
1. Giriş
Bu codelab'de, AlloyDB için QueryData'yı kullanmaya başlama ve bunu, ajan tabanlı uygulamalarda doğal dil girişinden doğru ve tahmin edilebilir SQL ifadeleri oluşturmak için kullanma hakkında bir kılavuz sunulmaktadır.
Ön koşullar
- Google Cloud Console hakkında temel bilgiler
- Komut satırı arayüzü ve Cloud Shell'de temel beceriler
Neler öğreneceksiniz?
- AlloyDB kümesi oluşturma ve örnek verileri içe aktarma
- AlloyDB Veri Erişimi API'sini etkinleştirme
- AlloyDB için QueryData'yı etkinleştirme
- Şablon oluşturma
- Özelliklere göre aramayı kullanma
- QueryData'yı yapay zeka aracılarıyla kullanma
Gerekenler
- Google Cloud hesabı ve Google Cloud projesi
- Google Cloud Console ve Cloud Shell'i destekleyen Chrome gibi bir web tarayıcısı
2. Kurulum ve Gereksinimler
Proje kurulumu
Google Cloud projesi oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin.
Cloud Shell'i başlatma
Google Cloud, dizüstü bilgisayarınızdan uzaktan çalıştırılabilir. Ancak bu codelab'de, Cloud'da çalışan bir komut satırı ortamı olan Google Cloud Shell'i kullanacaksınız.
Google Cloud Console'da sağ üstteki araç çubuğunda Cloud Shell simgesini tıklayın:
Alternatif olarak G, ardından S tuşuna basabilirsiniz. Bu sıra, Google Cloud Console'da veya bu bağlantıyı kullanıyorsanız Cloud Shell'i etkinleştirir.
Ortamın temel hazırlığı ve bağlanması yalnızca birkaç dakikanızı alır. İşlem tamamlandığında aşağıdakine benzer bir sonuç görürsünüz:

Bu sanal makine, ihtiyaç duyacağınız tüm geliştirme araçlarını içerir. 5 GB boyutunda kalıcı bir ana dizin sunar ve Google Cloud üzerinde çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde güçlenir. Bu codelab'deki tüm çalışmalarınızı tarayıcıda yapabilirsiniz. Herhangi bir şey yüklemeniz gerekmez.
3. Başlamadan önce
API'yi etkinleştirme
AlloyDB, Compute Engine, ağ hizmetleri ve Vertex AI'ı kullanmak için Google Cloud projenizde ilgili API'leri etkinleştirmeniz gerekir.
Cloud Shell terminalinde proje kimliğinizin ayarlandığından emin olun:
gcloud config get-value project
Çıkışta proje tID'nizi görmeniz gerekir:
student@cloudshell:~ (test-project-001-402417)$ gcloud config get-value project Your active configuration is: [cloudshell-23188] test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$
PROJECT_ID ortam değişkenini ayarlayın:
PROJECT_ID=$(gcloud config get-value project)
Gerekli tüm hizmetleri etkinleştirin:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Beklenen çıktı
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB'yi dağıtma
AlloyDB kümesi ve birincil örnek oluşturun. Gerekli tüm kaynakları dağıtacak şekilde hazırlanmış bir komut dosyası kullanarak dağıtabilir veya belgeleri inceleyerek adım adım kendiniz yapabilirsiniz.
Otomatik komut dosyası kullanarak AlloyDB'yi dağıtma
Bu yaklaşımda, AlloyDB kümesini dağıtmak için otomatik bir komut dosyası kullanılır ve dağıtılan kaynaklarla çalışmaya başlamak için gerekli bilgiler sağlanır.
Cloud Shell terminalinde, dağıtım komut dosyasını depodan klonlamak için komutu çalıştırın.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-querydata"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
Dağıtım komut dosyasını çalıştırın.
./deploy_alloydb.sh --public-ip
Komut dosyasının çalışması biraz zaman alır (genellikle yaklaşık 5-7 dakika). Bu süre içinde AlloyDB kümesi ve genel ve özel IP'ye sahip bir birincil örnek dağıtılır. Herkese açık IP yalnızca yetkilendirilmiş ağlar için veya AlloyDB Auth Proxy kullanılarak kullanılabilir. Herkese açık IP hakkında daha fazla bilgiyi belgelerde bulabilirsiniz. Komut dosyası, çıkış olarak dağıtılan AlloyDB kümeniz hakkında bilgi sağlamalıdır. Şifrenizin farklı olacağını lütfen unutmayın. Şifreyi ileride kullanmak üzere bir yere kaydedin.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
Yeni kümeyi ve birincil örneği web konsolunda da görebilirsiniz.
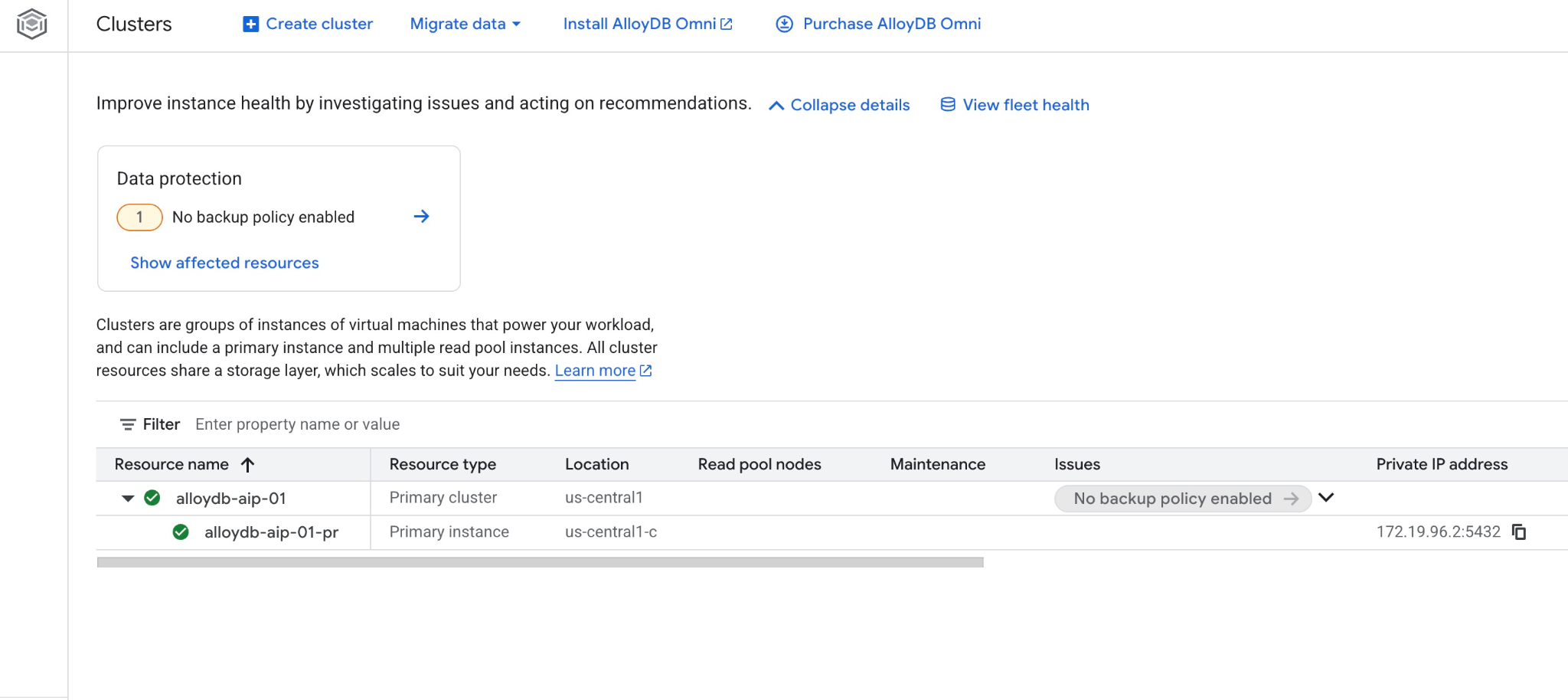
5. Veritabanını Hazırlama
Yapay zeka işlevlerini ve operatörlerini kullanmak için Vertex AI entegrasyonunu etkinleştirmeniz, veri erişimi API'sini etkinleştirmeniz ve örnek veri kümesi için bir veritabanı oluşturmanız gerekir.
AlloyDB'ye Gerekli İzinleri Verme
AlloyDB hizmet aracısına Vertex AI izinleri ekleyin.
En üstteki "+" işaretini kullanarak başka bir Cloud Shell sekmesi açın.
Yeni Cloud Shell sekmesinde şunu çalıştırın:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Veri Erişimi API'sini etkinleştirme
execute_sql gibi MCP araçlarını kullanabilmek için AlloyDB kümesinde Data Access API'yi etkinleştirmeniz gerekir.
Aynı terminal sekmesinde yürütün.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
IAM kimlik doğrulamasını etkinleştirme
Ajan tabanlı araçlarımız için IAM kimlik doğrulamasını kullanacağız. Bu nedenle, örnekte IAM kimlik doğrulamasını etkinleştirmeniz ve kendinizi veritabanı kullanıcısı olarak eklemeniz gerekiyor. IAM kimlik doğrulamasını örnek düzeyinde etkinleştirmeden önce lütfen veri erişimi API'sini etkinleştiren önceki adımın tamamlanmasını bekleyin. Örnek durumunuz yeşil olmalıdır.
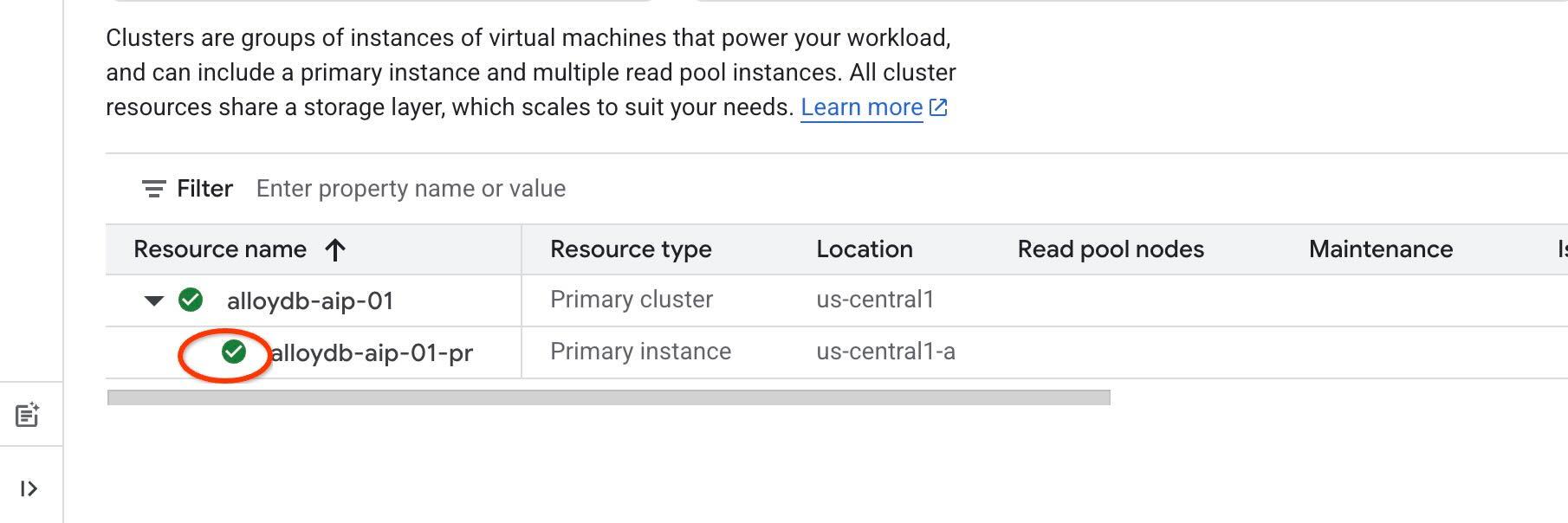
Örnek düzeyinde IAM'yi etkinleştirerek başlıyoruz. Aynı terminal sekmesinde yürütün.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags password.enforce_complexity=on,alloydb.iam_authentication=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Kendinizi AlloyDB kullanıcısı olarak ekleyin:
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud alloydb users create $(gcloud config get-value account) \
--cluster=$ADBCLUSTER \
--superuser=true \
--region=$REGION \
--type=IAM_BASED
Sekmede "exit" komutunu çalıştırarak sekmeyi kapatın:
exit
AlloyDB Studio'ya bağlanma
Aşağıdaki bölümlerde, veritabanına bağlantı gerektiren tüm SQL komutları AlloyDB Studio'da yürütülebilir. T
Postgres için AlloyDB'deki Kümeler sayfasına gidin.
Birincil örneği tıklayarak AlloyDB kümeniz için web konsolu arayüzünü açın.
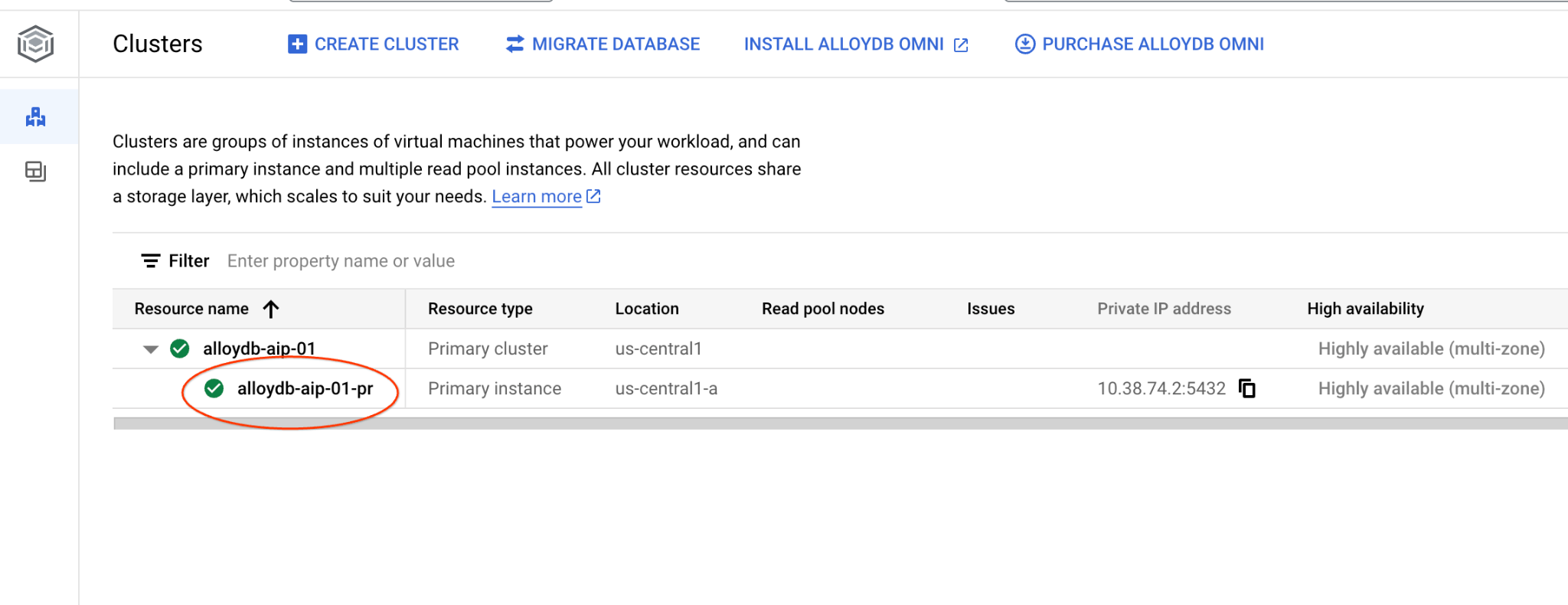
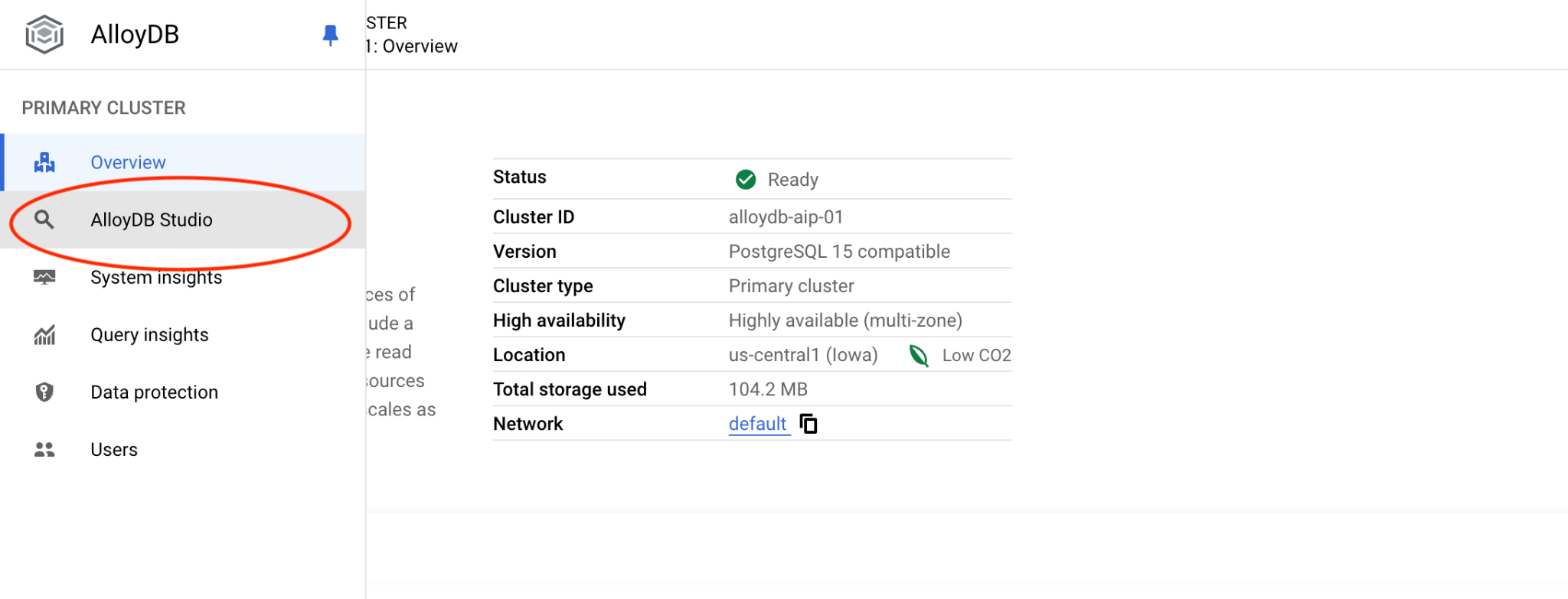
Ardından sol taraftaki AlloyDB Studio'yu tıklayın:
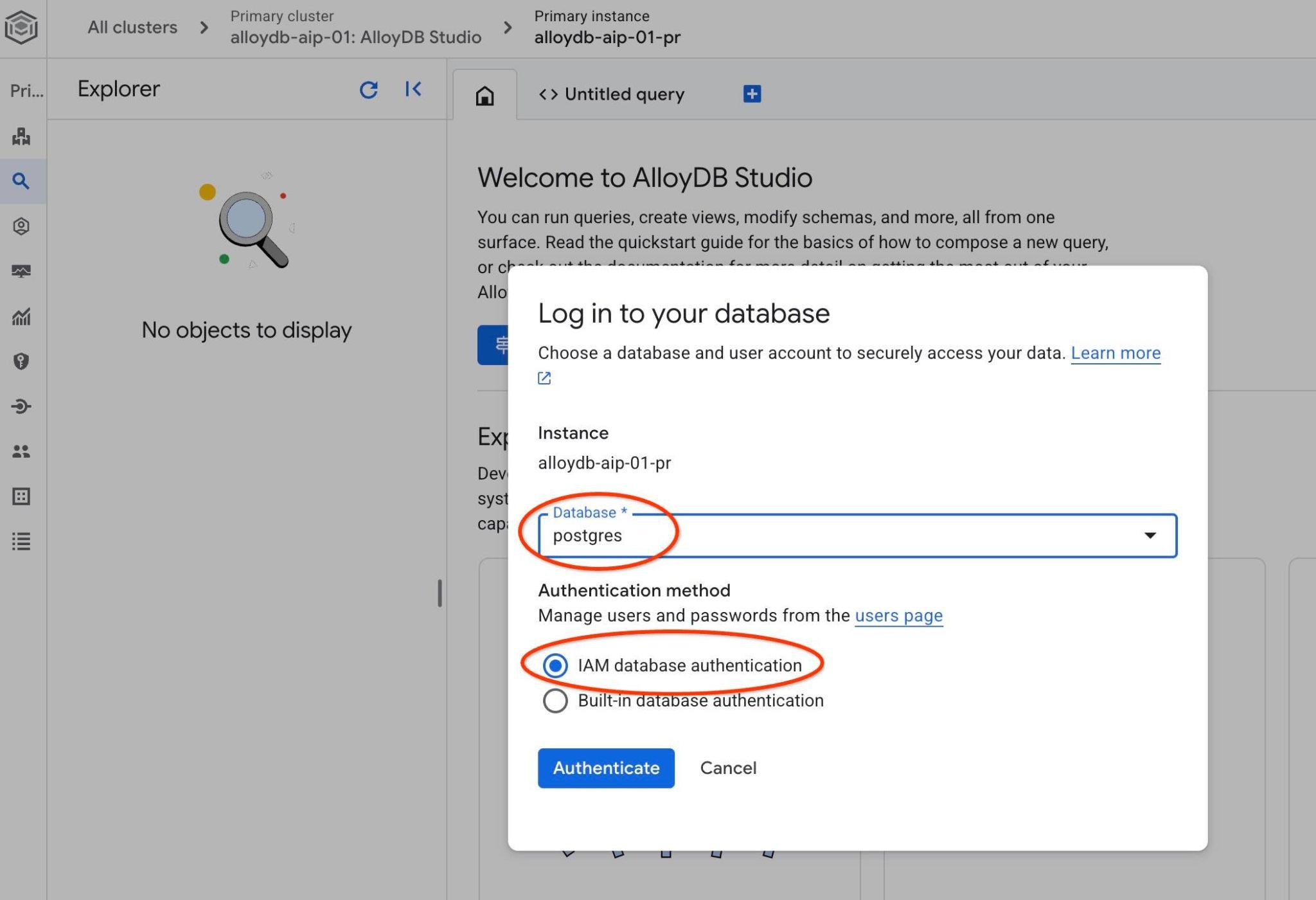
Postgres veritabanını ve IAM kimlik doğrulamasını seçin. Ardından "Kimlik doğrulama" düğmesini tıklayın.
AlloyDB Studio arayüzü açılır. Veritabanındaki komutları çalıştırmak için sağdaki "Untitled Query" (Adsız Sorgu) sekmesini tıklayın.
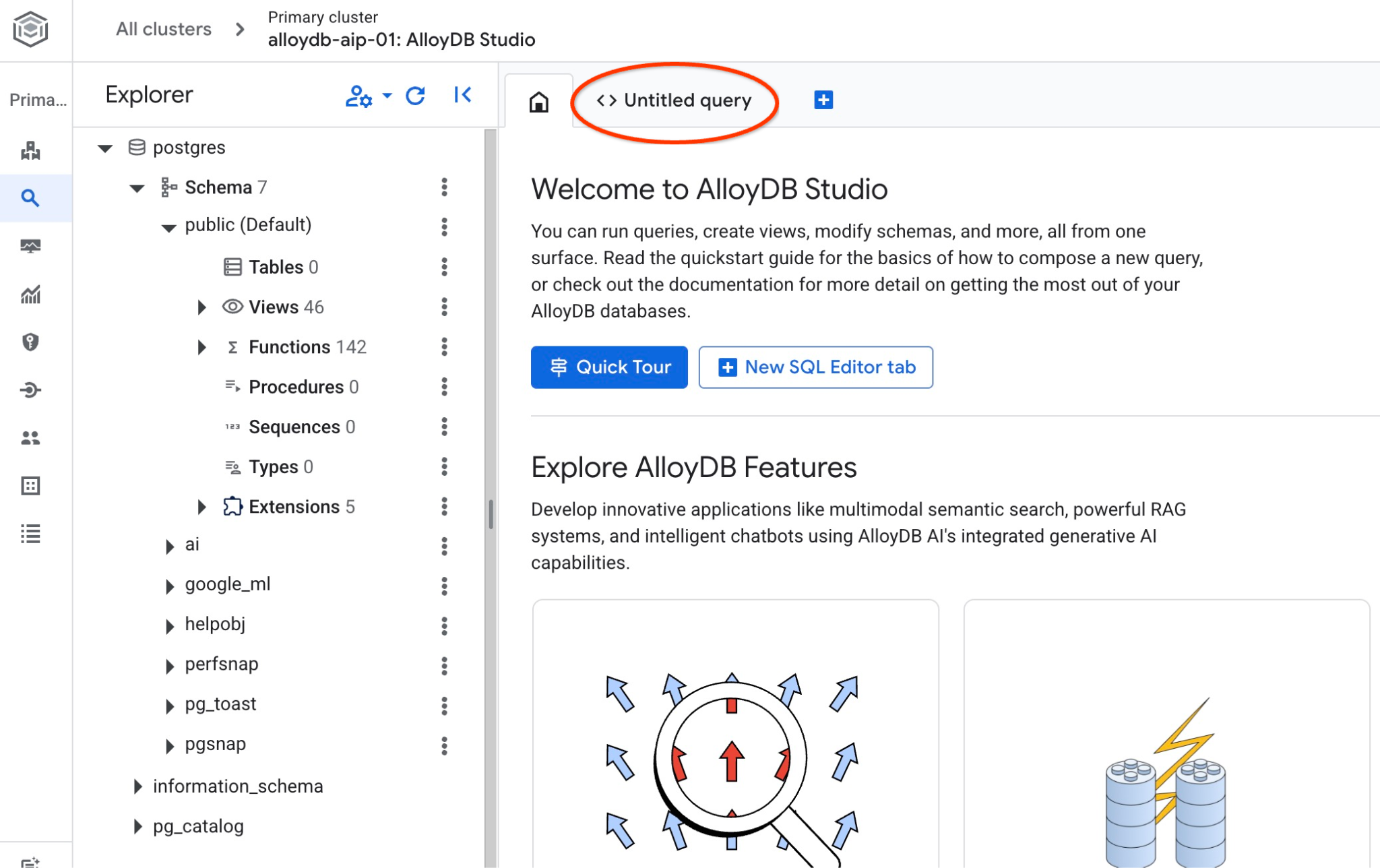
SQL komutlarını çalıştırabileceğiniz bir arayüz açılır.
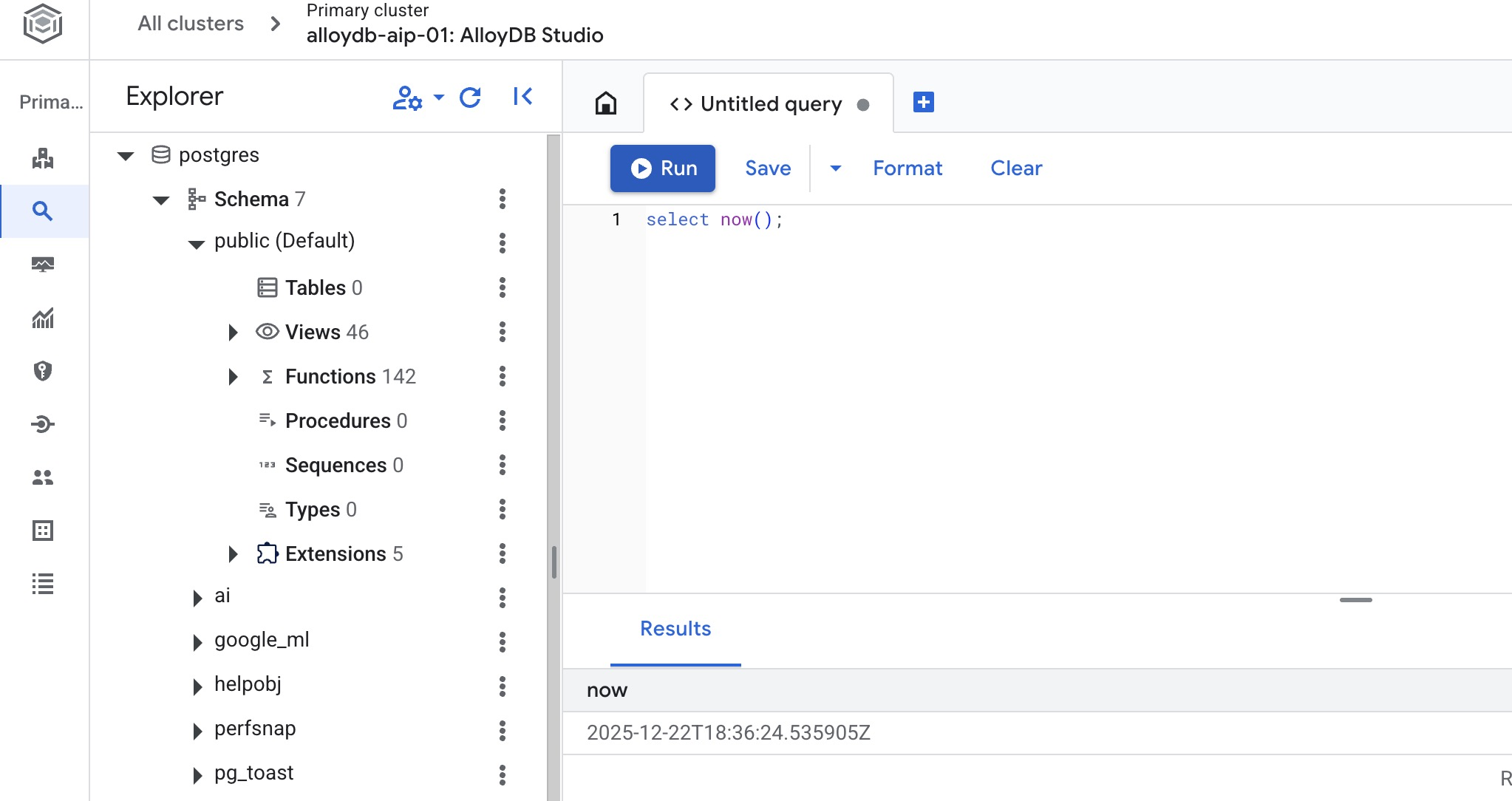
Veritabanı Oluşturma
Veritabanı oluşturma hızlı başlangıç kılavuzu.
AlloyDB Studio Düzenleyici'de aşağıdaki komutu yürütün.
Veritabanı oluşturma:
CREATE DATABASE quickstart_db
Beklenen çıktı:
Statement executed successfully
quickstart_db'ye bağlanma
Veritabanınıza bağlanarak oluşturulup oluşturulmadığını kontrol edin. Kullanıcı/veritabanı değiştirme düğmesini kullanarak stüdyoya yeniden bağlanın.
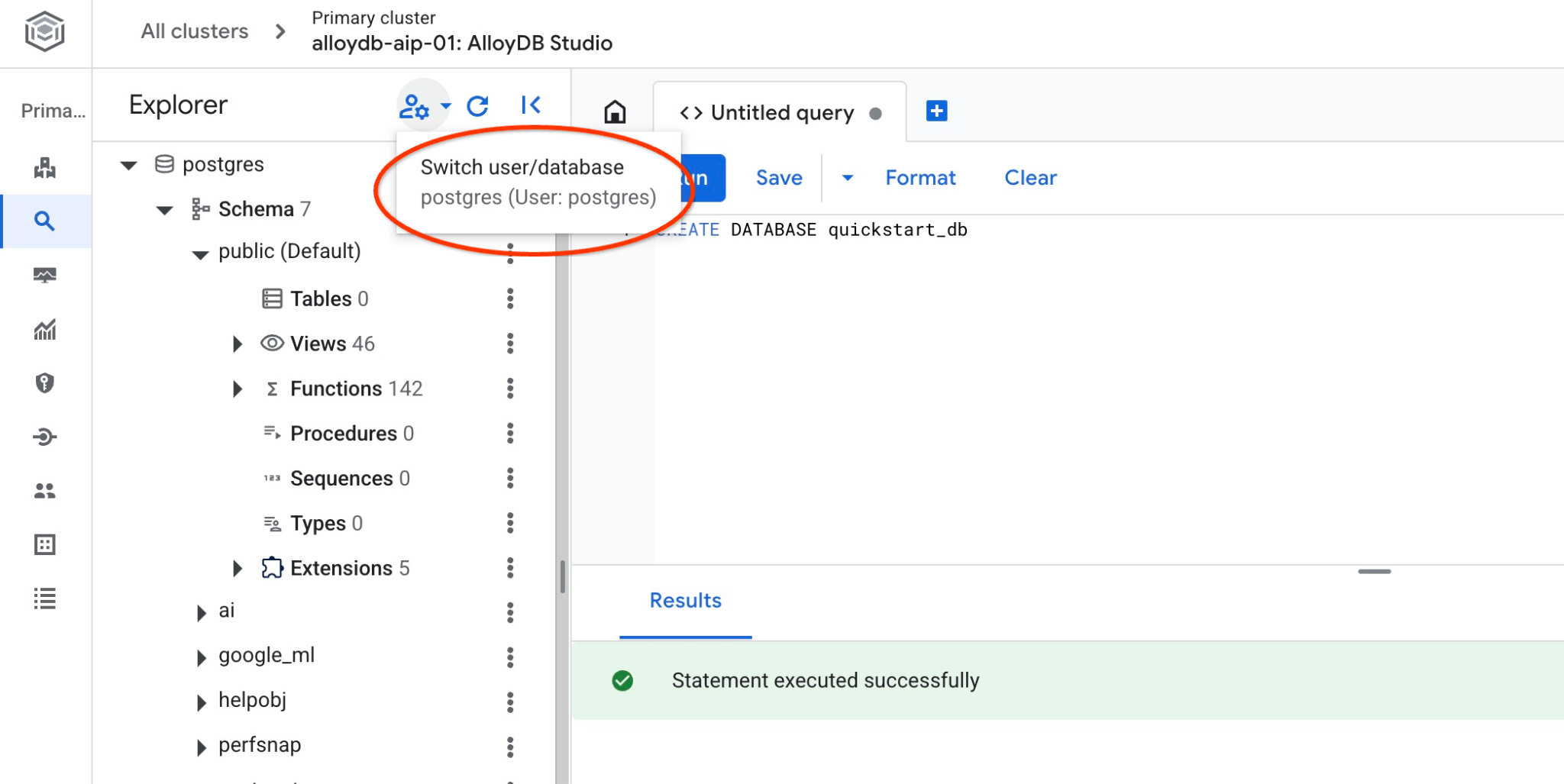
Açılır listeden yeni quickstart_db veritabanını seçin ve aynı IAM kimlik doğrulamasını kullanın.
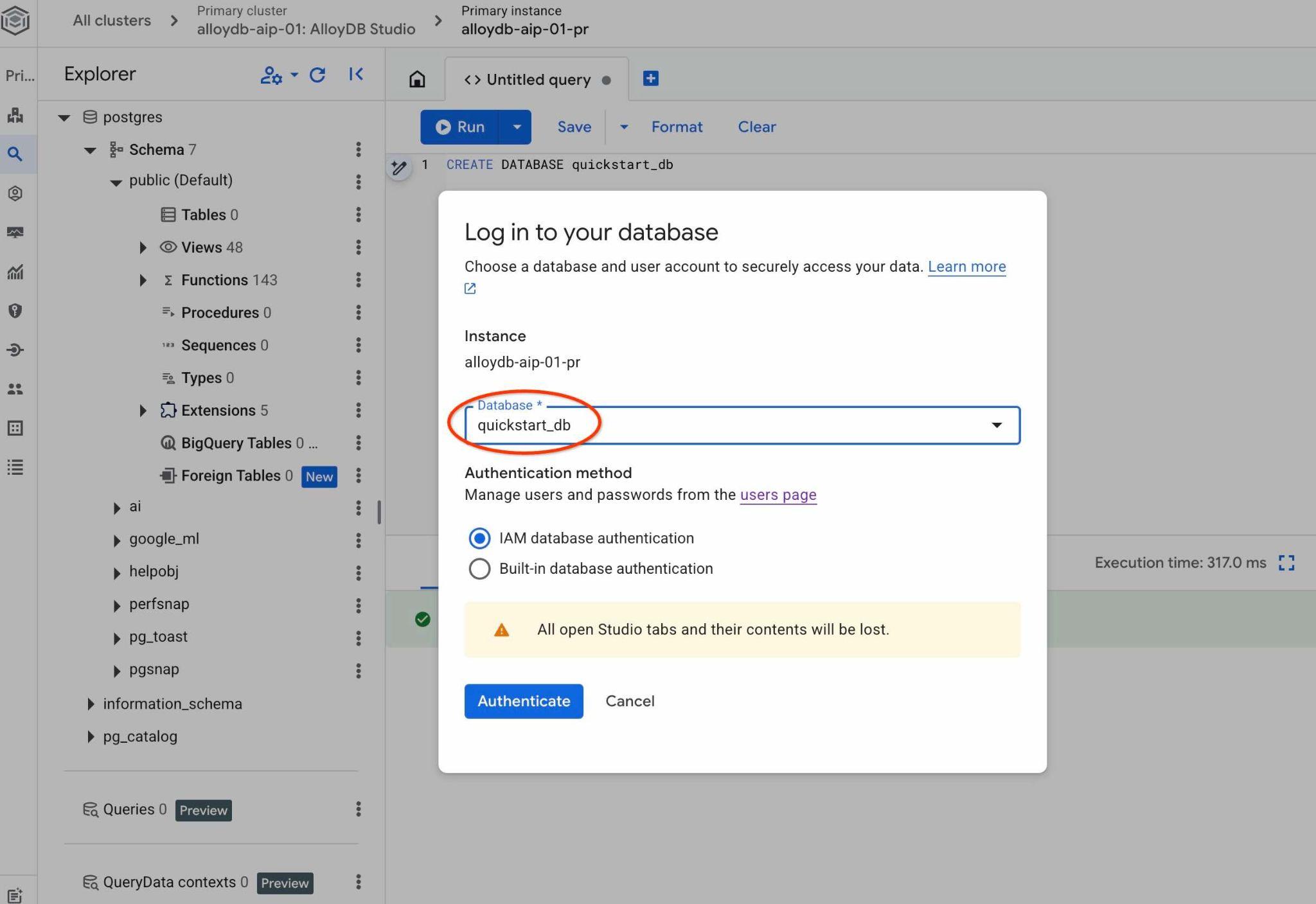
quickstart_db veritabanındaki nesnelerle çalışabileceğiniz yeni bir bağlantı açılır. Burada, içe aktarılan şemanızı ve verilerinizi inceleyebilir, QueryData bağlam kümeleriyle çalışabilirsiniz.
6. Örnek Veriler
Şimdi veritabanında nesneler oluşturmanız ve verileri yüklemeniz gerekiyor. Kurgusal bir Cymbal Shipping şirketi veri kümesini kullanacaksınız. Bu veri kümesinde, kurgusal sürücülerle birlikte mallar, kamyonlar, istekler ve kamyon yolculukları hakkında kurgusal veriler yer alır.
Storage paketi oluşturma
Klonlanmış deponuzdaki verileri AlloyDB veritabanına aktarmak için Google SDK'sını (gcloud) kullanacaksınız. Bunun için bir Cloud Storage paketi oluşturmanız ve AlloyDB hizmet hesabına erişim izni vermeniz gerekir. Alternatif olarak, dokümanda açıklandığı gibi web konsolunu kullanarak da yapmayı deneyebilirsiniz.
Google Cloud Shell terminalinde şunu çalıştırın:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
Veri Yükleme
Bir sonraki adım, verileri yüklemektir. Sıkıştırılmış SQL dökümümüz, klonlanmış depo klasöründe bulunur. Aşağıdaki komutta, AlloyDB kümesini oluştururken önceki adımda depoyu klonladığınızda başlangıç noktası olarak ana dizininizi kullandığınız varsayılır.
Sıkıştırılmış SQL dökümünü yeni depolama paketine kopyalayın:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
Ardından verileri quickstart_db veritabanına yükleyin:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
Komut, örnek veri kümesini quickstart_db veritabanına yükler. AlloyDB Studio'yu kullanarak tabloları ve kayıtları doğrulayabilirsiniz.
7. Veri Temsilcisi ile çalışma
Python için Google ADK kullanılarak oluşturulan ve veritabanları için MCP Araç Kutusu kullanılarak AlloyDB örneğimize bağlanan örnek bir yapay zeka aracısıyla başlayalım.
Veritabanları için MCP Araç Kutusu'nu yükleme
Veritabanları için MCP Araç Kutusu, PostgreSQL için AlloyDB dahil olmak üzere birden fazla veritabanı motoru için MCP desteği sağlayan açık kaynaklı bir projedir. MCP Toolbox hakkında belgelerden bilgi edinebilirsiniz.
Platformunuz için yazılımın en son sürümünü indirmeniz gerekir. En yeni sürüm için sürümler sayfasını kontrol edin. Aşağıdaki örnekte, MCP Toolbox'ın 31. sürümünün Cloud Shell'e nasıl indirileceği gösterilmektedir.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
export VERSION=0.31.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Araç kutusu için bir yapılandırma dosyası hazırlamanız gerekir. Mevcut dizinde bir örnek tools.yaml.example dosyamız var ve iki yer tutucuyu proje kimliği ve bölgeyle değiştirerek tools.yaml dosyasını hazırlayacağız.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
tools.yaml.example > tools.yaml
Veritabanları için MCP Araç Kutusu'nu başlatma
Artık hazırlanan yapılandırma dosyasıyla MCP araç kutusunu başlatabilirsiniz.
Google Cloud Shell arayüzünüzün üst kısmındaki "+" düğmesine basarak Google Cloud Shell'inizde yeni bir sekme açın.
Yeni sekmede, araç kutusu ikili program dosyasının ve yapılandırma dosyası tools.yaml'nin bulunduğu dizine geçin ve MCP sunucusunu başlatın.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config tools.yaml
Çıkışta aşağıdakine benzer şekilde "Server ready to serve!" (Sunucu hizmet vermeye hazır!) ifadesini görmeniz gerekir.
2026-03-30T10:28:03.614374-04:00 INFO "Initialized 1 sources: cymbal-logistics-sql-source" 2026-03-30T10:28:03.614517-04:00 INFO "Initialized 0 authServices: " 2026-03-30T10:28:03.614531-04:00 INFO "Initialized 0 embeddingModels: " 2026-03-30T10:28:03.614657-04:00 INFO "Initialized 2 tools: execute_sql_tool, list_cymbal_logistics_schemas_tool" 2026-03-30T10:28:03.614711-04:00 INFO "Initialized 1 toolsets: default" 2026-03-30T10:28:03.614723-04:00 INFO "Initialized 0 prompts: " 2026-03-30T10:28:03.614779-04:00 INFO "Initialized 1 promptsets: default" 2026-03-30T10:28:03.616214-04:00 INFO "Server ready to serve!"
Aracı kaynak kodunu kontrol etme
Klonlanan depo klasöründeki ilk sekmede, Google Cloud Shell düzenleyicisini kullanarak aracı kodunu inceleyin.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/agent.py
Aracımızda AlloyDB için Google Cloud MCP sunucusu bölümü olduğunu görebilirsiniz. MCP_SERVER_URL olarak bir uç nokta, kimlik doğrulama ve proje kimliği sağlarız ve bunu MCP araç setine ekleriz.
MCP_SERVER_URL = "http://127.0.0.1:5000"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
mcp_toolset = ToolboxToolset(
server_url=MCP_SERVER_URL,
)
Aracı kodunda ise MCP araç seti, aracı için tools parametresi olarak yer alır. Ayrıca, küme ve örnek adları, bölge ve veritabanı da aracı istemi için değişken olarak kullanılabilir.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
""",
tools=[mcp_toolset],
)
Kodu inceledikten sonra düzenleyici penceresinin sağ üst kısmındaki "Open terminal" (Terminali aç) düğmesine basarak terminale geri dönün.
Aracıyı başlatma
Artık Google ADK web arayüzünü kullanarak etkileşimli modda aracı başlatabilirsiniz. ADK web arayüzü, aracıların iş akışlarını test etmek ve sorunlarını gidermek için pratik bir yöntem sunar.
Öncelikle, uv paket yöneticisini kullanarak Python için gerekli tüm paketleri yükleyelim.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
uv sync
Tüm paketler yüklendikten sonra, temsilciyi yapay zeka modelleriyle tüm iletişimlerde Vertex AI'ı kullanmaya yönlendirmek için temsilci dizinine bir .env dosyası eklemeniz gerekir.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
Ardından, temsilciyi başlatabilirsiniz.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Şuna benzer bir çıkış görmelisiniz: http://127.0.0.1:8000 .
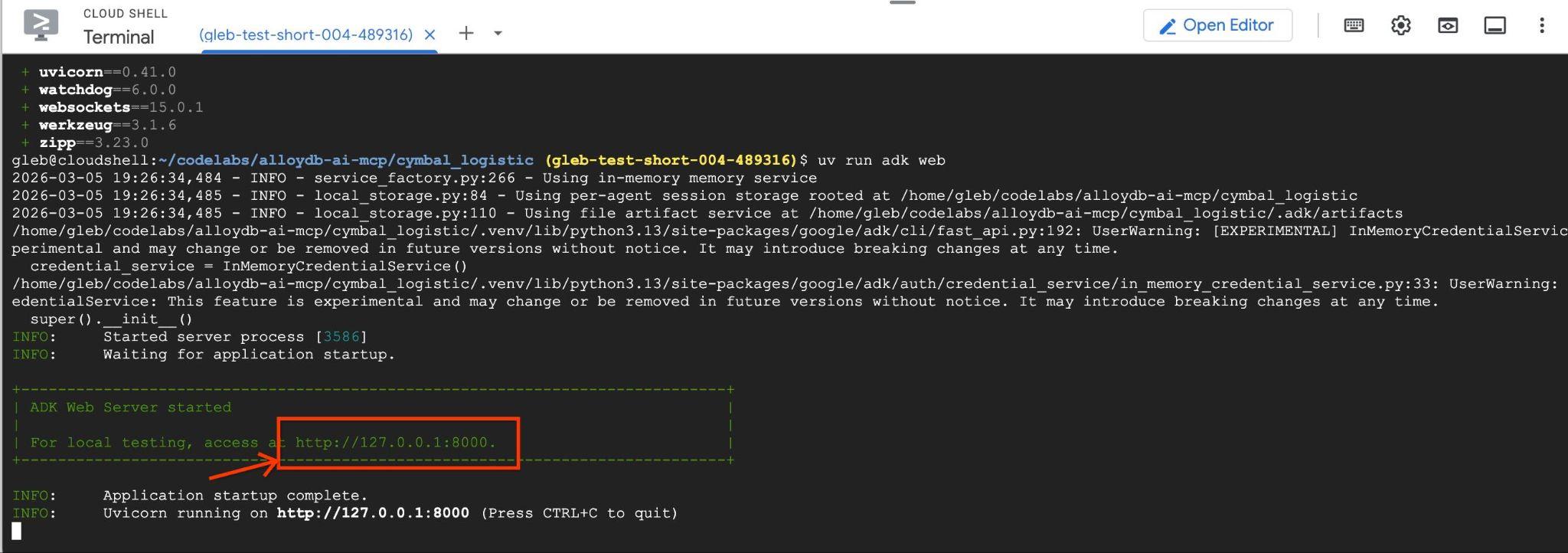
Cloud Shell'de bu URL'yi tıkladığınızda ayrı bir tarayıcı sekmesinde önizleme penceresi açılır. Burada, soldaki açılır listeden data_agent simgesini seçersiniz.
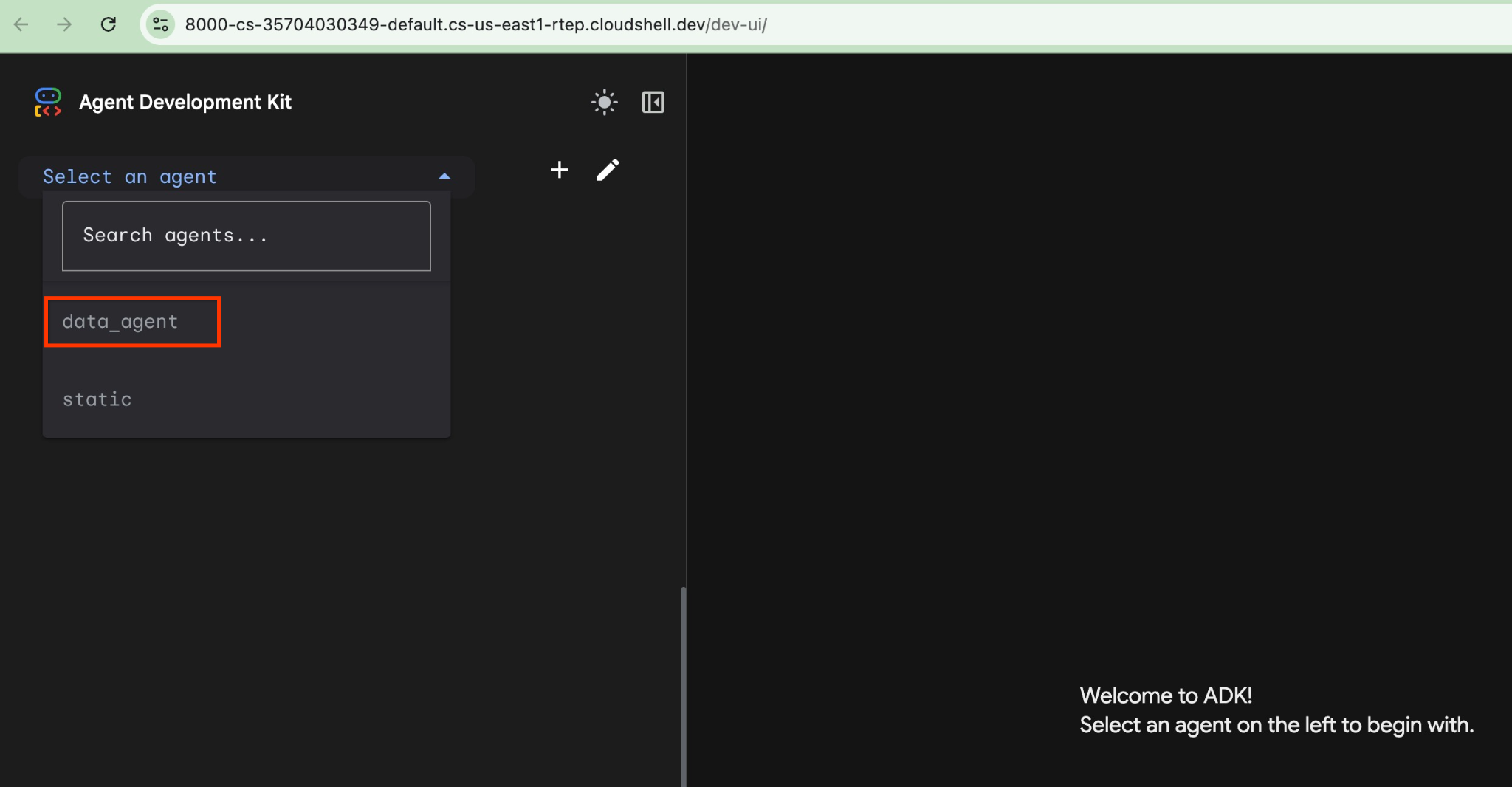
ADK web arayüzünde sorularınızı sağ alt kısımdan gönderebilir ve her adımın izlerini de içeren tam yürütme akışını sağ tarafta görebilirsiniz.
8. AlloyDB için QueryData olmadan NL2SQL'i test etme
Temsilci, doğal dil kullanarak serbest biçimde soru sormanıza olanak tanır. Temsilci, soruları yanıtlamak için veritabanları için MCP araç kutusunu kullanır. Sorular sağ altta yayınlanır ve araçlara yapılan tüm çağrıları içeren yanıt en üstte görünür.
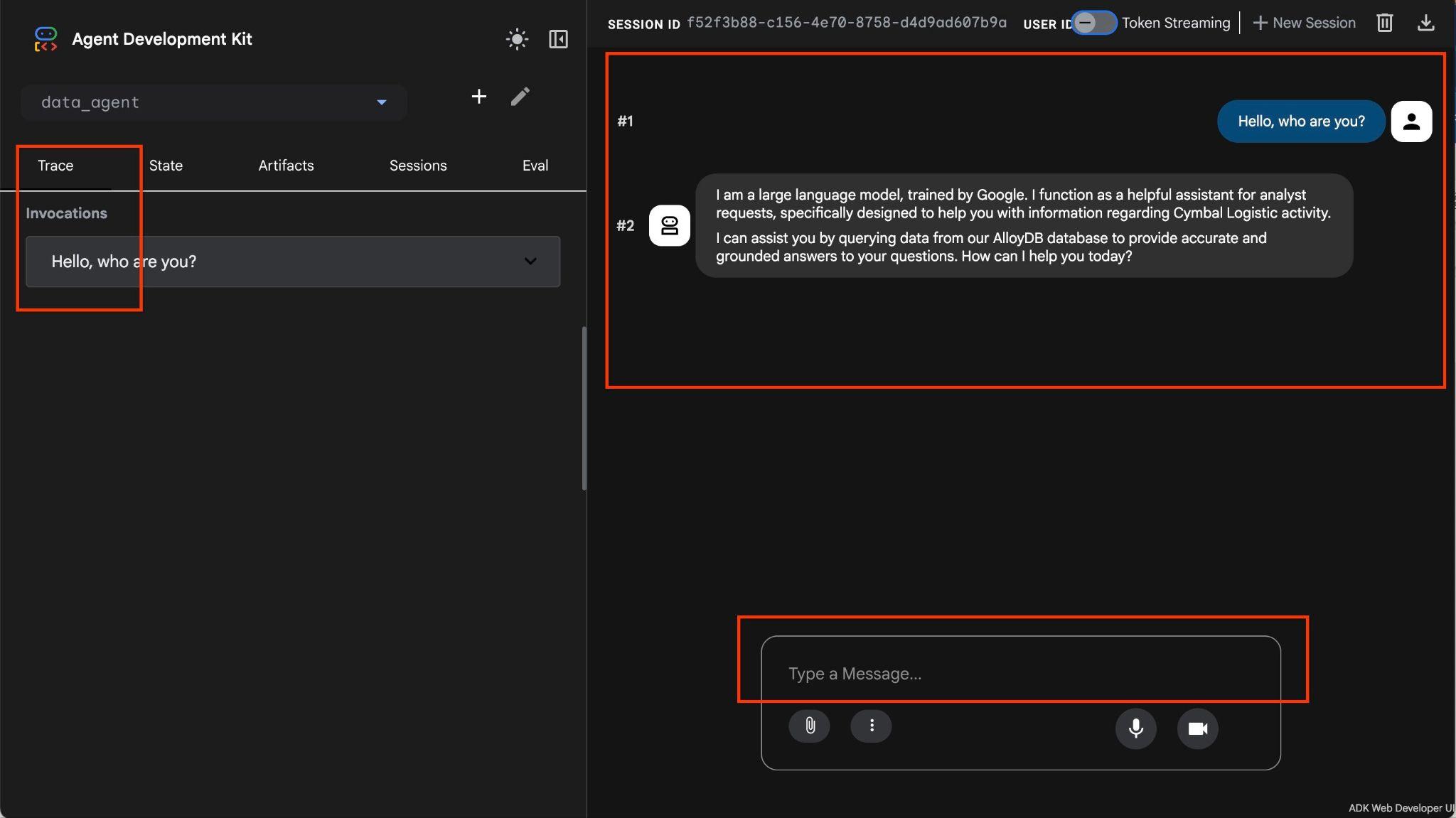
Kargo şirketinin operasyonel verileriyle çalışıyorsunuz. Bu verilerde kargo talepleri, kamyonlar, sürücüler ve sürücülerin yaptığı yolculuklarla ilgili bilgiler yer alıyor. İlk soru, Şubat 2026'da gerçekleştirilen seyahatlerin sayısı ile ilgilidir.
Sağ alttaki giriş alanına aşağıdakileri yazıp Enter tuşuna basın.
Hello, can you tell me how many trips we've done in February?
Aracı, list_cymbal_logistics_schemas_tool kullanarak şemadaki doğru tabloları belirlemek ve execute_sql_tool kullanarak doğru verileri almak için birden fazla araç çağrısı yürüterek çalışır.
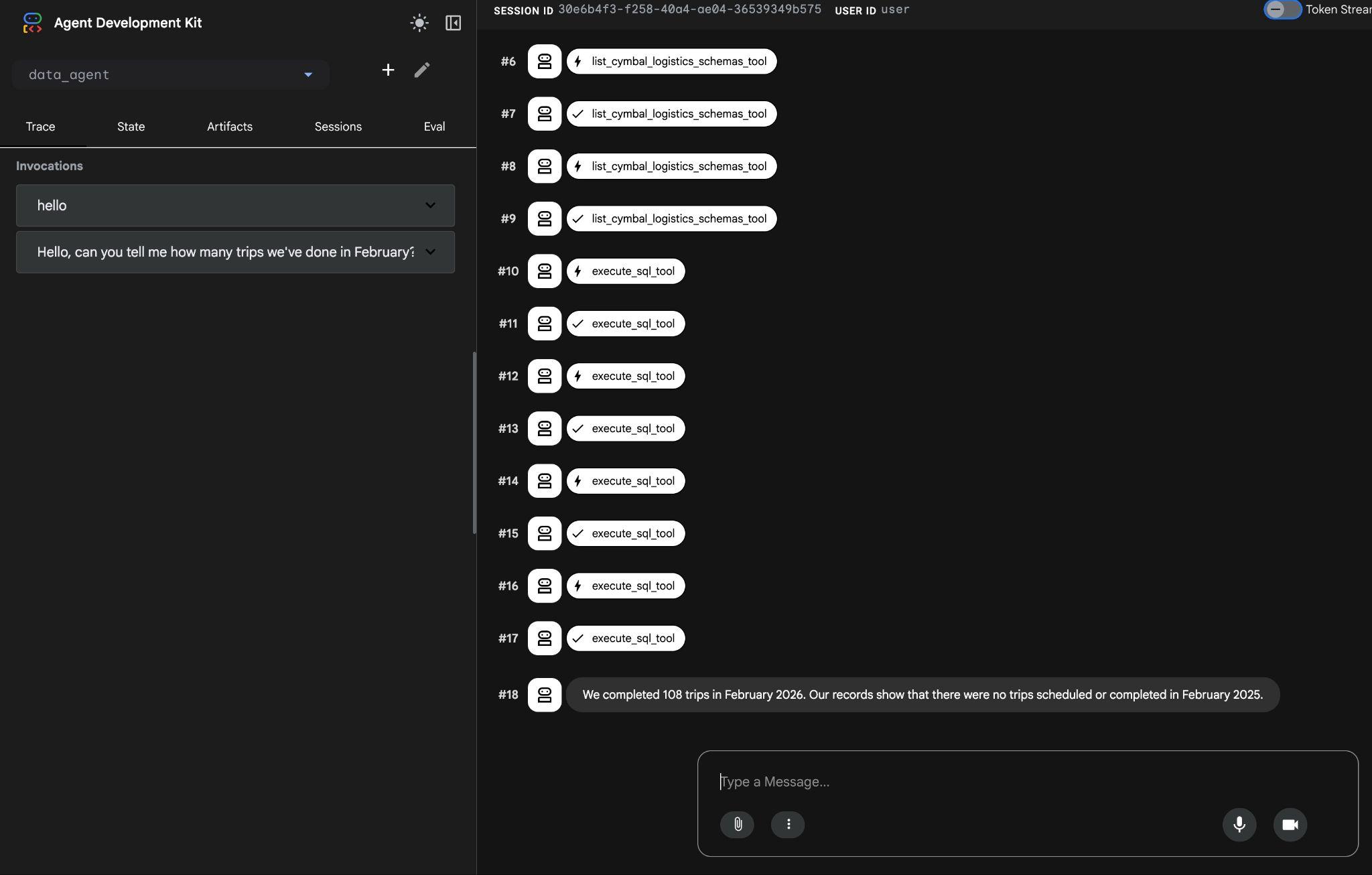
Sonunda, uygun sorguyu oluşturup veritabanında yürüttükten sonra doğru sonucu üretir.
Şubat 2026'da 108 gezi tamamladık. Kayıtlarımıza göre, Şubat 2025'te planlanmış veya tamamlanmış gezi yok.
Araç yürütmesini tıklayarak her araç çağrısının ne yaptığını görebilirsiniz. Örneğin, sonuçlarımızı almak için yürütülen sorgu aşağıda verilmiştir.
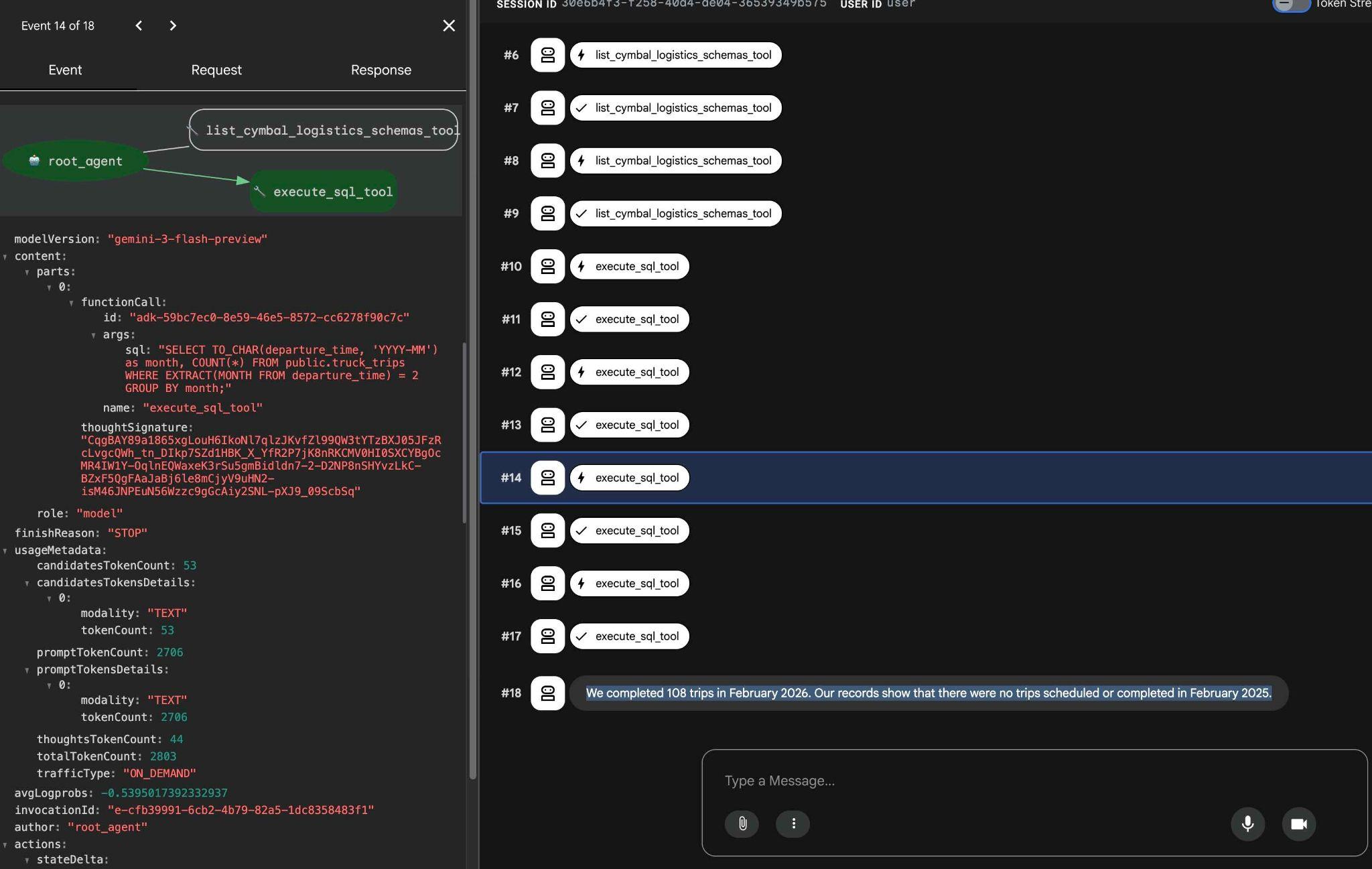
ADK web arayüzünü kullanarak diğer basit istekleri deneyin ve sonuçlara ulaşmak için farklı sorguları nasıl yürüttüğünü görün.
Terminalde ctrl+c tuşuna basarak aracı durdurun. ADK web arayüzünün bulunduğu tarayıcı sekmesini kapatabilirsiniz.
Aynı ctrl+c tuş kısayoluna basarak ikinci sekmedeki MCP Toolbox'ı durdurabilir ve ikinci sekmeyi kapatabilirsiniz.
Bir sonraki adımda, NL2SQL yanıtımızı ve performansımızı iyileştirmek için QueryData bağlamını oluşturacağız.
9. QueryData ContextSet oluşturma
Önceki adımda, yapay zeka modelinin SQL sorgusunu oluşturmak için hangi tablo ve sütunları kullanması gerektiğini belirlemek üzere veritabanının bilgi şemasına birden fazla çağrı yaptığını görmüş olabilirsiniz. Performansı ve doğruluğu artırmak, sonucu daha tahmin edilebilir hale getirmek için QueryData bağlamınızı ekleyeceğiz. Bu bağlam, belirli bir isteğe yanıt olarak hangi sorgunun yürütülmesi gerektiğini tanımlar.
Hedefe Yönelik Şablonlar Oluşturma
QueryData ContextSet, sorgu kalıpları ve yönleriyle birlikte bir JSON dosyasıdır. Bu dosya, sorgu kalıplarına ve veri yapısına göre istenen hedeflere ulaşmak için yapay zeka modeline doğru SQL sorgusunu veya SQL sorgusu bölümlerini kullanması için gerekli verileri ve talimatları sağlar.
Hedeflenmiş bir şablonla başlarsınız. Cloud Shell düzenleyicisini kullanarak dosya oluşturun. Cloud Shell terminalinde yürütün.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
Ayrıca, önceki bölümde kullandığımız doğal dil sorgusu şablonunu ("Şubat ayında kaç gezi yaptık?") ekleyin.
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a given month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
]
}
Ardından, indirme düğmesini kullanarak şablonu Cloud Shell'den bilgisayarınıza indirin.
Load QueryData Context Sets (Sorgu Verisi Bağlam Kümelerini Yükle)
QueryData bağlam kümelerimizi kullanmak için bunları veritabanımıza yüklememiz gerekir.
AlloyDB Studio'yu açın. Sol panelin en altında QueryData Context ve üç nokta simgesini görürsünüz.
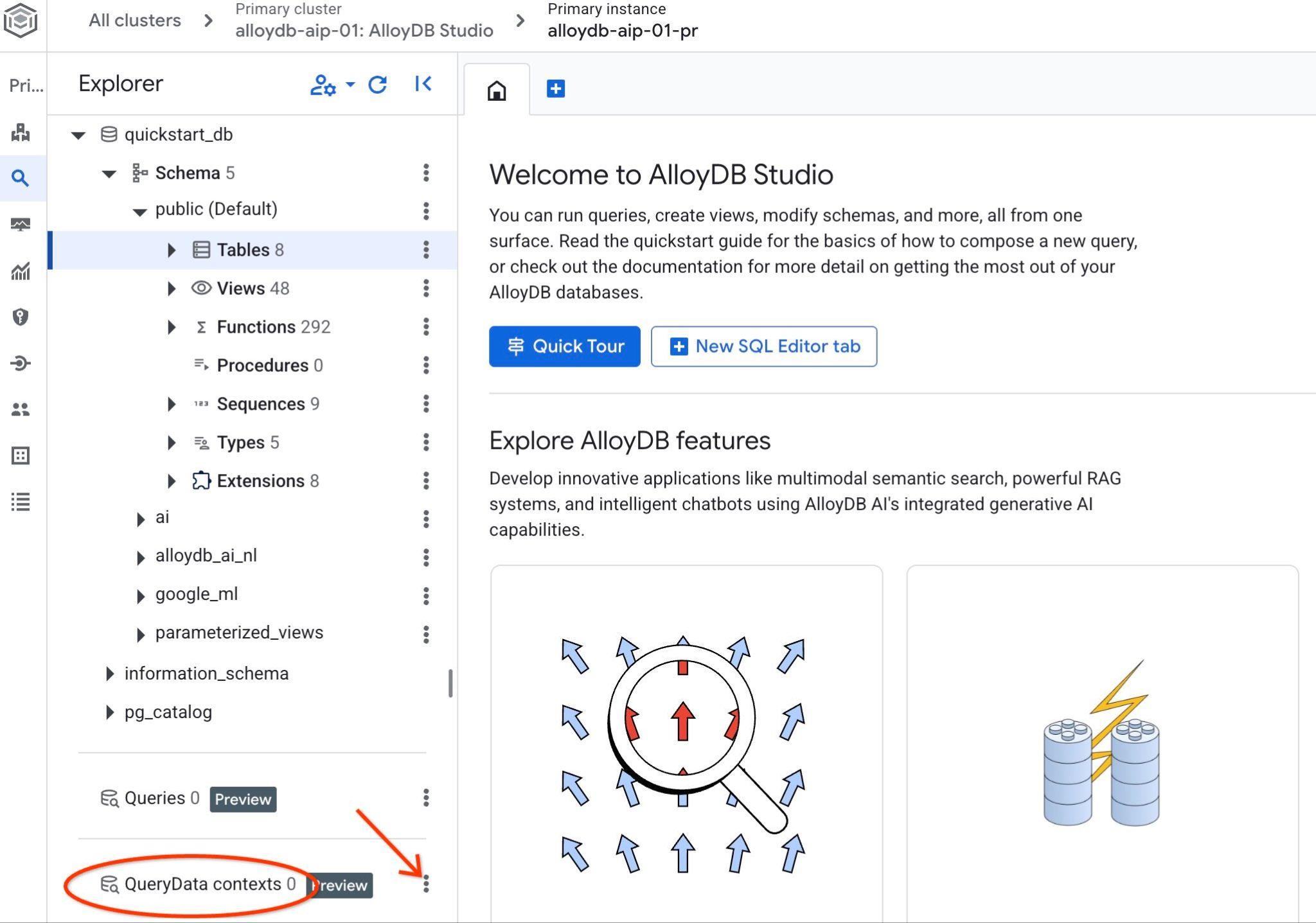
Üç noktayı tıklayın ve Bağlam Oluştur'u seçin. Bir iletişim kutusu açılır. Bu kutuya
- Ad:
cymbal_context_set - Açıklama:
Cymbal Logistic Query Data - Bağlam dosyasını yükleyin: "
Browse" düğmesini tıklayın ve QueryData ContextSet'i içeren JSON dosyanızı seçin.
Kaydet düğmesine bastığınızda, bağlam depolama alanını ilk kez kullanıyorsanız ilk kullanıma hazırlama işlemi biraz zaman alabilir.
İndirilen içeriği görebilirsiniz. Sağdaki üç dikey düğmeyi tıkladığınızda ise kullanılabilir işlemler gösterilir. Bir sonraki bölümde "Test bağlamı" işleminden başlayacağız.
10. QueryData bağlam kümesini test etme
Şablonu test etme
AlloyDB Studio'da bağlamımızı test etmek için "Test context" işlemini kullanın. "Test context"i (Bağlamı test et) tıkladığınızda "cymbal_context_set" başlıklı yeni bir AlloyDB Studio düzenleyici penceresi ve "Generate SQL using QueryData context: cymbal_context_set " başlıklı Gemini SQL oluşturma daveti açılır. SQL oluşturma seçeneğini tıklayın ve
Hello, can you tell me how many trips we've done in February?
Oluşturulan SQL'i kullanmak için "Insert" düğmesine basın.
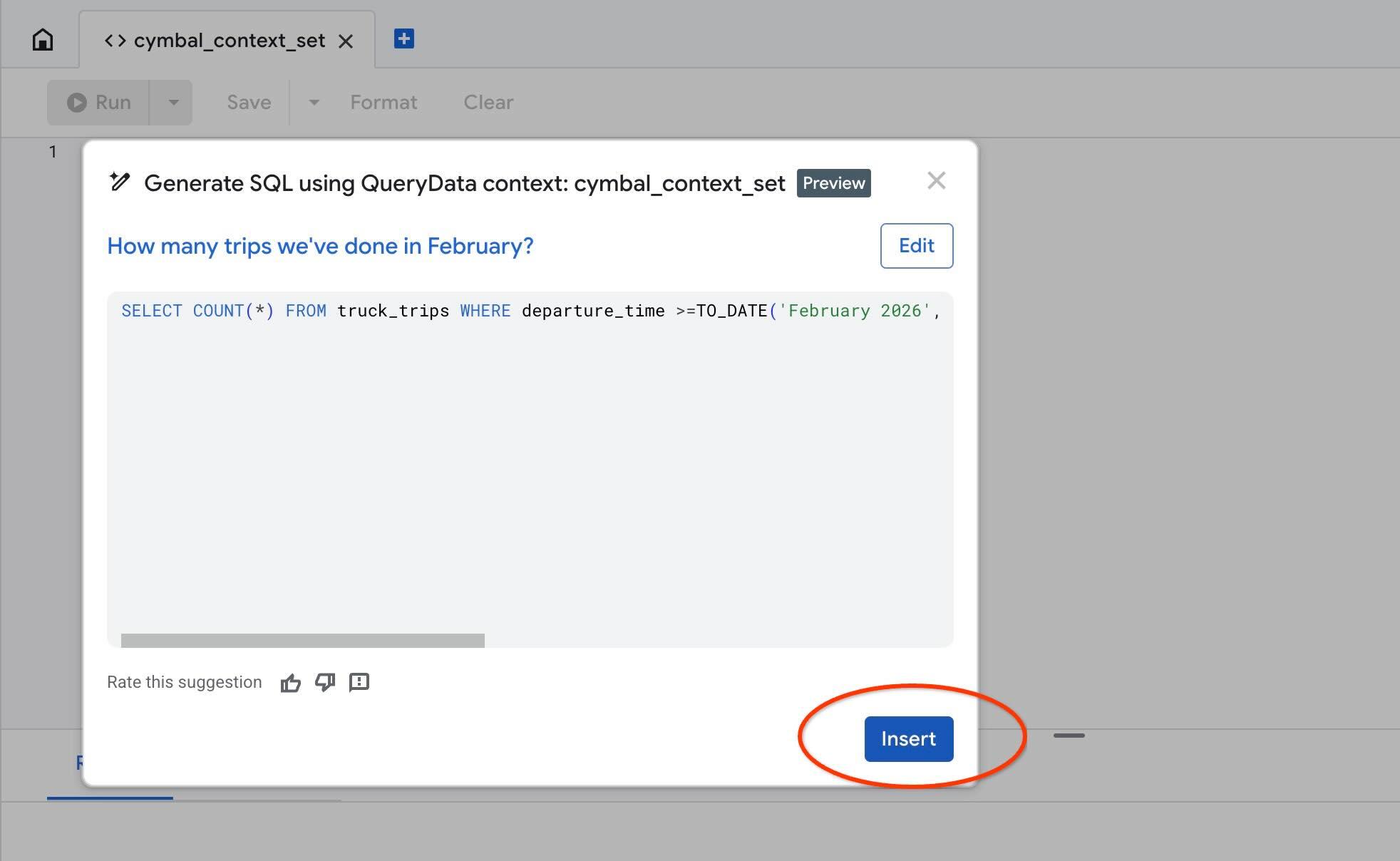
Daha önce bağlam şablonumuza girdiğimiz sorgunun aynısını göreceksiniz.
-- How many trips we've done in February?
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'
Ayı "Ocak" ile değiştirmeyi deneyin ve oluşturulan SQL ifadesini kontrol edin. Parametreli amaç için parametre olarak ayı kullanır ve SQL ifadesini otomatik olarak ayarlar.
Build QueryData Facets
Bir sorgu için şablon denedik ve ne tür bir kullanıcı isteği beklediğimizi bildiğimizde şablonun işe yaradığını gördük. Ancak bazen, yeniden tanımlanmış bir amaç için belirli bir sıranın veya özel bir maddenin kullanılmasını tercih ettiğimizde sorgunun yalnızca bir bölümüne (ör. koşul veya filtre) rehberlik etmek faydalı olur.
Örneğin, "geçen ay" için verilerin döndürülmesini istediğimizde son 30 gün için değil, ilgili ayın 1'inden son gününe kadar olan son takvim ayının raporunu almak isteriz.
Bu tür yönleri, daha önce eklediğimiz şablonla birlikte ContextSet yapılandırmasına SQL snippet'i olarak ekleyebiliriz. querydata_cymbal_contextset.json dosyasını açın.
edit ~/$REPO_NAME/$SOURCE_DIR/data_agent/querydata_cymbal_contextset.json
Ayrıca, halihazırda mevcut şablonlarımızın ardından yönleri ekleyin. Dosyadaki sonuçlanan içerik şu şekilde olmalıdır:
{
"templates": [
{
"nl_query": "How many trips we've done in February?",
"sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE('February 2026', 'Month YYYY') AND departure_time < TO_DATE('February 2026', 'Month YYYY') + INTERVAL '1 month'",
"intent": "Count trips done in a certain month like February 2026",
"manifest": "How many trips we've done in a given month",
"parameterized": {
"parameterized_intent": "How many trips we've done in $1",
"parameterized_sql": "SELECT COUNT(*) FROM truck_trips WHERE departure_time >=TO_DATE($1, 'Month YYYY') AND departure_time < TO_DATE($1, 'Month YYYY') + INTERVAL '1 month'"
}
}
],
"facets": [
{
"sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)",
"intent": "last month",
"manifest": "Records for the previous calendar month",
"parameterized": {
"parameterized_intent": "previous calendar month",
"parameterized_sql_snippet": "departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)"
}
}
]
}
Dosyayı kaydedin ve bilgisayarınıza yükleyin.
Ardından, "Bağlamı düzenle" sorgu bağlamı işlemini kullanın ve değiştirilen dosyayı yükleyerek eski bağlamı yenisiyle değiştirin.
Şimdi test bağlamını tekrar kullanmayı deneyin ve "geçen ay" amacını kullanarak bir SQL ifadesi oluşturun. Örneğin, "show trucks trips for the last month"" ifadesi için bir SQL oluşturursanız cymbal_context.json dosyamızda özellik olarak sağladığımız koşul kullanılır.
Aşağıdakine benzer bir sonuç alırsınız:
-- show trucks trips for the last month
SELECT COUNT(*) FROM truck_trips WHERE departure_time >=date_trunc('month', current_date - interval '1 month') AND departure_time < date_trunc('month', current_date)
Peki bunu yapay zeka temsilcilerle nasıl kullanabilirsiniz? Bir sonraki bölümde, Sorgu Verileri bağlamını yapay zeka temsilcileri için kullanılabilir hale getiriyoruz.
11. Yapay Zeka Temsilcileri ile QueryData
Aynı Veri Aracısı'nı kullanacaksınız ancak MCP araç kutusu artık QueryData ContextSet'i kullanacak şekilde yapılandırılacak.
Veritabanları için MCP Toolbox'ı hazırlama ve başlatma
MCP Toolbox için Gemini Veri Analizi API'sini ve veritabanı kaynağı olarak AlloyDB'yi kullanacak yeni bir yapılandırma dosyasına ihtiyacımız var.
Terminalde şunu çalıştırın:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
sed -e "s/##PROJECT_ID##/$PROJECT_ID/g" \
-e "s/##REGION##/$REGION/g" \
querydata.yaml.example > querydata.yaml
Düzenleyiciye geçin ve querydata.yaml dosyasını bulun. Yapılandırma dosyası querydata.yaml, ortamınızı yansıtacak proje kimliği ve bölge dışında aşağıdaki gibi görünecektir. Ancak yine de contextSetId değerinizi güncellemeniz ve "<add-context-set-id>" yer tutucusunu konsoldaki değerle değiştirmeniz gerekir.
kind: sources
name: gda-api-source
type: cloud-gemini-data-analytics
projectId: test-project-001-402417
---
kind: tools
name: cloud_gda_query_tool
type: cloud-gemini-data-analytics-query
source: gda-api-source
location: "us-central1"
description: Use this tool to send natural language queries to the Gemini Data Analytics API and receive SQL, natural language answers, and explanations.
context:
datasourceReferences:
alloydb:
databaseReference:
projectId: "test-project-001-402417"
region: "us-central1"
clusterId: "alloydb-aip-01"
instanceId: "alloydb-aip-01-pr"
databaseId: "quickstart_db"
agentContextReference:
contextSetId: "<add-context-set-id>"
generationOptions:
generateQueryResult: true
generateNaturalLanguageAnswer: true
generateExplanation: true
generateDisambiguationQuestion: true
ContextSet kimliğinizi bulmak için resimde gösterildiği gibi bağlam kümenizin düzenleme düğmesini tıklayın.
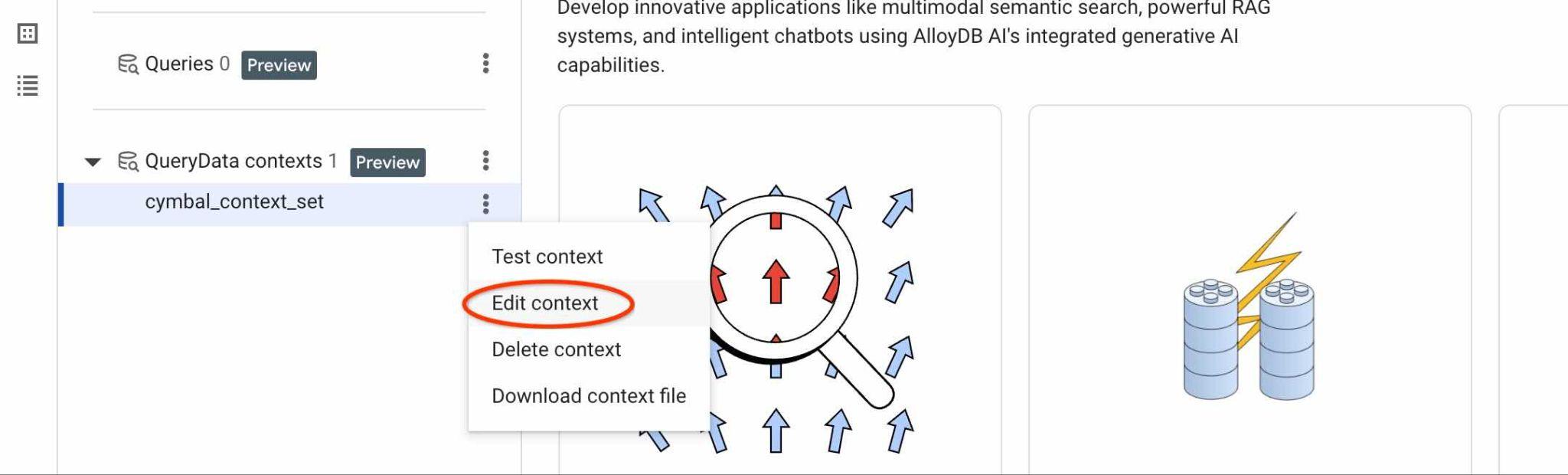
Bağlam grubu kimliğini sağdaki yeni sekmenin üst kısmında görürsünüz.
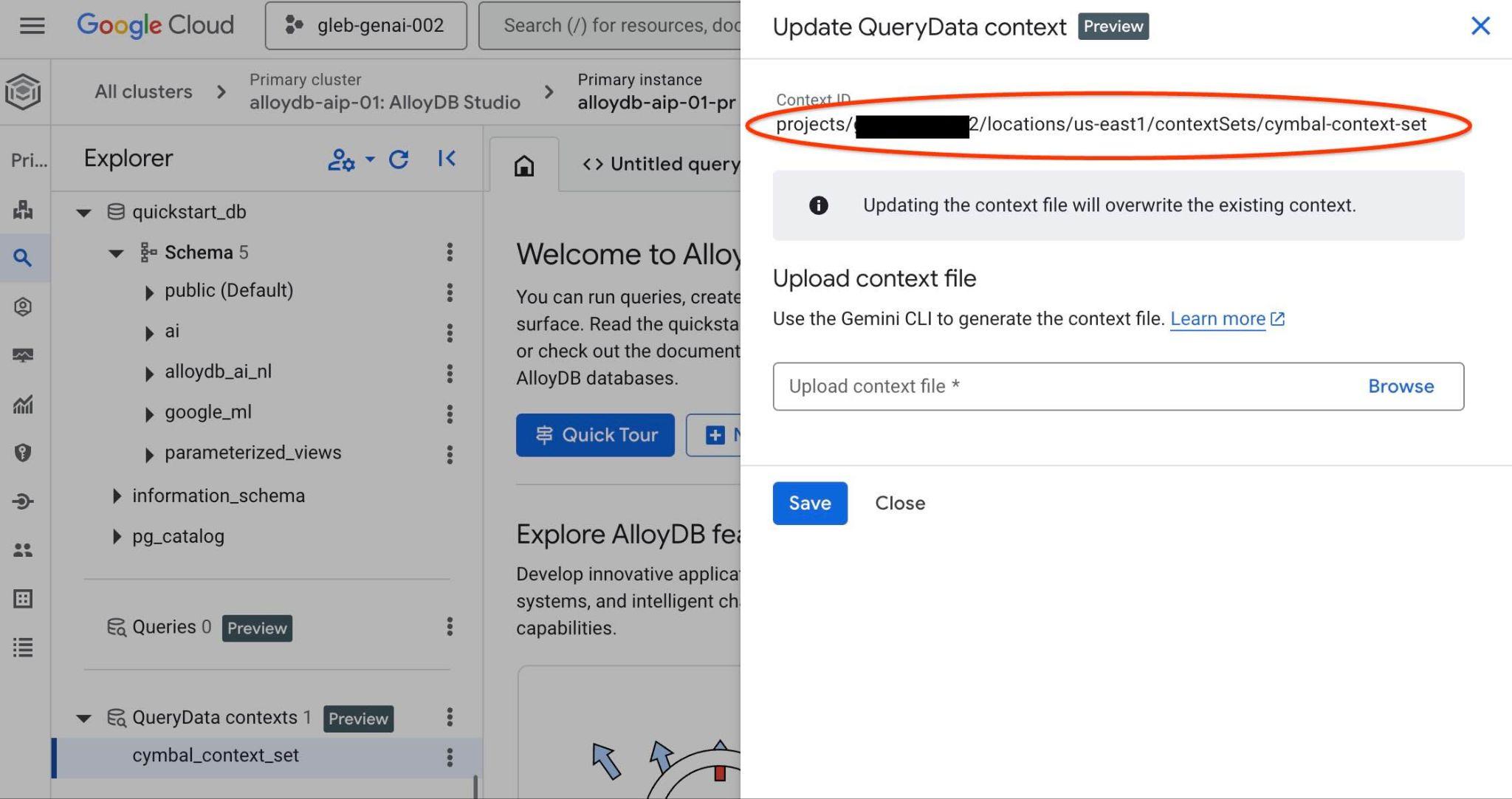
Bu tam yol, querydata.yaml dosyasındaki "<add-context-set-id>" yer tutucusunun yerine konmalıdır.
Terminale geri dönün.
Google Cloud Shell arayüzünüzün üst kısmındaki "+" düğmesine basarak Google Cloud Shell'inizde yeni bir sekme açın.
Yeni sekmede, araç kutusu ikili program dosyasının ve yapılandırma dosyası tools.yaml'nin bulunduğu dizine geçin ve MCP sunucusunu başlatın.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-querydata"
cd ~/$REPO_NAME/$SOURCE_DIR
./toolbox --config querydata.yaml
ADK aracısını çalıştırma
İlk Cloud Shell sekmesinde aracıyı başlatın.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Başlatıldıktan sonra http://127.0.0.1:8000 bağlantısını tekrar tıklayın .
Zaten aşina olduğunuz ADK web önizleme aracısı arayüzünü görürsünüz. Son seferkiyle aynı sorguyu gönderin.
Hello, can you tell me how many trips we've done in February?
Ayrıca, temsilci iş akışını da inceleyin. Her şey doğru şekilde yapılandırılmışsa aşağıdakine benzer bir sonuç görürsünüz.
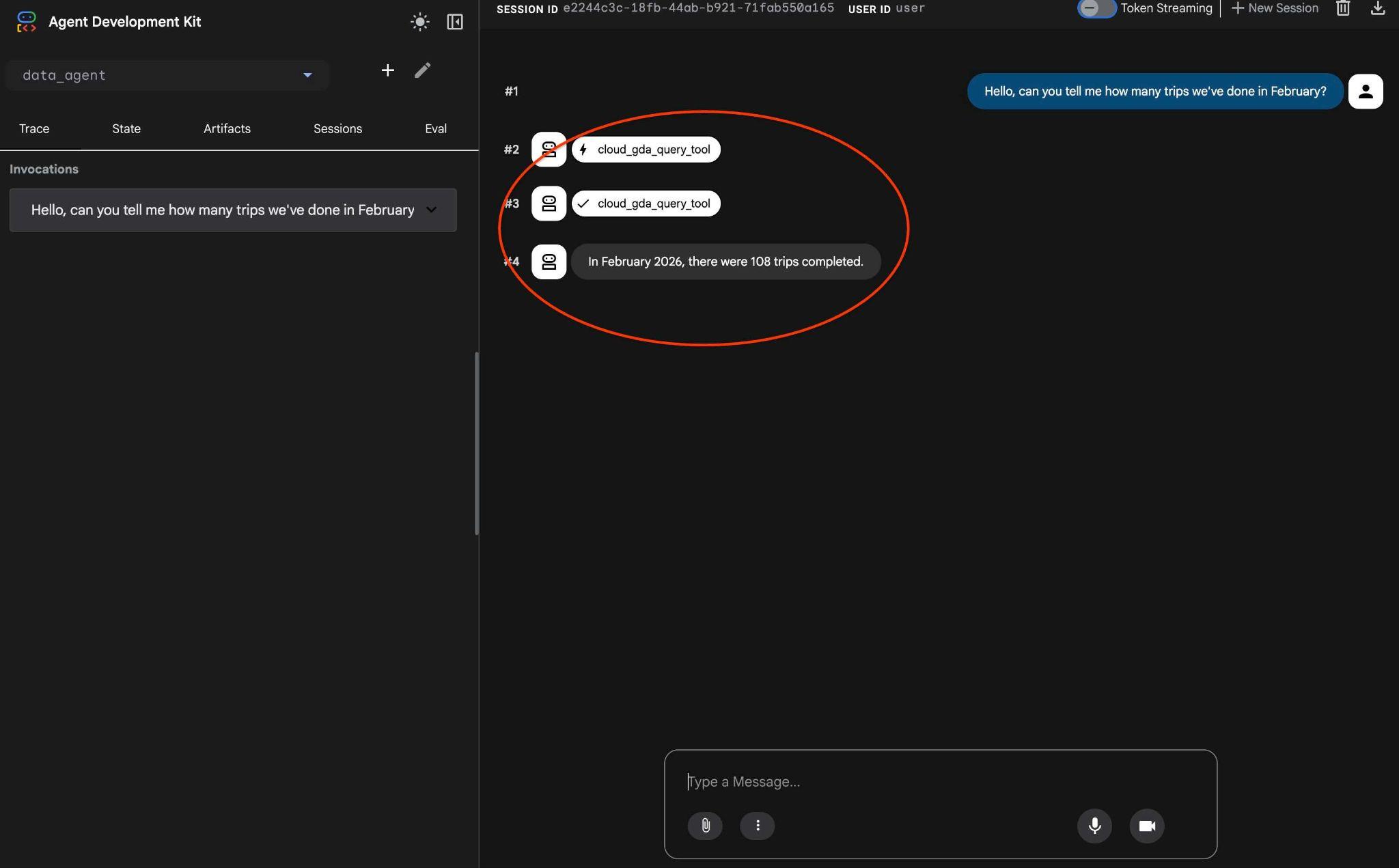
En son birden fazla dönüş yapılan istek, MCP aracına tek bir çağrıya dönüştürüldü ve tahmin edilebilir SQL ifadeleri kullanılarak yürütüldü.
Yapılandırılan yönleri aşağıdaki gibi bir istekle test edebilirsiniz:
how trucks trips for the last month
Ayrıca, çıkışta araç işlemine tıkladığınızda sonucu elde etmek için aynı aracın kullanıldığını ve yönlerin uygulandığını görebilirsiniz.
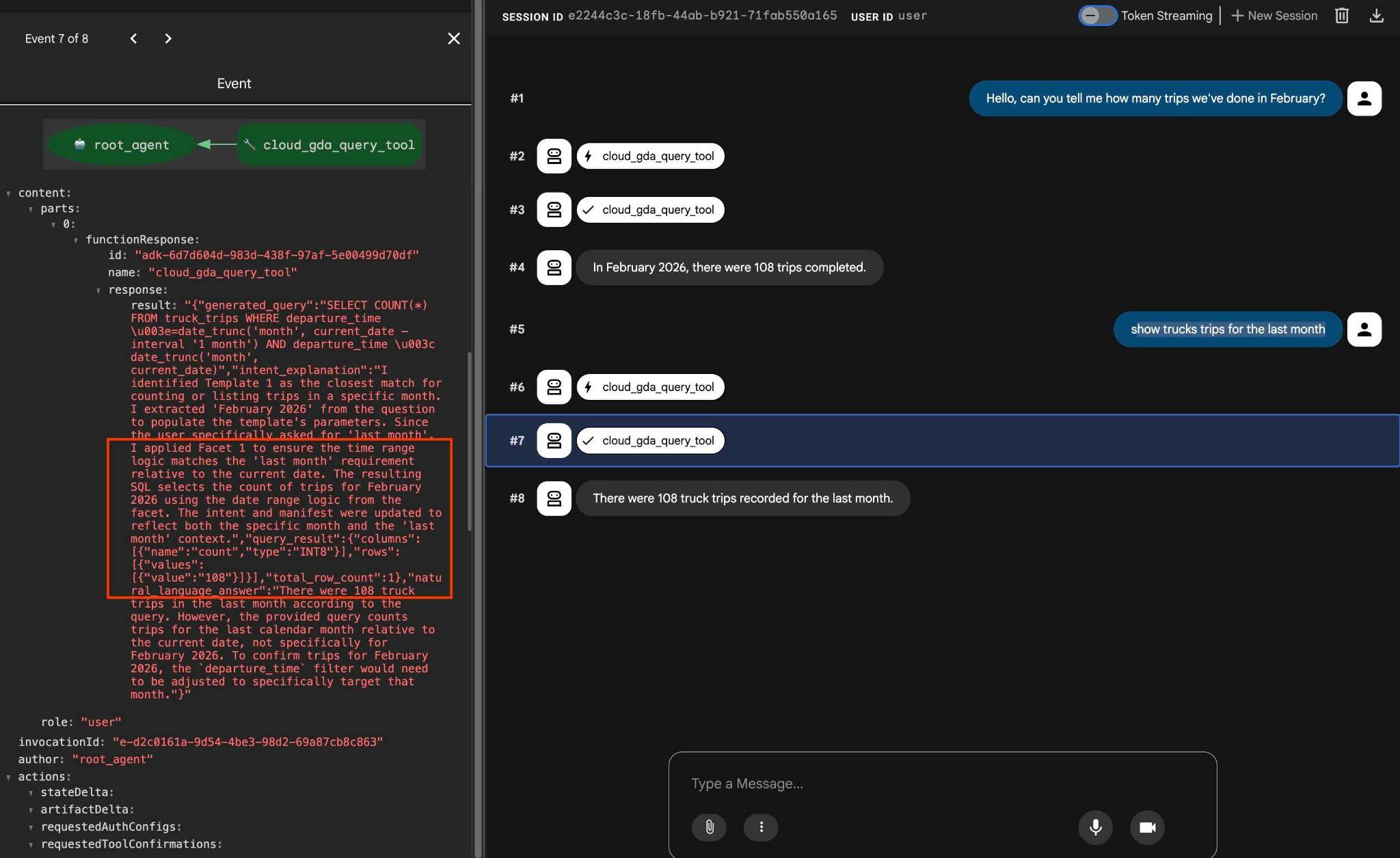
Laboratuvarımızın sonuna geldik. Umarız tüm örnekleri inceleyip AlloyDB için QueryData'yı nasıl kullanacağınızı öğrenmişsinizdir. Sağlanan teknoloji, temsilci tabanlı iş yükünüzün ve SQL oluşturma sürecinizin tahmin edilebilir ve güvenilir olmasını sağlar.
12. Ortamı temizleme
Beklenmedik ücretleri önlemek için geçici kaynakları temizlemek iyi bir uygulamadır. En güvenilir yöntem, iş akışını test ettiğiniz projeyi silmektir. Ancak isteğe bağlı olarak AlloyDB gibi tek tek kaynakları silerek kendinizi sınırlayabilirsiniz.
Laboratuvarı tamamladığınızda AlloyDB örneklerini ve kümeyi yok edin.
AlloyDB kümesini ve tüm örnekleri silme
AlloyDB'nin deneme sürümünü kullandıysanız Deneme kümesini kullanarak diğer laboratuvarları ve kaynakları test etmeyi planlıyorsanız deneme kümesini silmeyin. Aynı projede başka bir deneme kümesi oluşturamazsınız.
Küme, zorlama seçeneğiyle yok edilir. Bu seçenek, kümeye ait tüm örnekleri de siler.
Bağlantınız kesildiyse ve önceki tüm ayarlar kaybolduysa Cloud Shell'de proje ve ortam değişkenlerini tanımlayın:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Kümeyi silme:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB Yedeklemelerini Silme
Kümenin tüm AlloyDB yedeklerini silin:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
13. Tebrikler
Codelab'i tamamladığınız için tebrik ederiz.
İşlediğimiz konular
- AlloyDB kümesi oluşturma ve örnek verileri içe aktarma
- AlloyDB Veri Erişimi API'sini etkinleştirme
- AlloyDB için QueryData'yı etkinleştirme
- Şablon oluşturma
- Özelliklere göre aramayı kullanma
- QueryData'yı yapay zeka aracılarıyla kullanma
14. Anket
Çıkış: