
1. 简介
在此 Codelab 中,您将为在线车辆交易平台“Cymbal Autos”构建后端并部署前端。您将使用 BigQuery 和 Gemini Enterprise Agent Platform 上的 Gemini 模型来检查车辆照片、使用 BigQuery ML 预测价格、使用向量嵌入检测欺诈性商品详情,以及计算综合交易得分。最后,您将在部署到 Cloud Run 的 Next.js 前端上显示这些数据洞见。
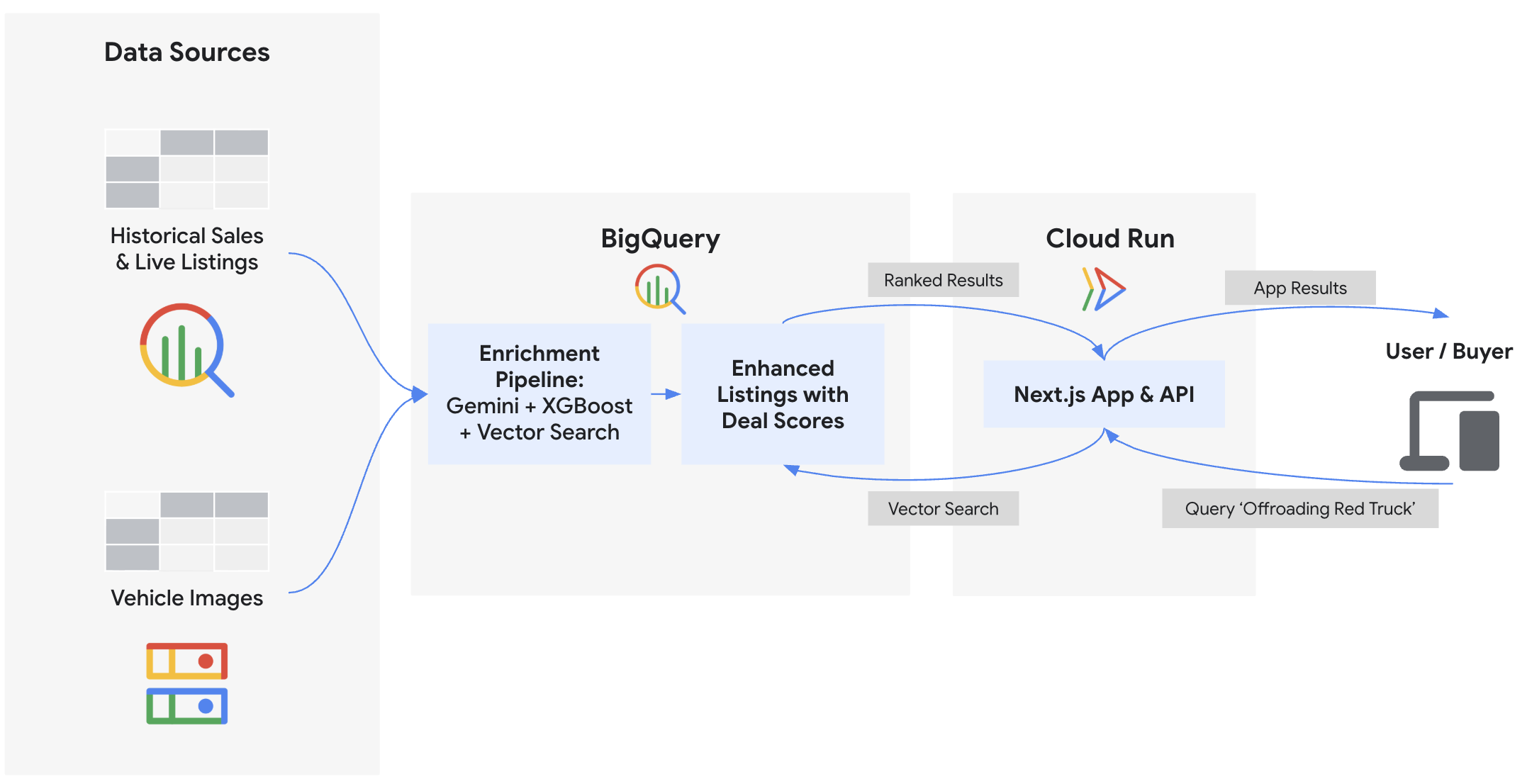
您将执行的操作
- 使用 ObjectRef 将 BigQuery 连接到非结构化的 Cloud Storage 图片
- 使用 BigQuery 和 Gemini 模型从照片中提取车辆属性
- 通过使用 BigQuery ML 训练 XGBoost 回归模型来预测公平市场价格
- 通过嵌入车辆说明并执行
VECTOR_SEARCH来识别潜在的欺诈性信息和可信的信息 - 使用
AI.SCORE根据卖家的商品说明纳入商品状况信号,为每条商品详情计算综合优惠分数 - 导出数据并将 Next.js Marketplace 应用部署到 Google Cloud Run
所需条件
- 网络浏览器,例如 Chrome
- 启用了结算功能的 Google Cloud 项目
- 基本熟悉 SQL、Python 和 Google Cloud
- 有足够的 IAM 权限来启用 API、创建资源和分配权限(例如 Project Owner)
本 Codelab 面向中级开发者。
本 Codelab 中创建的资源费用应低于 5 美元。
2. 准备工作
创建 Google Cloud 项目
- 在 Google Cloud 控制台的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
启动 Cloud Shell
您将使用 Google Cloud Shell 下载代码、运行设置脚本并部署应用。
- 点击 Google Cloud 控制台顶部的激活 Cloud Shell。

- 连接到 Cloud Shell 后,请对您的会话进行身份验证,以确保您的应用可以访问 Google Cloud API。按照提示为 Cloud Shell 授权:
gcloud auth application-default login
- 设置您的 Google Cloud 项目 ID 和 Google Cloud Storage 存储分区的唯一名称(您将在其中存储原始数据):
export PROJECT_ID=$(gcloud config get-value project)
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
gcloud config set project $PROJECT_ID
您应该会看到如下所示的消息:
Your active configuration is: [cloudshell-####] Updated property [core/project]
启用 API
在 Cloud Shell 中运行以下命令,以启用此 Codelab 所需的所有 API:
gcloud services enable \
aiplatform.googleapis.com \
artifactregistry.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
cloudbuild.googleapis.com \
run.googleapis.com
成功执行后,您应该会看到类似于以下内容的消息:
Operation "operations/..." finished successfully.
3. 获取代码和设置数据
首先,下载演示资源并配置环境变量。
- 在 Cloud Shell 中,克隆
devrel-demos代码库并前往项目目录:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos/data-analytics/cymbal-autos-multimodal
- 运行脚本以将数据复制到您的环境中。此脚本会将本地代码库数据集同步到您的个人 Cloud Storage 存储分区,并从公共存储分区中提取车辆图片:
chmod +x scripts/setup/*.sh
./scripts/setup/00_copy_data.sh
之后,您应该会看到类似如下内容的消息:
Average throughput: 87.8MiB/s Data copy complete!
- 接下来,设置 BigQuery Cloud 资源连接。如需分析 Cloud Storage 中的非结构化图片并直接从 SQL 查询中调用 Agent Platform 模型,BigQuery 必须将 IAM 权限委托给底层服务账号。此脚本会创建该安全连接,并向其授予必要的 Vertex AI User 和 Service Usage Consumer 角色(这需要大约一分钟的时间才能传播):
./scripts/setup/01_setup_api_connection.sh
您应会看到如下所示的消息:
Environment setup complete! Your BigQuery connection is ready.
- 最后,创建初始 BigQuery 数据集并加载原始表格数据。这会创建
model_dev数据集并填充起始表,从而在您编写任何机器学习查询之前奠定基础:
./scripts/setup/02_load_to_bq.sh
您应会看到如下所示的消息:
================================================================= BigQuery load complete! =================================================================
4. 多模态视觉提取
在对车辆商品详情进行评分之前,您需要从数百张原始照片中提取结构化数据(例如颜色、车身样式或外观损坏情况)。通过利用 ObjectRef 函数和 Agent 平台中托管的 Gemini 模型,您无需移动任何文件或编写复杂的数据流水线即可生成这些功能。此提取功能直接为前端应用中的 ✨ 视觉条件徽章提供支持。
- 在新浏览器标签页中打开 BigQuery Studio。
- 点击 + 编写新查询按钮。在此 Codelab 中,您将使用 SQL 编辑器与 SQL 代码进行交互。
- 在构建机器学习提取器之前,您可以快速查看原始图片。运行以下查询,以查看存储在 Google Cloud Storage 中的每个房源的图片 URI 数组:
SELECT auction_id, item_name, description, images
FROM `model_dev.vehicle_metadata` LIMIT 5;
- 现在,在 BigQuery Studio SQL 编辑器中,粘贴以下 SQL 以创建包含
image_ref列的新表。点击运行。
CREATE OR REPLACE TABLE `model_dev.vehicle_multimodal` AS
SELECT
*,
ARRAY(
SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF(uri, 'us.conn'))
FROM UNNEST(images) AS uri
) AS image_ref
FROM `model_dev.vehicle_metadata`;
- 查看您刚刚创建的新
image_refObjectRef 列。新表现在包含一个 ObjectRef 列,该列具有对映像本身执行操作的权限。运行以下查询即可查看:
SELECT auction_id, item_name, description, image_ref
FROM `model_dev.vehicle_multimodal` LIMIT 5;
- 现在,您将使用
AI.GENERATE和AI.CLASSIFY来分析图片。AI.GENERATE通过提示 Gemini 提取状况得分和一句损伤摘要,而AI.CLASSIFY则严格对车身样式和颜色进行分类。
执行以下查询,将这些数据洞见提取到专用特征表中。此过程预计需要大约 3 分钟才能完成。
CREATE OR REPLACE TABLE `model_dev.vehicle_vision_features` AS
WITH generated_data AS (
SELECT
auction_id,
AI.GENERATE(
prompt => ('Rate the condition of this car on a scale from 0-100. Output a 1 sentence description of any glaring red flags', image_ref),
output_schema => 'condition INT64, description_summary STRING'
).* EXCEPT(full_response,status)
FROM
`model_dev.vehicle_multimodal`
),
-- Object-centric Classifications
classified_data AS (
SELECT
auction_id,
AI.CLASSIFY(
('What type of automobile is this?', image_ref[0]),
categories => ['Truck', 'Sedan', 'SUV']) AS body_style,
AI.CLASSIFY(
('Color of the exterior of the automobile', image_ref[0]),
categories => ['Black', 'White', 'Silver', 'Gray', 'Red', 'Blue', 'Brown', 'Green', 'Beige', 'Gold']) AS color,
AI.CLASSIFY(
('Color of the interior of the automobile', image_ref[0]),
categories => ['Black', 'Gray', 'Beige', 'Tan', 'Brown', 'White', 'Red']) AS interior
FROM `model_dev.vehicle_multimodal`
)
-- Join the AI insights back together into the final feature table
SELECT
g.auction_id,
g.condition,
g.description_summary,
c.body_style,
c.color,
c.interior
FROM generated_data g
JOIN classified_data c ON g.auction_id = c.auction_id;
- 如需自行查看生成的特征,请运行以下查询,或直接查看下面的屏幕截图:
SELECT auction_id, condition, description_summary, body_style, color, interior FROM `model_dev.vehicle_vision_features` LIMIT 5;

本部分总结:您直接从 BigQuery 访问了原始图片,并使用 Gemini 模型提取了结构化视觉特征,而无需移动任何文件。
5. 使用 XGBoost 进行预测性定价
若要计算车辆是否真正划算,需要有可靠的公平市场价值基准。您无需将数据提取到本地脚本或笔记本中来训练模型,而是可以直接在 BigQuery 中使用标准 SQL 训练 XGBoost 模型。此价格预测会驱动前端应用中的 📈 公允市场价值逻辑。
- 返回到 BigQuery Studio 标签页。
- 首先,我们来看看训练数据集。与有效的车辆商品详情不同,此
synthetic_cars表包含 10 万条历史销售记录,将用于训练模型。运行以下快速查询即可查看:
SELECT
*
FROM
`model_dev.synthetic_cars`
LIMIT 10;
- 现在,执行以下 SQL 来训练 XGBoost 回归模型。此模型会从这 10 万条历史记录中学习里程、年份、品牌和外观状况等属性如何影响价格:
CREATE OR REPLACE MODEL `model_dev.car_price_model`
OPTIONS(
MODEL_TYPE = 'BOOSTED_TREE_REGRESSOR',
INPUT_LABEL_COLS = ['selling_price'],
MAX_ITERATIONS = 15,
TREE_METHOD = 'HIST'
) AS
SELECT
* EXCEPT(vin, sale_date, market_value, seller)
FROM
`model_dev.synthetic_cars`;
- 在预测有效且正在进行的车辆商品详情的价格之前,您必须将所有相关输入特征收集到一处。运行以下 SQL,将结构化车辆元数据与您刚刚生成的视觉提取特征合并:
CREATE OR REPLACE TABLE `model_dev.vehicle_prediction_features` AS
SELECT
meta.auction_id,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.transmission_type,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id;
- 最后,预测每条正在进行的车辆商品详情的公允市场价值。执行以下查询,将汇总的特征馈送到新训练的模型中,并将数值输出保存到安全的预测表中:
CREATE OR REPLACE TABLE `model_dev.vehicle_price_predictions` AS
SELECT
auction_id,
ROUND(predicted_selling_price, 2) AS predicted_market_value
FROM ML.PREDICT(
MODEL `model_dev.car_price_model`,
(SELECT * FROM `model_dev.vehicle_prediction_features`)
);
- 现在,验证模型的输出。运行以下快速查询,预览有效车辆商品详情的预测市场价值:
SELECT * FROM `model_dev.vehicle_price_predictions` LIMIT 5;
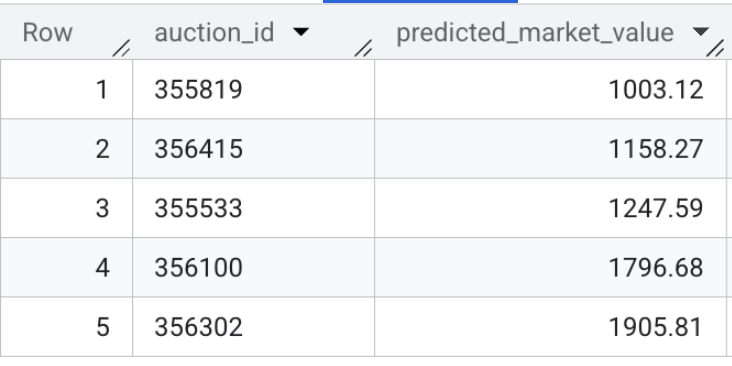
本部分总结:您使用 10 万个交易样本训练了一个 XGBoost 回归模型,并运行了批量推理,以预测数据集中每个有效车辆信息的公平市场价值。
6. 语义嵌入向量与真实性检测
在本部分中,您将执行两个不同的嵌入流水线,以针对车辆交易平台启用智能功能:
- 多模态图片搜索:将原始车辆照片转换为向量空间,以便用户使用自然语言(例如“可靠的作业卡车”)进行搜索。
- 文本嵌入和相似度搜索:将书面车辆描述转换为向量嵌入,以便使用
VECTOR_SEARCH将有效商品详情与已知的潜在诈骗或发烧友个人资料进行比较。此函数用于计算买家在应用中看到的 🔍 Authenticity Score。
- 首先,您需要为车辆商品详情生成多模态嵌入。借助
gemini-embedding-2-preview模型,您可以将图片和文本输入到完全相同的嵌入中。虽然此模型完全能够同时处理多种模态,但在本例中,我们仅嵌入车辆图片。这为前端应用提供了“语义搜索”栏,让买家能够使用自然语言(例如“可靠的皮卡”)快速检索匹配的商品详情。运行以下查询,使用AI.EMBED生成多模态向量:
CREATE OR REPLACE TABLE `model_dev.vehicle_images_embedded` AS
SELECT
auction_id,
AI.EMBED(
STRUCT(image_ref),
endpoint => 'gemini-embedding-2-preview').result AS multimodal_embedding
FROM `model_dev.vehicle_multimodal`
WHERE ARRAY_LENGTH(image_ref) > 0;
- 接下来,您将检查之前加载的风险概况数据。请注意,其中既包含已知的诈骗类型,也包含合法的发烧友示例商品详情。运行此查询以查看基准配置文件:
SELECT profile_id, profile_type, description
FROM `model_dev.seller_risk_profiles`;
- 现在,您将把这些原始风险说明转换为向量嵌入。您可以使用专门的文本嵌入模型 (
text-embedding-005) 来严格评估您刚刚预览的书面语言。粘贴以下 SQL,然后点击“运行”以嵌入基准配置文件:
CREATE OR REPLACE TABLE `model_dev.seller_risk_profiles_embedded` AS
SELECT
profile_id,
description AS content,
profile_type,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.seller_risk_profiles`;
- 接下来,为实际的实时车辆商品目录生成可比较的嵌入。运行以下查询,将每辆车的原始 HTML 说明转换为向量空间,以便与基准配置文件进行比较:
CREATE OR REPLACE TABLE `model_dev.vehicle_descriptions_embedded` AS
SELECT
auction_id,
description AS content,
AI.EMBED(description, endpoint => 'text-embedding-005').result AS text_embedding
FROM `model_dev.vehicle_metadata`
WHERE description IS NOT NULL;
- 最后,执行向量搜索,计算实时商品详情与基准个人资料之间的语义距离。运行以下 SQL 以执行映射。数学距离越小,表示相应房源与已知的欺骗手段群组高度相似;距离越大,表示相应房源的描述越合法。
CREATE OR REPLACE TABLE `model_dev.vehicle_authenticity_scores` AS
SELECT
scam_search.query.auction_id,
CAST(
GREATEST(0.0, LEAST(100.0, ROUND((MIN(scam_search.distance) - 0.33) / 0.12 * 100.0)))
AS INT64
) AS authenticity_score
FROM VECTOR_SEARCH(
TABLE `model_dev.seller_risk_profiles_embedded`,
'text_embedding',
(
SELECT text_embedding, auction_id
FROM `model_dev.vehicle_descriptions_embedded`
),
top_k => 15,
distance_type => 'COSINE'
) AS scam_search
WHERE scam_search.base.profile_type = 'scam'
GROUP BY 1;
此表的内容可能如下所示:
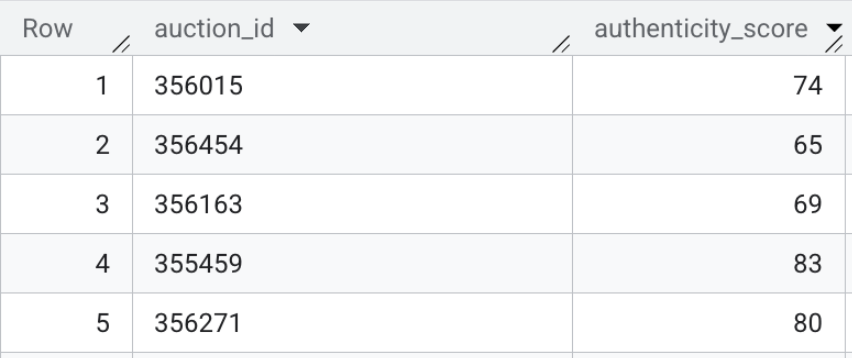
本部分总结:您为前端搜索栏生成了多模态嵌入,并直接在 BigQuery 中使用向量搜索功能,根据已知的诈骗个人资料评估原始 HTML 文本商品详情。
7. 生成式交易评分
现在,您已通过多种不同的机器学习技术生成结构化数据集,所有这些技术都完全在 BigQuery 中协调运行:视觉提取、用于预测公允市场价值的 XGBoost 模型和向量搜索嵌入。
最后一步是将这些 AI 信号合并为一个整合视图,作为前端应用的最终交易得分。
- 首先,将原始元数据与 AI 提取的视觉特征、预测性价格输出和语义真实性得分联接起来。执行以下 SQL:
CREATE OR REPLACE TABLE `model_dev.vehicle_features_enhanced` AS
SELECT
meta.auction_id,
meta.item_name,
meta.model_year,
meta.make,
meta.model,
meta.mileage,
meta.current_bid,
meta.listing_url,
meta.transmission_type,
meta.description,
meta.state,
COALESCE(vision.body_style, 'Unknown') AS body_style,
COALESCE(vision.condition, 50) AS condition,
COALESCE(meta.color, vision.color, 'Unknown') AS color,
COALESCE(vision.interior, 'Unknown') AS interior,
COALESCE(scam.authenticity_score, 100) AS authenticity_score,
vision.description_summary,
prices.predicted_market_value
FROM `model_dev.vehicle_metadata` meta
LEFT JOIN `model_dev.vehicle_vision_features` vision
ON meta.auction_id = vision.auction_id
LEFT JOIN `model_dev.vehicle_price_predictions` prices
ON meta.auction_id = prices.auction_id
LEFT JOIN `model_dev.vehicle_authenticity_scores` scam
ON meta.auction_id = scam.auction_id;
- 接下来,通过组合四种不同的 AI 信号来计算 0-100 分的特惠得分。此公式可平衡价值、质量和风险,从而显示最佳房源:
- 价格得分(40%):衡量与公平市场价值相比的节省金额。
- 视觉分数(30%):之前照片分析得出的数据洞见。
- 真实性得分(15%):欺诈风险评估。
- 商品状况得分(15%):通过
AI.SCORE根据卖家的商品说明实时推断得出。
CREATE OR REPLACE TABLE `model_dev.marketplace_listings` AS
WITH score_elements AS (
SELECT
*,
-- 1. SELLER DESCRIPTION SCORE (use AI.SCORE on seller description)
AI.SCORE(
FORMAT("Rate the vehicle condition (0-100) based ONLY on this text: '%s'", description)
) AS description_score,
-- 2. PRICE SCORE
-- Higher impact for underpricing, lower impact for overpricing.
CAST(LEAST(100.0, GREATEST(0.0,
75.0 + (
IF((predicted_market_value - current_bid) > 0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 250.0,
((predicted_market_value - current_bid) / NULLIF(predicted_market_value, 0)) * 40.0
)
)
)) AS INT64) AS price_score
FROM `model_dev.vehicle_features_enhanced`
),
final_calcs AS (
SELECT
*,
-- 3. Combine scores: Price (40%), Condition (30%), Description (15%), Authenticity (15%)
ROUND(
(
(price_score * 0.40) +
(CAST(condition AS INT64) * 0.30) +
(COALESCE(description_score, 50) * 0.15) +
(CAST(authenticity_score AS INT64) * 0.15)
)
-- Authenticity penalty for scores below 50.
* (IF(CAST(authenticity_score AS INT64) < 50, 0.20, 1.05))
) AS raw_score
FROM score_elements
)
SELECT
* EXCEPT(raw_score),
-- 4. Set floor values: low authenticity scores drop to 10; others floor at 35.
CAST(GREATEST(
(IF(CAST(authenticity_score AS INT64) < 50, 10, 35)),
LEAST(100, raw_score)
) AS INT64) AS deal_score
FROM final_calcs;
为了确保建议的质量,该查询应用了两个特定的逻辑层:
- 真实性门控:如果某个房源被标记为“高风险”(得分低于 50),系统会自动将总交易得分降低 80%,以防止可疑房源获得推广。
- “隐藏的宝藏”优化:该公式使用分段逻辑来积极奖励节省的费用,同时对加价更加宽容,确保即使是价格过高但车况极佳的车辆也能获得“一般”排名。
生成的表 model_dev.marketplace_listings 包含 deal_score 等字段,以及 price_score 和 authenticity_score。
- 如需自行查看交易得分,请运行以下查询,或直接查看下面的屏幕截图:
SELECT item_name, model_year, authenticity_score, predicted_market_value, price_score, deal_score FROM `model_dev.marketplace_listings`
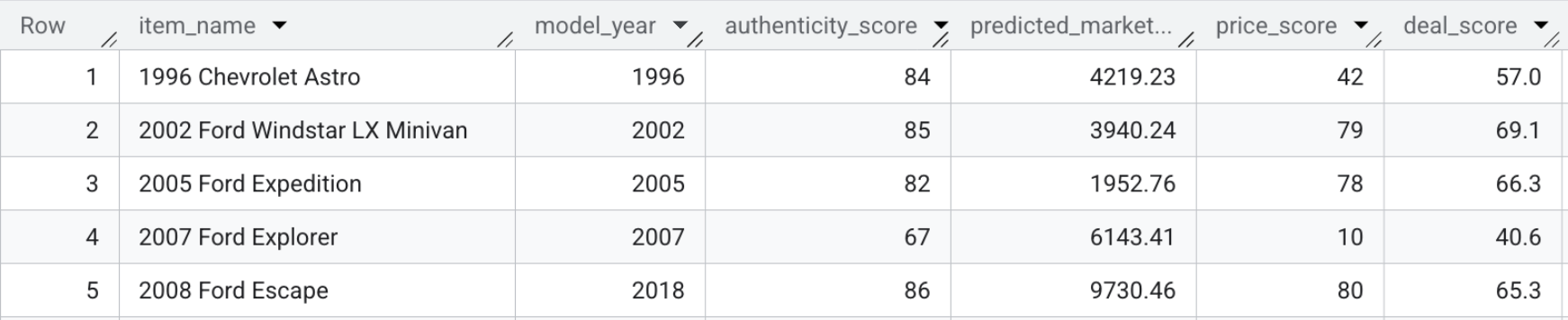
本部分总结:您将预测性价格、视觉特征和商品真伪度分数与卖家的说明相结合,为每条商品详情计算出一个“超值指数”。
8. 部署前端应用
现在,您可以启动前端应用了。这样,您就可以最终搜索车辆商品目录,并与您刚刚构建的 AI 生成的分析洞见(例如“超值指数”)互动。
将 AI 得分导出到前端
React 前端依赖于本地 JSON 载荷,以实现快速的初始网页加载。为了支持该市场,请从 BigQuery 中提取最终的生成式交易得分,然后将其注入回 Next.js 项目。
- 确保您的环境已准备就绪。如果 Cloud Shell 会话超时或您导航到了其他文件夹,请运行以下命令以返回到项目根目录并恢复环境变量:
cd ~/devrel-demos/data-analytics/cymbal-autos-multimodal && \
export PROJECT_ID=$(gcloud config get-value project) && \
export USER_BUCKET="cymbal-autos-${PROJECT_ID}"
- 运行提供的 Python 脚本,查询最终的 BigQuery 视图,并将新的交易得分合并到应用的基础数据存储区中:
python3 scripts/setup/08_export_frontend_data.py
您会收到一则确认消息,内容如下:
💾 Updated local file: app/src/data/cars.json
将应用部署到 Cloud Run
成功丰富数据后,您可以使用 Cloud Run 将 Next.js 前端应用部署到公共互联网。它具有现代化的界面,提供特惠评分、交互式图片轮播界面,以及可实时查询 BigQuery 的动态混合语义搜索栏。
- 在 Cloud Shell 中,前往克隆的代码库的
app/目录。这一点至关重要 - 如果停留在根目录中,构建将会失败。
cd app
- 使用 Cloud Run 将应用部署为无服务器容器。该命令将
PROJECT_ID作为环境变量传递,以便 Next.js API 知道要查询哪个 BigQuery 项目:
gcloud run deploy cymbal-autos-frontend \
--source . \
--region us-west1 \
--allow-unauthenticated \
--min-instances 1 \
--set-env-vars PROJECT_ID=$PROJECT_ID \
--project $PROJECT_ID
- 部署完成后,终端会输出一个安全的服务网址。类似于以下内容:
Service URL: https://cymbal-autos-frontend-[YOUR-PROJECT-NUMBER].us-west1.run.app/
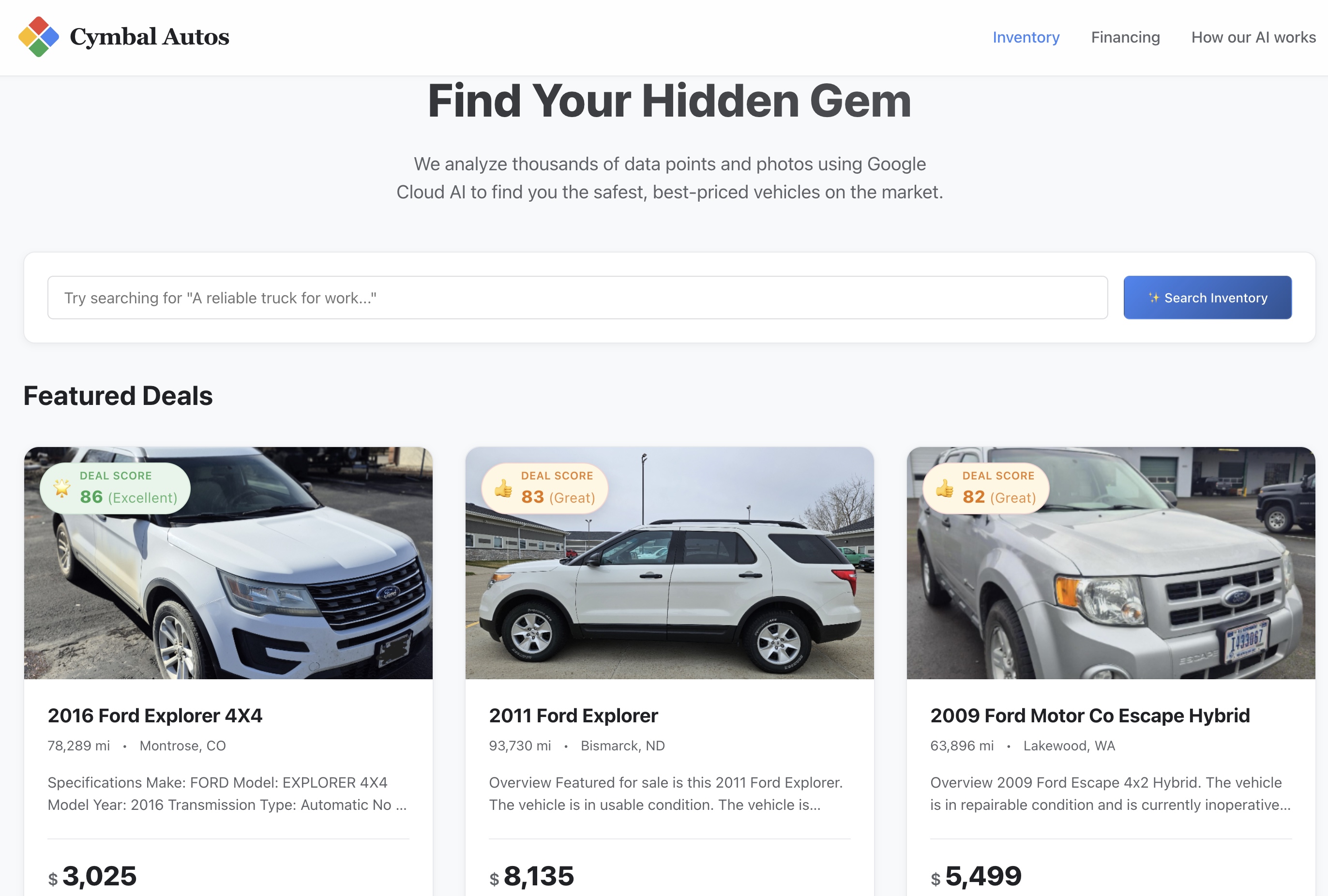
9. 探索 Cymbal Autos 应用
将前端容器推送到 Cloud Run 后,就可以测试应用了。
- 访问网站:打开 Cloud Run 返回的安全服务网址。
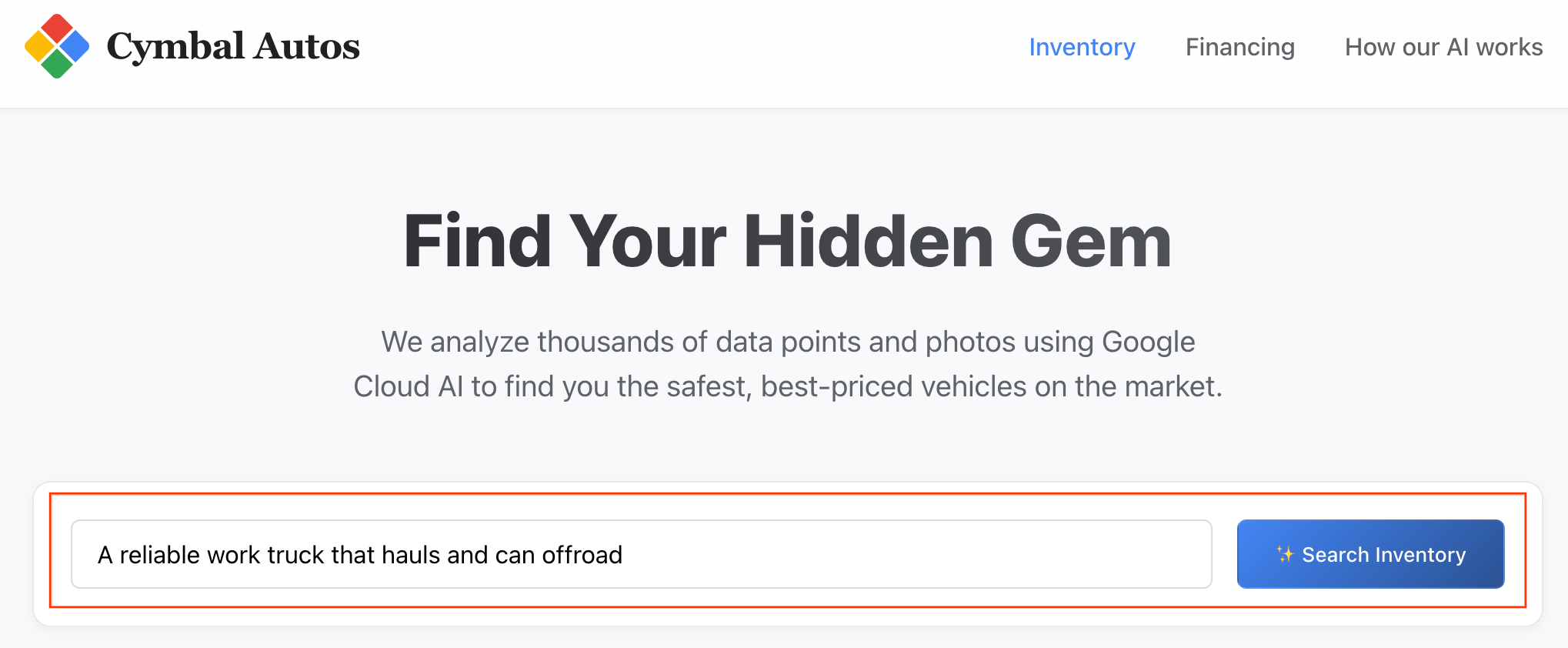
- 执行语义搜索:尝试搜索抽象概念,例如“一款可靠的拉货工作卡车,可用于越野”。Next.js 应用会将原始文本转换为多模态向量嵌入,并针对 BigQuery 实时触发
VECTOR_SEARCH,将您的想法与车辆生态系统进行匹配。
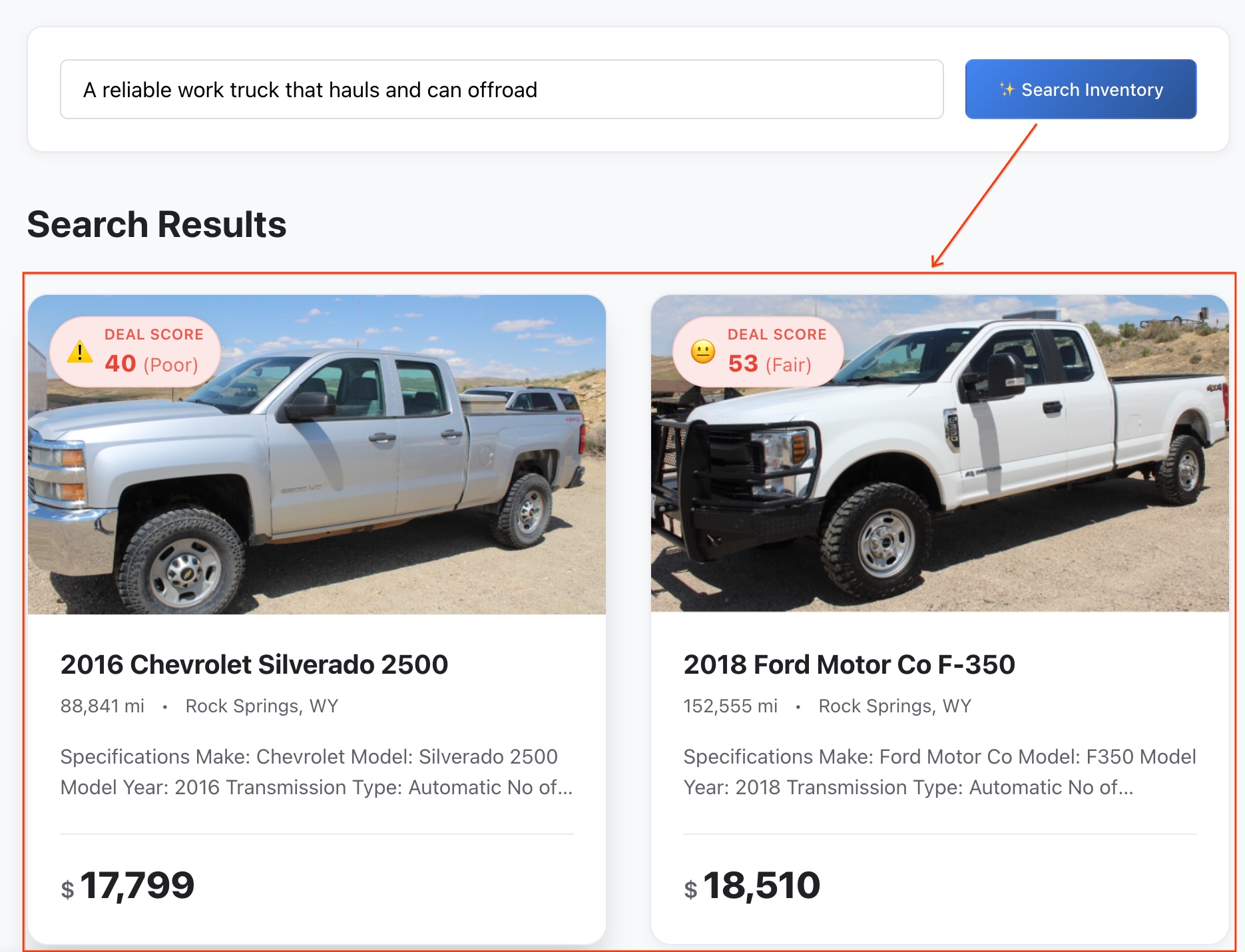
注意:列表按语义相似度排序。
- 查看结果:BigQuery 计算了抽象想法与车辆功能之间的确切数学距离,以返回最接近的语义匹配项。
- 深入了解详情:点击任意车辆即可打开其完整的商品详情资料。
- 检查 AI 信号:滚动浏览详细信息,查看您之前在本实验中生成的原始机器学习得分:
- 📈 公允市场价值:XGBoost 模型预测的基准价格。
- ✨ 视觉状况:由 Gemini 模型提取的实物损坏程度评级。
- 🔍 真实性得分:真实性向量指标可将合法卖家与潜在的诈骗者区分开来。

10. 清理
为避免因本 Codelab 中使用的资源而持续向您的 Google Cloud 账号收取费用,您可以删除为本 Codelab 创建的整个 Google Cloud 项目,也可以执行以下自动拆解脚本。
- 在 Cloud Shell 终端中,返回到包含目录的根目录:
cd ..
- 运行以下清理脚本。此操作会清空您的 Google Cloud Storage 存储分区,舍弃
model_devBigQuery 数据集,删除 BigQuery 连接,并删除 Cloud Run 服务。
chmod +x scripts/cleanup/teardown.sh
./scripts/cleanup/teardown.sh
11. 恭喜
恭喜!您已成功构建智能车辆市场。您使用 BigQuery 将非结构化数据分析、预测性建模和 AI 集成统一到一个工作区中。
您学到的内容
- 如何使用 ObjectRef 将 BigQuery 连接到非结构化的 Cloud Storage 图片
- 如何使用 BigQuery 和
AI.GENERATE和AI.CLASSIFY等 Gemini 模型从照片中提取车辆属性 - 如何使用 BigQuery ML 预测车辆价格
- 如何通过嵌入车辆说明和执行
VECTOR_SEARCH来识别潜在的欺诈性商品详情 - 如何使用
AI.SCORE实时评估非结构化数据,并将结果纳入全面的交易得分 - 如何导出数据并将 Next.js Marketplace 应用部署到 Cloud Run