
1. はじめに
この Codelab では、オンライン車両マーケットプレイス「Cymbal Autos」のバックエンドを構築し、フロントエンドをデプロイします。BigQuery と Gemini Enterprise Agent Platform の Gemini モデルを使用して、車両の写真を検査し、BigQuery ML を使用して価格を予測し、ベクトル エンベディングを使用して不正なリスティングを検出し、複合取引スコアを計算します。最後に、これらの分析情報を Cloud Run にデプロイされた Next.js フロントエンドに表示します。
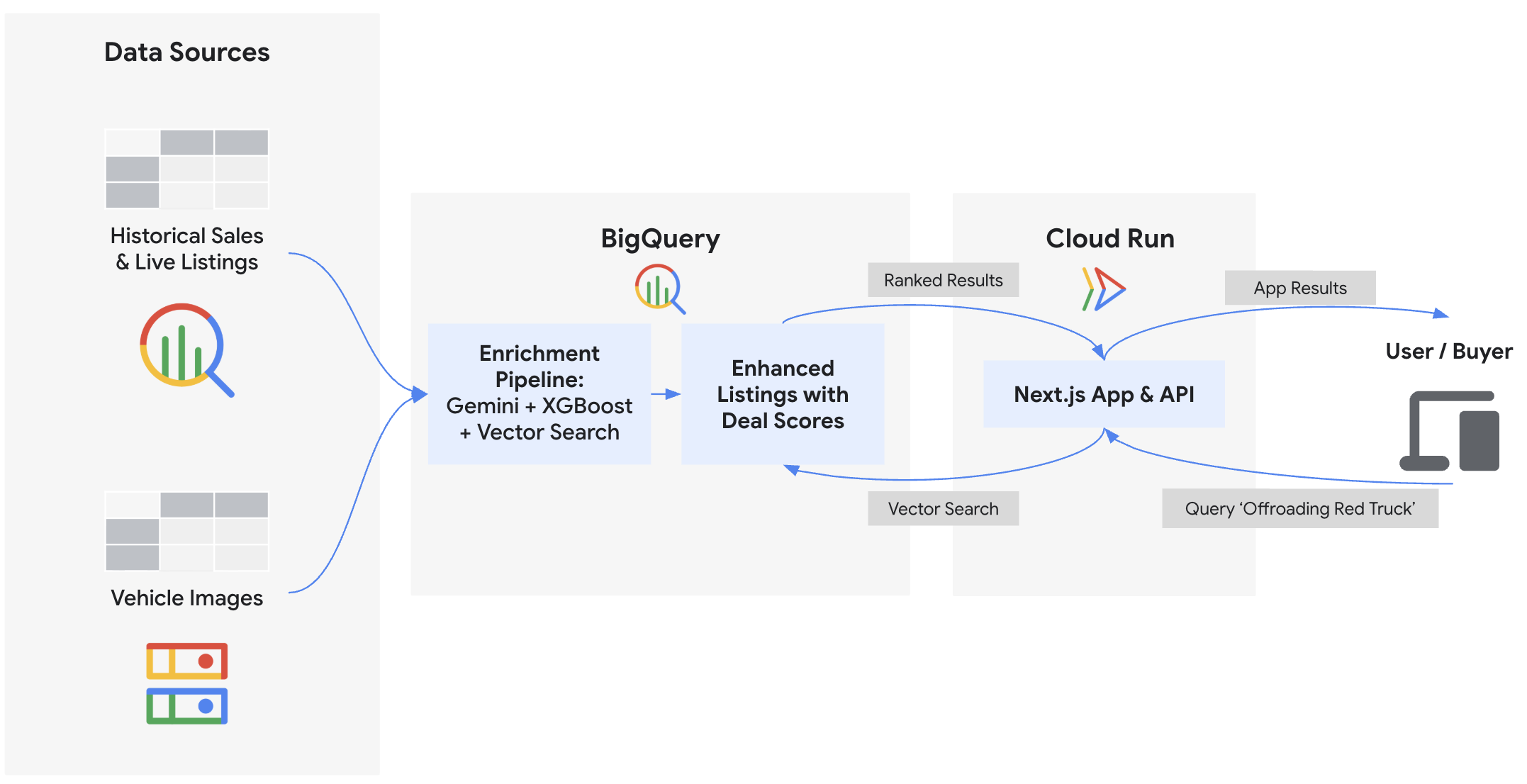
演習内容
- ObjectRef を使用して、BigQuery を非構造化 Cloud Storage 画像に接続する
- Gemini モデルを使用した BigQuery を使用して、写真から車両の属性を抽出する
- BigQuery ML で XGBoost 回帰モデルをトレーニングして、公正な市場価格を予測する
- 車両の説明を埋め込み、
VECTOR_SEARCHを実行することで、詐欺の可能性のあるリスティングと信頼できるリスティングを特定する AI.SCOREを使用して販売者の説明から条件シグナルを組み込みながら、各リスティングの包括的なお買い得度スコアを計算する- データをエクスポートして、Next.js Marketplace アプリケーションを Google Cloud Run にデプロイする
必要なもの
- ウェブブラウザ(Chrome など)
- 課金を有効にした Google Cloud プロジェクト
- SQL、Python、Google Cloud に関する基本的な知識
- API の有効化、リソースの作成、権限の割り当てを行うのに十分な IAM 権限(プロジェクト オーナーなど)
この Codelab は中級レベルのデベロッパーを対象としています。
この Codelab で作成するリソースの費用は 5 ドル未満です。
2. 始める前に
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト セレクタ ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell の起動
Google Cloud Shell を使用して、コードのダウンロード、設定スクリプトの実行、アプリケーションのデプロイを行います。
- Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] アイコンをクリックします。

- Cloud Shell に接続したら、セッションを認証して、アプリケーションが Google Cloud APIs にアクセスできるようにします。プロンプトに沿って Cloud Shell を承認します。
gcloud auth application-default login
- Google Cloud プロジェクト ID と Google Cloud Storage バケットの一意の名前(未加工のデータを保存する場所)を設定します。
export PROJECT_ID=$(gcloud config get-value project)
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
gcloud config set project $PROJECT_ID
次のようなメッセージが表示されます。
Your active configuration is: [cloudshell-####] Updated property [core/project]
API を有効にする
Cloud Shell で次のコマンドを実行して、この Codelab に必要な API をすべて有効にします。
gcloud services enable \
aiplatform.googleapis.com \
artifactregistry.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
cloudbuild.googleapis.com \
run.googleapis.com
実行が成功すると、次のようなメッセージが表示されます。
Operation "operations/..." finished successfully.
3. コードと設定データを取得する
まず、デモ アセットをダウンロードして、環境変数を構成します。
- Cloud Shell から
devrel-demosリポジトリのクローンを作成し、プロジェクト ディレクトリに移動します。
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos/data-analytics/cymbal-autos-multimodal
- スクリプトを実行して、環境にデータをコピーします。このスクリプトは、ローカル リポジトリのデータセットを個人の Cloud Storage バケットに同期し、一般公開バケットから車両の画像を取得します。
chmod +x scripts/setup/*.sh
./scripts/setup/00_copy_data.sh
その後、次のようなメッセージが表示されます。
Average throughput: 87.8MiB/s Data copy complete!
- 次に、BigQuery Cloud リソース接続を設定します。Cloud Storage 内の非構造化画像を分析し、SQL クエリから Agent Platform モデルを直接呼び出すには、BigQuery で基盤となるサービス アカウントに IAM 権限を委任する必要があります。このスクリプトは、安全な接続を作成し、必要な Vertex AI ユーザーロールと Service Usage ユーザーロールを付与します(伝播に約 1 分かかります)。
./scripts/setup/01_setup_api_connection.sh
次のようなメッセージが表示されます。
Environment setup complete! Your BigQuery connection is ready.
- 最後に、初期の BigQuery データセットを作成し、未加工の表形式データを読み込みます。これにより、
model_devデータセットが作成され、開始テーブルが入力されます。これにより、機械学習クエリを記述する前に基盤が設定されます。
./scripts/setup/02_load_to_bq.sh
次のようなメッセージが表示されます。
================================================================= BigQuery load complete! =================================================================
4. マルチモーダル ビジョン抽出
車両リスティングをスコアリングする前に、何百枚もの未加工の写真から構造化データ(色、ボディ スタイル、外観の損傷など)を抽出します。ObjectRef 関数と Agent Platform でホストされている Gemini モデルを活用することで、ファイルを移動したり、複雑なデータ パイプラインを作成したりすることなく、これらの特徴を生成できます。この抽出は、フロントエンド アプリケーションの ✨ ビジュアル条件バッジに直接反映されます。
- 新しいブラウザタブで BigQuery Studio を開きます。
- [+ クエリを新規作成] ボタンをクリックします。この Codelab では、SQL エディタを使用して SQL コードを操作します。
- ML エクストラクタを構築する前に、元の画像を簡単に確認できます。次のクエリを実行して、各リスティングについて Google Cloud Storage に保存されている画像 URI の配列を表示します。
SELECT auction_id, item_name, description, images
FROM `model_dev.vehicle_metadata` LIMIT 5;
- 次に、BigQuery Studio の SQL エディタに次の SQL を貼り付けて、
image_ref列を含む新しいテーブルを作成します。[実行] をクリックします。
CREATE OR REPLACE TABLE `model_dev.vehicle_multimodal` AS
SELECT
*,
ARRAY(
SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF(uri, 'us.conn'))
FROM UNNEST(images) AS uri
) AS image_ref
FROM `model_dev.vehicle_metadata`;
- 作成した新しい
image_refObjectRef 列を確認します。新しいテーブルには、画像自体で実行する権限を持つ ObjectRef 列が追加されました。次のクエリを実行して表示します。
SELECT auction_id, item_name, description, image_ref
FROM `model_dev.vehicle_multimodal` LIMIT 5;
- 次に、
AI.GENERATEとAI.CLASSIFYを使用して画像を分析します。AI.GENERATEは、Gemini にプロンプトを送信して、状態スコアと損傷の概要(1 文)を抽出します。一方、AI.CLASSIFYは、車両のボディスタイルと色を厳密に分類します。
次のクエリを実行して、これらの分析情報を専用の特徴テーブルに抽出します。完了までに 3 分ほどかかります。
CREATE OR REPLACE TABLE `model_dev.vehicle_vision_features` AS
WITH generated_data AS (
SELECT
auction_id,
AI.GENERATE(
prompt => ('Rate the condition of this car on a scale from 0-100. Output a 1 sentence description of any glaring red flags', image_ref),
output_schema => 'condition INT64, description_summary STRING'
).* EXCEPT(full_response,status)
FROM
`model_dev.vehicle_multimodal`
),
-- Object-centric Classifications
classified_data AS (
SELECT
auction_id,
AI.CLASSIFY(
('What type of automobile is this?', image_ref[0]),
categories => ['Truck', 'Sedan', 'SUV']) AS body_style,
AI.CLASSIFY(
('Color of the exterior of the automobile', image_ref[0]),
categories => ['Black', 'White', 'Silver', 'Gray', 'Red', 'Blue', 'Brown', 'Green', 'Beige', 'Gold']) AS color,
AI.CLASSIFY(
('Color of the interior of the automobile', image_ref[0]),
categories => ['Black', 'Gray', 'Beige', 'Tan', 'Brown', 'White', 'Red']) AS interior
FROM `model_dev.vehicle_multimodal`
)
-- Join the AI insights back together into the final feature table
SELECT
g.auction_id,
g.condition,
g.description_summary,
c.body_style,
c.color,
c.interior
FROM generated_data g
JOIN classified_data c ON g.auction_id = c.auction_id;
- 生成された特徴を自分で確認するには、次のクエリを実行するか、下のスクリーンショットをご覧ください。
SELECT auction_id, condition, description_summary, body_style, color, interior FROM `model_dev.vehicle_vision_features` LIMIT 5;

セクションのまとめ: BigQuery から未加工の画像に直接アクセスし、Gemini モデルを使用して、ファイルを移動せずに構造化された視覚的特徴を抽出しました。
5. XGBoost を使用した予測価格設定
車両が本当にお得な取引かどうかを判断するには、公正な市場価値の信頼できるベースラインが必要です。モデルをトレーニングするためにデータをローカル スクリプトやノートブックに pull するのではなく、標準 SQL を使用して BigQuery 内で直接 XGBoost モデルをトレーニングできます。この価格予測は、フロントエンド アプリケーションの 📈 Fair Market Value ロジックを駆動します。
- [BigQuery Studio] タブに戻ります。
- まず、トレーニング データセットを見てみましょう。アクティブな車両リスティングとは異なり、この
synthetic_carsテーブルには、モデルのトレーニングに使用される 100,000 件の過去の販売データが含まれています。次の簡単なクエリを実行して、確認してみましょう。
SELECT
*
FROM
`model_dev.synthetic_cars`
LIMIT 10;
- 次に、次の SQL を実行して XGBoost 回帰モデルをトレーニングします。このモデルは、走行距離、年式、メーカー、外観の状態などの属性が価格にどのように影響するかを、10 万件の過去のレコードから学習します。
CREATE OR REPLACE MODEL `model_dev.car_price_model`
OPTIONS(
MODEL_TYPE = 'BOOSTED_TREE_REGRESSOR',
INPUT_LABEL_COLS = ['selling_price'],
MAX_ITERATIONS = 15,
TREE_METHOD = 'HIST'
) AS
SELECT
* EXCEPT(vin, sale_date, market_value, seller)
FROM
`model_dev.synthetic_cars`;
- 現在掲載中の車両リスティングの価格を予測する前に、関連する入力特徴をすべて 1 か所に集める必要があります。次の SQL を実行して、構造化された車両メタデータと生成したばかりのビジョン抽出特徴を統合します。
CREATE OR REPLACE TABLE `model_dev.vehicle_prediction_features` AS
SELECT
meta.auction_id,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.transmission_type,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id;
- 最後に、進行中のすべての車両リスティングの公正な市場価値を予測します。次のクエリを実行して、集計された特徴を新しくトレーニングしたモデルにフィードし、数値出力を安全な予測テーブルに保存します。
CREATE OR REPLACE TABLE `model_dev.vehicle_price_predictions` AS
SELECT
auction_id,
ROUND(predicted_selling_price, 2) AS predicted_market_value
FROM ML.PREDICT(
MODEL `model_dev.car_price_model`,
(SELECT * FROM `model_dev.vehicle_prediction_features`)
);
- 次に、モデルの出力を確認します。次のクイック クエリを実行して、ライブ車両リスティングの予測市場価値をプレビューします。
SELECT * FROM `model_dev.vehicle_price_predictions` LIMIT 5;
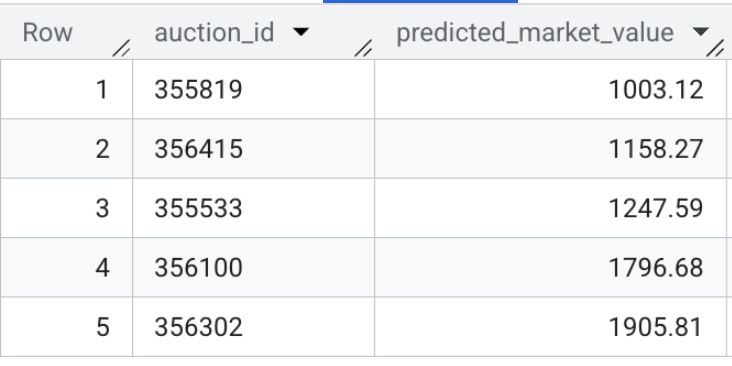
セクションのまとめ: 10 万件の取引サンプルを使用して XGBoost 回帰モデルをトレーニングし、バッチ推論を実行して、データセット内のすべてのアクティブな車両リスティングの公正市場価格を予測しました。
6. セマンティック エンベディングと信頼性の検出
このセクションでは、2 つの異なるエンベディング パイプラインを実行して、車両マーケットプレイスのスマート機能を有効にします。
- マルチモーダル画像検索: 車両の生写真をベクトル空間に変換し、ユーザーが自然言語(「信頼できる作業用トラック」など)を使用して検索できるようにします。
- テキスト エンベディングと類似度検索: 車両の説明文をベクトル エンベディングに変換し、
VECTOR_SEARCHを使用して、アクティブなリスティングと既知の潜在的な詐欺または愛好家のプロフィールを比較します。これにより、購入者がアプリで確認できる 🔍 信頼度スコアが計算されます。
- まず、車両リスティングのマルチモーダル エンベディングを生成する必要があります。
gemini-embedding-2-previewモデルを使用すると、画像とテキストの両方をまったく同じエンベディングに入力できます。このモデルは複数のモダリティを同時に処理できますが、この特定のケースでは車両の画像のみを埋め込んでいます。これにより、フロントエンド アプリケーションの「セマンティック検索」バーが強化され、購入者は自然言語(「信頼できるピックアップ トラック」など)を使用して、一致するリスティングをすばやく取得できます。このクエリを実行して、AI.EMBEDを使用してマルチモーダル ベクトルを生成します。
CREATE OR REPLACE TABLE `model_dev.vehicle_images_embedded` AS
SELECT
auction_id,
AI.EMBED(
STRUCT(image_ref),
endpoint => 'gemini-embedding-2-preview').result AS multimodal_embedding
FROM `model_dev.vehicle_multimodal`
WHERE ARRAY_LENGTH(image_ref) > 0;
- 次に、先ほど読み込んだリスク プロファイル データを調べます。このリストには、既知の詐欺の手口と、正当な愛好家のサンプル リストの両方が含まれています。次のクエリを実行して、ベースライン プロファイルを表示します。
SELECT profile_id, profile_type, description
FROM `model_dev.seller_risk_profiles`;
- 次に、これらのリスクの説明をベクトル エンベディングに変換します。専門のテキスト エンベディング モデル(
text-embedding-005)を使用して、プレビューしたばかりの書き言葉を厳密に評価できます。次の SQL を貼り付けて [実行] をクリックし、ベースライン プロファイルを埋め込みます。
CREATE OR REPLACE TABLE `model_dev.seller_risk_profiles_embedded` AS
SELECT
profile_id,
description AS content,
profile_type,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.seller_risk_profiles`;
- 次に、実際のライブ車両在庫の比較可能なエンベディングを生成します。このクエリを実行して、各車両の未加工の HTML 説明をベクトル空間に変換し、ベースライン プロファイルと比較できるようにします。
CREATE OR REPLACE TABLE `model_dev.vehicle_descriptions_embedded` AS
SELECT
auction_id,
description AS content,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.vehicle_metadata`
WHERE description IS NOT NULL;
- 最後に、ベクトル検索を実行して、ライブリスティングとベースライン プロファイル間のセマンティック距離を計算します。次の SQL を実行してマッピングを行います。数学的距離が小さいほど、リスティングが既知の不正行為クラスタに類似している可能性が高く、距離が大きいほど、正当な説明である可能性が高くなります。
CREATE OR REPLACE TABLE `model_dev.vehicle_authenticity_scores` AS
SELECT
scam_search.query.auction_id,
CAST(
GREATEST(0.0, LEAST(100.0, ROUND((MIN(scam_search.distance) - 0.33) / 0.12 * 100.0)))
AS INT64
) AS authenticity_score
FROM VECTOR_SEARCH(
TABLE `model_dev.seller_risk_profiles_embedded`,
'text_embedding',
(
SELECT text_embedding, auction_id
FROM `model_dev.vehicle_descriptions_embedded`
),
top_k => 15,
distance_type => 'COSINE'
) AS scam_search
WHERE scam_search.base.profile_type = 'scam'
GROUP BY 1;
このテーブルの内容は次のようになります。
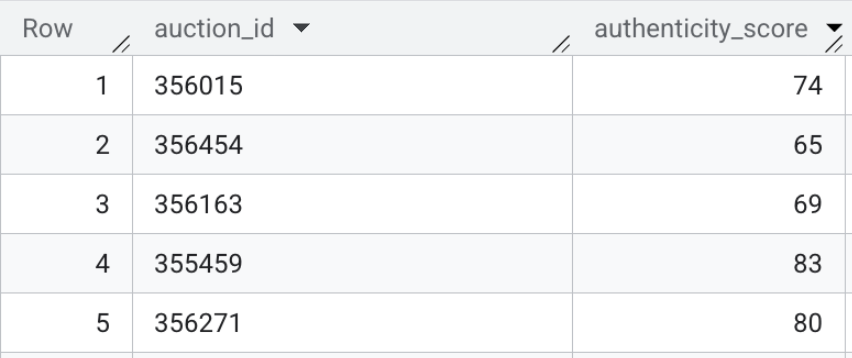
セクションのまとめ: フロントエンドの検索バー用のマルチモーダル エンベディングを生成し、BigQuery 内で直接ベクトル検索を使用して、既知の詐欺プロファイルに対して未加工の HTML テキスト リスティングを評価しました。
7. AI による取引スコアリング
これで、複数の異なる ML 手法で生成された構造化データセットができました。これらはすべて BigQuery 内で完全にオーケストレーションされています。ビジョン抽出、公正市場価値を予測する XGBoost モデル、ベクトル検索エンベディングです。
最後のステップは、これらの AI シグナルを統合ビューにマージして、フロントエンド アプリケーションの最終的な取引スコアとして表示することです。
- まず、未加工のメタデータを AI で抽出されたビジョン機能、予測価格の出力、セマンティックな信頼性スコアと結合します。次の SQL を実行します。
CREATE OR REPLACE TABLE `model_dev.vehicle_features_enhanced` AS
SELECT
meta.auction_id,
meta.item_name,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.current_bid,
meta.listing_url,
meta.transmission_type,
meta.description,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior,
COALESCE(scam.authenticity_score, 100) AS authenticity_score,
vision.description_summary,
prices.predicted_market_value
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id
LEFT JOIN `model_dev.vehicle_price_predictions` prices
ON meta.auction_id = prices.auction_id
LEFT JOIN `model_dev.vehicle_authenticity_scores` scam
ON meta.auction_id = scam.auction_id;
- 次に、4 つの異なる AI シグナルを組み合わせて 0 ~ 100 の取引スコアを計算します。この数式は、価値、品質、リスクのバランスを取り、最適なリスティングを表示します。
- 価格スコア(40%): 適正な市場価格に対する割引額を測定します。
- ビジョン スコア(30%): 過去の写真分析から得られた分析情報。
- 信頼性スコア(15%): 詐欺のリスク評価。
- 状態スコア(15%): 販売者の説明から
AI.SCOREを介してその場で推測されます。
CREATE OR REPLACE TABLE `model_dev.marketplace_listings` AS
WITH score_elements AS (
SELECT
*,
-- 1. SELLER DESCRIPTION SCORE (use AI.SCORE on seller description)
AI.SCORE(
FORMAT("Rate the vehicle condition (0-100) based ONLY on this text: '%s'", description)
) AS description_score,
-- 2. PRICE SCORE
-- Higher impact for underpricing, lower impact for overpricing.
CAST(LEAST(100.0, GREATEST(0.0,
75.0 + (
IF((predicted_market_value - current_bid) > 0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 250.0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 40.0
)
)
)) AS INT64) AS price_score
FROM `model_dev.vehicle_features_enhanced`
),
final_calcs AS (
SELECT
*,
-- 3. Combine scores: Price (40%), Condition (30%), Description (15%), Authenticity (15%)
ROUND(
(
(price_score * 0.40) +
(CAST(condition AS INT64) * 0.30) +
(COALESCE(description_score, 50) * 0.15) +
(CAST(authenticity_score AS INT64) * 0.15)
)
-- Authenticity penalty for scores below 50.
* (IF(CAST(authenticity_score AS INT64) < 50, 0.20, 1.05))
) AS raw_score
FROM score_elements
)
SELECT
* EXCEPT(raw_score),
-- 4. Set floor values: low authenticity scores drop to 10; others floor at 35.
CAST(GREATEST(
(IF(CAST(authenticity_score AS INT64) < 50, 10, 35)),
LEAST(100, raw_score)
) AS INT64) AS deal_score
FROM final_calcs;
高品質な推奨事項を確保するため、クエリでは 2 つの特定のロジックレイヤが適用されます。
- 信頼性の制限: リスティングが「高リスク」(スコアが 50 未満)と判定された場合、不審なリスティングが宣伝されないように、合計ディールスコアが自動的に 80% 削減されます。
- 「隠れた逸品」の最適化: この式では、区分的ロジックを使用して、値引きを積極的に評価する一方で、値上げに対しては寛容に対応します。これにより、状態の良い高額な車でも「適正」なランキングを獲得できます。
結果のテーブル model_dev.marketplace_listings には、price_score や authenticity_score とともに deal_score などのフィールドが含まれます。
- 取引スコアを自分で確認するには、次のクエリを実行するか、下のスクリーンショットをご覧ください。
SELECT item_name, model_year, authenticity_score, predicted_market_value, price_score, deal_score FROM `model_dev.marketplace_listings`
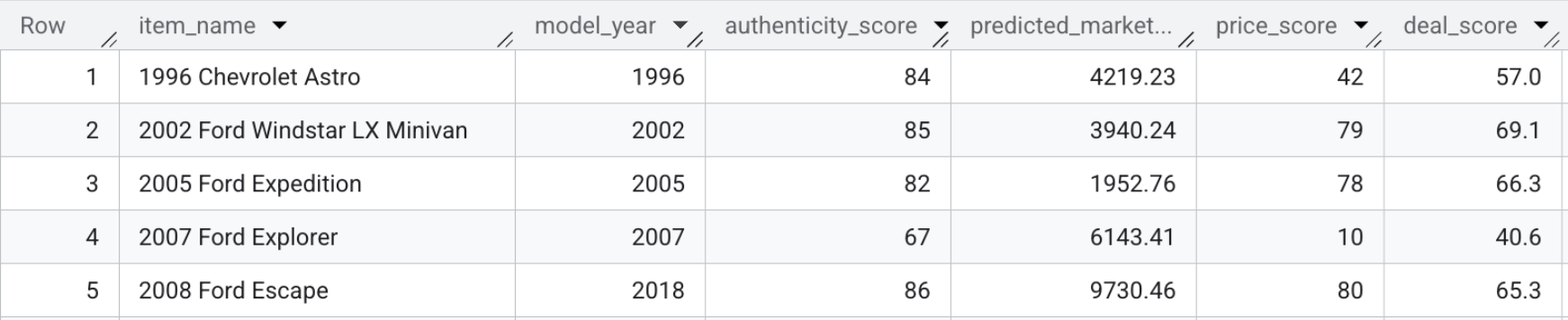
セクションのまとめ: 予測価格、視覚的特徴、信頼性スコアを販売者の説明と組み合わせて、各リスティングの単一のお得度スコアを計算しました。
8. フロントエンド アプリケーションをデプロイする
次に、フロントエンド アプリケーションを起動します。これにより、車両リスティングの在庫を検索し、作成したばかりの AI 生成の分析情報(お得度スコアなど)を操作できるようになります。
AI スコアをフロントエンドにエクスポートする
React フロントエンドは、初期ページの読み込みを高速化するためにローカル JSON ペイロードに依存しています。マーケットプレイスを強化するために、BigQuery から最終的な生成取引スコアを抽出し、Next.js プロジェクトに挿入します。
- 環境の準備が整っていることを確認します。Cloud Shell セッションがタイムアウトした場合や、別のフォルダに移動した場合は、次のコマンドを実行してプロジェクト ルートに戻り、環境変数を復元します。
cd ~/devrel-demos/data-analytics/cymbal-autos-multimodal && \
export PROJECT_ID=$(gcloud config get-value project) && \
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
- 提供された Python スクリプトを実行して、最終的な BigQuery ビューをクエリし、新しい取引スコアをアプリケーションの基盤となるデータストアに統合します。
python3 scripts/setup/08_export_frontend_data.py
次のような確認メッセージが表示されます。
💾 Updated local file: app/src/data/cars.json
アプリケーションを Cloud Run にデプロイする
データが正常に拡充されたら、Cloud Run を使用して Next.js フロントエンド アプリケーションを公共のインターネットにデプロイできます。このサイトは、取引の評価、インタラクティブな画像カルーセル、BigQuery にリアルタイムでクエリを実行する動的なハイブリッド セマンティック検索バーを備えた最新のインターフェースを備えています。
- Cloud Shell で、クローン作成されたリポジトリの
app/ディレクトリに移動します。これは重要です。ルート ディレクトリに留まると、ビルドが失敗します。
cd app
- Cloud Run を使用して、アプリケーションをサーバーレス コンテナとしてデプロイします。このコマンドは、
PROJECT_IDを環境変数として渡します。これにより、Next.js API はクエリする BigQuery プロジェクトを認識します。
gcloud run deploy cymbal-autos-frontend \
--source . \
--region us-west1 \
--allow-unauthenticated \
--min-instances 1 \
--set-env-vars PROJECT_ID=$PROJECT_ID \
--project $PROJECT_ID
- デプロイが完了すると、ターミナルに安全なサービス URL が出力されます。これは次のような内容になります。
Service URL: https://cymbal-autos-frontend-[YOUR-PROJECT-NUMBER].us-west1.run.app/
9. Cymbal Autos アプリケーションを確認する
フロントエンド コンテナを Cloud Run に push したので、アプリをテストしましょう。
- サイトにアクセス: Cloud Run から返された安全なサービス URL を開きます。
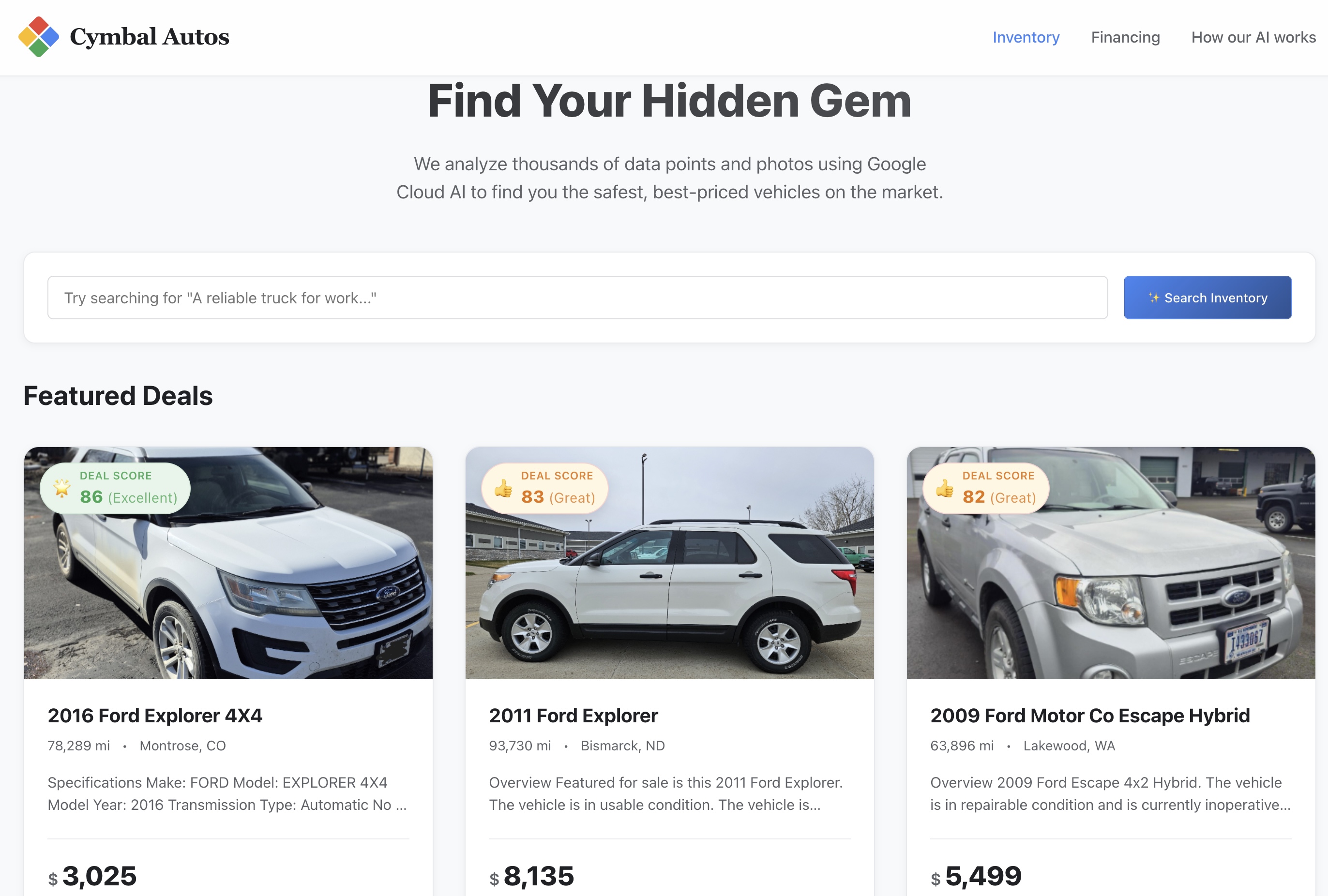
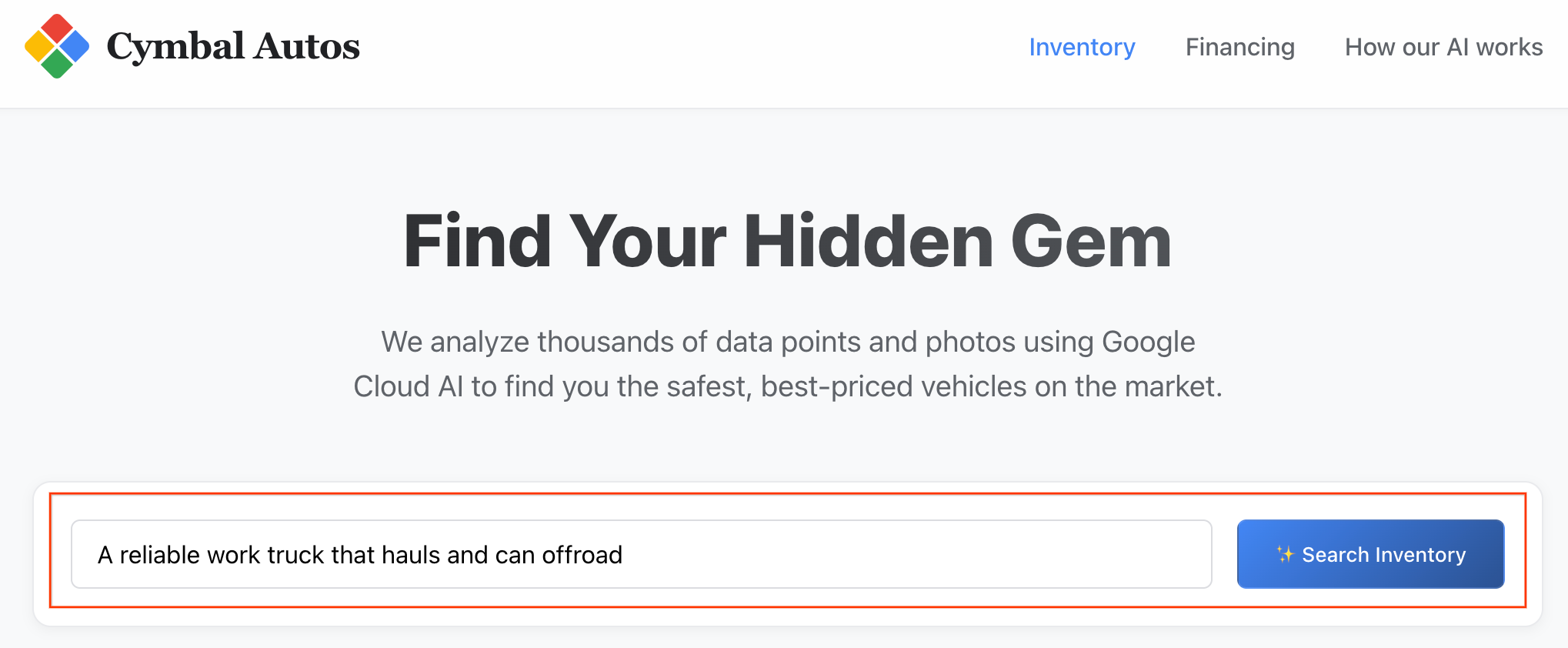
- セマンティック検索を実行する: 「荷物を運搬でき、オフロード走行も可能な信頼性の高い作業用トラック」などの抽象的なコンセプトを検索してみます。Next.js アプリは、未加工のテキストをマルチモーダル ベクトル エンベディングに変換し、BigQuery に対してリアルタイムの
VECTOR_SEARCHを実行して、アイデアを車両エコシステムにマッピングします。
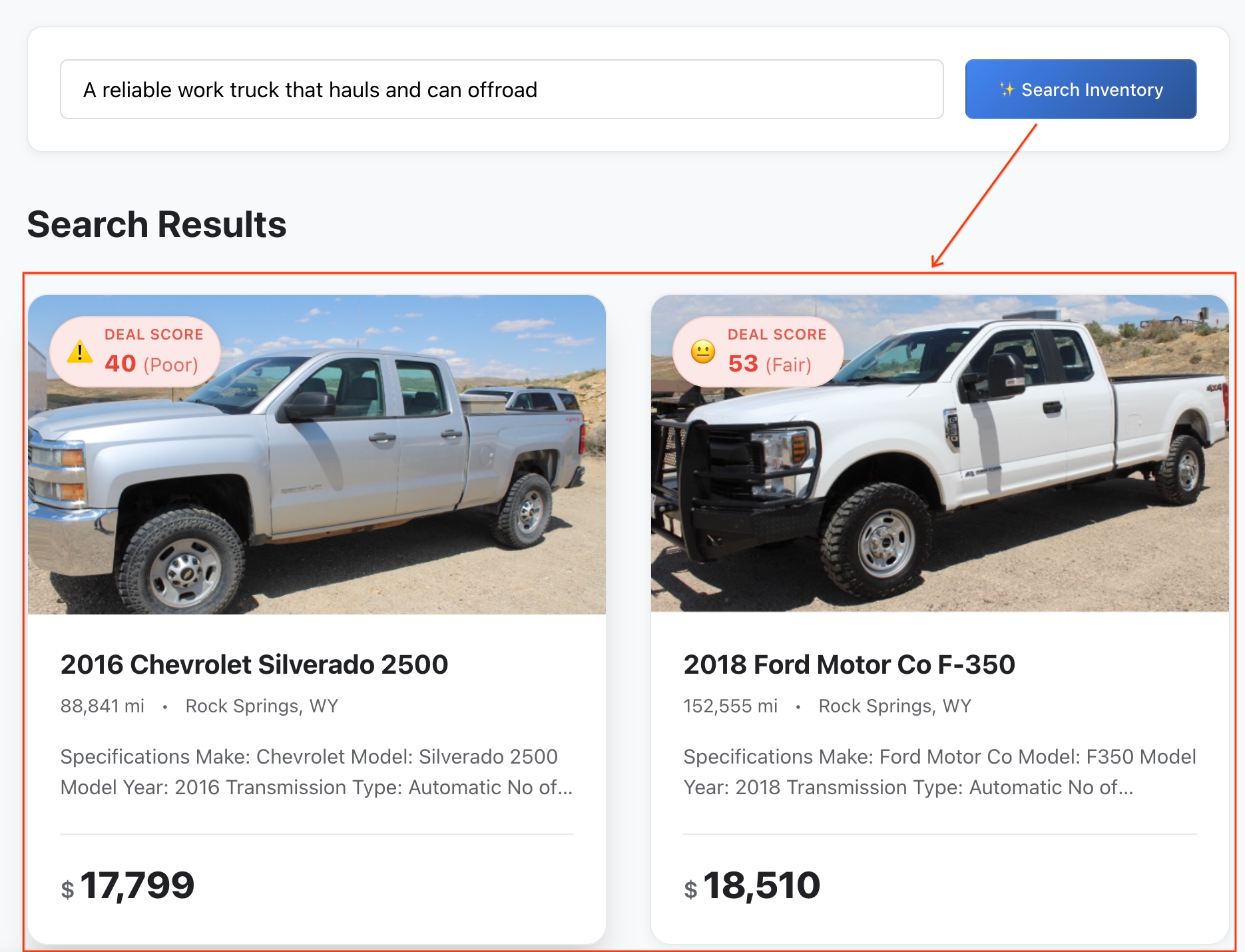
注: リスティングは意味的類似性で並べ替えられます。
- 結果を確認する: BigQuery は、抽象的なアイデアと車両の機能の間の正確な数学的距離を計算し、最も近いセマンティック一致を返しました。
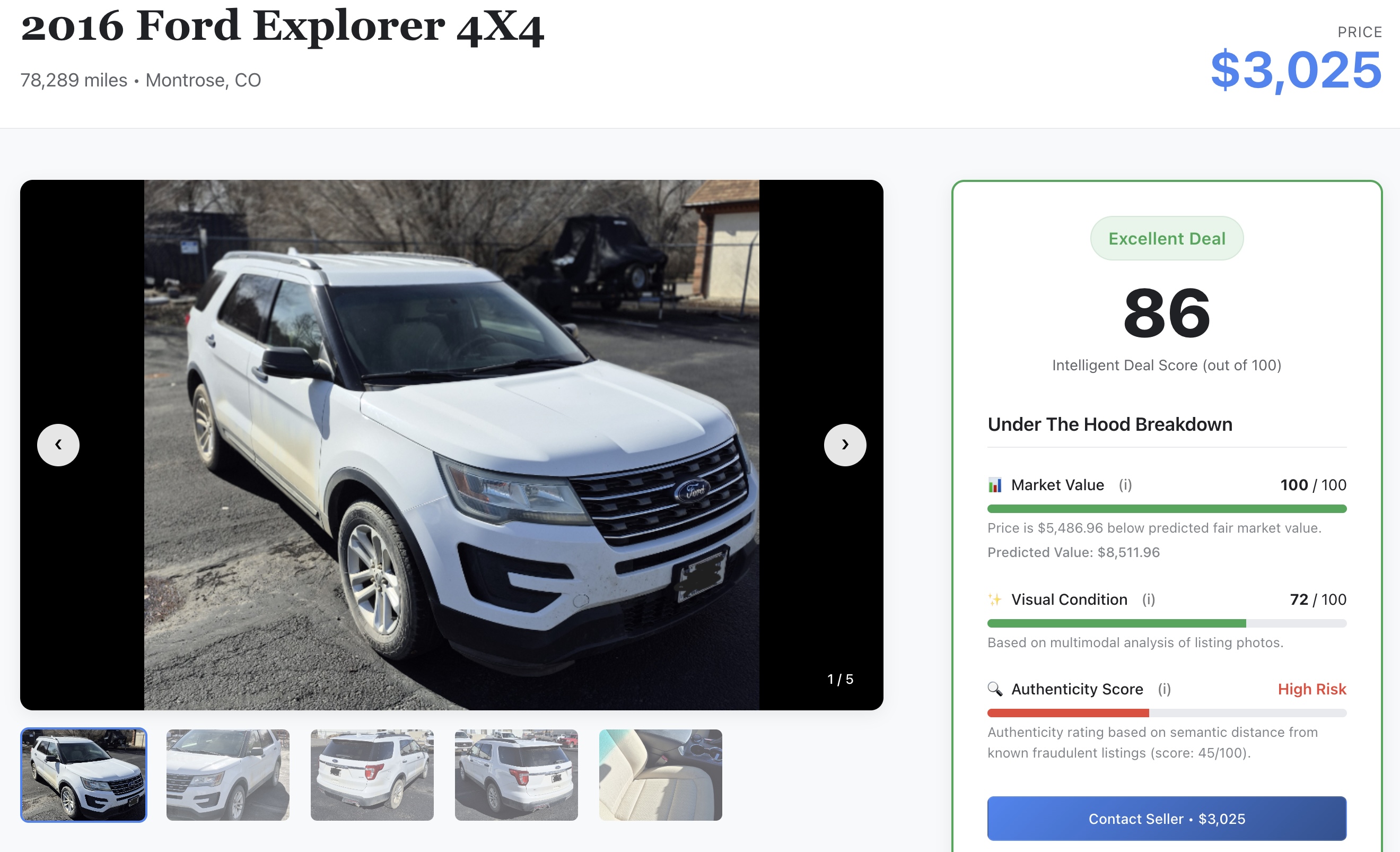
- 詳細を確認する: 車両をクリックすると、リスティング プロフィールの詳細が開きます。
- AI シグナルを確認する: 詳細をスクロールして、ラボで先ほど生成した ML の未加工スコアを確認します。
- 📈 公正な市場価格: XGBoost モデルで予測されたベースライン価格。
- ✨ 外観の条件: Gemini モデルによって抽出された物理的な損傷の評価。
- 🔍 信頼性スコア: 信頼性ベクトル指標は、正当な販売者と詐欺の可能性のある販売者を区別します。
10. クリーンアップ
この Codelab で使用したリソースに対して Google Cloud アカウントで継続的に課金されないようにするには、この Codelab 用に作成した Google Cloud プロジェクト全体を削除するか、次の自動クリーンアップ スクリプトを実行します。
- Cloud Shell ターミナルから、ルートを含むディレクトリに戻ります。
cd ..
- 次のクリーンアップ スクリプトを実行します。これにより、Google Cloud Storage バケットが空になり、
model_devBigQuery データセットが削除され、BigQuery 接続が削除され、Cloud Run サービスが削除されます。
chmod +x scripts/cleanup/teardown.sh
./scripts/cleanup/teardown.sh
11. 完了
おめでとうございます!インテリジェント車両のマーケットプレイスの構築が完了しました。BigQuery を使用して、非構造化データ分析、予測モデリング、AI 統合を単一のワークスペースに統合しました。
学習した内容
- ObjectRef を使用して BigQuery を非構造化 Cloud Storage 画像に接続する方法
AI.GENERATE関数やAI.CLASSIFY関数などの Gemini モデルを使用して、BigQuery で写真から車両の属性を抽出する方法- BigQuery ML を使用して車両価格を予測する方法
- 車両の説明を埋め込んで
VECTOR_SEARCHを実行し、詐欺の可能性があるリスティングを特定する方法 AI.SCOREを使用して非構造化データをオンザフライで評価し、結果を包括的な取引スコアに組み込む方法- データをエクスポートして Next.js Marketplace アプリケーションを Cloud Run にデプロイする方法
次のステップ
- BigQuery で使用できる生成 AI 関数の全範囲を確認する
- GoogleSQL を使用して予測モデルを作成する方法を確認する