
1. บทนำ
Codelab นี้มีคำแนะนำเกี่ยวกับวิธีเริ่มต้นใช้งาน QueryData สำหรับ AlloyDB และใช้เพื่อสร้างคำสั่ง SQL ที่แม่นยำและคาดการณ์ได้จากอินพุตภาษาธรรมชาติในแอปพลิเคชัน Agentic
ข้อกำหนดเบื้องต้น
- ความเข้าใจพื้นฐานเกี่ยวกับคอนโซล Google Cloud
- ทักษะพื้นฐานในอินเทอร์เฟซบรรทัดคำสั่งและ Cloud Shell
สิ่งที่คุณจะได้เรียนรู้
- วิธีสร้างคลัสเตอร์ AlloyDB และนําเข้าข้อมูลตัวอย่าง
- วิธีเปิดใช้ AlloyDB Data Access API
- วิธีเปิดใช้ QueryData สำหรับ AlloyDB
- วิธีสร้างเทมเพลต
- วิธีใช้การค้นหาตามประเภทที่จัดแบ่งไว้
- วิธีใช้ QueryData กับเอเจนต์ AI
สิ่งที่คุณต้องมี
- บัญชี Google Cloud และโปรเจ็กต์ Google Cloud
- เว็บเบราว์เซอร์ เช่น Chrome ที่รองรับ คอนโซล Google Cloud และ Cloud Shell
2. การตั้งค่าและข้อกำหนด
การตั้งค่าโปรเจ็กต์
สร้างโปรเจ็กต์ Google Cloud
- ในคอนโซล Google Cloud ในหน้าตัวเลือกโปรเจ็กต์ ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
เริ่มต้น Cloud Shell
แม้ว่าคุณจะใช้งาน Google Cloud จากระยะไกลจากแล็ปท็อปได้ แต่ใน Codelab นี้คุณจะใช้ Google Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานในระบบคลาวด์
จาก คอนโซล Google Cloud ให้คลิกไอคอน Cloud Shell ในแถบเครื่องมือด้านขวาบน
หรือจะกด G แล้วตามด้วย S ก็ได้ ลำดับนี้จะเปิดใช้งาน Cloud Shell หากคุณอยู่ในคอนโซล Google Cloud หรือใช้ลิงก์นี้
การจัดสรรและเชื่อมต่อกับสภาพแวดล้อมจะใช้เวลาเพียงไม่กี่นาที เมื่อเสร็จแล้ว คุณควรเห็นข้อความคล้ายกับตัวอย่างต่อไปนี้

เครื่องเสมือนนี้มาพร้อมเครื่องมือพัฒนาซอฟต์แวร์ทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหลักแบบถาวรขนาด 5 GB และทำงานบน Google Cloud ซึ่งช่วยเพิ่มประสิทธิภาพเครือข่ายและการตรวจสอบสิทธิ์ได้อย่างมาก คุณสามารถทำงานทั้งหมดใน Codelab นี้ได้ภายในเบราว์เซอร์ คุณไม่จำเป็นต้องติดตั้งอะไร
3. ก่อนเริ่มต้น
เปิดใช้ API
หากต้องการใช้ AlloyDB, Compute Engine, บริการระบบเครือข่าย และ Vertex AI คุณต้องเปิดใช้ API ที่เกี่ยวข้องในโปรเจ็กต์ที่อยู่ในระบบคลาวด์ของ Google
ตรวจสอบว่าได้ตั้งค่ารหัสโปรเจ็กต์ในเทอร์มินัล Cloud Shell แล้วโดยทำดังนี้
gcloud config get-value project
คุณควรเห็น tID ของโปรเจ็กต์ในเอาต์พุต
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
ตั้งค่าตัวแปรสภาพแวดล้อม PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
เปิดใช้บริการที่จำเป็นทั้งหมด
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
ผลลัพธ์ที่คาดหวัง
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. ติดตั้งใช้งาน AlloyDB
สร้างคลัสเตอร์และอินสแตนซ์หลักของ AlloyDB คุณจะติดตั้งใช้งานโดยใช้สคริปต์ที่เตรียมไว้ซึ่งจะติดตั้งใช้งานทรัพยากรที่จำเป็นทั้งหมด หรือจะติดตั้งใช้งานทีละขั้นตอนด้วยตนเองโดยทำตามเอกสารประกอบก็ได้
ติดตั้งใช้งาน AlloyDB โดยใช้สคริปต์อัตโนมัติ
แนวทางนี้ใช้สคริปต์อัตโนมัติเพื่อติดตั้งใช้งานคลัสเตอร์ AlloyDB และให้ข้อมูลที่จำเป็นในการเริ่มต้นใช้งานทรัพยากรที่ติดตั้งใช้งาน
ในเทอร์มินัลของ Cloud Shell ให้เรียกใช้คำสั่งเพื่อโคลนสคริปต์การทำให้ใช้งานได้จากที่เก็บ
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
เรียกใช้สคริปต์การติดตั้งใช้งาน
./deploy_alloydb.sh --public-ip
สคริปต์จะใช้เวลาสักครู่ในการเรียกใช้ โดยปกติจะใช้เวลาประมาณ 5-7 นาที และจะติดตั้งใช้งานคลัสเตอร์ AlloyDB และอินสแตนซ์หลักที่มี IP สาธารณะและส่วนตัว IP สาธารณะจะใช้ได้เฉพาะกับเครือข่ายที่ได้รับอนุญาตหรือโดยใช้พร็อกซีการตรวจสอบสิทธิ์ของ AlloyDB เท่านั้น อ่านเพิ่มเติมเกี่ยวกับ IP สาธารณะได้ในเอกสารประกอบ สคริปต์ควรให้ข้อมูลเกี่ยวกับคลัสเตอร์ AlloyDB ที่คุณติดตั้งใช้งานเป็นเอาต์พุต โปรดทราบว่ารหัสผ่านของคุณจะแตกต่างกัน ให้บันทึกรหัสผ่านไว้ที่ใดที่หนึ่งเพื่อใช้ในอนาคต
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
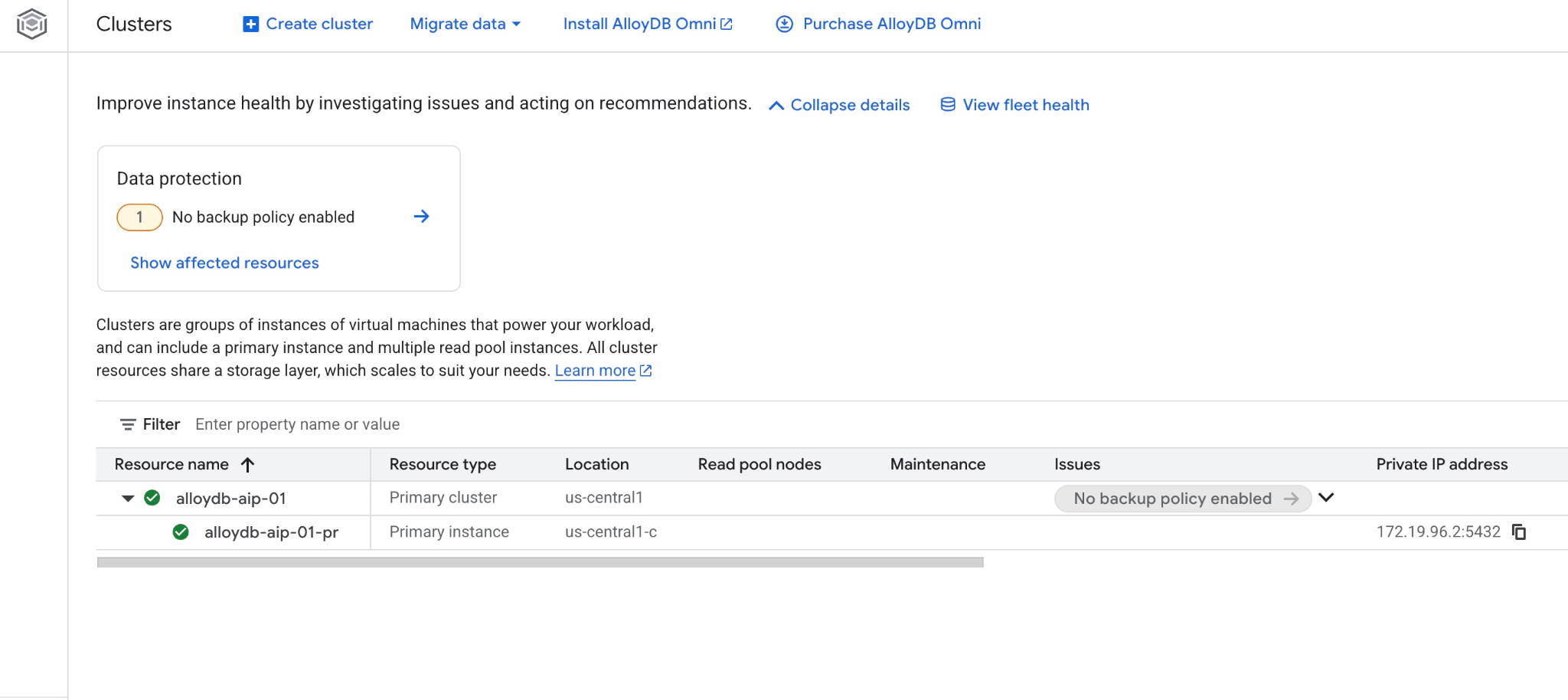
นอกจากนี้ คุณยังดูคลัสเตอร์ใหม่และอินสแตนซ์หลักในคอนโซลบนเว็บได้ด้วย
5. เตรียมฐานข้อมูล
คุณต้องเปิดใช้การผสานรวม Vertex AI เพื่อใช้ฟังก์ชันและตัวดำเนินการ AI, เปิดใช้ Data Access API และสร้างฐานข้อมูลสำหรับชุดข้อมูลตัวอย่าง
ให้สิทธิ์ที่จำเป็นแก่ AlloyDB
เพิ่มสิทธิ์ Vertex AI ให้กับตัวแทนบริการของ AlloyDB
เปิดแท็บ Cloud Shell อีกแท็บโดยใช้เครื่องหมาย "+" ที่ด้านบน
ในแท็บ Cloud Shell ใหม่ ให้เรียกใช้คำสั่งต่อไปนี้
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
เอาต์พุตของคอนโซลที่คาดไว้
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
เปิดใช้ Data Access API
คุณต้องเปิดใช้ Data Access API ในคลัสเตอร์ AlloyDB เพื่อให้ใช้เครื่องมือ MCP เช่น execute_sql ได้
ในแท็บเทอร์มินัลเดียวกัน ให้เรียกใช้
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
เปิดใช้การตรวจสอบสิทธิ์ IAM
เราจะใช้การตรวจสอบสิทธิ์ IAM สำหรับเครื่องมือที่ใช้เอเจนต์ และต้องเปิดใช้การตรวจสอบสิทธิ์ IAM ในอินสแตนซ์และเพิ่มตัวคุณเองเป็นผู้ใช้ฐานข้อมูล ก่อนที่จะเปิดใช้การตรวจสอบสิทธิ์ IAM ในระดับอินสแตนซ์ โปรดรอจนกว่าขั้นตอนก่อนหน้าในการเปิดใช้ Data Access API จะเสร็จสิ้น สถานะอินสแตนซ์ควรเป็นสีเขียว
เราเริ่มต้นด้วยการเปิดใช้ IAM ที่ระดับอินสแตนซ์ ในแท็บเทอร์มินัลเดียวกัน ให้เรียกใช้
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
เพิ่มตัวคุณเองเป็นผู้ใช้ AlloyDB โดยทำดังนี้
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
ปิดแท็บโดยใช้คำสั่งดำเนินการ "exit" ในแท็บ
exit
เชื่อมต่อกับ AlloyDB Studio
ในบทต่อไปนี้ คุณจะเรียกใช้คำสั่ง SQL ทั้งหมดที่ต้องเชื่อมต่อกับฐานข้อมูลได้ใน AlloyDB Studio T
ไปที่หน้าคลัสเตอร์ใน AlloyDB สำหรับ Postgres
เปิดอินเทอร์เฟซคอนโซลเว็บสำหรับคลัสเตอร์ AlloyDB โดยคลิกอินสแตนซ์หลัก
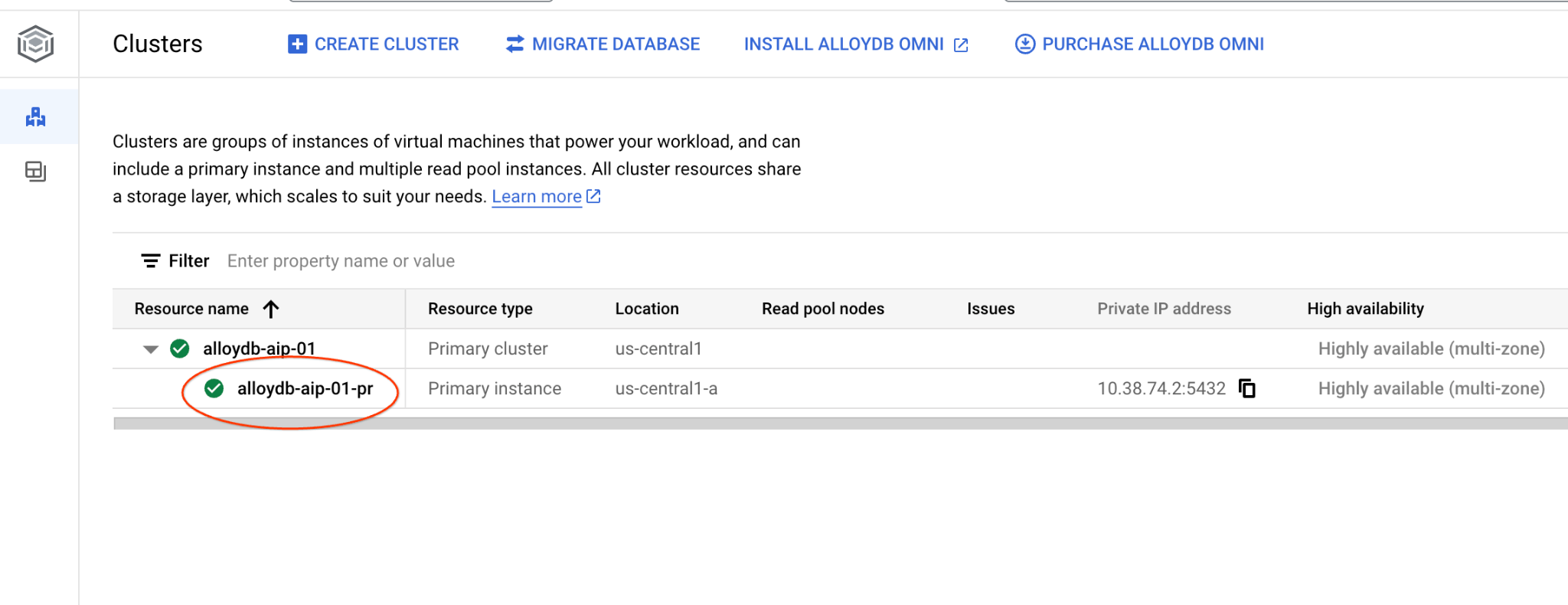
จากนั้นคลิก AlloyDB Studio ทางด้านซ้าย
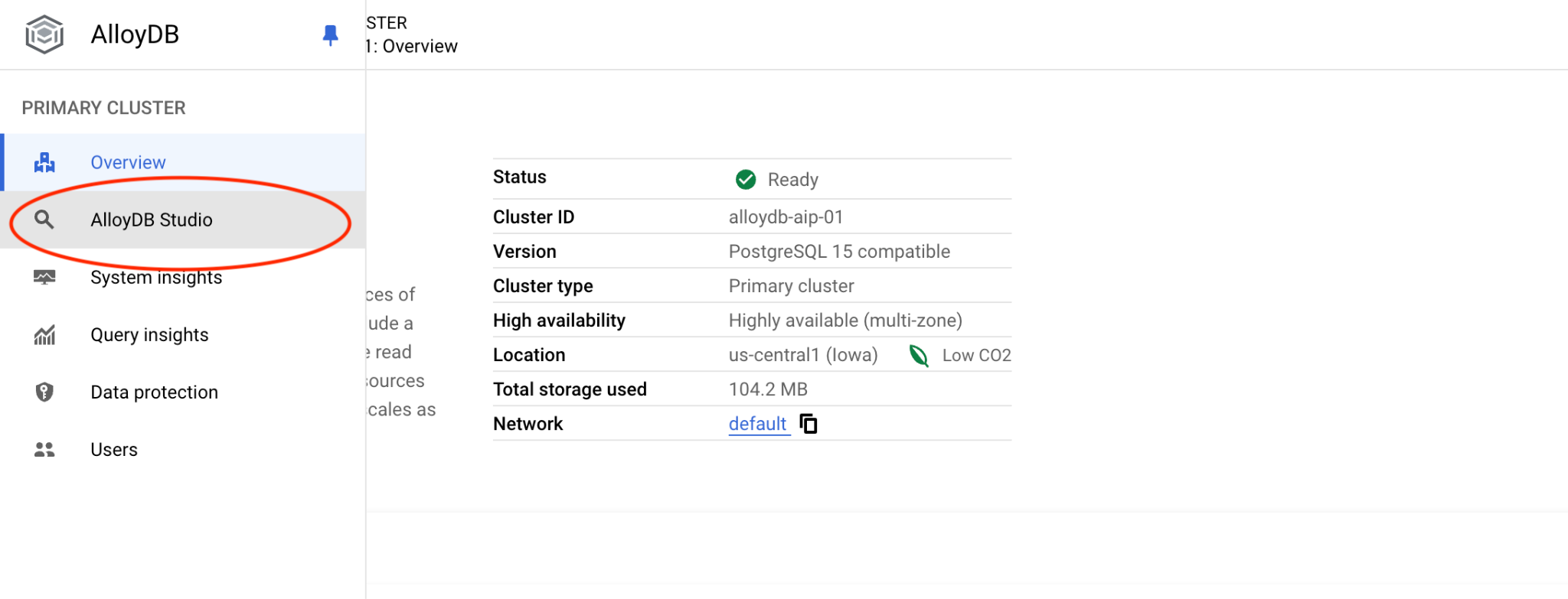
เลือกฐานข้อมูล Postgres และการตรวจสอบสิทธิ์ IAM จากนั้นคลิกปุ่ม "ตรวจสอบสิทธิ์"
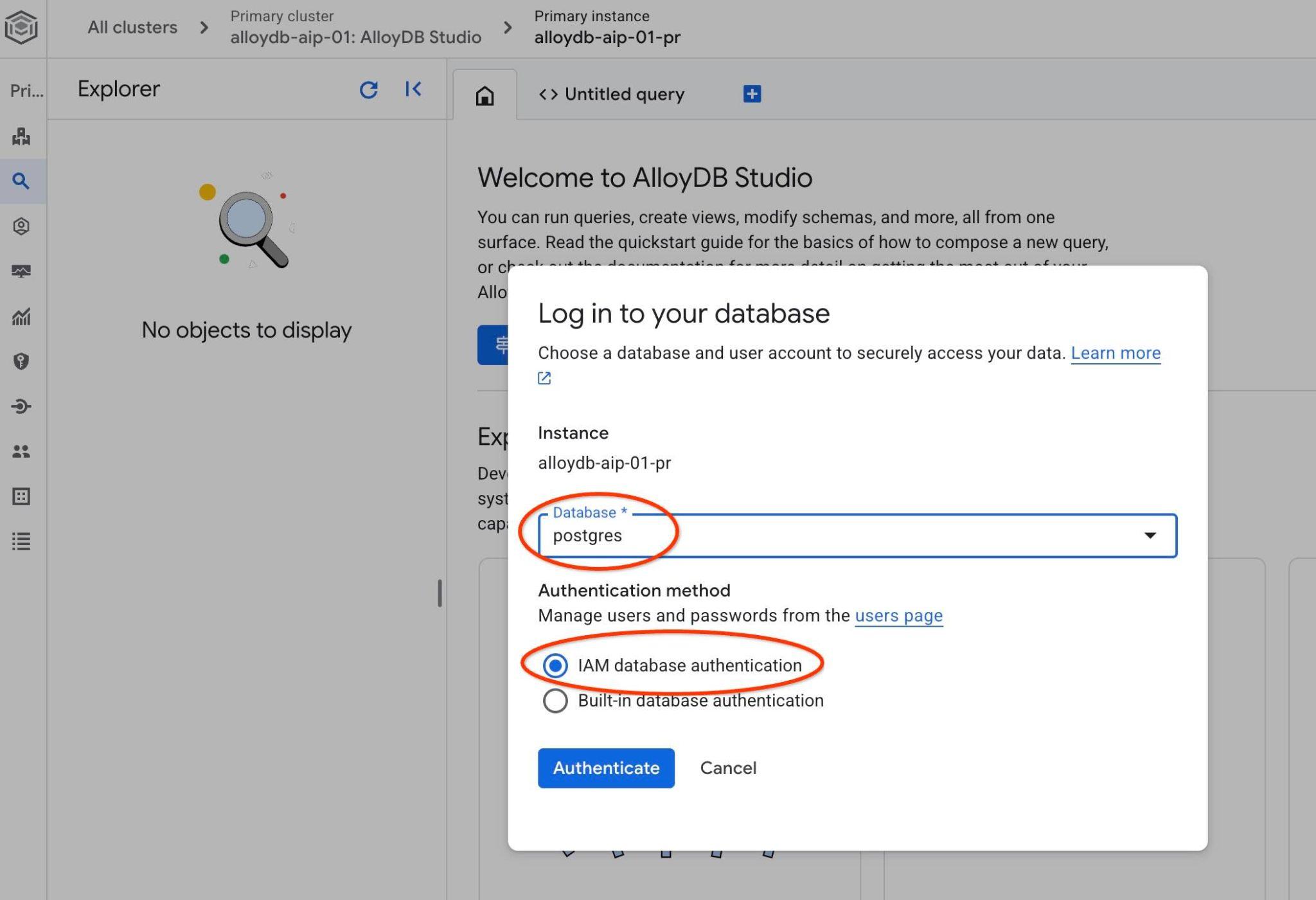
ซึ่งจะเปิดอินเทอร์เฟซ AlloyDB Studio หากต้องการเรียกใช้คำสั่งในฐานข้อมูล ให้คลิกแท็บ "คำค้นหาที่ไม่มีชื่อ" ทางด้านขวา
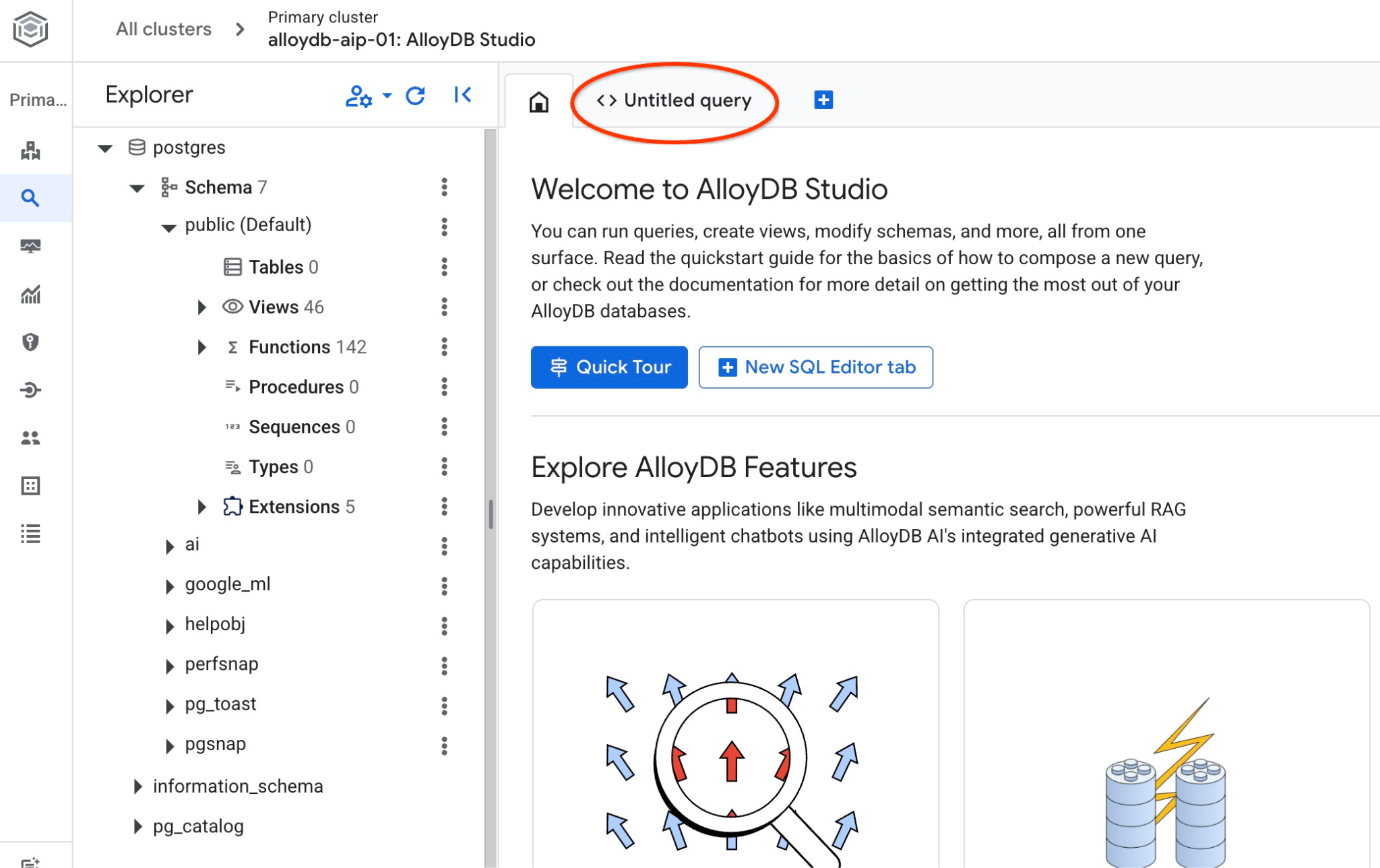
ซึ่งจะเปิดอินเทอร์เฟซที่คุณสามารถเรียกใช้คำสั่ง SQL ได้
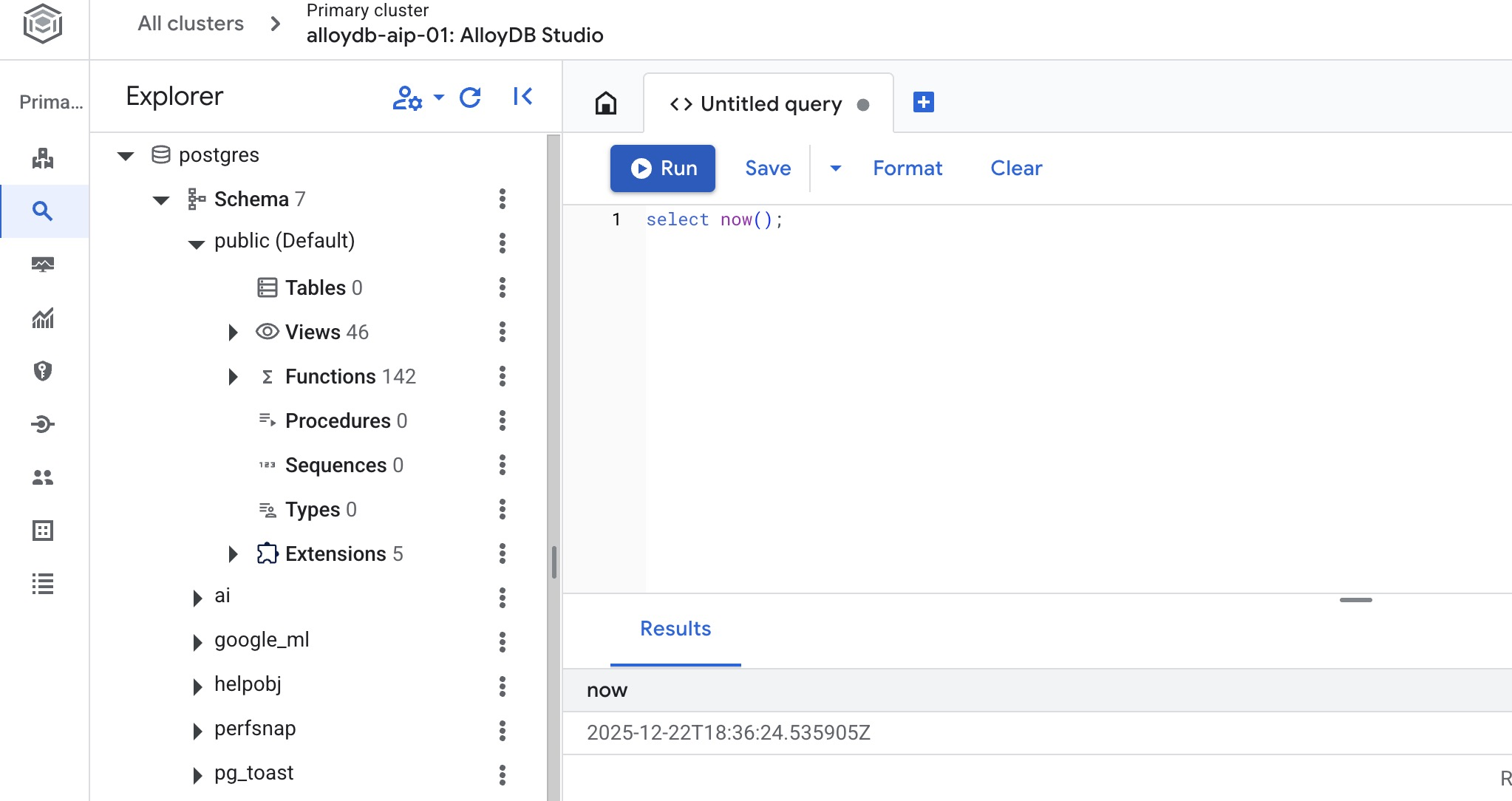
สร้างฐานข้อมูล
เริ่มต้นใช้งานฐานข้อมูลอย่างรวดเร็ว
เรียกใช้คำสั่งต่อไปนี้ในโปรแกรมแก้ไข AlloyDB Studio
สร้างฐานข้อมูล
CREATE DATABASE quickstart_db
ผลลัพธ์ที่คาดไว้
Statement executed successfully
เชื่อมต่อกับ quickstart_db
ตรวจสอบว่าสร้างฐานข้อมูลโดยการเชื่อมต่อกับฐานข้อมูลนั้นหรือไม่ เชื่อมต่อกับสตูดิโออีกครั้งโดยใช้ปุ่มเพื่อสลับผู้ใช้/ฐานข้อมูล
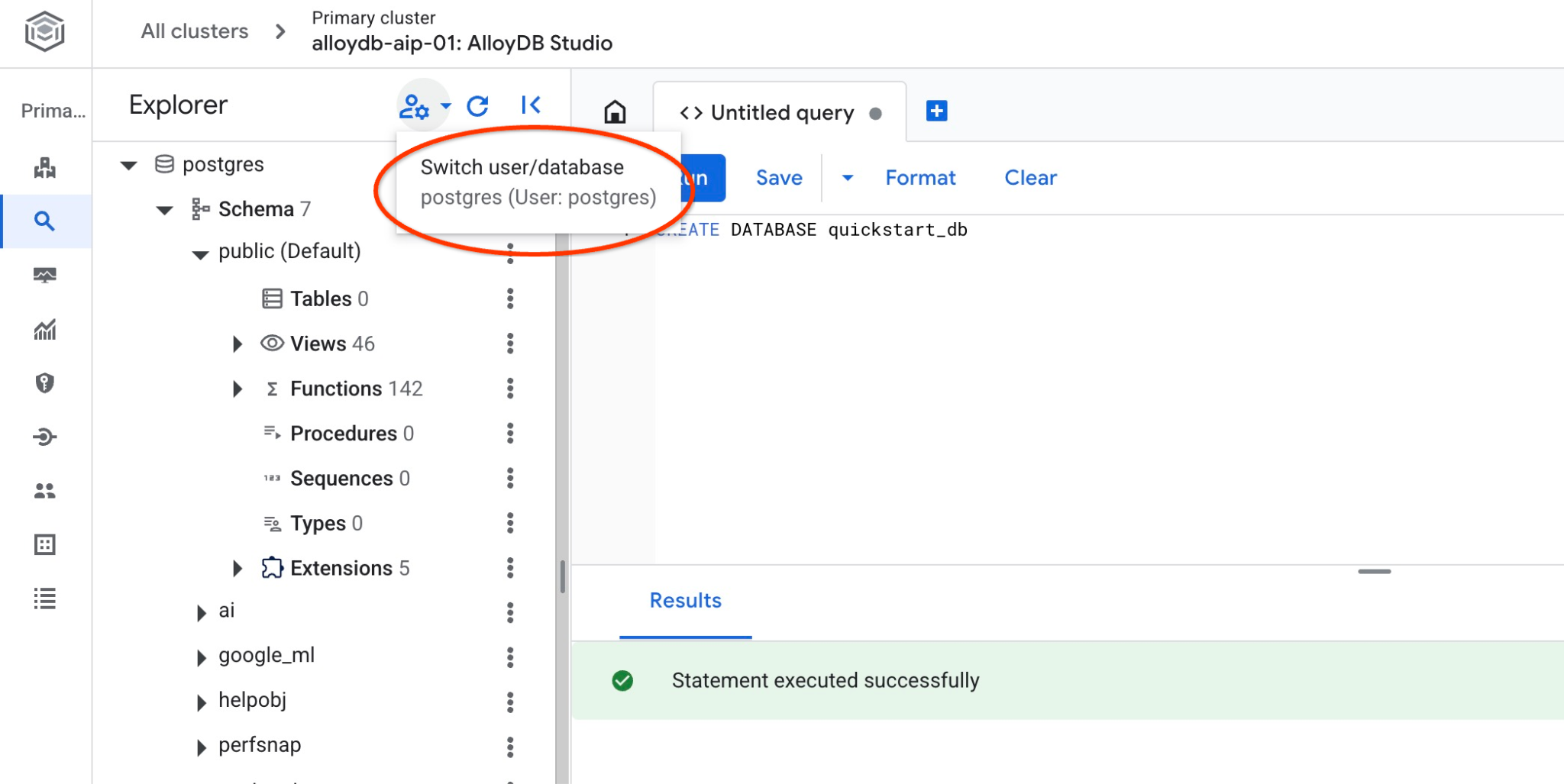
เลือกฐานข้อมูล quickstart_db ใหม่จากรายการแบบเลื่อนลง แล้วใช้การตรวจสอบสิทธิ์ IAM เดียวกัน
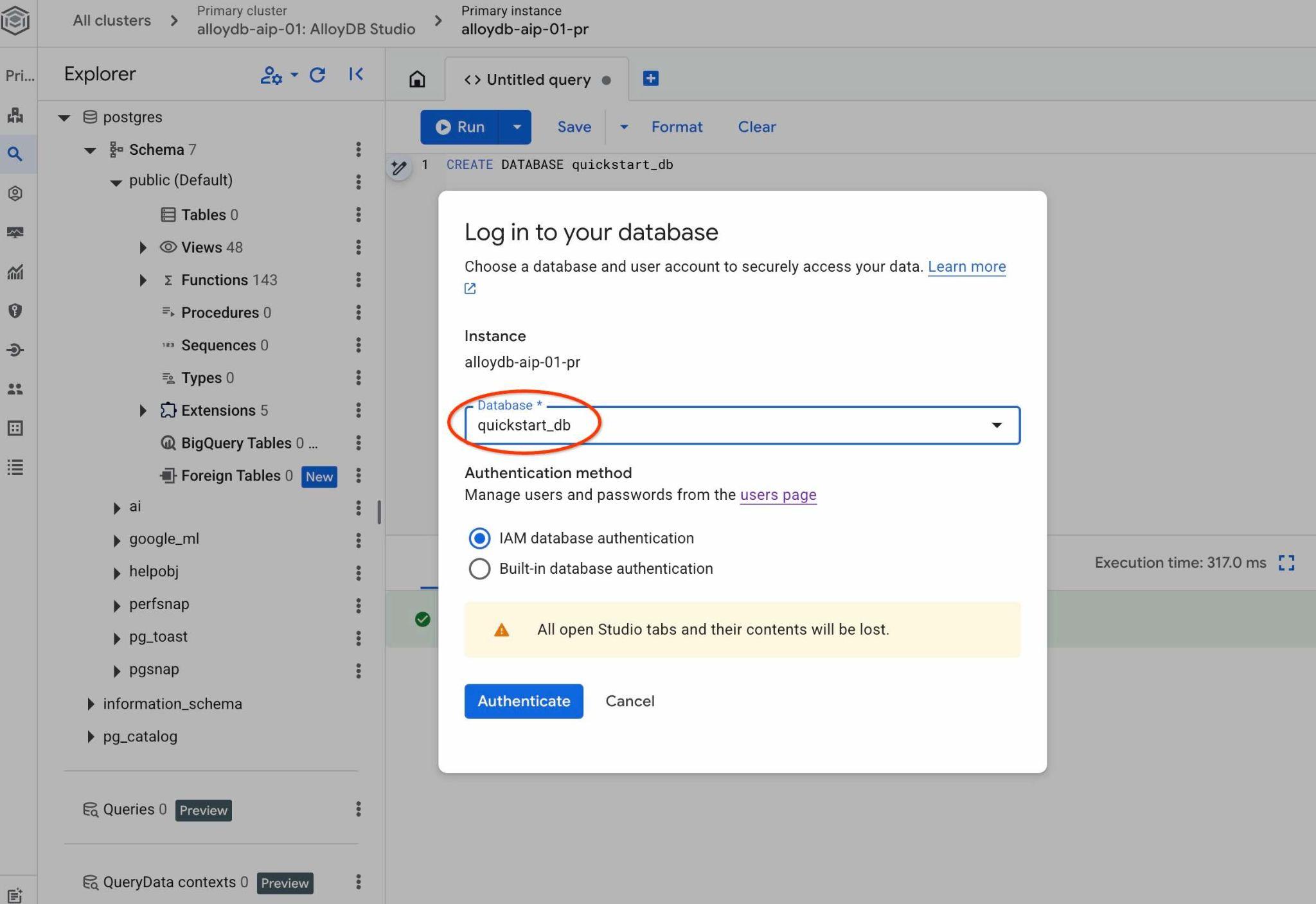
ระบบจะเปิดการเชื่อมต่อใหม่ที่คุณสามารถทำงานกับออบเจ็กต์จากฐานข้อมูล quickstart_db ได้ ที่นั่นคุณจะตรวจสอบสคีมาและข้อมูลที่นำเข้า รวมถึงทำงานกับชุดบริบท QueryData ได้
6. ข้อมูลตัวอย่าง
ตอนนี้คุณต้องสร้างออบเจ็กต์ในฐานข้อมูลและโหลดข้อมูล คุณจะใช้ชุดข้อมูลของบริษัท Cymbal Shipping ซึ่งเป็นบริษัทสมมติ โดยมีข้อมูลสมมติเกี่ยวกับสินค้า รถบรรทุก คำขอ และการเดินทางของรถบรรทุก รวมถึงคนขับรถสมมติ
สร้างที่เก็บข้อมูล
คุณจะใช้ Google SDK (gcloud) เพื่อนำเข้าข้อมูลจากที่เก็บที่โคลนไปยังฐานข้อมูล AlloyDB คุณจะต้องสร้าง Bucket ของ Cloud Storage สำหรับการดำเนินการดังกล่าวและให้สิทธิ์เข้าถึงบัญชีบริการ AlloyDB หรือคุณจะลองทำโดยใช้เว็บคอนโซลก็ได้เสมอตามที่อธิบายไว้ในเอกสารประกอบ
ในเทอร์มินัล Google Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
โหลดข้อมูล
ขั้นตอนถัดไปคือการโหลดข้อมูล SQL Dump ที่บีบอัดของเราจะอยู่ในโฟลเดอร์ที่เก็บที่โคลน คำสั่งต่อไปนี้ถือว่าคุณใช้ไดเรกทอรีหน้าแรกเป็นจุดเริ่มต้นเมื่อโคลนที่เก็บในขั้นตอนก่อนหน้าขณะสร้างคลัสเตอร์ AlloyDB
คัดลอกข้อมูลที่ส่งออกจาก SQL ที่บีบอัดไปยังที่เก็บข้อมูลใหม่
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
จากนั้นโหลดข้อมูลไปยังฐานข้อมูล quickstart_db โดยทำดังนี้
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
คำสั่งจะโหลดชุดข้อมูลตัวอย่างไปยังฐานข้อมูล quickstart_db คุณสามารถยืนยันตารางและบันทึกโดยใช้ AlloyDB Studio
7. ทำงานกับ Data Agent
มาเริ่มจาก AI Agent ตัวอย่างที่สร้างขึ้นโดยใช้ Google ADK สำหรับ Python และเชื่อมต่อกับอินสแตนซ์ AlloyDB โดยใช้ MCP Toolbox สำหรับฐานข้อมูลกัน
ติดตั้ง MCP Toolbox สำหรับฐานข้อมูล
MCP Toolbox สำหรับฐานข้อมูลเป็นโปรเจ็กต์โอเพนซอร์สที่ให้การสนับสนุน MCP สำหรับเครื่องมือฐานข้อมูลหลายรายการ รวมถึง AlloyDB สำหรับ PostgreSQL คุณสามารถอ่านข้อมูลเกี่ยวกับ MCP Toolbox ได้ในเอกสารประกอบ
คุณต้องดาวน์โหลดซอฟต์แวร์เวอร์ชันล่าสุดสำหรับแพลตฟอร์มของคุณ หากต้องการดูเวอร์ชันล่าสุด โปรดไปที่หน้ารุ่น ตัวอย่างต่อไปนี้แสดงวิธีดาวน์โหลด MCP Toolbox เวอร์ชัน 31 ไปยัง Cloud Shell
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
คุณต้องเตรียมไฟล์การกำหนดค่าสำหรับกล่องเครื่องมือ เรามีไฟล์ tools.yaml.example ตัวอย่างในไดเรกทอรีปัจจุบัน และจะเตรียมไฟล์ tools.yaml โดยแทนที่ตัวยึดตำแหน่ง 2 รายการด้วยรหัสโปรเจ็กต์และภูมิภาค
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
เริ่ม MCP Toolbox สำหรับฐานข้อมูล
ตอนนี้คุณเริ่มกล่องเครื่องมือ MCP ด้วยไฟล์การกำหนดค่าที่เตรียมไว้ได้แล้ว
เปิดแท็บใหม่ใน Google Cloud Shell โดยกดปุ่ม "+" ที่ด้านบนของอินเทอร์เฟซ Google Cloud Shell
ในแท็บใหม่ ให้เปลี่ยนไปที่ไดเรกทอรีที่มีไฟล์ไบนารีของกล่องเครื่องมือและไฟล์การกำหนดค่า tools.yaml แล้วเริ่มเซิร์ฟเวอร์ MCP
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
คุณควรเห็นข้อความ "เซิร์ฟเวอร์พร้อมให้บริการแล้ว" ในเอาต์พุต ซึ่งคล้ายกับข้อความต่อไปนี้
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
ตรวจสอบซอร์สโค้ดของ Agent
ในแท็บแรกของโฟลเดอร์ที่เก็บที่โคลน ให้ตรวจสอบโค้ดของเอเจนต์โดยใช้โปรแกรมแก้ไข Google Cloud Shell
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
คุณจะเห็นว่าในเอเจนต์มีส่วนสำหรับเซิร์ฟเวอร์ MCP ของ Google Cloud สำหรับ AlloyDB เรามีปลายทางเป็น MCP_SERVER_URL, การตรวจสอบสิทธิ์, รหัสโปรเจ็กต์ และการเพิ่มลงในชุดเครื่องมือ MCP
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
และในโค้ดของเอเจนต์ ชุดเครื่องมือ MCP จะรวมอยู่ในtoolsพารามิเตอร์สำหรับเอเจนต์ นอกจากนี้ยังมีชื่อคลัสเตอร์และอินสแตนซ์ ภูมิภาค และฐานข้อมูลเป็นตัวแปรสำหรับพรอมต์ของเอเจนต์
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
หลังจากตรวจสอบโค้ดแล้ว ให้กลับไปที่เทอร์มินัลโดยกดปุ่ม "เปิดเทอร์มินัล" ที่ด้านขวาบนของหน้าต่างเอดิเตอร์
เริ่มการทำงานของ Agent
ตอนนี้คุณสามารถเริ่มเอเจนต์ในโหมดอินเทอร์แอกทีฟได้โดยใช้อินเทอร์เฟซเว็บของ Google ADK อินเทอร์เฟซเว็บของ ADK ช่วยให้คุณทดสอบและแก้ปัญหาเวิร์กโฟลว์ของเอเจนต์ได้อย่างสะดวก
ก่อนอื่น ให้ติดตั้งแพ็กเกจที่จำเป็นทั้งหมดสำหรับ Python โดยใช้เครื่องมือจัดการแพ็กเกจ uv
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
เมื่อติดตั้งแพ็กเกจทั้งหมดแล้ว คุณต้องเพิ่มไฟล์ .env ลงในไดเรกทอรีของเอเจนต์เพื่อสั่งให้ใช้ Vertex AI ในการสื่อสารทั้งหมดกับโมเดล AI
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
จากนั้นคุณจะเริ่ม Agent ได้
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
คุณควรเห็นเอาต์พุตคล้ายกับเอาต์พุตต่อไปนี้ที่มีปลายทาง เช่น http://127.0.0.1:8000
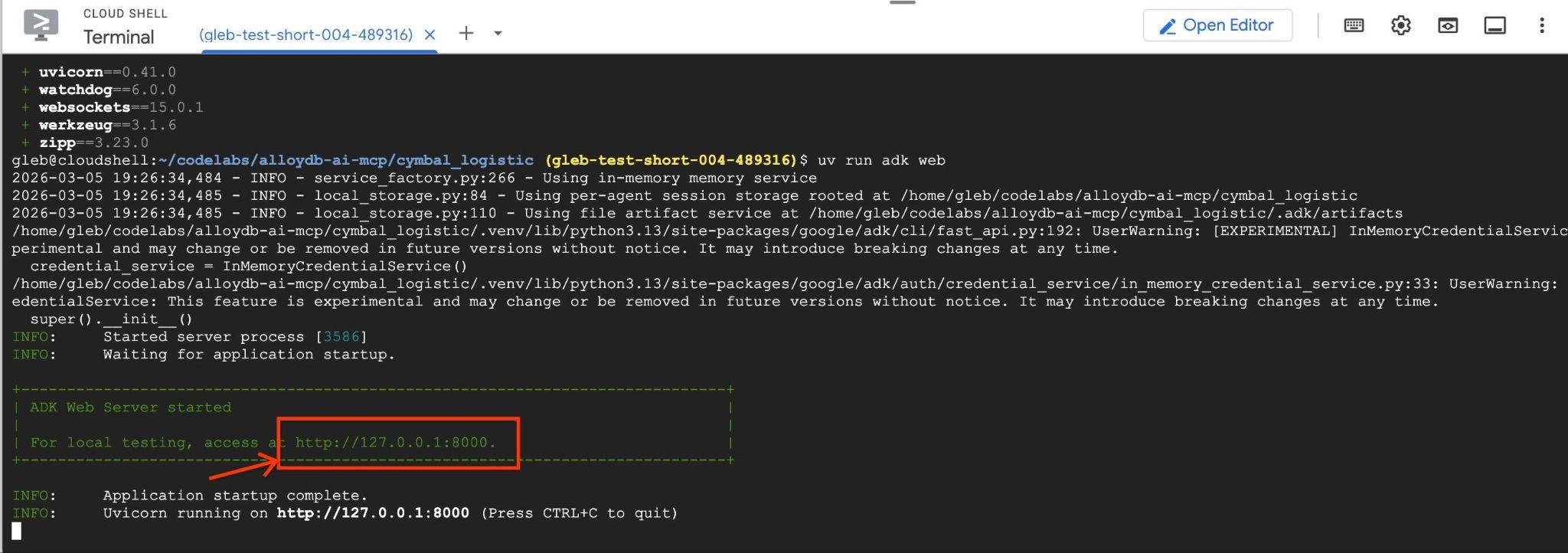
คุณคลิก URL นั้นใน Cloud Shell ได้ และระบบจะเปิดหน้าต่างแสดงตัวอย่างในแท็บเบราว์เซอร์แยกต่างหาก ซึ่งคุณเลือก data_agent จากรายการแบบเลื่อนลงทางด้านซ้ายได้
ในอินเทอร์เฟซเว็บของ ADK คุณสามารถโพสต์คำถามที่ด้านขวาล่างและดูขั้นตอนการดำเนินการทั้งหมด รวมถึงการติดตามสำหรับแต่ละขั้นตอนทางด้านขวา
8. ทดสอบ NL2SQL โดยไม่ต้องใช้ QueryData สำหรับ AlloyDB
Agent จะช่วยให้คุณถามคำถามในรูปแบบอิสระโดยใช้ภาษาที่เป็นธรรมชาติ และ Agent จะใช้กล่องเครื่องมือ MCP สำหรับฐานข้อมูลเป็นเครื่องมือในการตอบคำถาม คำถามจะโพสต์ที่ด้านขวาล่าง และคำตอบพร้อมการเรียกใช้เครื่องมือทั้งหมดจะปรากฏที่ด้านบน
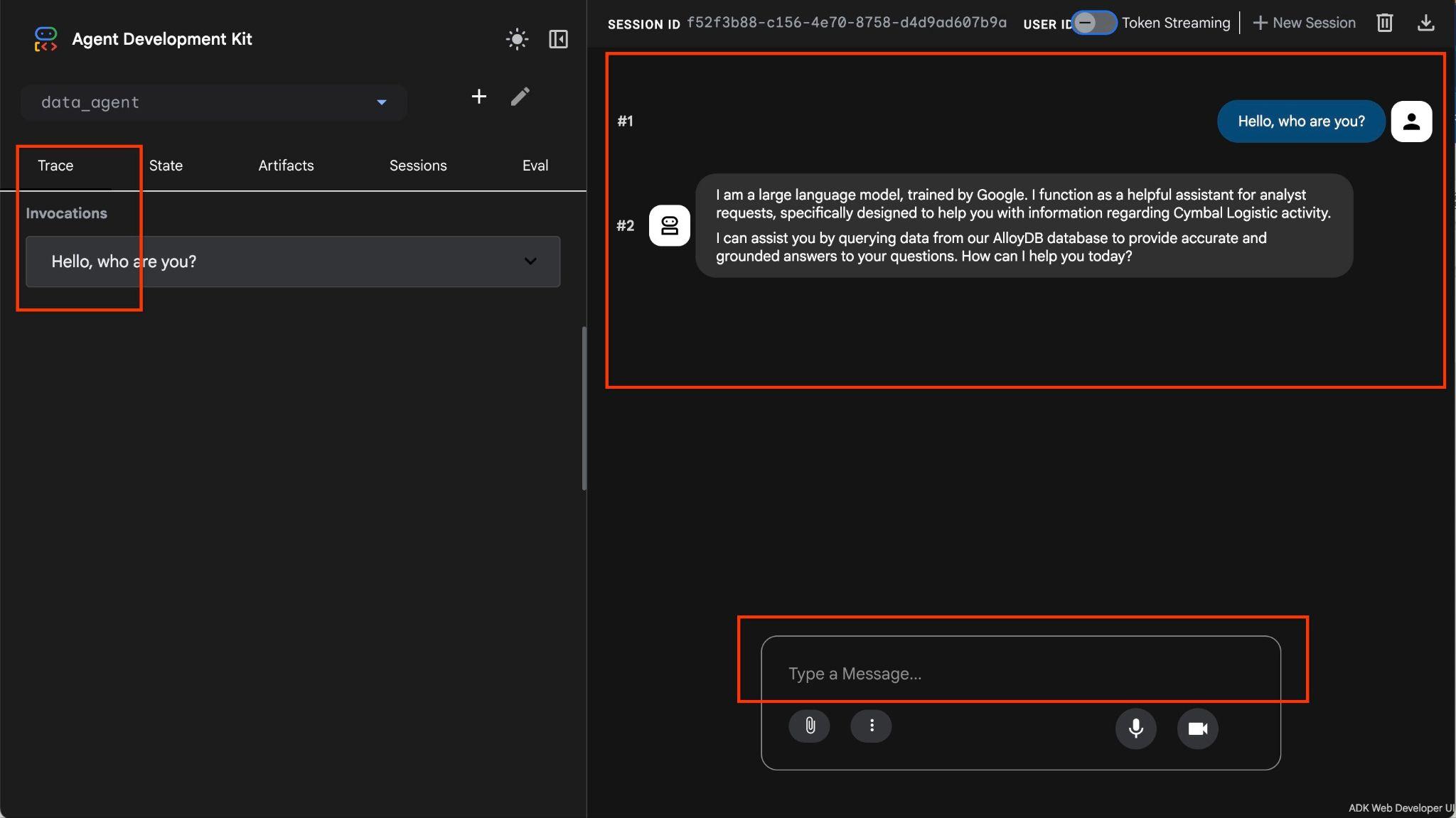
คุณกำลังทำงานกับข้อมูลการดำเนินงานของบริษัทขนส่งซึ่งมีข้อมูลเกี่ยวกับคำขอการจัดส่ง รถบรรทุก คนขับ และการเดินทางที่คนขับดำเนินการ คำถามแรกคือจำนวนการเดินทางที่ดำเนินการในเดือนกุมภาพันธ์ 2026
ในช่องป้อนข้อมูลที่ด้านขวาล่าง ให้พิมพ์ข้อความต่อไปนี้แล้วกด Enter
Hello, can you tell me how many trips we've done in February?
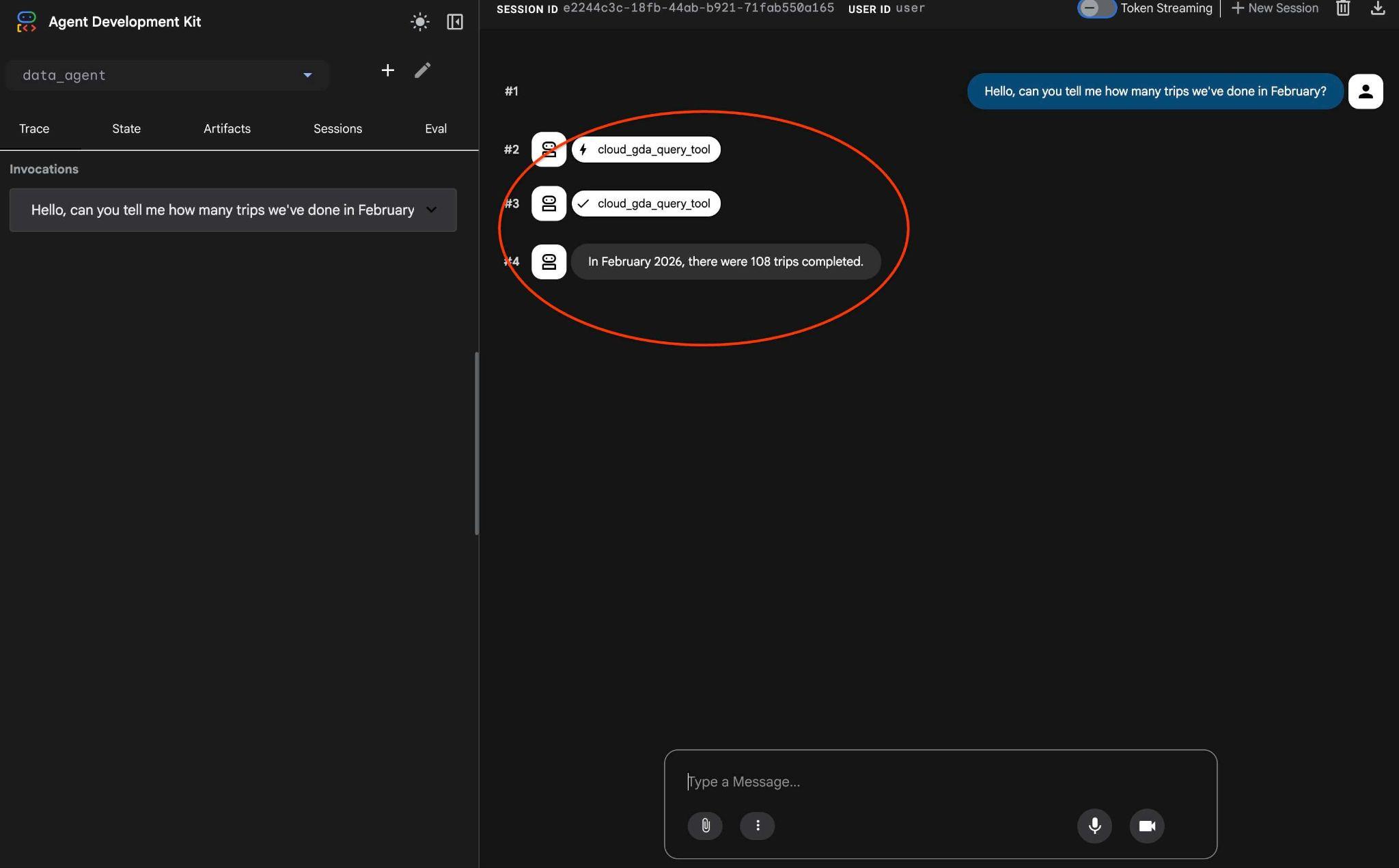
เอเจนต์จะทำงานโดยการเรียกใช้เครื่องมือหลายรายการเพื่อระบุตารางที่ถูกต้องในสคีมาโดยใช้ list_cymbal_logistics_schemas_tool และ execute_sql_tool ซึ่งจะเรียกใช้คำสั่ง SQL หลายรายการเพื่อรับข้อมูลที่ถูกต้อง
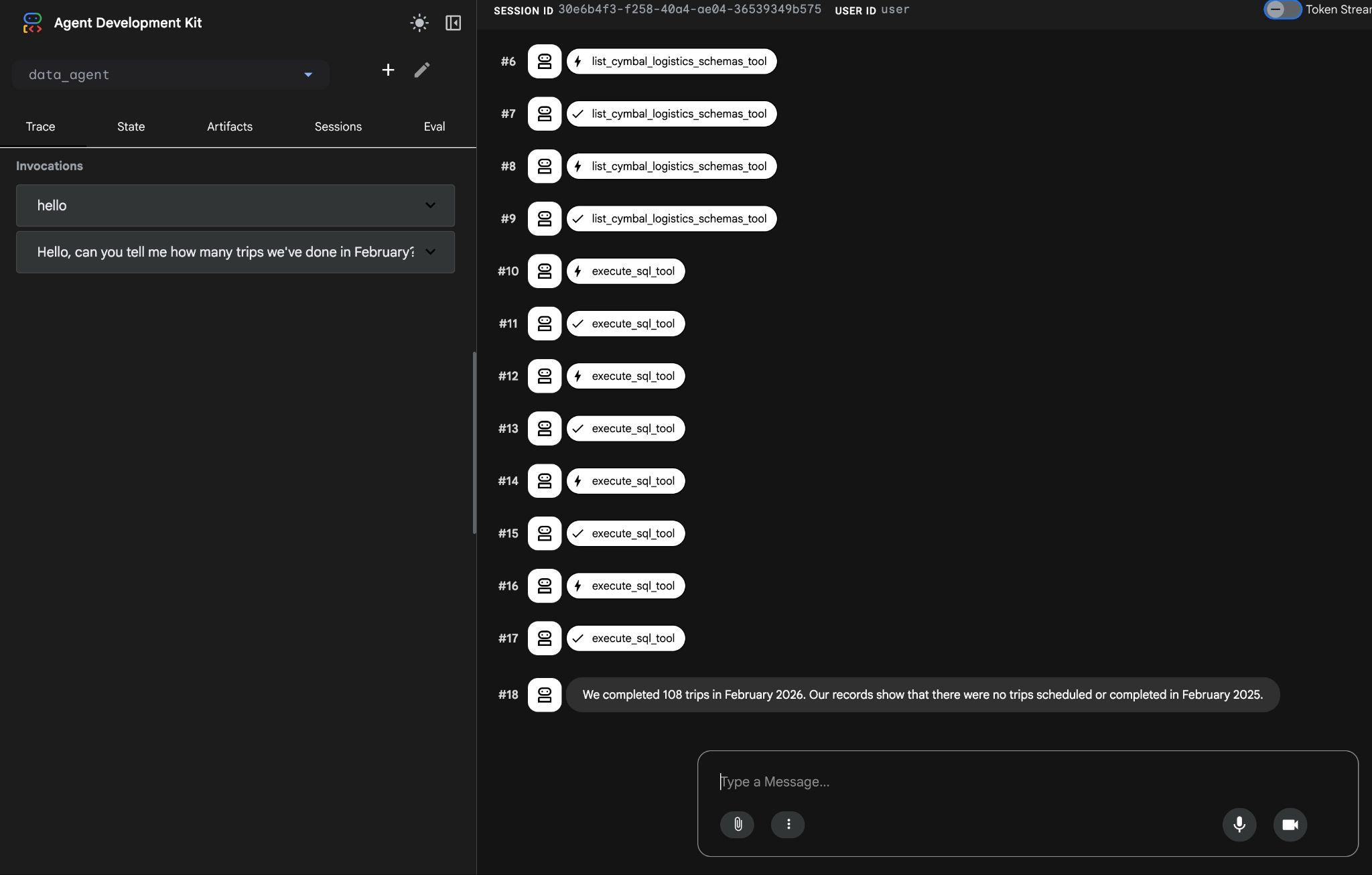
ในที่สุดก็จะให้ผลลัพธ์ที่ถูกต้องหลังจากสร้างคําค้นหาที่เหมาะสมและเรียกใช้ในฐานข้อมูล
เราเดินทางเสร็จสิ้น 108 ครั้งในเดือนกุมภาพันธ์ 2026 บันทึกของเราระบุว่าไม่มีการกำหนดเวลาหรือการเดินทางที่เสร็จสมบูรณ์ในเดือนกุมภาพันธ์ 2025
คุณดูสิ่งที่การเรียกใช้เครื่องมือแต่ละรายการทำได้โดยคลิกที่การดำเนินการเครื่องมือ ตัวอย่างเช่น นี่คือการค้นหาที่ดำเนินการเพื่อให้ได้ผลลัพธ์ของเรา
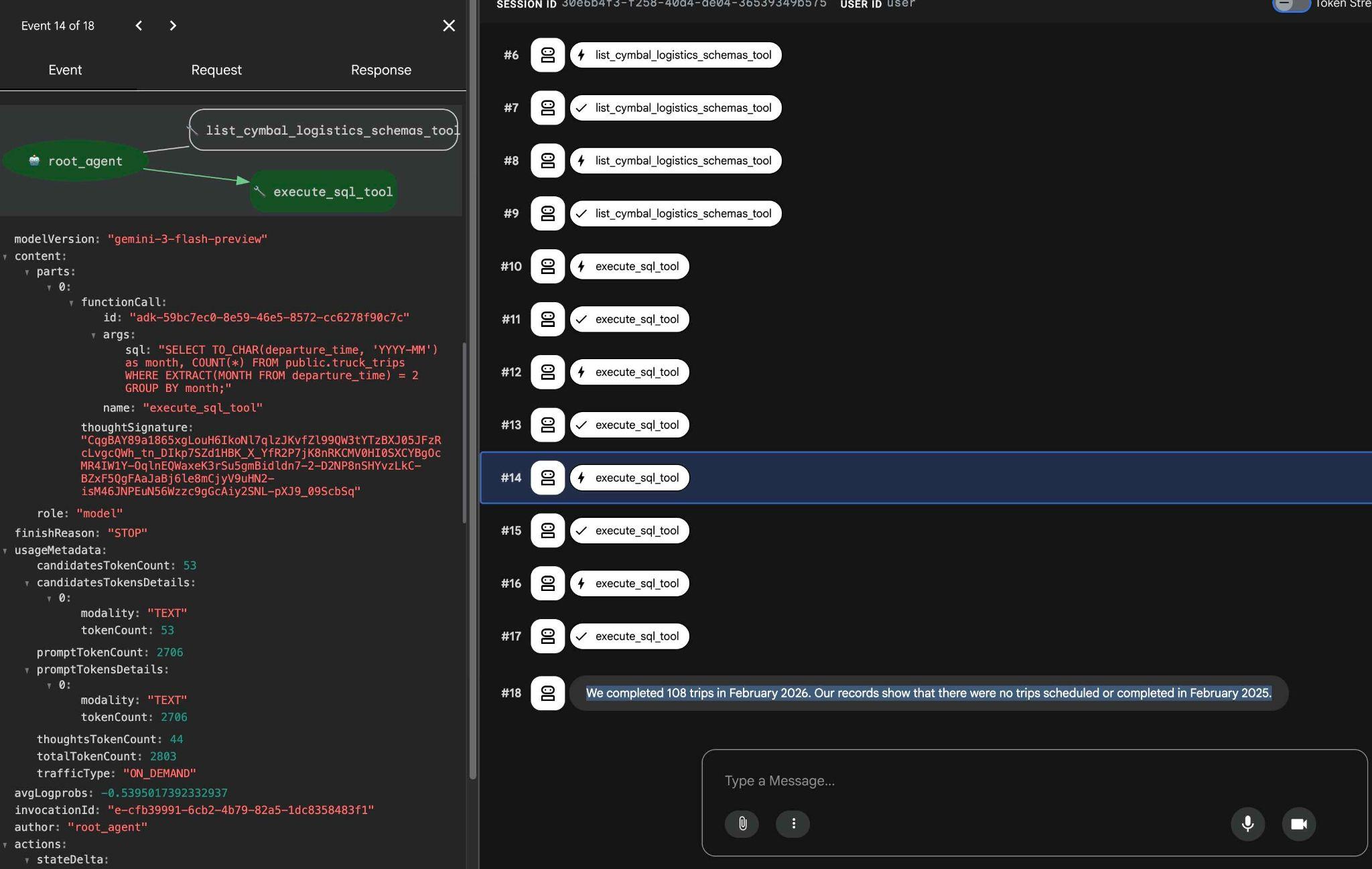
ลองใช้คำขออื่นๆ ที่ง่ายขึ้นโดยใช้อินเทอร์เฟซเว็บของ ADK แล้วดูว่า ADK จะดำเนินการค้นหาต่างๆ เพื่อให้ได้ผลลัพธ์อย่างไร
หยุด Agent โดยกด ctrl+c ในเทอร์มินัล คุณปิดแท็บเบราว์เซอร์ด้วยอินเทอร์เฟซเว็บของ ADK ได้
นอกจากนี้ คุณยังหยุด MCP Toolbox ในแท็บที่ 2 ได้โดยกดแป้นพิมพ์ลัด ctrl+c เดียวกัน แล้วปิดแท็บที่ 2
ในขั้นตอนถัดไป เราจะสร้างบริบท QueryData เพื่อปรับปรุงการตอบกลับและประสิทธิภาพของ NL2SQL
9. สร้าง ContextSet ของ QueryData
คุณอาจเห็นในขั้นตอนก่อนหน้าว่าโมเดล AI ทำการเรียกหลายครั้งไปยังสคีมาข้อมูลของฐานข้อมูลเพื่อดูว่าควรใช้ตารางและคอลัมน์ใดในการสร้างคําค้นหา SQL เราจะเพิ่มบริบท QueryData ที่กำหนดว่าควรเรียกใช้คำค้นหาใดเพื่อตอบสนองต่อคำขอหนึ่งๆ เพื่อปรับปรุงประสิทธิภาพ ความแม่นยำ และทำให้ผลลัพธ์คาดการณ์ได้มากขึ้น
สร้างเทมเพลตที่กำหนดเป้าหมาย
ContextSet ของ QueryData เป็นไฟล์ JSON ที่มีเทมเพลตการค้นหาและแง่มุมต่างๆ ซึ่งให้ข้อมูลและคำแนะนำที่จำเป็นแก่โมเดล AI เพื่อใช้คำค้นหา SQL หรือส่วนของคำค้นหา SQL ที่ถูกต้องเพื่อให้บรรลุเป้าหมายที่ขอตามรูปแบบการค้นหาและโครงสร้างข้อมูล
คุณเริ่มต้นจากเทมเพลตที่กำหนดเป้าหมาย สร้างไฟล์โดยใช้โปรแกรมแก้ไข Cloud Shell เรียกใช้ในเทอร์มินัล Cloud Shell
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
จากนั้นแทรกเทมเพลตสำหรับคำค้นหาที่เป็นภาษาธรรมชาติที่เราใช้ในบทก่อนหน้า ซึ่งก็คือ "เราเดินทางไปกี่ครั้งในเดือนกุมภาพันธ์"
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
จากนั้นดาวน์โหลดเทมเพลตไปยังคอมพิวเตอร์จาก Cloud Shell โดยใช้ปุ่มดาวน์โหลด
โหลดชุดบริบท QueryData
หากต้องการใช้ชุดบริบท QueryData คุณจะต้องอัปโหลดชุดบริบทดังกล่าวไปยังฐานข้อมูล
เปิด AlloyDB Studio ที่แผงด้านซ้ายด้านล่าง คุณจะเห็น QueryData Context และจุด 3 จุด
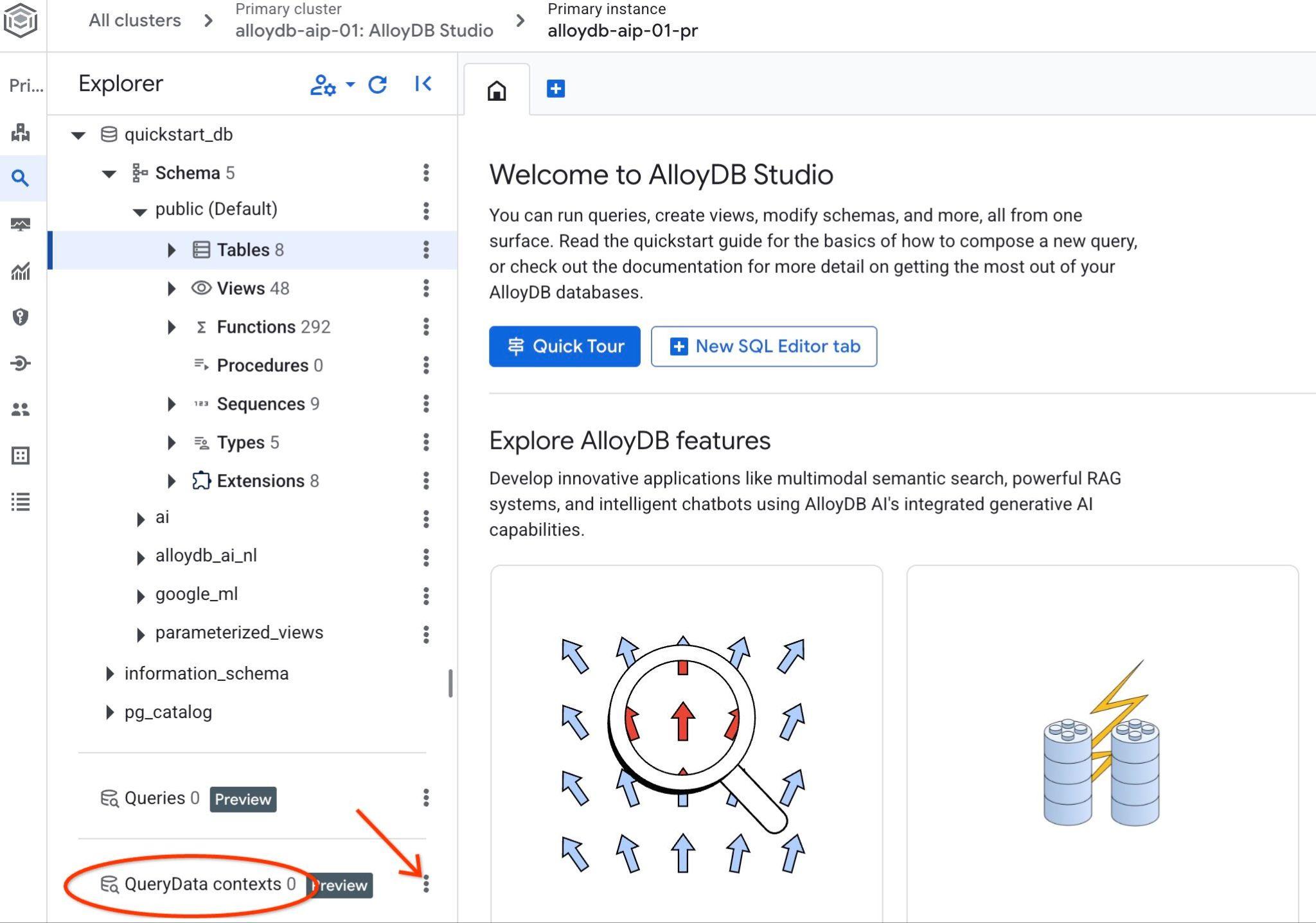
คลิกจุด 3 จุด แล้วเลือกสร้างบริบท ระบบจะเปิดกล่องโต้ตอบให้คุณใส่
- ชื่อ:
cymbal_context_set - คำอธิบาย:
Cymbal Logistic Query Data - อัปโหลดไฟล์บริบท: คลิกปุ่ม "
Browse" แล้วเลือกไฟล์ JSON ที่มี QueryData ContextSet
เมื่อกดปุ่มบันทึก ระบบอาจใช้เวลาสักครู่ในการเริ่มต้นพื้นที่เก็บข้อมูลบริบทหากคุณดำเนินการเป็นครั้งแรก
คุณควรจะเห็นบริบทที่ดาวน์โหลดไว้ และหากคลิกปุ่มแนวตั้ง 3 ปุ่มทางด้านขวา คุณจะเห็นการดำเนินการที่ใช้ได้ ในบทถัดไป เราจะเริ่มจากดำเนินการ "ทดสอบบริบท"
10. ทดสอบชุดบริบท QueryData
เทมเพลตการทดสอบ
ใช้การดำเนินการ "Test context" เพื่อทดสอบบริบทของเราใน AlloyDB Studio เมื่อคลิก "ทดสอบบริบท" ระบบจะเปิดหน้าต่างเอดิเตอร์ AlloyDB Studio ใหม่ที่มีชื่อว่า "cymbal_context_set" และคำเชิญให้สร้าง SQL ของ Gemini ที่มีชื่อว่า "Generate SQL using QueryData context: cymbal_context_set " คลิกการสร้าง SQL แล้วพิมพ์
Hello, can you tell me how many trips we've done in February?
และเมื่อ SQL สร้างขึ้น ให้กดปุ่ม "Insert"
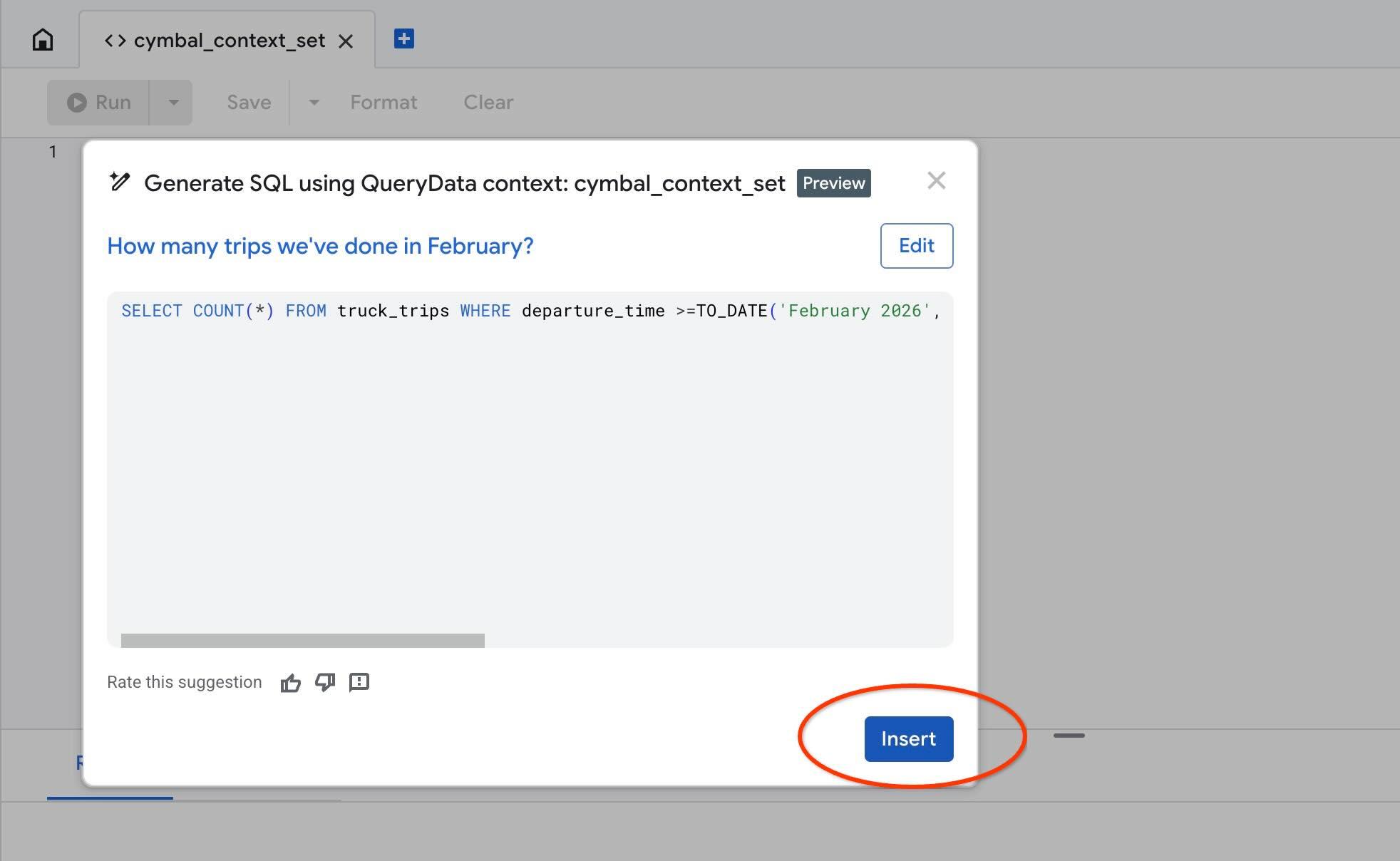
คุณจะเห็นคำค้นหาเดียวกันกับที่เราใส่ไว้ในเทมเพลตบริบทก่อนหน้านี้
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
ลองแทนที่เดือนด้วย "มกราคม" แล้วตรวจสอบคำสั่ง SQL ที่สร้างขึ้น โดยจะใช้เดือนเป็นพารามิเตอร์สำหรับ Intent ที่มีพารามิเตอร์ และปรับคำสั่ง SQL โดยอัตโนมัติ
สร้างแง่มุมของ QueryData
เราลองใช้เทมเพลตสำหรับคำค้นหาแล้ว และเทมเพมเพลตจะทำงานได้เมื่อเรารู้ว่าคำขอของผู้ใช้เป็นประเภทใด แต่บางครั้งการแนะนำเฉพาะส่วนของคำค้นหา เช่น เงื่อนไขหรือตัวกรอง ก็มีประโยชน์เมื่อเราต้องการให้ใช้ลำดับหรือข้อความที่เฉพาะเจาะจงเพื่อวัตถุประสงค์ที่กำหนดใหม่
เช่น หากเราขอให้แสดงข้อมูลของ "เดือนที่ผ่านมา" เราต้องการรับรายงานของเดือนตามปฏิทินที่ผ่านมาตั้งแต่วันที่ 1 ถึงวันสุดท้ายของเดือนนั้น แต่ไม่ใช่ในช่วง 30 วันที่ผ่านมา
เราสามารถเพิ่มแง่มุมดังกล่าวเป็นข้อมูลโค้ด SQL ลงในการกำหนดค่า ContextSet พร้อมกับเทมเพลตที่เราเพิ่มไว้ก่อนหน้านี้ เปิด querydata_cymbal_contextset.json
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
และเพิ่มแง่มุมหลังจากเทมเพลตที่มีอยู่แล้ว เนื้อหาที่ได้ในไฟล์ควรเป็นดังนี้
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
บันทึกไฟล์แล้วอัปโหลดไปยังคอมพิวเตอร์
จากนั้นใช้การดำเนินการบริบทของคำค้นหา "แก้ไขบริบท" แล้วอัปโหลดไฟล์ที่แก้ไขเพื่อแทนที่บริบทเก่าด้วยบริบทใหม่
ตอนนี้ลองใช้บริบทการทดสอบอีกครั้งและสร้างคำสั่ง SQL โดยใช้เจตนา "เดือนที่แล้ว" เช่น หากคุณสร้าง SQL สำหรับวลี "show trucks trips for the last month"" ระบบจะใช้เงื่อนไขที่เราให้ไว้เป็น Facet ในไฟล์ cymbal_context.json
คุณควรได้รับผลลัพธ์คล้ายกับตัวอย่างต่อไปนี้
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
แล้วคุณจะใช้ฟีเจอร์นี้กับ AI Agent ได้อย่างไร ในบทถัดไป เราจะทำให้บริบทของข้อมูลการค้นหาพร้อมใช้งานสำหรับเอเจนต์ AI
11. QueryData ด้วย AI Agent
คุณจะใช้ Data Agent ตัวเดิม แต่ตอนนี้จะมีการกำหนดค่า MCP Toolbox ให้ใช้ QueryData ContextSet
เตรียมและเริ่ม MCP Toolbox สำหรับฐานข้อมูล
เราต้องมีไฟล์การกำหนดค่าใหม่สำหรับ MCP Toolbox ซึ่งจะใช้ Gemini Data Analytics API และ AlloyDB เป็นแหล่งที่มาของฐานข้อมูล
เรียกใช้ในเทอร์มินัล
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
สลับไปที่เครื่องมือแก้ไขและค้นหาไฟล์ querydata.yaml ไฟล์การกำหนดค่า querydata.yaml จะมีลักษณะดังต่อไปนี้ ยกเว้นรหัสโปรเจ็กต์และภูมิภาคที่จะแสดงสภาพแวดล้อมของคุณ แต่คุณยังคงต้องอัปเดตcontextSetId value และแทนที่ตัวยึดตำแหน่ง "<add-context-set-id>" ด้วยค่าจากคอนโซล
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
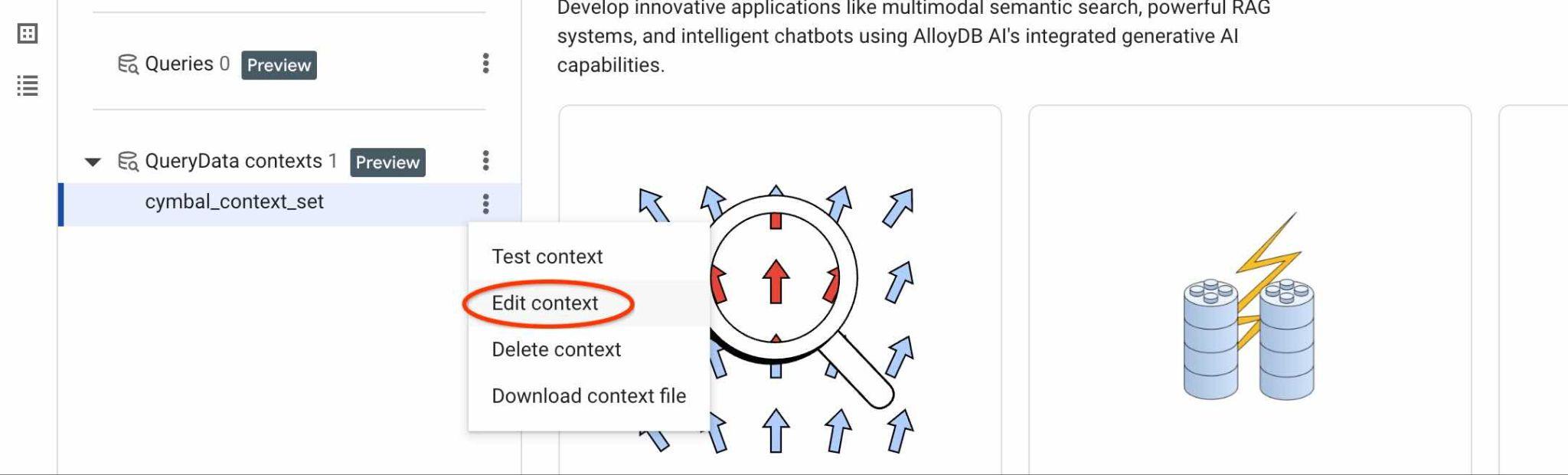
หากต้องการหารหัส ContextSet ให้คลิกปุ่มแก้ไขสำหรับชุดบริบทตามที่แสดงในรูปภาพ
คุณจะเห็นรหัสชุดบริบทที่ด้านบนในแท็บใหม่ทางด้านขวา
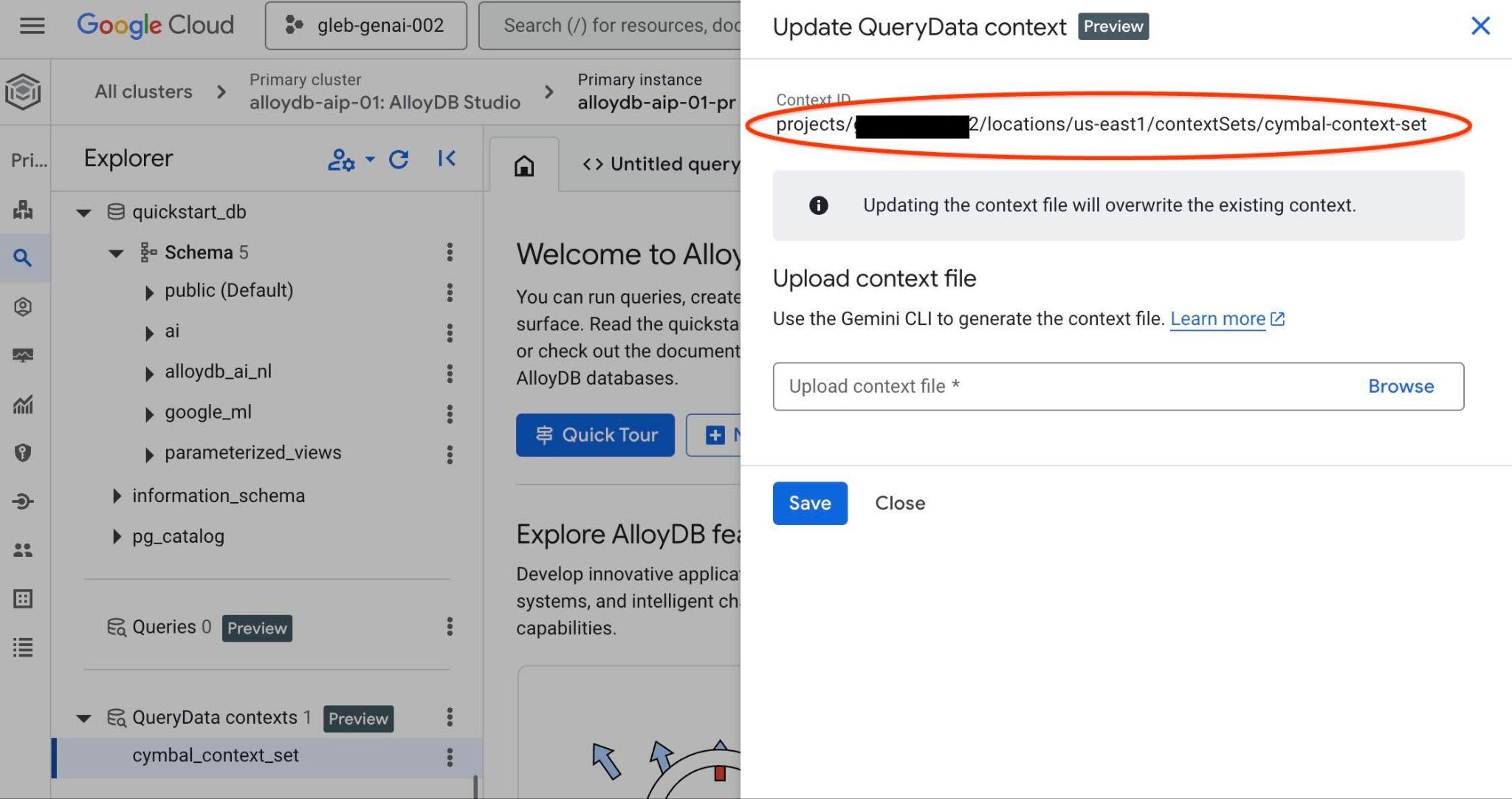
คุณควรใส่เส้นทางแบบเต็มดังกล่าวเพื่อแทนที่ตัวยึดตำแหน่ง "<add-context-set-id>" ในไฟล์ querydata.yaml
เปลี่ยนกลับไปที่เทอร์มินัล
เปิดแท็บใหม่ใน Google Cloud Shell โดยกดปุ่ม "+" ที่ด้านบนของอินเทอร์เฟซ Google Cloud Shell
ในแท็บใหม่ ให้เปลี่ยนไปที่ไดเรกทอรีที่มีไฟล์ไบนารีของกล่องเครื่องมือและไฟล์การกำหนดค่า tools.yaml แล้วเริ่มเซิร์ฟเวอร์ MCP
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
เรียกใช้ Agent ประเภท ADK
เริ่มตัวแทนในแท็บ Cloud Shell แรก
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
และเมื่อเริ่มแล้ว ให้คลิกลิงก์ http://127.0.0.1:8000 อีกครั้ง
คุณจะเห็นอินเทอร์เฟซของตัวแทนแสดงตัวอย่างเว็บ ADK ที่คุ้นเคยอยู่แล้ว โพสต์คำค้นหาเดียวกันกับครั้งล่าสุด
Hello, can you tell me how many trips we've done in February?
และดูเวิร์กโฟลว์ของตัวแทน หากกำหนดค่าทุกอย่างถูกต้อง คุณควรเห็นข้อความคล้ายกับข้อความต่อไปนี้
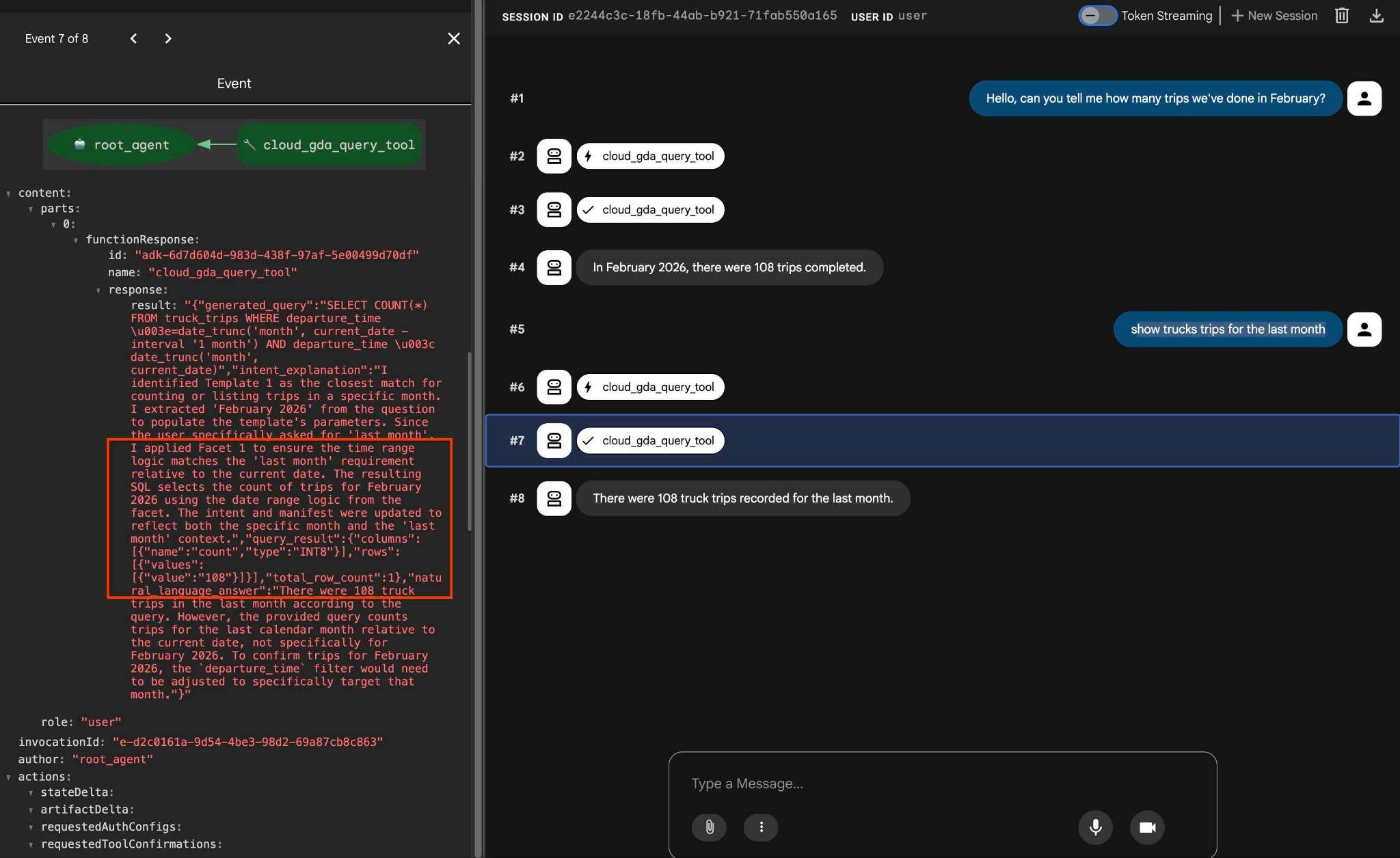
คำขอที่ต้องใช้หลายรอบเมื่อครั้งที่แล้วได้รับการเปลี่ยนเป็นการเรียกเครื่องมือ MCP ครั้งเดียวและดำเนินการโดยใช้คำสั่ง SQL ที่คาดการณ์ได้
คุณทดสอบแง่มุมที่กำหนดค่าได้โดยใช้คำขอ เช่น
how trucks trips for the last month
และในเอาต์พุต หากคลิกการดำเนินการของเครื่องมือ คุณจะเห็นว่าเครื่องมือใช้เครื่องมือเดียวกันและใช้แง่มุมต่างๆ เพื่อให้ได้ผลลัพธ์
ห้องทดลองของเราก็มีเพียงเท่านี้ เราหวังว่าคุณจะสามารถดูตัวอย่างทั้งหมดและเรียนรู้วิธีใช้ QueryData สำหรับ AlloyDB เทคโนโลยีที่ให้มาช่วยให้ปริมาณงานแบบเป็น Agent และการสร้าง SQL คาดการณ์ได้และเชื่อถือได้
12. ล้างสภาพแวดล้อม
แนวทางปฏิบัติแนะนำคือการล้างข้อมูลทรัพยากรชั่วคราวเพื่อป้องกันการเรียกเก็บเงินที่ไม่คาดคิด วิธีที่น่าเชื่อถือที่สุดคือการลบโปรเจ็กต์ที่คุณใช้ทดสอบเวิร์กโฟลว์ แต่คุณเลือกจำกัดตัวเองได้โดยการลบทรัพยากรแต่ละรายการ เช่น AlloyDB
ทำลายอินสแตนซ์และคลัสเตอร์ AlloyDB เมื่อคุณทำแล็บเสร็จแล้ว
ลบคลัสเตอร์ AlloyDB และอินสแตนซ์ทั้งหมด
หากคุณเคยใช้ AlloyDB เวอร์ชันทดลองใช้ อย่าลบคลัสเตอร์ทดลองหากคุณวางแผนที่จะทดสอบห้องทดลองและทรัพยากรอื่นๆ โดยใช้คลัสเตอร์ทดลอง คุณจะสร้างคลัสเตอร์ทดลองอื่นในโปรเจ็กต์เดียวกันไม่ได้
คลัสเตอร์จะถูกทำลายด้วยตัวเลือก force ซึ่งจะลบอินสแตนซ์ทั้งหมดที่เป็นของคลัสเตอร์ด้วย
ใน Cloud Shell ให้กำหนดตัวแปรโปรเจ็กต์และตัวแปรสภาพแวดล้อมหากคุณถูกตัดการเชื่อมต่อและสูญเสียการตั้งค่าก่อนหน้านี้ทั้งหมด
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
ลบคลัสเตอร์
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
เอาต์พุตของคอนโซลที่คาดไว้
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
ลบข้อมูลสำรองของ AlloyDB
ลบข้อมูลสำรอง AlloyDB ทั้งหมดสำหรับคลัสเตอร์
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
เอาต์พุตของคอนโซลที่คาดไว้
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
13. ขอแสดงความยินดี
ขอแสดงความยินดีที่ทำ Codelab นี้เสร็จสมบูรณ์
สิ่งที่เราได้พูดถึง
- วิธีสร้างคลัสเตอร์ AlloyDB และนำเข้าข้อมูลตัวอย่าง
- วิธีเปิดใช้ AlloyDB Data Access API
- วิธีเปิดใช้ QueryData สำหรับ AlloyDB
- วิธีสร้างเทมเพลต
- วิธีใช้การค้นหาตามประเภทที่จัดแบ่งไว้
- วิธีใช้ QueryData กับเอเจนต์ AI
14. แบบสำรวจ
เอาต์พุต: