
1. Einführung
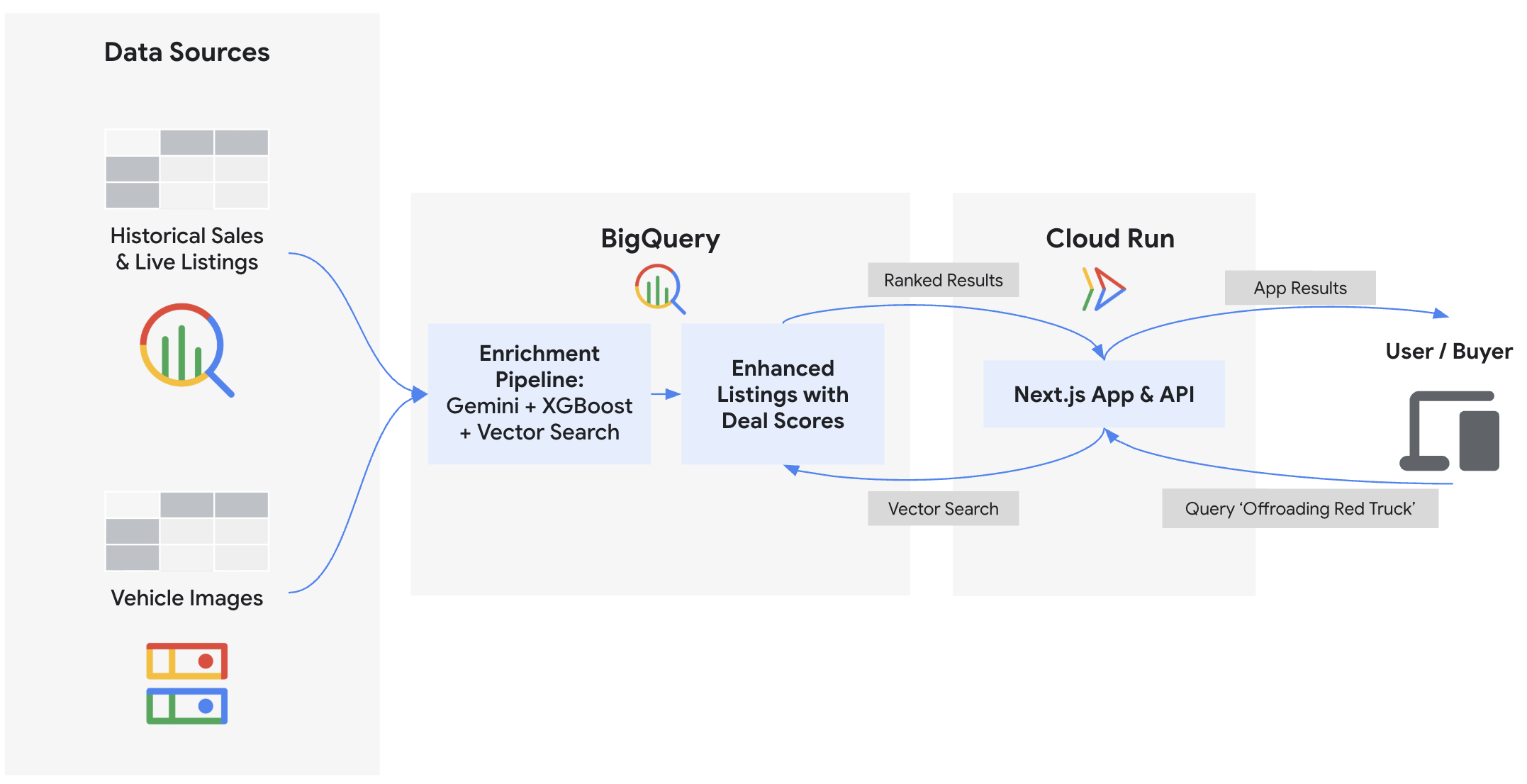
In diesem Codelab erstellen Sie das Backend und stellen das Frontend für „Cymbal Autos“ bereit, einen Online-Marktplatz für Fahrzeuge. Sie verwenden BigQuery und Gemini-Modelle auf der Gemini Enterprise Agent Platform, um Fahrzeugfotos zu prüfen, Preise mit BigQuery ML vorherzusagen, betrügerische Einträge mit Vektoreinbettungen zu erkennen und zusammengesetzte Deal-Scores zu berechnen. Schließlich werden Sie diese Statistiken in einem Next.js-Frontend präsentieren, das in Cloud Run bereitgestellt wird.
Aufgaben
- BigQuery mit unstrukturierten Cloud Storage-Bildern über ObjectRef verbinden
- Fahrzeugattribute aus Fotos mit BigQuery mit Gemini-Modellen extrahieren
- Faire Marktpreise vorhersagen, indem ein XGBoost-Regressionsmodell mit BigQuery ML trainiert wird
- Potenzielle Betrugsversuche und vertrauenswürdige Einträge durch Einbetten von Fahrzeugbeschreibungen und Ausführen von
VECTOR_SEARCHerkennen - Berechnen Sie für jedes Angebot einen umfassenden Deal-Score und berücksichtigen Sie dabei auch die Zustandssignale aus der Beschreibung des Verkäufers mit
AI.SCORE. - Daten exportieren und die Next.js Marketplace-Anwendung in Google Cloud Run bereitstellen
Voraussetzungen
- Ein Webbrowser wie Chrome
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
- Grundkenntnisse in SQL, Python und Google Cloud
- Ausreichende IAM-Berechtigungen zum Aktivieren von APIs, Erstellen von Ressourcen und Zuweisen von Berechtigungen (z.B. Projektinhaber)
Dieses Codelab richtet sich an Entwickler mit mittleren Kenntnissen.
Die in diesem Codelab erstellten Ressourcen sollten weniger als 5 $ kosten.
2. Hinweis
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Cloud Shell starten
Sie verwenden Google Cloud Shell, um den Code herunterzuladen, Einrichtungs-Scripts auszuführen und die Anwendung bereitzustellen.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.

- Sobald Sie eine Verbindung zu Cloud Shell hergestellt haben, authentifizieren Sie Ihre Sitzung, damit Ihre Anwendung auf Google Cloud APIs zugreifen kann. Folgen Sie der Anleitung, um Cloud Shell zu autorisieren:
gcloud auth application-default login
- Legen Sie Ihre Google Cloud-Projekt-ID und einen eindeutigen Namen für Ihren Google Cloud Storage-Bucket fest, in dem Sie Rohdaten speichern:
export PROJECT_ID=$(gcloud config get-value project)
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
gcloud config set project $PROJECT_ID
Es sollte eine Meldung ähnlich der folgenden angezeigt werden:
Your active configuration is: [cloudshell-####] Updated property [core/project]
APIs aktivieren
Führen Sie diesen Befehl in Cloud Shell aus, um alle für dieses Codelab erforderlichen APIs zu aktivieren:
gcloud services enable \
aiplatform.googleapis.com \
artifactregistry.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
cloudbuild.googleapis.com \
run.googleapis.com
Bei erfolgreicher Ausführung sollte eine Meldung ähnlich der folgenden angezeigt werden:
Operation "operations/..." finished successfully.
3. Code und Einrichtungsdaten abrufen
Laden Sie zuerst die Demo-Assets herunter und konfigurieren Sie Ihre Umgebungsvariablen.
- Klonen Sie in Cloud Shell das Repository
devrel-demosund wechseln Sie in das Projektverzeichnis:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos/data-analytics/cymbal-autos-multimodal
- Führen Sie das Skript aus, um Daten in Ihre Umgebung zu kopieren. Mit diesem Skript werden die Datasets des lokalen Repositorys mit Ihrem persönlichen Cloud Storage-Bucket synchronisiert und die Fahrzeugbilder aus einem öffentlichen Bucket abgerufen:
chmod +x scripts/setup/*.sh
./scripts/setup/00_copy_data.sh
Anschließend sollte eine Meldung wie die folgende angezeigt werden:
Average throughput: 87.8MiB/s Data copy complete!
- Richten Sie als Nächstes die BigQuery-Cloud-Ressourcenverbindung ein. Wenn Sie unstrukturierte Bilder in Cloud Storage analysieren und Agent Platform-Modelle direkt über Ihre SQL-Abfragen aufrufen möchten, muss BigQuery IAM-Berechtigungen an ein zugrunde liegendes Dienstkonto delegieren. Mit diesem Skript wird diese sichere Verbindung erstellt und ihr werden die erforderlichen Rollen „Vertex AI-Nutzer“ und „Service Usage Consumer“ zugewiesen. Die Übertragung dauert etwa eine Minute:
./scripts/setup/01_setup_api_connection.sh
Es sollte eine Meldung wie die folgende angezeigt werden:
Environment setup complete! Your BigQuery connection is ready.
- Erstellen Sie schließlich das erste BigQuery-Dataset und laden Sie die tabellarischen Rohdaten. Dadurch wird das Dataset
model_deverstellt und die Starttabellen werden mit Daten gefüllt. So wird die Grundlage geschaffen, bevor Sie Abfragen für maschinelles Lernen schreiben:
./scripts/setup/02_load_to_bq.sh
Es sollte eine Meldung wie die folgende angezeigt werden:
================================================================= BigQuery load complete! =================================================================
4. Multimodale Vision-Extraktion
Bevor Sie die Fahrzeugangebote bewerten, extrahieren Sie strukturierte Daten (z. B. Farbe, Karosseriebauform oder sichtbare Schäden) aus Hunderten von Rohfotos. Mithilfe von ObjectRef-Funktionen und Gemini-Modellen, die auf der Agent Platform gehostet werden, können Sie diese Funktionen generieren, ohne Dateien verschieben oder komplexe Datenpipelines schreiben zu müssen. Diese Extraktion ist direkt für das ✨ Visueller Zustand-Badge in der Frontend-Anwendung verantwortlich.
- Öffnen Sie BigQuery Studio in einem neuen Browsertab.
- Klicken Sie auf den Button + Neue Abfrage erstellen. In diesem Codelab verwenden Sie den SQL-Editor, um mit SQL-Code zu interagieren.
- Bevor Sie die Machine-Learning-Extraktoren erstellen, können Sie sich die Rohbilder ansehen. Führen Sie die folgende Abfrage aus, um das Array von Bild-URIs aufzurufen, die für jedes Angebot in Google Cloud Storage gespeichert sind:
SELECT auction_id, item_name, description, images
FROM `model_dev.vehicle_metadata` LIMIT 5;
- Fügen Sie nun im BigQuery Studio-SQL-Editor den folgenden SQL-Code ein, um eine neue Tabelle mit einer
image_ref-Spalte zu erstellen. Klicken Sie auf Ausführen.
CREATE OR REPLACE TABLE `model_dev.vehicle_multimodal` AS
SELECT
*,
ARRAY(
SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF(uri, 'us.conn'))
FROM UNNEST(images) AS uri
) AS image_ref
FROM `model_dev.vehicle_metadata`;
- Sehen Sie sich die neue Spalte
image_refObjectRef an, die Sie gerade erstellt haben. Die neue Tabelle enthält jetzt eine ObjectRef-Spalte mit Berechtigungen zum Ausführen von Aktionen für die Bilder selbst. Führen Sie die folgende Abfrage aus, um sie aufzurufen:
SELECT auction_id, item_name, description, image_ref
FROM `model_dev.vehicle_multimodal` LIMIT 5;
- Jetzt verwenden Sie
AI.GENERATEundAI.CLASSIFY, um die Bilder zu analysieren. MitAI.GENERATEwerden der Zustandswert und eine Zusammenfassung der Schäden in einem Satz extrahiert, indem Gemini aufgefordert wird, während mitAI.CLASSIFYKarosseriebauform und Farbe des Fahrzeugs kategorisiert werden.
Führen Sie die folgende Abfrage aus, um diese Statistiken in eine separate Featuretabelle zu extrahieren. Dieser Vorgang dauert etwa drei Minuten.
CREATE OR REPLACE TABLE `model_dev.vehicle_vision_features` AS
WITH generated_data AS (
SELECT
auction_id,
AI.GENERATE(
prompt => ('Rate the condition of this car on a scale from 0-100. Output a 1 sentence description of any glaring red flags', image_ref),
output_schema => 'condition INT64, description_summary STRING'
).* EXCEPT(full_response,status)
FROM
`model_dev.vehicle_multimodal`
),
-- Object-centric Classifications
classified_data AS (
SELECT
auction_id,
AI.CLASSIFY(
('What type of automobile is this?', image_ref[0]),
categories => ['Truck', 'Sedan', 'SUV']) AS body_style,
AI.CLASSIFY(
('Color of the exterior of the automobile', image_ref[0]),
categories => ['Black', 'White', 'Silver', 'Gray', 'Red', 'Blue', 'Brown', 'Green', 'Beige', 'Gold']) AS color,
AI.CLASSIFY(
('Color of the interior of the automobile', image_ref[0]),
categories => ['Black', 'Gray', 'Beige', 'Tan', 'Brown', 'White', 'Red']) AS interior
FROM `model_dev.vehicle_multimodal`
)
-- Join the AI insights back together into the final feature table
SELECT
g.auction_id,
g.condition,
g.description_summary,
c.body_style,
c.color,
c.interior
FROM generated_data g
JOIN classified_data c ON g.auction_id = c.auction_id;
- Wenn Sie sich die generierten Funktionen selbst ansehen möchten, führen Sie die folgende Abfrage aus oder sehen Sie sich den Screenshot unten an:
SELECT auction_id, condition, description_summary, body_style, color, interior FROM `model_dev.vehicle_vision_features` LIMIT 5;

Zusammenfassung des Abschnitts:Sie haben direkt über BigQuery auf die Rohbilder zugegriffen und Gemini-Modelle verwendet, um strukturierte visuelle Merkmale zu extrahieren, ohne Dateien zu verschieben.
5. Vorhersagepreise mit XGBoost
Um zu berechnen, ob ein Fahrzeug wirklich ein gutes Angebot ist, ist eine zuverlässige Grundlage für seinen fairen Marktwert erforderlich. Anstatt Daten in lokale Skripts oder Notebooks zu übertragen, um ein Modell zu trainieren, können Sie ein XGBoost-Modell direkt in BigQuery mit Standard-SQL trainieren. Diese Preisvorhersage ist die Grundlage für die Logik des 📈 fairen Marktwerts in der Frontend-Anwendung.
- Kehren Sie zum Tab BigQuery Studio zurück.
- Sehen Sie sich zuerst das Trainings-Dataset an. Im Gegensatz zu den aktiven Fahrzeugangeboten enthält diese
synthetic_cars-Tabelle 100.000 historische Verkäufe, die zum Trainieren des Modells verwendet werden. Führen Sie diese kurze Abfrage aus, um sich einen Überblick zu verschaffen:
SELECT
*
FROM
`model_dev.synthetic_cars`
LIMIT 10;
- Führen Sie nun den folgenden SQL-Code aus, um ein XGBoost-Regressionsmodell zu trainieren. Dieses Modell lernt anhand der 100.000 Datensätze, wie sich Attribute wie Laufleistung, Baujahr, Marke und optischer Zustand auf den Preis auswirken:
CREATE OR REPLACE MODEL `model_dev.car_price_model`
OPTIONS(
MODEL_TYPE = 'BOOSTED_TREE_REGRESSOR',
INPUT_LABEL_COLS = ['selling_price'],
MAX_ITERATIONS = 15,
TREE_METHOD = 'HIST'
) AS
SELECT
* EXCEPT(vin, sale_date, market_value, seller)
FROM
`model_dev.synthetic_cars`;
- Bevor Sie Preise für die aktiven Fahrzeugangebote vorhersagen, müssen Sie alle relevanten Eingabefunktionen an einem Ort zusammenführen. Führen Sie diesen SQL-Code aus, um die strukturierten Fahrzeugmetadaten mit den gerade generierten, aus Bildern extrahierten Merkmalen zusammenzuführen:
CREATE OR REPLACE TABLE `model_dev.vehicle_prediction_features` AS
SELECT
meta.auction_id,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.transmission_type,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id;
- Schließlich wird der faire Marktwert jeder laufenden Fahrzeuganzeige prognostiziert. Führen Sie die folgende Abfrage aus, um die aggregierten Features in Ihr neu trainiertes Modell einzufügen und die numerischen Ausgaben in einer sicheren Vorhersagetabelle zu speichern:
CREATE OR REPLACE TABLE `model_dev.vehicle_price_predictions` AS
SELECT
auction_id,
ROUND(predicted_selling_price, 2) AS predicted_market_value
FROM ML.PREDICT(
MODEL `model_dev.car_price_model`,
(SELECT * FROM `model_dev.vehicle_prediction_features`)
);
- Überprüfen Sie nun die Ausgabe des Modells. Führen Sie diese schnelle Abfrage aus, um eine Vorschau der prognostizierten Marktwerte für die aktiven Fahrzeugangebote zu sehen:
SELECT * FROM `model_dev.vehicle_price_predictions` LIMIT 5;
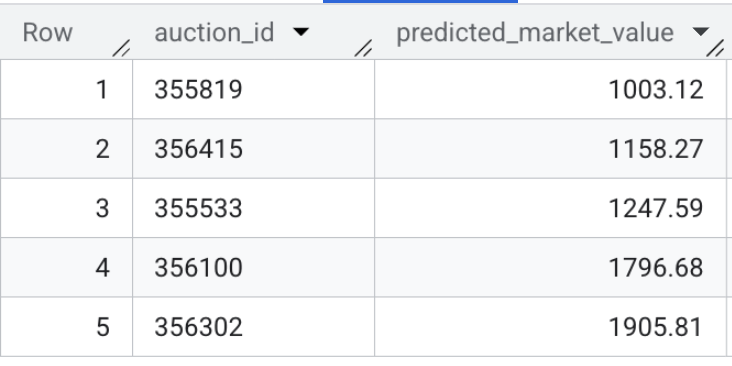
Zusammenfassung des Abschnitts:Sie haben ein XGBoost-Regressionsmodell mit 100.000 Beispieltransaktionen trainiert und die Batch-Inferenz ausgeführt,um den fairen Marktwert für jedes aktive Fahrzeugangebot im Datensatz vorherzusagen.
6. Semantische Einbettungen und Authentizitätserkennung
In diesem Abschnitt führen Sie zwei separate Embedding-Pipelines aus, um smarte Funktionen für den Fahrzeugmarktplatz zu aktivieren:
- Multimodale Bildersuche:Rohbilder von Fahrzeugen werden in den Vektorraum übersetzt, damit Nutzer mit natürlicher Sprache suchen können (z.B. „ein zuverlässiger Arbeits-Lkw“).
- Texteinbettungen und Ähnlichkeitssuche:Geschriebene Fahrzeugbeschreibungen werden in Vektoreinbettungen übersetzt, um aktive Einträge mithilfe von
VECTOR_SEARCHmit bekannten potenziellen Betrugs- oder Enthusiastenprofilen zu vergleichen. So wird der 🔍 Authentizitätsfaktor berechnet, den Käufer in der App sehen.
- Zuerst müssen Sie multimodale Einbettungen für die Fahrzeugangebote generieren. Mit dem Modell
gemini-embedding-2-previewkönnen Sie sowohl Bilder als auch Text in dieselbe Einbettung eingeben. Dieses Modell kann zwar mehrere Modalitäten gleichzeitig verarbeiten, in diesem speziellen Fall betten wir jedoch nur die Fahrzeugbilder ein. So wird die Suchleiste für die „semantische Suche“ für die Frontend-Anwendung unterstützt. Käufer können natürliche Sprache verwenden (z. B. „ein zuverlässiger Pickup-Truck“) und schnell passende Einträge abrufen. Führen Sie diese Abfrage aus, um die multimodalen Vektoren mitAI.EMBEDzu generieren:
CREATE OR REPLACE TABLE `model_dev.vehicle_images_embedded` AS
SELECT
auction_id,
AI.EMBED(
STRUCT(image_ref),
endpoint => 'gemini-embedding-2-preview').result AS multimodal_embedding
FROM `model_dev.vehicle_multimodal`
WHERE ARRAY_LENGTH(image_ref) > 0;
- Als Nächstes sehen Sie sich die zuvor geladenen Daten zum Risikoprofil an. Die Liste enthält sowohl bekannte Betrugstypologien als auch legitime Beispielangebote von Enthusiasten. Führen Sie diese Abfrage aus, um die Baseline-Profile aufzurufen:
SELECT profile_id, profile_type, description
FROM `model_dev.seller_risk_profiles`;
- Als Nächstes übersetzen Sie diese Rohrisikobeschreibungen in Vektoreinbettungen. Sie können ein spezielles Texteinbettungsmodell (
text-embedding-005) verwenden, um die gerade in der Vorschau angezeigte geschriebene Sprache genau zu bewerten. Fügen Sie den folgenden SQL-Code ein und klicken Sie auf „Ausführen“, um die Baseline-Profile einzubetten:
CREATE OR REPLACE TABLE `model_dev.seller_risk_profiles_embedded` AS
SELECT
profile_id,
description AS content,
profile_type,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.seller_risk_profiles`;
- Als Nächstes generieren Sie vergleichbare Einbettungen für das tatsächliche Live-Fahrzeuginventar. Führen Sie diese Abfrage aus, um die Roh-HTML-Beschreibung für jedes Fahrzeug in den Vektorraum zu übersetzen, damit sie mit den Baseline-Profilen verglichen werden kann:
CREATE OR REPLACE TABLE `model_dev.vehicle_descriptions_embedded` AS
SELECT
auction_id,
description AS content,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.vehicle_metadata`
WHERE description IS NOT NULL;
- Führen Sie zum Schluss die Vektorsuche aus, um die semantische Distanz zwischen den Live-Einträgen und den Baseline-Profilen zu berechnen. Führen Sie den folgenden SQL-Code aus, um die Zuordnung vorzunehmen. Ein geringerer mathematischer Abstand bedeutet, dass ein Eintrag einem bekannten Betrugscluster sehr ähnlich ist, während ein größerer Abstand auf eine legitime Beschreibung hindeutet.
CREATE OR REPLACE TABLE `model_dev.vehicle_authenticity_scores` AS
SELECT
scam_search.query.auction_id,
CAST(
GREATEST(0.0, LEAST(100.0, ROUND((MIN(scam_search.distance) - 0.33) / 0.12 * 100.0)))
AS INT64
) AS authenticity_score
FROM VECTOR_SEARCH(
TABLE `model_dev.seller_risk_profiles_embedded`,
'text_embedding',
(
SELECT text_embedding, auction_id
FROM `model_dev.vehicle_descriptions_embedded`
),
top_k => 15,
distance_type => 'COSINE'
) AS scam_search
WHERE scam_search.base.profile_type = 'scam'
GROUP BY 1;
Der Inhalt dieser Tabelle kann so aussehen:
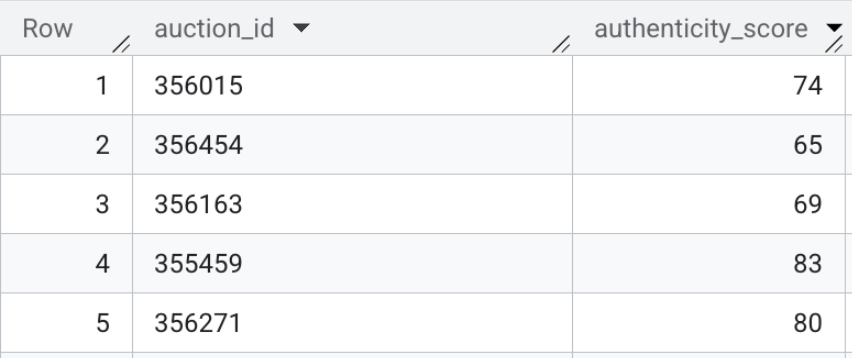
Zusammenfassung des Abschnitts:Sie haben multimodale Einbettungen für die Suchleiste im Frontend generiert und die Vektorsuche direkt in BigQuery verwendet, um Roh-HTML-Texteinträge mit bekannten Betrugsprofilen zu vergleichen.
7. Generative Deal Scoring
Sie haben jetzt strukturierte Datasets, die mit verschiedenen Machine-Learning-Techniken generiert wurden, die alle vollständig in BigQuery orchestriert werden: Vision-Extraktion, XGBoost-Modell zur Vorhersage des fairen Marktwerts und Vektorsucheinbettungen.
Im letzten Schritt werden diese KI-Signale in einer konsolidierten Ansicht als endgültiger Deal-Score für die Frontend-Anwendung zusammengeführt.
- Zuerst werden die Rohmetadaten mit den KI-basierten visuellen Merkmalen, den Vorhersagepreisausgaben und den semantischen Authentizitätswerten zusammengeführt. Führen Sie den folgenden SQL-Code aus:
CREATE OR REPLACE TABLE `model_dev.vehicle_features_enhanced` AS
SELECT
meta.auction_id,
meta.item_name,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.current_bid,
meta.listing_url,
meta.transmission_type,
meta.description,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior,
COALESCE(scam.authenticity_score, 100) AS authenticity_score,
vision.description_summary,
prices.predicted_market_value
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id
LEFT JOIN `model_dev.vehicle_price_predictions` prices
ON meta.auction_id = prices.auction_id
LEFT JOIN `model_dev.vehicle_authenticity_scores` scam
ON meta.auction_id = scam.auction_id;
- Als Nächstes berechnen Sie einen Deal-Score zwischen 0 und 100, indem Sie vier verschiedene KI-Signale kombinieren. In dieser Formel werden Wert, Qualität und Risiko berücksichtigt, um die besten Einträge zu präsentieren:
- Preisbewertung (40%): Hier wird die Ersparnis im Vergleich zum fairen Marktwert gemessen.
- Vision-Punktzahl (30%): Erkenntnisse aus der vorherigen Fotoanalyse.
- Authentizitätsquote (15%): Bewertung des Betrugsrisikos.
- Zustandsbewertung (15%): Wird anhand der Beschreibung des Verkäufers über
AI.SCOREabgeleitet.
CREATE OR REPLACE TABLE `model_dev.marketplace_listings` AS
WITH score_elements AS (
SELECT
*,
-- 1. SELLER DESCRIPTION SCORE (use AI.SCORE on seller description)
AI.SCORE(
FORMAT("Rate the vehicle condition (0-100) based ONLY on this text: '%s'", description)
) AS description_score,
-- 2. PRICE SCORE
-- Higher impact for underpricing, lower impact for overpricing.
CAST(LEAST(100.0, GREATEST(0.0,
75.0 + (
IF((predicted_market_value - current_bid) > 0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 250.0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 40.0
)
)
)) AS INT64) AS price_score
FROM `model_dev.vehicle_features_enhanced`
),
final_calcs AS (
SELECT
*,
-- 3. Combine scores: Price (40%), Condition (30%), Description (15%), Authenticity (15%)
ROUND(
(
(price_score * 0.40) +
(CAST(condition AS INT64) * 0.30) +
(COALESCE(description_score, 50) * 0.15) +
(CAST(authenticity_score AS INT64) * 0.15)
)
-- Authenticity penalty for scores below 50.
* (IF(CAST(authenticity_score AS INT64) < 50, 0.20, 1.05))
) AS raw_score
FROM score_elements
)
SELECT
* EXCEPT(raw_score),
-- 4. Set floor values: low authenticity scores drop to 10; others floor at 35.
CAST(GREATEST(
(IF(CAST(authenticity_score AS INT64) < 50, 10, 35)),
LEAST(100, raw_score)
) AS INT64) AS deal_score
FROM final_calcs;
Damit die Empfehlungen von hoher Qualität sind, werden in der Abfrage zwei spezifische Logikebenen angewendet:
- Authenticity Gating: Wenn ein Eintrag als „Hohes Risiko“ gekennzeichnet ist (Punktzahl < 50), wird die Gesamtpunktzahl für das Angebot automatisch um 80% reduziert, um zu verhindern, dass verdächtige Einträge beworben werden.
- Optimierung für „Hidden Gem“: In der Formel wird eine stückweise Logik verwendet, um Einsparungen aggressiv zu belohnen und gleichzeitig Preiserhöhungen zu berücksichtigen. So kann ein überteuertes Auto in neuwertigem Zustand trotzdem die Einstufung „Fair“ erhalten.
Die resultierende Tabelle model_dev.marketplace_listings enthält Felder wie deal_score sowie price_score und authenticity_score.
- Wenn Sie die Deal-Scores selbst sehen möchten, führen Sie die folgende Abfrage aus oder sehen Sie sich den Screenshot unten an:
SELECT item_name, model_year, authenticity_score, predicted_market_value, price_score, deal_score FROM `model_dev.marketplace_listings`
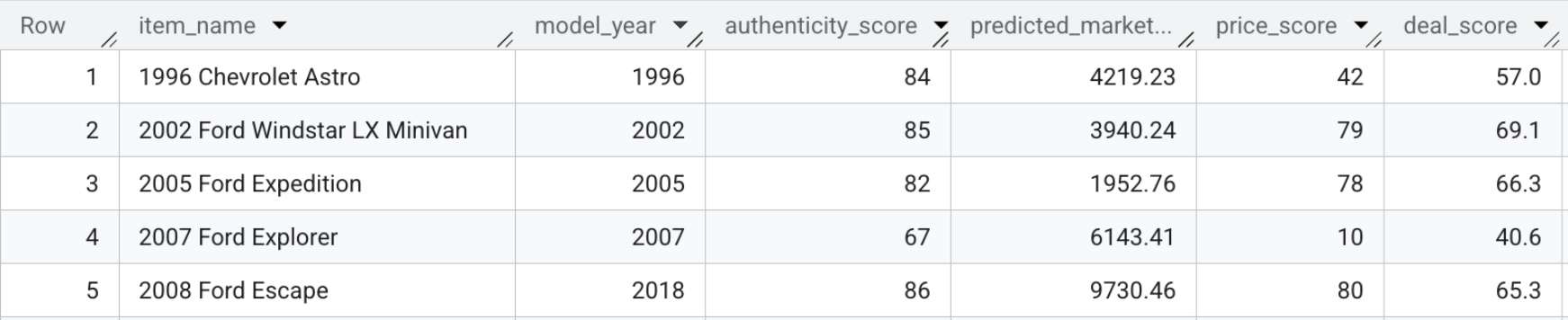
Zusammenfassung des Abschnitts:Sie haben die Vorhersagepreise, visuellen Funktionen und Authentizitätswerte zusammen mit der Beschreibung des Verkäufers verwendet, um für jedes Angebot einen einzelnen Deal-Score zu berechnen.
8. Frontend-Anwendung bereitstellen
Jetzt ist es an der Zeit, die Frontend-Anwendung einzurichten. So können Sie endlich das Inventar von Fahrzeugangeboten durchsuchen und mit den KI-generierten Statistiken interagieren, die Sie gerade erstellt haben, z. B. mit dem Deal-Score.
KI-Bewertungen ins Frontend exportieren
Das React-Frontend basiert auf einer lokalen JSON-Nutzlast, um die Seite schnell zu laden. Um den Marktplatz zu betreiben, extrahieren Sie die endgültigen Generative Deal Scores aus BigQuery und fügen Sie sie wieder in das Next.js-Projekt ein.
- Stellen Sie sicher, dass Ihre Umgebung bereit ist. Wenn das Zeitlimit für Ihre Cloud Shell-Sitzung überschritten wurde oder Sie zu einem anderen Ordner gewechselt haben, führen Sie den folgenden Befehl aus, um zum Projektstamm zurückzukehren und Ihre Umgebungsvariablen wiederherzustellen:
cd ~/devrel-demos/data-analytics/cymbal-autos-multimodal && \
export PROJECT_ID=$(gcloud config get-value project) && \
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
- Führen Sie das bereitgestellte Python-Skript aus, um die endgültige BigQuery-Ansicht abzufragen und die neuen Deal-Scores in den zugrunde liegenden Datenspeicher der Anwendung einzufügen:
python3 scripts/setup/08_export_frontend_data.py
Sie erhalten eine Bestätigungsnachricht wie:
💾 Updated local file: app/src/data/cars.json
Anwendung in Cloud Run bereitstellen
Nachdem die Daten erfolgreich angereichert wurden, können Sie die Next.js-Frontend-Anwendung mit Cloud Run im öffentlichen Internet bereitstellen. Sie bietet eine moderne Benutzeroberfläche mit Angebotsbewertungen, interaktiven Bilderkarussells und einer dynamischen hybriden semantischen Suchleiste, die BigQuery in Echtzeit abfragt.
- Wechseln Sie in Cloud Shell zum Verzeichnis
app/Ihres geklonten Repositorys. Das ist wichtig: Wenn Sie im Stammverzeichnis bleiben, schlägt der Build fehl.
cd app
- Stellen Sie die Anwendung als serverlosen Container mit Cloud Run bereit. Mit dem Befehl wird
PROJECT_IDals Umgebungsvariable übergeben, damit die Next.js API weiß, welches BigQuery-Projekt abgefragt werden soll:
gcloud run deploy cymbal-autos-frontend \
--source . \
--region us-west1 \
--allow-unauthenticated \
--min-instances 1 \
--set-env-vars PROJECT_ID=$PROJECT_ID \
--project $PROJECT_ID
- Wenn die Bereitstellung abgeschlossen ist, wird im Terminal eine sichere Dienst-URL ausgegeben. Die Ausgabe sieht etwa so aus:
Service URL: https://cymbal-autos-frontend-[YOUR-PROJECT-NUMBER].us-west1.run.app/
9. Cymbal Autos-Anwendung kennenlernen
Nachdem Sie den Frontend-Container per Push nach Cloud Run übertragen haben, können Sie die App testen.
- Website aufrufen:Öffnen Sie die sichere Dienst-URL, die von Cloud Run zurückgegeben wird.
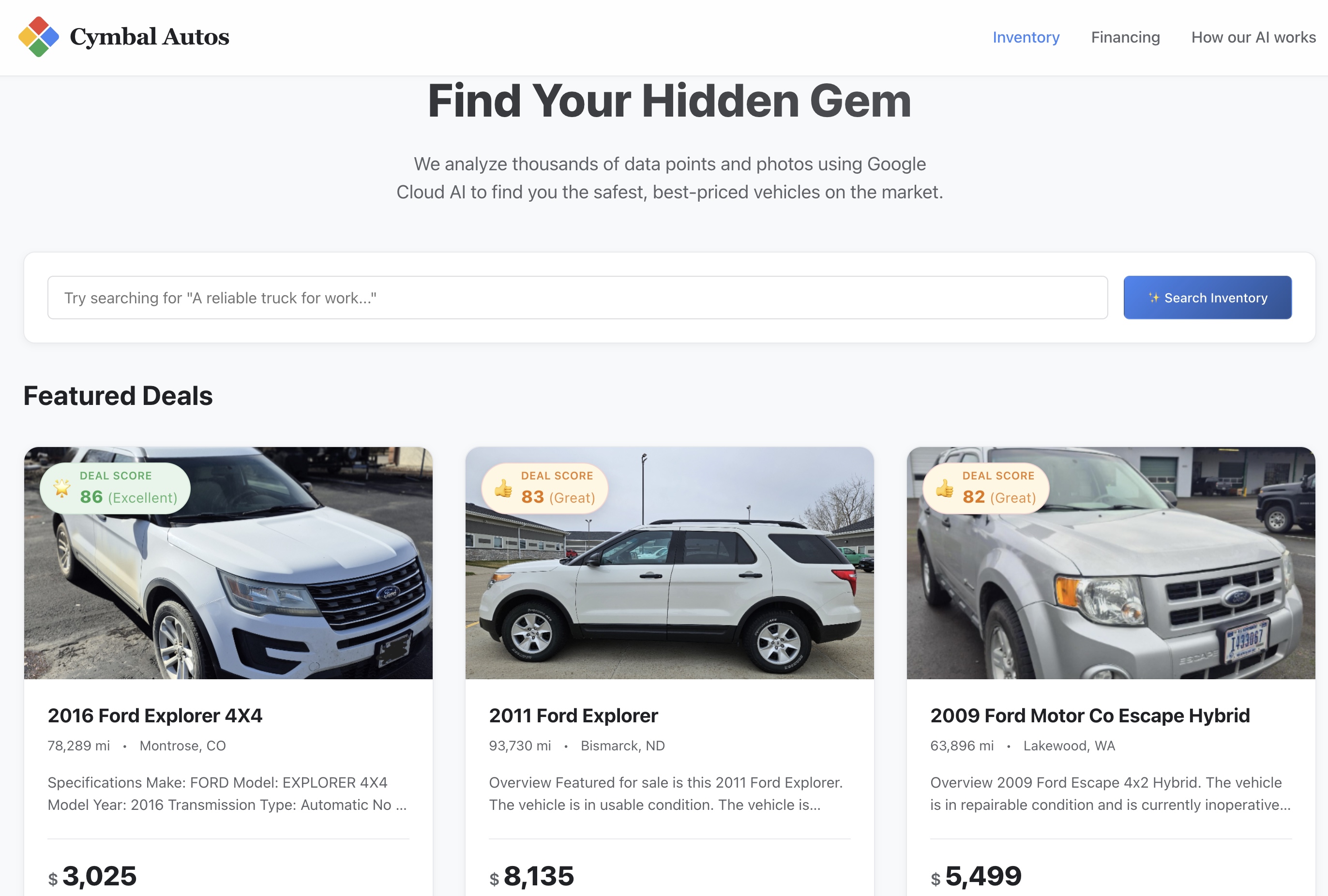
- Semantische Suche durchführen:Suchen Sie nach einem abstrakten Konzept, z. B. „Ein zuverlässiger Arbeits-Lkw, der auch im Gelände eingesetzt werden kann“. Die Next.js-App übersetzt Ihren Rohtext in eine multimodale Vektoreinbettung und führt in Echtzeit eine
VECTOR_SEARCHfür BigQuery aus, um Ihre Idee dem Fahrzeug-Ökosystem zuzuordnen.
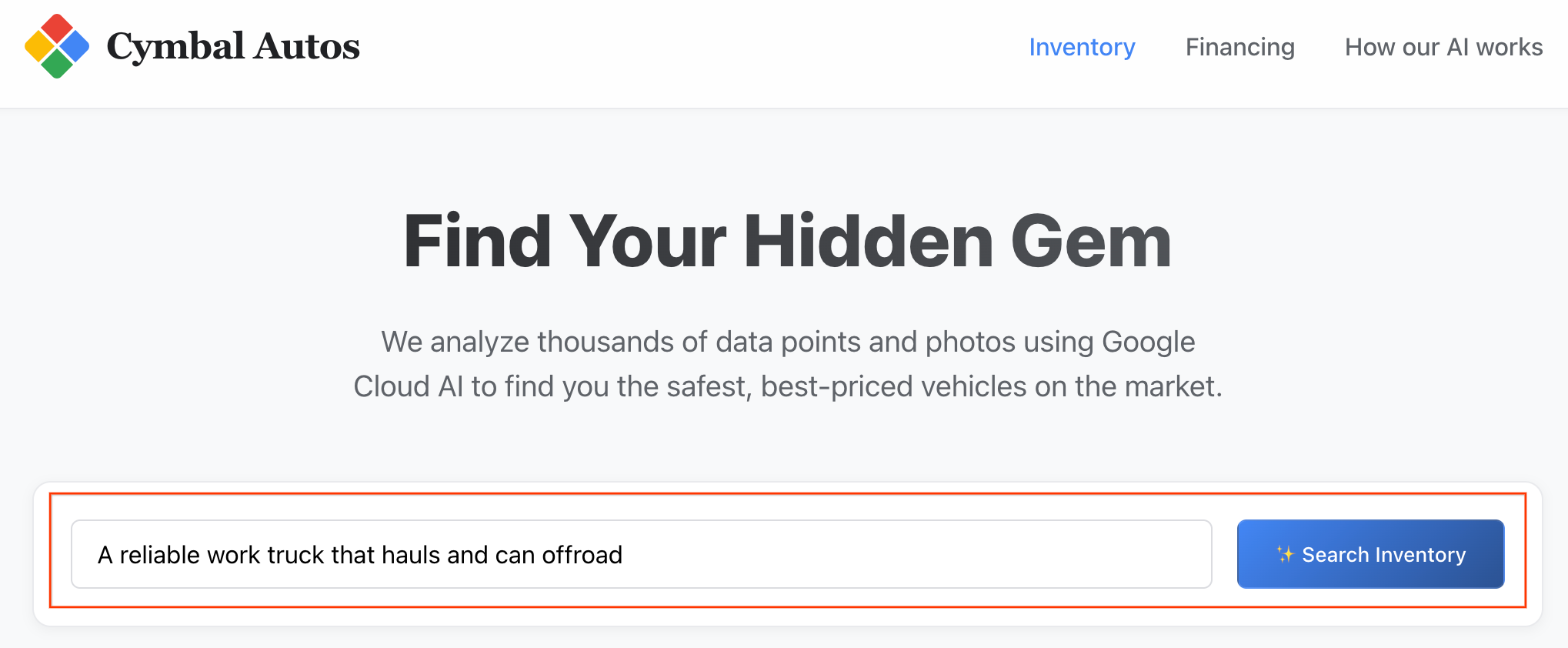
Hinweis: Die Einträge sind nach semantischer Ähnlichkeit sortiert.
- Ergebnisse ansehen:BigQuery hat den genauen mathematischen Abstand zwischen Ihrer abstrakten Idee und den Funktionen des Fahrzeugs berechnet, um die semantisch ähnlichsten Übereinstimmungen zu ermitteln.
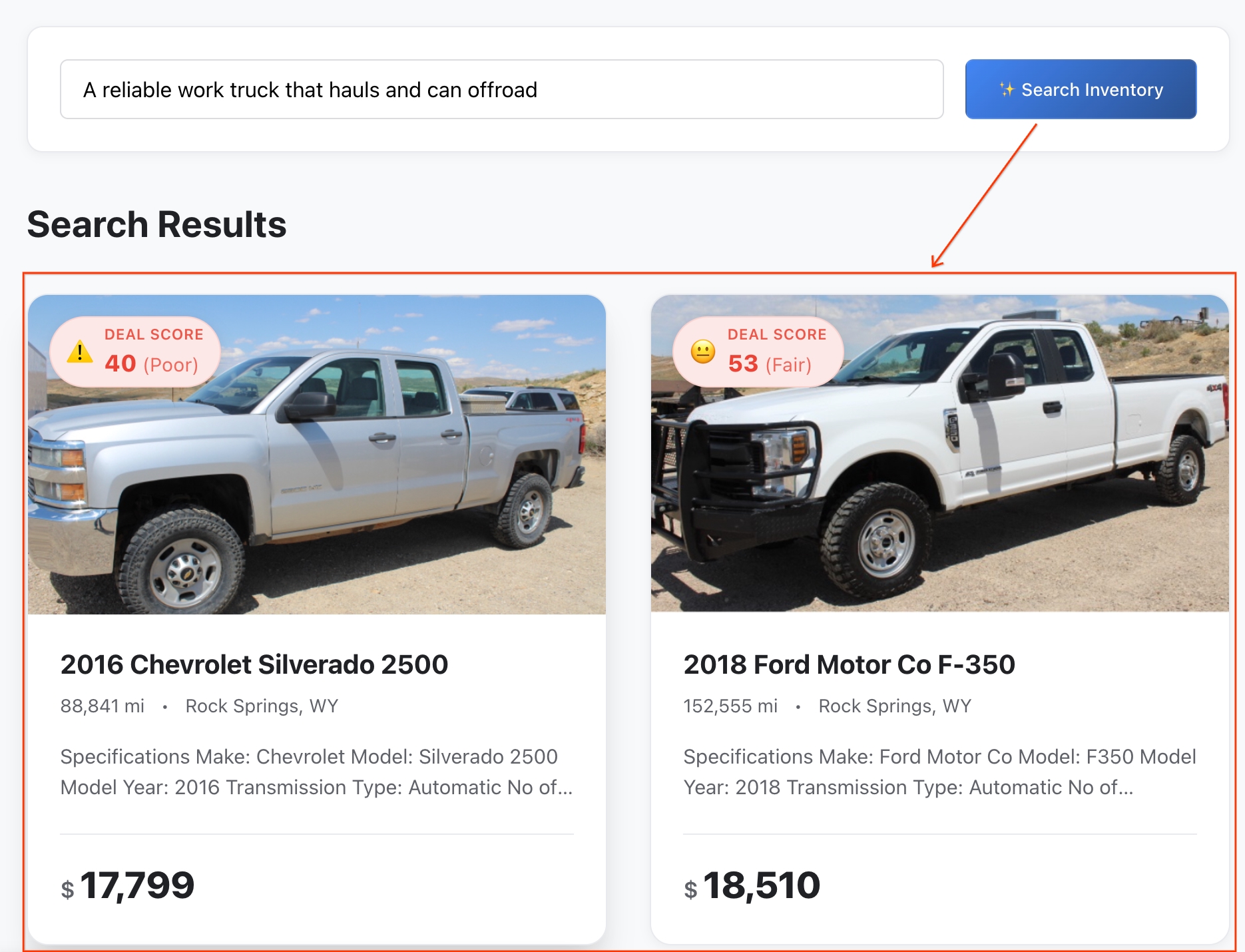
- Details ansehen:Klicken Sie auf ein beliebiges Fahrzeug, um das vollständige Angebotsprofil zu öffnen.
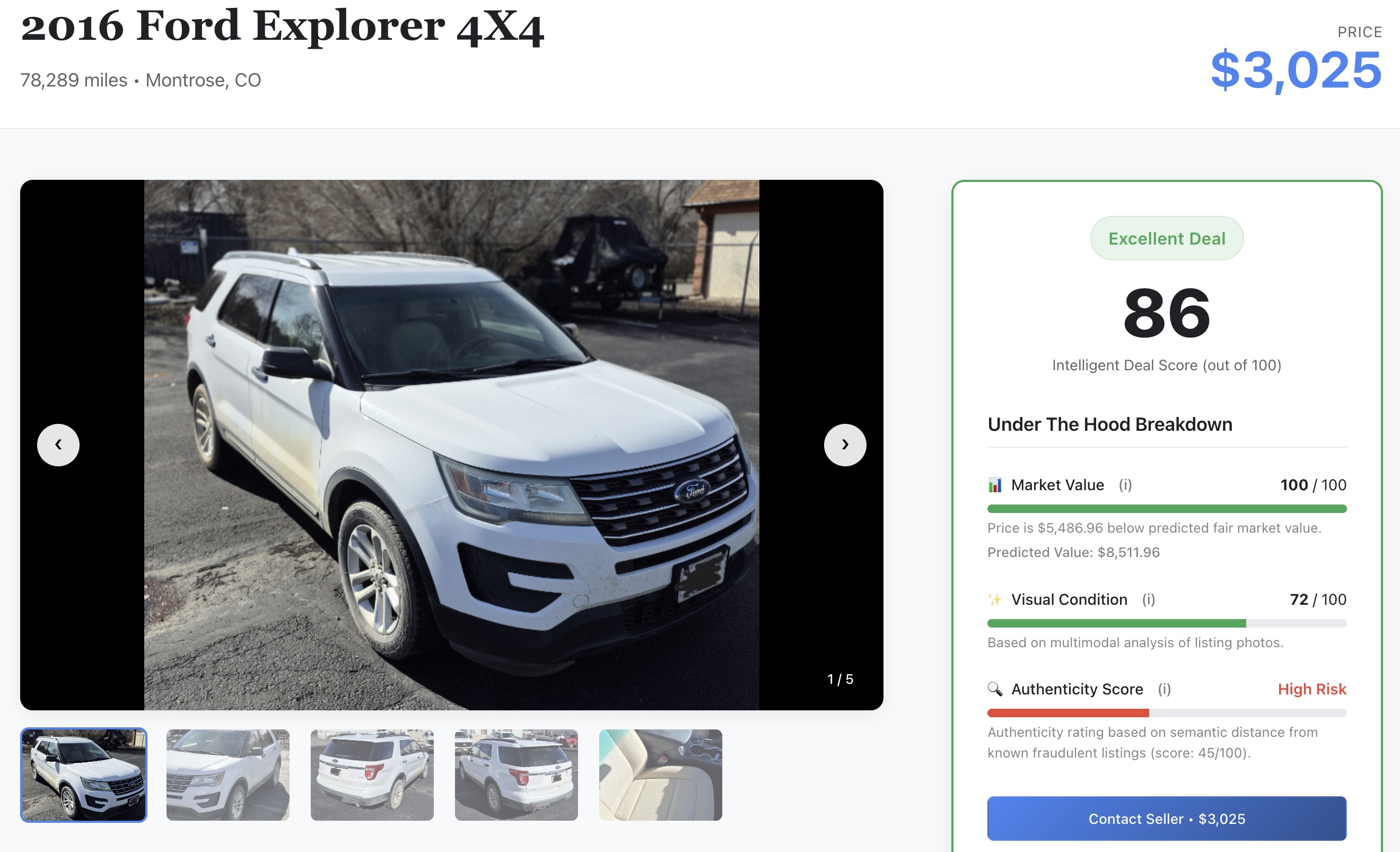
- KI-Signal prüfen:Scrollen Sie durch die Details, um die Rohwerte für maschinelles Lernen zu sehen, die Sie zuvor im Lab generiert haben:
- 📈 Fairer Marktwert:Der vom XGBoost-Modell prognostizierte Basispreis.
- ✨ Visueller Zustand:Die von Gemini-Modellen ermittelte Bewertung des physischen Schadens.
- 🔍 Authenticity Score:Mit dem Authenticity-Vektor-Messwert werden seriöse Verkäufer von potenziellen Betrügern unterschieden.
10. Bereinigen
Wenn Sie vermeiden möchten, dass Ihrem Google Cloud-Konto laufende Gebühren für die in diesem Codelab verwendeten Ressourcen in Rechnung gestellt werden, können Sie das gesamte Google Cloud-Projekt löschen, das Sie für dieses Codelab erstellt haben, oder das folgende automatische Abbau-Script ausführen.
- Wechseln Sie in Ihrem Cloud Shell-Terminal zurück zum Stammverzeichnis:
cd ..
- Führen Sie das Bereinigungsskript unten aus. Dadurch wird Ihr Google Cloud Storage-Bucket geleert, das BigQuery-Dataset
model_devgelöscht, die BigQuery-Verbindung gelöscht und der Cloud Run-Dienst gelöscht.
chmod +x scripts/cleanup/teardown.sh
./scripts/cleanup/teardown.sh
11. Glückwunsch
Glückwunsch! Sie haben erfolgreich einen intelligenten Fahrzeugmarktplatz erstellt. Sie haben BigQuery verwendet, um die Analyse unstrukturierter Daten, die Vorhersagemodellierung und KI-Integrationen in einem einzigen Arbeitsbereich zu vereinheitlichen.
Das haben Sie gelernt
- BigQuery mit unstrukturierten Cloud Storage-Bildern über ObjectRef verbinden
- So extrahieren Sie Fahrzeugattribute aus Fotos mit BigQuery und Gemini-Modellen wie den Funktionen
AI.GENERATEundAI.CLASSIFY - Fahrzeugpreise mit BigQuery ML vorhersagen
- Potenzielle Betrugseinträge durch Einbetten von Fahrzeugbeschreibungen und Ausführen von
VECTOR_SEARCHerkennen - Mit
AI.SCOREunstrukturierte Daten im Handumdrehen auswerten und Ergebnisse in einen umfassenden Deal-Score einbeziehen - Daten exportieren und die Next.js-Marketplace-Anwendung in Cloud Run bereitstellen