
1. はじめに
この Codelab では、BigQuery の継続的クエリ、Pub/Sub、Vertex AI Agent Engine でホストされている Agent Development Kit(ADK)を使用して構築された不正調査エージェントを組み合わせたイベント ドリブン アーキテクチャを構築します。
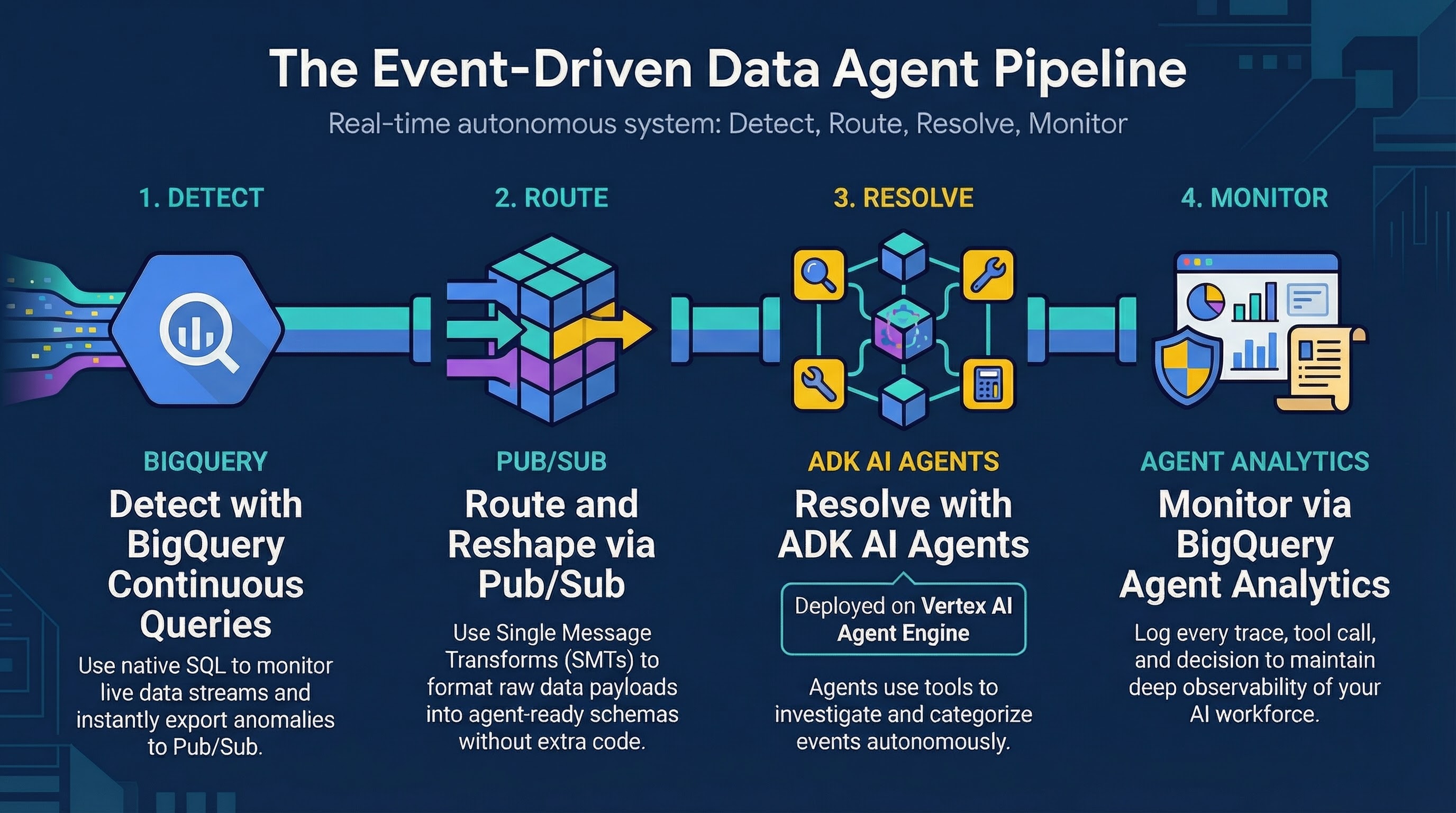
継続的クエリがリアルタイムの小売取引で異常(「不可能旅行」など)を検出し、これらの疑わしいイベントを Pub/Sub トピックにエクスポートするパイプラインを設定します。これにより、ADK エージェントがトリガーされ、各異常を個別に評価して対応します。
演習内容
- サンプル取引データを使用して BigQuery 環境を準備する
- リアルタイムの異常を検出する BigQuery の継続的クエリを作成する
- 単一メッセージ変換(SMT)を使用して Pub/Sub トピックとサブスクリプションを設定する
- ADK エージェントを pull、構成、デプロイして Vertex AI Agent Engine にデプロイする
- 取引データをストリーミングして、エージェントがエスカレーションを受信して処理することを確認する
必要なもの
- ウェブブラウザ(Chrome など)
- 課金を有効にした Google Cloud プロジェクト
- Google Cloud Shell へのアクセス
この Codelab は、BigQuery と基本的な Python に精通している中級レベルのデベロッパーを対象としています。
この Codelab で作成するリソースの費用は 2 ドル未満です。
所要時間: この Codelab の所要時間はおよそ 60 分です。
2. 始める前に
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell の起動
Cloud Shell は、必要なツールがプリロードされた Google Cloud 上で動作するコマンドライン環境です。
- Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする 」アイコン をクリックします。
- Cloud Shell に接続したら、認証を確認します。
gcloud auth list - プロジェクトが構成されていることを確認します。
gcloud config get project - プロジェクトが想定どおりに設定されていない場合は、設定します。
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
プロジェクト ID を設定する
次のコマンドを実行して、アクティブな Google Cloud プロジェクト ID を取得し、この Codelab 全体で使用する環境変数として保存します。
export PROJECT_ID=$(gcloud config get-value project)
コードを取得
このコマンドを実行してリポジトリのクローンを作成し、ADK エージェントと設定スクリプトを含むターゲット event_driven_agents_demo フォルダのみをダウンロードします。
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set data-analytics/event_driven_agents_demo && cd .. && mv temp-repo/data-analytics/event_driven_agents_demo . && rm -rf temp-repo
event_driven_agents_demo ディレクトリに移動します。
cd event_driven_agents_demo
Cloud Shell エディタを開くと、クローン作成されたリポジトリ構造が表示されます。
3. 環境を準備する
リポジトリに用意されている設定スクリプトを使用して、Google Cloud 環境を準備します。このスクリプトは次の処理を行います。
- Agent Developer Kit(ADK)をステージングするための Google Cloud Storage バケットをプロビジョニングする
- クエリ処理用に
CONTINUOUSEnterprise BigQuery 予約を作成する - BigQuery データセットを設定 し、初期
customer_profilesデータを読み込む - IAM 権限を構成 し、必要なロールを ADK エージェント サービス アカウントに付与する
Cloud Shell からスクリプトを実行します。
chmod +x setup/setup_env.sh
./setup/setup_env.sh
4. ADK エージェントを検査する
ADK エージェント コードを Vertex AI Agent Engine にデプロイします。最初にこれを行うことで、データ ストリーミングを開始する前にエージェントがデプロイされ、エスカレーションを処理する準備が整います。
cd agent
ADK(Agent Development Kit)エージェント コードについて
エージェントのコアロジックは adk_agent_app/agent.py 内で定義されています。
Gemini 2.5 Flash を使用して、異常なアラートを自律的に調査するエージェントを構築します。エージェントはアラート ペイロードを分析し、BigQuery から顧客履歴を取得し、ウェブ検索で販売者の詳細を確認してから、トランザクションを FALSE_POSITIVE(正当なトランザクション)または ESCALATION_NEEDED に分類します。
# Excerpt from agent/adk_agent_app/agent.py
investigation_agent = Agent(
model="gemini-2.5-flash",
name="Fraud_Investigation_Agent",
description="Expert fraud analyst agent that autonomously investigates alerts...",
instruction=(
"You are an expert fraud investigator for Cymbal Bank. "
"Your goal is to investigate financial transaction alerts, "
"determine if they are fraudulent, and take appropriate action. "
"Calculate risk, assess the logic_signals provided in the input, "
"query the database for past transactions, and search the merchant..."
),
tools=[
bigquery_toolset,
google_search,
],
)
エージェントには、次の 2 つの異なるツールが用意されています。
BigQueryToolset: エージェントがcymbal_bankデータセットを自律的にクエリして、追加の取引履歴を検索できます。google_search: エージェントがウェブを検索して販売者の評判を調査し、正当性を確認できます。
5. ADK エージェントをデプロイする
次のコマンドを実行して、エージェントのデプロイに必要な Python パッケージ(google-cloud-aiplatform、google-adk など)をインストールします。
pip install -r requirements.txt
次のコマンドを実行して、特定のプロジェクト ID を含む .env ファイルを動的に生成します。これはエージェントのデプロイ時に使用されます。
cat <<EOF > .env
PROJECT_ID=$PROJECT_ID
LOCATION=us-central1
STAGING_BUCKET=gs://$PROJECT_ID-adk-staging
SERVICE_ACCOUNT=adk-agent-sa@$PROJECT_ID.iam.gserviceaccount.com
BIGQUERY_DATASET=cymbal_bank
GOOGLE_GENAI_USE_VERTEXAI=1
EOF
次のコマンドを実行して、エージェントを Vertex AI Agent Engine にデプロイします。
python deploy_agent_script.py
注:deploy_agent_script.py は BigQueryAgentAnalyticsPlugin を初期化します。これにより、トレースデータとエージェント ツールの使用状況が BigQuery の agent_events テーブルに自動的に記録されます。
完了するまでに数分かかります。次のような出力が表示されます。
Deploying Agent... Deployed Resource Name: projects/<YOUR_PROJECT_ID>/locations/<REGION>/reasoningEngines/... ================================================================================ Pub/Sub Push Endpoint URL: https://<REGION>-aiplatform.googleapis.com/v1/projects/<YOUR_PROJECT_ID>/locations/<REGION>/reasoningEngines/...:streamQuery ================================================================================
このコマンドを実行して、デプロイされたエージェント エンドポイント URL を agent_endpoint.txt という名前のローカル ファイルに保存します。
export AGENT_ENDPOINT=$(cat agent_endpoint.txt)
この URL は、Pub/Sub push サブスクリプションを作成するときに使用します。
6. ADK エージェントをテストする
ライブ ストリーミング イベントを生成する前に、Agent Engine の ADK エージェントが手動エスカレーションを正しく処理していることをテストします。
- Google Cloud コンソールで、[Vertex AI Agent Engine] ページに移動します。
- デプロイしたエージェント(
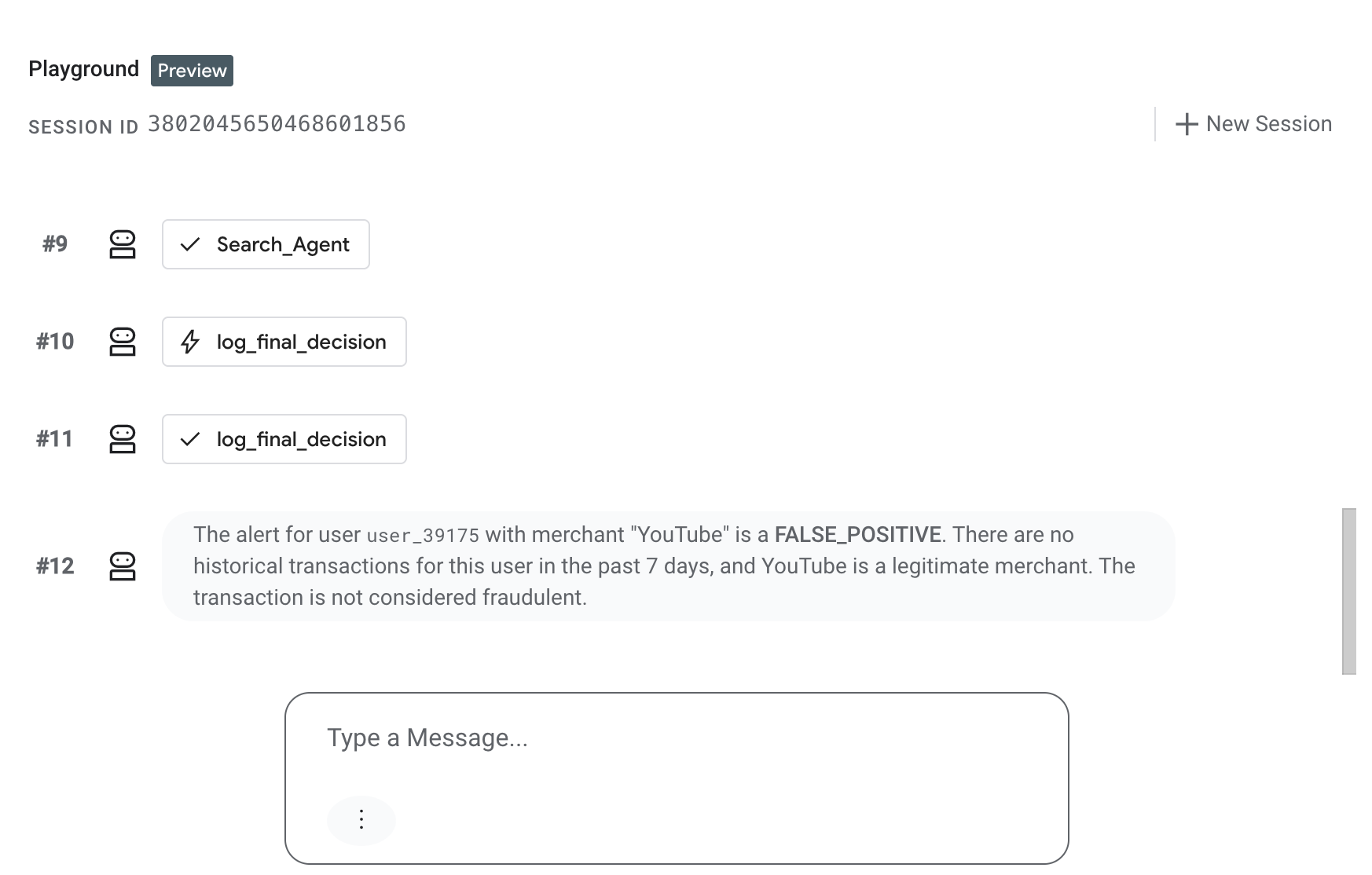
Cymbal Bank Fraud Assitant)の名前をクリックします。 - [Playground] タブに移動して、エージェントと直接やり取りします。
- チャット インターフェースに、エージェントが Pub/Sub から受信する内容を模倣した次のシミュレートされた JSON イベント ペイロードを貼り付けて、Enter キーを押します。
{ "window_end": "2026-03-15T10:00:00Z", "user_id": "user_39175", "customer_name": "Jonathan Mckinney", "tx_count": 1, "total_window_spend": 15.0, "highest_value_merchant": "Google One Subscription", "highest_value_mcc": "5732", "contains_international_tx": false, "contains_untrusted_device_tx": false, "final_risk_score": 2, "logic_signals": { "is_impossible_travel": false, "has_security_mismatch": false, "is_high_velocity": false } }
エージェントがトランザクションを評価し、Playground ウィンドウで FALSE POSITIVE 評価で応答することを確認します。
7. エスカレーションを Pub/Sub にストリーミングする BigQuery の継続的クエリを設定する
ADK エージェントがデプロイされ、イベントを受信する準備が整ったので、ルート ディレクトリに戻ってパイプラインの残りの部分を構築しましょう。
cd ../../event_driven_agents_demo
1. Pub/Sub トピックを作成する
このコマンドを実行して、Pub/Sub トピックを作成します。このトピックは、BigQuery の継続的クエリからエクスポートされた異常を受け取ります。
gcloud pubsub topics create cymbal-bank-escalations-topic
このトピックのサブスクリプションは、次のステップで作成します。
2. BigQuery の継続的クエリを実行する
エージェントがデプロイされ、Pub/Sub トピックの準備が整ったら、継続的クエリを開始して retail_transactions ストリームをリアルタイムでモニタリングします。このクエリは「不可能旅行」の異常を検出し、アラートを Pub/Sub にエクスポートします。
次のコマンドを実行してクエリを開始します。
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" setup/continuous_query.sql
bq query \
--use_legacy_sql=false \
--continuous=true \
--sync=false \
--connection_property=service_account=adk-agent-sa@$PROJECT_ID.iam.gserviceaccount.com \
"$(cat setup/continuous_query.sql)"
ターミナルに、継続的クエリが正常に開始されたことを示す出力が表示されます。
Successfully started query your-project-id:bqjob_r66189572226875ed_0000019d000000_1
8. push サブスクリプションを作成する
エージェントがデプロイされ、継続的クエリが実行されているので、トピックからエージェントの webhook URL に新しい異常メッセージを積極的に転送する「push」サブスクリプションを作成します。
エージェントが正しい形式でデータを受信するように、単一メッセージ変換(SMT) を使用します。SMT を使用すると、サブスクライバーに配信される前に、Pub/Sub 内でメッセージデータと属性に対する軽量な変更をオンザフライで行うことができます。
パイプラインでの変換の仕組みは次のとおりです。
- UDF:
setupディレクトリのtransform.yamlファイルには、メッセージを処理する JavaScript ユーザー定義関数(UDF)が含まれています。 - BigQuery データのアンラップ: BigQuery は、継続的クエリを使用して Pub/Sub にデータをエクスポートするときに、JSON ペイロードを外部オブジェクトでラップします。
- ADK の形式設定: UDF は二重エンコードをアンラップし、Agent Engine
streamQueryAPI で想定される厳密な形式でペイロードを再パッケージ化します。
次のコマンドを実行して、UDF 変換を適用したサブスクリプションを作成します。
gcloud pubsub subscriptions create cymbal-bank-escalations-sub \
--topic=projects/$PROJECT_ID/topics/cymbal-bank-escalations-topic \
--message-transforms-file=setup/transform.yaml \
--push-endpoint="$AGENT_ENDPOINT" \
--push-no-wrapper \
--push-auth-service-account="adk-agent-sa@$PROJECT_ID.iam.gserviceaccount.com" \
--ack-deadline=600
サブスクリプションが作成されたことを確認する出力が表示されます。
Created subscription [projects/your-project-id/subscriptions/cymbal-bank-escalations-sub].
9. イベントを生成する
最後に、generate_events.py を実行して、合成された「不可能旅行」トランザクションを cymbal_bank.retail_transactions テーブルにストリーミングし、エンドツーエンドのフローをテストします。
python simulator/generate_events.py
これは、先ほど読み込んだ顧客プロファイル データ(米国在住の Karen Burton)を使用し、オーストラリア(AUS)で発生した新しい 2,500 ドルの電子機器取引をシミュレートします。
イベントが到着したことを確認する: 継続的クエリのウィンドウ処理と ADK 処理に約 2 分間待ってから、デプロイされたエージェントのログを確認し、トリガーされた Pub/Sub メッセージが処理されたことを確認します。
10. BigQuery でエージェントのパフォーマンスを分析する
BigQuery コンソールに移動し、cymbal_bank データセットを選択します。agent_events テーブルを選択して [プレビュー] をクリックします。
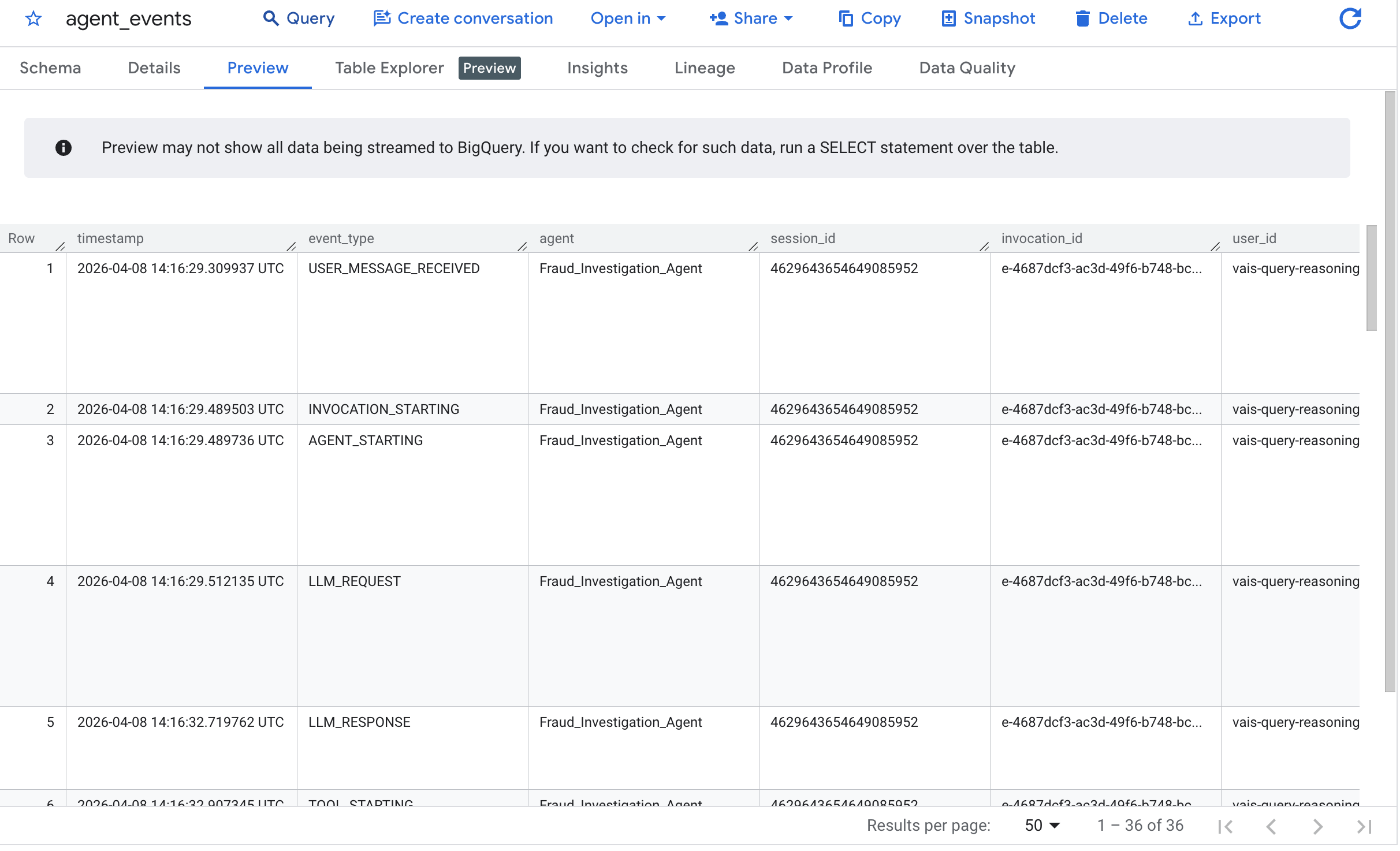
出力は、エージェントが「不可能旅行」のエスカレーションを正常に分析したことを示しています。
自律エージェントはバックグラウンドで永続的に実行されるため、オブザーバビリティが重要です。エージェントは、ADK プラグインを介して実行トレースを自動的に記録し、カスタムツールを介して決定をログに記録します。
次のクエリを実行して、エージェントの決定を agent_events テーブルでキャプチャされたレイテンシとトークンの使用状況の指標と結合します。
-- Create session-level metrics from detailed agent events
SELECT
MAX(d.timestamp) AS decision_time,
ANY_VALUE(d.user_id) AS user_id,
ANY_VALUE(d.merchant) AS merchant,
ANY_VALUE(d.decision) AS decision,
ANY_VALUE(d.summary) AS summary,
-- Calculate latency in seconds
TIMESTAMP_DIFF(MAX(e.timestamp), MIN(e.timestamp), SECOND) AS execution_latency_sec,
-- Aggregate total tokens from LLM calls
SUM(CAST(JSON_EXTRACT_SCALAR(e.content, '$.usage.total') AS INT64)) AS total_tokens_used,
-- Count total events logged to represent the agent's complex reasoning steps
COUNT(e.session_id) AS agent_reasoning_steps,
-- Count total tool calls
COUNTIF(e.event_type = 'TOOL_COMPLETED') AS total_tool_count
FROM
`cymbal_bank.agent_decisions` d
JOIN
`cymbal_bank.agent_events` e ON d.session_id = e.session_id
GROUP BY
d.session_id
ORDER BY
decision_time DESC
次のような結果テーブルが表示されます。
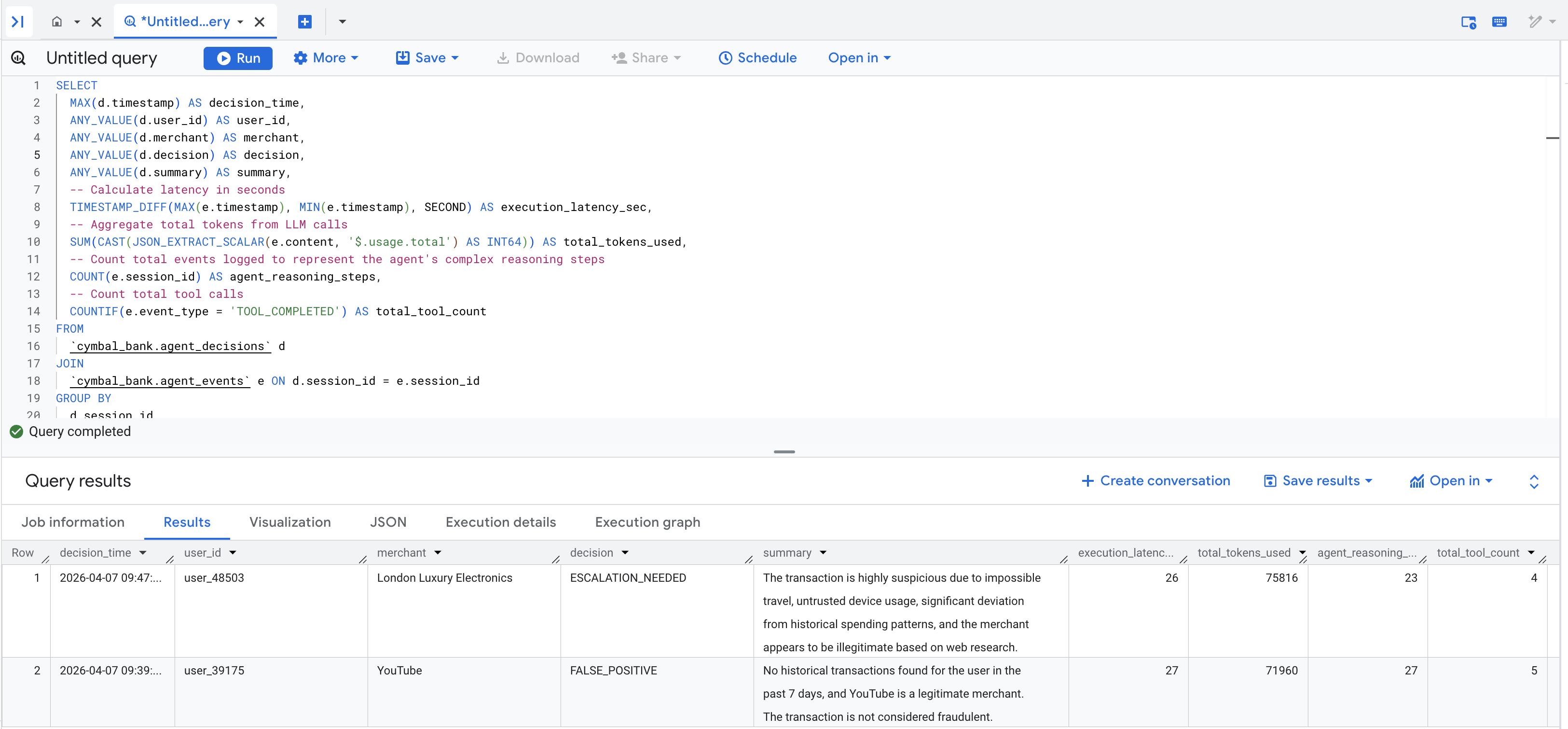
可能性の実現: この Codelab は、エージェントの決定を BigQuery に記録して可視化することで終了します。イベント ジェネレータ スクリプトは比較的簡単で、1 人のユーザーからの不正行為のみを挿入しましたが、エージェント ツールは単なる Python 関数です。つまり、デモがより多くのユースケースやシナリオにスケーリングされると、エージェントはあらゆるものとやり取りできます。
本番環境では、このアーキテクチャを簡単に拡張できます。エージェントは、データをログに記録するだけでなく、webhook を呼び出して Slack や Teams チャンネルにアラートを送信したり、PagerDuty インシデントをトリガーしたり、最終的な判定を Cloud Spanner などの低レイテンシ データベースに書き込んだり、新しい Pub/Sub メッセージをダウンストリーム マイクロサービスに公開して、不正使用されたクレジット カードを自動的に凍結したりできます。
11. クリーンアップ
Google Cloud アカウントに継続的に課金されないようにするには、この Codelab で作成したリソースを削除します。
Codelab リポジトリには、Pub/Sub デプロイ、BigQuery データセット、BigQuery 予約スロット、Vertex Agent Engine 構成、Cloud Storage ステージング バケット、IAM サービス アカウントを自動的に削除するクリーンアップ スクリプトが含まれています。
Google Cloud コンソールの BigQuery UI から BigQuery の継続的クエリがまだ実行されている場合は停止します。次に、クリーンアップ スクリプトを実行します。
chmod +x setup/cleanup_env.sh
./setup/cleanup_env.sh
または、この Codelab 専用にプロジェクトを作成した場合は、プロジェクト全体を削除することもできます。
12. 完了
おめでとうございます!BigQuery、Pub/Sub、ADK を使用して、イベント ドリブン データ エージェント パイプラインを構築しました。
学習した内容
- BigQuery の継続的クエリから Pub/Sub に異常をエクスポートする方法
- 変換された Pub/Sub メッセージを ADK エージェントにルーティングする方法
- Vertex AI Agent Engine でエージェントをデプロイして操作する方法