
1. Introduction
Dans cet atelier de programmation, vous allez créer le backend et déployer le frontend de "Cymbal Autos", une place de marché en ligne pour les véhicules. Vous utiliserez BigQuery et les modèles Gemini sur Gemini Enterprise Agent Platform pour inspecter les photos de véhicules, prédire les prix à l'aide de BigQuery ML, détecter les annonces frauduleuses à l'aide d'embeddings vectoriels et calculer des scores de transactions composites. Enfin, vous afficherez ces insights sur une interface Next.js déployée sur Cloud Run.
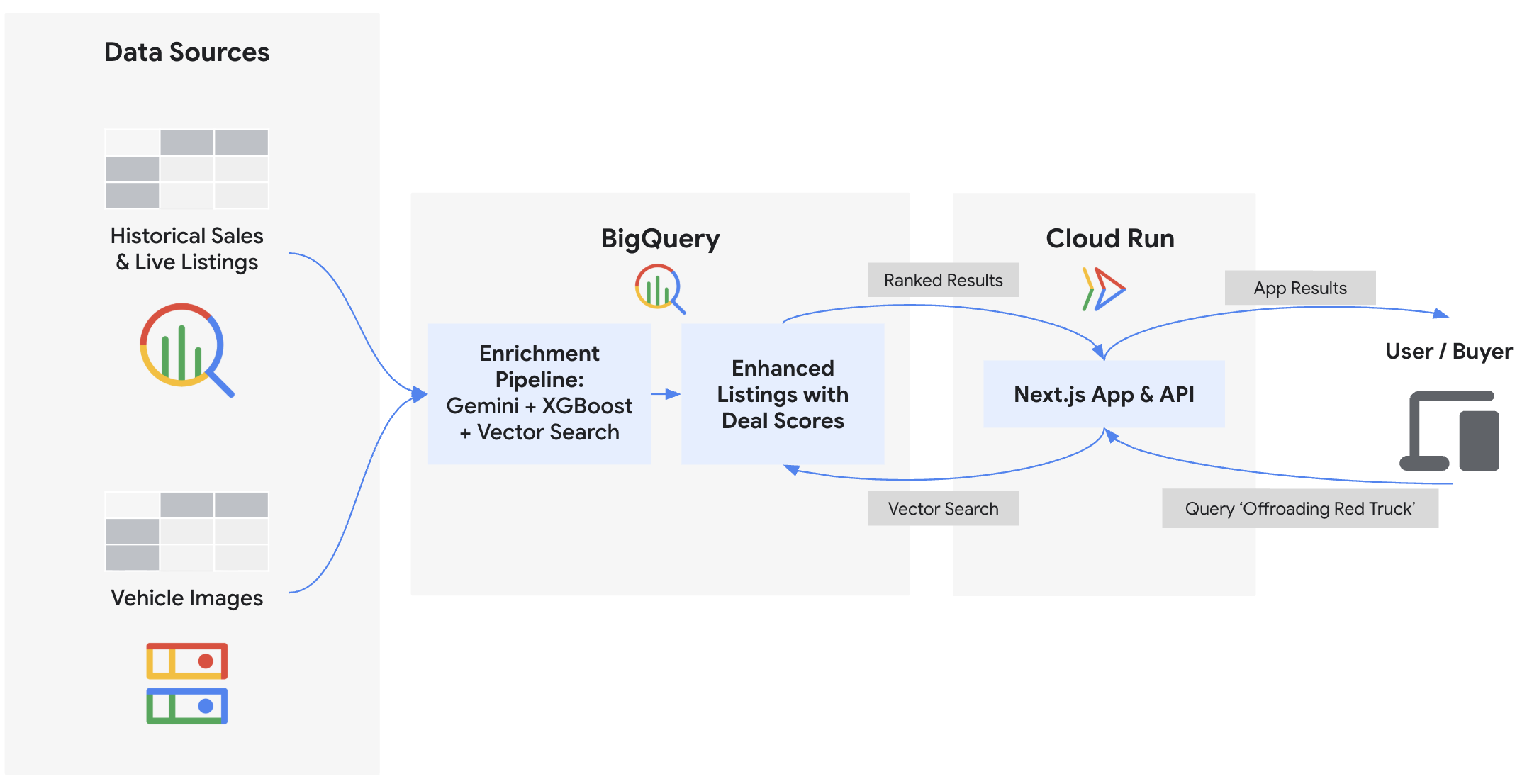
Objectifs de l'atelier
- Associer BigQuery à des images Cloud Storage non structurées à l'aide de ObjectRef
- Extraire les attributs des véhicules à partir de photos à l'aide de BigQuery avec les modèles Gemini
- Prédire les prix de marché équitables en entraînant un modèle de régression XGBoost avec BigQuery ML
- Identifiez les fiches potentiellement frauduleuses et fiables en intégrant des descriptions de véhicules et en effectuant des
VECTOR_SEARCH. - Calculer un score de bonne affaire complet pour chaque fiche, tout en intégrant les signaux d'état de la description du vendeur à l'aide de
AI.SCORE - Exporter des données et déployer l'application Marketplace Next.js sur Google Cloud Run
Prérequis
- Un navigateur Web (par exemple, Chrome)
- Un projet Google Cloud avec facturation activée
- Connaître les bases de SQL, Python et Google Cloud
- Autorisations IAM suffisantes pour activer les API, créer des ressources et attribuer des autorisations (par exemple, propriétaire du projet)
Cet atelier de programmation s'adresse aux développeurs de niveau intermédiaire.
Les ressources créées dans cet atelier de programmation devraient coûter moins de 5 $.
2. Avant de commencer
Créer un projet Google Cloud
- Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Démarrer Cloud Shell
Vous utiliserez Google Cloud Shell pour télécharger le code, exécuter les scripts de configuration et déployer l'application.
- Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, authentifiez votre session pour vous assurer que votre application peut accéder aux API Google Cloud. Suivez les instructions pour autoriser Cloud Shell :
gcloud auth application-default login
- Définissez l'ID de votre projet Google Cloud et un nom unique pour votre bucket Cloud Storage (où vous stockerez les données brutes) :
export PROJECT_ID=$(gcloud config get-value project)
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
gcloud config set project $PROJECT_ID
Un message semblable à celui-ci doit s'afficher :
Your active configuration is: [cloudshell-####] Updated property [core/project]
Activer les API
Exécutez cette commande dans Cloud Shell pour activer toutes les API requises pour cet atelier de programmation :
gcloud services enable \
aiplatform.googleapis.com \
artifactregistry.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
cloudbuild.googleapis.com \
run.googleapis.com
Si l'exécution réussit, un message semblable à celui ci-dessous s'affiche :
Operation "operations/..." finished successfully.
3. Obtenir le code et configurer les données
Commencez par télécharger les éléments de démonstration et configurer vos variables d'environnement.
- Dans Cloud Shell, clonez le dépôt
devrel-demoset accédez au répertoire du projet :
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos/data-analytics/cymbal-autos-multimodal
- Exécutez le script pour copier les données dans votre environnement. Ce script synchronise les ensembles de données du dépôt local avec votre bucket Cloud Storage personnel et récupère les images de véhicules à partir d'un bucket public :
chmod +x scripts/setup/*.sh
./scripts/setup/00_copy_data.sh
Un message semblable à celui-ci devrait s'afficher :
Average throughput: 87.8MiB/s Data copy complete!
- Ensuite, configurez la connexion de ressource cloud BigQuery. Pour analyser des images non structurées dans Cloud Storage et appeler des modèles Agent Platform directement à partir de vos requêtes SQL, BigQuery doit déléguer les autorisations IAM à un compte de service sous-jacent. Ce script crée cette connexion sécurisée et lui attribue les rôles nécessaires d'utilisateur Vertex AI et de consommateur Service Usage (la propagation prend environ une minute) :
./scripts/setup/01_setup_api_connection.sh
Un message de ce type doit s'afficher :
Environment setup complete! Your BigQuery connection is ready.
- Enfin, créez l'ensemble de données BigQuery initial et chargez les données tabulaires brutes. Cela crée votre ensemble de données
model_devet remplit les tables de départ, ce qui constitue la base avant que vous n'écriviez des requêtes de machine learning :
./scripts/setup/02_load_to_bq.sh
Un message de ce type doit s'afficher :
================================================================= BigQuery load complete! =================================================================
4. Extraction multimodale de données visuelles
Avant de noter les fiches de véhicules, vous extrairez des données structurées (comme la couleur, le type de carrosserie ou les dommages visibles) à partir de centaines de photos brutes. En exploitant les fonctions ObjectRef et les modèles Gemini hébergés dans Agent Platform, vous pouvez générer ces fonctionnalités sans déplacer de fichiers ni écrire de pipelines de données complexes. Cette extraction alimente directement le badge ✨ État visuel dans l'application d'interface.
- Ouvrez BigQuery Studio dans un nouvel onglet du navigateur.
- Cliquez sur le bouton + Saisir une nouvelle requête. Vous utiliserez l'éditeur SQL pour interagir avec le code SQL tout au long de cet atelier de programmation.
- Avant de créer les extracteurs de machine learning, vous pouvez jeter un coup d'œil aux images brutes. Exécutez la requête suivante pour afficher le tableau des URI d'images stockées dans Google Cloud Storage pour chaque fiche :
SELECT auction_id, item_name, description, images
FROM `model_dev.vehicle_metadata` LIMIT 5;
- Maintenant, dans l'éditeur SQL de BigQuery Studio, collez le code SQL suivant pour créer une table avec une colonne
image_ref. Cliquez sur Exécuter.
CREATE OR REPLACE TABLE `model_dev.vehicle_multimodal` AS
SELECT
*,
ARRAY(
SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF(uri, 'us.conn'))
FROM UNNEST(images) AS uri
) AS image_ref
FROM `model_dev.vehicle_metadata`;
- Examinez la colonne
image_refObjectRef que vous venez de créer. La nouvelle table comporte désormais une colonne ObjectRef qui dispose des autorisations nécessaires pour s'exécuter sur les images elles-mêmes. Exécutez la requête suivante pour l'afficher :
SELECT auction_id, item_name, description, image_ref
FROM `model_dev.vehicle_multimodal` LIMIT 5;
- Vous allez maintenant utiliser
AI.GENERATEetAI.CLASSIFYpour analyser les images.AI.GENERATEextrait le score d'état et un résumé des dommages en une phrase en interrogeant Gemini, tandis queAI.CLASSIFYcatégorise strictement le style de carrosserie et la couleur du véhicule.
Exécutez la requête suivante pour extraire ces insights dans une table de caractéristiques dédiée. Cette opération devrait prendre environ trois minutes.
CREATE OR REPLACE TABLE `model_dev.vehicle_vision_features` AS
WITH generated_data AS (
SELECT
auction_id,
AI.GENERATE(
prompt => ('Rate the condition of this car on a scale from 0-100. Output a 1 sentence description of any glaring red flags', image_ref),
output_schema => 'condition INT64, description_summary STRING'
).* EXCEPT(full_response,status)
FROM
`model_dev.vehicle_multimodal`
),
-- Object-centric Classifications
classified_data AS (
SELECT
auction_id,
AI.CLASSIFY(
('What type of automobile is this?', image_ref[0]),
categories => ['Truck', 'Sedan', 'SUV']) AS body_style,
AI.CLASSIFY(
('Color of the exterior of the automobile', image_ref[0]),
categories => ['Black', 'White', 'Silver', 'Gray', 'Red', 'Blue', 'Brown', 'Green', 'Beige', 'Gold']) AS color,
AI.CLASSIFY(
('Color of the interior of the automobile', image_ref[0]),
categories => ['Black', 'Gray', 'Beige', 'Tan', 'Brown', 'White', 'Red']) AS interior
FROM `model_dev.vehicle_multimodal`
)
-- Join the AI insights back together into the final feature table
SELECT
g.auction_id,
g.condition,
g.description_summary,
c.body_style,
c.color,
c.interior
FROM generated_data g
JOIN classified_data c ON g.auction_id = c.auction_id;
- Pour afficher vous-même les caractéristiques générées, exécutez la requête suivante ou consultez simplement la capture d'écran ci-dessous :
SELECT auction_id, condition, description_summary, body_style, color, interior FROM `model_dev.vehicle_vision_features` LIMIT 5;

Récapitulatif de la section : vous avez accédé aux images brutes directement depuis BigQuery et utilisé les modèles Gemini pour extraire des caractéristiques visuelles structurées sans déplacer aucun fichier.
5. Tarification prédictive avec XGBoost
Pour déterminer si un véhicule est une bonne affaire, il est nécessaire de disposer d'une référence fiable pour sa juste valeur marchande. Au lieu d'extraire les données dans des scripts ou des notebooks locaux pour entraîner un modèle, vous pouvez entraîner un modèle XGBoost directement dans BigQuery à l'aide du langage SQL standard. Cette prédiction du prix détermine la logique de la 📈 juste valeur marchande dans l'application d'interface.
- Revenez à l'onglet BigQuery Studio.
- Commencez par examiner l'ensemble de données d'entraînement. Contrairement aux fiches de véhicules actifs, ce tableau
synthetic_carscontient 100 000 ventes historiques qui seront utilisées pour entraîner le modèle. Exécutez cette requête rapide pour y jeter un coup d'œil :
SELECT
*
FROM
`model_dev.synthetic_cars`
LIMIT 10;
- Exécutez maintenant le code SQL suivant pour entraîner un modèle de régression XGBoost. À partir de ces 100 000 enregistrements historiques, ce modèle apprend comment des attributs tels que le kilométrage, l'année, la marque et l'état visuel affectent le prix :
CREATE OR REPLACE MODEL `model_dev.car_price_model`
OPTIONS(
MODEL_TYPE = 'BOOSTED_TREE_REGRESSOR',
INPUT_LABEL_COLS = ['selling_price'],
MAX_ITERATIONS = 15,
TREE_METHOD = 'HIST'
) AS
SELECT
* EXCEPT(vin, sale_date, market_value, seller)
FROM
`model_dev.synthetic_cars`;
- Avant de prédire les prix des annonces de véhicules en cours, vous devez rassembler toutes les caractéristiques d'entrée pertinentes en un seul endroit. Exécutez ce code SQL pour fusionner les métadonnées structurées du véhicule avec les caractéristiques extraites par vision que vous venez de générer :
CREATE OR REPLACE TABLE `model_dev.vehicle_prediction_features` AS
SELECT
meta.auction_id,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.transmission_type,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id;
- Enfin, prédisez la juste valeur marchande de chaque annonce de véhicule en cours. Exécutez la requête suivante pour insérer les caractéristiques agrégées dans votre nouveau modèle entraîné et enregistrer les résultats numériques dans une table de prédictions sécurisée :
CREATE OR REPLACE TABLE `model_dev.vehicle_price_predictions` AS
SELECT
auction_id,
ROUND(predicted_selling_price, 2) AS predicted_market_value
FROM ML.PREDICT(
MODEL `model_dev.car_price_model`,
(SELECT * FROM `model_dev.vehicle_prediction_features`)
);
- Vérifiez maintenant la sortie du modèle. Exécutez cette requête rapide pour prévisualiser les valeurs de marché prévues pour les fiches de véhicules en ligne :
SELECT * FROM `model_dev.vehicle_price_predictions` LIMIT 5;
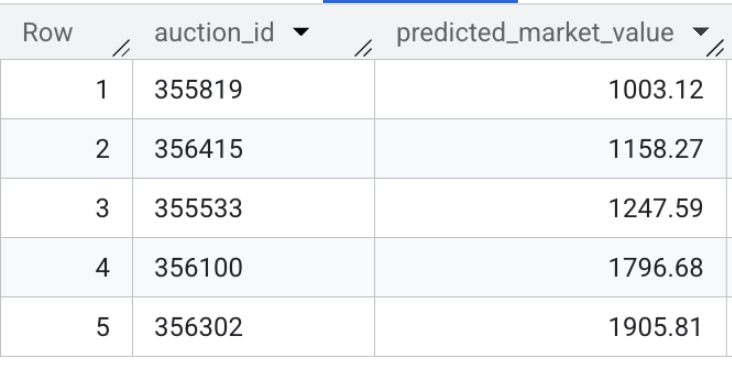
Récapitulatif de la section : vous avez entraîné un modèle de régression XGBoost à l'aide de 100 000 transactions échantillons et exécuté une inférence par lot pour prédire la juste valeur marchande de chaque fiche de véhicule active dans l'ensemble de données.
6. Embeddings sémantiques et détection de l'authenticité
Dans cette section, vous allez exécuter deux pipelines d'embedding distincts pour activer les fonctionnalités intelligentes de la place de marché de véhicules :
- Recherche d'images multimodale : traduisez les photos brutes de véhicules dans un espace vectoriel pour permettre aux utilisateurs de rechercher des véhicules en langage naturel (par exemple, "un utilitaire fiable").
- Représentations vectorielles continues de texte et recherche de similarité : traduisez les descriptions écrites de véhicules en représentations vectorielles continues pour comparer les annonces actives à des profils connus de potentiels escrocs ou passionnés à l'aide de
VECTOR_SEARCH. Cela permet de calculer le 🔍 score d'authenticité que les acheteurs voient dans l'application.
- Vous devez d'abord générer des embeddings multimodaux pour les fiches de véhicules. Avec le modèle
gemini-embedding-2-preview, vous pouvez saisir des images et du texte dans le même embedding. Bien que ce modèle soit tout à fait capable de traiter plusieurs modalités simultanément, dans ce cas précis, nous n'intégrons que les images de véhicules. Elle alimente la barre de "recherche sémantique" de l'application front-end, ce qui permet aux acheteurs d'utiliser le langage naturel (par exemple, "un pick-up fiable") et de récupérer rapidement les annonces correspondantes. Exécutez cette requête pour générer les vecteurs multimodaux à l'aide deAI.EMBED:
CREATE OR REPLACE TABLE `model_dev.vehicle_images_embedded` AS
SELECT
auction_id,
AI.EMBED(
STRUCT(image_ref),
endpoint => 'gemini-embedding-2-preview').result AS multimodal_embedding
FROM `model_dev.vehicle_multimodal`
WHERE ARRAY_LENGTH(image_ref) > 0;
- Vous allez maintenant examiner les données du profil de risque chargées précédemment. Notez qu'il contient à la fois des typologies d'escroquerie connues et des exemples d'annonces légitimes pour les passionnés. Exécutez cette requête pour afficher les profils de référence :
SELECT profile_id, profile_type, description
FROM `model_dev.seller_risk_profiles`;
- Vous allez maintenant traduire ces descriptions brutes des risques en embeddings vectoriels. Vous pouvez utiliser un modèle d'embedding de texte spécialisé (
text-embedding-005) pour évaluer précisément la langue écrite que vous venez de prévisualiser. Collez le code SQL suivant et cliquez sur "Exécuter" pour intégrer les profils de référence :
CREATE OR REPLACE TABLE `model_dev.seller_risk_profiles_embedded` AS
SELECT
profile_id,
description AS content,
profile_type,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.seller_risk_profiles`;
- Générez ensuite des embeddings comparables pour l'inventaire de véhicules en direct. Exécutez cette requête pour traduire la description HTML brute de chaque véhicule dans un espace vectoriel afin de pouvoir les comparer aux profils de référence :
CREATE OR REPLACE TABLE `model_dev.vehicle_descriptions_embedded` AS
SELECT
auction_id,
description AS content,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.vehicle_metadata`
WHERE description IS NOT NULL;
- Enfin, exécutez la recherche vectorielle pour calculer la distance sémantique entre les fiches en ligne et les profils de référence. Exécutez le code SQL suivant pour effectuer le mappage. Une distance mathématique faible signifie qu'une fiche est très semblable à un groupe d'escroqueries connu, tandis qu'une distance plus élevée suggère une description légitime.
CREATE OR REPLACE TABLE `model_dev.vehicle_authenticity_scores` AS
SELECT
scam_search.query.auction_id,
CAST(
GREATEST(0.0, LEAST(100.0, ROUND((MIN(scam_search.distance) - 0.33) / 0.12 * 100.0)))
AS INT64
) AS authenticity_score
FROM VECTOR_SEARCH(
TABLE `model_dev.seller_risk_profiles_embedded`,
'text_embedding',
(
SELECT text_embedding, auction_id
FROM `model_dev.vehicle_descriptions_embedded`
),
top_k => 15,
distance_type => 'COSINE'
) AS scam_search
WHERE scam_search.base.profile_type = 'scam'
GROUP BY 1;
Le contenu de cette table peut se présenter comme suit :
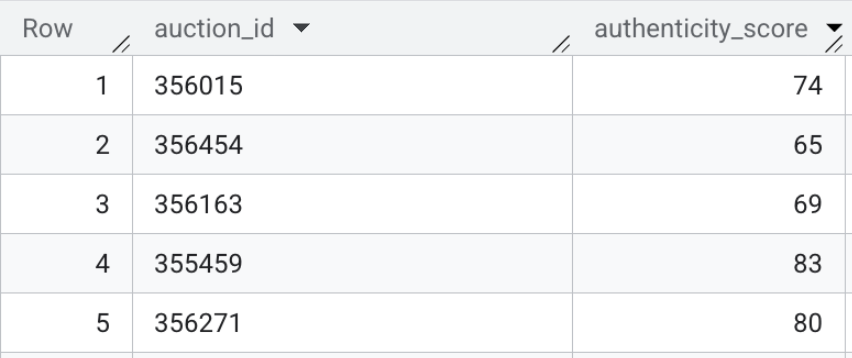
Récapitulatif de la section : vous avez généré des embeddings multimodaux pour la barre de recherche de l'interface utilisateur et utilisé la recherche vectorielle directement dans BigQuery pour évaluer les annonces textuelles HTML brutes par rapport aux profils d'escroquerie connus.
7. Évaluation générative des offres
Vous disposez désormais d'ensembles de données structurés générés à l'aide de plusieurs techniques de machine learning distinctes, le tout orchestré entièrement dans BigQuery : extraction de la vision, modèle XGBoost pour prédire la juste valeur marchande et embeddings de recherche vectorielle.
La dernière étape consiste à fusionner ces signaux d'IA dans une vue consolidée pour obtenir le score de la transaction définitif pour l'application frontend.
- Commencez par joindre les métadonnées brutes aux caractéristiques visuelles extraites par l'IA, aux résultats de la tarification prédictive et aux scores d'authenticité sémantique. Exécutez le code SQL suivant :
CREATE OR REPLACE TABLE `model_dev.vehicle_features_enhanced` AS
SELECT
meta.auction_id,
meta.item_name,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.current_bid,
meta.listing_url,
meta.transmission_type,
meta.description,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior,
COALESCE(scam.authenticity_score, 100) AS authenticity_score,
vision.description_summary,
prices.predicted_market_value
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id
LEFT JOIN `model_dev.vehicle_price_predictions` prices
ON meta.auction_id = prices.auction_id
LEFT JOIN `model_dev.vehicle_authenticity_scores` scam
ON meta.auction_id = scam.auction_id;
- Ensuite, calculez un score d'opportunité (de 0 à 100) en combinant quatre signaux d'IA distincts. Cette formule équilibre la valeur, la qualité et le risque pour afficher les meilleures fiches :
- Score de prix (40%) : mesure les économies réalisées par rapport à la juste valeur marchande.
- Score de vision (30%) : insights issus des analyses de photos précédentes.
- Score d'authenticité (15%) : évaluation du risque d'escroquerie.
- Score de l'état (15%) : déduit à la volée de la description du vendeur via
AI.SCORE.
CREATE OR REPLACE TABLE `model_dev.marketplace_listings` AS
WITH score_elements AS (
SELECT
*,
-- 1. SELLER DESCRIPTION SCORE (use AI.SCORE on seller description)
AI.SCORE(
FORMAT("Rate the vehicle condition (0-100) based ONLY on this text: '%s'", description)
) AS description_score,
-- 2. PRICE SCORE
-- Higher impact for underpricing, lower impact for overpricing.
CAST(LEAST(100.0, GREATEST(0.0,
75.0 + (
IF((predicted_market_value - current_bid) > 0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 250.0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 40.0
)
)
)) AS INT64) AS price_score
FROM `model_dev.vehicle_features_enhanced`
),
final_calcs AS (
SELECT
*,
-- 3. Combine scores: Price (40%), Condition (30%), Description (15%), Authenticity (15%)
ROUND(
(
(price_score * 0.40) +
(CAST(condition AS INT64) * 0.30) +
(COALESCE(description_score, 50) * 0.15) +
(CAST(authenticity_score AS INT64) * 0.15)
)
-- Authenticity penalty for scores below 50.
* (IF(CAST(authenticity_score AS INT64) < 50, 0.20, 1.05))
) AS raw_score
FROM score_elements
)
SELECT
* EXCEPT(raw_score),
-- 4. Set floor values: low authenticity scores drop to 10; others floor at 35.
CAST(GREATEST(
(IF(CAST(authenticity_score AS INT64) < 50, 10, 35)),
LEAST(100, raw_score)
) AS INT64) AS deal_score
FROM final_calcs;
Pour garantir des recommandations de haute qualité, la requête applique deux couches logiques spécifiques :
- Authenticity Gating : si une fiche est signalée comme "à risque élevé" (score inférieur à 50), le score total de l'offre est automatiquement réduit de 80% pour empêcher la promotion de fiches suspectes.
- Optimisation"Pépite cachée" : la formule utilise une logique par morceaux pour récompenser fortement les économies tout en étant plus tolérante envers les majorations. Ainsi, une voiture trop chère en parfait état peut toujours obtenir la mention "Correct".
La table obtenue, model_dev.marketplace_listings, contient des champs tels que deal_score, ainsi que price_score et authenticity_score.
- Pour afficher vous-même les scores des offres, exécutez la requête suivante ou consultez simplement la capture d'écran ci-dessous :
SELECT item_name, model_year, authenticity_score, predicted_market_value, price_score, deal_score FROM `model_dev.marketplace_listings`
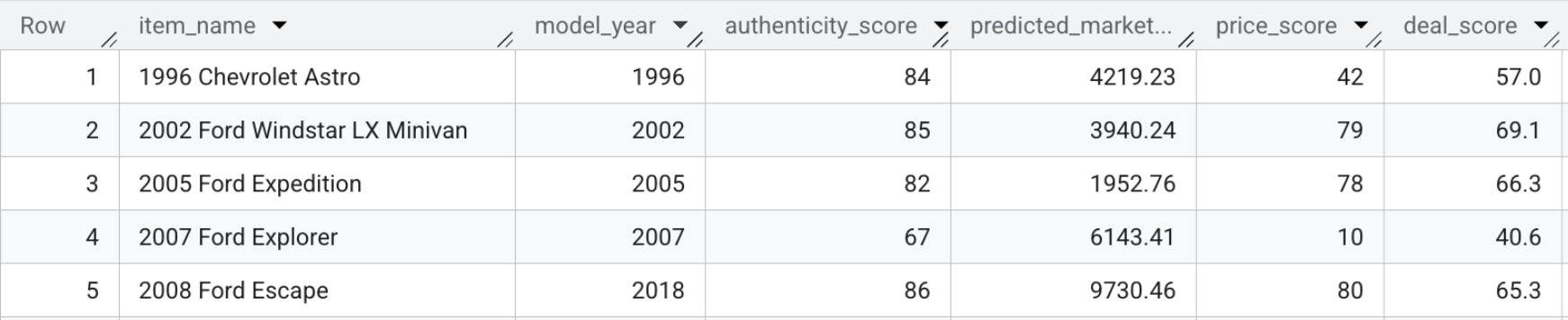
Récapitulatif de la section : vous avez combiné les prix prédictifs, les caractéristiques visuelles et les scores d'authenticité avec la description du vendeur pour calculer un score de remise unique pour chaque fiche.
8. Déployer l'application d'interface
Il est maintenant temps de configurer l'application frontend. Vous pouvez enfin rechercher des fiches de véhicules dans l'inventaire et interagir avec les insights générés par l'IA que vous venez de créer, comme le score de la bonne affaire.
Exporter les scores d'IA vers l'interface
L'interface utilisateur React s'appuie sur une charge utile JSON locale pour des chargements de page initiaux rapides. Pour alimenter la place de marché, extrayez les scores de deals génératifs finaux de BigQuery et réinjectez-les dans le projet Next.js.
- Assurez-vous que votre environnement est prêt. Si votre session Cloud Shell a expiré ou si vous avez accédé à un autre dossier, exécutez la commande suivante pour revenir à la racine du projet et restaurer vos variables d'environnement :
cd ~/devrel-demos/data-analytics/cymbal-autos-multimodal && \
export PROJECT_ID=$(gcloud config get-value project) && \
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
- Exécutez le script Python fourni pour interroger la vue BigQuery finale et fusionner les nouveaux scores de deal dans le datastore sous-jacent de l'application :
python3 scripts/setup/08_export_frontend_data.py
Vous recevrez un message de confirmation comme celui-ci :
💾 Updated local file: app/src/data/cars.json
Déployer l'application sur Cloud Run
Une fois les données enrichies, vous pouvez déployer l'application d'interface Next.js sur Internet à l'aide de Cloud Run. Elle propose une interface moderne avec des notes sur les offres, des carrousels d'images interactifs et une barre de recherche sémantique hybride dynamique qui interroge BigQuery en temps réel.
- Dans Cloud Shell, accédez au répertoire
app/de votre dépôt cloné. C'est une étape essentielle. Si vous restez dans le répertoire racine, la compilation échouera.
cd app
- Déployez l'application en tant que conteneur sans serveur à l'aide de Cloud Run. La commande transmet
PROJECT_IDen tant que variable d'environnement afin que l'API Next.js sache quel projet BigQuery interroger :
gcloud run deploy cymbal-autos-frontend \
--source . \
--region us-west1 \
--allow-unauthenticated \
--min-instances 1 \
--set-env-vars PROJECT_ID=$PROJECT_ID \
--project $PROJECT_ID
- Une fois le déploiement terminé, le terminal génère une URL de service sécurisée. Cela devrait ressembler à ce qui suit :
Service URL: https://cymbal-autos-frontend-[YOUR-PROJECT-NUMBER].us-west1.run.app/
9. Explorer l'application Cymbal Autos
Maintenant que votre conteneur d'interface est transféré vers Cloud Run, il est temps de tester l'application.
- Accédez au site : ouvrez l'URL de service sécurisée renvoyée par Cloud Run.
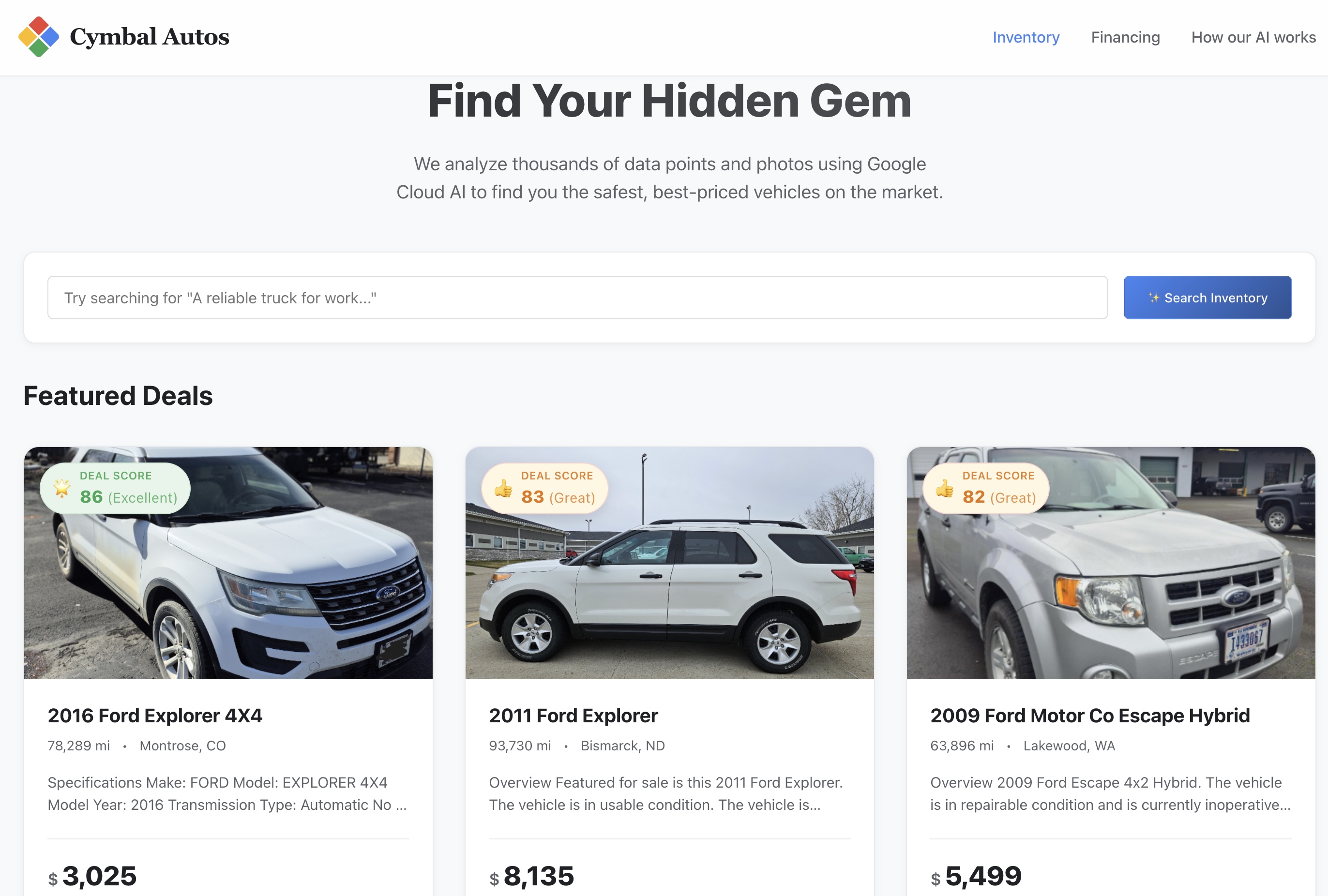
- Effectuez une recherche sémantique : essayez de rechercher un concept abstrait, comme "Un camion de travail fiable qui peut transporter des charges et faire du tout-terrain". L'application Next.js traduit votre texte brut en embedding vectoriel multimodal et déclenche une
VECTOR_SEARCHen temps réel par rapport à BigQuery, en mappant votre idée par rapport à l'écosystème automobile.
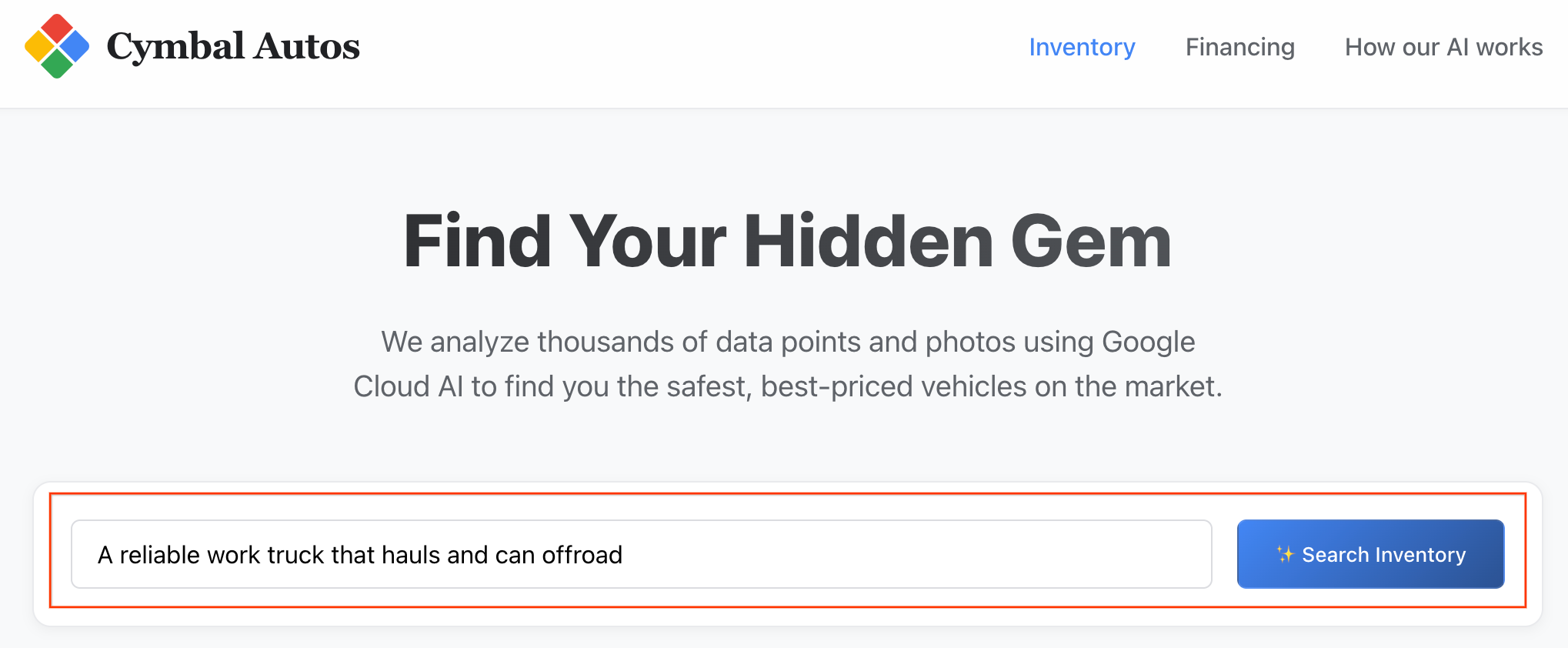
Remarque : Les fiches sont triées par similarité sémantique.
- Examiner les résultats : BigQuery a calculé la distance mathématique exacte entre votre idée abstraite et les caractéristiques du véhicule pour renvoyer les correspondances sémantiques les plus proches.
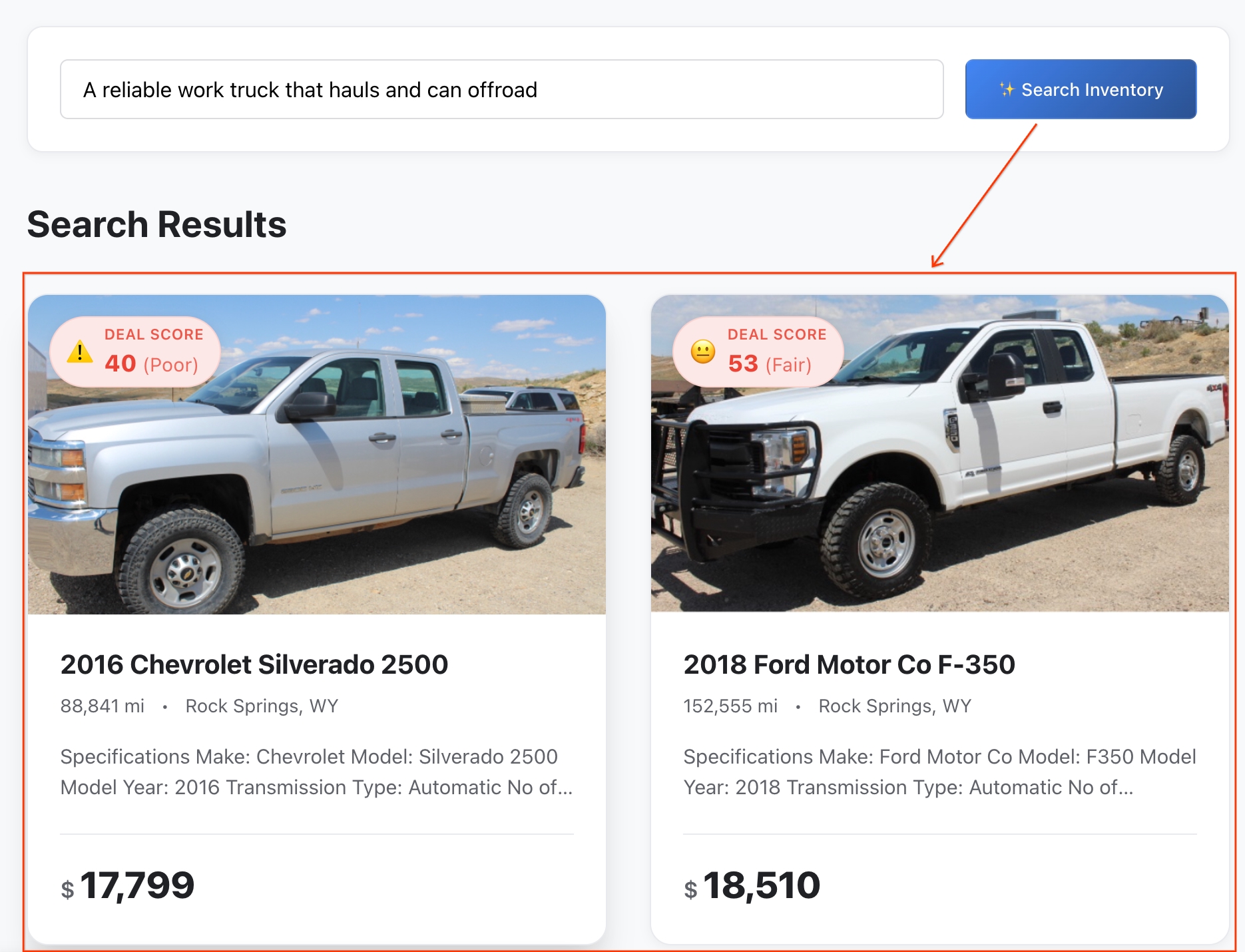
- Examiner les détails : cliquez sur un véhicule pour ouvrir sa fiche complète.
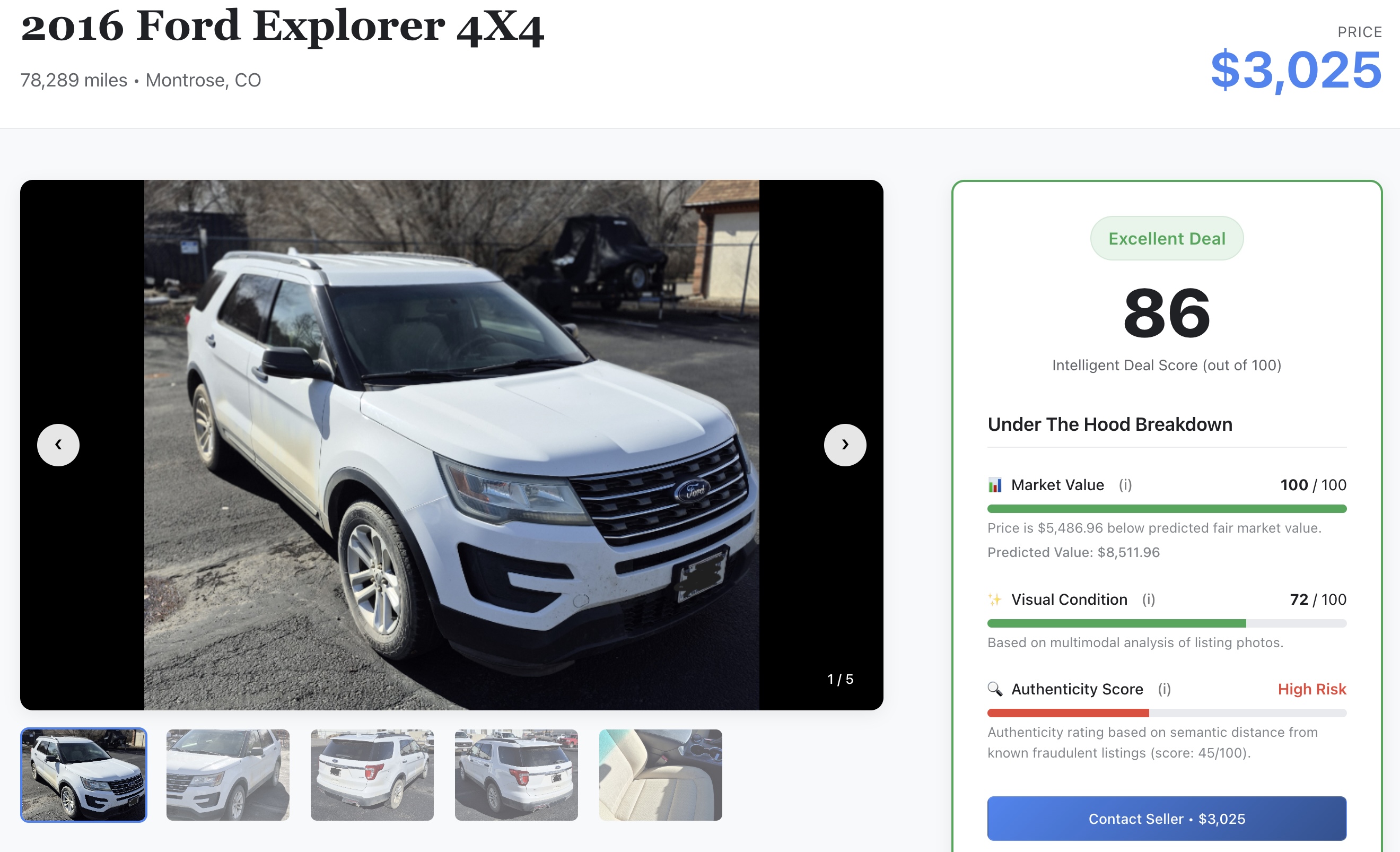
- Vérifiez le signal d'IA : parcourez les détails pour afficher les scores bruts de machine learning que vous avez générés précédemment dans l'atelier :
- 📈 Juste valeur marchande : prix de référence prédit par votre modèle XGBoost.
- ✨ État visuel : évaluation des dommages physiques extraite par les modèles Gemini.
- 🔍 Score d'authenticité : la métrique du vecteur d'authenticité permet de distinguer les vendeurs légitimes des escrocs potentiels.
10. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet atelier de programmation ne soient facturées sur votre compte Google Cloud, vous pouvez supprimer l'intégralité du projet Google Cloud que vous avez créé pour cet atelier de programmation ou exécuter le script de suppression automatisée suivant.
- Dans votre terminal Cloud Shell, revenez au répertoire racine contenant :
cd ..
- Exécutez le script de nettoyage ci-dessous. Cela videra votre bucket Google Cloud Storage, supprimera l'ensemble de données BigQuery
model_dev, supprimera la connexion BigQuery et supprimera le service Cloud Run.
chmod +x scripts/cleanup/teardown.sh
./scripts/cleanup/teardown.sh
11. Félicitations
Félicitations ! Vous avez réussi à créer une place de marché pour les véhicules intelligents. Vous avez utilisé BigQuery pour unifier l'analyse des données non structurées, la modélisation prédictive et les intégrations d'IA dans un seul espace de travail.
Connaissances acquises
- Connecter BigQuery à des images Cloud Storage non structurées à l'aide de ObjectRef
- Extraire des attributs de véhicules à partir de photos à l'aide de BigQuery avec des modèles Gemini tels que les fonctions
AI.GENERATEetAI.CLASSIFY - Prédire le prix des véhicules à l'aide de BigQuery ML
- Identifier les fiches frauduleuses potentielles en intégrant des descriptions de véhicules et en effectuant des
VECTOR_SEARCH - Utiliser
AI.SCOREpour évaluer les données non structurées à la volée et intégrer les résultats dans un score de transaction complet - Exporter des données et déployer l'application Marketplace Next.js sur Cloud Run
Étapes suivantes
- Découvrez toute la gamme de fonctions d'IA générative disponibles dans BigQuery.
- En savoir plus sur la création de modèles prédictifs avec GoogleSQL