
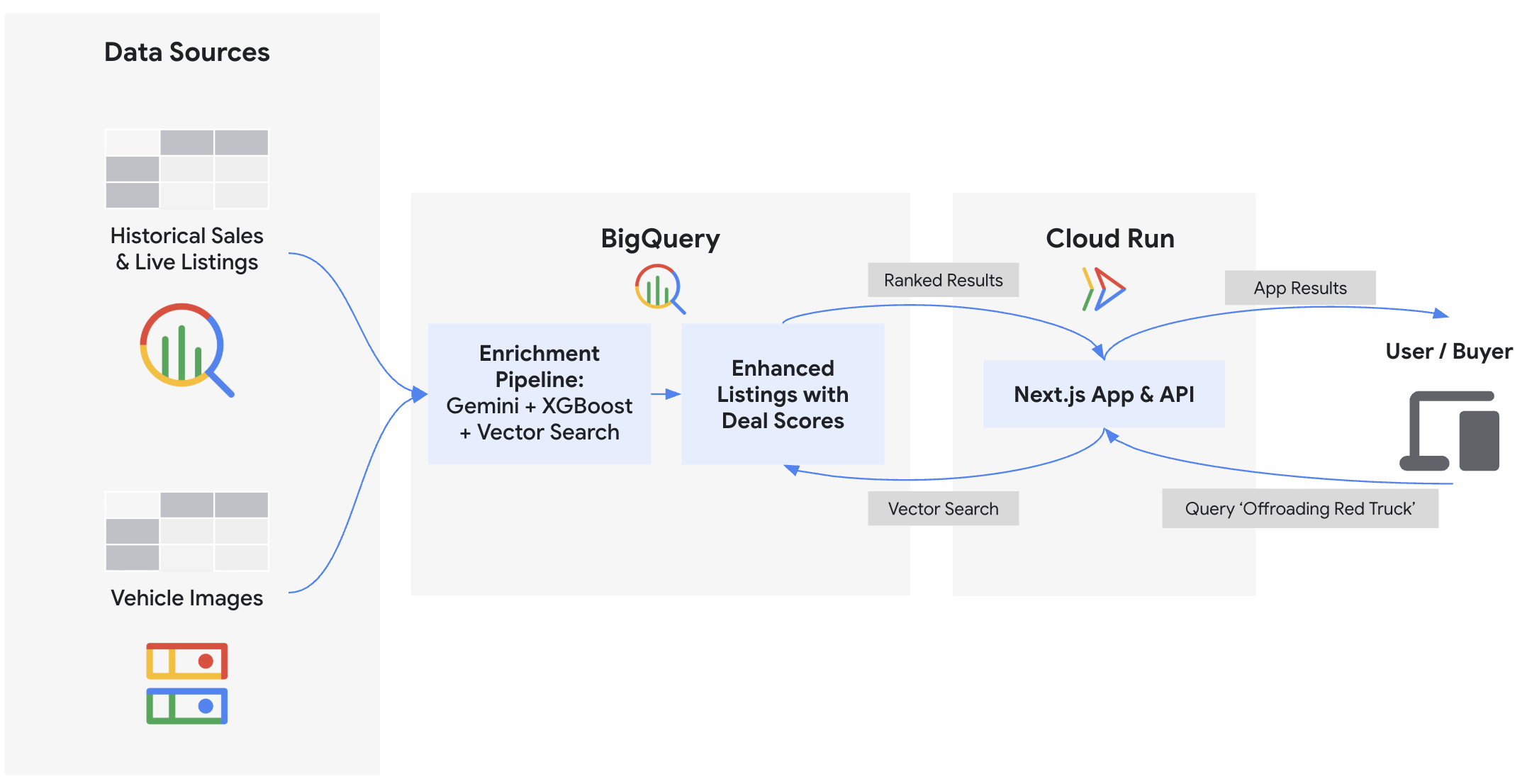
1. Wprowadzenie
W tym ćwiczeniu w Codelabs utworzysz backend i wdrożysz frontend dla „Cymbal Autos”, czyli internetowego rynku pojazdów. Do sprawdzania zdjęć pojazdów, prognozowania cen za pomocą BigQuery ML, wykrywania oszukańczych ofert za pomocą osadzania wektorowego i obliczania złożonych wyników ofert będziesz używać BigQuery i modeli Gemini na platformie agentów Gemini Enterprise. Na koniec wyświetlisz te statystyki w interfejsie Next.js wdrożonym w Cloud Run.
Jakie zadania wykonasz
- Łączenie BigQuery z nieuporządkowanymi obrazami z Cloud Storage za pomocą ObjectRef
- Wyodrębnianie atrybutów pojazdu ze zdjęć za pomocą BigQuery z modelami Gemini
- Prognozowanie cen rynkowych przez trenowanie modelu regresji XGBoost za pomocą BigQuery ML
- Identyfikuj potencjalne oszustwa i wiarygodne informacje, umieszczając opisy pojazdów i przeprowadzając
VECTOR_SEARCH. - Obliczanie kompleksowej wartości oferty dla każdej informacji o produkcie z uwzględnieniem sygnałów dotyczących stanu produktu z opisu sprzedawcy za pomocą
AI.SCORE. - Eksportowanie danych i wdrażanie aplikacji Next.js Marketplace w Google Cloud Run
Czego potrzebujesz
- przeglądarka, np. Chrome;
- projekt Google Cloud z włączonymi płatnościami;
- podstawowa znajomość SQL, Pythona i Google Cloud;
- wystarczające uprawnienia IAM do włączania interfejsów API, tworzenia zasobów i przypisywania uprawnień (np. właściciel projektu);
To ćwiczenie jest przeznaczone dla programistów na poziomie średniozaawansowanym.
Zasoby utworzone w tym laboratorium powinny kosztować mniej niż 5 USD.
2. Zanim zaczniesz
Tworzenie projektu Google Cloud
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt w chmurze Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Uruchamianie Cloud Shell
Do pobrania kodu, uruchomienia skryptów konfiguracji i wdrożenia aplikacji użyjesz Google Cloud Shell.
- U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell uwierzytelnij sesję, aby aplikacja mogła uzyskać dostęp do interfejsów Google Cloud API. Aby autoryzować Cloud Shell, postępuj zgodnie z instrukcjami:
gcloud auth application-default login
- Ustaw identyfikator projektu Google Cloud i unikalną nazwę zasobnika Cloud Storage (w którym będziesz przechowywać dane pierwotne):
export PROJECT_ID=$(gcloud config get-value project)
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
gcloud config set project $PROJECT_ID
Wyświetli się komunikat podobny do tego poniżej:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Włącz interfejsy API
Aby włączyć wszystkie interfejsy API wymagane w tym laboratorium, uruchom w Cloud Shell to polecenie:
gcloud services enable \
aiplatform.googleapis.com \
artifactregistry.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
cloudbuild.googleapis.com \
run.googleapis.com
Po pomyślnym wykonaniu polecenia powinien wyświetlić się komunikat podobny do tego poniżej:
Operation "operations/..." finished successfully.
3. Pobieranie kodu i danych konfiguracji
Najpierw pobierz zasoby wersji demonstracyjnej i skonfiguruj zmienne środowiskowe.
- W Cloud Shell sklonuj repozytorium
devrel-demosi przejdź do katalogu projektu:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos/data-analytics/cymbal-autos-multimodal
- Uruchom skrypt, aby skopiować dane do swojego środowiska. Ten skrypt synchronizuje zbiory danych z lokalnego repozytorium z Twoim osobistym zasobnikiem Cloud Storage i pobiera obrazy pojazdów z publicznego zasobnika:
chmod +x scripts/setup/*.sh
./scripts/setup/00_copy_data.sh
Następnie powinien wyświetlić się komunikat podobny do tego:
Average throughput: 87.8MiB/s Data copy complete!
- Następnie skonfiguruj połączenie z zasobem Cloud BigQuery. Aby analizować nieustrukturyzowane obrazy w Cloud Storage i wywoływać modele platformy Agent bezpośrednio z zapytań SQL, BigQuery musi delegować uprawnienia IAM na bazowe konto usługi. Ten skrypt tworzy bezpieczne połączenie i przyznaje mu niezbędne role użytkownika Vertex AI i użytkownika Wykorzystania usług (które propagują się przez około minutę):
./scripts/setup/01_setup_api_connection.sh
Wyświetli się komunikat podobny do tego:
Environment setup complete! Your BigQuery connection is ready.
- Na koniec utwórz początkowy zbiór danych BigQuery i wczytaj surowe dane tabelaryczne. Spowoduje to utworzenie zbioru danych
model_devi wypełnienie tabel początkowych, co stworzy podstawę przed napisaniem zapytań dotyczących uczenia maszynowego:
./scripts/setup/02_load_to_bq.sh
Wyświetli się komunikat podobny do tego:
================================================================= BigQuery load complete! =================================================================
4. Wyodrębnianie informacji z obrazów multimodalnych
Przed oceną ofert pojazdów wyodrębnisz z setek nieprzetworzonych zdjęć dane strukturalne (np. kolor, typ nadwozia czy uszkodzenia wizualne). Korzystając z funkcji ObjectRef i modeli Gemini hostowanych na platformie Agent Platform, możesz generować te funkcje bez przenoszenia plików ani pisania złożonych potoków danych. To wyodrębnianie bezpośrednio zasila plakietkę ✨ Stan wizualny w aplikacji front-end.
- Otwórz BigQuery Studio w nowej karcie przeglądarki.
- Kliknij przycisk + Utwórz nowe zapytanie. Podczas tych ćwiczeń z programowania będziesz używać edytora SQL do interakcji z kodem SQL.
- Zanim utworzysz ekstraktory uczenia maszynowego, możesz szybko przejrzeć nieprzetworzone obrazy. Aby wyświetlić tablicę identyfikatorów URI obrazów przechowywanych w Google Cloud Storage dla każdej oferty, uruchom to zapytanie:
SELECT auction_id, item_name, description, images
FROM `model_dev.vehicle_metadata` LIMIT 5;
- Teraz w edytorze SQL BigQuery Studio wklej ten kod SQL, aby utworzyć nową tabelę z kolumną
image_ref. Kliknij Uruchom.
CREATE OR REPLACE TABLE `model_dev.vehicle_multimodal` AS
SELECT
*,
ARRAY(
SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF(uri, 'us.conn'))
FROM UNNEST(images) AS uri
) AS image_ref
FROM `model_dev.vehicle_metadata`;
- Sprawdź nową kolumnę
image_refObjectRef, którą właśnie utworzono. Nowa tabela zawiera teraz kolumnę ObjectRef, która ma uprawnienia do wykonywania działań na samych obrazach. Aby ją wyświetlić, uruchom to zapytanie:
SELECT auction_id, item_name, description, image_ref
FROM `model_dev.vehicle_multimodal` LIMIT 5;
- Teraz użyjesz funkcji
AI.GENERATEiAI.CLASSIFYdo analizy obrazów.AI.GENERATEwyodrębnia ocenę stanu i jednozdaniowe podsumowanie uszkodzeń, prosząc Gemini o odpowiedź, aAI.CLASSIFYściśle kategoryzuje typ nadwozia i kolor pojazdu.
Wykonaj to zapytanie, aby wyodrębnić te statystyki do osobnej tabeli funkcji. Powinno to zająć około 3 minuty.
CREATE OR REPLACE TABLE `model_dev.vehicle_vision_features` AS
WITH generated_data AS (
SELECT
auction_id,
AI.GENERATE(
prompt => ('Rate the condition of this car on a scale from 0-100. Output a 1 sentence description of any glaring red flags', image_ref),
output_schema => 'condition INT64, description_summary STRING'
).* EXCEPT(full_response,status)
FROM
`model_dev.vehicle_multimodal`
),
-- Object-centric Classifications
classified_data AS (
SELECT
auction_id,
AI.CLASSIFY(
('What type of automobile is this?', image_ref[0]),
categories => ['Truck', 'Sedan', 'SUV']) AS body_style,
AI.CLASSIFY(
('Color of the exterior of the automobile', image_ref[0]),
categories => ['Black', 'White', 'Silver', 'Gray', 'Red', 'Blue', 'Brown', 'Green', 'Beige', 'Gold']) AS color,
AI.CLASSIFY(
('Color of the interior of the automobile', image_ref[0]),
categories => ['Black', 'Gray', 'Beige', 'Tan', 'Brown', 'White', 'Red']) AS interior
FROM `model_dev.vehicle_multimodal`
)
-- Join the AI insights back together into the final feature table
SELECT
g.auction_id,
g.condition,
g.description_summary,
c.body_style,
c.color,
c.interior
FROM generated_data g
JOIN classified_data c ON g.auction_id = c.auction_id;
- Aby wyświetlić wygenerowane funkcje, uruchom to zapytanie lub po prostu spójrz na zrzut ekranu poniżej:
SELECT auction_id, condition, description_summary, body_style, color, interior FROM `model_dev.vehicle_vision_features` LIMIT 5;

Podsumowanie sekcji: dostęp do surowych obrazów uzyskano bezpośrednio z BigQuery, a do wyodrębnienia uporządkowanych cech wizualnych bez przenoszenia plików użyto modeli Gemini.
5. Prognozowanie cen za pomocą XGBoost
Aby obliczyć, czy pojazd jest rzeczywiście dobrą ofertą, potrzebna jest wiarygodna wartość bazowa, która określa jego uczciwą wartość rynkową. Zamiast wyodrębniać dane do lokalnych skryptów lub notatników w celu trenowania modelu, możesz trenować model XGBoost bezpośrednio w BigQuery za pomocą standardowej wersji SQL. Ta prognoza ceny jest podstawą logiki 📈 uczciwej wartości rynkowej w aplikacji front-end.
- Wróć na kartę BigQuery Studio.
- Najpierw przyjrzyj się zbiorowi danych treningowych. W przeciwieństwie do aktywnych ofert sprzedaży pojazdów ta
synthetic_carstabela zawiera 100 tys. historycznych transakcji sprzedaży, które zostaną użyte do trenowania modelu. Aby to sprawdzić, uruchom to krótkie zapytanie:
SELECT
*
FROM
`model_dev.synthetic_cars`
LIMIT 10;
- Teraz wykonaj ten kod SQL, aby wytrenować model regresji XGBoost. Na podstawie tych 100 tys. rekordów historycznych model uczy się, jak atrybuty takie jak przebieg, rok produkcji, marka i stan wizualny wpływają na cenę:
CREATE OR REPLACE MODEL `model_dev.car_price_model`
OPTIONS(
MODEL_TYPE = 'BOOSTED_TREE_REGRESSOR',
INPUT_LABEL_COLS = ['selling_price'],
MAX_ITERATIONS = 15,
TREE_METHOD = 'HIST'
) AS
SELECT
* EXCEPT(vin, sale_date, market_value, seller)
FROM
`model_dev.synthetic_cars`;
- Zanim zaczniesz prognozować ceny w przypadku aktywnych, bieżących ofert pojazdów, musisz zebrać wszystkie odpowiednie funkcje wejściowe w jednym miejscu. Uruchom to zapytanie SQL, aby scalić uporządkowane metadane pojazdu z wygenerowanymi przed chwilą funkcjami wyodrębnionymi za pomocą funkcji Vision:
CREATE OR REPLACE TABLE `model_dev.vehicle_prediction_features` AS
SELECT
meta.auction_id,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.transmission_type,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id;
- Na koniec przewiduj uczciwą wartość rynkową każdej trwającej oferty sprzedaży pojazdu. Wykonaj to zapytanie, aby przekazać zagregowane cechy do nowo wytrenowanego modelu i zapisać wyniki liczbowe w bezpiecznej tabeli prognoz:
CREATE OR REPLACE TABLE `model_dev.vehicle_price_predictions` AS
SELECT
auction_id,
ROUND(predicted_selling_price, 2) AS predicted_market_value
FROM ML.PREDICT(
MODEL `model_dev.car_price_model`,
(SELECT * FROM `model_dev.vehicle_prediction_features`)
);
- Teraz sprawdź dane wyjściowe modelu. Uruchom to szybkie zapytanie, aby wyświetlić podgląd prognozowanych wartości rynkowych w przypadku aktywnych informacji o pojazdach:
SELECT * FROM `model_dev.vehicle_price_predictions` LIMIT 5;
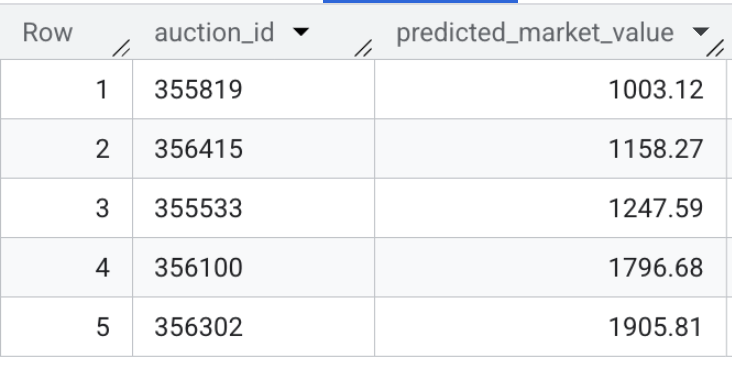
Podsumowanie sekcji: wytrenowano model regresji XGBoost na podstawie 100 tys. przykładowych transakcji i przeprowadzono wnioskowanie wsadowe,aby przewidzieć wartość rynkową każdego aktywnego wpisu dotyczącego pojazdu w zbiorze danych.
6. Semantyczne wektory dystrybucyjne i wykrywanie autentyczności
W tej sekcji wykonasz 2 różne potoki osadzania, aby włączyć inteligentne funkcje na platformie handlowej pojazdów:
- Wyszukiwanie obrazów multimodalnych: przekształcanie surowych zdjęć pojazdów w przestrzeń wektorową, aby umożliwić użytkownikom wyszukiwanie za pomocą języka naturalnego (np. „niezawodny samochód dostawczy”).
- Wektory dystrybucyjne tekstu i wyszukiwanie podobieństw: przetłumacz pisemne opisy pojazdów na wektory dystrybucyjne, aby porównać aktywne oferty z znanymi profilami potencjalnych oszustów lub entuzjastów za pomocą
VECTOR_SEARCH. Oblicza to 🔍 wynik autentyczności, który kupujący widzą w aplikacji.
- Najpierw musisz wygenerować osadzanie multimodalne dla informacji o pojazdach. Model
gemini-embedding-2-previewumożliwia wprowadzanie obrazów i tekstu do tego samego wektora dystrybucyjnego. Ten model może przetwarzać jednocześnie wiele rodzajów danych, ale w tym konkretnym przypadku osadzamy tylko obrazy pojazdów. Umożliwia to działanie paska „wyszukiwania semantycznego” w aplikacji front-end, dzięki czemu kupujący mogą używać języka naturalnego (np. „niezawodny pickup”) i szybko wyszukiwać pasujące oferty. Uruchom to zapytanie, aby wygenerować wektory multimodalne za pomocąAI.EMBED:
CREATE OR REPLACE TABLE `model_dev.vehicle_images_embedded` AS
SELECT
auction_id,
AI.EMBED(
STRUCT(image_ref),
endpoint => 'gemini-embedding-2-preview').result AS multimodal_embedding
FROM `model_dev.vehicle_multimodal`
WHERE ARRAY_LENGTH(image_ref) > 0;
- Następnie sprawdzisz dane profilu ryzyka wczytane wcześniej. Pamiętaj, że zawiera ona zarówno znane typologie oszustw, jak i przykłady ofert dla prawdziwych entuzjastów. Aby wyświetlić profile podstawowe, uruchom to zapytanie:
SELECT profile_id, profile_type, description
FROM `model_dev.seller_risk_profiles`;
- Teraz przetłumaczysz te surowe opisy ryzyka na wektory dystrybucyjne. Możesz użyć specjalistycznego modelu osadzania tekstu (
text-embedding-005), aby dokładnie ocenić właśnie wyświetlony tekst. Wklej ten kod SQL i kliknij Uruchom, aby osadzić profile podstawowe:
CREATE OR REPLACE TABLE `model_dev.seller_risk_profiles_embedded` AS
SELECT
profile_id,
description AS content,
profile_type,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.seller_risk_profiles`;
- Następnie wygeneruj porównywalne osadzanie dla rzeczywistego asortymentu pojazdów na żywo. Uruchom to zapytanie, aby przetłumaczyć surowy opis HTML każdego pojazdu na przestrzeń wektorową, dzięki czemu będzie można go porównać z profilami podstawowymi:
CREATE OR REPLACE TABLE `model_dev.vehicle_descriptions_embedded` AS
SELECT
auction_id,
description AS content,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.vehicle_metadata`
WHERE description IS NOT NULL;
- Na koniec przeprowadź wyszukiwanie wektorowe, aby obliczyć odległość semantyczną między aktywnymi informacjami o produktach a profilami bazowymi. Aby przeprowadzić mapowanie, uruchom ten kod SQL. Mniejsza odległość matematyczna oznacza, że oferta jest bardzo podobna do znanego klastra oszustw, a większa odległość sugeruje, że opis jest wiarygodny.
CREATE OR REPLACE TABLE `model_dev.vehicle_authenticity_scores` AS
SELECT
scam_search.query.auction_id,
CAST(
GREATEST(0.0, LEAST(100.0, ROUND((MIN(scam_search.distance) - 0.33) / 0.12 * 100.0)))
AS INT64
) AS authenticity_score
FROM VECTOR_SEARCH(
TABLE `model_dev.seller_risk_profiles_embedded`,
'text_embedding',
(
SELECT text_embedding, auction_id
FROM `model_dev.vehicle_descriptions_embedded`
),
top_k => 15,
distance_type => 'COSINE'
) AS scam_search
WHERE scam_search.base.profile_type = 'scam'
GROUP BY 1;
Zawartość tej tabeli może wyglądać tak:
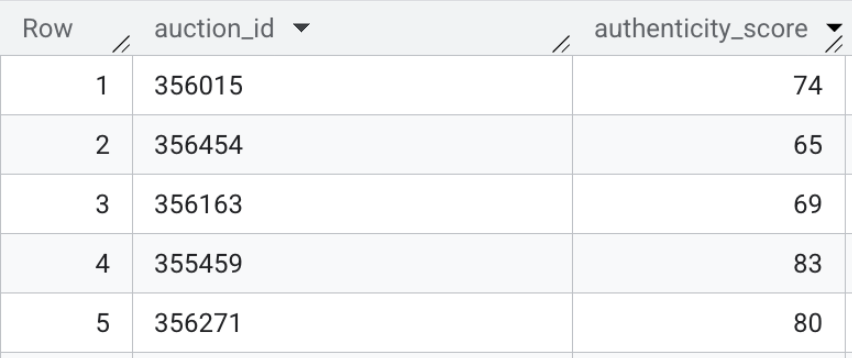
Podsumowanie sekcji: wygenerowano osadzanie multimodalne dla paska wyszukiwania interfejsu, a następnie użyto wyszukiwania wektorowego bezpośrednio w BigQuery, aby porównać surowe teksty ofert w HTML z znanymi profilami oszustów.
7. Generatywne ocenianie transakcji
Masz teraz uporządkowane zbiory danych wygenerowane za pomocą różnych technik uczenia maszynowego, w całości zorganizowanych w BigQuery: wyodrębnianie informacji z obrazów, model XGBoost do prognozowania wartości rynkowej i wektoryzacja wyszukiwania wektorowego.
Ostatnim krokiem jest połączenie tych sygnałów AI w skonsolidowany widok jako ostateczny wynik transakcji w aplikacji front-end.
- Najpierw połącz surowe metadane z wyodrębnionymi przez AI funkcjami dotyczącymi wzroku, wynikami prognozowania cen i ocenami autentyczności semantycznej. Wykonaj ten kod SQL:
CREATE OR REPLACE TABLE `model_dev.vehicle_features_enhanced` AS
SELECT
meta.auction_id,
meta.item_name,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.current_bid,
meta.listing_url,
meta.transmission_type,
meta.description,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior,
COALESCE(scam.authenticity_score, 100) AS authenticity_score,
vision.description_summary,
prices.predicted_market_value
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id
LEFT JOIN `model_dev.vehicle_price_predictions` prices
ON meta.auction_id = prices.auction_id
LEFT JOIN `model_dev.vehicle_authenticity_scores` scam
ON meta.auction_id = scam.auction_id;
- Następnie oblicz ocenę transakcji w skali od 0 do 100, łącząc 4 różne sygnały AI. Ta formuła równoważy wartość, jakość i ryzyko, aby wyświetlać najlepsze oferty:
- Wynik ceny (40%): mierzy oszczędności w porównaniu z wartością rynkową.
- Wynik wizualny (30%): statystyki z poprzednich analiz zdjęć.
- Ocena autentyczności (15%): ocena ryzyka oszustwa.
- Ocena stanu (15%): wywnioskowana na podstawie opisu sprzedawcy za pomocą
AI.SCORE.
CREATE OR REPLACE TABLE `model_dev.marketplace_listings` AS
WITH score_elements AS (
SELECT
*,
-- 1. SELLER DESCRIPTION SCORE (use AI.SCORE on seller description)
AI.SCORE(
FORMAT("Rate the vehicle condition (0-100) based ONLY on this text: '%s'", description)
) AS description_score,
-- 2. PRICE SCORE
-- Higher impact for underpricing, lower impact for overpricing.
CAST(LEAST(100.0, GREATEST(0.0,
75.0 + (
IF((predicted_market_value - current_bid) > 0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 250.0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 40.0
)
)
)) AS INT64) AS price_score
FROM `model_dev.vehicle_features_enhanced`
),
final_calcs AS (
SELECT
*,
-- 3. Combine scores: Price (40%), Condition (30%), Description (15%), Authenticity (15%)
ROUND(
(
(price_score * 0.40) +
(CAST(condition AS INT64) * 0.30) +
(COALESCE(description_score, 50) * 0.15) +
(CAST(authenticity_score AS INT64) * 0.15)
)
-- Authenticity penalty for scores below 50.
* (IF(CAST(authenticity_score AS INT64) < 50, 0.20, 1.05))
) AS raw_score
FROM score_elements
)
SELECT
* EXCEPT(raw_score),
-- 4. Set floor values: low authenticity scores drop to 10; others floor at 35.
CAST(GREATEST(
(IF(CAST(authenticity_score AS INT64) < 50, 10, 35)),
LEAST(100, raw_score)
) AS INT64) AS deal_score
FROM final_calcs;
Aby zapewnić wysoką jakość rekomendacji, zapytanie stosuje 2 warstwy logiki:
- Weryfikacja autentyczności: jeśli oferta zostanie oznaczona jako „Wysokie ryzyko” (wynik < 50), łączny wynik oferty zostanie automatycznie obniżony o 80%, aby zapobiec promowaniu podejrzanych ofert.
- Optymalizacja „ukrytych perełek”: formuła wykorzystuje logikę odcinkową, aby agresywnie nagradzać oszczędności, a jednocześnie być bardziej wyrozumiałą w stosunku do marż. Dzięki temu zawyżony cenowo samochód w idealnym stanie może nadal uzyskać ocenę „Odpowiednia”.
Wynikowa tabela model_dev.marketplace_listings zawiera pola takie jak deal_score, a także price_score i authenticity_score.
- Aby samodzielnie wyświetlić wyniki transakcji, uruchom to zapytanie lub po prostu spójrz na zrzut ekranu poniżej:
SELECT item_name, model_year, authenticity_score, predicted_market_value, price_score, deal_score FROM `model_dev.marketplace_listings`
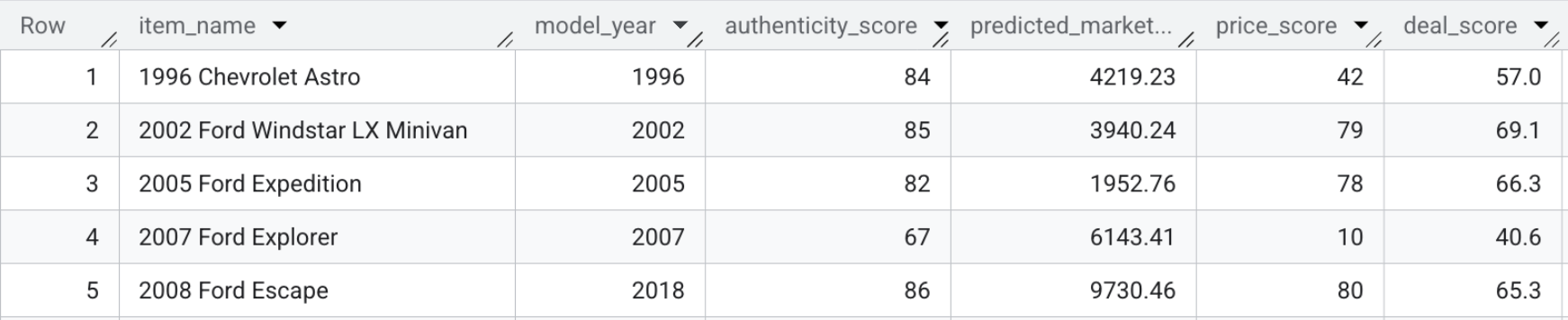
Podsumowanie sekcji: połączyliśmy prognozowane ceny, funkcje wizualne i oceny autentyczności z opisem sprzedawcy, aby obliczyć pojedynczą ocenę oferty dla każdej aukcji.
8. Wdrażanie aplikacji frontendowej
Teraz nadszedł czas na uruchomienie aplikacji frontendowej. Dzięki temu możesz wyszukiwać zasoby reklamowe z ofertami pojazdów i korzystać z wygenerowanych przez AI obserwacji, takich jak ocena oferty.
Eksportowanie wyników AI do frontendu
Interfejs React korzysta z lokalnego ładunku JSON, aby zapewnić szybkie początkowe ładowanie strony. Aby zasilać platformę handlową, wyodrębnij ostateczne wyniki generatywnych transakcji z BigQuery i wstrzyknij je z powrotem do projektu Next.js.
- Sprawdź, czy środowisko jest gotowe. Jeśli przekroczysz limit czasu sesji Cloud Shell lub przejdziesz do innego folderu, uruchom to polecenie, aby wrócić do katalogu głównego projektu i przywrócić zmienne środowiskowe:
cd ~/devrel-demos/data-analytics/cymbal-autos-multimodal && \
export PROJECT_ID=$(gcloud config get-value project) && \
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
- Uruchom podany skrypt w języku Python, aby wysłać zapytanie do końcowego widoku BigQuery i scalić nowe wyniki oceny transakcji z bazowym magazynem danych aplikacji:
python3 scripts/setup/08_export_frontend_data.py
Otrzymasz wiadomość z potwierdzeniem, np.:
💾 Updated local file: app/src/data/cars.json
Wdrażanie aplikacji w Cloud Run
Po pomyślnym wzbogaceniu danych możesz wdrożyć aplikację frontendu Next.js w publicznym internecie za pomocą Cloud Run. Ma nowoczesny interfejs z ocenami ofert, interaktywnymi karuzelami obrazów i dynamicznym hybrydowym paskiem wyszukiwania semantycznego, który w czasie rzeczywistym wysyła zapytania do BigQuery.
- W Cloud Shell przejdź do katalogu
app/sklonowanego repozytorium. Jest to bardzo ważne – pozostanie w katalogu głównym spowoduje niepowodzenie kompilacji.
cd app
- Wdróż aplikację jako bezserwerowy kontener za pomocą Cloud Run. Polecenie przekazuje
PROJECT_IDjako zmienną środowiskową, dzięki czemu interfejs Next.js API wie, do którego projektu BigQuery wysłać zapytanie:
gcloud run deploy cymbal-autos-frontend \
--source . \
--region us-west1 \
--allow-unauthenticated \
--min-instances 1 \
--set-env-vars PROJECT_ID=$PROJECT_ID \
--project $PROJECT_ID
- Po zakończeniu wdrażania terminal wygeneruje bezpieczny adres URL usługi. Będą one wyglądać mniej więcej tak:
Service URL: https://cymbal-autos-frontend-[YOUR-PROJECT-NUMBER].us-west1.run.app/
9. Poznaj aplikację Cymbal Autos
Po przeniesieniu kontenera frontendu do Cloud Run możesz przetestować aplikację.
- Otwórz witrynę: otwórz bezpieczny adres URL usługi zwrócony przez Cloud Run.
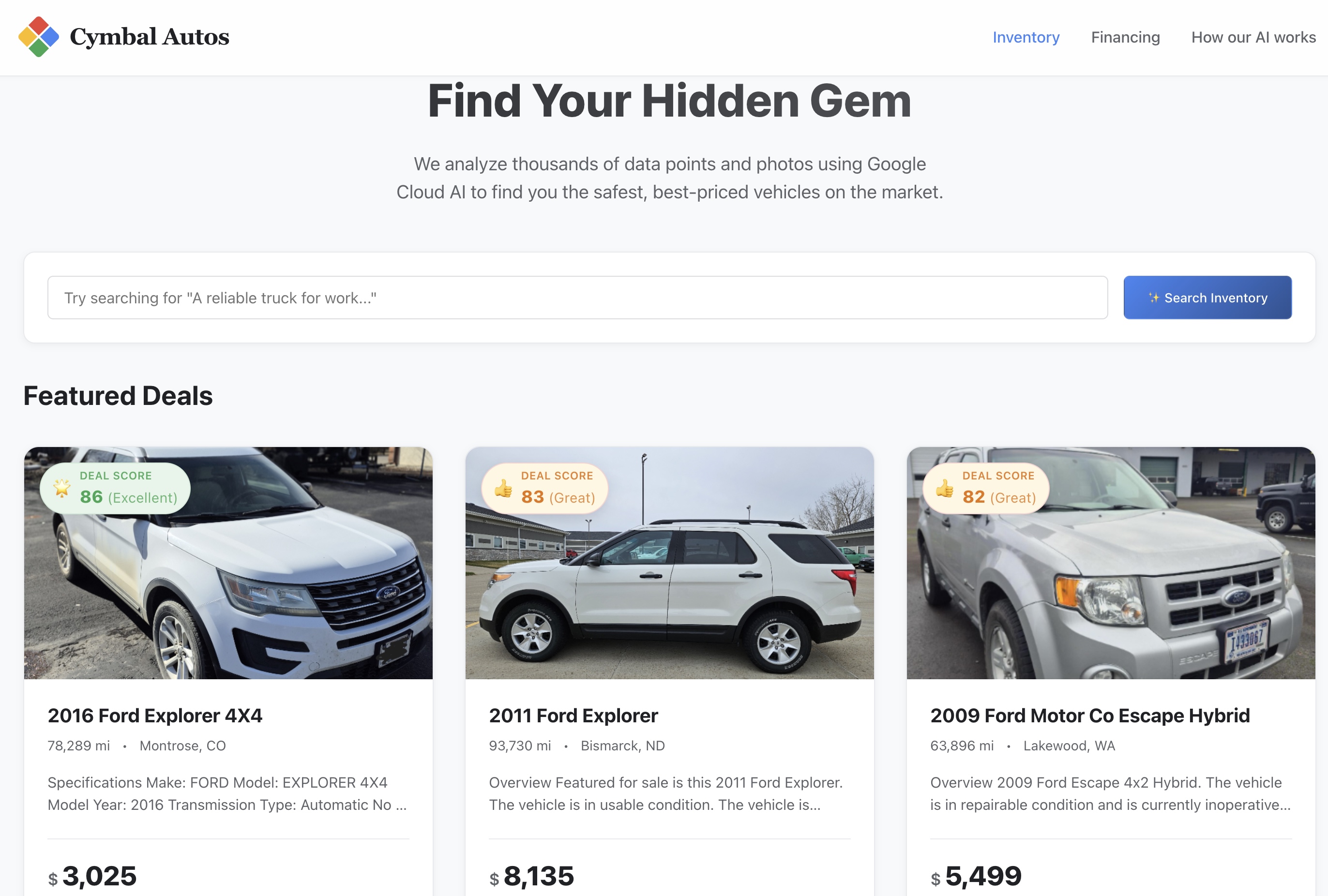
- Przeprowadź wyszukiwanie semantyczne: spróbuj wyszukać abstrakcyjne pojęcie, np. „Niezawodny samochód dostawczy, który może przewozić ładunki i jeździć w terenie”. Aplikacja Next.js tłumaczy nieprzetworzony tekst na wielomodalny wektor dystrybucyjny i wysyła zapytanie
VECTOR_SEARCHw czasie rzeczywistym do BigQuery, mapując Twój pomysł na ekosystem pojazdów.
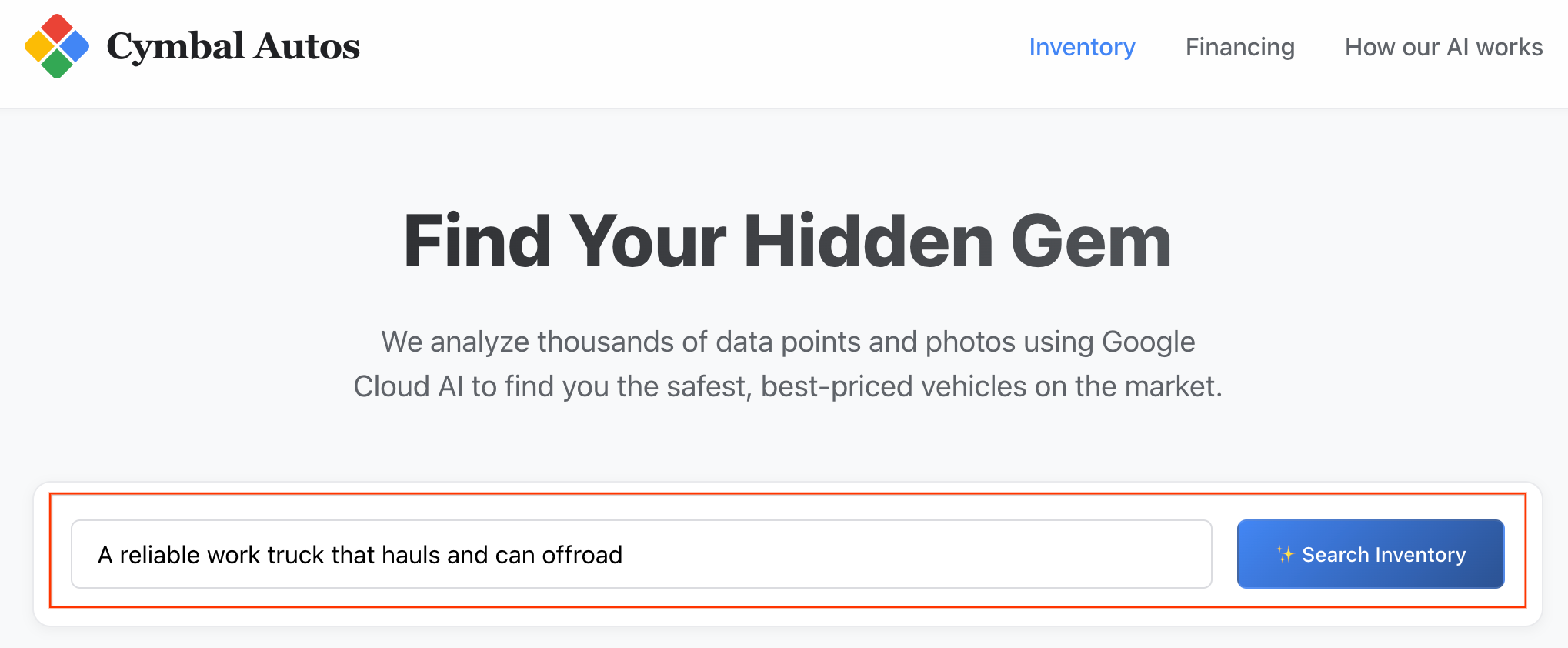
Uwaga: wyniki są sortowane według podobieństwa semantycznego.
- Sprawdź wyniki: BigQuery obliczył dokładną odległość matematyczną między Twoją abstrakcyjną ideą a cechami pojazdu, aby zwrócić najbliższe dopasowania semantyczne.
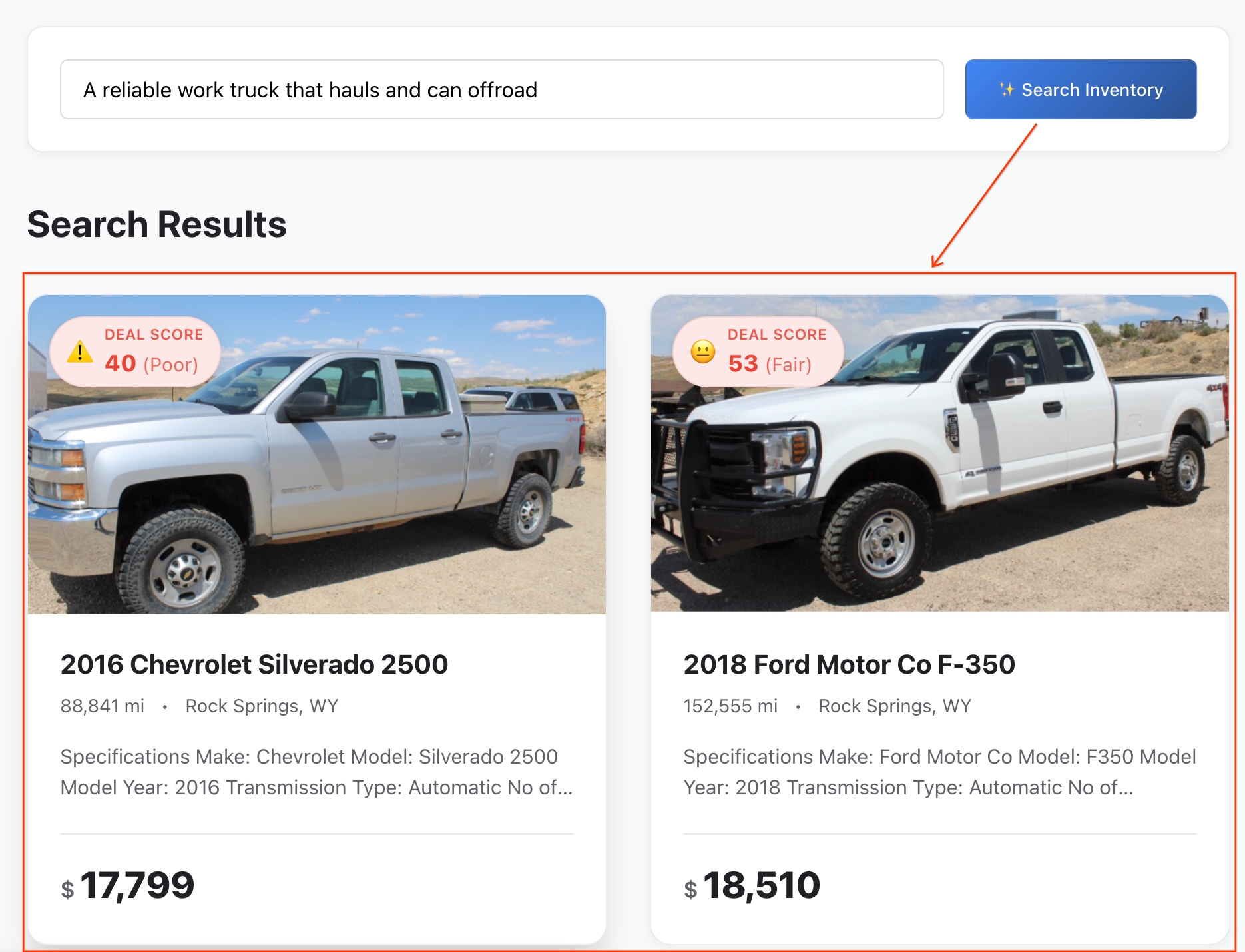
- Szczegółowe informacje: kliknij dowolny pojazd, aby otworzyć pełny profil oferty.
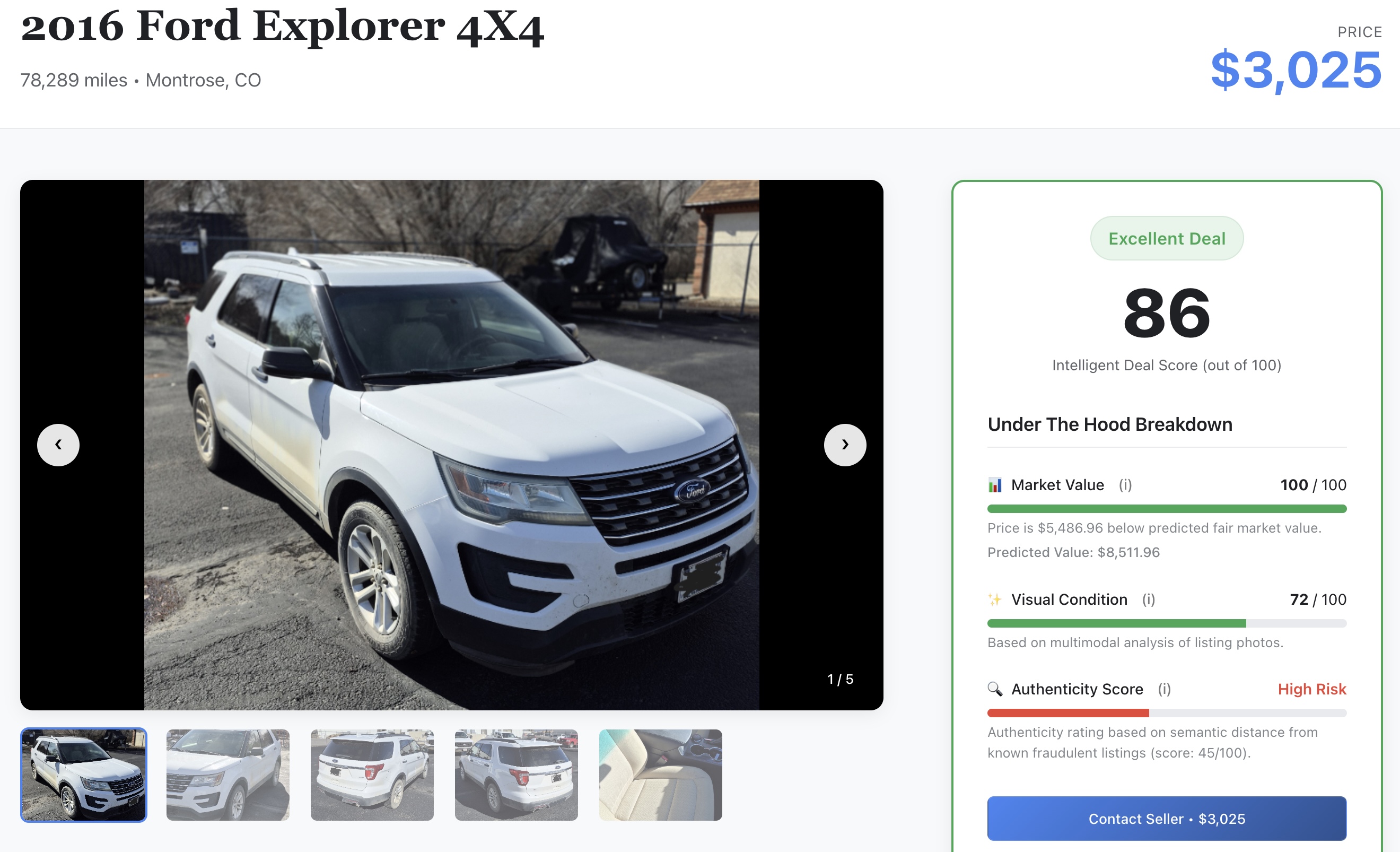
- Sprawdź sygnał AI: przewiń szczegóły, aby zobaczyć surowe wyniki uczenia maszynowego wygenerowane wcześniej w module:
- 📈 Wartość rynkowa: cena bazowa prognozowana przez model XGBoost.
- ✨ Stan wizualny: ocena uszkodzeń fizycznych wyodrębniona przez modele Gemini.
- 🔍 Wynik autentyczności: wektor autentyczności oddziela legalnych sprzedawców od potencjalnych oszustów.
10. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami za zasoby użyte w tym ćwiczeniu, możesz usunąć cały projekt w chmurze Google Cloud utworzony na potrzeby tego ćwiczenia lub uruchomić ten automatyczny skrypt zamykający.
- W terminalu Cloud Shell wróć do katalogu głównego:
cd ..
- Uruchom poniższy skrypt czyszczący. Spowoduje to opróżnienie zasobnika Cloud Storage, usunięcie
model_devzbioru danych BigQuery, usunięcie połączenia BigQuery i usunięcie usługi Cloud Run.
chmod +x scripts/cleanup/teardown.sh
./scripts/cleanup/teardown.sh
11. Gratulacje
Gratulacje! Udało Ci się utworzyć inteligentną platformę handlową pojazdów. Udało Ci się ujednolicić analizę danych nieustrukturyzowanych, modelowanie predykcyjne i integracje AI w jednym obszarze roboczym za pomocą BigQuery.
Czego się dowiedziałeś(-aś)
- Jak połączyć BigQuery z nieustrukturyzowanymi obrazami Cloud Storage za pomocą ObjectRef
- Jak wyodrębniać atrybuty pojazdów ze zdjęć za pomocą BigQuery z modelami Gemini, takimi jak funkcje
AI.GENERATEiAI.CLASSIFY - Prognozowanie cen pojazdów za pomocą BigQuery ML
- Jak rozpoznawać potencjalne oszustwa w ofertach, umieszczając opisy pojazdów i przeprowadzając
VECTOR_SEARCH - Jak używać
AI.SCOREdo oceny danych nieustrukturyzowanych w czasie rzeczywistym i włączania wyników do kompleksowego wyniku transakcji - Jak eksportować dane i wdrażać aplikację na platformie handlowej Next.js w Cloud Run
Dalsze kroki
- Poznaj pełen zakres funkcji generatywnej AI dostępnych w BigQuery
- Dowiedz się więcej o tworzeniu modeli prognozujących za pomocą GoogleSQL