
1. Introduzione
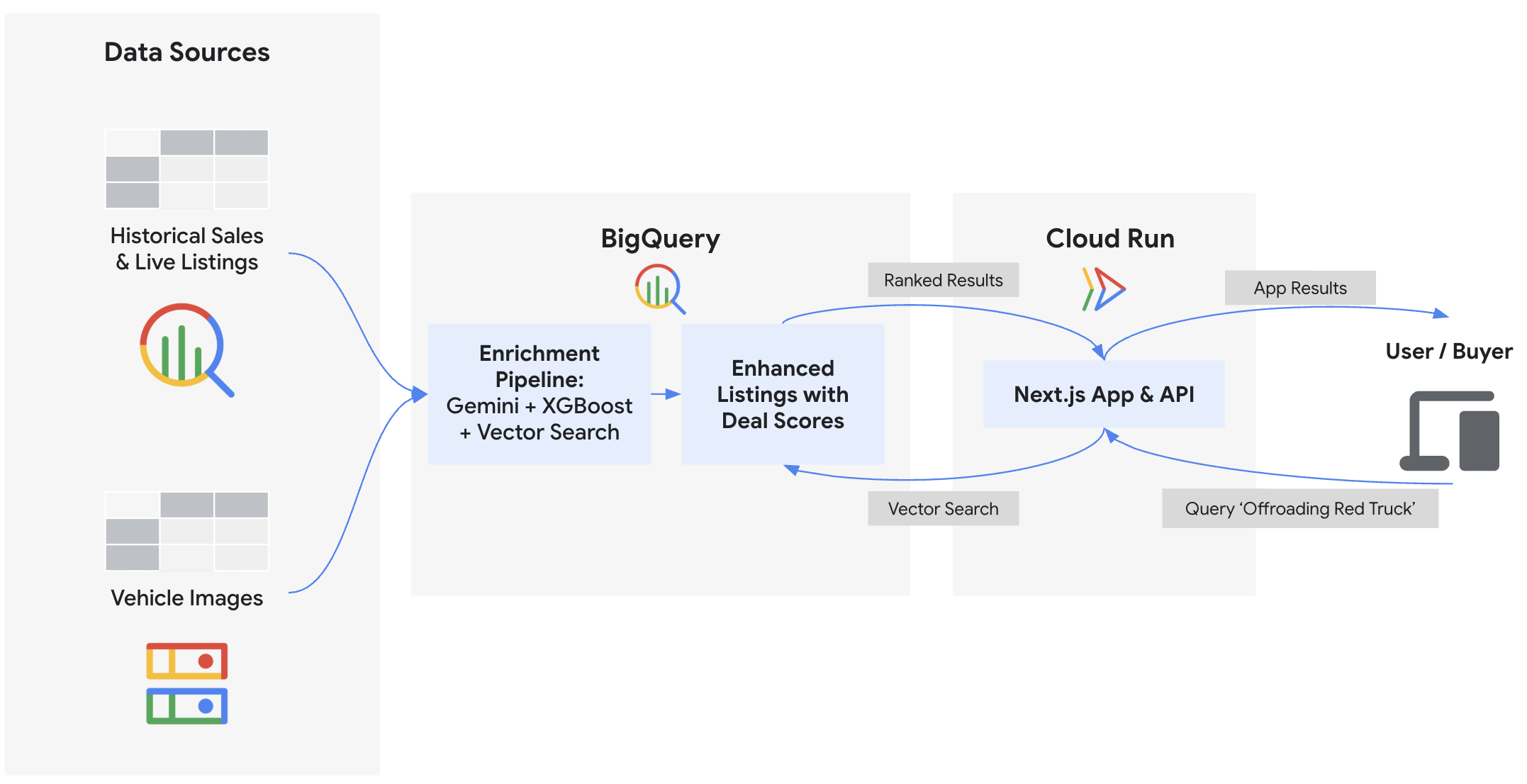
In questo codelab creerai il backend ed eseguirai il deployment del frontend per "Cymbal Autos", un marketplace online di veicoli. Utilizzerai BigQuery e i modelli Gemini sulla piattaforma Gemini Enterprise Agent per esaminare le foto dei veicoli, prevedere i prezzi utilizzando BigQuery ML, rilevare le inserzioni fraudolente utilizzando gli incorporamenti vettoriali e calcolare i punteggi compositi delle offerte. Infine, visualizzerai questi approfondimenti in un frontend Next.js di cui è stato eseguito il deployment in Cloud Run.
In questo lab proverai a:
- Collegare BigQuery alle immagini non strutturate di Cloud Storage utilizzando ObjectRef
- Estrarre gli attributi del veicolo dalle foto utilizzando BigQuery con i modelli Gemini
- Prevedi i prezzi di mercato equi addestrando un modello di regressione XGBoost con BigQuery ML
- Identifica le schede potenzialmente fraudolente e affidabili incorporando le descrizioni dei veicoli ed eseguendo
VECTOR_SEARCH - Calcola un punteggio affare completo per ogni scheda, incorporando gli indicatori di condizione dalla descrizione del venditore utilizzando
AI.SCORE - Esporta i dati ed esegui il deployment dell'applicazione marketplace Next.js in Google Cloud Run
Che cosa ti serve
- Un browser web come Chrome
- Un progetto cloud Google Cloud con la fatturazione abilitata
- Conoscenza di base di SQL, Python e Google Cloud
- Autorizzazioni IAM sufficienti per abilitare le API, creare risorse e assegnare autorizzazioni (ad es. Proprietario progetto)
Questo codelab è rivolto a sviluppatori di livello intermedio.
Le risorse create in questo codelab dovrebbero costare meno di 5 $.
2. Prima di iniziare
Crea un progetto Google Cloud
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
Avvia Cloud Shell
Utilizzerai Google Cloud Shell per scaricare il codice, eseguire gli script di configurazione ed eseguire il deployment dell'applicazione.
- Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta connesso a Cloud Shell, autentica la sessione per assicurarti che la tua applicazione possa accedere alle API Cloud. Segui i prompt per autorizzare Cloud Shell:
gcloud auth application-default login
- Imposta l'ID progetto Google Cloud e un nome univoco per il bucket Cloud Storage (dove archivierai i dati non elaborati):
export PROJECT_ID=$(gcloud config get-value project)
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
gcloud config set project $PROJECT_ID
Dovresti visualizzare un messaggio simile al seguente:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Abilita API
Esegui questo comando in Cloud Shell per abilitare tutte le API richieste per questo codelab:
gcloud services enable \
aiplatform.googleapis.com \
artifactregistry.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
cloudbuild.googleapis.com \
run.googleapis.com
Se l'esecuzione va a buon fine, dovresti visualizzare un messaggio simile a quello mostrato di seguito:
Operation "operations/..." finished successfully.
3. Recuperare i dati di programmazione e configurazione
Innanzitutto, scarica gli asset demo e configura le variabili di ambiente.
- Da Cloud Shell, clona il repository
devrel-demose vai alla directory del progetto:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos/data-analytics/cymbal-autos-multimodal
- Esegui lo script per copiare i dati nel tuo ambiente. Questo script sincronizza i set di dati del repository locale con il tuo bucket Cloud Storage personale e recupera le immagini dei veicoli da un bucket pubblico:
chmod +x scripts/setup/*.sh
./scripts/setup/00_copy_data.sh
Dovresti visualizzare un messaggio simile al seguente:
Average throughput: 87.8MiB/s Data copy complete!
- Poi, configura la connessione alle risorse Cloud BigQuery. Per analizzare le immagini non strutturate in Cloud Storage e chiamare i modelli di Agent Platform direttamente dalle query SQL, BigQuery deve delegare le autorizzazioni IAM a un service account sottostante. Questo script crea la connessione sicura e le concede i ruoli necessari Utente Vertex AI e Consumer Service Usage (la propagazione richiede circa un minuto):
./scripts/setup/01_setup_api_connection.sh
Dovresti visualizzare un messaggio simile al seguente:
Environment setup complete! Your BigQuery connection is ready.
- Infine, crea il set di dati BigQuery iniziale e carica i dati tabulari non elaborati. In questo modo viene creato il set di dati
model_deve vengono compilate le tabelle iniziali, creando le basi prima di scrivere qualsiasi query di machine learning:
./scripts/setup/02_load_to_bq.sh
Dovresti visualizzare un messaggio simile al seguente:
================================================================= BigQuery load complete! =================================================================
4. Estrazione di visione multimodale
Prima di assegnare un punteggio alle schede dei veicoli, estrai i dati strutturati (come colore, carrozzeria o danni visivi) da centinaia di foto grezze. Sfruttando le funzioni ObjectRef e i modelli Gemini ospitati in Agent Platform, puoi generare queste funzionalità senza spostare file o scrivere pipeline di dati complesse. Questa estrazione alimenta direttamente il badge ✨ Condizione visiva nell'applicazione frontend.
- Apri BigQuery Studio in una nuova scheda del browser.
- Fai clic sul pulsante + Crea nuova query. Utilizzerai l'editor SQL per interagire con il codice SQL durante questo codelab.
- Prima di creare gli estrattori di machine learning, puoi dare una rapida occhiata alle immagini non elaborate. Esegui la seguente query per visualizzare l'array di URI delle immagini archiviate in Google Cloud Storage per ogni scheda:
SELECT auction_id, item_name, description, images
FROM `model_dev.vehicle_metadata` LIMIT 5;
- Ora, nell'editor SQL di BigQuery Studio, incolla il seguente codice SQL per creare una nuova tabella con una colonna
image_ref. Fai clic su Esegui.
CREATE OR REPLACE TABLE `model_dev.vehicle_multimodal` AS
SELECT
*,
ARRAY(
SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF(uri, 'us.conn'))
FROM UNNEST(images) AS uri
) AS image_ref
FROM `model_dev.vehicle_metadata`;
- Dai un'occhiata alla nuova colonna
image_refObjectRef che hai appena creato. La nuova tabella ora ha una colonna ObjectRef con le autorizzazioni per l'esecuzione sulle immagini stesse. Esegui la seguente query per visualizzarlo:
SELECT auction_id, item_name, description, image_ref
FROM `model_dev.vehicle_multimodal` LIMIT 5;
- Ora utilizzerai
AI.GENERATEeAI.CLASSIFYper analizzare le immagini.AI.GENERATEestrae il punteggio delle condizioni e un riepilogo dei danni in una frase chiedendo a Gemini, mentreAI.CLASSIFYclassifica rigorosamente lo stile della carrozzeria e il colore del veicolo.
Esegui la seguente query per estrarre questi approfondimenti in una tabella delle funzionalità dedicata. L'operazione dovrebbe richiedere circa 3 minuti.
CREATE OR REPLACE TABLE `model_dev.vehicle_vision_features` AS
WITH generated_data AS (
SELECT
auction_id,
AI.GENERATE(
prompt => ('Rate the condition of this car on a scale from 0-100. Output a 1 sentence description of any glaring red flags', image_ref),
output_schema => 'condition INT64, description_summary STRING'
).* EXCEPT(full_response,status)
FROM
`model_dev.vehicle_multimodal`
),
-- Object-centric Classifications
classified_data AS (
SELECT
auction_id,
AI.CLASSIFY(
('What type of automobile is this?', image_ref[0]),
categories => ['Truck', 'Sedan', 'SUV']) AS body_style,
AI.CLASSIFY(
('Color of the exterior of the automobile', image_ref[0]),
categories => ['Black', 'White', 'Silver', 'Gray', 'Red', 'Blue', 'Brown', 'Green', 'Beige', 'Gold']) AS color,
AI.CLASSIFY(
('Color of the interior of the automobile', image_ref[0]),
categories => ['Black', 'Gray', 'Beige', 'Tan', 'Brown', 'White', 'Red']) AS interior
FROM `model_dev.vehicle_multimodal`
)
-- Join the AI insights back together into the final feature table
SELECT
g.auction_id,
g.condition,
g.description_summary,
c.body_style,
c.color,
c.interior
FROM generated_data g
JOIN classified_data c ON g.auction_id = c.auction_id;
- Per visualizzare le funzionalità generate, esegui la seguente query o guarda lo screenshot riportato di seguito:
SELECT auction_id, condition, description_summary, body_style, color, interior FROM `model_dev.vehicle_vision_features` LIMIT 5;

Riepilogo della sezione:hai eseguito l'accesso alle immagini non elaborate direttamente da BigQuery e hai utilizzato i modelli Gemini per estrarre le funzionalità visive strutturate senza spostare alcun file.
5. Prezzi predittivi con XGBoost
Per calcolare se un veicolo è davvero un buon affare, è necessario un punto di riferimento affidabile per il suo giusto valore di mercato. Anziché estrarre i dati in script o blocchi note locali per addestrare un modello, puoi addestrare un modello XGBoost direttamente in BigQuery utilizzando SQL standard. Questa previsione del prezzo determina la logica del 📈 Fair Market Value nell'applicazione frontend.
- Torna alla scheda BigQuery Studio.
- Per prima cosa, dai un'occhiata al set di dati di addestramento. A differenza delle schede veicolo attive, questa tabella
synthetic_carscontiene 100.000 vendite storiche che verranno utilizzate per addestrare il modello. Esegui questa rapida query per dare un'occhiata:
SELECT
*
FROM
`model_dev.synthetic_cars`
LIMIT 10;
- Ora esegui il seguente SQL per addestrare un modello di regressione XGBoost. Questo modello apprende come attributi come chilometraggio, anno, marca e condizioni visive influiscono sul prezzo da questi 100.000 record storici:
CREATE OR REPLACE MODEL `model_dev.car_price_model`
OPTIONS(
MODEL_TYPE = 'BOOSTED_TREE_REGRESSOR',
INPUT_LABEL_COLS = ['selling_price'],
MAX_ITERATIONS = 15,
TREE_METHOD = 'HIST'
) AS
SELECT
* EXCEPT(vin, sale_date, market_value, seller)
FROM
`model_dev.synthetic_cars`;
- Prima di prevedere i prezzi per le schede di veicoli live e in corso, devi raccogliere tutte le funzionalità di input pertinenti in un unico posto. Esegui questo SQL per unire i metadati strutturati del veicolo con le funzionalità estratte dalla visione che hai appena generato:
CREATE OR REPLACE TABLE `model_dev.vehicle_prediction_features` AS
SELECT
meta.auction_id,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.transmission_type,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id;
- Infine, prevedi il giusto valore di mercato di ogni scheda di veicolo in corso. Esegui la seguente query per inserire le funzionalità aggregate nel modello appena addestrato e salvare gli output numerici in una tabella delle previsioni sicura:
CREATE OR REPLACE TABLE `model_dev.vehicle_price_predictions` AS
SELECT
auction_id,
ROUND(predicted_selling_price, 2) AS predicted_market_value
FROM ML.PREDICT(
MODEL `model_dev.car_price_model`,
(SELECT * FROM `model_dev.vehicle_prediction_features`)
);
- Ora verifica l'output del modello. Esegui questa query rapida per visualizzare l'anteprima dei valori di mercato previsti per le schede di veicoli live:
SELECT * FROM `model_dev.vehicle_price_predictions` LIMIT 5;
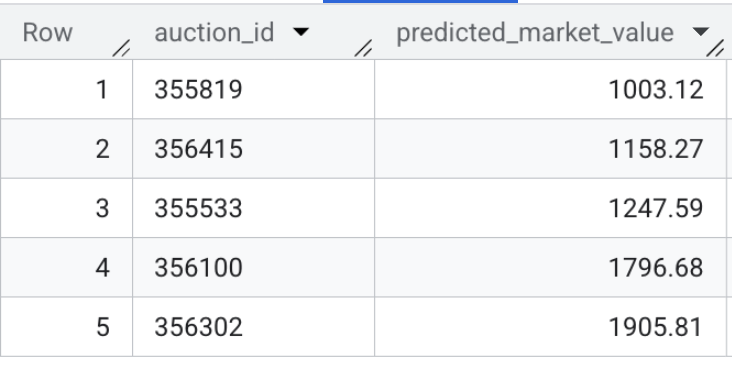
Riepilogo della sezione:hai addestrato un modello di regressione XGBoost utilizzando 100.000 transazioni di esempio e hai eseguito l'inferenza batch per prevedere il giusto valore di mercato per ogni scheda di veicolo attiva nel set di dati.
6. Incorporamenti semantici e rilevamento dell'autenticità
In questa sezione, eseguirai due pipeline di incorporamento distinte per attivare le funzionalità intelligenti per il marketplace di veicoli:
- Ricerca immagini multimodale:traduce le foto grezze dei veicoli in spazio vettoriale per consentire agli utenti di eseguire ricerche utilizzando il linguaggio naturale (ad es. "un camion affidabile per il lavoro").
- Incorporamenti di testo e ricerca per similarità:traduci le descrizioni scritte dei veicoli in incorporamenti vettoriali per confrontare le schede attive con potenziali profili di truffatori o appassionati noti utilizzando
VECTOR_SEARCH. In questo modo viene calcolato il 🔍 Punteggio di autenticità che gli acquirenti vedono nell'app.
- Innanzitutto, devi generare incorporamenti multimodali per le schede di veicoli. Con il modello
gemini-embedding-2-preview, puoi inserire sia immagini che testo nello stesso embedding. Sebbene questo modello sia in grado di elaborare più modalità contemporaneamente, in questo caso specifico incorporiamo solo le immagini del veicolo. In questo modo viene attivata la barra di "ricerca semantica" per l'applicazione frontend, consentendo agli acquirenti di utilizzare il linguaggio naturale (ad esempio "un pickup affidabile") e recuperare rapidamente gli annunci corrispondenti. Esegui questa query per generare i vettori multimodali utilizzandoAI.EMBED:
CREATE OR REPLACE TABLE `model_dev.vehicle_images_embedded` AS
SELECT
auction_id,
AI.EMBED(
STRUCT(image_ref),
endpoint => 'gemini-embedding-2-preview').result AS multimodal_embedding
FROM `model_dev.vehicle_multimodal`
WHERE ARRAY_LENGTH(image_ref) > 0;
- A questo punto, esaminerai i dati del profilo di rischio caricati in precedenza. Tieni presente che contiene sia tipologie di truffe note sia elenchi di campioni di appassionati legittimi. Esegui questa query per visualizzare i profili di base:
SELECT profile_id, profile_type, description
FROM `model_dev.seller_risk_profiles`;
- Ora tradurrai queste descrizioni del rischio non elaborate in vector embedding. Puoi utilizzare un modello di incorporamento di testo specializzato (
text-embedding-005) per valutare rigorosamente la lingua scritta di cui hai appena visualizzato l'anteprima. Incolla il seguente SQL e fai clic su Esegui per incorporare i profili di base:
CREATE OR REPLACE TABLE `model_dev.seller_risk_profiles_embedded` AS
SELECT
profile_id,
description AS content,
profile_type,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.seller_risk_profiles`;
- Poi, genera incorporamenti comparabili per l'inventario di veicoli live effettivo. Esegui questa query per tradurre la descrizione HTML non elaborata di ogni veicolo nello spazio vettoriale in modo che possa essere confrontata con i profili di base:
CREATE OR REPLACE TABLE `model_dev.vehicle_descriptions_embedded` AS
SELECT
auction_id,
description AS content,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.vehicle_metadata`
WHERE description IS NOT NULL;
- Infine, esegui la ricerca vettoriale per calcolare la distanza semantica tra le schede live e i profili di base. Esegui il seguente SQL per eseguire la mappatura. Una distanza matematica più bassa indica che una scheda è molto simile a un cluster di frodi noto, mentre una distanza più elevata suggerisce una descrizione legittima.
CREATE OR REPLACE TABLE `model_dev.vehicle_authenticity_scores` AS
SELECT
scam_search.query.auction_id,
CAST(
GREATEST(0.0, LEAST(100.0, ROUND((MIN(scam_search.distance) - 0.33) / 0.12 * 100.0)))
AS INT64
) AS authenticity_score
FROM VECTOR_SEARCH(
TABLE `model_dev.seller_risk_profiles_embedded`,
'text_embedding',
(
SELECT text_embedding, auction_id
FROM `model_dev.vehicle_descriptions_embedded`
),
top_k => 15,
distance_type => 'COSINE'
) AS scam_search
WHERE scam_search.base.profile_type = 'scam'
GROUP BY 1;
I contenuti di questa tabella potrebbero essere simili a quelli riportati di seguito:
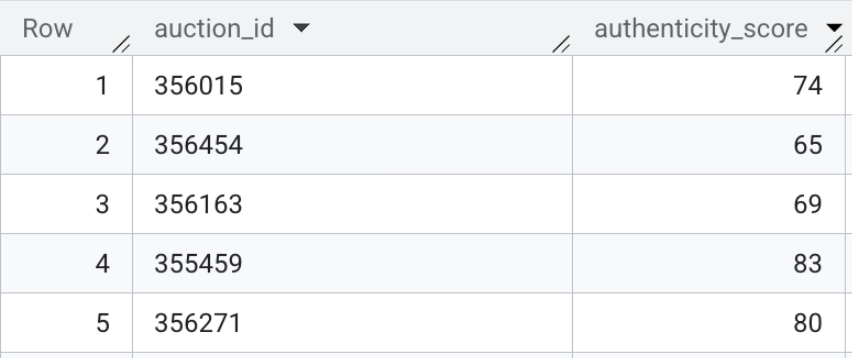
Riepilogo della sezione:hai generato incorporamenti multimodali per la barra di ricerca del frontend e hai utilizzato la ricerca vettoriale direttamente in BigQuery per valutare le schede di testo HTML non elaborato rispetto a profili di frode noti.
7. Punteggio generativo dell'affare
Ora disponi di set di dati strutturati generati tramite più tecniche di machine learning distinte, il tutto orchestrato interamente in BigQuery: estrazione della visione, modello XGBoost per prevedere il giusto valore di mercato ed embedding di ricerca vettoriale.
Il passaggio finale consiste nell'unire questi indicatori dell'AI in una visualizzazione consolidata come punteggio affare definitivo per l'applicazione frontend.
- Innanzitutto, unisci i metadati non elaborati alle funzionalità di visione estratte dall'AI, agli output di determinazione del prezzo predittiva e ai punteggi di autenticità semantica. Esegui il seguente SQL:
CREATE OR REPLACE TABLE `model_dev.vehicle_features_enhanced` AS
SELECT
meta.auction_id,
meta.item_name,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.current_bid,
meta.listing_url,
meta.transmission_type,
meta.description,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior,
COALESCE(scam.authenticity_score, 100) AS authenticity_score,
vision.description_summary,
prices.predicted_market_value
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id
LEFT JOIN `model_dev.vehicle_price_predictions` prices
ON meta.auction_id = prices.auction_id
LEFT JOIN `model_dev.vehicle_authenticity_scores` scam
ON meta.auction_id = scam.auction_id;
- Successivamente, calcola un Punteggio dell'affare compreso tra 0 e 100 combinando quattro diversi indicatori di AI. Questa formula bilancia valore, qualità e rischio per mostrare le schede migliori:
- Punteggio prezzo (40%): misura il risparmio rispetto al giusto valore di mercato.
- Punteggio della visione (30%): approfondimenti dall'analisi delle foto precedenti.
- Punteggio di autenticità (15%): valutazione del rischio di frode.
- Punteggio condizione (15%): dedotto al volo dalla descrizione del venditore tramite
AI.SCORE.
CREATE OR REPLACE TABLE `model_dev.marketplace_listings` AS
WITH score_elements AS (
SELECT
*,
-- 1. SELLER DESCRIPTION SCORE (use AI.SCORE on seller description)
AI.SCORE(
FORMAT("Rate the vehicle condition (0-100) based ONLY on this text: '%s'", description)
) AS description_score,
-- 2. PRICE SCORE
-- Higher impact for underpricing, lower impact for overpricing.
CAST(LEAST(100.0, GREATEST(0.0,
75.0 + (
IF((predicted_market_value - current_bid) > 0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 250.0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 40.0
)
)
)) AS INT64) AS price_score
FROM `model_dev.vehicle_features_enhanced`
),
final_calcs AS (
SELECT
*,
-- 3. Combine scores: Price (40%), Condition (30%), Description (15%), Authenticity (15%)
ROUND(
(
(price_score * 0.40) +
(CAST(condition AS INT64) * 0.30) +
(COALESCE(description_score, 50) * 0.15) +
(CAST(authenticity_score AS INT64) * 0.15)
)
-- Authenticity penalty for scores below 50.
* (IF(CAST(authenticity_score AS INT64) < 50, 0.20, 1.05))
) AS raw_score
FROM score_elements
)
SELECT
* EXCEPT(raw_score),
-- 4. Set floor values: low authenticity scores drop to 10; others floor at 35.
CAST(GREATEST(
(IF(CAST(authenticity_score AS INT64) < 50, 10, 35)),
LEAST(100, raw_score)
) AS INT64) AS deal_score
FROM final_calcs;
Per garantire consigli di alta qualità, la query applica due livelli logici specifici:
- Controllo dell'autenticità: se una scheda viene contrassegnata come "A rischio elevato" (punteggio < 50), il punteggio totale dell'offerta viene ridotto automaticamente dell'80% per impedire la promozione di schede sospette.
- Ottimizzazione "Gemma nascosta": la formula utilizza una logica a tratti per premiare in modo aggressivo i risparmi, pur essendo più indulgente nei confronti dei ricarichi, garantendo che un'auto troppo costosa in condizioni perfette possa comunque ottenere una classificazione "Equa".
La tabella risultante, model_dev.marketplace_listings, contiene campi come deal_score, oltre a price_score e authenticity_score.
- Per visualizzare personalmente i punteggi dell'offerta, esegui la seguente query o guarda lo screenshot riportato di seguito:
SELECT item_name, model_year, authenticity_score, predicted_market_value, price_score, deal_score FROM `model_dev.marketplace_listings`
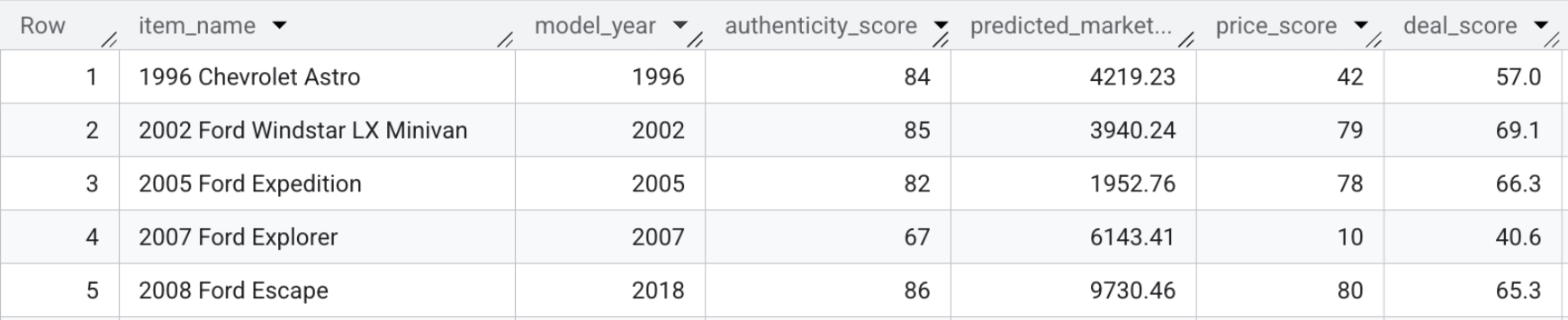
Riepilogo della sezione:hai combinato i prezzi predittivi, le funzionalità visive e i punteggi di autenticità con la descrizione del venditore per calcolare un unico punteggio offerta per ogni scheda.
8. Esegui il deployment dell'applicazione frontend
Ora è il momento di avviare l'applicazione frontend. In questo modo, puoi finalmente cercare nell'inventario delle schede di veicoli e interagire con gli approfondimenti generati dall'AI che hai appena creato, come il Punteggio offerta.
Esportare i punteggi AI nel frontend
Il frontend React si basa su un payload JSON locale per caricare rapidamente la pagina iniziale. Per potenziare il marketplace, estrai i punteggi finali degli accordi generativi da BigQuery e inseriscili di nuovo nel progetto Next.js.
- Assicurati che l'ambiente sia pronto. Se la sessione di Cloud Shell è scaduta o hai eseguito la navigazione in una cartella diversa, esegui questo comando per tornare alla radice del progetto e ripristinare le variabili di ambiente:
cd ~/devrel-demos/data-analytics/cymbal-autos-multimodal && \
export PROJECT_ID=$(gcloud config get-value project) && \
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
- Esegui lo script Python fornito per eseguire query sulla vista BigQuery finale e unire i nuovi Deal Score nel datastore sottostante dell'applicazione:
python3 scripts/setup/08_export_frontend_data.py
Riceverai un messaggio di conferma come il seguente:
💾 Updated local file: app/src/data/cars.json
Esegui il deployment dell'applicazione in Cloud Run
Una volta arricchiti i dati, puoi eseguire il deployment dell'applicazione frontend Next.js su internet pubblico utilizzando Cloud Run. È caratterizzata da un'interfaccia moderna con valutazioni delle offerte, caroselli di immagini interattivi e una barra di ricerca semantica ibrida dinamica che esegue query su BigQuery in tempo reale.
- In Cloud Shell, vai alla directory
app/del repository clonato. Questo è fondamentale: se rimani nella directory principale, la build non riuscirà.
cd app
- Esegui il deployment dell'applicazione come container serverless utilizzando Cloud Run. Il comando passa
PROJECT_IDcome variabile di ambiente in modo che l'API Next.js sappia quale progetto BigQuery interrogare:
gcloud run deploy cymbal-autos-frontend \
--source . \
--region us-west1 \
--allow-unauthenticated \
--min-instances 1 \
--set-env-vars PROJECT_ID=$PROJECT_ID \
--project $PROJECT_ID
- Al termine del deployment, il terminale restituirà un URL del servizio sicuro. che saranno simili a quanto segue:
Service URL: https://cymbal-autos-frontend-[YOUR-PROJECT-NUMBER].us-west1.run.app/
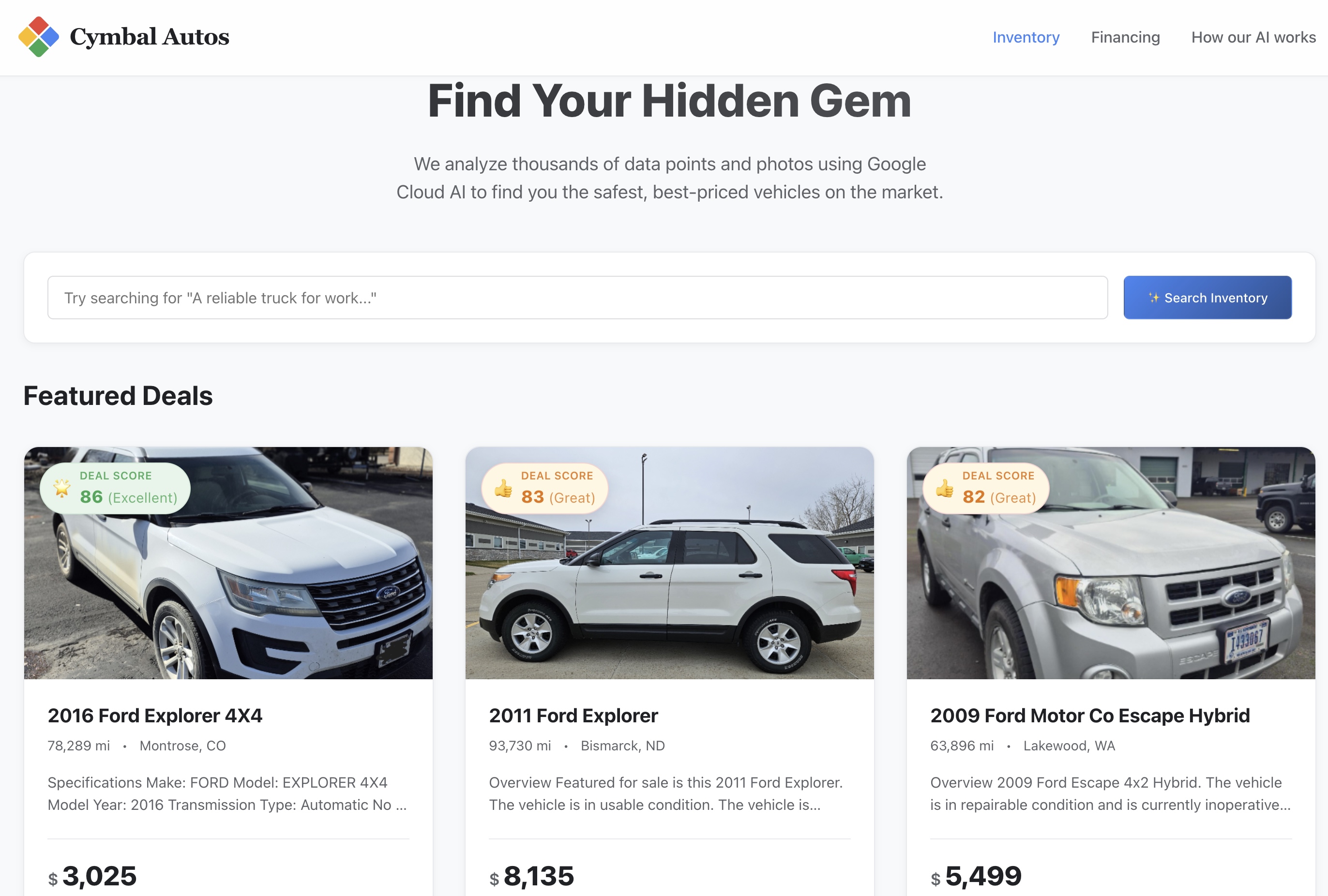
9. Esplora l'applicazione Cymbal Autos
Ora che il container frontend è stato inviato a Cloud Run, è il momento di testare l'app.
- Visita il sito:apri l'URL del servizio sicuro restituito da Cloud Run.
- Esegui una ricerca semantica:prova a cercare un concetto astratto, ad esempio "Un camion affidabile per il lavoro che trasporta e può fare fuoristrada". L'app Next.js traduce il testo non elaborato in un embedding vettoriale multimodale ed esegue una query
VECTOR_SEARCHin tempo reale su BigQuery, mappando la tua idea rispetto all'ecosistema dei veicoli.
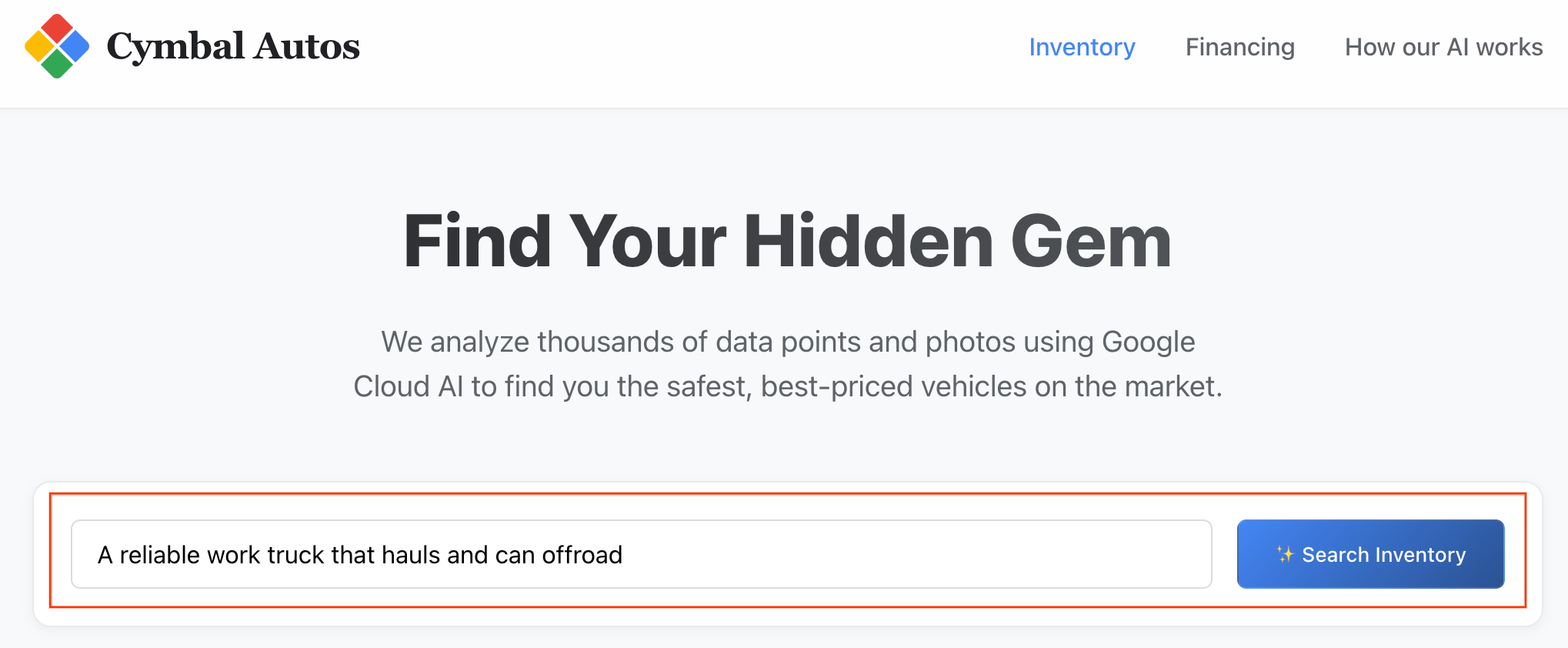
Nota: le schede vengono ordinate in base alla somiglianza semantica.
- Esamina i risultati:BigQuery ha calcolato la distanza matematica esatta tra la tua idea astratta e le funzionalità del veicolo per restituire le corrispondenze semantiche più vicine.
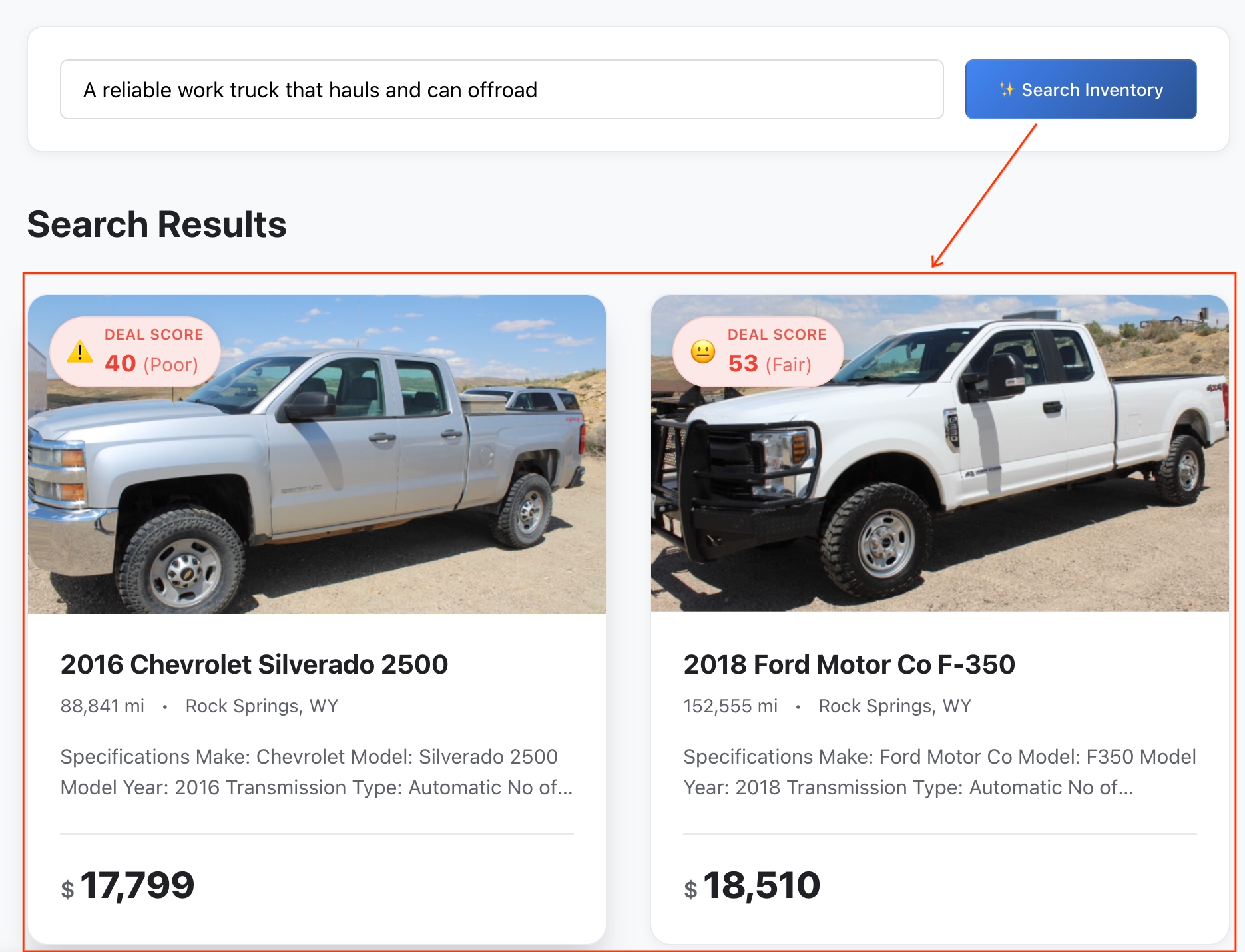
- Esamina i dettagli:fai clic su un veicolo per aprire il relativo profilo completo della scheda.
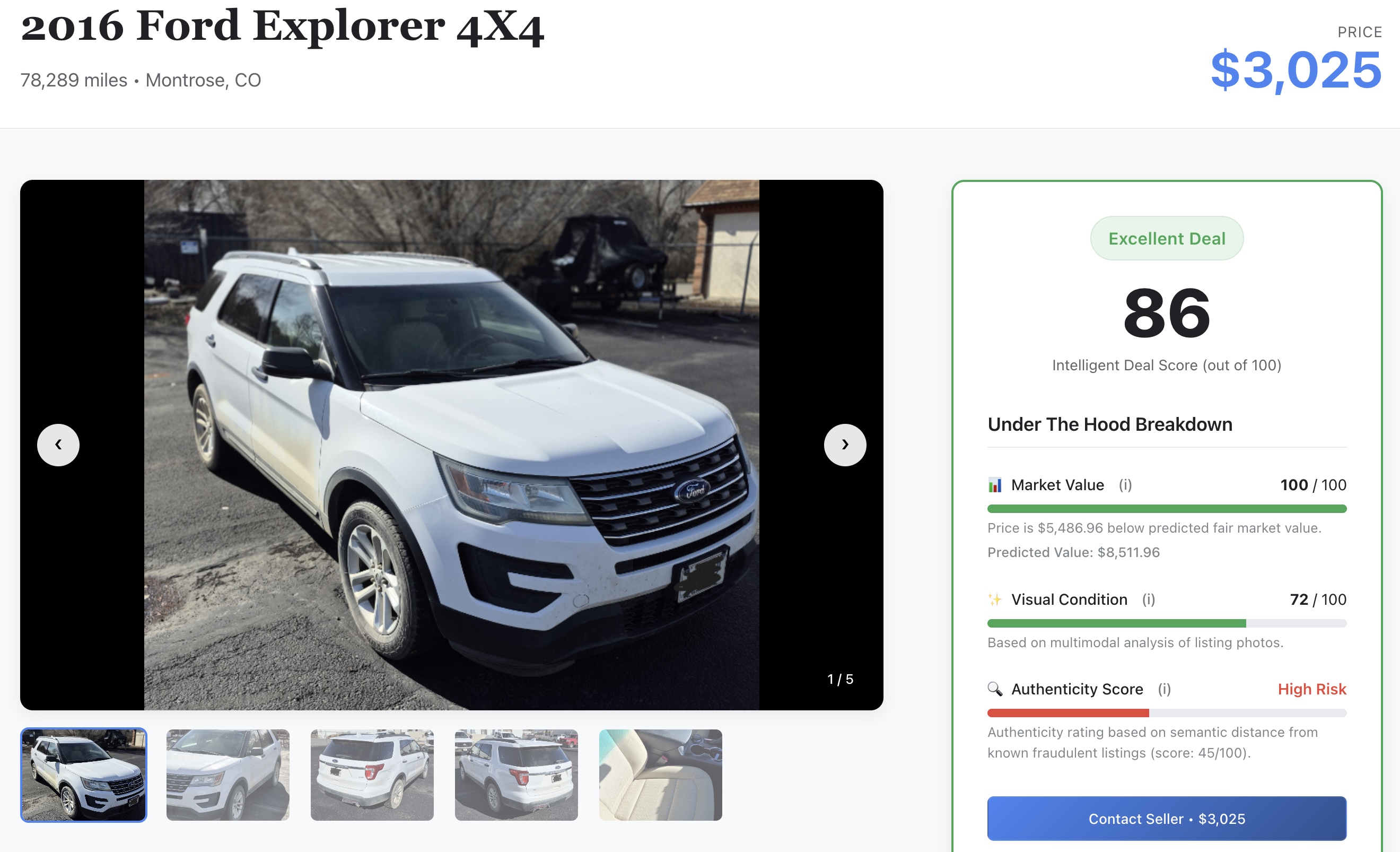
- Controlla il segnale AI: scorri i dettagli per visualizzare i punteggi di machine learning non elaborati che hai generato in precedenza nel lab:
- 📈 Fair Market Value: il prezzo di base previsto dal modello XGBoost.
- ✨ Condizione visiva: la valutazione dei danni fisici estratta dai modelli Gemini.
- 🔍 Punteggio di autenticità:la metrica del vettore di autenticità separa i venditori legittimi dai potenziali truffatori.
10. Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo codelab, puoi eliminare l'intero progetto Google Cloud che hai creato per questo codelab oppure puoi eseguire il seguente script di eliminazione automatica.
- Dal terminale Cloud Shell, torna alla directory radice contenente:
cd ..
- Esegui lo script di pulizia riportato di seguito. In questo modo, il bucket Cloud Storage verrà svuotato, il set di dati BigQuery
model_devverrà eliminato, la connessione BigQuery verrà eliminata e il servizio Cloud Run verrà eliminato.
chmod +x scripts/cleanup/teardown.sh
./scripts/cleanup/teardown.sh
11. Complimenti
Complimenti! Hai creato un marketplace di veicoli intelligenti. Hai utilizzato BigQuery per unificare l'analisi dei dati non strutturati, la modellazione predittiva e le integrazioni di AI in un unico spazio di lavoro.
Cosa hai imparato
- Come collegare BigQuery a immagini non strutturate di Cloud Storage utilizzando ObjectRef
- Come estrarre gli attributi del veicolo dalle foto utilizzando BigQuery con i modelli Gemini, come le funzioni
AI.GENERATEeAI.CLASSIFY - Come prevedere i prezzi dei veicoli utilizzando BigQuery ML
- Come identificare i potenziali annunci fraudolenti incorporando le descrizioni dei veicoli ed eseguendo
VECTOR_SEARCH - Come utilizzare
AI.SCOREper valutare i dati non strutturati al volo e incorporare i risultati in un punteggio affare completo - Come esportare i dati ed eseguire il deployment dell'applicazione marketplace Next.js in Cloud Run
Passaggi successivi
- Scopri l'intera gamma di funzioni di AI generativa disponibili in BigQuery
- Scopri di più sulla creazione di modelli predittivi con GoogleSQL.