
1. מבוא
בשיעור Codelab הזה תבנו את ה-Backend ותפרסו את ה-Frontend של "Cymbal Autos", שוק מקוון לכלי רכב. תשתמשו ב-BigQuery ובמודלים של Gemini בפלטפורמת הסוכנים של Gemini Enterprise כדי לבדוק תמונות של כלי רכב, לחזות מחירים באמצעות BigQuery ML, לזהות רשימות פיקטיביות באמצעות הטמעות וקטוריות ולחשב ציונים משולבים של עסקאות. לבסוף, תציגו את התובנות האלה בחלק הקצה הקדמי של Next.js שנפרס ב-Cloud Run.
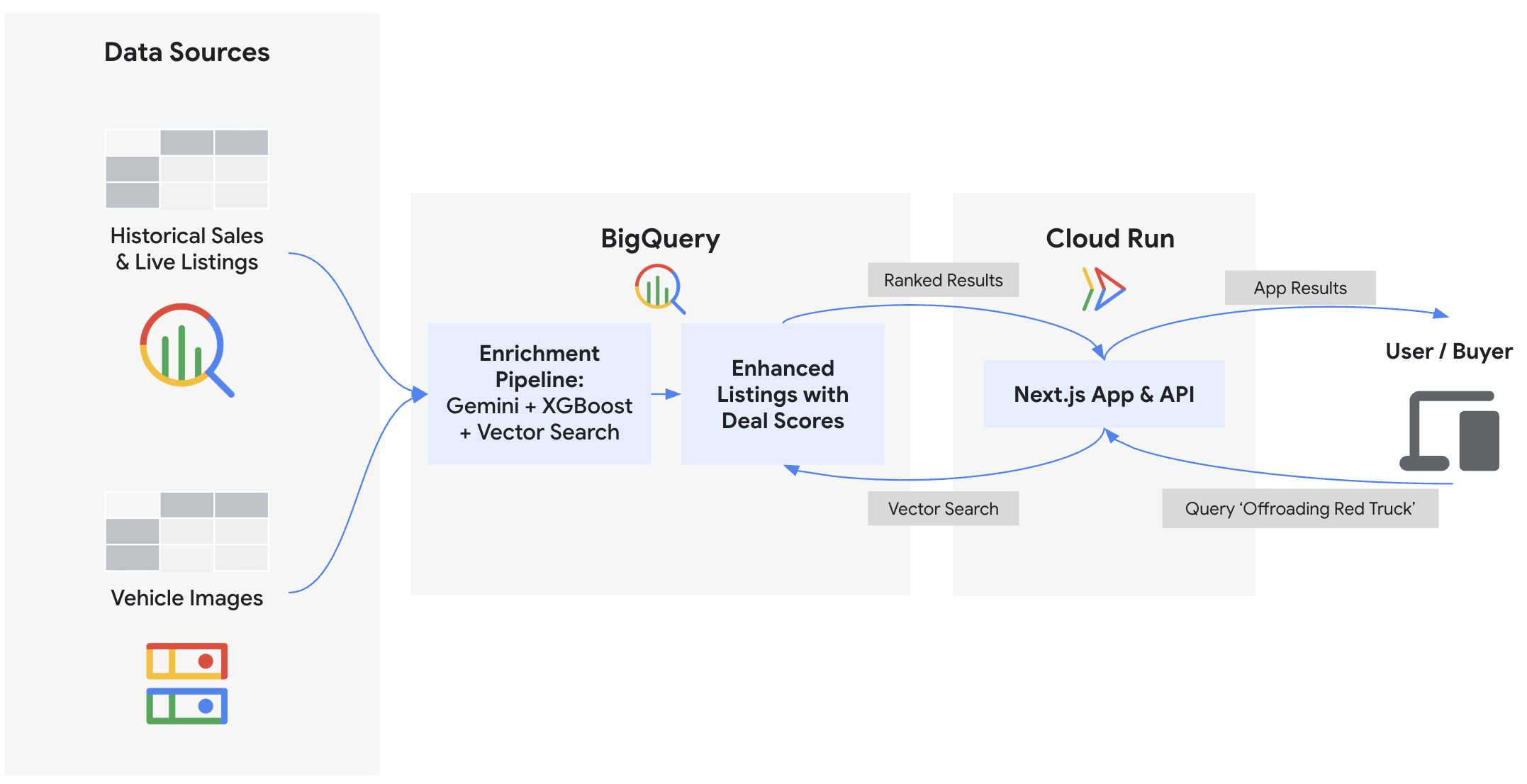
הפעולות שתבצעו:
- קישור BigQuery לתמונות לא מובנות ב-Cloud Storage באמצעות ObjectRef
- חילוץ מאפייני רכב מתמונות באמצעות BigQuery עם מודלים של Gemini
- חיזוי מחירים הוגנים בשוק באמצעות אימון מודל רגרסיה של XGBoost עם BigQuery ML
- לזהות רשימות פוטנציאליות של תרמיות ורשימות מהימנות על ידי הטמעת תיאורי כלי רכב וביצוע
VECTOR_SEARCH - חישוב של ציון עסקה מקיף לכל כרטיס מוצר, תוך שילוב של אותות לגבי מצב המוצר מתיאור המוכר באמצעות
AI.SCORE - ייצוא נתונים ופריסת אפליקציית Next.js Marketplace ב-Google Cloud Run
הדרישות
- דפדפן אינטרנט כמו Chrome
- פרויקט ב-Google Cloud שהחיוב בו מופעל
- היכרות בסיסית עם SQL, Python ו-Google Cloud
- הרשאות IAM מספיקות להפעלת ממשקי API, ליצירת משאבים ולהקצאת הרשאות (למשל, בעלי הפרויקט)
ה-Codelab הזה מיועד למפתחים ברמת ביניים.
העלות של המשאבים שנוצרו ב-codelab הזה צריכה להיות פחות מ-5$.
2. לפני שמתחילים
יצירת פרויקט ב-Google Cloud
- במסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים פרויקט ב-Google Cloud או יוצרים פרויקט.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
הפעלת Cloud Shell
תשתמשו ב-Google Cloud Shell כדי להוריד את הקוד, להריץ סקריפטים להגדרה ולפרוס את האפליקציה.
- לוחצים על Activate Cloud Shell (הפעלת Cloud Shell) בחלק העליון של מסוף Google Cloud.

- אחרי שמתחברים ל-Cloud Shell, צריך לאמת את הסשן כדי לוודא שהאפליקציה יכולה לגשת ל-Google Cloud APIs. פועלים לפי ההנחיות כדי לאשר את Cloud Shell:
gcloud auth application-default login
- מגדירים את מזהה הפרויקט ב-Google Cloud ואת השם הייחודי של קטגוריה של Cloud Storage ב-Google Cloud Storage (שבה יאוחסנו הנתונים הגולמיים):
export PROJECT_ID=$(gcloud config get-value project)
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
gcloud config set project $PROJECT_ID
אמורה להופיע הודעה דומה לזו שכאן למטה:
Your active configuration is: [cloudshell-####] Updated property [core/project]
הפעלת ממשקי ה-API
מריצים את הפקודה הזו ב-Cloud Shell כדי להפעיל את כל ממשקי ה-API הנדרשים ל-codelab הזה:
gcloud services enable \
aiplatform.googleapis.com \
artifactregistry.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
cloudbuild.googleapis.com \
run.googleapis.com
אם הפעולה בוצעה בהצלחה, תוצג הודעה שדומה לזו שמופיעה בהמשך:
Operation "operations/..." finished successfully.
3. קבלת הקוד ונתוני ההגדרה
קודם מורידים את נכסי ההדגמה ומגדירים את משתני הסביבה.
- מ-Cloud Shell, משכפלים את מאגר
devrel-demosועוברים לספריית הפרויקט:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos/data-analytics/cymbal-autos-multimodal
- מריצים את הסקריפט כדי להעתיק נתונים לסביבה. הסקריפט הזה מסנכרן את קבוצות הנתונים של המאגר המקומי עם הקטגוריה האישית שלכם ב-Cloud Storage, ומביא את תמונות הרכב מקטגוריה ציבורית:
chmod +x scripts/setup/*.sh
./scripts/setup/00_copy_data.sh
אחרי כן, אמורה להופיע הודעה דומה לזו:
Average throughput: 87.8MiB/s Data copy complete!
- לאחר מכן, מגדירים את קישור למשאבים ב-Cloud של BigQuery. כדי לנתח תמונות לא מובנות ב-Cloud Storage ולהפעיל מודלים של Agent Platform ישירות משאילתות SQL, BigQuery צריך להקצות הרשאות IAM לחשבון שירות בסיסי. הסקריפט הזה יוצר את החיבור המאובטח ומעניק לו את התפקידים הנדרשים של משתמש Vertex AI וצרכן השימוש בשירות (הפעולה הזו נמשכת כדקה):
./scripts/setup/01_setup_api_connection.sh
אמורה להופיע הודעה דומה לזו:
Environment setup complete! Your BigQuery connection is ready.
- לבסוף, יוצרים את מערך הנתונים הראשוני ב-BigQuery וטוענים את הנתונים הגולמיים בפורמט טבלאי. הפעולה הזו יוצרת את מערך הנתונים
model_devומאכלסת את טבלאות ההתחלה, ויוצרת את הבסיס לפני שכותבים שאילתות של למידת מכונה:
./scripts/setup/02_load_to_bq.sh
אמורה להופיע הודעה דומה לזו:
================================================================= BigQuery load complete! =================================================================
4. חילוץ נתונים באמצעות ראייה מולטי-מודאלית
לפני שתקבלו ציון לכרטיסי המוצר של כלי הרכב, תצטרכו לחלץ נתונים מובְנים (כמו צבע, סגנון מרכב או נזק ויזואלי) ממאות תמונות גולמיות. בעזרת פונקציות ObjectRef ומודלים של Gemini שמתארחים בפלטפורמת הסוכנים, אתם יכולים ליצור את התכונות האלה בלי להעביר קבצים או לכתוב צינורות נתונים מורכבים. המידע הזה משמש ישירות להצגת התג ✨ מצב חזותי באפליקציית הקצה.
- פותחים את BigQuery Studio בכרטיסייה חדשה בדפדפן.
- לוחצים על הלחצן + יצירת שאילתה חדשה. במהלך שיעור ה-Codelab הזה תשתמשו בכלי לעריכת SQL כדי ליצור אינטראקציה עם קוד SQL.
- לפני שיוצרים את כלי החילוץ של למידת המכונה, אפשר להסתכל על התמונות הגולמיות. מריצים את השאילתה הבאה כדי לראות את מערך כתובות ה-URI של התמונות שמאוחסנות ב-Google Cloud Storage לכל כרטיס מוצר:
SELECT auction_id, item_name, description, images
FROM `model_dev.vehicle_metadata` LIMIT 5;
- עכשיו, בעורך ה-SQL של BigQuery Studio, מדביקים את ה-SQL הבא כדי ליצור טבלה חדשה עם עמודה
image_ref. לוחצים על Run.
CREATE OR REPLACE TABLE `model_dev.vehicle_multimodal` AS
SELECT
*,
ARRAY(
SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF(uri, 'us.conn'))
FROM UNNEST(images) AS uri
) AS image_ref
FROM `model_dev.vehicle_metadata`;
- בודקים את העמודה החדשה
image_refObjectRef שיצרתם. בטבלה החדשה יש עכשיו עמודה ObjectRef עם הרשאות להפעלה על התמונות עצמן. מריצים את השאילתה הבאה כדי לראות את הנתונים:
SELECT auction_id, item_name, description, image_ref
FROM `model_dev.vehicle_multimodal` LIMIT 5;
- עכשיו נשתמש ב-
AI.GENERATEוב-AI.CLASSIFYכדי לנתח את התמונות. AI.GENERATEמחלץ את ציון המצב וסיכום נזק במשפט אחד באמצעות הנחיה ל-Gemini, ואילוAI.CLASSIFYמסווג באופן מדויק את סוג המרכב והצבע של הרכב.
מריצים את השאילתה הבאה כדי לחלץ את התובנות האלה לטבלת תכונות ייעודית. התהליך יימשך כ-3 דקות.
CREATE OR REPLACE TABLE `model_dev.vehicle_vision_features` AS
WITH generated_data AS (
SELECT
auction_id,
AI.GENERATE(
prompt => ('Rate the condition of this car on a scale from 0-100. Output a 1 sentence description of any glaring red flags', image_ref),
output_schema => 'condition INT64, description_summary STRING'
).* EXCEPT(full_response,status)
FROM
`model_dev.vehicle_multimodal`
),
-- Object-centric Classifications
classified_data AS (
SELECT
auction_id,
AI.CLASSIFY(
('What type of automobile is this?', image_ref[0]),
categories => ['Truck', 'Sedan', 'SUV']) AS body_style,
AI.CLASSIFY(
('Color of the exterior of the automobile', image_ref[0]),
categories => ['Black', 'White', 'Silver', 'Gray', 'Red', 'Blue', 'Brown', 'Green', 'Beige', 'Gold']) AS color,
AI.CLASSIFY(
('Color of the interior of the automobile', image_ref[0]),
categories => ['Black', 'Gray', 'Beige', 'Tan', 'Brown', 'White', 'Red']) AS interior
FROM `model_dev.vehicle_multimodal`
)
-- Join the AI insights back together into the final feature table
SELECT
g.auction_id,
g.condition,
g.description_summary,
c.body_style,
c.color,
c.interior
FROM generated_data g
JOIN classified_data c ON g.auction_id = c.auction_id;
- כדי לראות את המאפיינים שנוצרו בעצמכם, מריצים את השאילתה הבאה או מעיינים בצילום המסך שלמטה:
SELECT auction_id, condition, description_summary, body_style, color, interior FROM `model_dev.vehicle_vision_features` LIMIT 5;

סיכום הקטע: ניגשתם לתמונות הגולמיות ישירות מ-BigQuery והשתמשתם במודלים של Gemini כדי לחלץ תכונות חזותיות מובְנות בלי להעביר קבצים.
5. תמחור חיזוי עם XGBoost
כדי לחשב אם רכב מסוים הוא באמת עסקה טובה, צריך בסיס מהימן לחישוב שווי השוק ההוגן שלו. במקום לשלוף נתונים לסקריפטים או למחברות מקומיים כדי לאמן מודל, אפשר לאמן מודל XGBoost ישירות ב-BigQuery באמצעות SQL סטנדרטי. התחזית הזו של המחיר מפעילה את הלוגיקה של 📈 שווי השוק ההוגן באפליקציית הקצה.
- חוזרים לכרטיסייה BigQuery Studio.
- קודם, כדאי לעיין במערך הנתונים לאימון. בניגוד לרישומי הרכבים הפעילים, הטבלה
synthetic_carsהזו מכילה 100,000 נתוני מכירות היסטוריים שישמשו לאימון המודל. כדי לראות את הנתונים, מריצים את השאילתה הקצרה הזו:
SELECT
*
FROM
`model_dev.synthetic_cars`
LIMIT 10;
- עכשיו מריצים את ה-SQL הבא כדי לאמן מודל רגרסיה של XGBoost. המודל הזה לומד איך מאפיינים כמו מרחק הנסיעה המצטבר, שנת ייצור, יצרן ומצב ויזואלי משפיעים על המחיר מתוך 100,000 הרשומות ההיסטוריות האלה:
CREATE OR REPLACE MODEL `model_dev.car_price_model`
OPTIONS(
MODEL_TYPE = 'BOOSTED_TREE_REGRESSOR',
INPUT_LABEL_COLS = ['selling_price'],
MAX_ITERATIONS = 15,
TREE_METHOD = 'HIST'
) AS
SELECT
* EXCEPT(vin, sale_date, market_value, seller)
FROM
`model_dev.synthetic_cars`;
- לפני שחוזים את המחירים של כלי רכב שמוצעים למכירה בזמן אמת, צריך לאסוף את כל מאפייני הקלט הרלוונטיים במקום אחד. מריצים את ה-SQL הבא כדי למזג את המטא-נתונים המובְנים של הרכב עם התכונות שחולצו באמצעות ראייה ממוחשבת שיצרתם זה עתה:
CREATE OR REPLACE TABLE `model_dev.vehicle_prediction_features` AS
SELECT
meta.auction_id,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.transmission_type,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id;
- לבסוף, המערכת חוזה את שווי השוק ההוגן של כל כרטיס מידע פעיל של רכב. מריצים את השאילתה הבאה כדי להזין את התכונות המצטברות למודל החדש שאומן, ושומרים את הפלטים המספריים בטבלת חיזויים מאובטחת:
CREATE OR REPLACE TABLE `model_dev.vehicle_price_predictions` AS
SELECT
auction_id,
ROUND(predicted_selling_price, 2) AS predicted_market_value
FROM ML.PREDICT(
MODEL `model_dev.car_price_model`,
(SELECT * FROM `model_dev.vehicle_prediction_features`)
);
- עכשיו בודקים את הפלט של המודל. כדי לראות תצוגה מקדימה של ערכי השוק החזויים של כלי הרכב שמופיעים כרגע במלאי, מריצים את השאילתה המהירה הזו:
SELECT * FROM `model_dev.vehicle_price_predictions` LIMIT 5;
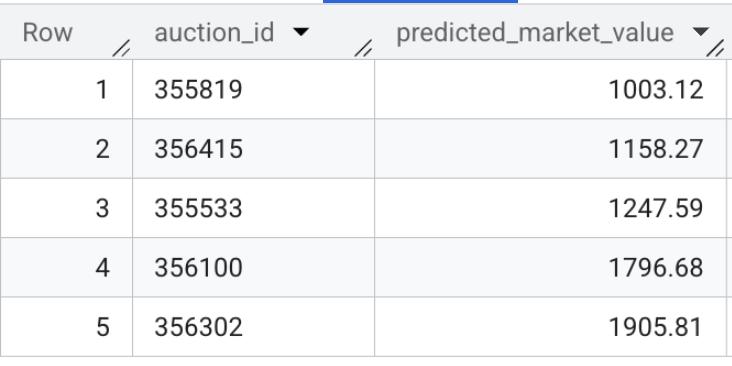
סיכום הקטע: אימנתם מודל רגרסיה של XGBoost באמצעות 100,000 עסקאות לדוגמה, והפעלתם הסקה של קבוצות כדי לחזות את שווי השוק ההוגן של כל כרטיס מוצר פעיל של רכב במערך הנתונים.
6. הטמעות סמנטיות וזיהוי אותנטיות
בקטע הזה נסביר איך להפעיל שתי צינורות הטמעה נפרדים כדי להפעיל תכונות חכמות בשוק למכירת רכב:
- חיפוש תמונות מולטימודאלי: תרגום של תמונות גולמיות של כלי רכב למרחב וקטורי כדי לאפשר למשתמשים לחפש באמצעות שפה טבעית (לדוגמה, "משאית עבודה אמינה").
- הטמעות של טקסט וחיפוש דמיון: תרגום של תיאורי כלי רכב כתובים להטמעות וקטוריות כדי להשוות בין כלי רכב פעילים לבין פרופילים ידועים של מתעניינים או של אנשים שמנסים לבצע הונאות באמצעות
VECTOR_SEARCH. החישוב הזה קובע את 🔍 ציון האותנטיות שמוצג לקונים באפליקציה.
- קודם כול, צריך ליצור הטמעות מולטימודאליות לכרטיסי המוצר של הרכבים. עם מודל
gemini-embedding-2-preview, אפשר להזין גם תמונות וגם טקסט באותו הטמעה בדיוק. המודל הזה מסוגל לעבד כמה אופנים בו-זמנית, אבל במקרה הספציפי הזה אנחנו מטמיעים רק את תמונות הרכב. הטכנולוגיה הזו מפעילה את סרגל ה'חיפוש סמנטי' באפליקציית הקצה הקדמי, ומאפשרת לקונים להשתמש בשפה טבעית (למשל, 'טנדר אמין') ולאחזר במהירות כרטיסי מוצר תואמים. מריצים את השאילתה הזו כדי ליצור את הווקטורים מרובי-האופנים באמצעותAI.EMBED:
CREATE OR REPLACE TABLE `model_dev.vehicle_images_embedded` AS
SELECT
auction_id,
AI.EMBED(
STRUCT(image_ref),
endpoint => 'gemini-embedding-2-preview').result AS multimodal_embedding
FROM `model_dev.vehicle_multimodal`
WHERE ARRAY_LENGTH(image_ref) > 0;
- בשלב הבא, תבדקו את נתוני פרופיל הסיכון שנטענו קודם. שימו לב שהיא מכילה גם טיפולוגיות ידועות של תרמיות וגם דוגמאות לגיטימיות של רישומים של חובבים. מריצים את השאילתה הזו כדי לראות את פרופילי ה-Baseline:
SELECT profile_id, profile_type, description
FROM `model_dev.seller_risk_profiles`;
- עכשיו תתרגמו את תיאורי הסיכון הגולמיים להטמעות וקטוריות. אתם יכולים להשתמש במודל מיוחד להטמעת טקסט (
text-embedding-005) כדי להעריך באופן מדויק את השפה הכתובה שזה עתה צפיתם בה בתצוגה מקדימה. מדביקים את ה-SQL הבא ולוחצים על Run (הפעלה) כדי להטמיע את פרופילי הבסיס:
CREATE OR REPLACE TABLE `model_dev.seller_risk_profiles_embedded` AS
SELECT
profile_id,
description AS content,
profile_type,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.seller_risk_profiles`;
- לאחר מכן, יוצרים הטמעות דומות למלאי הרכבים הזמין בפועל. מריצים את השאילתה הזו כדי לתרגם את תיאור ה-HTML הגולמי של כל רכב למרחב וקטורי, כדי שאפשר יהיה להשוות אותו לפרופילים של קו הבסיס:
CREATE OR REPLACE TABLE `model_dev.vehicle_descriptions_embedded` AS
SELECT
auction_id,
description AS content,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.vehicle_metadata`
WHERE description IS NOT NULL;
- לבסוף, מריצים את החיפוש הווקטורי כדי לחשב את המרחק הסמנטי בין כרטיסי המוצר הפעילים לבין פרופילי הבסיס. מריצים את ה-SQL הבא כדי לבצע את המיפוי. מרחק מתמטי נמוך יותר מצביע על כך שהמוצר דומה מאוד לקבוצת מוצרים ידועה שמשמשת להונאה, בעוד שמרחק גבוה יותר מצביע על תיאור לגיטימי.
CREATE OR REPLACE TABLE `model_dev.vehicle_authenticity_scores` AS
SELECT
scam_search.query.auction_id,
CAST(
GREATEST(0.0, LEAST(100.0, ROUND((MIN(scam_search.distance) - 0.33) / 0.12 * 100.0)))
AS INT64
) AS authenticity_score
FROM VECTOR_SEARCH(
TABLE `model_dev.seller_risk_profiles_embedded`,
'text_embedding',
(
SELECT text_embedding, auction_id
FROM `model_dev.vehicle_descriptions_embedded`
),
top_k => 15,
distance_type => 'COSINE'
) AS scam_search
WHERE scam_search.base.profile_type = 'scam'
GROUP BY 1;
התוכן של הטבלה הזו יכול להיראות כך:
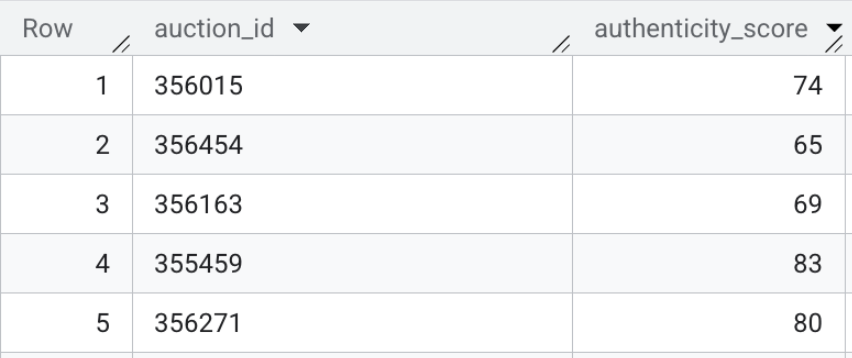
סיכום הקטע: יצרתם הטמעות מולטי-מודאליות עבור סרגל החיפוש בקצה הקדמי, והשתמשתם בחיפוש וקטורי ישירות ב-BigQuery כדי להעריך רשימות של טקסט HTML גולמי בהשוואה לפרופילים ידועים של תרמיות.
7. דירוג גנרטיבי של עסקאות
עכשיו יש לכם מערכי נתונים מובְנים שנוצרו באמצעות טכניקות שונות של למידת מכונה, והכול מתבצע באופן מלא ב-BigQuery: חילוץ נתונים באמצעות Vision, מודל XGBoost לחיזוי שווי שוק הוגן והטמעות של חיפוש וקטורי.
השלב האחרון הוא מיזוג האותות האלה מ-AI לתצוגה מאוחדת של ניקוד העסקה הסופי באפליקציית הקצה הקדמי.
- קודם כל, מצטרפים למטא-נתונים הגולמיים עם תכונות הראייה שחולצו על ידי AI, פלטים של תמחור חיזוי וציוני אותנטיות סמנטית. מריצים את ה-SQL הבא:
CREATE OR REPLACE TABLE `model_dev.vehicle_features_enhanced` AS
SELECT
meta.auction_id,
meta.item_name,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.current_bid,
meta.listing_url,
meta.transmission_type,
meta.description,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior,
COALESCE(scam.authenticity_score, 100) AS authenticity_score,
vision.description_summary,
prices.predicted_market_value
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id
LEFT JOIN `model_dev.vehicle_price_predictions` prices
ON meta.auction_id = prices.auction_id
LEFT JOIN `model_dev.vehicle_authenticity_scores` scam
ON meta.auction_id = scam.auction_id;
- בשלב הבא, מחשבים ציון עסקה בין 0 ל-100 על ידי שילוב של ארבעה אותות שונים מבוססי-AI. הנוסחה הזו מאזנת בין ערך, איכות וסיכון כדי להציג את כרטיסי המוצר הטובים ביותר:
- ציון המחיר (40%): מדד החיסכון בהשוואה לשווי השוק ההוגן.
- ציון Vision (30%): תובנות מניתוח תמונות קודם.
- ציון האותנטיות (15%): הערכת הסיכון להונאה.
- ציון המצב (15%): מוסק תוך כדי תנועה מתיאור המוצר של המוכר באמצעות
AI.SCORE.
CREATE OR REPLACE TABLE `model_dev.marketplace_listings` AS
WITH score_elements AS (
SELECT
*,
-- 1. SELLER DESCRIPTION SCORE (use AI.SCORE on seller description)
AI.SCORE(
FORMAT("Rate the vehicle condition (0-100) based ONLY on this text: '%s'", description)
) AS description_score,
-- 2. PRICE SCORE
-- Higher impact for underpricing, lower impact for overpricing.
CAST(LEAST(100.0, GREATEST(0.0,
75.0 + (
IF((predicted_market_value - current_bid) > 0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 250.0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 40.0
)
)
)) AS INT64) AS price_score
FROM `model_dev.vehicle_features_enhanced`
),
final_calcs AS (
SELECT
*,
-- 3. Combine scores: Price (40%), Condition (30%), Description (15%), Authenticity (15%)
ROUND(
(
(price_score * 0.40) +
(CAST(condition AS INT64) * 0.30) +
(COALESCE(description_score, 50) * 0.15) +
(CAST(authenticity_score AS INT64) * 0.15)
)
-- Authenticity penalty for scores below 50.
* (IF(CAST(authenticity_score AS INT64) < 50, 0.20, 1.05))
) AS raw_score
FROM score_elements
)
SELECT
* EXCEPT(raw_score),
-- 4. Set floor values: low authenticity scores drop to 10; others floor at 35.
CAST(GREATEST(
(IF(CAST(authenticity_score AS INT64) < 50, 10, 35)),
LEAST(100, raw_score)
) AS INT64) AS deal_score
FROM final_calcs;
כדי להבטיח שההמלצות יהיו איכותיות, השאילתה מפעילה שתי שכבות לוגיות ספציפיות:
- שער אותנטיות: אם מוצר מסוים מסומן כ'סיכון גבוה' (ציון נמוך מ-50), הציון הכולל של המבצע יופחת אוטומטית ב-80% כדי למנוע קידום של מוצרים חשודים.
- אופטימיזציה של"פנינה נסתרת": הנוסחה משתמשת בלוגיקה של פונקציה מוגדרת בקטעים כדי לתגמל חיסכון באופן אגרסיבי, ובו בזמן להיות סלחנית יותר לגבי העלאות מחירים. כך, מכונית במצב מעולה שמחירה גבוה מדי עדיין יכולה לקבל דירוג 'הוגן'.
הטבלה שמתקבלת, model_dev.marketplace_listings, מכילה שדות כמו deal_score, לצד price_score ו-authenticity_score.
- כדי לראות את ציוני העסקאות בעצמכם, מריצים את השאילתה הבאה או פשוט מעיינים בצילום המסך שלמטה:
SELECT item_name, model_year, authenticity_score, predicted_market_value, price_score, deal_score FROM `model_dev.marketplace_listings`
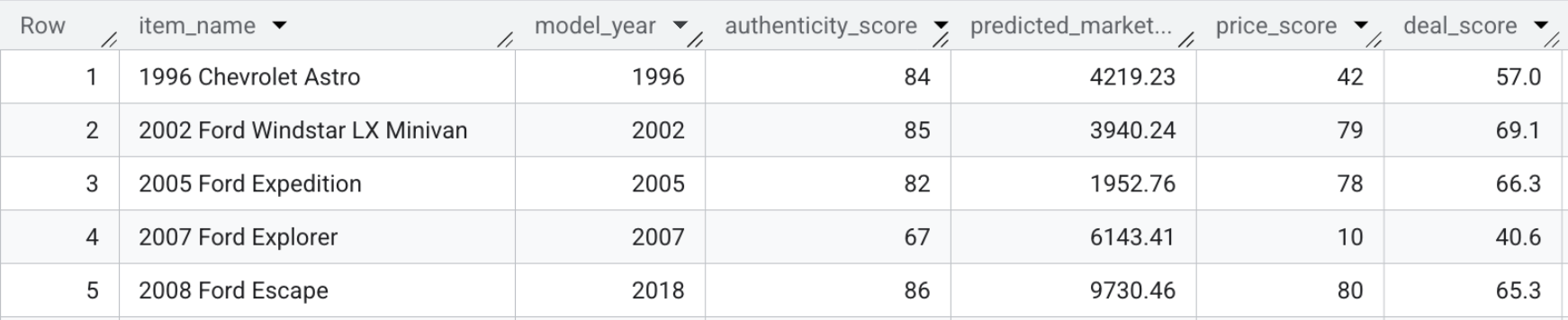
סיכום הקטע: שילבתם את התמחור החזוי, התכונות החזותיות וציוני האותנטיות עם התיאור של המוכר כדי לחשב ציון עסקה יחיד לכל כרטיס מוצר.
8. פריסת אפליקציית הקצה הקדמי
עכשיו הגיע הזמן להפעיל את אפליקציית ה-Frontend. כך תוכלו לחפש במלאי של כרטיסי המוצר של כלי רכב ולקיים אינטראקציה עם התובנות שנוצרו על ידי AI, כמו ציון העסקה.
ייצוא ציוני AI לחלק החזיתי
הקצה הקדמי של React מסתמך על מטען ייעודי (payload) מקומי של JSON לטעינות מהירות של דפים ראשוניים. כדי להפעיל את ה-Marketplace, צריך לחלץ את הניקוד הסופי של העסקאות הגנרטיביות מ-BigQuery ולהחדיר אותו בחזרה לפרויקט Next.js.
- מוודאים שהסביבה מוכנה. אם פג הזמן של סשן Cloud Shell או אם עברתם לתיקייה אחרת, מריצים את הפקודה הבאה כדי לחזור לתיקיית הבסיס של הפרויקט ולשחזר את משתני הסביבה:
cd ~/devrel-demos/data-analytics/cymbal-autos-multimodal && \
export PROJECT_ID=$(gcloud config get-value project) && \
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
- מריצים את סקריפט Python שסופק כדי להריץ שאילתה על התצוגה הסופית ב-BigQuery ולמזג את ציוני העסקאות החדשים במאגר הנתונים הבסיסי של האפליקציה:
python3 scripts/setup/08_export_frontend_data.py
תקבלו הודעת אישור כמו:
💾 Updated local file: app/src/data/cars.json
פריסת האפליקציה ב-Cloud Run
אחרי שהנתונים מועשרים בהצלחה, אפשר לפרוס את אפליקציית ה-frontend של Next.js באינטרנט הציבורי באמצעות Cloud Run. הממשק המודרני כולל דירוגים של מבצעים, קרוסלות אינטראקטיביות של תמונות וסרגל חיפוש סמנטי היברידי דינמי שמבצע שאילתות ב-BigQuery בזמן אמת.
- ב-Cloud Shell, נכנסים לספרייה
app/של המאגר המשוכפל. חשוב מאוד להקפיד על כך, כי אם תשארו בספריית הבסיס, הבנייה תיכשל.
cd app
- פורסים את האפליקציה כקונטיינר ללא שרת באמצעות Cloud Run. הפקודה מעבירה את
PROJECT_IDכמשתנה סביבה, כדי ש-Next.js API יידע איזה פרויקט BigQuery צריך לשאול:
gcloud run deploy cymbal-autos-frontend \
--source . \
--region us-west1 \
--allow-unauthenticated \
--min-instances 1 \
--set-env-vars PROJECT_ID=$PROJECT_ID \
--project $PROJECT_ID
- בסיום הפריסה, כתובת URL מאובטחת של השירות תוצג במסוף. הוא ייראה כך:
Service URL: https://cymbal-autos-frontend-[YOUR-PROJECT-NUMBER].us-west1.run.app/
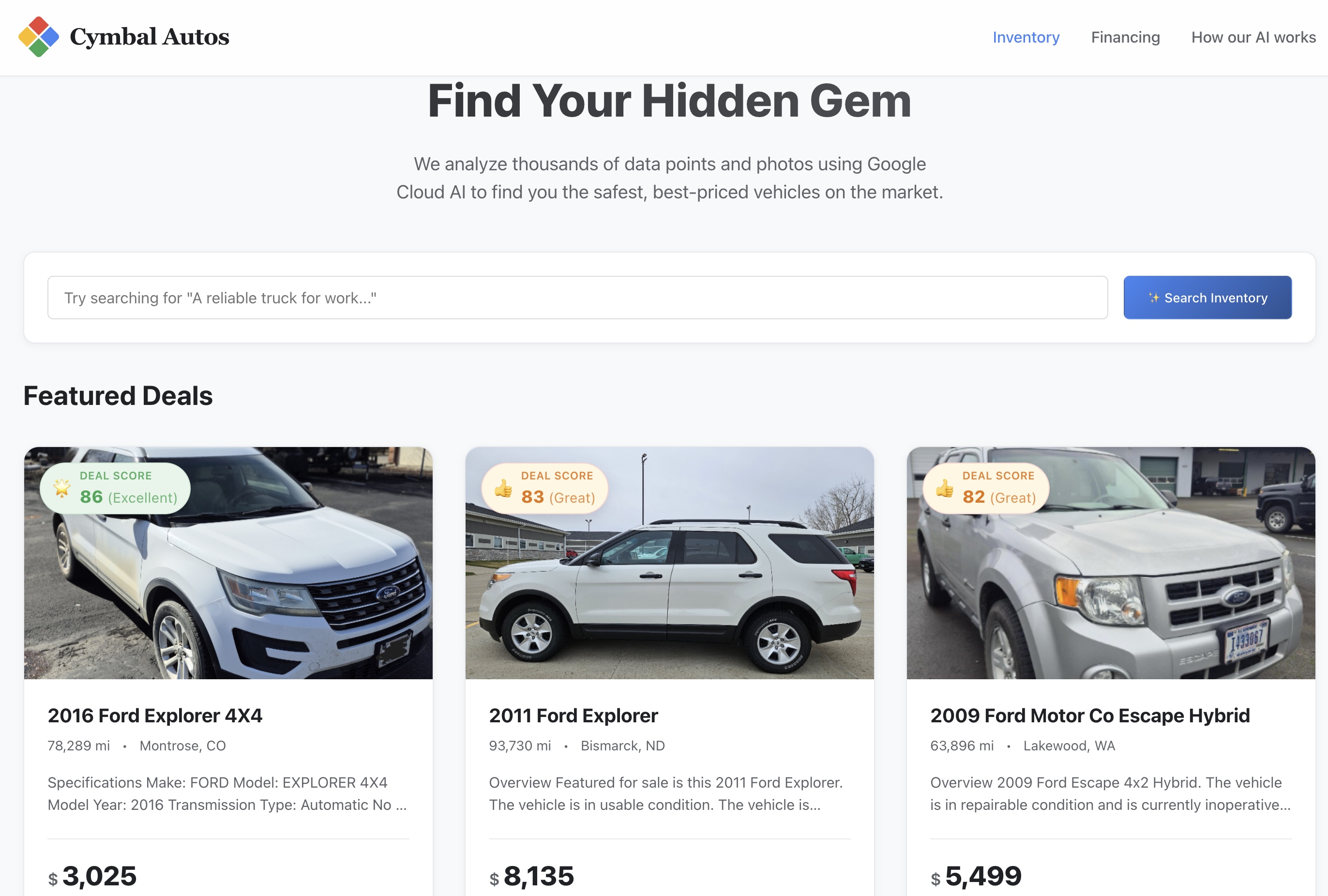
9. התנסות באפליקציית Cymbal Autos
אחרי שדוחפים את קונטיינר ה-קצה קדמי ל-Cloud Run, הגיע הזמן לבדוק את האפליקציה.
- נכנסים לאתר: פותחים את כתובת ה-URL המאובטחת של השירות שהוחזרה על ידי Cloud Run.
- ביצוע חיפוש סמנטי: אפשר לנסות לחפש מושג מופשט, כמו "משאית עבודה אמינה שמתאימה להובלה ולנסיעה בשטח". אפליקציית Next.js מתרגמת את הטקסט הגולמי להטמעה של וקטורים רב-אופניים ושולחת שאילתה בזמן אמת
VECTOR_SEARCHאל BigQuery, כדי למפות את הרעיון שלכם למערכת האקולוגית של הרכב.
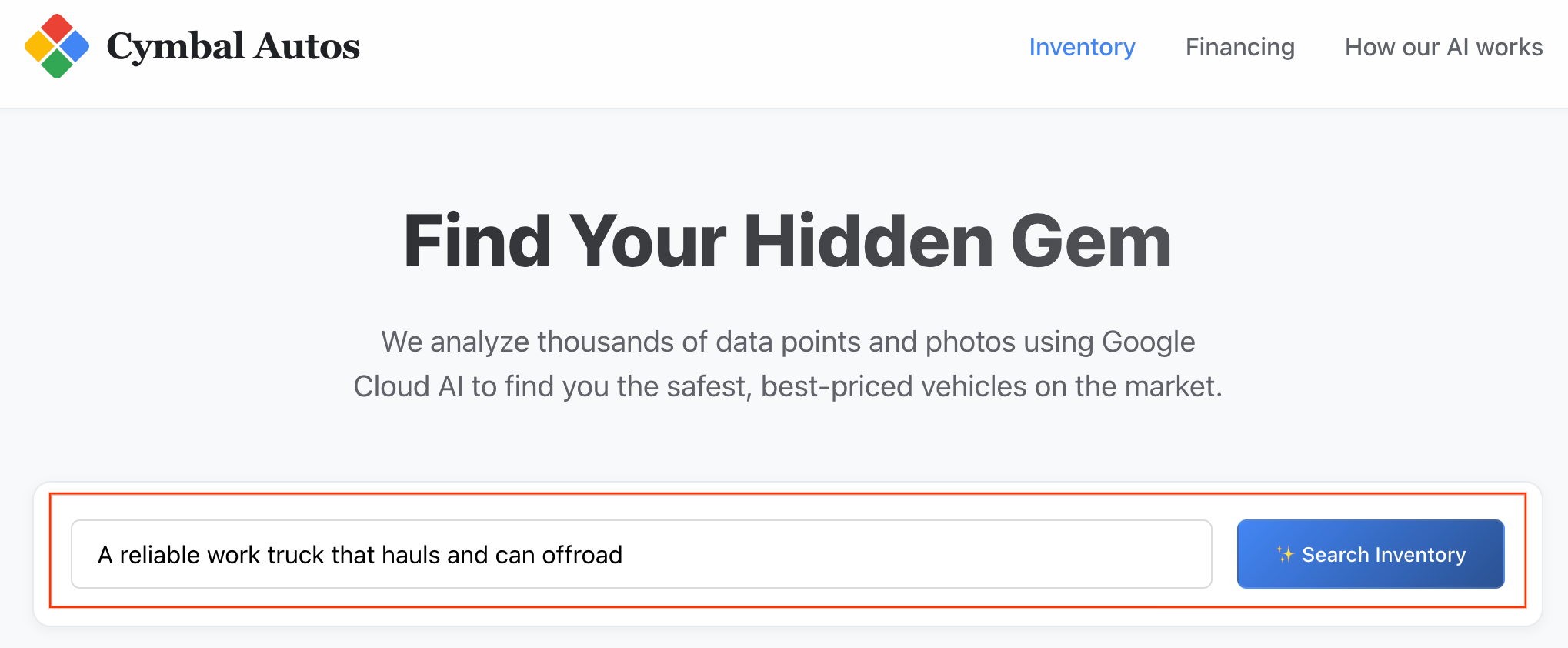
הערה: כרטיסי המוצר מסודרים לפי דמיון סמנטי.
- בדיקת התוצאות: מערכת BigQuery חישבה את המרחק המתמטי המדויק בין הרעיון המופשט שלכם לבין התכונות של הרכב, כדי להחזיר את ההתאמות הסמנטיות הכי קרובות.
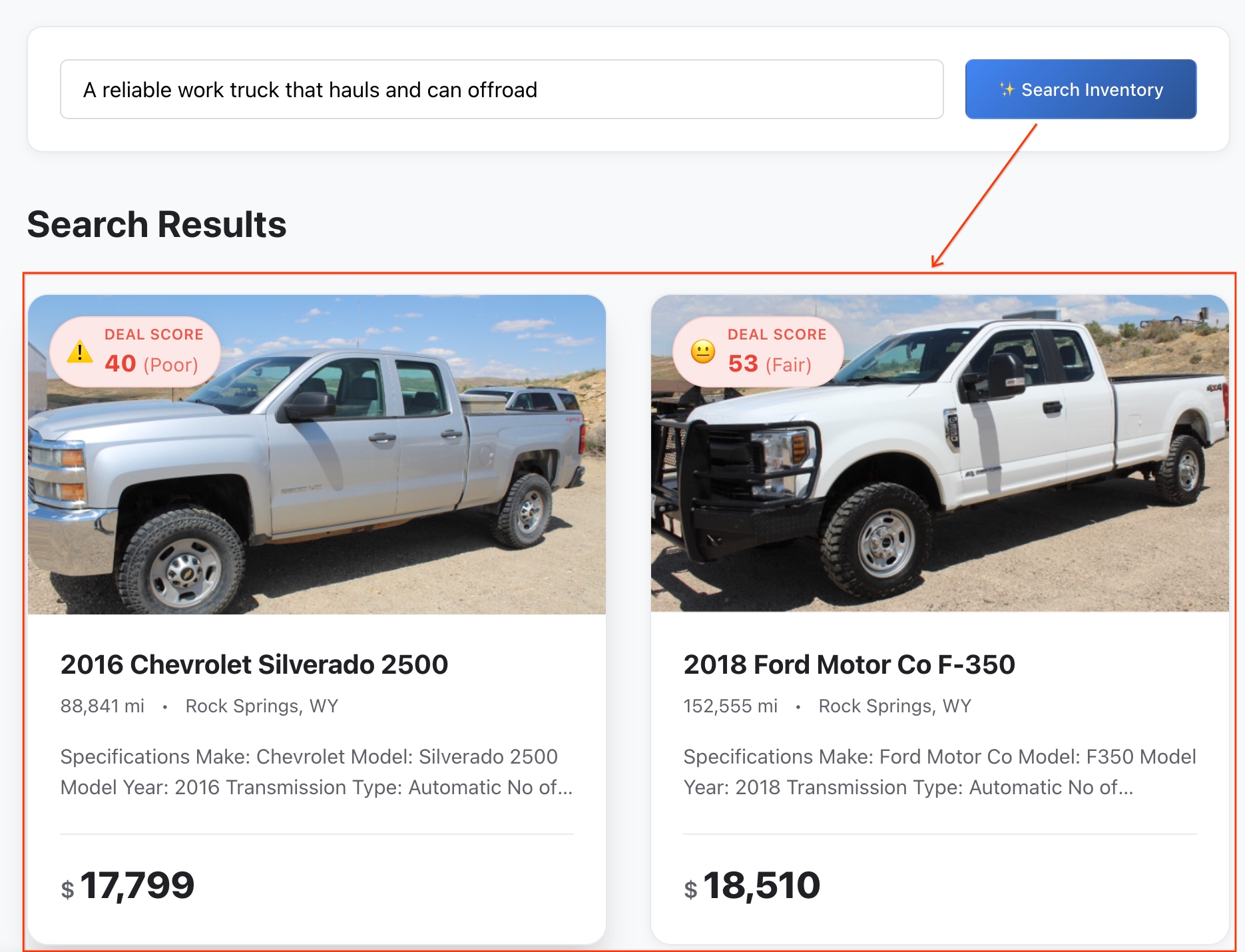
- עיון בפרטים: לוחצים על רכב כלשהו כדי לפתוח את פרופיל הרכב המלא.
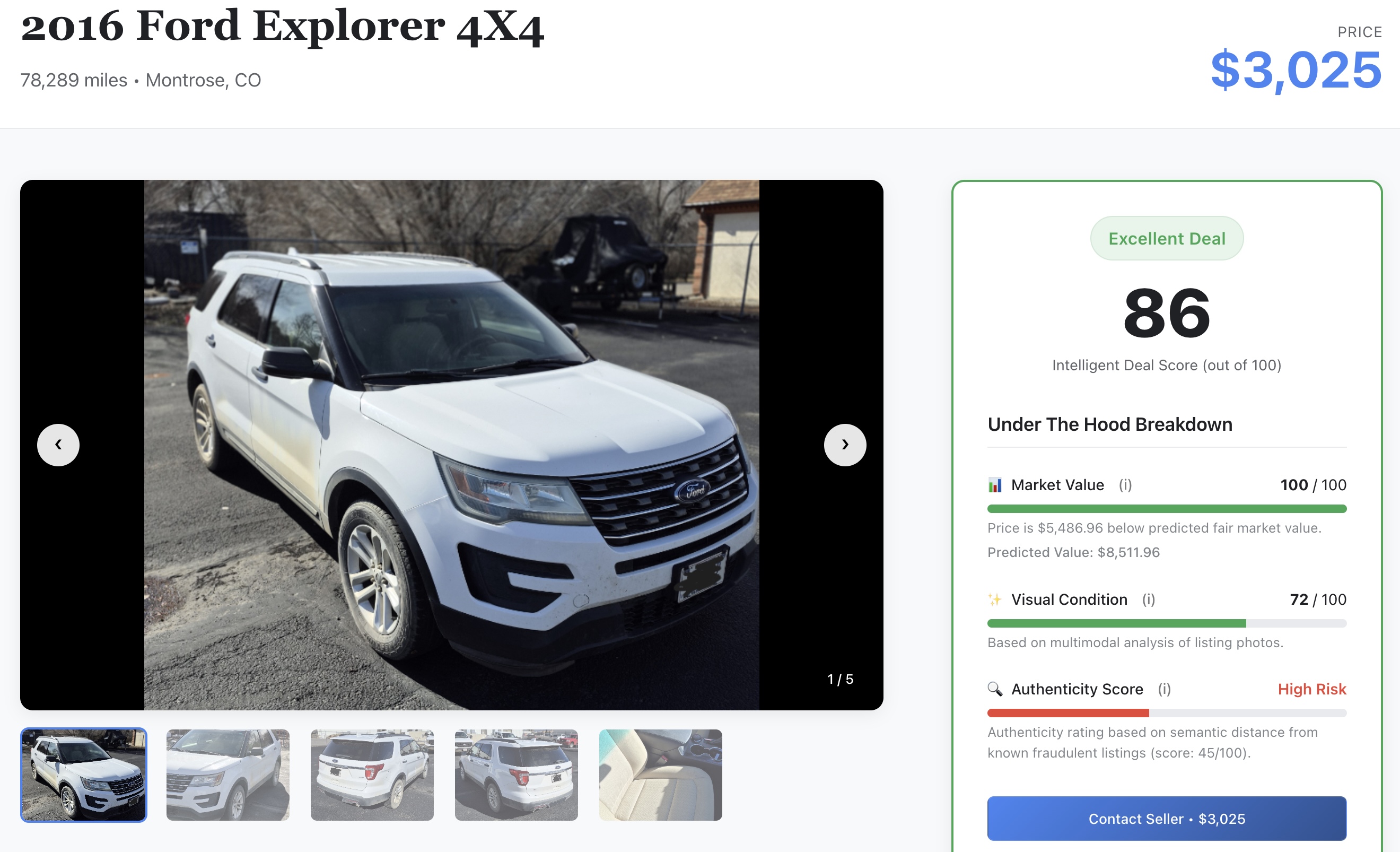
- בדיקת אות ה-AI: גוללים בין הפרטים כדי לראות את הציונים הגולמיים של למידת המכונה שנוצרו קודם במעבדה:
- 📈 שווי שוק הוגן: מחיר הבסיס שחזוי על ידי מודל ה-XGBoost.
- ✨ מצב ויזואלי: דירוג הנזק הפיזי שחולץ על ידי המודלים של Gemini.
- 🔍 ציון האותנטיות: מדד וקטור האותנטיות מבחין בין מוכרים לגיטימיים לבין מוכרים שהם נוכלים פוטנציאליים.
10. הסרת המשאבים
כדי להימנע מחיובים שוטפים בחשבון Google Cloud על המשאבים שבהם השתמשתם ב-Codelab הזה, אתם יכולים למחוק את כל הפרויקט בענן ב-Google Cloud שיצרתם בשביל ה-Codelab הזה, או להריץ את סקריפט ההסרה האוטומטי הבא.
- בטרמינל של Cloud Shell, חוזרים לספרייה הבסיסית שמכילה את:
cd ..
- מריצים את סקריפט הניקוי שבהמשך. הפעולה הזו תרוקן את קטגוריה של Cloud Storage, תמחק את
model_devמערך הנתונים ב-BigQuery, תמחק את החיבור ל-BigQuery ותמחק את שירות Cloud Run.
chmod +x scripts/cleanup/teardown.sh
./scripts/cleanup/teardown.sh
11. מזל טוב
מעולה! יצרת בהצלחה שוק חכם למכירת כלי רכב. השתמשתם ב-BigQuery כדי לאחד את הניתוח של נתונים לא מובְנים, את המודלים לחיזוי ואת שילובי ה-AI בסביבת עבודה אחת.
מה למדתם
- איך מקשרים בין BigQuery לבין תמונות לא מובנות ב-Cloud Storage באמצעות ObjectRef
- איך לחלץ תכונות של כלי רכב מתמונות באמצעות BigQuery עם מודלים של Gemini כמו הפונקציות
AI.GENERATEו-AI.CLASSIFY - איך לחזות מחירי רכבים באמצעות BigQuery ML
- איך מזהים כרטיסי מוצר של רכבים שעשויים להיות תרמית על ידי הטמעת תיאורי רכבים וביצוע
VECTOR_SEARCH - איך משתמשים ב-
AI.SCOREכדי להעריך נתונים לא מובנים תוך כדי תנועה ולשלב את התוצאות בציון מקיף של העסקה - איך מייצאים נתונים ופורסים את אפליקציית Cloud Marketplace של Next.js ב-Cloud Run