB. Обратите внимание, что ваш пароль будет другим — запишите его где-нибудь для дальнейшего использования .
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
А новый кластер и основной экземпляр можно увидеть в веб- консоли.
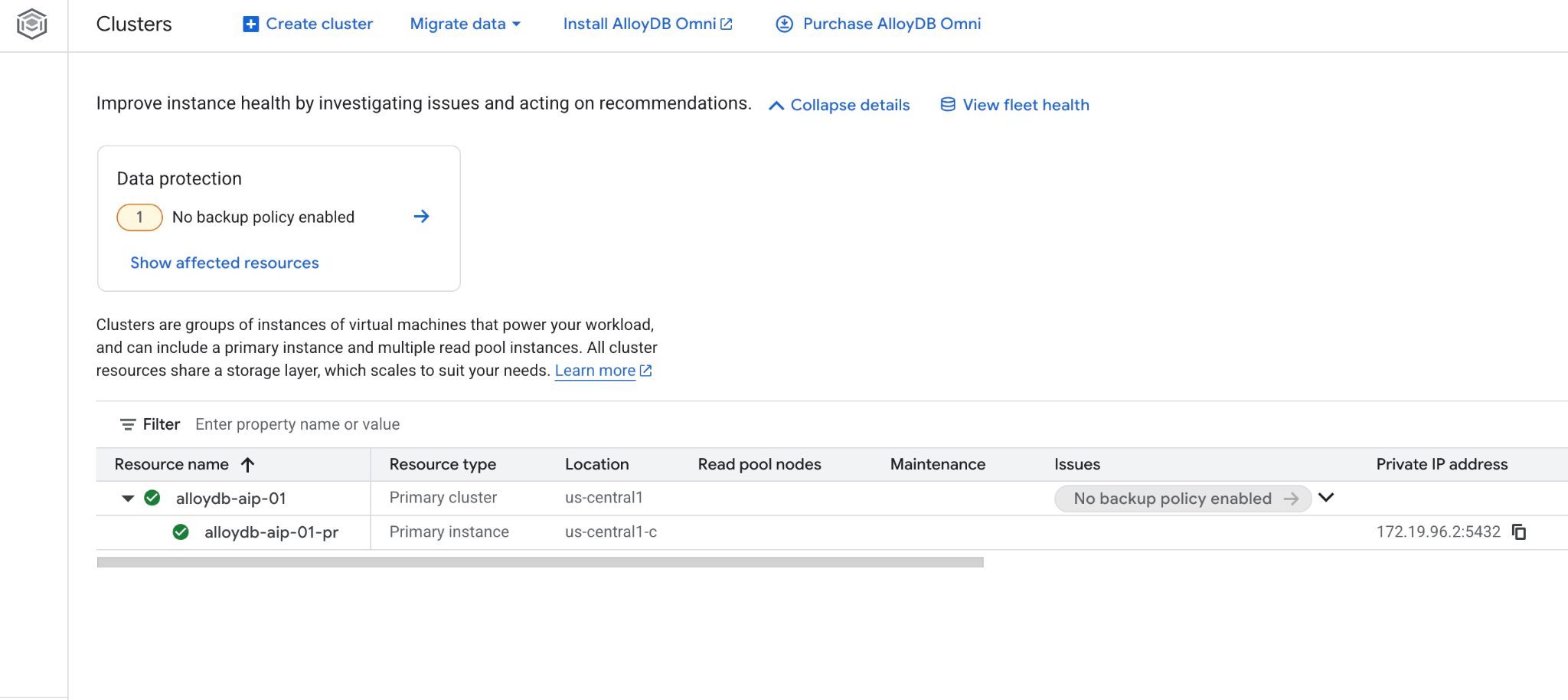
5. Подготовка базы данных
Для использования функций и операторов ИИ необходимо включить интеграцию с Vertex AI, активировать API доступа к данным и создать базу данных для тестового набора данных.
Предоставьте необходимые разрешения AlloyDB
Добавьте разрешения Vertex AI для агента службы AlloyDB.
Откройте еще одну вкладку Cloud Shell, используя знак "+" вверху.
В новой вкладке облачной оболочки выполните:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Включить API доступа к данным
Для использования инструментов MCP, таких как execute_sql , необходимо включить API доступа к данным в кластере AlloyDB.
В той же вкладке терминала выполните команду.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
Включить аутентификацию IAM
Для работы с инструментами Agentic мы будем использовать аутентификацию IAM, и для этого необходимо включить аутентификацию IAM на экземпляре и добавить себя в качестве пользователя базы данных. Прежде чем включать аутентификацию IAM на уровне экземпляра, пожалуйста, дождитесь завершения предыдущего шага — включения доступа к данным через API. Статус вашего экземпляра должен быть зеленым.
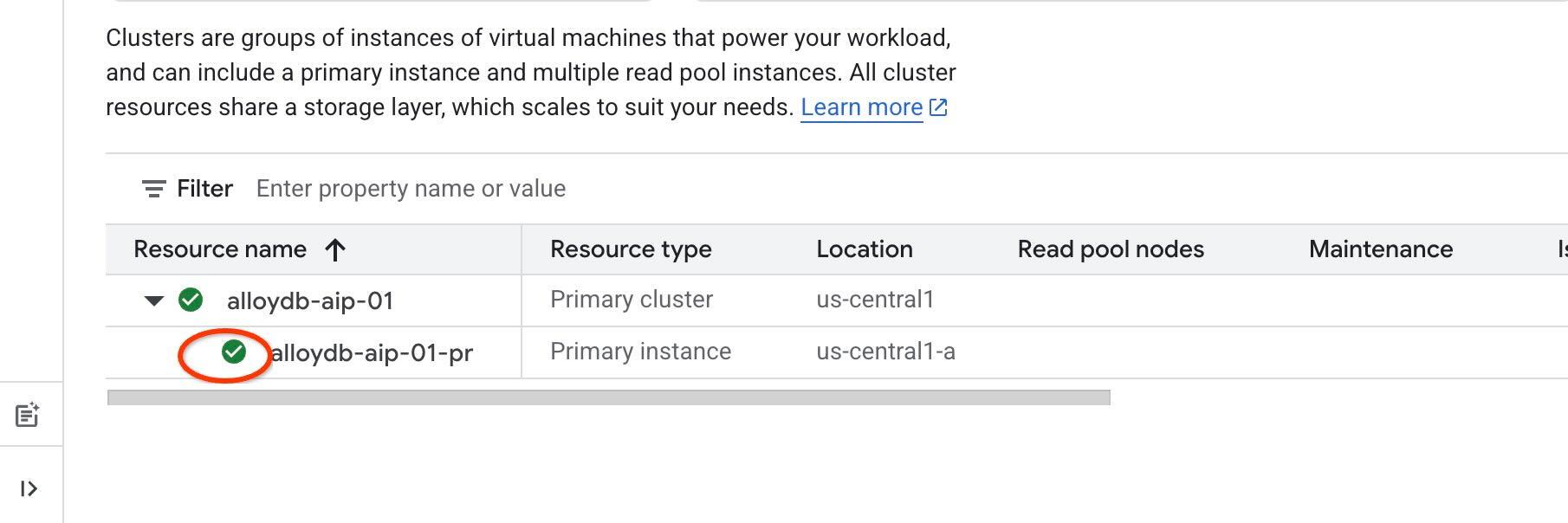
Начнём с включения IAM на уровне экземпляра. В той же вкладке терминала выполните команду.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Добавьте себя в качестве пользователя AlloyDB:
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
Закройте вкладку, выполнив одну из команд, указанных на вкладке, например, «Выход»:
exit
Подключитесь к AlloyDB Studio
В следующих главах все команды SQL, требующие подключения к базе данных, можно выполнить в AlloyDB Studio.
Перейдите на страницу «Кластеры» в AlloyDB для Postgres .
Откройте веб-консоль вашего кластера AlloyDB, щелкнув по основному экземпляру.
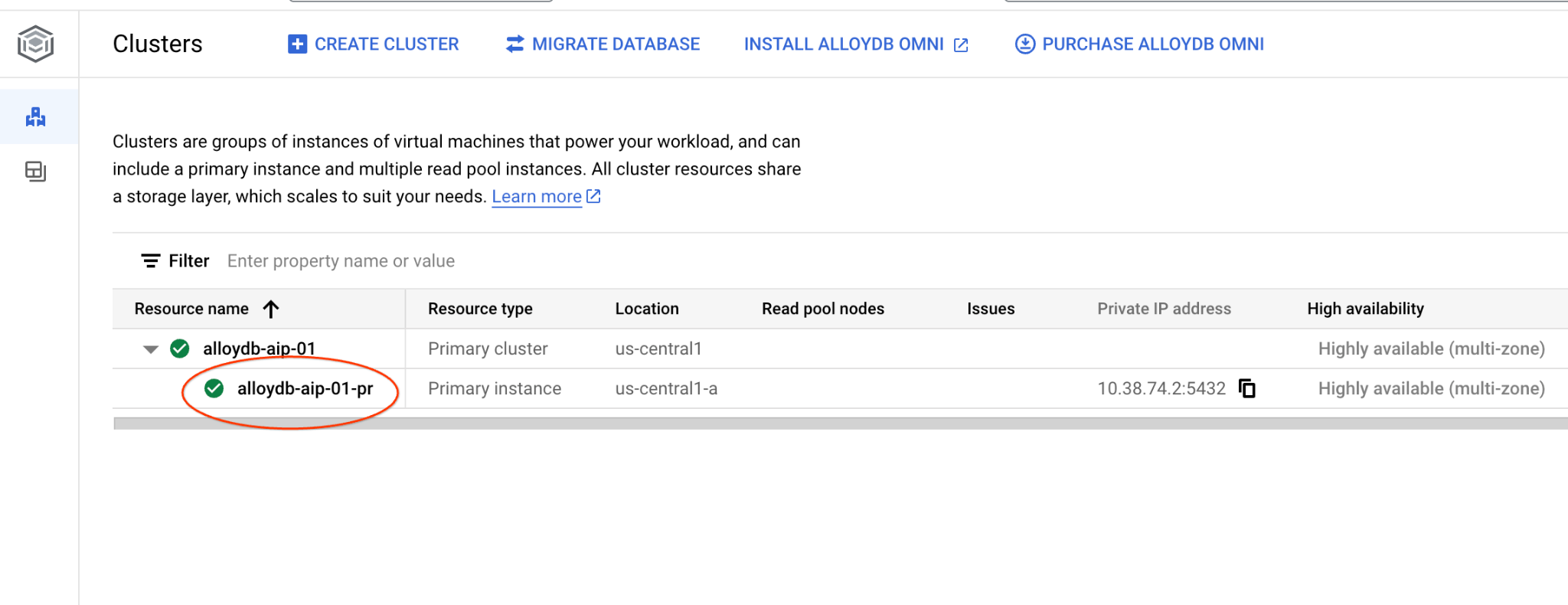
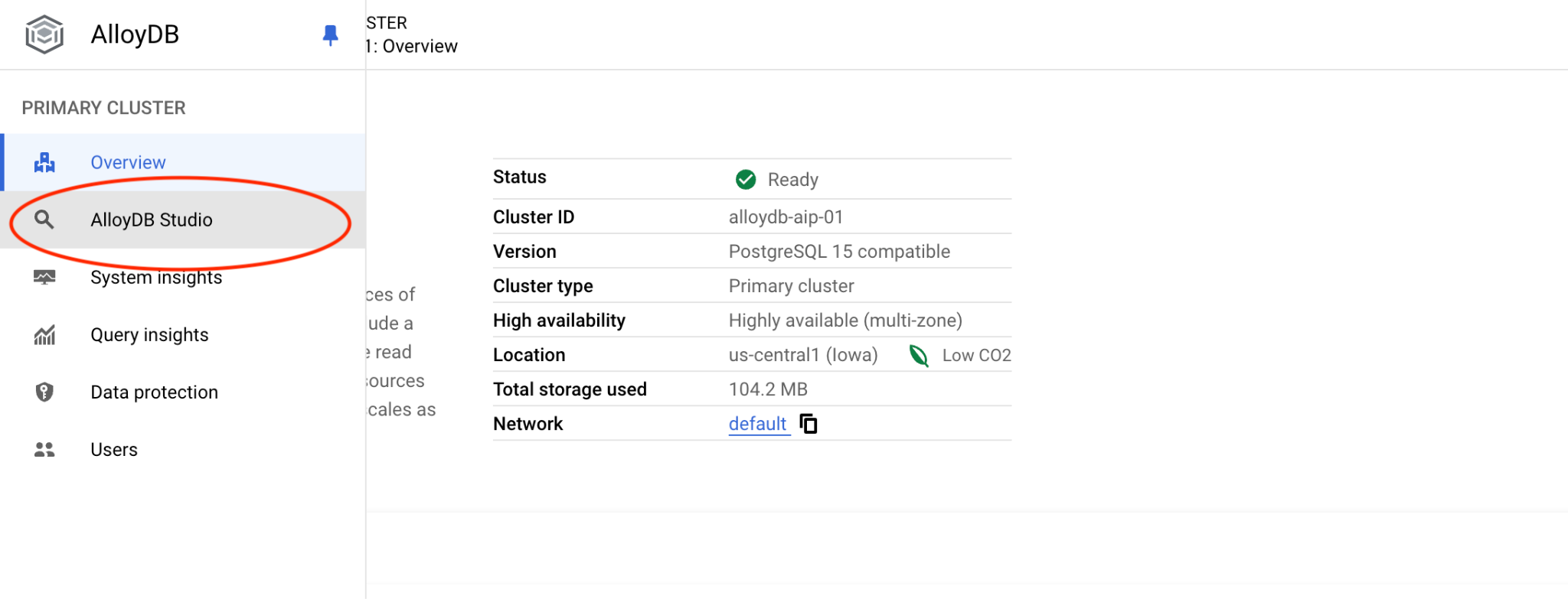
Затем нажмите на AlloyDB Studio слева:
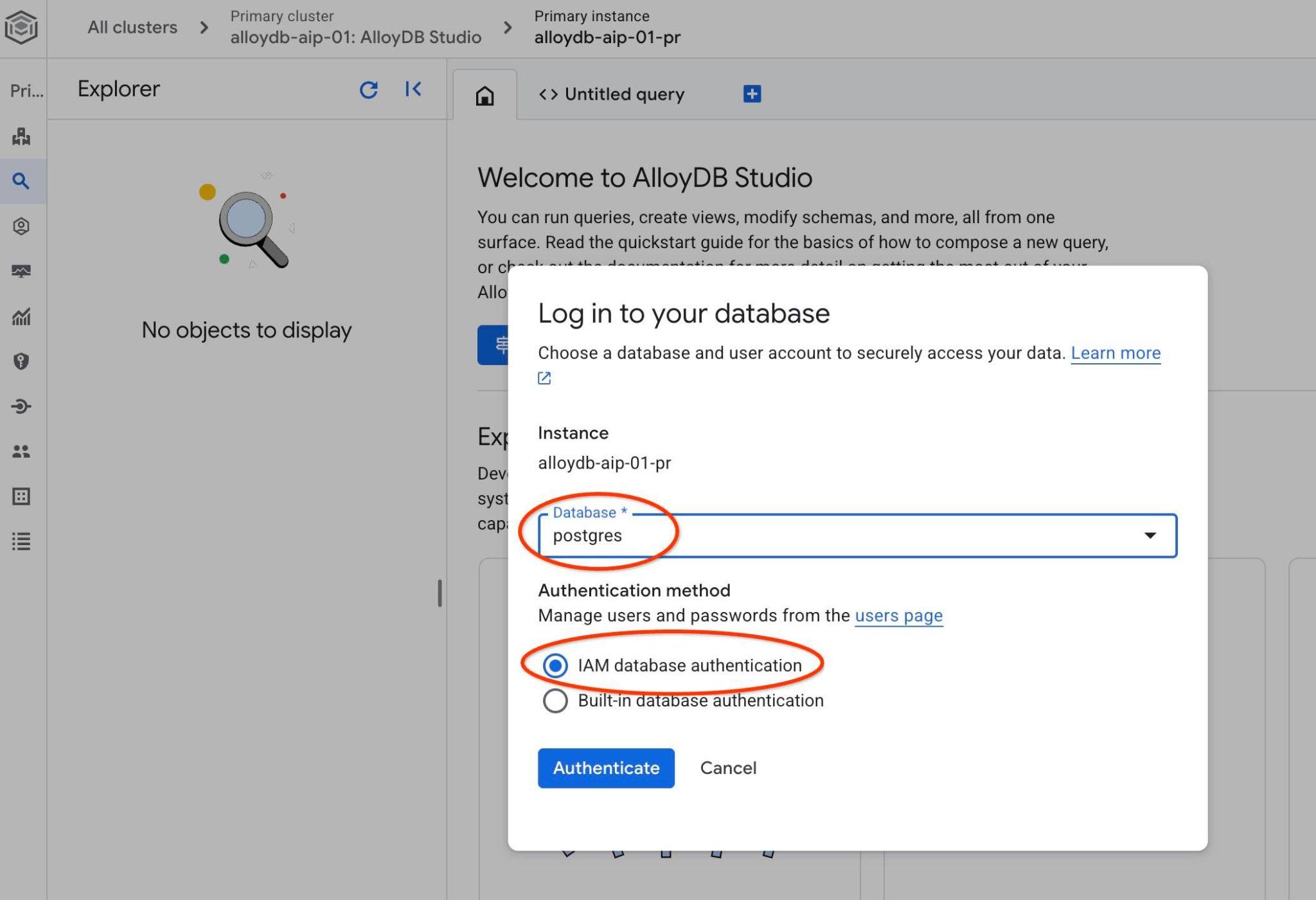
Выберите базу данных PostgreSQL и аутентификацию IAM. Затем нажмите кнопку «Аутентифицировать».
Откроется интерфейс AlloyDB Studio. Чтобы выполнить команды в базе данных, щелкните вкладку "Untitled Query" справа.
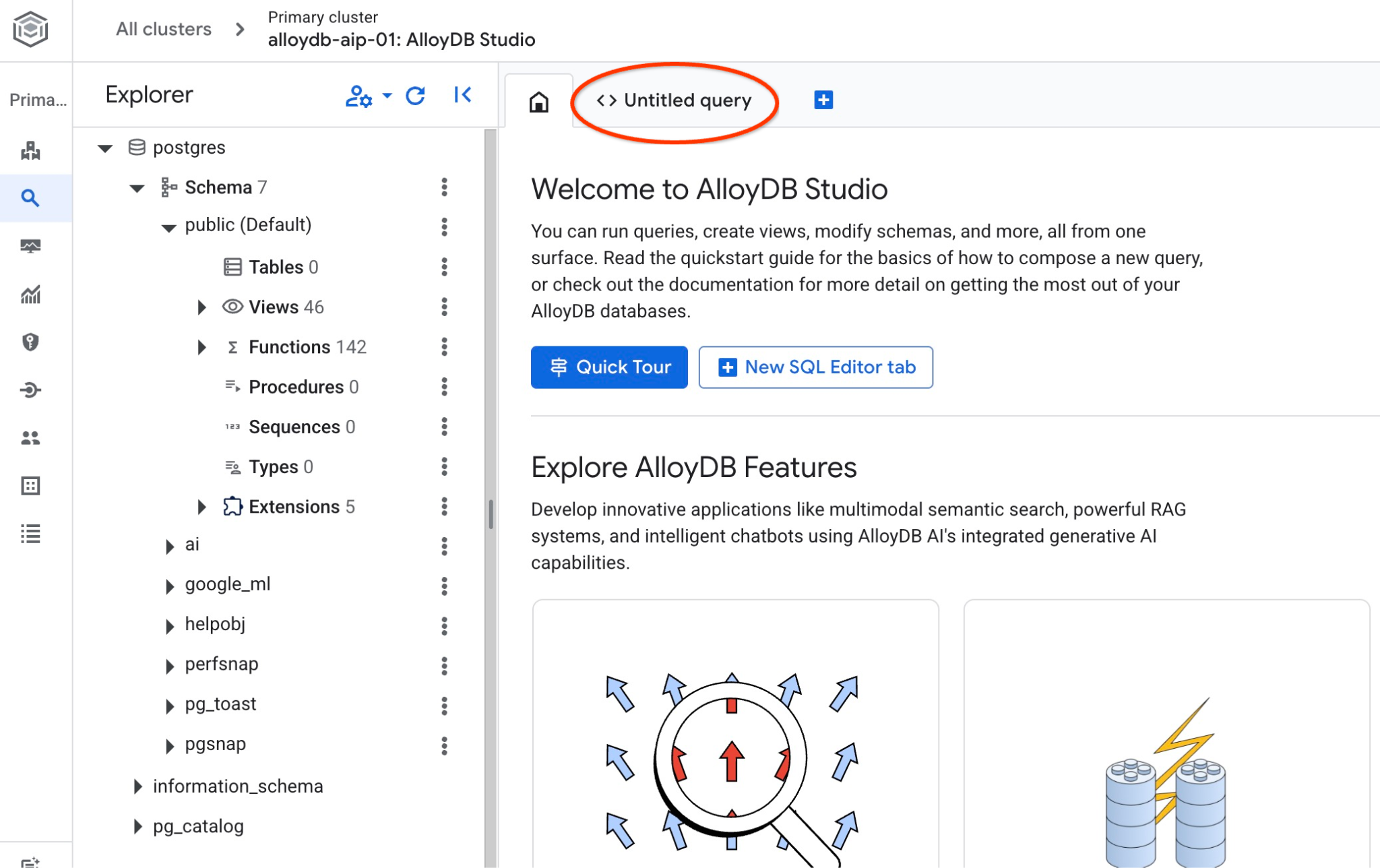
Открывается интерфейс, в котором можно выполнять команды SQL.
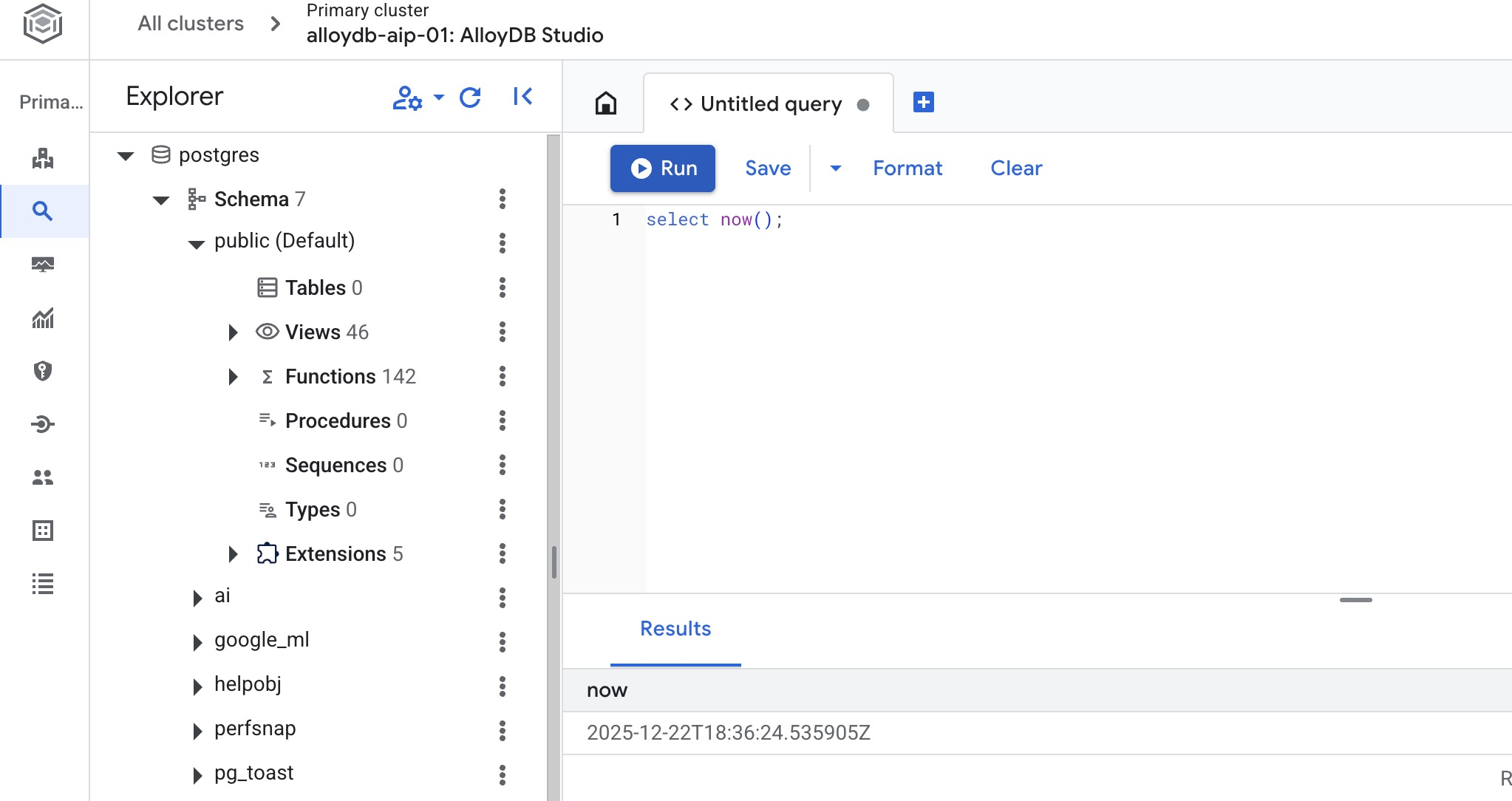
Создать базу данных
Быстрый старт создания базы данных.
В редакторе AlloyDB Studio выполните следующую команду.
Создать базу данных:
CREATE DATABASE quickstart_db
Ожидаемый результат:
Statement executed successfully
Подключитесь к quickstart_db
Проверьте, создана ли ваша база данных, подключившись к ней. Переподключитесь к студии, используя кнопку для переключения пользователя/базы данных.
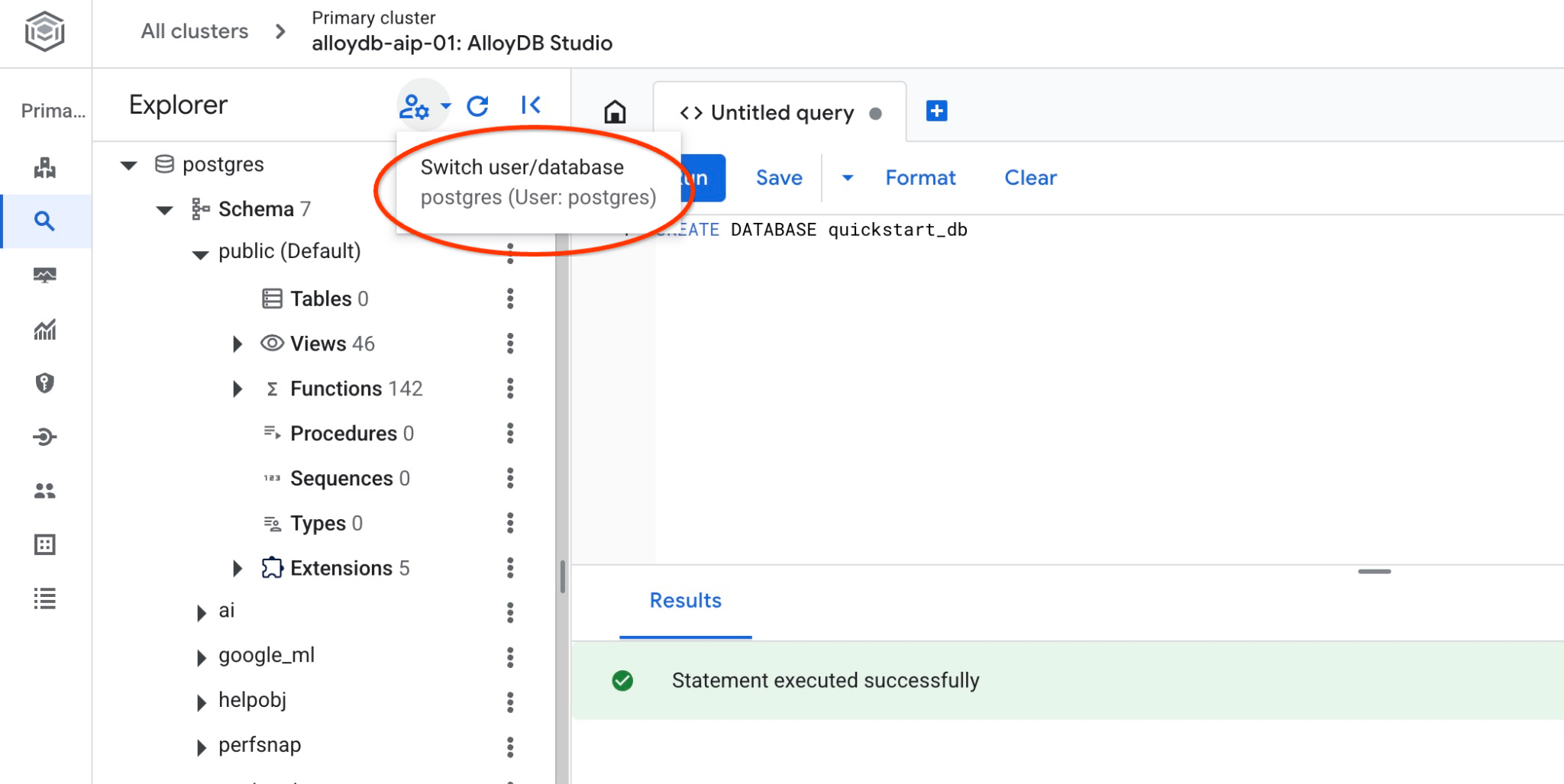
Выберите из выпадающего списка новую базу данных quickstart_db и используйте ту же аутентификацию IAM.
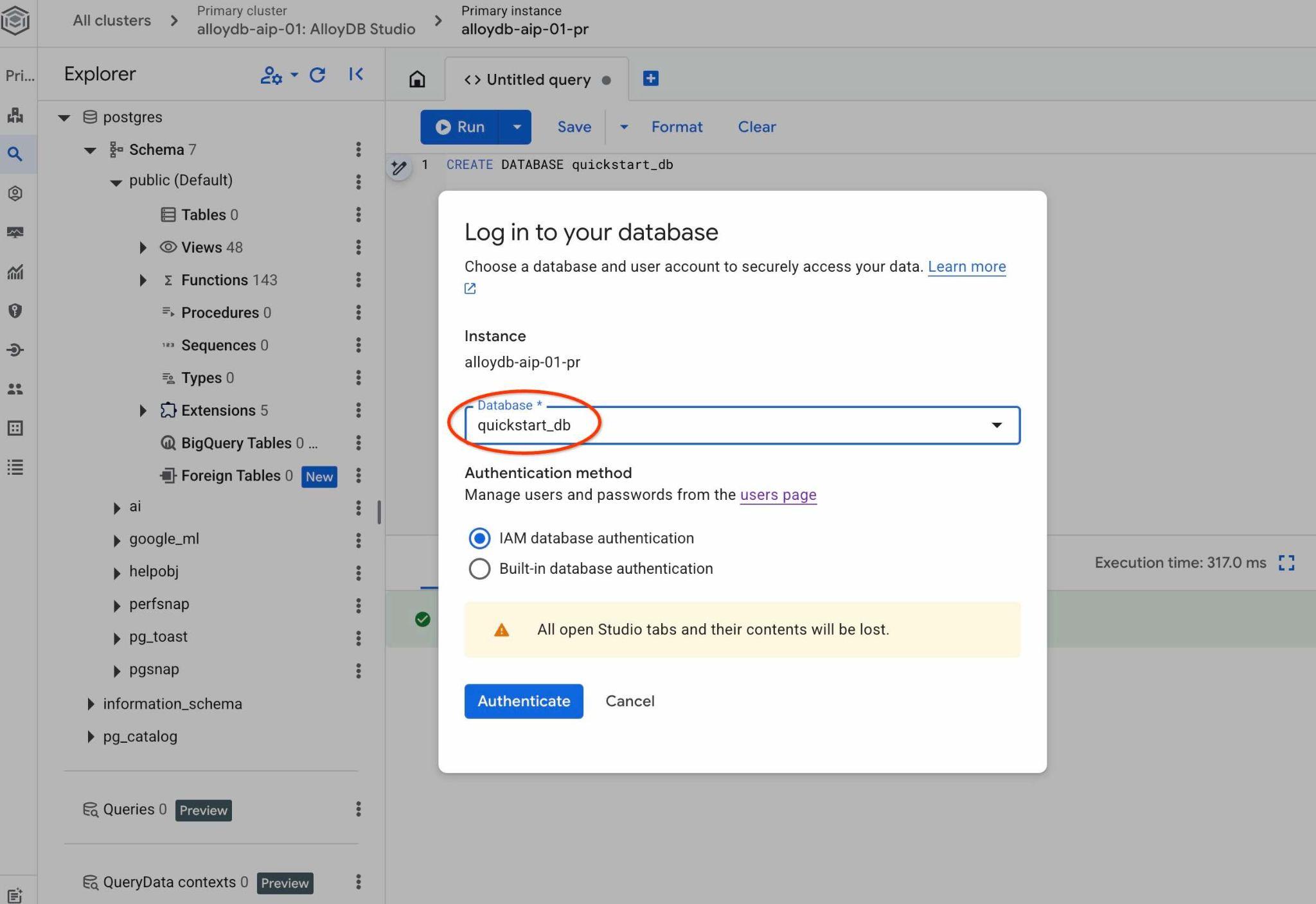
Это откроет новое соединение, через которое вы сможете работать с объектами из базы данных quickstart_db . Там вы сможете изучить импортированную схему и данные, а также работать с контекстными наборами QueryData.
6. Пример данных
Теперь вам нужно создать объекты в базе данных и загрузить данные. Вы будете использовать вымышленный набор данных компании Cymbal Shipping. Он содержит вымышленные данные о товарах, грузовиках, запросах и рейсах грузовиков, а также вымышленных водителях.
Создать корзину хранения
Для импорта данных из клонированного репозитория в базу данных AlloyDB вам потребуется использовать Google SDK (gcloud). Для этого необходимо создать хранилище Cloud Storage и предоставить доступ к нему учетной записи службы AlloyDB. В качестве альтернативы вы всегда можете попробовать сделать это через веб-консоль, как описано в документации .
В терминале Google Cloud Shell выполните следующую команду:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
Загрузка данных
Следующий шаг — загрузка данных. Наш сжатый SQL-дамп находится в папке клонированного репозитория. Следующая команда предполагает, что вы использовали свой домашний каталог в качестве отправной точки при клонировании репозитория на предыдущем шаге при создании кластера AlloyDB.
Скопируйте сжатый дамп SQL в новый сегмент хранения:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
Затем загрузите данные в базу данных quickstart_db :
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
Эта команда загрузит пример набора данных в базу данных quickstart_db. Вы можете проверить таблицы и записи с помощью AlloyDB Studio.
7. Работа с агентом данных
Начнём с примера ИИ-агента, созданного с использованием Google ADK для Python и подключающегося к нашему экземпляру AlloyDB с помощью MCP Toolbox для работы с базами данных.
Установите MCP Toolbox для работы с базами данных.
MCP Toolbox for databases — это проект с открытым исходным кодом, предоставляющий поддержку MCP для различных движков баз данных, включая AlloyDB для PostgreSQL. Подробнее о MCP Toolbox можно прочитать в документации .
Вам необходимо загрузить последнюю версию программного обеспечения для вашей платформы. Актуальную версию можно найти на странице релизов. В следующем примере показано, как загрузить версию 31 MCP Toolbox в Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Вам необходимо подготовить конфигурационный файл для панели инструментов. В текущем каталоге есть пример файла tools.yaml.example , и мы собираемся подготовить файл tools.yaml, заменив два заполнителя на идентификатор проекта и регион.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
Запустите MCP Toolbox для баз данных.
Теперь вы можете запустить MCP Toolbox, используя подготовленный конфигурационный файл.
Откройте новую вкладку в Google Cloud Shell, нажав кнопку «+» в верхней части интерфейса Google Cloud Shell.
В новой вкладке перейдите в каталог, содержащий исполняемый файл инструментария и файл конфигурации tools.yaml, и запустите сервер MCP.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
В выводе вы должны увидеть сообщение "Сервер готов к работе!", похожее на следующее.
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
Проверьте исходный код агента.
На первой вкладке в папке клонированного репозитория просмотрите код агента с помощью редактора Google Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
В агенте вы можете увидеть раздел для сервера Google Cloud MCP для AlloyDB. Мы указываем конечную точку в виде MCP_SERVER_URL, параметры аутентификации, идентификатор проекта и добавляем его в набор инструментов MCP.
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
В коде агента набор инструментов MCP включен в качестве параметра tools для агента. Также в качестве переменных для командной строки агента используются имена кластера и экземпляра, регион и база данных.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
После изучения кода вернитесь в терминал, нажав кнопку «Открыть терминал» в правом верхнем углу окна редактора.
Запустить агент
Теперь вы можете запустить агента в интерактивном режиме, используя веб-интерфейс Google ADK. Веб-интерфейс ADK предоставляет удобный способ тестирования и устранения неполадок в рабочих процессах агентов.
Для начала установим все необходимые пакеты для Python, используя менеджер пакетов uv.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
После установки всех пакетов необходимо добавить файл .env в каталог агента, чтобы указать ему использовать Vertex AI для всех взаимодействий с моделями ИИ.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
Затем вы можете запустить агента.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Вы должны увидеть вывод, подобный следующему, с конечной точкой вида http://127.0.0.1:8000 .
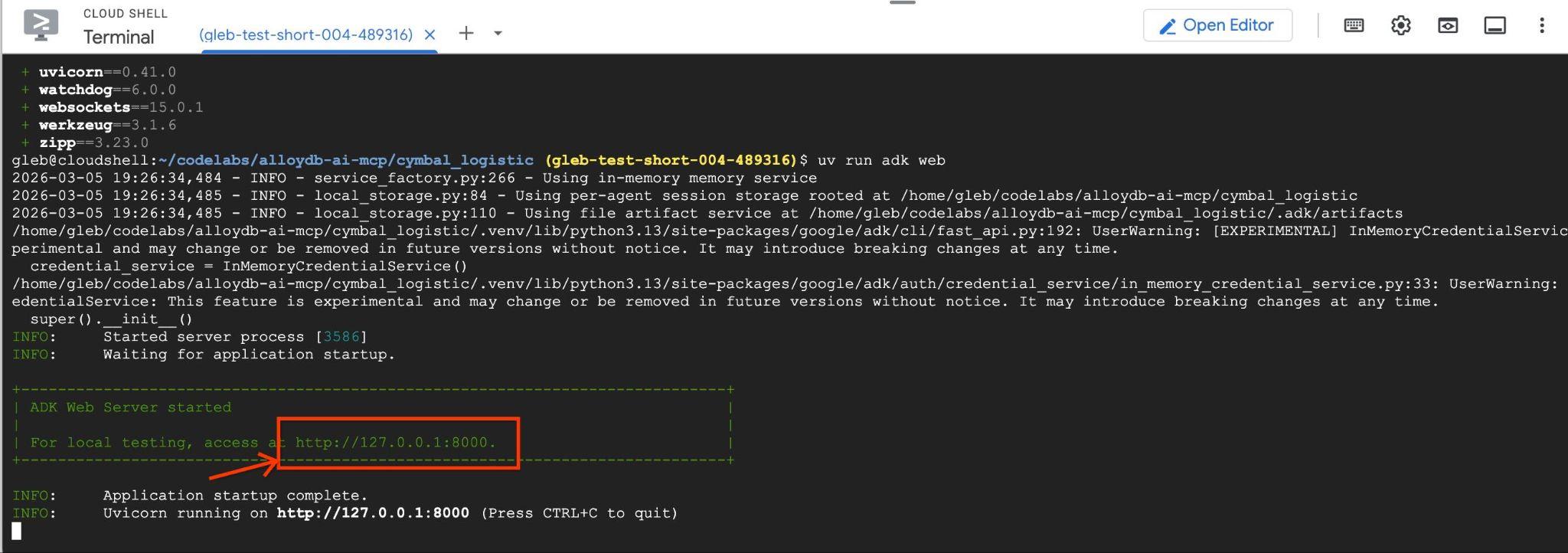
Вы можете щелкнуть по этой ссылке в облачной оболочке, и откроется окно предварительного просмотра в отдельной вкладке браузера, где вы выберете data_agent из выпадающего списка слева.
В веб-интерфейсе ADK вы можете задавать вопросы в правом нижнем углу и просматривать полный ход выполнения, включая трассировку каждого шага, справа.
8. Тестирование NL2SQL без QueryData для AlloyDB.
Агент позволяет задавать вопросы в свободной форме, используя естественный язык, а для ответа на вопросы будет использовать инструментарий MCP для работы с базами данных. Вопросы отображаются в правом нижнем углу, а ответ со всеми обращениями к инструментам — вверху.
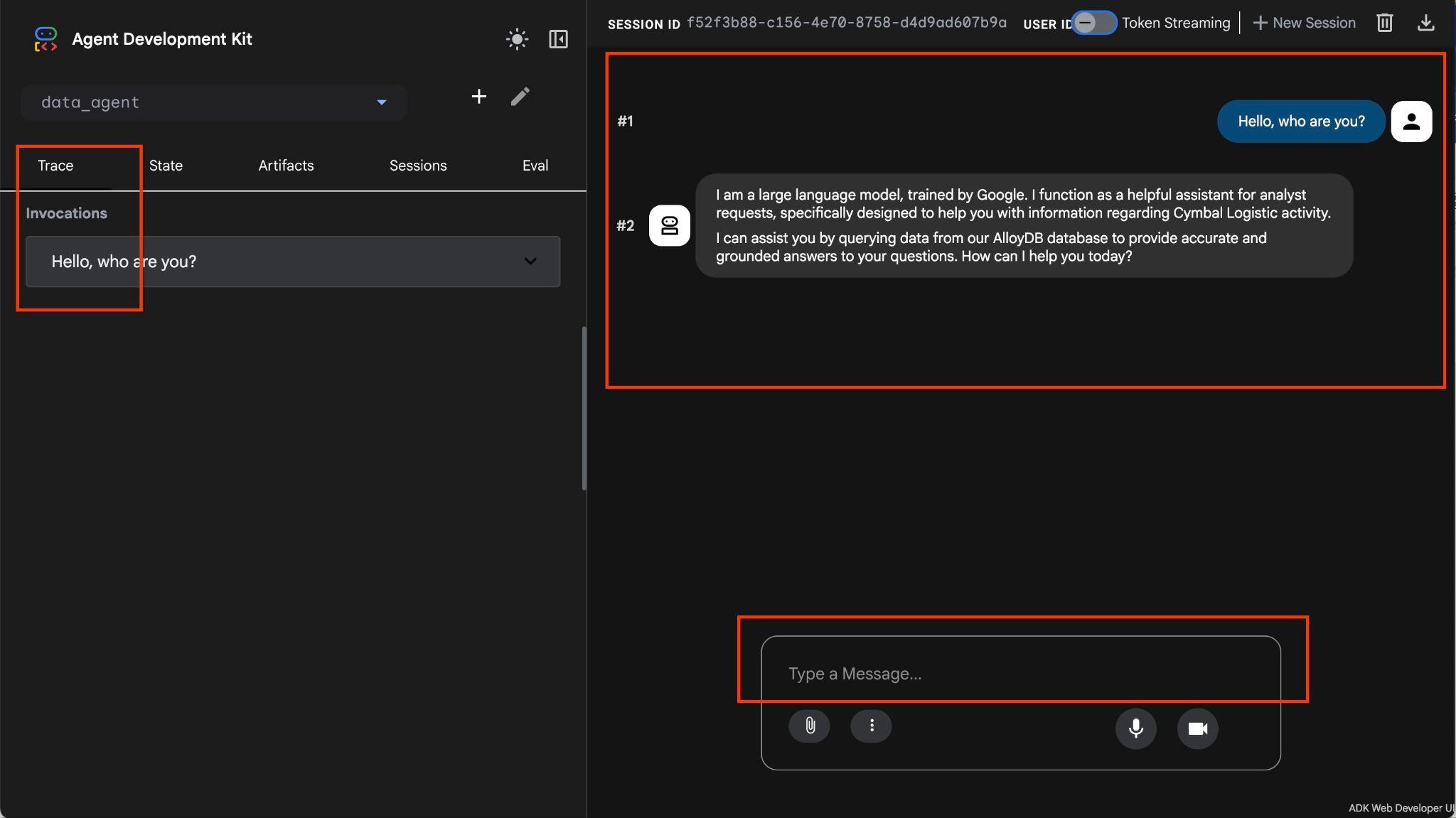
Вы работаете с оперативными данными транспортной компании, которые содержат информацию о запросах на перевозку, грузовиках, водителях и рейсах, совершенных водителями. Первый вопрос касается количества рейсов, выполненных в феврале 2026 года.
В поле ввода в правом нижнем углу введите следующее и нажмите Enter.
Hello, can you tell me how many trips we've done in February?
Агент будет выполнять множество вызовов инструментов для определения нужных таблиц в схеме, используя инструменты list_cymbal_logistics_schemas_tool и execute_sql_tool которые будут выполнять несколько SQL-запросов для получения необходимых данных.
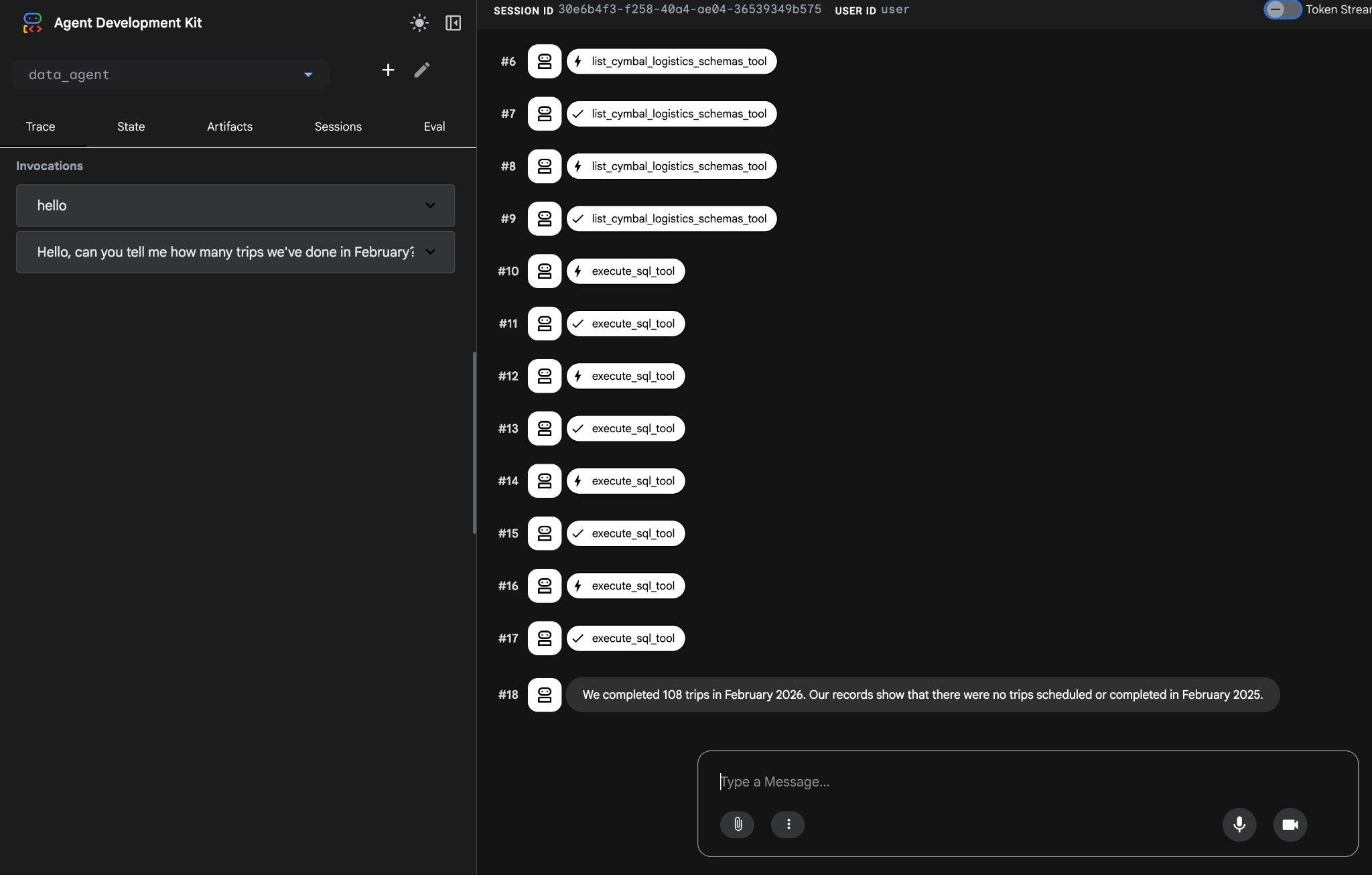
В конечном итоге, после составления соответствующего запроса и его выполнения в базе данных, будет получен правильный результат.
В феврале 2026 года мы совершили 108 поездок. Согласно нашим данным, в феврале 2025 года запланированных или совершенных поездок не было.
Вы можете увидеть, что делает каждый вызов инструмента, щелкнув по его выполнению. Например, вот запрос, выполненный для получения результатов.
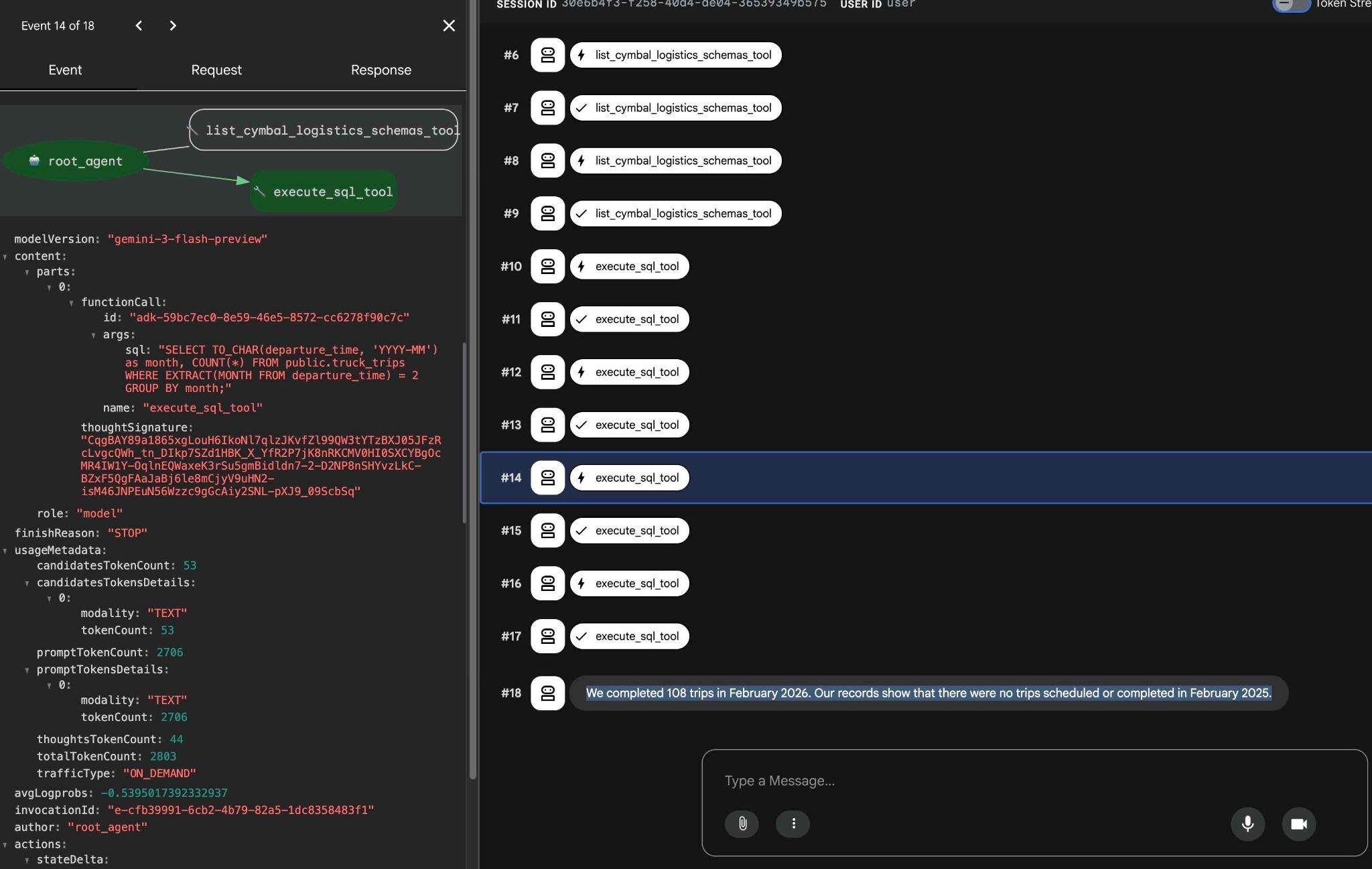
Попробуйте выполнить другие простые запросы через веб-интерфейс ADK и посмотрите, как он обрабатывает различные запросы для получения результатов.
Остановить работу агента можно, нажав ctrl+c в терминале. Закрыть вкладку браузера можно через веб-интерфейс ADK.
Также вы можете остановить работу панели инструментов MCP на второй вкладке, нажав ту же комбинацию клавиш ctrl+c , и закрыть вторую вкладку.
На следующем этапе мы создадим контекст QueryData для улучшения ответа и производительности нашего NL2SQL-запроса.
9. Создание контекстного набора QueryData
Как вы могли видеть на предыдущем шаге, модель ИИ выполняла множество обращений к информационной схеме базы данных, чтобы определить, какую таблицу и столбцы следует использовать для построения SQL-запроса. Для повышения производительности, точности и предсказуемости результата мы добавим ваш контекст QueryData, определяющий, какой запрос должен быть выполнен в ответ на определенный запрос.
Создание целевых шаблонов
QueryData ContextSet — это JSON-файл с шаблонами запросов и фасетами, которые предоставляют модели ИИ необходимые данные и указания для использования правильных SQL-запросов или их частей для достижения поставленных целей на основе шаблонов запросов и структуры данных.
Вы начинаете с целевого шаблона. Создайте файл с помощью редактора Cloud Shell. В терминале Cloud Shell выполните команду.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
И вставьте шаблон для запроса на естественном языке, который мы использовали в предыдущей главе: "Сколько поездок мы совершили в феврале?"
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
Затем загрузите шаблон на свой компьютер из Cloud Shell, используя кнопку загрузки.
Загрузка наборов контекста QueryData
Для использования наших наборов контекста QueryData нам необходимо загрузить их в нашу базу данных.
Откройте AlloyDB Studio. В левой панели внизу вы увидите QueryData Context и три точки.
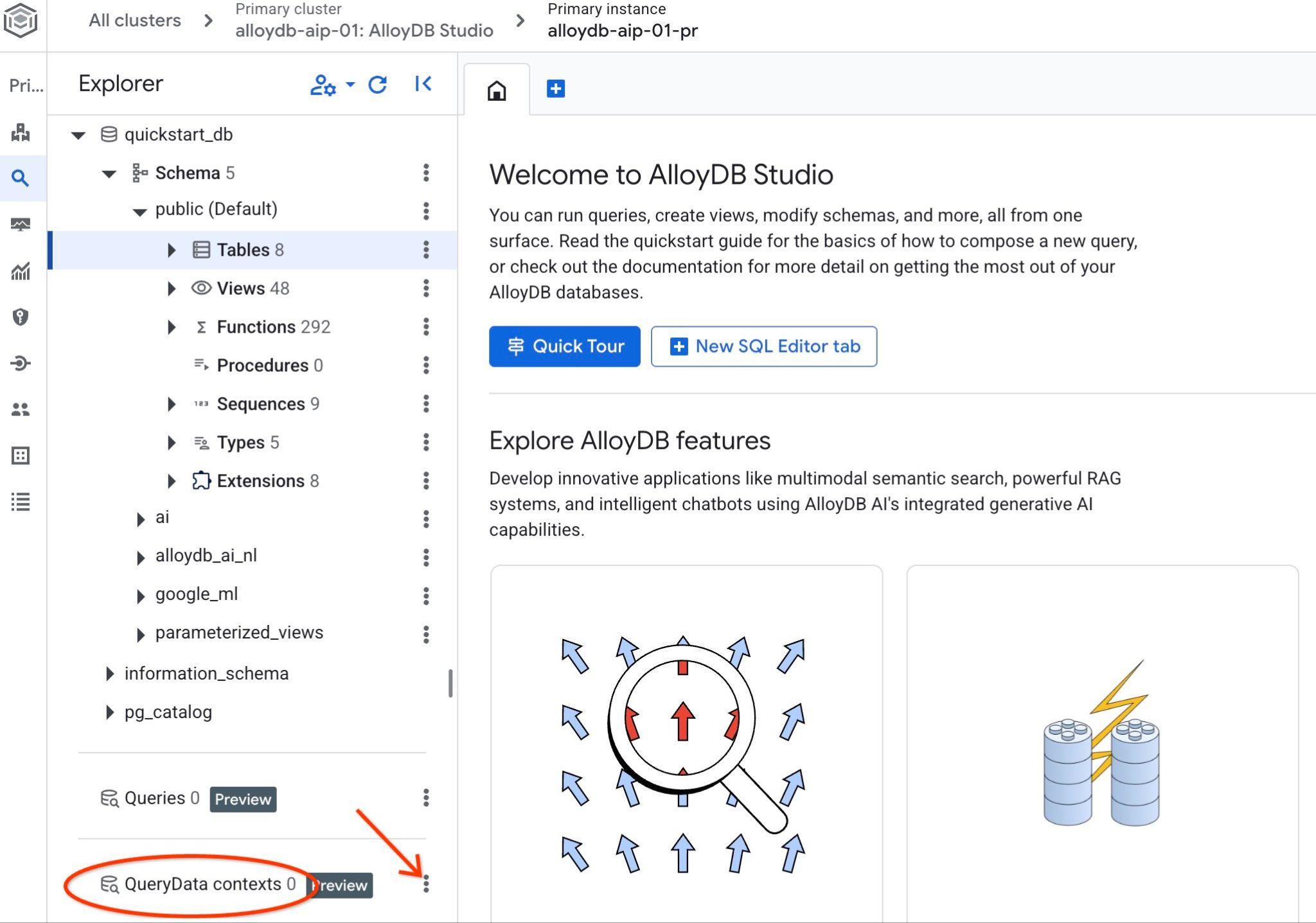
Нажмите на эти три точки и выберите «Создать контекст». Откроется диалоговое окно, в которое вы должны ввести...
- Имя:
cymbal_context_set - Описание:
Cymbal Logistic Query Data - Загрузка контекстного файла: нажмите кнопку «
Browse» и выберите свой JSON-файл с контекстным набором QueryData.
При первом нажатии кнопки сохранения может потребоваться некоторое время для инициализации контекстного хранилища.
Вы должны увидеть загруженный контекст, а если нажмете на три вертикальные кнопки справа, то увидите доступные действия. В следующей главе мы начнем с действия «Проверить контекст».
10. Проверка контекста QueryData
Тестовый шаблон
Используйте действие « Test context », чтобы протестировать контекст в AlloyDB Studio. При нажатии на «Проверить контекст» откроется новое окно редактора AlloyDB Studio с заголовком « cymbal_context_set » и приглашением к генерации SQL-запросов Gemini под заголовком « Generate SQL using QueryData context: cymbal_context_set ». Нажмите на кнопку генерации SQL-запроса и введите текст.
Hello, can you tell me how many trips we've done in February?
После того, как будет сгенерирован SQL-код, нажмите кнопку « Insert ».
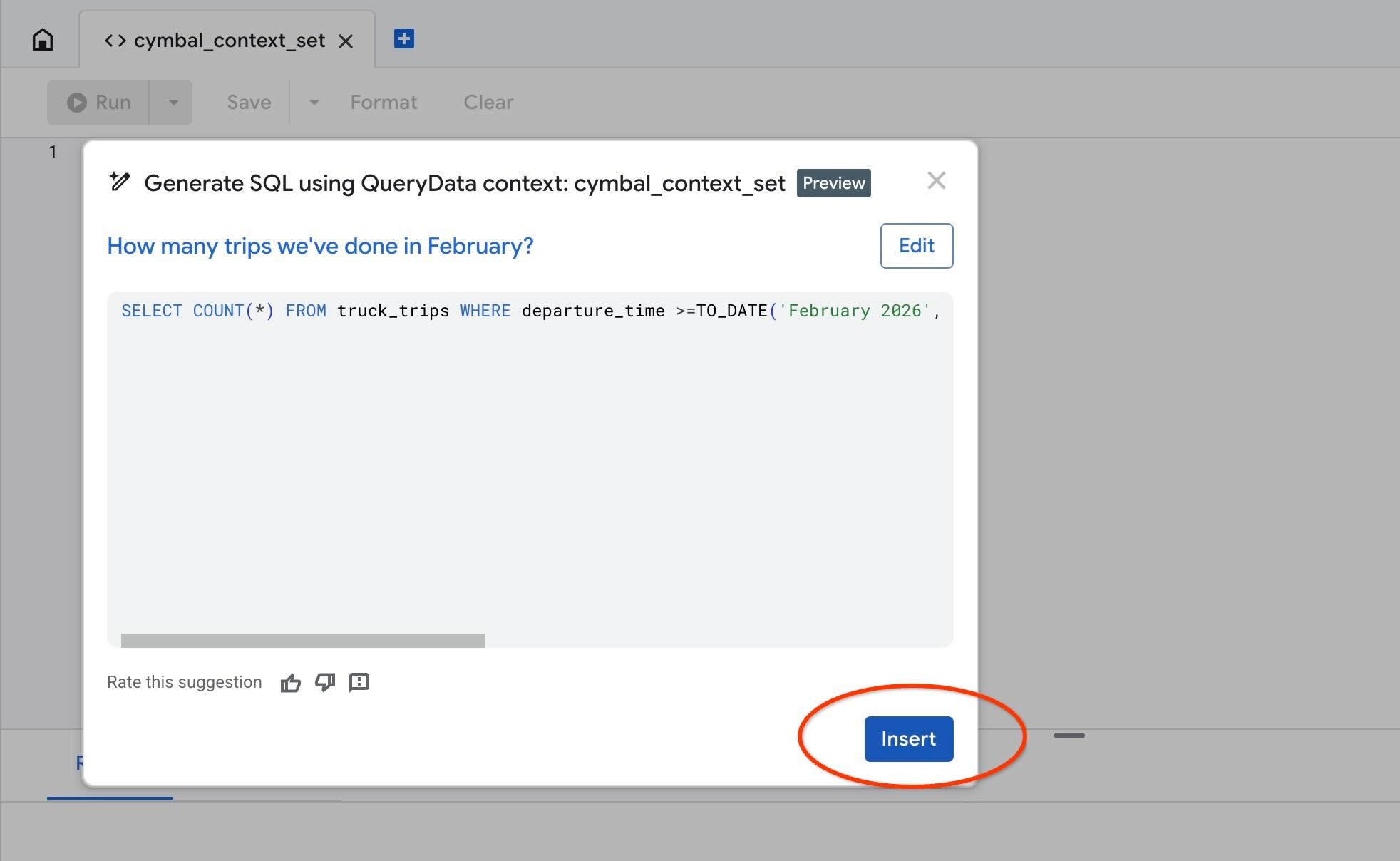
Вы увидите точно такой же запрос, который мы ранее использовали в нашем шаблоне контекста.
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
Попробуйте заменить месяц на "январь" и проверьте сгенерированный SQL-запрос. Он будет использовать месяц в качестве параметра для параметризованного намерения и автоматически скорректирует SQL-запрос.
Создание фасетов QueryData
Мы попробовали использовать шаблон запроса, и он работает, когда мы знаем, какой запрос ожидает пользователь. Но иногда полезно направлять запрос только в части, например, в условии или фильтре, когда мы предпочитаем определенный порядок или конкретное условие для использования в соответствии с переопределенным намерением.
Например, если мы запрашиваем данные за «прошлый месяц», мы хотим получить отчет за последний календарный месяц с 1-го по последний день этого месяца, но не за последние 30 дней.
Мы можем добавить такие аспекты в виде фрагмента SQL-запроса в конфигурацию ContextSet вместе с ранее добавленным шаблоном. Откройте файл querydata_cymbal_contextset.json.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
И добавьте параметры после уже существующих шаблонов. В результате содержимое файла должно выглядеть следующим образом.
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
Сохраните файл и загрузите его на свой компьютер.
Затем воспользуйтесь действием «Редактировать контекст» в разделе «Контекст запроса» и загрузите измененный файл, чтобы заменить старый контекст новым.
Теперь попробуйте снова использовать тестовый контекст и сгенерировать SQL-запрос, используя намерение "последний месяц". Например, если вы сгенерируете SQL-запрос для фразы " show trucks trips for the last month" он будет использовать условие, которое мы указали в качестве фасета в нашем файле cymbal_context.json.
В результате у вас должно получиться что-то подобное:
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
Итак, как это можно использовать с агентами ИИ? В следующей главе мы сделаем контекст данных запроса доступным для агентов ИИ.
11. Запрос данных с помощью агентов ИИ.
Вы будете использовать тот же Data Agent, но теперь панель инструментов MCP будет настроена на использование ContextSet QueryData.
Подготовьте и запустите MCP Toolbox для работы с базами данных.
Нам нужен новый конфигурационный файл для MCP Toolbox, который будет использовать API Gemini Data Analytics и AlloyDB в качестве источника данных.
Выполните в терминале:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
Переключитесь в редактор и найдите файл querydata.yaml . Конфигурационный файл querydata.yaml будет выглядеть примерно так, за исключением идентификатора проекта и региона, которые будут отражать вашу среду. Но вам все равно нужно обновить значение contextSetId и заменить заполнитель "<add-context-set-id>" значением из консоли.
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
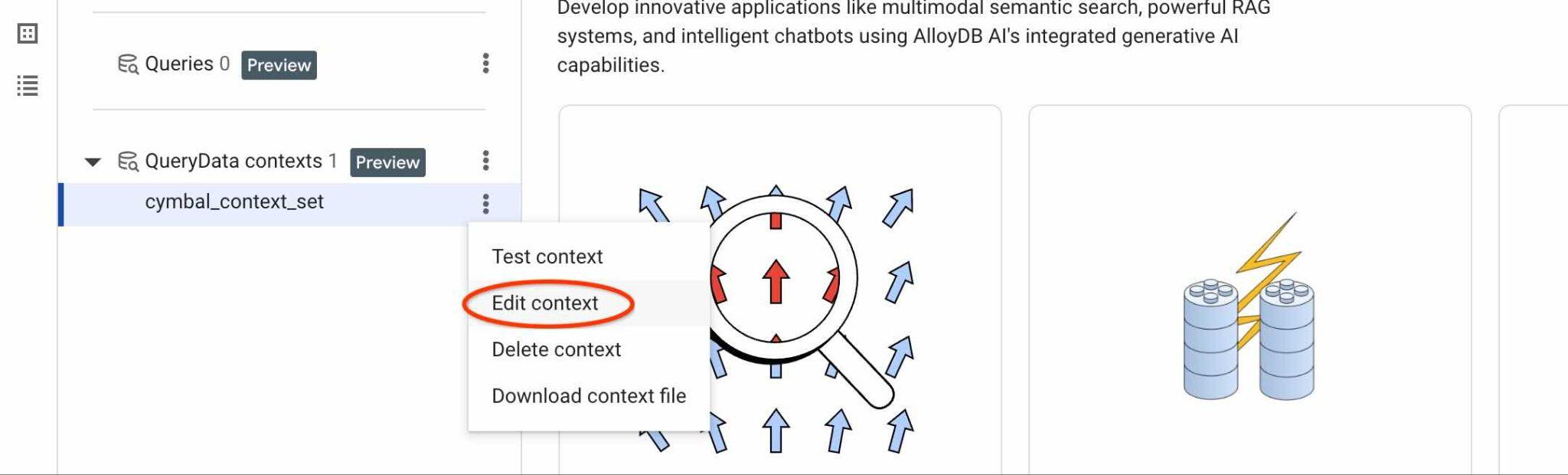
Чтобы найти идентификатор вашего ContextSet, нажмите кнопку редактирования для вашего набора контекстов, как показано на рисунке.
Идентификатор набора контекста вы увидите вверху в новой вкладке справа.
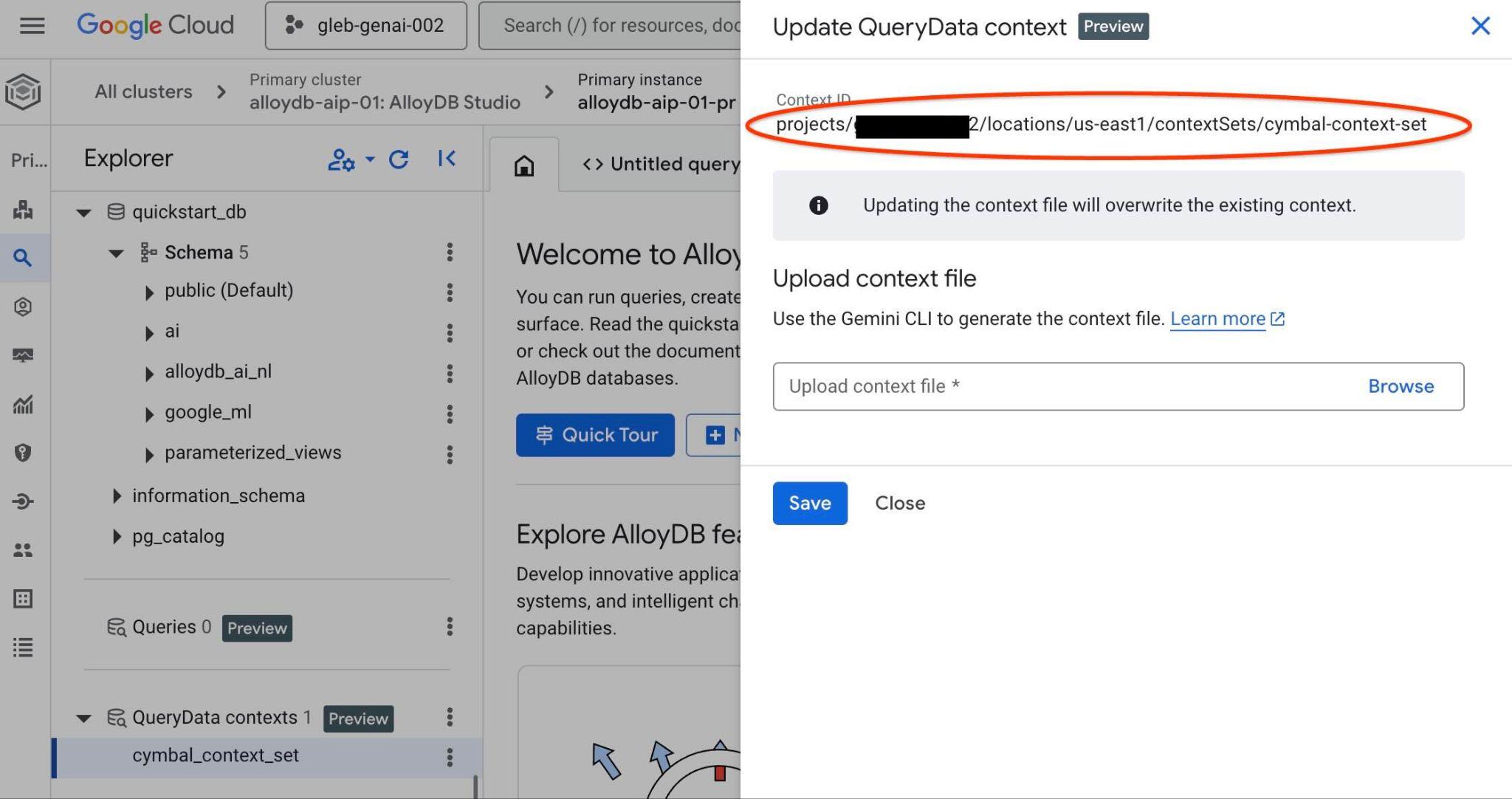
Этот полный путь следует использовать для замены заполнителя "<add-context-set-id>" в файле querydata.yaml .
Вернитесь обратно в терминал.
Откройте новую вкладку в Google Cloud Shell, нажав кнопку «+» в верхней части интерфейса Google Cloud Shell.
В новой вкладке перейдите в каталог, содержащий исполняемый файл инструментария и файл конфигурации tools.yaml, и запустите сервер MCP.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
Запустите агент ADK.
На первой вкладке Cloud Shell запустите агент.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
После запуска снова нажмите на ссылку http://127.0.0.1:8000 .
Вы увидите уже знакомый интерфейс веб-агента предварительного просмотра ADK. Отправьте точно такой же запрос, как и в прошлый раз.
Hello, can you tell me how many trips we've done in February?
И посмотрите на рабочий процесс агента. Если все настроено правильно, вы должны увидеть что-то подобное.
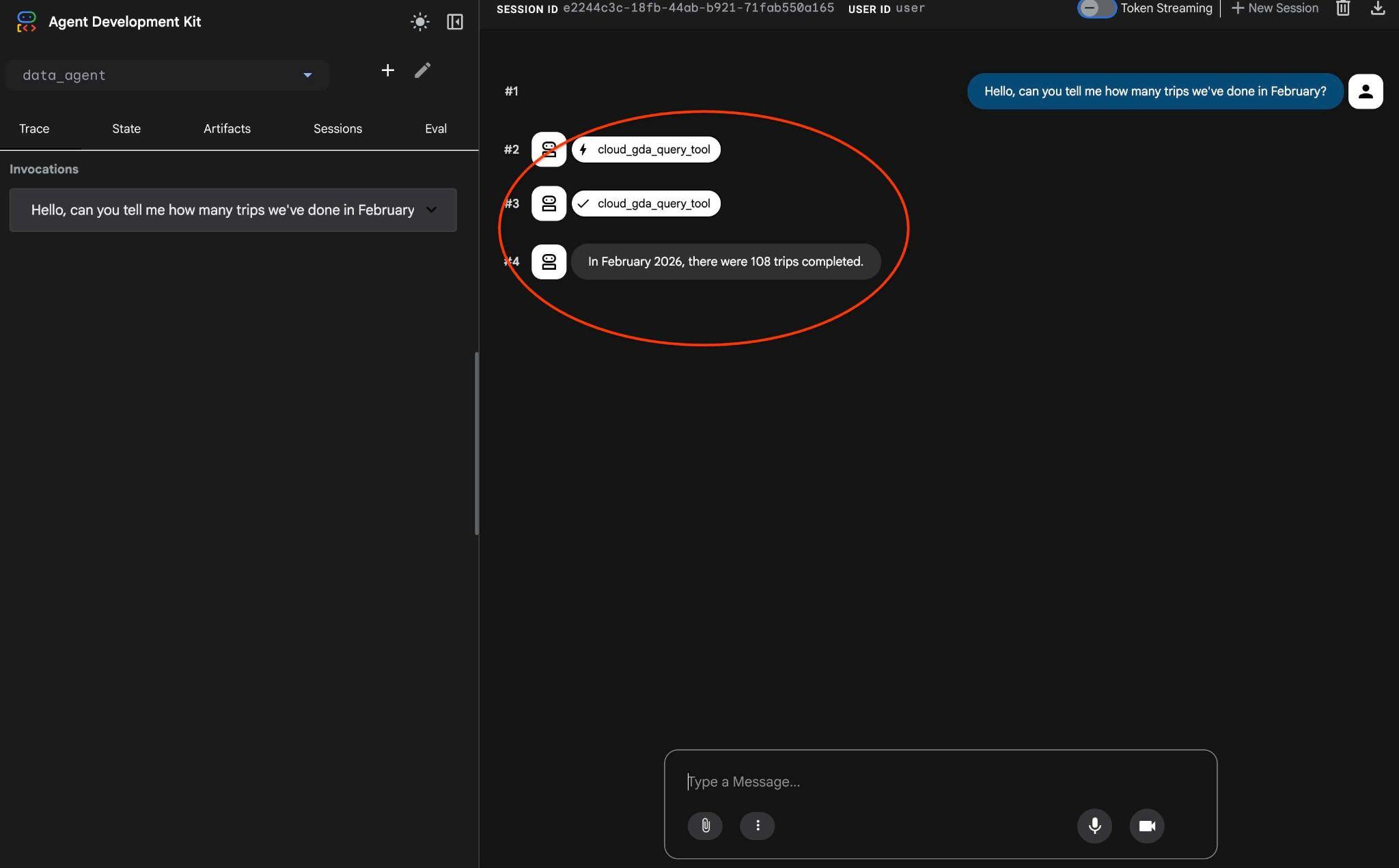
Запрос, который в прошлый раз выполнялся в несколько этапов, был преобразован в один вызов инструмента MCP и выполнен с использованием предсказуемых SQL-запросов.
Вы можете проверить настроенные параметры, используя следующий запрос:
how trucks trips for the last month
А в результате, если вы щелкнете по действию инструмента, вы увидите, что для получения результата использовался тот же инструмент, и были применены грани.
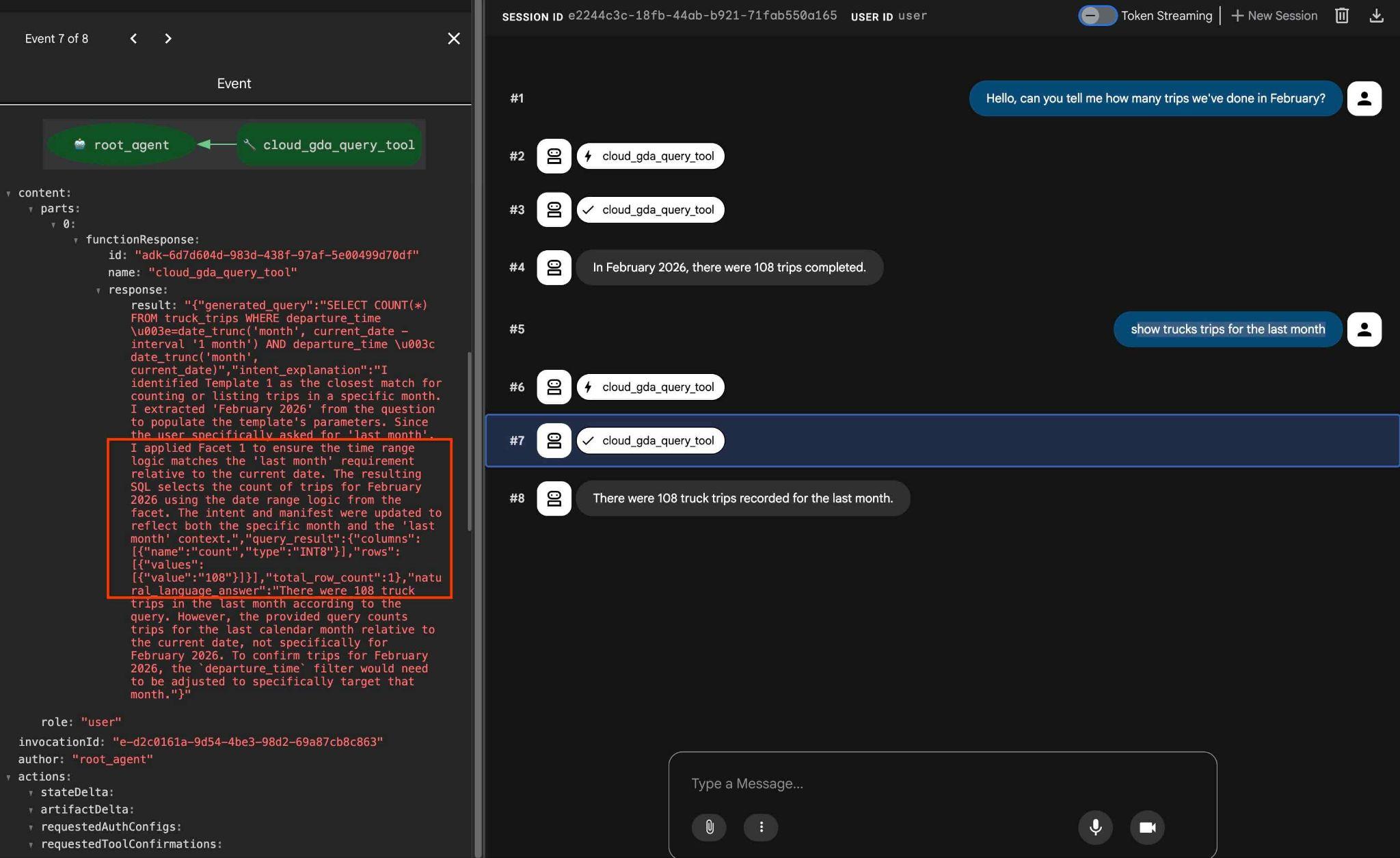
На этом наша лабораторная работа завершена. Надеюсь, вы смогли ознакомиться со всеми примерами и научиться использовать QueryData для AlloyDB. Предложенная технология помогает сделать вашу агентскую нагрузку и генерацию SQL-запросов предсказуемыми и надежными.
12. Очистка окружающей среды
Чтобы избежать непредвиденных расходов, рекомендуется очищать временные ресурсы. Наиболее надежный способ — удалить проект, в котором вы тестировали рабочий процесс. Но при желании можно ограничиться удалением отдельных ресурсов, таких как AlloyDB.
После завершения лабораторной работы удалите экземпляры AlloyDB и кластер.
Удалите кластер AlloyDB и все его экземпляры.
Если вы использовали пробную версию AlloyDB, не удаляйте пробный кластер, если планируете тестировать другие тестовые среды и ресурсы с его помощью. Вы не сможете создать другой пробный кластер в том же проекте.
Кластер уничтожается с помощью опции force, которая также удаляет все экземпляры, принадлежащие кластеру.
В облачной оболочке укажите переменные проекта и среды на случай, если соединение было разорвано и все предыдущие настройки были потеряны:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Удалите кластер:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Удалить резервные копии AlloyDB
Удалите все резервные копии AlloyDB для кластера:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
13. Поздравляем!
Поздравляем с завершением практического занятия!
Что мы рассмотрели
- Как создать кластер AlloyDB и импортировать тестовые данные
- Как включить API доступа к данным AlloyDB
- Как включить QueryData для AlloyDB
- Как создавать шаблоны
- Как использовать фасетный поиск
- Как использовать QueryData с агентами искусственного интеллекта
14. Опрос
Выход: