
1. Introdução
Neste codelab, você vai criar o back-end e implantar o front-end do "Cymbal Autos", um mercado on-line de veículos. Você vai usar o BigQuery e os modelos do Gemini na plataforma de agentes do Gemini Enterprise para inspecionar fotos de veículos, prever preços usando o BigQuery ML, detectar anúncios fraudulentos usando incorporações de vetores e calcular pontuações de ofertas compostas. Por fim, você vai mostrar esses insights em um front-end Next.js implantado no Cloud Run.
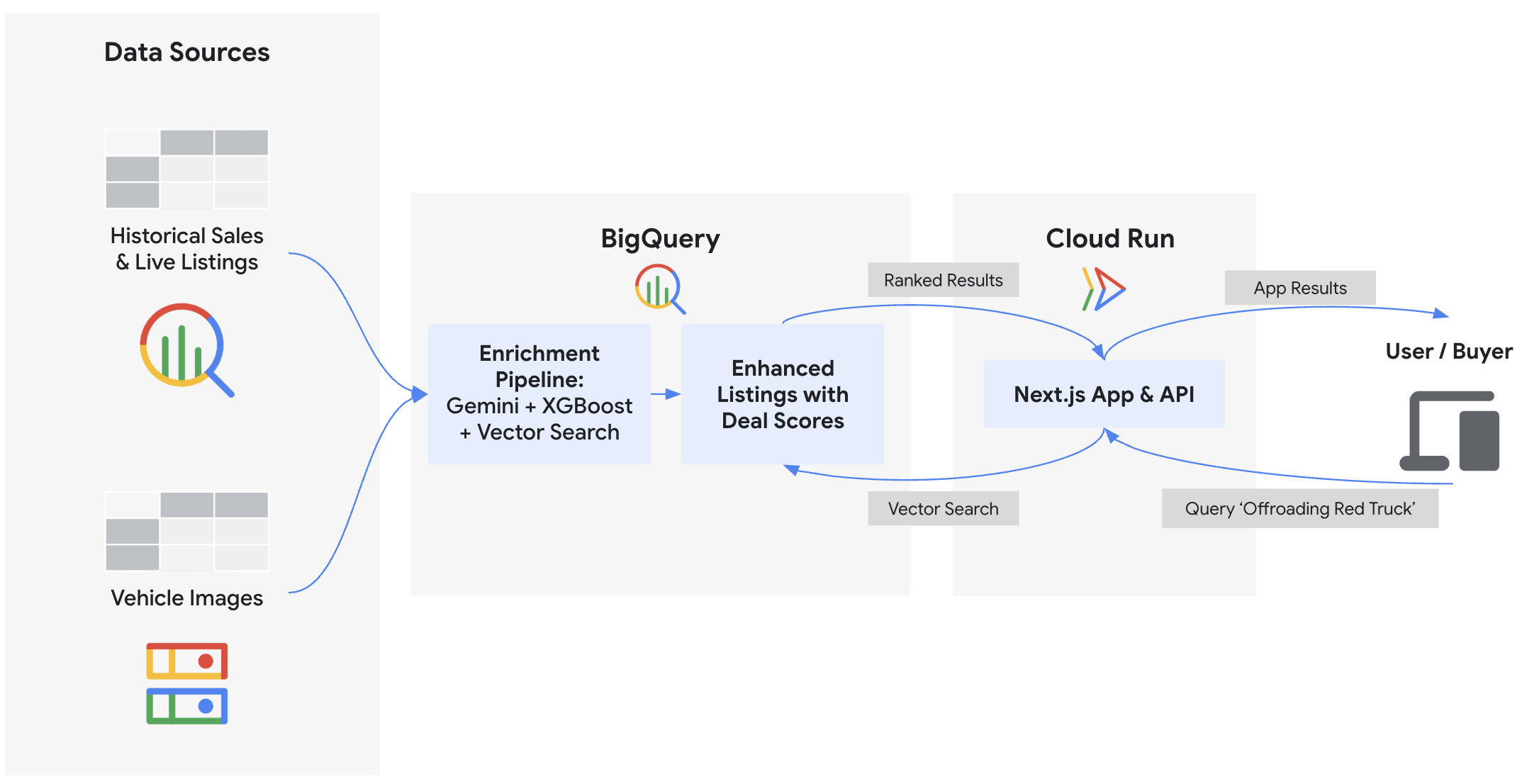
Atividades deste laboratório
- Conectar o BigQuery a imagens não estruturadas do Cloud Storage usando ObjectRef
- Extrair atributos de veículos de fotos usando o BigQuery com modelos do Gemini
- Prever preços justos de mercado treinando um modelo de regressão XGBoost com o BigQuery ML
- Identifique possíveis golpes e anúncios confiáveis incorporando descrições de veículos e realizando
VECTOR_SEARCH - Calcular uma pontuação de oferta abrangente para cada ficha, incorporando indicadores de condição da descrição do vendedor usando
AI.SCORE - Exportar dados e implantar o aplicativo do marketplace Next.js no Google Cloud Run
O que é necessário
- Um navegador da web, como o Chrome
- Tenha um projeto do Google Cloud com o faturamento ativado.
- Noções básicas de SQL, Python e Google Cloud
- Permissões suficientes do IAM para ativar APIs, criar recursos e atribuir permissões (por exemplo, proprietário do projeto)
Este codelab é para desenvolvedores de nível intermediário.
Os recursos criados neste codelab custam menos de US $5.
2. Antes de começar
Criar um projeto do Google Cloud
- No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto na nuvem do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
Iniciar o Cloud Shell
Você vai usar o Google Cloud Shell para baixar o código, executar scripts de configuração e implantar o aplicativo.
- Clique em Ativar Cloud Shell na parte de cima do Console do Google Cloud.

- Depois de se conectar ao Cloud Shell, autentique sua sessão para garantir que o aplicativo possa acessar as APIs do Cloud. Siga as instruções para autorizar o Cloud Shell:
gcloud auth application-default login
- Defina o ID do projeto do Google Cloud e um nome exclusivo para o bucket do Cloud Storage (onde você vai armazenar os dados brutos):
export PROJECT_ID=$(gcloud config get-value project)
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
gcloud config set project $PROJECT_ID
Você vai ver uma mensagem semelhante a esta:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Ativar APIs
Execute este comando no Cloud Shell para ativar todas as APIs necessárias para este codelab:
gcloud services enable \
aiplatform.googleapis.com \
artifactregistry.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
cloudbuild.googleapis.com \
run.googleapis.com
Se a execução for bem-sucedida, você vai receber uma mensagem semelhante a esta:
Operation "operations/..." finished successfully.
3. Receber o código e os dados de configuração
Primeiro, faça o download dos recursos de demonstração e configure as variáveis de ambiente.
- No Cloud Shell, clone o repositório
devrel-demose navegue até o diretório do projeto:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos/data-analytics/cymbal-autos-multimodal
- Execute o script para copiar os dados no seu ambiente. Esse script sincroniza os conjuntos de dados do repositório local com seu bucket pessoal do Cloud Storage e busca as imagens de veículos em um bucket público:
chmod +x scripts/setup/*.sh
./scripts/setup/00_copy_data.sh
Depois disso, você vai ver uma mensagem semelhante a esta:
Average throughput: 87.8MiB/s Data copy complete!
- Em seguida, configure a conexão a recursos do Cloud do BigQuery. Para analisar imagens não estruturadas no Cloud Storage e chamar modelos da plataforma de agentes diretamente das suas consultas SQL, o BigQuery precisa delegar permissões do IAM a uma conta de serviço subjacente. Esse script cria a conexão segura e concede a ela os papéis necessários de usuário da Vertex AI e consumidor do Service Usage (o que leva cerca de um minuto para ser propagado):
./scripts/setup/01_setup_api_connection.sh
Você verá uma mensagem semelhante a:
Environment setup complete! Your BigQuery connection is ready.
- Por fim, crie o conjunto de dados inicial do BigQuery e carregue os dados tabulares brutos. Isso cria o conjunto de dados
model_deve preenche as tabelas iniciais, definindo a base antes de você escrever qualquer consulta de machine learning:
./scripts/setup/02_load_to_bq.sh
Você verá uma mensagem semelhante a:
================================================================= BigQuery load complete! =================================================================
4. Extração de visão multimodal
Antes de pontuar as informações do veículo, você vai extrair dados estruturados (como cor, estilo de carroceria ou danos visuais) de centenas de fotos brutas. Ao usar as funções ObjectRef e os modelos do Gemini hospedados na plataforma de agentes, é possível gerar esses recursos sem mover arquivos ou escrever pipelines de dados complexos. Essa extração alimenta diretamente o selo ✨ Condição visual no aplicativo de front-end.
- Abra o BigQuery Studio em uma nova guia do navegador.
- Clique no botão + Escrever nova consulta. Você vai usar o editor de SQL para interagir com o código SQL ao longo deste codelab.
- Antes de criar os extratores de machine learning, dê uma olhada rápida nas imagens brutas. Execute a consulta a seguir para ver a matriz de URIs de imagem armazenados no Google Cloud Storage para cada ficha:
SELECT auction_id, item_name, description, images
FROM `model_dev.vehicle_metadata` LIMIT 5;
- Agora, no editor de SQL do BigQuery Studio, cole o seguinte SQL para criar uma tabela com uma coluna
image_ref. Clique em Executar.
CREATE OR REPLACE TABLE `model_dev.vehicle_multimodal` AS
SELECT
*,
ARRAY(
SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF(uri, 'us.conn'))
FROM UNNEST(images) AS uri
) AS image_ref
FROM `model_dev.vehicle_metadata`;
- Confira a nova coluna
image_refObjectRef que você acabou de criar. A nova tabela agora tem uma coluna "ObjectRef" com permissões para execução nas próprias imagens. Execute a consulta a seguir para conferir:
SELECT auction_id, item_name, description, image_ref
FROM `model_dev.vehicle_multimodal` LIMIT 5;
- Agora você vai usar
AI.GENERATEeAI.CLASSIFYpara analisar as imagens. OAI.GENERATEextrai a pontuação da condição e um resumo de danos de uma frase ao solicitar o Gemini, enquanto oAI.CLASSIFYcategoriza estritamente o tipo de carroceria e a cor do veículo.
Execute a consulta a seguir para extrair esses insights em uma tabela de recursos dedicada. Esse processo leva cerca de três minutos.
CREATE OR REPLACE TABLE `model_dev.vehicle_vision_features` AS
WITH generated_data AS (
SELECT
auction_id,
AI.GENERATE(
prompt => ('Rate the condition of this car on a scale from 0-100. Output a 1 sentence description of any glaring red flags', image_ref),
output_schema => 'condition INT64, description_summary STRING'
).* EXCEPT(full_response,status)
FROM
`model_dev.vehicle_multimodal`
),
-- Object-centric Classifications
classified_data AS (
SELECT
auction_id,
AI.CLASSIFY(
('What type of automobile is this?', image_ref[0]),
categories => ['Truck', 'Sedan', 'SUV']) AS body_style,
AI.CLASSIFY(
('Color of the exterior of the automobile', image_ref[0]),
categories => ['Black', 'White', 'Silver', 'Gray', 'Red', 'Blue', 'Brown', 'Green', 'Beige', 'Gold']) AS color,
AI.CLASSIFY(
('Color of the interior of the automobile', image_ref[0]),
categories => ['Black', 'Gray', 'Beige', 'Tan', 'Brown', 'White', 'Red']) AS interior
FROM `model_dev.vehicle_multimodal`
)
-- Join the AI insights back together into the final feature table
SELECT
g.auction_id,
g.condition,
g.description_summary,
c.body_style,
c.color,
c.interior
FROM generated_data g
JOIN classified_data c ON g.auction_id = c.auction_id;
- Para conferir os recursos gerados, execute a consulta a seguir ou confira a captura de tela abaixo:
SELECT auction_id, condition, description_summary, body_style, color, interior FROM `model_dev.vehicle_vision_features` LIMIT 5;

Resumo da seção:você acessou as imagens brutas diretamente do BigQuery e usou modelos do Gemini para extrair recursos visuais estruturados sem mover nenhum arquivo.
5. Preços preditivos com XGBoost
Para calcular se um veículo é um bom negócio, é necessário ter um valor de mercado justo confiável. Em vez de extrair dados para scripts ou notebooks locais para treinar um modelo, é possível treinar um modelo XGBoost diretamente no BigQuery usando o SQL padrão. Essa previsão de preço impulsiona a lógica de 📈 valor justo de mercado no aplicativo de front-end.
- Volte para a guia do BigQuery Studio.
- Primeiro, confira o conjunto de dados de treinamento. Ao contrário das informações do produto de veículos ativos, essa tabela
synthetic_carscontém 100.000 vendas históricas que serão usadas para treinar o modelo. Execute esta consulta rápida para dar uma olhada:
SELECT
*
FROM
`model_dev.synthetic_cars`
LIMIT 10;
- Agora, execute o seguinte SQL para treinar um modelo de regressão XGBoost. Esse modelo aprende como atributos como quilometragem, ano, marca e condição visual afetam o preço com base nesses 100.000 registros históricos:
CREATE OR REPLACE MODEL `model_dev.car_price_model`
OPTIONS(
MODEL_TYPE = 'BOOSTED_TREE_REGRESSOR',
INPUT_LABEL_COLS = ['selling_price'],
MAX_ITERATIONS = 15,
TREE_METHOD = 'HIST'
) AS
SELECT
* EXCEPT(vin, sale_date, market_value, seller)
FROM
`model_dev.synthetic_cars`;
- Antes de prever os preços dos anúncios de veículos ativos, reúna todos os recursos de entrada relevantes em um só lugar. Execute este SQL para mesclar os metadados estruturados do veículo com os recursos extraídos pela visão que você acabou de gerar:
CREATE OR REPLACE TABLE `model_dev.vehicle_prediction_features` AS
SELECT
meta.auction_id,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.transmission_type,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id;
- Por fim, preveja o valor justo de mercado de todas as informações de produtos de veículos em andamento. Execute a consulta a seguir para inserir os recursos agregados no modelo recém-treinado e salvar as saídas numéricas em uma tabela de previsões segura:
CREATE OR REPLACE TABLE `model_dev.vehicle_price_predictions` AS
SELECT
auction_id,
ROUND(predicted_selling_price, 2) AS predicted_market_value
FROM ML.PREDICT(
MODEL `model_dev.car_price_model`,
(SELECT * FROM `model_dev.vehicle_prediction_features`)
);
- Agora, verifique a saída do modelo. Execute esta consulta rápida para conferir os valores de mercado previstos para os anúncios de veículos ativos:
SELECT * FROM `model_dev.vehicle_price_predictions` LIMIT 5;
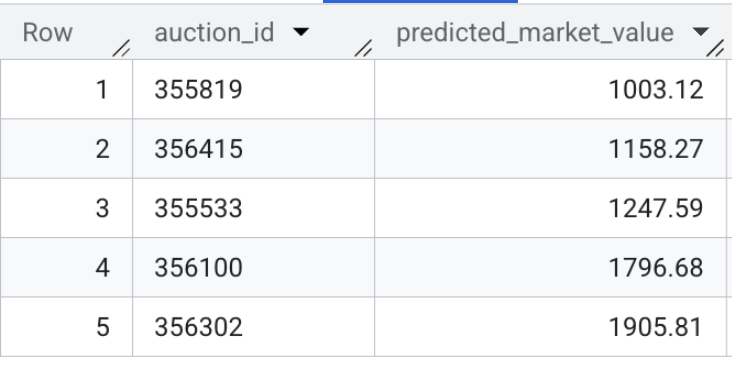
Resumo da seção:você treinou um modelo de regressão XGBoost usando 100.000 transações de amostra e executou a inferência em lote para prever o valor justo de mercado de todos os anúncios de veículos ativos no conjunto de dados.
6. Incorporações semânticas e detecção de autenticidade
Nesta seção, você vai executar dois pipelines de incorporação distintos para ativar recursos inteligentes no mercado de veículos:
- Pesquisa de imagens multimodal:traduz fotos brutas de veículos em espaço vetorial para permitir que os usuários pesquisem usando linguagem natural (por exemplo, "um caminhão de trabalho confiável").
- Embeddings de texto e pesquisa de similaridade:traduza descrições de veículos escritas em embeddings vetoriais para comparar anúncios ativos com possíveis perfis de golpistas ou entusiastas conhecidos usando
VECTOR_SEARCH. Isso calcula a 🔍 Pontuação de autenticidade que os compradores veem no app.
- Primeiro, você precisa gerar embeddings multimodais para as informações dos veículos. Com o modelo
gemini-embedding-2-preview, é possível inserir imagens e texto no mesmo embedding. Embora esse modelo seja totalmente capaz de processar várias modalidades simultaneamente, neste caso específico, estamos incorporando apenas as imagens do veículo. Isso alimenta a barra de "pesquisa semântica" para o aplicativo front-end, permitindo que os compradores usem linguagem natural (como "uma caminhonete confiável") e recuperem rapidamente os anúncios correspondentes. Execute esta consulta para gerar os vetores multimodais usandoAI.EMBED:
CREATE OR REPLACE TABLE `model_dev.vehicle_images_embedded` AS
SELECT
auction_id,
AI.EMBED(
STRUCT(image_ref),
endpoint => 'gemini-embedding-2-preview').result AS multimodal_embedding
FROM `model_dev.vehicle_multimodal`
WHERE ARRAY_LENGTH(image_ref) > 0;
- Em seguida, você vai analisar os dados de perfil de risco carregados anteriormente. Ela contém tipologias de golpes conhecidas e exemplos legítimos de anúncios de entusiastas. Execute esta consulta para conferir os perfis de valor de referência:
SELECT profile_id, profile_type, description
FROM `model_dev.seller_risk_profiles`;
- Agora você vai traduzir essas descrições de risco brutas em embeddings de vetor. Você pode usar um modelo especializado de incorporação de texto (
text-embedding-005) para avaliar estritamente a linguagem escrita que acabou de visualizar. Cole o seguinte SQL e clique em "Executar" para incorporar os perfis de referência:
CREATE OR REPLACE TABLE `model_dev.seller_risk_profiles_embedded` AS
SELECT
profile_id,
description AS content,
profile_type,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.seller_risk_profiles`;
- Em seguida, gere embeddings comparáveis para o inventário de veículos reais disponíveis. Execute esta consulta para traduzir a descrição HTML bruta de cada veículo em espaço vetorial para que possam ser comparados com os perfis de base:
CREATE OR REPLACE TABLE `model_dev.vehicle_descriptions_embedded` AS
SELECT
auction_id,
description AS content,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.vehicle_metadata`
WHERE description IS NOT NULL;
- Por fim, execute a pesquisa vetorial para calcular a distância semântica entre as informações de imóveis disponíveis e os perfis de base. Execute o seguinte SQL para fazer o mapeamento. Uma distância matemática menor significa que um anúncio é muito semelhante a um cluster de golpe conhecido, enquanto uma distância maior sugere uma descrição legítima.
CREATE OR REPLACE TABLE `model_dev.vehicle_authenticity_scores` AS
SELECT
scam_search.query.auction_id,
CAST(
GREATEST(0.0, LEAST(100.0, ROUND((MIN(scam_search.distance) - 0.33) / 0.12 * 100.0)))
AS INT64
) AS authenticity_score
FROM VECTOR_SEARCH(
TABLE `model_dev.seller_risk_profiles_embedded`,
'text_embedding',
(
SELECT text_embedding, auction_id
FROM `model_dev.vehicle_descriptions_embedded`
),
top_k => 15,
distance_type => 'COSINE'
) AS scam_search
WHERE scam_search.base.profile_type = 'scam'
GROUP BY 1;
O conteúdo dessa tabela pode ser semelhante a este:
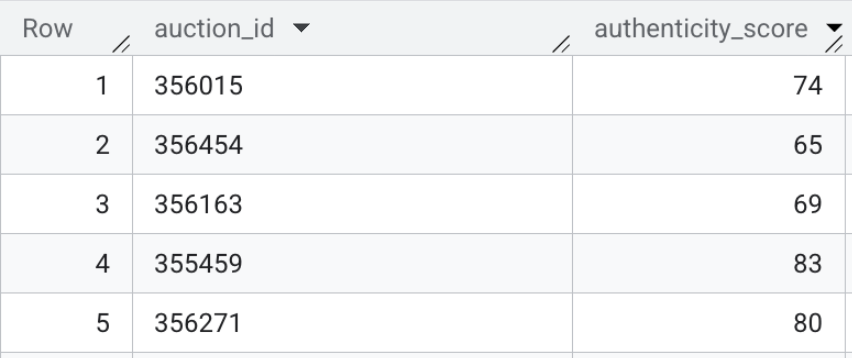
Resumo da seção:você gerou embeddings multimodais para a barra de pesquisa do front-end e usou a pesquisa vetorial diretamente no BigQuery para avaliar listagens de texto HTML bruto em relação a perfis de fraude conhecidos.
7. Pontuação generativa de transações
Agora você tem conjuntos de dados estruturados gerados por várias técnicas distintas de machine learning, todos organizados inteiramente no BigQuery: extração de visão, modelo XGBoost para prever o valor justo de mercado e incorporações de pesquisa vetorial.
A etapa final é mesclar esses indicadores de IA em uma visualização consolidada como a pontuação da oferta definitiva para o aplicativo front-end.
- Primeiro, combine os metadados brutos com os recursos de visão extraídos pela IA, as saídas de preços preditivos e as pontuações de autenticidade semântica. Execute o seguinte SQL:
CREATE OR REPLACE TABLE `model_dev.vehicle_features_enhanced` AS
SELECT
meta.auction_id,
meta.item_name,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.current_bid,
meta.listing_url,
meta.transmission_type,
meta.description,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior,
COALESCE(scam.authenticity_score, 100) AS authenticity_score,
vision.description_summary,
prices.predicted_market_value
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id
LEFT JOIN `model_dev.vehicle_price_predictions` prices
ON meta.auction_id = prices.auction_id
LEFT JOIN `model_dev.vehicle_authenticity_scores` scam
ON meta.auction_id = scam.auction_id;
- Em seguida, calcule uma Pontuação de negócio de 0 a 100 combinando quatro indicadores distintos de IA. Essa fórmula equilibra valor, qualidade e risco para mostrar os melhores anúncios:
- Pontuação de preço (40%): mede a economia em relação ao valor justo de mercado.
- Pontuação de visão (30%): insights da análise de fotos anterior.
- Pontuação de autenticidade (15%): avaliação de risco de golpe.
- Pontuação de condição (15%): inferida na hora com base na descrição do vendedor via
AI.SCORE.
CREATE OR REPLACE TABLE `model_dev.marketplace_listings` AS
WITH score_elements AS (
SELECT
*,
-- 1. SELLER DESCRIPTION SCORE (use AI.SCORE on seller description)
AI.SCORE(
FORMAT("Rate the vehicle condition (0-100) based ONLY on this text: '%s'", description)
) AS description_score,
-- 2. PRICE SCORE
-- Higher impact for underpricing, lower impact for overpricing.
CAST(LEAST(100.0, GREATEST(0.0,
75.0 + (
IF((predicted_market_value - current_bid) > 0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 250.0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 40.0
)
)
)) AS INT64) AS price_score
FROM `model_dev.vehicle_features_enhanced`
),
final_calcs AS (
SELECT
*,
-- 3. Combine scores: Price (40%), Condition (30%), Description (15%), Authenticity (15%)
ROUND(
(
(price_score * 0.40) +
(CAST(condition AS INT64) * 0.30) +
(COALESCE(description_score, 50) * 0.15) +
(CAST(authenticity_score AS INT64) * 0.15)
)
-- Authenticity penalty for scores below 50.
* (IF(CAST(authenticity_score AS INT64) < 50, 0.20, 1.05))
) AS raw_score
FROM score_elements
)
SELECT
* EXCEPT(raw_score),
-- 4. Set floor values: low authenticity scores drop to 10; others floor at 35.
CAST(GREATEST(
(IF(CAST(authenticity_score AS INT64) < 50, 10, 35)),
LEAST(100, raw_score)
) AS INT64) AS deal_score
FROM final_calcs;
Para garantir recomendações de alta qualidade, a consulta aplica duas camadas de lógica específicas:
- Controle de autenticidade: se uma informação do produto for sinalizada como "Alto risco" (pontuação < 50), a pontuação total da transação será reduzida automaticamente em 80% para evitar a promoção de informações do produto suspeitas.
- Otimização de"jóia rara": a fórmula usa uma lógica segmentada para recompensar as economias de forma agressiva, mas é mais tolerante com as margens, garantindo que um carro caro em perfeitas condições ainda possa alcançar uma classificação "Justo".
A tabela resultante, model_dev.marketplace_listings, contém campos como deal_score, além de price_score e authenticity_score.
- Para conferir as pontuações de negócios, execute a consulta a seguir ou confira a captura de tela abaixo:
SELECT item_name, model_year, authenticity_score, predicted_market_value, price_score, deal_score FROM `model_dev.marketplace_listings`
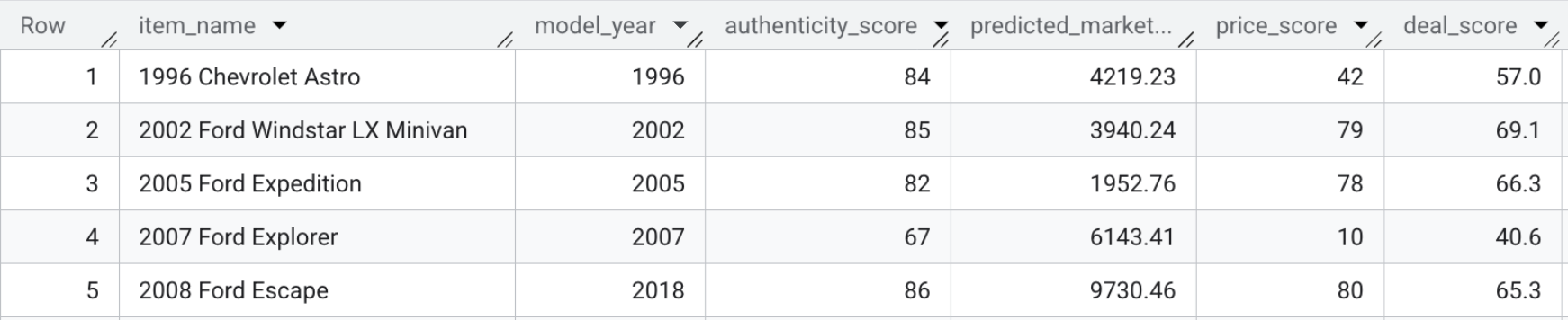
Resumo da seção:você combinou os preços preditivos, os recursos visuais e as pontuações de autenticidade com a descrição do vendedor para calcular uma única pontuação de oferta para cada anúncio.
8. Implantar o aplicativo de front-end
Agora é hora de ativar o aplicativo de front-end. Assim, você pode pesquisar o inventário de anúncios de veículos e interagir com os insights gerados por IA que acabou de criar, como a pontuação do negócio.
Exportar pontuações de IA para o front-end
O front-end do React depende de um payload JSON local para carregamentos rápidos da página inicial. Para impulsionar o marketplace, extraia as pontuações finais de negócios generativos do BigQuery e injete-as de volta no projeto Next.js.
- Verifique se o ambiente está pronto. Se a sessão do Cloud Shell expirou ou você navegou para outra pasta, execute o seguinte comando para voltar à raiz do projeto e restaurar as variáveis de ambiente:
cd ~/devrel-demos/data-analytics/cymbal-autos-multimodal && \
export PROJECT_ID=$(gcloud config get-value project) && \
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
- Execute o script Python fornecido para consultar a visualização final do BigQuery e mesclar as novas pontuações de negócios no repositório de dados subjacente do aplicativo:
python3 scripts/setup/08_export_frontend_data.py
Você vai receber uma mensagem de confirmação como:
💾 Updated local file: app/src/data/cars.json
Implantar o aplicativo no Cloud Run
Com os dados enriquecidos, é possível implantar o aplicativo de front-end Next.js na Internet pública usando o Cloud Run. Ele tem uma interface moderna com classificações de ofertas, carrosséis de imagens interativos e uma barra de pesquisa semântica híbrida dinâmica que consulta o BigQuery em tempo real.
- No Cloud Shell, navegue até o diretório
app/do repositório clonado. Isso é fundamental: permanecer no diretório raiz vai causar falha na build.
cd app
- Implante o aplicativo como um contêiner sem servidor usando o Cloud Run. O comando transmite o
PROJECT_IDcomo uma variável de ambiente para que a API Next.js saiba qual projeto do BigQuery consultar:
gcloud run deploy cymbal-autos-frontend \
--source . \
--region us-west1 \
--allow-unauthenticated \
--min-instances 1 \
--set-env-vars PROJECT_ID=$PROJECT_ID \
--project $PROJECT_ID
- Quando a implantação for concluída, o terminal vai gerar um URL de serviço seguro. Será semelhante a:
Service URL: https://cymbal-autos-frontend-[YOUR-PROJECT-NUMBER].us-west1.run.app/
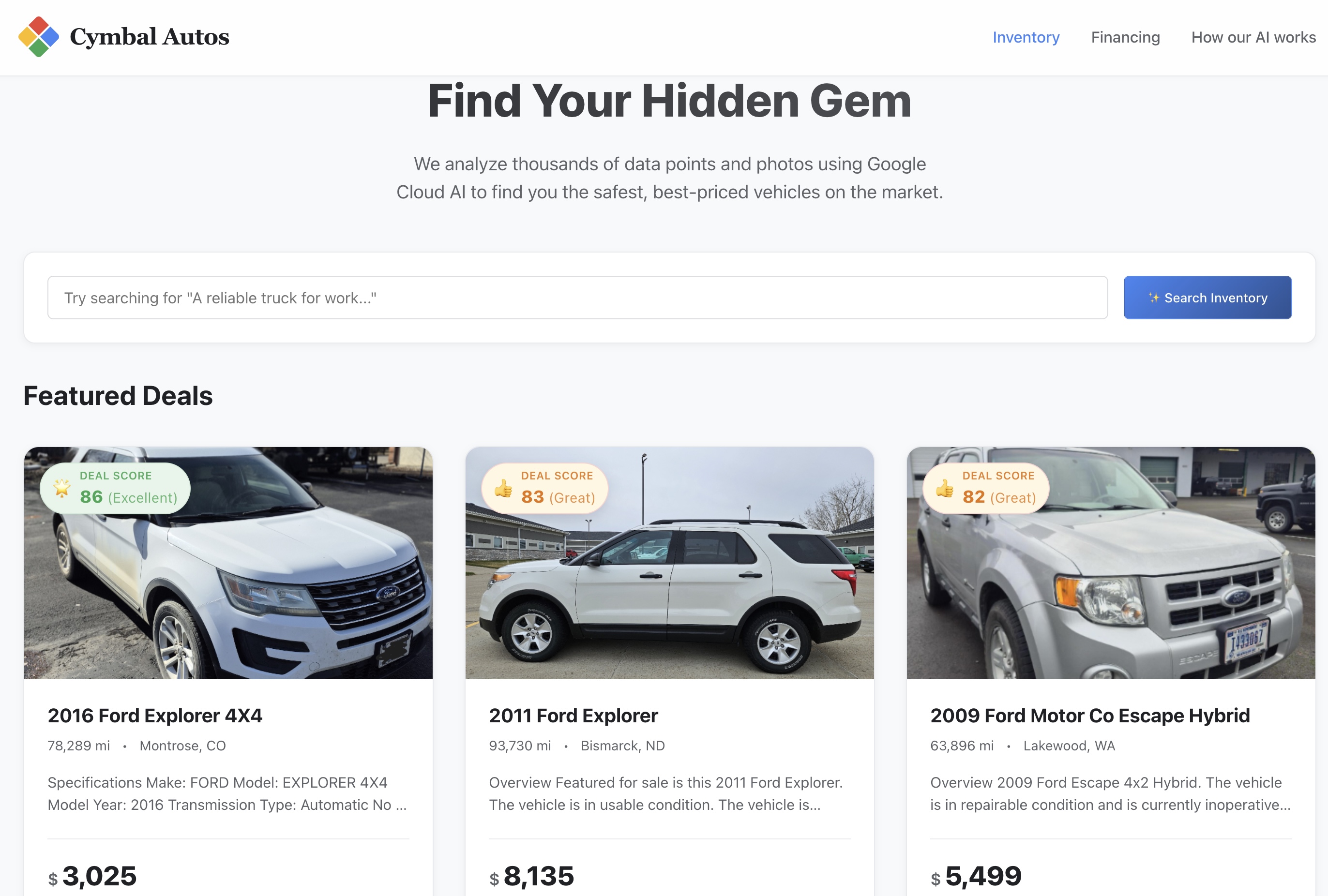
9. Conhecer o aplicativo Cymbal Autos
Agora que o contêiner de front-end foi enviado para o Cloud Run, é hora de testar o app.
- Acesse o site:abra o URL seguro do serviço retornado pelo Cloud Run.
- Faça uma pesquisa semântica:tente pesquisar um conceito abstrato, como "Um caminhão de trabalho confiável que transporta e pode fazer off-road". O app Next.js traduz seu texto bruto em um embedding de vetor multimodal e dispara uma
VECTOR_SEARCHem tempo real no BigQuery, mapeando sua ideia no ecossistema de veículos.
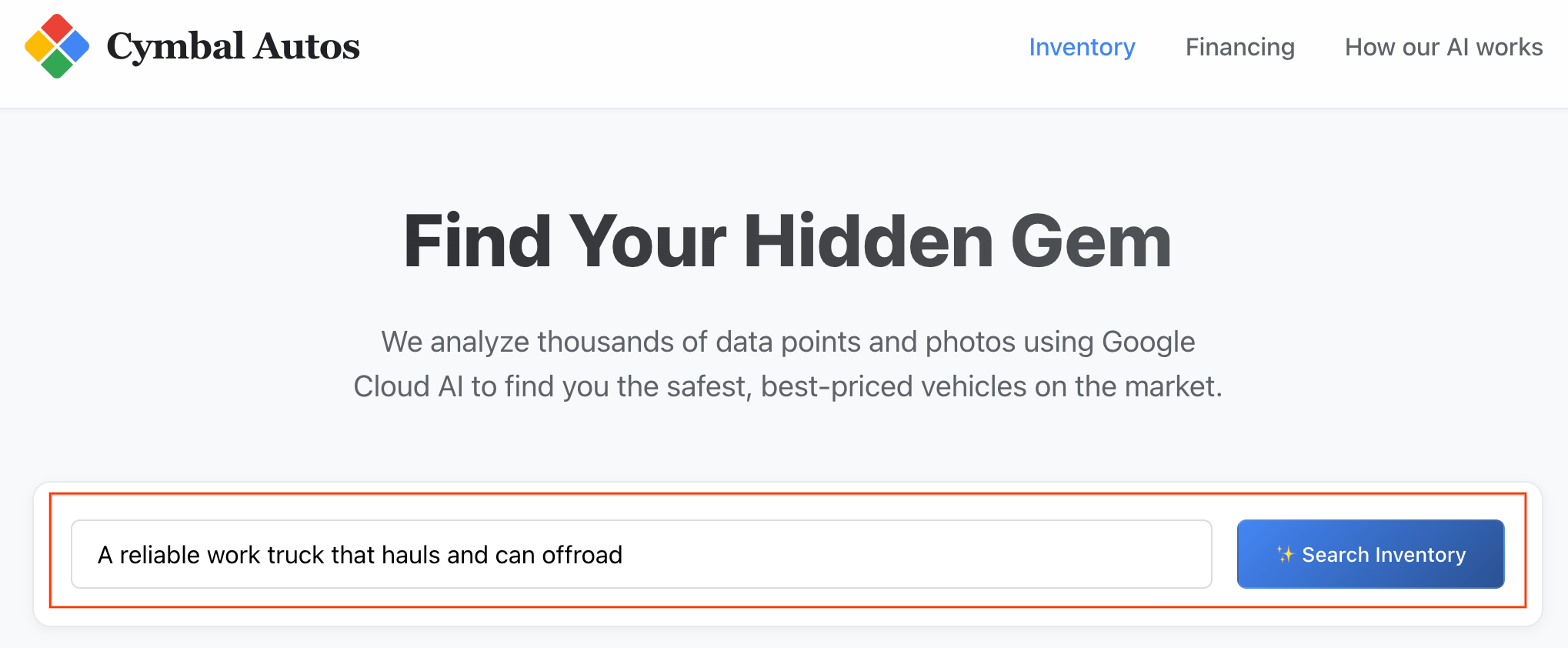
Observação: as listagens são classificadas por semelhança semântica.
- Analise os resultados:o BigQuery calculou a distância matemática exata entre sua ideia abstrata e os recursos do veículo para retornar as correspondências semânticas mais próximas.
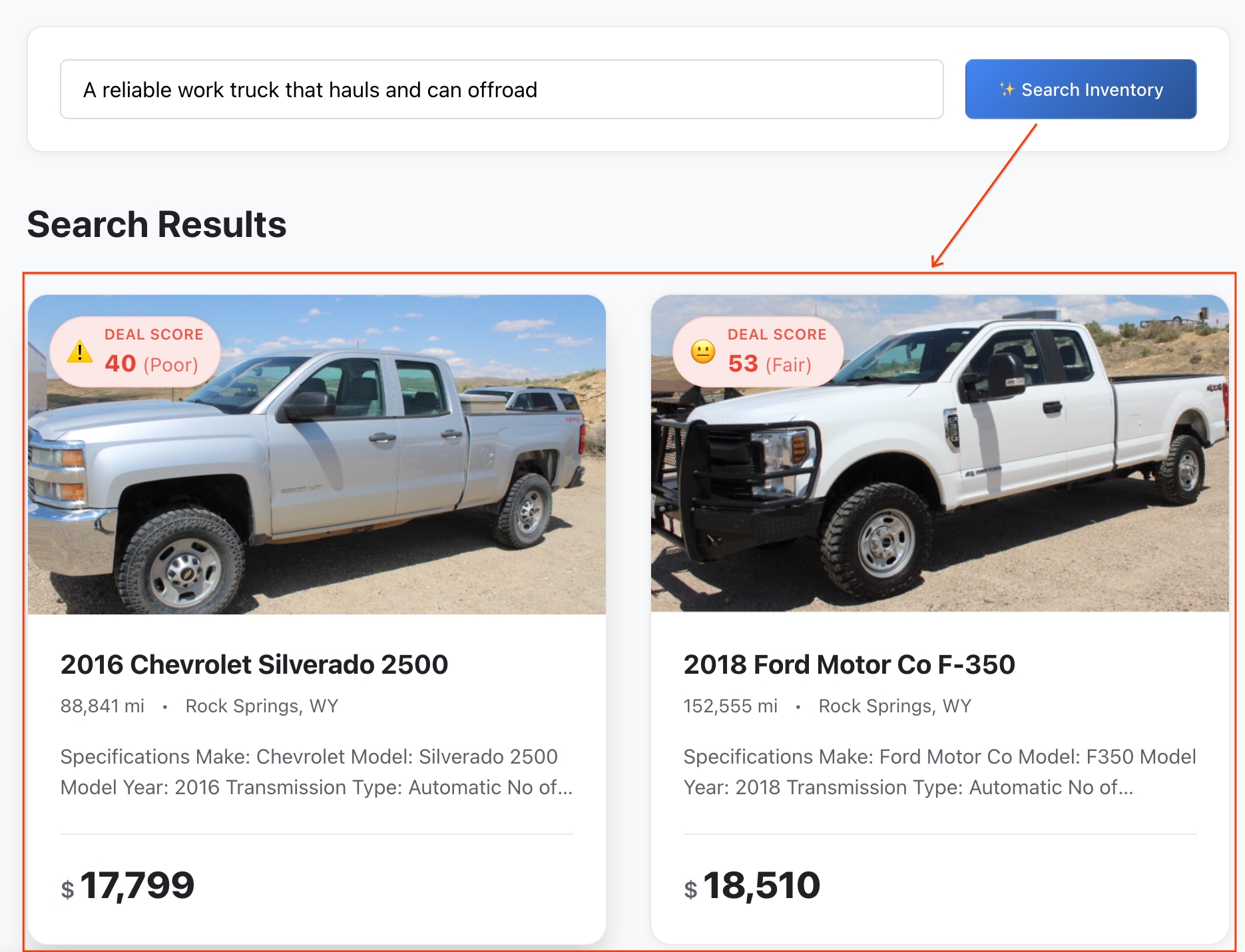
- Confira os detalhes:clique em qualquer veículo para abrir o perfil completo da listagem.
- Verifique o indicador de IA:role os detalhes para conferir as pontuações brutas de machine learning geradas anteriormente no laboratório:
- 📈 Valor justo de mercado:o preço de referência previsto pelo seu modelo XGBoost.
- ✨ Condição visual:a classificação de danos físicos extraída pelos modelos do Gemini.
- 🔍 Pontuação de autenticidade:a métrica de vetor de autenticidade separa vendedores legítimos de possíveis golpistas.

10. Limpar
Para evitar cobranças contínuas na sua conta do Google Cloud pelos recursos usados neste codelab, exclua todo o projeto na nuvem do Google Cloud criado para este codelab ou execute o seguinte script de encerramento automático.
- No terminal do Cloud Shell, volte para o diretório raiz:
cd ..
- Execute o script de limpeza abaixo. Isso vai esvaziar seu bucket do Cloud Storage, descartar o conjunto de dados
model_devdo BigQuery, excluir a conexão do BigQuery e excluir o serviço do Cloud Run.
chmod +x scripts/cleanup/teardown.sh
./scripts/cleanup/teardown.sh
11. Parabéns
Parabéns! Você criou um marketplace de veículos inteligentes. Você usou o BigQuery para unificar a análise de dados não estruturados, a modelagem preditiva e as integrações de IA em um único espaço de trabalho.
O que você aprendeu
- Como conectar o BigQuery a imagens não estruturadas do Cloud Storage usando ObjectRef
- Como extrair atributos de veículos de fotos usando o BigQuery com modelos do Gemini, como as funções
AI.GENERATEeAI.CLASSIFY - Como prever preços de veículos usando o BigQuery ML
- Como identificar possíveis anúncios fraudulentos incorporando descrições de veículos e realizando
VECTOR_SEARCH - Como usar o
AI.SCOREpara avaliar dados não estruturados na hora e incorporar os resultados a uma pontuação de negócio abrangente - Como exportar dados e implantar o aplicativo de marketplace Next.js no Cloud Run
Próximas etapas
- Conheça toda a gama de funções de IA generativa disponíveis no BigQuery
- Saiba mais sobre como criar modelos preditivos com o GoogleSQL.