
1. परिचय
इस कोडलैब में, आपको "Cymbal Autos" के लिए बैकएंड बनाने और फ़्रंटएंड डिप्लॉय करने का तरीका बताया जाएगा. "Cymbal Autos", वाहनों का एक ऑनलाइन मार्केटप्लेस है. BigQuery और Gemini Enterprise Agent Platform पर Gemini मॉडल का इस्तेमाल करके, वाहनों की फ़ोटो की जांच की जाएगी. साथ ही, BigQuery ML का इस्तेमाल करके, कीमतों का अनुमान लगाया जाएगा. इसके अलावा, वेक्टर एम्बेडिंग का इस्तेमाल करके, धोखाधड़ी वाली लिस्टिंग का पता लगाया जाएगा और कंपोज़िट डील स्कोर का हिसाब लगाया जाएगा. आखिर में, आपको इन अहम जानकारियों को Cloud Run पर डिप्लॉय किए गए Next.js फ़्रंटएंड पर दिखाना होगा.
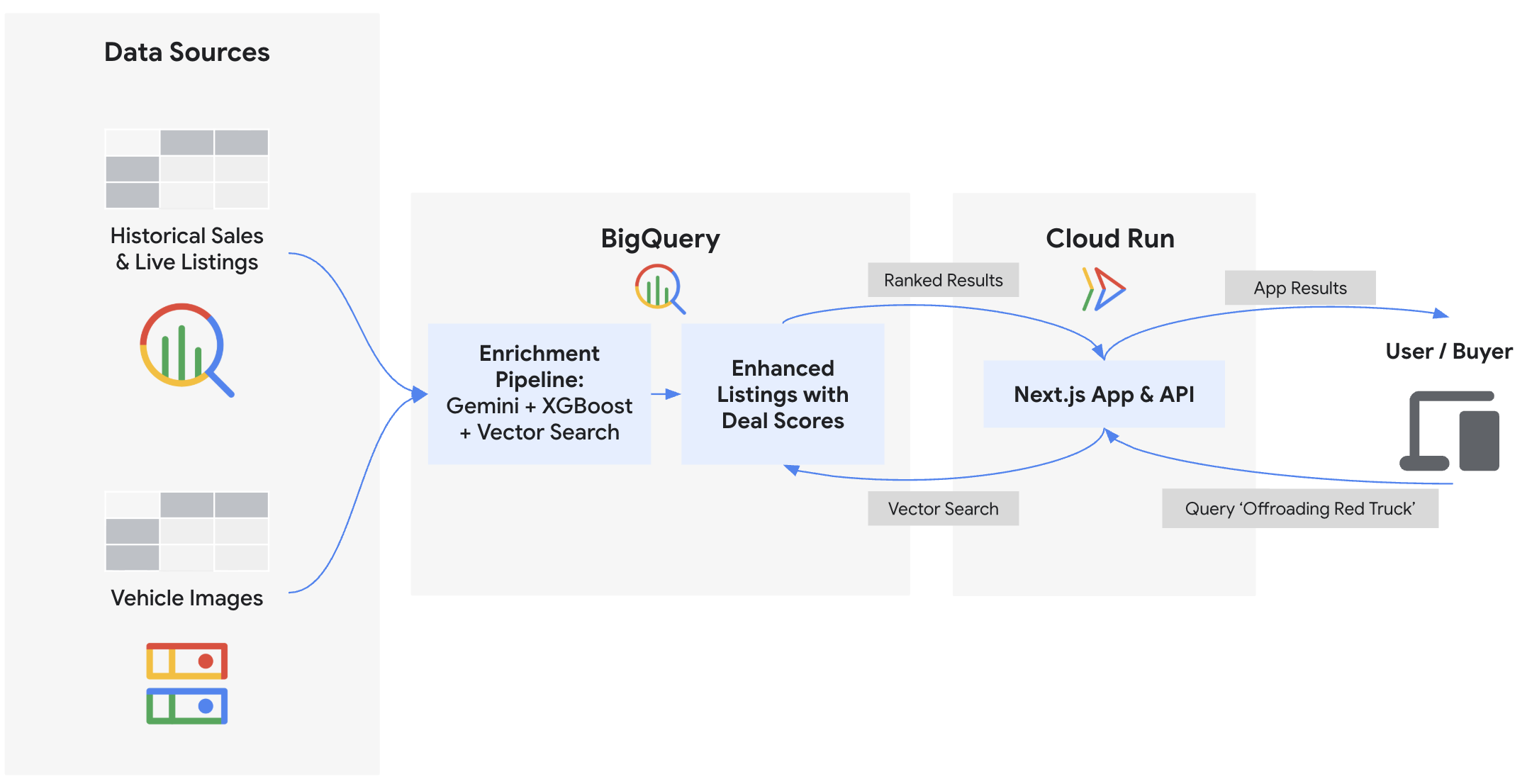
आपको क्या करना होगा
- ObjectRef का इस्तेमाल करके, BigQuery को Cloud Storage में मौजूद अनस्ट्रक्चर्ड इमेज से कनेक्ट करना
- Gemini मॉडल के साथ BigQuery का इस्तेमाल करके, फ़ोटो से वाहन की एट्रिब्यूट की जानकारी निकालना
- BigQuery ML की मदद से XGBoost रिग्रेशन मॉडल को ट्रेनिंग देकर, उचित बाज़ार कीमतों का अनुमान लगाना
- वाहन के ब्यौरे शामिल करके और
VECTOR_SEARCHकरके, संभावित धोखाधड़ी और भरोसेमंद लिस्टिंग की पहचान करना - हर लिस्टिंग के लिए, डील स्कोर का हिसाब लगाएं. साथ ही, सेलर के ब्यौरे में दी गई स्थिति की जानकारी को शामिल करें. इसके लिए,
AI.SCOREका इस्तेमाल करें - डेटा एक्सपोर्ट करना और Next.js मार्केटप्लेस ऐप्लिकेशन को Google Cloud Run पर डिप्लॉय करना
आपको किन चीज़ों की ज़रूरत होगी
- कोई वेब ब्राउज़र, जैसे कि Chrome
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट
- एसक्यूएल, Python, और Google Cloud के बारे में बुनियादी जानकारी
- एपीआई चालू करने, संसाधन बनाने, और अनुमतियां असाइन करने के लिए, आईएएम की ज़रूरी अनुमतियां (जैसे, प्रोजेक्ट के मालिक की भूमिका)
यह कोडलैब, इंटरमीडिएट डेवलपर के लिए है.
इस कोडलैब में बनाए गए संसाधनों की लागत 5 डॉलर से कम होनी चाहिए.
2. शुरू करने से पहले
Google Cloud प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
Cloud Shell शुरू करना
कोड डाउनलोड करने, सेटअप स्क्रिप्ट चलाने, और ऐप्लिकेशन को डिप्लॉय करने के लिए, Google Cloud Shell का इस्तेमाल किया जाएगा.
- Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.

- Cloud Shell से कनेक्ट होने के बाद, अपने सेशन की पुष्टि करें. इससे यह पक्का किया जा सकेगा कि आपका ऐप्लिकेशन, Google Cloud API को ऐक्सेस कर सकता है. Cloud Shell को अनुमति देने के लिए, निर्देशों का पालन करें:
gcloud auth application-default login
- Google Cloud Storage बकेट के लिए, Google Cloud प्रोजेक्ट आईडी और कोई यूनीक नाम सेट करें. इसी बकेट में आपको रॉ डेटा सेव करना है:
export PROJECT_ID=$(gcloud config get-value project)
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
gcloud config set project $PROJECT_ID
आपको यहां दिया गया मैसेज दिखेगा:
Your active configuration is: [cloudshell-####] Updated property [core/project]
एपीआई चालू करें
इस कोडलैब के लिए ज़रूरी सभी एपीआई चालू करने के लिए, Cloud Shell में यह कमांड चलाएं:
gcloud services enable \
aiplatform.googleapis.com \
artifactregistry.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
cloudbuild.googleapis.com \
run.googleapis.com
टैग को सही तरीके से लागू करने के बाद, आपको यहां दिखाए गए मैसेज जैसा मैसेज दिखेगा:
Operation "operations/..." finished successfully.
3. कोड और सेटअप डेटा पाना
सबसे पहले, डेमो ऐसेट डाउनलोड करें और अपने एनवायरमेंट वैरिएबल कॉन्फ़िगर करें.
- Cloud Shell से,
devrel-demosरिपॉज़िटरी को क्लोन करें और प्रोजेक्ट डायरेक्ट्री पर जाएं:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos/data-analytics/cymbal-autos-multimodal
- अपने एनवायरमेंट में डेटा कॉपी करने के लिए, स्क्रिप्ट चलाएं. यह स्क्रिप्ट, लोकल रिपॉज़िटरी के डेटासेट को आपके निजी Cloud Storage बकेट से सिंक करती है. साथ ही, सार्वजनिक बकेट से वाहन की इमेज फ़ेच करती है:
chmod +x scripts/setup/*.sh
./scripts/setup/00_copy_data.sh
इसके बाद, आपको इस तरह का मैसेज दिखेगा:
Average throughput: 87.8MiB/s Data copy complete!
- इसके बाद, BigQuery Cloud Resource Connection सेट अप करें. Cloud Storage में मौजूद बिना स्ट्रक्चर वाली इमेज का विश्लेषण करने और अपनी एसक्यूएल क्वेरी से सीधे तौर पर एजेंट प्लैटफ़ॉर्म मॉडल को कॉल करने के लिए, BigQuery को IAM अनुमतियां किसी सेवा खाते को सौंपनी होंगी. यह स्क्रिप्ट, सुरक्षित कनेक्शन बनाती है और इसे Vertex AI User और Service Usage Consumer की ज़रूरी भूमिकाएं असाइन करती है. इन भूमिकाओं को लागू होने में करीब एक मिनट लगता है:
./scripts/setup/01_setup_api_connection.sh
आपको इस तरह का मैसेज दिखेगा:
Environment setup complete! Your BigQuery connection is ready.
- आखिर में, शुरुआती BigQuery डेटासेट बनाएं और रॉ टेबल डेटा लोड करें. इससे आपका
model_devडेटासेट बनता है और शुरुआती टेबल भर जाती हैं. इससे मशीन लर्निंग की कोई भी क्वेरी लिखने से पहले, आपको बुनियादी जानकारी मिल जाती है:
./scripts/setup/02_load_to_bq.sh
आपको इस तरह का मैसेज दिखेगा:
================================================================= BigQuery load complete! =================================================================
4. मल्टीमॉडल विज़न एक्सट्रैक्शन
वाहन की लिस्टिंग को स्कोर करने से पहले, आपको सैकड़ों रॉ फ़ोटो से स्ट्रक्चर्ड डेटा (जैसे कि रंग, बॉडी स्टाइल या विज़ुअल डैमेज) निकालना होगा. ObjectRef फ़ंक्शन और Agent Platform में होस्ट किए गए Gemini मॉडल का इस्तेमाल करके, इन सुविधाओं को जनरेट किया जा सकता है. इसके लिए, न तो किसी फ़ाइल को ट्रांसफ़र करने की ज़रूरत होती है और न ही जटिल डेटा पाइपलाइन लिखने की. इस एक्सट्रैक्शन से, सीधे तौर पर फ़्रंटएंड ऐप्लिकेशन पर मौजूद ✨ विज़ुअल कंडीशन बैज को जानकारी मिलती है.
- BigQuery Studio को ब्राउज़र के नए टैब में खोलें.
- + नई क्वेरी लिखें बटन पर क्लिक करें. इस कोडलैब में, एसक्यूएल कोड के साथ इंटरैक्ट करने के लिए एसक्यूएल एडिटर का इस्तेमाल किया जाएगा.
- मशीन लर्निंग एक्सट्रैक्टर बनाने से पहले, रॉ इमेज को देखा जा सकता है. हर लिस्टिंग के लिए, Google Cloud Storage में सेव किए गए इमेज यूआरआई की ऐरे देखने के लिए, यह क्वेरी चलाएं:
SELECT auction_id, item_name, description, images
FROM `model_dev.vehicle_metadata` LIMIT 5;
- अब BigQuery Studio के एसक्यूएल एडिटर में,
image_refकॉलम वाली नई टेबल बनाने के लिए, यह एसक्यूएल चिपकाएं. Run पर क्लिक करें.
CREATE OR REPLACE TABLE `model_dev.vehicle_multimodal` AS
SELECT
*,
ARRAY(
SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF(uri, 'us.conn'))
FROM UNNEST(images) AS uri
) AS image_ref
FROM `model_dev.vehicle_metadata`;
- अभी बनाए गए नए
image_refObjectRef कॉलम को देखें. नई टेबल में अब एक ObjectRef कॉलम है. इसमें इमेज पर कार्रवाई करने की अनुमतियां हैं. इसे देखने के लिए, यह क्वेरी चलाएं:
SELECT auction_id, item_name, description, image_ref
FROM `model_dev.vehicle_multimodal` LIMIT 5;
- अब इमेज का विश्लेषण करने के लिए,
AI.GENERATEऔरAI.CLASSIFYका इस्तेमाल करें.AI.GENERATEGemini को प्रॉम्प्ट करके, वाहन की स्थिति का स्कोर और एक वाक्य में नुकसान की खास जानकारी निकालता है. वहीं,AI.CLASSIFYवाहन के बॉडी स्टाइल और रंग को कैटगरी के हिसाब से बांटता है.
इन अहम जानकारी को किसी खास फ़ीचर टेबल में निकालने के लिए, यहां दी गई क्वेरी चलाएं. इसमें करीब तीन मिनट लगेंगे.
CREATE OR REPLACE TABLE `model_dev.vehicle_vision_features` AS
WITH generated_data AS (
SELECT
auction_id,
AI.GENERATE(
prompt => ('Rate the condition of this car on a scale from 0-100. Output a 1 sentence description of any glaring red flags', image_ref),
output_schema => 'condition INT64, description_summary STRING'
).* EXCEPT(full_response,status)
FROM
`model_dev.vehicle_multimodal`
),
-- Object-centric Classifications
classified_data AS (
SELECT
auction_id,
AI.CLASSIFY(
('What type of automobile is this?', image_ref[0]),
categories => ['Truck', 'Sedan', 'SUV']) AS body_style,
AI.CLASSIFY(
('Color of the exterior of the automobile', image_ref[0]),
categories => ['Black', 'White', 'Silver', 'Gray', 'Red', 'Blue', 'Brown', 'Green', 'Beige', 'Gold']) AS color,
AI.CLASSIFY(
('Color of the interior of the automobile', image_ref[0]),
categories => ['Black', 'Gray', 'Beige', 'Tan', 'Brown', 'White', 'Red']) AS interior
FROM `model_dev.vehicle_multimodal`
)
-- Join the AI insights back together into the final feature table
SELECT
g.auction_id,
g.condition,
g.description_summary,
c.body_style,
c.color,
c.interior
FROM generated_data g
JOIN classified_data c ON g.auction_id = c.auction_id;
- जनरेट की गई सुविधाओं को खुद देखने के लिए, यह क्वेरी चलाएं या नीचे दिया गया स्क्रीनशॉट देखें:
SELECT auction_id, condition, description_summary, body_style, color, interior FROM `model_dev.vehicle_vision_features` LIMIT 5;

सेक्शन की खास जानकारी: आपने सीधे तौर पर BigQuery से रॉ इमेज ऐक्सेस कीं. साथ ही, किसी भी फ़ाइल को ट्रांसफ़र किए बिना, Gemini मॉडल का इस्तेमाल करके स्ट्रक्चर्ड विज़ुअल फ़ीचर निकालीं.
5. XGBoost की मदद से अनुमानित किराया तय करना
यह हिसाब लगाने के लिए कि कोई वाहन वाकई में अच्छी डील है या नहीं, उसकी उचित बाज़ार कीमत के लिए भरोसेमंद बेसलाइन की ज़रूरत होती है. मॉडल को ट्रेन करने के लिए, डेटा को लोकल स्क्रिप्ट या नोटबुक में ले जाने के बजाय, स्टैंडर्ड एसक्यूएल का इस्तेमाल करके सीधे BigQuery में XGBoost मॉडल को ट्रेन किया जा सकता है. किराये के अनुमान से, फ़्रंटएंड ऐप्लिकेशन पर 📈 उचित बाज़ार कीमत का लॉजिक तय होता है.
- BigQuery Studio टैब पर वापस जाएं.
- सबसे पहले, ट्रेनिंग डेटासेट देखें. चालू वाहन लिस्टिंग के उलट, इस
synthetic_carsटेबल में 1,00,000 पुरानी बिक्री की जानकारी शामिल है. इसका इस्तेमाल मॉडल को ट्रेनिंग देने के लिए किया जाएगा. इस क्वेरी को चलाकर देखें:
SELECT
*
FROM
`model_dev.synthetic_cars`
LIMIT 10;
- अब, XGBoost रिग्रेशन मॉडल को ट्रेन करने के लिए, यहां दिया गया एसक्यूएल कोड चलाएं. यह मॉडल, 1,00,000 पुराने रिकॉर्ड से यह पता लगाता है कि माइलेज, साल, ब्रैंड, और विज़ुअल कंडीशन जैसे एट्रिब्यूट, कीमत पर कैसे असर डालते हैं:
CREATE OR REPLACE MODEL `model_dev.car_price_model`
OPTIONS(
MODEL_TYPE = 'BOOSTED_TREE_REGRESSOR',
INPUT_LABEL_COLS = ['selling_price'],
MAX_ITERATIONS = 15,
TREE_METHOD = 'HIST'
) AS
SELECT
* EXCEPT(vin, sale_date, market_value, seller)
FROM
`model_dev.synthetic_cars`;
- लाइव और मौजूदा समय में मौजूद वाहन की लिस्टिंग के लिए कीमतों का अनुमान लगाने से पहले, आपको सभी ज़रूरी इनपुट सुविधाओं को एक जगह इकट्ठा करना होगा. वाहन के स्ट्रक्चर्ड मेटाडेटा को विज़न से निकाली गई उन सुविधाओं के साथ मर्ज करने के लिए, यह एसक्यूएल चलाएं जिन्हें आपने अभी जनरेट किया है:
CREATE OR REPLACE TABLE `model_dev.vehicle_prediction_features` AS
SELECT
meta.auction_id,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.transmission_type,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id;
- आखिर में, मौजूदा समय में मौजूद हर वाहन की लिस्टिंग की उचित बाज़ार कीमत का अनुमान लगाएं. एग्रीगेट की गई सुविधाओं को अपने नए मॉडल में शामिल करने के लिए, यह क्वेरी चलाएं. साथ ही, संख्यात्मक आउटपुट को अनुमानों की सुरक्षित टेबल में सेव करें:
CREATE OR REPLACE TABLE `model_dev.vehicle_price_predictions` AS
SELECT
auction_id,
ROUND(predicted_selling_price, 2) AS predicted_market_value
FROM ML.PREDICT(
MODEL `model_dev.car_price_model`,
(SELECT * FROM `model_dev.vehicle_prediction_features`)
);
- अब मॉडल के आउटपुट की पुष्टि करें. वाहन की लाइव लिस्टिंग के लिए, अनुमानित बाज़ार वैल्यू की झलक देखने के लिए, यह क्वेरी चलाएं:
SELECT * FROM `model_dev.vehicle_price_predictions` LIMIT 5;
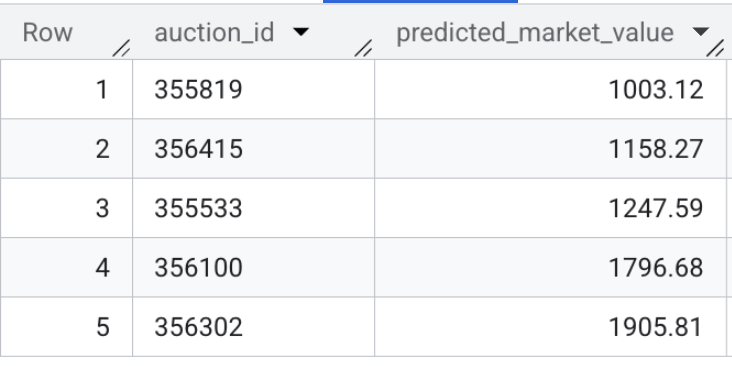
सेक्शन की खास जानकारी: आपने 1,00,000 सैंपल ट्रांज़ैक्शन का इस्तेमाल करके, XGBoost रिग्रेशन मॉडल को ट्रेन किया. साथ ही, डेटासेट में मौजूद हर वाहन की चालू लिस्टिंग के लिए, उचित बाज़ार कीमत का अनुमान लगाने के लिए बैच इन्फ़रेंस चलाया.
6. सिमेंटिक एम्बेडिंग और कॉन्टेंट के असली होने की पहचान करना
इस सेक्शन में, आपको दो अलग-अलग एम्बेडिंग पाइपलाइन लागू करनी होंगी, ताकि वाहन के मार्केटप्लेस के लिए स्मार्ट फ़ीचर चालू की जा सकें:
- मल्टीमोडल इमेज सर्च: वाहन की सामान्य फ़ोटो को वेक्टर स्पेस में बदलें, ताकि लोग सामान्य भाषा का इस्तेमाल करके खोज सकें. जैसे, "काम के लिए भरोसेमंद ट्रक".
- टेक्स्ट एम्बेडिंग और मिलती-जुलती खोज: वाहन के ब्यौरे को वेक्टर एम्बेडिंग में बदलें. इससे,
VECTOR_SEARCHका इस्तेमाल करके, सक्रिय लिस्टिंग की तुलना उन संभावित स्कैम या उत्साही लोगों की प्रोफ़ाइलों से की जा सकती है जिनके बारे में जानकारी है. इससे 🔍 ओरिजनल होने का स्कोर कैलकुलेट किया जाता है. यह स्कोर, खरीदारों को ऐप्लिकेशन पर दिखता है.
- सबसे पहले, आपको वाहन की लिस्टिंग के लिए मल्टीमोडल एम्बेडिंग जनरेट करनी होंगी.
gemini-embedding-2-previewमॉडल की मदद से, एक ही एम्बेडिंग में इमेज और टेक्स्ट, दोनों को इनपुट किया जा सकता है. यह मॉडल एक साथ कई तरह के डेटा को प्रोसेस कर सकता है. हालांकि, इस मामले में हम सिर्फ़ वाहन की इमेज एम्बेड कर रहे हैं. यह फ़्रंटएंड ऐप्लिकेशन के लिए "सिमैंटिक सर्च" बार को चालू करता है. इससे खरीदार, नैचुरल लैंग्वेज (जैसे, "एक भरोसेमंद पिकअप ट्रक") का इस्तेमाल कर सकते हैं और मिलती-जुलती लिस्टिंग को तुरंत ढूंढ सकते हैं.AI.EMBEDका इस्तेमाल करके मल्टीमॉडल वेक्टर जनरेट करने के लिए, यह क्वेरी चलाएं:
CREATE OR REPLACE TABLE `model_dev.vehicle_images_embedded` AS
SELECT
auction_id,
AI.EMBED(
STRUCT(image_ref),
endpoint => 'gemini-embedding-2-preview').result AS multimodal_embedding
FROM `model_dev.vehicle_multimodal`
WHERE ARRAY_LENGTH(image_ref) > 0;
- इसके बाद, आपको पहले से लोड किए गए जोखिम प्रोफ़ाइल के डेटा की जांच करनी होगी. ध्यान दें कि इसमें धोखाधड़ी के ज्ञात तरीके और उत्साही लोगों की सैंपल लिस्टिंग, दोनों शामिल हैं. बेसलाइन प्रोफ़ाइलें देखने के लिए, यह क्वेरी चलाएं:
SELECT profile_id, profile_type, description
FROM `model_dev.seller_risk_profiles`;
- अब जोखिम के बारे में दी गई जानकारी को वेक्टर एम्बेडिंग में बदला जाएगा. आपने जिस भाषा में लिखे गए टेक्स्ट की झलक देखी है उसका आकलन करने के लिए, टेक्स्ट-एम्बेडिंग मॉडल (
text-embedding-005) का इस्तेमाल किया जा सकता है. बेसलाइन प्रोफ़ाइलें एम्बेड करने के लिए, यहां दिया गया एसक्यूएल चिपकाएं और 'चलाएं' पर क्लिक करें:
CREATE OR REPLACE TABLE `model_dev.seller_risk_profiles_embedded` AS
SELECT
profile_id,
description AS content,
profile_type,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.seller_risk_profiles`;
- इसके बाद, लाइव इन्वेंट्री में मौजूद वाहनों के लिए मिलते-जुलते एम्बेडिंग जनरेट करें. हर वाहन के लिए, रॉ एचटीएमएल ब्यौरे को वेक्टर स्पेस में बदलने के लिए यह क्वेरी चलाएं, ताकि उनकी तुलना बेसलाइन प्रोफ़ाइलों से की जा सके:
CREATE OR REPLACE TABLE `model_dev.vehicle_descriptions_embedded` AS
SELECT
auction_id,
description AS content,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.vehicle_metadata`
WHERE description IS NOT NULL;
- आखिर में, वेक्टर सर्च को लागू करें, ताकि लाइव लिस्टिंग और बेसलाइन प्रोफ़ाइलों के बीच सिमैंटिक दूरी का हिसाब लगाया जा सके. मैपिंग करने के लिए, यह SQL चलाएं. गणितीय दूरी कम होने का मतलब है कि कोई लिस्टिंग, धोखाधड़ी वाले किसी जाने-पहचाने क्लस्टर से काफ़ी मिलती-जुलती है. वहीं, दूरी ज़्यादा होने का मतलब है कि जानकारी सही है.
CREATE OR REPLACE TABLE `model_dev.vehicle_authenticity_scores` AS
SELECT
scam_search.query.auction_id,
CAST(
GREATEST(0.0, LEAST(100.0, ROUND((MIN(scam_search.distance) - 0.33) / 0.12 * 100.0)))
AS INT64
) AS authenticity_score
FROM VECTOR_SEARCH(
TABLE `model_dev.seller_risk_profiles_embedded`,
'text_embedding',
(
SELECT text_embedding, auction_id
FROM `model_dev.vehicle_descriptions_embedded`
),
top_k => 15,
distance_type => 'COSINE'
) AS scam_search
WHERE scam_search.base.profile_type = 'scam'
GROUP BY 1;
इस टेबल का कॉन्टेंट ऐसा दिख सकता है:
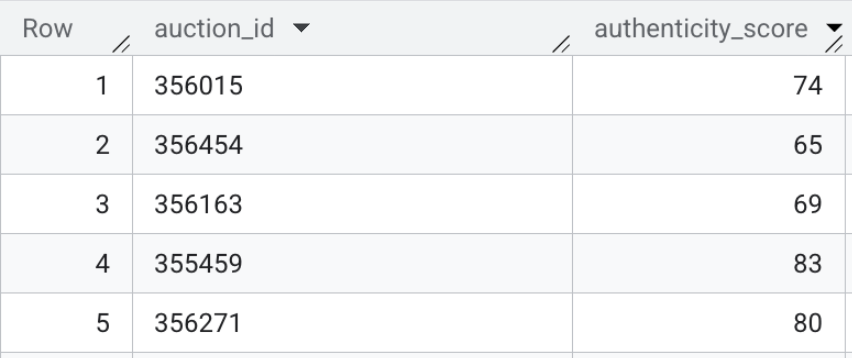
सेक्शन की खास जानकारी: आपने फ़्रंटएंड सर्च बार के लिए मल्टीमॉडल एम्बेडिंग जनरेट की हैं. साथ ही, जानी-पहचानी धोखाधड़ी वाली प्रोफ़ाइलों के ख़िलाफ़ रॉ एचटीएमएल टेक्स्ट लिस्टिंग का आकलन करने के लिए, BigQuery में सीधे तौर पर वेक्टर सर्च का इस्तेमाल किया है.
7. जनरेटिव डील स्कोरिंग
अब आपके पास कई अलग-अलग मशीन लर्निंग तकनीकों से जनरेट किए गए स्ट्रक्चर्ड डेटासेट हैं. ये सभी BigQuery में पूरी तरह से व्यवस्थित किए गए हैं: विज़न एक्सट्रैक्शन, उचित बाज़ार कीमत का अनुमान लगाने के लिए XGBoost मॉडल, और वेक्टर सर्च एम्बेडिंग.
आखिरी चरण में, इन एआई सिग्नल को एक साथ मिलाकर, फ़्रंटएंड ऐप्लिकेशन के लिए डील स्कोर के तौर पर दिखाया जाता है.
- सबसे पहले, रॉ मेटाडेटा को एआई से निकाली गई विज़न सुविधाओं, अनुमानित कीमत के आउटपुट, और सिमैंटिक ऑथेंटिसिटी स्कोर के साथ जोड़ें. यह एसक्यूएल क्वेरी चलाएं:
CREATE OR REPLACE TABLE `model_dev.vehicle_features_enhanced` AS
SELECT
meta.auction_id,
meta.item_name,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.current_bid,
meta.listing_url,
meta.transmission_type,
meta.description,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior,
COALESCE(scam.authenticity_score, 100) AS authenticity_score,
vision.description_summary,
prices.predicted_market_value
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id
LEFT JOIN `model_dev.vehicle_price_predictions` prices
ON meta.auction_id = prices.auction_id
LEFT JOIN `model_dev.vehicle_authenticity_scores` scam
ON meta.auction_id = scam.auction_id;
- इसके बाद, चार अलग-अलग एआई सिग्नल को मिलाकर, 0 से 100 तक का डील स्कोर कैलकुलेट करें. यह फ़ॉर्मूला, वैल्यू, क्वालिटी, और जोखिम को ध्यान में रखकर सबसे अच्छी लिस्टिंग दिखाता है:
- किराया स्कोर (40%): इससे पता चलता है कि फ़ेयर मार्केट वैल्यू के मुकाबले, किराये में कितनी बचत हुई.
- विज़न स्कोर (30%): पिछली फ़ोटो के विश्लेषण से मिली अहम जानकारी.
- भरोसेमंद होने का स्कोर (15%): धोखाधड़ी के जोखिम का आकलन.
- स्थिति का स्कोर (15%): यह स्कोर, सेलर के ब्यौरे से
AI.SCOREके ज़रिए तुरंत पता लगाया जाता है.
CREATE OR REPLACE TABLE `model_dev.marketplace_listings` AS
WITH score_elements AS (
SELECT
*,
-- 1. SELLER DESCRIPTION SCORE (use AI.SCORE on seller description)
AI.SCORE(
FORMAT("Rate the vehicle condition (0-100) based ONLY on this text: '%s'", description)
) AS description_score,
-- 2. PRICE SCORE
-- Higher impact for underpricing, lower impact for overpricing.
CAST(LEAST(100.0, GREATEST(0.0,
75.0 + (
IF((predicted_market_value - current_bid) > 0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 250.0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 40.0
)
)
)) AS INT64) AS price_score
FROM `model_dev.vehicle_features_enhanced`
),
final_calcs AS (
SELECT
*,
-- 3. Combine scores: Price (40%), Condition (30%), Description (15%), Authenticity (15%)
ROUND(
(
(price_score * 0.40) +
(CAST(condition AS INT64) * 0.30) +
(COALESCE(description_score, 50) * 0.15) +
(CAST(authenticity_score AS INT64) * 0.15)
)
-- Authenticity penalty for scores below 50.
* (IF(CAST(authenticity_score AS INT64) < 50, 0.20, 1.05))
) AS raw_score
FROM score_elements
)
SELECT
* EXCEPT(raw_score),
-- 4. Set floor values: low authenticity scores drop to 10; others floor at 35.
CAST(GREATEST(
(IF(CAST(authenticity_score AS INT64) < 50, 10, 35)),
LEAST(100, raw_score)
) AS INT64) AS deal_score
FROM final_calcs;
अच्छी क्वालिटी के सुझाव पाने के लिए, क्वेरी में दो खास लॉजिक लेयर लागू की जाती हैं:
- असली होने की पुष्टि करने वाली सुविधा: अगर किसी लिस्टिंग को "ज़्यादा जोखिम वाली" (स्कोर < 50) के तौर पर फ़्लैग किया जाता है, तो डील का कुल स्कोर अपने-आप 80% कम हो जाता है. ऐसा इसलिए किया जाता है, ताकि संदिग्ध लिस्टिंग का प्रमोशन न हो.
- "छुपा हुआ रत्न" ऑप्टिमाइज़ेशन: फ़ॉर्मूला, पीसवाइज़ लॉजिक का इस्तेमाल करके, बचत को ज़्यादा से ज़्यादा बढ़ावा देता है. साथ ही, मार्कअप के मामले में ज़्यादा उदार होता है. इससे यह पक्का होता है कि अच्छी स्थिति में मौजूद ज़्यादा कीमत वाली कार को अब भी "सामान्य" रैंकिंग मिल सकती है.
इसके बाद, model_dev.marketplace_listings टेबल में deal_score जैसे फ़ील्ड के साथ-साथ price_score और authenticity_score भी शामिल होते हैं.
- डील के स्कोर खुद देखने के लिए, यह क्वेरी चलाएं या सिर्फ़ नीचे दिया गया स्क्रीनशॉट देखें:
SELECT item_name, model_year, authenticity_score, predicted_market_value, price_score, deal_score FROM `model_dev.marketplace_listings`
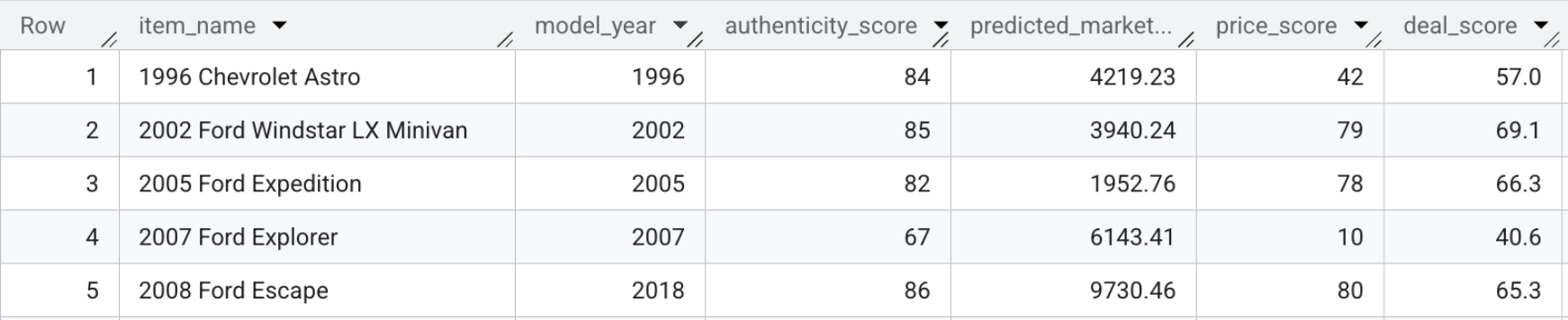
सेक्शन की खास जानकारी: आपने हर लिस्टिंग के लिए एक डील स्कोर का हिसाब लगाने के लिए, अनुमानित कीमत, विज़ुअल सुविधाओं, और असली होने के स्कोर को सेलर के ब्यौरे के साथ जोड़ा है.
8. फ़्रंटएंड ऐप्लिकेशन डिप्लॉय करना
अब फ़्रंटएंड ऐप्लिकेशन को सेट अप करने का समय है. इससे आपको वाहन की लिस्टिंग की इन्वेंट्री खोजने और एआई से जनरेट की गई अहम जानकारी के साथ इंटरैक्ट करने की सुविधा मिलती है. जैसे, डील स्कोर.
एआई स्कोर को फ़्रंटएंड में एक्सपोर्ट करना
React फ़्रंटएंड, पेज को तेज़ी से लोड करने के लिए लोकल JSON पेलोड पर निर्भर करता है. मार्केटप्लेस को बेहतर बनाने के लिए, BigQuery से जनरेटिव डील के फ़ाइनल स्कोर निकालें और उन्हें वापस Next.js प्रोजेक्ट में डालें.
- पक्का करें कि आपका एनवायरमेंट तैयार हो. अगर आपका Cloud Shell सेशन खत्म हो गया है या आपने किसी दूसरे फ़ोल्डर पर नेविगेट किया है, तो प्रोजेक्ट के रूट पर वापस जाने और एनवायरमेंट वैरिएबल को वापस लाने के लिए, यह कमांड चलाएं:
cd ~/devrel-demos/data-analytics/cymbal-autos-multimodal && \
export PROJECT_ID=$(gcloud config get-value project) && \
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
- BigQuery के फ़ाइनल व्यू को क्वेरी करने के लिए, दी गई Python स्क्रिप्ट चलाएं. साथ ही, ऐप्लिकेशन के मौजूदा डेटा स्टोर में नए डील स्कोर मर्ज करें:
python3 scripts/setup/08_export_frontend_data.py
आपको पुष्टि करने वाला यह मैसेज मिलेगा:
💾 Updated local file: app/src/data/cars.json
ऐप्लिकेशन को Cloud Run पर डिप्लॉय करना
डेटा को बेहतर बनाने के बाद, Cloud Run का इस्तेमाल करके Next.js फ़्रंटएंड ऐप्लिकेशन को सार्वजनिक इंटरनेट पर डिप्लॉय किया जा सकता है. इसमें आधुनिक इंटरफ़ेस है. इसमें डील की रेटिंग, इंटरैक्टिव इमेज कैरसेल, और डाइनैमिक हाइब्रिड सिमैंटिक सर्च बार की सुविधा है. यह बार, BigQuery से रीयल-टाइम में क्वेरी करता है.
- Cloud Shell में, क्लोन की गई अपनी रिपॉज़िटरी की
app/डायरेक्ट्री पर जाएं. यह ज़रूरी है—रूट डायरेक्ट्री में रहने से, बिल्ड नहीं हो पाएगा.
cd app
- Cloud Run का इस्तेमाल करके, ऐप्लिकेशन को बिना सर्वर वाले कंटेनर के तौर पर डिप्लॉय करें. यह कमांड,
PROJECT_IDको एनवायरमेंट वैरिएबल के तौर पर पास करती है, ताकि Next.js API को पता चल सके कि किस BigQuery प्रोजेक्ट से क्वेरी करनी है:
gcloud run deploy cymbal-autos-frontend \
--source . \
--region us-west1 \
--allow-unauthenticated \
--min-instances 1 \
--set-env-vars PROJECT_ID=$PROJECT_ID \
--project $PROJECT_ID
- डप्लॉयमेंट पूरा होने पर, टर्मिनल एक सुरक्षित सेवा यूआरएल आउटपुट करेगा. यह कुछ इस तरह दिखेगा:
Service URL: https://cymbal-autos-frontend-[YOUR-PROJECT-NUMBER].us-west1.run.app/
9. Cymbal Autos ऐप्लिकेशन के बारे में जानकारी
फ़्रंटएंड कंटेनर को Cloud Run पर पुश करने के बाद, अब ऐप्लिकेशन को टेस्ट करने का समय है.
- साइट पर जाएं: Cloud Run से मिले सुरक्षित सेवा यूआरएल को खोलें.
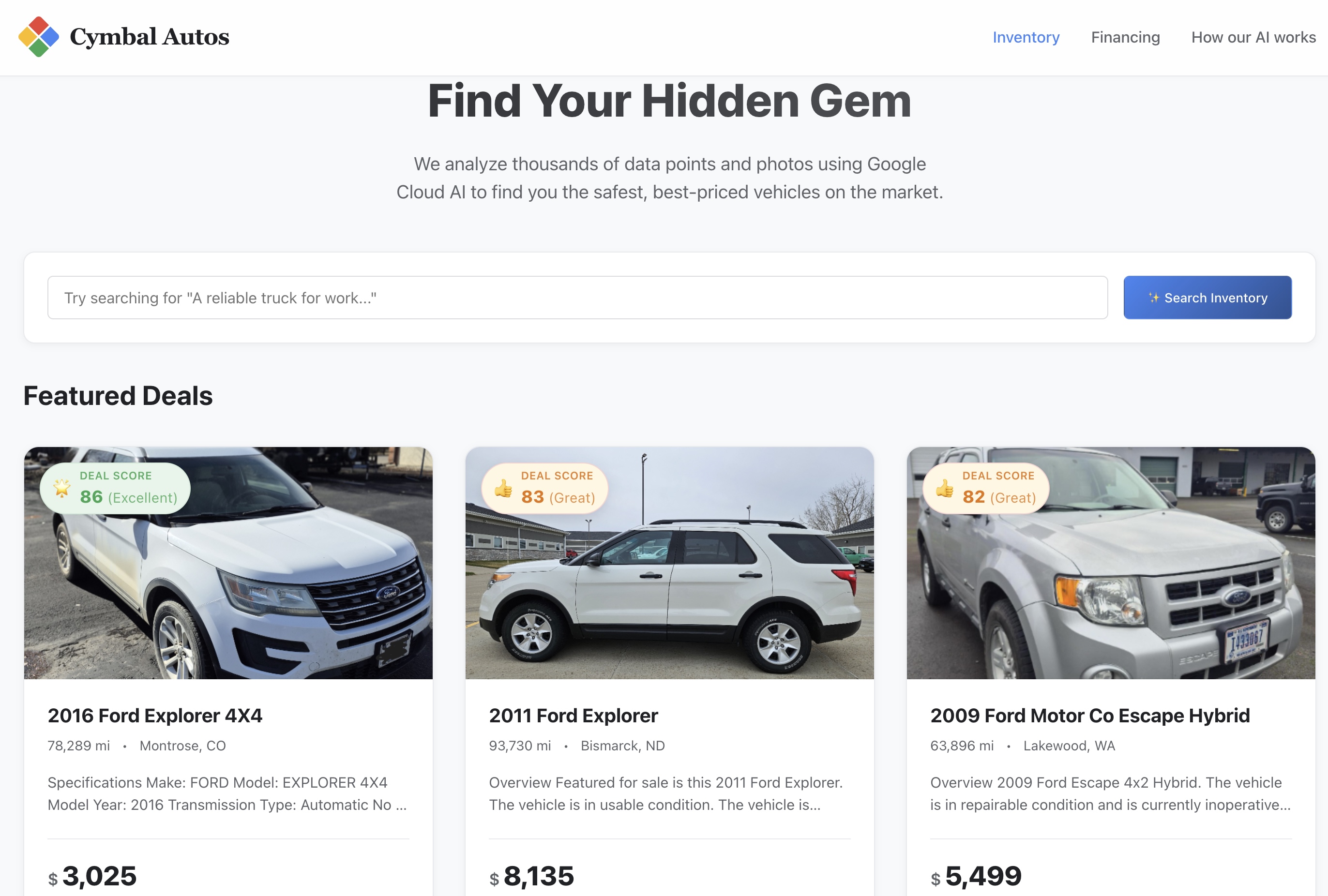
- सिमैंटिक सर्च करें: किसी ऐब्स्ट्रैक्ट कॉन्सेप्ट को खोजें. जैसे, "एक भरोसेमंद वर्क ट्रक जो सामान ढो सकता हो और ऑफरोड पर चल सकता हो". Next.js ऐप्लिकेशन, आपके टेक्स्ट को मल्टीमॉडल वेक्टर एम्बेडिंग में बदलता है. साथ ही, BigQuery के ख़िलाफ़ रीयल-टाइम
VECTOR_SEARCHको ट्रिगर करता है. इससे आपके आइडिया को वाहन के इकोसिस्टम के हिसाब से मैप किया जाता है.
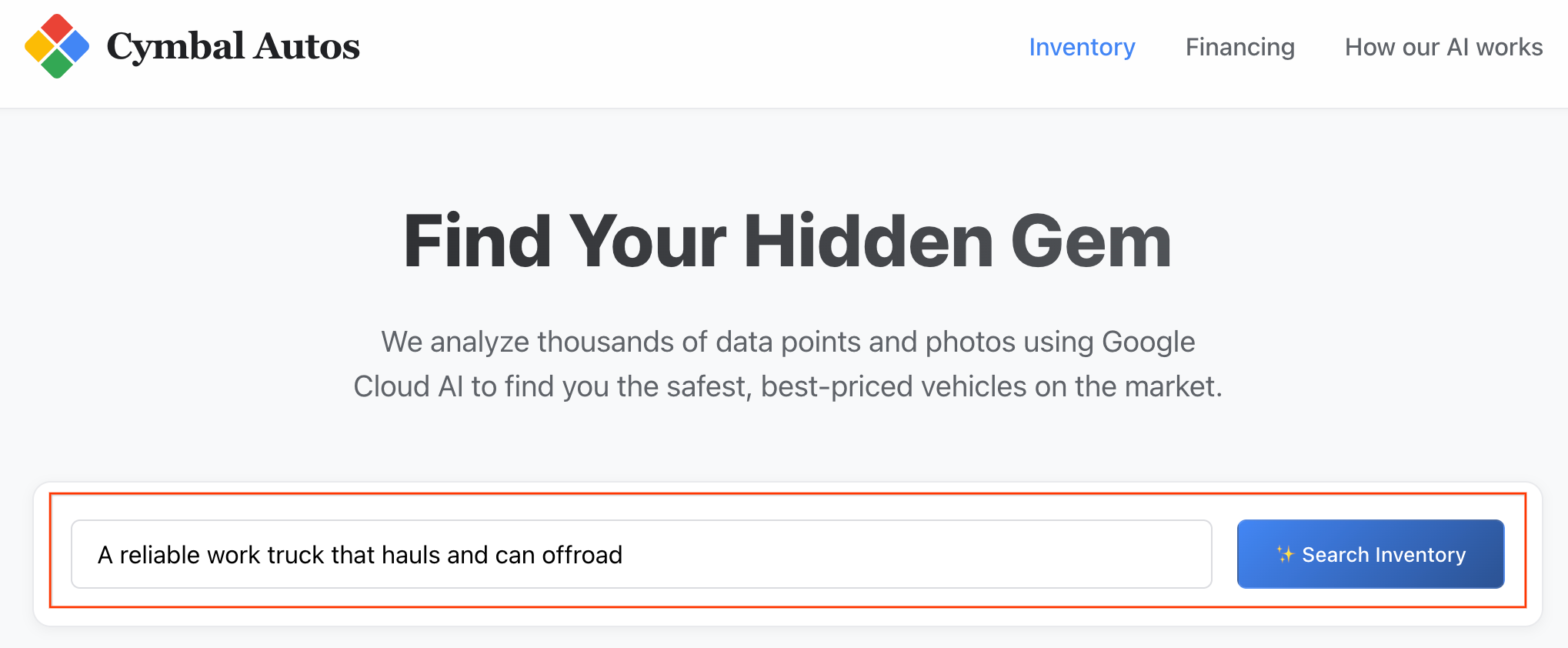
ध्यान दें: लिस्टिंग को मिलते-जुलते कॉन्टेंट के आधार पर क्रम से लगाया जाता है.
- नतीजों की समीक्षा करें: BigQuery ने आपके ऐब्स्ट्रैक्ट आइडिया और वाहन की सुविधाओं के बीच की सटीक दूरी का हिसाब लगाया है, ताकि आपको सबसे मिलते-जुलते सिमैंटिक मैच मिल सकें.
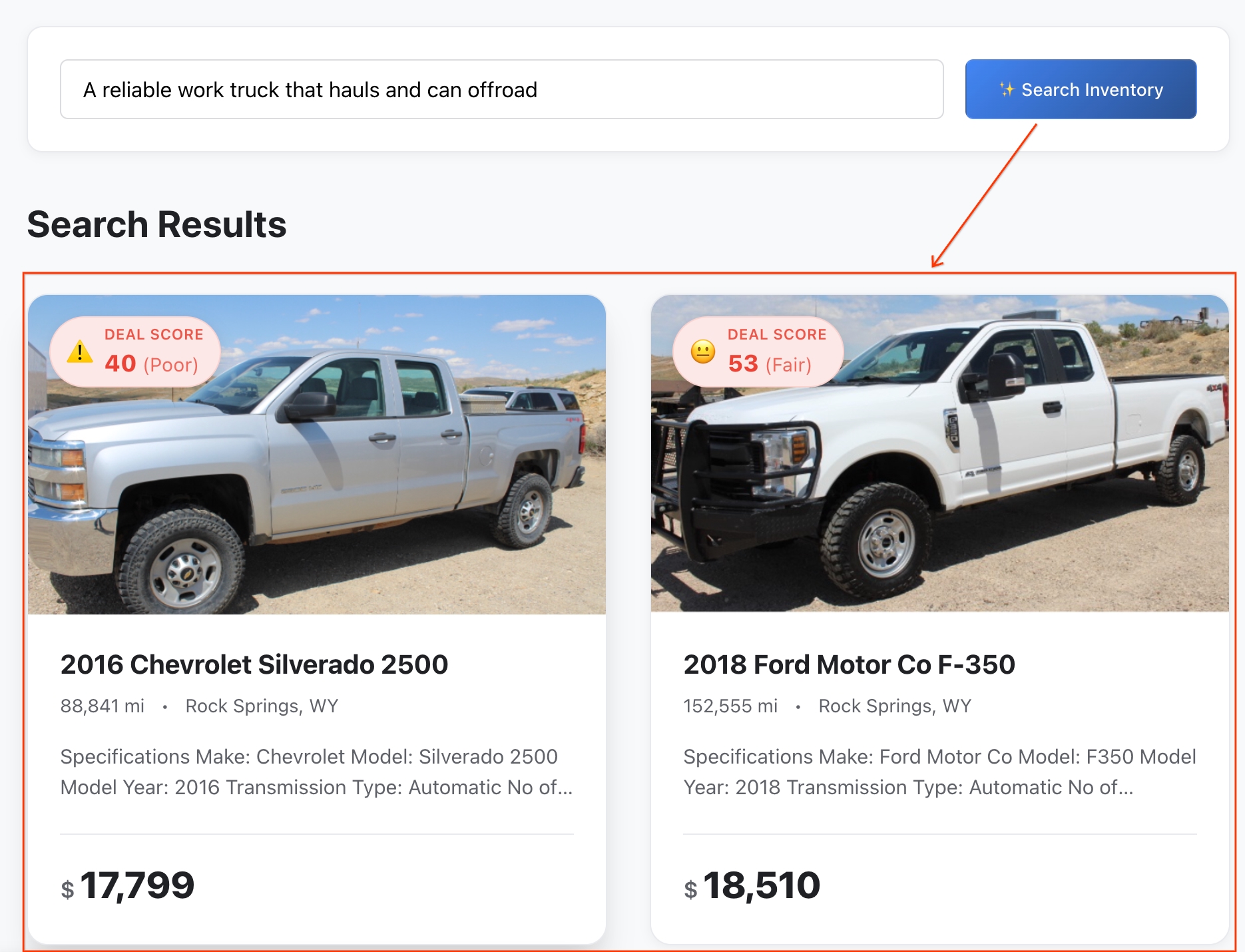
- ज़्यादा जानकारी देखें: किसी भी वाहन की पूरी लिस्टिंग प्रोफ़ाइल खोलने के लिए, उस पर क्लिक करें.
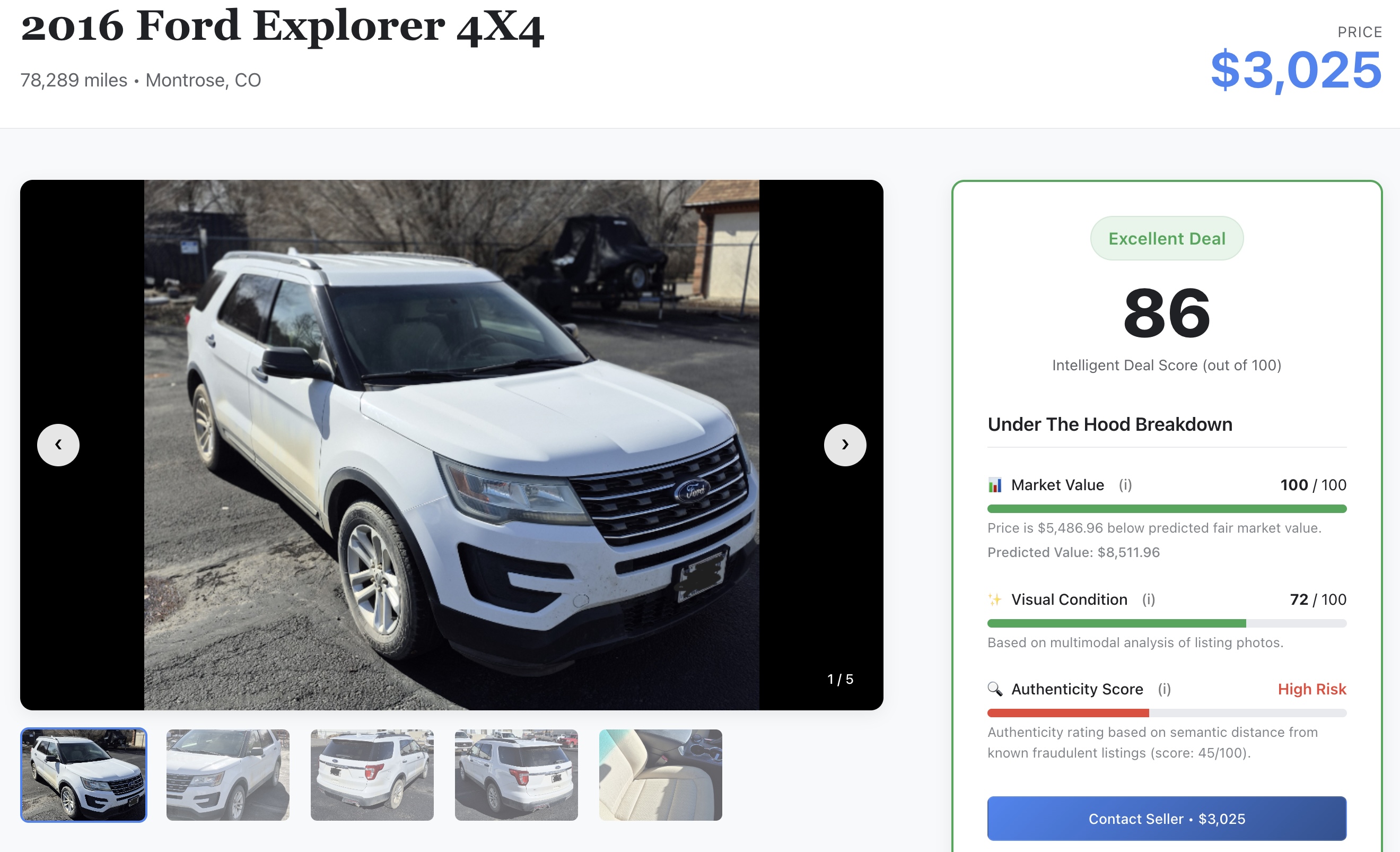
- एआई सिग्नल की जांच करें: जानकारी को स्क्रोल करके, लैब में पहले जनरेट किए गए रॉ मशीन लर्निंग स्कोर देखें:
- 📈 उचित बाज़ार कीमत: यह आपके XGBoost मॉडल से अनुमानित बेसलाइन कीमत होती है.
- ✨ विज़ुअल कंडीशन: Gemini के मॉडल से निकाली गई, डिवाइस को हुए नुकसान की रेटिंग.
- 🔍 भरोसेमंद होने का स्कोर: भरोसेमंद होने का स्कोर देने वाली मेट्रिक, असली सेलर को संभावित धोखाधड़ी करने वाले लोगों से अलग करती है.
10. व्यवस्थित करें
इस कोडलैब में इस्तेमाल किए गए संसाधनों के लिए, Google Cloud खाते से लगातार शुल्क लिए जाने से बचने के लिए, इस कोडलैब के लिए बनाया गया पूरा Google Cloud प्रोजेक्ट मिटाया जा सकता है. इसके अलावा, अपने-आप बंद होने वाली इस स्क्रिप्ट को भी चलाया जा सकता है.
- अपने Cloud Shell टर्मिनल में, रूट डायरेक्ट्री पर वापस जाएं:
cd ..
- नीचे दी गई क्लीनअप स्क्रिप्ट चलाएं. इससे आपका Google Cloud Storage बकेट खाली हो जाएगा,
model_devBigQuery डेटासेट हट जाएगा, BigQuery कनेक्शन मिट जाएगा, और Cloud Run सेवा मिट जाएगी.
chmod +x scripts/cleanup/teardown.sh
./scripts/cleanup/teardown.sh
11. बधाई हो
बधाई हो! आपने एक स्मार्ट वाहन मार्केटप्लेस बना लिया है. आपने BigQuery का इस्तेमाल करके, अनस्ट्रक्चर्ड डेटा के विश्लेषण, अनुमान लगाने वाले मॉडल, और एआई इंटिग्रेशन को एक ही वर्कस्पेस में इकट्ठा किया.
आपको क्या सीखने को मिला
- ObjectRef का इस्तेमाल करके, BigQuery को Cloud Storage में मौजूद बिना स्ट्रक्चर वाली इमेज से कनेक्ट करने का तरीका
AI.GENERATEऔरAI.CLASSIFYजैसे Gemini मॉडल के साथ BigQuery का इस्तेमाल करके, फ़ोटो से वाहन की एट्रिब्यूट वैल्यू निकालने का तरीका- BigQuery ML का इस्तेमाल करके, वाहनों की कीमतों का अनुमान कैसे लगाएं
- वाहन के ब्यौरे एम्बेड करके और
VECTOR_SEARCHकरके, धोखाधड़ी वाली संभावित लिस्टिंग की पहचान कैसे करें AI.SCOREका इस्तेमाल करके, बिना किसी स्ट्रक्चर वाले डेटा का तुरंत आकलन कैसे करें और नतीजों को डील स्कोर में कैसे शामिल करें- डेटा एक्सपोर्ट करने और Next.js मार्केटप्लेस ऐप्लिकेशन को Cloud Run पर डिप्लॉय करने का तरीका
अगले चरण
- BigQuery में उपलब्ध जनरेटिव एआई के सभी फ़ंक्शन के बारे में जानें
- GoogleSQL की मदद से अनुमानित मॉडल बनाने के बारे में ज़्यादा जानें