
1. Introducción
En este codelab, compilarás el backend e implementarás el frontend de "Cymbal Autos", un mercado de vehículos en línea. Usarás BigQuery y modelos de Gemini en Agent Platform de Gemini Enterprise para inspeccionar fotos de vehículos, predecir precios con BigQuery ML, detectar publicaciones fraudulentas con incorporaciones de vectores y calcular puntuaciones compuestas de ofertas. Por último, mostrarás estas estadísticas en un frontend de Next.js implementado en Cloud Run.
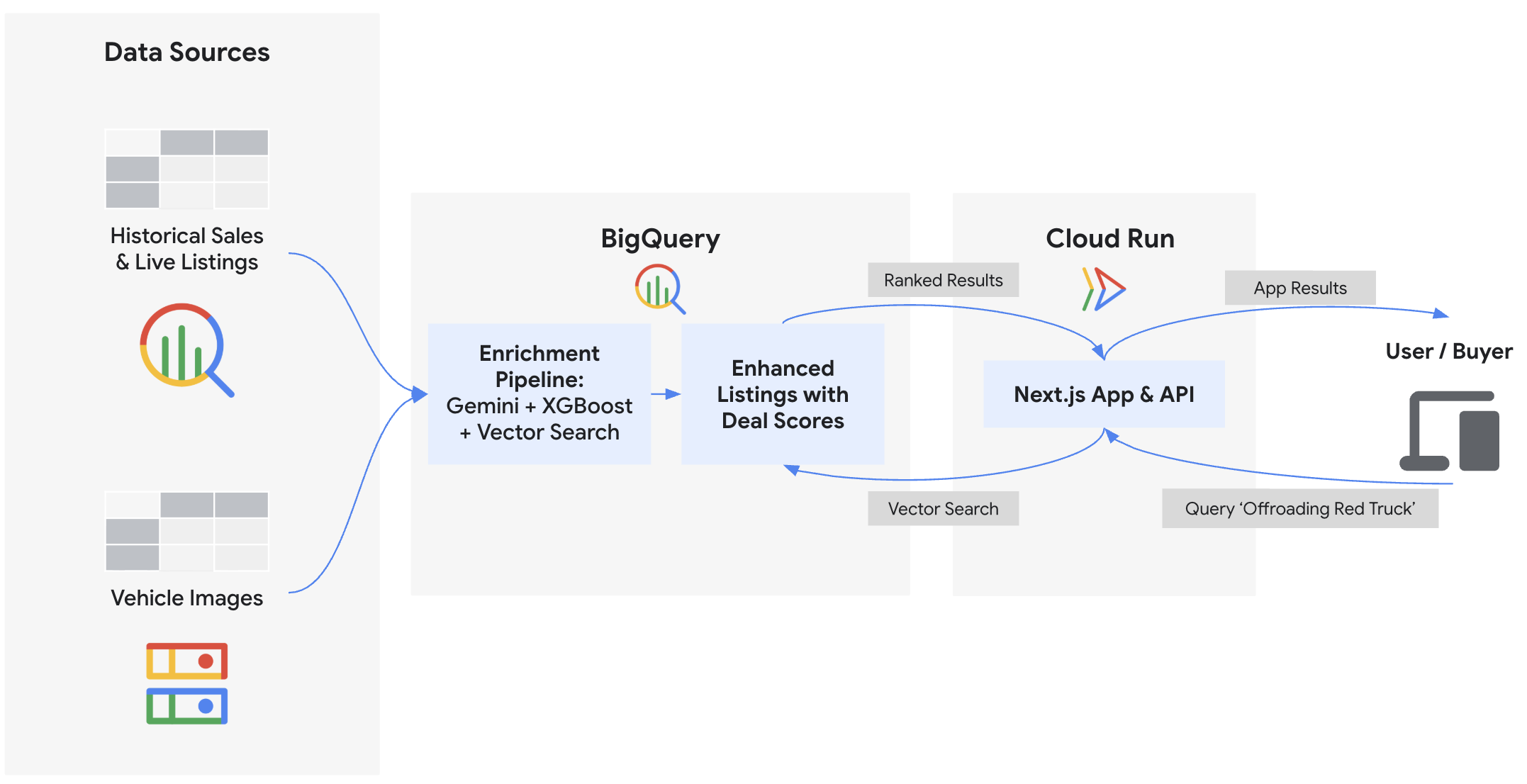
Actividades
- Conecta BigQuery a imágenes no estructuradas de Cloud Storage con ObjectRef
- Extrae atributos de vehículos de fotos con BigQuery y los modelos de Gemini
- Predecir precios de mercado justos entrenando un modelo de regresión de XGBoost con BigQuery ML
- Identifica las publicaciones potencialmente fraudulentas y las confiables incorporando descripciones de vehículos y realizando
VECTOR_SEARCH. - Calcula una Puntuación de oferta integral para cada ficha, a la vez que incorpora indicadores de condición de la descripción del vendedor con
AI.SCORE. - Exporta datos e implementa la aplicación de mercado de Next.js en Google Cloud Run
Requisitos
- Un navegador web, como Chrome
- Un proyecto de Google Cloud con la facturación habilitada.
- Conocimientos básicos sobre SQL, Python y Google Cloud
- Permisos de IAM suficientes para habilitar APIs, crear recursos y asignar permisos (p.ej., propietario del proyecto)
Este codelab es para desarrolladores intermedios.
Los recursos creados en este codelab deberían costar menos de USD 5.
2. Antes de comenzar
Crea un proyecto de Google Cloud
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
Inicie Cloud Shell
Usarás Google Cloud Shell para descargar el código, ejecutar secuencias de comandos de configuración y, luego, implementar la aplicación.
- Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, autentica tu sesión para asegurarte de que tu aplicación pueda acceder a las APIs de Google Cloud. Sigue las indicaciones para autorizar Cloud Shell:
gcloud auth application-default login
- Configura tu ID del proyecto de Google Cloud y un nombre único para tu bucket de Cloud Storage (donde almacenarás los datos sin procesar):
export PROJECT_ID=$(gcloud config get-value project)
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
gcloud config set project $PROJECT_ID
Deberías ver un mensaje similar al siguiente:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Habilita las APIs
Ejecuta este comando en Cloud Shell para habilitar todas las APIs requeridas para este codelab:
gcloud services enable \
aiplatform.googleapis.com \
artifactregistry.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
cloudbuild.googleapis.com \
run.googleapis.com
Si la ejecución se realiza correctamente, deberías ver un mensaje similar al que se muestra a continuación:
Operation "operations/..." finished successfully.
3. Obtén el código y configura los datos
Primero, descarga los recursos de la demostración y configura tus variables de entorno.
- Desde Cloud Shell, clona el repositorio
devrel-demosy navega al directorio del proyecto:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos/data-analytics/cymbal-autos-multimodal
- Ejecuta la secuencia de comandos para copiar datos en tu entorno. Esta secuencia de comandos sincroniza los conjuntos de datos del repositorio local con tu bucket personal de Cloud Storage y recupera las imágenes de vehículos de un bucket público:
chmod +x scripts/setup/*.sh
./scripts/setup/00_copy_data.sh
Luego, deberías ver un mensaje similar al siguiente:
Average throughput: 87.8MiB/s Data copy complete!
- A continuación, configura la conexión de recursos de Cloud de BigQuery. Para analizar imágenes no estructuradas en Cloud Storage y llamar a los modelos de Agent Platform directamente desde tus consultas SQL, BigQuery debe delegar permisos de IAM a una cuenta de servicio subyacente. Esta secuencia de comandos crea esa conexión segura y le otorga los roles necesarios de usuario de Vertex AI y consumidor de Service Usage (lo que tarda aproximadamente un minuto en propagarse):
./scripts/setup/01_setup_api_connection.sh
Deberías ver un mensaje similar a este:
Environment setup complete! Your BigQuery connection is ready.
- Por último, crea el conjunto de datos inicial de BigQuery y carga los datos tabulares sin procesar. Esto crea tu conjunto de datos
model_devy propaga las tablas iniciales, lo que establece la base antes de que escribas cualquier consulta de aprendizaje automático:
./scripts/setup/02_load_to_bq.sh
Deberías ver un mensaje similar a este:
================================================================= BigQuery load complete! =================================================================
4. Extracción de visión multimodal
Antes de calificar los anuncios de vehículos, extraerás datos estructurados (como el color, el tipo de carrocería o los daños visuales) de cientos de fotos sin procesar. Si aprovechas las funciones ObjectRef y los modelos de Gemini alojados en Agent Platform, puedes generar estas funciones sin mover archivos ni escribir canalizaciones de datos complejas. Esta extracción alimenta directamente la insignia ✨ Condición visual en la aplicación de frontend.
- Abre BigQuery Studio en una nueva pestaña del navegador.
- Haz clic en el botón + Redactar consulta nueva. Usarás el editor de SQL para interactuar con el código SQL a lo largo de este codelab.
- Antes de compilar los extractores de aprendizaje automático, puedes echar un vistazo rápido a las imágenes sin procesar. Ejecuta la siguiente consulta para ver el array de URIs de imágenes almacenadas en Google Cloud Storage para cada ficha:
SELECT auction_id, item_name, description, images
FROM `model_dev.vehicle_metadata` LIMIT 5;
- Ahora, en el editor de SQL de BigQuery Studio, pega el siguiente código SQL para crear una tabla nueva con una columna
image_ref. Haga clic en Ejecutar.
CREATE OR REPLACE TABLE `model_dev.vehicle_multimodal` AS
SELECT
*,
ARRAY(
SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF(uri, 'us.conn'))
FROM UNNEST(images) AS uri
) AS image_ref
FROM `model_dev.vehicle_metadata`;
- Echa un vistazo a la nueva columna
image_refObjectRef que acabas de crear. La nueva tabla ahora tiene una columna ObjectRef que tiene permisos para ejecutarse en las imágenes. Ejecuta la siguiente consulta para verla:
SELECT auction_id, item_name, description, image_ref
FROM `model_dev.vehicle_multimodal` LIMIT 5;
- Ahora usarás
AI.GENERATEyAI.CLASSIFYpara analizar las imágenes.AI.GENERATEextrae la puntuación de la condición y un resumen de daños de una oración escribiendo instrucciones a Gemini, mientras queAI.CLASSIFYcategoriza estrictamente el tipo de carrocería y el color del vehículo.
Ejecuta la siguiente consulta para extraer estas estadísticas en una tabla de funciones dedicada. Deberías esperar que este proceso tarde unos 3 minutos en finalizar.
CREATE OR REPLACE TABLE `model_dev.vehicle_vision_features` AS
WITH generated_data AS (
SELECT
auction_id,
AI.GENERATE(
prompt => ('Rate the condition of this car on a scale from 0-100. Output a 1 sentence description of any glaring red flags', image_ref),
output_schema => 'condition INT64, description_summary STRING'
).* EXCEPT(full_response,status)
FROM
`model_dev.vehicle_multimodal`
),
-- Object-centric Classifications
classified_data AS (
SELECT
auction_id,
AI.CLASSIFY(
('What type of automobile is this?', image_ref[0]),
categories => ['Truck', 'Sedan', 'SUV']) AS body_style,
AI.CLASSIFY(
('Color of the exterior of the automobile', image_ref[0]),
categories => ['Black', 'White', 'Silver', 'Gray', 'Red', 'Blue', 'Brown', 'Green', 'Beige', 'Gold']) AS color,
AI.CLASSIFY(
('Color of the interior of the automobile', image_ref[0]),
categories => ['Black', 'Gray', 'Beige', 'Tan', 'Brown', 'White', 'Red']) AS interior
FROM `model_dev.vehicle_multimodal`
)
-- Join the AI insights back together into the final feature table
SELECT
g.auction_id,
g.condition,
g.description_summary,
c.body_style,
c.color,
c.interior
FROM generated_data g
JOIN classified_data c ON g.auction_id = c.auction_id;
- Para ver las funciones generadas, ejecuta la siguiente consulta o mira la captura de pantalla que aparece a continuación:
SELECT auction_id, condition, description_summary, body_style, color, interior FROM `model_dev.vehicle_vision_features` LIMIT 5;

Resumen de la sección: Accediste a las imágenes sin procesar directamente desde BigQuery y usaste modelos de Gemini para extraer características visuales estructuradas sin mover ningún archivo.
5. Precios predictivos con XGBoost
Para calcular si un vehículo es una buena oferta, se necesita un valor de referencia confiable para su valor justo de mercado. En lugar de extraer datos en notebooks o secuencias de comandos locales para entrenar un modelo, puedes entrenar un modelo de XGBoost directamente en BigQuery con SQL estándar. Esta predicción de precios impulsa la lógica del 📈 Valor de mercado justo en la aplicación de frontend.
- Regresa a la pestaña de BigQuery Studio.
- Primero, echa un vistazo al conjunto de datos de entrenamiento. A diferencia de las fichas de vehículos activos, esta tabla
synthetic_carscontiene 100,000 ventas históricas que se usarán para entrenar el modelo. Ejecuta esta consulta rápida para echar un vistazo:
SELECT
*
FROM
`model_dev.synthetic_cars`
LIMIT 10;
- Ahora, ejecuta el siguiente SQL para entrenar un modelo de regresión de XGBoost. Este modelo aprende cómo los atributos, como el kilometraje, el año, la marca y el estado visual, afectan el precio a partir de esos 100,000 registros históricos:
CREATE OR REPLACE MODEL `model_dev.car_price_model`
OPTIONS(
MODEL_TYPE = 'BOOSTED_TREE_REGRESSOR',
INPUT_LABEL_COLS = ['selling_price'],
MAX_ITERATIONS = 15,
TREE_METHOD = 'HIST'
) AS
SELECT
* EXCEPT(vin, sale_date, market_value, seller)
FROM
`model_dev.synthetic_cars`;
- Antes de predecir los precios de las fichas de vehículos en vivo y en curso, debes recopilar todas las variables de entrada pertinentes en un solo lugar. Ejecuta este código SQL para combinar los metadatos estructurados del vehículo con las características extraídas por visión que acabas de generar:
CREATE OR REPLACE TABLE `model_dev.vehicle_prediction_features` AS
SELECT
meta.auction_id,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.transmission_type,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id;
- Por último, predice el valor de mercado justo de cada publicación de vehículo en curso. Ejecuta la siguiente consulta para ingresar los atributos agregados en tu modelo recién entrenado y guardar los resultados numéricos en una tabla de predicciones segura:
CREATE OR REPLACE TABLE `model_dev.vehicle_price_predictions` AS
SELECT
auction_id,
ROUND(predicted_selling_price, 2) AS predicted_market_value
FROM ML.PREDICT(
MODEL `model_dev.car_price_model`,
(SELECT * FROM `model_dev.vehicle_prediction_features`)
);
- Ahora, verifica el resultado del modelo. Ejecuta esta consulta rápida para obtener una vista previa de los valores de mercado previstos para las fichas de vehículos en vivo:
SELECT * FROM `model_dev.vehicle_price_predictions` LIMIT 5;
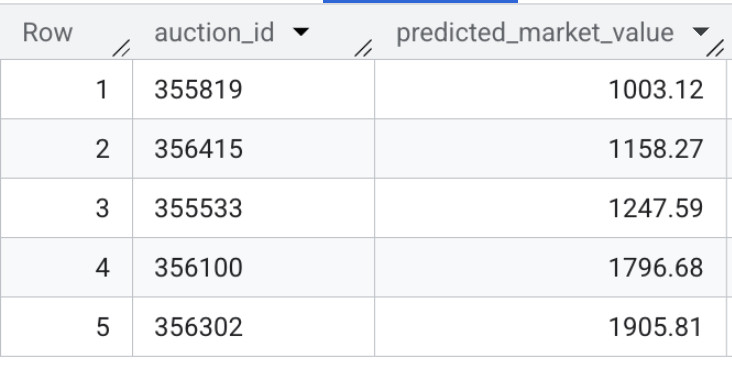
Resumen de la sección: Entrenaste un modelo de regresión de XGBoost con 100,000 transacciones de muestra y ejecutaste la inferencia por lotes para predecir el valor de mercado justo de cada ficha de vehículo activa en el conjunto de datos.
6. Incorporación semántica y detección de autenticidad
En esta sección, ejecutarás dos canalizaciones de incorporación distintas para habilitar funciones inteligentes en el mercado de vehículos:
- Búsqueda con imágenes multimodal: Traduce fotos de vehículos sin procesar al espacio vectorial para permitir que los usuarios realicen búsquedas con lenguaje natural (p.ej., "una camioneta de trabajo confiable").
- Incorporaciones de texto y búsqueda de similitud: Traduce las descripciones escritas de los vehículos en incorporaciones de vectores para comparar los anuncios activos con los perfiles conocidos de posibles estafadores o entusiastas con
VECTOR_SEARCH. Esto calcula la 🔍 Puntuación de autenticidad que los compradores ven en la app.
- Primero, debes generar embeddings multimodales para las fichas de vehículos. Con el modelo
gemini-embedding-2-preview, puedes ingresar imágenes y texto en el mismo embedding. Si bien este modelo es totalmente capaz de procesar varias modalidades de forma simultánea, en este caso específico solo incorporamos las imágenes de los vehículos. Esto impulsa la barra de "búsqueda semántica" de la aplicación de frontend, lo que permite a los compradores usar lenguaje natural (como "una camioneta confiable") y recuperar rápidamente las fichas coincidentes. Ejecuta esta consulta para generar los vectores multimodales conAI.EMBED:
CREATE OR REPLACE TABLE `model_dev.vehicle_images_embedded` AS
SELECT
auction_id,
AI.EMBED(
STRUCT(image_ref),
endpoint => 'gemini-embedding-2-preview').result AS multimodal_embedding
FROM `model_dev.vehicle_multimodal`
WHERE ARRAY_LENGTH(image_ref) > 0;
- A continuación, examinarás los datos del perfil de riesgo que se cargaron antes. Ten en cuenta que contiene tanto tipologías de estafas conocidas como muestras de fichas de entusiastas legítimos. Ejecuta esta consulta para ver los perfiles de Baseline:
SELECT profile_id, profile_type, description
FROM `model_dev.seller_risk_profiles`;
- Ahora traducirás esas descripciones de riesgo sin procesar en embeddings de vectores. Puedes usar un modelo de incorporación de texto especializado (
text-embedding-005) para evaluar estrictamente el lenguaje escrito que acabas de obtener en la vista previa. Pega el siguiente código SQL y haz clic en Ejecutar para incorporar los perfiles de Baseline:
CREATE OR REPLACE TABLE `model_dev.seller_risk_profiles_embedded` AS
SELECT
profile_id,
description AS content,
profile_type,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.seller_risk_profiles`;
- A continuación, genera incorporaciones comparables para el inventario de vehículos en vivo real. Ejecuta esta consulta para traducir la descripción HTML sin procesar de cada vehículo al espacio vectorial, de modo que se puedan comparar con los perfiles de referencia:
CREATE OR REPLACE TABLE `model_dev.vehicle_descriptions_embedded` AS
SELECT
auction_id,
description AS content,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.vehicle_metadata`
WHERE description IS NOT NULL;
- Por último, ejecuta la búsqueda de vectores para calcular la distancia semántica entre las fichas en tiempo real y los perfiles de referencia. Ejecuta el siguiente SQL para realizar la asignación. Una distancia matemática más baja significa que la ficha es muy similar a un clúster de estafas conocido, mientras que una distancia más alta sugiere una descripción legítima.
CREATE OR REPLACE TABLE `model_dev.vehicle_authenticity_scores` AS
SELECT
scam_search.query.auction_id,
CAST(
GREATEST(0.0, LEAST(100.0, ROUND((MIN(scam_search.distance) - 0.33) / 0.12 * 100.0)))
AS INT64
) AS authenticity_score
FROM VECTOR_SEARCH(
TABLE `model_dev.seller_risk_profiles_embedded`,
'text_embedding',
(
SELECT text_embedding, auction_id
FROM `model_dev.vehicle_descriptions_embedded`
),
top_k => 15,
distance_type => 'COSINE'
) AS scam_search
WHERE scam_search.base.profile_type = 'scam'
GROUP BY 1;
El contenido de esta tabla puede verse de la siguiente manera:
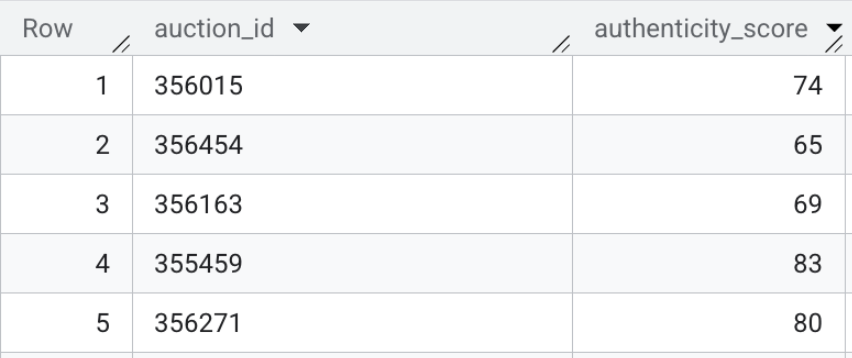
Resumen de la sección: Generaste embeddings multimodales para la barra de búsqueda de la interfaz y usaste la búsqueda de vectores directamente en BigQuery para evaluar las fichas de texto HTML sin procesar en comparación con los perfiles de estafas conocidos.
7. Puntuación de acuerdos generativa
Ahora tienes conjuntos de datos estructurados generados a través de varias técnicas distintas de aprendizaje automático, todo orquestado por completo dentro de BigQuery: extracción de visión, modelo XGBoost para predecir el valor de mercado justo y las incorporaciones de búsqueda vectorial.
El paso final es combinar estos indicadores de IA en una vista consolidada como la Puntuación del acuerdo definitiva para la aplicación de frontend.
- Primero, une los metadatos sin procesar con las características visuales extraídas por la IA, los resultados de precios predictivos y las puntuaciones de autenticidad semántica. Ejecuta el siguiente SQL:
CREATE OR REPLACE TABLE `model_dev.vehicle_features_enhanced` AS
SELECT
meta.auction_id,
meta.item_name,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.current_bid,
meta.listing_url,
meta.transmission_type,
meta.description,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior,
COALESCE(scam.authenticity_score, 100) AS authenticity_score,
vision.description_summary,
prices.predicted_market_value
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id
LEFT JOIN `model_dev.vehicle_price_predictions` prices
ON meta.auction_id = prices.auction_id
LEFT JOIN `model_dev.vehicle_authenticity_scores` scam
ON meta.auction_id = scam.auction_id;
- A continuación, calcula una Puntuación del acuerdo de 0 a 100 combinando cuatro indicadores distintos basados en IA. Esta fórmula equilibra el valor, la calidad y el riesgo para mostrar las mejores fichas:
- Puntuación del precio (40%): Mide los ahorros en comparación con el valor justo de mercado.
- Puntuación de visión (30%): Estadísticas del análisis de fotos anterior.
- Puntuación de autenticidad (15%): Evaluación del riesgo de fraude.
- Puntuación de la condición (15%): Se infiere sobre la marcha a partir de la descripción del vendedor a través de
AI.SCORE.
CREATE OR REPLACE TABLE `model_dev.marketplace_listings` AS
WITH score_elements AS (
SELECT
*,
-- 1. SELLER DESCRIPTION SCORE (use AI.SCORE on seller description)
AI.SCORE(
FORMAT("Rate the vehicle condition (0-100) based ONLY on this text: '%s'", description)
) AS description_score,
-- 2. PRICE SCORE
-- Higher impact for underpricing, lower impact for overpricing.
CAST(LEAST(100.0, GREATEST(0.0,
75.0 + (
IF((predicted_market_value - current_bid) > 0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 250.0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 40.0
)
)
)) AS INT64) AS price_score
FROM `model_dev.vehicle_features_enhanced`
),
final_calcs AS (
SELECT
*,
-- 3. Combine scores: Price (40%), Condition (30%), Description (15%), Authenticity (15%)
ROUND(
(
(price_score * 0.40) +
(CAST(condition AS INT64) * 0.30) +
(COALESCE(description_score, 50) * 0.15) +
(CAST(authenticity_score AS INT64) * 0.15)
)
-- Authenticity penalty for scores below 50.
* (IF(CAST(authenticity_score AS INT64) < 50, 0.20, 1.05))
) AS raw_score
FROM score_elements
)
SELECT
* EXCEPT(raw_score),
-- 4. Set floor values: low authenticity scores drop to 10; others floor at 35.
CAST(GREATEST(
(IF(CAST(authenticity_score AS INT64) < 50, 10, 35)),
LEAST(100, raw_score)
) AS INT64) AS deal_score
FROM final_calcs;
Para garantizar recomendaciones de alta calidad, la búsqueda aplica dos capas de lógica específicas:
- Restricción de autenticidad: Si un anuncio se marca como "Riesgo alto" (puntuación inferior a 50), la Puntuación total del acuerdo se reduce automáticamente en un 80% para evitar que se promocionen los anuncios sospechosos.
- Optimización de"Joya oculta": La fórmula usa una lógica por partes para recompensar los ahorros de forma agresiva y, al mismo tiempo, ser más indulgente con los aumentos, lo que garantiza que un automóvil con un precio excesivo en perfectas condiciones pueda alcanzar una clasificación de "Justo".
La tabla resultante, model_dev.marketplace_listings, contiene campos como deal_score, junto con price_score y authenticity_score.
- Para ver las puntuaciones de los acuerdos, ejecuta la siguiente consulta o mira la captura de pantalla que aparece a continuación:
SELECT item_name, model_year, authenticity_score, predicted_market_value, price_score, deal_score FROM `model_dev.marketplace_listings`
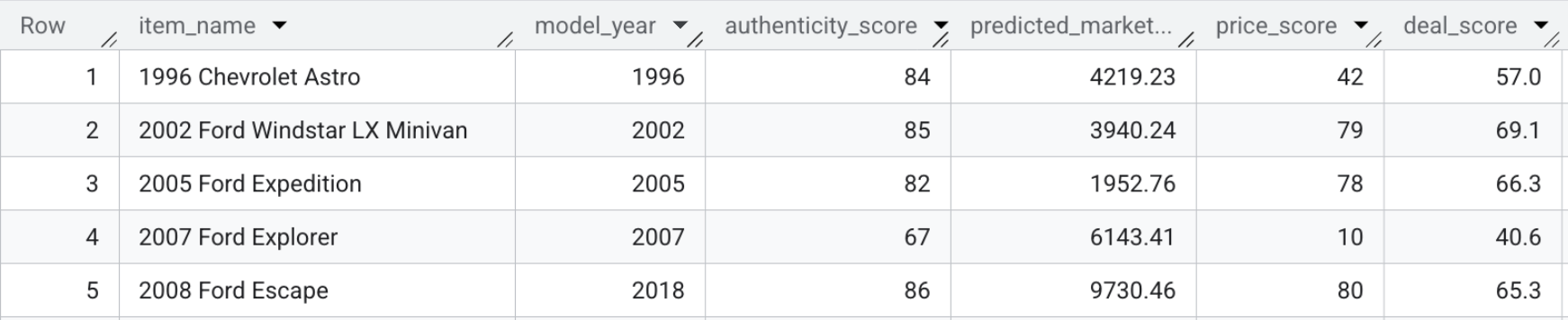
Resumen de la sección: Combinaste los precios predictivos, las funciones visuales y las puntuaciones de autenticidad junto con la descripción del vendedor para calcular una sola Puntuación de la oferta para cada ficha.
8. Implementa la aplicación de frontend
Ahora es momento de iniciar la aplicación de frontend. Esto te permite, por último, buscar en el inventario de fichas de vehículos y, luego, interactuar con las estadísticas generadas por IA que acabas de crear, como la Puntuación de la oferta.
Exporta las puntuaciones de IA al frontend
El frontend de React depende de una carga útil JSON local para cargas iniciales rápidas de la página. Para potenciar el mercado, extrae las puntuaciones finales de acuerdos generativos de BigQuery y vuelve a insertarlas en el proyecto de Next.js.
- Asegúrate de que tu entorno esté listo. Si se agotó el tiempo de espera de tu sesión de Cloud Shell o navegaste a otra carpeta, ejecuta el siguiente comando para volver a la raíz del proyecto y restablecer tus variables de entorno:
cd ~/devrel-demos/data-analytics/cymbal-autos-multimodal && \
export PROJECT_ID=$(gcloud config get-value project) && \
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
- Ejecuta la secuencia de comandos de Python proporcionada para consultar la vista final de BigQuery y combinar las nuevas puntuaciones de acuerdos en el almacén de datos subyacente de la aplicación:
python3 scripts/setup/08_export_frontend_data.py
Recibirás un mensaje de confirmación como el siguiente:
💾 Updated local file: app/src/data/cars.json
Implementa la aplicación en Cloud Run
Una vez que los datos se hayan enriquecido correctamente, puedes implementar la aplicación de frontend de Next.js en Internet pública con Cloud Run. Cuenta con una interfaz moderna con calificaciones de ofertas, carruseles de imágenes interactivos y una barra de búsqueda semántica híbrida dinámica que consulta BigQuery en tiempo real.
- En Cloud Shell, navega al directorio
app/de tu repositorio clonado. Esto es fundamental, ya que permanecer en el directorio raíz provocará un error en la compilación.
cd app
- Implementar la aplicación como un contenedor sin servidores con Cloud Run El comando pasa
PROJECT_IDcomo una variable de entorno para que la API de Next.js sepa qué proyecto de BigQuery consultar:
gcloud run deploy cymbal-autos-frontend \
--source . \
--region us-west1 \
--allow-unauthenticated \
--min-instances 1 \
--set-env-vars PROJECT_ID=$PROJECT_ID \
--project $PROJECT_ID
- Cuando se complete la implementación, el terminal generará una URL de servicio segura. Tendrán un aspecto similar a este:
Service URL: https://cymbal-autos-frontend-[YOUR-PROJECT-NUMBER].us-west1.run.app/
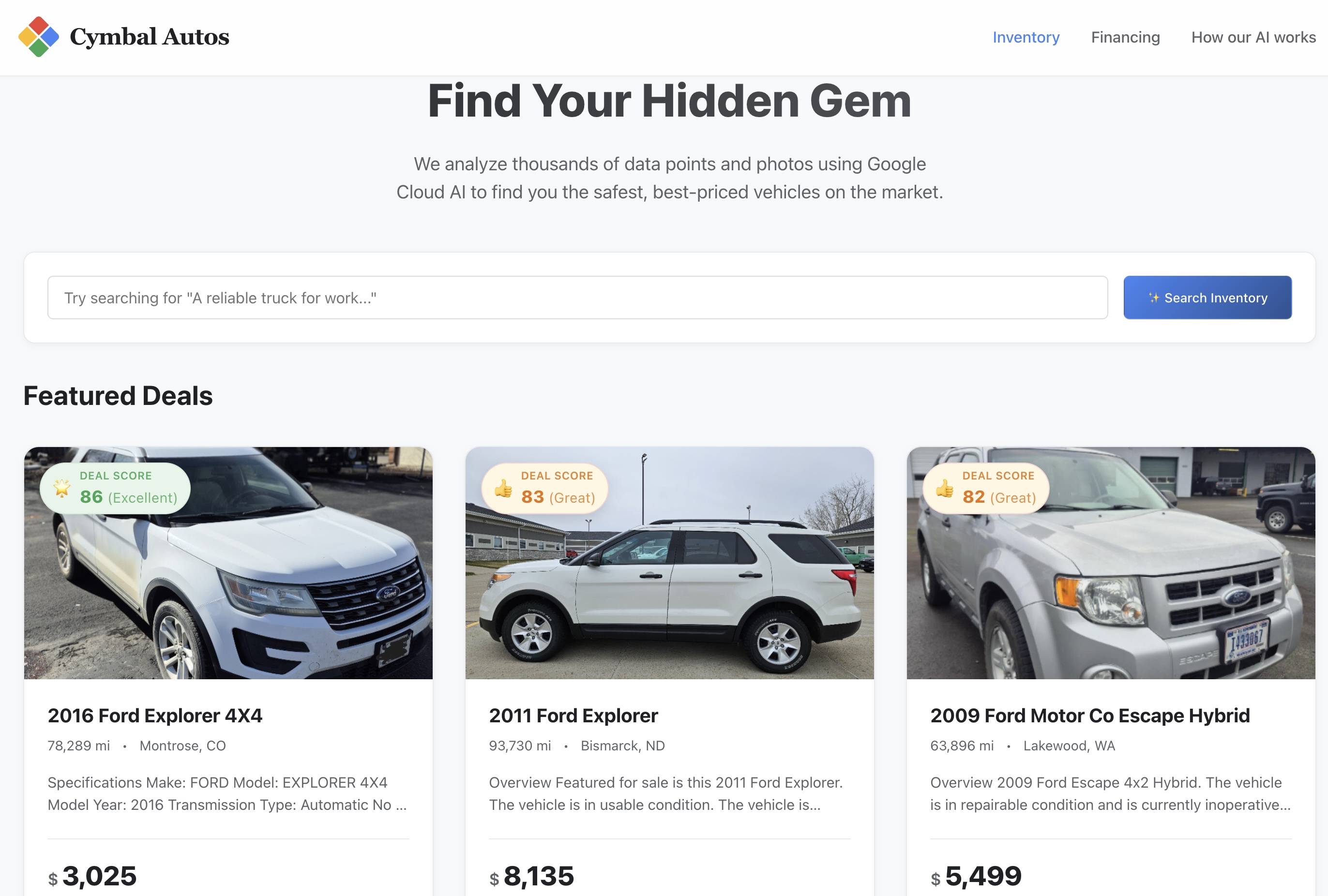
9. Explora la aplicación de Cymbal Autos
Ahora que enviaste tu contenedor de frontend a Cloud Run, es momento de probar la app.
- Visita el sitio: Abre la URL de servicio segura que devolvió Cloud Run.
- Realiza una búsqueda semántica: Intenta buscar un concepto abstracto, como "Una camioneta de trabajo confiable que pueda transportar cargas y conducir fuera de la ruta". La app de Next.js traduce tu texto sin procesar en un embedding de vector multimodal y activa una
VECTOR_SEARCHen tiempo real en BigQuery, lo que asigna tu idea al ecosistema de vehículos.
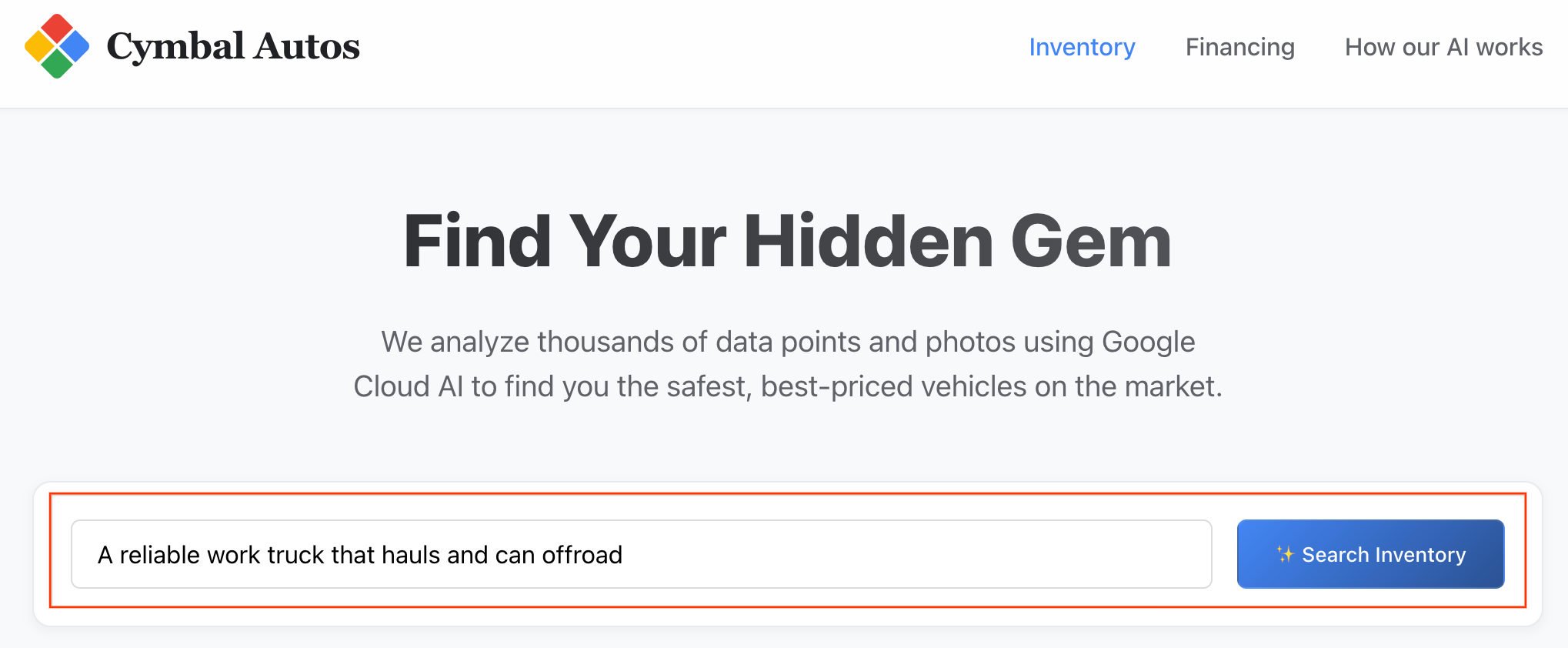
Nota: Los resultados se ordenan según la similitud semántica.
- Revisa los resultados: BigQuery calculó la distancia matemática exacta entre tu idea abstracta y las características del vehículo para devolver las coincidencias semánticas más cercanas.
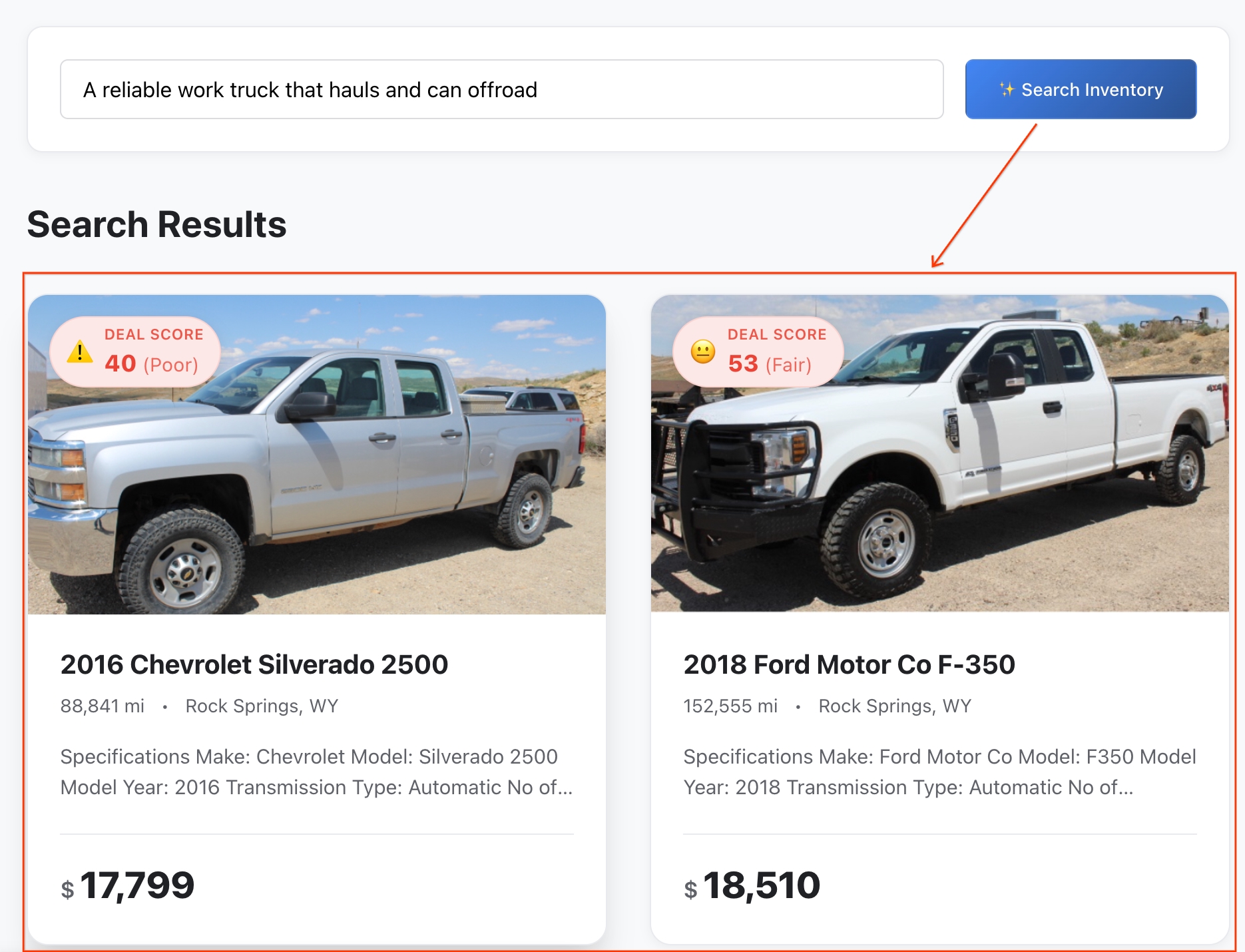
- Explora los detalles: Haz clic en cualquier vehículo para abrir su perfil de publicación completo.
- Verifica el indicador de IA: Desplázate por los detalles para ver las puntuaciones sin procesar del aprendizaje automático que generaste anteriormente en el lab:
- 📈 Valor de mercado justo: Es el precio de referencia que predice tu modelo de XGBoost.
- ✨ Estado visual: Es la calificación de daño físico que extraen los modelos de Gemini.
- 🔍 Puntuación de autenticidad: La métrica del vector de autenticidad separa a los vendedores legítimos de los posibles estafadores.

10. Limpia
Para evitar que se apliquen cargos continuos a tu cuenta de Google Cloud por los recursos que usaste en este codelab, puedes borrar todo el proyecto de Google Cloud que creaste para este codelab o ejecutar el siguiente script de desmantelamiento automatizado.
- Desde la terminal de Cloud Shell, vuelve al directorio raíz que contiene el directorio:
cd ..
- Ejecuta la siguiente secuencia de comandos de limpieza. Esto vaciará tu bucket de Cloud Storage, descartará el conjunto de datos de
model_devBigQuery, borrará la conexión de BigQuery y borrará el servicio de Cloud Run.
chmod +x scripts/cleanup/teardown.sh
./scripts/cleanup/teardown.sh
11. Felicitaciones
¡Felicitaciones! Creaste correctamente un mercado de vehículos inteligentes. Usaste BigQuery para unificar el análisis de datos no estructurados, el modelado predictivo y las integraciones de IA en un solo espacio de trabajo.
Qué aprendiste
- Cómo conectar BigQuery a imágenes no estructuradas de Cloud Storage con ObjectRef
- Cómo extraer atributos de vehículos de fotos con BigQuery y modelos de Gemini, como las funciones
AI.GENERATEyAI.CLASSIFY - Cómo predecir los precios de los vehículos con BigQuery ML
- Cómo identificar posibles fichas de estafa incorporando descripciones de vehículos y realizando
VECTOR_SEARCH - Cómo usar
AI.SCOREpara evaluar datos no estructurados sobre la marcha y, luego, incorporar los resultados a una puntuación integral del acuerdo - Cómo exportar datos e implementar la aplicación de mercado de Next.js en Cloud Run
Próximos pasos
- Descubre la gama completa de funciones de IA generativa disponibles en BigQuery
- Obtén más información para crear modelos predictivos con GoogleSQL